
Abstract
Conventional optimal design frameworks consider a narrow range of sampling cost structures that thereby constrict their capacity to identify the most powerful and efficient designs. We relax several constraints of previous optimal design frameworks by allowing for variable sampling costs in cluster-randomized trials. The proposed framework introduces additional design considerations and has the potential to identify designs with more statistical power, even when some parameters are constrained due to immutable practical concerns. The results also suggest that the gains in efficiency introduced through the expanded framework are fairly robust to misspecifications of the expanded cost structure and concomitant design parameters (e.g., intraclass correlation coefficient). The proposed framework is implemented in the R package odr.
Keywords
The statistical power to detect treatment effects in cluster-randomized trials is, in part, governed by how the total sample size is allocated across levels of the hierarchy and treatment conditions (Bloom, 2005; Hedges & Borenstein, 2014; Kelcey et al., 2016; Liu, 2003; Spybrook et al., 2016). For instance, holding constant the total sample size, designs can achieve different levels of statistical power under different sampling plans (Hedges & Borenstein, 2014; Liu, 2003; Raudenbush, 1997). Equally, holding constant the total sample size, designs with different sampling plans may require different total costs because the costs of sampling a unit are not always equal across levels (Hedges & Borenstein, 2014; Raudenbush, 1997) and treatment conditions (Cochran, 1963; Liu, 2003; Nam, 1973).
As a result, an important first step in the design of such studies is to consider theoretical guidelines for sample allocation. Such guidelines have been typically derived from the conventional optimal design framework (e.g., Raudenbush, 1997). The conventional framework seeks to identify the sample allocation that produces the greatest statistical power to detect a treatment effect given a fixed budget by leveraging information regarding the marginal costs of sampling additional clusters and individuals (Hedges & Borenstein, 2014; Liu, 2003; Raudenbush, 1997). Implicit in this framework is the assumption that the costs of sampling additional control and treatment units are invariable.
However, prior theoretical and empirical work in the context of cluster-randomized trials suggests that the marginal costs potentially vary across treatment conditions and sampling levels. The potential for differences in costs of sampling a unit across levels in cluster-randomized trials has been recognized and modeled in previous literature (e.g., Hedges & Borenstein, 2014; Raudenbush, 1997). For example, in a classroom-randomized trial in which classrooms are the primary unit of randomization (e.g., Mosteller, 1995), recruiting one additional classroom is much harder, also more expensive, than sampling one additional student from an already sampled classroom.
The costs of sampling potentially vary between treatment conditions as well (Cochran, 1963; Liu, 2003; Nam, 1973). The marginal cost of sampling a unit in the control condition (C) includes the expenditures used to recruit and measure such a unit (e.g., business travels and work time of data collectors, incentive paid to the unit). The marginal cost of sampling a unit in the treatment condition (CT) usually includes the same marginal cost of sampling a control unit (C) plus the marginal fees associated with the delivery and implementation of interventions to this unit (CI; e.g., specialized training to become an intervention provider, work time of an intervention provider), or
There are notable examples of studies in which expenses varied across treatment conditions. Take for example the study reported by Springer et al. (2011) regarding a cluster-randomized evaluation of whether incentives in teacher performance improve student outcomes. In this study, teachers in the experimental group were eligible to receive a bonus payment of up to US$15,000 per year based on their students’ performance on tests. In contrast, teachers in the control condition carried on with business as usual. As a result, the costs of sampling each additional teacher in the experimental group typically exceed the cost associated with sampling an additional control teacher.
A similar example of differences in costs unfolded in the Tennessee class size experiment (Mosteller, 1995). This experiment evaluated the effects of student–teacher ratios on student achievements (Mosteller, 1995). Students and teachers were randomly assigned to one of three treatment conditions: regular classrooms of 22 to 25 students (the control condition), small classrooms of 13 to 17 students, and regular classrooms of 22 to 25 students assisted by a paid and trained teacher aide. In this setting, classrooms staffed with an aide are likely to incur additional costs as are smaller classrooms.
Examples of differential sampling costs among treatment conditions are not limited to classrooms and schooling. This type of cost disparity often arises in health care. For example, many community health interventions include public education messaging and activities or the general promotion of novel policies (e.g., Glynn et al., 1995) and incorporate costly trainings for health care providers (e.g., Hiscock et al., 2008). In many of these instances, the nature of an intervention and its deployment incurs marginal costs above and beyond those realized in the control condition. A study of 4-year smoking cessation community intervention includes activities of public education, training of health care providers, and promotion of policies to restrict the sale and use of tobacco (Glynn et al., 1995); another intervention is a three-session training program co-led by well child providers and a parenting expert (Hiscock et al., 2008). Some additional examples of costly interventions are 10 days of training and travels to professional development conferences (Greenleaf et al., 2011); 10 two-day on-site training sessions (Jacob et al., 2015); 4-day professional trainings with 1 day per month (Jayanthi et al., 2017).
Although sampling costs plausibly vary across treatment conditions, empirical research suggests that such cost differences are predominantly found at the cluster level where the interventions are implemented (e.g., Liu, 2003; Mosteller, 1995; Springer et al., 2011). The differences in sampling costs at the individual level, if there are any, will be relatively small comparing with the sampling costs at the cluster level.
Even the cost of sampling a unit potentially varies across levels of the design and treatment conditions, the budget functions in previous optimal design frameworks do not fully consider these variations in the cost structures of sampling, and the optimal design parameters chosen to maximize the statistical power in these frameworks are also limited. For example, in the optimal design framework developed by Raudenbush (1997) for two-level cluster-randomized trials, the budget function only considers the cost variation across levels and assumes the cost of sampling one additional individual or cluster in the experimental group is equal to that in the control group. Along with the between-treatment equal cost assumption in the budget function, the Raudenbush (1997) framework optimizes the sampling ratio across levels but not between treatment conditions. Alternatively, Liu (2003) developed a framework that allows cost variation between treatment conditions. Yet, the Liu (2003) framework does not model cost variation across levels and thus optimizes the sampling ratio between treatment conditions but not across levels.
More generally, the perspectives presented in previous frameworks (e.g., Connelly, 2003; Liu, 2003; Raudenbush, 1997; Turner et al., 2004) only partially consider the potential sampling costs of a cluster-randomized trial and optimize the sample ratio either across levels or between treatment conditions. Each of these previous frameworks present a type of constrained optimization—that is, they optimize only one of the sampling ratios across levels and between treatment conditions and constrain the another one. As a result, each of these frameworks potentially returns suboptimal sampling schemes when sampling costs vary across levels of the design and treatment conditions.
In this study, we develop an optimal sampling framework that considers the potential for variation in costs across treatment conditions and levels of the hierarchy. We consider the design of two- and three-level cluster-randomized trials and organize our study as follows. We begin with a review of the literature regarding previous optimal design frameworks. We follow with the development of a more flexible optimal design framework that relaxes the typical parameter and cost constraints for two-level cluster-randomized designs and derives optimal sample allocation across levels and treatment conditions from multiple perspectives. We then extend this framework to three-level cluster-randomized trials. We follow by detailing the relative design precision and efficiency between different sample allocations and subsequently use it to compare the results between the proposed and previous frameworks. In turn, we investigate the robustness of the proposed optimal sample scheme to the misspecification of design parameter values and cost structures. We end with a discussion.
Literature Review
For single-level experiments in which individuals are assigned at random to experimental and control groups, prior literature has developed strategies to maximize statistical power under a fixed budget by minimizing the variance of a treatment effect (Cochran, 1963; Nam, 1973). The historical framework begins with a sample size for the experimental group (nT) and the control group (nC) and assumes that the costs of sampling an individual in the experimental and control groups are nT and nC. In turn, the total cost or budget function of the study can be described as

