
Abstract
Clustering-based unsupervised domain adaptive person re-identification methods have achieved remarkable progress. However, existing works are easy to fall into local minimum traps due to the optimization of two variables, feature representation and pseudo labels. Besides, the model can also be hurt by the inevitable false assignment of pseudo labels. In order to solve these problems, we propose the Doubly Stochastic Subdomain Mining (DSSM) to prevent the nonconvex optimization from falling into local minima in this paper. And we also design a novel reweighting algorithm based on the similarity correlation coefficient between samples which is referred to as Maximal Heterogeneous Similarity (MHS), it can reduce the adverse effect caused by noisy labels. Extensive experiments on two popular person re-identification datasets demonstrate that our method outperforms other state-of-the-art works. The source code is available at https://github.com/Tchunansheng/DSSM.
Introduction
Person re-identification (ReID) aims to identify a specific pedestrian across different surveillance cameras, which has wide range of applications such as suspect tracking, finding lost kids or aged man, crowd trajectory analysis and etc. Existing works have achieved satisfactory performance for supervised person re-identification [17,18,27,28,30], in which the training data and testing data are collected from the same domain. But the performance of these models usually drops dramatically while generalizing to a new target domain. To address this problem, more and more researchers concentrate on Unsupervised Domain Adaptive (UDA) person ReID tasks [21,34,41], in which both labeled source domain data and unlabeled target domain data are utilized in model training.
For UDA person ReID tasks, many methods [5,7,13,22,25,33,43] devote to reducing the gaps between source domain and target domain. Along the typical GAN-based approach, some models [5,7,33,43] map the data from source domain to target domain while retaining their labels. Other approaches [13,22,25] focus on aligning the source and target domains in feature level. But all these methods do not use the target domain data in model training, the model’s performance is not satisfactory.
Another typical approach to UDA person ReID focuses on the generation of pseudo labels [4,10,37,41], which consists of three steps: model pre-training with labeled source domain data, clustering-based pseudo label assignment for samples in target domain, fine-tune the model using the target domain data with pseudo labels. The last two steps are generally carried out iteratively to optimize the feature representation and the clustering results. However, noisy pseudo labels are inevitably generated due to the gaps between the source domain and the target domain and the unstable clustering algorithm. These noisy labels would mislead the model training, and then lead to the inaccurate clustering results. Therefore, addressing the mutual negative influence for the last two steps is important and necessary for UDA person ReID models.
To address this problem, there are two challenges. For the first one, UDA person ReID involves the optimization of two variables, feature representation and pseudo labels, which is more complicated than the traditional supervised ReID tasks and brings more risk of falling into local minimum traps. The second challenge arises from the interaction between the two variables, since the feature learning is based on the pseudo labels and the pseudo labels are obtained from the clustering result which is calculated according to the feature space. In the early stage of the iterative optimization, the feature space has not been trained well to distinguish different person IDs while pseudo labels are still noisy.
To solve the first challenge, we propose a stochastic sampling scheme to prevent the model from falling into local minimum traps. Although the previous works used the minibatch-based SGD methods to reduce the risk of falling into local minima for feature learning, they still adopted all training samples to generate pseudo labels, which makes the clustering results easy to fall into local minima. Moreover, the adverse effect of the noisy labels in the current epoch is difficult to be corrected in the next epoch if the training target samples remain constant. To overcome these issues, we present a new sampling algorithm, referred to as Doubly Stochastic Subdomain Mining (DSSM), with which both the feature learning and the sample clustering in each training round are implemented based on a part of randomly selected samples instead of the whole training set. These samples can be viewed as a subdomain of the training set, which provides better diversity for model learning, and therefore reduces the risk of falling into local minimum traps and helps to correct noisy pseudo labels.
For the second challenge, we propose a new sample reweighting algorithm to reduce the adverse impact of noisy labels. The weight of each sample is generated based on a new metric referred to as Maximal Heterogeneous Similarity (MHS), which reflects the confidence level of the assigned pseudo label. The proposed MHS-based sample Reweighting algorithm (R-MHS) can effectively suppress the negative impact of noisy pseudo labels and consequently break down the vicious circle between poor feature representation and false clustering results.
