
Abstract
Sentiment analysis of scientific citations is a novel and remarkable research area. Most of the work on opinion or sentiment analysis has been suggested on social platforms such as Blogs, Twitter, and Facebook. Nevertheless, when it comes to recognizing sentiments from scientific citation papers, investigators used to face difficulties due to the implied and unseen natures of sentiments or opinions. As the citation references are reflected implicitly positive in opinion, famous ranking and indexing prototypes frequently disregard the sentiment existence while citing. Hence, in the proposed framework the paper emphasizes the issue of classifying positive and negative polarity of reference sentiments in scientific research papers. First, the paper scraps the PDF articles from arxiv.org under the computer science group consisting of articles that are comprised of ‘autism’ in their title, then the paper extracted cited references and assigns polarity scores to each cited reference. The paper uses a supervised classifier with a combination of significant feature sets and compared the performance of the models. Experimental results show that a combined CNN-LSTM deep neural network model results in 85% of accuracy while traditional models result in less accuracy.
Introduction
Opinion mining or sentiment analysis is the computing analysis of opinions expressed in the text. This analysis is usually accomplished based on words in a sentence. Words are indicators of the sentiment polarity of a sentence. A disadvantage of this approach is handling inconsistent words. A word is said to be inconsistent when its sentiment polarity is reversed by the context of the sentence.
An instance of an inconsistent word is the sentence containing the word “consequence” in it such as “he is not responsible for the consequences” where the word “not” is negating the polarity of “consequence”, so that the final polarity becomes negative. The traditional sentimental analysis approach classifies this statement as negative because of the negative word. This raises an issue because, if words are treated independently, the existence of a single negative word negates the entire sentence. Recognizing user sentiment precisely leads any system to guess the alerts on products and makes it possible to direct users to the best reviews, improving overall customer experience.
The notion of reviewing the sentiment of a sentence is not new [13]. Researchers offered this problem on different social platforms (i.e., Twitter, IMDB, Amazon, and Facebook), scientific research to analyse product reviews, and for recommending precise articles to customers. Machine learning (ML) approaches have already been implemented for predicting sentence sentiment. This job involves the model to be effective at Natural Language Understanding (NLU). The job of NLU is to figure out good exemplifications of textual data. The task of determining the sentiment of a sentence entails a model to capture the semantic, syntactic, and intent of the sentences presented. Hence the model must incur to handle linguistic occurrences like quantifiers, tense, aspect, modality, and lexical ambiguity.
Corpus, features and classifier differences in sentiment analysis studies
Corpus, features and classifier differences in sentiment analysis studies
Owing to the effort of this functionality, the authors of this paper thought that the sentiment analysis of scientific research constitutes a fascinating problem. This paper intended to present an inclusive set of ML models and to examine their performance on the citation data using fundamental as well as advanced models. The authors built and tested the Term frequency–inverse document frequency (TF-IDF) vectorizer, Word2vec, Support Vector Machine (SVM), and Convolutional Neural Network (CNN) deep neural network model and exposed the considered models in detail with the results that are discovered.
Sentiment analysis falls into the binary classification category on variable-length strings. The interesting task is how textual data is represented in a machine-understandable format (i.e., numeric) such that the ML models can be processed on it. With the improvement of deep neural networks, there has been a further enhancement for text classification and representation [8]. Feature generation is a widely used technique which can be combined with other ML models; the proposed approach comes under this category, by automatically differentiating consistent from inconsistent sentiment words in the context of improving performance.
Sentiment analysis is the basis for all platforms such as Twitter, Facebook, and Quora that hosts millions of customers, where the users post millions of textual messages per day. It has to turn into a direct association between organizations and their consumers, and such it is being used to form bonding with branding, to understand demands [6]. From a researcher’s point of view, text mining in the scientific citation is an interesting task that can be used amongst other fascinating things for assessing reference sentiment towards a citation.
The authors of the paper interest lay in having a better understanding of the exploration of various basic as well as advanced machine learning models and their performance by considering different feature vectors [6].
Related work
Pang and Lee [1] suggested a graph-based sentiment analysis that uses the minimum cuts for classifying sentences so that the contextually similar sentences plot nearly. Hence, they generated a score for individual text and virtually separated each class. In contrast to this proposed framework, they castoff only two classes on movie review dataset.
