
Abstract
This study investigates the application of deep learning models to predict MBTI personality types, leveraging their potential to identify prevalent patterns and support organizational interventions. Four models were evaluated: 1-layer, 2-layer, and 3-layer Convolutional Neural Networks (CNNs), and a hybrid CNN-LSTM model. The performance of these models was assessed using metrics such as accuracy, precision, recall, F1-score, and confusion matrices. Training involved 60 epochs with regularization techniques like early stopping, batch normalization, and dropout to mitigate overfitting and enhance model performance. Key findings reveal that the 1-layer CNN demonstrated superior performance among standalone CNN models, while the hybrid CNN-LSTM outperformed all models, achieving a high F1-score of 97.16%. The hybrid model's balanced metrics highlight its robustness and efficiency in classifying personality types within the MBTI dataset. Insights from confusion matrices further emphasize the hybrid model's ability to provide correct predictions across multiple classes, surpassing simpler and multi-layer architectures. The study underscores the utility of hybrid architectures in complex classification tasks and their potential for workplace applications, such as task assignments and promoting inclusivity. By integrating personality insights, organizations can foster more effective work environments, boosting employee satisfaction and productivity. These findings offer a solid foundation for refining model selection in future personality prediction research.
Introduction
Motivation
The rapid expansion of the IT revolution has posed significant challenges for organizations and recruiters in identifying the ideal candidate from a vast pool of applicants exhibiting diverse skill sets and personalities. Consequently, this has become a pivotal challenge for HR departments worldwide. 1 It further reinforces integrations of the Internet into people's lives, making improvements in convenient analysis of user preferences and behavior predictions can be made. This allows optimization of information structures and raising of service accuracy, enriching users’ online experiences. 2 Better insight into the target groups in such diverse fields as law enforcement agencies, institutional administrations, human resource departments, and advertisement companies has never been in greater demand. The identification of individual characteristics and the ability to predict personality traits are central to ensuring that decisions are made wittily. At the same time, leveraging the large repository of data emanating from social media platforms-appropriately deemed ‘prolific’ sources of user-generated content to provide insight into the lives and dispositions of individuals, in truth, shall only be possible by applying rigorous structural analyses to such data in ways unique and peculiar to each respective social media platform. Besides, much work has to be done to create well-organized labeled datasets that will build solid predictive models with high accuracy in identifying personality traits from social media data. The enhancements can go a long way in assisting decision-making for the identified domains. 3
Neuro-Linguistic Programming is one of the intervention strategies to enhance personality development through meta programs: a predetermined pattern for processing, sorting, and filtering information. The meta-programming of individuals has been claimed to influence their behavioral patterns tremendously. The study of meta-programs can help identify and know personality types, and the MBTI® has been one of the most popular and reliable questionnaires predicting and characterizing the traits of personality. 4
Personality is the collections of traits, such as characteristic thoughts, feelings, and behaviors that differentiate individuals. It is refined since it develops from interaction with other people. Over the years, research has progressed toward improving methods for analyzing personality traits using textual communication. For example, interview responses offer great insights that could be used to predict various personality attributes. The junction of psychology and computer science has made personality prediction a vital research area in connection with the analysis of activities and textual expressions of thoughts and feelings. Personality prediction has practical applications in current job performance evaluation and medical forums using the MBTI and other indicators. 5 The scale and complexity of user data are such that automated methods of prediction have to effectively deal with large sets of data. 6
Personality is a view into behavior, mental health, emotions, life choices, social tendencies, and ways of cognition. The wide range of insights serves several practical purposes in various fields, such as cyber forensics, personalized services, and recommender systems.7,8This has led to the development of computer-based learning systems specifically designed to address individual differences, especially regarding personality aspects.9,10,11
Literature review
The following segment discusses a review of some literature and studies related to neural networks for diagnosing personality types. Tlili et al. (2016) have produced a study on the impact of personality differences in computer-based learning. Their investigation showed that individual personality traits influence the learners’ preferences in content and approach, including the style of communication, tendencies to behave, and ways of making decisions. Then, identifying a new model with personality variables has led them to request a departure from questionnaires to big data and learning analytics. Besides, they presented an innovative implicit approach based on learning analytics data to detect learners’ personality traits. They allowed for greater insight into learners’ needs and preferences. Keh and Cheng (2019) 12 investigated the power of pre-trained models of language to predict MBTI personality types on labeled textual data, which was scrapped from diverse sources. The suggested model has 0.47 accuracy for all four personality type predictions and an accuracy of 0.86 for predicting at least 2 out of 4 personality types. The study also explored the possible applications of the fine-tuned BERT models in generating personality-specific language and provided valuable insights concerning present psychology and the construction of intelligent empathetic systems. Amir Hosseini & Kazemian (2020) proposed a new ML model for predicting personality types using the MBTI system. A comparative analysis was conducted using the presented method against other existing approaches, showing better accuracy and reliability. Therefore, the results of this study would be of great importance to NLP practitioners and psychologists in general since it gives them an excellent tool to base their assessment of personality types and the associated cognitive processes.
Choong & Varathan (2021) comprehensively assessed various individual features and classifiers related to predicting the J/P dichotomy of personality computing. These authors discovered cases of leakage in one of the datasets from the Personality Forum Café that had been used in related research. Surprisingly, this work outperformed earlier studies conducted under similar conditions. These researchers analyzed five various ML algorithms and evaluated the effectiveness of each in predicting the J/P dichotomy within the framework of MBTI personality. Following extensive experimentation and evaluation, the LightGBM model emerged as the most promising candidate for conducting accurate predictions of the J/P dichotomy, hence its usefulness for providing valuable insight into the advancement of personality computing within the MBTI framework. Shafi 2021 13 discusses a comparison study that considers classical ML algorithms with respect to MBTI. This work applied a supervised ML methodology, including learning from the dataset. The performance of different algorithms was tested. Among all, the Ensemble Bagged Trees algorithm produced the highest training accuracy of 98.4% with a test accuracy of 70.75%. This algorithm performs with medium prediction speed, 11 K-Obs/sec.
In the paper “Exploring Personality Traits from User Behavior on Social Networking Platforms Using a Deep Learning Approach” by Qin et al. 2022 the researchers investigated the relationship between user behavior in the use of social networking platforms and their personality traits through the application of the OCEAN model of personality. The proposed model utilized the LDA topic model for textual feature extraction on user interactions, which was used as sample inputs for a BP neural network. The results of the OCEAN model, extracted using a questionnaire, were applied as an output for training the neural network. This approach effectively optimized the performance and accuracy in predicting user behavior based on their digital footprint and personality traits. Kosan et al. (2022) built their study based on creating a personality dataset from Twitter and then annotated it using IBM Personality Insight. Then, the unstructured data was converted into a readable and analyzable form. The researchers constructed LSTM-based prediction models using their framework by embedding structural analyses. Extensive evaluations of their deployed models were conducted on the performance and efficacy of their own PAN-2015-EN datasets. Suman et al. (2022) developed a deep learning-based personality prediction framework through a multi-modal design. They then extracted the ambient and facial features using MTCNN and ResNet, respectively, using VGGish CNN for audio features and n-gram CNN for textual features. Then, such different features in multi-modal settings were combined by incorporating various attention mechanisms to fuse them effectively in this system. The performance analysis on the Chalearn-17 dataset, as they have provided, shows comparative results with existing works, including the simple averaging method, with only a smaller number of input images. Pansare et al. (2022) have carried out the most detailed analysis of a number of ML models for predicting personality types according to MBTI efficiently. Random Forest, Logistic Regression, SVM, and XGBoost were outstanding compared to other algorithms for all personality traits like Introversion/Extroversion, Sensing/Intuition, Thinking/Feeling, and Perceiving vs. Judging. The authors also identified count vectorization as the best technique to ensure high personality prediction accuracy. The results further confirm that state-of-the-art ML algorithms using appropriate feature engineering methods are essential to predict personality traits using the MBTI framework.
