
Abstract
Smartwatches have become increasingly popular due to their ability to track human activities. The tracked information can be shared with other devices, such as smartphones, and used for scheduling, time management, and health management. Although several studies have focused on developing techniques for natural language text, users intention-to-recommend smartwatches have never been investigated. Consequently, the manufacturers, as well as potential buyers cannot get a holistic view of users’ perception of the smart device of their interest. Also, the non-availability of publicly available benchmark corpus has thwarted the development of intention mining techniques. Retrospectively, this study has proposed an approach for mining users’ intention to recommend smartwatches. In particular, we have employed an innovative approach, involving a screening processing and annotation guidelines, to develop the first-ever manually annotated corpus for mining intention-to-recommend smartwatches. Furthermore, we have performed experiments using two deep-learning techniques and five types of word embeddings to evaluate their effectiveness for intention mining. Finally, the recommendation sentences are synthesized to develop a deeper understanding of the user feedback on the selected products.
Keywords
Introduction
We are surrounded by numerous IoT devices, such as temperature, vision, motion, and medical sensors, which capture various types of data about persons, environment, and associated objects [11]. Among these devices, smartwatches are of paramount importance as they are adequately intelligent to reliably and precisely track human activities [9]. Furthermore, they are equipped with the ability to pair with smartphones for data exchange [26,27,30]. The exchanged data can be used for diverse purposes, such as food management, activity scheduling, time management, energy prediction, diet management, and health management. Examples of these devices are Apple Watch, Pebble smartwatch, Samsung Watch, and Fitbit.
International Data Corporation’s (IDC) report revealed that the global market of wearable devices grew by 31.4% during the last quarter of 2018 [16]. Additionally, Gartner predicted that the sales of wearable devices would grow by 26% during 2019, with end-user spending to reach 42 billion dollars [17]. It was further predicted that 74 million smartwatches would be shipped in 2019, which are expected to grow to 115 million by 2022 [14]. It is a common practice that potential buyers read product reviews and comments of previous users, before purchasing a product. Similarly, the manufactures are interested in parsing the reviews and elicit important information about their products. Given that a large number of comments, blogs, and reviews are available, the comprehension of these comments, their synthesis, and eliciting conclusions is a cumbersome task. To that end, several studies have been conducted that focus on developing techniques for sentiment analysis and opinion mining of products [10].
For this study, we have conducted a thorough literature survey of the studies that involved smart wearable devices. The survey involved three researchers, dozens of keywords, multiple search engines, digital libraries, screening of existing datasets, and the application of machine learning, for sentiment analysis or opinion mining of different products. The study has revealed the following:
Lack of attention. A vast majority of the studies, such as [5,9,27,30], have focused on investigating the accuracy or reliability of the products in controlled settings [9,12]. Furthermore, attempts have been made to develop techniques for sentiment analysis and opinion mining for these products [10]. However, to the best of our knowledge, no study has been conducted to evaluate the users’ intention-to-recommend smartwatches. In the absence of such a study, potential customers, as well as the manufacturers, cannot precisely grasp customers’ actual perception of a device.
Inadequate corpora. Our comprehensive search has revealed that there is no publicly available benchmark corpus for evaluating users’ intention-to-recommend smart wearable devices. The absence of such a corpus has thwarted the development and evaluation of techniques for mining users’ intention to recommend a product.
Scarcity of machine learning application. Several attempts have been made to use machine learning techniques for sentiment analysis and opinion mining of product reviews. However, such a study has never been conducted for mining users’ intention-to-recommend smartwatches.
Retrospectively, this study proposes a two-phase approach to evaluate users’ intention-to-recommend smartwatches. The key contributions of this study are as follows:
Firstly, we have scrapped a large number of publicly available user comments about three smartwatches having the largest market share. Subsequently, the comments are cleaned and divided into sentences to generate a very large seed corpus of over a million tokens and 101,907 sentences. The manual annotation of such a large seed corpus is a cumbersome task. To address this challenge, an innovative approach is adopted to identify the candidate sentences that should be screened manually for the development of our corpus. The corpus, as well as the detailed settings are publicly available and can be used for training and testing of various existing and forthcoming machine learning techniques.
