
Abstract
Cluster analysis is a set of statistical methods for discovering new group/class structure when exploring data sets. This article reviews the following popular libraries/commands in the
1. Introduction
Cluster analysis is an area of statistics involved with finding groups in data by aggregating items that are similar in some sense into separate classes (Everitt, Landau, Leese, & Stahl, 2011). Any field that has interest in finding meaningful groups within data could benefit from statistical clustering. Some recent applications have included using clustering to group student skill set profiles (Dean & Nugent, 2013), to group rates of obesity and diabetes in U.S. counties (Flynt & Daepp, 2015), and to estimate the spatial patterns in disease risk (Anderson, Lee, & Dean, 2014).
This article discusses a selection of libraries and commands in the
2. Common Cluster Analysis Methods and Their Implementation
Given that data are clustered such that the objects within groups found are similar in some way(s), there are obviously different methods for defining similarity. For example, one of the most popular methods for defining dissimilarity is using Euclidean distance from the cluster center which leads to the k-means method, or using the density of points in the surrounding area that leads to MBC. The many different definitions of (dis)similarity have led to a wide variety of clustering methodologies. These can be roughly divided into three main categories: algorithmic, parametric, and nonparametric. Some of the oldest cluster analysis methods such as k-means (MacQueen, 1967) and hierarchical clustering (Ward, 1963) are examples of the algorithmic class of methods. Methods such as MBC (Wolfe, 1963; Fraley & Raftery, 2002) and LCA (Lazarsfeld, 1950a, 1950b; Lazarsfeld & Henry, 1968), based on finite mixture models (McLachlan & Peel, 2000), are examples of parametric clustering. Nonparametric clustering (mentioned again in Section 3) looks to identify modes in the estimated density surface for the data with clusters.
We now introduce the simulated data set used to illustrate the cluster analysis methods described and implemented in the remaining subsections. Code and selected output will be presented that can be adapted for the reader’s own data analysis.
2.1. Data
To illustrate the discussed
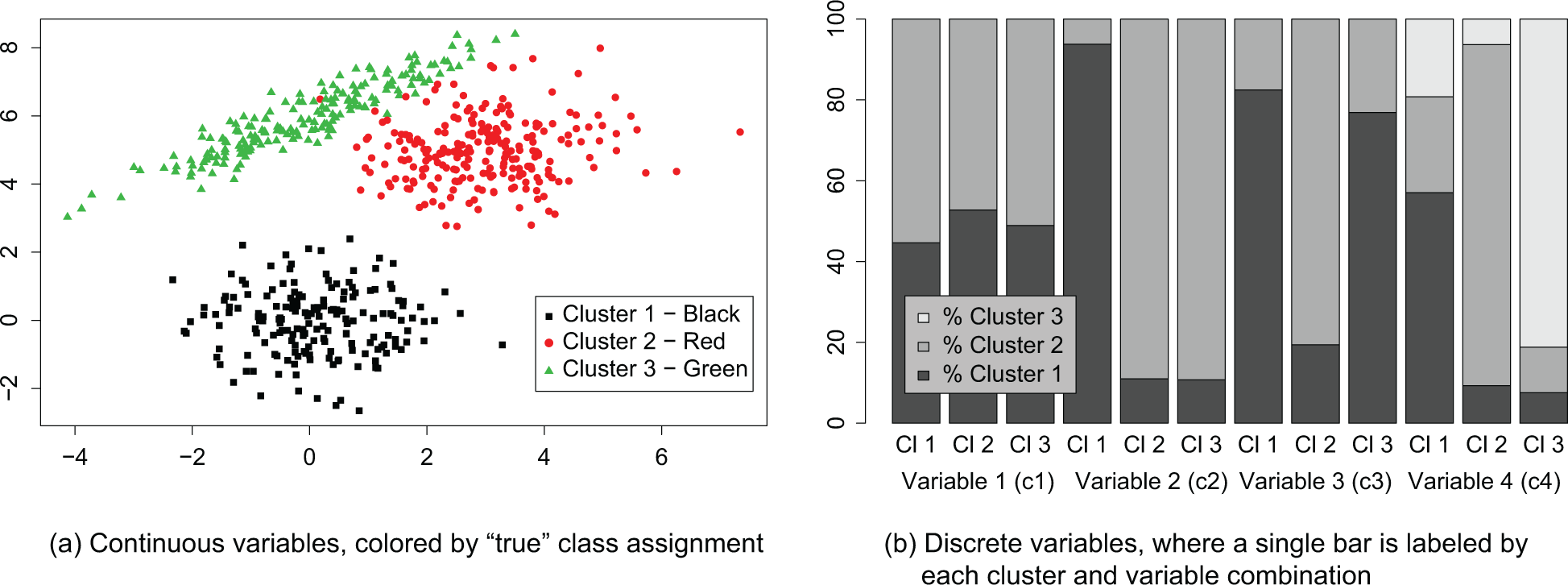
Simulated data set.