Godbole [2] proposed a sentiment analysis for Blogs and News. Different from other methods, they castoff antonym and synonym requests concerning the same polarity to increase their vocabulary. Hence, they proposed a function that reduces the importance if the distance among words is big, it also computes a trust and sentiment score estimate for all the paths.
Pak and Paruoubek [3] suggested a sentiment analysis on a micro blogging website called twitter. They used a Naïve Bayes classification method and used n-gram, POS-tagging features to observe positive, neutral, and negative polarities.
Kouloumpis et al. [4] presented a method that uses linguistic features to identify the sentiment of a text message [10]. They used altered features like unigram, bigram, sentiment scores, and part-of-speech as features to train and test classifiers. They used twitter dataset to assess the worth of features to capture the polarity. Methodology to find author-author relations in the citation networks using co-occurrence analysis was proposed in the earlier work [12].
Bahrainian and Dengel [5] proposed an unsupervised as well as a hybrid sentiment detection system. They used binary SVM classifier to classify tweets. They showed that the hybrid approach outperforms better than state-of-the-art algorithms by taking advantage of various features. In latest studies, as shown in Table 1, combination of multiple features has been frequently used.
Dataset preparation
To study the sentiment of citations, this paper used the dataset under computer science group consisting of 1000 articles that are comprised of ‘autism’ in their title. These articles are gathered using a python scraper application that randomly downloads documents from arxiv.org based on users’ category. This category can be filtered based on the title, authors, abstract or related keyword. A downloaded corpus is in Portable Document Format (pdf) format. From these pdf articles citing sentences are extracted based on reference numbers and multiple citation references were preserved as a distinct citation since they share the same sentiment citation polarity and gathered into a Comma-separated values (CSV) file for further analysis. During this process some citation references are found as ‘self’ studies, this approach excluded those citations.
To simplify the computation step the authors used Pandas Library in Python for reading the dataset. This papers’ experimental study exhibited an inequality among the three sentiment classes with 4178 labeled as neutral, 1499 labeled as negative, and 1963 labeled as positive instances. This spreading could be produced by likelihood of testing occurrences that skewed our study towards neutral sentiment as shown in Fig. 1.
Histogram of citation sentiment counts.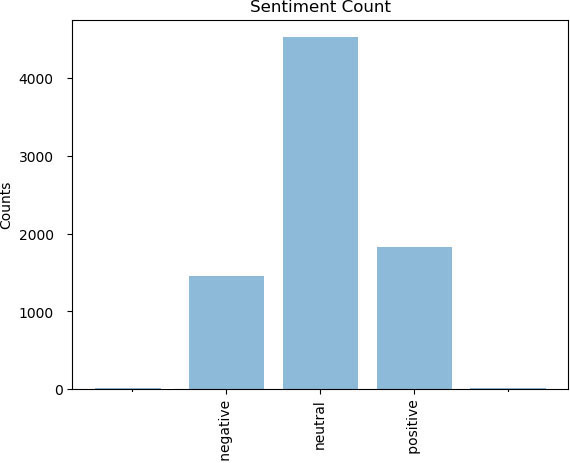
To revise the sentiment of citation data, the exploratory analysis was accompanied on a dataset of citations relating to users’ familiarities by citing sentences. The dataset consists of cited sentences and their corresponding sentiment label. The user familiarity is labeled as positive, neural, and negative as displayed in Table 2.
Sample polarity of cited sentences in the dataset
Sentiment estimate has been an on-going area of research and is an interesting task particularly in morphologically rich languages. The task involves categorizing an input sentence either as “Positive” or “Negative” as shown in Fig. 2. To accomplish this, this paper experimented with models that targets to combine the standard Long-Short Term Memory Neural Networks with Convolutional Neural Networks, however this paper attained better results with a word-level multi-layer Convolutional Neural Network and used it as a final model.
Negative and Positive word cloud made up of the most frequent words in the dataset.
