
Abstract
Swin Transformers have been designed and used in various image super-resolution (SR) applications. One of the recent image restoration methods is RSTCANet, which combines Swin Transformer with Channel Attention. However, for some channels of images that may carry less useful information or noise, Channel Attention cannot automatically learn the insignificance of these channels. Instead, it tries to enhance their expression capability by adjusting the weights. It may lead to excessive focus on noise information while neglecting more essential features. In this paper, we propose a new image SR method, RSVTCANet, based on an extension of Swin2SR. Specifically, to effectively gather global information for the channel of images, we modify the Residual SwinV2 Transformer blocks in Swin2SR by introducing the coordinate attention for each two successive SwinV2 Transformer Layers (S2TL) and replacing Multi-head Self-Attention (MSA) with Efficient Multi-head Self-Attention version 2 (EMSAv2) to employ the resulting residual SwinV2 Transformer coordinate attention blocks (RSVTCABs) for feature extraction. Additionally, to improve the generalization of RSVTCANet during training, we apply an optimized RandAugment for data augmentation on the training dataset. Extensive experimental results show that RSVTCANet outperforms the recent image SR method regarding visual quality and measures such as PSNR and SSIM.
Keywords
Introduction
Image super-resolution (SR) [15] technology uses deep learning algorithms to reconstruct low-resolution (LR) images into their corresponding high-resolution (HR) counterparts. This technique holds significant importance in restoring old and blurry photographs and is currently a popular research direction with promising prospects. Over the years, deep learning-based image SR technology has undergone substantial development. Initially, the field was dominated by Convolutional Neural Network (CNN) and Generative Adversarial Network (GAN)-based [24,28,35,36,39,40] models, starting with the pioneering work of SRCNN [12]. However, the emergence of the Transformer [38] has disrupted this landscape. With its inherent self-attention mechanism capable of capturing global contextual information in images, the Transformer is more suitable for image SR tasks than GAN-based models.
Consequently, a myriad of Transformer-based image SR models have been proposed successively. The initial Transformer-based image SR model, IPT [5], holds particular significance. It showcased the potential of incorporating the Transformer architecture in image SR tasks. Subsequently, building upon the remarkable performance of the Swin Transformer [30] in various domains, Liang et al. took the lead in applying it to image SR. They successfully introduced SwinIR [27], the first image SR model based on the Swin Transformer. A notable breakthrough achieved by SwinIR is introducing a sliding window mechanism, enabling information transmission between adjacent windows. This advancement marks a significant milestone for the Transformer series in image SR.
Numerous image SR models based on the Swin Transformer have been proposed [4,6–9,25,46,51], taking inspiration from SwinIR. For example, Choi et al. proposed Swin2SR [10] by replacing the Swin Transformer with Swin Transformer V2 [29]. Zhang et al. introduced ART [47] by incorporating Dense Attention and Sparse Attention [34] into SwinIR. Moreover, Transformer-based techniques for image SR are extensively utilized across different domains [20,21,53,54]. For instance, in medical imaging, the predominance of global information over local details by multi-layer perceptrons, coupled with abundant low-frequency data in LR inputs, impedes the efficacy of shift-window self-attention mechanisms. To tackle this challenge, Lu et al. [31] introduced a novel asymmetric convolutional Swin Transformer layer, building upon SwinMR [18], that adeptly integrates global and local information from neighboring windows or pixels. As an illustration, in response to the challenges of proficiently restoring terrain details and creating an HR Digital Elevation Model (DEM) that retains coordinate information within the realm of SR techniques involving CNN and GAN, Li [26] and colleagues introduced an enhanced DEM SR Transformer (DSRT) Network. Specifically tailored for large-scale DEM SR, this network strategically considers the continuity of geographic information. In recent years, notable progress has been made in image SR techniques applied to natural and text images. For example, within digital wallpaper image enhancement, existing methods have encountered challenges preserving intricate details within text regions while enhancing the overall visual appeal. Huang et al. [43] introduced an innovative model named Real Text-SwinIR to tackle this challenge. This model integrates a novel, plug-and-play attention-based approach known as Learned Text Loss (LTL), ensuring the clarity of graphics while effectively preserving well-defined text structures.
Furthermore, Xing et al. Introduced channel attention [50] to the Swin Transformer and effectively combined them, resulting in a superior network structure known as RSTCANet. However, the channel attention mechanism calculates the importance of each channel using average pooling operations and applies the resulting weights to feature maps. This averaging operation may underestimate or overlook crucial channels, failing to capture subtle differences. Furthermore, in some instances, spatial correlations exist between different spatial positions of feature maps, but traditional channel attention focuses solely on inter-channel relationships, disregarding spatial relationships. To address these issues, this paper introduces coordinate attention [16] to the image SR network, thus resolving the challenges posed by channel attention. The main contributions of this paper are as follows:
- Based on a comprehensive analysis of the issues associated with the channel attention, we propose a novel image SR method called RSVTCANet.
- We design a novel residual SwinV2 Transformer coordinate attention block (RSVTCAB) that combines efficient multi-head self-attention version 2 (EMSAv2) [49], coordinate attention to activate more pixels for better reconstruction.
- We utilized RandAugment [11] for data augmentation on the training set, which effectively enhances the generalization and final performance of RSVTCANet during training.
The main objective of this paper is to propose an image SR model called RSVTCANet. The remaining parts of this paper are outlined as follows: Section 2 provides a detailed overview of related works in the field of image SR, including Transformer and Swin Transformer. Section 3 presents the methodology of this study. The experimental section of this paper, including ablation studies and classical image SR, is covered in Section 4. Section 5 concludes the article with a summary and overview of the study.
Related work
Transformer
Traditional RNNs and related algorithms can only compute sequentially from left to right to left. This mechanism limits the model’s parallel capability and leads to information loss during sequential computation. To address this issue, Vaswani et al. proposed the Transformer, a model composed entirely of attention mechanisms distinct from traditional CNNs and RNNs [38]. The basic structure of the Transformer consisting of two main parts: the encoder and the decoder, each comprising six blocks. The primary function of the encoder is to extract features from the input, providing adequate semantic information for the decoding process. On the other hand, the decoder utilizes the results from the encoder and the previous predictions to output the following result in the sequence.