In the following sections, R code to be implemented is prefaced by the prompt symbol
2.2. Algorithmic Clustering Methods
2.2.1. k-Means
k-Means is based on the idea that points should be assigned to the clusters that minimize the overall distance between points and the cluster means/centroids to which they have been assigned. The typical distance measure used is Euclidean (although other distances can theoretically be used), so the method is usually only applied to continuous data. k-Means assumes the variability in all clusters in all variables is the same, resulting in the discovery of spherical clusters which each take up an equal volume in variable space. If variables are measured on vastly different scales, it is a good idea to scale them prior to applying k-means; the R command
One of the issues in any clustering method is the decision as to how many clusters are present in the data being examined. The most common way to choose the number of clusters for k-means is by fitting k-means models for a range of consecutive numbers, usually 1 up to some maximum number, and plotting an elbow plot of the total within sum of squares value for each number of clusters versus that cluster number. An example is given in Figure 2 in subsection 2.2.2. The number of clusters is taken to be the “elbow” or turning point in the line plot where the reduction in sum of squares seems to drop off. The assignment of points into clusters for a particular model is obtained by extracting the cluster assignment,
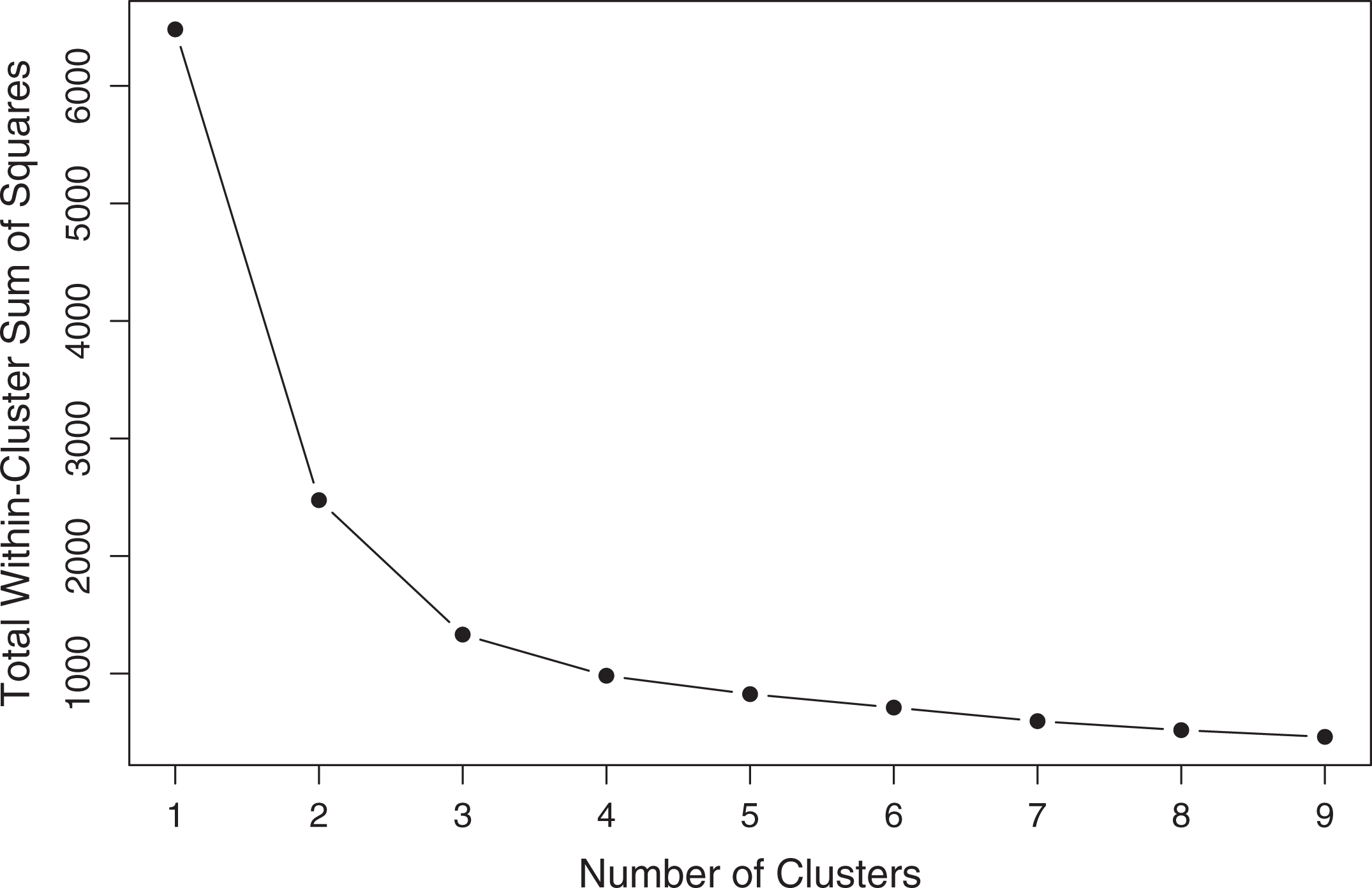
Elbow plot for the total within-cluster sum of squares from k-means models.
