
Abstract
We propose a new item response theory growth model with item-specific learning parameters, or ISLP, and two variations of this model. In the ISLP model, either items or blocks of items have their own learning parameters. This model may be used to improve the efficiency of learning in a formative assessment. We show ways that the ISLP model’s learning parameters can be estimated in simulation using Markov chain Monte Carlo (MCMC), demonstrate a way that the model could be used in the context of adaptive item selection to increase the rate of learning, and estimate the learning parameters in an empirical data analysis using the ISLP. In the simulation studies, the one-parameter logistic model was used as the measurement model to generate random response data with various test lengths and sample sizes. Ability growth was modeled with a few variations of the ISLP model, and it was verified that the parameters were accurately recovered. Secondly, we generated data using the linear logistic test model with known Q-matrix structure for the item difficulties. Using a two-step procedure gave very comparable results for the estimation of the learning parameters even when item difficulties were unknown. The potential benefit of using an adaptive selection method in conjunction with the ISLP model was shown by comparing total improvement in the examinees’ ability parameter to two other methods of item selection that do not utilize this growth model. If the ISLP holds, adaptive item selection consistently led to larger improvements over the other methods. A real data application of the ISLP was given to illustrate its use in a spatial reasoning study designed to promote learning. In this study, interventions were given after each block of ten items to increase ability. Learning parameters were estimated using MCMC.
Introduction
Differentiated Instruction
Vygotsky (1980) theorized a zone of proximal development (ZPD), defined as the range between what a child can do alone without guidance and what the child can do with guidance. In differentiated learning, if the teacher can push the child into their ZPD and coach with a task slightly more complex than the child can manage alone, then the child can master new skills and learn to become an independent thinker and problem solver through repetition (Joseph et al., 2013).
Differentiated instruction is common in the modern classroom and has been shown to be beneficial for both remedial and advanced students (Manning et al., 2010). Over the past decade, online learning sites, such as IXL, Khan Academy, and Dream Box, have become quite popular, perhaps due to the demand for extra help and practice and their ability to give immediate feedback. These online learning platforms provide differentiated instruction to students by means of computerized adaptive testing and interventions. Adaptive testing can improve the quality of measurement by presenting individuals with items targeted to their current ability level, which can be assessed dynamically.
Several methods of item selection have been developed for adaptive learning, such as item-pool partitioning (Kingsbury & Zara, 1989), the weighted-deviation method (Swanson & Stocking, 1993), the maximum priority index method (Cheng & Chang, 2009), testlet-based adaptive testing (Wainer et al., 2007), and constrained adaptive testing with shadow tests (van der Linden & Glas, 2009). In this work, we propose a model for the ability growth of individuals throughout the course of a formative assessment and show an example of how it could be used to select items adaptively.
Latent Variable Models for Learning
Item response theory (IRT) is a paradigm that relates a subject’s performance on an assessment to a measure of their overall ability level,
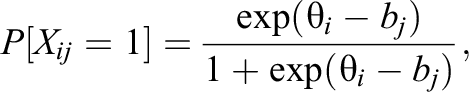
where
Of the many methods for parameter estimation in the Rasch model, two important approaches are widely used because the asymptotic properties of the estimates are known and desirable: conditional maximum likelihood (CML) and unconditional maximum likelihood (Fischer, 1981). CML (Andersen, 1972) is a parameter estimation method that is applicable to the one-parameter model. In CML estimation of item parameters, subjects’ ability levels are treated as arbitrarily given; item and ability parameters are estimated simultaneously (Bock & Lieberman, 1970). The subject’s ability is treated like a nuisance parameter, which is eliminated from the likelihood by conditioning on the number of items answered correctly, which is a sufficient statistic for the ability (Bock & Aitkin, 1981). In the Rasch model, an advantage of CML is that the distribution of
Alternatively, if the ability distribution is assumed to have a particular form, marginal maximum likelihood (MML) can be used to estimate item parameters. Here, the data are regarded as arising from a sample of subjects from a specified population. Item parameters can be estimated by integrating over the distribution of
Linear Logistic Test Model (LLTM)
Scheiblechner (1972) proposed a more structured version of the Rasch model called the LLTM, in which the item difficulties are subject to the linear restrictions:

where
IRT Growth Models
Item response models that allow for growth in the ability parameter can be applied when learning is the goal of the assessment. By continually measuring the latent ability and adapting the assessment and intervention, one can increase efficiency by avoiding overtesting and undertesting at a particular level. In addition to evaluation, items or bundles of items may be seen as educational interventions. In this work, we consider methods for modeling growth of the latent trait and also study the benefits of adaptive item selection using these models. There is vast literature on learning and growth models in IRT, though it is not focused on item-level or testlet-level learning parameters.
Longitudinal IRT (LIRT) is a branch of IRT that allows researchers to measure individual growth and change using longitudinal data (Ong, 2017). An early example of LIRT is Fischer’s extension of the LLTM to multiple time points in the linear logistic model with relaxed assumptions (LLRAs; Fischer & Formann, 1982). This model drops the assumption of unidimensionality, which may be difficult to attain in educational or clinical settings (Fischer & Formann, 1982). The LLRA supposes that the reactions of J individuals to n items have been observed at several time points

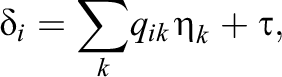
for
The additive nature of
Andersen (1985) analyzed scenarios where the same set of items was used to measure a latent variable at two different points in time, with values,
Embretson (1991) points out that although Andersen’s model is appropriate for understanding the impact of time or treatment on the ability distribution, it does not contain change parameters for individuals. To that effect, Embretson (1991) developed a multidimensional Rasch model for learning and change (MRMLC), which is appropriate for ability measurements, where items are not repeated to avoid bias from repeated testing.