Figure 1 illustrates the detailed internal structure of the transformer, showcasing the encoder block on the left and the decoder block on the right. The model’s input comprises two components: Input Embedding and Positional Encoding. The embedding layer transforms input data, such as text, into vector representations that the model can process to convey the information encapsulated in the original data. Positional Encoding, on the other hand, provides the model with details regarding the sequential order of the current time step. The red section denotes Multi-Head Attention, which encompasses multiple instances of Self-Attention. Each encoder and decoder block incorporates a Multi-Head Attention mechanism. This design choice enables each attention mechanism to specialize in different aspects of the vocabulary, effectively balancing biases that could arise from a sole attention mechanism. It facilitates the expression of multiple interpretations of word meanings and ultimately enhances the model’s performance [38].
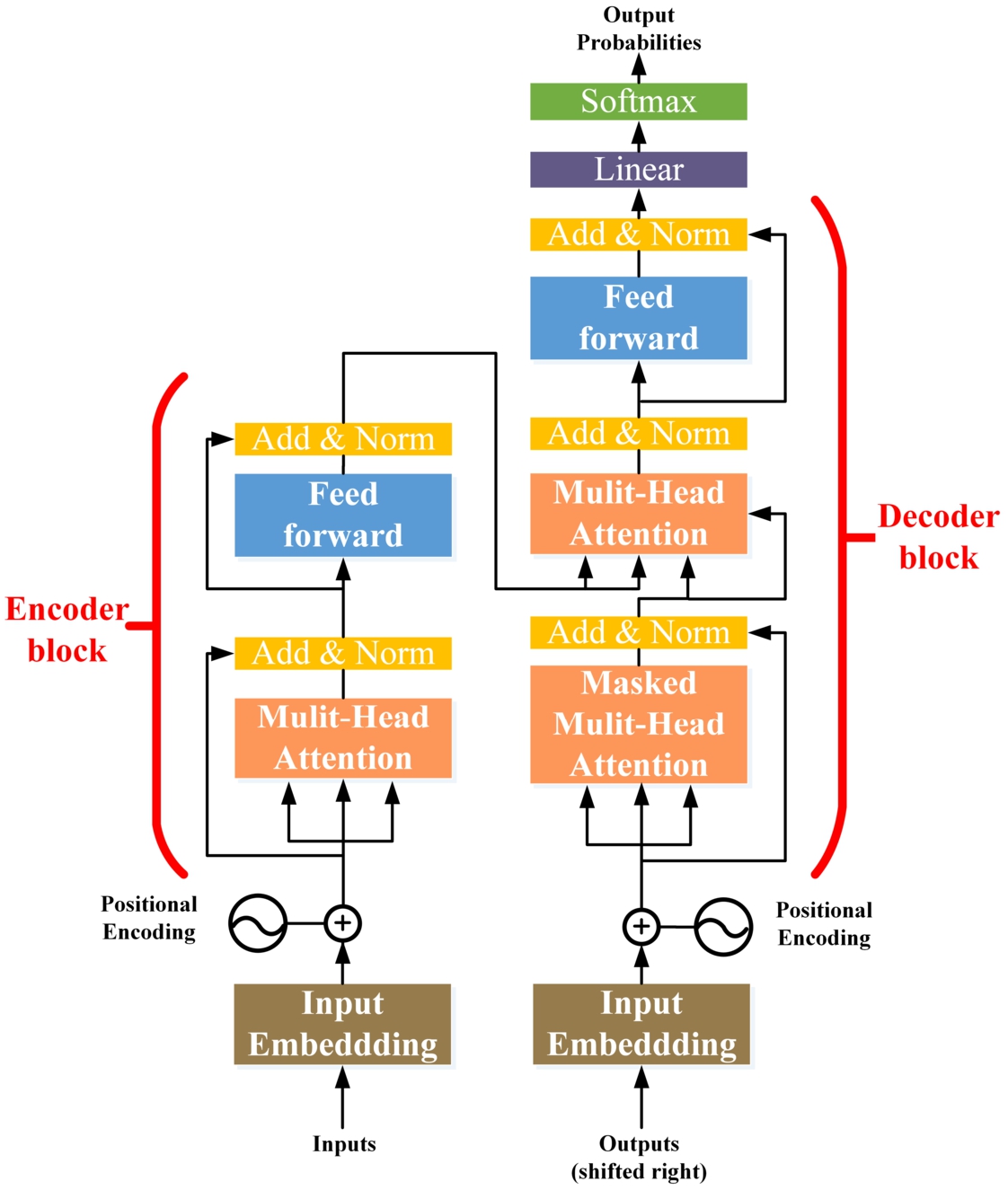
The transformer - model architecture.
Additionally, the decoder block includes Masked Multi-Head Attention. In the transformer, masking serves two primary purposes: masking out uninformative padding regions and information from the “future”. While masking in the encoder primarily fulfills the first purpose, it simultaneously serves both goals in the decoder. The yellow section represents Add & Norm. The term “Add” refers to residual connections, which prevent network degradation, whereas “Norm” pertains to Layer Normalization, which normalizes the activation values of each layer. The model’s output is obtained by passing the result of the decoder through linear and softmax operations. The primary purpose of the Linear layer is to perform a linear transformation on the output of the previous step to achieve the desired output dimension [38].
Traditional vision transformers [14] process features of a single size, making them unsuitable for handling dense prediction tasks that involve downsampled components by a factor of 16. Moreover, self-attention is continuously computed on the entire image, resulting in computational complexity that quadratically increases with the image size. This high complexity can be prohibitive. To address these challenges, Liu et al. proposed the swin transformer [30]. Unlike the vision transformer, the swin transformer computes self-attention within smaller sliding windows, significantly reducing computational complexity and increasing efficiency. By shifting the operation, neighboring windows can interact, enabling cross-window connections between upper and lower layers and effectively achieving global modeling. Figure 2 illustrates the overall network architecture of the swin transformer. The patch partition step divides the input image (H × W × 3) into non-overlapping patches of size 4 × 4. H and W respectively represent the length and width of the input image. These patches are then flattened in the channel direction, resulting in a shape transformation from H × W × 3 to (H/4) × (W/4) × 48. The linear embedding layer applies a linear transformation to the channel data of each pixel, reducing the dimension from 48 to C. Consequently, the image undergoes another shape transformation from (H/4) × (W/4) × 48 to (H/4) × (W/4) × C. The swin transformer block is responsible for feature extraction and comprises two types of attention mechanisms, W-MSA and SW-MSA, which are used sequentially in pairs. Therefore, the total number of swin transformer blocks in the framework is always even. Each stage consists of a linear embedding layer and a swin transformer block to construct feature maps of different sizes. Furthermore, except for stage 1, which initially passes through a linear embedding layer, the remaining stages undergo a patch merging layer. This layer performs downsampling to reduce resolution and halves the channel number. This hierarchical design effectively reduces computational overhead [30].
