
Abstract
Nowadays, sentiment analysis has been a very active research area with the increase of social media data. It presents a very useful task for product evaluation, social recommendation and popularity analysis. It constitutes also a crucial move towards natural language processing (NLP) domains. Our main goal is to identify sentiments towards aspect in the sentence. An aspect presents a specific entity or object features (price, product quality, etc.). Therefore, its analysis requires two primordial steps: extract entity aspects and identify the sentiments from all these aspects.
In our research work, we propose a new hybrid method to detect sentiments towards aspects. We start with a machine learning method to detect the different aspects within a given sentence, followed by a rule based method to identify sentiments within these aspects. The evaluation of our hybrid system based on a reference dataset of Arabic Hotels’ reviews Semantic Evaluation-2016 shows that our system outperforms baseline research to achieve encouraging results (96% of F-score).
Keywords
Introduction
Sentiment analysis (SA) is considered as a classification task. This classification can be binary to represent only positive and negative sentiment or multi-class when the text presents the positive, negative and neutral classes. SA can hold at various levels: document, sentence and aspect. At the document level, the task is to classify whether a whole opinionated document has a positive, negative or neutral sentiment. At the sentence level, the task is to classify whether an individual sentence has a positive, negative or neutral sentiment. At the aspect level, the task is to classify the sentiment of individual sentences or phrases intended towards certain entities or aspects. When the SA is done at aspect level, we speak about the Aspect Based Sentiment Analysis (ABSA).
Since this aspect is considered as the attributes of an entity, the results in ABSA are more detailed, interesting and accurate. For example in the following sentence: “The crew is excellent and the technique is bad”, at the sentence level, the sentiment expressed is neutral (positive and negative at the same time). Whereas, at aspect level, the sentiment is positive for “the crew” and negative for “the technique”. ABSA helps us to decide whether specific item or service is good/bad or preferred or not preferred. It is also useful to identify opinions of people about any entity. Here, an entity can be a product, person, event, organization, or topic on which an opinion is expressed. This entity is composed both of components and a set of attributes. For example, a cell phone is composed of a screen, a battery, and the attributes are the size and the weight. For the sake of simplicity, components and attributes are referred to as aspects.
Several studies on ABSA have already been performed in many languages, such as English and French. There is relatively less work on Arabic language [1] despite Arabic is currently ranked as the fourth language used in the web, and there are about 168 million of Arabic Internet users.1 This is explained by the lack of available resources of Arabic sentiment analysis like lexicons and datasets. For this reason, we are interested in Arabic ABSA.
In the literature, three types of approaches have been proposed for ABSA systems. Some of the proposed systems rely on handcrafted rules, namely, the rule-based approach [2]. Other studies use a machine learning-based approach (ML). They utilize a set of features that were extracted from an annotated corpus. In this context, [3] tested several classifiers on SemEval 2016 corpus-based on morphological, syntactic and semantic features. The classifiers used are IBK, SVM (SMO), J48 and NaiveBayes. Finally, a few studies in Arabic ABSA have used a mixed approach. We mention [4], who concentrated on a hybrid approach. They used symbolic parser designed with special lexicon and combined with SVM and obtained F-score of 82.28%
In this paper, Arabic ABSA is tackled through developing a hybrid system to combine the advantages of ML and rule-based approaches.
The remainder of this paper is organized as follows: First, we survey prior studies on ABSA. Then, we explain the ABSA task as well as the different challenges. The third section illustrates the architecture of our hybrid process, in which we detail the main steps of our proposed method. Finally, we present the different experiments from which we discuss the reported results.
Related studies
In the literature, several methods have been proposed to ABSA. These methods can be divided into three categories: the rule-based approach, ML-based approach and hybrid approach.
Rule-based approach
In this approach, the rules are usually implemented in the form of regular expressions or pattern. From the studies performed in the Arabic language, we mention [2] who developed a system based on a linguistic approach using the NooJ tool for the sentiments analysis for Arabic online texts. Another early work relevant to ABSA is the work of [5] on what they call Feature-Based SA (FBSA) of Arabic reviews related to Sudanese Telecommunication Companies. Specifically, the considered extracting the product features being discussed in each review using POS tagging, dependency parsing and n-gram language model. It is mandatory to note that authors do not consider a predefined set of features. Instead, they used the FP-Growth algorithm to extract the features and applied a lexicon-based approach to determine sentiment of the sentences about these features. They evaluated their system on a dataset of 600 reviews. Also, we mention the work of [6] who proposed a new system called “Opinion Observer” which is based on some linguistic rules with a new opinion aggregation function to detect sentiments towards aspects. Moreover, we can cite [7]. In this work, authors performed firstly a dependency parsing on sentences, and then they used predefined rules to determine the sentiment towards aspects. In addition, we mention the work elaborated by [8] who have improved the target-dependent sentiment classification by creating several target-dependent features based on the sentences’ grammar structures. [9] summed up sentiment scores of all sentiment words. [10] proposed a holistic lexicon-based approach considering both explicit and implicit opinions.