Secondly, we have employed an iterative approach to developing a set of guidelines for unambiguous and consistent annotation of sentences, with a high inter-annotator-agreement. A vital feature of the guidelines is that they are generic and can be used to develop similar corpora for other products.
Thirdly, we have also performed experiments, using two variants of deep-learning techniques, Recurrent Neural Networks, and Convolutional Neural Networks. Furthermore, for the experiments, the existing word-embeddings, as well as our self-generated embeddings, are used. Furthermore, we have used the developed corpus for a deeper understanding of the users’ intention for each product.
Finally, the corpus of recommendation sentences is synthesized to develop a deeper understanding of the features that were mostly highlighted during recommendation, and the audience to whom the recommendations are made.
The rest of the paper is organized as follows. Section 2 briefly discusses the related work. Section 3 provides a conceptual overview of the approach that is used in this study. Section 4 presents the details of our i-Recommend corpus. Section 5 presents the settings that are used for experimentation and application of deep-learning techniques. The results of the experiments are discussed in Section 6, whereas the synthesis and deeper understanding of the recommendations is presented in Section 7. Finally, Section 8 concludes the study.
Related work
We have conducted a comprehensive search of the studies that focus on wearable devices in general, and smart wearables in particular. The search involved several relevant keywords including wearable devices, perception, activity tracking, health-monitoring, customer feedback, customer reviews, the accuracy of a wearable device, intention mining, opinion mining, sentiment analysis, and intelligent wearable devices. These keywords were used for searching through several widely established digital libraries and search engines including ACM DL, Springerlink, ScienceDirect, Google Scholar, and PubMed. Our search and screening procedure revealed that there are two major directions of research for wearable devices: (a) effectiveness of wearable devices, (b) adoption of wearable devices. A brief overview of each research direction is as follows:
Effectiveness of wearable devices
A vast majority of studies focus on evaluating the accuracy or reliability of wearable devices for patients. For instance, notable studies [30,31] have evaluated the accuracy of Apple Watch, Fitbit Charge HR, Samsung Gear S, and Mio Alpha, to measure heart rate. Another significant study [23] has evaluated and compared the accuracy of two wearable devices to track the activities among patients with Parkinson’s disease. Furthermore, an evaluation of the effectiveness of these devices has been conducted in various other healthcare settings, such as Aerobic exercises [15], monitoring ICU patients [22], and high-risk surgical patients [4].
It is observed that several studies have been conducted using Fitbit, which is one of the most widely used activity monitoring devices in the market [9]. For instance, an investigation has highlighted that Fitbit reasonably meets the validity and reliability standards, and therefore can objectively be used by primary care physicians to monitor patients’ physical activities [9]. Furthermore, similar to other devices, studies have been conducted using Fitbit in different settings, such as during treadmill walking [27], depressed alcohol-dependent women [1], physical activities of women [5], and in post-cardiac surgery population [8].
Adoption of wearable devices
Several studies [18,20,25] have examined the adoption of wearable devices. For instance, a recent study has explored the contributing and inhibiting factors that influence the adoption of wearable devices using Google Glass and Sony Smartwatch 3, as representative devices. Some studies, such as [18,25], have investigated the adaption of wearable devices including Fitbit, from an end-user perspective. However, these studies have the following limitations: (a) They either focus on evaluating the users’ acceptance on the conceptual level, rather than their perception of the actual usage of the devices [20]. (b) They either empirically evaluate the tendency of users to recommend the technology to other users [28], or acceptability of these technologies [7], rather than relying on the actual comments of users that are available in natural language text. Therefore, none of these quantitative evaluations can be used to develop deeper insights into users’ intention.
Conceptual approach: An overview
This section presents a conceptual overview of our approach for intention mining of smartwatches. We have used a natural language processing-based approach to investigate whether a user intends to recommend a smartwatch or not. In contrast to the traditional approaches that rely on a quantitative survey of end-users on a scale of 1 to 5 [25], our approach takes into consideration the free text written by the users. A key benefit of using natural language feedback over the quantitative survey is that it offers abundant opportunities to synthesize the text to gain a deeper insight into the recommendation of wearable devices. Hence, providing reliable and elaborated insights about the intention-to-recommend smartwatches.