Embretson’s model extends the Rasch model to include M abilities measured on K occasions. It assumes that on the first occasion,
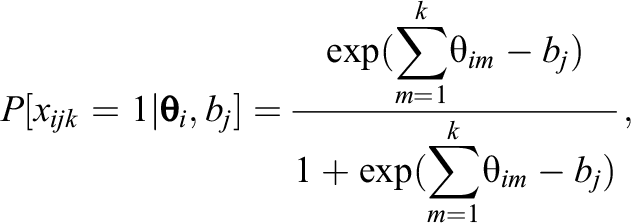
where
Across conditions, the MRMLC is multidimensional, but within any condition, item response probabilities can be given by a unidimensional model (Embretson, 1991). For all items within condition k, and for all k, the probability of a correct response depends on the composite ability
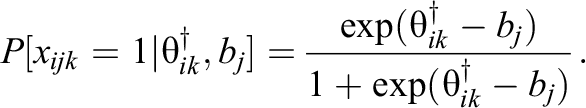
In this article, we propose an IRT growth model for learning, in which items or testlets have their own learning parameters that may be estimated from data. We demonstrate an estimation procedure for its learning parameters. Then, we assess the finite sample properties in simulation under a variety of conditions. A separate simulation study is then conducted to examine the gains in learning efficiency that a learning model may afford while paired with an adaptive item selection algorithm. Finally, we fit our learning model to a real dataset that involves an intervention to help students learn spatial rotation skills.
IRT Models for Learning
The models we consider can be broken into two distinct parts, the measurement model and the latent growth model. The measurement model we use is the 1-parameter logistic (1PL) model,
Proposed Models
The other component of an IRT growth model describes how learning or growth takes place. We propose a new model called the IRT growth model with item-specific learning parameters (ISLPs). The ISLP model can be used to explain the ability growth of an examinee throughout the course of an assessment. These assessments are broken into groups of items called blocks. For the sake of simplicity, we suppose that blocks have the same number of items and that items are presented in the same order within each block. Blocks can be presented in any order to the examinees. After an examinee completes each block of items, they are given an intervention that corresponds to that block. An intervention could be something as simple as providing feedback explaining the solutions to incorrect items from the previous block or something more complex such as an interactive applet the examinee can use to learn. Larger block sizes may correspond to an assessment that is more focused on measurement. Smaller block sizes indicate more frequent interventions and may be the focus of a formative assessment. For instance, a block size of one would correspond to providing an intervention after each item.
We assume that ability growth only takes place during the intervention phase and model the learning benefit provided by each intervention,
For example, consider an assessment of length
The ISLP asserts that more learning takes place if the item difficulties are similar to the ability level of the subjects. If an item is much too difficult for an examinee, little can be gained from providing a teaching intervention afterwards. Similarly, if an item is so easy that it requires little thought, we can also expect little growth. This model scales the intervention effects by a dampening factor of
This model includes an extra parameter,
On the other hand, the ISLP can be reduced into a model that has no dampening terms.
The reduced model is the simplest and assumes that the ability growth caused by the
Estimation of Learning Parameters
Markov chain Monte Carlo (MCMC) is an attractive choice for the estimation of learning parameters due to the wide variety of possible models that can be considered and the varying difficulty of numerical estimation problems that arise. In this section, we give an example where the 1PL model is used as the measurement model and the extended ISLP model is used as the learning model. However, the following procedure can be modified to fit any model.
Learning model parameters may be estimated by using the Metropolis-Hastings algorithm to simulate draws from their conditional posterior distributions. We first assume that the item difficulty parameters and discrimination parameter are known. This could correspond to a scenario where one has access to a calibrated item bank from a testing company and wishes to evaluate the efficacy of newly created learning tools pertaining to those items. The structure for estimating the extended ISLP model learning parameters, {
MCMC Parameters:
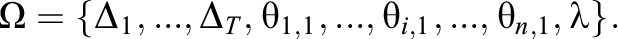
Joint Posterior Distribution:
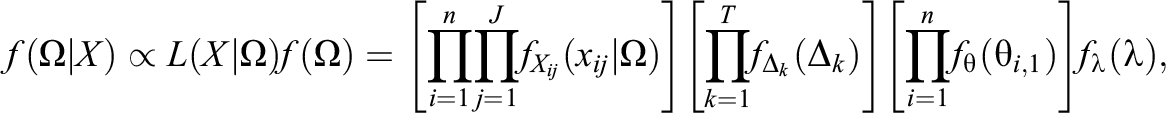
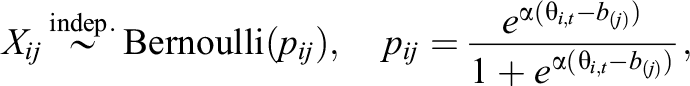
where
Parameter starting values may be initialized arbitrarily. For example, they may be randomly drawn from their respective prior distributions. Or, baseline data may be used to estimate initial values for ability parameters using standard Gaussian quantiles based on proportion correct to speed up convergence. Candidate parameters may be proposed using a Gaussian distribution with mean at the current value, and standard deviations tuned to yield the desired acceptance rates, adjusting for different models or prior distributions.
For every parameter, the Metropolis-Hastings acceptance ratio, a, can be calculated and compared to a randomly generated Uniform(0,1) random variable, U. If
If the item difficulty parameters are unknown, they can either be estimated first with a method such as MML, or jointly with MCMC. If the difficulty parameters are estimated first, they can then be fixed for the MCMC estimation of learning model parameters.
Simulation Studies
The first study aims to see how well the learning model parameters for the ISLP can be recovered using MCMC when the item difficulties are known. The second study examines how well ISLP learning parameters can be recovered when item difficulties are unknown but are assumed to follow the LLTM. We expand this second study to look at the effect on learning parameter estimation when random effects (RE) are incorporated into the ISLP model to generate the data. We also look at parameter estimation under the reduced and extended ISLP models.