The rule-based systems offer a significant analysis of the context for each sentiment within aspects. However, the complexity of Arabic sentences and the high variability in the expressions used make it intricate to detect some of them. These rules are characterized by a certain flexibility (rapid addition and/or modification of new rules) which allow taking into account both very frequent and particular cases in the corpus used to generate rules. Thus, these rules make it possible to obtain a relatively high level of precision. On the other hand, rule-based approach is a domain dependent. Hence, the adaptation of these rules to other domains is expensive in terms of manual effort and time. So, we often have to rewrite a new set of suitable rules.
To overcome these problems some research studies have been oriented towards ML methods in order to automate the task of sentiment analysis.
Machine learning-based approach
The general idea of this approach is to define a statistical classification model, which is able to automatically associate classes with elements. Thus, we distinguish two main learning approaches: un-supervised and supervised learning methods.
The un-supervised methods make use of massive quantities of unlabeled text. For example, [11] proposed a near unsupervised system (W2VLDA) based on Latent Dirichlet Allocation (LDA) that could perform sentiment analysis tasks with minimal pre- configuration and outperform similar existing systems. W2VLDA needs at least one-word seed for every domain aspect and it translation to handle multilingual environments, which tackled partially the classification task on multilingual environment since most studies focuses on English. Here, authors stated also the need for an automated way to handle preprocessing tasks. In the same context, [12] explored several unsupervised methods for word meaning representation. They created word clusters and used them as features for the ABSA task. They achieved considerable improvements for both the English and Czech languages. They also used the unsupervised stemming algorithm called HPS, which helps them to deal with the rich morphology of Czech.
The unsupervised methods have the advantage of being robust by adapting to any type of text and whatever the language and field of study. Also, these methods do not rely on an annotated corpus which saves time and effort. However, they can extract a large number of aspects. However, these extracted aspects are too generic. To overcome this problem, supervised learning makes it possible to fix in advance the number of aspects to extract.
The supervised methods rely on a fully labeled corpus. This approach considers ABSA as a classification task. Among the works coming under this approach, we cite [3] who present an enhanced approach for ABSA of Hotels’ Arabic reviews using supervised machine learning. The proposed approach employs a state-of-the-art research of training a set of classifiers with morphological, syntactic, and semantic features to address the problem pf ABSA. They used a set of classifiers such as Naïve Bayes, Bayes Networks, Decision Tree, K-Nearest Neighbor (KNN), and Support-Vector Machine (SVM). The approach was evaluated using a reference dataset based on Semantic Evaluation 2016 workshop (SemEval-2016). Additionally, we can cite [13] who used hinge-loss Markov random fields to tackle aspect sentiment problem in MOOC. [14] solved the problem of ABSA with recurrent neural network, and proposed two methods TD-LSTM and TC-LSTM. [15] proposed an attention-based LSTM method.
Every recent research is the work presented in SemEval 2016 ABSA based on Task 5 [16]. A reference Arabic dataset of Hotels’ reviews was annotated to support the task requirements and was provided with baseline research using SVM along with N-grams. The best performing system that participated in that task for the Arabic track was INSIGHT-1 [17]. INSIGHT-1 employed a deep learning based approach that implemented a convolutional neural network (CNN) for the tasks of aspect extraction and aspect-based sentiment identification. INSIGHT-1 achieved around 11% of enhancement over the baseline results in the task of aspect term extraction and around 6% of enhancement over the baseline results in the aspect sentiment polarity identification task.
Hybrid approach
The hybrid approach consists in combining the rule based approach with the ML approach. Recently, research studies are oriented toward the use of hybrid approaches because they achieve an enhanced performance that is better than either the rule-based or the ML based approach alone.
