
Abstract
Significance:
Pediatric pressure injuries (PIs) are a distinct and preventable clinical challenge, yet risk prediction models tailored to children remain underdeveloped. This systematic review critically evaluates existing pediatric PI prediction models to assess their methodological rigor, predictive performance, and clinical applicability.
Recent Advances:
Following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses 2020 guidelines, nine databases were searched to identify studies developing or validating PI risk prediction models for hospitalized patients younger than 18 years. Twelve models from nine studies were included. Risk of bias and applicability were assessed using the Prediction Model Risk Of Bias Assessment Tool (PROBAST) and PROBAST + AI tool.
Critical Issues:
All models demonstrated acceptable discrimination (area under the curve [AUC] range: 0.612–0.978), with seven exceeding an AUC of 0.75. However, calibration was inconsistently reported, and only two models evaluated clinical utility—just one showed net benefit across a realistic threshold range. All models were rated as high risk of bias, and 10 had major concerns regarding applicability. Common methodological flaws included low events per variable <10, inappropriate categorization of continuous variables, poor handling of missing data, and lack of external validation. Most models were developed in single-center studies from China, limiting generalizability. Compared with adult PI models, pediatric models lacked age stratification, standardized outcome definitions, and robust validation. The first application of PROBAST + AI for evaluating machine learning prediction models highlighted algorithmic fairness and ethical risks within these models, but it showed insufficient interpretability regarding aspects such as the optimization process and the transparency of “black box” data leakage.
Future Directions:
To improve predictive accuracy and clinical relevance, future models should adopt the Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis, PROBAST, and PROBAST + AI standards, use multicenter data, stratify by age and clinical setting, and focus on early-stage PIs. Incorporating objective measures and evaluating clinical utility will enhance model integration into practice. PROBAST + AI, in alignment with the advancements in information technology, requires widespread attention for its practical utility and ease of use to be further validated and optimized.
Hongying Pan

Yihong Xu

Conclusion:
Current pediatric PI prediction models show promise but fall short in methodological rigor and clinical applicability. Addressing these gaps is essential to support early identification and targeted prevention in pediatric care.
SCOPE AND SIGNIFICANCE
Pressure injuries (PIs) are a unique and preventable clinical challenge in pediatrics, imposing a significant medical burden on patients. Risk prediction models possess specificity and broad clinical utility, helping to identify high-risk patients to guide the clinical implementation of preventive measures; however, their methodological rigor, predictive performance, and clinical applicability require close attention. This study systematically examines and evaluates existing pediatric PI models, identifying key issues and clinical gaps. Compared with adult PI models, it highlights disparities associated with age and clinical environments. Furthermore, based on the research findings, a clinical pathway was established to serve as a reference for the clinical translation of current pediatric PI risk prevention practices and to offer constructive recommendations for the future development of pediatric PI models.
TRANSLATIONAL RELEVANCE
Pediatric patients have unique physiological and developmental characteristics, and PI imposes a heavy burden on the skin management of pediatric patients, highlighting the urgent clinical need for predictive models that specifically and accurately identify the risk of PI. This systematic review, through rigorous examination, found critical deficiencies in current pediatric PI predictive model research and reporting, including a high risk of bias, insufficient internal and external validation, and limited clinical applicability. Addressing these issues can facilitate the development and validation of high-quality risk prediction models, thereby bridging the gap between current risk prediction models and clinical practice and, by using PI risk prediction models, enabling individualized and specific PI risk identification while strengthening prevention strategies, reducing PI incidence, and improving the medical burden associated with skin management in pediatric patients.
CLINICAL RELEVANCE
Pediatric PI can occur across different age groups and clinical settings, and common predictors for pediatric PI risk prediction models, such as operation time, intraoperative blood loss, and preoperative skin condition, deserve special attention when assessing PI risk in pediatric patients. Predicting the risk of pediatric PI is of significant clinical utility, as it can not only guide the implementation of targeted preventive measures to reduce PI incidence or improve its severity but also optimize clinical resources. It is crucial to develop robust and validated models by integrating and screening the predictors from existing literature, drawing upon adult strategies, and considering age and clinical setting differences. This can strengthen clinical decision-making and guide the formulation and clinical practice of more effective PI prevention strategies.
INTRODUCTION
The “Prevention and Treatment of Pressure Ulcers/Injuries: Clinical Practice Guideline” released in 2019 defines pressure injury (PI) as localized damage to the skin and/or underlying soft tissue, usually over a bony prominence, or related to a medical device or other object, resulting from pressure or pressure in combination with shear. The skin may be intact or present as an open ulcer, often accompanied by pain. 1 PIs can occur in all health care settings and affect people of all ages. It has imposed a huge health burden, with the annual cost in the United States alone reaching as high as $17.8 billion. 2 As early as 2016, the General Office of the National Health Commission of China had already included PIs as one of the nursing quality control indicators and updated the document in 2020, which sufficiently demonstrates the importance of PIs. 3
However, PIs occurring during hospitalization (after 24 h of admission) are termed hospital-acquired PIs (HAPIs). 4 Research indicates a global adult PI incidence of 12.8%, with HAPIs accounting for 8.5%, 5 whereas the cumulative incidence of HAPIs in the pediatric population is 14.9%. 6 The higher incidence of PIs during pediatric hospitalization, and the significant difference from adults, may be attributed to anatomical, physiological, and risk factor disparities in the pediatric population. 7 The study by Schindler et al. 8 further confirmed that the majority of PIs in pediatric patients (including hospitalized pediatric patients) primarily occur during hospitalization and are independent of age or developmental level. Furthermore, it is noteworthy that the occurrence of PIs in pediatric patients during hospitalization increases the medical burden; pediatric patients who develop PIs incur an average additional cost of $85,853 compared with non-PI pediatric patients, 9 and the estimated daily expenditure for PI treatment ranges from €1.71 to €470.49. 10 This alerts us to the critical importance of reducing the incidence of PIs during pediatric hospitalization.
Although the “Prevention and Treatment of Pressure Ulcers/Injuries: Clinical Practice Guideline” 1 published in 2019 addresses the unique risk factors for pediatric PIs and states that PIs are preventable, there are scarce guidelines and risk prediction tools specifically for pediatric PI prevention. Moreover, the increased medical burden caused by pediatric PIs highlights the necessity of risk prediction. Therefore, accurately assessing risk factors for PIs during pediatric hospitalization is crucial for preventing PIs and enabling clinical nurses to implement targeted nursing preventions.
Identifying at-risk patients is central to preventing PI. The current primary method for clinically assessing PI risk involves visual and tactile evaluations combined with scale-based tools; among these, the Braden scale 11 is the most widely used PI risk assessment tool, yet it is primarily designed for adults. In 2019, “Pressure Injuries in the Pediatric Population: A National Pressure Ulcer Advisory Panel (NPUAP) White Paper” 12 identified 18 PI risk assessment tools covering pediatric patients of all age groups and settings, including neonates and premature infants; Among them, the widely validated Western pediatric scales such as Braden Q, Glamorgan, and Braden QD, despite having certain predictive value in different domains, show variation in their predictive performance due to differences in study populations, clinical settings, and disease specificity. 13 For example, the Braden Q scale is applicable to children aged from 21 days to 8 years, focuses on predicting mobility-related PI, lacks assessment related to medical devices, and generally has a mediocre predictive effect for critically ill children 14 ; however, it is frequently used in other subjects and settings 15 ; although the Glamorgan scale includes assessment related to medical devices and has a better predictive effect than Braden Q, it has not been widely used; and the Braden QD scale is applicable to patients from premature infants up to 21 years, involves patients older than 18 years, and has a relatively low specificity for pediatric PI prediction. 16 However, most of these tools were extended from adult versions, and while they can assess pediatric PI risk, their clinical specificity and predictability are limited, leading to a somewhat chaotic clinical use of PI risk assessment tools, with some even applying the adult-specific Braden scale for PI risk assessment, which fails to provide specific risk assessment for pediatric patients.