Once the optimal ratio is identified, the total sample size is a straightforward function of the available budget (through the budget function) or power (through a power formula). Equation 1 shows that the more expensive sampling an individual in the treatment condition is, the smaller the proportion of individuals that should be assigned to the treatment condition. If there is no difference in the cost of sampling between treatment conditions (
Compared to single-level experiments that only need to identify the optimal sampling ratio between treatment conditions, cluster-randomized trials need to additionally identify optimal sampling ratio across levels. Literature on the optimal sample size allocation for two-level cluster-randomized trials has separately addressed these two facets of optimal ratio in different frameworks but has not developed expressions to optimize them simultaneously in a single framework.
For example, Raudenbush (1997) developed an optimal design framework for two-level cluster-randomized trials in which there are a total number of J clusters and n individuals in each cluster. The budget function in the framework is

where
An implicit assumption of the conventional optimal design framework (Raudenbush, 1997) is that the cost of sampling a unit in the treatment condition is equal to that of a unit in the control condition, and only balanced designs with an equal number of clusters in each treatment condition are considered. As a result, the Raudenbush (1997) framework presents a type of constrained optimal design framework in which sample allocations are constrained to designs with an equal sample size and equal sampling costs between treatment conditions. However, such constraints are potentially incongruous with other frameworks that recognize the potential for unequal sampling costs between treatment conditions (Cochran, 1963; Liu, 2003; Nam, 1973) and potentially restrictive in practice (e.g., Greenleaf et al., 2011; Jacob et al., 2015; Mosteller, 1995; Springer et al., 2011) because they limit researchers abilities to identify the sample size allocation that produces the greatest statistical power under a fixed budget.
Liu (2003) relaxed the between-treatment equal cost assumption and the constraint of balanced designs in the Raudenbush (1997) framework and shifted the optimal design in multilevel experiments back to the optimal sample size ratio between treatment conditions in single-level experiments. However, by allowing sampling costs to vary between treatment conditions and considering unbalanced designs, the Liu (2003) framework omitted the optimization of sample size ratio across levels. More specifically, under this framework, a unitary total cost for sampling an additional cluster and its individuals is considered but that total cost is allowed to differ by treatment condition.
For instance, presume that the combined cost of sampling an additional cluster together with its individuals in the treatment and control groups are CT and C, respectively. The budget function is
Under this scenario, Liu (2003) derived the optimal sampling ratio between treatment conditions as

Although the work by Liu (2003) widened the scope and flexibility of cost structures and is consistent with earlier literature (Cochran, 1963; Nam, 1973), it did not model the cost variation across levels and retained constraints on the sample allocation across levels. Thus, the resulting framework presents a type of constrained optimal design, which often results in suboptimal sample allocation.
The Raudenbush (1997) framework has also been extended to three-level cluster-randomized trials with the same between-treatment equal cost assumption and the balanced-design constraint (Hedges & Borenstein, 2014; Konstantopoulos, 2009, 2011; Moerbeek et al., 2000). Suppose K is the total number of level-three clusters, n and J are the sample sizes per level-two and level-three unit, respectively. The budget function is
Given the above budget function, the optimal sample allocation across levels in a three-level cluster-randomized trial (Hedges & Borenstein, 2014; Konstantopoulos, 2009, 2011; Moerbeek et al., 2000) as
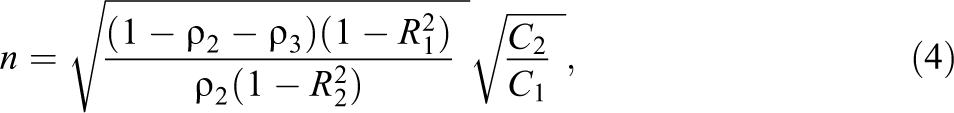
and

