
Abstract
This paper proposes to see the way to integrate recommendations and direct experiences into reputational images as a planning problem. Specifically we achieve this goal through a combination of a fuzzy cognitive map and probabilistic planning with RDDL. Both were implemented inside a deliberative agent architecture that intends to appropriately represent the uncertain nature of data (with a Markov decision process) and the involved deliberative reasoning (with a fuzzy cognitive map). We are interested in the viability of using this view so it was tested by the simulations inspired in the ART testbed domain, but our final intention is proposing an alternative and richer representation of concepts involved in reputation problems instead of increasing the accuracy of trust predictions at any cost.
Introduction
In recent years, the capacity offered by Multi-Agent Systems (MAS) in order to provide jointly Context-Aware services have increased. One of the reasons of these advances has been the capacity offered by agents in order to cooperate themselves in a given situational state (context). When this context involves subjective criteria or uncertainty, this cooperation makes trust playing a fundamental role to provide reliable and useful Context-Aware services. Therefore, the decision process of trusting target agents is dependent on their reputational images computed from the shared data/knowledge by the cooperation. These data have different nature/source (subjectivity, freshness, similarity, etc.), mainly third party-recommendations and previously provided services. Therefore the addressed problem consists of the process of integration of multiple data and knowledge (recommendations and past actions) representing the same real-world object (target agent) into a consistent, accurate and useful representation (reputational image or trust level).
Regarding the critical points of this trusting problem depends on the nature of source data to fuse: (i) uncertainty of the agent’s action, e.g.: one agent A does not desire to share its knowledge with the agent B; and (ii) dynamic evolution in the trust level of agents. According to these points, we suggest that considering the integration of the very different nature and source of the information and its sequential use in each iteration cycle as a probabilistic plan, and therefore trusting agents can be seen as probabilistic planners. A plan would be dynamically built at each iteration cycle, and is made of a sequence of actions such as which agents ask for reputation, for opinions, which agents to share with opinions, etc. Since the potential execution of this trusting actions depends on probabilities (concluded from reputation values) agents reasoning and acting in a trusting system become a form of probabilistic planners. Our point is that this approach might allow agents to cooperate in a efficient way, adapting themselves and responding under a trusted way to other agents.
The paper is organized as follows. Section 2 summarizes the previous contributions to this research issue. Section 3 explains ART and its terminology and protocols, discussing the reason to define a possible generalization of ART domain. Section 4 describes the hybrid architecture which has been suggested, where the first part explained the deliberative process with the MDP model and the second part, it is explained the Cognitive Module by the design that was carried out in the FCM. Finally, Section 5 explains the results of the proposed model to verify the feasibility of the deliberative and cognitive approach in MAS and finally, in Section 6 is shown conclusions and future works.
Related work
In recent years, trust and reputation relevance has been recognized by journals, conferences and governmental calls. The main reason is because managing both concepts is a key factor to generalize the use of software agents intelligent enough to search and select potential partners without enough prior interaction or experience [23].
Although trust and reputation are often indistinctly used, and many definitions of them have been proposed, trust stands for a more general concept that describes an attitude or predisposition to make some costly decisions based on several decision criteria such as trustee’s privacy policy, legal requirements, and system’s properties such as transparency, authenticity, confidentiality, and non-repudiation [21], reputation can be considered as just another criterion to measure the confidence level, it represents the image that an agent has shown in previous interactions according to its honesty, motivation, competence and predictability [1]. With such approach the reputation of an agent can be seen as a statistical value about the trust probability computed from previous interactions and recommendations. In this way, reputation-based trust models should provide an incentive mechanism that would decrease the level of risks involved in the interaction with potential malicious agents [9].
Many reputation-based trust models have been published as these surveys show [29,31], but from them, we can distinguish two main alternatives: The ones exclusively based on mathematical methods such as Bayesian probability, maximum likelihood, Beta probability, weighted arithmetic means, game theory, and average of weighted recommendations [4,15,18,22,30,35,38,40], while others pay attention to broader requirements which these models have to request [2]: (i) cognitive approach to resolve complex trust problems; (ii) reasoning of the agent as a module of the multi-agent architecture, providing agents of reactive capacity; and (iii) interoperable solution to compare different trust models. These belief/cognitive trust models are built on abstractions of the human concept of trust [11,39].
