
Abstract
The rapid progress of Internet technology has accelerated the development of natural language processing technology. To address the current issue of poor adaptability and accuracy in cross-language text matching and translation, firstly, a multi-head attention mechanism and convolutional neural network are introduced. Moreover, a cross-language text matching model based on similarity-based attention convolutional neural network is constructed. Then, visual features are added to the Transformer model to build a real-time machine translation model based on the improved Transformer. The results showed that the accuracy of the proposed text matching model could reach 83.42% when the epoch was 4. The proposed model achieved accuracy rates of 78.96%, 77.55%, and 79.86% in the experiment of matching French, German, and Spanish with English, respectively, while the accuracy rates were 79.16%, 75.03%, and 76.54% in the experiment of matching English with three languages. In addition, as the training data size increased from 1 M to 3 M, the Bilingual Evaluation Understud score of the proposed translation model improved by 36.45%, demonstrating good scalability. In summary, the model constructed in the study not only has high accuracy and adaptability but also demonstrates significant advantages in scalability.
Introduction
The development of artificial intelligence technology has made significant progress in neural machine translation (NMT) technology, providing convenience for cross-cultural communication and new language learning. Machine translation (MT) model is the process of translating text from one language to another, typically requiring more complex language structure transformations, grammar rules, and semantic understanding.1,2 The text matching (TextM) model refers to a model used to compare the similarity or correlation between two pieces of text. The cross-language text matching model (CL-TMM) is mainly used to handle the matching and alignment problems between texts from different languages, which involves understanding the semantics and structure between different languages.3,4 Therefore, CL-TMM can be regarded as the foundation of the MT model to a certain extent. However, traditional text matching (TextM) models lack adaptability in cross linguistic scenarios and are difficult to effectively handle vocabulary, grammar, and cultural differences between different languages. In addition, existing models have limitations in capturing deep semantic and structural information of text, resulting in a need to improve matching accuracy and adaptability. 5 In this context, this study builds CL-TMM based on similarity attention convolutional neural network (SACNN) and real-time MT model based on improved transformer (ITransRT). Compared with previous models, SACNN combines multi-head attention mechanism and CNN to more comprehensively capture the global semantics and local features of text, enabling the model to exhibit higher accuracy and adaptability in processing texts from different languages and domains. The objective of this research is to propose a novel solution to the challenge of cross-language TextM and translation. The aim is to enhance the ability to accurately and adaptively capture the semantic similarity and grammatical structure between texts. The significance of the research lies in improving the accuracy and adaptability of cross-language TextM and translation, better meeting practical needs, and providing new possibilities for real-time MT, making it perform better in processing multi-modal text.
The innovation of this study lies in: (1) combining the global information extraction capability of multi-head attention mechanism and the local feature extraction capability of convolutional neural network (CNN) to better capture semantic similarity between cross linguistic texts. (2) On the basis of the traditional Transformer model, visual features are added as auxiliary modalities, and the Wait-k strategy is introduced to compensate for the semantic loss caused by insufficient input information at the source end. (3) By utilizing a hierarchical attention mechanism and feature fusion module, the model effectively integrates image and text information, enhancing its ability to understand complex semantics.
The main structure of the research content consists of four parts. The first part is to analyze the current research status to point out the shortcomings of the current research. The second part focuses on the problem of cross-language TextM and translation, building a CL-TMM based on the SACNN and the ITransRT. The third part is to analyze the application effect of the research model. The last part is a summary of the research results, pointing out the shortcomings of the research and the prospects for future research.
Related works
TextM is an important foundational problem in natural language processing (NLP), which can be applied to a large number of NLP tasks, such as information retrieval, question answering systems, retelling questions, dialogue systems, and MT. Li et al. addressed the issue of images often lacking semantic concepts in cross-modal retrieval between images and text, and integrated semantic relationship information into visual and text features. A model was introduced to learn the common embedding space for aligning image and text descriptions, which has high efficiency and performance. 6 Rossi et al. proposed the application of prefix free parsing to establish an r index to address the issue of precise pattern matching being used to support approximate pattern matching, but the r index cannot effectively support important queries. Meanwhile, thresholds related to the size of prefix free parsing were found in both linear time and space, proving that the proposed method has a fast index construction speed. 7 Iqbal et al. reviewed many deep learning models used for text generation, focusing on the design and architecture of deep learning models and their application in NLP. They also summarized various models and provided a detailed understanding of the past, present, and future of text generation models in deep learning. 8 The controllable text generation of pre-trained language models (PTLM) based on Transformer was difficult to ensure due to the limited interpretability level of deep neural networks. Zhang et al. conducted a systematic and critical review of the main methods, common tasks, and evaluation methods to address this issue. They also discussed the challenges faced in this field and proposed various promising future directions. 9 Avrahami et al. proposed an accelerated solution for general image local text driven editing tasks by utilizing a potential text to image diffusion model to address the issue of relatively slow inference time in image processing using diffusion models. This scheme had good efficiency and accuracy. 10 Hickman et al. stated that decisions made during text preprocessing can affect the capture of language content or style, the statistical ability of subsequent analysis, and the effectiveness of insights derived from text mining. Therefore, a review was conducted on the research of organizational text mining and computational linguistics to provide experiential decision recommendations for text preprocessing. 11
NLP is the bridge between machine language and human language to achieve the purpose of human-machine communication and is the foundation of MT. Khurana D et al. stated that NLP has been widely applied in fields such as MT, information extraction, and question answering. They discussed the different levels of NLP and the components of natural language generation to distinguish the four stages, and also introduced the history and evolution of NLP, as well as the current trends and challenges. 12 Min B et al. pointed out that the key idea of large-scale PTLM is to learn a universal language representation from a universal task once. Then, it was applied in different NLP tasks, and the key basic concepts of the large-scale PTLM architecture were introduced, and the transition to NLP technology driven by large-scale PTLM was comprehensively introduced. 13 Ranathunga et al. provided a detailed introduction to the research progress of LRL on NMT, addressing the issue of poor performance of NMT on low resource language (LRL) pairs. Through quantitative analysis, technical guidelines were provided for the selection of data settings for a given LRL. 14 Li et al. addressed the issue of unsupervised multi-modal MT models being sensitive to false correlations and adopted multi-modal reverse translation. It used spatio-temporal maps obtained from videos to utilize object interactions in space and time to eliminate ambiguity and used visual center subtitles as additional weak supervision. This model had good translation and generalization abilities. 15 Zhang et al. proposed a frequency aware token level contrastive learning method for low-frequency word prediction in NMT systems by pushing the hidden state of each decoding step away from the corresponding words of other target words. This method had good robustness while maintaining high accuracy in predicting low-frequency words. 16 Chung E S et al. addressed the lack of research on the comprehensive evaluation of the effectiveness of MT and examined the impact of MT use on second language writing among learners through automatic calculation tools and manual raters. They also investigated the impact of proficiency and text type on learners’ use of MT, verifying that MT helps improve accuracy. 17
In summary, although cross-language TextM tasks have made positive progress, in practical situations, TextM still faces problems such as poor language adaptability and high cost of data annotation for new languages. At present, mainstream methods rely on large-scale pre training to capture deep semantics, with high inference costs and insufficient explicit modeling of syntactic structure changes, such as BERT and its multilingual variant mBERT. SACNN combines lightweight multi-head attention and CNN to enhance robustness against word order differences, achieving effective fusion of global semantic associations and local structural features, which is more conducive to deployment in resource sensitive scenarios. Therefore, the research on constructing a CLTMM based on SACNN has important practical application value and prospects in balancing model performance and cross language robustness.
CLTMM and NMT research
The development of the Internet has accelerated the worldwide information flow and resource sharing, but the communication barriers caused by cultural differences and language differences have blocked the process of information exchange around the world. To improve the adaptability and accuracy of cross-language TextM and translation, this study builds SACNN-based CL-TMM and ITransRT.