Linear model
ML models use n-grams, part of speech tagging (POS) to figure out the features to be used in a model. The following is the description of the basic features:
N-grams
It is a sequence of ‘n’ contiguous words in textual data. If
POS
POS tags are used as features in a classifier to separate between word arrangements with dissimilar part-of-speech. POS tags are labelled with NNP, VBG to represent noun, verb, etc. The token type assists to specify the prominence of the token, for example a JJ token is more prominent than a VB or NNP token. We use the nltk package in python to extract POS tags of the cited sentences. The feature value for this task would be a token type, length or participation in the top N frequently capitalized items.
Tf-idf model
It is another approach to represent textual data into machine-understandable format. The first term denotes term frequency and the second term denotes the importance of that word in an article. Without any former knowledge, other than textual data, the Tf-idf score will focus on all the words that can categorize that particular word from other words, reduce-weighting of all the regular words that won’t give any information, such as articles, verb, and conjunction. For this task, the authors of this paper used the scikit-learn package in python [7].
TF-IDF and SVD
It is a feature decomposition approach and it stands for singular value decomposition. It is mostly used in NLP because of a method called Latent Semantic Analysis (LSA). To create a feature for this task the authors of this paper used the scikit-learn package in python, a method truncatedsvd that offered reliable SVD matrix.
Architecture for citation classification.
Working model of the proposed framework.
Word embeddings signify words as small dimensional vectors that are qualified by a model like word2vec and mark the likely or related words that are nearer in the vector space. In contrast, one-hot vector representation is autonomous and a correlation between the words cannot be computed. The word2vec model gets a corpus of text as input and creates the word vectors as output. First, it builds a vocabulary from the training data set and then learns vector representation of words. The subsequent word vector file can be used as features in machine learning applications and natural language processing [9]. To compute the polarity of a reference word2vec uses word mover’s distance algorithm to find the distance between words as shown in Fig. 3. The feature value for this task is cosine or Jaccard distance between words, the angle of the vector for a sentence. There are two major algorithms in the word2vec model, one is Continuous Bag-of-Words and a Continuous Skip-gram model. Skip-gram model predicts the context of the words built on the existing word. More exactly, it uses each existing word as an input to a classifier and predicts words within a specified range. In contrast, continuous bag of words (CBOW) predicts the existing word from the context of words nearby it.
The data set was divided into two clusters. Going by the rule of thumb, 70% of the data set is used for training, and the rest is used for testing. This research also experimented 80/20 and 60/40 split up and found the considered split was the best. To train the model, the parameters have to be specified as shown in Fig. 4.
The following are the parameter specifications as shown in Table 3.
Sample parameter specification of the model
Sample parameter specification of the model
The scikit-learn module is used to split the data into training and testing sets. The training set consists of 70% of the samples and 30% were given for testing set.
Prior to training the word2vec model, the data is pre-processed, where all the uppercase letters, extra spaces, stop word and special characters are removed as they don’t deliver any suitable data to find strong semantic associations in the sentences. The library nltk in python is used to serve this purpose, for natural language processing and English written script in the Python programming language.
Once the citation corpus is pre-processed, the word entrenching technique word2vec is used to characterize words as a sequence of vector space where nearby semantically equivalent words are mapped as points in vector space. Word embeddings are learned from raw text using an efficient word2vec model. Two dissimilar designs are embedded inside word2vec model one being Continuous Bag-of-Words and later being Skip-Gram model, both models are related, except that the first method predicts source words from context and the second does inversely. Both representations can be subsequently used in many natural language processing applications and for further research. These models overwhelmed the drawback of a one-hot illustration that feature vectors cannot replicate the dependency relationship among words.
A neural network is trained with text corpus, as a substitute a convolutional neural network is applied instead of the traditional network since it has been proven in the earlier researches that it is very efficient in fields such as classification and image recognition. There are six major operations to achieve notable results by using convolutions over the input layer to compute output in CNN that are listed as: embedding, dropout, convolutional block, concatenate, dropout and activation function.
Word2vec models’ weights in the Embedding layer are smeared to the network. Dropout benefits to evade overfitting by assigning some random weights to zero. Later, a convolutional block affects the size of the network drastically, with several filters such as Convolution, Max pooling and Flatten layers.