The third simulation study gives an example of an application of pre-estimated ISLP models in the context of an assessment utilizing adaptive item selection. Assuming that the ISLP is the true growth model, the growth of the ability level,
Learning Parameter Estimation With Known Item Difficulties
Using the ISLP as the growth model, random response data were generated with different sample sizes (
Questions were divided into five blocks of either ten questions (J = 50) or six questions (J = 30). Subjects were randomly assigned into five test groups. Each group was presented with the blocks in a different order. Each block corresponded to an intervention with learning parameter,
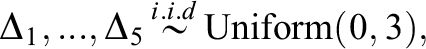

The following proposal step sizes were tuned to give acceptance rates around 20% for
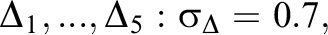
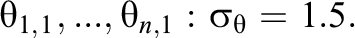
For each simulation condition, 25 chains of length 10,000 iterations were run. Starting values for item learning parameters were drawn randomly from their prior distributions, and starting values for
Mean Absolute Deviation in the Estimation of

Note. Results are averaged across 25 repetitions. ISLP = item-specific learning parameter; 1PL = one-parameter logistic.
Estimation of Learning Parameters Under the LLTM
Next, we analyzed the performance of the model under the assumption that the LLTM holds but item difficulty parameters are unknown. To estimate the item difficulty parameters, we assumed that all items can be studied at baseline prior to learning interventions. The underlying distribution of each initial ability was assumed to be
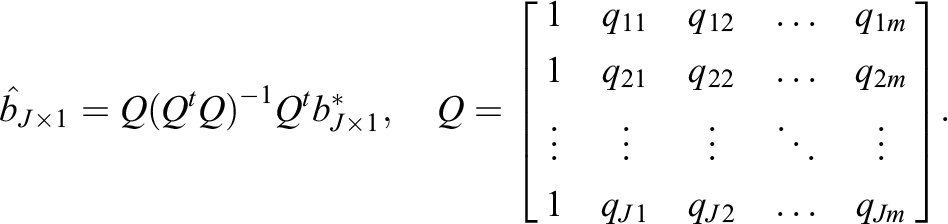
Once the item difficulty parameters have been estimated in this way, they are fixed and used as the true values of bj
in the MCMC step. In this simulation, the same process is repeated as in the first simulation study. The original, reduced, and extended ISLP models were all used as the true model to generate response data, while varying test length (J) and the number of examinees (n). For each model, simulations were performed with
For each condition, item and learning parameters were fixed and 25 replications were performed. Proposal steps were the same as before. For each replication, a chain of length 10,000 was run with a burn-in segment of 2,000. The posterior means of
Mean Absolute Deviation in Estimation of
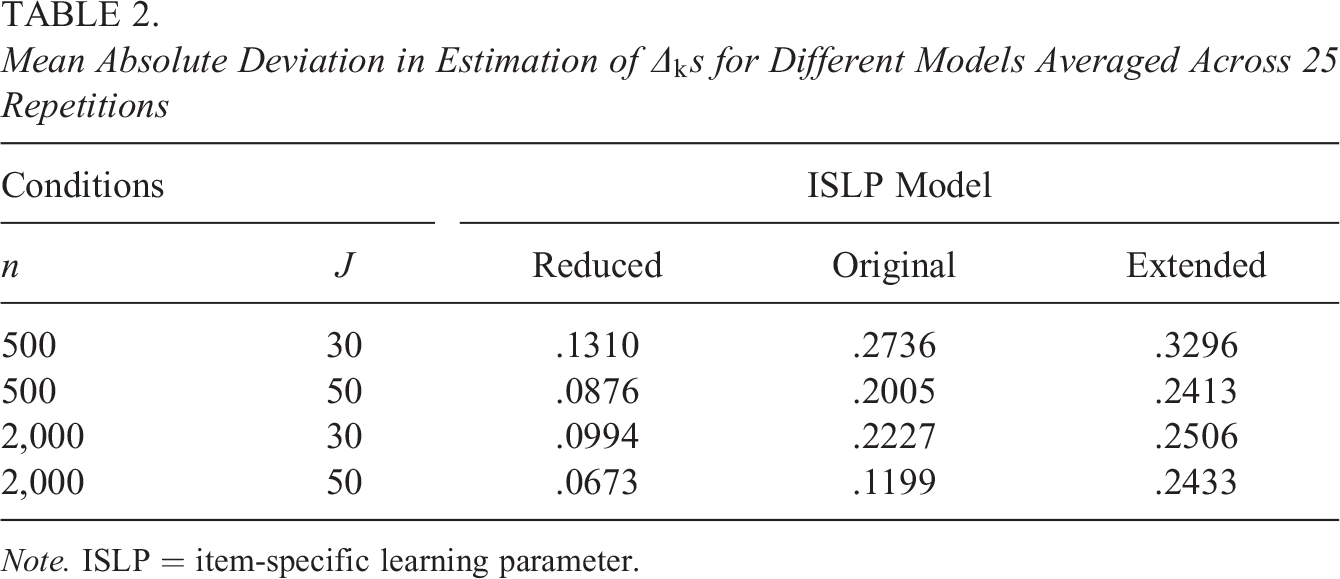
Note. ISLP = item-specific learning parameter.