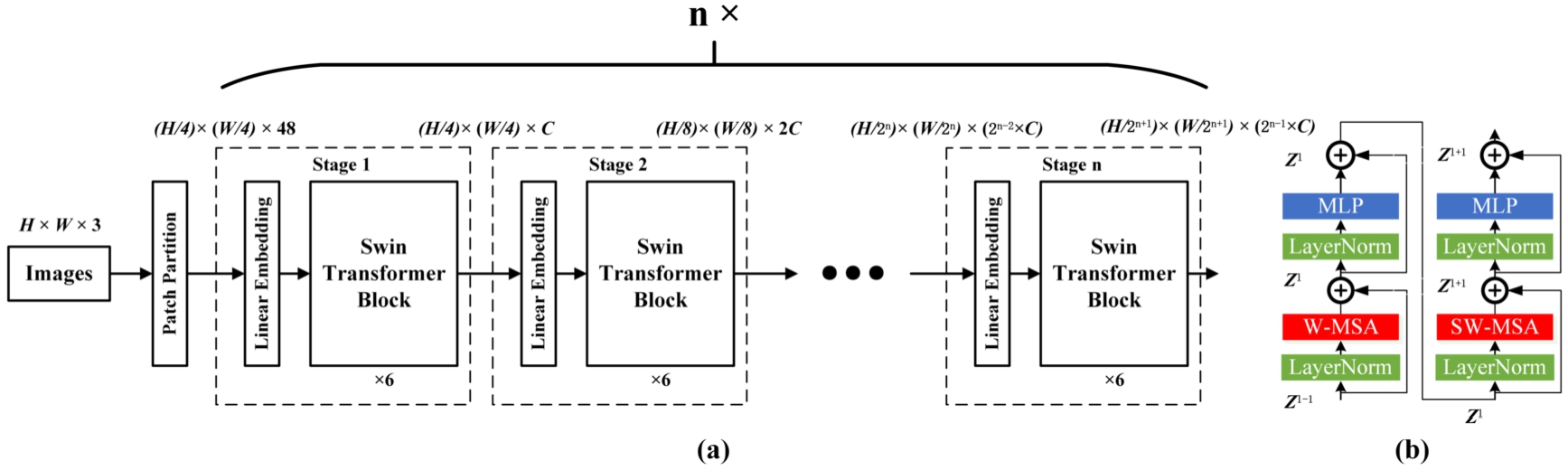
(a) The architecture of a Swin Transformer; (b) two successive Swin Transformer blocks.
In recent years, incorporating attention modules into network architectures has emerged as one of the most commonly used methods for improving image SR models. However, while attention modules significantly enhance model performance, most existing approaches solely focus on modeling the relationships between channels to weigh each channel, thereby overlooking the crucial importance of positional information. This positional information plays a vital role in generating spatially selective feature maps. To address this limitation, Hou et al. [16] proposed a novel “coordinate attention” module that simultaneously considers channel relationships and positional information. The coordinate attention module captures information across channels and integrates direction awareness and position sensitivity, enabling the model to localize and identify target regions more accurately. By encoding precise positional information by considering channel relationships and long-range dependencies, the coordinate attention module is structured into two main steps: coordinate information embedding and coordinate attention generation. Refer to Fig. 3 for a visual representation of this module.
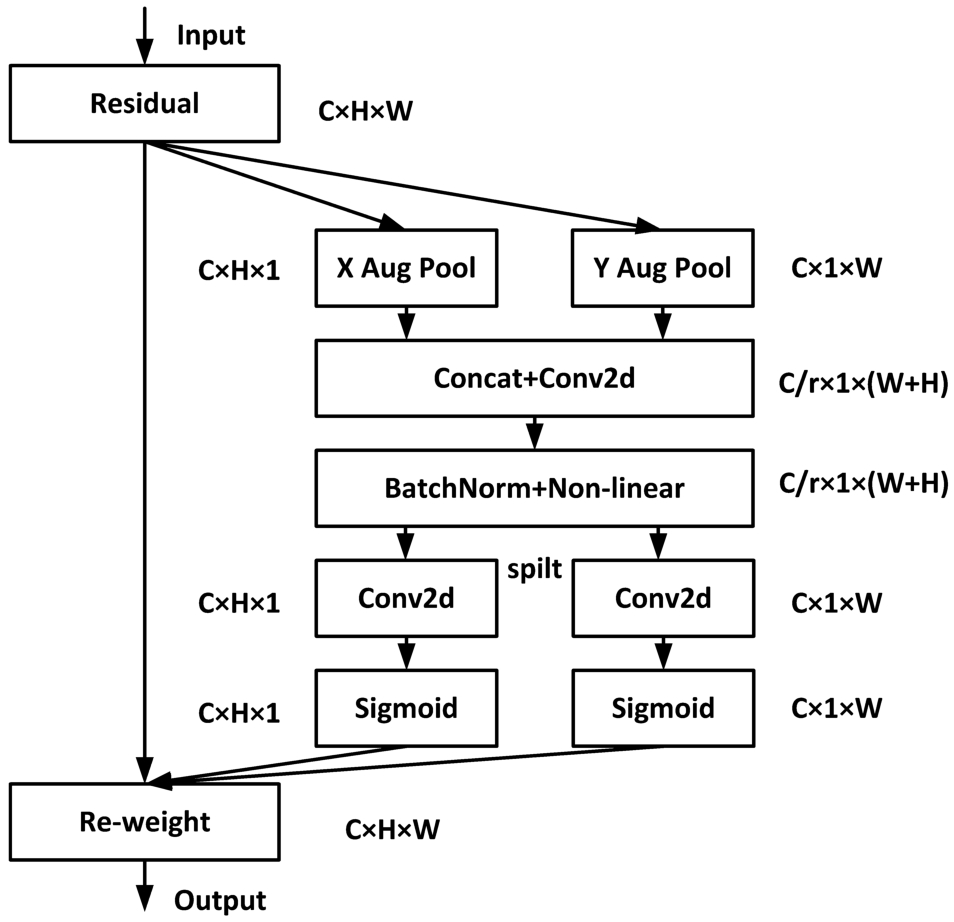
Basic structure of the coordinate attention.