where
More specifically, by omitting the top-level units, a three-level cluster-randomized trial conceptually reduces to a two-level cluster-randomized trial with an (pseudo) intraclass correlation coefficient of
Optimal Sample Allocation in Two-Level Cluster-Randomized Trials
We first develop our framework within the context of two-level cluster-randomized trials. We begin with an assumption that sets the individual-level sample sizes to be equal between treatment conditions (i.e.,
Models
Assuming a cluster-randomized design, we let the number of sampled individuals in each cluster be n, the number of total sampled clusters be J, and the proportion of clusters to be assigned to the treatment condition be p with
We present the analytic models in the format of multilevel linear models, and the individual-level model is
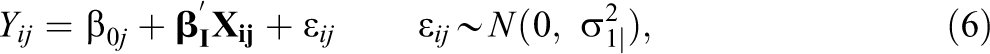
where
Similarly, the cluster-level model is
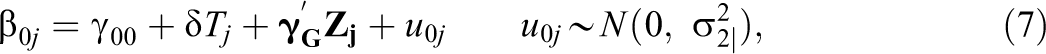
where

If we standardize the outcome to have a variance of one in a population, the treatment effect (
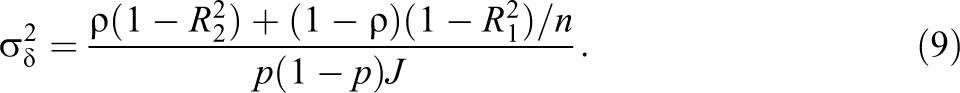
When the null hypothesis is false (i.e.,

The statistical power at the significance level
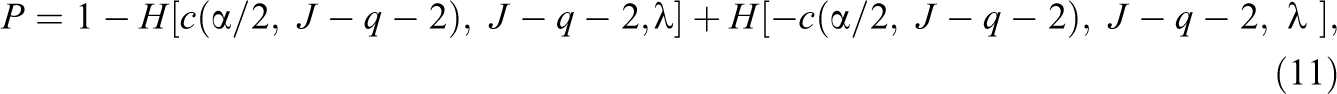
where
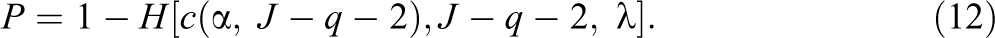
Method
The intersection of the optimal design frameworks presented by Raudenbush (1997) and others (Cochran, 1963; Liu, 2003; Nam, 1973), with the cost structures often observed in multilevel studies (e.g., Tennessee class size experiment; Mosteller, 1995), suggests another prospect—the budget function should let the cost of sampling vary across both levels of the hierarchy and treatment conditions. For this reason, we integrate these frameworks to develop a more flexible framework with potentially more realistic cost structures. In this extended framework, we first assign c1 as the cost of enrolling each additional individual within a cluster in the control condition and
Thus, the budget function is
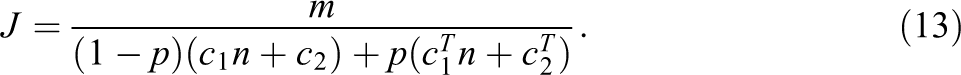
Substituting J in Equation 13 to Equation 9, we can rewrite the variance of the treatment effect as

Optimal Sample Allocation
We can derive optimal sample size allocation from several different but linked perspectives, including minimizing the variance of the treatment effect under a fixed budget, minimizing the budget requested to achieve a fixed variance of the treatment effect, and maximizing the noncentrality parameter
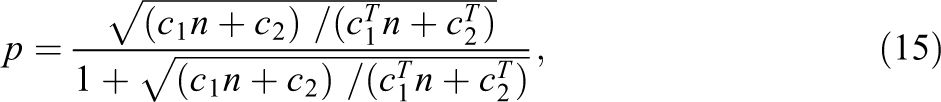

The above expressions can be used to identify the optimal sampling ratio across levels and treatment conditions. There are no simple closed form solutions to the roots of p and n in Equations 15 and 16. We can numerically solve the roots by (1) initiating random values for n (e.g., sample one integer of
Similar to the results of prior frameworks, the results indicate that the optimal p and optimal n are not a function of total budget m but rather are driven by the relative cost structure of sampling. Only the total number of clusters J is impacted by the total budget through Equation 13. The optimal p is driven by the control/treatment cost ratio of sampling a cluster and its individuals
The optimal n in Equation 16 is driven by two factors. The first factor is the square root of conditional variance ratio between levels
The second factor is the square root of the weighted sampling cost ratio between levels, with the proportion of clusters assigned to the experimental group as the weight
Constrained Optimal Sample Allocation and Relations to Previous Frameworks
There are practical considerations that may limit the use of optimal sample allocation (Hedges & Borenstein, 2014). For example, many classrooms have an upper limit of about 20 to 30 students, and this may constitute a common constraint in classroom-based designs. We probe several such constraints in p and n in order to (a) delineate the conditions under which the proposed framework reduces to previous frameworks and (b) outline the flexibility of the proposed framework.
Constrained p
Suppose the constrained proportion of clusters to be assigned to the treatment condition is p0 (i.e.,
Constrained n
Suppose the constrained individual-level sample size is n0 (i.e.,
Optimal Sample Allocation in Three-Level Cluster-Randomized Trials
Similar to those for two-level cluster-randomized trials, the potential gains in design efficiency and/or statistical power in three-level cluster-randomized trials can mostly be achieved by optimizing sampling ratios between treatment conditions and among levels. We subsequently present the optimal sample allocation with the constraint of equal sample sizes at the individual and subcluster levels (i.e.,
Models
Suppose a three-level cluster sampling design has a total number of K clusters (level-three units) with
When the sample size per (sub-)cluster does not vary across (sub-)clusters within each treatment condition, we can estimate the treatment effect using ordinary least squares or multilevel linear models (Raudenbush & Bryk, 2002). Under the multilevel formulation, the level-one model is
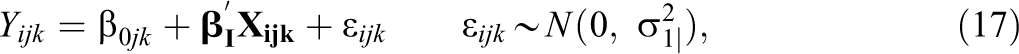
where