In contrast, risk prediction models, which identify and predict high-risk populations based on multiple risk factors, are common tools known for their specificity and broad clinical applicability, making them more suitable for pediatric PI risk identification. 17 An increasing number of scholars are constructing pediatric PI risk prediction models for PI risk identification and prediction, providing valuable tools for specific risk identification and prevention in this population; however, their practical utility still requires assessment of the rigor of model development, completeness of reporting, reproducibility, and generalizability. Therefore, a systematic evaluation of the bias risk and applicability of existing pediatric PI risk prediction models using the Prediction Model Risk of Bias Assessment Tool (PROBAST) provides a reference for constructing high-performance models with clinical applicability. 17 With the continuous development of machine learning (ML) technology, the number of prediction models based on ML has gradually increased; however, PROBAST has limitations in evaluating such models, which led Moons et al. 18 to develop the PROBAST + AI assessment tool for a more comprehensive and scientific evaluation. This study aims to explore the early identification of pediatric PI risk factors based on existing research and to provide a foundation for optimizing models with greater clinical practical value.
METHODS
The protocol for this systematic review was registered with PROSPERO (CRD42024605734). This study followed the 2020 version of the Preferred Reporting Items for Systematic Reviews and Meta-Analyses statement. 19 The summary of this study is provided in Fig. 1.

The summary graphic illustration of this study.
Search strategy
The systematic search was performed in PubMed, Embase, Web of Science, the Cochrane Library, CINAHL, SinoMed, CNKI, VIP, and Wanfang Database for literature published up to December 31, 2024. The synonyms of search terms are obtained by using the medical subject heading function of PubMed, and logical search is conducted by combining subject terms and free terms. The search terms included “child*/infants/neonat*/adolescent*/youth*/newborn/pediatrics,” “pressure injur*/pressure ulcer*,” “model*/Risk Assessment/nomogram*/risk factor/predict*/diagnos*/prognos*.” In addition, the references of retrieved studies are reviewed for further relevant articles. The specific search strategies for each database are detailed in Supplementary Data S1. Electronic laboratory notebook was not used.
Inclusion and exclusion criteria
The inclusion criteria for the study were as follows: (1) Participants included hospitalized patients younger than 18 years in any clinical setting (intensive care unit [ICU] or general ward); (2) the outcome measure was objectively confirmed as PI; (3) studies reported a risk prediction model for PI; and (4) articles were published in Chinese or English. The exclusion criteria were as follows: (1) Studies that only analyzed risk factors without constructing a prediction model; (2) nonpeer-reviewed publications, such as conference abstracts, preprints, unpublished theses, or gray literature; and (3) studies for which the full text could not be obtained.
Study selection
After removing duplicate literature, two researchers (X.Z. and Y.X.) independently screened and extracted data based on the inclusion and exclusion criteria, first screening articles by title and abstract and then reading the full text for further screening. Furthermore, we evaluated the references of the included studies and conducted manual searches when necessary to identify other potential eligible literature. Each step was cross-checked, and any disagreements were resolved through discussion or consultation with a third researcher (Z.Y.). The detailed process of literature selection is shown in Fig. 2.

The Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) flow diagram of study selection process.
Data extraction
A standardized data extraction form was developed based on a checklist for critical appraisal and data extraction for systematic reviews of prediction modeling studies.20–21 The extracted information was divided into two parts: (1) Table 1 presents the basic characteristics of the included studies, including author/year, country, study design, type of prediction model, participants, data source, PI measurement time, and case/sample size (%). (2) Table 2 details the prediction model information, including continuous variable handling, candidate variables, events per variable (EPV), variable selection handling, missing data handling, model development method, model area under the curve (AUC), calibration method, and model presentation. Two researchers (X.Z. and Y.X.) independently extracted data according to the data extraction form, and any disagreements were resolved through discussion or consultation with a third reviewer (Z.Y.). If necessary, the authors of the included studies were contacted to obtain additional data.
Overview of basic data of the included studies (n = 9)
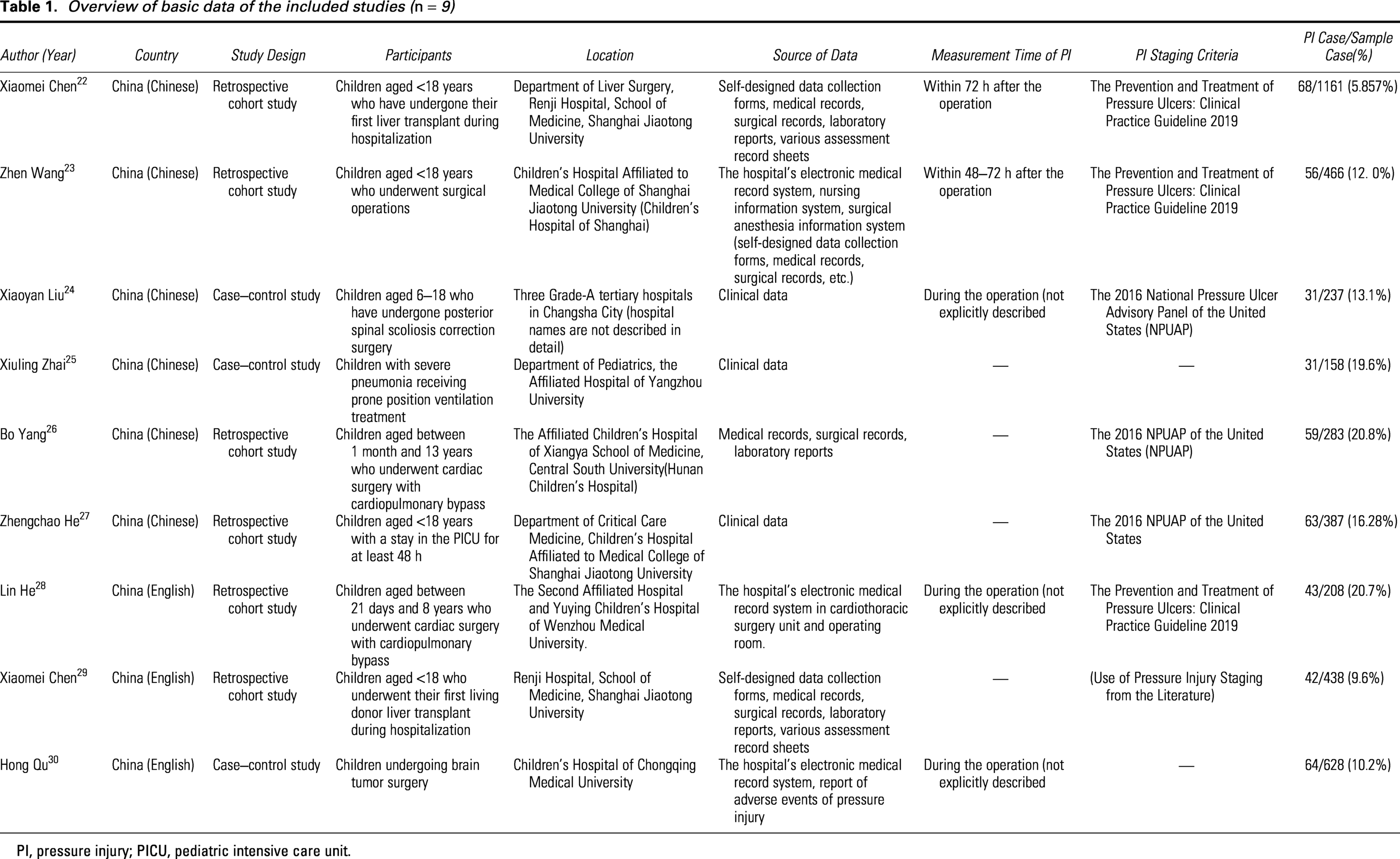
PI, pressure injury; PICU, pediatric intensive care unit.