Figure 1 presents a conceptual overview of the approach used in this study. It can be observed from the figure that our approach consists of two phases: (a) preparation phase that involves scraping the web, data cleansing, segregating into sentences, and the development of a benchmark, (b) analysis phase that involves experimentation and synthesis of users’ intentions about smart devices. The preparation phase is discussed in Section 4, whereas, the details of the analysis phase are discussed in Section 5, 6, and 7.

A conceptual overview of our approach.

Protocol to generate our I-recommend corpus.
This section introduces the protocol, followed by the execution details of the protocol employed to generate i-Recommend corpus.
The protocol
The inputs to our innovative protocol are online-portals of two widely-used retailers, whereas the output is our i-Recommend corpus. As a part of the protocol, we scrapped the users’ feedback from the retailers’ webpages, extracted natural language text, and tokenized it to generate a large corpus of sentences. Given that the manual evaluation of such a large corpus is a cumbersome task, an innovative approach was employed to identify a realistic subset of sentences that can be evaluated manually. An overview of the protocol is depicted in Fig. 2.
Starting from the large pool of sentences, firstly, each sentence was tokenized to generate unigrams and the frequency of each unigram was computed from the sentence corpus. Two researchers independently screened the unigrams to identify the ones that may represent a recommendation. Subsequently, all the sentences that contained the identified unigrams were extracted for the manual evaluation. Furthermore, those unigrams whose surrounding words could potentially be used as a recommendation were also identified. These unigrams are referred to as ‘candidate unigrams’.
Secondly, the bigrams that include candidate unigrams were generated from the sentence corpus and the frequency of each bigram was computed. Subsequently, two researchers independently screened the bigrams to identify the ones that represents a recommendation, as well as candidate bigrams. The screened bigrams, as well as the candidate bigrams, were used to identify the set of sentences that should be manually evaluated for a recommendation.
Finally, a set of concrete guidelines were developed to annotate each sentence as ‘recommendation’ or ‘not recommendation’. Accordingly, the generated guidelines were used to manually annotate the realistic subset of sentences, which resulted in the development of the first-ever i-Recommend corpus. We contend that the generated benchmark can be used for learning and subsequently predicting users’ intention to ‘recommend’ or ‘not recommend’ a device. The details of the protocol are as follows:
Generating the i-Recommend corpus
For generating the i-Recommend corpus, we scrapped the user comments from the web portals of two widely used retailers, Amazon and Google Express. The primary reasons for the choice of the retailers were their world-wide presence, large customer base, and the market value of these corporations. For example, the Amazon portal is widely acknowledged as the most valuable global retailer [29] and the most valuable public company in the US, having the largest market of smart devices [2]. Furthermore, recent data show that half of the web shoppers go to Amazon for searching products and 50% of the US consumers use it for holidays shopping [3].
The scrapping of comments was limited to three widely-used and state-of-the-art wearable devices, Apple Watch Series 3, Samsung Galaxy Smart Watch, and Fitbit Alta HR. The reason for selection of these watches stems from the reputation, as well as the market value of the products. For instance, according to the IDC, Apple shipped over 10.4 million watches in the fourth quarter of 2018 [16]. Furthermore, IDC announced that Fitbit and Samsung Watches are among the top five best selling wearable devices for the year 2019 [16]. Additionally, a leading business platform (statista.com) has shown that the top three vendors, in terms of the market share of smartwatch units shipped during the second quarter of 2019, are Apple Inc., Samsung, and Fitbit Inc. [24].
A Python script was used to scrap the web and store the source content in a text file. Subsequently, data cleansing was performed using another script that identified the junk snippets, such as html tags and non-English text. Keeping in view the ethical aspects, we only extracted the real-world and publicly available data that is written as natural language text to avoid any proprietary claims. Also, the comments posted from March 1, 2017 to August 18, 2019, were extracted.
Our screening of the cleaned data revealed the diversity and complexity of comments. Some comments were composed of a single sentence and few words, whereas, other comments were composed of over one dozen sentences. The single sentence comments posed less complexity as it was relatively easy to determine their ‘recommendation’ or ‘not-recommendation’ status. On the contrary, the long comments were more complex as it was not always possible to determine whether the overall intention of the user is to ‘recommend’ or ‘not recommend’ the device. To address this complexity, all the comments were broken down into individual sentences, where punctuations were considered as sentence boundaries. Accordingly, we generated a large collection of 101,907 sentences. The details of the dataset are presented in Table 1.