First is the embedding of positional information. While global pooling is commonly used in channel attention to encode spatial information as channel descriptors, it often loses positional information. To address the positional information loss caused by 2D global pooling, we propose using coordinate attention, which decomposes channel attention into two parallel 1D feature encodings. This method efficiently integrates spatial coordinate information. Specifically, for the input x, pooling kernels of size
Equation (1) and Eq. (2) perform feature aggregation along two spatial directions, yielding a pair of direction-aware attention maps. These transformations enable the attention module to capture long-range dependencies in one spatial order while preserving precise positional information in the other spatial direction. Consequently, this facilitates more accurate localization of the target of interest within the network. The coordinate information embedding corresponds to the X Avg Pool and Y Avg Pool depicted in Fig. 3.
The next step is coordinate attention generation, which fully utilizes positional information to accurately locate the regions of interest and effectively capture the relationships between channels. Specifically, the two feature maps,
Next, the tensor
Finally, by expanding
The transformer’s core lies in the Multi-head Self-Attention (MSA) [38], as illustrated in Fig. 4. However, MSA encounters two primary challenges. Firstly, the computational requirements of MSA grow quadratically with the increase in input token dimensions (referred to as
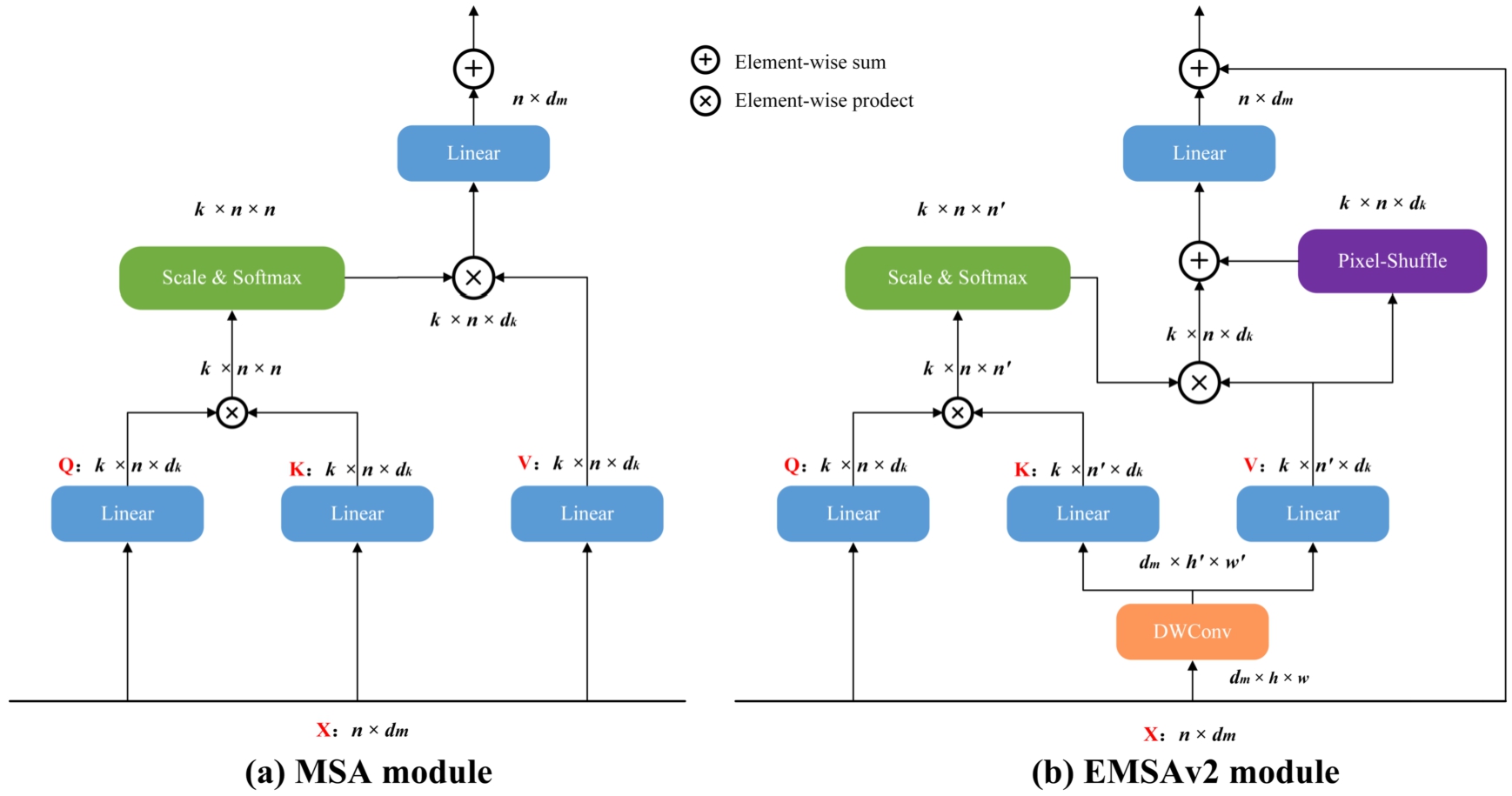
Comparison of MSA and EMSAv2.
Given a 1D input token
Data augmentation [2,44] is commonly employed in deep learning and other tasks to enhance model generalization. Randaugment, proposed by Ekin D et al., is an automatic data augmentation algorithm. Its working principle primarily revolves around enriching the dataset through the use of two parameters, N and M. Specifically, it randomly selects N operations from a set of 14 predefined functions (Identity, AutoContrast, Equalize, Rotate, Solarize, Color, Posterize, Contrast, Brightness, Sharpness, ShearX, ShearY, TranslateX, TranslateY). It applies them to the images in the dataset with an intensity level of M. As the values of N and M increase, the regularization strength also magnifies [11]. Figure 5 illustrates several examples of images processed using Randaugment.

Several good results for images in DIV2K [1] processed using the RandAugment algorithm.
