
Abstract
The aim of unsupervised domain adaptation (UDA) in person re-identification (re-ID) is to develop a model that can identify the same individual across different cameras in the target domain, using labeled data from the source domain and unlabeled data from the target domain. However, existing UDA person re-ID methods typically assume a single source domain and a single target domain, and seldom consider the scenario of multiple source domains and a single target domain. In the latter scenario, differences in sample size between domains can lead to biased training of the model. To address this, we propose an unsupervised multi-source domain adaptation person re-ID method via sample weighting. Our approach utilizes multiple source domains to leverage valuable label information and balances the inter-domain sample imbalance through sample weighting. We also employ an adversarial learning method to align the domains. The experimental results, conducted on four datasets, demonstrate the effectiveness of our proposed method.
Keywords
Introduction
Research challenges
Person re-identification (re-ID) is a task that involves identifying a specific individual across different cameras by retrieving relevant images from a large set of candidate images captured under non-overlapping camera views. This is considered an open-set problem because the identity information known at the time of testing is not the same as at the time of training. In order to identify person features, valid feature representations that are unknown in training have to be learned. Recently, person re-ID methods in a supervised scenario have made significant progress [1, 2, 3], but learning a person re-ID model that generalizes well over an unlabeled target domain is still very difficult. That is, when tested on top of an unknown dataset, person re-ID methods in a supervised scenario suffer from severe degradation in recognition retrieval. One of the primary causes for these issues stems from dissimilarities in the distribution of data between the source and target domains. These differences can be attributed to several factors, such as discrepancies in body posture, camera perspective, lighting conditions, image quality, surroundings, and obstructing objects. Hence, to overcome these challenges [4, 5, 6], it is crucial to gather a substantial amount of training data and manually label it for a specific setting. However, this process can be incredibly time-consuming and arduous. To mitigate the burden of labeling data, various unsupervised domain adaptation (UDA) methods [7, 8, 9, 10, 11, 12, 13] have been developed.
To deal with the person re-ID problem in UDA scenarios, some recent works [14, 15, 16, 17, 18, 19] have focused on migrating knowledge from a labeled source domain to a target domain or using clustering algorithms on an unlabeled target domain. When applied to a novel target domain scenario, many person re-ID methods in the context of UDA rely on source domain data for pre-training or joint training [20]. Recently, a large number of UDA background person re-ID methods have been proposed. One of the most effective class of these methods is the person re-ID methods based on pseudo-labeling strategies [21, 22, 23]. This category of methods can be divided into two main stages. First, a pre-trained model is obtained by training on the source domain. Next, an iterative pseudo-label prediction and fine-tuning strategy is employed to train the model on the target domain. While pseudo-label-based methods have demonstrated their effectiveness, a majority of these methods only use a limited amount of data from a single source domain for pre-training the model. Since such methods do not fully utilize label information, they result in a large amount of wasted label information.
Multi-source domain adaptation scenario. In the figure, 
In order to effectively utilize a vast amount of available labeled data, we have introduced multi-source domain adaptation into the realm of UDA for person re-identification. Figure 1 shows the multi-source domain adaptation scenario. The multi-source domain adaptation scenario involves the utilization of multiple domain datasets during both the pre-training and fine-tuning stages of the model. This approach leverages both the true labels from the source domains and the pseudo labels generated from the target domain to provide joint supervision. Furthermore, prior methods [24, 25, 26] did not address the issue of imbalanced domain sample sizes when working with multiple domains. Specifically, domains with larger sample sizes have greater weights in the model optimization process. This sample size imbalance can easily cause model bias problems during training. Additionally, this imbalance can easily deteriorate the discrimination effect. To address the issue of imbalanced sample sizes across different domains, we suggest employing a sample weighting strategy to balance out the variations in samples between domains.
In summary, the main contributions of this paper are as follows:
We propose an unsupervised multi-source domain adaptation person re-ID method based on sample weighting. By applying multi-source domain adaptation to UDA person re-ID, valuable label information is fully utilized. We propose the sample weighting method to weight the samples as a way to balance the problem of unbalanced sample size between domains. Then, the adversarial learning method is used for domain alignment. To evaluate the effectiveness of the proposed approach, we carry out a comprehensive set of comparison experiments, ablation experiments, and supplementary experiments on four different datasets: Market1501, DukeMTMC-reID, CUHK03 and MSMT17. Our experimental results demonstrate the effectiveness of the proposed method and show its superior performance compared to other existing methods.
