
Abstract
Recycled coarse aggregate exhibits significant heterogeneity in its physical and chemical properties, along with complex interdependencies among various feature attributes. These characteristics often lead to challenges in achieving high accuracy in attribute recognition, highlighting the urgent need for a structured and intelligent analytical framework. To address this issue, this study proposes a novel hybrid approach that integrates graph convolutional networks (GCN) with attribute mathematics theory, aiming to enhance feature representation and improve recognition performance. The method begins by constructing a multi-dimensional attribute graph based on the physicochemical properties of recycled coarse aggregate, capturing the intrinsic correlations among different features. A multilayer GCN is then employed to extract deep-level, globally coupled feature representations. Subsequently, attribute mathematics theory is applied to simplify and logically abstract the output features through membership functions and covering operators, enabling effective feature selection and dimensionality reduction. The refined feature set is finally fed into a discriminant classifier to achieve accurate attribute recognition. Experimental results demonstrate the superiority of the proposed fusion model over traditional machine learning methods such as SVM, random forest, and MLP. The model achieves average recognition accuracies and recall rates of 0.89 and 0.89 across eight material categories, and 0.90 and 0.89 across seven particle size ranges, respectively. Five-fold cross-validation yields an average accuracy between 0.889 and 0.918, with a low standard deviation of 0.012, indicating strong stability and generalization performance. Moreover, the feature simplification strategy achieves an average feature reduction rate of 0.67 while retaining 0.92 of the original information. These results confirm that the proposed GCN–attribute mathematics framework significantly enhances the attribute recognition capability of recycled coarse aggregate, offering a robust and efficient solution for intelligent identification in sustainable construction materials research.
Keywords
Introduction
The resource utilization of recycled coarse aggregate plays an important role in the green building materials industry chain. Its quality and performance are directly related to the durability and frost resistance of concrete engineering.1,2 The error in the identification of recycled coarse aggregate properties directly affects the material classification and engineering adaptation, and increases the cost of testing and screening. The fusion method helps to improve the identification efficiency and application reliability. The physical properties of recycled coarse aggregate include density, porosity, and water content, while the chemical composition includes indicators such as carbonate content, silicate content, and alkali metal content.3,4 There is a complex coupling between these attributes, and nonlinear dependence affects the subsequent mechanical property judgment and environmental risk assessment. Faced with the increasing requirements for aggregate performance in reinforced concrete structures, traditional feature extraction strategies make it difficult to accurately distinguish different quality levels in a high-dimensional redundant information environment, and classifiers are prone to misjudgment or missed detection in practical applications.5,6 In the green building materials development strategy, the quality control and application requirements of recycled coarse aggregate are becoming increasingly stringent. The current specifications set clear boundaries for particle size distribution and calcium carbonate content.7,8 In the face of the dual goals of resource recycling and emission reduction, it is necessary to accurately identify the properties of recycled coarse aggregate to achieve safe and reliable material performance assurance.9,10 The current evaluation methods rely on manual sampling and traditional testing methods for physical and chemical properties, which are inefficient and cannot reveal the deep correlation between properties. Innovative solutions based on big data and intelligent algorithms are urgently needed.
Figure 1 shows several types of recycled coarse aggregates. Aggregates with a particle size between 5 mm and 40 mm are coarse aggregates, commonly known as stones. Commonly used ones are crushed stone and pebbles. In concrete, coarse aggregates act as skeletons with sand and stone. Recycled coarse aggregate.
At present, machine learning algorithms such as multi-dependent support vector machine (SVM),11,12 random forest (RF)13,14 and multilayer perceptron (MLP)15,16 are widely used in the identification of recycled coarse aggregate properties. Salimbahrami SR proposed to produce green concrete using recycled concrete waste. Through experiments, the mechanical properties of natural concrete, recycled concrete and recycled fiber concrete were compared, and the SVM method was used to predict their compressive strength. The SVM performed more consistently in 124 groups of tests, verifying the feasibility of recycled concrete in terms of mechanical properties and environmental benefits. 17 SVM realized nonlinear mapping through kernel function and is suitable for small sample classification, but its training complexity was high and its ability to scale to large-scale data is limited. Some studies on the identification of recycled coarse aggregate properties had the problems of high training complexity and limited ability to scale to large-scale data.18,19 Yang found that RF showed significant advantages in predicting the compressive strength of recycled aggregate self-compacting concrete. Its error index was low, and the tree-based characteristics gave the model stronger a parameter interpretation ability. It had better interpretability while maintaining high accuracy, and was particularly suitable for modeling the nonlinear behavior of composite materials. 20 Random forests improve noise resistance by integrating decision trees, but it is difficult to explicitly express the complex coupling between attributes, which limits the deep mining of associated features.21,22 As a classic neural network structure, multilayer perceptron can capture nonlinear relationships, but it lacks an effective screening mechanism for high-dimensional redundant features, which easily leads to model overfitting. When dealing with multi-dimensional attribute coupling, the above methods often ignore the structured dependency between attributes, which limits the improvement of recognition performance. The uneven distribution of samples and high-dimensional redundant information also increases the difficulty of model recognition, affecting its promotion and application in practical engineering.23,24 Existing research still has obvious deficiencies in accurately revealing the coupling relationship between attributes and improving recognition efficiency, and it is difficult to meet the dual requirements of high accuracy and real-time performance in the application of recycled coarse aggregate.
In order to deal with the problem of multi-dimensional attribute coupling and redundant features, some studies have applied principal component analysis (PCA)25,26 and maximum relevance and minimum redundancy (mRMR)27,28 algorithms for dimensionality reduction, but their linear assumptions limit the revelation of nonlinear dependencies. Attribute mathematical theory is based on lattice theory and membership function, which can achieve logical simplification and rule extraction of attributes, and has shown strong explanatory power in system reasoning and classification tasks.29,30 Graph convolutional networks (GCNs) have been widely used in many fields due to their efficient integration of node and neighbor information. They are suitable for modeling complex correlation structures between attributes.31,32 However, the use of GCN alone lacks support for logical simplification of deep features, making it difficult to eliminate redundant information and improve the interpretability of results. Combining attribute mathematical theory with GCN can capture global coupling features, complete the screening and abstraction of key attributes through membership and covering operators, and enhance the model’s discrimination ability and logical expression. Based on this fusion idea, this paper aims to improve the accuracy and stability of recycled coarse aggregate attribute recognition and overcome the limitations of traditional methods in feature redundancy and nonlinear association processing.33,34
This study addresses the challenge of attribute recognition for recycled coarse aggregate, where conventional methods face limitations in handling complex coupling relationships among multi-dimensional features. To enhance both accuracy and efficiency, we propose a novel hybrid framework that integrates graph convolutional networks (GCN) with attribute mathematics theory, enabling deep modeling and logical simplification of attribute association structures. The proposed approach leverages the topological learning capability of GCNs to model the global interdependencies among various physicochemical attributes of recycled coarse aggregate. This is achieved by constructing a multi-dimensional attribute graph that captures the intrinsic correlations among heterogeneous features. Subsequently, attribute mathematics theory is applied to refine the extracted features through membership functions and covering operators. This step effectively eliminates redundancy, highlights key discriminative attributes, and enhances both the interpretability and generalization performance of the model. Unlike traditional recognition models that are sensitive to high-dimensional and redundant data, the proposed method combines data-driven feature fusion with logical reasoning mechanisms, offering a more robust and explainable solution. Through graph-based attribute mapping, coupled with mathematical feature simplification, the framework significantly improves the classification performance of downstream discriminant models.