Construction of CL-TMM based on SACNN
The TextM algorithm aims to determine the relationship between two texts by comparing their similarity and is an important component of a question answering system. Cross-language TextM refers to the task of matching and comparing text from different languages. In the field of NLP, cross-language TextM is an important issue because there are differences in vocabulary, grammar, and culture between different languages, so it is necessary to cross these differences for TextM. The study innovatively combines multi-head self-attention mechanism (SAM) and improved CNN to extract global and fragment information of sentences, and uses fully connected networks for feature fusion. Cross language text matching requires simultaneous processing of semantic correspondences at the lexical level and structural differences at the syntactic level. SACNN utilizes SAM to capture global semantic information of text, effectively understanding the overall semantics of texts in different languages. Simultaneously utilizing CNN to extract local features can handle syntactic differences and phrase structure correspondence issues. The combination of the two enables the model to understand text more comprehensively, especially for the challenge of cross linguistic text matching, which is superior to traditional architectures that only rely on local features, such as Bilinear Convolutional Neural Network. The CL-TMM based on SACNN proposed in this study mainly includes three matching modules: multi-head SAM, convolutional features matching, and fusion output. The structure of SACNN is shown in Figure 1. Structure diagram of SACNN.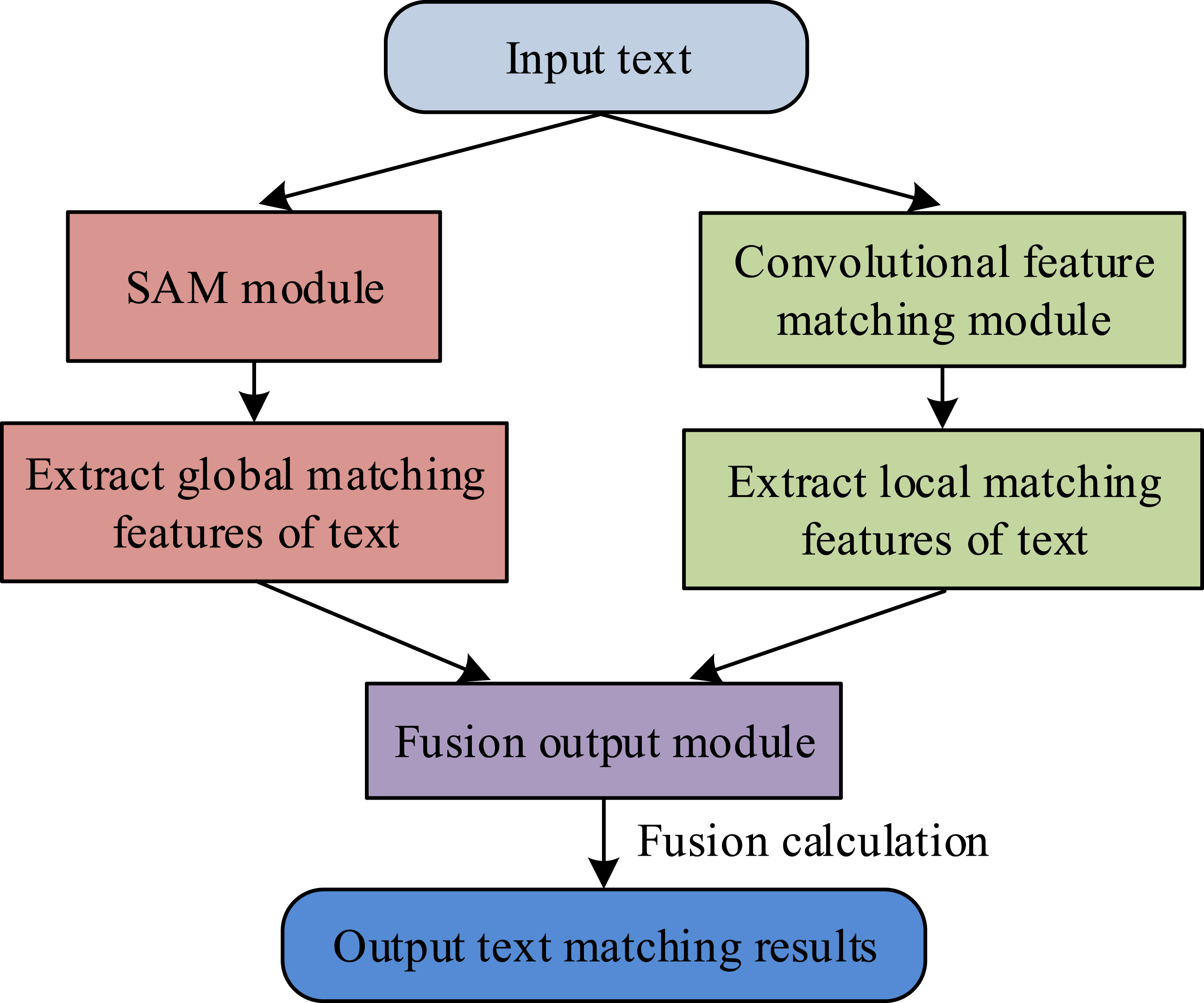
Multi-head SAM is a mechanism used in deep learning to enhance the model’s ability to pay attention to input information. It is initially introduced into attention models and has been widely used, especially in Transformer models.
18
