
Abstract
The item response times (RTs) collected from computerized testing represent an underutilized type of information about items and examinees. In addition to knowing the examinees’ responses to each item, we can investigate the amount of time examinees spend on each item. Current models for RTs mainly focus on parametric models, which have the advantage of conciseness, but may suffer from reduced flexibility to fit real data. We propose a semiparametric approach, specifically, the Cox proportional hazards model with a latent speed covariate to model the RTs, embedded within the hierarchical framework proposed by van der Linden to model the RTs and response accuracy simultaneously. This semiparametric approach combines the flexibility of nonparametric modeling and the brevity and interpretability of the parametric modeling. A Markov chain Monte Carlo method for parameter estimation is given and may be used with sparse data obtained by computerized adaptive testing. Both simulation studies and real data analysis are carried out to demonstrate the applicability of the new model.
1. Introduction
Response times (RTs) on test items provide a valuable source of information on examinees and test items. For instance, RTs can help in evaluating the speededness of the test, offering collateral information for calibrating test items and estimating examinees’ abilities, and they can be used for detecting cheating behaviors and designing a better test (e.g., Bridgeman & Cline, 2004; Fan, Wang, Chang, & Douglas, 2012; van der Linden & Guo, 2008). With the prevalence of computerized testing, their collection has become straightforward. To make full use of RTs to enhance online testing’s efficiency and security, appropriate psychometric models for RTs should be developed.
In the past decades, researchers have been trying to formulate models that can maximally explain the variance of RTs as well as the connections among RTs, item characteristics, and examinees’ behaviors. Most of the models are motivated by the curve-fitting principle in the sense that the proposed models are parametric representations of the underlying RT distributions (e.g., Klein Entink, van der Linden, & Fox, 2009; Rounder, Sun, Speckman, Lu, & Zhou, 2003; Schnipke & Scrams, 1997). Although parametric models have the advantage of conciseness, they may suffer from reduced flexibility to fit real data. In addition, with an unknown data set, one often needs to fit each parametric model separately until a best fitting model is decided based upon some model diagnostic criterion (Schnipke & Scrams, 1997). However, the best fitting model may not be the best one for each individual item in the item bank. A recent example presented in Ranger and Kuhn (2011) demonstrated that item RT distributions differed dramatically from one test to another, which calls for the need of a flexible model that relaxes such distributional assumptions.
To simplify the fitting procedure and to emphasize the individual characteristics of each item, Ying and Chang (2005) suggested constructing a “generalized model” that subsumes various parametric models as submodels. By fitting the generalized model to a data set, one can immediately pinpoint the most appropriate parametric form for each item from the estimation results. One such example is the Box-Cox normal model (Klein Entink et al., 2009), in which a power parameter is introduced to represent a number of different transformations. Most recently, Ranger and Kuhn (2011) proposed a generalized linear model with a flexible link function to model discrete RTs. Specifically, their model includes a shape parameter (either item level or test level) that determines the form of the link function, and their model unifies both proportional hazards (PH) models and accelerated lognormal failure time models. A common ground for the above two general models is they both contain an item-level parameter that controls the shapes of the RT distributions, and they are still parametric models. In this article, we propose a semiparametric approach that combines the flexibility of nonparametric modeling and the brevity of the parametric modeling. To be specific, we propose a hierarchical PH frailty model. We will show how the new models exhibit greater flexibility than the previous proposed parametric models. A two-stage estimation method is developed for model calibration, and methods for model diagnosis are presented.
1.1. Survival Analysis and RT Modeling
Survival analysis is a branch of statistics which concerns the analysis of time-to-event data. Survival analysis has benefited medical scientists in the study of mortality due to chronic diseases and has helped industrial statisticians to model the longevity of machinery and parts in manufacturing processes. In principle, survival analysis techniques could be used in any science in which outcomes are measured as the time until an awaited event. Psychology is also a specific area that survival analysis can shed light on. For instance, Douglas, Kosorok, and Chewning (1999) proposed a discrete version of the PH frailty model to explain substance abuse of youths. In particular, they modeled the ages at which youths first tried alcohol, cigarettes, marijuana, and inhalants, as a function of their latent psychological abilities to abstain from substance abuse. Another example is by Singer and Willett (1993), who used discrete-time survival analysis to study when public school teachers stopped teaching between their year of hire and the year when the data collection ended. The discrete-time hazard model proposed in their paper not only answers these descriptive questions but also models the relationship between event occurrence and predictors. One specific area in educational measurement that survival analysis comes into play is RT analysis. RT is the time period from the onset of an item until the examinee provides an answer to the item. If viewing “giving a response” as an event, RT shares the same meaning as the survival time in biostatistics, and therefore RTs can be modeled similarly.
Many regression models have been proposed in survival analysis to account for the effect of the explanatory covariates. Oftentimes, the covariates enter into the model through the hazard function. The hazard function (usually denoted as

In psychological terms, the hazard rate is the conditional probability of finishing the task in the next moment; thus, it is viewed as the processing capacity of an individual. In other words, the hazard rate measures the individual’s relative ability to perform mental work in a unit of time. High hazard rates correspond to a high processing capacity and indicate that the examinee works more intensely (Wenger & Gibson, 2004). The hazard rate relates to the survival function through

where
When
In the above models, the covariates are assumed to be observed. Biostatisticians first recognize the usefulness of latent variables to model survival times that are correlated due to either repeated measurements taken on a single subject, or measurements of a common variable taken on genetically associated subjects. These needs give rise to frailty models, in which a latent frailty random variable is included in the model to account for possible correlations in failure time distributions (Clayton, 1991; Clayton & Cuzick, 1985). The frailty variables may be viewed as random effects and usually only the influence of the explanatory covariates on failure time is the primary concern. Douglas et al. (1999) used the frailty model in psychology, and their model is a similar version of the conditional PH model (Clayton & Cuzick, 1985), in which the hazard function for each failure time is a product of the baseline hazard, frailty random variable, and covariate effects. The unique feature of their model is that it has an item-level parameter that measures the influence of the latent variable on the failure time. Thus separate items differ with respect to the extent that the latent variable influences responses. In fact, the Cox PH model represents a standard approach in survival time analysis, it makes only very mild distributional assumptions and is a flexible semiparametric model. However, it is only very recently that the Cox model has been introduced in the field of measurement to analyze RTs (Ranger & Ortner, 2011). This article is complementary to the existing parametric approaches and Ranger and Ortner’s earlier research.
1.2. RT Modeling
RT has been a preferred dependent variable in cognitive psychology since the mid-1950s (Luce, 1986). For relatively uncomplicated cognitive tasks such as Posner’s perceptual matching task (Posner & Boies, 1972), RTs naturally indicate the processing procedures of each individual. In educational testing, RTs are usually analyzed along with the response accuracy. Such models include Thissen (1983), van der Linden (2007), Roskam (1997), Wang and Hanson (2005), among others. Most of these models are motivated by the idea of a speed-accuracy relationship. Cognitive psychologist often focus on the within-person relationship, that is, whether a person’s response accuracy will decrease if he or she chooses to perform a task more quickly? This is termed as speed–accuracy trade-off. Psychometricians, however, are more interested in the across-person relationship between speed and accuracy. For example, one question that psychometricians often explore is whether examinees with higher ability tend to answer items faster. Both types of speed–accuracy relationships are considered within the model suggested by Verhelst, Verstralen, and Jansen (1997). In their models, the speed–accuracy trade-off is reflected by letting response accuracy depend on the time devoted to the item—spending more time on an item increases the probability of a correct response. The speed–accuracy correlation across examinees is reflected by the separate parameters of examinees’ ability (or mental power) and speed.
Van der Linden (2007) argued that although the speed–accuracy trade-off is prevalent in reaction-time research, on a test with a reasonable time limit, there is no need to incorporate a trade-off in an RT model for a fixed person and a fixed set of test items. In other words, the trade-off is a within-person constraint only. Thus, the speed at which the test taker operates on the items should be assumed as a latent trait, and the response accuracy should only be determined by the examinees’ abilities. This conclusion is supported by Tate (1948), who investigated the speed accuracy relationship on number series, arithmetic reasoning, and spatial relations questions. He found that when accuracy is controlled, the fastest examinees are not the most accurate but fast subjects are consistently fast and slow subjects are consistently slow. These research results indicate that we need to model accuracy exclusively dependent on ability, and RT exclusively dependent on examinees’ latent speeds. But on the higher level, the speed and ability variables may be correlated. The correlation may differ depending upon the test context and content (Schnipke & Scrams, 2002). Following this argument, van der Linden (2007) proposed a hierarchical framework, in which RT and responses are modeled separately at the measurement model level; and at a higher level, a population model for the person parameters (speed and ability) is constructed to account for the correlation between them. This framework allows “plug-and-play” in that one can insert different measurement models in the first level and assume different covariance structures in the second level. The new model we will present in the next section is one application of this framework.
2. Semiparametric RT Model
We propose a hierarchical PH model to model RTs and response accuracy simultaneously. A critical feature of the models is that we distinguish examinees’ abilities from their latent speed and assign separate latent traits to both of them. This leads to the key assumption of the current model: A test taker operates at a fixed level of speed during the course of the tests. This stationarity assumption excludes changes in behavior during the test due to fatigue, learning, strategy shifts, and other factors. The hierarchical framework proposed by van der Linden (2007) is adopted here. Measurement models at the first level separate the variability in the observed responses and RTs into item and person effects. At a higher level, we assume the examinee’s ability θ and latent speed τ are from a bivariate normal distribution. The specific formulation of the model is as follows.
2.1 First-level model. At the first level, two models for the responses and RTs are specified separately. For the item response model, any appropriate parametric model may be used, but we focus on the three-parameter logistic model:

with

with the survival function being

where
2.2 Second-level model. This part of the model captures the joint distribution of the person parameters in a population. The values of
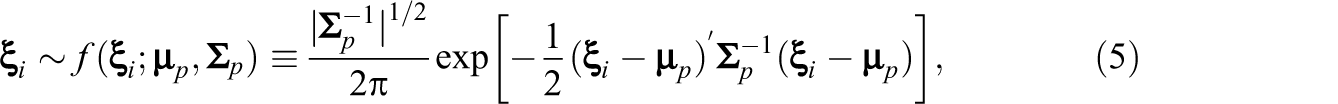
with mean vector

and covariance matrix

2.3 Identifiability. To establish identifiability, we suggest the constraints
In van der Linden’s (2007) model, he imposed a covariance structure on item parameters, whereas we assume that item parameters are independent of one another. There are three reasons. First, according to the results in van der Linden (2007), only the correlation between item time intensity and item difficulty is nonzero (with posterior mean 0.3), all the rest correlations are either very close to 0 or have posterior confidence interval covering 0. Second, the item time intensity information in the new model is reflected in the nonparametric baseline hazard
3. Model Estimation
The goal of our investigation is to accurately estimate θ and τ, as well as the regression parameter β in RT model of Eqaution 4 and item parameters in Equation 2. In many Cox frailty model applications, only the regression parameter β and frailty τ need to be estimated, but in our case, in order to make inference about the examinees and items, the nonparametric cumulative baseline hazard H 0 also needs to be estimated. Several approaches are proposed in the past to estimate both parametric and nonparametric parts of the Cox model, such as estimation based on a spline approximation of the baseline hazard rate (Cai, Hyndman, & Wand, 2002) or estimation based on piecewise exponential models (Friedman, 1982). Two approaches that have advantages (Ranger & Ortner, 2011) are (1) estimation by treating RT as a discrete variable (McCullagh, 1980), such that the Cox model can be viewed within the generalized linear model framework and standard software can be used for model estimation; (2) estimation based on profile likelihood; this approach does not require categorization of the RTs and thus it is more efficient (Ranger & Ortner, 2011). In this study, we propose a two-stage estimation method that employs a divide-and-conquer strategy, specifically, we estimate the parametric part first and nonparametric part second. Instead of using the marginalized maximum likelihood framework as in Ranger and Ortner (2011), we use the Markov chain Monte Carlo (MCMC) framework which is more flexible.
Marginal likelihood inference involving latent variables is usually challenging because of the integrals that are sometimes numerically intractable. One approach that avoids such difficulties is to use the MCMC method to obtain draws from a distribution that has a density proportional to the joint posterior distribution of the item and person parameters. Another motivation for using the MCMC method is that in computerized adaptive testing (CAT), every test taker is given different items, based on his or her adaptively estimated θ level. So the random sampling of θ (or τ due to the possible correlation between them) from a common distribution can not be assumed. We wish for our estimation technique to allow for data obtained by CAT. Consequently, the usual marginal likelihood approaches used in latent variable modeling are no longer appropriate.
Estimating Cox’s PH frailty model with MCMC is not entirely new. Clayton (1991) used Gibbs sampling to fit frailty models to clustered failure data. He sampled iteratively from the full conditional distribution of
Although the Sharef et al. (2010)’s method is flexible and promising, it does not lend itself directly to our case because of two reasons: (1) In our model, we assign an item level regression coefficient
3.1. Partial Likelihood
For the jth item, suppose that there are no ties between the RTs. Let

The partial likelihood for the vector

Kalbfleisch and Prentice (1973) demonstrated that the partial likelihood is a marginal likelihood for β arising out of the distribution of the rank vector associated with the failure times (or RTs). The use of the partial likelihood for inference on β has been justified from both the frequentist viewpoint (Anderson, Borgan Gill, & Keiding, 1982) and the Bayesian viewpoint (Kalbfleisch, 1978).
3.2. Parameter Estimation: MCMC
For the ith test taker, his or her responses and RTs are denoted by

To estimate the parameters
Our objective is utilizing the RT information to estimate the nonparametric baseline hazard
3.2.1 Prior Specification
A bivariate normal prior is chosen for the latent parameters

and assume normal and lognormal priors for a and b parameters separately as


The detailed Metropolis-Hastings algorithm for model estimation is given in Appendix A.
3.2.2 Justification of the Partial Likelihood
The partial likelihood may not be seen as a likelihood in a strict sense; yet, Kalbfleisch (1978) provided rigorous justification of using partial likelihood in a Bayesian context. Specifically, he showed that marginalizing with respect to an independent-increment gamma process prior on a baseline cumulative hazard led to a posterior density of β that is proportional to the partial likelihood. In the usual Cox model with covariates (denoted as τs) observed, when integrating out

where

where
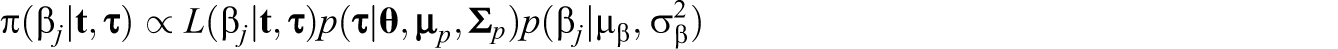
for updating the chain of β. The second-level model on person parameters is reflected via the term
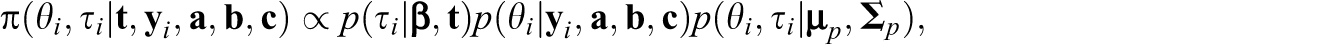
as a result of local independence assumption, where
3.3. Estimation of the Cumulative Baseline Hazard
The nonparametric cumulative baseline hazard can be estimated via the Breslow estimator (Breslow, 1972). For the jth item, in order to estimate
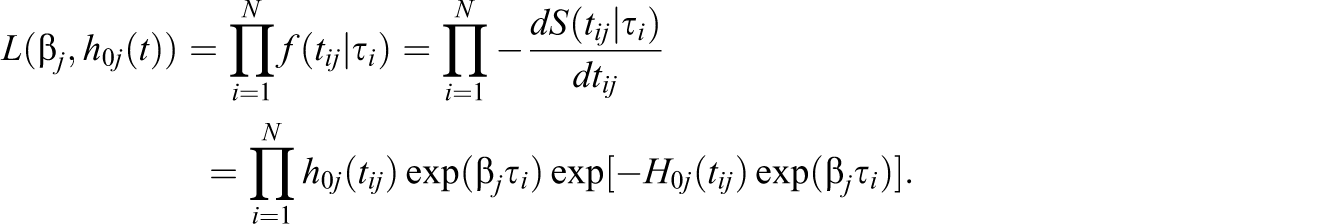
Replace

The nonparametric baseline hazard
Specifically, we will adopt a cubic B-spline basis. The basis functions are determined recursively when the knots and boundary points are specified. The knots are often chosen to be evenly spanned along the range of the data. Usually, increasing the number of knots or increasing the degree will lead to a better fit. But oftentimes, the degree is chosen to be 3, indicating a cubic basis function. Once the B-spline basis is specified, we treat the components of the basis as predictors and fit a linear regression model to the Breslow estimator of the cumulative baseline hazard. In this way, we obtain the regression coefficient for each basis. For details about B-spline, please refer to de Boor (1978) and He and Shi (1998). An apparent advantage of the B-spline is that only the knots, boundary points, and regression parameters are needed to recover the whole baseline hazard.
3.4. Model Diagnosis
Model fit checking is an important step in any model development. In this section, we propose to use three approaches of evaluating model fit: (1) posterior predictive checks (Gelman, Carlin, Stern, & Rubin, 1995), (2) cross-validation, and (3) a survival analysis specific residual method.
3.4.1.Posterior predictive checks
Given the posterior distribution of the model parameters, one can calculate the predicted RT for test taker i and item j, denoted as