Experimental results demonstrate the superiority of the GCN–attribute mathematics fusion scheme over conventional machine learning approaches such as SVM, random forest, and MLP. The model achieves high recognition accuracy and recall across multiple material categories and particle size ranges, along with strong stability and low variance in cross-validation tests. Furthermore, the feature simplification strategy achieves substantial dimensionality reduction while preserving most of the original information, validating its effectiveness in enhancing recognition performance. The innovation of this work lies in the development of a hybrid model that seamlessly integrates deep learning with mathematical logic, providing a new paradigm for intelligent detection in the field of recycled construction materials. This approach not only advances theoretical methodologies but also offers significant potential for practical engineering applications, contributing to the development of sustainable infrastructure technologies.
Method
Figure 2 systematically presents the architecture of recycled coarse aggregate attribute recognition based on GCN and attribute mathematical theory. A multi-level layout design is adopted. The data input layer collects physical and chemical attributes and generates an attribute matrix, correlation matrix, and co-occurrence frequency matrix. The processing area displays the core modules of graph structure modeling (Z-score standardization and adjacency matrix construction), GCN double-layer feature extraction, and attribute mathematical simplification (membership calculation → covering operator → logical simplification). The decision output layer realizes quality grade classification and contribution analysis. Recycled coarse aggregate attribute recognition architecture based on GCN and attribute mathematical theory.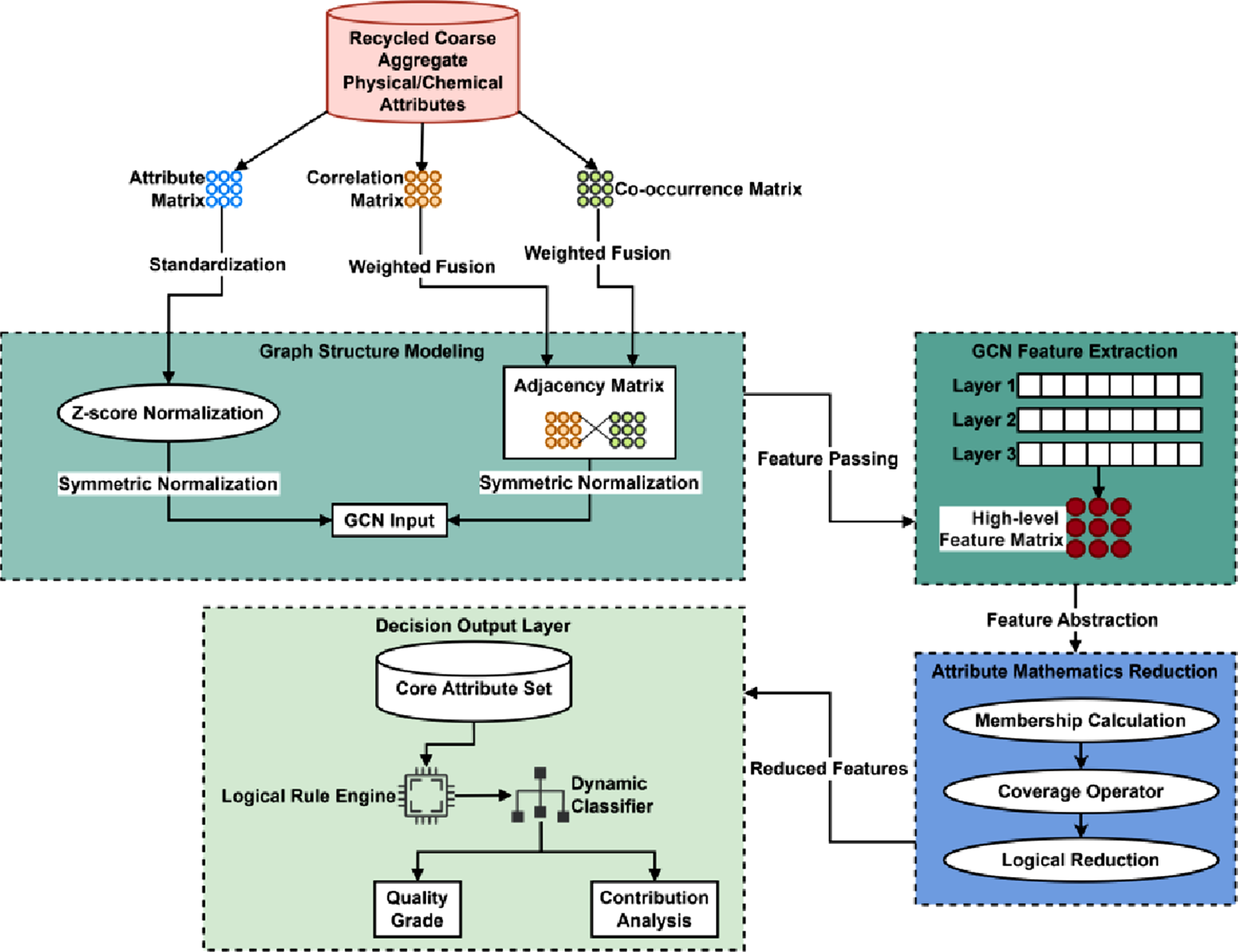
Building a multi-dimensional attribute graph structure model
The various physical and chemical properties of recycled coarse aggregate are noded, and a graph structure adjacency matrix is constructed based on statistical correlation and attribute co-occurrence. This graph is used to represent the spatial coupling and logical association between the internal attributes of the sample, providing an input graph for GCN processing.
Attribute node definition and graph structure construction
In the identification of recycled coarse aggregate properties, physical and chemical properties are regarded as nodes in the graph, and each type of property data is systematically integrated. For the attribute data set of the sample, the correlation index between the attributes is calculated based on the statistical analysis method. Specifically, the Pearson Correlation Coefficient35,36 is used as a tool to quantify the degree of linear correlation between the attributes. Its calculation formula is
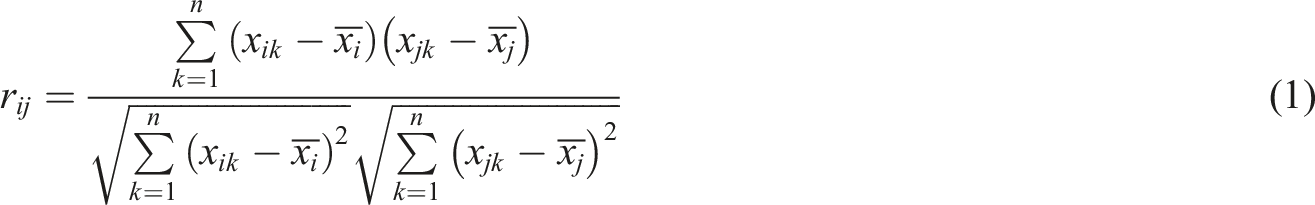
Combined with the co-occurrence frequency analysis of attributes, attribute pairs with significant statistical significance are further screened out as the basis for connecting edges between nodes in the graph. The node connection weight is obtained by weighted fusion of the correlation coefficient and the co-occurrence frequency to express the spatial coupling strength between attributes. The adjacency matrix is defined, and the element

Attribute correlation statistics and weight configuration parameters.

Property graph data preprocessing and standardization
Standardize the constructed attribute node feature matrix. The original attribute data has problems such as inconsistent dimensions and large differences in numerical ranges. Directly inputting the graph convolutional network may apply training bias. The Z-score standardization method is used to adjust the attribute value distribution. The calculation formula is as follows:
The adjacency matrix of the attribute graph is symmetrically normalized to improve the stability and convergence speed of graph convolution. The normalization operation of the adjacency matrix is expressed as
Apply GCN to extract related attribute features
The constructed attribute graph is input into the graph convolutional network, and the hidden feature expression under the global coupling attribute is extracted through adjacency propagation and convolution operations. The extraction process uses a multilayer GCN structure to transmit attribute information layer by layer to obtain a comprehensive representation with context dependency.