Overall, the main contributions of this paper can be summarized in three aspects:
We propose the Doubly Stochastic Subdomain Mining sampling algorithm to supply different sample subdomains for each training epoch, which helps prevent the model from falling into local minimum traps. A new sample reweighting algorithm is designed based on Maximal Heterogeneous Similarity to reduce the negative impact caused by noisy pseudo labels. Extensive experiments on popular benchmarks show that our model achieves the state-of-the-art performance, which demonstrates the effectiveness of our proposed model.
Related work
Unsupervised domain adaptive person ReID
The UDA person ReID aims at transferring the knowledge from labeled source domain to unlabeled target domain. Existing UDA person ReID methods can be summarized into two categories. For the first category, some methods attempt to reduce the domain gaps between the source domain and target domain. Among which, some works [5,7,33,43] apply the Generative Adversarial Network to transform the image style from source domain to target domain, which can reduce the domain bias in image level. Some existing methods attempt to eliminate the domain bias in feature level. Mekhazni et al. [22] proposed to utilize the maximum mean discrepancy to reduce the difference between the distributions of source and target domains. Eanet [13] utilized the key points to align the features across source domain and target domain distributions. However, the samples of target domain and their underlying identity information are not fully used in the training of the feature network. For the second category, clustering-based methods are widely used to generate pseudo labels as supervision to fine-tune the model. Some methods [10,20,35] use the pseudo labels which are generated based on the clustering algorithm to fine-tune the pretrained model directly. Since noisy pseudo labels are inevitably introduced in the clustering step, some works strive to reduce the negative impact caused by these noisy labels, such as MMT [9], NRMT [37] and MEB-Net [36]. But these methods can still fall into the local minimum traps through the alternate iterative learning between the feature network and the pseudo labels.
In this paper, we follow the clustering-based approach to solve the UDA person ReID task. The difference compared with the above mentioned works is that our model is motivated to learn knowledge from diverse target subdomains instead of the whole target domain in different training rounds, and a new reweighting method is proposed to alleviate the influence of noisy pseudo labels.
Dealing with local minimum traps
The training of deep neural network can easily fall into local minimum traps. In order to analyse this phenomenon and address this issue, a lot of works focus on this purpose. Some of these methods [15,19,23,29] concentrate on the objective functions, which attempt to avoid the problem that cannot achieve the global optimal solution by imposing some constraints on the objective functions. And some works [3,31,42] aim at the convergence of gradient-based methods for optimizing losses. For example, Liang et al. [19] proposed to add one special neuron with a skip connection to the output or one special neuron per layer, with the help of these new structures, the new loss function can eliminate spurious local minima. Brutzkus et al. [3] showed that when the input data follows the gaussian distribution, the gradient descent of lightweight network would converge to the global optimum solution. However, these methods only focus on the problem that the supervised learning of model is easy to fall into local minima, they cannot solve the local minimum problem in the iterative optimization process between the clustering and feature learning in UDA person ReID. In order to address this problem, we propose a new stochastic sampling scheme to supply various subdomains for clustering and feature learning in different training rounds, which can prevent the nonconvex iterative optimization between both of them from falling into local minima.
Sample reweighting
In some tasks, there exists some outlier samples or some noisy data that would confuse the model training. However, these samples can’t be found directly, therefore sample reweighting strategy is frequently utilized to reduce their adverse impact. In order to enable the model to avoid suffering from these noisy labels, some methods [4,6,11] discard the samples which may have the noisy labels during the training phase. Co-teaching [11] proposed to train the two networks at the same time and then the two networks work together to select partial samples as reliable data to update the parameters of models. DCML [4] proposed to progressively adopt samples based on two credibility metrics which include K-Nearest Neighbor similarity for density evaluation and the prototype similarity for centrality evaluation. All these works need pre-defined threshold as empirical parameter to filter out noisy labels. Cheng et al. [6] proposed an adaptive dynamic threshold to ensure that the clean samples are selected. However, it is hard to guarantee that the discarded samples are noisy, which reduces the diversity in training data while wasting some useful samples. Therefore some works [26,38] assign continuous weights to different samples instead of removing these samples directly, which can make the training process robust. Shu et al. [26] used an MLP with one hidden layer to reweight each sample, which can automatically learn the mapping relationship from loss to weight under the guidance of the unbiased meta data. UNRN [38] adopted the KL divergence to evaluate the reliability of each sample and utilize this uncertainty to reweight its contribution for model training. However, these methods do not consider the correlations between samples which may neglect hidden information.