The attention mechanism is proposed to address the problem that during the training process of recurrent neural network models. If the information transmission process is prolonged, the model will forget the information transmitted in the previous time steps. The calculation process is shown in Figure 2. The calculation process of attention mechanism.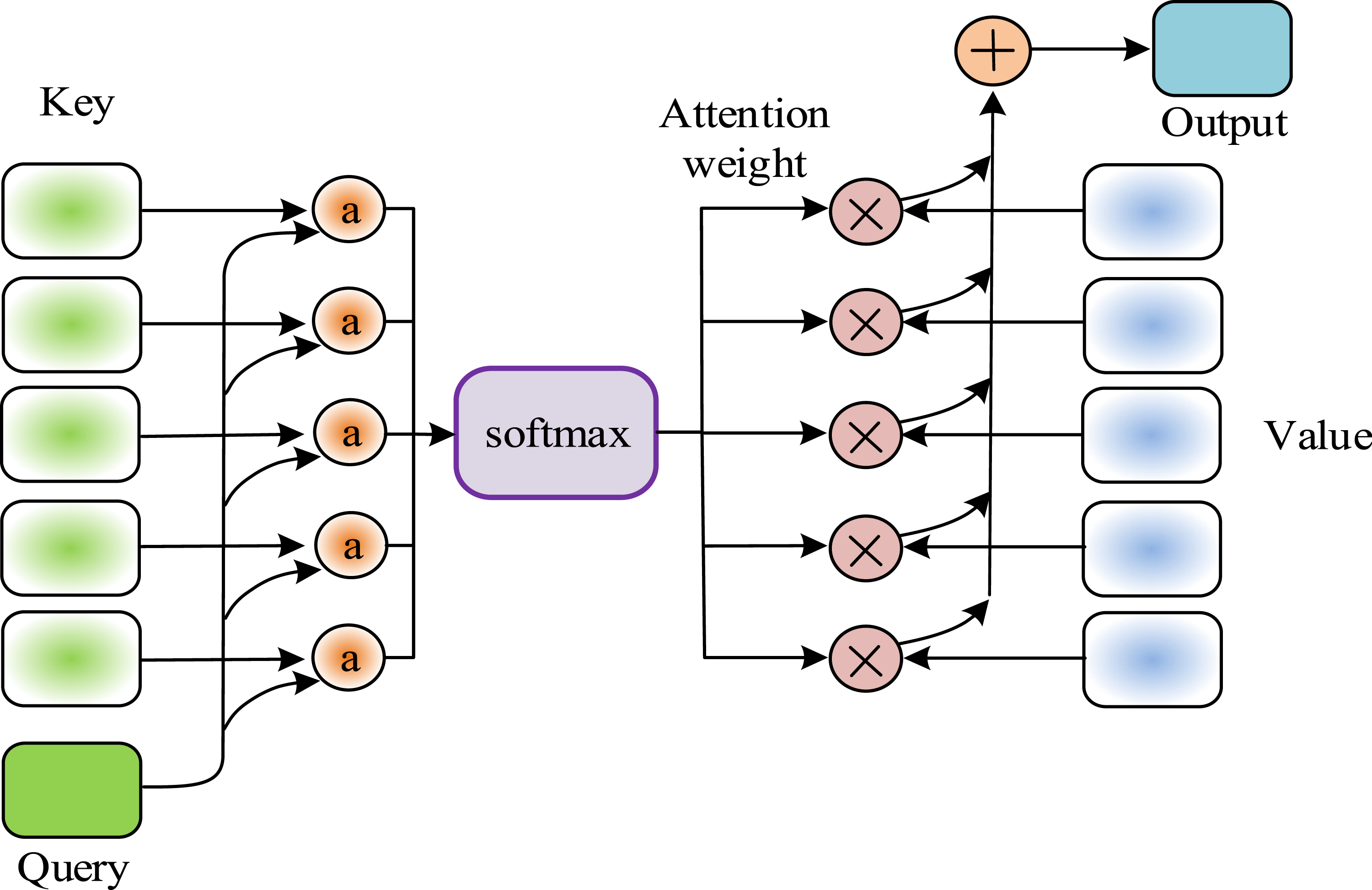
In traditional attention mechanisms, models learn to weight and combine information from different positions in the input sequence to incorporate the information carried by each position into the final representation. Multi-head SAM further expands this concept. It allows the model to simultaneously focus on different parts of the input and integrate these focused results, thereby enabling a more comprehensive understanding of the input sequence. Multi-head SAM can extract global information within a sentence, and its formal description is formula (1). Schematic diagram of multi-head SAM and CNN feature module.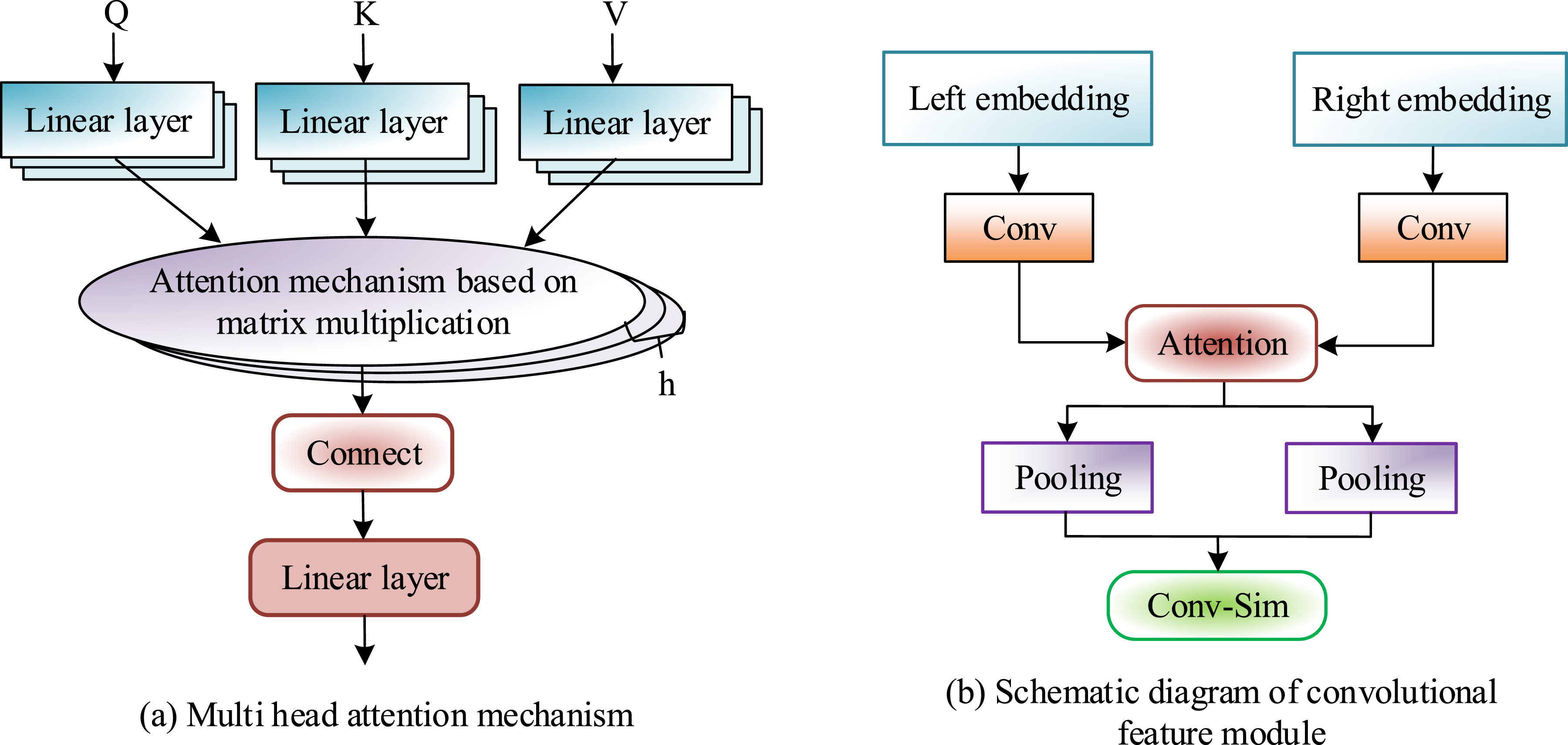
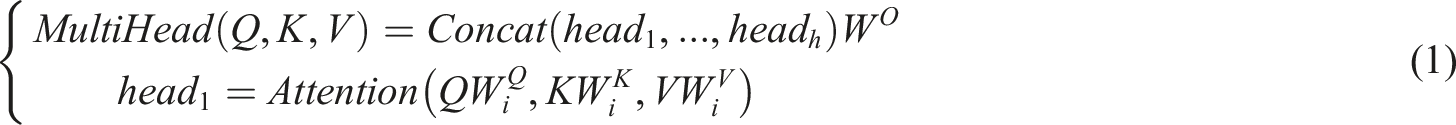


Firstly, the text on both sides is fed into a convolutional layer for computation. Assuming the word vector in the sentence is Flowchart of a CL-TMM based on SACNN.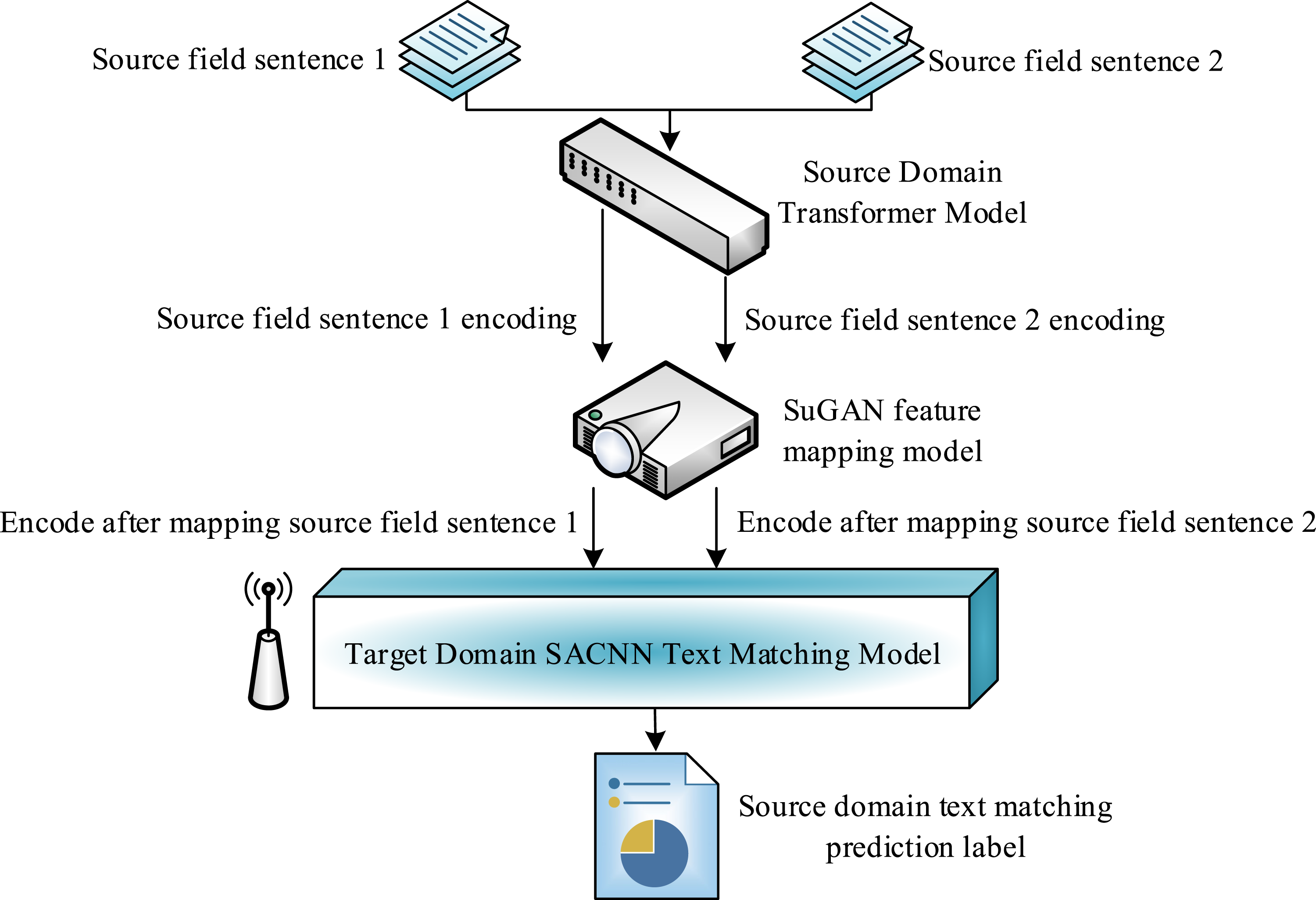

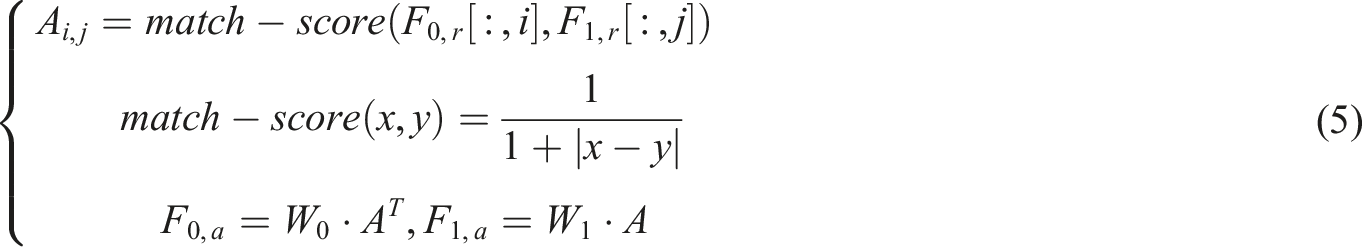

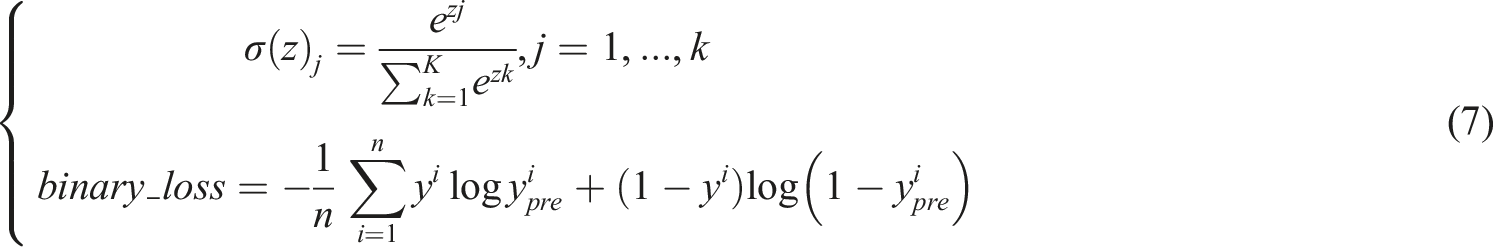
Construction of the ITransRT model
After implementing cross language TextM, further MT can be carried out. Real-time MT refers to the real-time conversion of text or speech from one language to another through a computer system to achieve real-time cross-language communication. It is one of the most difficult MT tasks to handle. The limited resources provided by traditional MT inputs can to some extent affect the translation results. The Transformer model is a deep learning model based on attention mechanism, widely used in NLP tasks, and has achieved significant breakthroughs in handling long-distance dependencies and modeling sequence information.19,20 Therefore, based on the Transformer model, this study introduces images corresponding to the source language text description as auxiliary modalities to enrich translation resources and