where

where
Let the unconditional variances at the individual-, sub-cluster-, and cluster-level be

The intraclass correlation coefficient at the level three is
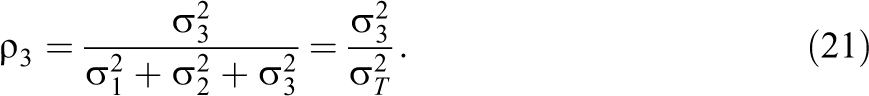
If we standardize the outcome to have a variance of one, the treatment effect (
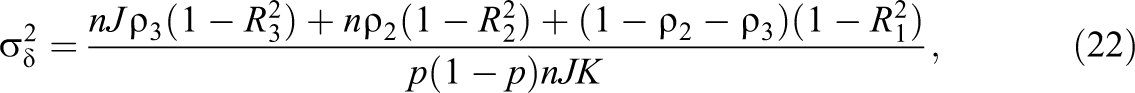
where
When the null hypothesis is false (i.e.,

Statistical power for three-level cluster-randomized trials can be obtained by inserting the above noncentrality parameter into Equation 11 for the two-tailed test or Equation 12 for the one-tailed test with substituting J as K in the degree of freedom expression.
Optimal Sample Allocation
Suppose the respective costs of enrolling each additional level-one, level-two, and level-three unit in the control condition are c1, c2, and c3, and the costs of enrolling each additional level-one, level-two, and level-three unit in the treatment condition are

Substituting K in Equation 24 to Equation 22, we have the variance of the treatment effect as
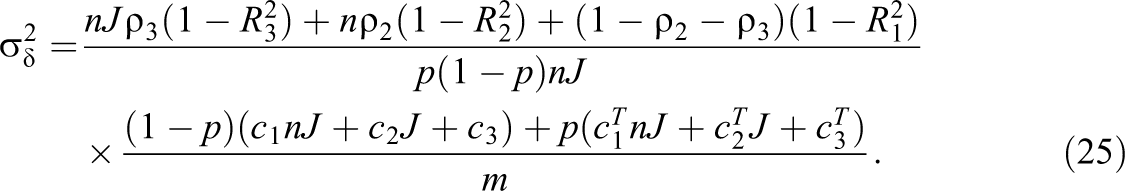
Following similar methods of minimizing the error variance of the treatment effect, the optimal sampling plan for each parameter can then be delineated as

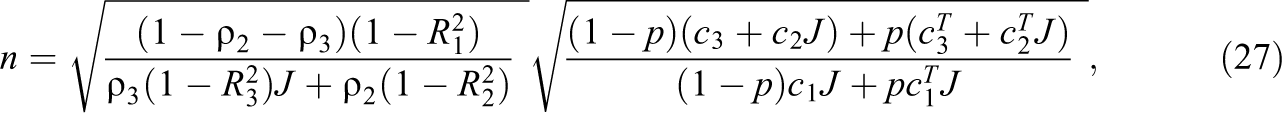
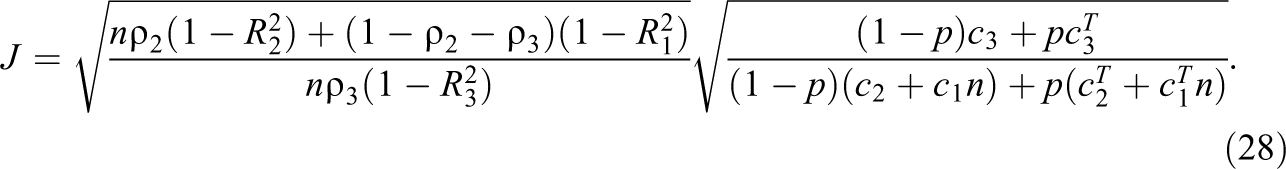
Each of the expressions in Equations 26 through 28 identifies the optimal sampling plan when one of the parameters is malleable. When all three of these parameters are freed, there are no simple closed-form solutions. However, we can solve the multivariate partial derivatives numerically. We implement these solutions in the R package odr (Shen & Kelcey, 2020).
Implications
The optimal design parameters in Equations 26
through 28 provide a more flexible framework for identifying optimal sample allocations across levels and treatment conditions. These optimal design parameters are driven by cost structure and design parameters in a similar but extended fashion with those in two-level cluster-randomized trials. These equations can also be used to improve the precision of cluster-randomized trials with additional constraints. For any given constraint, one just needs to use the relevant constraint to substitute the corresponding optimal design parameter expressions and solve the remaining equations. For example, researchers may constrain the level-one sample size per level-two unit as 20 (i.e.,
Again, we can see that a balanced design with
Relative Precision (RP) and Relative Cost Efficiency (RCE)
There are many practical reasons that may constrain the use of the optimal sampling allocation guidelines derived above. From a practical standpoint, for instance, the number of clusters available to researchers in a particular study may be below the number suggested by the formulas. In response, researchers may intentionally expend resources by sampling additional individuals within clusters in an attempt to compensate for this constraint. Similarly, from a design standpoint, we may eventually find that the parameter values used to plan a study differ from the observed values. Here, we suffer from a type of design misspecification because the proposed optimal sampling plan (based on predicted values) may prove to be suboptimal once data have been collected. When the optimal sample allocation is not a viable option or was incorrectly identified, we can identify the specific loss of statistical precision and efficiency an alternative design presents relative to the true optimal design (based on true values). Such statistical precision and efficiency analyses help provide a sense of what constitutes efficient designs and can assist researchers in identifying designs with the most statistical precision and efficiency among the many constrained designs that may be viable.
Our analysis of statistical precision and design efficiency considers two complementary planning perspectives. In the first perspective, we consider the statistical precision as measured through the relative variance of studies in which the sampling plan is malleable, but the budget and remaining parameters are constrained to preset values. In this setting, we compare the variances of the treatment effect estimator under a suboptimal sampling plan with that of an optimal sampling plan. Conceptually, this assessment of relative statistical precision captures the increased sampling variance incurred by using suboptimal sample allocations. To facilitate interpretations using a common metric, we subsequently frame this analysis in terms of the minimum detectable effect size (MDES; Bloom, 1995) because the MDES is a design parameter that researchers often use in planning studies.
In the second perspective, we consider the relative efficiency of designs in terms of study cost such that the total budget is now free, but the effect size, statistical power, and other parameters are fixed. Under this approach, we detail the total additional cost a study under suboptimal sampling would require to achieve an error variance comparable to a study that used optimal sampling. Conceptually, this evaluation quantifies the increased resources required to carry out suboptimal designs.
For the first perspective, the RP is