Different from the above works, this paper proposes a novel sample reweighting method based on a new metric referred to as Maximal Heterogeneous Similarity, which takes the similarity between different samples into account. Based on the MHS, samples with high credibility labels are enhanced and the samples with low quality labels are suppressed in the training of the model, which can reduce the negative impact caused by noisy pseudo labels.
Method
Overall framework
Given a labeled training dataset
According to the above analysis, model training involves the co-optimization problem of two interacting factors, feature representation and pseudo labels, which is easy to fall into local minimum traps, and the optimization process is also prone to fall into a vicious circle due to the adverse effect caused by noisy pseudo labels. Therefore, this paper proposes two new modules based on the traditional mean-teacher architecture: Doubly Stochastic Subdomain Mining (DSSM) and sample Reweighting based on Maximal Heterogeneous Similarity (R-MHS) as Fig. 1 shows. The former effectively reduces the risk of falling into a local minimum trap in the training process by enhancing the diversity of clustering in each training round; the latter reduces the adverse effect of noisy pseudo labels on the model by reweighting the samples.
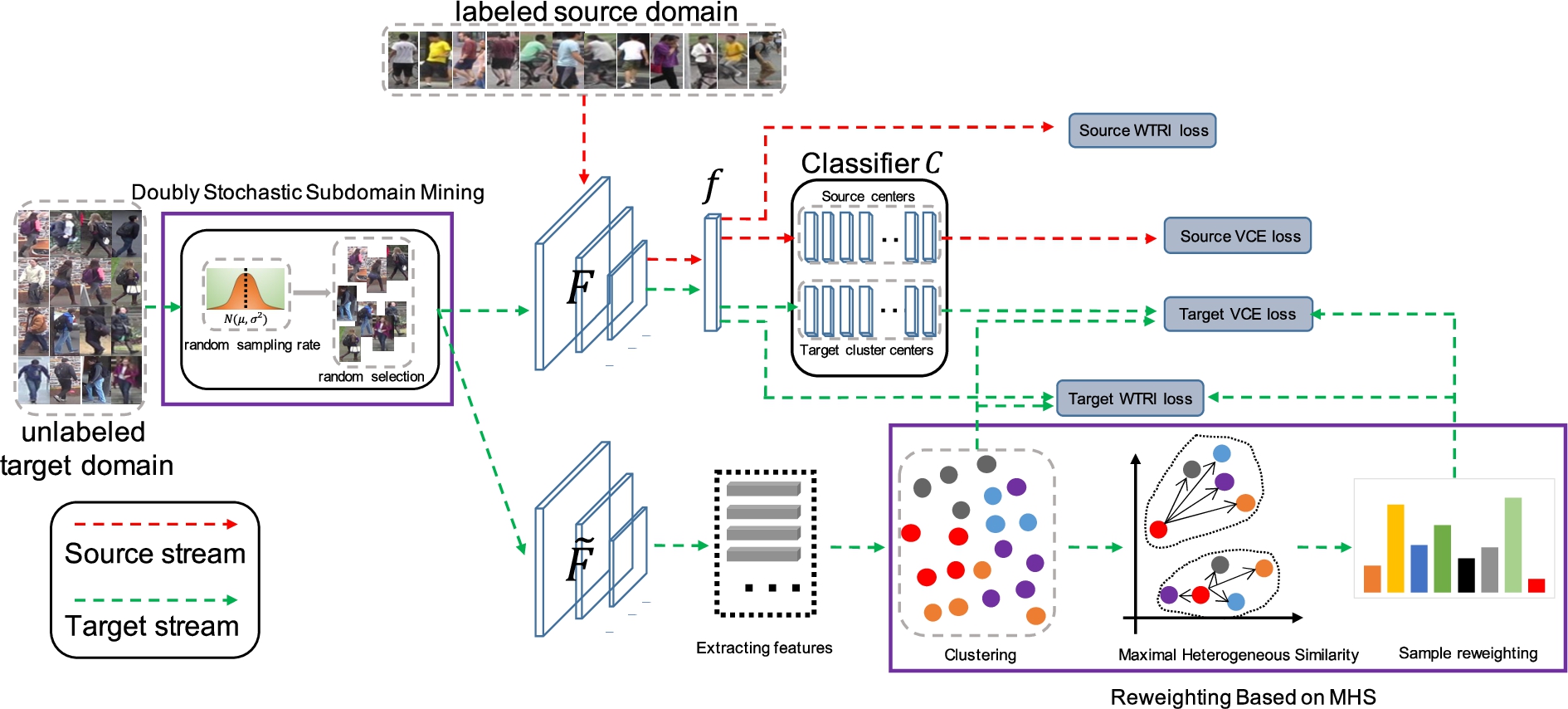
The framework of our work, among which the two parts circled by purple rectangles respectively represent the doubly stochastic subdomain mining (DSSM) and reweighting method based on our proposed maximal heterogeneous similarity (R-MHS) modules.