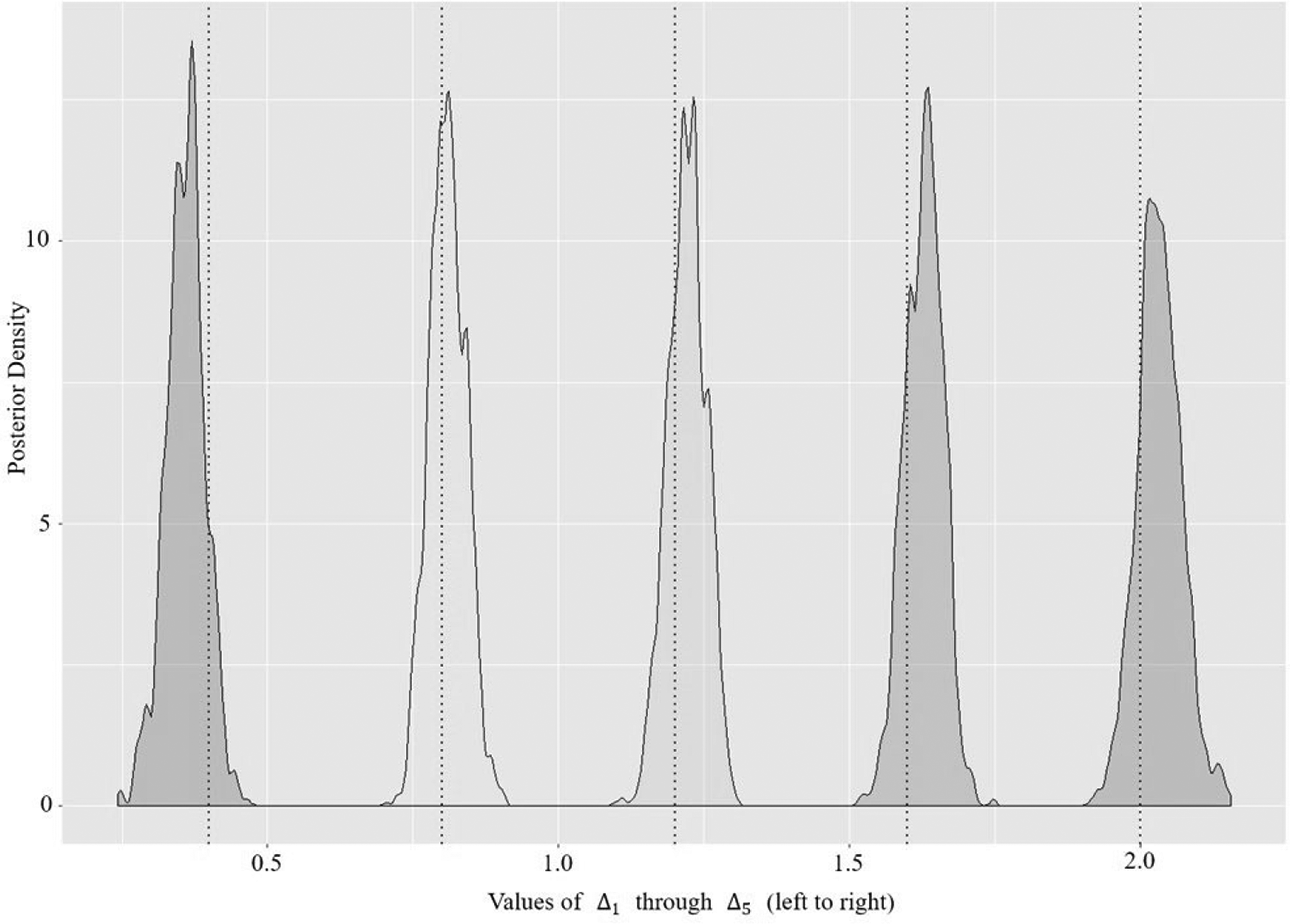
Posterior distributions of
Sensitivity Analysis
The proposed ISLP models all make the assumption that subjects with the same
ISLP-RE Model:
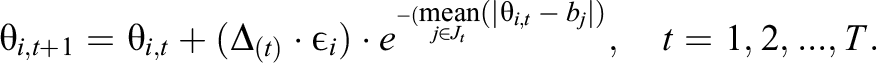
The sensitivity analysis was repeated for various distributions of
These underlying beta distributions for the