The distributions of the above probabilities over all the person item combinations in the sample will be used to evaluate the global fit of the model (van der Linden, Breithaupt, Chauah, & Yang, 2007). If the model fits, the cumulative distributions of these probabilities will follow the identity line. This model diagnosis method is appropriate for any kind of model.
3.4.2.Cross-validation
It is a widely used technique for assessing how the results of a statistical model could be generalized to an independent data set. Specifically, we want to show whether the model estimated from the current sample (denoted as the calibration sample) can accurately predict the outcome variables (response accuracy and RTs) in a cross-validation sample. Because the item 3PL parameters are precalibrated and assumed known in real data example (Section 5), the correct prediction of response accuracy under different models will be rather close; therefore, the accurate prediction of RTs is our interest. If the semiparametric model is considered, for the ith examinee in the cross-validation sample, we can calculate the average residual RT as

where both
3.4.3.Item-level residual checks
This residual index allows for checking the item-level fit, and it is constructed for Cox model specifically. The Cox model can be rewritten as

We can further rewrite the equation as

where

If the model fits the data well, the
4. Simulation Studies
4.1. Study 1
A simulation study is carried out to check the performance of the proposed MCMC estimation method. As a starting point, we only consider the nonadaptive situation, in which each examinee has taken the same set of items. A total of 2 × 2 × 3 = 12 different test conditions are simulated. The first factor represents test length J, and two levels (
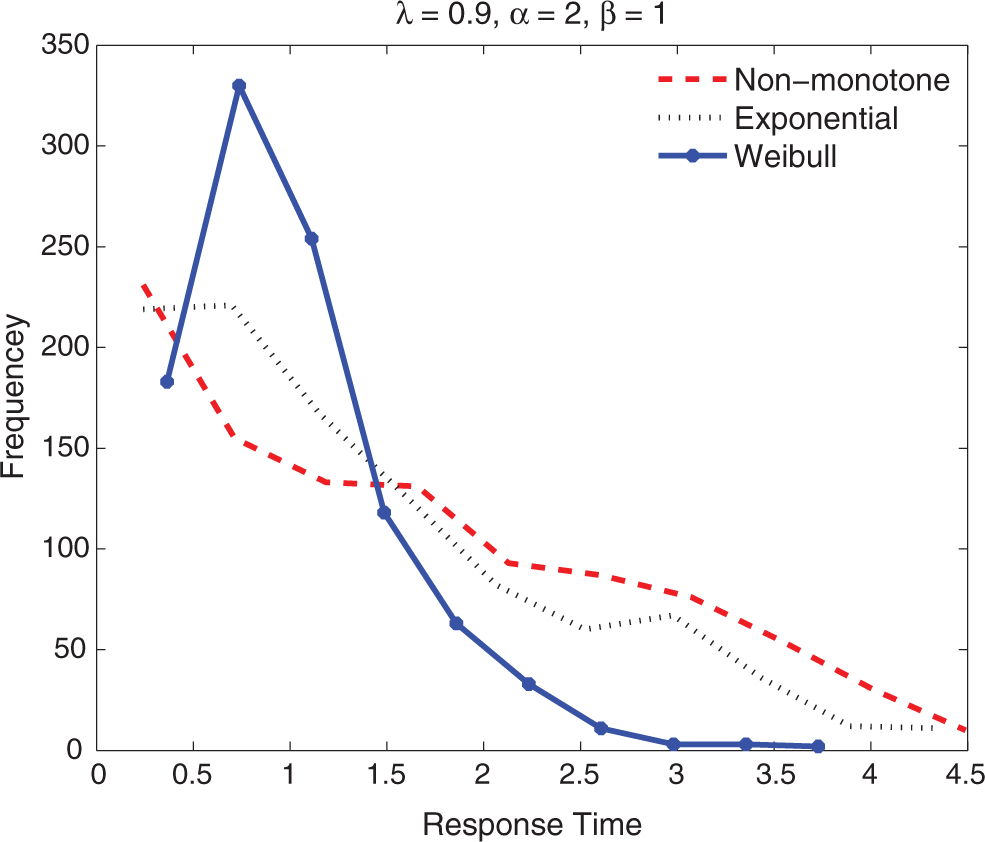
Illustration of response time distributions under different shapes of baseline hazard.
The three-parameter logistic model is used for generating item responses. Item discrimination and difficulty parameters are simulated from
4.2. Results
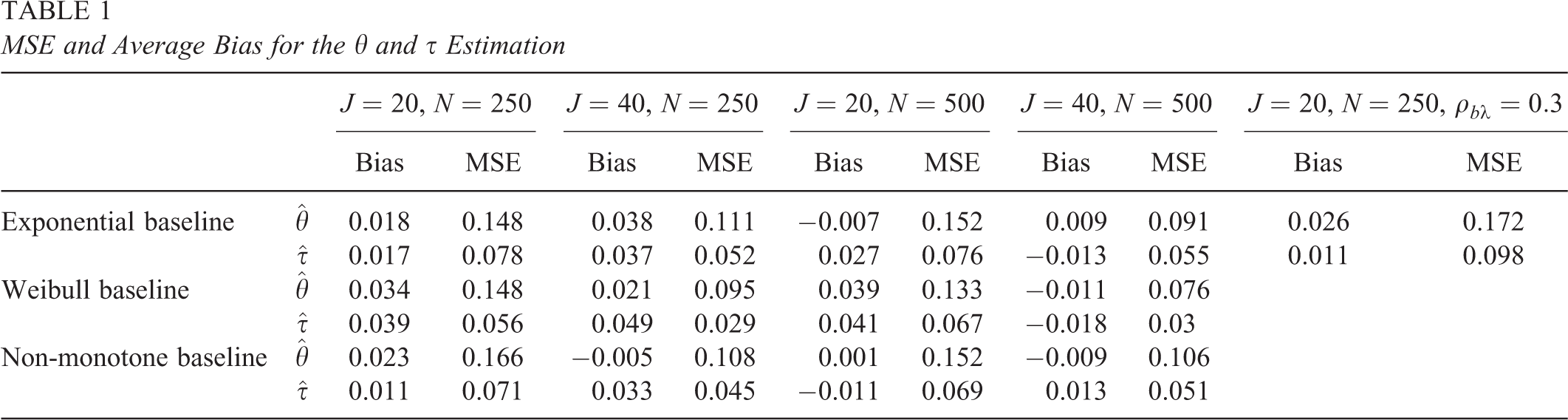
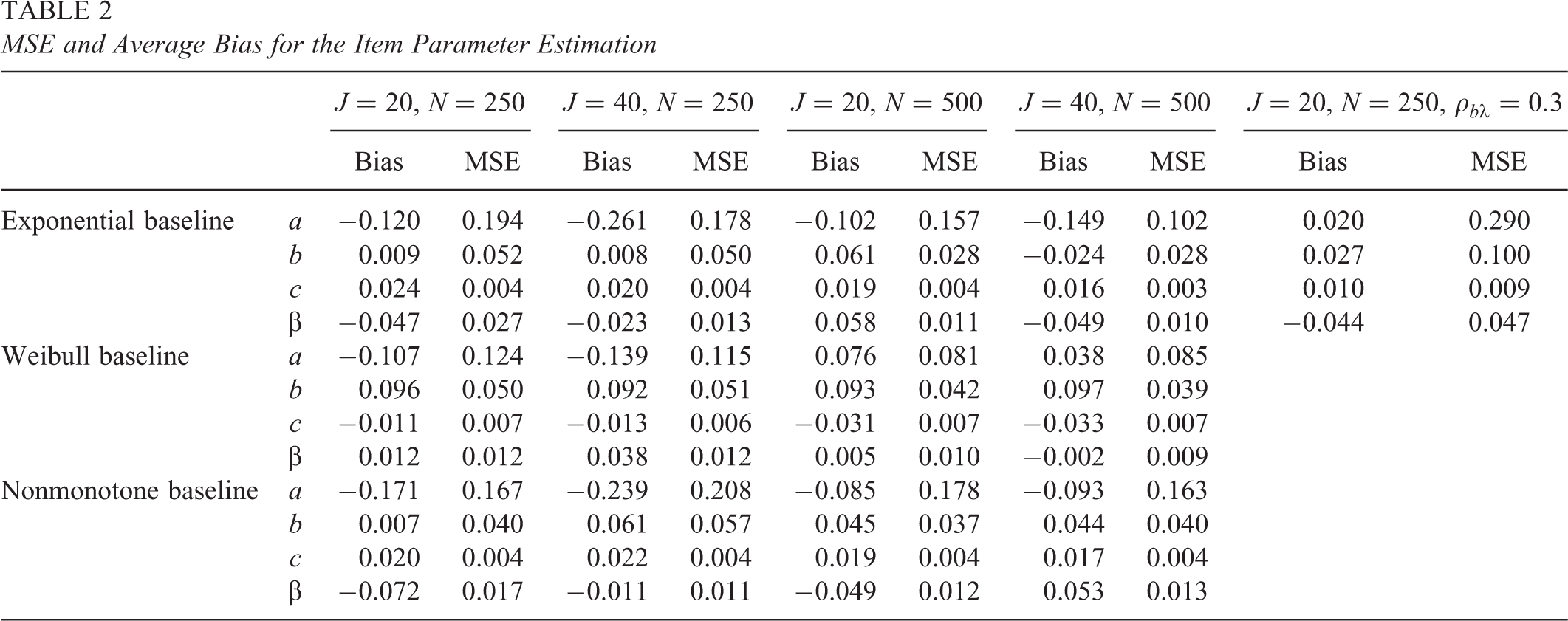
The Markov chain for each parameter appears to reach equilibrium and has small autocorrelations beyond the first couple of lags. Mean squared error (MSE) and average bias are calculated to check how close the estimated parameters were to their true values. Table 1 presents the MSE and bias of θ and τ for the 12 simulation conditions. All values are averaged over all examinees and all replications within a simulation condition. Table 2 tabulates the MSE and average bias for item parameters, including β and a, b, and c. Notice that the true value of
MSE and Average Bias for the θ and τ Estimation
MSE and Average Bias for the Item Parameter Estimation
Mean and Standard Deviation for the Integrated Absolute Difference Between