Specification of the source data
Specification of the source data
As discussed in the preceding section, to reduce the number of sentences to a manageable level, firstly, we tokenized each sentence into words and computed the frequency of each unigram. In total, there were 10,693 unigrams, whose frequency varied between 1 and 22,280. Two researchers manually screened each unigram having a frequency greater than or equal to 5 to identify the ones that represent a recommendation. Note that the variations of spellings, abbreviations, or synonyms of recommendation were included in the recommendation. Consequently, we identified three types of unigrams: (i) that represents an intention-to-recommend are categorized Type A, (ii) the may be used in a sentence with intention-to-recommendation are categorized as Type B, and (iii) the remaining unigrams are categorized as Type C. Using the unigrams of Type B, we identified the bigrams by pairing the preceding and subsequent tokens.
Secondly, using the bigrams, that were generated using unigrams of Type B, we computed their frequencies. As a result, 6389 bigrams were identified, whose frequency varied between 1 and 510. Like the screening of unigrams, two researchers manually screened bigram to determine the type of bigram i.e. Type A and B. After that, all the sentences with the unigrams of Type A, bigrams of Type A and B (total of 156 n-grams), were extracted for manual screening and further development of i-Recommend corpus. A key benefit of employing this annotative approach is that instead of annotating 101,907 sentences, we merely annotated 7947 sentences. The details of the sentence corpus are presented in Table 2. The table includes the number of sentences extracted using 156 n-grams, the source of the sentences, as well as the target products of the users’ comments.
Details of the sentence corpus
Annotation guidelines
A pre-requisite to the unambiguous and consistent annotation of sentences is a set of clearly defined guidelines. As established in several existing studies [19,24], higher inter-annotator-agreement between two researchers, while working independently, is a key indicator for such an unambiguous and consistent annotation [13]. To that end, we randomly selected a sample of sentences (10% sample) from each data source, Amazon and Google Express. Subsequently, two researchers independently screened the sample and developed an initial set of guidelines, which were discussed by both researchers. Subsequently, a new random sample of 10% sentences was selected and two researchers annotated the same sample independently using the defined guidelines. The inter-annotator agreement between the two researchers was computed using the Kappa statistic [13].
Based on the Kappa statistic score, confusion matrix, and synthesis of the inconsistent annotations, the initial set of guidelines were refined. The improvements involved adding new guidelines and refining existing guidelines. An example of each type of improvement is as follows:
The second recommendation guideline (‘a piece of advice or suggestion against buying a product is also a recommendation’) was added after the first iteration. The reason for the addition of this guideline stems from the observation that one researcher did not mark negative sentences as recommendations i.e. the sentences that advise against buying a smartwatch.
The third guideline (‘suggestion to gift the product to a friend or family member’) was refined (‘suggestion to buy a product for himself, or gift for a friend or family member’) to ensure consistent annotation of the sentences
As a result of the two iterations, a high inter-annotator agreement of over 0.76 was achieved. The finalized guidelines that are used in the rest of the study are presented in Table 3. In essence, a sentence will be declared as a recommendation if and only if it explicitly gives a recommendation in favor of or against purchasing the product. If the person shows intention to buy another product, gift the product to another person, or spreads awareness about buying or not buying the product is also a recommendation. On the contrary, a sentence that merely praises the product, its specific feature, the quality of service delivered by the retailer or the manufacturing, is not a recommendation. Furthermore, if the person expresses that he/she received it as a gift, or expresses his dissatisfaction with the product, it is marked as not recommendation.
Specifications of corpus
Table 4 summarizes the specifications of the i-Recommend corpus. It can be observed from the table that the corpus is composed of 2586 positive examples and 5364 negative examples. Given the higher significance of the two types of examples for learning and prediction, the detailed distribution of these examples is presented in Table 5. It can be observed from the table that the corpus includes positive examples from both retailers, as well as for each product.
Summary specification of the recommendation corpus
Summary specification of the recommendation corpus
For a further comparison of the data collected from the two retailers, we extracted their vocabularies and frequency distribution of each token. We removed punctuations and remove stop words, and developed a word-cloud of each source. Figure 3 shows the word-cloud of the top 70 words from the Amazon corpus, whereas, Fig. 4 shows the word-cloud of the top 70 words from the Google Express corpus.