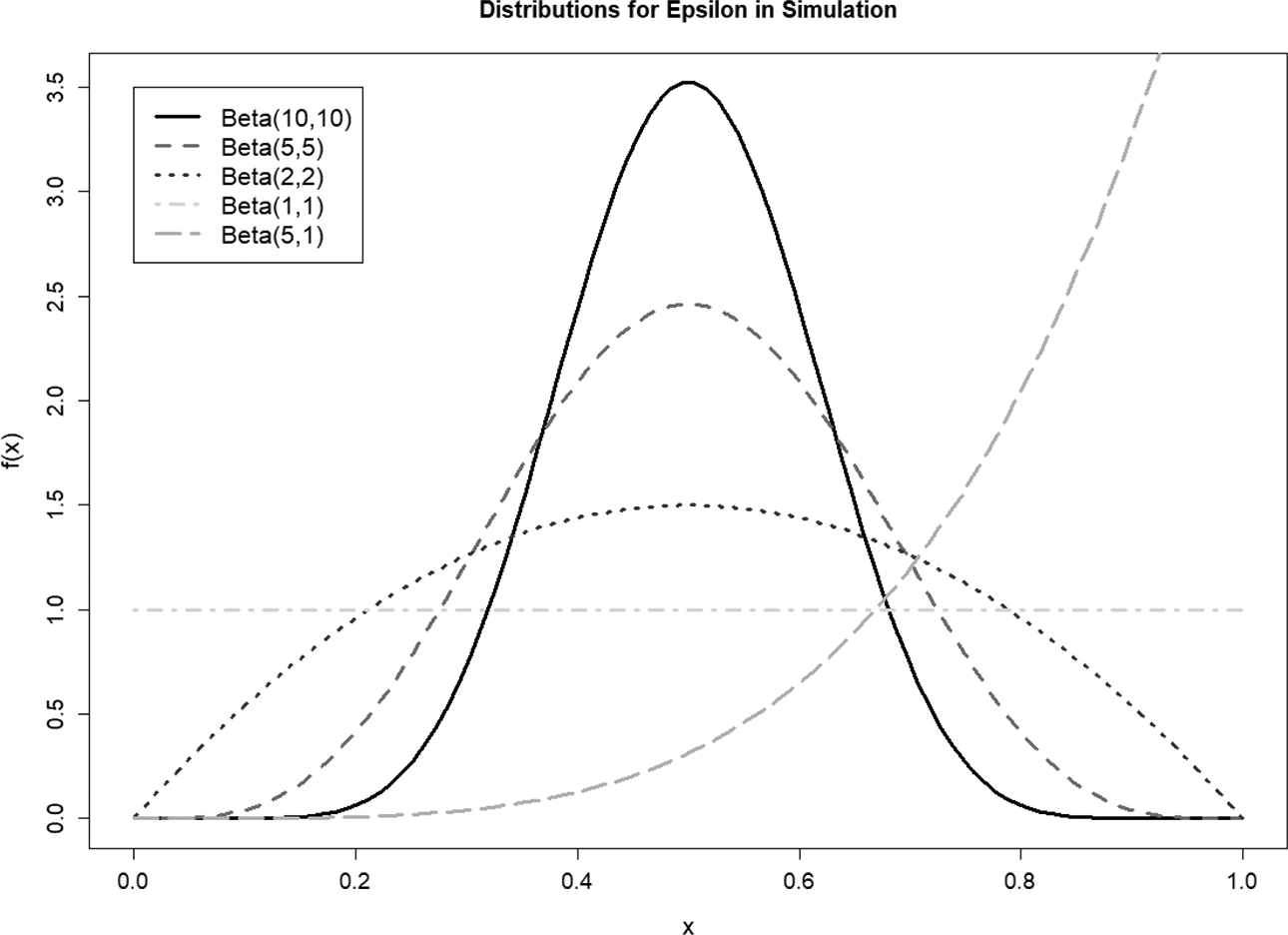
Beta distributions used to generate
Table 3 shows a comparison of the results from the ISLP model and ISLP-RE model. The results showed that estimates for
Sensitivity Analysis: Mean Absolute Deviation in the Estimation of
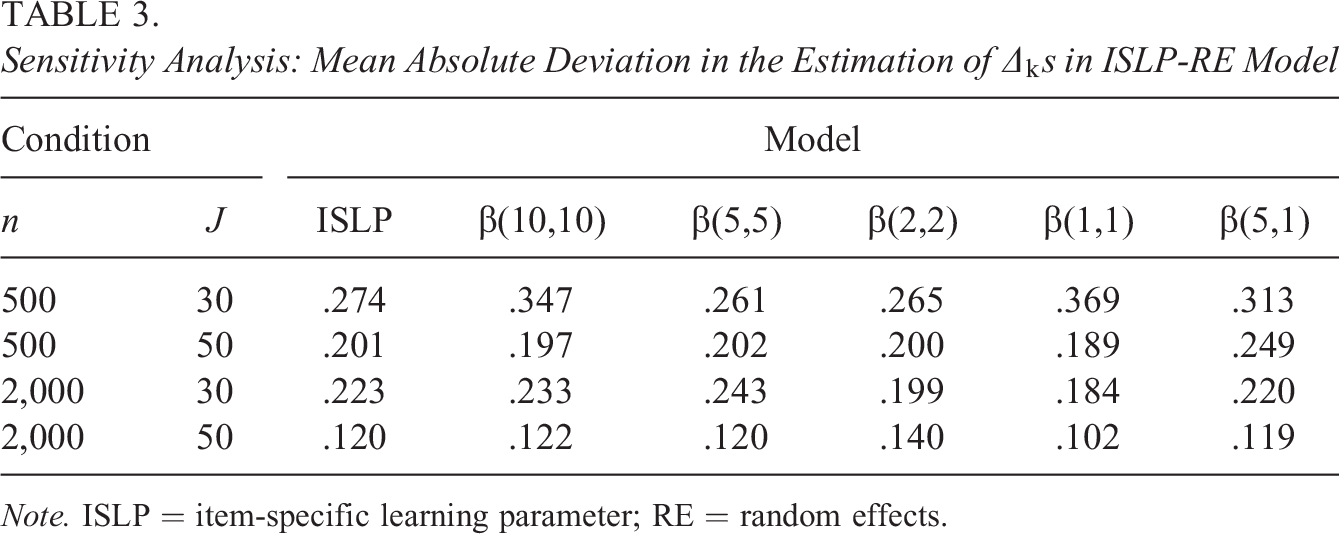
Note. ISLP = item-specific learning parameter; RE = random effects.
