
Abstract
A critically important balance in educational measurement between practical concerns and matters of technique has atrophied in recent decades, and as a result, some important issues in the field have not been adequately addressed. I start with the work of E. F. Lindquist, who exemplified the balance that is now wanting. Lindquist was arguably the most prolific developer of achievement tests in the history of the field and an accomplished statistician, but he nonetheless focused extensively on the practical limitations of testing and their implications for test development, test use, and inference. I describe the withering of this balance and discuss two pressing issues that have not been adequately addressed as a result: the lack of robustness of performance standards and score inflation. I conclude by discussing steps toward reestablishing the needed balance.
The critically important balance in educational measurement between issues of technique and issues of practice has atrophied over the past few decades, with practical concerns receiving progressively less attention. I define these two categories more clearly in the following. As a consequence of this unfortunate trend, some critically important challenges have not been addressed sufficiently, including some that were first described many decades ago.
I begin with the work of the testing pioneer E. F. Lindquist, whose work illustrates both of these points. Lindquist’s work exemplifies the essential balance that has withered in recent years, and he explicated critically important practical problems that the field has yet to address adequately, nearly three quarters of a century later.
Lindquist is best known as one of the most prolific developers of achievement tests in the history of the field. In 1929, he first implemented the Iowa Every Pupil Test of Basic Skills, also known as the Iowa Academic Meet and by the press and public as the Iowa Brain Derby. He developed the Iowa Tests of Basic Skills, first administered in 1935, and the Iowa Tests of Educational Development (ITED), first administered in 1942. In addition to the various Iowa tests, Lindquist directed the development of the first General Educational Development Test in the 1940s. In the 1950s, he developed the initial National Merit Scholarship Qualifying Test. He oversaw the creation of the first ACT, which was initially based on the ITED. Lindquist was also an accomplished applied statistician who published an explanation of what we now know as generalizability theory several years before Cronbach and his colleagues began publishing their work in the area. He was also an inventor; he devised the first practical optical scanning machine for scoring tests. Lindquist was also an entrepreneur. He co-founded ACT, and he founded the Measurement Research Center in Iowa City (later National Computer Systems and currently a part of Pearson PLC) to machine-score tests.
Yet for all his work developing tests and facilitating their use through his work as a statistician, inventor, and entrepreneur, Lindquist was also a skeptic about testing. Clearly, he was confident that standardized tests could inform and improve education, as he devoted his entire career to that goal. However, he thought deeply about the limitations of testing and the implications of these limitations for test development, test use, and inference. And in exploring these limitations, he focused substantially on the functioning of tests in schools and in the educational system more generally, not just on test content and psychometric issues.
An excellent illustration of this side of Lindquist’s work is his chapter entitled “Preliminary considerations in objective test construction” published in 1951 in the first edition of Educational Measurement, which he also edited. Lindquist used the term “preliminary considerations” to refer to the work that is done before an operational test is fielded, including planning the test, writing items, and determining procedures for administration and scoring. Despite the title, however, the focus of the chapter was far broader than these initial tasks. Lindquist (1951) also addressed “the various possible ‘approaches’ which the test constructor may take to the measurement of educational achievement in general” (p. 119) and discussed numerous issues that arise after a test has been administered and scored. The chapter is not a how-to; it is for the most part a discussion of the inherent limitations of standardized measurement and of the obstacles the test developer should confront. Indeed, Lindquist (1951) noted that “Upon considering the difficulties of measuring the objective that he has tentatively selected, the test constructor may often decide to forego its measurement entirely, and may turn instead to other more easily tested outcomes” (p. 119).
In the space of only 40 pages, Lindquist discussed a remarkably wide range of issues raised by standardized testing. He was adamant that the constructs amenable to standardized testing constitute only a modest portion of what schools should endeavor to accomplish. He discussed the large and in his view unavoidable gap between test content and the “ultimate” and “general” goals of education. He stressed that achievement, even construed more broadly than the subset of skills and knowledge assessed by standardized tests, is only one of many goals. Lindquist also emphasized the diverse effects of testing. He wrote: It is, of course, important that…tests…measure validly and dependably whatever they do attempt to measure, but it is even more important that what they do attempt to measure be worthwhile and significant, and that through their use the tests…exercise a desirable influence upon the aims, habits, attitudes, and achievements of students, teachers, counselors, and school administrators. (Lindquist, 1951, p. 120, emphasis added) There are many high schools, for example, in which all pupils are required to learn how to divide higher order polynomials and to factor quadratic equations. (p. 134)
Lindquist (1951) also wrote about the problem of inappropriate test preparation of the sort that inflates test scores. He wrote: The…continued use of a test…will…tend to reduce the correlation between the test series and the criterion series…Because of…rewards and penalties…the behavior measured by a…test tends…to become the real objective of instruction, to the neglect of the (different) behavior with which the ultimate objective is concerned. (p. 152)
Technique Versus Practice in Educational Measurement
Much of the material in Lindquist’s (1951) chapter illustrates what I am calling issues of practice. The terms practice and technique are ambiguous, so additional clarification is needed.