Figure 5 shows that lighting adjustments were implemented in the image (a), significantly enhancing the visibility of the previously subtle green leaves along the edges of the original image. Image (b) utilized color enhancement techniques to deepen the red and blue components, imparting a more vibrant and three-dimensional appearance to the entire porcelain object. Image (c) underwent simultaneous adjustments in brightness and color, resulting in an overall increase in brightness and introducing distinctive color variations across different regions of the image, thus creating a more layered visual effect. Image (d) underwent style processing, rendering the snake’s skin darker and giving the sand a more granular texture. Finally, image (e) intensified the almost imperceptible underwater fine lines from the original image, making them discernible to the naked eye.
Network architecture
The overall structure
The overall network structure of the proposed model is illustrated in Fig. 6. Similar to Swin2SR, it primarily consists of the shallow feature extraction module, the deep feature extraction module, and the image reconstruction module. The shallow feature extraction module comprises a single 3 × 3 convolutional layer. Its primary purpose is to preprocess the input images by converting the channel number to match the required features for the deep feature extraction module. The image reconstruction module combines convolution and up-sampling with specific structures determined by the intended application. These structures include classical image SR, lightweight image SR, real-world image SR, and image JPEG Compression Artifact Reduction. The classical image SR structure involves up-sampling [37] and two 3 × 3 convolutional layers. Additionally, there is a long skip connection between the shallow feature extraction module and the deep feature extraction module, directly connecting to the image reconstruction module. We introduce a novel basic block called RSVTCAB for the deep feature extraction module, which incorporates coordinate attention and EMSAv2. The enhanced overall network structure is referred to as RSVTCANet.
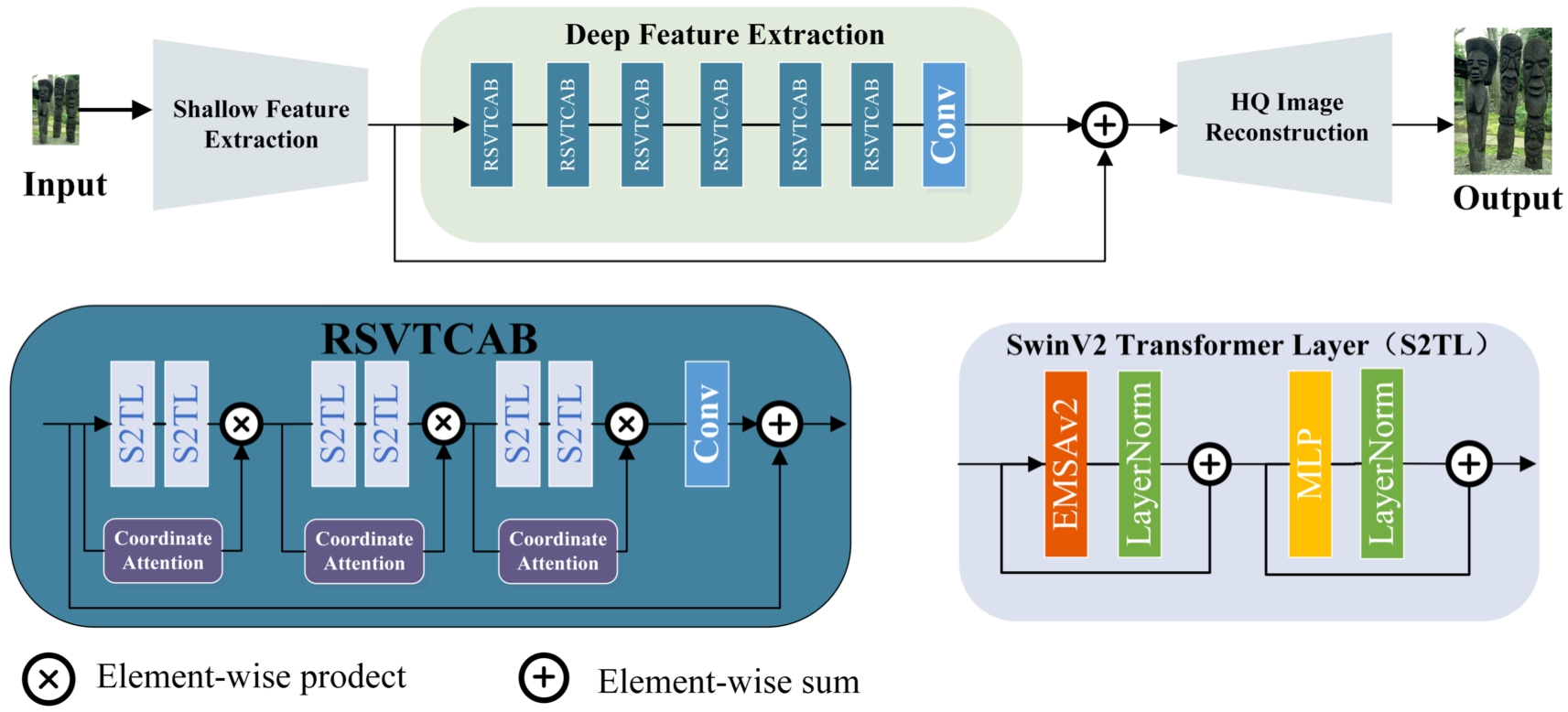
Residual SwinV2 Transformer Coordinate Attention Network (RSVTCANet) and Residual SwinV2 Transformer Coordinate Attention Block (RSVTCAB).
Figure 6 shows that the deep feature extraction module primarily consists of N RSVTCABs and a 3 × 3 convolutional layer. Each RSVTCAB consists of N S2TLs and a 3 × 3 convolutional layer. Additionally, there is a long skip connection connecting the head and tail of the RSVTCAB. We have made improvements both internally and externally to the S2TL. Externally, we introduce a Coordinate Attention Block by connecting every two consecutive S2TL with residual connections. Therefore, in each RSVTCAB, the number of Coordinate Attention Blocks is half that of S2TL. Internally, we replaced the original MSA with EMSAv2 in the S2TL. The revised S2TL consists of EMSAv2 and MLP, each followed by a normalization layer connected through residual connections.