Adaptive Item Selection
Next, we demonstrate how the ISLP models can be implemented in an assessment to choose the best items for an individual using adaptive item selection. The total increase in ability parameters for all individuals from the beginning to the end of an assessment is measured and compared against two other methods of item selection, which do not depend on the ISLP model: (1) random item selection and (2) selecting items with the highest
Item difficulty and learning parameters were assumed to be known. True initial ability parameters,
A test of length
For initial estimation of ability levels, a calibration set of 10 predetermined questions of varying difficulty levels was administered one question at a time. Based on the difficulty of these questions and performance on the responses, maximum likelihood estimation was used to obtain the estimates of the initial abilities,
To illustrate the process for updating


Then, the current ability estimates can be found in real time through recursive application of the ISLP model after computing the MLE,
Since the same calibration set was used in all three methods of item selection, the estimates of ability levels at the end of the calibration set,
Starting from Item
Adaptive item selection results
Figures 3 and 4 show that the vast majority of subjects using adaptive item selection ended the assessment with a higher final ability level versus the other two methods regardless of
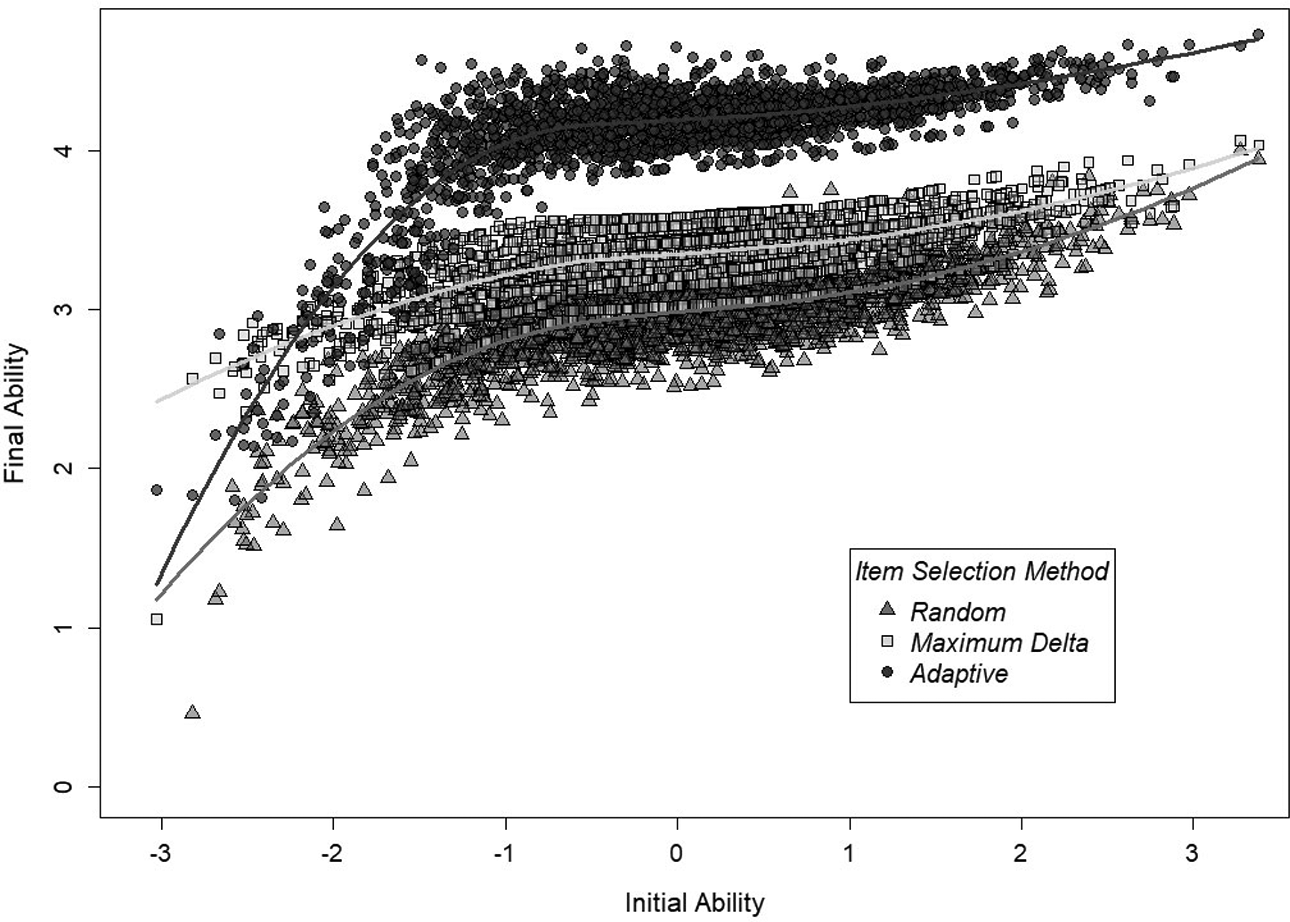
Initial ability (
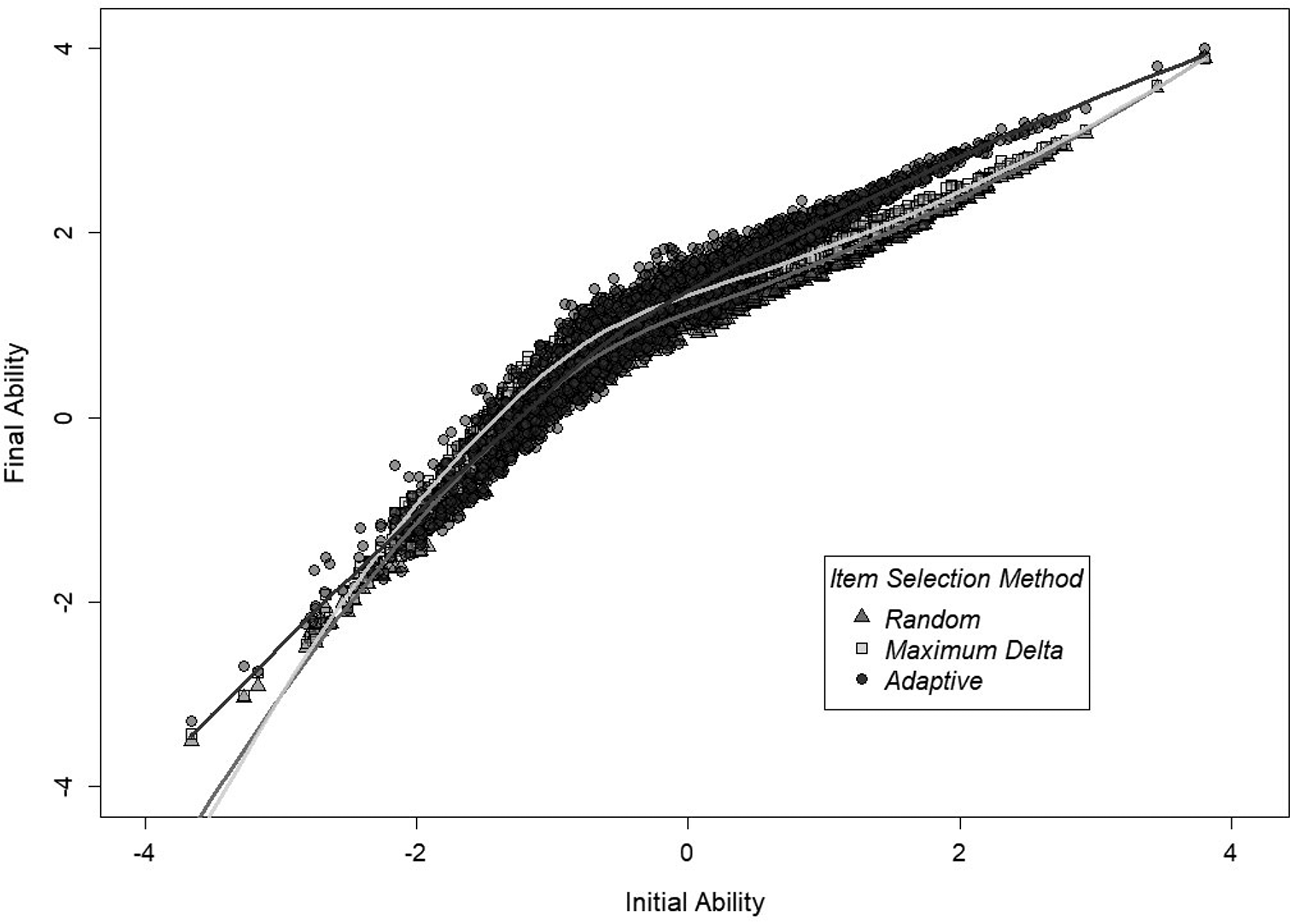
Initial ability (
Proportion of Examinees With Higher Final

Note. Adaptive selection resulted in higher performance for a vast majority of subjects.
Total Mean Improvement
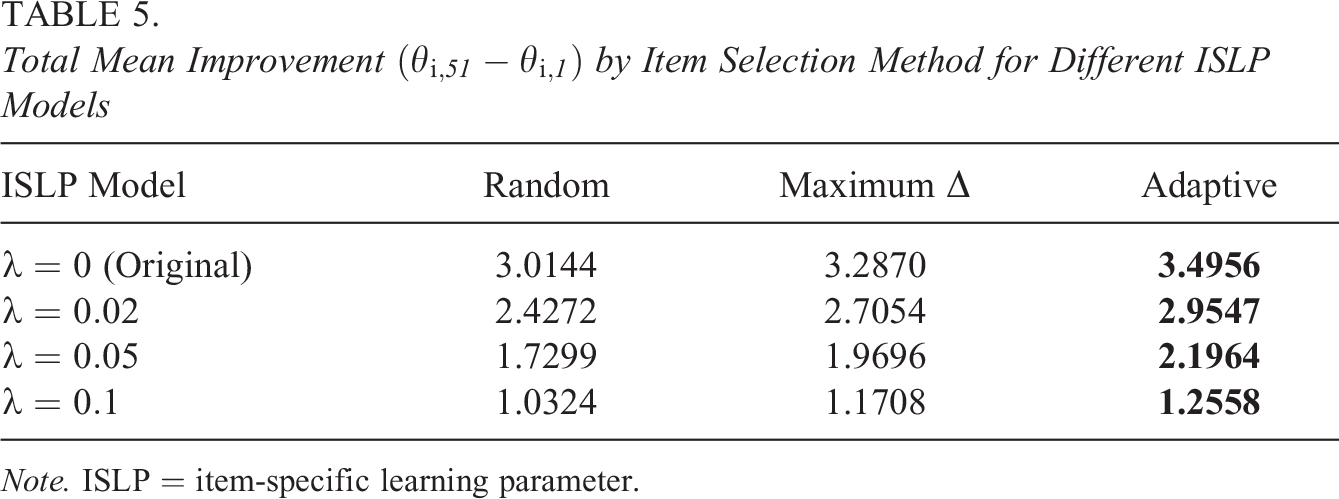