Overview of the information of the included prediction models (n = 9)
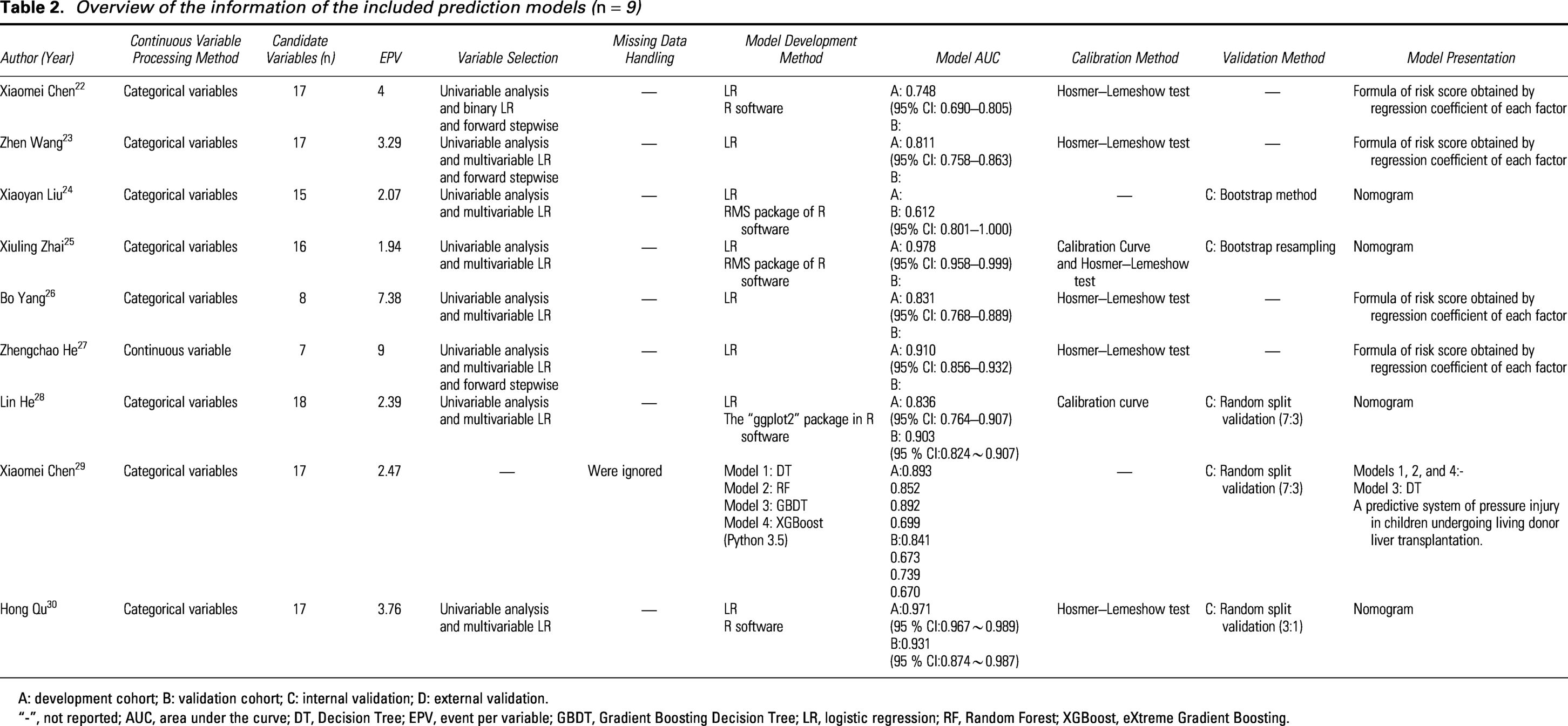
A: development cohort; B: validation cohort; C: internal validation; D: external validation.
“-”, not reported; AUC, area under the curve; DT, Decision Tree; EPV, event per variable; GBDT, Gradient Boosting Decision Tree; LR, logistic regression; RF, Random Forest; XGBoost, eXtreme Gradient Boosting.
Quality assessment
Two researchers (X.Z. and Y.X.) independently assessed the risk of bias and applicability of the included studies using the PROBAST and PROBAST + AI; in case of disagreements, any discrepancies were resolved through discussion or negotiation with a fourth researcher (X.L.) to reach a final consensus on the assessment results.
The PROBAST tool for assessing the risk of bias in prediction model studies is divided into four domains: Participants (two signaling questions), predictors (three signaling questions), outcome (six signaling questions), and analysis (nine signaling questions), totaling 20 signaling questions. PROBAST + AI consists of two distinct parts, model development and model evaluation, and also assesses the four aforementioned domains. For model development, 16 signaling questions are used to assess methodological quality, and for model evaluation, 18 signaling questions are used to assess risk of bias and applicability. The applicability assessment for PROBAST and PROBAST + AI shows no differences, both focusing on the first three domains—study population, predictors, and outcome—following a process similar to the risk-of-bias assessment, but without including specific item questions. Reviewers evaluate each item based on the literature content, and each item can be rated as Yes (Y), Probably Yes (PY), Probably No (PN), No (N), or No Information (NI). An answer of “Yes” indicates a low risk of bias, while “No” indicates a high risk. If the original study did not address a relevant signaling question, it is categorized as “No Information.” A domain is considered low risk only if every item within it is rated Y or PY. As long as one item is rated N or PN, the domain is rated as high risk. If at least one item is rated NI while all other items are rated Y or PY, then the domain is rated as unclear risk. If all four domains have a low risk of bias, the overall risk of bias is judged as low; if one or more of the four domains have a high risk of bias, the overall risk of bias is judged as high. If at least one domain is judged to have an unclear risk of bias, and all other domains have a low risk of bias, the overall risk of bias is judged as unclear. It is noteworthy that even if all four domains are assessed as low risk, the overall risk of bias for the model may still be downgraded to high risk due to a lack of external validation.
Data synthesis
We presented the basic characteristics and detailed information of the risk prediction models for the included studies in tabular form. Due to the substantial heterogeneity among the included studies, meta-analysis was not appropriate. Therefore, this study used a descriptive review method to analyze, summarize, and compare the included studies, with a focus on identifying sources of bias and reporting shortcomings in the included research.
RESULTS
Search results
The literature search strategy and results are shown in Fig. 2. A systematic search identified 1,143 records; after removing 231 duplicates, 861 records were excluded based on title and abstract review. The remaining 51 records underwent full-text screening, of which 42 were excluded for reasons listed in Fig. 2. Ultimately, this systematic review included nine studies, all published within the last 5 years (100%), with six Chinese articles (67%) and three studies (33%) published in English journals, collectively reporting 12 PI risk prediction models.
Model development and validation
Table 1 presents the basic characteristics of the nine included studies,22–30 and Table 2 details the features of the 12 risk prediction models. These models were developed based on nine data sources. The model by Liu et al. 24 utilized data from three hospitals, while the remaining 11 models were based on single-center data. All data originated from China (n = 9, 100%), with data from three studies24,25,30 deriving from traditional case–control studies (n = 3, 33.3%) and the remaining six studies22,23,26–29 being retrospective cohort studies (n = 6, 66.7%). Four studies explicitly included pediatric patients younger than 18 years,22,23,27,29 three studies24,26,28 specified pediatric patients within particular age ranges (6–18 years, 1 month–13 years, 21 days–8 years), and two studies25,30 did not explicitly define the age range of pediatric patients. Notably, nine out of 12 models were single-specialty surgery-related PI risk prediction models (n = 9, 75%),22,24,26,28–30 including liver transplant-related (n = 5, 41.7%), extracorporeal circulation (n = 2, 16.7%), brain tumor (n = 1, 8.3%), and scoliosis (n = 1, 8.3%). Only one model 23 targeted all the surgical pediatric patients (n = 1, 8.3%), while two other models25,27 focused on nonsurgical pediatric PI, specifically for PICU patients and pediatric patients with severe pneumonia undergoing prone ventilation (n = 2, 16.7%).