Architecture of a CNN model.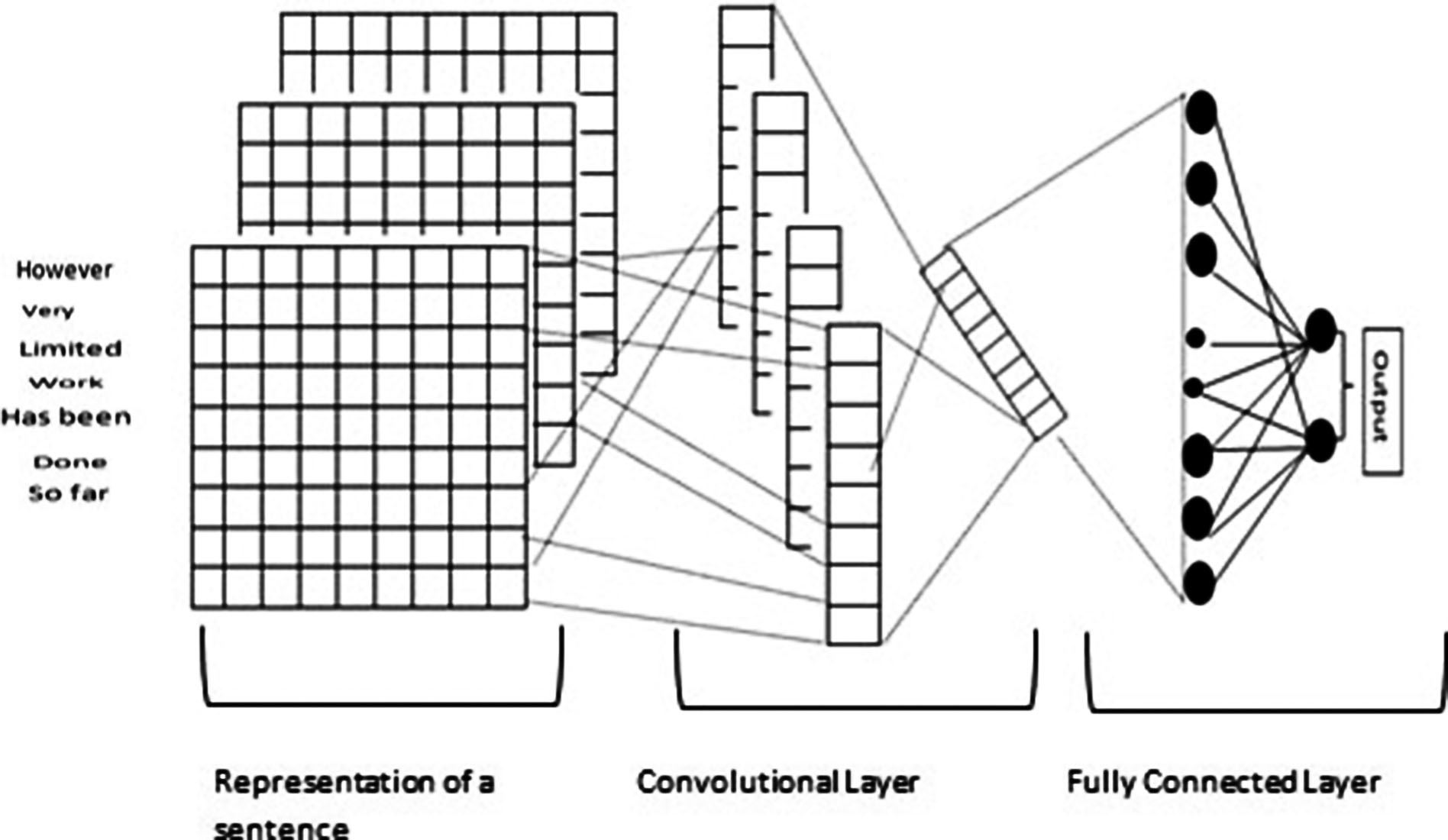
Convolution generates a convolution kernel and the converted vector of each word/character of an embedding layer is given as an input to CNN. These vectors are then forwarded to various layers of CNN to predict the output class. Originally considered for image recognition, CNN has been a popular model for multi-dimensional arrays of tasks. CNN’s have the capability of identifying local features inside multi-dimensional tasks. For instance, on an image, regardless of image quality, features will be captured and distinguished such as cat, dog, and pictures faces, irrespective of where these might be located. Basic CNNs will take multidimensional data as input to a convolutional layer which consists of several filters that will learn multiple features.