The main idea of using a hybrid method, combining a knowledge-driven approach and a statistical method has been marked as the most promising way to improve the effectiveness of affective computing, which includes sentiment analysis [17]. [18] propose two hybrid methods for ABSA where their previously mentioned ontology-based approach is used as a knowledge-based method. As a ML approach, a bag-of-words model combined with an SVM classifier is used. The first approach proposed by [18] uses this bag-of-words model with the addition of two binary features that indicate the sentiment prediction from the ontology method. The second approach uses a two-steps procedure where first the ontology method is used to predict a sentiment and if this method is not able to make a prediction, the bag-of-words model is used as a backup method. The latter model performs the best and has a state-of-the-art performance of 85.7% on the SemEval-2016 [16] data. Finally, [19] combined lexicon-based method and feature-based SVM, and took the first place in detecting sentiment towards aspect categories in SemEval-2014 competitions.
The research of ABSA of Arabic text is recent. As proven in [20], before 2015 no SA work has targeted ABSA of Arabic text. As far as we know there is no hybrid works done in Arabic. This explains the fact that the Arabic language is a complex language which is the subject of the next section.
Arabic ABSA challenges
Arabic is one of the six official languages of the United Nations and it is a morphologically rich language. This language has two main forms, standard and dialectal. Modern Standard Arabic (MSA) used in formal speeches and writing like book and newspapers while dialect Arabic used in informal writing especially in social media and it varies from one country to another. Analyzing Arabic text is very complicated; the following points explain the complexity of applying sentiment analysis on Arabic language.
Every Arabic country has its own dialect that varies from other country, and people tend to use their dialect instead of using MSA. The same word can be written by different users in different ways. The negation words can invert the meaning of the sentence, so if the sentence had a positive sentiment then after adding the negation word in the sentence then it will express a negative sentiment. The same verb can be written in different ways based on the subject of the verb, singular or plural, feminine or masculine. Some Arabic named entities are derived from adjectives, and the name itself does not have sentiment while the adjective may have a sentiment. For example, the name (Øميلة) and the adjective Beautiful have the same form in Arabic.
All these complexities have a great influence on the task of ABSA. Similarly, this task encountered many problems. Some of these problems are related to the aspect extraction task and some others are related to the sentiment detection. Among the problems related to aspects extraction task, we can cite the presence of compound aspects. In fact, aspect can be either introduced through one word (example 1) or expressed via more than one word as illustrated in the examples (2, 3, and 4).
The
ÙÙŠ هذا الÙندق لذيذ
Pleasant
ممØØØ©
The
رائØ
لا ØØمل
The hotel does not provide
Indeed, this type of aspect can have several forms: the set of words expressing this aspect can be additional compound (room location/Ù…ÙˆÙ‚Ø Ø§Ù„Ø°Ø±ÙØ©) or synthetic compound (swimming pools/ ØÙ…Ø§Ù…Ø§Ø ØباØØ©, Air conditioners/ المكيÙØ§Ø Ø§Ù„Ù‡ÙˆØ§Ø¦ÙŠØ©). In addition, the compound aspect can be expressed through 2 words (room location/Ù…ÙˆÙ‚Ø Ø§Ù„Ø°Ø±ÙØ©) or 3 words (parking service/ خدمة إيقا٠الØياراØ) or more (parking service/ خدمة إيقا٠ØÙŠØ§Ø±Ø§Ø Ø§Ù„Øمل). Additionally, an aspect can be expressed directly through word(s) or introduced implicitly from a context or from the mining of a sentence. This type of aspect is not expressed through any words; it is deduced by the semantics of the sentence as illustrated in the following example.
The car is expensive (6)
الØيارة ذالية الثمن
In this sentence, the aspect is the price and not the car.
Furthermore, an aspect trigger in a sentence can take a variety of parts of speech (POS) for the words in the sentence such as noun (example 7), verb (example 8), adverb (example 9) or adjective (example 10). In this context, (Naveen Kumar et Suresh, 2016) has proved that 60% or 70% of aspect terms are explicit nouns.
Great Location (7)
Ù…ÙˆÙ‚Ø Ø±Ø§Ø¦Ø
This hotel is well located (8)
ÙŠØÙ…ÙˆÙ‚Ø Ù‡Ø°Ø§ الÙندق ÙÙŠ مكان Øيد
Locally, this hotel is one of the best hotels (9)
موقØيا ÙŠØØبر هذا الÙندق من Ø£ØØÙ† الÙنادق
This hotel is expensive (10)
هذا الÙندق باهض
In example 7, the aspect is expressed through a noun (location/موقØ). In example 8, the aspect is introduced by the verb (located/ÙŠØموقØ). Example 9 presents an aspect as an adverb (locally/موقØيا). Finally, example 10 demonstrates that an adjective (expensive/باهض) also can express an aspect.