Among the 3,966 participants involved in model development, the number of PI cases ranged from 31 to 68, with an incidence rate of 5.857 − 20.8%. Although all the included participants were pediatric patients younger than 18 years, three studies24,26,28 further refined age categorization, revealing differences in intraoperative PI incidence among surgical pediatric patients of various age groups. Regarding PI diagnosis, six (50%) models25,29,30 did not explicitly state the diagnostic criteria for PIs; the remaining models adopted the standards from “The Prevention and Treatment of Pressure Ulcers: Clinical Practice Guideline 2019”22,23,28 and the 2016 NPUAP.24,26,27 Regarding the predicted outcomes, all models classified patients into two groups based on PI occurrence (PI vs. non-PI). Among the PI-occurring groups, eight models23,26,28–30 only included PIs staged 1 to 2. Notably, Chen et al.’s model 22 also included deep tissue PIs as a predicted outcome; He et al.’s model 27 used stages 1 to 3 as the predicted outcome. In addition, two models24–25 had missing reports on PI staging. Regarding the timing of PI occurrence, there were significant differences among the included models. Only two models22–23 defined the assessment time, generally considered within 72 h postsurgery, with Wang et al. 23 further narrowing it to 48–72 h postsurgery. Furthermore, eight of the remaining 10 models24,26,28–30 were surgery-related, but aside from Liu, Lin, QU et al.24,28,30 explicitly studying intraoperative PI without describing specific assessment times, the other two nonsurgical-related models25,27 also did not mention PI assessment times.
Regarding the methods used for model development, eight (66.7%) models22–28,30 utilized traditional logistic regression (LR), and five (41.7%)22,24,25,28,30 models used R language packages. In addition, eight (33.3%) models 29 adopted ML methods, including Decision Trees (DT), Random Forest (RF) models, Gradient Boosting Decision Trees, and eXtreme Gradient Boosting (XGBoost). The number of candidate predictors ranged from 7 to 18.8 (66.7%) models,22–28,30 using univariate analysis and multivariate LR to determine the final predictors.
The number of predictors included in each risk prediction model ranged from 3 to 10, totaling 30 distinct predictors, as detailed in Fig. 3. The most common predictors were operation time (n = 5, 10.9%), followed by intraoperative blood loss (n = 3, 6.5%) and preoperative skin condition (n = 3, 6.5%); furthermore, the final predictors included in each prediction model are detailed in Tables 3 and 4, with other detailed descriptions available in Supplementary Data S4. EPV reflects the ratio of the number of outcome events to the number of candidate predictors; the results show that all models had an EPV below 10, increasing the risk of overfitting. For continuous variables, more than half (83.3%) of the models22–26,28,29 categorized continuous variables, mainly focusing on operation time, intraoperative blood loss, age, BMI, and preoperative albumin.

Summary of predictors included in the prediction models.
Final predictor of the included prediction models (n = 9)

SpO2, oxygen saturation.
The summary of final predictors included in the prediction models

Regarding data analysis, the majority (n = 8, 66.7%) did not report missing data. Chen et al. 29 conducted predictor preprocessing for their four ML models, standardizing continuous variables; however, the authors opted for complete case deletion to handle missing data and did not recalibrate. Furthermore, this ML study neither mentioned class imbalance during model construction and internal validation nor reported data leakage during internal validation, and its ethical risks were not considered. All of the above can affect the stability and interpretability of the model.
During the model development phase, internal validation using the same dataset through specific methods is necessary to assess model performance and reliability, preventing overfitting in the final model due to inappropriate variable selection, low EPV, categorized continuous variables, and improper handling of missing data. Among the models included in this study, two (16.7%) models24–25 used Bootstrap resampling validation, and six (50.0%) models28–30 performed random split validation. Of the eight models that underwent internal validation, only two models28,30 had internal validation spanning the entire model construction process, including dataset partitioning, selection and execution of validation methods, and performance evaluation such as discrimination and calibration. Four (33.3%) models22,23,26,27 did not perform internal validation. None of the models included in this study underwent external validation, which may lead to a decrease in model performance in real-world applications. Regarding model presentation, four models24,25,28,30 were presented as nomograms, four22,23,26,27 used risk score formulas derived from LR coefficients, and one model 29 was presented as a DT and formed a web-based prediction system. Only three models 29 lacked a final presentation.
Model performance
Discrimination of the included models
Discrimination refers to the model’s ability to accurately distinguish between the occurrence and nonoccurrence of an outcome event. 31 All models primarily used AUC to assess discrimination, with values ranging from 0.612 to 0.978 during model development. Among the eight models that underwent internal validation,24,25,28–30 six models28–30 reported discrimination results; all AUCs, except for Chen et al.’s 29 RF and XGBoost models, exceeded 0.7, indicating good discrimination; Qu et al. 30 achieved the highest AUC value of 0.931. However, none of the included studies underwent external validation, which may affect the assessment of the model’s generalizability and extrapolability. 19
Calibration of the included models
Calibration refers to the agreement between observed and predicted outcomes. 31 Among the included studies, two (16.6%) models25,28 used calibration curves to assess calibration performance. Five (41.7%) models22,23,26,27,30 used the Hosmer–Lemeshow test for calibration assessment. Only one (8.3%) model 25 simultaneously presented both calibration curves and Hosmer–Lemeshow test results, while five (41.7%) models24,29 did not report their calibration. This is similar to the study by Wynants et al., 32 where the vast majority of models failed to adequately assess or report their calibration performance, affecting the assessment of model reliability and the interpretability of clinical applications. 20
Practical applicability of the models
Decision curve analysis (DCA) is used to evaluate the clinical utility of prediction models. 31 It reflects the clinical practical value of prediction models. Among all models included in this study, only two (16.7%) models28,30 performed DCA. DCA was conducted in both the training and validation cohorts of these nomogram models, demonstrating good net benefit within the threshold range. However, for the model constructed by Qu et al., 30 the threshold range was 0 to 1, indicating near-perfect predictive value with net benefit consistently superior to no prevention. Yet, in real clinical practice, it is generally unlikely that no measures would be taken until the risk threshold reaches 1. This result might be related to a low PI incidence, potentially leading to low credibility for the model’s practical clinical applicability, which still warrants further investigation. However, other studies did not explore the practical applicability of their models, which poses a significant obstacle to evaluating their suitability in clinical settings.
Risk of bias and applicability of included studies
Based on the Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis (TRIPOD), PROBAST, and PROBAST + AI criteria, we assessed the risk of bias and applicability of the nine included studies across four domains (participants, predictors, outcome, statistical analysis). According to PROBAST and PROBAST + AI standards, all 12 models were rated as having a high overall risk of bias. Two models22,23 had low applicability concerns, two models24,27 had unclear applicability, and eight models25,26,28–30 had high applicability concerns. Table 5 displays the risk of bias and applicability for the prediction models included in this review, and Figs. 4 and 5 present the assessment results for risk of bias and applicability, respectively. Other detailed descriptions are available in Supplementary Data S2 and S3.

Risk of bias in included studies.

Applicability in included studies.