Multilayer graph convolution information propagation mechanism
After the constructed multi-dimensional attribute graph is input into the graph convolution network, the node connection relationship described by the adjacency matrix is used to realize the diffusion and aggregation of attribute information. The features of each node in the network are propagated weightedly through the adjacency relationship to form a high-dimensional implicit feature expression. The convolution operation is performed on the graph structure. Different from the traditional two-dimensional convolution, it uses the spectral domain filtering theory and combines the normalized adjacency matrix to realize information transmission. The calculation form of a single-layer graph convolution is defined as
The hierarchical structure allows attribute information to diffuse in multiple steps in the graph, capturing the deep coupling relationship between attributes. With multiple layers of stacking, node features not only reflect their own attributes but also integrate multi-order neighbor information to enhance the contextual semantics of node features. This mechanism effectively solves the bottleneck that nonlinear and complex associations between attributes are difficult to express with traditional feature engineering, laying a solid foundation for subsequent feature extraction.
Feature representation optimization and global coupling capture
The node feature matrix output by multilayer convolution is updated layer by layer through iteration, and a comprehensive representation of the fusion graph structure information is obtained. In order to improve the discriminability of features, a convolution kernel design with weight sharing is adopted to ensure the consistency of the feature extraction process and the control of parameter quantity. The node feature expression not only considers the local neighbor relationship but also integrates the context of the entire graph to reflect the global coupling characteristics of the attributes. This process can be described in the following mapping function form:
During the training process, the cross entropy loss function is used to optimize the model, which enables the network to learn high-quality feature expressions. This training strategy strengthens the ability to express complex relationships between attributes and improves the generalization performance of the model. The multilayer GCN architecture and its parameter tuning effectively solve the problem of insufficient attribute coupling information extraction, so that the associated attribute features are reflected in a structured form, supporting subsequent in-depth analysis and refined applications.
Implement attribute mathematical feature simplification mechanism
In the feature representation of GCN output, the membership function and covering operator in attribute mathematics are applied to construct the attribute dependency matrix. Through the logical simplification of redundant attributes, the core attribute set that maintains the classification discriminative power is screened out.
Constructing the attribute dependency matrix
The attribute features are extracted from the node feature matrix output by the graph convolutional network, and the membership function is used to evaluate the fuzzy attribution of each attribute to quantify the correlation and dependence between the attributes. The specific operation uses the membership function 

The three-dimensional heat map shown in Figure 3 reflects the spatial distribution characteristics of the attribute dependency matrix and reveals the complex changes in the coupling strength between different attributes. The horizontal and vertical axes represent the attribute index, and the vertical axis shows the dependency strength between two attributes. The overall matrix maintains a certain regular symmetry, reflecting the mutuality of the attribute dependency relationship. The local peak area in the heat map highlights that some attributes have a strong influence on multiple related attributes. This phenomenon usually originates from the inherent logic or physical and chemical connection between attributes, reflecting the heterogeneity of attribute coupling within the sample. In contrast, some regions show low-intensity dependence, indicating that the association between attributes is weak or even relatively independent, which helps to identify redundant information and provides theoretical support for attribute simplification. The diversity of dependency strength reflects the complexity of sample attribute performance, emphasizing the necessity of accurately screening key attributes in the mathematical feature reduction mechanism. The overall spatial coupling pattern provides an intuitive and rigorous basis for a deep understanding of the intrinsic correlation of recycled coarse aggregate properties. 3D heat map of attribute dependency matrix.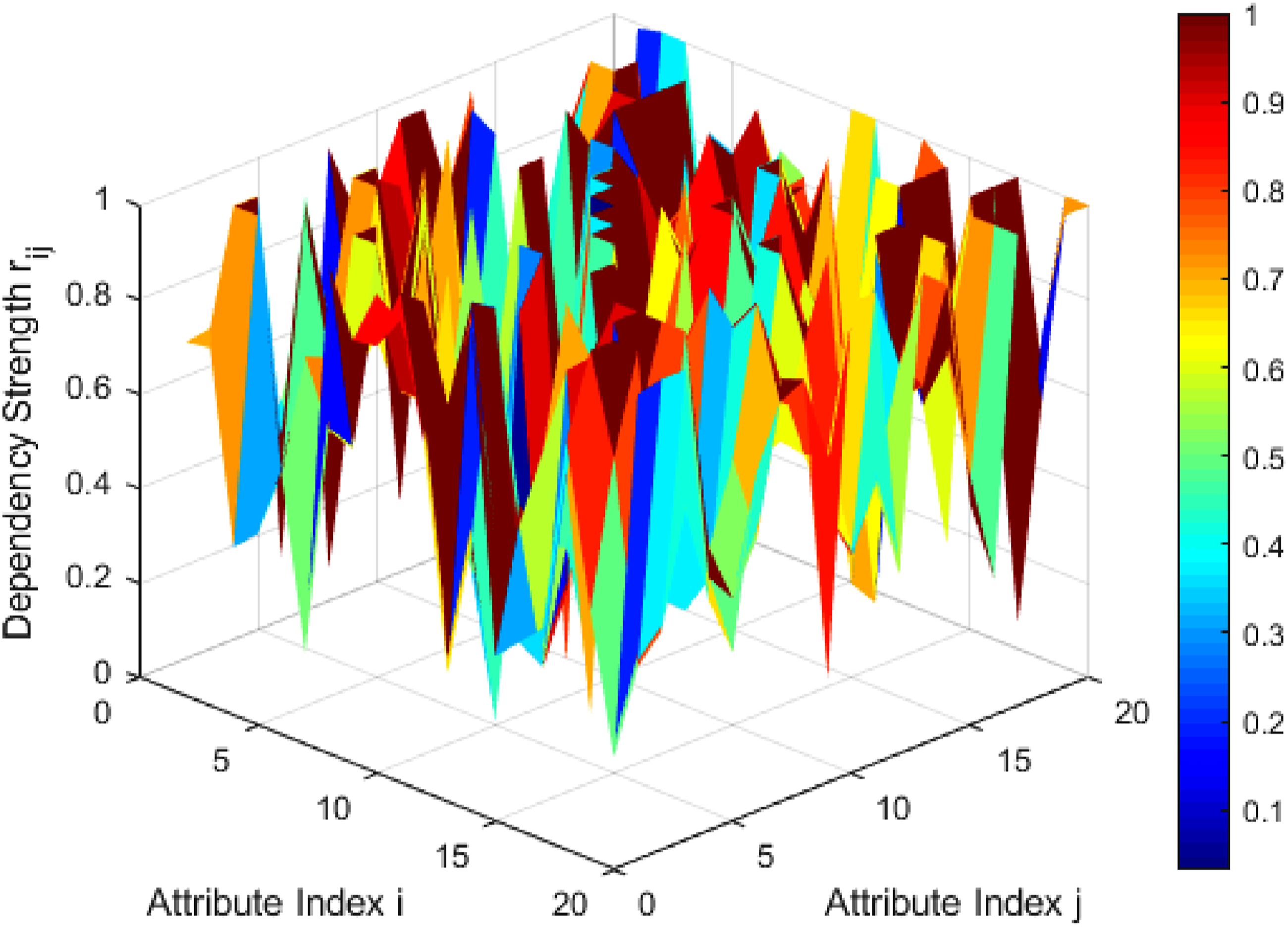
Logical simplification core attribute screening
By using the constructed attribute dependency matrix, logical simplification is performed on the attribute set with redundant information to eliminate the influence of redundant attributes on classification discrimination performance. The simplification process verifies the coverage ability of attribute subsets and confirms that the minimized attribute set can still maintain the overall discrimination power. Defining the simplified set 
Complete attribute recognition logic modeling and classification prediction
The attribute features after simplification and graph learning are input into the discriminant classifier model for training. The classifier uses logical rule generation and feature matching mechanisms to make the final prediction output of the sample attribute type.