The first one, Convolution, extracts input image features and generates a tensor of outputs by convolving the input layer over a spatial dimension of features. It requires multiple parameters such as kernel size, filters, activation function, padding, and regularizer. The authors in this paper set kernel size as 3, filters as 32, and ReLU as an activation function in the initial layers. The ReLU activation is applied after each pixel value is convolved. The motive of this layer is to familiarize non-linearity to the network. ReLU will save all pixel values above zero and replace all negative values with zero. The padding is fixed to ‘valid’ and the filter is just sliding over the pixel values it can reach, this means that some values might be skipped. The final parameter is Regularizer, which can be either L1 or L2 that are expected to avoid overfitting. The proposed method uses L2 as a regularizer.
This layer reclusively executes in parallel and dropout is applied next. Activation function softmax is applied in the final layer to classify the polarity of the sentences.
The idea behind using CNNs on text depends on the statement that text is organized and structured; As such, we can imagine a CNN model to determine and study patterns in a feed-forward network. For instance, it can distinguish that using “serious” in the context of “serious-minded” is true positive polarity as opposite to other axioms such as “so serious”. Moreover, it can extract these features irrespective of where they occur in the sentence. Traditional approaches suffer from this problem it misclassifies the sentences as negative when the model finds a negative word. The proposed approach considers context using CNN and Long Short Term Memory (LSTM). LSTMs are adaptable to memorizing and learning over long categorizations of inputs.
The Dropout layer is employed to avoid the neural network to overfit the model. This means that the neural network accomplishes good accuracy on the training data and poor accuracy on the testing data. This layer works in the technique that it restricts a random set of neurons in each training phase. Since these neurons will not contribute to the learning phase when the data is further progressed through the network.
A convolutional fully connected layer is connected to all its preceding layers. This layer receives the former tensor as one argument, the number of classes to guess, and an activation function in the form of a softmax function. In this proposed approach the LSTM layer will turn as more than just a fully connected layer. The activation function sigmoid is applied to the LSTM layer to output the probabilities of a class.
Architecture of a combined CNN-LSTM model.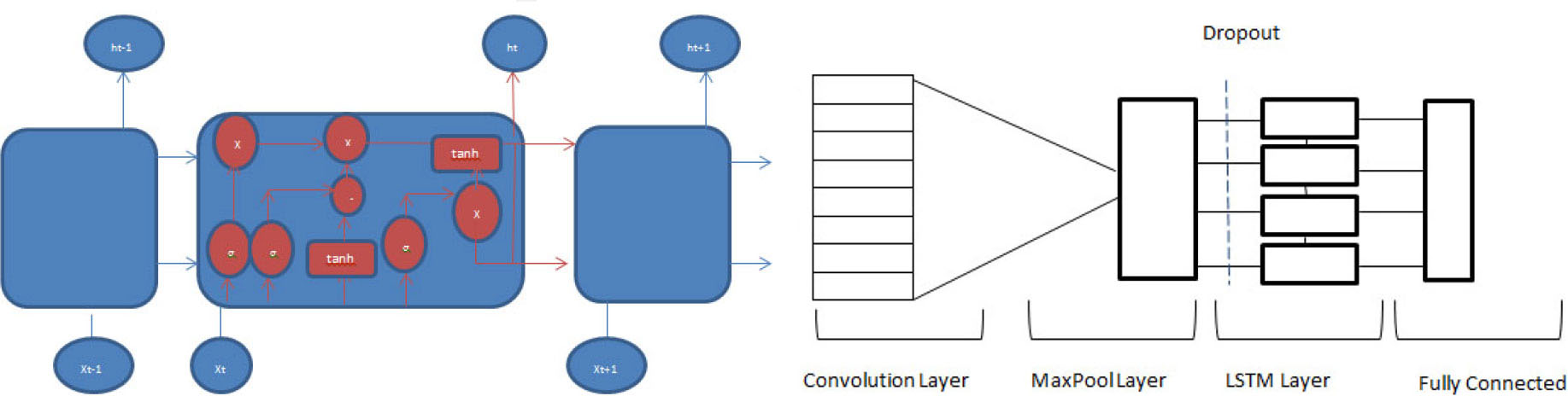
The Adam (Adaptive Moment Estimation) optimization algorithm is used in this model. Adam optimizes both the arguments and weights to reduce the loss function. Adam is one such variant of the optimization algorithm that optimizes the gradient descent [11]. Adam is a stochastic gradient descent algorithm that updates each data’s parameters, unlike the Batch gradient descent algorithm which updates whole dataset parameters after every epoch.