Another relevant issue is determining which of this trust model is more effective. However, performance of trust models tends to be evaluated with ad-hoc simulations and metrics that combine different frequency and intensity of change in agent behaviours. Therefore it was difficult to conclude fair comparisons among the so many proposed reputation-based trust models, and the Agent Reputation Testbed (ART) initiative was launch with this aim [14].1
The claim of this work is to present this agent trust reasoning process following a cognitive approach guided by a probabilistic planning as the Markov Decision Process (MDP). Although, as we have mentioned some of them before, the use of probabilistic approach to trust models is not new, these approaches do not combine it with a deliberative reasoning architecture. Furthermore, the originality of this paper also comes from the point that no author has seen this trust reasoning process from the planning perspective as we suggest to do. In both senses our contribution is innovative.
The closest contributions to our proposed architecture that adds a socio-cognitive module into the agent’s trust strategy, are the theories proposed in [7,12] with Fuzzy Cognitive Maps (FCM) and the integration of a socio-cognitive module with ART architecture in [20]. Another obvious precedent is the first approach in the design of the trusting process as planning problem was carried out in [6] using Probabilistic Planning Domain Definition Language (PPDDL). However, this first attempt has shown a number of critical points which PPDDL has not managed correctly. It can be summarized in: (i) preconditions with probabilities; (ii) definition of dynamic rewards (in discrete time); and (iii) usage of non-quantitative probabilities.
Agent Reputation Testbed (ART), defined in [14], is a multi-agent platform to compare different reputation models in the appraisal domain. In this domain, agents are players/competitors that appraise paintings and implement trust strategies. Very close valuations of paintings to the real value would lead to more future clients, and therefore to more earning so win the competition. Each painting belongs to an era among a finite set of possible artistic eras. All the interactions which take place in the ART domain can be enumerated in the following steps:
Client makes a request to appraiser agent to ask the evaluation of a painting over an era.
Appraiser tries to make the evaluation but if he does not have the enough knowledge to carry out the appraisal, he will have to ask to other appraisers to share the knowledge over the requested era or share its own evaluation for the same painting and era. This task is named Reputation process.
This appraiser decides to reply or not according to its strategy in the process of sharing the reputation knowledge. In consequence, agents can perform different strategies to obtain a better result in the competition: (i) getting more money if they share the reputation; or (ii) generating bad opinions by appraisers and so they are penalized by clients.
The aim of ART platform is to provide a ranking of best agents in terms of efficiency (economic balance results) obtained from the sum of the received rewards from their actions: performing correctly opinions to clients over the pair painting – era and selling its knowledge or sharing opinions with other appraisers. While the way to obtain such rewards is choosing the best partner in each interaction in terms of reputational image obtained from the perception of its actions. This research does not aim to increase ART capabilities, the utility of ART testbed for us is because it has clearly specified the steps to be taken in each trusting iteration cycle while all concepts involved are clearly stated and defined. So we can use ART testbed as a case of use of a probabilistic planner acting as a trusting agent.
Regarding the previous description, ART Testbed was defined to the appraisal domain, but to generalize our approach we renamed concepts and predicates to achieve the independence of the domain in the model. In this sense, we propose: Service instead of Painting; Type of Service instead of Artistic Era; Provider Agent instead of Appraiser Agent; and Capacity instead of Certainty.
Trusting process as a probabilistic planning problem
We decided the usage of Relational Dynamic Influence Diagram Language (RDDL), developed by Sanner in [32] because RDDL could model complex probabilistic domains more effectively due to the expressiveness which is introduced in the following points:
Usage of fluents variables with in the definition of every domain element: actions, states, constants and observations;
Support to define dynamic strategies for rewards;
Possibility of using non-quantitative probabilities;
Support to use the most important probability distributions: KronDelta, DiracDelta or Bernoulli;
Management of the concurrence in action preconditions/effects. Due to the design by a Dynamic Bayesian Network (DBN) of RDDL, it is not allowed conflict in the global restrictions of the domain because action preconditions are not checked locally.