compensate for semantic deficiencies caused by insufficient input information at the source end. Specifically, for the input source language text, this study utilizes a pre trained visual model to extract the global visual feature vector of its corresponding image. Visual features corresponding to the text are added to the decoder, and visual feature encoding, positional encoding, and lexical encoding are combined to assist translation to improve translation quality. The introduction of visual features provides additional semantic information for translation models, especially when processing multimodal text, which can significantly improve the accuracy and fluency of translation. The structural framework of the Transformer model is shown in Figure 5. The structural framework of the Transformer model.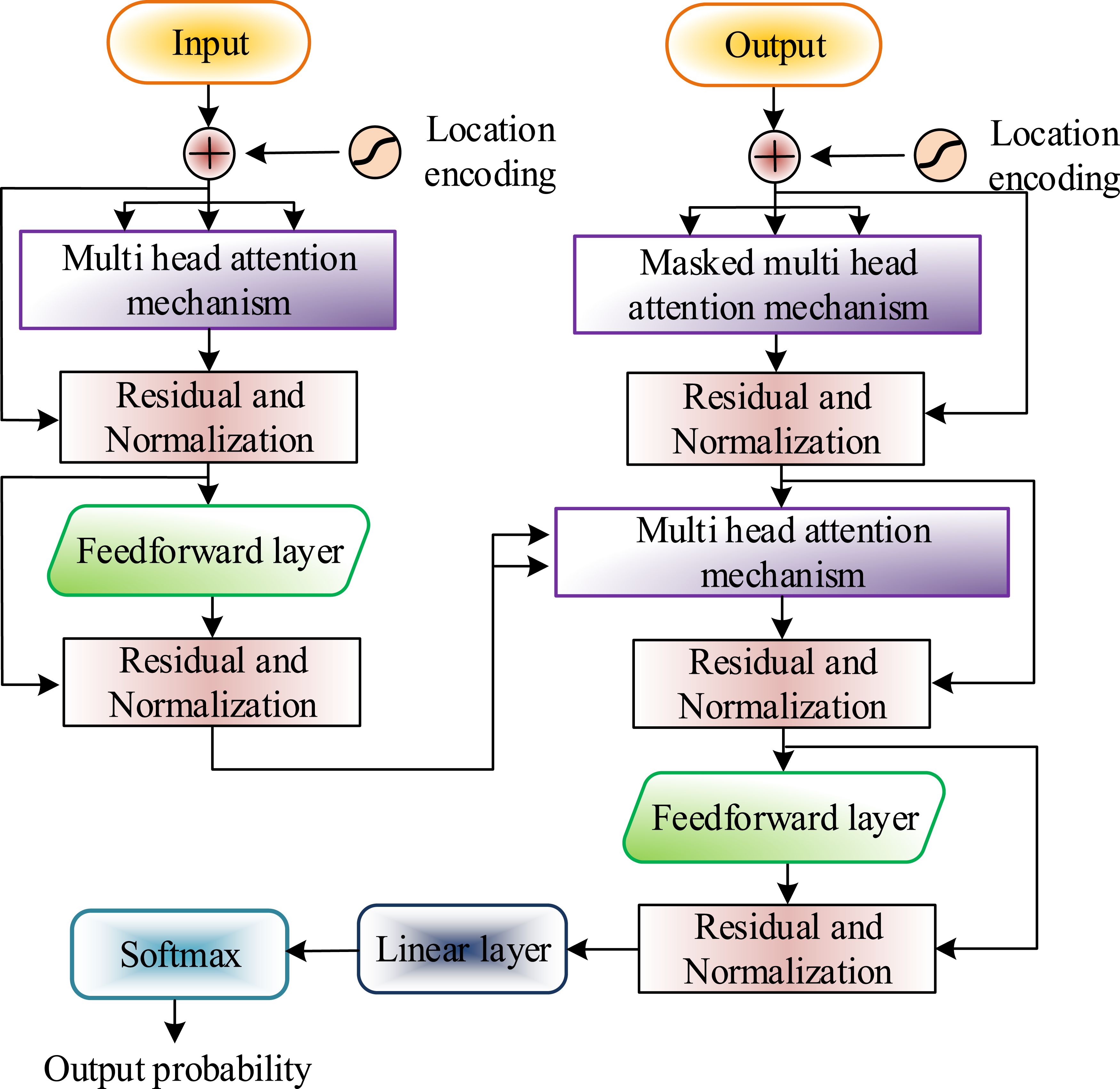
In traditional NMT tasks, the decoder generates a vocabulary at each time step, inputs the sequence

Traditional NMT may lead to premature generation of incomplete or incorrect translations, hence the Wait-k strategy has emerged. The Wait-k strategy is a strategy used to improve the NMT decoding process by delaying generation and waiting for more information to be transmitted to improve translation accuracy and fluency. Specifically, the Wait-k strategy requires the decoder to generate only one special “wait mark” as output at each time step, rather than directly generating vocabulary. Once Real-time MT model structure diagram.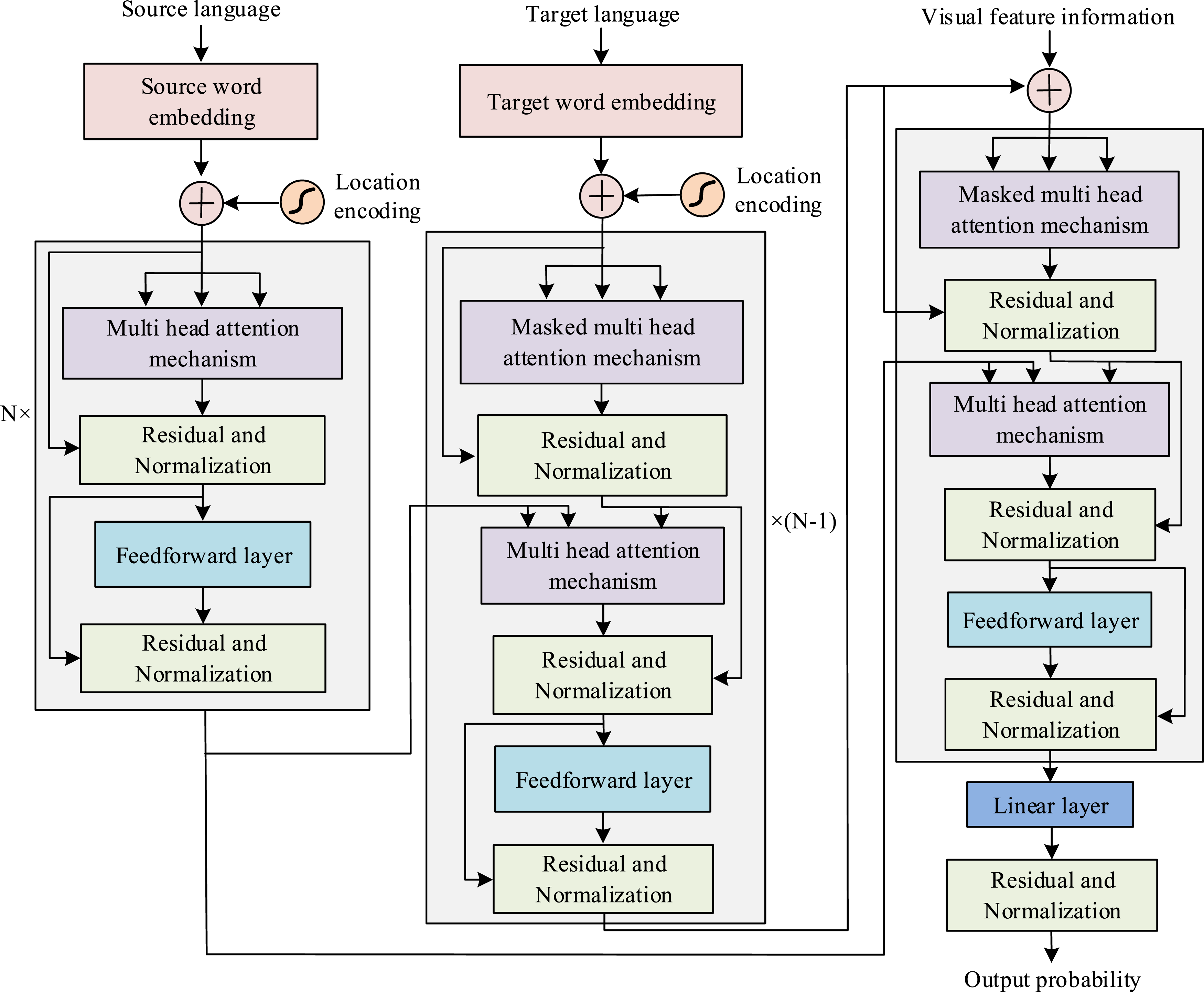
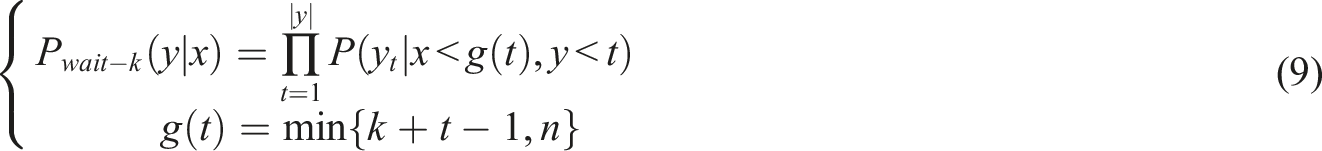




In summary, the improvement of the standard Transformer architecture in this study is mainly reflected in three aspects. Firstly, introducing visual features related to the text as auxiliary modalities and integrating them with text features to enrich translation resources and compensate for semantic deficiencies. Then, a hierarchical attention scheme is adopted to encode the text and image features separately, and the feature weights are dynamically adjusted through a multi-layer attention mechanism to achieve more effective information fusion. Finally, combined with the Wait-k strategy, the generation process of the decoder is delayed, waiting for more contextual information to be passed in, thereby improving the accuracy and fluency of the translation.