Logical rule generation and feature matching mechanism construction
The core attribute features obtained after simplification are integrated into a unified input vector and input into the discriminant classifier for training. The discriminant model is based on the generation of logical rules and feature matching mechanisms. Through hierarchical analysis of input features, it automatically extracts the implicit discriminant relationship between attributes. The construction process sets the corresponding logical expression for each dimension in the attribute vector to describe its degree of association with the classification label. The logical rule function form is as follows:
Classification prediction and output result optimization
The trained discriminant model predicts the attribute feature vector of the new input, and determines the category label based on the activation degree of the logical rule and the matching confidence. The prediction process is defined as
The result output link incorporates post-processing optimization, using threshold adjustment and confidence correction to suppress the probability of misjudgment caused by noise interference. Specifically, by setting a dynamic threshold, samples with prediction confidence lower than the threshold are marked as uncertain categories, further triggering manual review or model retraining strategies. This ensures the stability and reliability of the classifier in practical applications. The overall process design completes the closed loop from attribute feature extraction and logical expression construction to classification prediction output, meeting the accuracy and efficiency requirements of recycled coarse aggregate attribute identification.
Method effectiveness evaluation
Experimental data and environment construction
Experimental data
The study used a data set of recycled coarse aggregate samples from a building materials laboratory, which included 150 groups of samples, covering 8 different material categories and 7 particle size ranges. The physical and chemical properties of each sample are measured, including 6 key indicators: density, porosity, water absorption, compressive strength, pH value, and chloride ion content. During the data collection process, standard experimental methods are used to ensure the accuracy of the measurement results.
Environment setup
Hardware configuration
NVIDIA RTX 3090 GPU (24 GB video memory), Intel Xeon Gold 6248R CPU (3.0 GHz, 48 cores), and 128 GB memory to ensure efficient processing of large-scale graph data.
Software framework
Based on Python 3.8, PyTorch 1.10.0 is used to implement the GCN model, and Scikit-learn 1.0.2 is used to complete the traditional machine learning comparison experiments (such as SVM and random forest). The core algorithms of attribute mathematical theory (membership calculation and covering operator) are implemented through NumPy and SciPy.
Experimental settings
GCN uses a two-layer structure, with hidden layer dimensions of 64 and 128, respectively; the activation function is ReLU (Rectified Linear Uni), and the optimizer is Adam (learning rate 0.001). Five-fold cross-validation is used during training, and the number of epochs per fold is set to 200. The early stopping strategy (patience = 20) prevents overfitting. The parameters of the comparison methods (SVM, RF, MLP) are all tuned through grid search to ensure fairness.
Internal correlations among key properties of recycled coarse aggregate
The experimental determination of 30 groups of different recycled coarse aggregate samples covers six properties: density, porosity, water absorption, compressive strength, pH value and chloride ion content. The data of each attribute are standardized to eliminate the dimension effect, and then the Pearson correlation coefficient between the attributes is calculated to generate a symmetric correlation matrix. In order to construct the weighted structure of the graph, the synchronous occurrence probability of the high-frequency co-occurrence intervals of each attribute value in the sample is further counted to form an asymmetric co-occurrence weight matrix, which is then fused with the correlation matrix. The construction of the weighted adjacency matrix is achieved through threshold screening and structural normalization.
Figure 4 shows the internal correlation structure between the key attributes of recycled coarse aggregate, which is visualized in the form of correlation matrix and weighted adjacency matrix. The correlation heat map in Figure a shows that physical properties such as density, porosity, water absorption and compressive strength are highly synergistic, forming a tightly coupled substructure, and the color represents the correlation coefficient. This correlation is derived from the consistency of the material microstructure, indicating that the pore distribution has a dominant influence on the overall physical properties. There is a certain degree of negative correlation between physical properties and chemical indicators (pH value and chloride content), revealing that the compositional differences during the production process may lead to dual constraints of physical stability and chemical corrosiveness. Figure b applies co-occurrence frequency for structural weighting, which allows weakly connected nodes that do not reflect significant correlation to be retained, enhancing the connectivity and information integrity of the graph structure. The color represents the joint frequency weight. The connection strength between attributes not only retains the significant relationship but also further reflects the logical coupling pattern of attribute co-occurrence. The edge weights of some weakly correlated nodes are increased under the action of co-occurrence weights, which shows that statistical co-occurrence has complementary value in revealing potential structures. This weighted structure provides a more reasonable connection semantic basis for graph neural networks, helps to accurately model the complex and nonlinear interaction mechanism between attributes, and improves the adaptability and stability of the overall structural representation. Internal correlations among key attributes of recycled coarse aggregate.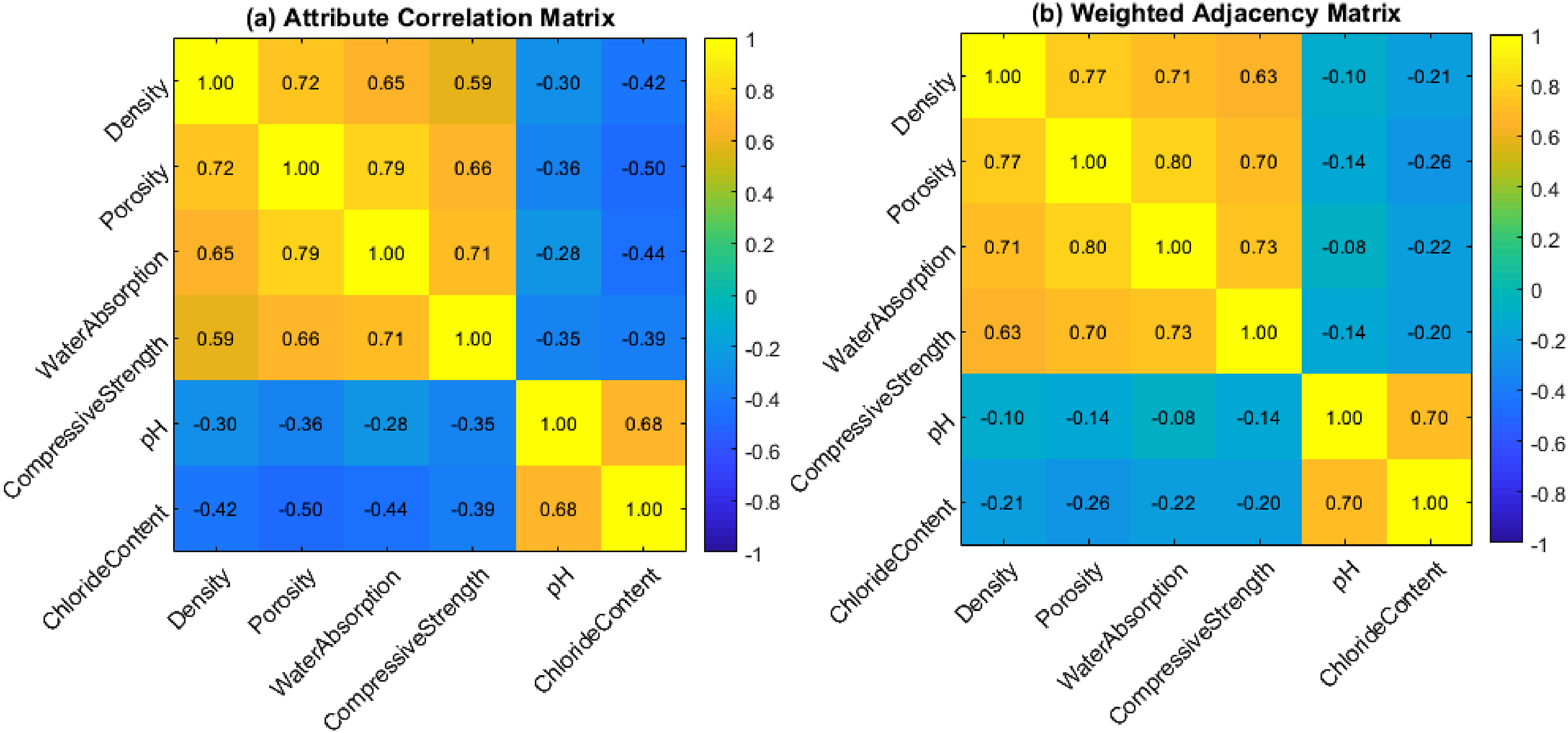
Hidden feature extraction effect
Contribution of GCN hierarchical structure to attribute feature extraction.