Note. ISLP = item-specific learning parameter.
Real Data Analysis
We analyzed data from a computer-based assessment of spatial reasoning ability. 350 subjects selected from a University of Illinois–Department of Psychology paid subject pool were given a series of 50 items. Items were presented in blocks of 10 questions with a learning intervention after each block. Subjects were randomly assigned to one of the five test versions, which presented the blocks in different orders. This test was developed based on the Purdue Spatial Visualization Test (PSVT; Yoon, 2011). Thirty of the questions were taken from the PSVT, while 20 of the questions were created by Wang et al. (2018). The dataset was obtained from the hmcdm (hidden Markov cognitive diagnosis models for learning) package in
The items in this assessment are comprised of operations requiring either 90° rotations, 180° rotations, or both. There are seven distinct combinations in the Q-matrix structure. Due to the Q-matrix underlying item construction, this initially suggested that the LLTM might be an appropriate choice for the measurement model. The plot in Figure 5 shows the proportion of correct answers for each item grouped by their Q-matrix entries. It can be seen that questions involving two operations were more difficult overall than items involving a single operation. However, based on the proportion correct, it can be seen that items with the same Q-matrix entries have a wide range of difficulties. We concluded that the LLTM was not an appropriate measurement model for this dataset because when it holds, items with the same Q-matrix entries should have been answered correctly in very similar proportions. The 1PL model without LLTM constraints was selected as the measurement model.