Additionally RDDL is becoming the standard language where probabilistic planning Community is going to focus their efforts in searching new designs and improvements; for instance, International Probabilistic Planning Competition (IPPC) 2011.2
Usage of RDDL in IPPC 2011, see http://users.cecs.anu.edu.au/~ssanner/IPPC_2011.
We have also another reason to choose RDDL: it puts forward a design which was shaped taking the flexibility as a significant point. This fact has offered the possibility of mixing the two kinds of layers to model the trust process for the agent: Deliberative and Cognitive layers. However, this solution is not valid to be integrated in the official ART Simulator (there would be to implement a middleware between this architecture and ART simulation engine and we did not take such approach in this paper).
Since the aim of this work is to propose a new deliberative approach in the MAS communication exploring solutions in Cognitive Trust [13,20,37], the proposed agent architecture embraces: (i) a Deliberative Layer, which is in charge of solving the communication problem through a DBN [3,32]; and (ii) a Cognitive Layer, which computes the fusion of heterogeneous data into the concept of trust in this problem in order to supervise the communication of the agent in a reliable way [7,12]. This architecture lead the agent to create an action plan that agent will use it to infer what type of message (opinion or reputation) has to be sent to providers in each step of the ART simulation.
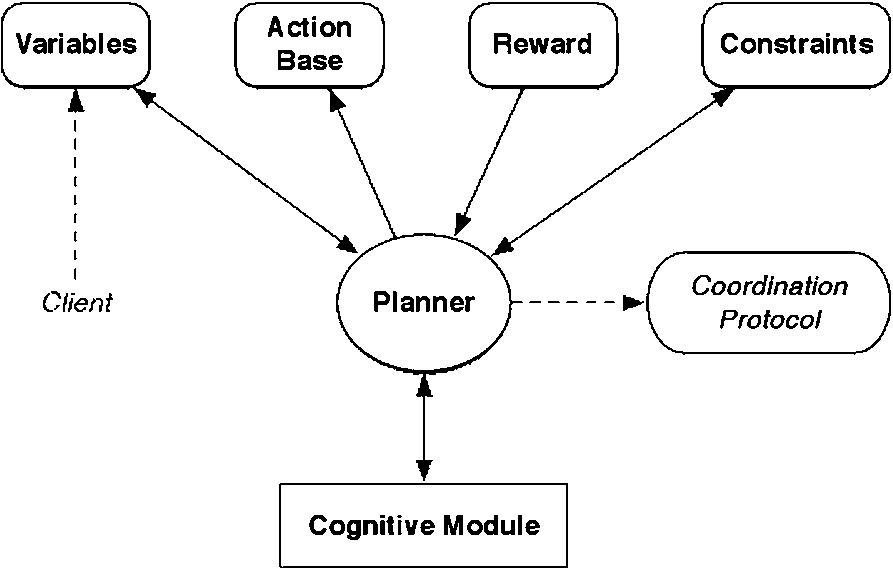
Hybrid architecture for a trusted communication in ART agent.
Figure 1 shows the main components of the agent architecture. The client updates the set of Variables, that is to say a new request predicate is put as a initial state for the RDDL planner. Then, the planner starts to instantiate the agent-action from the Action Base maximizing the Reward function (to get the highest number of coins in ART Simulator) according to Constraints (of the agent-action, i.e.: available coins, necessity of knowledge, etc.) and the trust-level of each Provider-Agent has got from the FCM in the Cognitive Module of the agent. Therefore, every agent-action is required to obtain a minimum trust-level during the decision process in order to be instantiated.
RDDL uses the Markov Decision Process (MDP) to model problems with sequential decision where the system is evolving in the time and it is controlled by an agent [3,33], assuming this agent will always know its own state before applying their actions. A MDP is described formally as the following variable
According to this, it is defined the stationary policy as the association
The main problem which MDP planners have to resolve is in the resolution of problems where the size and dimensionality are too high. According to this, it has been described in [8,17] that one of the two critical points that MDP planners have to manage is the exponential growth of DBN model when the number of random variables increase.