With the participation of the above two novel modules, the learning process of the entire model can be described as the following steps: 1) sampling from the target domain based on the DSSM; 2) generating pseudo labels for the samples of target domain using the DBSCAN [1] clustering algorithm; 3) reweighting samples using the R-MHS algorithm; 4) training the model with source samples and target samples according to their weights. Through the iterative optimization between feature representation and pseudo labels, the training process will be finished till the model converges, and the performance of the model will be effectively boosted.
Traditional clustering-based UDA person ReID methods generally generate pseudo labels for the whole target training set. Unfortunately, clustering itself is a nonconvex combinatorial optimization problem with many local minima. In addition, the feature space is not reliable in the early stage of training, and then the clustering results are unreliable at that time, which will lead to more noisy pseudo labels and further increase the risk of falling into local minimum traps. To address this issue, this paper proposes the DSSM algorithm, in which a part of samples are randomly selected as a subdomain of the target domain in each training epoch. Since the subdomains in each round are different, the objective function of clustering changes along with the training rounds. It can effectively prevent the optimization process from falling into some local minimum traps. Besides, the proposed sampling scheme based on DSSM can effectively reduce the dependence of subdomain selection on the hyperparameters and consequently improve the universality and reliability of the algorithm.
Randomly selecting subsets from the whole training set is a classic strategy to reduce the local minimum risk and improve the generalization ability of the model. It is widely used in ensemble learning and SGD. But most of these methods apply a fixed size for subset selection. It is easy to understand that the diversity between subdomains will decline while the reliability of each subdomain will increase if the size of the subdomain becomes large, and vice versa. That means the convergence and the generalization ability of the model are sensitive to the size of subdomains. To overcome this limitation, we propose the doubly stochastic subdomain mining algorithm. By “doubly stochastic”, we mean each subdomain is mined with a random size and random sampling. The size of subdomain
With the help of the doubly stochastic sampling, better diversity between different subdomains can be preserved in the whole training process while the model’s sensitivity to the size of subdomains can be effectively suppressed. Experimental results demonstrate that the reliability of the convergence is improved remarkably when DSSM algorithm is applied.
Sample reweighting based on maximal heterogeneous similarity
Because the generation of pseudo labels is based on an unsupervised clustering algorithm, the false assignment of pseudo labels is unavoidable, especially for the samples on the boundaries of the clusters. Once these noisy labels are introduced in the training process, the optimization of feature representation could be misled to a wrong direction, and in turn, make the clustering results in the next epoch get worse. The iterative accumulation of these errors could reinforce a vicious circle which can break down the whole training process. To reduce the adverse impact of these noisy labels, we propose a new sample reweighting algorithm to control the influence of the samples according to their confidence level. We present a new metric, referred to as Maximal Heterogeneous Similarity (MHS), to measure the reliability level of each pseudo label quantitatively.
The similarity between any two samples
Figure 2 illustrates the effect of the proposed sample reweighting algorithm by analyzing the calculation of MHS values between different samples. Among them, different shapes and colors represent different ground-truth labels and pseudo labels respectively. For the red square sample in the left column, assuming that it is assigned with a false pseudo label, then there must be a sample with the true pseudo label among all its heterogeneous samples, such as the sample corresponding to the green square in the middle column. At this time, the correlation coefficient between the two samples is high and the MHS value is correspondingly large, so the weight calculated by Eq. (5) is small, which is consistent with the assumption that the pseudo label of the red square sample has low reliability.