where
For the second perspective, we can define RCE as

where mo is the smallest budget to achieve a desired level of variance of the treatment effect (or statistical power) under the optimal sample allocation, and m is the budget to achieve the same level of design precision under an alternative and suboptimal design.
Using information from Equation 14, both perspectives share a more general relative precision and efficiency (RPE) expression for a suboptimal design relative to the optimal design for two-level cluster-randomized trails as

where po and no represent the optimal design parameter values or the roots of p and n in Equations 15 and 16, and n and p represent the alternative parameter values identified under a different framework or a study actually carried out. The values of RPE range from 0 to 1, with the RPE approaching 1 when a suboptimal design achieves a precision level near the optimal design benchmark. Comparing with the optimal design benchmark, the percentage of increased variance/budget by a study is
Unlike power, effect size, or sample sizes, the variance of the treatment effect is not the simplest design parameter researchers usually face. To systematically improve statistical precision for designs, it is important to transfer such a measure to the ultimate parameter researchers can directly consider. We can further transfer the measure under the first perspective. Let the statistical power and the budget be fixed between the optimal and suboptimal designs and further compare the relative values of MDES between two designs. Under this perspective, the statistical power and thus the noncentrality parameter
Thus, we have

where
Similarly, the RPE for a suboptimal design relative to the optimal design for three-level cluster-randomized trails is
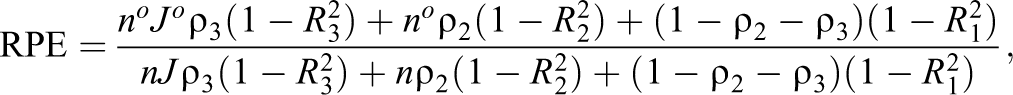