The topological structure of the input graph convolutional network (GCN) is formed by processing the data of the recycled coarse aggregate sample. GCN propagates and aggregates node information layer by layer through multilayer convolution operations to extract hidden features of global coupling. The first layer captures local neighbor relationships; the second layer fuses multi-order neighbor information; the third layer further abstracts global contextual dependencies and finally outputs feature representations with contextual semantics. This process reveals the coupling relationship between attributes from shallow to deep, providing a high-quality feature foundation for logical reduction and classification prediction.
Figure 5 shows the hidden feature representation extracted by the multilayer graph convolutional network, including the feature distribution of the first, second, and third layer GCN outputs. The horizontal axis represents the sample index (from 1 to 150), the vertical axis represents the node index, and the color represents the feature value range (normalized between −2 and 2). Each sample has different feature values at different nodes. The data is normalized to eliminate dimensional differences and ensure that the input features are on a uniform numerical scale. As the number of GCN layers increases, the range of feature values in different nodes gradually decreases, indicating that the model gradually transitions from local features to global features. The first layer of GCN mainly captures the information of local neighbors, and the range of feature values is large, reflecting the initial modeling of direct associations between attributes. The second-layer GCN begins to integrate multi-order neighbor information, and the range of feature value changes is reduced, showing more contextual dependencies. The third-layer GCN further captures global coupling features, and the features are more concentrated, indicating that the model can effectively integrate multi-order neighbor information and enhance the contextual semantics of node features. These changes show that GCN improves the attribute recognition effect by gradually excavating the deep coupling relationship between the attributes of recycled coarse aggregate by transmitting attribute information layer by layer. This hierarchical feature extraction mechanism enables node features to not only reflect their own attributes but also integrate multi-order neighbor information, providing higher quality feature representation. Hidden feature representation extracted by GCN.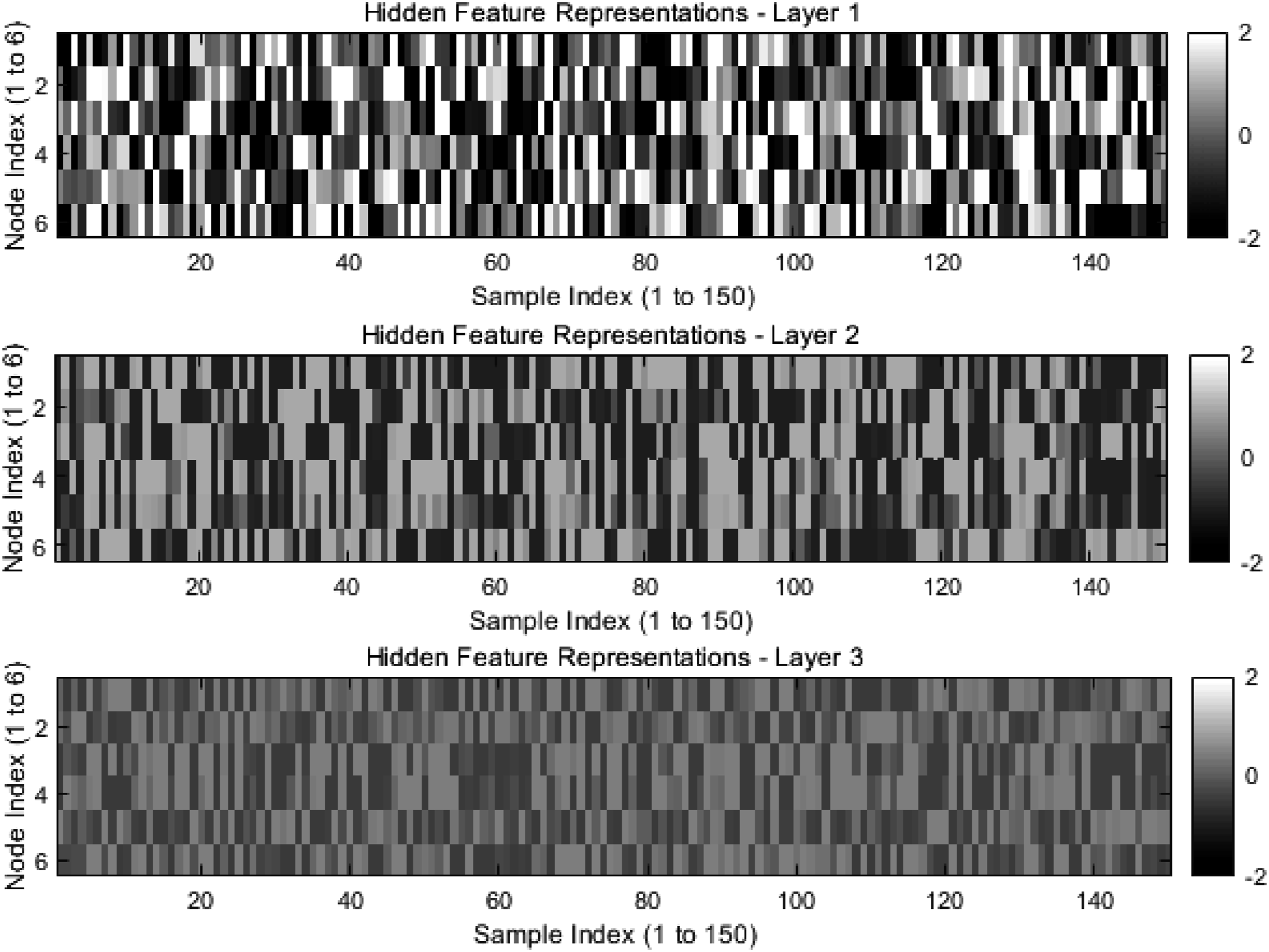
Changes in attribute membership and mathematical feature simplification effects
The membership function curve calculates the corresponding membership based on the feature value range by setting different α parameters to achieve the regulation of attribute sensitivity. The specific steps include first mapping the high-dimensional features output by GCN to the membership space, and then adjusting the α parameter to gradually generate different curves to reflect the changes in attribute membership. The coverage and attribute compression ratio data come from the redundant attribute elimination records during the attribute reduction process. By calculating the impact of the remaining attributes on the overall discrimination ability, the attribute dependency matrix is constructed to evaluate the coverage changes of the attribute set at each stage. The attribute compression ratio is expressed as the ratio of the number of remaining attributes to the number of initial attributes, showing the reduction effect.