Analysis of the effect of TextM and real-time MT
This study constructs CL-TMM and ITransRT based on SACNN, but their practical application effects still need further verification. This study mainly analyzes from two aspects. Firstly, the effectiveness of CL-TMM is analyzed, and then the feasibility of the real-time MT model is verified.
Analysis of the effect of CL-TMM
To verify the effectiveness of the TextM model based on SACNN, this study used the English Spanish and Spanish English matching question datasets provided in the CIKM AnalyticCup 2018 competition. Using Google Translate’s API, the dataset was translated into French and German versions. The CIKM AnalytiCup 2018 dataset contains 20,000 English question pairs and 1400 Spanish question pairs, all of which are manually annotated and matched by language experts. Remove samples with a length greater than 50 words after translation, and filter samples containing special symbols or invalid characters. However, relying on API to translate datasets may lead to the model learning specific translation styles or biases, thereby affecting the model’s generalization ability. Therefore, this study manually validated the translated data to identify and correct possible errors or unnatural translations. Four TextM models were independently trained for English, Spanish, French, and German. 80% of each language was extracted as training data and 20% as testing data to test the SACNN TextM model. It was compared with three models: bidirectional long short term memory network (Bi-LSTM), bilinear convolutional neural network (BCNN), and attention-based convolutional neural network (ABCNN). The accuracy of the each models on the English TextM dataset is shown in Figure 7. Compared to the other three models, the accuracy of the model in this study is the highest, reaching 