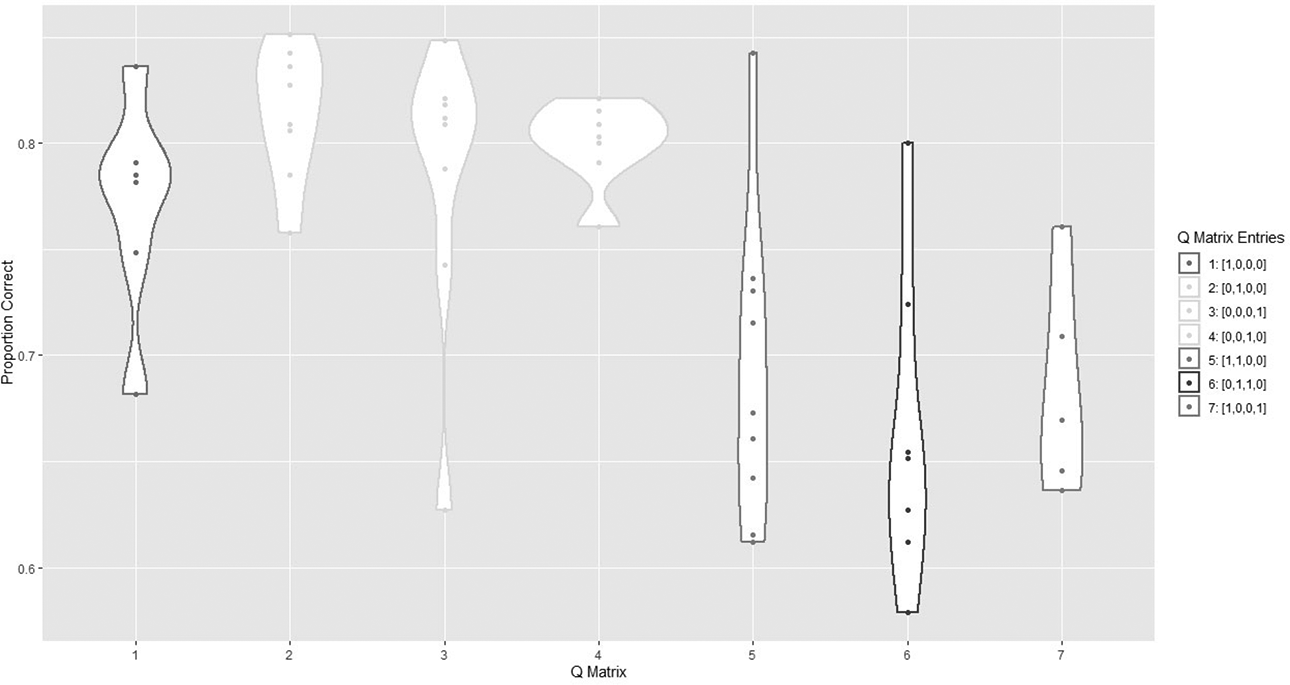
Scatterplot and violin plot of questions (grouped by Q matrix entries) versus proportion correct.
A further exploratory analysis revealed that the only significant improvement in ability level was realized when an examinee completed their first block and intervention. Table 6 shows that on average, virtually no improvement occurs starting from the second intervention onward for all test versions. This phenomenon may be due to a lack of incentive for the subjects to perform well and declining motivation. If the decline of improvement had been less abrupt, the extended ISLP model could have been a good choice for the learning model. For our analysis, the ISLP was chosen as the learning model, and only data from the first 20 items (two blocks) answered by each examinee were used to estimate the learning parameters.
Performance of Examinees Did Not Increase Significantly After Time 2

Real data learning parameter estimation
Learning parameters

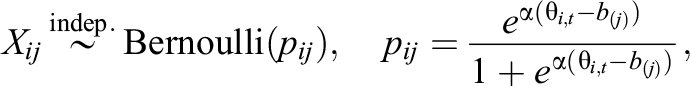
where
Prior distributions:
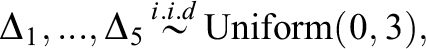
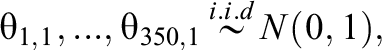
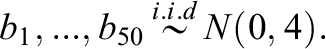
When specifying the prior distributions for each
To test convergence, five separate chains of length 10,000 were run. Starting values for each
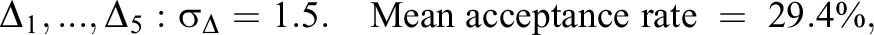


The first 2,000 samples were discarded as burn-in. The posterior means of the remaining 8,000 samples used to estimate the learning parameters. According to the Gelman–Rubin statistic, all of the parameter estimates appeared to converge well before the first 2,000 samples. An example of a Gelman–Rubin diagnostic plot for

Gelman–Rubin plot showing convergence of
The average posterior mean of all item difficulties was
Analyzing this dataset with a subset of the first 20 items is similar to using the extended ISLP with a large value of
Summary
The ISLP model was presented along with a couple variations as a model capable of assessing learning at the item level or block level. In this study it was used with the 1PL and LLTM but can be used in conjunction with any IRT model. The ISLP model can be applied to precalibrated items after learning interventions are developed. The item difficulty parameters may be treated as known if they were obtained in a setting where ability is expected to be constant prior to any interventions associated with the items. Learning parameters may also be estimated simultaneously with the item parameters in other designs. Simulation results showed that parameters can be accurately recovered under the study conditions. An additional simulation studied the benefit of utilizing learning parameters in an adaptive exam when the aim is to promote learning.
A real data application involving spatial reasoning was given to illustrate the ISLP. It was seen that while all blocks were capable of helping the examinees learn the spatial rotation tasks, only those that we administered at the very beginning helped, and learning appeared to end after the second block. Because the exam in this dataset contained 50 questions, it is possible that fatigue and lack of motivation were responsible for the observed plateau in examinees’ performance after the second time point.
Due to the need for shorter exams, adaptive item selection would be a good choice. We can see that when these models hold, selecting items adaptively gives us a large advantage, even over choosing items with the maximum
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.