PROBAST results of the included studies

+ indicates low ROB/low concern regarding applicability; − indicates high ROB/high concern regarding application;? indicates unclear ROB/unclear concern regarding applicability.
PROBAST, Prediction model Risk Of Bias Assessment Tool; ROB, risk of bias.
Risk-of-bias assessment
Bias in participant selection
In accordance with the TRIPOD and PROBAST guidelines, all included studies exhibited a high risk of bias in participant selection. First, most studies were single-center investigations with retrospective data sourced exclusively from China. The participants were primarily focused on specific surgical subspecialties, while also involving pediatric patients from other clinical backgrounds, such as ICUs and general wards. Second, regarding sample selection, all studies use certain inappropriate exclusion criteria. Eight (88.9%) studies directly excluded samples with incomplete data, and seven (77.8%) excluded patients with skin diseases that might interfere with skin observation. Other exclusions involved specific populations and specialized conditions, such as a history of using immunosuppressants or corticosteroids, malignancy-related diseases, and the postoperative use of extracorporeal membrane oxygenation. Furthermore, restrictions on age ranges introduced bias in the representativeness of the participants. Although all participants were pediatric patients younger than 18 years, three studies24,26,28 further stratified age ranges (e.g., 6–18 years, 1 month–13 years, and 21 days–8 years). We unexpectedly found variations in the incidence of intraoperative PI across different pediatric age groups, with higher incidence rates reported in the two studies26,28 featuring narrower age ranges. According to the TRIPOD and PROBAST guidelines, the prediction models in the included studies carry a high risk of bias due to discrepancies in study populations, clinical backgrounds, and disease specificity. Similarly, widely validated Western pediatric scales, such as Braden Q and Glamorgan, exhibit varying predictive performance due to these differences. 13 Consequently, pediatric PI risk is highly heterogeneous and significantly influenced by the use of medical devices 33 ; due to its specificity, it is supported by validated scales outside of China. Future research should focus on constructing models stratified by age and clinical setting (e.g., ICU, surgical department, general ward). Utilizing large-scale datasets, incorporating device-related predictors, and conducting multiregion, multicenter external validation will be essential to enhance the generalizability and global applicability of these models.
Bias in predictor measurement
In accordance with the TRIPOD and PROBAST guidelines, during the assessment of predictors across the nine included studies, we found that six (66.7%) exhibited a high risk of bias in predictor assessment. Specifically, these six studies did not explicitly state whether the personnel involved in measuring the predictors had received standardized training. For example, preoperative skin condition assessment, the most frequent predictor, requires subjective judgment of skin moisture to distinguish dermatitis from reactive hyperemia. However, the absence of clearly standardized professional training and guidance may lead to significant information bias. In addition, the study by Zhai et al. 25 uniquely utilized prone ventilation training for health care personnel as a predictor but similarly failed to clearly define the specific training content or criteria for evaluating its effectiveness. Furthermore, individual differences in professional knowledge and nursing proficiency among clinical staff result in measurement bias. In contrast, the study by Chen et al. 30 stands out among the included studies as a model for future research, as it provided rigorous training and reliability assessments for evaluators and implemented unified preprocessing of predictors to ensure consistency. Furthermore, seven (77.8%) studies provided insufficient descriptions of the measurement methods and time points for predictors. Notably, among studies focusing on pediatric intraoperative PI, only two explicitly defined the measurement time frame as within 72 h postoperatively. This aligns with the risk assessment and measurement timing for adult intraoperative PI reported by Xu et al. 21 This suggests that assessment within 72 h postoperatively may be the optimal window for establishing pediatric intraoperative PI models, a finding that provides a valuable reference for future research.
Bias related to outcomes
We found that seven out of the nine studies (77.8%) exhibited a high risk of bias in outcome assessment, while the remaining two (22.2%) were categorized as having an unclear risk of bias. Specifically, regarding the clinical diagnostic criteria for pediatric PI, one study 24 omitted the definition entirely, and three studies25,29,30 failed to provide explicit descriptions. Although the remaining six studies22–24,26–28 clarified their diagnostic criteria, they adopted two different sets of public guidelines, leading to inconsistencies in outcome definitions. For instance, the diagnostic criteria in two of these studies26–27 did not encompass unstageable and deep tissue PIs. Despite these inconsistencies, we found that five studies23,26,28–30 consistently utilized stages 1 and 2 PIs as outcome indicators. This aligns with previous research reports 34 indicating that the majority of pediatric PIs in hospital settings are classified as stage 1 or 2. In addition, the study by He et al., 27 which focused on patients in pediatric ICUs (PICUs), used stage 3 PI as a predictive outcome, even though their results showed that PIs primarily occurred at stage 1. We maintain that PI progression is gradual, suggesting that stage 3 PIs likely transitioned through stages 1 and 2. Furthermore, adult PI models 21 typically focus on stage 1 to 2 PIs to facilitate early prevention, highlighting that these stages are crucial outcome indicators. Conversely, utilizing stage 3 PI as an outcome indicator diminishes its practical clinical significance for early prevention. Regarding the assessment of pediatric PI, seven studies24–30 failed to detail the timing and frequency of outcome evaluations. Moreover, individual differences exist among health care professionals regarding their understanding and experience in the clinical determination of PI. Among the included studies, only three22,28,29 explicitly stated that clinical assessment and data collection were performed by trained professionals to differentiate confounding factors and accurately identify specific stages. In summary, the prediction models in the included studies exhibit substantial variation in outcome definitions and assessments, with questionable reporting accuracy, thereby limiting their actual clinical predictive efficacy.
Bias related to analysis
In accordance with PROBAST and PROBAST + AI,17–18 we found that all nine included studies exhibited a high risk of bias. Specifically (1) low EPV values: All models had EPV <10, which increases the risk of overfitting and compromises model stability. (2) Continuous variables were frequently handled inappropriately, as most models arbitrarily categorized continuous predictors, particularly operative time (10.9%) and intraoperative blood loss (6.5%), leading to loss of information and neglect of their potentially important continuous relationships with outcomes. (3) Improper handling of missing data: eight studies did not report missing data, and one ML study directly deleted missing data without addressing the issue of class imbalance, thereby increasing the risk of overfitting. (4) Except for one study utilizing ML algorithms, the remaining studies (88.9%) selected predictors based on univariate and multivariate analyses. (5) Only two studies mentioned patient skin protection measures, and none accounted for competing risks such as death. (6) Two studies failed to report calibration status or calibration/discrimination data, while five studies relied solely on the Hosmer–Lemeshow test for calibration assessment. (7) Four studies did not perform internal validation, and while five studies did, most utilized simple random split-sample validation, with only two using the bootstrap method. However, these studies failed to fully report all steps of model development. (8) None of the models across all studies underwent external validation, which impacts their generalizability and external portability. (9) Four studies presented prediction models as nomograms but did not provide risk scoring formulas derived from the regression coefficients of each factor, making it impossible to assess whether the predictors aligned with the multivariate analysis results. Another four studies constructed models using only risk scoring formulas derived from regression coefficients, lacking visual presentation of the models. Only one study 29 developed four models using four ML algorithms; however, these models lacked transparency, and the issues of class imbalance were not reported during the model development and evaluation processes. Furthermore, except for the DT model, this study did not demonstrate the variable selection process for any of the models, making it difficult to interpret the internal logic and data processing methods, thereby raising concerns regarding model stability and applicability. In summary, the prediction models in the included studies exhibited a high risk of bias in data analysis, which restricts their stability and external portability, ultimately impacting their clinical applicability.