For the log hazard ratio regression parameter β, the estimation is quite accurate in general, as indicated by the small MSE in Table 2. There is an apparent trend that increasing the population size reduces the MSE of β. The results also show that no matter which shape the baseline hazard takes, the model can always be accurately recovered. Increasing the test length reduces the MSE of τ and θ. Figure 2 shows the true and estimated cumulative baseline hazards. Here we only present the results for True and estimated cumulative baseline hazard for different shapes of baseline hazard. continued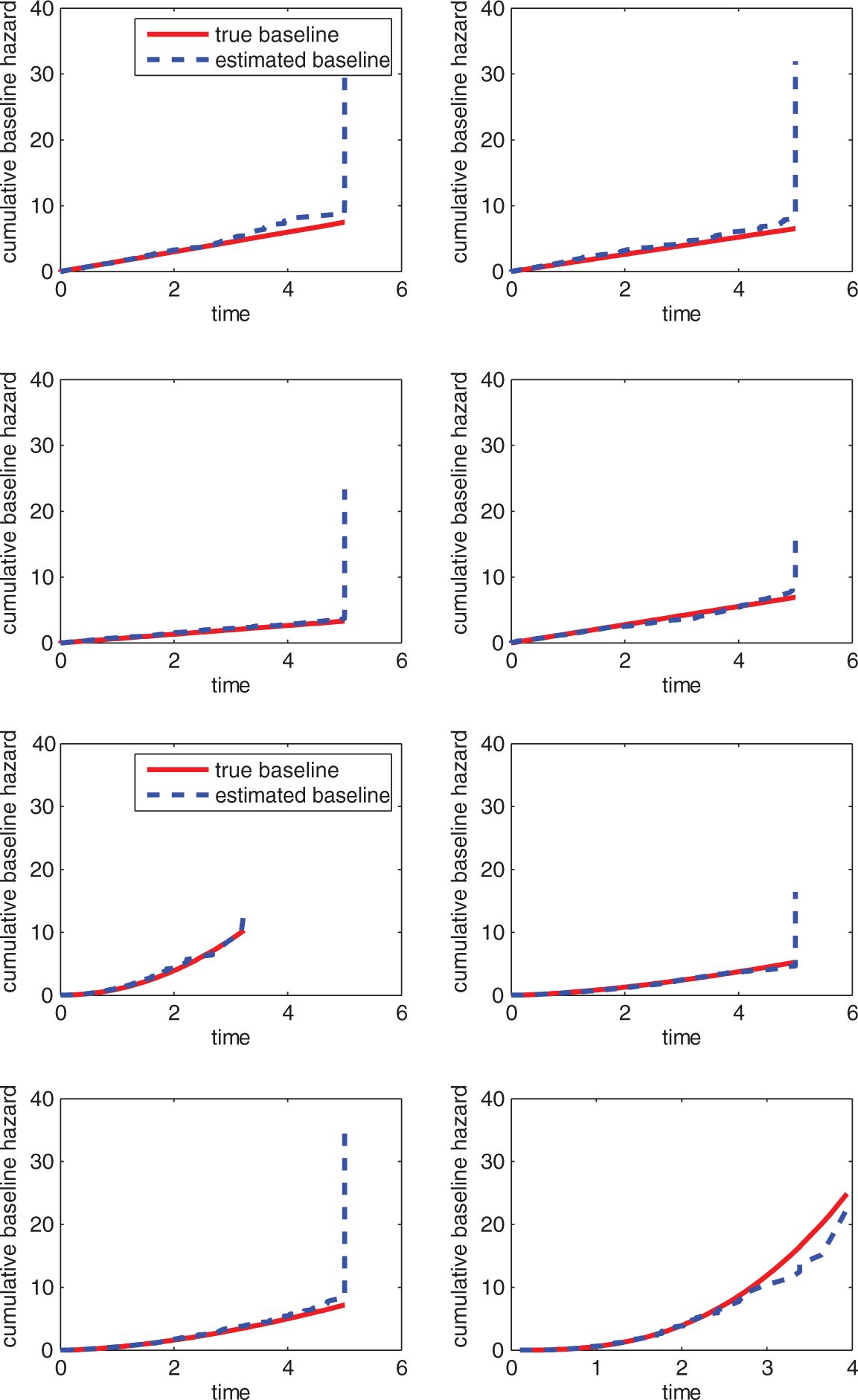
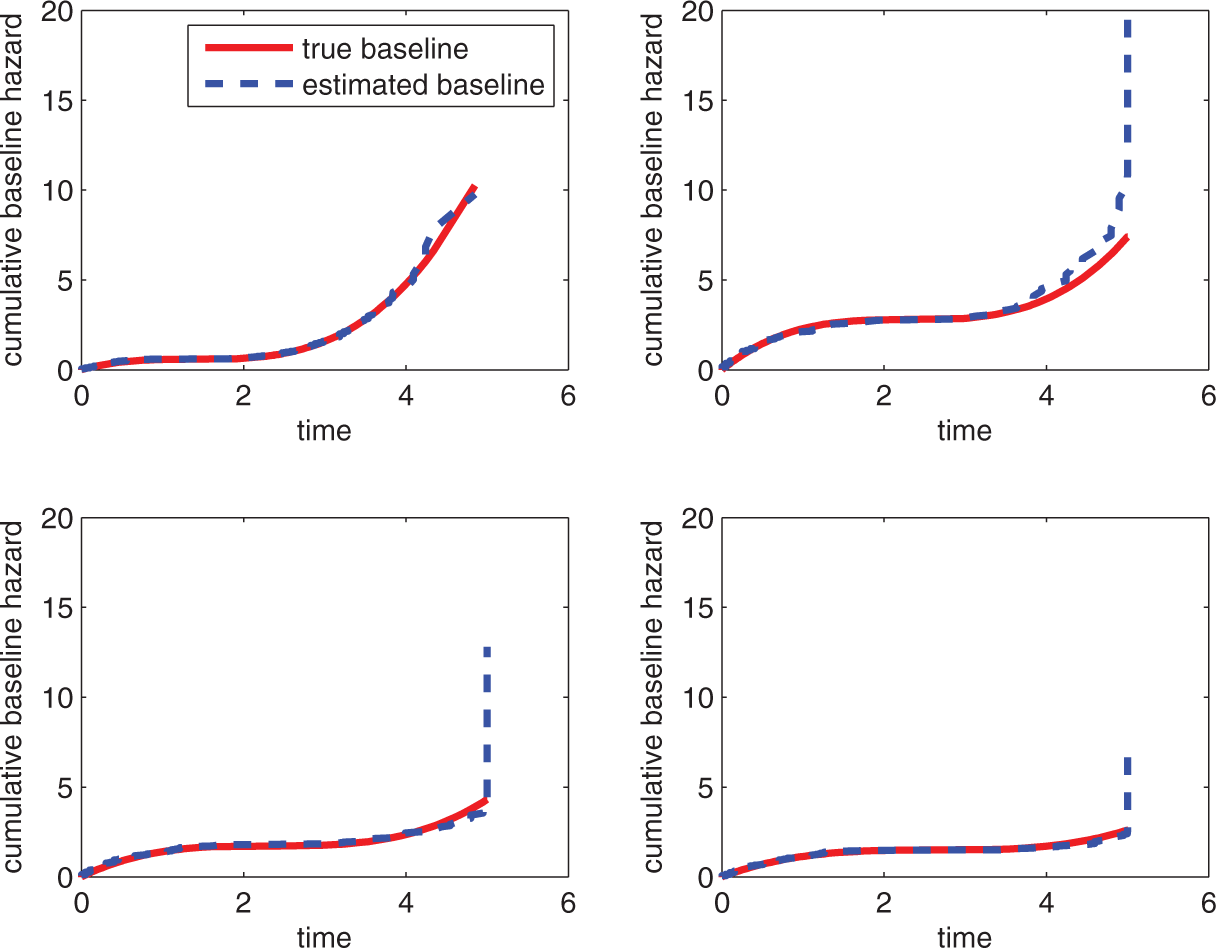