I use technique and technical work to refer to the mathematical and procedural aspects of test construction, scaling, linking, and reporting. I use practice to refer to issues that arise from the actual use of tests, including the purposes and goals of testing, the limitations of testing, the trade-offs between different approaches to testing, the diverse effects of testing, and the implications of these issues for test design, test use, and inference.
These two categories clearly overlap, and the defining difference between them is often focus and motivation rather than substance. For example, Lindquist devoted a substantial portion of his 1951 chapter to test construction, but his focus was not procedural concerns, such as maintaining appropriate item-test correlations. His focus was on the practical considerations constraining test construction. The is also true of his much briefer discussion of task formats. Moreover, addressing practical issues often requires technical work. In contrast, issues of technique can be, and often are, discussed without reference to practical problems or implications.
Inappropriate test preparation and the score inflation that it can create provide a clear illustration. These are clearly issues of practice, that is, they arise from the particular uses of tests in schools, admissions, and certification, and they create severe practical problems of inference. This is not to say, however, that they lack technical elements. Evaluating score inflation entails technical work, and addressing and ameliorating these problems entail difficult technical work in test design, linking, and validation (e.g., Haertel, 2013; Koretz, 2015; Koretz & Beguin, 2010; Morley et al., 2004). However, the motivation for this technical work is to address a practical problem that arises from test use. It is not motivated purely by an interest in technique per se, that is, by an interest in technical advancement or refinement.
These definitions help clarify the balance in E. F. Lindquist’s work. His stature stems in large part from his work in the realm of technique, in particular, from his exceptional productivity as a developer of achievement tests. Yet throughout his career, he maintained a strong and unflinching focus on issues of practice, including some that were—and remain today—serious problems for standardized assessment.
It is easy to find other eminent scholars in the field whose work has shown a balance of this sort. I would include many of the scholars who previously received the E. F. Lindquist Award established in his honor. I cite numerous other examples in the following. Nonetheless, the balance that Lindquist and other scholars exemplified is atrophying in the field as a whole, to the detriment of both the field and the people it should serve.
The Content Mix of Journals
The waning focus on issues of practice can be seen clearly in the content of professional journals. I will discuss two: Educational Measurement: Issues and Practice (EM:IP) and the Journal of Educational Measurement (JEM). These are among the most important journals in the field.
EM:IP was traditionally the premier journal for discussing what I have labeled issues of practice. It was an outlet of choice for practical work by scholars whose primary work was technical—for example, Robert Brennan, Robert Linn, and H. D. Hoover. This has changed dramatically over the past two decades. While a thorough review is beyond the scope of this article, a few examples contrasting issues published before the change to recent ones will illustrate the change clearly.
Volume 20 number 4 (December 2001) included an article by Brennan (2001) entitled “Some Problems, Pitfalls, and Paradoxes in Educational Measurement.” A second paper by Cizek (2001) described 10 positive unintended effects of high-stakes testing. Two additional papers described testing systems in other countries (Alsarimi, 2001; Amedahe, 2001). A year and a half later, volume 22 number 1 (March 2003) led with a paper based on H. D. Hoover’s 2002 National Council on Measurement in Education presidential address, which focused on two issues of practice: misconceptions about gender differences and misconceptions about the purposes of norms (Hoover, 2003). Hoover’s discussion of the later point included concrete illustrations of the lack of robustness of performance standards, an issue to which I will return in the following section. This issue also included a paper about an effort to get judges to reconcile the differences from three standards-setting methods (Green et al., 2003), a paper exploring the accuracy of National Assessment of Educational Progress (NAEP) self-reports of course taking (Niemi & Smith, 2003), two responses to the earlier Cizek paper (Camilli, 2003; Rich, 2003), and a rejoinder by Cizek (2003). In addition, it included a commentary by Popham (2003), “Seeking Redemption for Our Psychometric Sins,” rebuking the measurement field for not doing enough to stop the pernicious instructional effects of high-stakes testing. I’ll return to this as well.
Compare this to any set of recent issues. The journal still includes papers discussing important practical issues. An excellent recent example is a set of papers in a special edition addressing college admissions testing and social responsibility (Harris, 2021). Another example is a special issue examining the impact of the COVID-19 epidemic on educational measurement (Cui, 2022). And the journal still publishes individual papers on important practical issues, for example, a recent paper by Student and Gong (2022) exploring limitations in extrapolation from the results of large-scale assessments of the Next Generation Science Standards.
However, papers addressing issues of practice now constitute a modest share of the journal’s contents, and the majority of papers published in this journal would be suitable for an explicitly technical journal that makes no claim about addressing issues of practice. For example, one recent paper included nearly 30 equations (Almehrizi, 2022). I cite this paper not to criticize it; I found it both interesting and important. However, the issue here is not the quality of the papers published in EM:IP, but rather the extent to which the journal has come to focus less on issues of practice and more on issues of technique. That a majority of papers published in the premier journal dedicated to issues of practice would be fit very well into a purely technical journal is an important sign of the declining focus on issues of practice.
One might suggest that the technical papers now published in EM:IP would be a better fit in JEM, which has a clear focus on technical issues. However, it is important to recognize that while JEM has always been a more technically focused journal than EM:IP, it also used to publish important papers on issues of practice. JEM also shows the declining emphasis on such issues in the field, as papers of this sort have largely disappeared from it in recent decades.