Santhosh et al. (2023) 14 further presented a comparative study where different ML models, such as Stochastic Gradient Descent, Naive Bayes, k-Nearest Neighbours, and Logistic Regression, were used to identify the Myers-Briggs personality type from textual inputs. The proposed research reviewed main measures for the performance evaluation: accuracy, support, recall, precision, and F1-score on a dataset of textual inputs labeled for different Myers-Briggs types. Hence, this study's results will be highly instructive for elaborating robust and accurate personality prediction models using state-of-the-art natural language processing methodologies.
Contribution
MBTI is one of the most popular and widely used personality assessment instruments recognized for distinguishing variation in individuals’ personalities by categorizing them into specific personality types according to four fundamental attribute dichotomies: Extraversion-Introversion, Sensing-Intuition, Thinking-Feeling, and J/P. The test is designed to provide the respondent with helpful insights into his or her psychological preference to attain a better understanding of self and to make conscious decisions on various issues in life. Although the existing research has been able to predict attributes such as Extraversion-Introversion, Sensing-Intuition, and Thinking-Feeling with high accuracy from textual data, the J/P dichotomy poses an exciting challenge. The J/P dichotomy reflects individual differences in preferred ways of processing information, making decisions, and organizing one's life. It influences human behavior, perception, and decision-making habits about the environment. Given the complexity of the Judging-Perceiving dichotomy and the fact that it is considered one of the most influential features in individuals’ cognitive processes and behavior, interest in exploring new methodologies for the effective discerning and prediction of this personality attribute from textual data is similarly growing. The value of such endeavors would be immense, thereby increasing the validity and reliability of personality questionnaires like the MBTI, providing more insight into the personalities of the individuals answering and further influencing personal development. 15 Therefore, this research provides comprehensive insights into personality dynamics and how such dynamics influence a person's behavior within organizational settings. According to Setiadi, personality is viewed as one dynamic system: human personality is balanced by various environments. Its in-depth analysis of such critical dimensions as valuing, visioning, relating, and directing underlines a complex interplay between individual preferences and environmental interactions. This study also focuses on the probable, personal, rational, and actual dimensions that are beneficial while trying to conceptualize behavioral propensities.
Based on the outlined contents and the review of existing literature and conducted research, there appears to be a pressing requirement for methods characterized by high precision and efficiency. Previous studies indicate that while these methods have been explored extensively, they often rely on limited datasets. Consequently, their accuracy and performance tend to diminish when applied to more comprehensive datasets. Overall, it can be concluded that existing methods in this domain are lacking in completeness. Therefore, this study adopts a meticulous approach to data preparation and preprocessing to ensure the integrity and quality of the datasets, establishing a robust foundation for subsequent model training and evaluation. Leveraging the MBTI, the study aims to predict personality types and identify prevalent patterns among participants. By employing a diverse range of models, including the 1-layer, 2-layer, and 3-layer CNN architectures, alongside the hybrid CNN-LSTM classification model, the study explores various model complexities and capabilities, offering valuable insights into their performance characteristics. Further, these models were compared in terms of performance for factors like accuracy, precision, recall, F1-score, and confusion matrix analysis, which helped make decisions toward model selection and refinement. This generally contributes to enhancing personality prediction and pattern recognition among participants by comprehensively analyzing different models and their efficacy in detection.
Organization of article
The rest of the study is organized as follows:
Methodology
The systematic methodology followed for this study primarily focused on predicting personality types using MBTI with the dataset from Kaggle. The methodologies involved preparing the data by addressing missing values, converting text to lowercase, and removing punctuation from both datasets. Extensive preprocessing followed, involving data tokenization by a custom tokenizer for deep learning models. The dataset was then stratified into the training set, testing set, and validation set to ensure proper balance in class distribution and, therefore, robustness in the model's performance evaluation. The model deployed used, ranging from the CNN-LSTM to 1-layer, 2-layer, and 3-layer CNN architecture to explore and realize different complexities and the various capabilities inherent in each model. During the final stages of research, a serious evaluation of the results was conducted using multi-faceted criteria based on accuracy, precision, recall, F1-score, and confusion matrix analysis. The deep models were trained, by default, for 60 epochs. An early stopping mechanism had been implemented wherein the training would stop when the validation loss had plateaued for five consecutive epochs. This provided a complete comparison, which allowed a subtle understanding of the performance characteristics of each model and informed decisions on model selection and refinement. Figure 1. It represents the flowchart of such a complex processing workflow of the study, showing in detail the step-by-step process through data pre-processing, training, and evaluation of the models. This encapsulates the essence of the methodological framework for the study, bringing out the structured approach employed to serve the research objectives.
