
Abstract
Providing diagnostic feedback about growth is crucial to formative decisions such as targeted remedial instructions or interventions. This article proposed a longitudinal higher-order diagnostic classification modeling approach for measuring growth. The new modeling approach is able to provide quantitative values of overall and individual growth by constructing a multidimensional higher-order latent structure to take into account the correlations among multiple latent attributes that are examined across different occasions. In addition, potential local item dependence among anchor (or repeated) items can be taken into account. Model parameter estimation is explored in a simulation study. An empirical example is analyzed to illustrate the applications and advantages of the proposed modeling approach.
Keywords
The central topic in educational research and assessment is to measure change in student learning on different occasions (Fischer, 1995). Measuring individual growth or change relies on longitudinal data collected over multiple measures of achievement construct along the growth trajectory (Wang, Jiao, & Zhang, 2013; Wang, Kohli, & Henn, 2016). Up to now, much research concerning individual or overall changes has been conducted in fields such as developmental, educational, and applied psychology.
In recent years, cognitive diagnosis has received great attention, particularly in the areas of educational and psychological measurement (Rupp, Templin, & Henson, 2010). One of the main objectives of cognitive diagnosis is to evaluate respondents’ status of mastery or nonmastery of skills (also called “attributes”) and then it provides diagnostic feedback for teachers or clinicians to help them make decisions regarding remedial teachings or targeted interventions (Zhan, Jiao, & Liao, 2018). Several diagnostic classification models (DCMs), also known as cognitive diagnosis models, have been developed, such as the deterministic inputs, noisy “and” gate (DINA) model (Haertel, 1989; Junker & Sijtsma, 2001; Macready & Dayton, 1977) and the deterministic inputs, noisy “or” gate (DINO) model (Templin & Henson, 2006). Some general DCMs are also available (de la Torre, 2011; Henson, Templin, & Willse, 2009; von Davier, 2008). However, most DCMs are not concerned about measuring growth in terms of several possibly related attributes over multiple occasions, which could be potentially very important for remedial teaching or targeted intervention.
Unlike continuous latent variables in the item response theory (IRT) models, the attributes in DCMs are categorical (typically, binary). Therefore, the methods for modeling growth in the IRT framework may not be directly extended to capture growth in the mastery of attributes. For example, the change in the mastery of attributes may not be directly modeled by the variance–covariance-based methods (Collins & Wugalter, 1992) when assuming multiple continuous latent variables follow a multivariate normal distribution (e.g., Andrade & Tavares, 2005; von Davier, Xu, & Carstensen, 2011).
In DCMs, to account for change in attributes, Li, Cohen, Bottge, and Templin (2016) proposed a latent transition analysis (LTA; Collins & Wugalter, 1992), also known as mixed hidden (or latent) Markov model (Van de Pol & Langeheine, 1990), in combination with the DINA model in repeated measures. Likewise, Kaya and Leita (2017) combined the LTA with the DINA model and the DINO model, respectively. Such LTA-based methods provided an attribute-level transition probability matrix rather than a quantitative value of change, which was used more commonly. Additionally, it was assumed that attributes are independent and their transition probabilities are also independent. However, those independence assumptions may be tenuous as the attributes may be correlated (de la Torre & Douglas, 2004; Rupp et al., 2010). Recently, focusing on modeling learning trajectory, Wang, Yang, Culpepper, and Douglas (2018) proposed a higher-order, hidden Markov model for attribute transitions. Compared with the above two LTA-based methods, Wang et al.’s model used a set of observed and latent covariates, such as intervention indicators and a time-invariant general learning ability, to model the attribute-level transition probabilities. The correlations among attributes on the first occasion and the correlations among different transition probabilities were also accounted for. Additionally, Wang et al.’s model assumed learning trajectories to be nondecreasing. Rather than employing attribute-level hidden Markov models, Chen, Culpepper, Wang, and Douglas (2017) considered an attribute–pattern-level approach for approximating the learning trajectory space. In Chen et al.’s model, the attribute–pattern-level transition probability matrix explicitly provides the probabilities of remaining in the same pattern or changing to other patterns from one occasion to the next one. However, Chen et al.’s model assumed the transition probabilities of different attribute patterns were the same on different occasions, which were also the same for each individual.
Essentially, these transition probability-based methods analyzed the longitudinal data from the latent class modeling perspective, which can all be taken as a special case or an application of the mixture hidden Markov model (Vermunt, Tran, & Magidson, 2008). Moreover, despite the use of the repeated measures design in these studies, local item dependence among a person’s responses to the repeated items on different occasions (Cai, 2010; Paek, Park, Cai, & Chi, 2014) was not taken into account. In the IRT framework, it has been demonstrated that the local item dependence affects model parameter estimation, equating, and estimation of test reliability (e.g., Bradlow, Wainer, & Wang, 1999; Jiao, Kamata, Wang, & Jin, 2012; Jiao & Zhang, 2015; Sireci, Tissen, & Wainer, 1991; Tao & Chao, 2016; Wang & Wilson, 2005; Zhan, Wang, Wang, & Li, 2014). Similarly, in the DCM framework, if local item dependence is ignored, large estimation errors of item parameters could appear, and the correct classification rate of attributes might reduce (Zhan, Li, Wang, Bian, & Wang, 2015; Zhan, Liao, & Bian, 2018).
Additionally, Hansen (2013) proposed a longitudinal unidimensional DCM for the repeated measures when only one attribute is required on each occasion, and multiple attributes are required on different occasions. Further, a higher-order latent structural model (also known as the higher-order latent trait model; de la Torre & Douglas, 2004) is employed to account for associations among the attributes across different time points, where local item dependence among repeated items was accounted for by using additional random-effect latent variables. Although theoretically DCMs have been employed to measure multiple dimensions of latent constructs rather than a unidimensional attribute on a given occasion, this model provides insight of longitudinal analysis in diagnostic assessment from another perspective that is different from transition probability-based methods.
This study proposes a new longitudinal diagnostic classification modeling approach for measuring growth, which can be used in not only the repeated measures design but also the anchor-item design. Among numerous DCMs, the interpretability of the DINA model makes it the most popular one. Thus, in this study, the DINA model is taken as an example to illustrate the conceptualization of the proposed modeling approach. The proposed method can be easily extended to many other DCMs such as the log-linear DCM (LCDM; Henson et al., 2009) and its special cases. The rest of the article starts with a review of the DINA model with a higher-order latent structure. Then the proposed longitudinal DINA (denoted as the Long-DINA) model is presented and illustrated. Item response data from a physical achievement test was analyzed to illustrate the application of the proposed modeling approach.
Longitudinal Diagnostic Classification Modeling
DINA Model With a Higher-Order Latent Structure
Let Yni be the observed response of person n to item i. In the DINA model, the relationship among attributes and an observed response can be expressed as (DeCarlo, 2011; Rupp et al., 2010; von Davier, 2014):
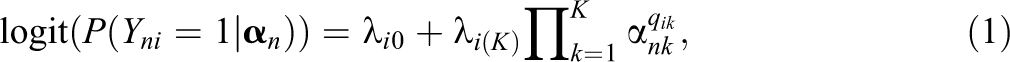
where logit(x) = log(x / (1 − x)); P(Yni = 1 |
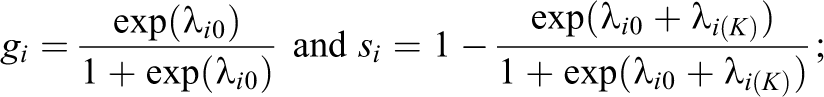
α nk is the attribute for person n on attribute k (k = 1,…, K), with α nk = 1 if person n masters attribute k, and α nk = 0 otherwise. Q-matrix (Tatsuoka, 1983) is an I × K matrix with element qi k indicating whether attribute k is required to answer item i correctly; qik = 1 if the attribute is required and 0 otherwise.
In practice, attributes in a test are often correlated. In such cases, it may be assumed that a general continuous latent ability underlies these attributes. Let α nk be person n’s attribute k and θ n be the general ability of person n. The probability of α nk = 1 conditional on θ n is defined as follows (de la Torre & Douglas, 2004):

where δ k and β k are the slope and intercept parameters of attribute k, respectively. To reduce computational burden, the attribute slope parameter δ k can be further constrained as δ k = δ, suggesting all attributes share the same slope parameter (de la Torre, Hong, & Deng, 2010), or δ k = 1 for all attributes (Ma & de la Torre, 2016), similar to the Rasch modeling.
Modeling Growth in DCMs
Basic modeling
In DCMs, attributes are typically modeled as categorical, especially binary variables. Thus, the longitudinal modeling approaches within the IRT framework such as the multivariate normal distribution strategy (e.g., von Davier et al., 2011) and the latent growth (curve) model-based strategy (e.g., Wang et al., 2016) cannot be employed directly. However, the general continuous latent trait θ in the higher-order latent structural model (Equation 2) can be an alternative.
The proposed model for two time points can be graphically presented in Figure 1; it can also be extended to more time points. The DINA model (or other DCMs) is specified as the first-order model to link the attributes of a respondent to the observed response data at each time point. Further, a second-order latent structural model is specified to determine the mastery status for attributes of the respondents. Thus, at a given time point, the first two orders represent the higher-order DINA model (Equation 2). For the proposed model, the relationship between the general latent traits measured at different time points is specified at the third order. In other words, the Long-DINA model is a multidimensional extension of the higher-order DINA model, but the multidimensionality does not refer to different general ability dimensions rather the same general ability measured at different time points. Theoretically, this third-order model utilizes both strategies for measuring individual growth, that is, the multivariate normal distribution strategy and the latent growth model-based strategy. As the repeated measures design is not always feasible in educational measurement, a more common practice of test administration over time involves multiple test forms that share anchor items. This design is called the anchor-item design such as the nonequivalent groups with anchor test design; however, it may induce local item dependence among a respondent’s responses to the same anchor items on multiple occasions. Therefore, additional random-effect latent variables or testlet effects (Bradlow et al., 1999; e.g., γ1 in Figure 1) can be introduced to account for local item dependence. The number of such random-effect variables is the same as the number of anchor items (Cai, 2010).

A graphical representation of the Long-DINA model for two time points.
First order
In Figure 1, responses Y2(1) and Y2(2) are for the same anchor item at two time points. The specific factor γ1 should be added in the first-order model to capture local item dependence. To account for local item dependence in DCMs, Hansen (2013) and Hansen, Cai, Monroe, and Li (2016) proposed a higher-order, hierarchical DCM, which can be viewed as a combination of the two-tier item factor model (Cai, 2010) and the LCDM. Like the two-tier item factor model, Hansen’s model can only account for local item dependence due to one source. Zhan, Li, Wang, Bian, and Wang (2015) proposed (within item) multidimensional testlet-effect DCMs, which simultaneously account for multiple sources of local item dependence within one item (Rijmen, 2011; Zhan et al., 2014). Multiple within-item local item dependence may be presented in assessment when testlet-based items are repeatedly used or used as anchor items (e.g., Zu & Liu, 2010). However, modeling an additional tier of specific factors could substantially increase model complexity. To simplify the proposed model, only one source of local item dependence is modeled in this study.