The remainder of this paper is organized as follows. Section 2 introduces the related work. Section 3 firstly gives an overview of the proposed unsupervised multi-source domain adaptation for person re-ID via sample weighting framework, then explains the sample weighting strategy and the various loss functions in this paper. Section 4 illustrates the implementation details and discusses the experimental results. Section 5 describes the threats to this work and potential solutions. Section 6 concludes this paper and gives an outlook on future work.
Unsupervised domain adaptation in person re-ID
The current mainstream UDA person re-ID methods are mainly divided into the following aspects. One is by using a family of generative adversarial networks (GANs) to transfer the style of labeled images from the source domain to the target domain, and the transferred images are then used for training. Based on this pipeline, PTGAN [16] uses semantic segmentation techniques to constrain the consistency of human regions during style migration. Similarly, SPGAN [27] proposes a method which maintains image similarity before and after image translation. Although these methods have achieved some results, the performance of these methods is still unsatisfactory.
The other is through the use of pseudo-label methods. Along this line, ACT [22] mitigates label noise generated by clustering algorithms in an asymmetric cooperative teaching framework. MMT [23] utilizes both hard and soft labels by constructing a mutual mean-teacher network. SSG [28] uses both global and local features, and when assigning pseudo-labels, pseudo-label assignments are performed separately for global features and local features. Moreover, DG-Net
Moreover, there are deep domain adaptation methods that have been utilized in person re-ID to reduce the inter-domain distance between the source and target domains through feature representation. MMFA [31] reduces the inter-domain interval by using the Maximum Mean Discrepancy (MMD). CAT [32] introduces an adversarial framework to mitigate inter-camera differences by confusing a camera discriminator. ACAN [33] reduces the distribution differences by using only intra-camera labeling information and not inter-camera labeling information.
Multi-source unsupervised domain adaptation
The UDA methods mentioned above mainly consider UDA methods for a single source domain, these methods are limited in their adaptation scenarios and are not as practical as multi-source domain adaptation methods. The wide application of multi-source domain adaptation has been illustrated by key studies in [34, 35, 36]. Based on the above work, MDAN [37] aligns source and target domains by using domain adversarial networks. M3SDA [38] migrates knowledge learned from multiple labeled source domains to unlabeled target domains by dynamically aligning feature distribution moments. Besides, MDDA [39] not only considers the difference in distance between multiple source and target domains, but also investigates the dissimilarity between source and target domain samples. LtC-MSDA [40] performs class-level alignment by using graph convolutional networks.
In recent years, more and more multi-source domain adaptation methods have been proposed for practical application perspectives. DSBN [41] reduces the inter-domain interval by integrating different BN. CMSS [42] sets up an adversarial agent through which the dynamic curriculum of the source domain samples is learned. RDSBN [43] reduces the inter-domain interval by reducing the inter-domain interval from both domain-invariant view and multi-domain fusion view to make full use of the labeled data.
Sample weighting
When there is an imbalance in the sample size between domains, it can result in model bias and negative transfer during training. To address this issue, several methods have been proposed. DWL [44] dynamically weights the learning loss of alignment and discrimination by taking into account the degree of alignment and discrimination, while also ensuring the balance of information between domains by weighting the samples. DSW [45] balances positive and negative samples by spatial location and confidence level, respectively. In addition, DRMN [46] uses a pairwise re-weighting mechanism to address the domain discrepancy and mis-matching problem between source and target domains in multi-source domain adaptation. DWDA [47] performs sample weighting on source and target domain samples separately by k-means clustering algorithm. TIT [48] weights the samples by increasing the weights of pivot samples and decreasing the weights of outlier samples.
To summarize, researches on person re-ID in UDA, at present, are carried out in the scenario of single-source domain and single-target domain, but few are carried out in the scenario of multi-source domain and single-target domain. Therefore, inspired by multi-source UDA, we propose unsupervised multi-source domain adaptation for person re-ID. Although previous work [43] introduced the concept of multi-source to the field of person re-ID for the first time, this method did not consider the problem of sample size imbalance between each domain. To solve this problem, we propose to weight the samples in each domain, as a way to balance the difference in sample size between domains. In summary, in this work, we propose an unsupervised multi-source domain adaptation method for person re-ID via sample weighting.
