
Abstract
This article will focus on abstracting and generalising a well-studied paradigm in visual, event-related potential based brain–computer interfaces, for the spelling of characters forming words, into the visually encoded discrimination of shape features forming design aggregates. After identifying typical technologies in neuroscience and neuropsychology of high interest for integrating fast cognitive responses into generative design and proposing the machine learning model of an ensemble of linear classifiers in order to tackle the challenging features that electroencephalography data carry, it will present experiments in encoding shape features for generative models by a mechanism of visual context updating and the computational implementation of vision as inverse graphics, to suggest that discriminative neural phenomena of event-related potentials such as P300 may be used in a visual articulation strategy for modelling in generative design.
Keywords
Introduction
Since the progressive evolution of a branch of architectural phenomenology oriented towards neuroscience,1,2 a direct projection has been made clear between sensory experiences of architectural objects and the dynamics of neural networks, 3 or the influence of the built environment on human physiology. 4 This article proposes that some existing technologies in neuroscience, artificial intelligence and neuropsychology, generally used to segment such transitions into greater resolutions of study, may support an inverse and more computationally active approach integrating neural phenomena into generative design (GD) models to infer on the experienced object itself. Through a technical introspection on testing this idea, this article will first focus on generalising a well-studied paradigm in visual, event-related potential (ERP) based brain–computer interface (BCI),5,6 for the spelling of characters forming words and applying it into the visually encoded discrimination of shape features forming design aggregates (Figure 1). The current assumption is that such direction may very well enrich the contemporary research efforts on the topic of GD by bridging specific human cognitive capacities of early visual discrimination and dedicated machine learning (ML) models. It will then propose a method for applying the studied spelling model to encode shape features from design aggregates and finally conclude on the future potentials of such method.

Left to right, a typical session using the developed design aggregate model and techniques. Left, beginning of the session with the initial state. Right, middle of the session presenting its evolution.
Background
Precedents
This research is a direct continuation of prior work and scientific collaborations done in the field of computer-aided architectural design (CAAD) and human–machine interaction (HMI) by applying evidences found in visual, ERP-based, non-invasive BCI using electroencephalography (EEG), to a GD approach by rapid serial visual presentation (RSVP) tasks and combining both human intelligence (HI) and machine intelligence, or ML in a closed loop. While establishing a prior background for applicative potentials, and experiments, suggestions have been made on the specificities of acquiring, treating and integrating peculiar neurosignals such as ERP for iterative shape generation and selection systems.7,8 In addition to a broader understanding of the technologies involved in BCI and in-depth experiments of their applications, these precedents offered a ground for reactivating architectural research in the context of HMI and neural phenomena. This article focuses on proposing a method for encoding shape features with a deeper interest in practical future deployments and ML contributions in a context of mixed intelligence (HI and ML) for the generation of features of design and architectural interests. The next section will provide details on the type of BCI identified and used.
BCI and EEG signals
There are several, well-established, techniques for measuring brain activities such as magnetoencephalography (MEG), near-infrared spectroscopy (NIRS), electrocorticography (ECoG), functional magnetic resonance imaging (fMRI) and EEG. Each technique has some advantages and disadvantages compared to other techniques. For example, in EEG, the temporal resolution is high but the spatial resolution is low, compared to fMRI. But despite its drawbacks, and because of low cost and portability, EEG has been increasingly largely used in both clinical and research applications. 9 Since their first recordings, 10 and with the evolution of its signal processing,11,12 EEG became a primordial component of non-invasive BCI technologies. 