Following Hansen’s and Zhan et al.’s models, for a given occasion t (t = 1,…, T), the first order of the Long-DINA model can be expressed as
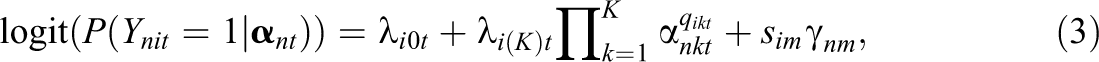
where Ynit denotes the response of person n to item i at occasion t;
Second order
In the IRT framework, the multidimensional IRT models allow for the modeling of individual growth (te Marvelde, Glas, Van Landeghem, & Van Damme, 2006). Andersen (1985) proposed a between-item multidimensional Rasch model to measure individual differences on different occasions. Embretson (1991) proposed a within-item multidimensional Rasch model for learning and change. As the between-item multidimensionality is a special case of the within-item multidimensionality, Embreton’s model can be taken as an extension of Andersen’s model (Adams, Wilson, & Wang, 1997; von Davier et al., 2011). In addition, two- and three-parameter logistic multidimensional IRT models (e.g., von Davier et al., 2011; Paek et al., 2014) can be employed in longitudinal studies.
In this study, a two-parameter logistic multidimensional higher-order latent structural model was used. For a given occasion t, the second order of the Long-DINA model can be expressed as

where θ nt is person n’s general ability on occasion t, δ kt and β kt are the slope and intercept parameters of attribute k on occasion t, respectively. θns are constrained to be independent with γns. Equation 4 is a between-attribute multidimensional model which is similar to Andersen’s model. However, the major difference between these two models is that α nkt in Equation 4 is latent, but the item response in Andersen’s model is observed. As a starting and a reference point for subsequent occasions, θ n 1 is constrained to follow a standard normal distribution, θ n1 ∼ N(0, 1), the mean values and variances of θ nt (t ≥ 2) are free to estimate. In addition, the same attributes are assumed to be measured on different occasions with the same latent construct on different occasions (Bianconcini, 2012), that is, Kt = K. Correspondingly, the slope and intercept parameters of the kth attribute are constrained to be constants across occasions, δ kt = δ k and β kt = β k . Each respondent’s general ability and attribute mastery probabilities are allowed to change over occasions.
Third order
The most straightforward and general method assumes multiple general abilities follow a T-way multivariate normal distribution. Thus, the third order of the Long-DINA model assumes that
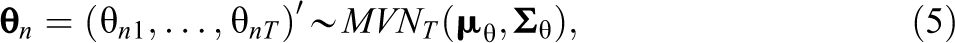
with a mean vector

where μ1 = 0 and
Rebuilt the Longitudinal Data and Longitudinal Q-Matrix
In the Long-DINA model, response data from different occasions were combined and calibrated simultaneously. Then, the longitudinal data is a
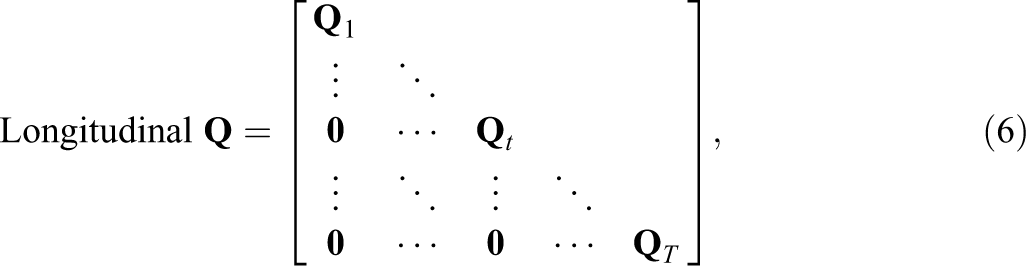
where Q
t
is the sub-Q-matrix for the test on the tth occasion. In such a case, the length of the estimated attribute pattern of each person was TK, which represented the attribute mastery status of K attributes at T occasions rather than TK attributes for each person. Correspondingly, the posterior mixing proportions were computed at each occasion separately. Further, items from different occasions should be sequentially recoded for simultaneous estimation: Items from tth occasion are recoded as
Overall and Individual Growth
Equations 3
through 6 together are the Long-DINA model. Using the Long-DINA model, both the overall and individual growth can be computed. The overall mean growth at the population level is
In the Long-DINA model, the number of estimated parameters is
Overall, as the proposed modeling approach is similar to the longitudinal IRT modeling approach, the interpretation of the proposed model is more straightforward than transition probability-based methods. The Long-DINA model uses a multidimensional higher-order latent structural model to approximate the correlations among attributes at each occasion as well as across occasions. More importantly, local item dependence among a respondent’s responses to the same anchor items on multiple occasions can be modeled in the Long-DINA model. Essentially, the Long-DINA model can be seen as a special application of the higher-order, hierarchical DCM (Hansen, Cai, Monroe, & Li, 2016) in longitudinal studies. The relationship between these two models is quite similar to that between the multidimensional IRT models and the longitudinal IRT models (e.g., te Marvelde et al., 2006).
A Simulation Study
Design and Data Generate
A simulation study was conducted to evaluate the parameter recovery of the Long-DINA model on different conditions. Three independent variables were manipulated including (a) the sample sizes (N) at two levels of 200 and 500; (b) the qualities of anchor items (QA) at two levels of high (λ i 0t = −2.197 and λ i (K)t = 4.394) and moderate (λ i 0t = −1.387 and λ i (K)t = 2.774). For the high-quality anchor items, the aberrant response (i.e., guessing and slipping) probabilities are approximately equal to 0.1, while for the moderate-quality anchor items, the aberrant response probabilities are approximately equal to 0.2. In practice, it is not common to use low-quality items as anchor items and (c) the number of occasions (T) at two levels of two and three.
Within each occasion, three attributes (Kt = 3) were measured by 20 items (It = 20), and first 4 items are used as anchor items. A condition (T = 2) of simulated test structure is presented in Figure 2 as an example. The simulated Q-matrices are presented in Figure 3. Nonanchor-item parameters were fixed at λ
i
0t = −2.197 and λ
i
(K)t = 4.394. For the general abilities, the correlations among them were set as .9. The overall mean growths were set as 0.5, and the overall scale changes were set as 1.25. Three specific dimensions were assumed to follow a standard normal distribution, and the slopes of the specific dimension were set as 0.8. In sum, the true person parameters including T general abilities and four specific dimensions were generated from a (T + 4)-way multivariate normal distribution as

A condition (T = 2) of simulated test structure in simulation study. Occasion is in parenthesis.
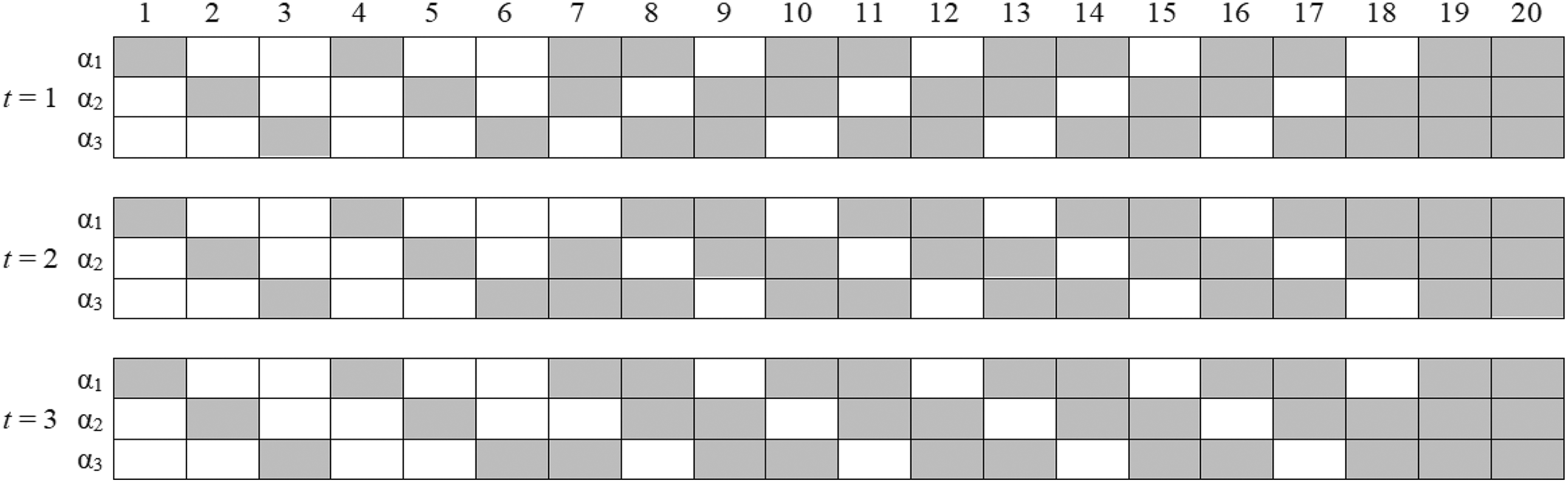
K × It Q-matrices of three occasions in the simulation study. t = tth occasion; gray = 1; blank = 0. When T = 2, only first two Q-matrices were used.
Estimation and Analysis
Response data from different occasions were combined and calibrated simultaneously. Thus, items on Occasion 2 were recoded as Items 21 through 40, and items on Occasion 3 were recoded as Items 41 through 60, accordingly. Then, for the conditions of T = 2, the longitudinal data was a N × 40 matrix, and the longitudinal Q-matrix was constructed as a 40 × 6 matrix; for the conditions of T = 3, the longitudinal data was a N × 60 matrix, and the longitudinal Q-matrix was constructed as a 60 × 9 matrix.
For the model parameter estimation, flexMIRT, version 3.5 (Cai, 2015), was used. In flexMIRT, the default Bock–Aitkin expectation maximization (EM) algorithm (Bock & Aitkin, 1981) was used for parameter estimation, and the Richardson extrapolation method was used to compute standard error. Specifically, the maximum number of cycles was set as 20,000 and 100 for the E-step and M-step, respectively; and the convergence criteria were 10−4 and 10−7 for the E-step and the M-step, respectively. Sample codes with comments are provided in the Appendix.
Thirty replications were implemented in each simulated condition. To evaluate model parameter recovery, bias and root mean square error (RMSE) were computed. The attribute correct classification rate (ACCR) and the pattern correct classification rate (PCCR) were computed to evaluate the classification accuracy of individual attributes and profiles. Additionally, the recovery of the overall mean and scale growths across different occasions were computed.
Results
Figure 4 summarizes the recovery of item parameters. First, the recovery of the intercept parameters was better than that of the interaction parameters. Further, the mean bias and mean RMSE for the study condition with a sample size of 200 were larger than those with a sample size of 500, indicating that a larger sample size led to better recovery of item parameters. In addition, the number of occasions and the quality of anchor item had little effect on the recovery of item parameters.