Distribution of recommendation sentences in the corpus
It can be observed from the two figures that there is a substantial difference between the two word-clouds. For example, the most visible common words in the two clouds include, watch, Fitbit, one, great, day, and use. Whereas, the most visible words that can be found in Amazon but not in Google Express are heart rate, feature, time, and charge. Similarly, there are several words that are found in Google Express sentences but not in Amazon. It includes, highly recommended, phone, bought, recommend, good, day, and buy. The differences in the vocabularies of two retailers justify the choice of the data sources for comprehensiveness.

Word-cloud of Amazon sentences.

Word-cloud of Google sentences.
In this section, we discuss the details of the experiments performed using two deep learning techniques and five types of word embeddings. Below, we discuss the dataset, the evaluation measures, and the detailed settings of the experiments that constitutes the analysis phase of the proposed approach. Subsequently, in the next section, the results are analyzed and key findings are discussed.
Dataset
For the experimentation, we have used our newly developed i-Recommend corpus which is composed of 7947 sentences, including 2586 positive examples and 5364 negative examples. It is important to highlight that we have not used the very large source corpus of 101,907 sentences due to a very high imbalance ratio of 1:39. The reason for avoiding imbalance dataset is that it impedes the performance of machine learning techniques, as the imbalanced dataset does not offer equal opportunities for learning and prediction of both classes. Also, to cater the impact of imbalanced classes in the existing dataset (7947 sentences), we have used Pre-cision, Recall and F1 score as evaluation measures.
Evaluation measures
To evaluate the effectiveness of deep learning techniques for their ability to distinguish between two types of sentences, we have adopted three measures Precision, Recall, and F1 score. These measures are widely used in the information interval, as well as the natural language processing domain, to evaluate the effectiveness of supervised learning techniques.
To eliminate the bias that may have been induced due to the choice of training and testing sample, we have performed 10-folds cross-validation. For each fold, we computed Precision, Recall, and F1 scores, and subsequently computed the average score of the 10-folds.
For a formal specification of the evaluation measures, let
In the context of this study, Precision is the fraction of comments that are correctly classified by a deep learning technique, whereas, recall is the fraction of comments that should have been correctly classified by the technique. Formally, the Precision and Recall are defined as follows:
Word embeddings
Word embeddings are features learning techniques in natural language processing in which words are typically mapped to vectors of real numbers [21]. It is widely acknowledged that these representations have played a pivotal role in making major breakthroughs for various NLP tasks [6]. Recognizing the importance of these representations, leading corporations, such as Facebook Inc. and Google, as well as a leading research group (NLP group at Stanford University) have developed techniques for generating word embeddings. Both corporations and the research group have generated embeddings using billions of tokens and made them publicly available for research and development. Furthermore, they have made their techniques publicly available for generating new embeddings.
As shown in Table 6, this study has used five types of word embeddings, which include three types of existing word embeddings and two types of word embeddings that have been generated for this study. The existing word embeddings are as follows: (a) Facebook released word embeddings that are generated using fastText technique, (b) Google released word embeddings that are generated using Word2vec, and (c) the word embeddings available in Keras, an established API for generating embeddings.
In addition to these three existing embeddings, we have also generated two types of word embeddings. These embeddings are generated using two established techniques, Word2vec and fastText, and our seed corpus that is composed of over one million tokens and 101,907 sentences. For generating the embeddings we used the context of size 5 and vectors of 300 dimensions.
Specifications of word embeddings
Specifications of word embeddings
Parameter settings of deep-learning techniques
Summary of results for the i-Recommend corpus
For the experiments, we used training to the testing ratio of 70:30, meaning that 70% of the randomly selected sentences were used for training and the remaining 30% sentencing were used for testing. Furthermore, we repeated the experiments ten times, formally called 10-folds cross-validation, to neutralize any bias in the dataset. The results presented in this paper are an average of the ten iterations that we have performed. The experiments were performed using state-of-the-art deep learning techniques Convolutional Neural Networks (CNN) and a specific variant of Recurrent Neural Networks (RNN) i.e. Long Short-Term Memory (LSTM).