13 BCI research itself began in the early 70s, contemporary to first-order cybernetics,14,15 and had, since then, evolved its paradigm and spread across multiple research disciplines and fields of applications beyond communication and control.16,17 A general definition of a BCI involves the digitisation of neural activity transduced into signals, acquired from the central nervous system (CNS, or brain), and then translated to messages or commands for an interactive application, once such signals have been first measured and processed into classifiable patterns (Figure 2). For applicative reasons, the present research focuses on real-time, synchronous, 18 non-invasive EEG methods and its related signal features. Although most of electrical potentials derived from neural activity are studied through generalised models of pattern recognition and localisation in time and frequency domains, EEG signals remain non-stationary and constitute a challenge to be aforementioned for any research involving ML in encoding the recognition of neural patterns, 19 in comparison to advancements in other applicative fields of ML. In general, the poor signal-to-noise ratio of such signals (noise and outliers), the high dimensionality of feature vectors, the time-dependent information of signals leading to a time segmentation of its data, the non-stationarity over time sessions and sessions even for a single user, the generally small amount of data per training set due to the mentioned factors above and the time consuming and demanding cognitive load of data acquisition sessions constitute critical factors in the design of a BCI. But aside from any technical challenges, the mentioned non-stationarity of EEG signals is also to be considered as an asset to enrich generalised ML models with its variability and diversity of cognitive responses. The following section will focus on the peculiar neural pattern extensively used throughout the research.
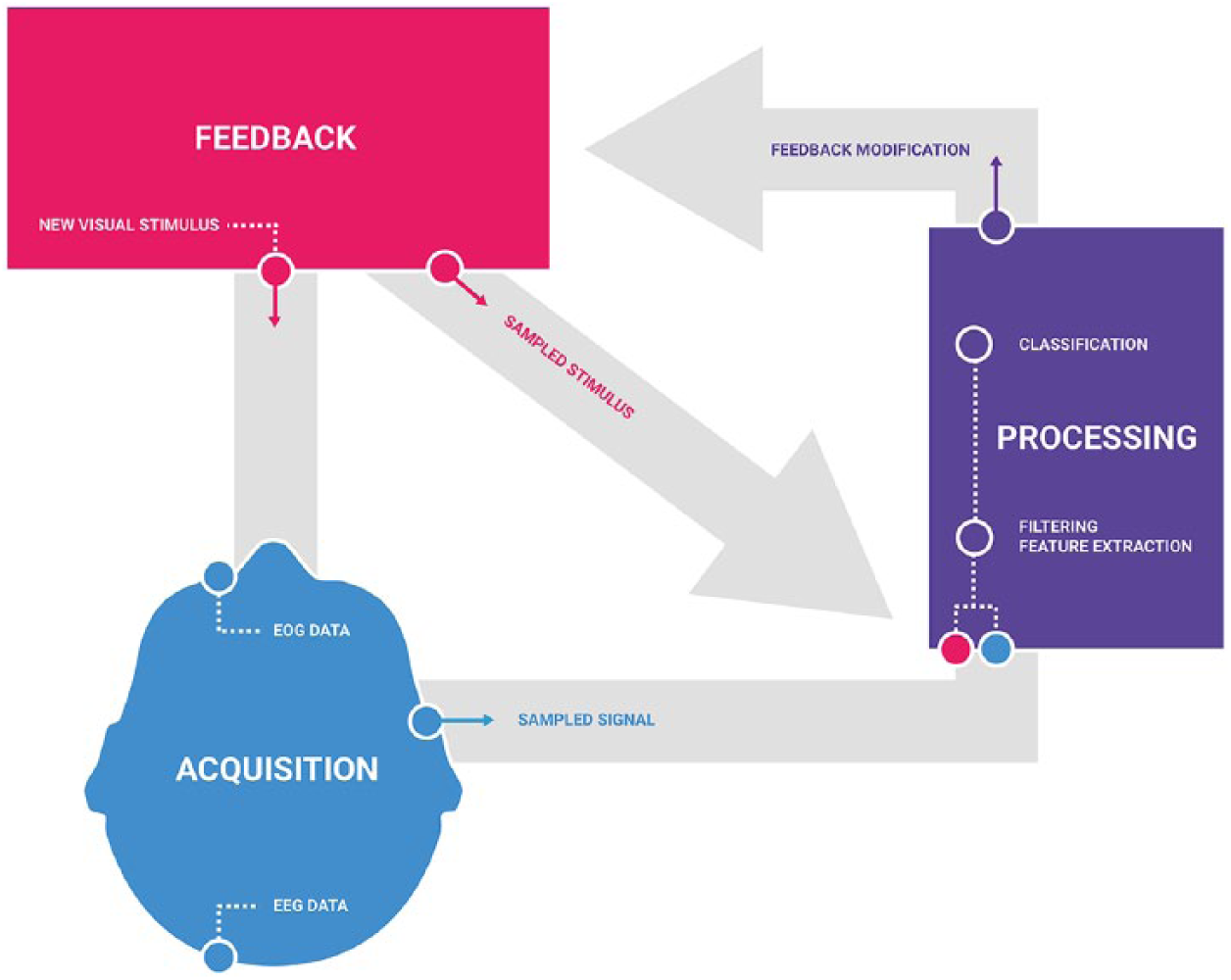
A typical ERP-BCI involving a visual elicitation paradigm and presenting its three main components: data acquisition (blue), signal processing (purple) and stimuli feedback (magenta). All three main components may greatly vary depending on the BCI type and purpose. Stimuli may be uni- or multi-modal (visual, auditory). Acquisition may be uni- or multi-modal (EEG, EOG, etc.), and processing may vary greatly in the vast range of ML models depending on the classification or regression tasks at work for the given data. A typical synchronous BCI nonetheless will include the temporal segmentation, or sampling, and synchronisation of both stimuli and signals in order to process data and output a correlated modulated feedback.
ERP and the P300 wave
ERPs are a set of standard and robust electrophysiological potentials of small voltages, abbreviated as ERP, and resulting from specific events or stimuli. They are generally characterised, in the time domain, as exogenous when detected within the first 100 ms onset stimulus and endogenous after that, while reflecting cognitive tasks of higher-order invoked in relation to working memory, expectation, attention or changes in the mental state, 20 rather than simply evoked by the physical impingement of external stimuli. Currently, ERP is one of the most widely used methods in cognitive neuroscience research to study the physiological correlates of sensory, perceptual and cognitive activity associated with information processing. 5 For similar reasons, they constitute neural phenomena of high interest when considered in HMI together with CAAD.7,8 One of the major ERP components of interest for this research is the P300 wave (or P3), often used as metrics of cognitive functions in decision-making processes, as its two sub-components (p3a and p3b) are mostly correlated with the processing of novelty and improbable events. 21 Since its discovery 22 as a large positive wave occurring approximately between 250 and 700 ms onset stimulus, the P300 has become a popular signal to integrate in BCI, once combined with RSVP of elicitation paradigms. For their correlation in the real-time discrimination of events in similar contexts, they may also constitute early cognitive HI features of high interest to pair with discriminative models of supervised or unsupervised ML. The following section describes the elicitation paradigm used for P300 waves.
The oddball paradigm and the P300 speller
The scientific study of cognitive responses to eliciting events has greatly benefitted from a common junction of two disciplines in neuropsychology by combining techniques of specific neural electrical potentials (i.e. ERP) and elicitation paradigms. Although psychological elicitation paradigms were first introduced into the neuroscientific study of ERP before becoming a generalised technique for event-related cognitive responses,23,24 it later became a common neuropsychological technique due to the short latency and high temporal resolution of event–stimuli correlation such combination can provide. 25 There is a limited set of well-studied paradigms in correlation with known ERP but which allows for a wide range of inferences on cognitive processes such as inattentive auditory processing, selective attention, stimulus evaluation, working memory updating, movement preparation and inhibition, error processing memory, language processing, face processing or even mental chronometry. 6 This research focuses on a well-studied paradigm used to elicit a P300 wave and based on the principle of discrimination: the oddball paradigm (OP). The OP is a typical RSVP task with frequent, random, deviant stimuli: the oddball. 6 These peculiar stimuli are then used to detect the elicitation of an ERP. In the case of a visual OP, a series of self-similar events are shown at fast pace in sequences of a few milliseconds (Figure 3).
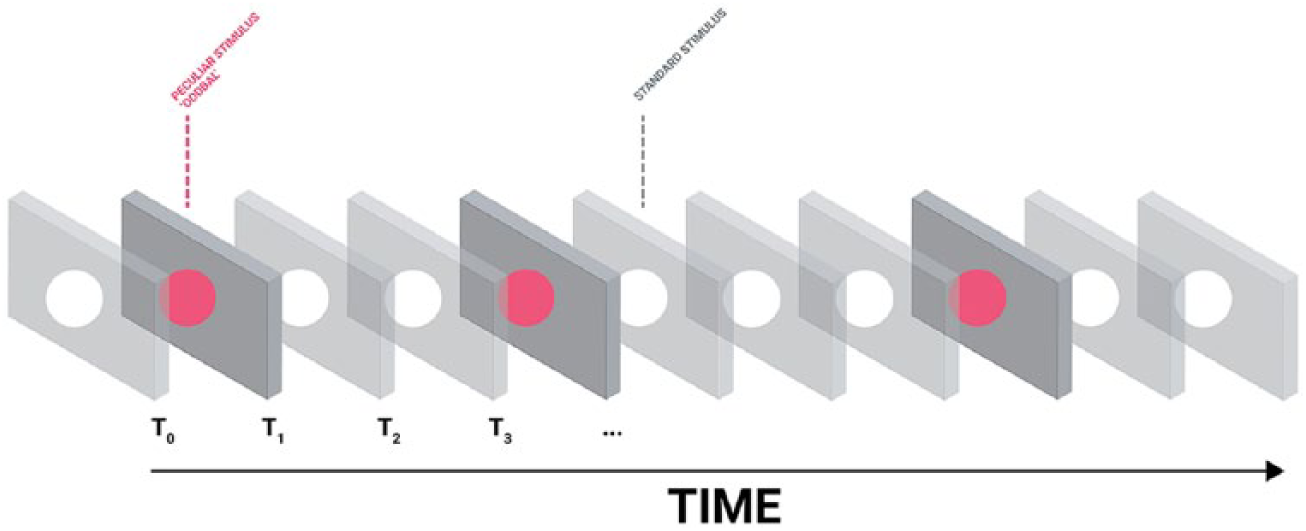
A typical visual oddball paradigm in a RSVP task to elicit ERP. Each stimulus presentation epochs and in-between epochs consist of a few milliseconds in the time domain and in the elicitation range of the studied ERP wave.