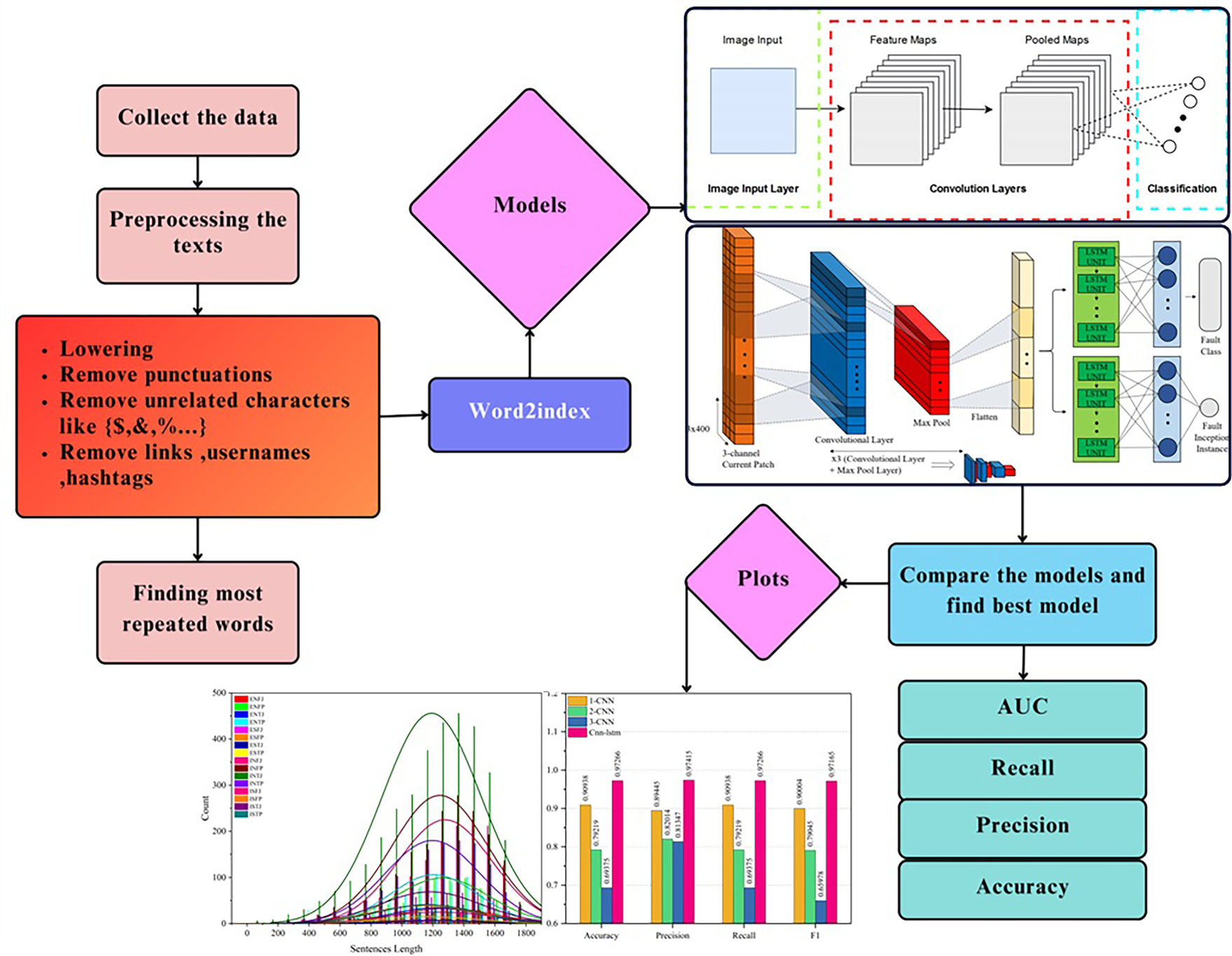
Flowchart of the workflow of the current study.
The CNNs introduced during the 1980s achieved remarkable improvements in digital handwriting recognition. However, their complexity hindered the broader adaptation of more ambitious applications. However, with the rapid evolution of computer technology, the CNN structure has undergone expansion and found extensive utilization. CNNs work primarily because of their network structures, including the back-propagation algorithm and elements like convolutional, pooling, and fully connected layers. These elements collectively enable CNNs to efficiently process and learn from input data, making them a cornerstone in various fields beyond digital handwriting recognition. 16
A critical component of the CNN is the convolution layer. There are several kinds of convolutional kernels in each layer; these kernels are organized according to the input data to find hidden characteristics and produce feature maps. A non-linear activation function and feature mappings are used to create the output of the convolutional layer. This is how the convolutional layer is expressed:

Pooling layers take the result of that convolutional layer and do image processing easier with reduced computational load. Recent techniques like max-pooling have divided an image into rectangular subregions, retaining the maximum value within each segment. This ensures that optimum information is conveyed from one layer to the next, and optimum optimization of deep learning algorithms.
18
The max-pooling is expressed as the following equations:


In this, the dense layer is a fully connected layer, which will act importantly as a classifier in design. It connects features to classify and establishes how features relate to classification outcomes. It assigns class labels to input samples and delineates complex attributes onto decision boundaries. It will make informed categorization decisions by leveraging network information.
20
In this layer, the model computes the final output vector, as shown below:

The LSTM technique is a powerful deep-learning methodology developed by Hochreiter and Schmidhuber in 1997 to detect and predict critical events in time series data with long lags. It has gained considerable attention because of its ability to work with time series data incorporating complex temporal dependencies and long-range dependencies. Basically, an LSTM network is dependent on three kinds of memory cell gates: the forget gate, the input gate, and the output gate.
21
Each one of them plays a vital role in model training: capturing state transitions carefully, evaluating the relevance of previous state information, adding new data, and controlling predictions according to the interaction between updated state and current input.
22
The input gate, forget gate, and output gate mathematical processes at time t can be structured as follows:






Various deep learning models have been designed to serve different purposes in this arena of deep learning. This paper presented 4 such key models with their specifications.
Then, tokenization of input data is done using the Word2Vec technique. In that, a vocabulary size of 8000 with a dimensionality of 128 is used to create word embeddings. Using Word2Vec, words are powerfully represented in the input data due to which models can successfully capture semantic relationships and contextual information during the learning process. This careful approach reinforces the capability of the models to make more sense while understanding textual data and, hence, enhances the overall performance and predictive capabilities.
Datasets
The present study relied on the Myers-Briggs personality type dataset provided by Kaggle. MBTI can be described as one of the most popular tests that divide participants into 16 kinds of personality types based on 4 axes: Extroverts (E) and Introverts (I): A measure of the degree to which a person favors the outer or inner world. Sensors (S) and Intuitive (N): An assessment of the level of knowledge a person processes via their 5 senses vs impressions from patterning. Thinkers (T) and Feelers (F): An expression of preference for objective ideas and facts over assessing feelings and opinions of others. Judgers (J) and perceivers (P): An assessment of the extent to which a person likes a planned and structured existence over a flexible and unplanned life. The MBTI personality dimension of the dataset was presented in Figure 2. Carl Jung's Jungian Typology, a concept of eight distinct mental functions or thinking processes, serves as the foundation for the MBTI system. This study was eventually adapted into a variety of personality systems, including the MBTI.