Methodology
Overview
In the scenario of unsupervised multi-source domain adaptation, given multiple source domains
Definition of symbols involved in this paper
Definition of symbols involved in this paper
To avoid model bias caused by the imbalance in the number of samples between different domains during model training, we first weight the samples of multiple source domains and a single target domain, as shown in Fig. 2. Next, the feature extractor
The overall framework of the proposed methodology. Firstly, sample weighting is performed on the input samples. Secondly, the feature extractor 
In the field of unsupervised multi-source domain adaptation for person re-ID, in general, an imbalance in sample size between domains can lead to model bias and poor alignment and discrimination effects, resulting in negative transfer. To address this issue, we propose a sample weighting method in this paper. Specifically, we assign weights to all samples from all domains, where the weight for each domain is inversely proportional to the proportion of samples from that domain to the total sample size of all domains. This weighting scheme aims to achieve a more balanced representation of samples from all domains during training. Specifically, our proposed sample weighting method is as follows:
Normalization:
Weighted sample:
where
Adversarial domain adaptation [53, 54, 55] is based on the concept of generative adversarial networks (GANs) [56], which consists of a generator and a discriminator. In adversarial domain adaptation, the generator is a feature extractor that learns domain-invariant features from both the source and target domains. The discriminator, on the other hand, is responsible for distinguishing whether the samples come from the source domain or the target domain. During model training, the feature extractor and discriminator are trained in an adversarial manner. When a feature cannot be distinguished by the discriminator from the source domain or the target domain, the feature is domain-invariant. Our goal is to train a feature extractor to learn these domain-invariant features. In this paper, we use
To obtain domain-invariant feature representations, the weighted samples
where
Since this paper is a research on person re-ID method in UDA scenarios, the data of the target domain is without labels, and labeling data is a time-consuming and laborious task. In order to make full use of the data information in the target domain, we adopt a pseudo-label generation strategy. In this paper, we apply the DBSCAN [52] clustering algorithm as a pseudo-label generator to generate pseudo-labels. In each epoch, the target domain feature are input to the pseudo-label generator, which outputs the clustering results.
During this stage, we leverage the labeled data from both the source and target domains to effectively utilize the domain-invariant feature representations and train the final model in a fully supervised mode. The model architecture incorporates two classification losses: the first one corresponds to the classification loss of the source domain with the true labels, while the second one corresponds to the classification loss of the target domain with pseudo-labels. The total classification loss is obtained by adding the classification loss of the source domain and the classification loss of the target domain in the following form:
where
In Eqs (9) and (10),
To enhance the discriminative power of our person re-ID model, we propose a hard batch triplet selection strategy. This approach selects the most difficult positive and negative samples for each anchor sample, which brings samples with the same person identity closer and separates samples with different person identities. Our model framework includes two triplet losses: one for the source domain sample and one for the target domain sample. The total triplet loss is the sum of the source and target domain triplet losses in the following form:
Inspired by PPLR [30], the definition of triplet loss is as follows:
where
The final loss function of the proposed method is shown in Eq. (14):
where
[ht] Unsupervised Multi-source Domain Adaptation for Person Re-ID via Sample WeightingSource domain data
not converge and epoch
Apply DBSCAN clustering algorithm to generate pseudo-labels
Calculate
Calculate
Calculate
Calculate
Update
Datasets and evaluation schemes
We conducted experiments to evaluate the effectiveness of our proposed method on four popular person re-ID datasets: Market1501 (Market) [57], DukeMTMC-reID (Duke) [58], CUHK03 (CUHK) [59] and MSMT17 (MSMT) [15]. A dataset represents a domain. Examples of person images from the four datasets are shown in Fig. 3.
Market consists of 32688 images of 1501 person identities from 6 non-overlapping camera views. The dataset is split into a training set, which includes 12936 images of 751 person identities, and a test set, which includes 19732 images of 750 person identities.
Duke contains 36411 images of 702 person identities captured by 8 cameras. The dataset is split into a training set, which has 6522 images from 702 people, and a test set, which has 19889 images from the same 702 people.
Examples of persons from different datasets: (a) Market1501, (b) DukeMTMC-reID, (c) CUHK03, (d) MSMT17.
CUHK contains 14096 images of 1467 individuals captured from 6 camera views. The dataset is split into a training set comprising 767 person ID images and a test set comprising 700 person ID images.