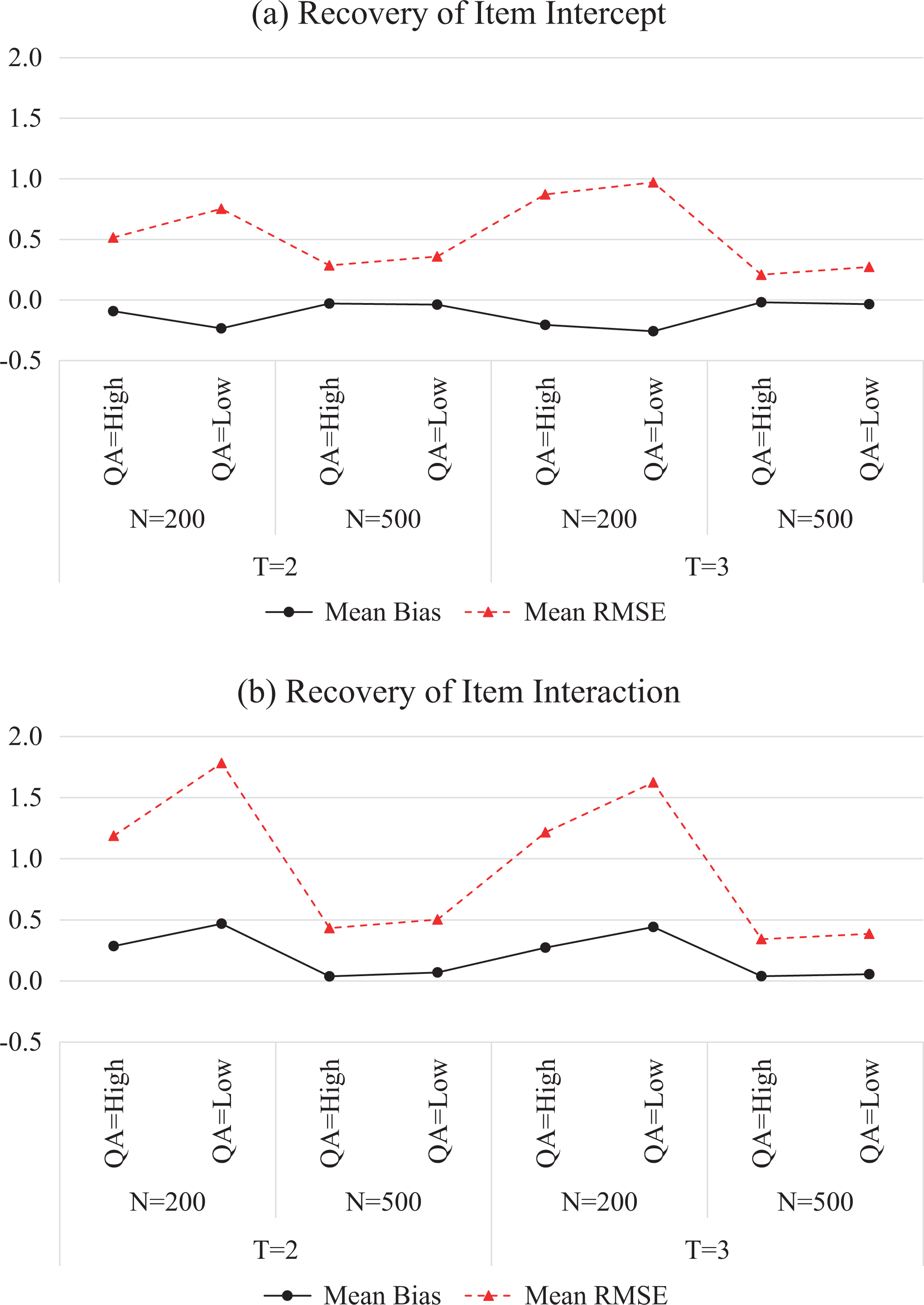
Recovery of item parameters. T = the number of occasions; N = sample size; QA = the quality of anchor item.
The recovery of attributes on different occasions is summarized in Table 1. The PCCR focuses on whether K attributes can be correctly recovered on a given occasion; in contrast, the Longitudinal PCCR focuses on whether all TK attributes can be correctly recovered. It can be found that the value of ACCR and PCCR both increased with time. According to the Longitudinal PCCR, it is evident that anchor items with high quality improved the recovery of the attributes, and it is less evident that a larger sample size improved the recovery of the attributes. In addition, the Longitudinal PCCR decreased as the number of occasions increased.
Recovery of Attributes in Different Simulation Condition
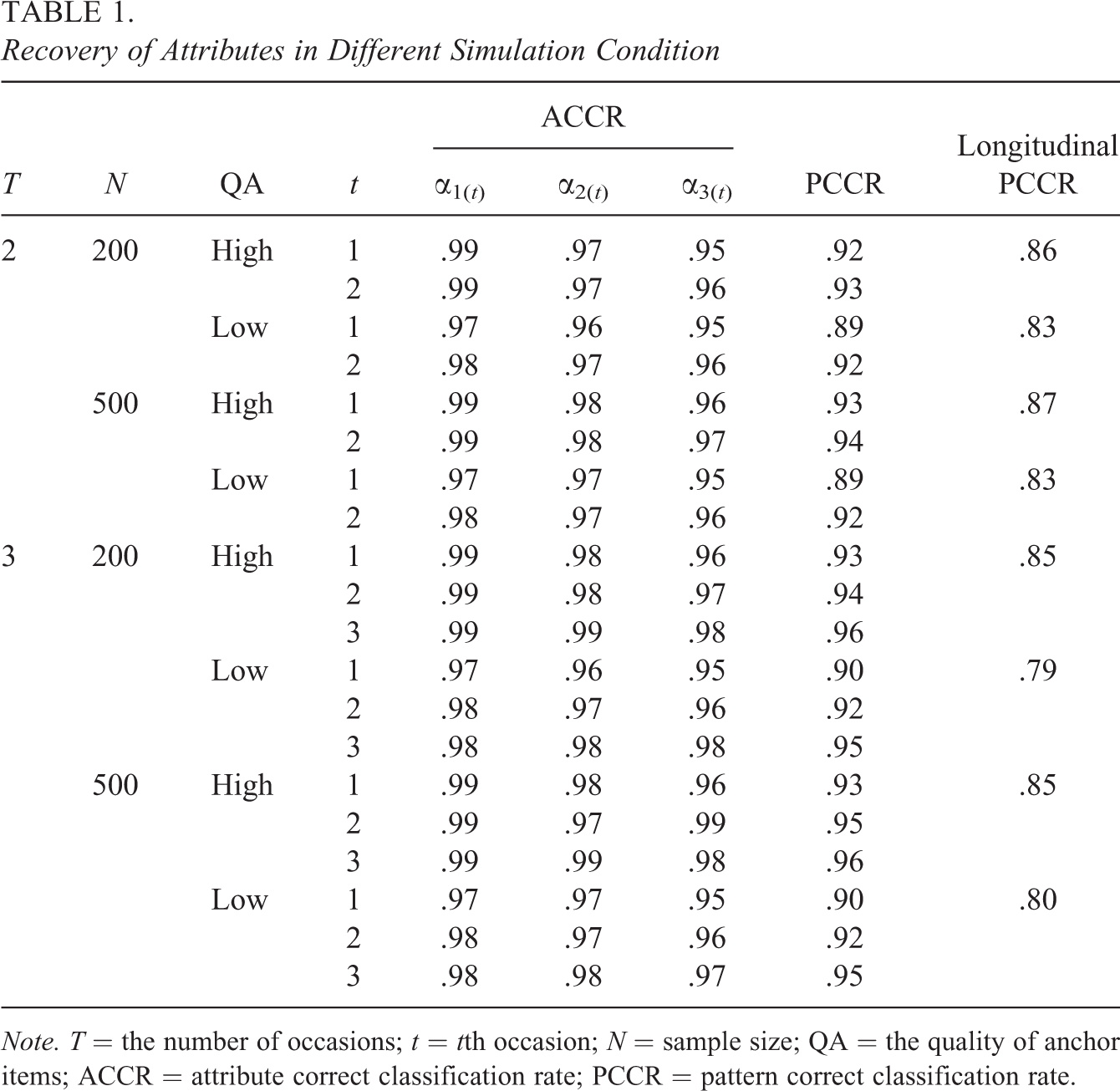
Note. T = the number of occasions; t = tth occasion; N = sample size; QA = the quality of anchor items; ACCR = attribute correct classification rate; PCCR = pattern correct classification rate.
Table 2 presents the recovery of the general abilities on different occasions. For Occasion 1, virtually all conditions resulted in similar mean absolute bias; for Occasions 2 and 3, the mean absolute bias was a little bit higher. Overall, the effects of the sample size and the quality of anchor items were not evident on the recovery of the general abilities. Further, the RMSE of θ t +1 is larger than that of θ t , which means that the accuracy in the recovery of the general abilities diminished with time.
Recovery of the General Abilities

Note. T = the number of occasions; N = sample size; QA = the quality of anchor item; AI = the number of anchor items; MA_Bias = mean absolute bias across all respondents; M_RMSE = mean RMSE across all respondents; RMSE = root mean square error.
Table 3 summarizes the recovery of the overall mean and the overall scale growth. For the overall mean growth, the bias is close to zero across all conditions; by contrast, for the overall scale growth, negative biases can be found, indicating that the Long-DINA model underestimated overall scale changes. Larger sample sizes seem to help the recovery, especially in terms of RMSE. The quality of anchor items did not evidently affect the recovery of these parameters.
Recovery of the Overall Mean Growth and the Scale Growth
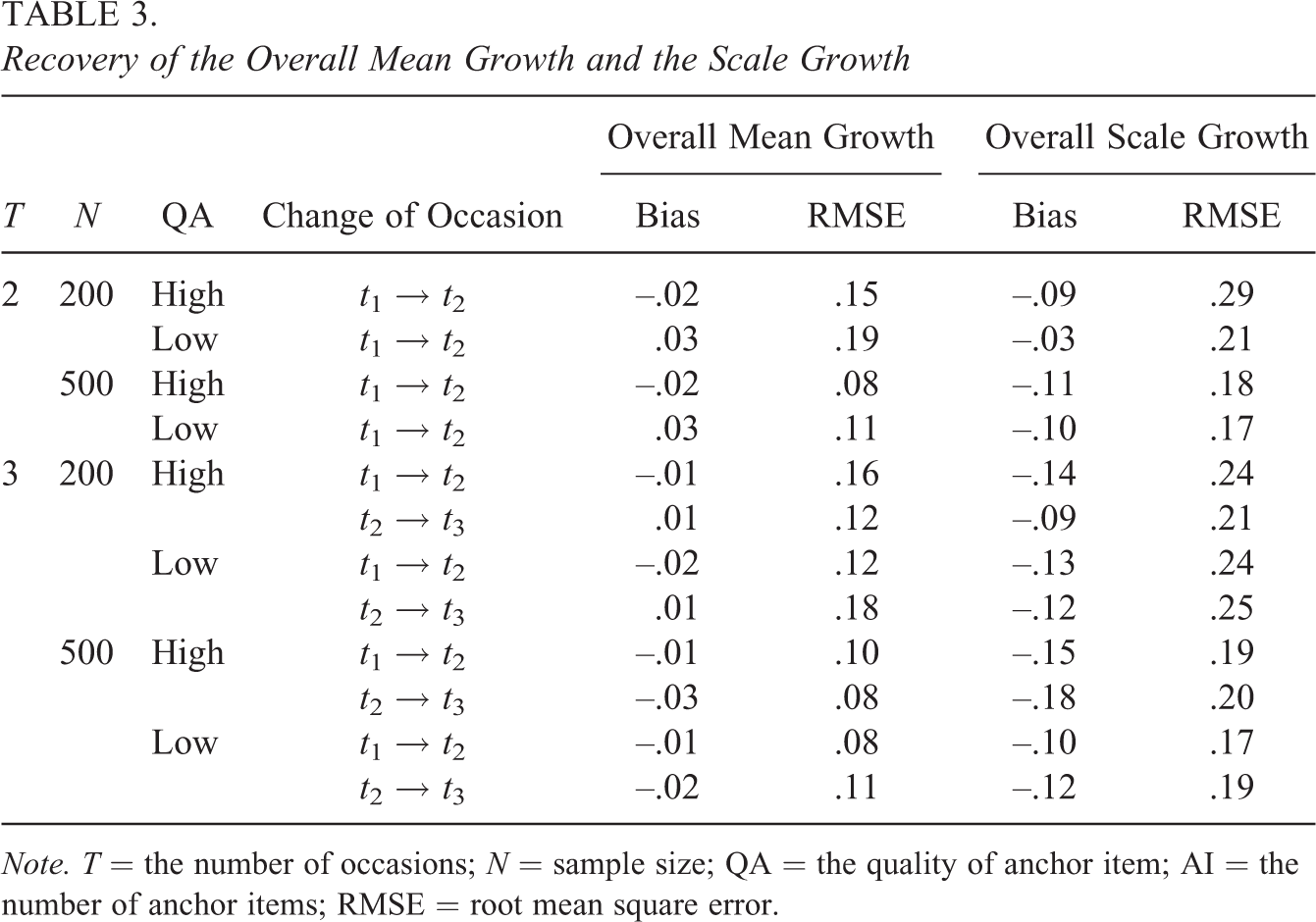
Note. T = the number of occasions; N = sample size; QA = the quality of anchor item; AI = the number of anchor items; RMSE = root mean square error.