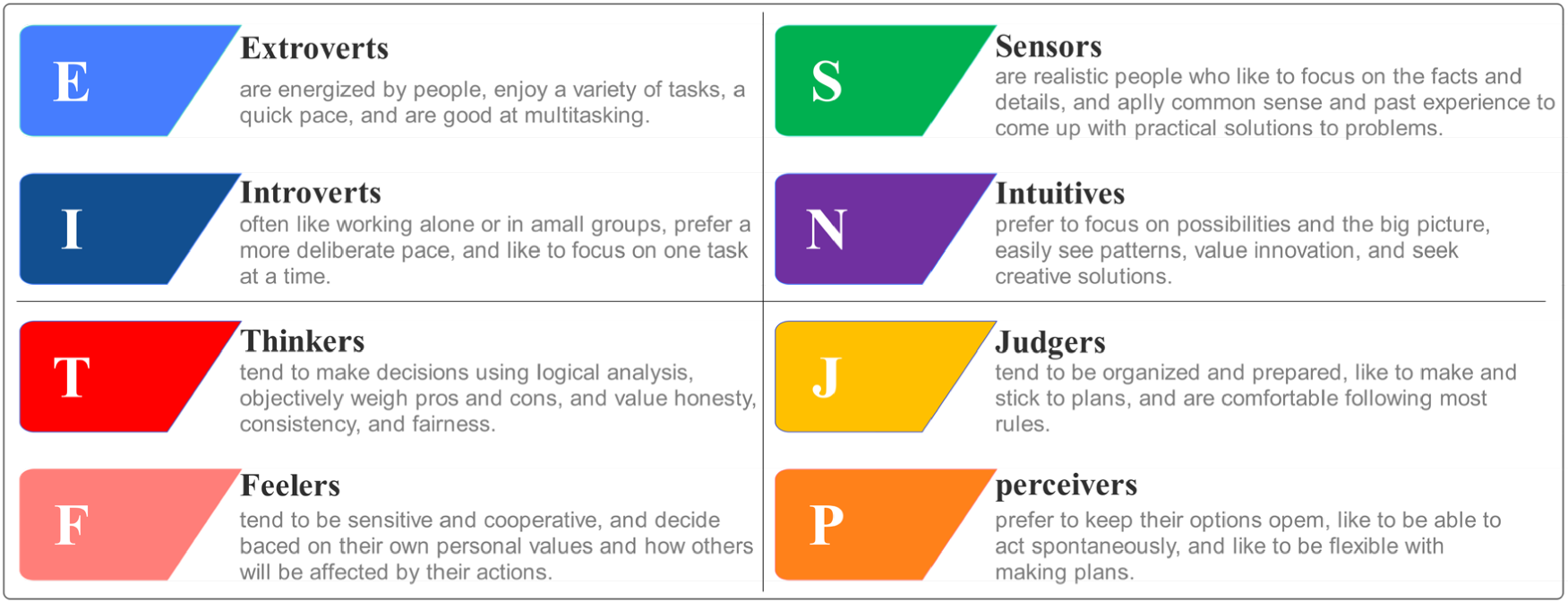
The MBTI personality dimension of the dataset.
The dataset comprises about 8600 rows of data, each of which includes a person's MBTI code/type, recent 50 postings, and acknowledgments. The data was gathered through the PersonalityCafe forum, which included a huge sample of users, their MBTI personality type, and written material.
Despite the fact that its value and validity have been called into doubt due to experimental unreliability, the MBTI remains a useful tool in a variety of fields. The dataset seeks to find trends in certain kinds and their writing styles, with the goal of determining the test's validity in evaluating, forecasting, or classifying behavior.
The personality is shown in various attitudes that distinguish it from others. This framework defines the distinctive way in which each individual navigates their environment. Personality represents an individual's self-perception, which shapes their conduct in a unique and dynamic manner impacted by learning, experiences, and education. Setiadi views personality as a dynamic orchestration of systems that carefully determine an individual's adaptability to their surroundings. Individual preferences are divided into 4 dimensions, and the MBTI identifies 16 unique personality types based on different combinations of these personality type indications. Figure 2 depicts the 16 personality types that emerge from the interaction of individual preferences.
This study focuses on the concept of valuing, visioning, relating, and directing in the dataset, which is crucial in understanding how individuals perceive and interact with their environment. These dimensions shape their personality and determine their adaptation to various situations. It also puts more emphasis on the possible, personal, logical, and present aspects of the exploration of how individuals perceive and act upon their environment. The dynamic interaction between such dimensions underlines the complexity of human behavior and the importance of the recognition and appreciation of these dimensions in delineating personality types.
As a consequence, the study uses the MBTI to forecast the personality types of the participants. Furthermore, it aims to determine the most common meta-programs and personality types in the sample population. This detailed research serves as a foundation for prospective changes to the current organizational culture and task distribution practices. Figure 3 shows a graphic depiction in which each term correlates to a certain personality type, allowing for easy reference. Figure 4 provides a more extensive description of the cognitive functions linked with each MBTI personality type. This breakdown provides information on the primary function, indicated by the background color, and the auxiliary function, represented by the text color. Such granularity in comprehending cognitive functions facilitates a deeper knowledge of individual behavior patterns and inclinations, allowing for more targeted organizational interventions and task allocations.
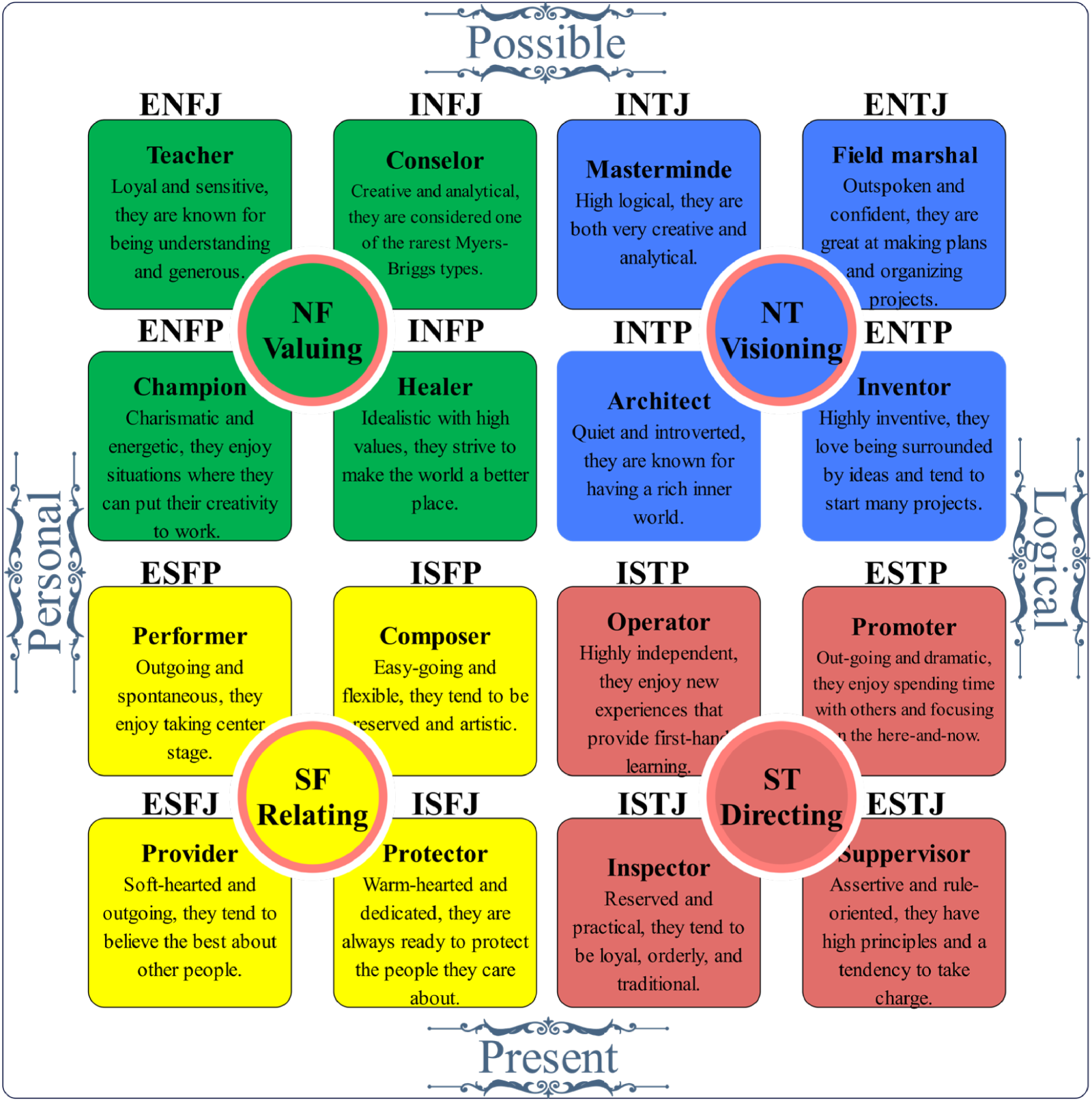
The personality type of the MBTI dataset.