MSMT is a challenging dataset that contains 126441 images of 4101 persons from 15 camera views. The dataset is split into a training set of 32621 images with 1041 person identities and a test set of 93820 images with 3060 person identities. It is more challenging compared to the other three datasets mentioned above.
We use mean average precision (mAP) and Rank-1 (R-1), Rank-5 (R-5), Rank-10 (R-10) accuracies in cumulative matching characteristic (CMC) to assess the effectiveness of our method.
Experimental results of different quantities of source domain datasets on the target domain Market dataset
We utilize the ResNet-101 [51] architecture, which was pre-trained on ImageNet [60], as the backbone network. The experiment is conducted on two NVIDIA GeForce RTX3090 GPUs. We follow the experimental settings of MMT [23]. Specifically, we use the Adam optimizer [61] with a weight decay of 0.0005 to optimize the network. The input image data is resized to 256
Experimental results of different quantities of source domain datasets using the sample weighting method on the target domain Market dataset
Experimental results of different quantities of source domain datasets using the sample weighting method on the target domain Market dataset
The necessity of multi-source domains
In order to verify the necessity of multi-source domains, without using the sample weighting algorithm, we conduct the following experiments: Duke
Comparison with the state-of-the-art methods on Duke
Market and Market
Duke tasks
Comparison with the state-of-the-art methods on Duke
Comparison with the state-of-the-art methods on Market
In order to assess the impact of the sample weighting module on the performance of our model, on the basis of the previous experiments, we continue to do the following experiments: sample weighting on Duke
Comparison with the state-of-the-art methods on Duke
CUHK
MSMT
Market task
Comparison with the state-of-the-art methods on Duke
Comparison with the state-of-the-art methods on Market
To demonstrate the effectiveness of our proposed method, we conduct a comparison with state-of-the-art unsupervised domain adaptive person re-ID methods on four datasets: Duke, CUHK, MSMT and Market. We evaluate our method on the following domain adaptation tasks: Duke
Parameter sensitivity analysis. (a) Experiment of different values of 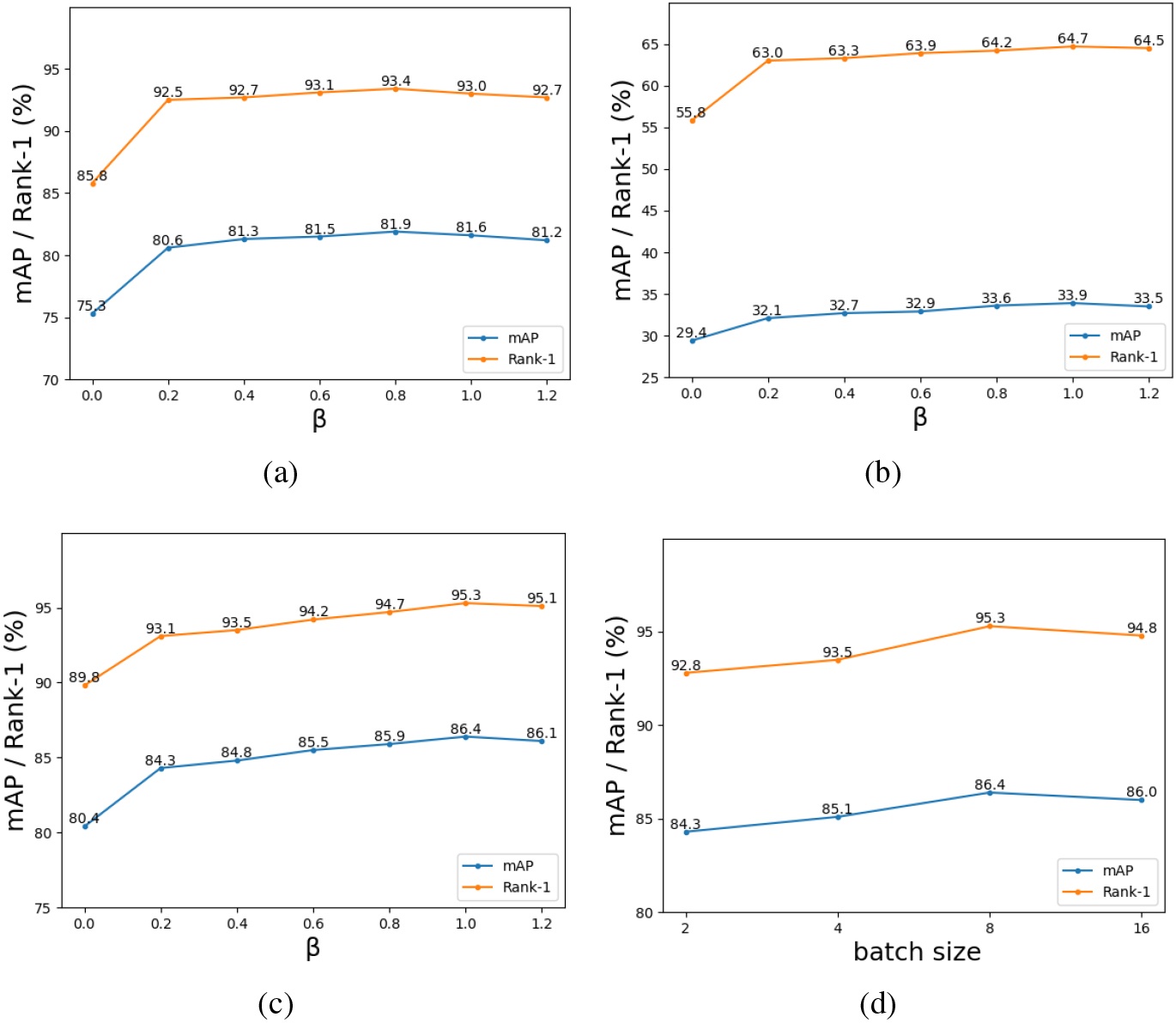
Firstly, we carry out the UDA person re-ID experiments in the scenario of a single source domain and a single target domain. We compare the proposed method with recently advanced unsupervised domain adaptive person re-ID methods, and the results are presented in Tables 4 and 5. The results indicate that our proposed method outperforms the current state-of-the-art methods. On the Duke
Next, we extend the experiments to UDA person re-ID experiments in multiple source domains and single target domain, since there is not much research literature on unsupervised multi-source domain adaptation person re-ID, therefore, we follow the experimental setup of the literature [43] and carry out experiments on the Duke