where po, no, and Jo represent the solved values for optimal design parameters expressed in Equations 26 –28, respectively. p, n, and J represent the actual values a three-level design carried out or identified under a different framework.
A Comparison With Previous Frameworks
In the derivation section, we have shown that previous optimal design frameworks for two-level cluster-randomized trials (Liu, 2003; Raudenbush, 1997) are special cases of our proposed framework. The optimal design parameters for two-level cluster-randomized trials are n and p in our proposed framework. They are n and the constraint of
For the cost structures, we considered both equal and unequal costs between treatment conditions and set the cost of sampling one additional individual in the control condition as one (i.e.,
Comparison of Proposed Framework With Previous Frameworks for Two-Level Cluster-Randomized Trials
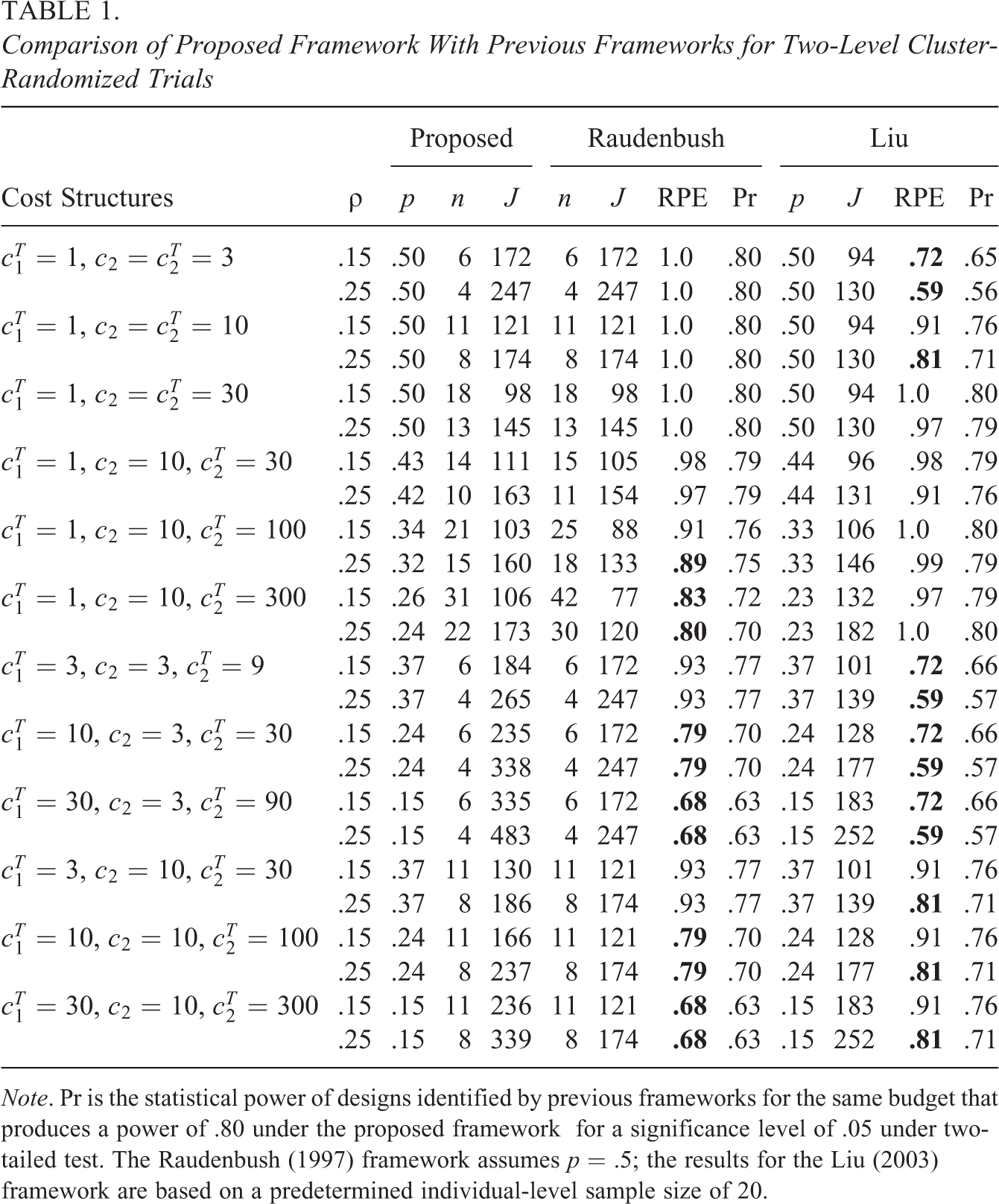
Note. Pr is the statistical power of designs identified by previous frameworks for the same budget that produces a power of .80 under the proposed framework for a significance level of .05 under two-tailed test. The Raudenbush (1997) framework assumes p = .5; the results for the Liu (2003) framework are based on a predetermined individual-level sample size of 20.
For the intraclass correlation coefficient, we considered values of 0.15 and 0.25 (e.g., Hedges & Hedberg, 2007). For the R squared values or the proportions of outcome variance explained by covariates, we considered three types of design. The first type of design has no covariate adjustment (i.e.,
For simplicity, we used
Across all values of cost structures and design parameters, there are 11 of 24 designs identified under the Raudenbush (1997) framework have RPE values below the good level of .90 (see bold RPE values in Table 1). From a relative precision perspective, designs identified under the Raudenbush (1997) framework achieve lower statistical power under the same budgets requested by the proposed framework. The statistical power drops to .70 when the treatment/control sampling cost ratio is 10, and .63 for a cost ratio of 30 (Table 1). Half (12 of 24) of the designs identified under the Liu (2003) framework have RPE values below the good level of .90 (see the bold values in Table 1).
For designs identified under previous frameworks, the RPE values and the relative statistical power are directly influenced by how far the constrained values depart from the optimal values in our proposed framework. For example, when the costs of sampling are equal between treatment conditions (e.g., first three cost structures in Table 1), the constrained p under the Raudenbush (1997) framework is equal to the optimal
We can see similar patterns for the Liu (2003) framework in Table 1; when the predetermined
To illustrate the difference in the required total sample size under different optimal design framework, further suppose researchers plan to implement the cluster-randomized trials to detect a standardized effect of 0.2 (Spybrook et al., 2016). We reported the total number of clusters (J) needed to have a power level of 0.8 for the effect size of 0.2 in Table 1. The results show that we can sample more clusters under the proposed framework than those under the Raudenbush (1997) framework but with less budget required to achieve a power of 0.8 (e.g., see J and RPE values for the forth to last cost structures in Table 1).
Comparing with the Raudenbush (1997) framework, the proposed framework gains efficiency mainly through sampling less clusters in the experimental group but much more clusters in the control group. This mechanism results in the opposite directions in the change of the optimal proportions p and the number of total clusters J. For example, comparing results in the first and last three cost structures in Table 1, we can clearly see that the more expensive sampling in treatment is, the smaller the optimal p and the larger the number of total clusters J. This mechanism of opposite directions in the change of p and J ensures that we still have enough clusters (e.g., classrooms) in the treatment condition.