Figure 6 shows the change in attribute membership and the effect of mathematical feature simplification: Changes in attribute membership and mathematical feature simplification effects.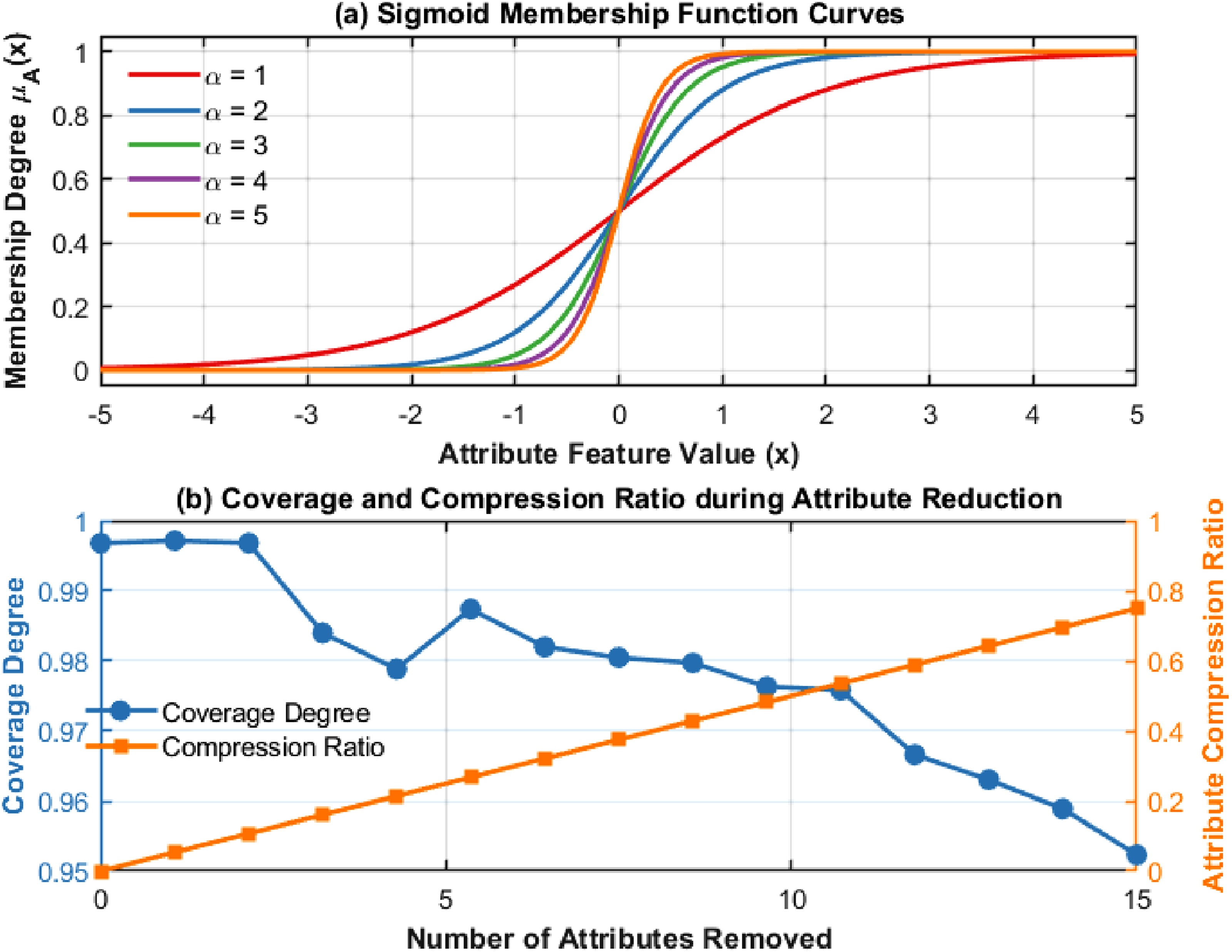
Figure a shows the response characteristics of the membership function as the parameter α changes. The horizontal axis is the attribute feature value, and the vertical axis is the corresponding membership. As the α value gradually increases from 1 to 5, the transition interval of the function curve narrows significantly, showing a steeper change trend. This change reflects the increased sensitivity of the membership to the attribute characteristics; that is, the high α value strengthens the influence of the attribute on the discrimination, making the discrimination of some key attributes more prominent in the feature space. This feature helps to capture core attributes more accurately during mathematical feature reduction and avoid feature ambiguity or confusion caused by low sensitivity. Figure b reveals the dynamic relationship between coverage and attribute compression ratio during attribute reduction. The horizontal axis represents the number of attributes removed, the left vertical axis corresponds to coverage, and the right vertical axis reflects the attribute compression ratio. As the number of attributes gradually decreases, the coverage shows a slow downward trend, indicating that the discriminative ability of the overall feature set remains stable, and the elimination of redundant information does not cause obvious coverage loss. This phenomenon shows that the screening strategy effectively retains the discriminative information while compressing the size of the feature set, ensuring that the model performance is not weakened. At the same time, the compression ratio has steadily increased, indicating that the feature space has been effectively simplified, reducing the complexity and computational burden of model training. The data revealed that the mathematical feature reduction mechanism has achieved a good balance between maintaining discriminant performance and reducing redundancy. By adjusting the sensitivity of the membership function and covering operator analysis, the constructed attribute dependency relationship achieves efficient and accurate core attribute screening.
Evaluation of attribute recognition accuracy and recall
Accuracy and recall are used as the main quantitative indicators. Accuracy is used to reflect the correctness of the model’s overall discrimination of various types of recycled coarse aggregate samples, while recall focuses on the model’s ability to detect samples of the target category, especially in multi-class fine-grained classification tasks. Each method is run in a unified test set environment to maintain the consistency of sample distribution and feature dimension. The classification results are counted according to the two dimensions of material type and particle size. The material type and particle size represent different attribute compositions. The accuracy and recall curves of the four methods of GCN and attribute mathematical fusion method, SVM, random forest and MLP are extracted in each category. The classification performance differences of each method are compared horizontally to verify the recognition effect advantage of the fusion mechanism under high coupling feature expression.
Figure 7 shows the accuracy and recall performance of four different methods in material category recognition and particle size recognition tasks, including GCN-attribute mathematical fusion method, support vector machine (SVM), random forest (RF) and multilayer perceptron (MLP). In the Figure, sub-graphs a and b respectively show the recognition accuracy and recall rates of eight different material categories, while sub-graphs c and d correspond to the recognition accuracy and recall rates of seven particle size ranges. Attribute recognition accuracy and recall.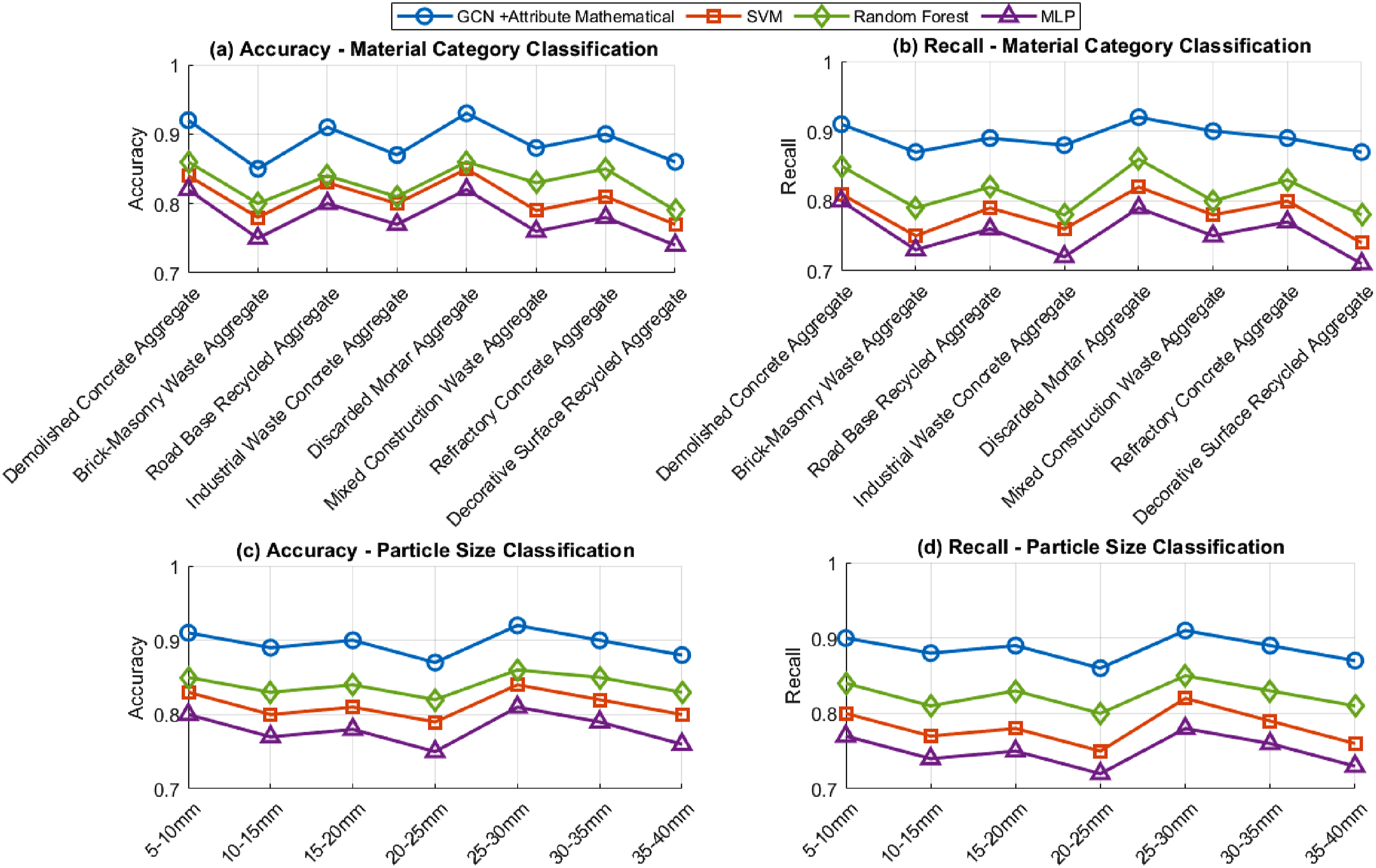