83.42% at an epoch of 4, followed by the ABCNN model, and the Bi-LSTM mode has the lowest accuracy. In addition, as the number of iterations increases, the accuracy of the research model fluctuates less and has good stability. The results indicate that the SACNN model has good accuracy and stability. Accuracy of various models on English TextM datasets.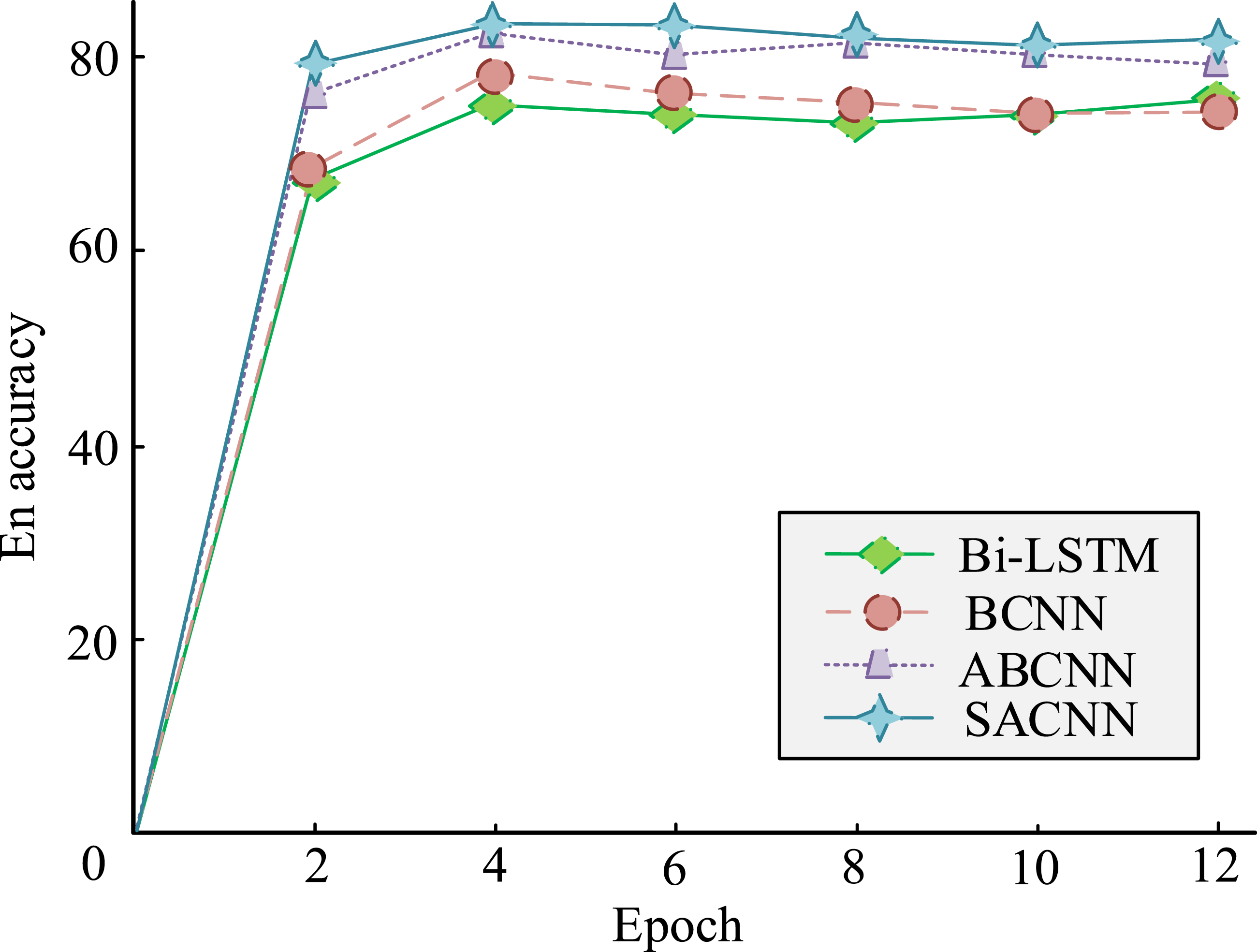
The TextM accuracy results of the above four models in four languages are shown in Figure 8. In Figure 8(a), SACNN has the highest matching accuracy in the English dataset, at 83.22%. In Figure 8(b), the matching accuracy of SACNN in French is higher than the other three models, at 84.47%. In Figure 8(c), the matching accuracy of SACNN in German is higher than the other three models, at 78.63%. In Figure 8(d), SACNN has a higher matching accuracy in Spanish, but slightly lower than the ABCNN model at 80.21%, which is 0.15% lower than the ABCNN model. The results show that the proposed SACNN TextM model has good overall language matching performance and high accuracy. TextM accuracy results in four languages.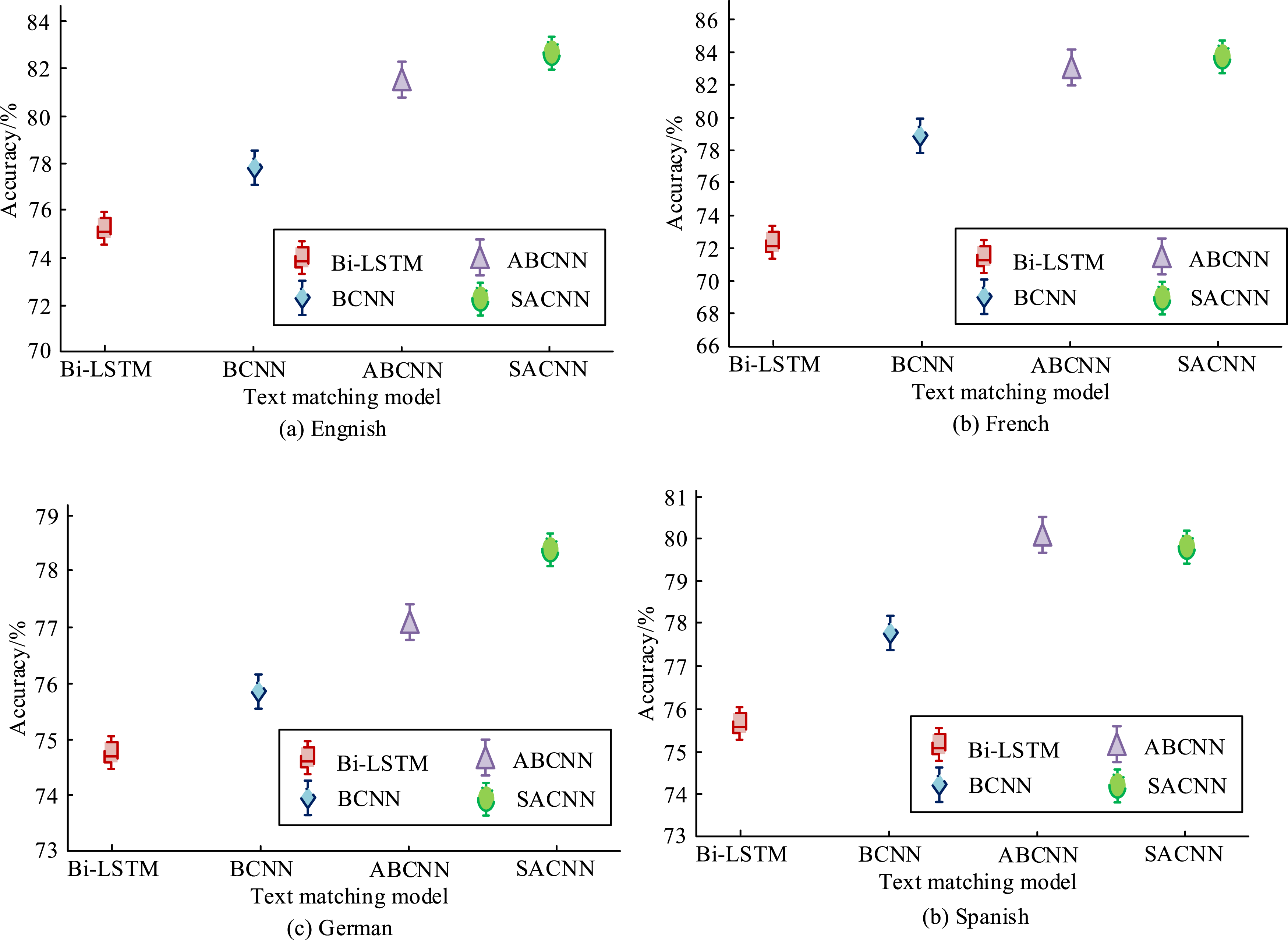
To further validate the effectiveness of SACNN based CL-TMM, this study conducted cross-language TextM experiments using the aforementioned dataset, and the results are shown in Figure 9. In the experiment of matching French, German, and Spanish with English in Figure 9(a), the accuracy of the research model remained the highest, with 78.96%, 77.55%, and 79.86%, respectively. In Figure 9(b), in the experiment of matching French, German, and Spanish with English, SACNN still had the highest accuracy, with 79.16%, 75.03%, and 76.54%, respectively. The results showed that the CL-TMM based on SACNN had good adaptability in different fields, and the matching accuracy was also better than the comparison model, which had certain feasibility and superiority. Results of CL-TMM experiment.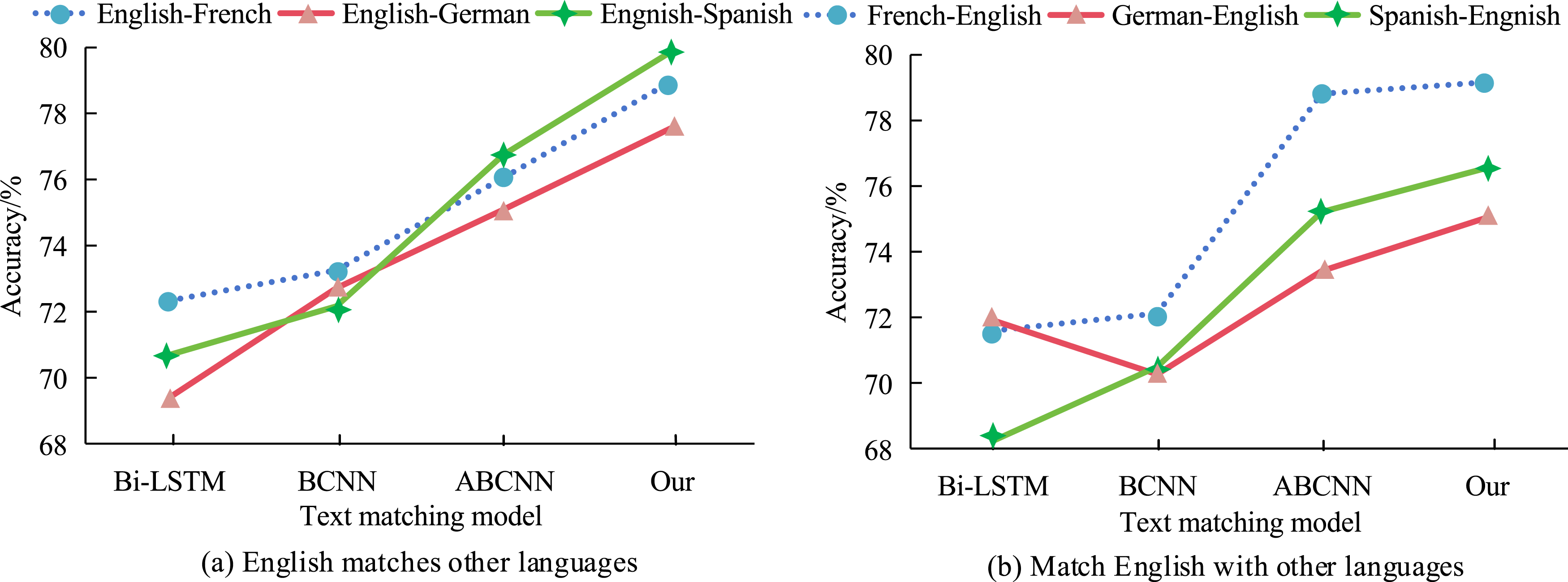
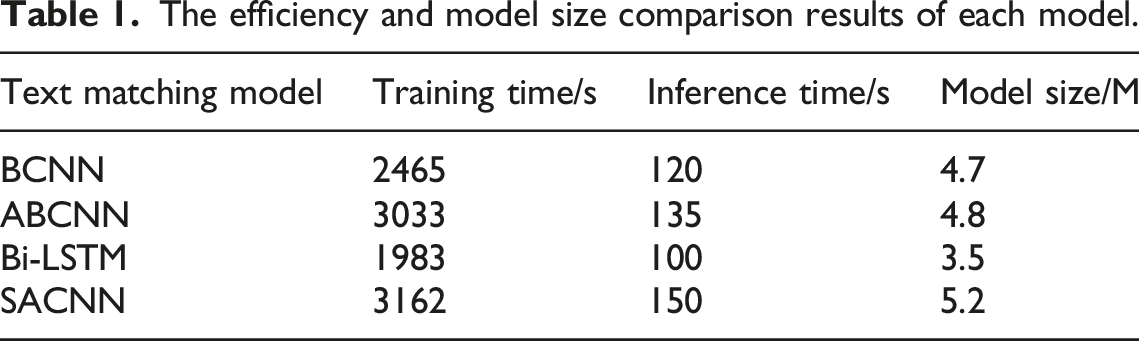
The efficiency and model size comparison results of each model.