The recovery of attribute intercept and slope parameters are presented in Figure 5. For the attribute intercepts, the bias is close to zero across all conditions, while the bias for the attribute slopes is slightly larger. Large sample sizes seem to help the recovery, especially in terms of RMSE. On the contrary, the quality of the anchor items has no evident effect on the recovery of the attribute intercept parameters.
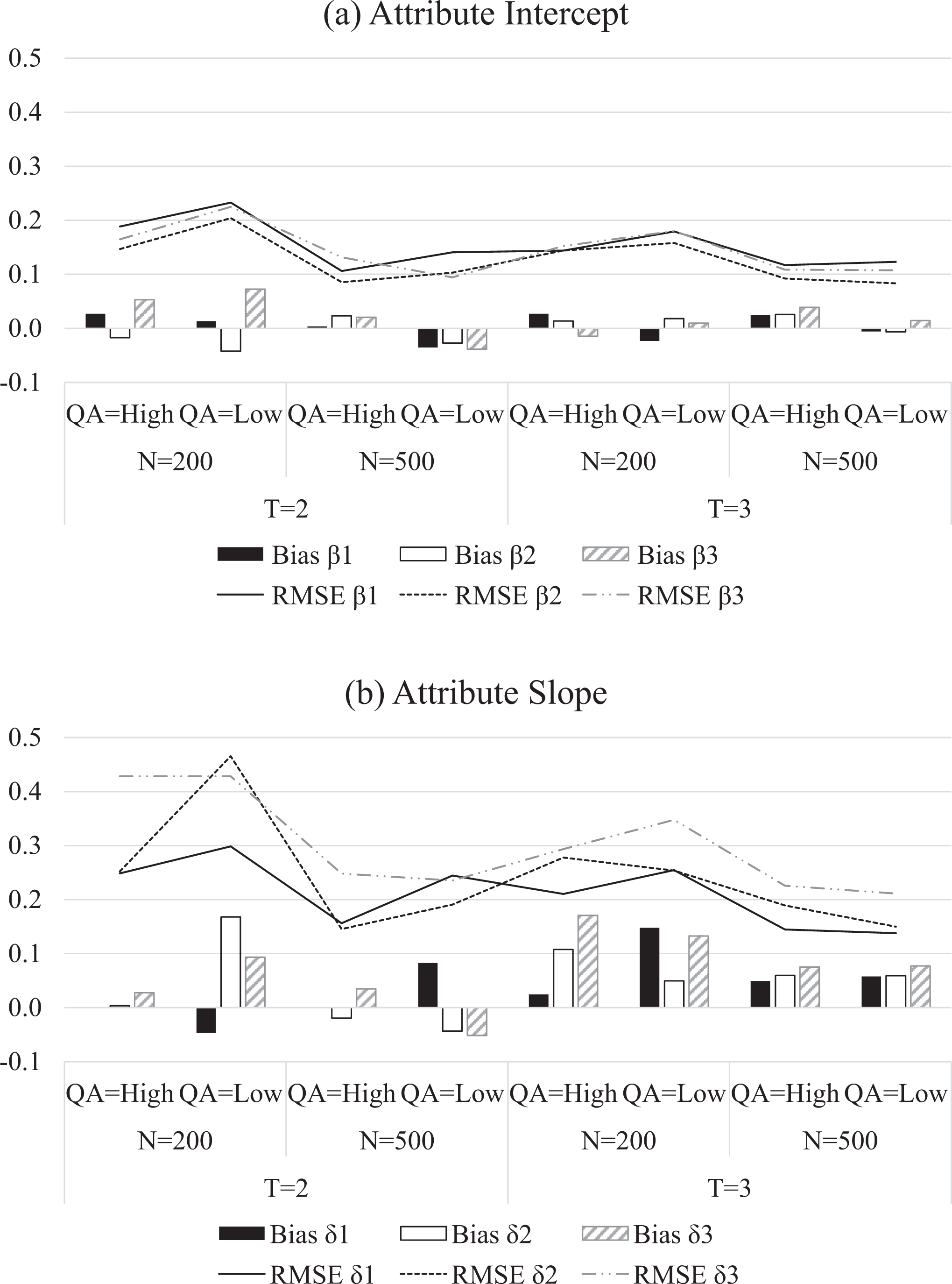
Recovery of the attribute intercept and attribute slope parameters. T = the number of occasions; N = sample size; QA = the quality of anchor item.
An Empirical Example
Data Description
Item response data from a physics achievement test about electric current and voltage were used to illustrate the application of the proposed Long-DINA model. Response data were available for three occasions. On Occasion 1, 264 eighth-grade students from seven classrooms took part in the assessment in a school in Hangzhou, Zhejiang Province, China. After 1 week, 221 students from six classrooms remained on Occasion 2. Another week later, 209 students from the same six classrooms remained on Occasion 3. Among the 209 students, seven students missed data collection on Occasion 2. Thus, 202 respondents took part in all three tests. The same four attributes were assessed by all tests, namely, electric current (α1), voltage (α2), circuit analysis (α3), and Ohm’s law (α4; resistance).
There were 17 items in the first two tests. Items 1 through 5 were dichotomous fill-in-the-blanks items, Items 6 through 15 were dichotomous multiple-choice items, and the last 2 constructed-response items were polytomously scored. Among the 20 items in the last test, Items 1 through 6 were dichotomous fill-in-the-blanks items, Items 7 through 17 were dichotomous multiple-choice items, and last 3 constructed-response items were polytomously scored. For the current study, only dichotomous items were used. Items 1, 3, 6, 7, and 8 on Occasion 1 were the same as Items 2, 5, 9, 12, and 15 on Occasion 2. Items 1 and 8 on Occasion 1 were the same as Items 5 and 16 on Occasion 3, and Items 7 and 10 on Occasion 2 were the same as Items 13 and 8 on Occasion 3. Three Q-matrices and test structure are presented in Figures 6 and 7, respectively. Students with missing responses to more than 7 items were removed, while other missing data were treated as missing at random. The final cleaned data set contained 197 students, 15 dichotomous items in the first two occasions and 17 dichotomous items on the last occasion.
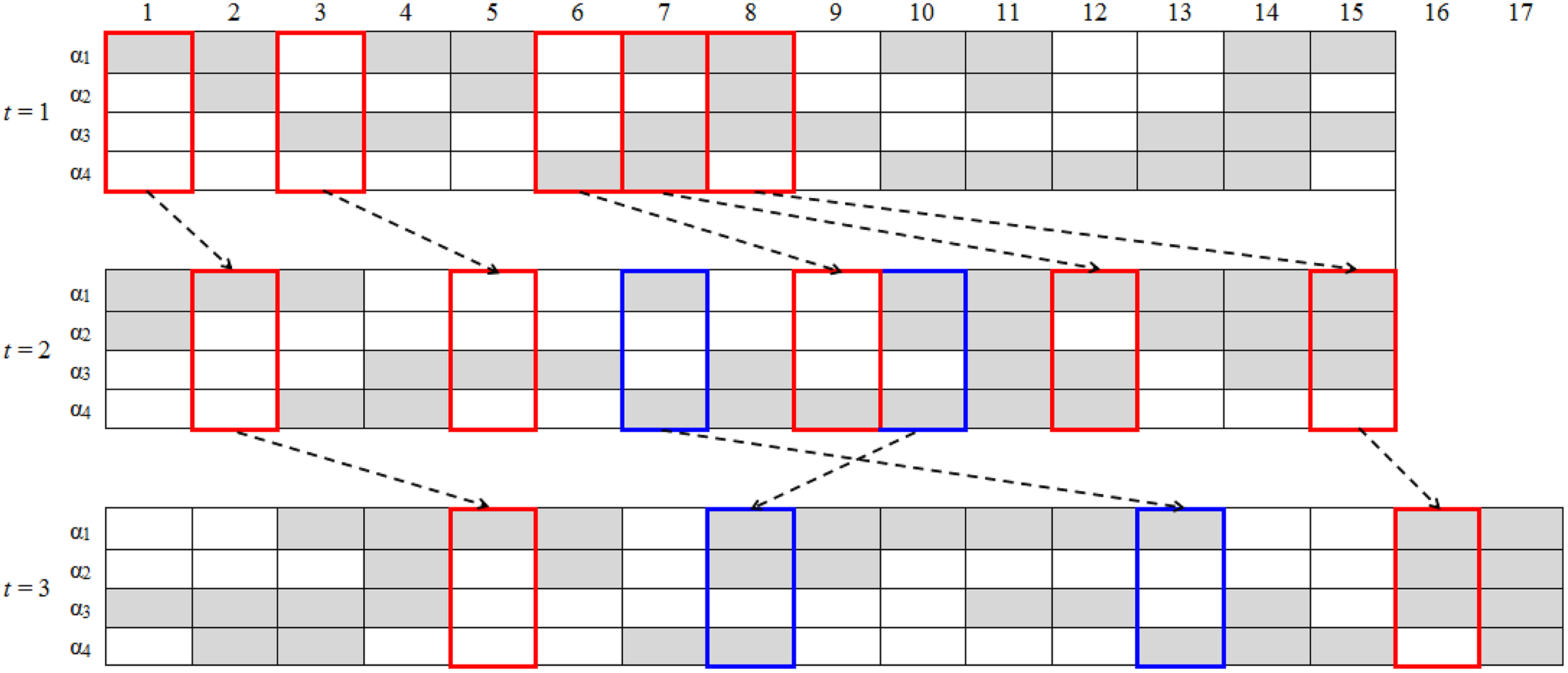
Three K × It Q-matrices for the empirical example where blank means 0, gray means 1, red or blue square represents anchor items.