As an example of JEM’s earlier focus, I will point to one issue that included some of the most important early papers on one of the practical issues I discuss in the following section, the lack of robustness of performance standards. In 1978, JEM published an issue (volume 15 number 4, December) devoted entirely to the use of performance standards as a reporting metric. These papers largely focused on practical rather than procedural matters, for example, the role of judgment and their implications for validity and the effects of applying standards, as opposed to details of standard-setting methods. I will return to this specific issue of JEM in the following.
Important Issues That Remain Inadequately Addressed
I focus on two serious problems of standardized testing that have not been addressed adequately despite decades of discussion. The first postdates Lindquist’s career but has been debated for at least 45 years and has been well documented empirically for almost as long: the lack of robustness of performance standards. The second is one that Lindquist first confronted nearly a century ago: test preparation and score inflation.
The Lack of Robustness of Performance Standards
In K–12 achievement testing in the United States, reporting in terms of performance standards (now the pervasive term for cut scores) began gradually with the use of cut scores in minimum competency testing programs in the 1970s (Koretz, 2008). Standards-based reporting gradually came to dominate reporting in the late 1980s and 1990s because of misconceptions about norm-referenced reporting (see Hoover, 2003) and a widespread view in the policy community that norm-referenced reporting made people inappropriately satisfied with current levels of performance (Koretz, 2008). 1 Some test-score reports still include scale scores, but sometimes the public receives little more than standards-based descriptions. For example, the student reports from the New York State testing program in Grades 3 through 8 contain only two types of information: the student’s placement on a four-level standards-based metric and the percentage of each of several skill sets mastered. There is no explanation of how these percents are calculated and no scale scores (New York State Education Department, 2019).
The Evidence
This shift to reliance on standards-based reporting has occurred despite a recognition in the field that the results of standard-setting are arbitrary and often dramatically inconsistent across alternatives. This fundamental threat to valid inference was the focus of debate decades ago but has largely faded from professional discussion, replaced by copious discussions of procedural issues.
This lack of robustness was one focus of the special issue of JEM 45 years ago that I noted above. In that issue, Glass (1978) wrote that standard-setting is unavoidably arbitrary and maintained that the consequences of the arbitrary decisions are so varied that it is necessary either to reduce their arbitrariness, and hence the unpredictability, or to abandon the search for criterion levels altogether in favor of ways that are less arbitrary and, hence, safer. (p. 237)
Glass’s choice of wording was unfortunate, because capriciousness is a red herring. The threat to valid inference arises from two factors: the arbitrariness of procedural decisions and the magnitude of the resulting variation in performance. Capriciousness is not essential. If a state can choose arbitrarily between one method that labels 15% of students as “proficient” and another than labels 60% as “proficient,” users of scores clearly cannot have confidence in either estimate.
Unfortunately, the inconsistency among standards-setting results is sometimes even larger than this hypothetical example. This was made clear by additional research over the two decades following that 1978 debate.
A decade after that special issue, Richard Jaeger, then one of the nation’s leading experts on performance standards, published a review in the third edition of Educational Measurement (Jaeger, 1989). He included a table showing 32 contrasts between methods drawn from 12 studies. In each case, he tabulated the ratio of the higher percentage passing to the lower percentage passing. These ratios ranged from 1 to 42, with a mean of 5.3 and a median of 1.5. A decade and a half later, Linn (2003) evaluated the results of three standard-setting methods (bookmark, contrasting groups, and Jaeger-Mills) for elementary-school tests in five subject areas in a new Kentucky assessment (Table 1). The ratios of highest to lowest percentage proficient ranged from 1.8 in mathematics to 10.8 in social studies, with a mean across subjects of 5.2.
Percent of Students Labeled “Proficient” Using Three Methods for Applying Standards in Kentucky

Note. Adapted from Linn (2003).