Statistical significance test results.

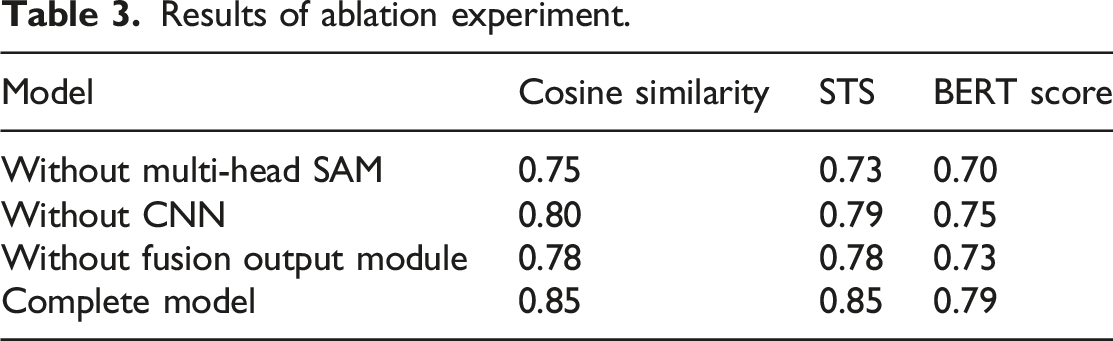
Results of ablation experiment.
To further validate the superiority of the proposed TextM model, this study evaluates its accuracy in English and French, and compares it with the Bidirectional Encoder Representation from Transformers model combined with the SimCSE framework (SimCSE-BERT), the Text Semantic Matching Model based on Knowledge Enhancements (TSM-KE), and the BERT model combined with the Linguistic Knowledge Enhanced Graph Transformer (LET-BERT). These three comparative models are currently three advanced TextM models. The result is shown in Figure 10. From Figure 10(a) and (b), in the TextM tasks of English and French, the matching accuracy of the research model is the highest, with 83.46% and 85.86%, respectively. The results indicate that the CL-TMM based on SACNN has high matching accuracy, and has certain feasibility and superiority. Comparison results of matching accuracy.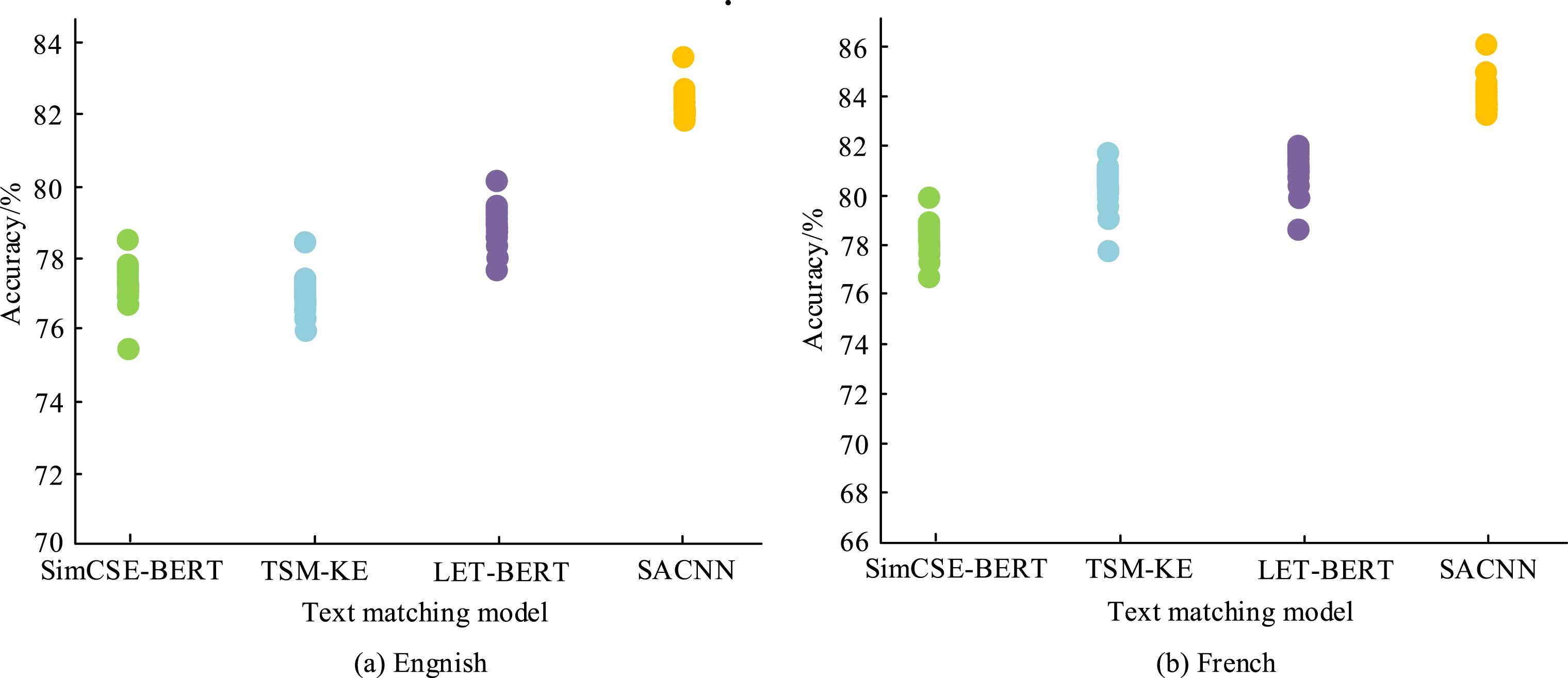
Feasibility analysis of real-time MT model
To verify the performance of ITransRT, this study uses bilingual evaluation study (i.e., BLEU) as the evaluation metric and tested it using the Multi30 K dataset. The Multi30 K dataset contains approximately 30,000 images and their corresponding textual descriptions in English, German, French, and other languages, with over 100,000 sentences. The images are mainly from the Flickr30k and MSCOCO datasets, covering daily life scenes. The image undergoes standardization processing, resizing, and normalizing pixel values. The text description has undergone preprocessing steps such as word segmentation and stop word removal, and has been fused with corresponding image features. The comparison with the traditional Wait-k strategy is shown in Figure 11. In Figure 11(a), in the French-English translation task, as the K value increases, the BLEU of both models increases. In Figure 11(b), in the English-French translation task, the BLEU indicator of the research model is higher. As the K value increases, the difference in indicators between the two models gradually decreases and even tends to be consistent. In Figure 11(c), the research model performs better in terms of indicators in the German-English translation task. In Figure 11(d), there is no significant difference in indicators between the two models in the English-German translation task when K = 3. In summary, ITransRT has higher BLEU indicators in most cases, which can effectively improve the quality of real-time MT and has certain feasibility and effectiveness. BLEU score results for different translation tasks.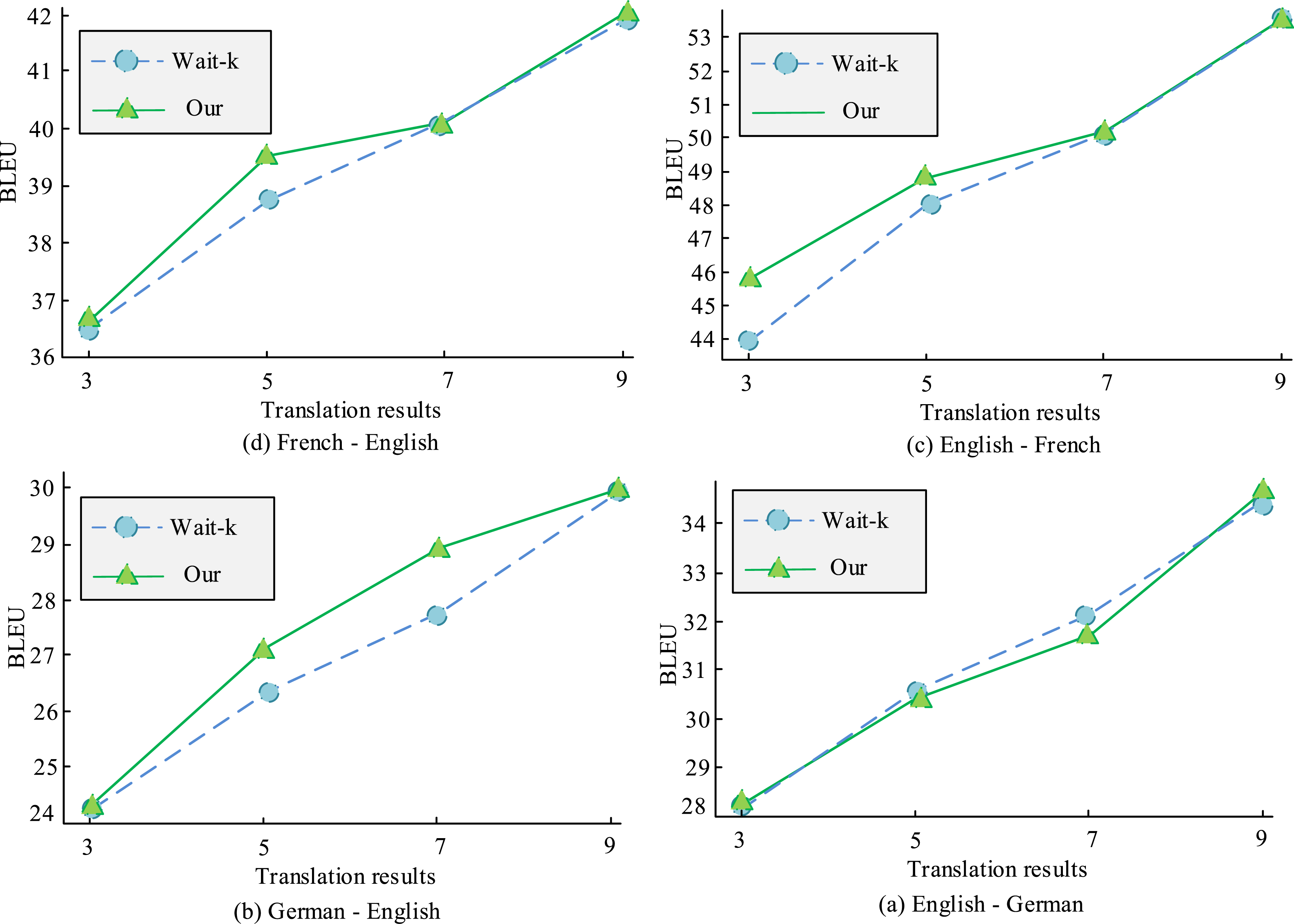
To verify the adaptability of the translation model in Chinese-English translation, this study conducts experiments using UNv1.0 bilingual parallel corpus. The 1 M, 2 M, and 3 M parallel sentence corpora are selected as training sets for experiments. 5k sentences are used as the test set, and 8k sentences are used as the validation set. Python is used as the development language, and Jieba and NLTK tools are, respectively, used to process Chinese and English word segmentation. The vocabulary size for both Chinese and English is set to 30k. The comparison results with traditional Transformer and LSTM translation models are shown in Figure 12. As the size of the training set increases, the BLEU index of all three translation models increases. The BLEU index of the research model is the highest at the scale of 1 M, 2 M, and 3 M training sets, with values of 20.19, 26.65, and 27.55, respectively. The results indicate that although the performance of the model improves with increasing training set size, the BLEU score is still low at the minimum training set size, indicating the performance limitations of the model when the data volume is small. Future research can focus on optimizing model architecture, increasing diversity of training data, and improving feature fusion strategies to further enhance translation quality. The BLFU score results of three models for Chinese-English translation.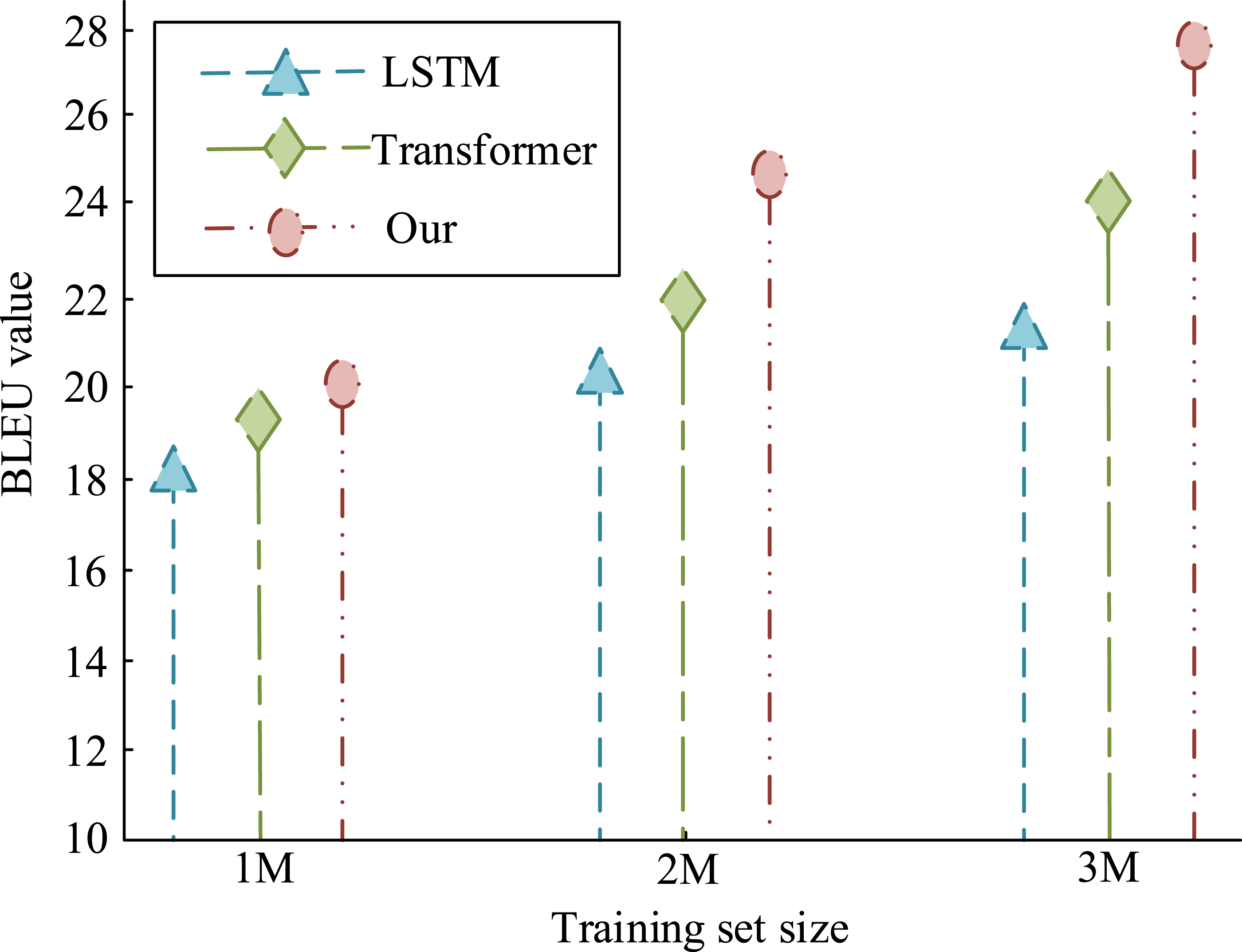