Assessment of applicability
The PROBAST applicability assessments for all the included studies revealed that only two (22.2%) studies were categorized as low risk,22–23 while the majority were rated as “high risk” or “unclear,” indicating significant deficiencies in the applicability of most models. Specifically, the insufficient applicability regarding participants is attributed to the fact that the majority of pediatric PI risk models in this review (n = 9, 75%)22,24,26,28–30 focused on specific surgical subgroups (e.g., liver transplantation, extracorporeal circulation) across diverse pediatric age groups (e.g., neonates and children). A minority of models (n = 2, 16.7%)25,27 encompassed pediatric populations from varied clinical settings, such as ICUs and general wards. Moreover, restrictions on age ranges and the inappropriate exclusion of medically complex children or device-dependent patients further limited the applicability of the models. The selection of predictors was constrained by the distinct physiological characteristics of different age groups and the lack of clearly defined criteria for preoperative skin assessments. Regarding outcome applicability, inconsistent criteria for assessing pediatric PI and the lack of clarity concerning the timing of PI evaluations restricted the early predictive capacity of the models. Three (33.3%) studies25,29,30 were limited by a lack of PI assessment standards and undefined evaluation timelines, while four (44.4%) studies24,26–28 provided unclear criteria for the timing of PI assessments. As noted by Minozzi et al., 35 even when formal risk-of-bias assessment tools are used, their implementation and reporting are often suboptimal due to the influence of real-world clinical environments. Given that this study included a broad range of pediatric populations, the limited general clinical applicability of most current PI models for specific clinical scenarios or age cohorts may be inevitable. This highlights the urgent need for specialized PI risk prediction for pediatric populations; achieving precise screening in clinical practice requires balancing specificity with broad clinical applicability. Consequently, the findings regarding clinical applicability in this study should be interpreted with caution.
DISCUSSION
Early prediction and identification of pediatric PI risk play a crucial role in preventing the occurrence and progression of injuries and improving the quality of nursing care. However, this study represents the first to focus on an important yet underexplored field—pediatric PI prediction models—and assesses the methodology and clinical applicability of current models in accordance with the TRIPOD, PROBAST, and PROBAST + AI guidelines. Notably, we found that currently reported models lack methodological rigor and clinical applicability, as all models were assessed as having a high risk of bias, and 10 models exhibited significant applicability concerns. However, research by Minozzi et al. 35 indicates that even when formal assessment tools (such as TRIPOD or PROBAST) are used, implementation results may be unsatisfactory and models may remain suboptimal due to practical factors or poor original reporting. Accordingly, we adopted a more cautious approach to the assessment results, moving beyond a purely methodological critique to center on the core clinical question: “Can these models actually guide preventive nursing and medical actions in pediatric patients?” Our findings reveal that current models are not yet suitable for direct bedside application. To facilitate the translation of theoretical models into clinical practice, this study systematically evaluated and identified structural and conceptual barriers to clinical translation, including variations across clinical settings, predictor lag, ambiguous outcome definitions, and the absence of decision support tools. Based on these findings, we constructed a “Evidence-Informed Pathway for Pediatric PI Risk Recognition Based on Clinical Scenarios and Predictive Factors” to provide health care personnel with substantive preventive nursing guidance.
Mismatch between model populations and real-world pediatric care settings
In accordance with TRIPOD and PROBAST, this review reveals a mismatch between the population characteristics of current models and broad, real-world clinical environments. Previous evidence indicates that pediatric populations exhibit physiological uniqueness due to significant differences in skin anatomical structures compared with adults, with neonates and infants being particularly distinctive.12,36 The results of this study also demonstrate a strong correlation between age and the risk of PI development. Furthermore, the incidence of pediatric PIs varies considerably across clinical settings (2.25 − 41.67%), 37 with potentially higher incidence and severity in ICUs, 38 and a substantial influence of medical devices on PI occurrence in neonates and children. 33 These findings underscore the unique nature of pediatric groups and the imperative to develop specialty-specific tools tailored to distinct clinical scenarios and age cohorts. However, most models in this study are strictly confined to highly selected surgical subgroups (e.g., liver transplant or extracorporeal circulation) and rely on surgery-specific risk factors, which complicates PI risk identification in general wards or other settings where risks stem from prolonged immobilization or developmental delays. Second, inappropriate exclusion criteria have led models to overlook medically complex children, neonates, and device-dependent patients who are prevalent in general pediatric wards. Furthermore, none of the included models specifically targets pediatric device-related PIs, which impose a significant clinical burden; the development of models for this population may be constrained by the complexities of physiological structures and clinical environments.
In summary, current models are insufficient for effective clinical translation within complex pediatric health care environments. This phenomenon stems largely from the fact that the models included in this study focus predominantly on generalized pediatric populations. For pediatric cohorts in specific clinical settings (e.g., ICUs, general wards), age groups (e.g., neonates), and surgical subgroups (e.g., liver transplant), the limited general clinical applicability of most PI models may be inevitable. Similar to the widely validated universal Western pediatric scales such as Braden Q and Glamorgan, these models exhibit insufficient clinical applicability and restricted translation across diverse scenarios. This further emphasizes the urgent necessity for specialty-specific tools in pediatric PI risk prediction. Consequently, we propose that developing specialized PI models that better align with broad real-world clinical environments requires a comprehensive and multidimensional evaluation of pediatric PI-specific risk factors across diverse health care settings, including, but not limited to, pediatric cohorts in specific clinical environments (e.g., ICUs, general wards), age groups (e.g., neonates), and surgical subgroups (e.g., liver transplant) to achieve precise screening and prediction while providing preventive guidance and early prevention strategies for high-risk populations.
Predominance of exposure-related “damage markers” rather than early vulnerability indicators
This study involves 30 distinct pediatric PI predictive variables, providing insights and references for the construction of future prediction models. However, current prediction models exhibit a lag in the selection of predictors, which hinders their ability to function effectively as early warning systems in clinical practice. Specifically, most final predictors (e.g., operation time, blood loss, anhepatic phase, prone ventilation duration, and extracorporeal circulation) are only identified during or after prolonged exposure. These predictors reflect cumulative tissue stress rather than intrinsic susceptibility; this implies that by the time a model generates a “high-risk” score, the pathological processes leading to PI may have already been initiated or completed, thereby diminishing the model’s predictive value in identifying early vulnerability before exposure. Most model data in this study are derived from retrospective records, which possess an inherent lag and cannot guarantee the timely acquisition of predictors or an adequate window for prevention, thus weakening the models’ prospective warning role and potentially rendering them “retrospective injury classifiers” in clinical practice. For instance, frequently occurring predictors for pediatric intraoperative PI in this study (e.g., operation time, blood loss) were collected after exposure; however, this phenomenon is equally prevalent in adult intraoperative PI risk models, as most models inevitably incorporate intraoperative data and utilize damage markers as predictors. 21 Although we recognize that using damage markers as predictors increases the risk of methodological bias and diminishes clinical utility by missing the early prevention window, significant challenges remain due to clinical realities such as the difficulty of obtaining prospective data, variations in pediatric PI incidence, the uncertainty of prevention windows, and high resource costs, which explains why retrospective data remain the mainstream in most prediction model research. In addition, we identified variations in PI-specific indicators across different settings and conditions; for instance, the study by Zhai et al. 25 incorporated health care staff training due to prone ventilation in severe pneumonia, while the number of medical devices used was found to correlate with the skin contact area in the PICU. 27 Consequently, we suggest that for patients across diverse clinical scenarios and specialties, multidimensional baseline data should be collected promptly upon admission to secure an adequate prevention window, reduce reliance on exposure-related damage markers, and incorporate more early susceptibility indicators, thereby maximizing model robustness and performance while facilitating clinical translation through multicenter, temporal, and spatial validation of external portability and clinical utility. 39
Outcome timing and staging issues that undermine prevention
Our study reveals that, according to PROBAST and PROBAST + AI, there are variations in outcome definitions, inconsistent staging, and poor reporting of the timing of PI assessments among the included models. While the choice of outcome metrics in most models aligns with adult PI models (i.e., stages 1 and 2), 21 other models lack clear staging criteria or include stage 3 and more severe injuries, resulting in ambiguous outcome definitions and a low correlation between such severe injuries and early prevention. These factors lead to a high risk of bias and low applicability, thereby reducing the likelihood of predicting outcome events and the potential for clinical translation. Nevertheless, the findings of Minozzi et al. 35 suggest that evaluation results should be interpreted with caution in light of practical circumstances. First, previous research indicates that skin maturity in pediatric patients differs from that of adults; specifically, children possess a thinner stratum corneum and sebaceous layer, 36 while neonates and infants are even more vulnerable and prone to developing PIs. 12 This unique anatomical structure poses a significant challenge to PI staging and assessment, increasing the difficulty of measuring predictive indicators and explaining why current models often function as injury classifiers. Second, there are currently no diagnostic criteria or guidelines specifically dedicated to pediatric PI; instead, it is addressed as a subbranch of the 2019 Clinical Practice Guideline. 1 In accordance with this guideline, we emphasize that the development of PI is progressive; however, some models in this study define PI as “stage 2 and above,” and predicting stage 3 or more severe injuries undoubtedly compromises the model’s early warning capability and clinical utility. Although statistical analyses demonstrate acceptable sensitivity and discrimination, these models are inadequate or essentially meaningless for clinical prediction, thereby contradicting the fundamental intent of precise risk prediction and the ultimate core objective of achieving preventive wound care. Finally, we must acknowledge the unique characteristics of pediatric patients and the urgent necessity for establishing specific guidelines dedicated to pediatric PI diagnosis and prevention. Furthermore, we maintain that the construction of PI models must account for the “prevention window” as a critical clinical requirement. Following the PI definition in the 2019 Clinical Practice Guideline, 1 the classification system of the NPUAP should be adopted. Structured assessments should be performed as soon as possible upon admission or transfer to the department, with a primary focus on stages 1 to 2 PIs. This ensures that pediatric PI prediction occurs during the physiologically reversible stage of tissue damage and facilitates the exploration of early susceptibility indicators. Consequently, this approach effectively guides health care personnel in implementing early clinical prevention strategies and rationally allocating resources to mitigate the incidence of pediatric PI.