For RNN, the context window of 5 words and 100 dimensions were used, whereas, for CNN the context window of 5 words and 300 dimensions were used. Additionally, a dropout layer of 10%, Relu activation function was used in the hidden layer, and Softmax activation was used in the output layer. The other details of the settings are presented in Table 7.
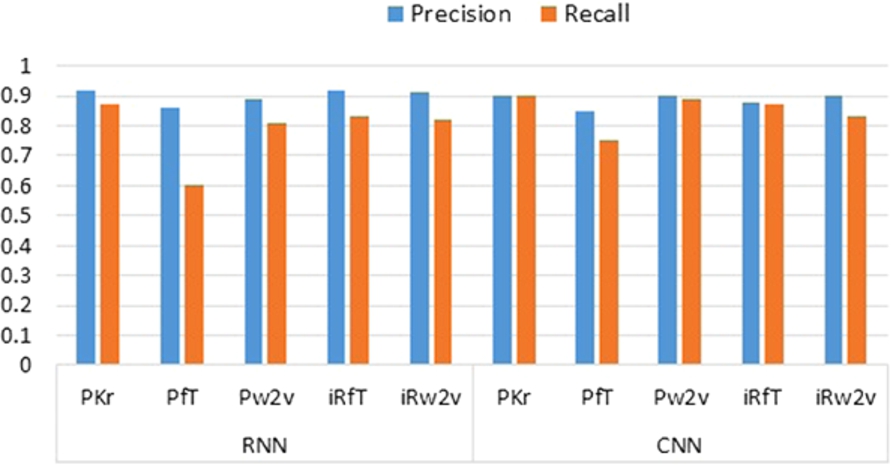
Comparison of precision and recall scores.
The Precision, Recall, and F1 scores of all the experiments are presented in Table 8. Note that each value presented in the table is an average of 10-folds. Additionally, the table contains the standard deviation of F1 scores across 10-folds. It can be observed from the table that the standard deviation across the folds is minuscule, as it varies between 0.01 and 0.04. This small variation represents the consistent performance of all the combinations of deep learning techniques and word embeddings.
It can be observed from the table that the minimum and maximum F1 score achieved by any technique is 0.71 and 0.90, respectively. The very high value of the maximum score indicates the ability of deep learning techniques to identify recommendation sentences. The key observations from the results are as follows:
Precision vs recall Fig. 5 shows a comparison of the Precision and Recall scores. It can be observed from the graph that the Precision score is higher than the Recall score for both deep learning techniques and all types of embeddings. These results show that most of the sentences that were declared as ‘recommendation’ by a classification technique were actually ‘recommendation’ sentences in the benchmark corpus. However, there were some recommendation sentences which were not identified by the techniques.
A further investigation of the cause of the lower Recall score revealed that the benchmark corpus contains several sentences that advise about the process of buying or the use of a product, rather than the product itself. These sentences were marked as not recommendations in the benchmark, however, due to significant vocabulary overlap of these sentences with the recommendation sentences, these sentences were misclassified.
Most effective technique A comparison of the F1 score of the two deep learning techniques is presented in Fig. 6. It can be observed from the figure that CNN achieved a comparable or higher F1 score than RNN for all types of embeddings. Hence, establishing that CNN is the most effective technique for mining sentences with users intention to recommend a smartwatch.
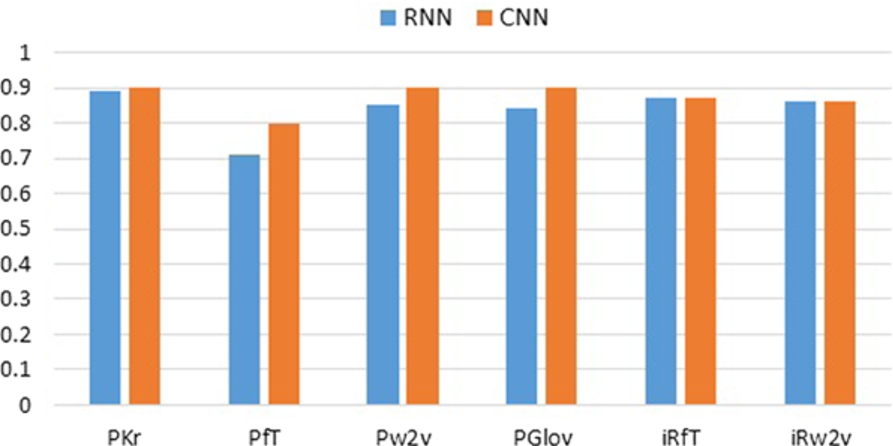
Comparison of deep learning techniques.