The mean and standard deviation of
4.3. Study 2
This study is designed to show that even if the item parameters have some moderate correlation, especially between item time intensity and item difficulty parameters, the proposed algorithm can still generate satisfactory results, with the item covariance matrix unestimated. As an illustration, we only consider the exponential model, in which the baseline hazard
5. Empirical Example
This model is applied to a data set from a large scale high-stakes computerized adaptive test. The original data set is comprised of 21,444 examinees and 620 multiple choice items in total. The item 3PL parameters were precalibrated and were assumed known in this analysis. The default test length is 37, but the number of items that each examinee answers ranges from 25 to 37. Because of the computerized adaptive version, each item is answered by different sets of examinees, and the number of examinees taking each item rangs from 6 to 489. We randomly sample 3,000 examinees from this population for analysis. However, we delete 319 examinees because their RTs are not recorded; we further delete 548 examinees because their total RTs are either too long (longer than 75 minutes) or because they fail to finish the whole test (i.e., test length is shorter than 37). Longer than 75 minute tests occur because some examinees take the test under nonstandard “accommodation” settings. The resulting 2,061 observations are used in the analysis. The original RTs are recorded in a millisecond scale, and for ease of calculation, we rescale the RTs to the “minute” scale by dividing each RT record by
To show that the new semiparametric model fits the empirical data better than the more restrictive parametric models, we consider three alternative parametric models: (1) the exponential model, with hazard function
5.1. Model Selection
Model fit is checked via the three approaches introduced above. We first check the global fit of the semiparametric model against the parametric models, as shown in Figure 3a. This figure presents the cumulative distribution of the predictive probabilities for the observed RTs in Equation 10 for all person–item combinations in the data set. The data set is large enough (55,500 data points) to expect the empirical distribution to coincide with the identity line. The impression from Figure 3a is that the semiparametric model fits the data much better than the lognormal model and Weibull model, and the most restricted exponential model displays worst fit. Although the lognormal model does not show a good fit, one potential useful result from the lognormal model is that the covariance matrix on item parameters have all off-diagonal elements within the range of [−0.1, 0.05]. This indicates that the item parameters are nearly independent, although this conclusion should be made with caution because of the misfit of the model.
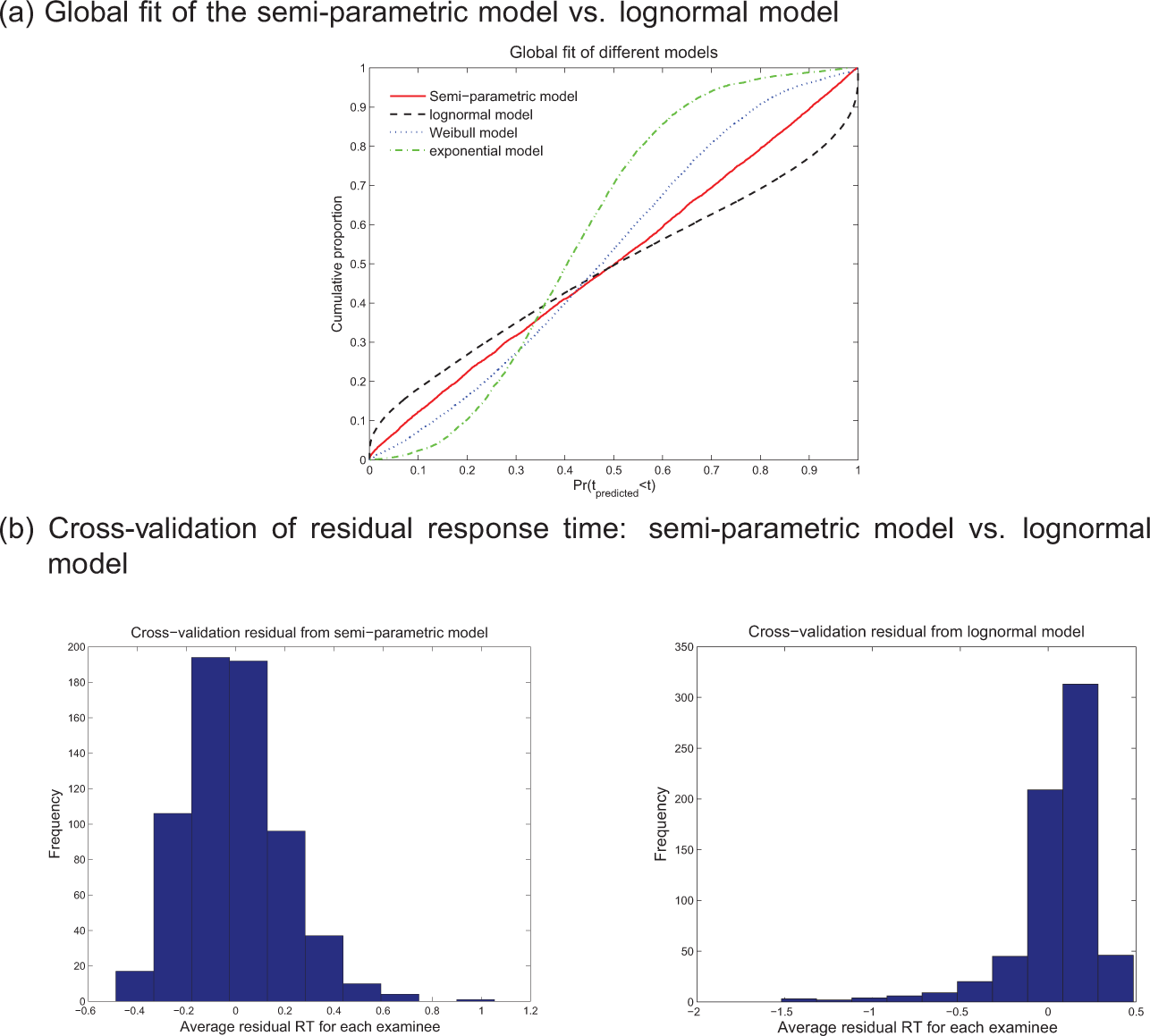
Diagnostic plots for different models.
Model fit is further checked by cross-validation, and a comparison is conducted between the semiparametric model and the lognormal model. A new independent sample of 1,500 examinees is drawn from the original data set, and 432 examinees are excluded due to the same criterion mentioned earlier. The remaining 1,068 examinees form the cross-validation sample.