Worse, inconsistencies across methods are not the only source of a lack of robustness. It has been documented for at least 30 years that procedural differences within a given method can create substantial inconsistencies in results. For example, an evaluation of the 1992 NAEP Achievement Levels (NAEP’s terminology for performance standards) conducted by a panel of the National Academy of Education (Shepard et al., 1993) found that the backgrounds of the panelists, item format, and item difficulty all affected the cut scores set using the modified Angoff method. And the problem of within-method inconsistencies is not limited to the Angoff method. In the bookmark method, the predominant method in U.S. K–12 education, panelists are given definitions of the performance standards, an ordered item booklet (OIB) that presents test items in ascending order of difficulty, and a response probability (RP), which is the proportion of students at the cut score that should answer the target item correctly. They must then imagine students at the cut score and select the item from the OIB that these students will answer correctly with a probability equal to the RP. The RP is a largely arbitrary number, and researchers working in the area have argued for different values (see, e.g., Lewis et al., 2012; National Research Council, 2005). If panelists were able to perform this task well, the choice of RP shouldn’t matter; changing the RP should simply lead the panelists to select a different item from the OIB, and the same students would be identified as reaching the cut score. However, a number of studies have shown that panelists cannot do this, and changing the RP results substantially different cut scores (e.g., National Research Council, 2005). 2
The Responses in the Field
Inconsistencies of this magnitude create a fundamental—I would claim unsurmountable—barrier to valid inference unless there is either clear justification for choosing one specific method and one specific approach for implementing that method or other data supporting the validity of the inference. There is generally neither. As Linn (2003) aptly stated: The variability in the percentage of students who are labeled proficient or above due to the context in which the standards are set, the choice of judges, and the choice of method to set the standards is, in each instance, so large that the term proficient becomes meaningless. (p. 13)
Linn’s suggestion that we not rely on performance standards has been almost universally ignored, despite his eminence in the field. To a substantial degree, the blame for this lies with policy decisions, not decisions by people in the field, but in recent years, the field also has largely ignored the truly fundamental problems that Jaeger, Linn, Hoover, Shepard, and others documented. To be fair, a modest number of people have tried to address the lack of robustness. For example, both Linn (2003) and Jaeger (1989) suggested that if cut scores are used, the results of more than one method should be presented. Unfortunately, this isn’t a practical suggestion; it is hard to image a department of education releasing conflicting estimates. Another example is the work of Haertel (2002) and Haertel and Lorié (2004), who proposed a new approach to setting standards, labeled the briefing book method, that might tie cut scores more clearly to the inferences they are intended to support. But for the most part, the field has ignored these issues and has devoted its energies to copious additional technical work on standard-setting. Some years ago, I had a conversation with a leading researcher in the area of performance standards in which I lamented the lack of a thorough review of the robustness of performance standards more recent than Jaeger’s (1989) chapter. Their answer was that people working in the area were no longer very interested in the question of robustness and instead were focusing more on procedural issues. That seemed to me to be a damning indictment of the field’s atrophying attention to practical issues, even when they are fundamental.
Inappropriate Test Preparation and Score Inflation
Inappropriate teaching to the test was not a new or abstract concern for Lindquist when he wrote about it in 1951. His first large-scale testing program was inherently and deliberately competitive—hence the name “Iowa Brian Derby”—and by the mid-1930s, Lindquist was deeply concerned about the inappropriate test preparation it spawned. Over several years, he made a number of attempts to reduce that problem, but none worked. In the early 1940s, he took advantage of the fact that the press and public were much more concerned with the war than the Iowa Brain Derby to abolish the program and replace it with the ITED. Educators were advised to administer the ITED in the fall, not at the end of the school year, in order to maximize its diagnostic value and lessen the incentive to indulge in undesirable test preparation (H. Hoover, personal communication, February 15, 2023).
Thus, it has been nearly a century since one of the leading figures in the field publicly confronted undesirable test preparation, and it has been roughly three quarters of a century since this fundamental problem was described in a leading professional publication. Both warnings and empirical evidence have continued to accumulate in the intervening decades.
A quarter century after Lindquist’s (1951) paper, social scientists were again warned about score inflation, this time in far more widely read papers. In his seminal papers on the corruption of social indicators, Donald Campbell wrote that The more any quantitative social indicator is used for social decision making, the more subject it will be to corruption pressures and the more apt it will be to distort and corrupt the social processes it is intended to monitor. (Campbell, 1976, p. 49; 1979, p. 85) Achievement tests may well be valuable indicators of…achievement under conditions of normal teaching aimed at general competence. But when test scores become the goal of the teaching process, they both lose their value as indicators of educational status and distort the educational process in undesirable ways. (1976, p. 52; 1979, p. 85)
The Evidence
During the 1980s, as high-stakes testing gradually spread in the United States, a number of prominent scholars in the measurement field warned about the risk of score inflation (e.g., Koretz, 1988; Linn, 1987; Madaus, 1988a, 1988b; Shepard, 1988). Empirical evidence of both inappropriate test preparation practices and score inflation began to accumulate shortly afterward.
The types of behavioral responses to testing and their relationship to score inflation have been clarified by work over the past several decades. Some “teaching to the test” is of course desirable—for example, finding areas in which instruction needs to be strengthened and identifying students’ weaknesses for remediation—but a number of responses can bias scores. One is cheating. While data on the incidence of cheating are sparse, it is not rare (Koretz, 2017). Another response to testing can be called gaming, such as manipulating the sample of students tested (e.g., Figlio & Getzler, 2002; Jennings & Beveridge, 2009). Two responses that are particularly relevant to Lindquist’s and Campbell’s concerns and that have been the focus of considerable subsequent research have been labeled reallocation and coaching (Koretz & Hamilton, 2006; Koretz et al., 2001). Reallocation refers to shifting time and other instructional resources to better match the specific content of a particular test. Reallocation from untested to tested subjects does not in itself inflate test scores, although it can be undesirable for other reasons and can distort some inferences based on scores. For example, it remains unclear how much if any of the much discussed rapid rise in fourth-grade mathematics scores on the NAEP that began in 1990 stemmed from instructional time shifted from other subjects to mathematics rather than improved mathematics instruction or other factors (Koretz, 2017). Reallocation within a tested subject, which has been the focus of numerous studies, inflates scores when the de-emphasized material is relevant to the inferences based on scores.
Although it can inflate scores, reallocation is often encouraged by education authorities, as illustrated by a PowerPoint presentation placed online by a Massachusetts school district (Quincy Public Schools, 2004). Each slide showed a chapter of the algebra I text used in the district, broken into numbered sections. Each section showed the numbers of all of the released state test items from the last several years that had measured content from that section, which made it immediately apparent which sections—most of them—had not been tested at all.