Concerning the problems related to the sentiments detection, we can cite that the sentiment trigger can also take various POS. Let’s take a look at the following examples:
I
هذا الÙندق
Ùندق Øلى البØر
This hotel is characterized by
In example 11, the sentiment is positive and the trigger of this sentiment is the verb (liked/Ø£ØØبني). On the contrary, the sentiment in example 12 is negative and the trigger is an adjective (Bad/Øيء). In example 13, the trigger of positive sentiment is a superlative adjective. And in the last example, we have also a positive sentiment expressed through a noun.
Furthermore, the sentiment trigger can take different positions in a given sentence. It can be in the beginning of a sentence as illustrated in example 11, in the least of a sentence (example 14) or in the beginning and in the least of a sentence (example 15):
Finally, we notice the presence of negation sentiment which can in turn change the polarity of a given sentiment. This negation can be expressed through various forms and take different positions in the sentence. In other words, each sentence either verbal or nominal can be in negative form using the negation particles (“لن/ln, Ù„/lA, لم /lm/not”) (example 17) or the verb expressing the negation (example 18) such as (رÙض./refuse, deny/ندد, Ù†ÙÙ‰./refuse). Also, a sentiment can be negated through the incomplete verbs called in Arabic (“أخواث كان/sisters of kaan(a)” like “ليØ/lays(a) /is not”) or an adverb like (ذير/not) which can be placed just before the noun that expresses the polarity of a sentiment (example 16).
The bathroom is
In example 16, the negation is introduced through the adverb (not/ذير) that comes before the sentiment trigger or between the aspect and the sentiment trigger.
The hotel was not luxurious (17)
لم يكن الÙندق ÙØ®Ù
Here, the negation is illustrated through the negation particle (“لم/not”) in the beginning of the sentence. Moreover, the negation can be expressed through negative verbs as illustrated in example 18:
The tourist denied that the food was delicious (18)
Ù†ÙÙ‰ الØØ§Ø¦Ø Ø£Ù† الطØام لذيذ
In this example, the sentiment trigger is (delicious/ لذيذ) and the polarity of the sentence is positive but the presence of verb (denied/Ù†ÙÙ‰) change the polarity of this aspect into negative. In our work, all these problems will be considered in order to achieve more accurate and precise results.
Drawing inspiration from the main idea of previous studies, we propose our novel process, which is based on a hybrid approach and aims at detecting aspects and determining the corresponding sentiments for each one. Our method is distinct from the mixed proposed approaches in that we use ML method for detecting aspects and the rule-based method to rectify the output of ML system and to identify sentiments towards these aspects.
Given that it is proven in the literature that ML methods is more efficient in terms of its recall and its coverage of a given dataset, we start with a ML method to detect Arabic aspects. The output of this method suffers from a low precision. Therefore, we use the rule-based method for two main reasons. We treat the noise produced by the proposed ML model by adding some grammatical patterns and constraints to exclude ambiguous and invalid aspects. Additionally, we plan to enhance the quality and the accuracy of our system output. And finally, we focus on a set linguistic rules to identify sentiments toward aspects.
The proposed method is illustrated in Fig. 1. It shows our method’s working model divided into two general modules. The first one represents the supervised method which consists in detecting the different aspects existing in a sentence [21]. The second module concerns the rule-based method which aims at identifying the sentiment towards the different aspects extracted by the first module. This level is able also to rectify the outputs of ML method, mainly the erroneous extracted aspects.