We analyze the importance of hyperparameter in the proposed method, and hyperparameter
Time cost comparasion on Duke
In addition, in order to verify the influence of batch size values and model performance, we conducted a series of experiments on the Duke
The time cost comparison between the proposed method and other methods is shown in Fig. 5. We notice that ResNet-101, despite being a non-DA method that doesn’t require time-costing iterations, exhibits significantly lower accuracy compared to other methods. Although it has the advantage of being the fastest in terms of time consumption, its performance in terms of accuracy is notably inferior. Regarding the two methods MMT
Threats to validity
While the work in this paper provides valuable insights into the research on person re-ID methods in the unsupervised multi-source domain adaptation scenario, we must acknowledge and address potential threats to the validity of our findings. Since this paper is researched in the multi-source and single target scenario, there will inevitably be domain gaps between multiple domains, and the existence of domain gaps will also limit the improvement of model performance. In addition, this paper uses a clustering algorithm to generate pseudo-labels, but the generated pseudo-labels may contain label noise, and the existence of label noise will also affect the performance of the model. Therefore, in the future, we need to find a suitable and effective method to narrow the domain interval between multiple domains and adopt an effective pseudo-label refinement method to reduce the deviation of the model and improve the performance of the model.
Conclusion
This paper proposed an unsupervised multi-source domain adaptation method for person re-ID based on sample weighting. Firstly, multiple datasets were used as source domains to make full use of valuable label information. Secondly, the samples of each domain were weighted to reduce the model deviation caused by the difference in the number of samples during training. Next, we used adversarial learning for domain alignment. Finally, in order to verify the effectiveness of the proposed method, we conducted sufficient comparative experiments, ablation experiments and parameter sensitivity experiments on Market, Duke, CUHK and MSMT datasets. The experimental results verified the effectiveness and superiority of the proposed method. Nevertheless, there may be domain gaps between multiple different domains, and in addition, pseudo-labels generated by clustering methods may contain label noise, which can impact the performance of the model. Therefore, in the future work, efforts will be made to address these issues and further improve the proposed method.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China under Grant 62176128, the Open Projects Program of State Key Laboratory for Novel Software Technology of Nanjing University under Grant KFKT2022B06, the Fundamental Research Funds for the Central Universities No. NJ2022028, the Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions (PAPD) fund, as well as the Qing Lan Project.