Then, the section is focused in formalizing the types, predicates and actions (asking-opinion and asking-reputation) under the probabilistic planning paradigm. The basic concept of ART domain are: (i) agent, both clients and appraisers; (ii) service; and (iii) type of service. Previously, it is defined the RDDL requirements, following the same process like other languages with imports. In this case, the domain is provided to manage real and integer numbers, deterministic reward function, intermediate states and the usage of global constraints for states (see Fig. 2).

RDDL Basic concepts in ART domain.

Examples of state-variables according to the MDP model proposed by RDDL.

Transition map for the Fluent variable
Then, it is described the variables which will model the different states where the previous concepts can be. There are the following groups to manage these variables:
Non-fluents variables, those variables will be remained constant during all planning process; it will only change in the definition of each problem. They represent the different constants of the domain and the predicates whose value does not change along time.
Fluents variables, they are the states in the DBN model. They are those variables whose value changes along time–execution, either stochastic way as is-cooperative(agent) variable or determined by agent-action/other variables (both fluents or non-fluents).
Agent-Actions, they represent the actions in the PPDDL model and they enclose the two main actions that an agent carries out: asking-reputation and asking-opinion. Regarding that: (i) action preconditions are defined in the point Action Constraints in this section; and (ii) action effects are performed in the transition model cfp, specified latter.
In the following lines, it is presented an example of RDDL for each one of the previous classes of variables. Regard that the whole definition of RDDL variables is defined in the Appendix of this document (see Fig. 3).

Example of transition map for thresholds-variables.
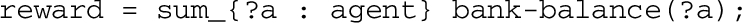
Reward function defined for each ART agent.

Preconditions in agent-action
In the next point, it is defined the logic in the MDP model, named in RDDL as Conditional Probabilistic Function (cfp), that is to say transitions which Fluent variables has to carry out.
Below and more specifically, it is shown the Fluent
According to [6, Section 6], it has to be designed an additional strategy over the previous logic. Agents does not know a priori the behaviour of others in their process where they exchange and share the reputation.
In this sense, it is set out a exploration vs. exploitation strategy (similar to others agent competitions) where the agent may have the possibility to acquire the knowledge which others agents have got in the first steps of the planning process. Along this planning process draws on, agents will change toward a exploitation of their knowledge instead of their initial behaviour of exploration.
To achieve this, it has been employed a technique based on thresholds which rule the trigger of agents’ actions according to the values obtained in the knowledge, capacity, cooperation and experience threshold-variables. Below, it is shown an example to control the cooperation variable (see Fig. 5).
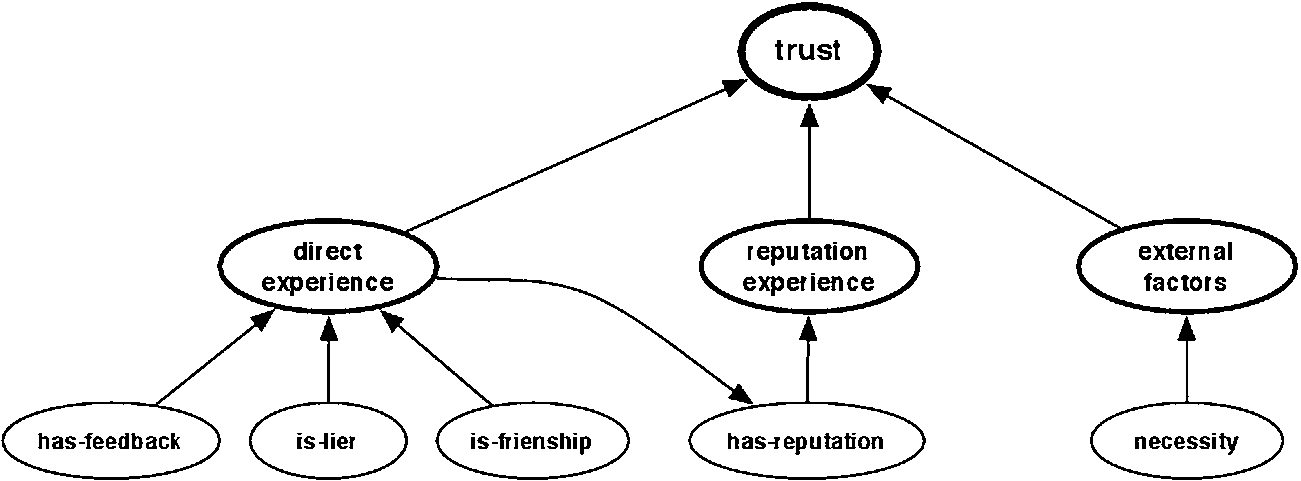
Fuzzy cognitive map to calculate the trust-level for each Provider Agent in actions.