The residual in Equation 11 is calculated for each examinee in the cross-validation sample. Observe that in the calibration sample, there are 30 items that are answered by fewer than 20 examinees, and the parameter estimations for those items are expected to be less accurate and reliable. Therefore, rather than presenting the mean residual RTs for every examinee in the cross-validation sample, we decide to only present the residuals calculated from those examinees who answered items with item parameters estimated from a sample size larger than 40 in the calibration sample. The cross-validation residuals are presented in Figure 3b. Apparently, both models generate acceptably small residuals. The lognormal model, which has fewer parameters, tends to generate smaller residuals for a larger number of people, as indicated by more than 220 examinees with residuals falling into the range of [−0.05, 0.05], versus 190 from semiparametric model. On the other hand, the semiparametric model is more flexible to capture various shapes of RT distributions, some of which might be hard to represent by the lognormal distribution. Accordingly, the lognormal model is a poor fit for certain items and yields a greater proportion of the more extreme cross-validation residuals.
To show the item-level fit of the semiparametric model, we draw the distribution plot of
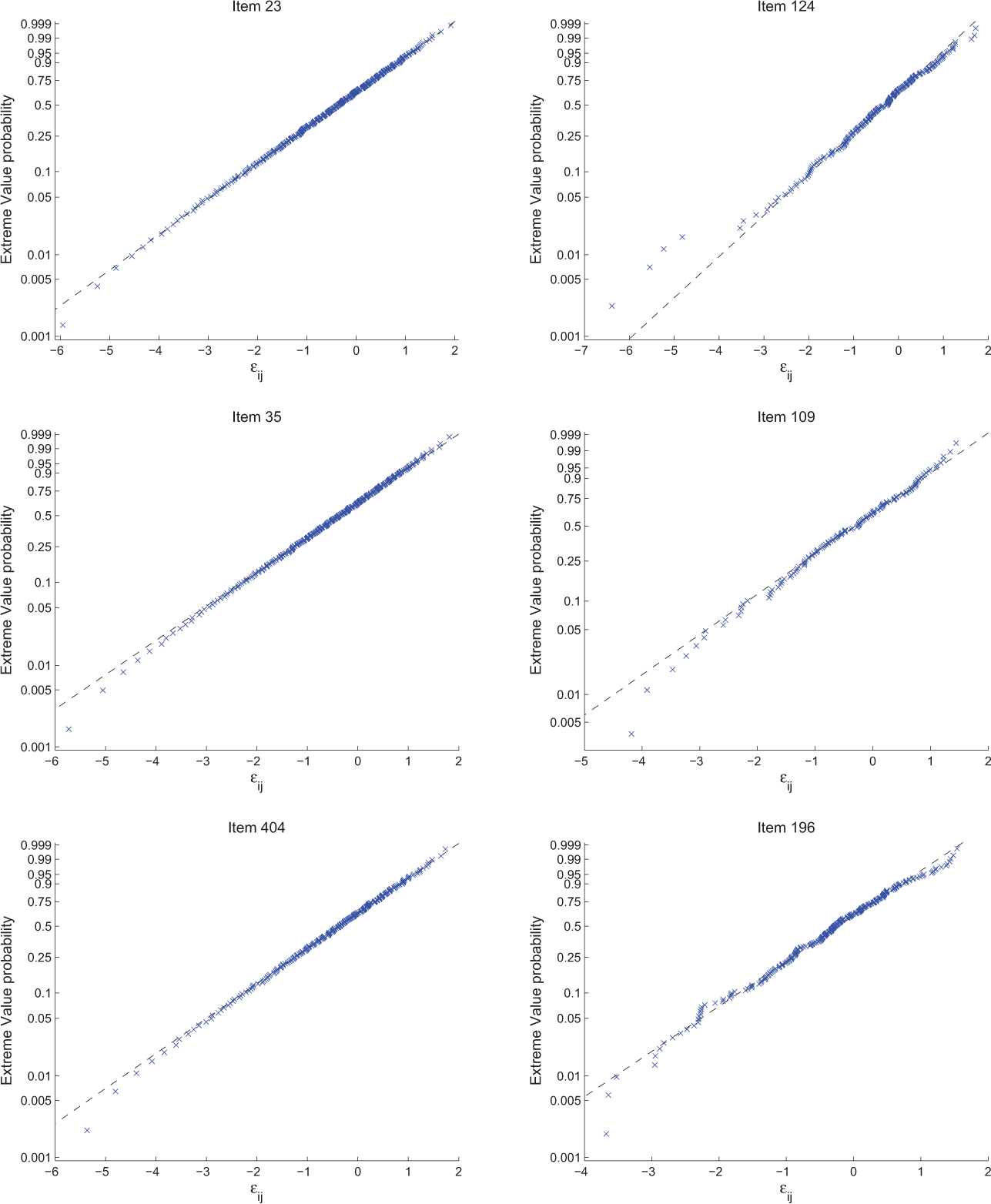
Item-level residuals for 6 items.
5.2. Parameter Estimates
Because the model fit checking indicates that the semiparametric model fits the data best, in this subsection, we will only report the model calibration result from this new model. The correlation between τ and θ is as high as .71, meaning that more capable examinees tended to answer the items faster. The average value of
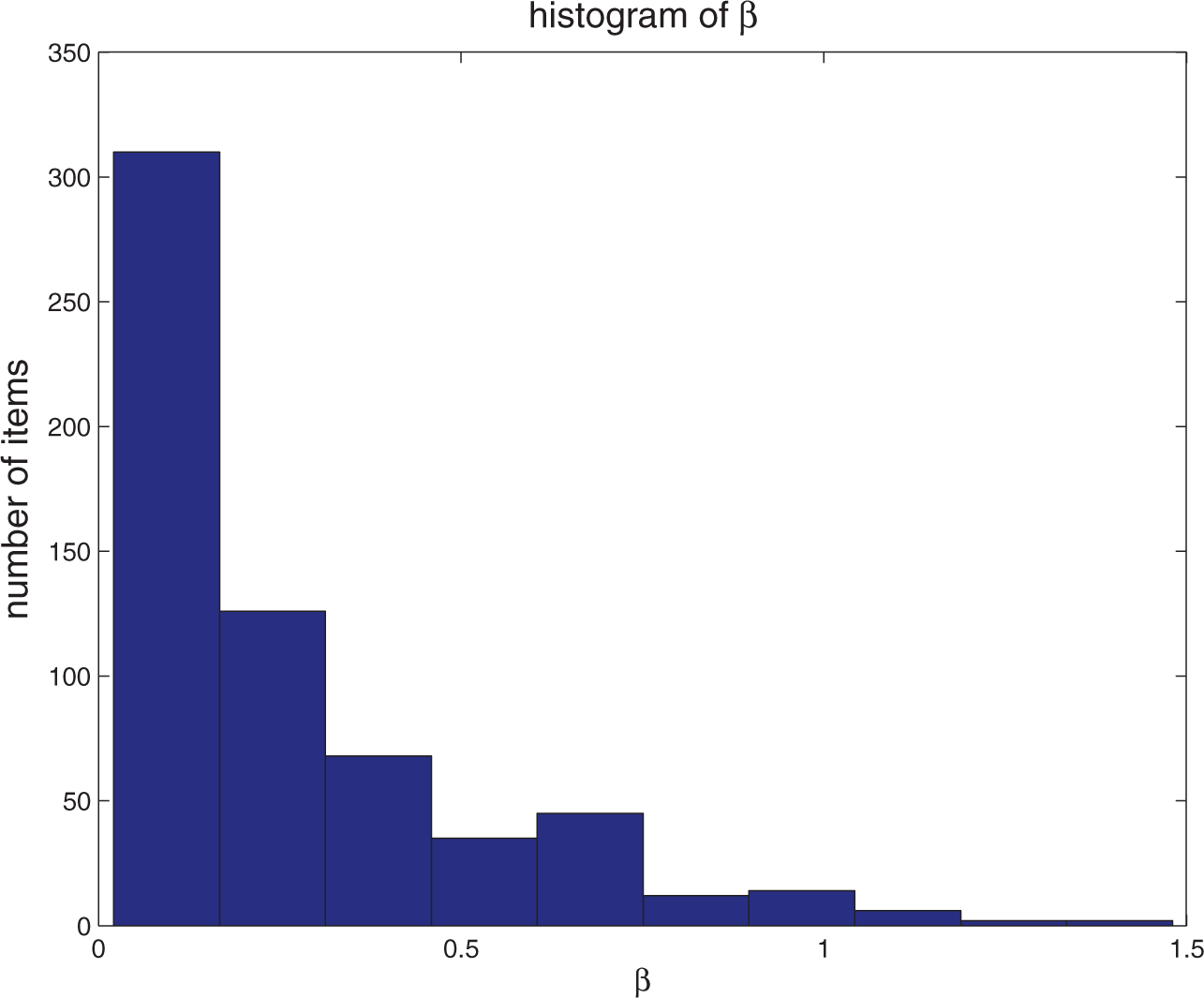
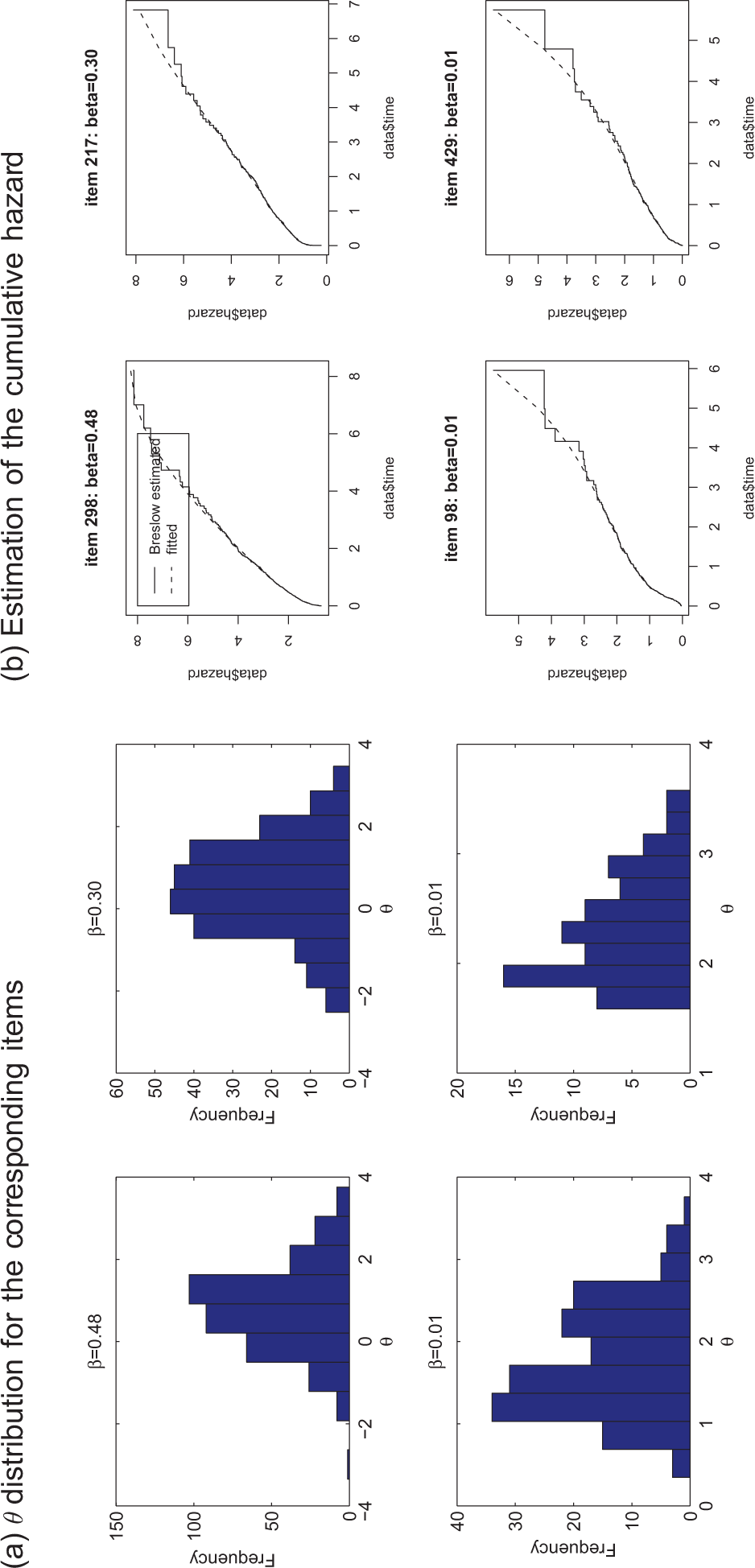
Illustration of the RT histogram, cumulative baseline hazard, and examinees’ ability distribution for 4 items.
The baseline cumulative hazards calculated from the Brewslow estimator are also provided in Figure 6b. When fitting the B-spline, the degree of the B-spline basis was set to be 3, and three inner knots were chosen to construct the basis. R functions bs in “splines”package were used to carry out the B-spline fitting, and function lm was used to regress the B-spline bases on the Breslow estimation results through linear models. The B-spline curve is plotted against the Breslow estimator for the 4 items, as presented in Figure 6b. It shows that the B-spline curves fit well with the points estimated from the nonparametric Breslow estimator, and therefore, we can largely reduce the number of parameters needed to adequately recover the entire cumulative baseline hazard estimate.
5.3. Further Model Diagnostics
Two key assumptions of the model are the local independence and stationarity assumptions. Van der Linden and Glas (2010) proposed a score test statistic (also known as Lagrange Multiplier [LM] test statistic) to check the local independence of responses and RTs. The same idea is applied in this study and is briefly presented below and in Appendix B. First, the assumption of conditional independence between RT and response accuracy can be equivalently expressed as