Other nonvisual methods for choosing the number of clusters (for any clustering method, not just k-means) are performed by calculating some metric that measures goodness of aspects of the clustering. Examples of these measures found in the
2.2.2. Simulated data results and code for k-means
The first argument in the
Here we run k-means for different values of k, from 1 to 9, with 50 random starts on the first two columns/continuous variables in our simulated data set
The elbow plot from the resulting k-means models can be seen in Figure 2. This plot suggests the choice of the three-cluster model. It is common to create a cross-classification table (see table in output) comparing the true simulated groups and the estimated clusters. Note that the estimated clusters may have labels switched from the true groups (as seen above) but can be reordered appropriately. The misclassification rate is calculated as the number of misclassified observations out of the total number of observations. We see that for the three-cluster solution produced by k-means, the black group was perfectly recovered, but 43 observations were misclassified in the overlapping red and green groups, resulting in a misclassication rate of
2.2.3. Hierarchical agglomerative clustering
Hierarchical agglomerative clustering is based on the idea of successively merging the pair of closest/most similar clusters together to form a new larger cluster until all points are merged into one cluster. Usually, the order and height of merges are visualized in a tree-like diagram called a dendrogram (sometimes dendogram; see, e.g., Figure 3). The advantage of this method is the ability to easily visualize the structure of the data regardless of how high dimensional it may be. This method of clustering also allows for hierarchy in the clusters found.