For example, in the last cost structure where sampling a treatment cluster (e.g., regular class assisted by a teacher aide; Mosteller, 1995) costs 30 times that of sampling a cluster in control (e.g., a regular class), with
Given the same requested budget by previous framework to detect an effect of 0.20 with a power of 0.8, we can detect a smaller effect under the proposed framework, and the MDES under proposed framework can be calculated based on these RPE values. Taking the same example mentioned above with an RPE of .68, we can detect an effect of 0.16 under the proposed framework with the same budget, which is 20% smaller than 0.20. The optimal sample allocation can improve design precision than that under the previous framework, and a smaller MDES can account for the overestimate of an effect size due to sampling error and other factors. In conclusion, we have shown that the proposed framework can be used to recover more gains in statistical precision and efficiency that have gone unconsidered in previous frameworks.
Design Sensitivity
To further probe the loss of efficiency resulting from constrained designs and the sensitivity of optimal designs to misspecifications of parameter values at the planning stage, we examined the extent to which proposed designs are robust to incorrect initial values of the cost structure and the design parameter values. Similarly, we only present the results for two-level cluster-randomized trials, as the conclusion is the same for three-level experiments.
In our analyses, we first calculated the true optimal design parameter values (no and po) based on the true values and then computed the optimal design parameter values (n and p) under misspecified initial values. Using Equation 31, we then computed the RPE value designs achieved. For the comparison, we used the same cost structures and design parameter values that have been used in the previous section. We rounded the values of n to integers and the values of p and RPE to two decimal places in the computation. We presented the result for designs with a covariate at the cluster level (
Robustness of Optimal Sample Allocation to the Misspecification of Intraclass Correlation Coefficients
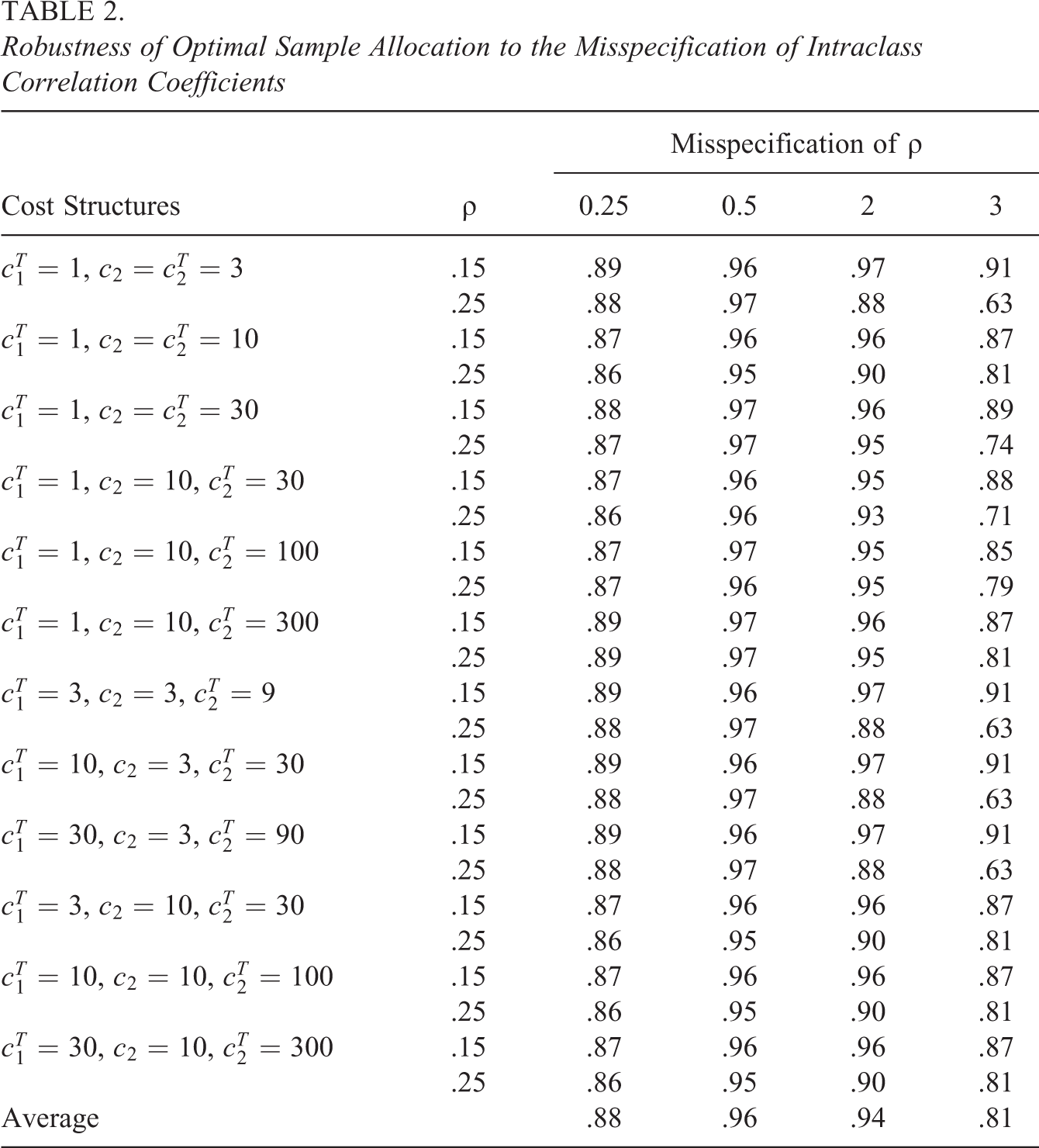
Robustness to the Misspecification of Intraclass Correlation Coefficient
In terms of the range of misspecification on intraclass correlation coefficient, we considered multiplicative values of the true parameter—0.25, 0.5, 2, and 3 times the true values—mapping the range of 0.25 to 2.75 times the true values within which constrained optimal designs (
When the misspecification of the intraclass correlation coefficient is even larger—for example, 0.25 or 3 times the true values—the average RPE values are about .88 and .81, respectively (Table 2). Our initial probe suggests that the optimal sample allocation identified under the proposed framework is fairly robust to the misspecification of the intraclass correlation coefficients.
Robustness to the Misspecification of Cost Structures
As for the misspecification of initial cost structure, we investigated the robustness of optimal design to the misspecification on initial CICR and TCCR. The range of the misspecification was set as 0.25, 0.5, 2, and 4 times the true values. The results are presented in Table 3. When the misspecification is 0.5 or 2 times the true CICR, designs have an average RPE value of .97. Even when the misspecification is 0.25 or 4 times the true CICR, designs have average RPE values of .89 or .90, respectively. As for the misspecification of initial TCCR values, the results are similar. Even when the misspecification is 0.25 or 4 times the true TCCRs, designs have an average RPE value of .90. The results suggest that designs optimized under moderate misspecifications of cost ratios largely retain their RPE values.
Robustness of Optimal Sample Allocation to Misspecification of Cost Structures Measured by Relative Precision and Efficiency