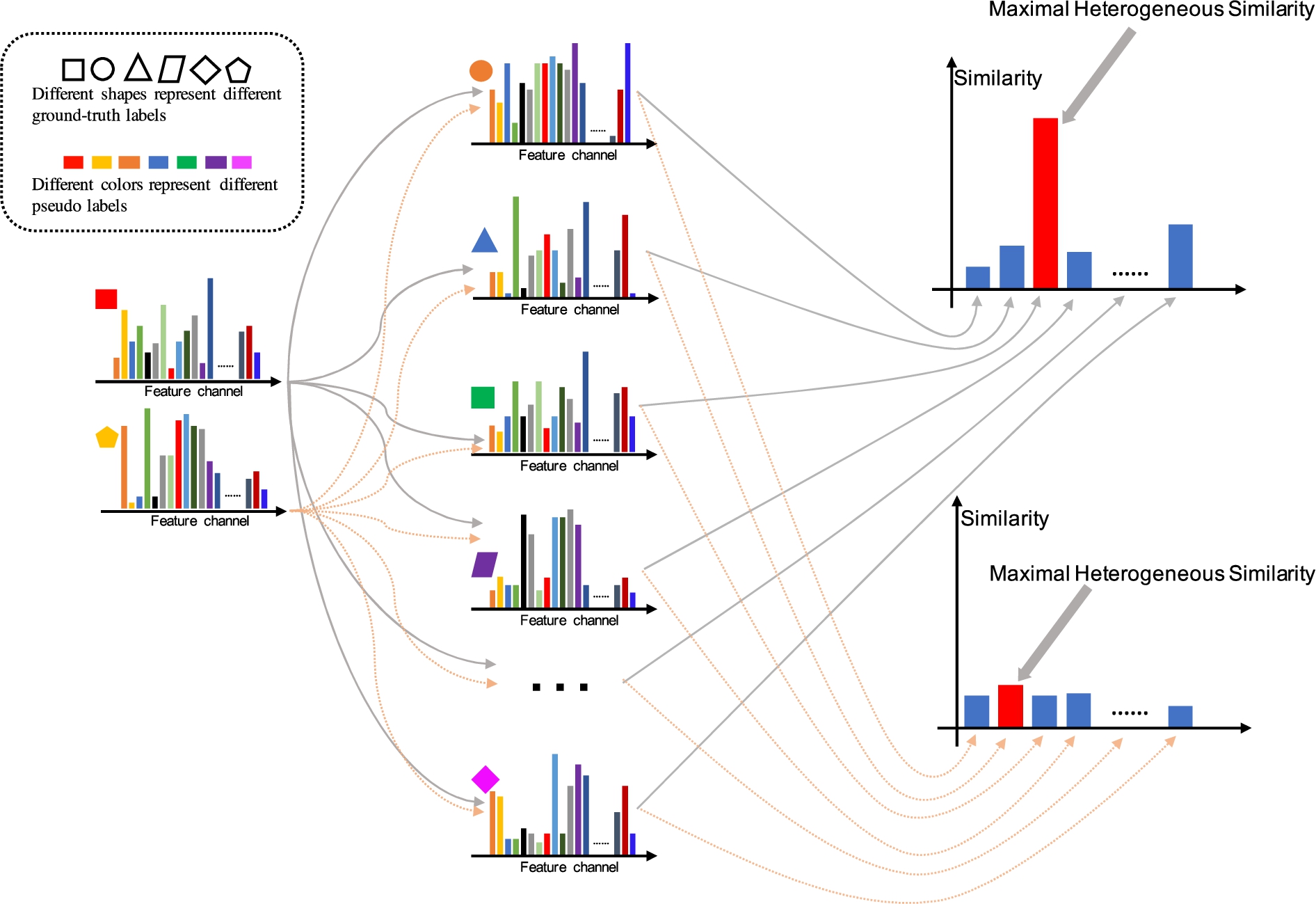
The description of our proposed R-MHS algorithm.
For the yellow pentagon sample in the left, we assume that its pseudo label is true and the samples with the same ground-truth labels are all clustered into the same class and assigned with the same pseudo labels. Then there is no sample with high correlation in the heterogeneous samples of this sample, the corresponding MHS value is consequently low, and the weight of this sample according to Eq. (5) is large, which is also consistent with the assumption that the pseudo label of this sample is reliable.
According to the above analysis, the proposed Reweighting algorithm based on MHS (R-MHS) can assign reasonable weights for different samples, which can further improve the reliability of model by modulating the training process with these weights. The results of ablation study in Section 4 confirm the effect of our proposed R-MHS algorithm.