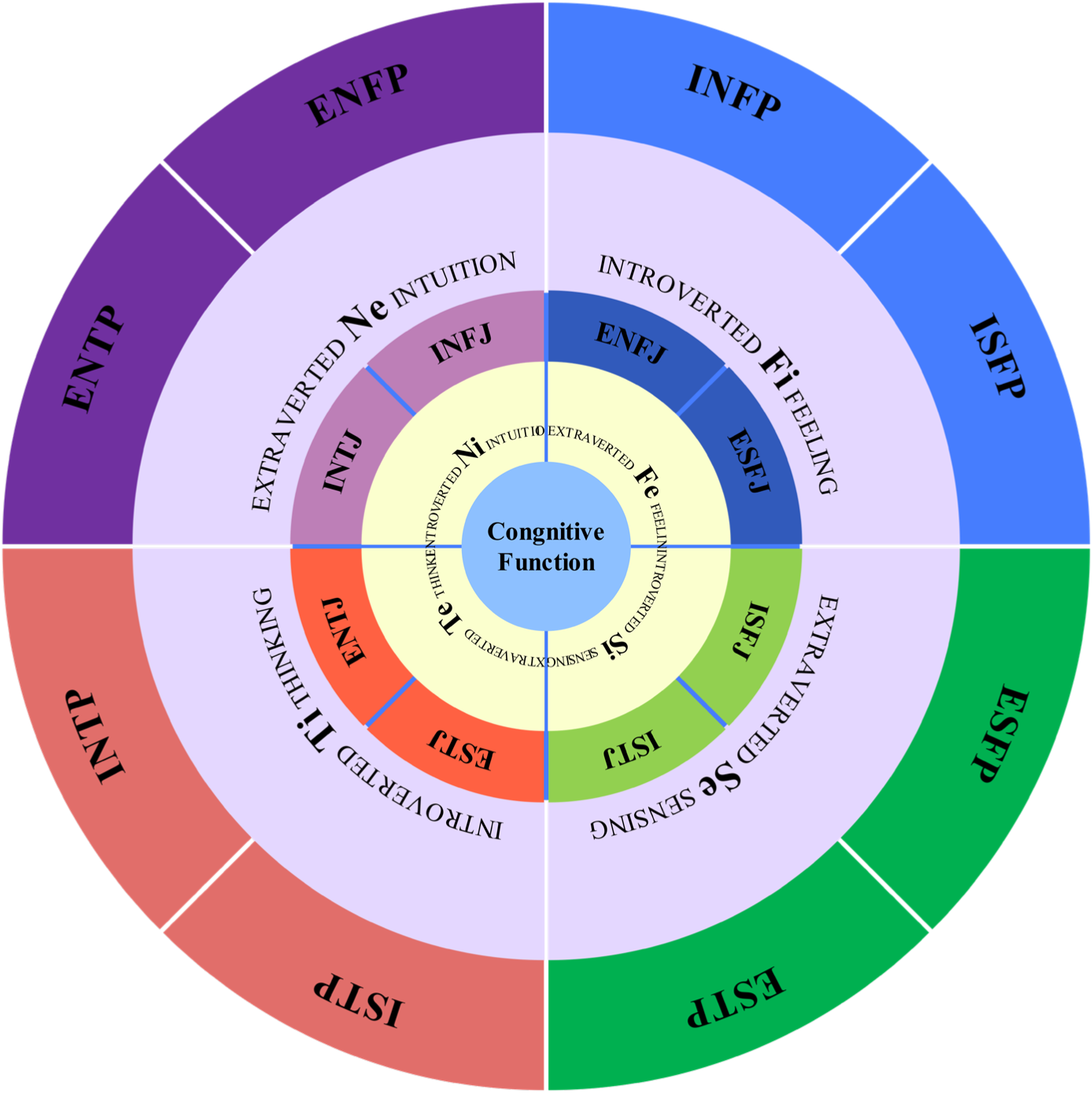
Cognitive processes for every kind of personality style.
The dataset's breakdown of personality types is depicted in Figure 5. One interesting observation that could be drawn would be the fact that the dataset indeed hosts more of the personality types starting with “IN”, that is Introverts and Intuitives, while for personality types starting with “ES” standing for Extroverts and Sensors, it is smaller by a factor in exactly 4 of the classes. This would, therefore, hint at possible imbalances in some personality traits being represented in this dataset, and going in depth as to why such distributions occur will be quite useful.