for examinee i and item j. If this assumption is violated, the RT model could be modified as

thus the assumption check reduces to check the significance of

whereas the alternative hypothesis is
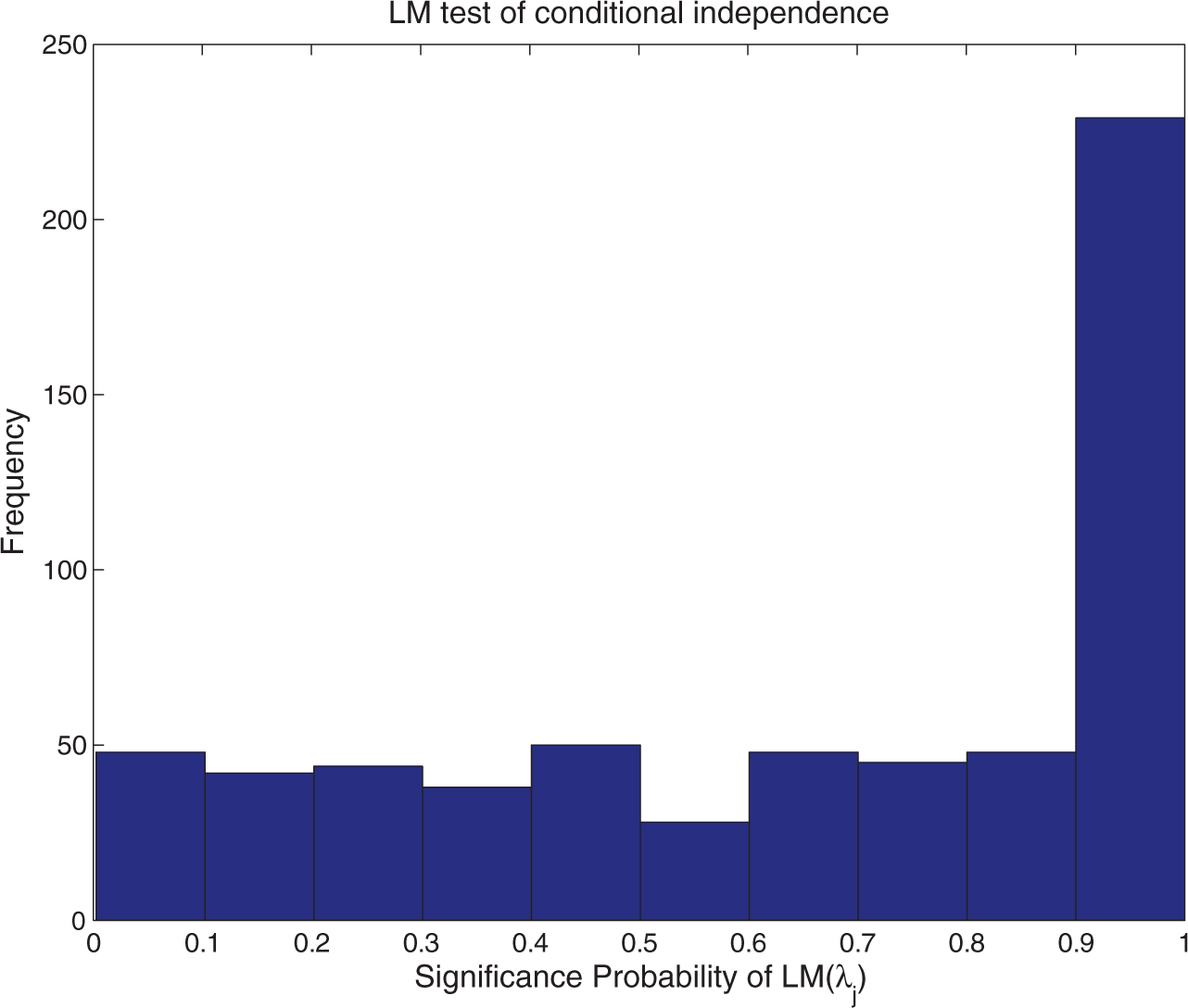
Lagrange multiplier probability for conditional independence.
The stationary assumption claims that examinees’ speed and ability are constant during the test. While constant ability is standard in item response modeling, the constant speed assumption needs to be checked. For examinee i, we calculated the residual RTs as
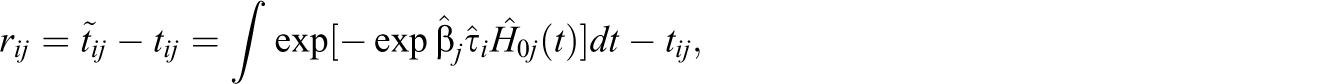
for
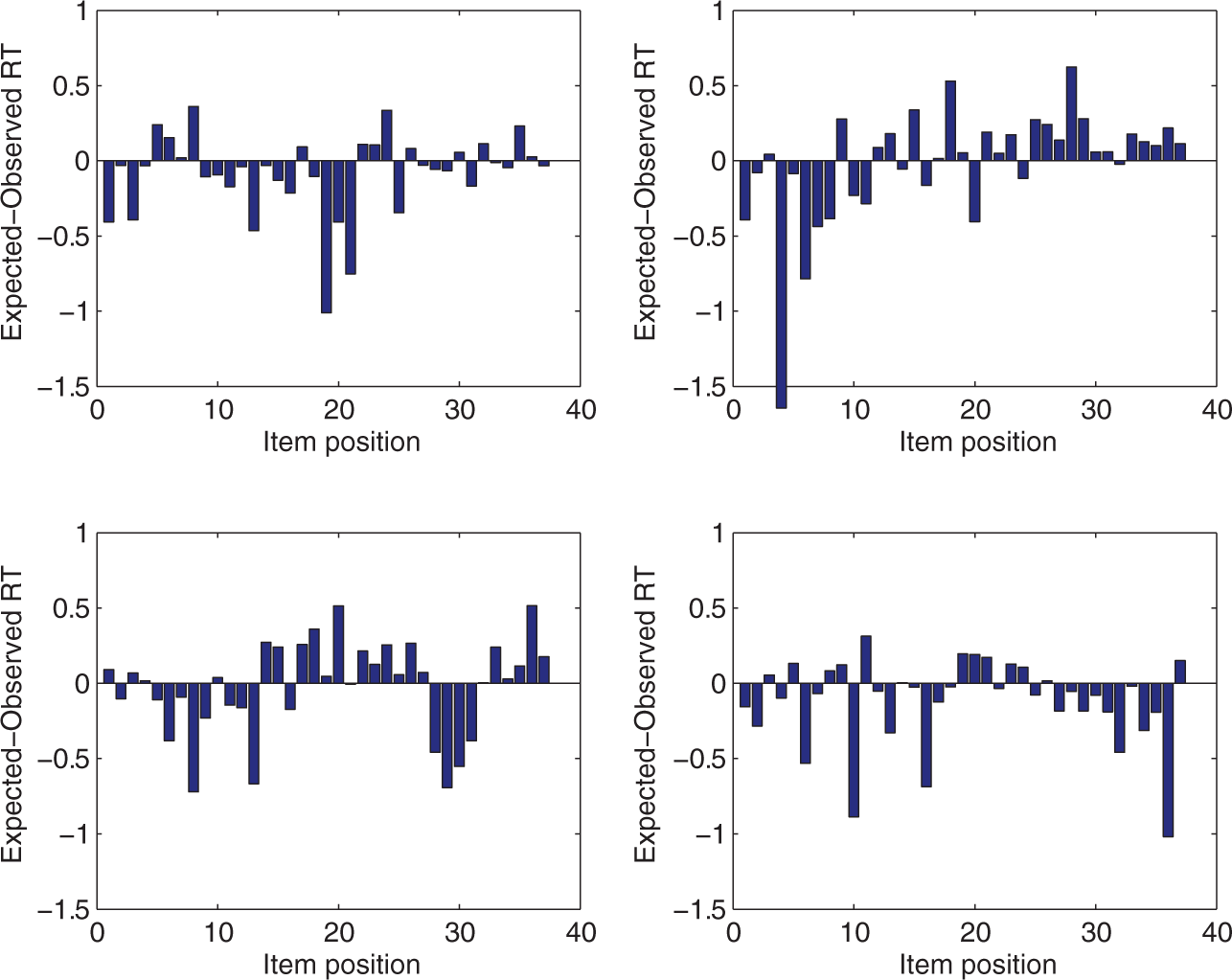
Mean residual times on the items as a function of their position in the test: four selected examinees.
6. Discussion and Future Work
Since the 1972 publication of Cox’s seminal article on statistical models for lifetime data, survival methods, especially those for continuous time data, have enjoyed increasing popularity in a variety of disciplines ranging from medicine and industrial testing to economics and sociology. RT analysis, a specific research topic in educational measurement, will also benefit from advances in survival methods. In fact, the semiparametric modeling approach in survival analysis opens another avenue for RT modeling. Most recently, Ranger and Ortner (2011) proposed to use Cox model in RT modeling, and they replaced the observed covariates in the Cox model with the test takers’ latent speed. In this article, we proposed to insert their model in the two-level framework proposed by van der Linden (2007) such that the RT and response accuracy are modeled simultaneously. This model hinges on the assumption that examinees’ latent speed determine their RTs directly. This new model assigns a separate speed parameter τ to account for the individual differences in speed, while allowing τ to be correlated with θ at population level. The hierarchical framework (van der Linden, 2007) distinguishes the speed–accuracy trade-off within a person from the speed accuracy correlation across persons. Simulation studies show that the new model can be estimated accurately via a two-stage estimation method. One apparent advantage of the proposed model comes from its semiparametric nature. The nonparametric baseline hazard is flexible enough to accommodate different shapes of RT distributions in real data. Once the nonparametric baseline hazard is recovered by the Breslow estimator, we can further fit it either with a parametric form or with a curve generated by B-spline basis, depending upon the specific shapes of the baseline hazard. Also due to the nonparametric term, the new models subsume a variety of different models, such as the exponential regression model, the Weibull regression model and others.