As the proposed DSSM sampling and R-MHS reweighting modules are embedded into the pipeline of our model, the whole framework can be trained with our proposed loss functions on source domain during the pretraining process, and then both source domain and target domain training sets are used to further fine-tune the model.
For both of the mini-batch
To further improve the recognition ability of the model on some hard samples, we combine the classic triplet loss with the sample weights
At last, the proposed VCE loss and WTRI loss are combined to train the model in an end-to-end fashion. The overall loss function can be written as Eq. (8):
Under the guidance of the above overall loss, the pretrained model can be adapted to the target domain until it converges. The whole training process is described as follow (see Algorithm 1).

Training process
Datasets
All the experiments are carried out on two popular person ReID datasets Market-1501 [40] and DukeMTMC-reID [24] respectively. Market-1501 dataset contains 32668 labeled images of 1501 identities from disjoint cameras, in which the training set includes 751 identities and 12936 images, the gallery set contains 19732 images from 750 identities and the query set contains 3368 images from 750 identities. DukeMTMC-reID dataset is collected from 8 non-overlapping cameras, which includes 16522 images of 702 identities for training, 2228 images for query and 17661 images for gallery set. Based on above two datasets, two inverse domain adaptation tasks, Market-to-Duke (M2D) and Duke-to-Market (D2M), are designed for testing.
Settings
Comparison with the state-of-the-art methods
We compare our model with some state-of-the-art works on both of the M2D and D2M tasks. The comparison results are shown in Table 1.
As shown in Table 1, our method is evaluated and compared with the state-of-the-art methods on the two domain adaptation tasks respectively. At first, we compare our work to the methods which attempt to reduce the gaps between target and source domains, including GAN-based models such as PTGAN [33], SPGAN [7], CR-GAN [5] and feature alignment-based methods such as DAAM [14], D-MMD [22] and SADA [32]. The comparison results show that our work outperforms these methods by a large margin about 13–21% (map:69.0% vs 55.8% on the M2D task, and 80.8% vs 59.8% on the D2M task).
Performance (%) comparison with the state-of-the-art methods for UDA person ReID on M2D and D2M domain adaptation tasks
Performance (%) comparison with the state-of-the-art methods for UDA person ReID on M2D and D2M domain adaptation tasks
Compared with clustering-based methods such as SSG [8] and ECN [41], our approach also leads the way in all the metrics on both the two adaptation tasks. Besides the above works, there are also some latest models which aim at addressing the noisy labels such as NRMT [37], SpCL [10], UNRN [38] and GLT [39], which have achieved remarkable performance. Though some methods show little advantages on scores of mAP or Rank-1, our method still has competitive results in other metrics. For example, GLT and UNRN have about 0.2% improvement on mAP score for M2D task, but our approach outperforms them by a large margin on the D2M task. Similarly, the scores of MMT + RDSBN on D2M task is good, but its performance drops dramatically on M2D task. And the same phenomenon happens on the Rank1 score. All of these methods can achieve better performance on the single task, but their performance drops significantly when they are adopted on the other task. Compared with these methods, our method has better generalization and our approach performs well on both of the M2D and D2M tasks, so the university of our approach is better than them and we provide a solid and universal baseline for future research on UDA person ReID tasks.
We design a group of experiments to validate our proposed Doubly Stochastic Subdomain Mining (DSSM) algorithm. Two different sampling schemes, including “Without Subdomain Mining (WSM)” and “Single Stochastic Subdomain Mining (SSSM)”, are presented as comparative experiments to study the effect of DSSM, where WSM refers to using all the training samples of the target domain for clustering and training, SSSM refers to that the subdomain sampling ratio
Performance (%) of the model on the M2D and D2M tasks under different experimental settings, in which the parameter μ represents the fixed sample rate of SSSM and the mean in normal distribution of DSSM
Performance (%) of the model on the M2D and D2M tasks under different experimental settings, in which the parameter μ represents the fixed sample rate of SSSM and the mean in normal distribution of DSSM
It can be observed clearly that either SSSM or DSSM outperforms the scheme of WSM by a large margin, which proves that the stochastic sampling strategy can improve the performance of the model significantly. It is because that the stochastic sampling can counteract the misleading of noisy labels across different epochs, avoid converging to suboptimal clustering results, and consequently prevent the model from falling into local minima. From another perspective, each round of sampling can be regarded as the knowledge mining for a subdomain, which makes it equal to the ensemble learning across the whole target domain and displays better generalization ability of the model.