Translation results with different proportions of correct translations.
Conclusion
The advancement of technology has brought about the flourishing development of NLP technology. In response to the problem of cross-language TextM and translation, this study innovatively combined multi-head SAM and CNN to build a CL-TMM, and added visual features to the Transformer model to build a real-time MT model based on an improved Transformer. The experiment showed that the accuracy of the SACNN model was the highest, reaching 83.42% when the epoch was 4. With the increase of iteration times, the accuracy fluctuated less and had good stability. The accuracy of the SACNN model in English, French, and German matching was higher than the other three models at 83.22%, 84.47%, and 78.63%, respectively. The accuracy of SACNN-based CL-TMM was the highest in the experiment of matching French, German, and Spanish in English, with 78.96%, 77.55%, and 79.86%, respectively. Its accuracy in matching English in French, German, and Spanish was still the highest, at 79.16%, 75.03%, and 76.54%, respectively. The BLEU metric of ITransRT was higher, with BLEU metrics of 20.19, 26.65, and 27.55 for 1 M, 2 M, and 3 M training sets, respectively. When the accuracy rate of the input translation was 40%, the BLEU scores of the models in all three training set sizes were the highest, at 52.79, 55.93, and 57.17, respectively. In summary, the constructed model has certain feasibility and effectiveness. The proposed SACNN model and improved Transformer model have good generalizability in other language pairs, domains, and text types. Without extensive retraining, adaptability to new languages or domains can be enhanced through the universality of multilingual pre training and feature extraction. The SACNN model, through multi-head SAM and CNN, can handle lexical and grammatical differences in different language pairs, adapt to formal and informal texts, and can be used for multilingual social media monitoring and multi domain literature retrieval. Meanwhile, the improved Transformer model, by incorporating visual features and hierarchical attention schemes, combined with the Wait-k strategy, can effectively improve translation quality and adaptability, making it suitable for multilingual real-time communication and multi domain document translation.
However, while the SACNN model has improved accuracy compared to the baseline model, its model size and training time are also higher than some baseline models, which poses challenges for deployment in resource constrained environments. In addition, the performance of the SACNN model on different language pairs is influenced by various factors such as language complexity, data quality and quantity, cultural differences, and language characteristics. Therefore, future research should further explore model compression techniques such as knowledge distillation and model quantification, or lightweight architecture design, while ensuring model accuracy, to reduce computational costs. And further improve the performance of the model by increasing the scale and diversity of training data, optimizing the model architecture, and introducing more linguistic knowledge.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.