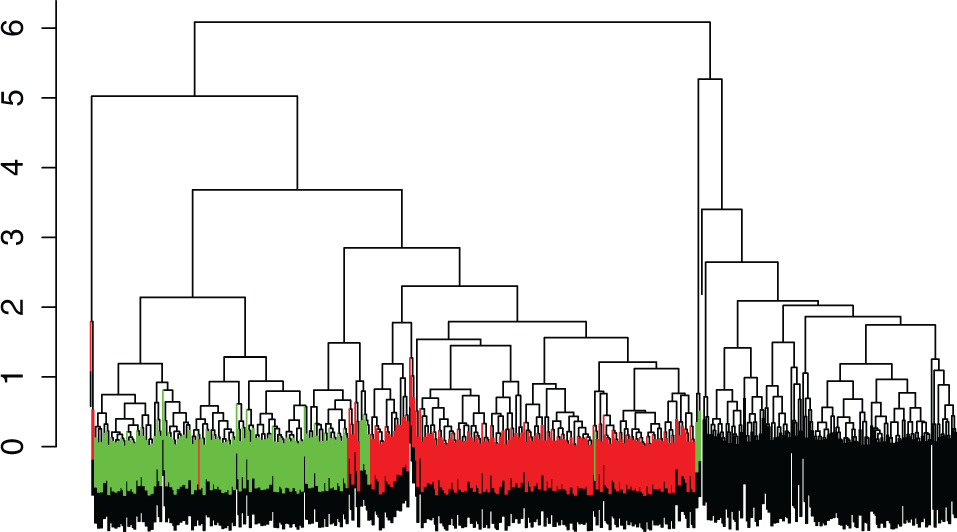
Colored dendrogram resulting from hierarchical clustering using average linkage.
There are several ways to calculate linkages: the distance between pairs of nonsingelton clusters. Each definition of linkage gives rise to a different type of clustering solution on the same data. Single linkage defines the distance between two clusters as the minimum of all the pairwise distances between pairs of points in the different clusters. This type of linkage gives rise to “chaining,” where the merges are more likely to have points or small clusters joining with a large cluster rather than forming new large clusters. This effect can lead to groups that are of unusual shape (e.g., nonspherical and nonelliptical) but can also lead to close groups being incorrectly merged if there is any degree of overlap. Single linkage is usually very useful in identifying outliers. This linkage is also related to the minimal spanning tree (see Gower & Ross, 1969, for details). Complete linkage is the maximum of the pairwise distances between all pairs of points in the different clusters. It tends to separate out overlapping groups well but will do poorly recovering nonstandard shapes of groups. Average linkage uses the average pairwise distance between all pairs of points in the different clusters as the measure of distance. The clustering for average linkage usually lies somewhere between the solutions given by single and complete linkage. Centroid linkage defines distance between clusters as the distance between the cluster centroids. Ward’s linkage looks at the increase in sum of squared deviations from cluster means before and after a merge, as the measure of similarity. This linkage tends to find compact spherical clusters similar to k-means clustering.
2.2.4. Simulated data results and code for hierarchical clustering
Hierarchical agglomerative clustering in
The first argument is a distance object, containing all the pairwise distances between points in the data set. This can be created using the
Figure 3 shows a colored dendrogram of the results from hierarchical clustering with average linkage. If we choose to cut the tree at three clusters, the black group is completely recovered, but the green group is almost entirely merged into the red group, resulting in a misclassification rate of 0.30. The code for implementing this is given below.