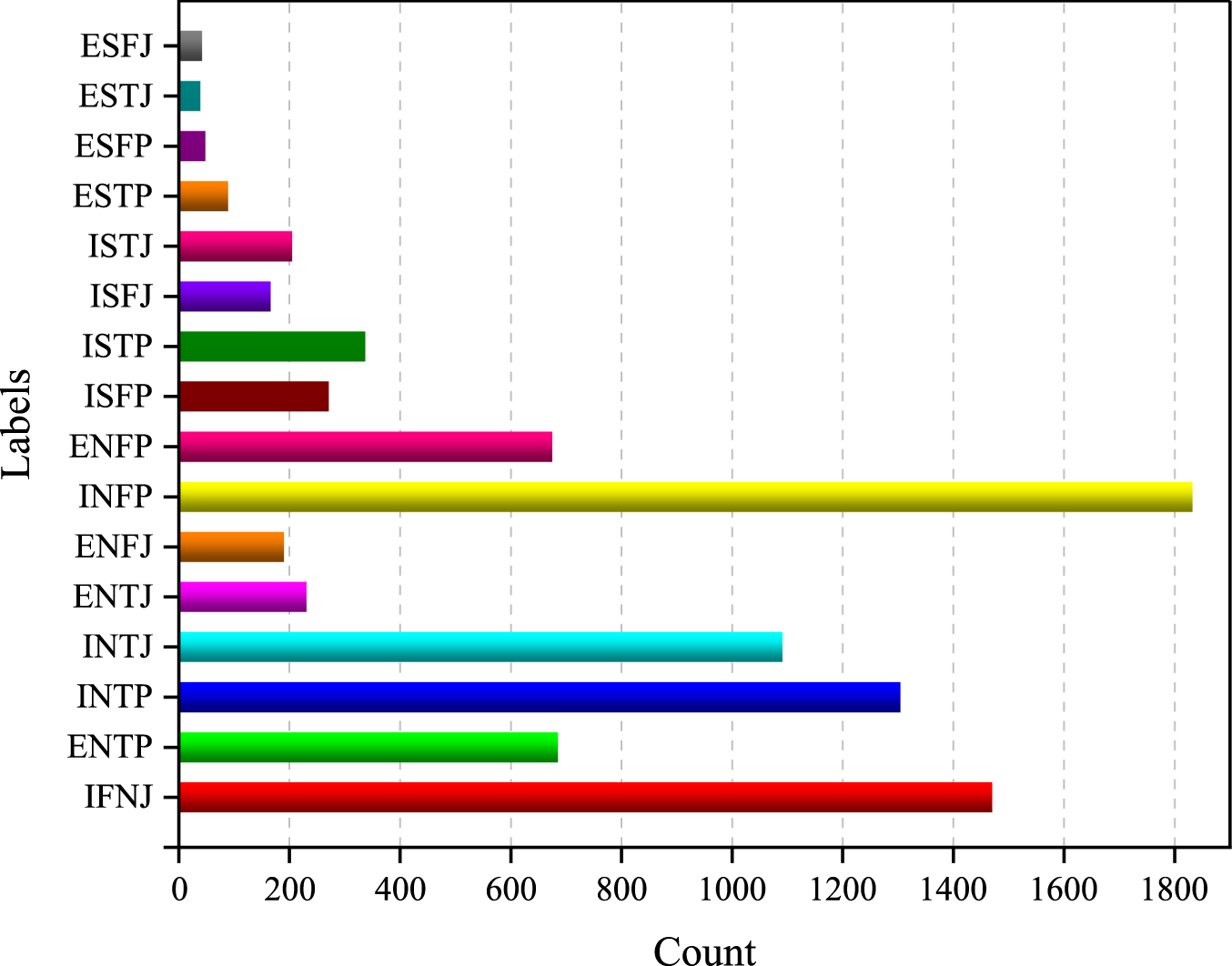
The count of datasets in every personality type class.
Figure 6 gives the frequency distribution of sentence lengths in each personality type class. From this figure, the following patterns are observed: with the increase in sentence length, the repetition count increases differently in different classes of personality types. In particular, classes that have “ES” in their personality types show a higher increase in repetition count with growth in sentence length. This increase is relatively smaller compared to the other classes. Classes with “IN” types of personalities have a higher number of repetitions, showing that they respond more to the variation of sentence lengths in their classes. This again points to possible differences in communication styles and preferences of different personality types, which would call for further explorations of such dynamics.
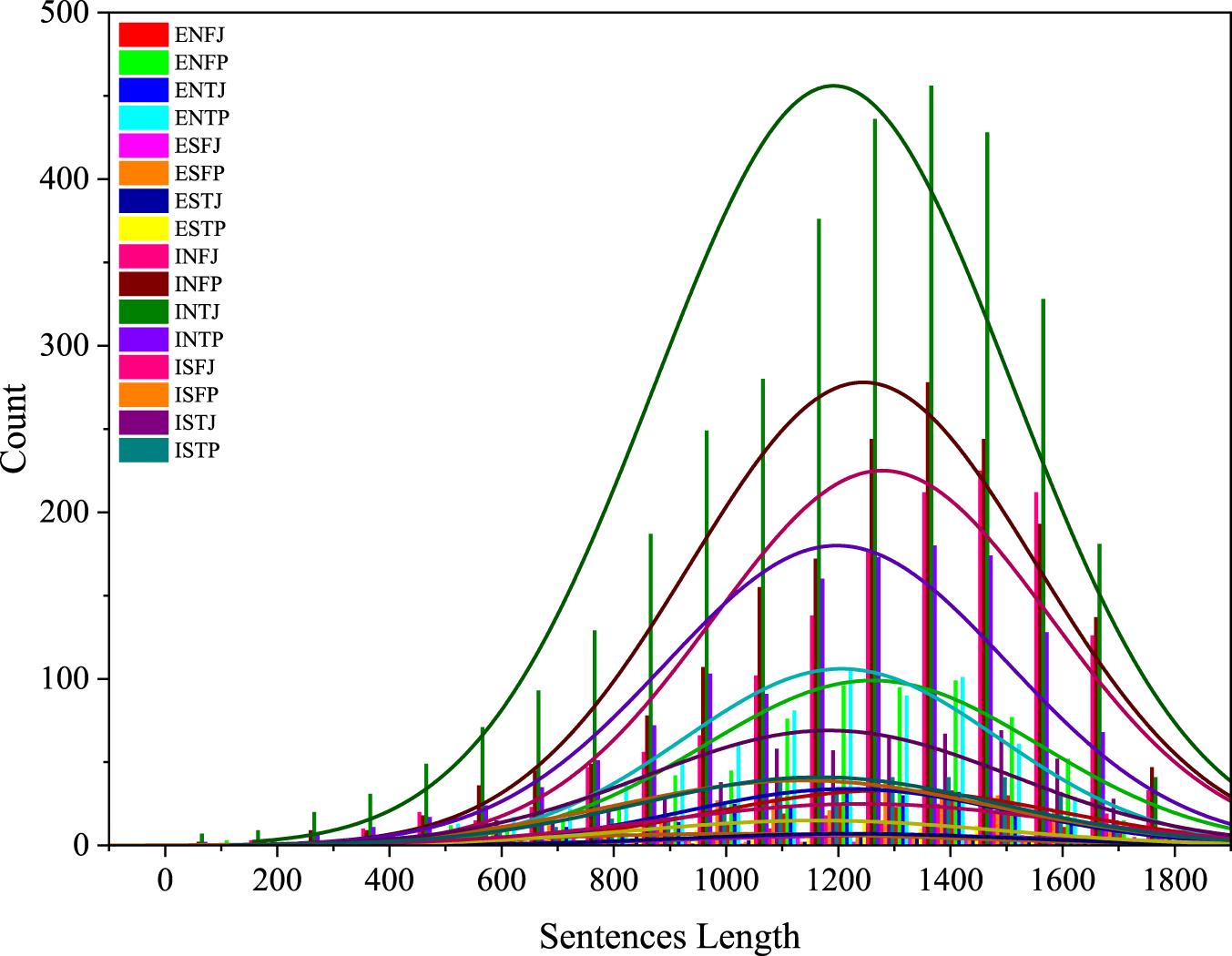
Histogram of input datasets.
Figure 7 shows the word clouds of the personality type class datasets, which can intuitively display illustrative examples of most topics in each dataset. These visualizations treat the frequently occurring terms to larger font sizes, while being less often words are shown with smaller sizes. By taking a closer look, some interesting patterns arise: terms like “like”, “think”, “im” feature prominently in the real class dataset, which reflects common topics related to MBTI dataset sources. These findings reveal a set of unique lexical features that belong exclusively to each class and provide much information on the linguistic subtlety that underpins the classification of personality types.

The word clouds of the MBTI dataset.