The interpretability of models based on ML algorithms remains ill-defined
In addition, with the continuous advancement of ML, an increasing number of ML-based PI risk prediction models have emerged21,40; however, the evaluation and interpretability of these ML algorithms remain ill-defined. Notably, PROBAST + AI provides a robust foundation for evaluating ML prediction models and, for the first time, incorporates algorithmic fairness assessment and ethical risk considerations into the evaluation framework. This study represents the first instance of utilizing PROBAST + AI to evaluate four ML-based PI models; however, the evaluation results were suboptimal. With the exception of the DT model, the other models lacked clarity in their internal logic and data processing methods, raising concerns regarding their stability and applicability. Nevertheless, the research by Cianciulli et al. 41 explicitly states that while the contribution of AI and digital tools to public health is unquestionable, the evidence remains inconsistent. To bridge this gap, future efforts must ensure the transparency of “black box” data, clarify algorithmic risks, and improve the interpretability of data processing to facilitate the fair and safe integration of ML-based models into clinical practice. Currently, the Shapley additive explanation method is widely utilized for interpreting prediction models. 42 Regrettably, compared with traditional tools, PROBAST + AI has omitted the evaluation of predictor selection, considerations of data complexity, and the assessment of final predictors and their assignments within the model. While this aligns with technological advancements, it introduces risks such as optimization errors, “black box” data leakage, and challenges related to model visualization and interpretability. These findings indicate that continuous optimization of these critical issues remains necessary in the future. Such improvements will safeguard algorithmic fairness and ethical dimensions, promote the robustness and clinical integration of ML models, and provide essential decision support for health care professionals.
Discrimination versus clinical utility
In accordance with PROBAST and PROBAST + AI,17–18 although seven models in this study achieved AUC values exceeding 0.75, demonstrating acceptable discriminatory power to distinguish the occurrence of pediatric PI, these results cannot yet be directly applied to guide clinical prevention strategies for practitioners. A sole reliance on statistical analysis represents a significant barrier to clinical translation, which is consistent with findings in adult PI risk research.21,30 However, decision thresholds must carefully balance the consequences of missing high-risk PIs against the costs of preventive strategies. DCA is the standard method for evaluating clinical utility by determining the threshold probability associated with clinical net benefit. 30 Although two models (16.7%)25,28 in this study performed DCA, their threshold ranges fail to provide actionable clinical decisions. Specifically, one model reported a clinically meaningless threshold range of 0 to 1. While the other model identified a threshold probability range of 0.05–0.65 for maximum clinical net benefit, a higher threshold (0.65) in pediatric populations may delay or even miss prevention, leading to the omission of high-risk cases. In clinical practice, early prevention must be prioritized for special populations such as pediatrics. Although this study cannot yet definitively delineate the most reasonable threshold for clinical decision support, this review has clarified the predictors ultimately included in current models, and specific risk factors are strongly correlated with the occurrence of PI. Therefore, we suggest combining specific predictors with the cumulative number of factors to stratify pediatric PI risk and implement targeted prevention strategies. Compared with threshold probabilities, this method is simpler and more operational for frontline clinical staff and is highly likely to be accepted and executed in clinical practice.
Evidence-informed pathway for pediatric PI risk recognition based on clinical scenarios and predictive factors
This study systematically evaluated the methodological and clinical applicability of current pediatric PI risk models. Although no optimal model suitable for clinical translation was identified, efforts were made to bridge the gap between theory and clinical practice and facilitate the clinical translation of models. We stratified the results according to the clinical scenarios of pediatric PI occurrence and established a predictor-oriented clinical pathway to trigger preventive decisions, as illustrated in Fig. 6. First, clinical scenarios are stratified based on the patient’s clinical environment, including the PICU, operating room, and general wards. Multidimensional baseline screening is conducted as soon as possible upon admission or transfer of pediatric patients, integrating widely validated pediatric scales (e.g., Braden Q) to collect data on multidimensional baseline risk factors, including demographic profiles, clinical signs, and risk factors. Concurrently, a comprehensive PI risk assessment is performed tailored to different clinical scenarios. This process utilizes objective assessment tools such as subepidermal moisture measurement devices, which are recommended and validated in the 2019 Clinical Guidelines.1,43 Assessments focus on the physiologically reversible stage (stages 1 to 2 PI) and specialty-specific early intrinsic susceptibility indicators, such as medical device use, operation time, surgical positioning, and state of consciousness. The objective of this phase is to identify the specific risk factors and cumulative factors associated with pediatric PI across diverse clinical scenarios. This progresses to the subsequent phase: Predictor-oriented triggering of preventive decisions. Based on previous studies,1,33 special populations utilizing medical devices can be directly identified as high risk, triggering intensive preventive measures irrespective of age or clinical environment. Accordingly, in this phase, we uniformly perform pediatric PI risk stratification based on specific predictors and the cumulative number of factors. The presence of scenario-specific high-risk predictors and/or multiple cumulative risk factors triggers intensive prevention strategies for the high- or very high-risk categories. When no dominant scenario-specific predictor is identified but several cumulative risk factors are present, enhanced prevention strategies are triggered for the moderate-risk category. The absence of scenario-specific high-risk predictors, coupled with few or no cumulative risk factors, triggers routine prevention strategies for the low-risk category. This stage aims to achieve risk stratification based on identified predictors, thereby triggering actionable preventive strategies tailored to the patient’s risk level. Finally, for pediatric PI patients across diverse clinical scenarios, we emphasize the formulation of prevention strategies guided by clinical practice guidelines. These strategies are categorized into intensive, enhanced, and routine prevention, encompassing key domains such as skin management, resource allocation, and nutritional support to provide a comprehensive reference for clinical practice. The objective is to reduce the incidence of PI and arrest its progression during the physiologically reversible stage (stages 1 to 2 PI). Established based on the findings of this systematic review, this clinical pathway guides health care personnel across diverse specialty settings to make predictor-oriented, actionable clinical decisions and implement corresponding preventive strategies. Furthermore, it encourages practitioners to collect as many specialty-specific early intrinsic susceptibility indicators as possible to facilitate more in-depth research. Nevertheless, the actual utility of this pathway in clinical practice necessitates prospective validation by more researchers. We anticipate that this pathway will provide significant clinical value for current pediatric PI prevention and effectively reduce the incidence of pediatric PIs.