In the scope of implementing such paradigm used in ERP for design purposes, we propose as a case study, an existing and stable model on visual ERP, widely used for BCI research competitions and benchmarks: the P300 speller.18,26 It should provide a stable ground for study, discussion and implementation of new hypothesis. It typically consists of a matrix of characters. Each row or column is flashed as a stimulus, according to the OP (Figure 4). The oddball is then the character to be spelled to form a word, with the probability of being contained in the presented row or column. The following section will propose a method to derive from word spelling to a more generalised model of discriminating visual features.

A custom p300 word speller developed for the research. Rows and columns are flashed independently in a predefined random sequence.
Methods
Support vector machine for EEG BCI signals
Discriminative classifiers such as support vector machine (SVM) are adequate candidates for such models as they learn discriminant hyperplanes on data points with robust regularisation and generalisation properties on high dimensional feature vectors and small training sets.27,28 They may be used for linear decision boundaries (i.e. linear support vector machine (lSVM)) or non linear ones (i.e. Gaussian, RBF SVM) once data points are projected to a higher dimensional feature space via a kernel function. 29 The margin maximisation of the hyperplanes improves the generalisation of classes and controlled by one of the very few hyperparameters to be explicitly assigned (Figure 5). The main cost of SVM simplicity and robustness in generalisation, insensitivity to overfitting and curse of dimensionality, is a decreased speed of execution. 19 Nevertheless, in the context of a synchronous BCI, data acquisition and processing can be successively executed without perturbation on the overall feedback loop or high latency between cycles as it remains fast enough for real-time BCI. 30 Based on such characteristics, this research implements and considers lSVM as the first benchmark to confront every other future new ML model to study. Precisions on the type of visual character discrimination involving SVMs are added in the following section.
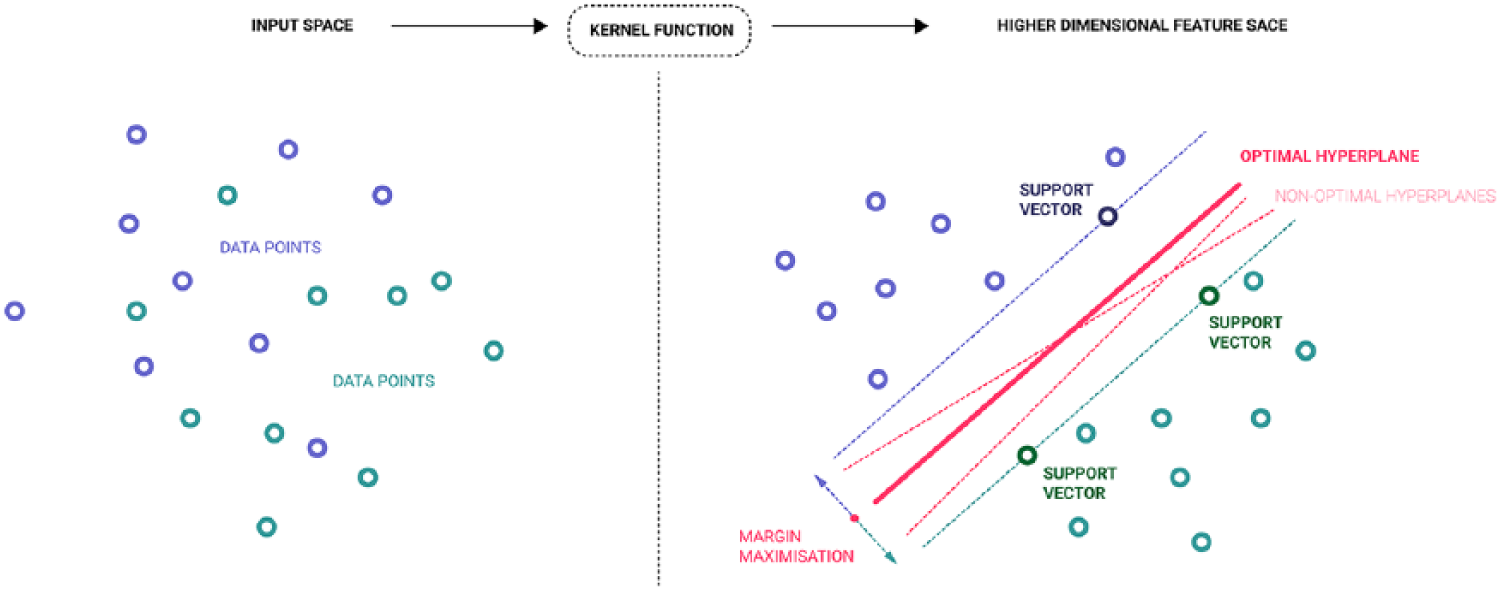
SVM hyperplane margin maximisation for generalising classes discrimination.
Visual character discrimination
In the context of the aforementioned P300 speller (see section ‘The oddball paradigm and the P300 speller’), and in similar ERP applications in general, a clear distinction should be made between the classification of ERPs, and character recognition for the visual spelling of a word or a phenomena (i.e. an ERP), and its correlation to a particular event (i.e. the RSVP of the OP). As the former is used and implemented in the design of the latter, we are using this particular combination to generalise a first visual feature discrimination model. As the target character is contained in a set (a row or column of characters), the positive elicitation of a P300 wave would correlate with the high probability of the target character being in this set. On the overall flashing sequence dedicated to a particular character, the learned character would be the one with the most of intersections between eliciting sets (Figures 4 and 6). Such an analogy of visual sets intersections must then have to be translated into probability scores for a target character to be learned among others, and for a single SVM classifier to encode several sequences as a given word through linear summation (i.e. MONKEY, SHOE, CAT, HAT, TIME, etc.). The following section will describe the use of lSVMs in an ensemble method for better discrimination.
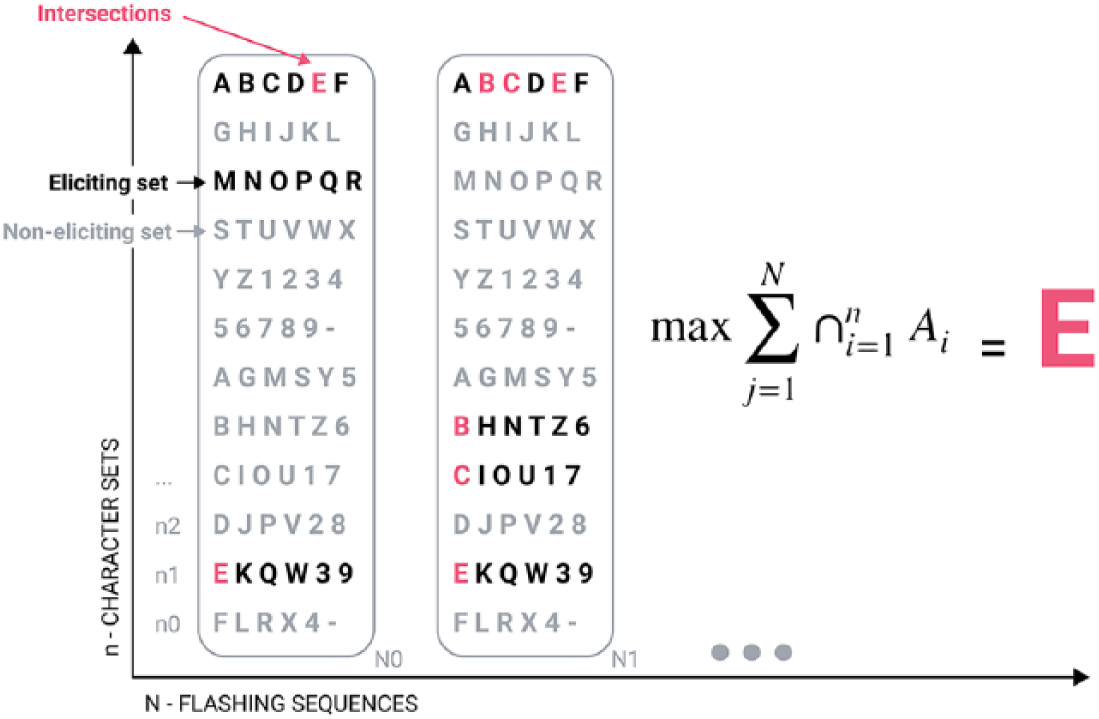
Typical character spelling session. For N-flashing sequences of n-character sets, the target character (E) corresponds to the maximum summation of N-intersections of all n-character sets (A).