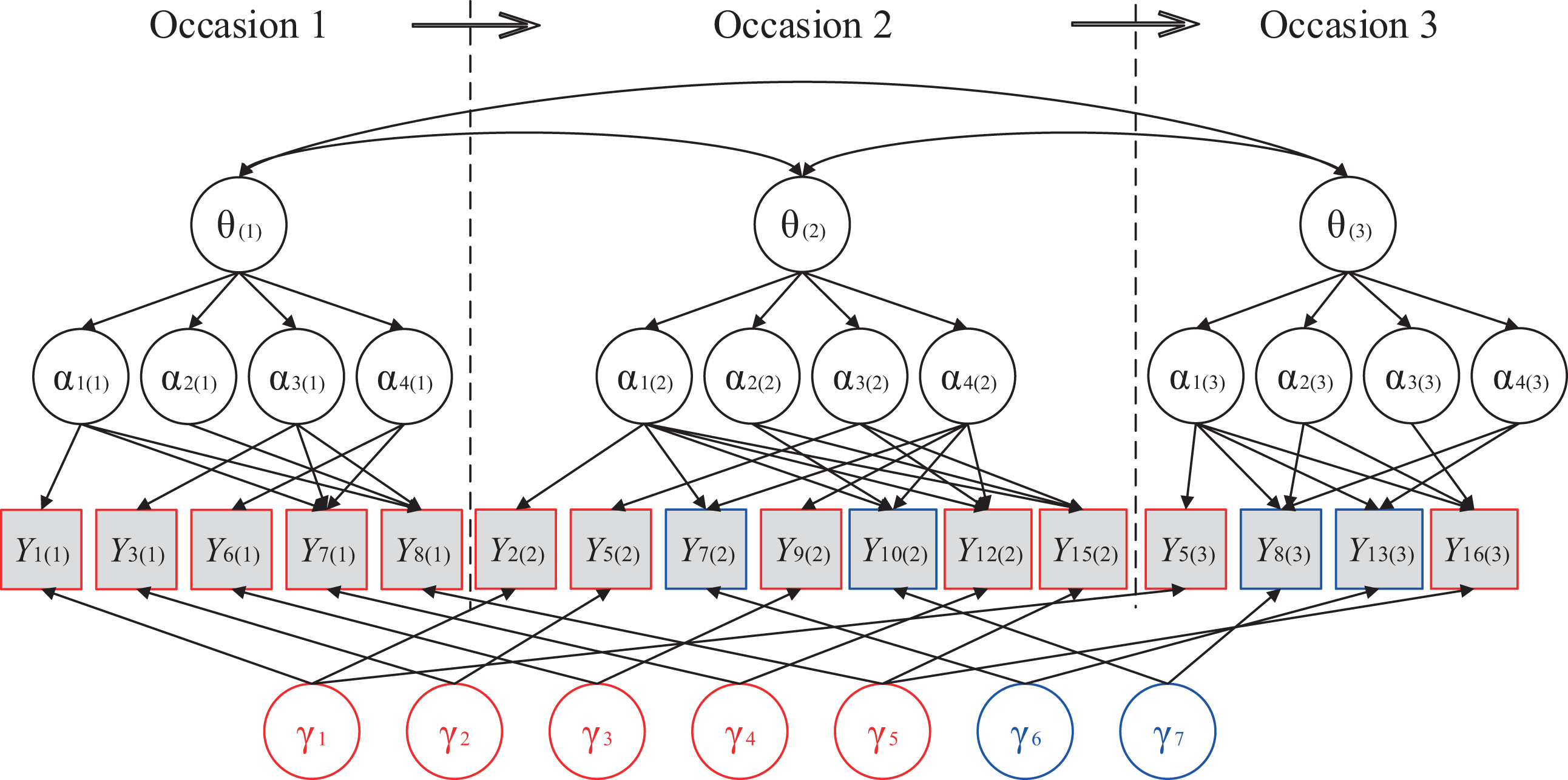
Test structure for the empirical example. Nonanchor items are omitted. Occasion is in parenthesis.
Analysis
Consistent with the simulation study, response data from different occasions were combined and calibrated simultaneously. Likewise, items on Occasion 2 were recoded as Items 16 through 30 and those on Occasion 3 were recoded as Items 31–47, accordingly. Thus, the longitudinal data was a 197 × 47 matrix and the longitudinal Q-matrix was constructed as a 47 × 12 matrix.
Two models were fitted to the data, a complete model (denoted as cLong-DINA), in which seven specific dimensions (γ1–γ7) were included for all anchor items, and a simple model (denoted as sLong-DINA) that ignored any specific dimensions. As aforementioned, θ n 1 and all γ m s were constrained to follow a standard normal distribution, and the item slopes on each γ m were constrained to be equal and need to be estimated. The M2 statistic (Hansen et al., 2016) was used to evaluate the absolute model data fit, and the Akaike information criterion (AIC; Akaike, 1974) and Bayesian information criterion (BIC; Schwarz, 1978) were computed for each model to evaluate the relative model data fit. The likelihood ratio test (i.e., ▵ −2 log-likelihood [▵ −2LL]) was also employed as the sLong-DINA model is nested within the cLong-DINA model.
Results
Table 4 presents the model data fit indexes of the compared two models. The value of M2 for the cLong-DINA model was 1,091.88, with 1,030 degrees of freedom (df), and the RMSEA based on M2 has a value of 0.02. By contrast, the value of M2 for the sLong-DINA model was 1,097.96, with 1,037 df, and the RMSEA based on M2 has a value of 0.02. Such results indicating both the cLong-DINA model and sLong-DINA model appear to provide reasonable good fit. Additionally, −2LL of cLong-DINA model is slightly better. This is expected because cLong-DINA model is more general than the sLong-DINA model. However, AIC and BIC both chose the sLong-DINA model as a better fitting model, and the likelihood ratio test also shows that the sLong-DINA model does not fit significantly worse than the cLong-DINA model (▵ −2LL = 1.61, df = 7, p > .05). The estimated sm for each specific dimension is presented in Table 5. Under the cLong-DINA model, only estimates of s1 and s3 are higher than 0.01, which means that local item dependence among the anchor items had limited impact. This may also explain why AIC and BIC tend to choose the sLong-DINA model. Thus, only the results pertain to the sLong-DINA model are discussed next.
Summary of Model Data Fit in the Empirical Example
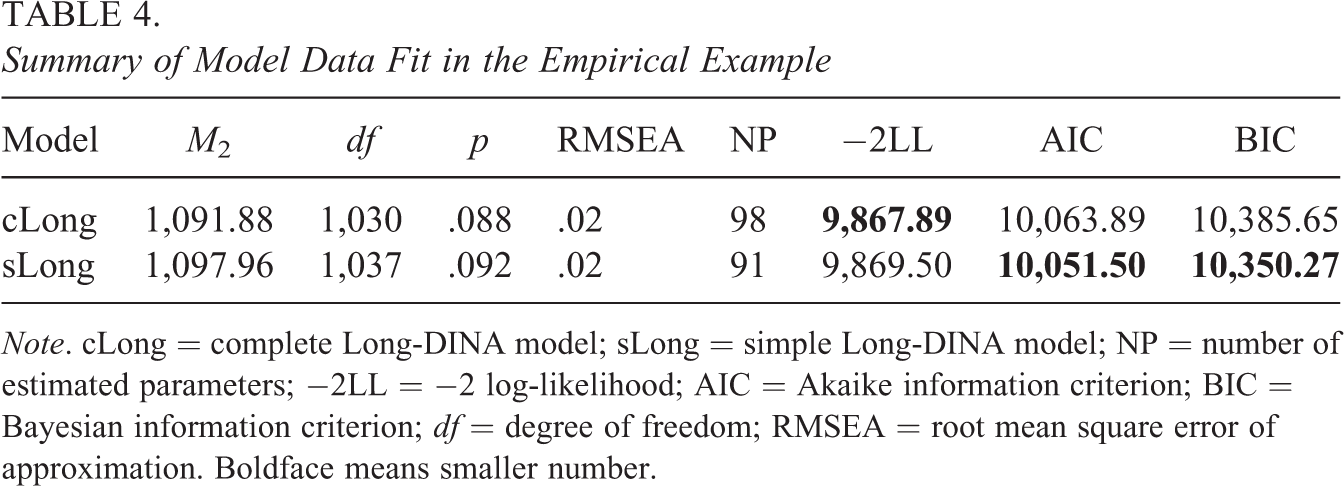
Note. cLong = complete Long-DINA model; sLong = simple Long-DINA model; NP = number of estimated parameters; −2LL = −2 log-likelihood; AIC = Akaike information criterion; BIC = Bayesian information criterion; df = degree of freedom; RMSEA = root mean square error of approximation. Boldface means smaller number.
Estimated Item Slopes of Specific Dimensions

Note. Standard error is in parentheses. cLong = complete Long-DINA model.