These thresholds are defined ad-hoc, as they were defined in the other implemented and published ART competition agents. The chosen values have impact on the accuracy of trust predictions, and the specific instantiation of them could be relevant to win ART games against published competition agents, but in fact one of the conclusions of the ART discussion notes3
One of the most important point in the design of probabilistic planning is the definition of the reward function. In the ART context, the designed function compensates to agents due to the cooperation which may be exchanged among them, either in the reputation or opinion processes.
Regarding that agents must search a trade-off solution between capacity over types of services and invested money in getting the knowledge to perform good opinions, i.e. REPUTATION-COST and OPINION-COST when fluent-state
We used the First-order logic in order to specify preconditions, inhibiting the available actions for each agent when any precondition is not asserted. Taking into the logic for the Fluent variable
All it is showed up to this moment is the Probabilistic planner following MDP model to create a plan of action for the communication among agents. However, the reader may have checked that the main state related about the trust-level has not defined yet; i.e.:
The fluent state
FCM integrates the accumulated experience, making it available a straightforward decision in different applications and domains where the knowledge of human expert can be model.
Figure 8 shows the FCM proposed to calculate what trust-level has the provider agent over the agent may instantiate the
Direct Experience, it manages the past experience that was got from that provider, taking into account whether the provider had a possible friendship-relation, as well as UNO strategy defined in [27].
Reputation Experience, it defines the trust information about this Provider by others, regarding that reputation information is weighted according to the direct experience that the agent had about others which make this reputation; see the interconnection between direct experience node and the provider agent node to model this kind of feedback.
External Factors, it concerns the opportunity of performing the ART Coordination protocol in order to increase the own capacity, so it has been defined the necessity by: 1 −
Percentages of wins by the ART agent with FCM over fully deliberative agents
In this section, the proposed architecture was built to demonstrate the performance of the cognitive model under two experimental scenarios. The purpose is to evaluate the behaviour of the trust strategy, the interaction and cooperation with other agents and how to manage unfair agents.
Evaluation settings
The evaluation was analysed following two different approaches. All experiments were implemented using SPUDD,4
General information about SPUDD and source-code download, see
Results in simulation process where an agent can instantiate actions concurrently in MDP problems by means of RDDL
Concerning about the set-up of FCM, experiments have to define two values to initialize the map. First, the weight of each link in the FCM, shown in Fig. 8, reflects the impact of the corresponding concept in the final trust. In this work, these weights are constant and this FCM does not utilize any learning technique to update them. In consequence, we have decided to set out the FCM with 50% for Direct Experience, 40% for Reputation Experience and 10% in External Factor. Second and about the activation function, we have decided to use the Sigmoid Function
In the first experiment, the aim was to compare two kind of agents. The first one was defined by the FCM template of this work in the process of instantiation of agent-actions. The other kind of agents defines the rest of agents implemented by the initial version of RDDL in ART problem [26], where the inference process were managed by the deliberative planner SPUDD. Besides, for each problem it is added cheating providers, which does not collaborate, and honest providers, which always performs the best opinion and reputation for requesters.