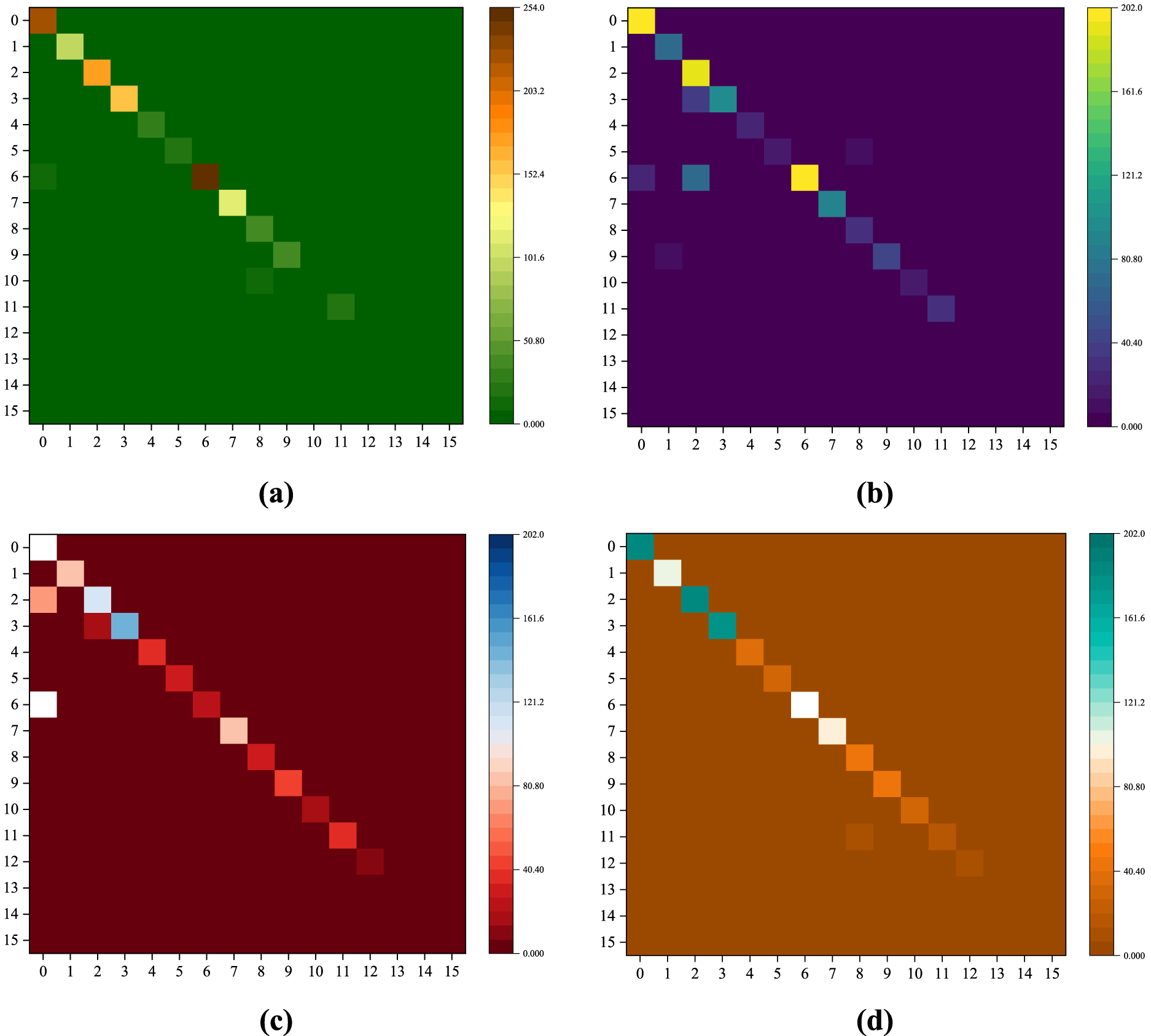
The confusion matrices 1-Layer (a), 2-Layer (b), 3-Layer (c) CNN and CNN-LSTM (d) classification model.
The data has to go through certain preprocessing steps before analysis to ensure that these are quality data on which further application can be made. The preprocessing involved in this study includes the following:
Handling Missing Values: Replace all NaN or missing values with appropriate placeholders or imputation techniques fitting the dataset. Normalize the text: The purpose is to change all characters into lowercase to maintain uniformity in the data so that further stages in processing are easier. Noise removal: Those are punctuation marks, links, IDs, hashtags, and usernames, which are otherwise unnecessary in the text. Such artifacts could lead to biased analytical results and degrade the performance of models. Vectorizing Text: It involves the conversion of preprocessed text into numerical format suitable for the application of ML methods. Methods such as TF-IDF transformation and word embeddings transform text into numerical features while preserving semantic information.
Spilt of dataset
The training, validation, and test sets are well distinguished for the dataset used in this work, divided into three well-marked subsets. The training set covers 70% of the data and, therefore, is a substantial proportion for the training of the model. The validation set will account for 15% of the data, serving as a touchstone during the development of the model to enable its tuning of parameters, preventing overfitting. Similarly, the test set includes 15% of the data and is never used in either training or model validation to assess the performance of the model on new, unseen data. This stratified division ensures each subset properly represents the overall dataset distribution, enhancing the reliability of the model assessment.
Performance assessment of the classification model
An overview of the matrix of confusion.
An overview of the matrix of confusion.





The classification of MBTI personality types within this study has been done using neural networks through the utilization of four different models: 1-layer, 2-layer and 3-layer CNN architectures, as well as hybrid CNN-LSTM for the classification of results. A few of the criteria used to evaluate the performance of these models under consideration include the confusion matrix, accuracy, precision, recall, and F1-score. Deep model training was conducted for 60 epochs by default, although early stopping was also available to end the training if the validation loss did not decrease after 5 epochs. Additionally, for further performance enhancement and regularization against overfitting, batch normalization and dropout were added to 3 of the deep learning models. These techniques stabilize and accelerate the training process while reducing the risk of overfitting by controlling the distribution of input values and strategically dropping neurons during training. A full comparison of the classification models with respect to these metrics provides rich understanding regarding their efficacy and strength in the task of predicting MBTI personality types that will guide informed decisions on model selection and refinement.
Confusion matrices visualize the performance of each model in the classification of personality types in MBTI. It gives the complete view of the models performance while color gradients indicate magnitudes of values. Brighter colors off the diagonal mean larger values, which signify poor performance of a model while on the other hand, darker colors on the diagonal mean larger values, signifying good performance.
From the confusion matrices, some general observations stand out: This model provides better prediction capability compared to 2-layer and 3-layer CNN. The lighter shades mean high precision in the predictions of this confusion matrix. Relatively worse performance of 3-layer CNN as compared to 2-layer CNN was depicted by misclassifications across certain classes. In particular, errors in class 7 in column one point toward lower accuracy compared to that of the 2-layer CNN model. The hybrid model emerges as the top performer among all models evaluated. It achieves accurate predictions across most classes, as depicted by the lighter shades in its confusion matrix. This underscores its superior accuracy and effectiveness in classifying MBTI personality types compared to the other models.