As can be seen from sub-graphs a and b, the overall accuracy and recall of the GCN-attribute mathematics fusion scheme are better than those of the other three methods. The average recognition accuracy and recall of eight different material categories are both 0.89, reflecting its ability to efficiently mine the multi-dimensional properties of materials and capture associated features. The performance fluctuates between different material categories, indicating that the method can adapt to the heterogeneity of material properties, and performs particularly well in key categories such as demolished concrete aggregate and waste mortar aggregate. The support vector machine and random forest have similar accuracy performance on some materials, and the performance difference is mainly reflected in the stability of the recall rate. The overall performance of the multilayer perceptron is slightly inferior, and the recall ability on complex material categories is insufficient. Sub-figures c and d reflect the ability of each method to identify particle size. The GCN fusion method still maintains its leading position, with the average recognition accuracy and recall rate of 0.90 and 0.89 in the seven particle size ranges, respectively, showing robust performance in all particle size ranges, while other models perform poorly in the particle size range, indicating that their generalization ability is limited. Support vector machines and random forests have a certain performance in particle size recognition, but there is a gap with the GCN-attribute mathematical fusion solution, and the multilayer perceptron has the worst overall performance. The data verifies the advantages of the GCN-attribute mathematical fusion method in the case of complex attribute multi-dimensional coupling and fully demonstrates the effect of this method on improving the recognition accuracy and recall ability of different material categories and particle sizes.
Evaluation of model stability and generalization ability
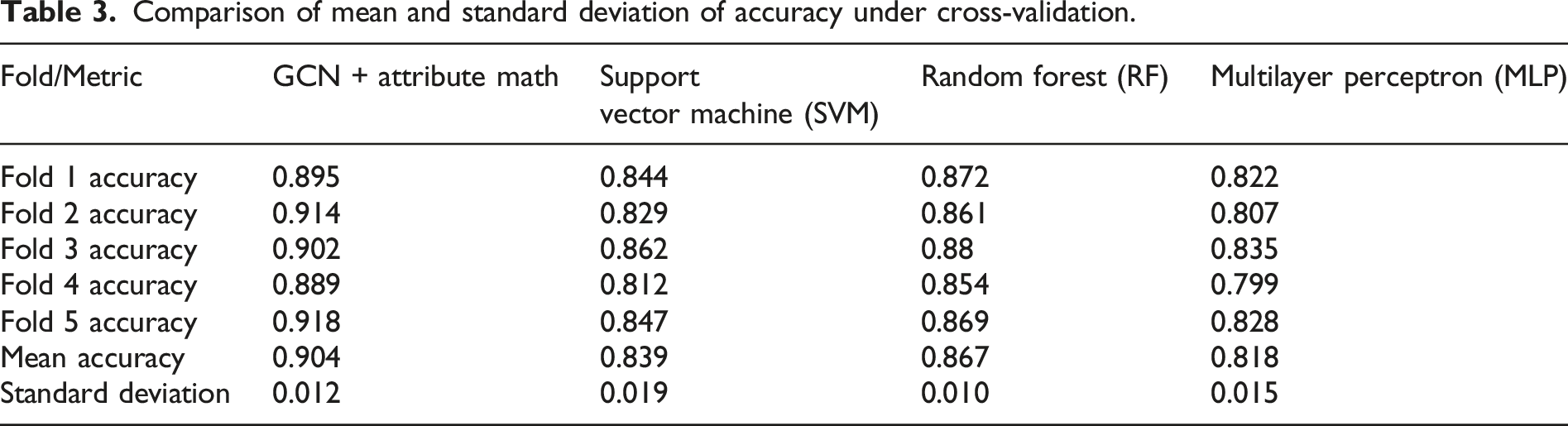
In order to verify the robustness of the model under different sample division conditions, a 5-fold cross-validation strategy is adopted. The training and testing phases are independently modeled according to the five subsets after division, and the accuracy of each method in each fold is statistically analyzed. The mean and standard deviation of the 5-fold accuracy sequence are then extracted to measure the model’s ability to maintain performance consistency in a multi-sample structure. The mean accuracy describes the overall prediction ability, and the standard deviation reflects the degree of fluctuation of the model response under different data partitioning conditions. The combination of the two reflects the generalization performance of the algorithm in complex attribute disturbance scenarios. The experiment sets up multiple comparison models at the same time, maintaining the same sample splitting strategy and parameter configuration to ensure the fairness and comparability of the indicator results.
Comparison of mean and standard deviation of accuracy under cross-validation.
Comparison of feature dimension compression effects
In the process of evaluating the effect of feature dimension compression, multi-fold data subsets are constructed to verify the trade-off ability of different feature selection methods between redundancy elimination and information retention. The feature reduction rate and information retention rate of the attribute mathematical reduction strategy (Attr-Reduction) and PCA and mRMR in each folded subset are calculated to measure their effectiveness and information integrity performance when compressing dimensions. The feature reduction rate reflects the proportion of dimensions that are successfully compressed in the initial feature set, and the information retention rate describes the contribution of the key attributes retained after compression to the original classification task. The attribute mathematical reduction strategy performs attribute pruning based on its internal logical consistency. PCA focuses on variance coverage, and mRMR emphasizes the minimum redundancy between features and the maximum inter-class difference.