Ensemble learning
Ensemble learning models have a great variance reduction property and an increased generalisation performance over a single neural network. 31 From several, self-similar or different weak classifiers, a stronger one can be generated 32 through different strategies such as voting, boosting, bagging and stacking. Given the previously mentioned properties of the data to be classified (see sections ‘BCI and EEG signals’ and ‘ERP and the P300 wave’), and the single-class classification type of the visual discriminative model to encode (eliciting an ERP or not), an ensemble of lSVM can be trained, where each lSVM is trained individually on a specific word to form a majority-voting ensemble (Figure 7). Despite the single-class classification context of each lSVM, the decision function used for the ensemble method of voting classifiers is one-vs-rest, 33 as each lSVM of the ensemble encodes the probability of an eliciting character belonging to a specific word. The practicality of such system relies on maintaining a fairly decent amount of word-encoded classifiers and of spelling sequences during individual training. For both the study and reproducing of the P300 word speller, and the implementation in the discrimination of shape features, we maintained a common range of sequences from 1 to 10 per word, and 12 classifiers; each one trained on a specific word and where some of these words share similar characters, as used for typical benchmarks. 34 The following section will propose an assumption to derive this spelling model and use such ensemble methods.
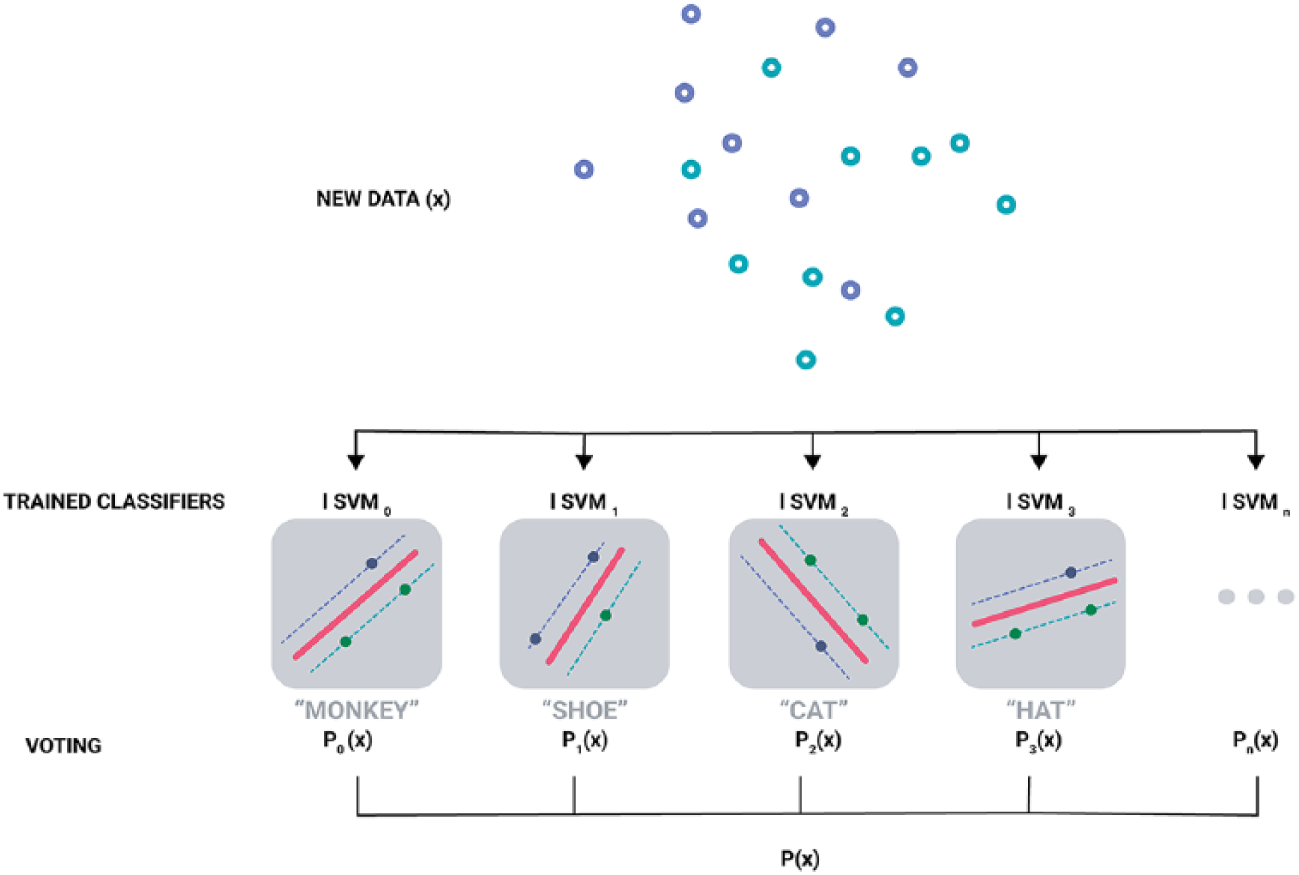
Ensemble learning of voting classifiers where each classifier is trained on sequences of recorded signals for a given character and a given word.
Decoding discrimination for higher visual complexity
As such method is mainly used in neuroscience and neuropsychology for the study of the neural phenomena, the detection of cognitive dysfunctions or their rehabilitation, it is rarely studied for a generative approach in the widest creative industry but for relatively limited interactions with pre-built visual narratives such as in the gaming industry. 35 The main interest supported by this research is to reduce the rigidity of such models to a more adaptive and practical approach that CAAD might computationally integrate later as a cognitive-creative approach. Given evidences that endogenous ERP is exposed to language (see section ‘ERP and the P300 wave’), this research proposes that stimuli of higher visual complexity (i.e. containing larger amount of information within the same epoch) can be similarly used for such discriminative models, as they may not be fully cognitively indexed in the short successive time windows of a RSVP but may expose partial ensembles of features to be discriminated. Therefore, the assumption is that an ensemble method may gather trained classifiers which have been exposed to robust visual models such as the P300 word speller (see section ‘The oddball paradigm and the P300 speller’) and can still work effectively on decoding discrimination on RSVP models containing a higher visual complexity, even in the case of context updating, as originally defined. 21 The following section describes a derived generative visual stimuli model for relatively simple design aggregates in order to apply such assumption.