The estimation method proposed in this article uses the partial likelihood function, which is motivated as resulting from integrating out the baseline cumulative hazard function with respect to a gamma process prior. Although Clayton (1991) also adopts a gamma process prior, he includes the cumulative baseline hazard as a “parameter” to be updated within each Markov chain. Sharef et al. (2010) advocated using B-splines on H 0 and update it in MCMC as well. An apparent advantage of their approaches is that inference can be made on the baseline hazard. However, with a somewhat complicated posterior distribution encountered here, it seems more beneficial to use a divide-and-conquer approach. That is, treat the nonparametric baseline hazard as a nuisance parameter and integrate it out first, and once the parameters are accurately calibrated, estimate the nonparametric hazard secondly.
A future direction is to introduce additional covariates in the model, such as examinees’ demographic information, to better explain the RT variance. A survival model that is suitable for such a purpose is

where
The real-data example shows that the proposed semiparametric model tends to fit the data better than the more restricted lognormal model, or other parametric models. One limitation of this study is that we only compared the performance of the semiparametric model with simpler parametric models. In the future, more flexible parametric models, such as the Box-Cox normal model (Klein Entink et al., 2009) or the generalized linear model with flexible link function (Ranger & Kuhn, 2011) should be considered as potential alternative models. Further studies should also confirm the applicability of the new model for other types of test data (such as nonadaptive achievement tests). Another future direction is to further break down the latent speed parameter τ into different information processing components, because different examinees might employ different strategies when solving an item. Response caution also plays an important role in examinees’ processing speed (van der Mass, Molenaar, Maris, Kievit, & Borsboom, 2011).
The ultimate goal of RT research is to further enhance the quality of tests and to improve the estimation accuracy of the examinees’ abilities. A test’s quality includes test fairness, test efficiency, and so on. In particular, concerning test fairness, RTs allow us to formulate constraints on item selection (in adaptive tests) or test assembly (in linear form tests) that guarantee the multiple forms of a test to be equally speeded. In our modeling approach here,
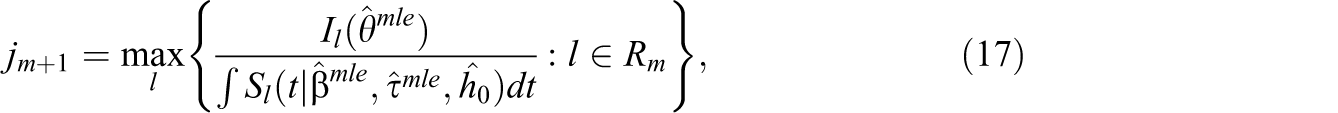
where Rm
denotes the available items in the item pool and
Footnotes
Appendix A
For the ith test taker, his or her responses and RTs are denoted by
Appendix B
Similar to van der Linden and Glas (2010), we assumed the item parameters, including
where
and
For item j, the LM statistic is constructed as
where
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by a grant from the National Science Foundation, NSF-MMS 0960822.