A detailed comparison of the hybrid CNN-LSTM classification model with the 1-layer, 2-layer, and 3-layer CNN models’ performances is shown in Figure 9. For this comparison, the assessment criteria used are F1-score, accuracy, precision, and recall.
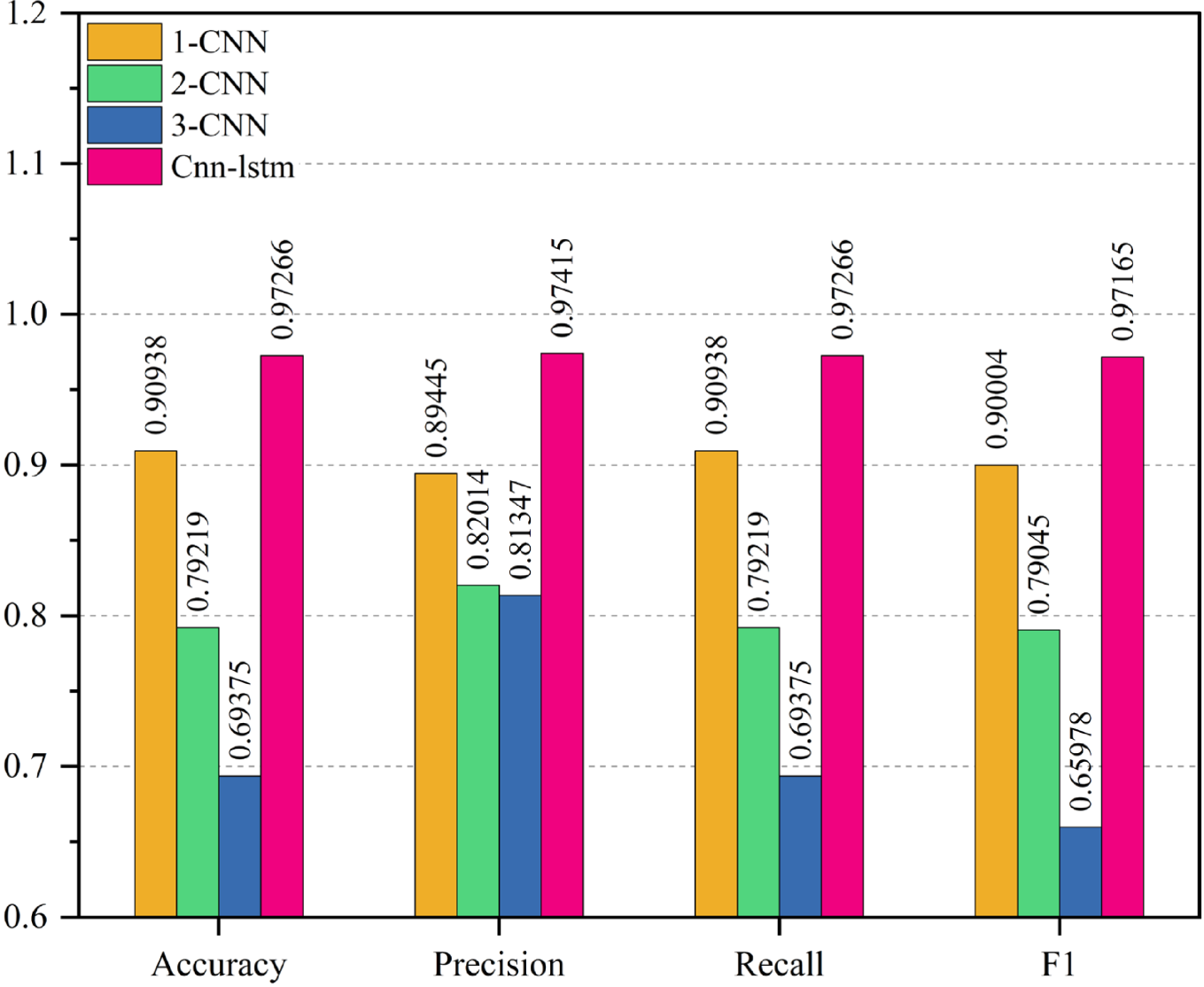
The performance metrics were obtained from 1-layer, 2-layer, 3-layer CNN, and hybrid CNN-LSTM classification models.
Upon analysis of the plot, several key observations can be made:
While this model achieves a higher recall compared to the other models, its precision is relatively lower, resulting in an unbalanced performance across metrics. This suggests that the model may exhibit a tendency to classify some classes more accurately at the expense of precision in others. Similar to the 3-layer CNN model, the 2-layer Bi-LSTM model demonstrates a pattern of performance with slightly higher recall than the 3-layer model. However, it does show a lower precision, which might indicate a trade-off between recall and precision. Unlike the multi-layer models, the 1-layer CNN model performs considerably better by all measures. That would indicate that added layers in the other models have little impact on improved performance. The proposed model Hybrid CNN-LSTM turned out to perform the best among all models using LSTMs with the F1-score of 97.16%, with an overall best performance showing a balanced distribution of values across the metrics, establishing the effectiveness in handling the Fake News Detection dataset for emotion detection. It follows that the overall results demonstrate how hybrid CNN-LSTM outperforms the performance of CNN-based models in classification, indicating its efficiency in the accurate classification of the MBTI personality types dataset.
The research study utilized the MBTI as a tool to try and predict personality type and find some patterns which were prevalent. This data-driven approach gives a basis for possible organizational interventions and task assignments that are best fitted. A study on neural network-based MBTI personality type classification used four different models, namely: the 1-layer, 2-layer, and 3-layer CNN architectures, together with the hybrid CNN-LSTM classification model. Extensive performance evaluation using metrics like accuracy, precision, recall, F1-score, and confusion matrices have been given to shed light on the efficacy and robustness of these models in predicting personality types according to MBTI. Training for deep models was done by default for 60 epochs, while early stopping was introduced as a regularizer to prevent overfitting. Also, batch normalization and dropout were added to improve the performance of the model further and avoid overfitting. The key findings of the study could be summarized below:
The confusion matrices graphically presented the performance of the different classification tasks of each model, which helps to have a full picture about the performance. More precisely, the 1-Layer CNN was relatively superior in its forecasting ability compared to its multi-layer model, while the CNN-LSTM model became the best performing model showing correct predictions on the majority of classes. Hybrid CNN-LSTM outperformed any of the LSTM-based models since it yielded the highest value for all the metrics-recommendation, precision, and F1, with close values, hence establishing its efficiency in classifying the emotions correctly in the Fake News Detection dataset, as a detailed comparison of the results of different models has shown. Results highlight that the hybrid CNN-LSTM classifier outperforms the CNN-based model, underlining basically how the complexity of the classification tasks is overwhelming, such as in the case of the MBTI personality type prediction. These insights give grounds for the making of informed decisions on the choice and refinement of models in subsequent research. Embracing the study indicates a realization of individual differences in organizations. Personality insight knowledge can be used to promote inclusion and facilitate a more effective workplace-a workplace that will boost the output and job satisfaction of the workforce.
Footnotes
Abbreviations
Greek letters
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.