2.3. Clustering Methods Based on Finite Mixture Models
MBC, a parametric method, is based on estimating a statistical model rather than optimizing a function. The model on which MBC and LCA is based is the finite mixture model (McLachlan & Peel, 2000). Instead of modeling the data as a single population with a single distribution, the finite mixture model assumes that the population is made up of multiple subpopulations. Each of the subpopulations has an associated weight equal to its associated proportion in the whole population as well as a component-specific distribution that models the data in the subpopulation. The density for the data is then given by the following equation:
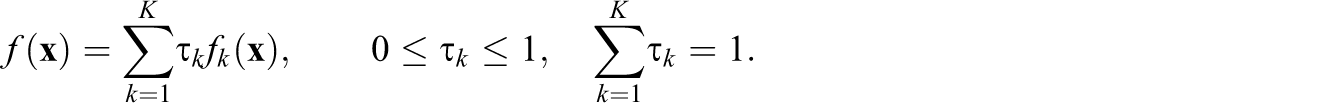
Here τ k is the kth mixing proportion equal to the proportion this component subpopulation makes up of the whole population and fk () is the kth component density. Usually, the component densities all come from the same parametric family. The expectation-maximization (EM) algorithm (Dempster, Laird, & Rubin, 1977) is used to estimate the model parameters. It is common for each component to be associated with a cluster. The probability of belonging to each component is calculated for each observation, and the observation can be assigned to the component/cluster for which it has largest probability of membership.
Often, the number of components that best fits the data is equivalent to the number of clusters present in the data, so that choosing the number of clusters becomes a model-choice problem, with different numbers of clusters/components defining a different model. The most common way to identify the best fitting number of components is to fit different models for a range of numbers of clusters, score each model, and select the model with the best score. The most common scoring measure used is the Bayesian Information Criterion (BIC; Schwarz, 1978), which can be calculated in a number of different ways. If calculated for model M as