Figure 8 shows the comparison of feature reduction rate and information retention rate of three feature dimension compression methods on the 50% data subset. The attribute mathematical simplification strategy shows a high level of feature reduction rate, with an average of 0.67, indicating that it is more efficient in removing redundant features and can effectively reduce irrelevant or repeated information. PCA can also maintain a relatively stable dimensionality reduction effect, reflecting that it relies on the feature variance contribution ranking and can reasonably compress the data dimension, but the overall feature reduction rate is lower than that of the attribute mathematical method. The mRMR method has the lowest feature reduction rate and focuses on maximizing the difference between features and the distinction between categories, thus retaining more information dimensions to enhance the discrimination ability. In terms of information retention rate, the attribute mathematical simplification strategy also shows excellent performance, with an average of 0.92, indicating that while ensuring compression efficiency, it relies on the dependency matrix between attributes to accurately screen out core features and effectively retain the key information required for classification and discrimination. PCA is dominated by variance explanation and may ignore some low-variance features that have a subtle contribution to classification. mRMR considers redundancy minimization and correlation balance in feature selection, so the amount of information retained in the folding is sacrificed. The attribute mathematical simplification strategy accurately identifies redundant features by establishing an attribute dependency network, achieving a balance between stability and information integrity in a diverse data environment, and showing a better balance between dimensionality reduction and information retention. Comparison of feature compression efficiency and information preservation.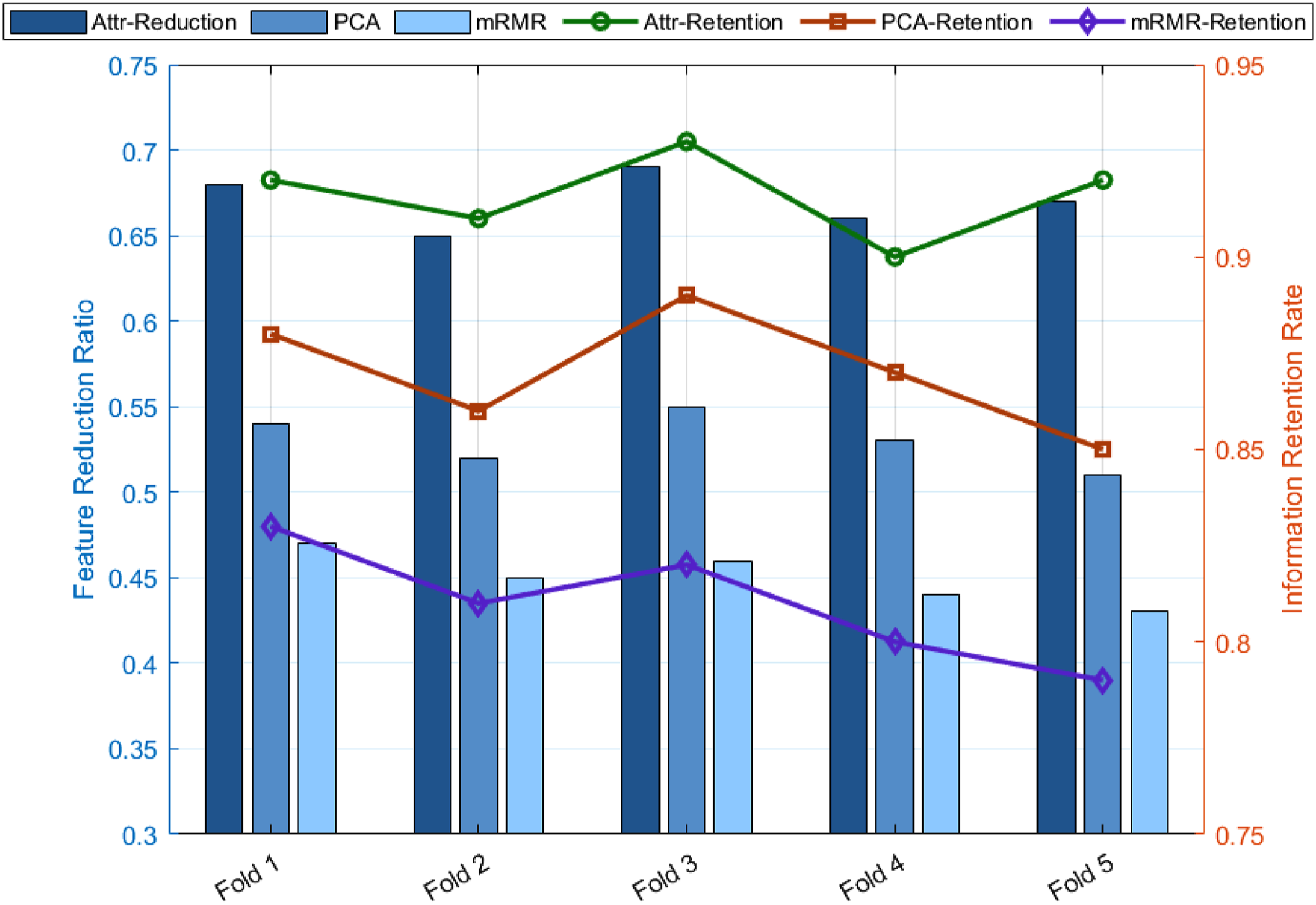
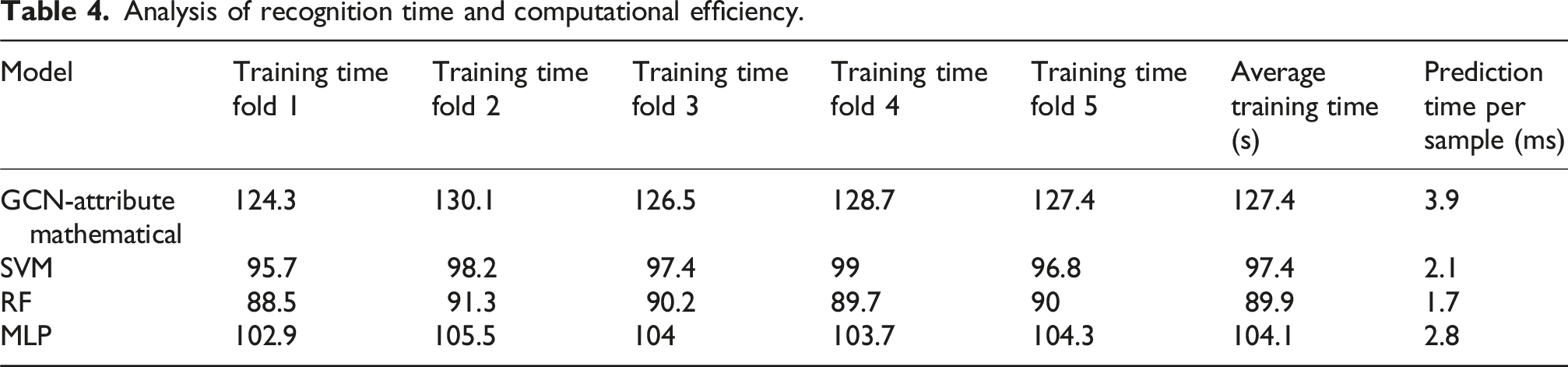
Analysis of recognition time consumption and computational efficiency
The model efficiency is quantified by the average training time and single sample prediction time. The computational resource consumption of the GCN-attribute mathematical method is compared with that of the support vector machine (SVM), random forest (RF), and multilayer perceptron (MLP) methods when processing the same test set.
Analysis of recognition time and computational efficiency.
Conclusion
To address the challenge of complex feature coupling in the identification of recycled coarse aggregate properties, this study proposes a novel framework that integrates graph learning with attribute mathematical simplification for feature modeling and classification. By constructing an attribute graph structure, the intrinsic relationships among various physicochemical indicators are effectively captured, while graph convolution operations enable deep extraction of coupled information, thereby overcoming the limitations of traditional methods in modeling global correlations. To tackle the issue of high-dimensional feature complexity, a logical relationship compression mechanism based on attribute mathematics is introduced. This mechanism accurately identifies the core attribute set that most significantly influences the classification task, achieving effective feature dimensionality reduction while preserving the integrity of decision boundaries. In the classification stage, the integration of attribute logic modeling and matching rules enables precise recognition of both material categories and particle size classifications of recycled aggregates. Comprehensive performance evaluation demonstrates that the proposed GCN–attribute mathematics fusion model outperforms conventional machine learning methods—including SVM, random forest, and MLP—in terms of recognition accuracy and recall across multiple material types and particle size ranges. The attribute mathematical simplification strategy achieves an impressive average feature reduction rate of 67%, while retaining 92% of the original information, confirming its effectiveness in enhancing recognition performance without sacrificing classification fidelity. The proposed fusion strategy provides a promising approach for the intelligent identification of samples characterized by multi-source attributes and complex structural relationships, exhibiting strong generalization capability and engineering applicability. Future work will explore the application of time-series graph modeling in dynamic multi-source attribute scenarios, aiming to further enhance the adaptability and robustness of the recognition model under time-varying feature structures.
Footnotes
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Science and Research Project of the Hunan Provincial Department of Education (Project No.: 23C0481).
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.