The architecture of our hybrid method.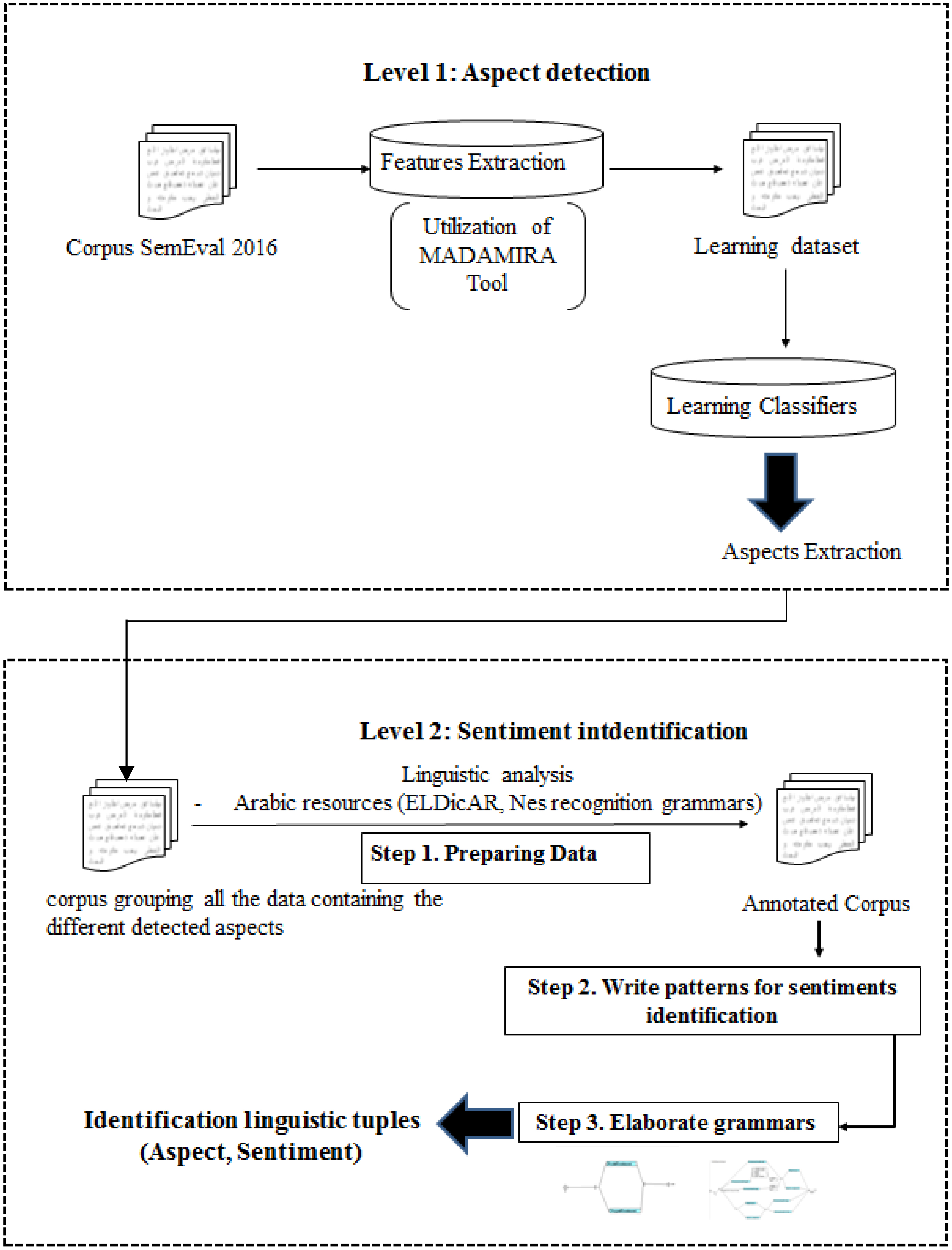
Used features
In this method, we propose a supervised machine learning method [21] for aspects extraction applied to the Arabic language. The corpus that we used is the corpus of SemEval 2016 which introduced the task ABSA for Arabic. Regardless, they contributed a large Arabic hotel review dataset labeled for aspect extraction, aspect sentiment identification and also aspect categorization.
In order to detect the aspects, it is necessary to choose a set of attributes. Since, we are based on aspect level for sentiment analysis and an aspect can be identified through one or multiple words, it is mandatory to propose word based features method. This method aims at identifying a set of semantic and syntactic features of words. In fact, relying on some semantic information can help our process to identify the right aspect. For example, in the sentence (Ahmed’s car is grateful/ Øيارة Ø£Øمد Øميلة) when knowing that (Ø£Øمد/Ahmed) is a person named entity implies that the word cannot be identified as an aspect. Also, some sentiment words are verbs, nouns, adjectives or adverbs can express a sentiment in the text. Therefore, it will be significant to used lexical features.
The different learning features used in our work are listed in Table 1. To extract these learning features, we used the MADAMIRA2 system. This tool is widely used in the NLP application. It allows segmentation, lemmatization, morph syntactic categorization and named entities detection. As illustrated in Table 1, we compiled four types of features to describe the dataset:
Lexical features to identify the morphological category of a current word, words before and after it. Semantic features that are interested in identifying named entities types in the sentence. Syntactic features consist in determining the type that can be verbal or nominal. Also, we used a suffix attribute for testing if the current word is a suffix or not. Numeric features, including the number of words in the sentence, the number of words of each context (before and after the current word) and the current word position.