The results are showed in the Table 1. As it may be appreciated, strategies which were guided by the FCM have won in all problems (better than 50% of wins). It is also important to note that the percentage of wins for our FCM agent increases according to the number of agents does in each problem, both honest and liars agents. For this reason, a trust-cognitive strategy is more optimal in coordination problems where relationships among agents are increased and it is needed some mechanism to control the fusion process.
When the problem has set up with only 4 agents, Cognitive agent does not improve significantly instead of the Deliberative agent; SPUDD planner got a 50% of success to instantiate the agent-action. However, when the number of agents is increased, agent’s reasoning with FCM offers an efficient results, both Agent’s Wins and Time Reduction, due to:
Management about providers (Who is a liar?, Did I receive a good feedback from that provider?, etc.) by Direct Experience. Making trust-bonds with providers through the Reputational Experience. Evaluation whether new opinions should be gathered from providers by means of Knowledge Necessity.
Evaluation in problems with concurrent agent-actions
In the second experiment, the goal was to identify the expected improve when our agent is deployed in a more realistic environment by means of allowing a higher number of parallel actions for each agent, that is to say a concurrent MDP problem. All problems have been set up with the identical parameters: 5 services, 3 types of service and the same features in SPUDD. Regard that the number of agents has been set up in four agents for all problems: our FCM agent, one non-cognitive, a cheating/liar provider and finally, an honest provider; RDDL cannot manage a higher number of agent due to a scalability problem when agent-actions are performed concurrently.
The experiment, presented in the Table 2, showed a satisfactory results. On the one hand, results haven confirmed that our trust-cognitive strategy offers a better response according to the environment is more realistic. Our FCM agent got better result for problems with four agents where it is allowed to use parallel agent-actions, as well as the number of agents increased in the previous evaluation.
On the other, there is a loss of the scalability when concurrent agent-actions grows. We can only launch three problems under this context, however, FCM agent gives a significant reduction in the execution time in contrast with results offered by the initial deliberative agent in [26].
Conclusions and future works
Addressing the coordination process in Multi-Agent Systems as a probabilistic planning problem of Deliberative agents offers a new, descriptive and complete solution to trust and reputation discipline. We introduce a Deliberative Architecture based on the concept of Trust proposed by Castelfranchi and Falcone and after this work, we have confirmed the possibility of integrating a deliberative reasoning guided by Cognitive Trust module in a seamless way, thanks for the flexibility which RDDL offers. In the first evaluation, our agent guided by fuzzy cognitive map decides a better plan for the ART coordination problems thanks to a better state-space search as a result of: (i) efficient modelling for Trust and Reputation concept to detect the nature of agents (reliable vs. liar; trust vs. mistrust providers) and, (ii) agent awareness to represent its knowledge level (either innate or gathered from other agents) and the necessity to improve it.
In second evaluation about concurrent MDP problems, FCM agent does not offer the expected result due to the loss of scalability according to the parallel actions are incremented. In a full deliberative approach we see the same problem [26], so RDDL planner as well as the hardware environment may be the reasons to explain this disadvantage. Despite this lack of scalability, we present an innovative approach that addresses the deliberative reasoning for trusting decision as a probabilistic planning Problem improved by a fuzzy cognitive map to make more reliable the trust predictions.
Future works will be discoursed in two lines: (i) we will give a learning machine for the fuzzy cognitive map to complete the design, for example we could update weights in the interconnections in consonance with the feedback protocol in ART either perform new strategies to balance the weight the reputation or opinion actions in the value of the Trust concept; and (ii) we will have to plan to translate this agent architecture in a specified Programming language such as JADE or JASON to propose an evaluation of this work in more complex scenarios than RDDL allows, including comparisons with other Trust Cognitive strategies for Multi-Agent Systems such those who participate in ART competitions.
Footnotes
Acknowledgements
This work was supported in part by Projects MINECO TEC2012-37832-C02-01, CICYT TEC2011-28626-C02-02, CAM CONTEXTS (S2009/TIC-1485).
Implementation of the probabilistic planning domain in RDDL
This appendix presents the complete design of the probabilistic planning domain in RDDL. It has been divided in the different sections which defined a domain in RDDL, i.e.: first, definition of state-variables; second, transition map for each state-variable including the variable