In addition, the comparison results between DSSM and SSSM reveals the advantages of our proposed DSSM algorithm on precision and stability. To be specific, DSSM achieves about 1% improvement on mAP for both of the M2D and D2M tasks. We believe that this advantage derives from that the DSSM algorithm adopts a random sampling ratio
Besides, the comparison results show that the proposed DSSM is more robust than SSSM in terms of the hyperparameter μ. For example, when the parameter μ changes from 0.6 to 0.4, the mAP scores of SSSM drop about 1.1–3.9% (map:67.9% vs 66.8% on the M2D task, and 79.8% vs 75.9% on the D2M task); and the same performance degradation also occurs on Rank-1 score. However, when the same change of the hyperparameter μ happens to DSSM, the performance of our model remains stable throughout. Due to the sampling rate
The experiments described above only discussed the impact of the DSSM algorithm on the model performance. In this section, the combinations of different sampling algorithms and reweighting algorithms are used to verify the effectiveness of our proposed method in this paper. We design three groups of experiments to validate the proposed method by comparing with different ablation settings on sampling and reweighting algorithms. In the first group, SSSM and DSSM are compared without employing sample reweighing algorithm, which can be regarded as a baseline model. In the second group, three different sample reweighing schemes, including without reweighting, a classic reweighing algorithm according to CleanNet [16] and our proposed R-MHS algorithm, are compared by combining them with DSSM respectively. A point to note, CleanNet reweights samples based on the similarity between the sample and its corresponding class prototype. This group of experiments are designed to evaluate the influence of our proposed R-MHS reweighting algorithm. In the third group, we combine the proposed R-MHS method with DSSM and SSSM jointly to evaluate the overall performance of our model.
Ablation studies on the effectiveness of our proposed R-MHS and DSSM on the domain adaptation tasks between Market and Duke
Ablation studies on the effectiveness of our proposed R-MHS and DSSM on the domain adaptation tasks between Market and Duke
As shown in Table 3, the results of the first group show that the proposed pipeline based on mean teacher architecture and stochastic sampling can provide a great baseline for UDA person ReID task. Besides, the proposed DSSM algorithm has a little advantage over SSSM even without sample reweighting. The results of second group reveal that our proposed R-MHS reweighting algorithm is effective, and it is also superior to the popular reweighting algorithm CleanNet. Comparing with the baseline without reweighting, our approach achieves 2.2% improvement on mAP score on the M2D task and 1.9% on the D2M task. The CleanNet method can boost the performance on both of the domain adaptation tasks too, but it only has limited improvements due to the generation of a class’s prototype is based on all the samples in the same cluster and once there exist noisy samples, it can affect all the weights in this cluster. However, the proposed R-MHS takes the correlations between all the samples of subdomain into account, it can suppress the negative effect of noisy labels better. The results of the third group of experiments demonstrate that the R-MHS algorithm proposed in this paper achieves about 2% improvement on mAP score when combines it with both of the stochastic sampling strategies SSSM and DSSM. Among them, the combined setting of R-MHS + DSSM achieves the best performance, it shows that the R-MHS algorithm and DSSM algorithm can not only boost performance when they are adopted alone, but also can further improve the performance when they work together. Through the joint experiments, we achieve the state-of-the-art performance when the DSSM and R-MHS are all employed to the model training.
In this paper, we propose a novel method to address the local minimum traps and noisy labels in unsupervised domain adaptive person re-identification, which adopts doubly stochastic subdomain mining to supply different sample subdomains for each training round, it is helpful to prevent the model from falling into local minimum traps. And we also propose a new sample reweighting algorithm to reduce the negative impact caused by noisy pseudo labels. We introduced the knowledge mining in subdomains and the sample reweighting method base on our proposed Maximal Heterogeneous Similarity. Extensive experiments prove the effectiveness and superiority of different components, and the results indicate that our method outperforms most state-of-the-art methods on popular datasets. We also show that our method is robust and then it is feasible to be applied in real-world scenes.
Footnotes
Acknowledgement
This work was supported in part by The Fundamental Research Funds for the Central Universities (N2104027), Innovation Fund of Chinese Universities Industry University Research (2020HYA06003), Guangdong Basic and Applied Basic Research Foundation (2021B1515120064).