Loss function
We utilize the L1 loss [23] as our loss function to train our model. Its operation can be expressed as:
Improved RandAugment for image preprocess
Before formal training, we preprocess the images in the training dataset using the RandAugment. For each image, we apply two augmentation operations randomly selected with equal probability from a set of 14 functions, enhancing the image with an intensity of 10 (N = 2, M = 10). However, during the augmentation process, we encountered challenges such as blurring or excessive noise in particular images, leading to a decline in image quality compared to their pre-augmentation state. Some images even suffered from structural damage. Figure 7 presents examples of inadequately enhanced images.

Several bad results for images in DIV2K [1] processed using the RandAugment.
Figure 7 illustrates the impact of various image issues on image quality. In the image (a), the stone is excessively illuminated, resulting in a nearly transparent white appearance and the loss of all texture details. Image (b) showcases the blurry and noisy processing of the window and staircase, completely distorting their original appearance. The most severe destruction is evident in the image (c), where the resultant image differs entirely from the original in content and structure. Image (d) introduces unknown and discomforting irregular light spots. Excessive darkening in the image (e) has rendered the grass and water details unrecognizable compared to the original image. To ensure that the training process does not affect the model’s performance, we selectively retain and replace the authentic images with those yield better augmentation results. Conversely, images with poor augmentation effects are excluded from the training dataset and are not replaced.
Datasets
For training, we use sub-images (480 × 480 for ×4 SR task, 240 × 240 for ×8 SR task) that were generated by cropping the DIV2K [1] dataset, consisting of 32,592 pairs of cropped HR and LR images. The LR images were obtained by downscaling the HR images using MATLAB’s bicubic kernel interpolation method. The downscaling factors were set to 4 or 8. For testing, we evaluate our method on six benchmark datasets:Set5 [3], Set14 [45], BSD100 [32], Urban100 [19], General100 [13], and Manga109 [33]. PSNR and SSIM [41] values are used to calculate the experimental results computed on the Y channel in the YCbCr space.
Implementation details
We set the batch size to 4 and the training HR patch size to 48. The window size, channel number, and reduction factor are typically set to 8, 180, and 2, respectively. We use the Adam [22] with
Our implementation is built on BasicSR. Our experiments were conducted using the PyTorch framework. The training was performed on four GPUs with NVIDIA GeForce GTX 1080 Ti for the ablation study and one GPU with NVIDIA A100-SXM-80GB for the classical image SR task. The tests were conducted on a CPU with an Intel(R) Core(TM) i3-8130U clocked at 2.2 GHz.
Ablation study
We conducted an ablation study before performing the classical image SR tasks to validate the effectiveness of the three proposed improvement methods for RSVTCANet. The ablation study consisted of three groups of experiments corresponding to this paper’s proposed improvement methods: coordinate attention, EMSAv2, and RandAugment.
We conduct ablation studies to investigate the importance of different network architectures. We design the corresponding networks with comparable parameters. As shown in Table 1, we present six different networks according to different improvement methods. The model using V1+Channel+MSA-based (ID:1) is degraded to a complete network like the architecture of RSTCANet. The model using the SwinV2 Transformer-based network (ID:2) obtains better performance gains than that using the SwinV1 Transformer-based network (ID:1). It demonstrates that scaled cosine attention in SwinV2 Transformer produces a gentler attention weight than dot product attention in SwinV1 Transformer, thereby improving the accuracy of the trained model.
To verify whether the RandAugment can genuinely enhance the model’s generalization during the training process, we conducted a comparative analysis between two scenarios: one involved processing the DIV2K datasets using the RandAugment, while the other did not. The model that incorporated the RandAugment was named RSVTCANet+. The comparative results are presented in Table 1. As we can see, our model using RandAugment (ID:6) achieves dramatically enhanced performance. It further verifies that RandAugment plays an essential role in improving the model’s generalization ability during training and its final performance.
Finally, by comparing experimental groups 2 and 3 (ID:2 vs. ID:3) or experimental groups 4 and 5 (ID:4 vs. ID:5), which can be found that the model using EMSAv2 structure can achieve more efficient performance than the model using MSA structure. It shows that Pixel-Shuffle and DWConv in EMSAv2 can play their respective roles in improving model performance.
Comparison of different network architectures for ×4 SR on the six benchmark datasets. Best performance are in red colors. The higher the SSIM, the better

Comparison of different network architectures for ×4 SR on the six benchmark datasets. Best performance are in red colors. The higher the SSIM, the better
The ablation study of different RSVTCABs in the RSVTCANet and different S2TLs in one RSVTCAB for ×4 SR. The parameter settings of different model variants. N and K denote the number of RSVTCAB in RSVTCANet and the number of S2TL in one RSVTCAB, respectively. Best performance are in red colors. The higher the PSNR and SSIM, the better

Due to the inability to determine conclusively whether both Coordinate Attention and EMSAv2 have positive effects on the model, to avoid the situation where one module has a positive effect while the other has a negative effect, but the overall effect remains positive when combined, we conducted an ablation study on RSVTCAB with only the inclusion of Coordinate Attention. The ablation study for the different RSVTCABs in the RSVTCANet and different S2TLs in one RSVTCAB was divided into six distinct scenarios by setting different learning rates (
Table 2 presents the results of the ablation study for the different RSVTCABs in the RSVTCANet and different S2TLs in one RSVTCAB. In the table, N represents the number of RSVTCAB in the deep feature extraction module, while K represents the number of S2TL in each RSVTCAB. According to Table 2, it can be observed that when the learning rate is set to
Impact of window size in RSVTCANet
EMSAv2 provides an efficient and effective way to enlarge window size. To investigate the impact of different window sizes on model performance, we conduct the ablation study and report in Table 3. In the Table, we do not use the RandAugment in our RSVTCANet and set the window size to
Ablation study on the window size in RSVTCANet for ×4 SR. w/o denote the without. Larger windows can result in better performance. Best performance are in red colors. The higher the PSNR and SSIM, the better

Ablation study on the window size in RSVTCANet for ×4 SR. w/o denote the without. Larger windows can result in better performance. Best performance are in red colors. The higher the PSNR and SSIM, the better
We introduce EMSAv2 in Section 2.4, which aims to encode more local information without increasing too many computations. To explore which kernel size can improve the best performance, we attempt to use
Ablation study on DWConv of EMSAv2 for ×4 SR. From the results on the six benchmark datasets, we can see that using 3 × 3 depthwise convolution yields the best results. Best performance are in red colors. The higher the PSNR and SSIM, the better

Ablation study on DWConv of EMSAv2 for ×4 SR. From the results on the six benchmark datasets, we can see that using 3 × 3 depthwise convolution yields the best results. Best performance are in red colors. The higher the PSNR and SSIM, the better
We designed four variant structures based on RSVTCANet, as shown in Fig. 8, to examine the influence of different coordination attention blocks on the model. Three other variations of RSVTCANet are designed to investigate the effect of coordination attention blocks. In the RSVTCAB of RSVTCANet-CA1, there is only one coordinate attention block, and the input of this coordinate attention block is the input of RSVTCAB. The attention generated by this coordinate attention block is multiplied by the features produced by the sixth S2TL of RSVTCAB. There are two coordinate attention blocks in RSVTCANet-CA2. Note that the attention generated by this coordinate attention block is multiplied by the features produced by the third and sixth S2TL of RSVTCAB. For RSVTCANet-CA6, in the RSVTCAB, there is one coordinate attention block for each S2TL.