The corpus of SemEval-ABSA16 contains both simple and compound aspects. Compound aspect is determined through more than one word. For this reason, we use the schema NBE to label each word in the sentence: N indicates the no aspect, B indicates the beginning of an aspect and E indicates the end of an aspect. For example, in the following sentence:
Great location and pleasant swimming pools
Ù…ÙˆÙ‚Ø Ø±Ø§Ø¦Ø Ùˆ ØÙ…Ø§Ù…Ø§Ø ØباØØ© ممØØØ©
The word (موقØ/location) is annotated by the predefined tag ‘B-Aspect’, the word (رائØ/Great) is annotated by the tag ‘N-aspect’, the word (ØماماØ/pools) is annotated by ‘B-Aspect’, the word (ØباØØ©/swimming) is annotated by the tag ‘E-Aspect’ and the word (ممØØØ©/ Great) is annotated by ‘N-aspect’.
In the literature, there are works based on 3 classes [3] and others on 2 classes (aspect/not aspect) [22]. The case of 3 classes is very necessary, let’s take the following example:
Pleasant swimming pools
ØÙ…Ø§Ù…Ø§Ø ØباØØ© ممØØØ©
In this sentence, if we are based on 2 classes, the aspect detection system can recognize only the word (ØماماØ/pools) as an aspect and the word (ØباØØ©/ swimming) will not be taken into account as an aspect. Whereas, when basing on 3 classes, our process output is as follows: the word (ØماماØ/pools) is the begin of an aspect, the word (ØباØØ©/swimming) is the end of an aspect and (ممØØØ©/pleasant) is not an aspect. In our case, we will treat both cases.
The Rule-based methods are based on a set of rules or patterns: A pattern is defined as a sentence pattern that identifies a particular form of expression of the aspect or sentiment to be extracted. An aspect or a sentiment can be expressed in various ways in a sentence. Thus, it is necessary to define patterns that are neither too specific nor too generic. Our linguistic method is not only used to identify the classes of sentiments towards aspects, but also it used to rectify some aspects extracted from the first module. Therefore, it is able to identify some aspects that are not properly detected by the supervised method. It is performed in three steps:
Data preparation
The input of our method is a corpus grouping all the sentences containing the different detected aspects. Then, we have applied a linguistic analysis on this corpus. This analysis consists in using two Arabic resources of [23]; the first one is used to attribute the morphological category (noun, verb, ..) to each word while the latter consists of detecting the Arabic named entities (Person, Location, Organization, Number, Time).
Patterns creation for aspect extraction and sentiments identification
The second step is to develop rules to extract both aspects and sentiments towards these aspects. To classify the sentiment polarity of an aspect, we have collected a set trigger words. We obtain two lists of triggers, the first list contains the negative sentiments triggers and the second presents the positive sentiments triggers. Indeed, the collection of these triggers is done from the training corpus of where we collected all the adjectives, the verbs, the nouns and the superlative adjectives expressing the sentiments. For each trigger word extracted, we seek their synonyms using Arabic WordNet [12]. As a result, we have collected 327 triggers for the positive sentiments and 287 triggers for the negative sentiments related to hotel domain.
To be able to detect the aspects, we have to focus on the morphological category of the word. Moreover, we have worked to detect the simple aspects, the compound aspects, the dispersed aspects and the non-dispersed aspects. Detecting the simple aspects is the easiest case. Patterns are considered as regular expressions integrating different elements representing an aspect and sentiments. Let’s take a look at the following example of a pattern:
[
This pattern can be applied to this sentence (the breakfast was good at this hotel/ كان الÙطور Øيد ÙÙŠ هذا الÙندق) to obtain the couple
The dispersed aspect presents the case where the adjective is not directly located after or before a given aspect. For example, in the sentence (The waiter at the hotel was jovial/النادل ÙÙŠ الÙندق كان بشوشا) the aspect is (waiter/النادل) and the adjective is (jovial/بشوشا). As we see, these two elements are distant from each other. In the case of non-dispersed aspects, it is the opposite of the dispersed aspects where the sentiment trigger is located directly after the aspect.
The presence of the negation in a sentence reverses its polarity. In fact, if we have a positive sentiment trigger and a negation particle is presented in this sentence, the polarity of the sentence becomes negative. Whereas, if we have a negative sentiment trigger and a negation particle is presented in this sentence, the polarity of the sentence changes into positive. To illustrate this issue, let’s take the same pattern in positive and negative forms (see Table 2).
Negation patterns
Negation patterns
Main grammar of ABSA.