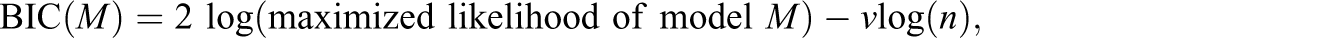
2.3.1. MBC
MBC is the common name for finite mixture model clustering for continuous data. In MBC, the component density fk is Gaussian with corresponding mean and variance estimates. That is, each component can be summarized by a mean, variance, and a mixing proportion.
2.3.2. Simulated data results and code for MBC
In MBC, the unrestricted variance matrix for component k is high dimensional and difficult to estimate, so the
The first argument for the
The three-component model with variance matrix parameterization “VVE” had the highest BIC. The
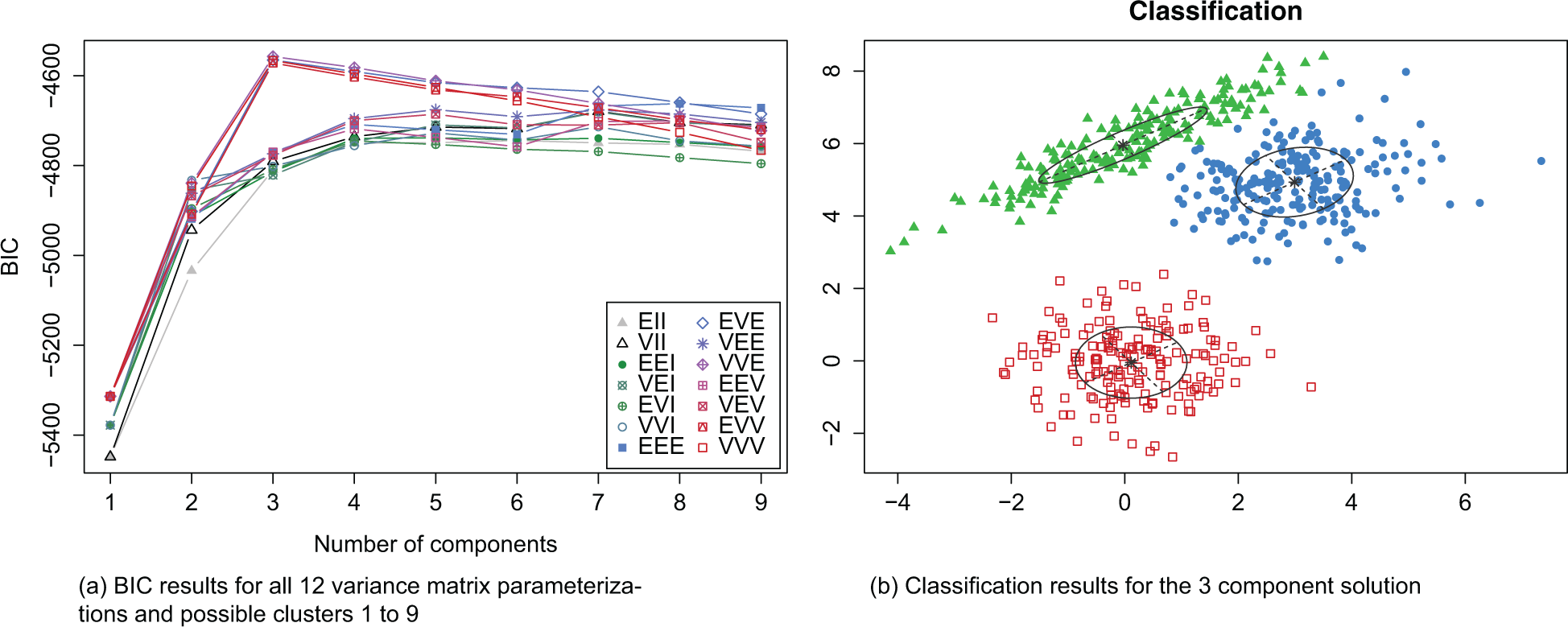
Two example plots produced by
2.3.3. LCA
LCA is the common name for finite mixture model clustering for categorical data. LCA assumes conditional independence for the variables given component membership, that is, all the variables are independent within the clusters (but not marginally independent) similar to the “XXI” models in the continuous case for MBC. Each variable within each component is modeled by a multinomial variable. Each component can be summarized using the proportions for each category in each variable (as well as the mixing proportion).
On a technical note, a necessary (but not sufficient) condition for identifiability of a G component/class/cluster LCA model to be fit to data with k variables, each having levels di , i = 1,…, k is:
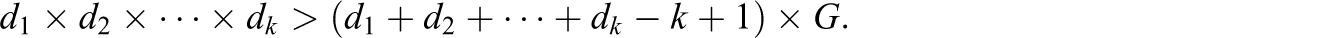
2.3.4. Simulated data results and code for LCA
In the
The first argument in the