Coaching refers to focusing on specifics of a test that are not germane to the inference but that can nonetheless affect performance, such as item format, other aspects of item presentation, and the specifics of scoring rubrics. Test-taking tricks, such as the process of elimination for multiple-choice items, are also examples of coaching. A clear illustration of coaching is provided by a test-preparation book for the tenth-grade Massachusetts MCAS test published by Princeton Review (Rubinstein, 2000). The tests at that time typically included an item about the Pythagorean Theorem. The preparation for these items offered in the book was of two types. One simply stated the formula so that students could memorize it. While this may be, in the words of one of my students, “garden-variety lousy teaching,” it is not coaching, and there is no reason to expect it to bias scores. The second type of preparation, however, capitalized on the substantively irrelevant fact that test items about the theorem typically have simple integer solutions because students do not know how to calculate square roots without a calculator. Many students who know the theorem would not be able to demonstrate that knowledge if the item required a noninteger solution. In response, the Princeton Review materials instructed students that one of two “common” or “popular” ratios, 3:4:5 or 5:12:13, or multiples of these, would solve the item (Rubinstein, 2000, p. 56). These ratios are not particularly common in the real world, but they are popular among item writers. This coaching permits students to answer the item correctly without learning the theorem, thereby inflating their scores.
A considerable number of studies over more than 40 years have documented behavioral responses of educators that can inflate scores, in particular reallocation (e.g., Hamilton et al., 2007, 2008; Koretz, Barron, et al., 1996; Koretz, Mitchell, et al., 1996; Luna & Turner, 2001; Pedulla et al., 2003; Romberg et al., 1989; Shepard & Dougherty, 1991; Smith, 1991; Smith & Rottenberg, 1991; Stecher, 2002; Stecher & Barron, 2001).
The first empirical evidence of score inflation may have been two papers by John Jacob Cannell, a West Virginia physician who began investigating when young patients of his who were experiencing academic difficulty nonetheless reported that they scored well on achievement tests (Cannell, 1987, 1989). He found that although his state of West Virginia scored very poorly on other educational indicators, the state’s students scored at the 65th percentile rank in grade three and at the 62nd percentile rank in grade six (Cannell, 1987, p. 1; subject not specified). He then began collecting data nationwide and found that: No state scores below the publisher’s “national norm” at the elementary level on any of the six major nationally normed, commercially available tests. A few states had one or two elementary grade levels or an occasional subject that was below average, but most states had all subject areas and all elementary grade levels well above the publisher’s “national norm” of the 50th percentile. (1987, p. 2)
Unambiguous evidence of score inflation began accumulating a few years later. The first of these studies was a cluster-randomized administration of multiple tests carried out in a district that had by today’s standards only moderately high stakes (Koretz et al., 1991). The study included two primary comparisons: the difference in performance between a new test administered by the district and a quite similar test administered the previous year, and the difference in performance on the old test in its last operational year and when readministered by the researchers four years later. Both comparisons suggested that that performance in third-grade mathematics was inflated by roughly half an academic year.
Additional confirmation of score inflation continued to accumulate, usually from studies that compared the performance of the same students or randomly equivalent groups of students on a high-stakes test and a lower stakes audit test of similar content—often, the NAEP (e.g., Fuller et al., 2006; Haladyna et al., 1991; Haney, 2000; Ho, 2007, 2009; Ho & Haertel, 2006; Jacob, 2005, 2007; Jennings & Bearak, 2014; Klein et al., 2000). Two early studies found severe inflation in Kentucky’s KIRIS program, which relied largely on constructed-response items and performance tasks (Hambleton et al., 1995; Koretz & Barron, 1998). These were particularly important at the time in showing that score inflation is not limited to multiple-choice tests.
Moreover, the magnitude of score inflation is often very large. For example, a number of studies have found gains on high-stakes tests two to six times as large as those on NAEP (e.g., Jacob, 2007; Klein et al., 2000; Koretz & Barron, 1998). In the first three years that New York State administered a new test introduced in 2006, the mean score in eighth-grade mathematics increased by 0.58 standard deviation, seven times the gain the state’s students showed on NAEP, 0.08 standard deviation (Figure 1). In one case, the gains of 0.76 standard deviation on a fourth-grade high-stakes reading test were accompanied by no gains whatever on the NAEP (Hambleton et al., 1995).