CNN models are skilled in mining local features but may fail to mine long term dependencies; the LSTM model will be merged to disregard this limitation. This combined model is different from the CNN model, where the main notion was to hold both representations.
The input layer takes two parameters one is shaped and the other is the label of the layer. This layer is used to feed the data to the network. Parameter shape designates the shape of input being fed to the network and the label of the layer is optional. For example, if the input is an image of size (32, 32, 3) defines 1024 pixel with RGB colors. In the proposed work the shape is a one-dimensional vector and its size is the longest sentence in the corpus as shown in Fig. 5. The output layer is a two-dimensional tensor one is shape and the other is batch size.
The embedding layer takes input and output dimensions, weights, and size of the input as parameters. Input and output dimensions represent the size of the vocabulary index and embedding size. The output dimension is the only one parameter that changes between different models.
Recurrent Neural Networks (RNNs) are frequently used for constructing classifiers and are with self-loops and functions on sequential data. In principle, vanilla RNNs is skilled in learning long term dependencies among data points. But, it has been shown by Bengio et al. (Bengio et al., 1994) that they frequently fail in the case of vanishing gradients. LSTMs are a class of RNNs which were proposed by Hochreiter et al. (Hochreiter and Schmidhuber, 1997) to overwhelm this problem and are practiced at learning long term dependencies. An LSTM proceeds by taking sequential data of the form (
Word2vec word vectors plot.
this proposed framework used a pre-trained vector dataset that was used in the Google News dataset. This model comprises 300-dimensional vectors for 3 million phrases and words.
Require: PDF file
Output: CSV file
Begin:
1. Look for the references in a file
# Traditional approach
2. for each (reference) do
Return (citation statement, polarity)
#Proposed approach
3. for each (reference) do
Return (Word2Vec (citation statement, polarity))
End
In a traditional approach, every citing sentence was considered and the sentiment polarity was labeled as the citation context at the sentence level. In the proposed approach, each citing sentence is interpreted based on its context. The context level interpretation is applied for the subsequent motives as shown in Fig. 7. First, inconsistency classification is taken into the account by considering sentence structure, not by word structure as in traditional approaches. Second, sentences referred by more than one citation and with different polarities.
The result in Table 5 illustrates the average accuracy of models. The authors in this paper considered training sets of 6000 citations and testing sets of 2000 labeled citations from the dataset. Both training and testing datasets comprise an equal quantity of positive and negative sentences. The dataset is trained using the hyper parameters offered in Table 4, and then verified the accuracy of the model when executing, for labelling the test dataset.
Hyper parameters
The finest arguments for the proposed model were primarily chosen based on earlier applications of CNNs and LSTMs and additionally fine-tuned through manual verification as shown in Table 5. The following section analysed the properties of these hyper parameters and the used parameters are:
Hyper parameters of the deep learning model
Hyper parameters of the deep learning model
Accuracies in machine learning models
This section illustrates the effects of citation sentiment analysis using different network models. This paper compares the standard CNN model against CNN-LSTM networks. Table 6 depicts the accuracy of state-of-art methods against the proposed method which gave an accuracy of 85%. From Fig. 8 it is observed that CNN-LSTM network preserved the upward trend in accuracy till 703 epochs.