Grammars elaboration
The patterns elaborated in the second stage are transformed into a grammar. This grammar allows us to detect sentiments towards aspects. Before describing the implementation of our work, we present the output of our local grammar. In our case, we are interested to binary sentiment classification. The polarity can be positive or negative. For this reason, we used the form of two arguments: the first argument is an aspect and the second is its polarity. The obtained output is represented through this couple:
Figure 2 shows the main graph allowing the identification of sentiments towards aspects. It is composed of two sub-grammars; the first concerns the positive sentiments and the second is for the negative sentiments. Each graph contains a set of patterns. As mentioned previously, the sentiment triggers can appear directly before or after an aspect. This case is treated in the sub grammar “NondispersedSentiment”. These triggers can appear also dispersed in the sentence and not conjunctional to an aspect. This case is treated by the “dispersed Sentiment”. At least, 32 sub-grammars have been elaborated. To understand this main graph, let’s explain the sub-graph labeled “PositifSentiment”.
The sub-grammar presented in Fig. 3 concerns only the positive sentiments. It is composed of two other sub-grammars; the dispersed and non-dispersed aspects.
Sub-graph for the recognition of sentiments towards non-dispersed aspect.
The non-dispersed sub-grammar presents the sentiments which are expressed through trigger word located directly before or after an aspect. Whereas, the dispersed sub-grammar treats the case of sentiment which is introduced through trigger word located indirectly before or after an aspect. Detecting the sentiments towards the non-dispersed aspects is the case where the triggers of sentiments (adjectives, verbs, adverbs, ..) are directly located after or before the aspects (simple or compound).
As we see in Fig. 3, it is composed of two main paths. The first path treats the case in which we have a simple (“SimpleAspect”) or a compound aspect (“aspects_composés”) followed by the positive sentiments triggers. In this case, we treat also the case we have the negations triggers (particles, adverbs …) followed by negative sentiment triggers. If these aspects are directly related to positive sentiment triggers then the polarity is positive. If they are not directly related to the positive sentiment triggers and they are related to the negation particles and these particles are related to the negative sentiment triggers then the polarity becomes positive.
To resolve the problem of agglutination in Arabic language, we add the node containing the pronouns that can be attached to an aspect. The second path is intended to extract the case in which we have the positive sentiments triggers followed by simple or compound aspects.
To obtain the couple
In this paper, all the reported experiments were performed on the test SemEval 2016 corpus using of standard evaluation metrics; precision, recall and F-score.
The SemEval-ABSA16 is a multi-lingual task for ABSA covering customer reviews of 8 different languages (i.e. Arabic, English, Chinese, Dutch, French, Russian, Spanish, and Turkish) and 7 different domains (i.e. restaurants, laptops, mobile phones, digital cameras, hotels, museums, and telecommunications).
Table 3 summarizes the dataset size and distribution over Arabic ABSA research tasks.
Hotels’ dataset description
Hotels’ dataset description
A set of classifiers were evaluated such as Naïve Bayes, Decision Tree, RepTree and Adaboost. These classifiers are available in WEKA.3 Also, we use the CRF classifier which is available in Yet Another CRF toolkit.4 The SemEval 2016 corpus has been used by many researchers. Some research studies treated only 2 classes (Aspect, No aspect) [22], some others are based on three classes [3] (B-Aspect, I-Aspect and No aspect). For this reason, we propose to treat these two cases.
A sample of concordance obtained from the evaluation corpus.
When basing on only two classes (a word can be aspect or not aspect), results show that Adaboost achieves the best results (F-score
Evaluation of learning features
The next experiment aims at assessing the performance of the proposed features. We use four types of features: lexical, semantic, syntactic and numeric. We evaluate the performance of each combination of features when applying the AdaBoost classifier.
We should remember that the F-score obtained for the first corpus and the second corpus are respectively 96.9% and 96.2% (with Adaboost) when applying all features. The following table represents the obtained results.
As indicated in Table 4, the reported results show that the use of numeric attributes gives 13% as f-score while basing on lexical attributes we get an f-score equals to 70%. This is significant since the lexical attributes give more information about the category of words, and subsequently the morphological category of words helps us to detect more easily the aspects as we cited previously. We also notice that using these two types of attributes (numeric and lexical) together is better than using them separately. Indeed, the combination of numeric, lexical, semantic and syntactic features improves the overage performance of our system. This finding can be explained by the fact that we focused on these features.
The application of NooJ local grammars of sentiments towards aspects obtains the following results.