The elbow plot illustrating the BIC results for fitting an LCA model to the discrete variables for one to four clusters is given in Figure 5. Note that lower BIC is better here. This plot suggests the use of three clusters. Because the underlying simulated groups were less defined by the discrete variables (see subsection 2.1), this model has a higher misclassification rate of
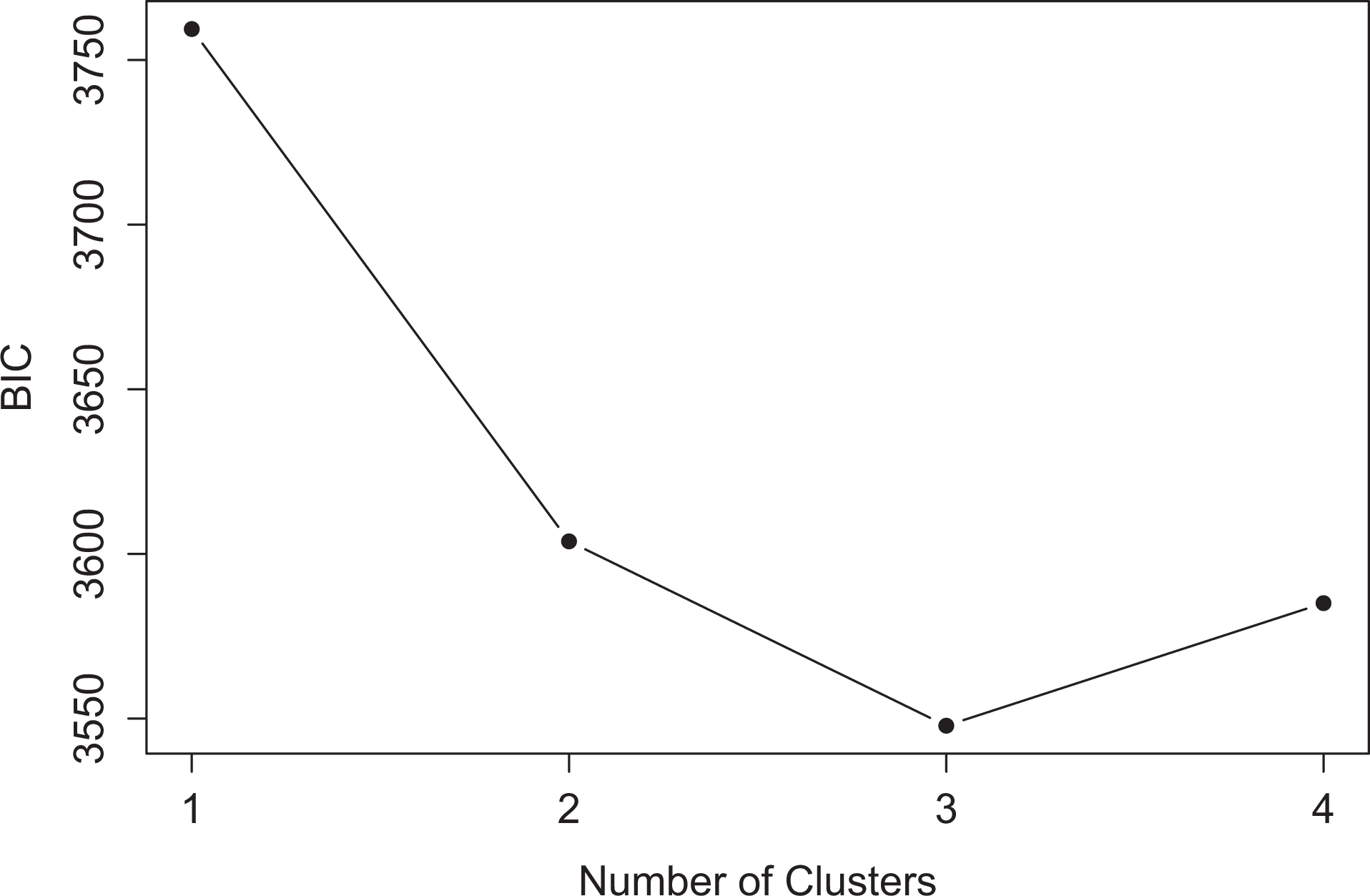
Elbow plot for
2.3.5. MBC for mixed data
The
2.3.6. Simulated data results and code for MBC for mixed data
The first argument of
The function
The model with the highest BIC (see Figure 6a) was the four-cluster solution with parameterization EEI. As seen in Figure 6b where observations are colored by their estimated cluster, this model has essentially split the original green group into two clusters and resulted in a misclassification rate of
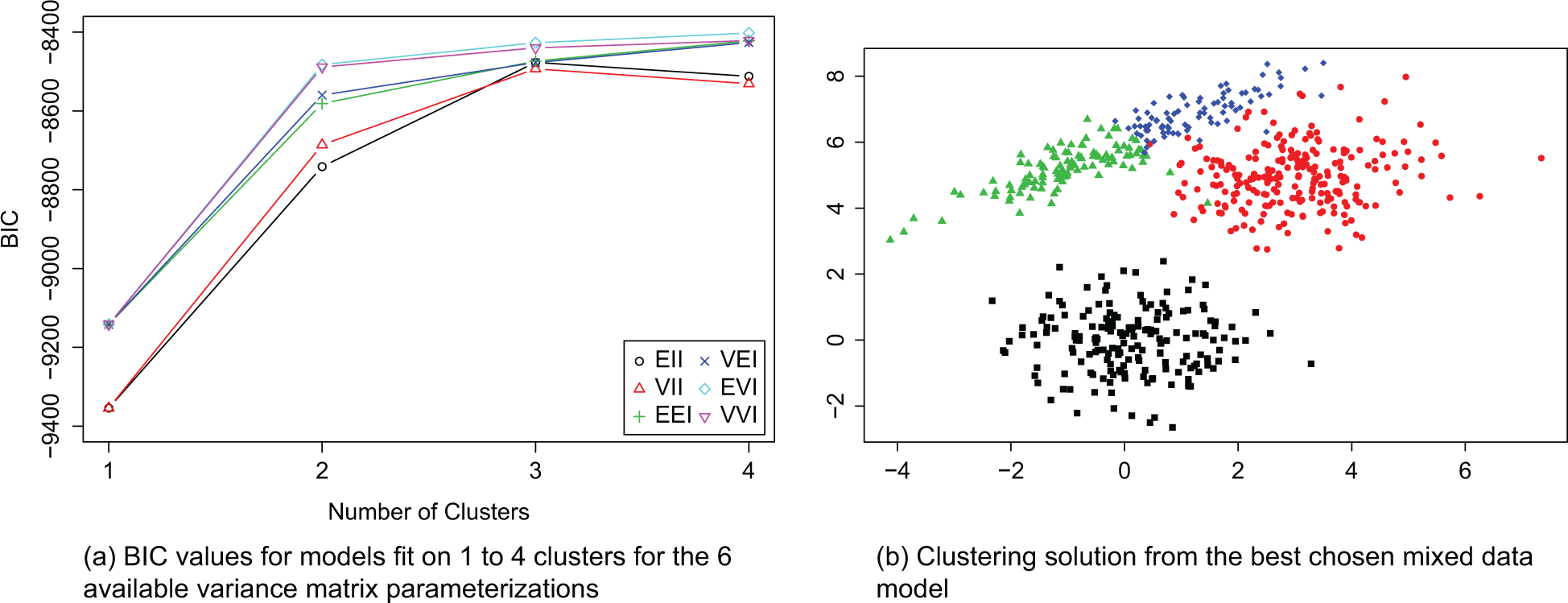
Results for
3. Discussion
As illustrated in Section 2, different clustering methods applied to the same data can produce vastly different results. It is difficult to recommend which method will work in practice since different group/data types will require different methods and it is seldom obvious a priori which is optimal. There is no one cluster method that is best in every situation, unfortunately. Cluster analysis as discussed in this article should be considered an exploratory analysis, and we recommend replicating/validating cluster results on one data set with a later data set of the same type before making any definitive statements.