(a) accuracy and (b) sample evaluation.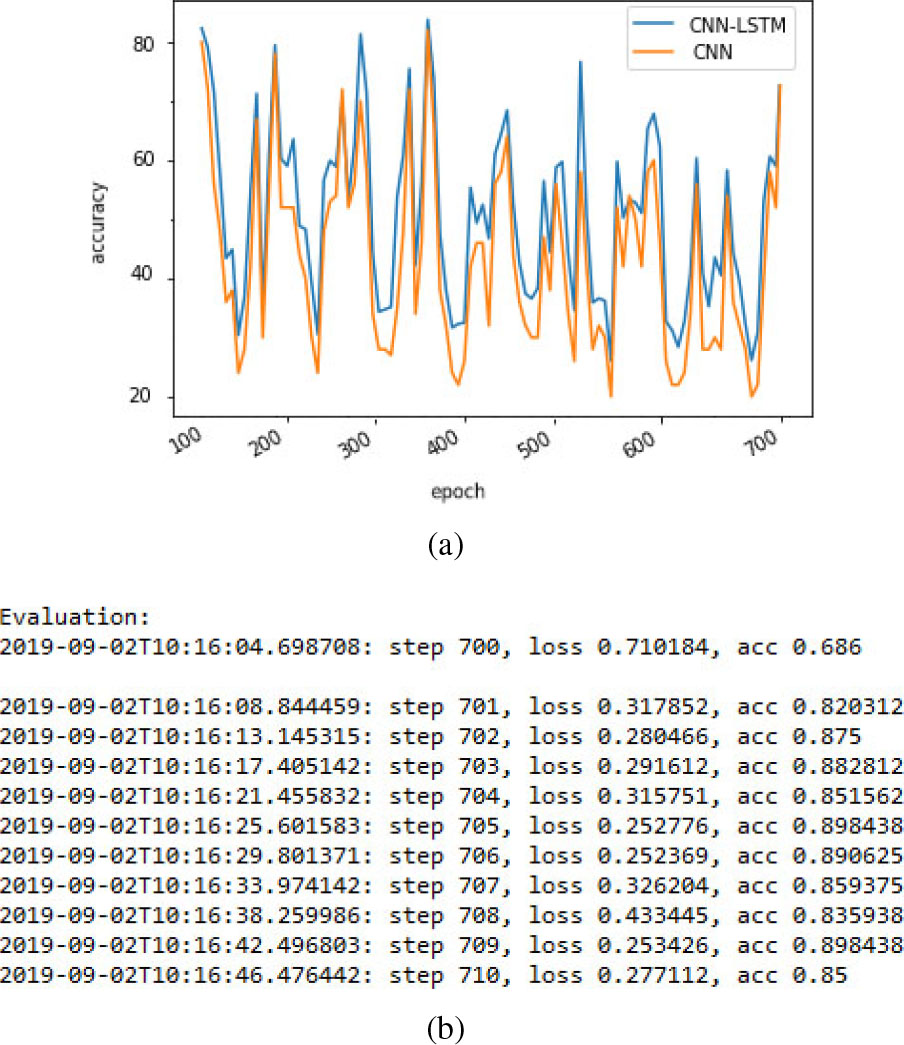
Accuracy of state-of-art methods
The evaluation outcome confirms that citation sentiment analysis relies on good training and feature selection for the input. CNN-LSTM model achieved more accuracy than standard models, the CNN model, and word embeddings. These outcomes specify that this paper formal perception was accurate and that by merging CNN and LSTM, it increased the capability of CNN’s in identifying local patterns, and the LSTM’s capability to identify the text order. Hence, the assembling of the layers shows a vital role in the performance of accuracy.
The ideal number of epochs to train our model was 15. Though it is observed every model had altered “learning rates” and some models learn and overfit quickly. As shown in results, CNN and CNN-LSTM conquered minimized log loss when compared to other machine learning models. In this implementation of both the models, that comprised dropout layers to verify if that would increase the accuracy. Also included a dropout layer closely after the CNN layer before serving into the LSTM to acquire higher accuracy.
However, using pre-trained GloVe word embeddings ensued in poorer accuracy. This is because many citation statements are neutral, not context-dependent and many negative sentences are not containing straight negative words. This paper concludes that it is likely to classify citations to acquire a better understanding of how essential a referred citation is. A quantity that does not consider the frequency of citations and can recommend or rank papers based on citation context.