Figure 8 presents the overall mean and scale growth of general ability with time. The overall means are
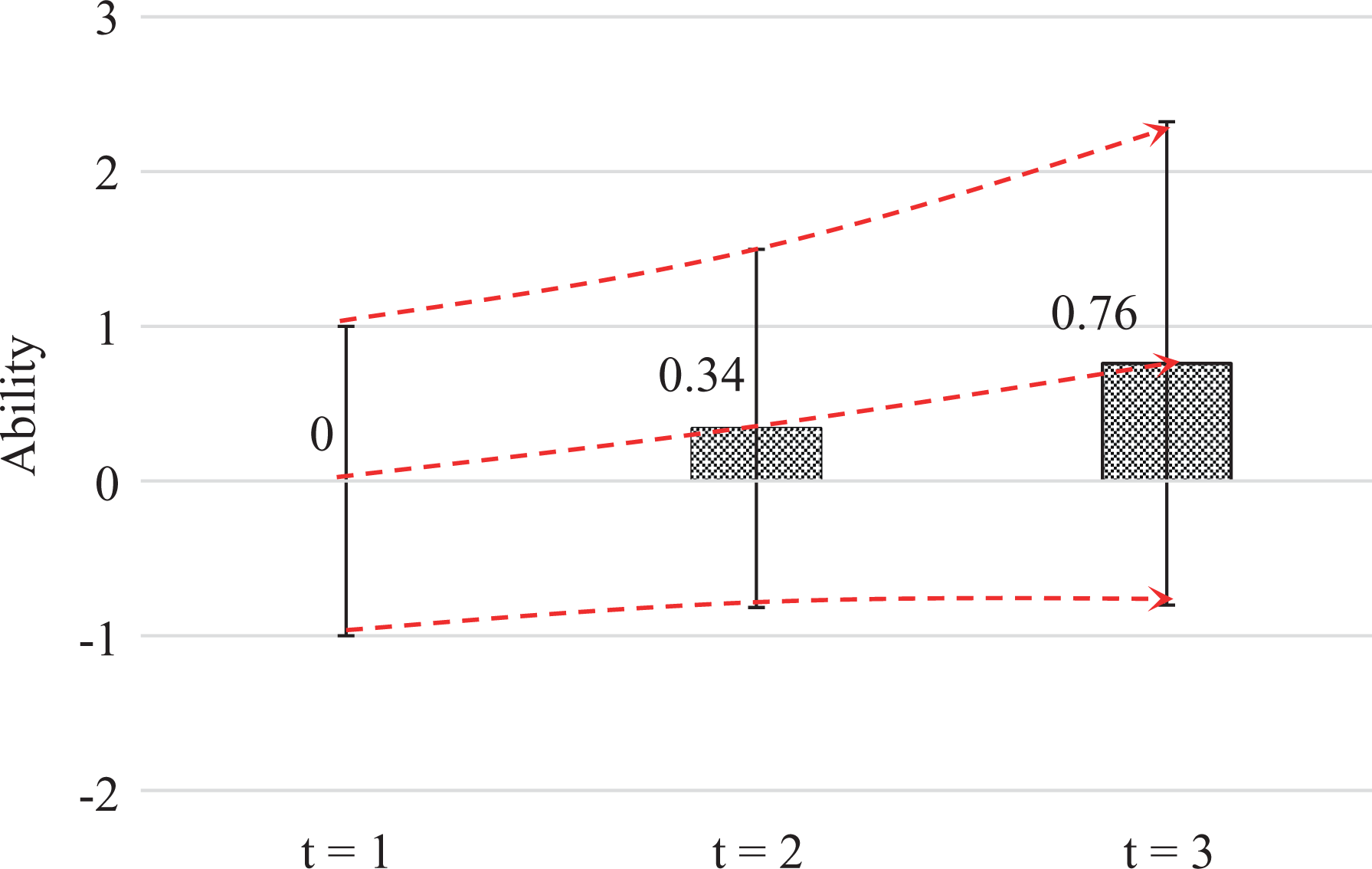
The overall mean and scale growth of the general ability with time.
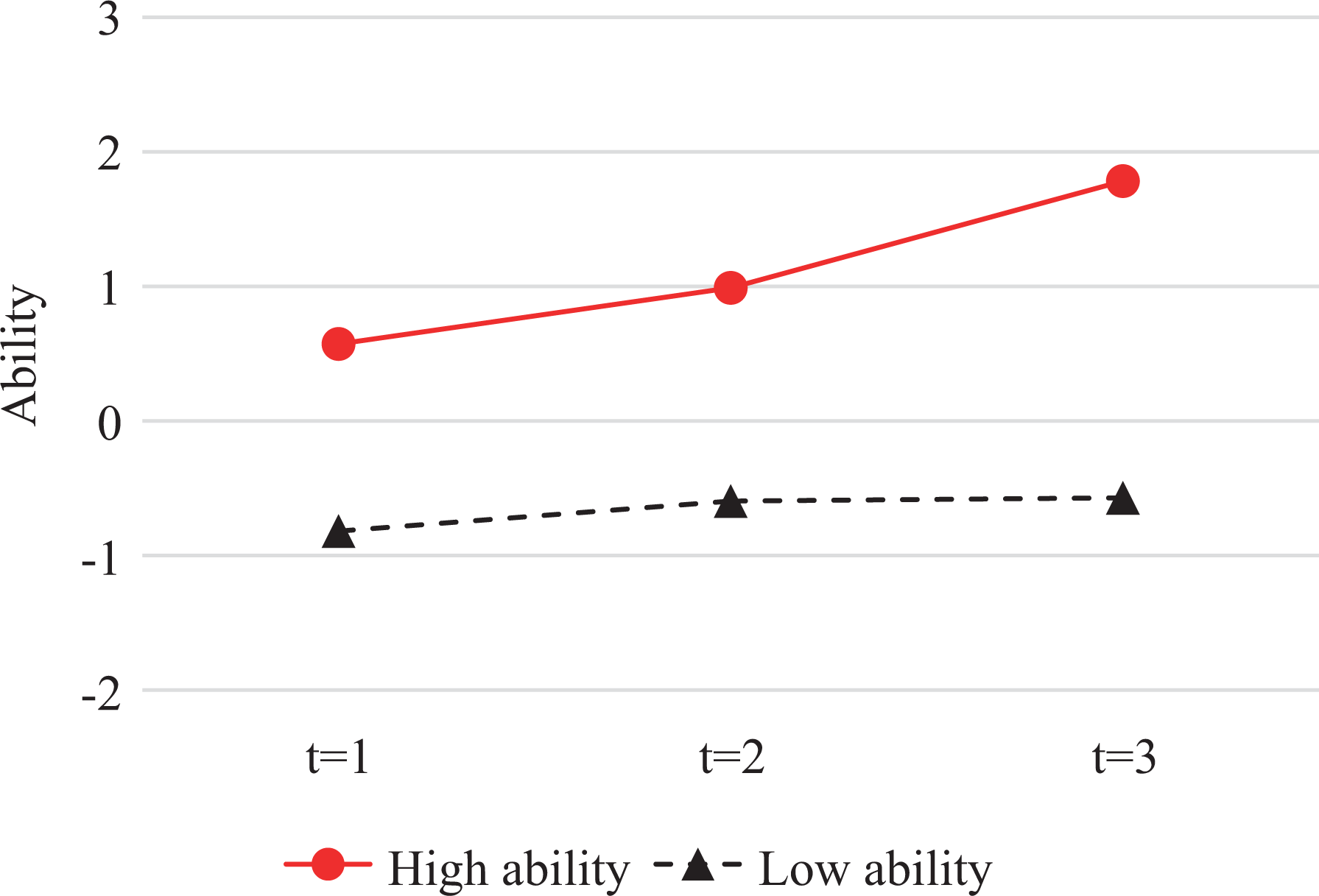
The overall mean growth of the high- and low-ability students.
Figure 10 presents the estimated overall growth of mean mastery probability across all students with time. In sum, the mean mastery possibilities of all four attributes increase with time. The mastery probability and the growth tendency of Attribute 1 are close to those of Attribute 2, and similar relationship can be found between Attributes 3 and 4. Figure 11 presents the overall change of the number of students who mastered each attribute with time. Similarly, such numbers increase with time.
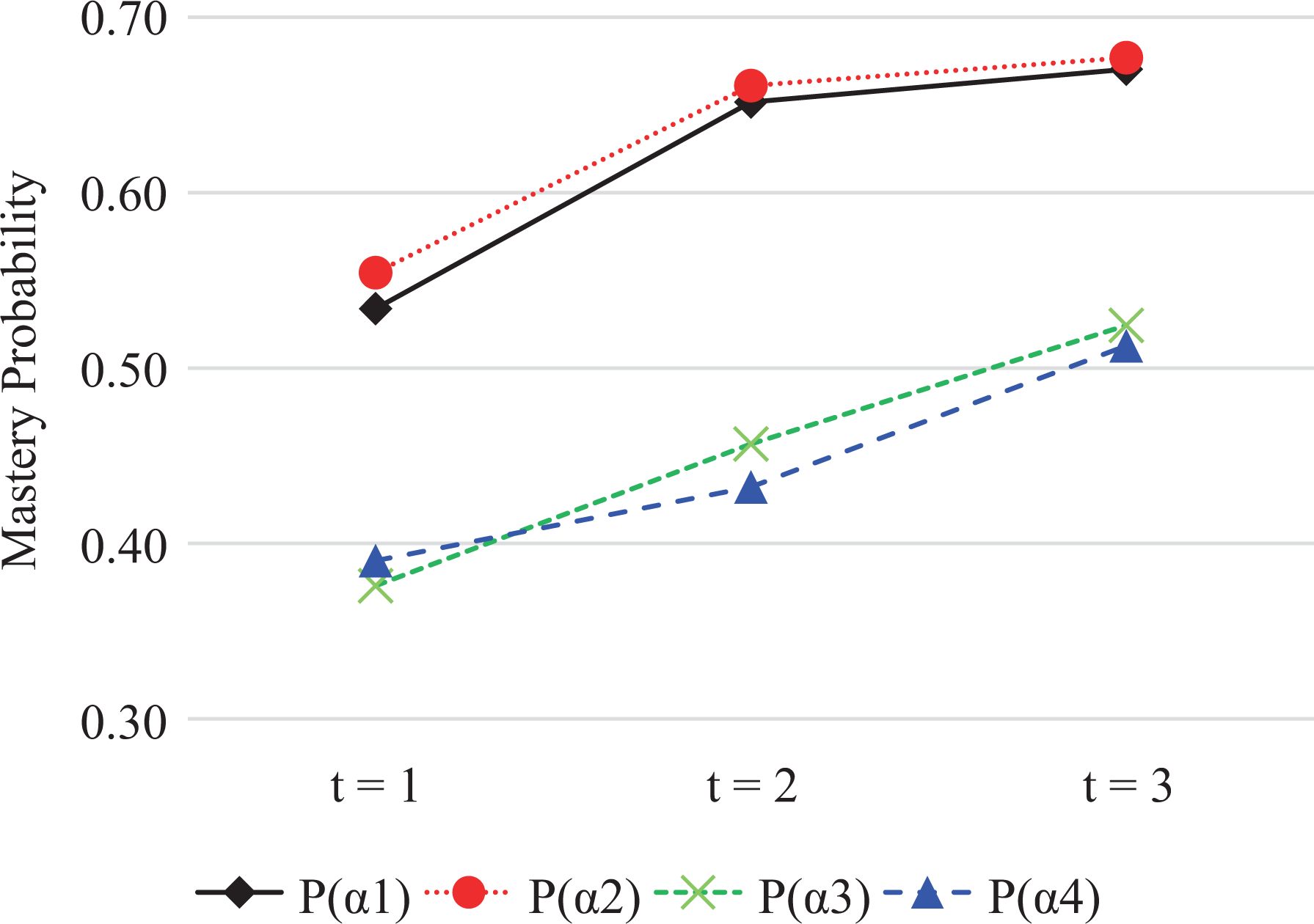
The overall growth of the mean mastery probability of each attribute with time.