Visual stimuli and design aggregates
Given early semantic exposure mentioned previously, deriving visual stimuli from word spelling to shape features discrimination with ensemble models offers both an open context for classification, and a certain range of self-similarity of events for discrimination. The order of a character given by a word to spell can be transposed to the context of an evolving shape given by an object during training, if a similar temporal segmentation is respected. We thus start by transposing the training of each lSVM from word spelling to shape spelling, assuming the partial encoding of its features. The adapted visual stimuli use 3D metaballs rendered by a typical marching cubes algorithm.36,37 Each flashing epoch previously showing a row or a column is replaced by the uniform random position of a new metaball instance in spherical coordinates (Figure 8). The discrimination occurs between each epoch to determine and fix the position, enabling a new sequence of epochs for a new position to be discriminated. In order to avoid an early fatigue and decreased focus from a user, and considering RSVP regarding cognitive loads, the temporal segmentation of events to be discriminated has been reduced to the positions of new metaballs while the overall shape constituted of already fixed ones remains viewed but rotates around its centroid (Figure 9). This discrete-continuous setup allows as well to focus of the discrimination of new positions while offering an updated visual context throughout the entire session.
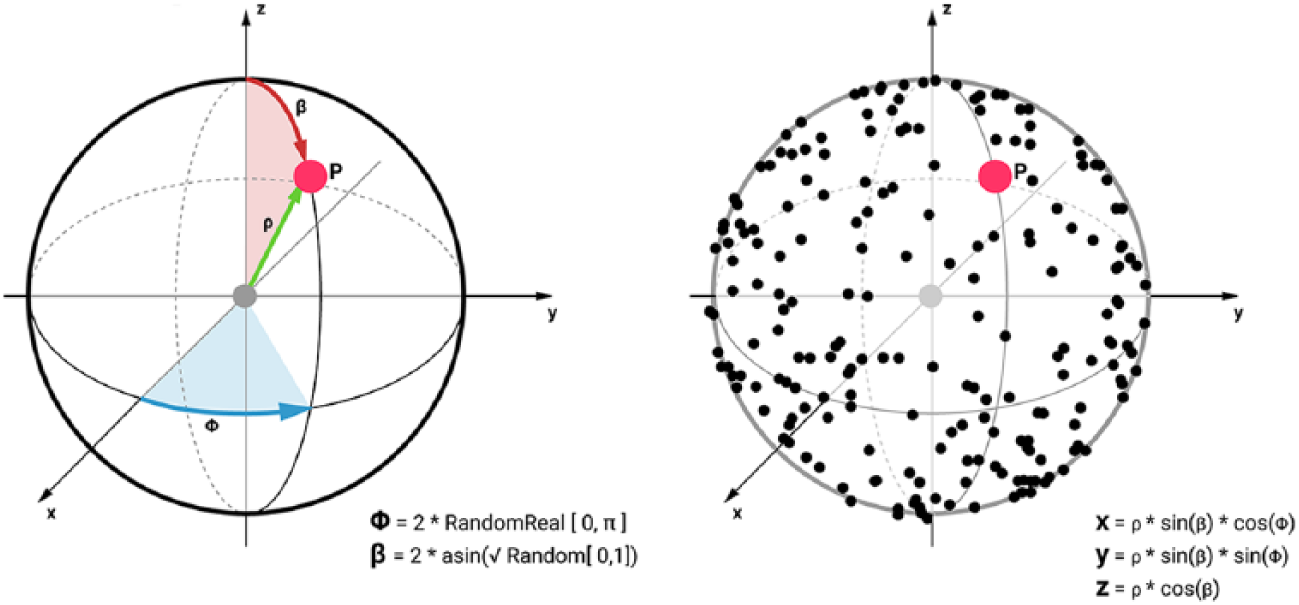
Random uniform spherical distribution of solutions for new possible coordinates of a metaball instance being later presented as a new stimulus.
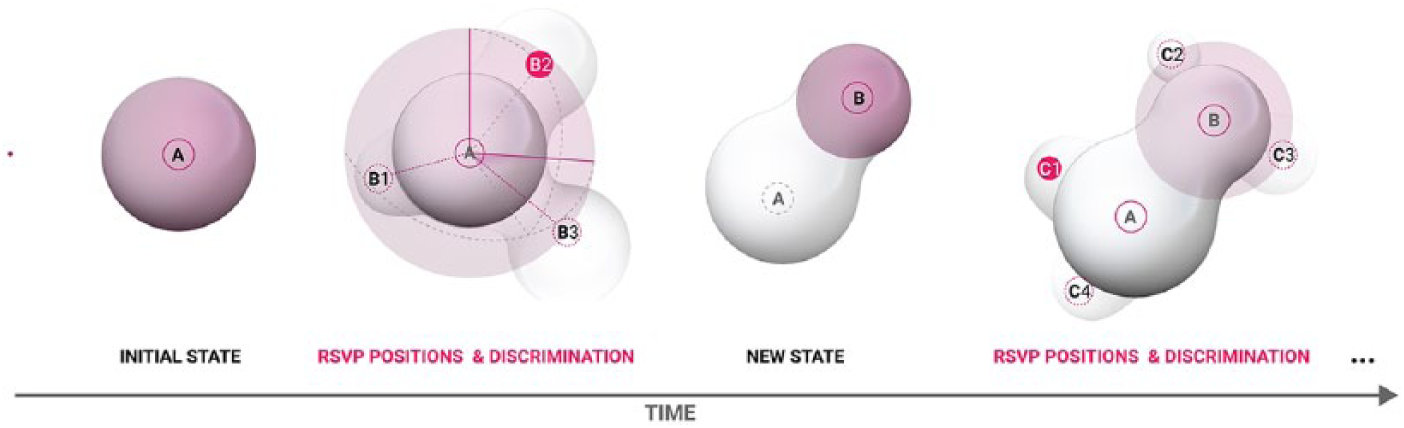
From left to right, sequence of the generated visual stimuli. The initial state starts from a given centred position on the screen (A). A RSVP period starts and presents possible positions (B1, B2, B3) from a uniform random spherical distribution based on (A). Once a possible solution has been correlated to a discriminative p300 neural pattern, the general isosurface rendering the metaballs is updated by adding the new position (B) to the previous ones (A) and a new state of the shape is generated. A new RSVP period begins and generates possible positions (C1, C2, C3, C4) similarly but takes the origin of the uniform random spherical distribution also randomly among the stored positions (A and B). The sequence repeats until a given end.