In general, single linkage hierarchical clustering should really only be used for the identification of outliers because it is rarely useful otherwise. Sometimes the type of cluster solution you want should be driven by substantive reasons, rather than by the data. If one believes a genuine hierarchy of clustering solutions for the data, hierarchical clustering is then preferred. If long, elongated clusters do not make substantive sense (do you want a cluster with wide variability in one variable and not others?), then general MBC models might be avoided in favor of spherical models (like
Although a full survey of the available extensions outside of the basic models/algorithms already introduced is beyond the scope of this article, we offer references to a few popular alternatives and extensions.
3.1. Alternative Methods
An alternative to k-means that does not use the centroid as a measure of the center of the cluster but instead uses an actual central data point is called k-medoids. This is useful when you want real data points as the prototypes for the clusters found. The command for implementing this in the
Instead of agglomerative merging, it is also possible to have a divisive version of hierarchical clustering which starts with all observations in one cluster and successively splits clusters in two. This is not generally as popular as the agglomerative version, but the command
As an alternative to MBC of mixed data, one can define a distance measure on the continuous and categorical variables and apply distance methods such as hierarchical clustering (as discussed previously) if preferred. Hennig and Liao (2013) gives a good example of how to construct such a measure in a principled fashion.
3.2. Extensions
Due to space limitations, this article does not discuss extensions on clustering methodology like clusterwise regression (see the package
One of the most up-to-date resources for finding cluster analysis packages on
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.