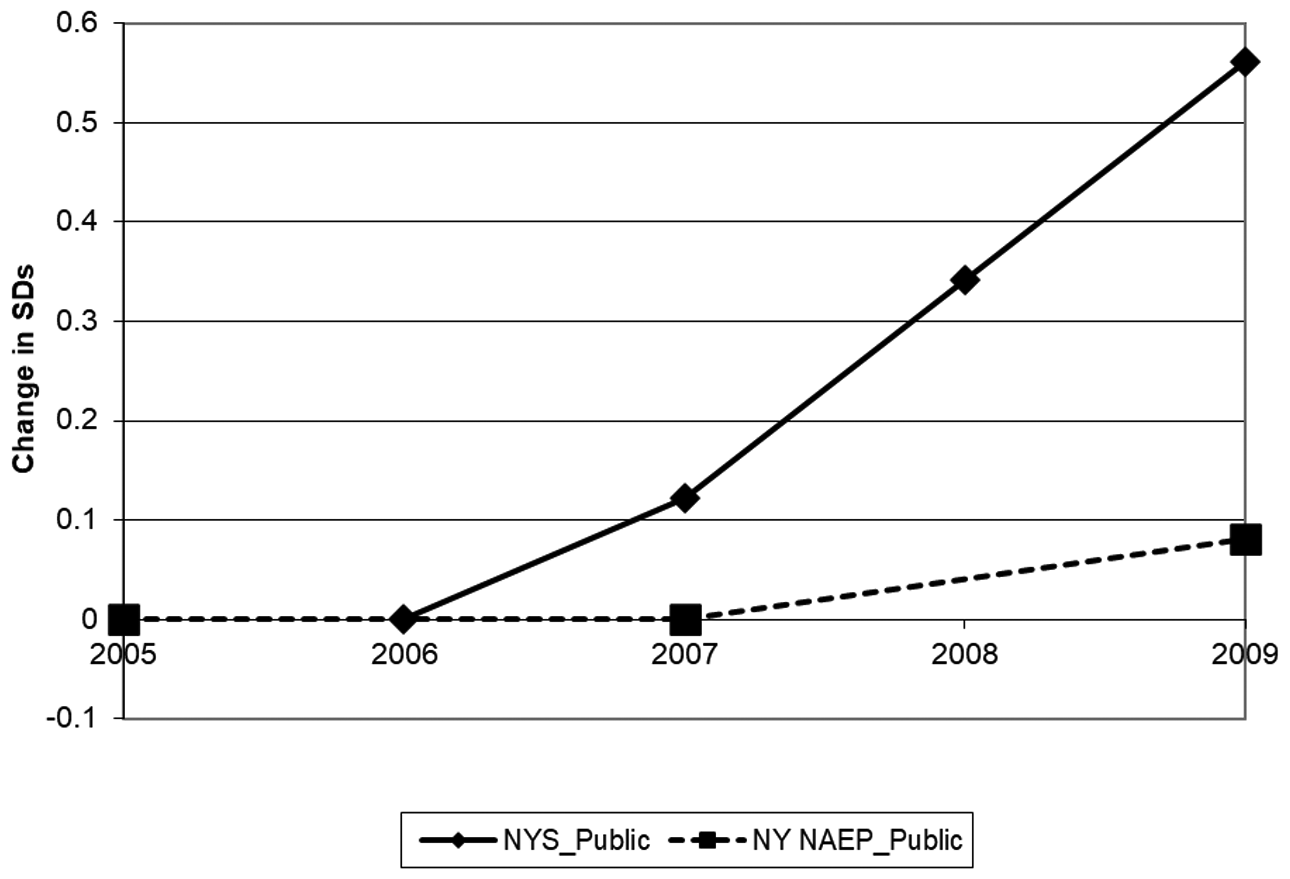
Trends in Eighth Grade Mathematics Scores in New York State, State Test and National Assessment of Educational Progress (Koretz, 2017).
The Responses in the Field
The accumulation of empirical evidence of score inflation and inappropriate test preparation generated substantial discussion in the field of educational measurement and, to a much lesser degree, economics (e.g., Neal, 2011). Recall that Lindquist raised the issue in the first edition of Educational Measurement (Lindquist, 1951). Fifty-five years later, inflation, the behaviors producing it, and methods for evaluating it were all discussed in detail in the fourth edition of Educational Measurement (Koretz & Hamilton, 2006). Perhaps the single most striking indication of the extent to which the problem of test preparation and inflation was recognized is the aforementioned 2003 paper by Popham, who had been one of the most influential proponents of measurement-driven instruction, that is, high-stakes testing. In that paper, entitled “Seeking redemption for our psychometric sins,” Popham (2003) excoriated the field for failing to respond to the degradation of instruction caused by high-stakes testing, including reduced attention to untested curricular content and the use of “seemingly interminable test preparation practice sessions” (p. 46) in an effort to boost scores. While some in the field of measurement might disagree about the magnitude and frequency of inappropriate test preparation and score inflation, it seems that recognition these problems is nearly ubiquitous in the field of educational measurement.
Inappropriate test preparation and score inflation have critically important implications for several core aspects of measurement practice. Yet despite the very long time that these problems have been recognized—nearly a century, if one goes back to the Iowa Brain Derby, and three-quarters of a century if one starts the clock with Lindquist’s (1951) chapter—standard measurement practice has not changed appreciably in response.