Note. CICR is the cluster/individual cost ratio. TCCR is the treatment/control cost ratio.
Discussion
Prior literature has developed a host of strategies and tools to improve the efficiency with which designs can estimate effects (e.g., Bloom et al., 2007; Borenstein et al., 2012; Dong & Maynard, 2013; Kelcey & Phelps, 2013; Kelcey et al., 2016; Schochet, 2008; Raudenbush et al., 2007). Previous optimal design frameworks have been limited in their modeling the cost structures of sampling and optimizing the sampling ratios across levels and treatment conditions. In this article, our proposed framework addresses this need by developing a flexible cost framework that more naturally maps onto practical design settings. The results of the extended framework identify potentially important gains in statistical precision and efficiency that have previously gone unconsidered.
Even when some of the parameters are constrained by practical considerations, our results suggest that within a broad range of applied settings the proposed framework can identify sampling strategies with more precision and efficiency than those detailed in previous literature. In this way, the introduction of a treatment-condition specific cost framework and the optimization of sampling ratios across levels and treatment conditions can be useful for adjudicating among several potential designs with varying constraints. Additionally, the proposed framework performed better than previous frameworks even when the parameter values are misspecified.
To design cluster-randomized trials with adequate statistical power and efficiency under an optimal design framework, researchers additionally need the cost information about sampling. The information about the cost of sampling a unit can usually be estimated through pilot studies, budget planning, similar studies, or cost centers (e.g., CostOut at https://www.cbcse.org/costout). Even when cost estimation may not be strictly accurate, our initial probe of the proposed optimal design framework suggested that the results are fairly robust to the misspecification on initial values of intraclass correlation coefficient and cost structures. In this way, our results suggest that even when some parameters are constrained, and some are misspecified, there are still advantages to probing more flexible sampling plans.
In the presence of unequal sampling costs between treatment conditions, we have illustrated that unbalanced designs can be more efficient than balanced ones. Put another way, unbalanced designs can return more statistical power than balanced designs under unequal sampling costs between treatment conditions. It is generally assumed that the treatment or intervention itself does not change the standardized variance of an outcome. For designs with unequal number of clusters between treatment conditions, the assumption of homogeneity of variance between treatment conditions (controlling for the treatment effect) can still be tested the same way with balanced designs as the variance formulas adjust for the number of clusters.
We illustrated the opposite directions in the change of the optimal p and the number of total clusters needed for a certain level of statistical power. This mechanism ensures that unbalanced designs still result in enough clusters to be sampled in a treatment condition. However, when the number of total clusters is small and the proportion of clusters to be assigned to the treatment condition is also small, there may be an issue whether the treatment arm can correctly reflect the population variance, and thus there may be a homoskedasticity issue between treatment conditions. Further studies address a small number of clusters in unbalanced design is needed.
Despite the utility of our framework and the potential gains in statistical precision and efficiency it offers, we caution readers that the resulting optimal sampling plans are intended to serve as a starting point for planning a cluster-randomized trial rather than a rigid tool. For example, an analysis of optimal design may suggest a small value of optimal proportion (p) if sampling costs are vastly different between treatment conditions. In power analysis, a small value of p may suggest a large number of total clusters that exceeds the clusters researchers could practically reach. In this case, researchers should constrain the optimal proportion to a larger number than that the analysis gives so that a feasible design can be achieved. In practice, the optimal sampling plan operates as a type of initial strategy or benchmark that is subsequently moderated by practical design considerations and constraints to reach a final sampling plan.
To facilitate end-user calculations, we have developed a freely available R package odr (Shen & Kelcey, 2020) that implements the proposed framework. The package also can perform power analysis accommodating costs by default (e.g., required budget/sample size calculation, power calculation under a given budget, MDES calculation under a given budget) and conventional power analysis (e.g., sample size, power, and MDES calculation).
Footnotes
Appendix A
Appendix B
Acknowledgments
We thank the editor, Dr. Daniel McCaffrey, three anonymous reviewers, and Dr. Luke Miratrix at Harvard University for their insightful comments and suggestions on earlier drafts of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This article is based in part on work supported by the National Academy of Education (NAEd) and Spencer Foundation through a NAEd/Spencer Dissertation Fellowship awarded to the first author.