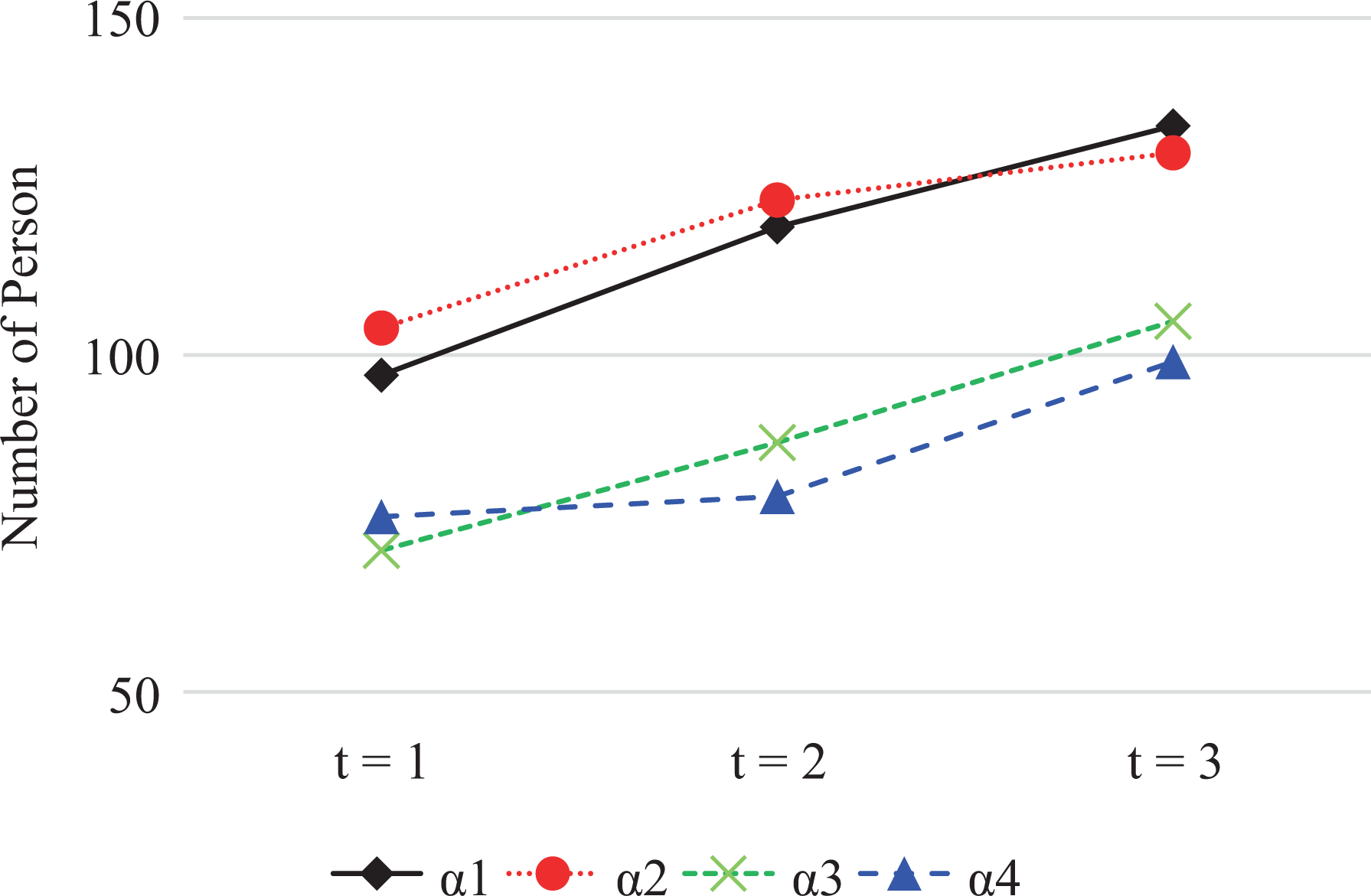
The overall growth of the number of students who mastered each attribute with time.
Table 6 presents the estimated means, variances, and covariances of the general abilities. The correlation between general Abilities 1 and 2 is 0.95, between general Abilities 1 and 3 is 0.91, and between general Abilities 2 and 3 is 0.86. High correlations may be due to the short-time intervals. In addition, the model-implied (tetrachoric) correlations among attributes are presented in Table 7, which were computed after assigning a classification of all respondents. Moderate correlations are found among attributes regardless of the number of attributes within and across occasions. Such results indicate that the LTA-based method with attribute independence assumptions may oversimplify the real-world complexity.
The Estimated Mean Vector and Variance and Covariance Matrix
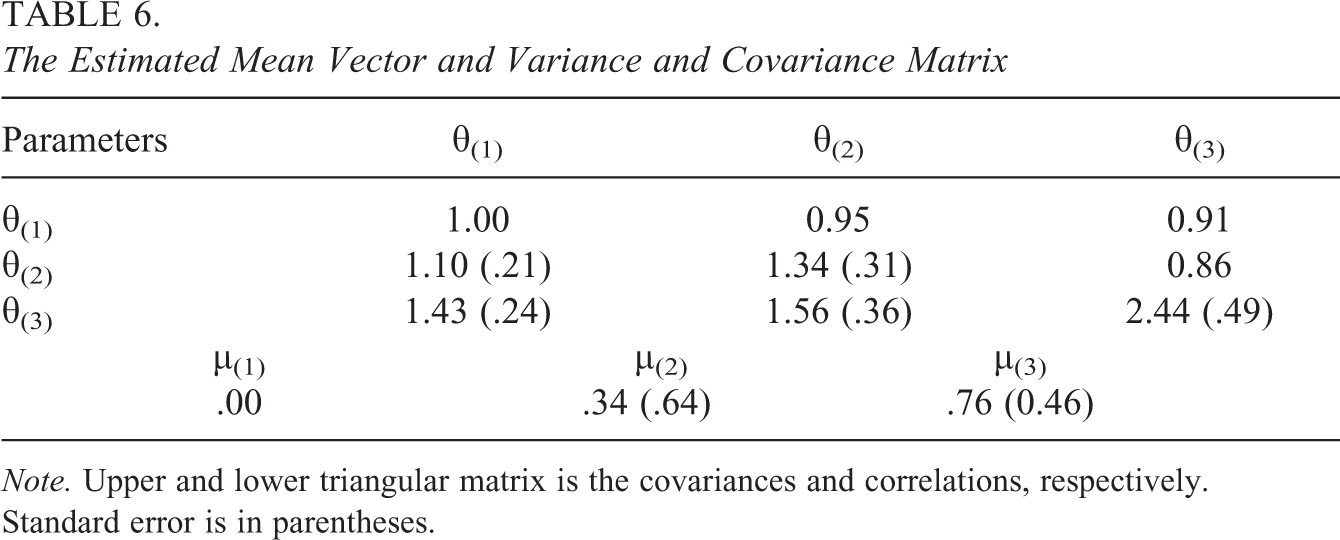
Note. Upper and lower triangular matrix is the covariances and correlations, respectively. Standard error is in parentheses.
The Model-Implied Correlation Among Attributes
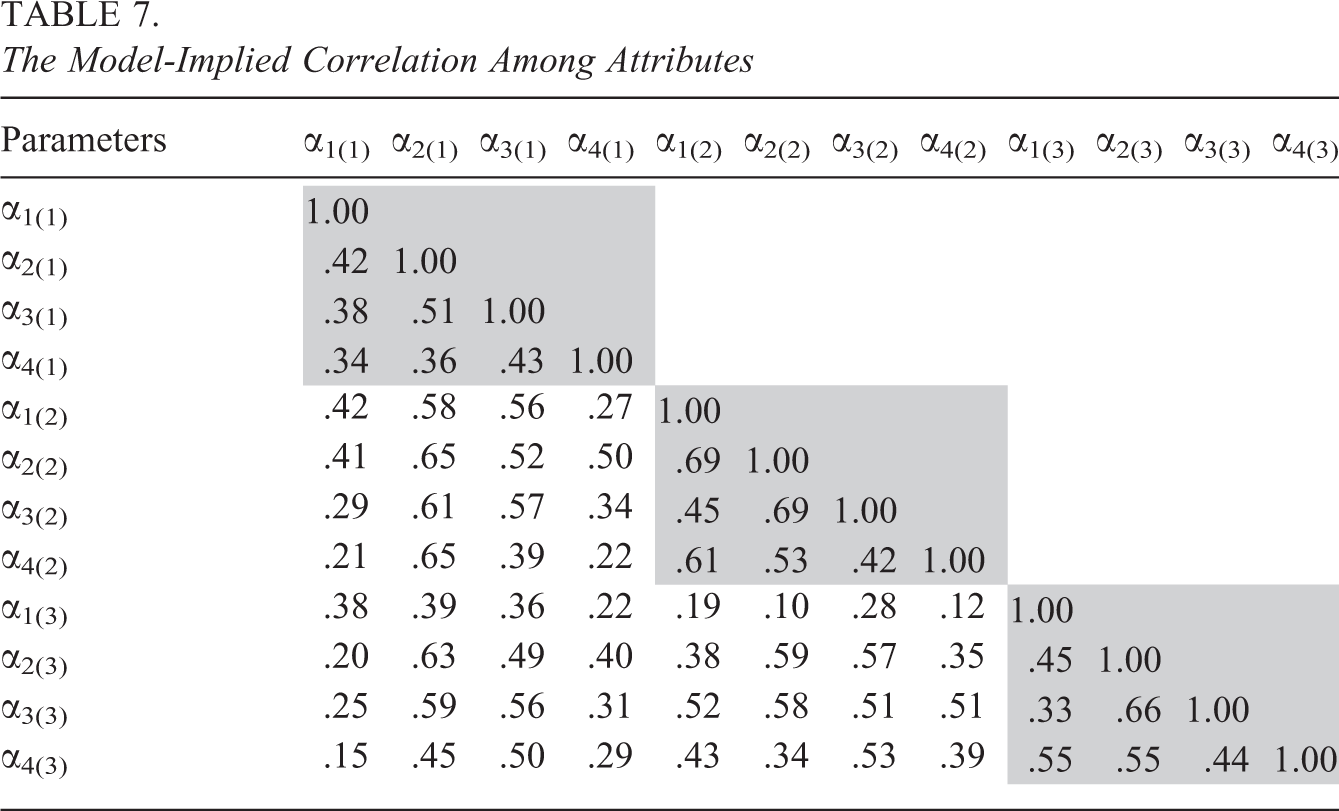
Figure 12 presents the change of the posterior mixing proportion with time. Take the (0000) and (1111) as two examples. The posterior mixing proportion of (0000) on Occasions 1, 2, and 3 is .18, .15, and .12, respectively. In contrast, the posterior mixing proportion of (1111) at Occasions 1, 2, and 3 is .14, .21, and .29. In sum, the proportion of students who master all attributes increases with time and the proportion of students who master zero attributes decreases with time.