Results and reflection
Session recordings
For the recording of large P300 potentials evoked by the previously described RSVP change of states of a shape (see section ‘The oddball paradigm and the P300 speller’), 16 channels from electrodes are positioned respectively on FCz, FC3, FC4, Cz, C3, C4, T7, T8, Pz, P3, P4, P7, P8, Oz, O1, O2. 38 The recorded signals are digitised at 125 Hz. Each signal is then filtered with an eight-order bandpass filter with low and high cut-off frequencies of 0.1 and 20 Hz. After a time segmentation of 0.700 ms onset visual stimulus, each signal is downsampled to 20 Hz. Many elements used in the objective function of an lSVM assume that all features are centred around 0 and have variance in the same order. If a feature has a variance with orders of magnitude larger than others, it might dominate the objective function and make the estimator unable to learn from other features correctly as expected. Prior to training each lSVM with such datasets, we then perform a normalisation to zero mean and unit variance. Each trained lSVM is set with a regularisation parameter C of 0.1. We justify the settings fixation for the session recordings by following a similar method than the model previously described (see section ‘The oddball paradigm and the P300 speller’) while operating with minimal amount of channels and frequency. The adapted method was first tested successfully by replicating the typical word speller with both data provided from the related BCI competition and classification strategy of study (see http://bbci.de/competition/ii/) 34 and raw data on a single user (Figure 10). For both acquisition and classification training parameters varying from previously referred research, it is worth to evaluate the necessary amount of data for training such lSVM and the minimal number of classifiers in such ensemble method for a decent accuracy of predictions. The table shows that given stated parameters, the spelling accuracy reaches 90% from training with five characters on average. And an ensemble of 11 lSVM trained similarly reaches an average prediction accuracy of 90% (Table 1). The temporal settings have also been preserved and graphic properties of the visual feedback remain the same during every session. Results are presented in the following section.
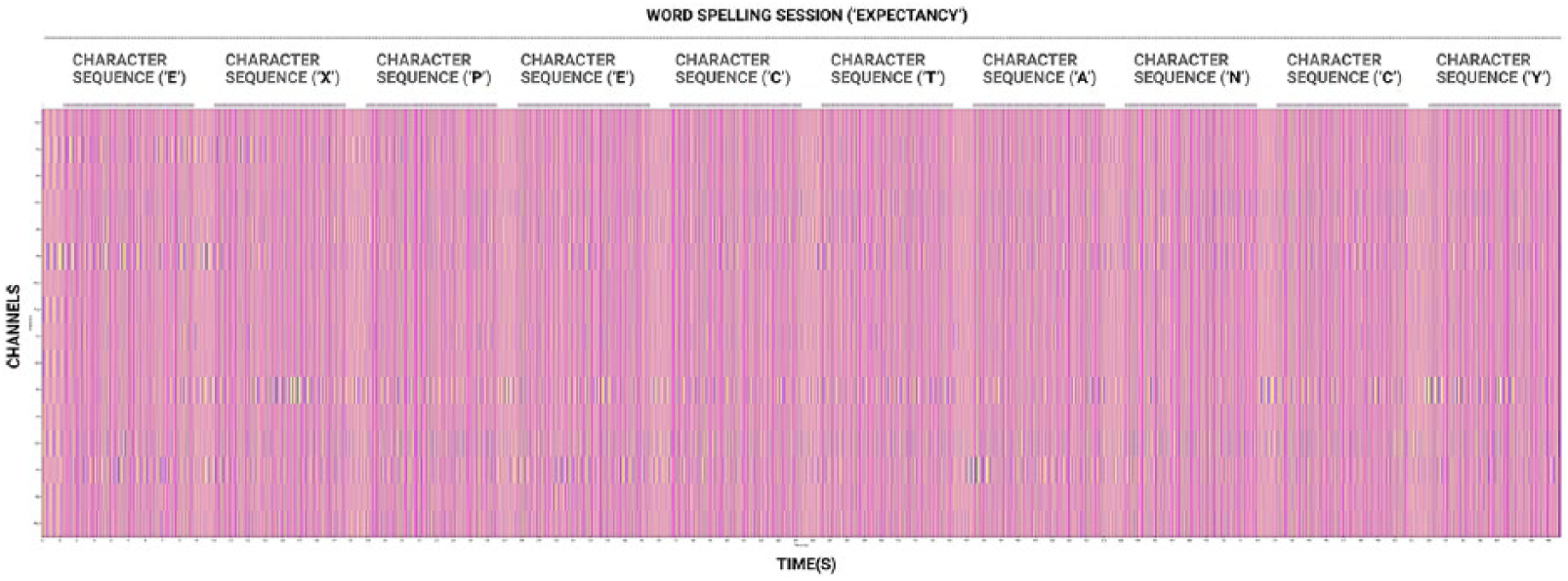
Image representation of the EEG signals recorded during one word-spelling session. The temporal segmentation is fixed between each character sequences. Each one of the character sequence flashes randomly a row or a column. For training purpose, the sampled signals are correlated with the sampled stimulus. Overlayed vertical lines show stimuli of row and columns flashed. Vertical lines in magenta are the flashed rows or columns supposed to elicit a P300 wave as true positive. Following acquired data for experiments are organised and correlated similarly in time for classification training.
Left: average spelling accuracy (non-mispelled characters in %) for the training of a single lSVM on words, according to the length of characters used. Words used for training are all 10 characters long: complexity, mozzarella, sophistics, quantizing, projective, expectancy, hybridized, cognizable, formalized, conjecture, maximizing, highjacked; right: average spelling accuracy of an ensemble of lSVM trained with five characters. Words used for testing are unpuzzling, equivoques, highjacked, intermezzo, circumflex, interstate, entireties, iterations, tonalities, generative.