Evidence-Informed Pathway for Pediatric PI Risk Recognition Based on Clinical Scenarios and Predictive Factors.
Limitations
This systematic review has several limitations: (1) All data from the included studies originated from China, and this geographic concentration—potentially linked to the use of three Chinese literature databases—constitutes a primary source of bias in this study. We maintain that this concentration limits the generalizability of our findings. We have now more explicitly identified this as an urgent research gap and call for international multicenter validation efforts. (2) As a systematic review, the findings are constrained by the quality and methodological flaws of the original studies. These include participant selection bias involving diverse ages, clinical backgrounds, and inappropriate exclusions; and predictor bias related to limited consistency and a predominance of exposure-related damage markers. Outcome-related bias involves variations in outcome definitions, inconsistent staging, and unclear assessment timing. The most significant analysis-related bias is that none of the included models underwent external validation, alongside methodological flaws such as low event rates, improper categorization of continuous variables, and inadequate handling of missing data. (3) Clinical applicability bias: Model populations consist primarily of highly selected surgical cohorts, where exposure-related damage markers outnumber early susceptibility indicators. Furthermore, outcome definitions often lack early recognition or focus on late-stage staging, with an over-reliance on AUC and DCA metrics to evaluate clinical utility. (4) Due to significant heterogeneity in the populations, predictors, and disease types of the included studies, combined with the incomplete methodology for meta-analyzing risk prediction models, a meta-analysis could not be performed. In summary, we maintain that current research limits the generalizability and clinical applicability of pediatric PI models, rendering them unable to safely guide clinical decision-making. Therefore, with prevention and clinical decision support at the core, future model development must specify early susceptibility indicators, include populations prone to device-related injuries, standardizing outcome definitions and evaluation timelines, conduct cross-scenario external validation, and integrate decision support. These structural and conceptual barriers are directly relevant to clinical practice; addressing them will empower nurses to implement proactive prevention, representing a significant and practical contribution to the field of wound care.
CONCLUSIONS
This systematic review included 9 studies and 12 prediction models. While most included prediction models demonstrated acceptable discrimination, all studies exhibited a high risk of bias, and 10 models presented significant concerns regarding applicability. The findings indicate that current pediatric PI prediction models are not yet suitable for direct bedside application, nor can they function as tools to provide targeted clinical prevention decision support. The primary sources of bias include single data sources, inappropriate participant exclusions, inconsistent age ranges, unclear outcome measurements, low EPV values, categorization of continuous variables, neglect of missing data, and a lack of internal and external validation. The insufficient clinical applicability stems primarily from unrepresentative participants whose characteristics mismatch broad real-world environments, a lag in predictor screening dominated by exposure-related “damage markers,” and inconsistent outcome definitions and assessment timing that diminish predictive performance, coupled with inadequate clinical utility assessment; however, a robust model must be clinically interpretable, externally validated, embeddable into workflows, and equipped with clear action thresholds. Consequently, to foster the advancement of future pediatric PI risk prediction models, it is imperative to strictly adhere to the TRIPOD and PROBAST guidelines while concurrently addressing fundamental structural deficiencies. These include ensuring participant representativeness across diverse clinical environments, identifying early susceptibility markers, and standardizing outcome definitions and evaluation timelines. Addressing these limitations, alongside implementing cross-scenario external validation and integrating clinical decision support, is essential to bolster model robustness and utility. Ultimately, to facilitate the translation of theoretical models into clinical practice, this study established a “Evidence-Informed Pathway for Pediatric PI Risk Recognition Based on Clinical Scenarios and Predictive Factors.” This pathway aims to provide health care personnel with substantial preventive nursing guidance, thereby reducing the incidence of PI and delivering tangible advancements to the field of pediatric wound care.
TAKE-HOME MESSAGE
As the first systematic review of pediatric PI prediction models, this study used the critical appraisal and data extraction for systematic reviews of prediction modeling studies checklist to summarize the characteristics of the included studies and used the PROBAST and PROBAST + AI frameworks to structurally assess the model’s risk of bias and applicability. This study identified key shortcomings in the current research and reporting of pediatric PI prediction models, which may provide a reference for improving model quality in the future. This study also identified the most widely recognized predictors for pediatric PI. This study established a “Pediatric PI Risk Management Decision Pathway Based on Clinical Scenarios and Predictive.”
ACKNOWLEDGMENTS AND FUNDING INFORMATION
None declared. This study was supported by the following two projects:
AUTHORS’ CONTRIBUTIONS
X.Z.: Writing—original draft, methodology, review and editing, data curation, and conceptualization. Z.Y.: Writing—methodology, data curation, formal analysis, and visualization. X.L.: Writing—review and editing, formal analysis, and data curation. J.W.: Writing—review and editing, methodology, and visualization. R.P.: Data curation and supervision. H.L.: Methodology and supervision. K.Y.: Formal analysis and data curation. H.P.: Resources, methodology, formal analysis, writing—review and editing, and funding acquisition. Y.X.: Writing—review and editing, methodology, and formal analysis. All authors read and approved the final article.
Footnotes
AVAILABILITY OF DATA AND MATERIALS
Data are provided within the article or Supplementary Data.
AI DISCLOSURE
To better enhance visual presentation, the ![]() file in this study, located in the “Evidence-Informed Pathway for Pediatric PI Risk Recognition Based on Clinical Scenarios and Predictive Factors section,” used the AI-assisted tool ChatGPT-5.5 for structural adjustment and aesthetic refinement. The content included in the figure, such as the construction of the overall framework, risk stratification based on predictive factors, and the criteria for risk stratification, was generated by the author team and was manually reviewed, revised, and confirmed by the author team (X.Z. and Y.X.). ChatGPT was not used to generate any full-text content of the article. Conceptualization, methodology, review and editing, data curation, formal analysis, and article writing were all contributed by the author team, and the specific contributions of the team are presented in the “Authors’ Contributions” section of the article.
file in this study, located in the “Evidence-Informed Pathway for Pediatric PI Risk Recognition Based on Clinical Scenarios and Predictive Factors section,” used the AI-assisted tool ChatGPT-5.5 for structural adjustment and aesthetic refinement. The content included in the figure, such as the construction of the overall framework, risk stratification based on predictive factors, and the criteria for risk stratification, was generated by the author team and was manually reviewed, revised, and confirmed by the author team (X.Z. and Y.X.). ChatGPT was not used to generate any full-text content of the article. Conceptualization, methodology, review and editing, data curation, formal analysis, and article writing were all contributed by the author team, and the specific contributions of the team are presented in the “Authors’ Contributions” section of the article.
We reiterate that all core logical frameworks and research conclusions were independently completed and rigorously reviewed by the author team.
AUTHOR DISCLOSURE AND GHOSTWRITING
The authors of this article have no financial conflicts of interest to disclose. No ghostwriters were involved in the writing of this article.
ABOUT THE AUTHORS
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Abbreviations and Acronyms
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.