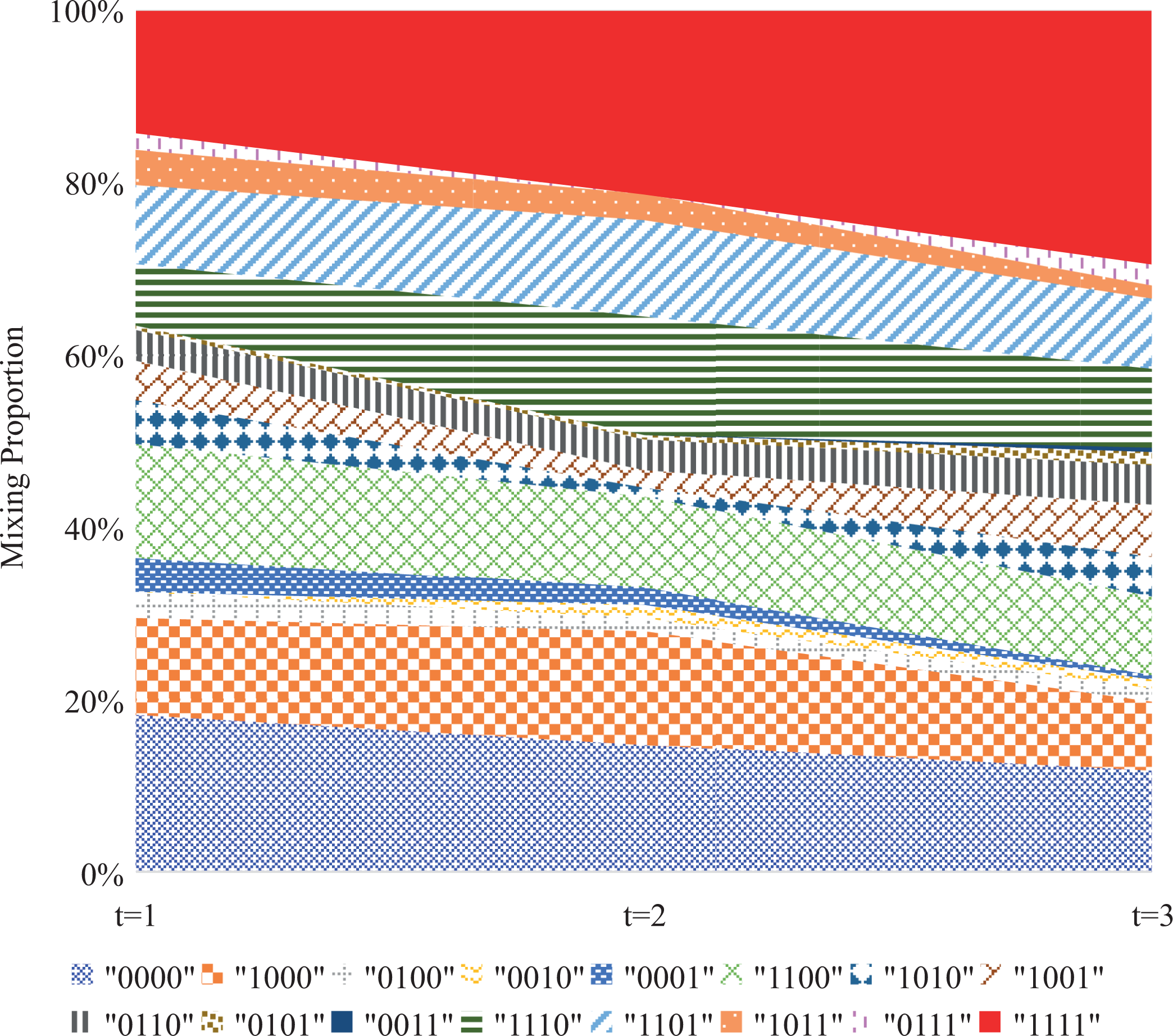
Overall change of posterior mixing proportion with time.
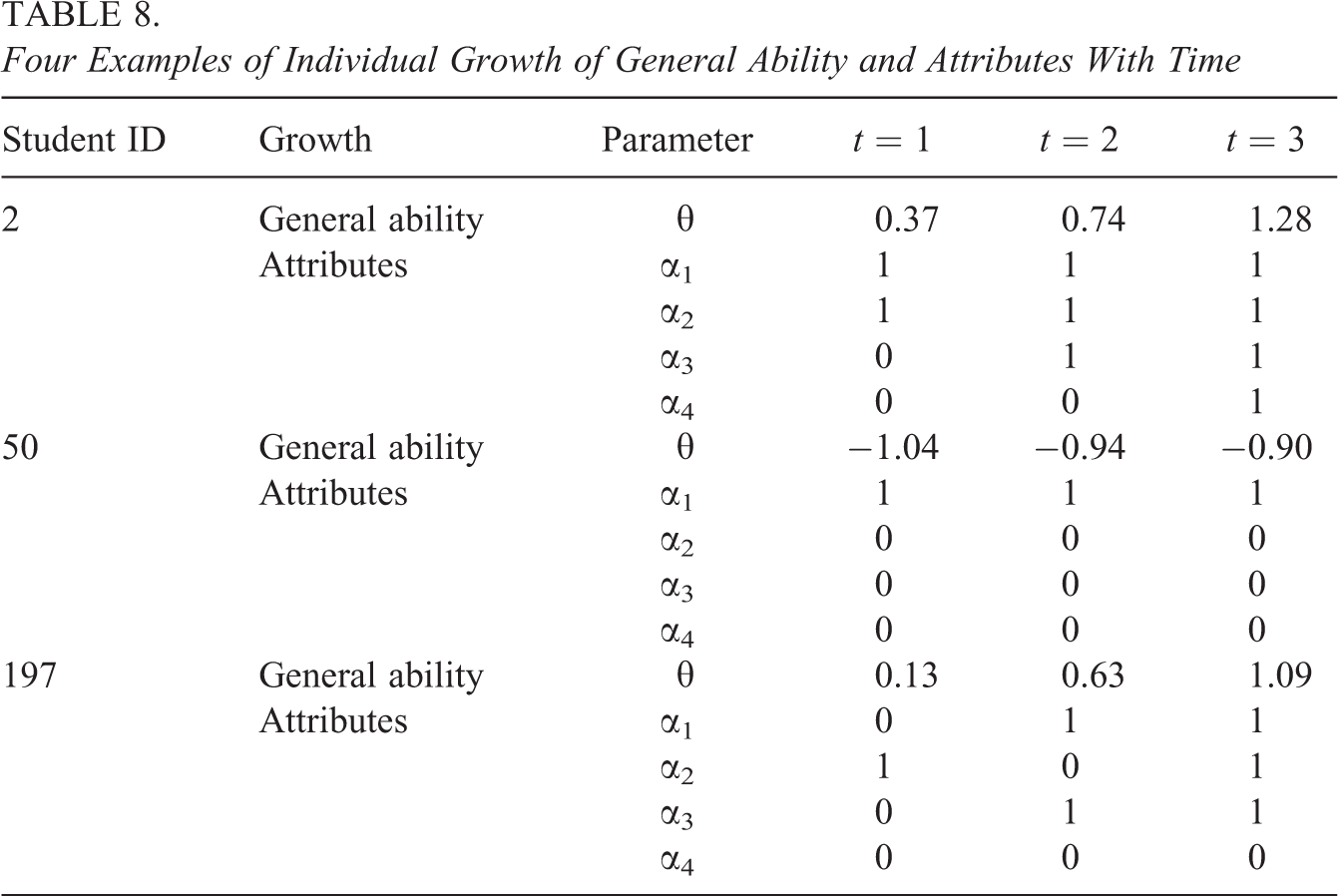
In addition to the overall growth, the growth of individuals can be analyzed by the Long-DINA model. Three examples are presented in Table 8. For student ID = 2, after twice remedial teaching, the general ability increased significantly, from 0.37 to 1.28. Similarly, the attribute mastery status all change to 1. This indicates that the remedial teaching was effective for this person. By contrast, for student ID = 50, the general ability almost kept constant on three occasions. This means that the remedial teaching was not effective for this person. Similar conclusions can be drawn for this person’s mastery of attributes. In addition, even though the general ability increased from 0.13 to 1.09, the student with an ID of 197 still has not mastered the fourth attribute after twice remedial teaching. Meanwhile, this student may have forgotten the second attribute during the second occasion.
Four Examples of Individual Growth of General Ability and Attributes With Time
Overall, the results from fitting the data to the Long-DINA model indicate that the remedial teaching was more effective for high-performing students than low-performing students. This result is consistent with the Matthew effect in education (Walberg & Tsai, 1983), which means students starting out at a higher level gain more on average than students starting at a lower level of proficiency (von Davier et al., 2011).
Conclusions and Discussions
This study proposed a longitudinal diagnostic classification modeling approach for measuring individual growth, especially for the anchor-item design (also can be used in repeated measures design). Unlike the LTA-based method, the new modeling approach estimates the overall and individual growth and simultaneously retains the advantages of the higher-order latent structure (e.g., reduction in the number of model parameters) by constructing a multidimensional higher-order latent structure to take into account the correlations among multiple attributes. Additionally, potential local item dependence among anchor items can be taken into account. An empirical example was analyzed to illustrate the application and advantages of the proposed modeling approach.
The proposed modeling approach is the first attempt to measuring individual growth in cognitive diagnostic assessments by incorporating the multidimensional higher-order latent structure. Despite the promising findings, further study is still needed. For example, (a) only a DINA-based model was employed for illustrating the modeling approach, though the proposed modeling approach can be easily extended to the LCDM and its special cases. However, the performance of the proposed modeling approach based on other DCMs still needs further investigation. (b) Currently, only the single-group situation was considered, multiple group modeling (e.g., von Davier et al., 2011) can be extended in the future. (c) Additionally, in practice, students are nested in classrooms, and classrooms are further nested in schools. Thus, multilevel modeling (e.g., Fox & Glas, 2001; Huang, 2015; Jiao & Zhang, 2015) also can be incorporated into the third order of the proposed modeling approach. (d) Furthermore, theoretically polytomous attributes (Karelitz, 2004) provide more information than dichotomous attributes in describing the growth in longitudinal studies, as the former is more refined than the latter. Although the proposed modeling approach currently focuses on binary attributes, there is no conceptual challenge in extending the idea to model polytomous attributes by using the polytomous higher-order latent structural model (Zhan, Wang, & Li, in press). (e) Detailed comparisons between other longitudinal diagnosis methods, for example, transition probability-based methods, within the same conditions could be an interesting topic in the future. (f) In our empirical example, most respondents are allocated into the patterns that master the first or the second attribute; meanwhile, less respondents are allocated into the patterns that do not master the first two attributes (see Figure 12), which means these four attributes may follow a hierarchical structure (Leighton, Gierl, & Hunka, 2004). It is meaningful and practical to explore how to apply the Long-DINA model to hierarchical attribute situations. (g) Recently, some studies focus on utilizing response time information in cognitive diagnosis (e.g., Minchen, de la Torre, & Liu, 2017; Zhan, Jiao, et al., 2018). How to incorporate response time information into the proposed longitudinal modeling approach is also an interesting topic (e.g., Wang, Zhang, Douglas, & Culpepper, 2018). (h) Parameters in the Long-DINA model also can be estimated by using the Bayesian Markov chain Monte Carlo algorithms, which can be found in a tutorial by Zhan, Jiao, and Man (2017). Finally, it should be noted that the current Long-DINA model is complicated enough, which has already lead to heavy computing burdens, especially for complex test situations (e.g., more occasions, more attributes, and more anchor items). Thus, the computing capability of computers should also be considered in further extension.
It is worthy of note that a necessary condition should be satisfied when using the proposed modeling approach, that is, the latent attributes measured by multiple tests must be invariant over time, that is, the achievement construct does not shift across occasions. Occasionally, such assumption may be violated in practice. For instance, for cognitive areas (e.g., mathematics and reading), those target dimensions may change as students’ grade levels increase (Wang & Jiao, 2009; Wang et al., 2013). In such cases, different attributes due to construct shift may be examined in multiple measures on different occasions. Therefore, the general abilities on different occasions may have different meanings (i.e., contain different target attributes). The complexity in computation and interpretation in this extension needs further exploration.
Footnotes
Appendix
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (Grant No. 31600908) and the Key Program of Educational Science Planning of Zhejiang Province, China (Grant No. 2019SB112), and the MOE (Ministry of Education in China) Project of Humanities and Social Sciences (Grant No. 19YJC190025).