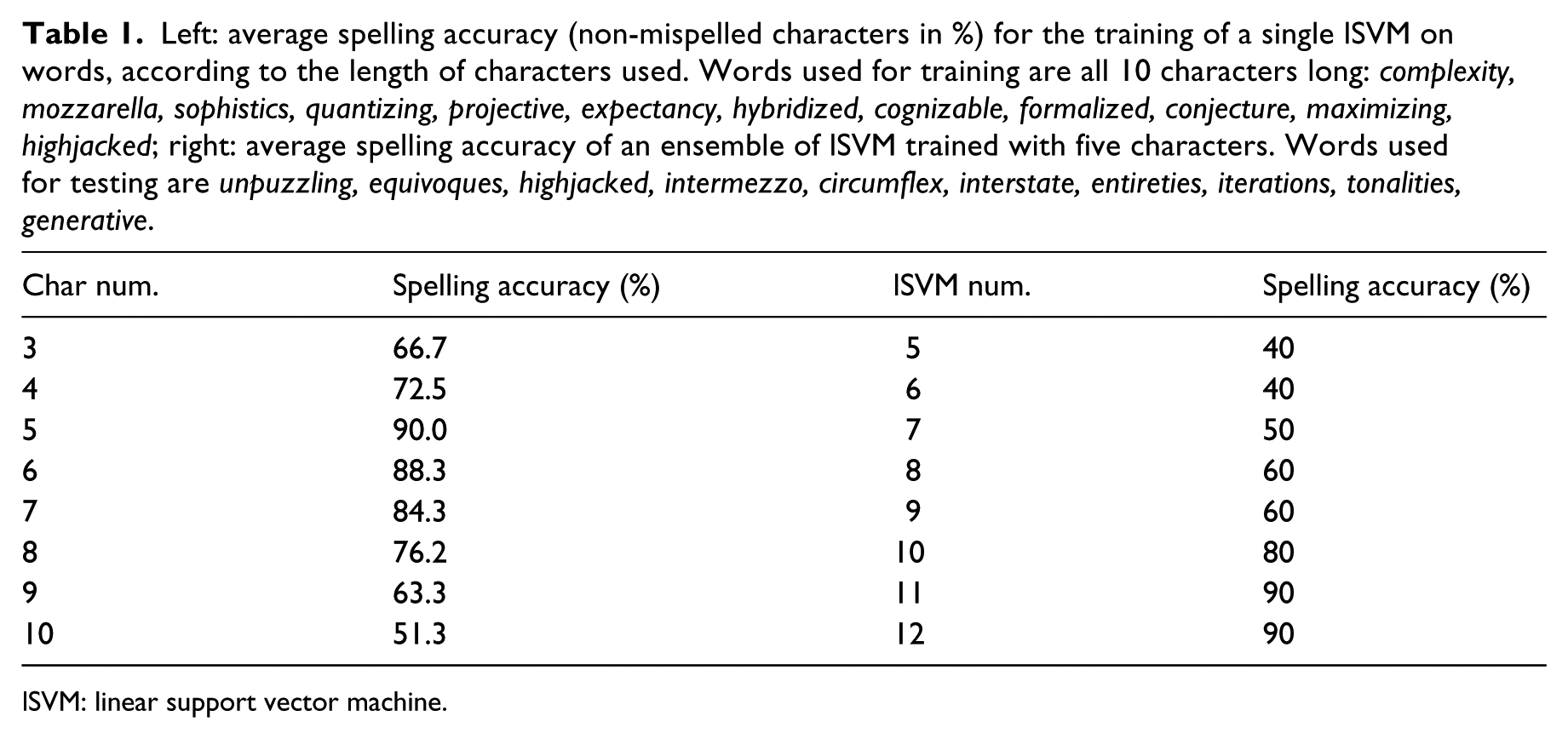
lSVM: linear support vector machine.
Results
For the pre-trained ensemble method with the P300 word speller, we used, without showing any prior visual cues, the previously described RSVP model (see section ‘Visual stimuli and design aggregates’). Results show that for a diverse range of visual features within the model, the prior assumption may hold true and allow for visual discrimination of such shapes (Figure 11). However, as the model was designed to generate stimulus in large variance, it might not support the progressive formation of significant shapes for GD. Therefore, a new training is proposed on the RSVP model of shapes and design assumptions (or design beliefs) are used to identify true positive responses and replace the previous speller matrix. These design beliefs consist on reduced domains of the solution space to support the progressive formation of trivial archetypes such as a column, an arch and a dome (Figure 12) without specifying further constraints. A similar evaluation has been conducted to assess the length of data necessary for training a single lSVM on each design belief, and the amount of classifiers needed in an ensemble to reach a satisfying prediction score (Table 2). Results show that with an ensemble of 12 classifiers individually trained with the same design belief for a sequence of 10 stimuli, the progressive generation of such archetypes is possible while maintaining variance (Figure 13).

Shape representations generated by reusing the BCI ensemble model of feature classification with no prior cues and for a fixed amount of time of 30 s. The discrimination at work operates on the constantly updated visual context. From top to bottom, three different programmed shaders used to evaluate the discrimination of new states on states with different sizes (top row), different sizes and colours (middle row), different sizes and frequency dot patterns (bottom row).
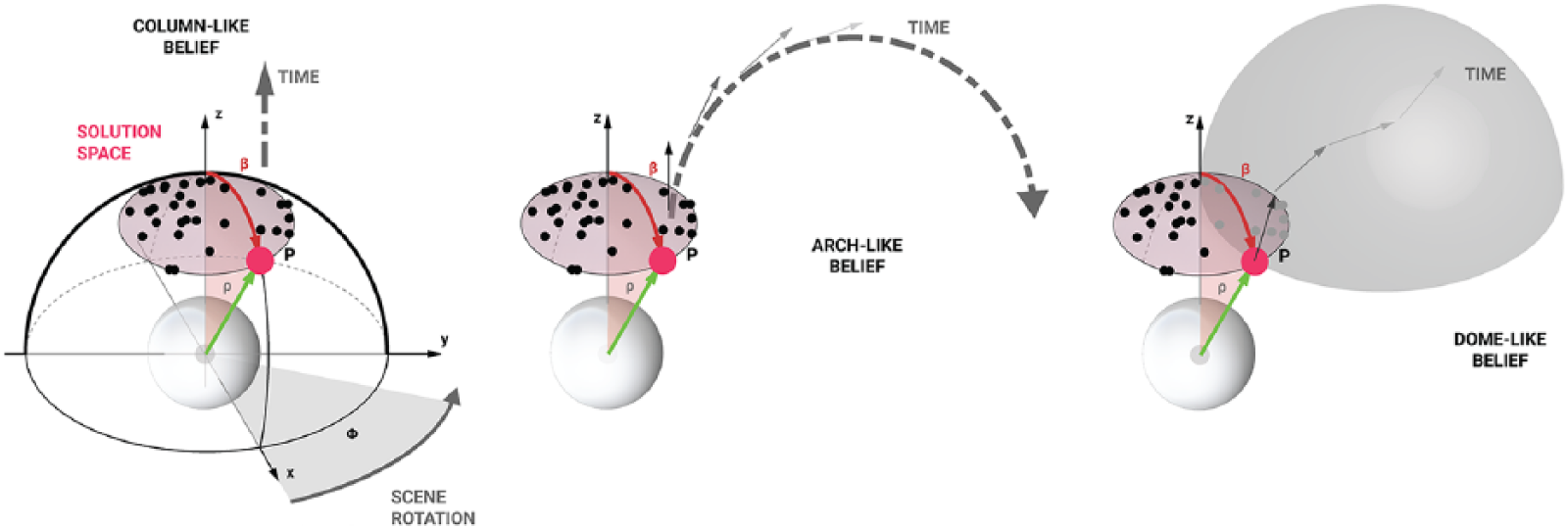
From left to right: a column-like, an arch-like and a dome-like design beliefs. Each one of them describes a selective domain of solutions for each new possible state and used to identify a true positive response as belonging to the domain.