As illustrated in Fig. 4, our rule-based method can detect both aspects and its corresponding sentiments. Also, we are able to determine both simple and compound aspects and we identify sentiments whatever they are located nearly (non dispersed aspects) or far away (dispersed aspect) a given aspect. We pass now, to the numeric results that illustrate the results of the evaluation of our system when applied to the test SemEval 2016.
Obtained results by a linguistic method
Obtained results by a linguistic method
Table 5 shows that our system gets a high recall with an acceptable value of the precision. Firstly, we can notice the influence of aspect detectin in our ABSA. In fact, given that since we are based on morphological category of words to detect aspect, some extracted aspects are non-related to hotel domain. Moreover, we find also other extracted aspects are ambiguous given that they are not associated to the appropriate sentiment. Finally, some other cases characterized by lower precision caused by the incorrect identification of the sentiment polarity due to the non voyellation of texts or the non-existence of them in the sentiments triggers list.
The goal of using a hybrid method for analyzing sentiments towards aspects is to improve results. For that, we combine the supervised method which is used to detect the aspects with the linguistic method which is used to identify the classes of sentiments towards aspects. In addition, the rule-based method is used to rectify some aspects extracted by the supervised method. This latter treats the incomplete aspects extracted from ML system. This is performed since we give the high priority to the grammar of compound aspect. Consequently, our linguistic system identifies firstly the compound aspects and then, treats the simple aspects. Table 6 presents the results of the evaluation of our hybrid system when applied to the test SemEval 2016. The use of the linguistic method gives us an f-score equals to 87.94 for the positive class and 84.49 for the negative class. The coupling of the supervised method and the linguistic method allows us to improve the results because the supervised method aims to detect the aspects and the linguistic method makes it possible to correct the aspects badly detected by ML. According to Table 6, it is clear that the hybrid method outperforms the linguistic method with a clear difference of 11% in term of f-score.
Obtained results by our hybrid method
Obtained results by our hybrid method
Finally, the purpose of the next experiment is to provide a performance comparison with previous studies based on supervised learning methods when applying to the same test corpus SemEval 2016. The obtained results are reported in Table 7. As cited in this table, the baselines obtain an accuracy of 76.4%. Hence, our proposed method outperforms the baseline approach with a clear difference of 21% in term of accuracy. We also obtain the best result compared to the result of [3] who used a supervised method.
Comparative performance of our system and previous studies
As shown above, our hybrid method outperforms both the baseline and the work of [3] to exhibit the best performance, which is 97% in terms of accuracy.
The experimental results lead to some observations. Firstly, the combination between the two approaches shows a significant improvement. The ML module aims at detecting aspects with a very high recall. It is more efficient in terms of its coverage of our dataset. Whereas, it is not the case of the precision value. In fact, some extracted aspects are incomplete. Concerning the rule based module, it can discover sentiments towards aspects if the sentiment triggers belong to our trigger words list in spite of its position in the sentence. In our case, we have used the Arabic wordnet to enrich this trigger list which in return enhances the coverage of our system. However, the problem is disengaged when a trigger word did not exist in our predefined list. Additionally, this module offers a good precision value, while it can be weak when faced to sentence complexity and heterogeneous vocabulary. Finally, thanks to the constraints added to each pattern, we treat the case of negation in a given sentence.
As a conclusion, we can notice that our proposed hybrid method exploits both ML and rule-based methods for aspects detection. It inherits the high coverage from the ML approach and the precision and the stability from the rule-based approach.
In this paper, we combine the advantages of ML techniques and rule-based methods to Arabic ABSA. For the supervised method, our main goal is to extract various features of each word in the sentence to predict which term can be an aspect. Thanks to the schema NBE, we resolve the problem of compound aspects. Several classifiers were applied to the SemEval 2016 corpus. Concerning the rule based method; our goal is not only to detect sentiments towards aspects extracted from supervised model, but also it can rectify some aspects extracted by the supervised method.
Our hybrid process obtains an overall 97% for the accuracy. The obtained results are promising and motivate the strategy of combining both types of methods to boost the overall performance of our process.
For future work, we intend to treat the case of implicit aspects. Additionally, we plan to evaluate our method with different classes of sentiments (very positive, very negative, moderate, …).
And finally, it would also be mandatory to test our mixed system to other languages and other domains. We plan to use other learning models (such as deep learning), which have been used in prior ABSA tasks and they are proven to be highly efficient technique.
Footnotes
Top ten internet languages homepage.
Madamira homepage,
Weka homepage,
CRF homepage,