Perhaps most obvious, the risk of inflation requires augmenting conventional validation. Haertel (2013) noted that “Using high-stakes tests to focus the system on specific subjects or specific kinds of knowledge and skills carries substantial risks of unintended consequences, including score inflation and distortion of curriculum coverage” (p. 13) and argued that validation must evaluate these effects. Clearly, traditional validation methods cannot accomplish this. Koretz (2015) clarified that The empirical evidence adduced in traditional validation is typically collected before high stakes have influenced educator and student behavior—that is, before there has been an opportunity for score inflation to occur. This evidence is also primarily cross-sectional and correlational, so it is insensitive to changes in level even if collected repeatedly. (p. 20)
Inappropriate test preparation and score inflation also have critically important implications for test design (Koretz, 2015). Reallocation and coaching can only inflate scores when there is unnecessary predictability of content or of substantively irrelevant details of item and test construction. One can see this predictability documented in test-preparation materials, but for a systematic exploration of these recurrences in two testing programs, see Holcombe et al. (2013). The unnecessary recurrences that afford the opportunity for coaching improve item-level performance (Morley et al., 2004).
The consequences of test preparation and score inflation for test design have received even less attention from the field. I am aware of only two suggestions for new approaches in test design to lessen the opportunities for inappropriate test preparation and score inflation, and only one of these is from the field of educational measurement. The economists Barlevy and Neal (2012) suggested an approach that they labeled pay for percentile in which the test is entirely replaced for each administration with a test that lacks unnecessary predictability. However, this approach is intended for cases where only rank order matters and is not useful for applications where scaling is necessary, for example, for description of trends. Koretz and Beguin (2010) suggested self-monitoring assessments that would include embedded audit items that do not share unnecessary characteristics with other items.
These two approaches have had no appreciable impact on the practice of educational measurement. The pay for percentile approach has had limited application in development economics, but some of these studies do not implement the key feature of Barlevy and Neal’s approach, that is, the elimination of predictable elements (Taylor, 2023). Moreover, to my knowledge, this approach has not been implemented in the American educational system. Self-monitoring assessments have been tried in a few pilot studies in a single state (Koretz et al., 2016) but have not been otherwise used in operational assessments.
Test preparation and score inflation also have major, troubling implications for linking. Most large-scale assessments are linked over time using some form of nonequivalent groups anchor test (NEAT) linking, in which a small number of anchor items are repeated from one administration to the next, and performance on those items is used to estimate aggregate change. In testing programs that use NEAT linking, which includes most assessments in which score inflation has been evaluated, inflation can only arise when NEAT linking fails, that is, if the estimated difficulty of the anchor items in a new administration is biased (Koretz, 2015). This need not require that the anchor items themselves become familiar; it may be sufficient for the anchor items to share attributes with other items that are familiar. Either way, the fact of score inflation necessarily indicates that linking has failed. Therefore, in the absence of other data, NEAT linking cannot be trusted under high-stakes conditions.
Nonetheless, NEAT linking is still generally conducted as if this problem did not exist. Standard methods of screening out individual linking items, which eliminate anchor items that lie far from the equating line that relates performance on the prior and current administrations, do not address the problem of inflation, which entails a displacement of the entire equating line.
Thus, to a large degree, large-scale tests are still designed, linked, and validated as if inappropriate test preparation and score inflation were not an issue, even though empirical studies have shown that this bias is not rare and can be extremely large.
Toward Restoring Needed Balance
What can be done to begin restoring the balance between technical and practical issues that has atrophied in recent decades? Clearly, this depends on individual scholars making different decisions about their own work, but the problem is more complex. A number of factors impede reestablishing the appropriate balance, particularly in the case of practical issues that call current practices into question.
One external impediment is the lack of effective oversight that would pressure the field to confront serious problems of practice. Unlike many other technical fields that have important effects on policy or public welfare—for example, drug efficacy and safety, environmental regulation, and auto safety—there is no effective external oversight of educational testing. As a contrast, consider the Volkswagen diesel emissions control scandal that came to the surface in 2015 (Koretz, 2017). The VW scandal was in some ways a close analogy to one form of inappropriate test preparation—specifically, reallocation. VW engineers learned the characteristics of the sample of driving conditions simulated by the EPA’s emissions-control test (analogous to the content sampled in constructing an achievement test), and they engineered their diesel engines to perform very well on the tested sample, allowing them to perform far worse under many other conditions in actual use (in psychometric terms, the domain or target of inference). In actual use, the engines failed to meet emission limits by a large amount. This misconduct did not end because of a crisis of conscience on the part of VW executives or because a professional association of automobile manufacturers chastised them for inappropriate behavior. It ended because VW was caught by agencies that had the power to enforce the rules and that used that power to levy billions of dollars in fines and other penalties. Less than a decade later, VW is a leader in the transition to electric vehicles and is spending a great deal of money (part of their settlement with government agencies) to build a large network of vehicle chargers.
In contrast, there is no effective body to which inappropriate testing practices can be referred. This misconduct includes sins of omission as well as those of commission. For example, many local and state education agencies distribute materials that facilitate inappropriate test preparation and score inflation. Some refuse to allow data to be used to evaluate potential inflation or, for that matter, to conduct other research that might yield uncomfortable answers to important questions of practice. They are free to do this, with no oversight by any organization. VW had no such option. Neither did the diesel truck manufacturers caught in a similar scandal some years earlier (Koretz, 2017).