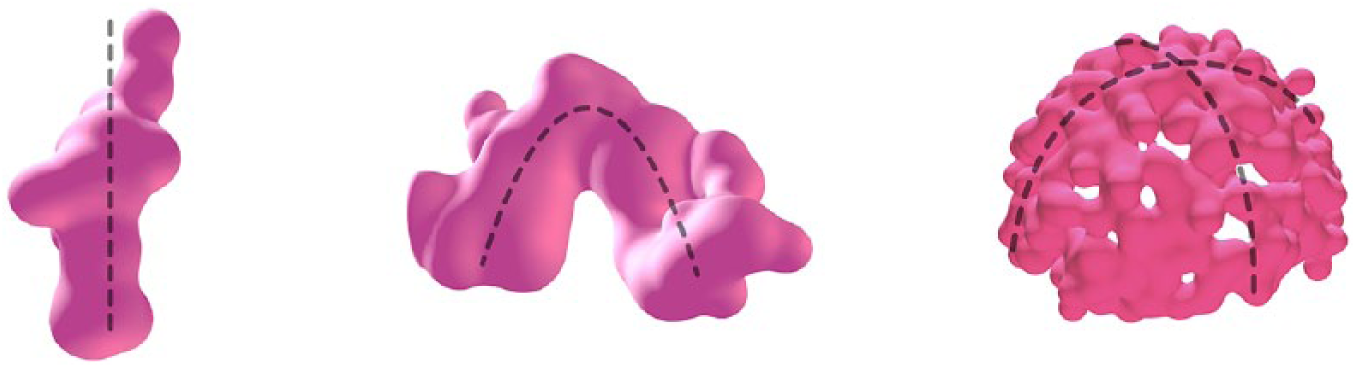
Selected successful sessions, resulting of the voting ensemble model. Left to right: generated shapes for the targeted design beliefs column-like, arch-like, dome-like, without prior cues or additional geometric constraints.
Left: average discrimination accuracy of responses in the solution domain of the used design belief (%) for the training of a single lSVM on 10 recording sessions. Right: Average prediction accuracy of an ensemble for a given design belief and a number of lSVM. Also for 10 recording sessions).
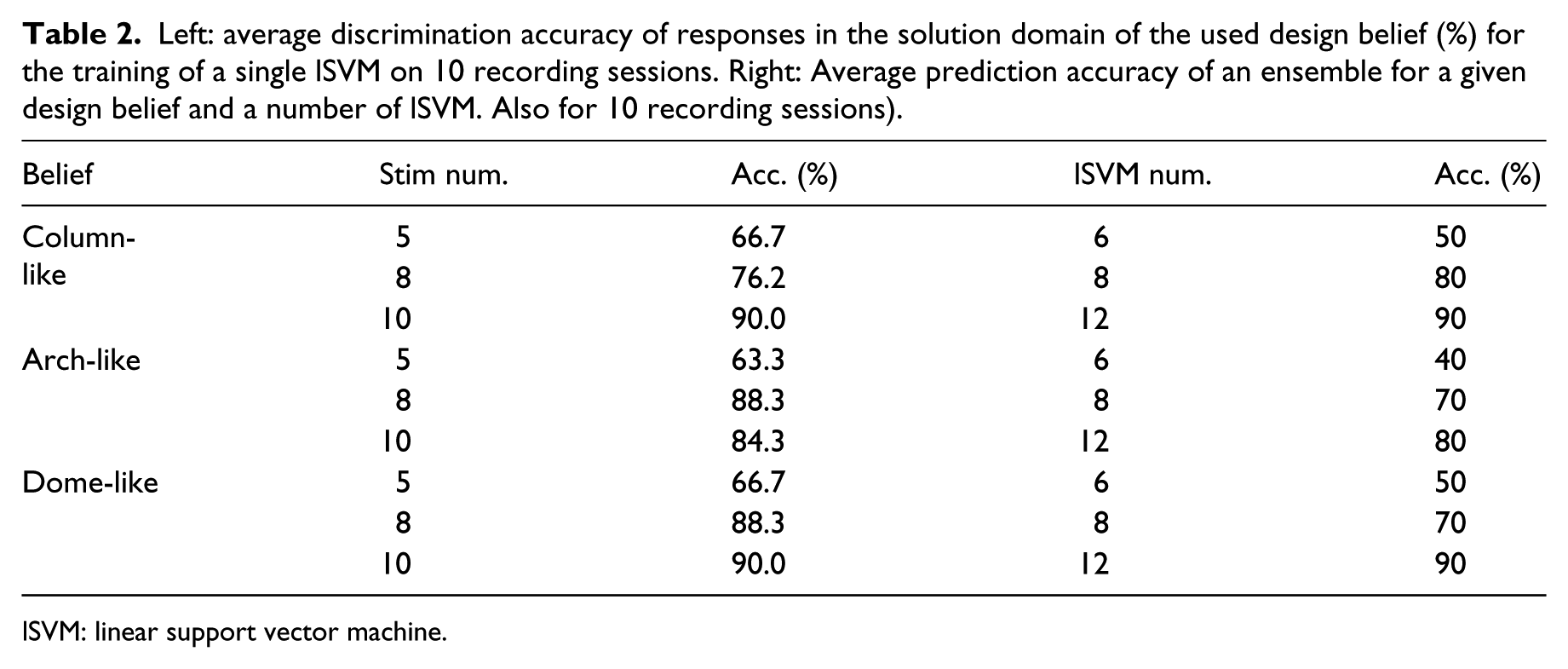
lSVM: linear support vector machine.
Reflection
Can we generalise this mechanism to modulate ensembles of shape features? This article suggests evidence on the portability of the model and brings it into perspective and discussion. It is to be noted that the range of successful visual outputs of such abstracted ensemble methods may greatly vary due to the non-stationarity and other challenging specificities of EEG signals described above (see section ‘BCI and EEG signals’). Nevertheless, in order to address architectural and design-related reflections regarding a cognitive-generative approach in CAAD, the implementation of HMI involving neural phenomena correlated to early decision-making in visual information processing must operate a certain technical abstraction, such as this one, in order to address the wider visual and semantic complexity of architectural and design objects. At this point of the reflection, it may not be necessary anymore to focus on which wave pattern in which time window an eliciting event may occur, but rather establish an individually adaptive timeframe of comfort to adjust and learn discriminatory features of EEG signals from a user. Also, the necessity to widen the context of discrimination may not hold true for more recent ML models with a generative approach. They should be confronted with this method to provide the previously identified capacity of context updating of HI and modulate classification through time. A model of interest to pursue this research for GD should integrate these comments in its development. One possible way to reframe such research would be to embrace vision as inverse graphics. Meaning that such models would be used as a search for features compound of an image to be progressively rendered. A first step towards this idea can be seen using the present ensemble model of features discrimination for the generation of shape without predefined cues.
Contribution, conclusion and future works
This article has identified typical technologies in neuroscience and neuropsychology of high interest for GD and proposed the ML model of an ensemble of linear classifiers in order to tackle the challenging features that EEG data carry and address the visual complexity of GD models. It has shown that besides a targeted implementation in CAAD strategies, generative models can be designed iteratively with an ERP–OP combination with adaptive ML discriminative models in a BCI closed loop. With regard to the progressive development of encoding shape features with an ERP–oddball RSVP paradigm, this research will continue to refine the described visual context update, by developing the strategy of discrete-continuous visual cues and ensembles of design beliefs for the computational modelling of architectural designs. Prior to confront future models with prolonged testing, this research will extend the present reflection to more recent state-of-the art adaptive ML models specifically addressing an update towards challenging EEG features, 39 as well as elicitation paradigms 40 and more advanced artificial neural networks such as GAN 41 for the generative visual model itself. The assumption is to be able to shift, within such framework of understanding vision as inverse graphics, from the encoding of shape features to the encoding of spatial features. And finally suggest that neural phenomena correlated with visual discrimination such as P300 may be used as a general visual articulation strategy for generative models in architectural computing.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.