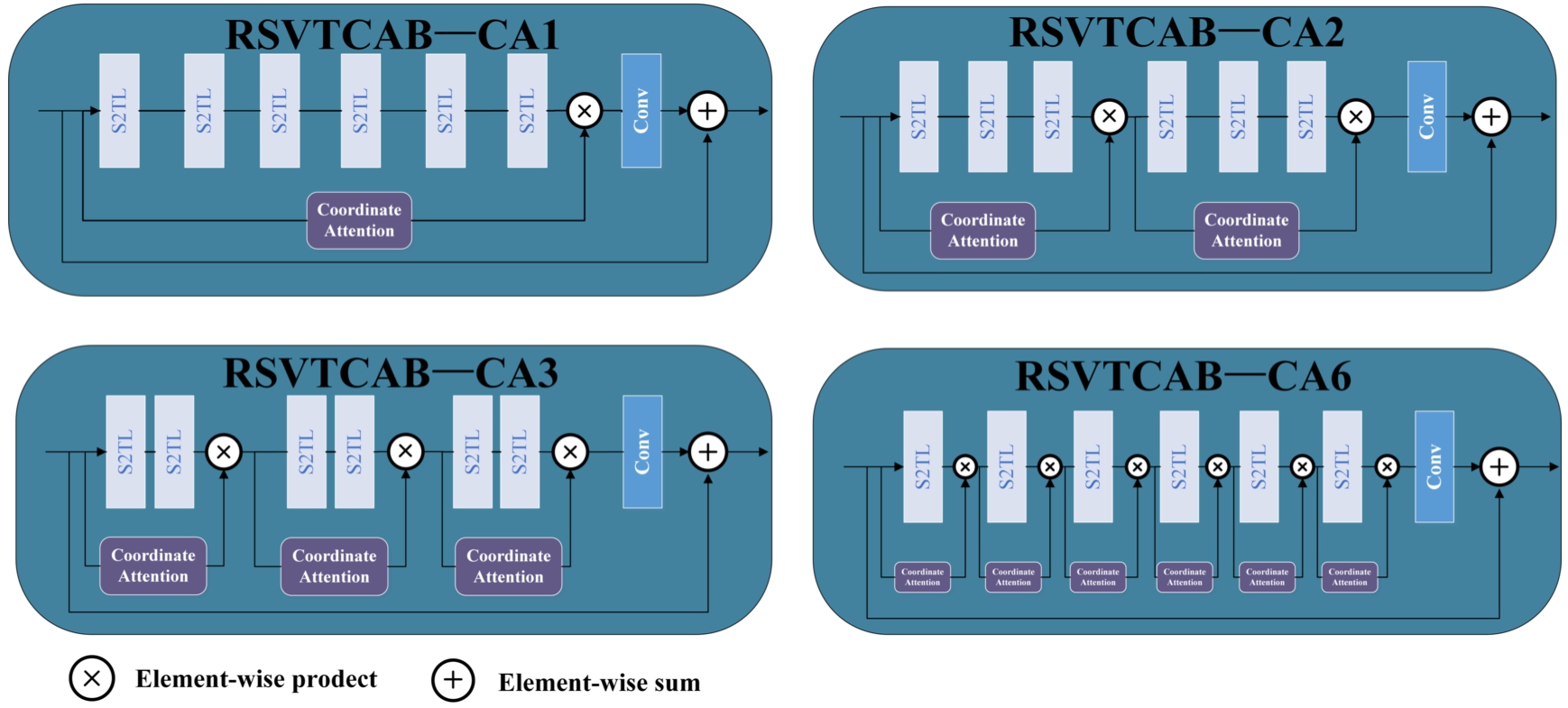
Four variant structures with different numbers of coordinate attention blocks in one RSVTCAB are designed based on RSVTCANet.
A comparison with RSVTCANet-CA1 presented in Table 5, shows that exploiting one coordinate attention block for each three successive S2TLs (RSVTCANet-CA2) or applying one coordinate attention block for each two successive S2TLs (RSVTCANet) can improve the performance of the RSVTCAB. However, with the inclusion of six coordinate attention blocks in RSVTCAB (RSVTCANet-CA6), the performance of RSVTCANet tends to degrade. This phenomenon can be attributed to the shifting window partition mechanism of two consecutive S2TLs. In response to the limitation of cross-window connections in window-based self-attention modules, the authors introduced a strategic shifting window partition approach within two successive SwinV2 transformer blocks. While learning to coordinate attention for each S2TL, connections across windows are disregarded. Conversely, the application of coordinate attention for every two consecutive S2TLs proves to have a positive impact, thereby augmenting the efficacy of the shifting window partition strategy.