A second obstacle is market pressure. Educational measurement is for the most part a market-driven field, and a substantial proportion of the professionals in the field are employed by organizations that sell tests or related services. In some fields, market pressure can limit bad practice. In the case of the VW emissions scandal, market pressure arguably helped terminate the misconduct. The scandal hurt the company’s position in the market, and its stock took a beating, which added an incentive to change course. In contrast, in the case of educational testing, market pressure often inhibits improvement by pressuring the field to give short shrift to some difficult problems. This results partly from the fact that K–12 tests are mostly marketed to organizations, not to individuals. Even when individuals purchase testing services, the decision is often not theirs; for example, students buy college admissions tests because the colleges to which they want to apply request the scores. And this institutional market does not always encourage addressing problems of practice. For example, local and state education agencies are not demanding tests that are less susceptible to score inflation, and they sometimes refuse outright requests to evaluate data for possible inflation.
An example clearly illustrates this perverse market pressure. Years ago, when Gregory Anrig was CEO of ETS, a state government asked to buy the National Teacher Examination to evaluate practicing teachers for possible merit pay. The National Teacher Examination was a test designed for use in the certification and licensure of new teachers. Anrig refused to sell the test for the proposed use, explaining that the purpose of the test was only to predict teachers’ performance before there was an opportunity to observe it. He explained that it would not be appropriate to use a predictive measure after teachers had already demonstrated their performance (B. Bridgeman, personal communication, January 7, 2023). The state’s response was simply to buy a test from another vendor. Anrig had not managed to head off an inappropriate use of a test; he had merely cost his organization market share.
These impediments are likely to remain. Although I participated decades ago in an effort to create an oversight body—George Madaus’s efforts to create a National Board on Educational Testing and Public Policy—I was skeptical then for several reasons that such an organization could be maintained, and nothing in the intervening years has provided reason for more optimism. And the market for educational testing is not likely to change for the better.
However, these external impediments, while substantial, do not free those of us in the field from responsibility. The field exhibited better balance in the past while facing these same barriers, and that balance can be re-established, if scholars in the field have the will. There are many steps we can take, but I will note here only a few.
Most generally, we need to focus work on pressing problems in measurement practice. A part of this is refocusing discussion and debate on these issues, but that is in itself insufficient. We need to target technical work to address these pressing problems and not treat technical elegance as an end in itself. That is, in our own work, we need to bridge the gap between what I have called practical issues and technique. Lindquist provides an example: He developed the ITED program partly in response to what he perceived as the negative effects of the predecessor program, the Iowa Brain Derby.
The example of the Iowa Brain Derby points to a second needed step: We need to strengthen the field’s focus on appropriate and inappropriate uses of tests. Popham (2003) was justified in accusing the field of the “psychometric sin” of paying too little heed to the negative effects of testing programs on educational practice, and the intervening two decades have not seen substantial improvement in this respect. Here too, Lindquist warned of this need more than 70 years ago, when he wrote that the effects of a testing program on “the aims, habits, attitudes, and achievements of students, teachers, counselors, and school administrators” is even more important than whether it measures well what it purports to measure (Lindquist, 1951, p. 120).
Third, we need to refocus on the larger goals of education, and that requires being humbler about the appropriate uses of tests and more explicit about their limitations with respect to the broader goals of education. Policymakers and parts of the educational community have been all too eager to treat test scores as meaning more than they do about the quality of education, so it falls in part to the measurement community to provide a countervailing pressure. As Lindquist’s work illustrates so well, this does not imply that testing should be curtailed; remember that while he was outspoken about the limitations of testing, he was one of the most prolific developers of achievement tests in the history of the field.
The final recommendations stem from a change since Lindquist’s time, that is, from the now seemingly unbreakable connection between testing and accountability. As Haertel (2013), Koretz (2015), and Popham (2003) have argued, it is necessary for us in the field to confront the implications of high stakes for educational practice. This adds urgency to Lindquist’s call to examine the diverse effects of testing—unintended as well as intended—on education. In addition, it requires focusing technical work on very difficult issues of design and test construction, linking, and validation. Here too, what is required is bridging the gap between practical and technical concerns.
To be fair, some of the needed work will be very challenging. For example, some of the inflation-related problems with testing practices, particularly those pertaining to test design and linking, are daunting. The design and use of self-monitoring assessments pose a number of difficult problems (see Koretz & Beguin, 2010), and effective use of this technique requires lengthening tests to provide room for enough audit items for reliable estimates (Koretz et al., 2016). To address failures of NEAT linking may require additional data beyond that provided by the operational assessment (R. Brennan, personal communication, October 11, 2007).
However, the difficulty of confronting pressing practical problems is no justification for ignoring them. On the contrary, the difficulty in tackling these issues is reason for allocating substantial technical work to addressing them.
Finally, it is essential to recognize that re-establishing an appropriate balance will require more than the decisions of individual scholars about their own work. It isn’t reasonable to expect large numbers of scholars—particularly, junior scholars whose careers depend on finding a valued niche in the field—to swim against the tide and refocus their work in this manner unless there are broader changes in the field. The field must demonstrate that it values and rewards work on practical problems. This will require changes in the work solicited for journals and meetings and in the way we review papers, funding proposals, and colleague’s work, particularly the work of more junior researchers. The responsibility falls to all of us.
Footnotes
Author’s Note
This article is an adaptation of my E. F. Lindquist Award address, delivered at the American Educational Research Association annual meeting on April 14, 2023.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research and/or authorship of this article.