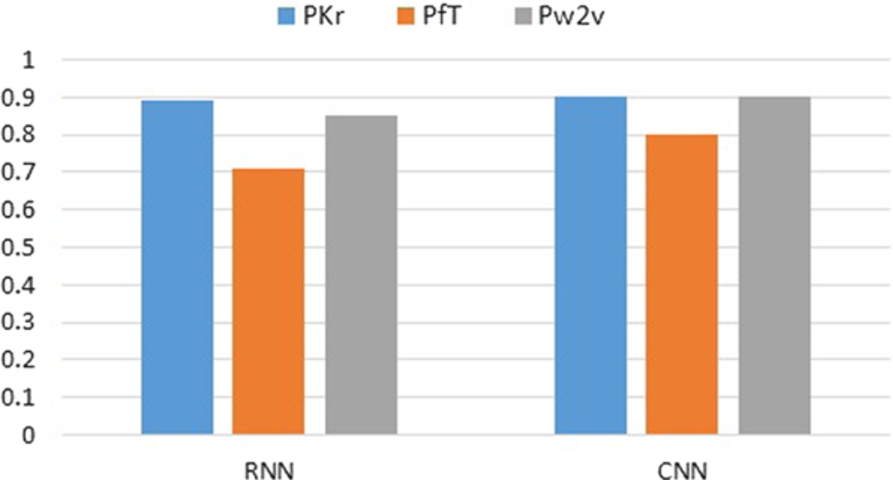
Comparison of embedding types.
Type of embedding A comparison of the three types of word embeddings is presented in Fig. 7. It can be observed from the figure that the use of word embeddings available in the Keras library achieved a higher F1 score for both deep learning techniques. A possible reason to that stems from the fact that these embeddings were generated using our source corpus that contains vocabulary about smartwatches. On the contrary, the other types of embeddings are generated from the raw text which includes vocabulary from diverse domains.
It can also be observed from Fig. 7 that the use of Facebook released word embedding achieved the lowest F1 score for both deep learning techniques. A possible reason to that stems from the fact that Facebook used news text for generating words embeddings, which is composed of a formally written text, whereas, the vocabulary used in our text is a casually written text, which also includes incorrect use of spellings, abbreviations, short words, as well as spelling variations.
Error analysis To understand the underlying reasons for misclassification, we performed an error analysis of the most effective technique. To that end, we generated a confusion matrix and extracted both false positive and false negative sentences, for Type 1 and Type 2 errors, respectively. Our manual synthesis of these misclassified false positive sentences revealed the two main types of sentences that were not correctly classified by CNN:
Firstly, the sentences that include the word ‘recommend’ or its modified form, however, these sentences do not meet our criteria presented as recommendation guidelines in Table 3. An example of such a sentence is ‘would recommend making sure the watch band is completely dry after washing hands’. According to our guidelines, such a sentence is not a recommendation as it does not advise in favor of or against buying a product, rather it gives a recommendation about the use of the product.
Secondly, the sentences that give advise about the process of buying a product or its associated issues, such as buying the product from a specific place or time, is not a recommendation. An example of such a sentence is ‘just buy it on the special prime day!’. According to our guidelines, such a sentence is not a recommendation as it gives a piece of advice about buying the product at a specific time only.
An in-depth analysis of the misclassified false negative sentences was also performed to reveal the three main types of sentences that were incorrectly classified. These are as follows:
Firstly, the sentences that give a piece of advice in favor of or against buying a product. However, the word or phrase that gives advice has incorrect spellings. An example of such a sentence is ‘overall I would reccomend this, make sure during workouts you tighten the band so it gets a good read on your heartbeat’.
Secondly, the sentences that are very long and include special characters that were not available in the training dataset. An example of such a sentence is ‘does what it says on the tin … had a Apple watch … prefer this due to upgrade to a Samsung phone … which lets me use on both products…. A must have piece for sure…’. Thirdly, the sentences that express the plan to buy another watch for personal use or to gift it to someone. The example of such a sentence is ‘I’m disappointed with the Fitbit bands since they do not last and will probably not buy another activity tracker from Fitbit’.