The ablation study of different coordinate attention blocks in one RSVTCAB for ×4 SR. Best performance are in red colors. The higher the SSIM, the better

To demonstrate the performance of RSVTCANet in classical image SR tasks, we compared it with the following classical models: SwinIR, Swin2SR, RSTCANet [42], ART, and SRFormer [52]. We reproduced all models using the same settings in a consistent environment to ensure experimental rigor. Since all models share a similar overall network structure, we made uniform adjustments based on the results of the ablation study. We set the number of basic blocks in the deep feature extraction module to 4 and the number of STLs in each basic block to 6. The learning rate was set to
Quantitative comparison (average PSNR/SSIM) of our RSVTCANet with recent classical image SR methods on six benchmark datasets. Best performance are in red colors. The higher the PSNR and SSIM, the better
Quantitative comparison (average PSNR/SSIM) of our RSVTCANet with recent classical image SR methods on six benchmark datasets. Best performance are in red colors. The higher the PSNR and SSIM, the better
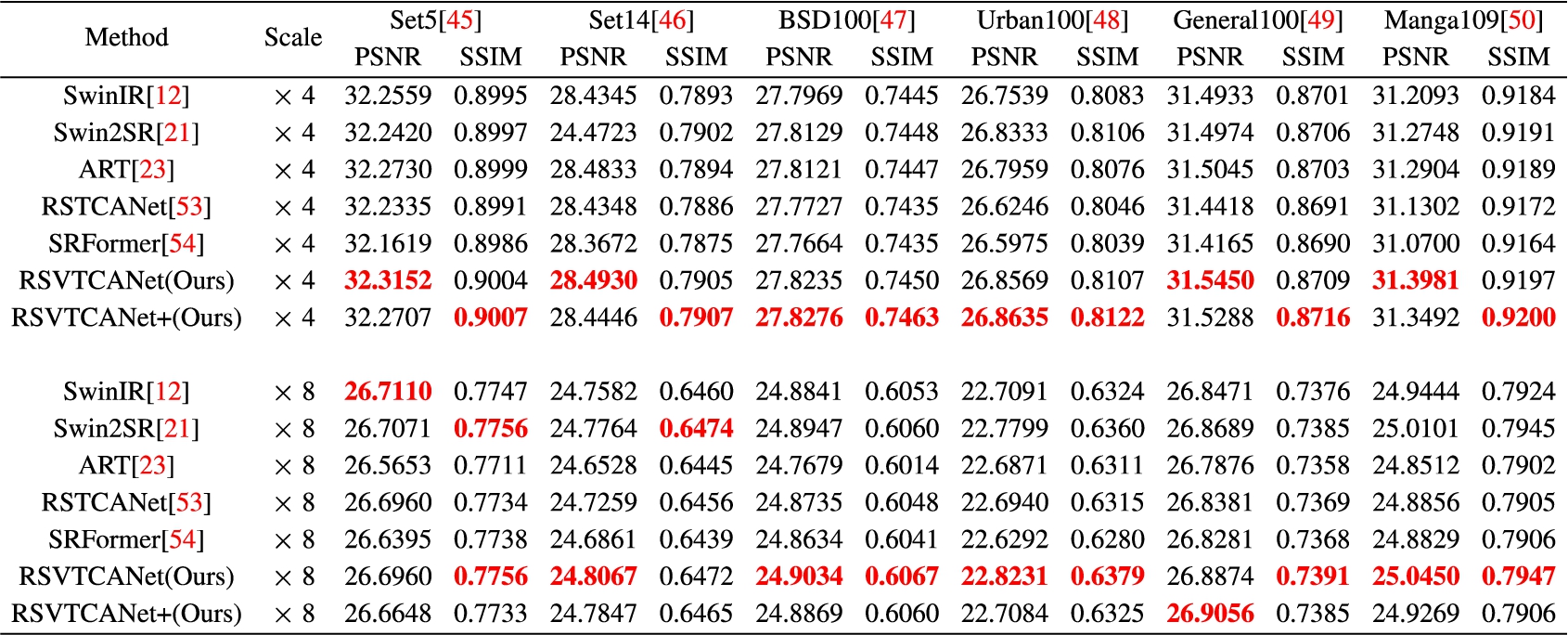
Table 6 presents the quantitative comparison of classical image SR tasks. The results of ×4 SR are shown in the Table 6, It can be seen that RSVTCANet achieves the best performance on almost all six benchmark datasets. Specifically, RSVTCANet achieves a higher PSNR of 0.04 dB compared to ART on Set5 and General100 datasets. Moreover, substantial improvement in PSNR of 0.11 dB is achieved compared to Swin2SR on Manga109 datasets. The performance boost gets even more significant when using RandAugment to augment the DIV2K datasets as RSVTCANet+.

Qualitative comparison of our RSVTCANet with recent classical image SR methods for the ×4 SR task. For each example, our RSVTCANet can restore the structures and details better than other methods.
Unlike most works in the field of image SR, this paper also conducted an additional ×8 SR task to validate the versatility of RSVTCANet across different upscaling factors. As presented in Table 6, among the 12 metrics measured across 6 benchmark datasets, RSVTCANet achieved the best values for 10 of the metrics. This demonstrates that RSVTCANet performs admirably in ×4 SR tasks and excels in ×8 SR tasks. Specifically, RSVTCANet achieved a superior PSNR to Swin2SR by 0.03 dB on Set14, General100, and Manga109 while exhibiting a 0.04 dB higher PSNR on Urban100. Additionally, our investigation revealed that the metrics obtained from RSVTCANet+ did not surpass the performance of RSVTCANet. One possible explanation for this outcome is the unsuitability of the randaugment algorithm for ×8 SR tasks. The above strongly supports that our RSVTCANet is effective and efficient.
Figure 9 presents the qualitative comparison between the proposed model and other classical models. From “ppt3” in Set14, it can be observed that although none of the models can perfectly restore English words, the letters generated by RSVTCANet+ exhibit the highest level of clarity. Each letter is distinctively separated, unlike the letters generated by other models that blend. In Urban100, specifically in the “img002”, RSVTCANet+ generates window grids with the most pronounced hierarchical structure. Similarly, in Manga109, the lines caused by RSVTCANet+ in the “ARMS” are also the clearest. In summary, the images generated by the proposed model in this paper exhibit more rich texture details than other classical models.
Conclusion
This paper proposes a SwinV2 Transformer-based image restoration model RSVTCANet, based on the residual SwinV2 Transformer Coordinate Attention blocks (RSVTCAB). Our model combines coordinate attention and efficient multi-head self-attention version 2 (EMSAv2) to activate more pixels for HR reconstruction. Furthermore, we propose an optimized data augmentation method based on RandAugment, which effectively enhances both the generalization during training and the overall performance of RSVTCANet. Quantitative and qualitative results also demonstrate that RSVTCANet exhibits superior performance in image reconstruction and can generate richer texture details in the resulting images. In the future, we aim to apply RSVTCANet to other image restoration tasks, such as real-world image SR, image denoising and JPEG compression artifact reduction. Finally, we hope our RSVTCANet can serve as a useful tool for research in SR model design.