To develop a deeper understanding, the recommendation sentences were synthesized to generate valuable insights about each product. For synthesis, we first classified the sentences into two categories, generic and feature specific. A sentence that intends to give a recommendation (as per our guidelines), without highlighting any feature of the product is a generic sentence. Whereas, the sentence that intends to give a recommendation based on a specific feature of the product is feature specific sentence.
The need for further synthesis of the recommendations is evident from Table 9 which shows the distribution of the two types of sentences for each product. It can be observed from the table that a large percentage of the sentences (825 of 922s = 89.5%) about Apple Watch are generic recommendations. On the contrary, a substantial percentage of sentences (309 of 791 = 39%) about Samsung Watch have based their recommendation on some features.
Summary of results for the i-Recommend corpus
Summary of results for the i-Recommend corpus
Features highlighted in recommendations
Distribution of recommendations for audience
Retrospectively, we further synthesized the feature specific recommendations to extract the key features that have been taken into consideration. The key features and their frequencies are presented in Table 10. It can be observed from the shaded boxes that the two key features highlighted in the recommendation sentences are the presence of phone and activity tracking. Most of the sentences recommended buying the Samsung Watch conditional to the presence of a smart phone. Furthermore, for all the three smartwatches, the advice took into consideration the ability to track activities. For Fitbit Alta HR, a large majority of the sentences (105 of 114) advised to purchase the product due to its ability to track activities.
Finally, we identified three types of audiences to whom recommendations have been made in the sentence: personal use, friends & family, and masses. The sentences that intend to buy another smart-watch for himself/herself is referred to as personal use. The sentences that intend to gift a smartwatch to a friend, child, parent, sibling, wife, or fiance, are categorized as friends and family. Whereas, the sentences that simply intends to recommend a device without specifying an individual or a small group, are categorized as a recommendation for masses.
The frequency distribution of all the recommendation sentences along with the negative or positive recommendation is presented in Table 11. All the bold values represent the positive recommendations, whereas the remaining sentences are negative recommendations. It can be observed from the table that the positive recommendations are at least double than the negative recommendations. Also, it can be observed that nearly all the sentences in the family and friends group recommended devices to family and friends. Hence, establishing a positive perception of users.
In this study, we have for the very first time investigated users’ intention-to-recommend smart wearable devices, such as smartwatches. In this study, we have developed the first-ever benchmark corpus for investigating users’ intention-to-recommend smartwatches, formally called i-Recommend corpus. For developing the corpus, we scrapped a large amount of publicly available user comments, that are composed of over one million tokens, from the webpages of two large retailers. Subsequently, to avoid the cumbersome effort of manually annotating all the comments, we employed an innovative approach to identify a subset of sentences as candidates for manual annotation. Furthermore, for an unambiguous and consistent annotation of sentences, we have employed an iterative approach to developing a set of guidelines for annotating the intention-to-recommend dataset. The key features of the guidelines are that, due to comprehensiveness, they achieve higher inter-annotator-agreement, and due to their generic nature, they can be used for annotating several other benchmarks.
Subsequently, we have performed ten experiments using state-of-the-art deep learning techniques and five types of word embeddings. The techniques include Convolutional Neural Networks and Recurrent Neural Networks, whereas, the five types of word embeddings include three types of embeddings released by leading corporations and research groups and two types of embeddings have been generated by us for this study. We have performed 10-fold cross-validation of the experiments to cater for the variance in dataset and to reveal that the combination of Convolutional Neural Networks and the word embeddings that we have generated using Keras library is most effective for the classification of sentences. Hence, we recommend that this combination can be used for developing systems that evaluate users intention-to-recommend smart-watches.
Also, as a part of this study, we have synthesized the sentences where users intention-to-recommend smartwatches. The synthesis and the deeper understanding of the recommendation sentences revealed: (a) positive perception of the devices, (b) users intention-to-recommend the devices to family and friends.
The future work includes increasing the size of the i-Recommend corpus and enhancing the accuracy of identifying recommendation sentences by employing a more reliable and more effective technique.