
Abstract
Aspect-based sentiment analysis (ABSA) is a challenging task of sentiment analysis that aims at extracting the discussed aspects and identifying the sentiment corresponding to each aspect. We can distinguish three main ABSA tasks: aspect term extraction, aspect category detection (ACD), and aspect sentiment classification. Most Arabic ABSA research has relied on rule-based or machine learning-based methods, with little attention to deep learning techniques. Moreover, most existing Arabic deep learning models are initialized using context-free word embedding models, which cannot handle polysemy. Therefore, this paper aims at overcoming the limitations mentioned above by exploiting the contextualized embeddings from pre-trained language models, specifically the BERT model. Besides, we combine BERT with a temporal convolutional network and a bidirectional gated recurrent unit network in order to enhance the extracted semantic and contextual features. The evaluation results show that the proposed method has outperformed the baseline and other models by achieving an F1-score of 84.58% for the Arabic ACD task. Furthermore, a set of methods are examined to handle the class imbalance in the used dataset. Data augmentation based on back-translation has shown its effectiveness through enhancing the first results by an overall improvement of more than 3% in terms of F1-score.
Keywords
Introduction
Sentiment analysis, also known as opinion mining, automates the extraction of opinions, thoughts, and attitudes towards services, products, events, or public issues. Therefore, it has become one of the most active natural language processing (NLP) tasks. Moreover, opinion mining has been widely applied in various domains, such as healthcare [1], business [2], social networks [3], and education [4].
Sentiment analysis can be performed on three main levels: document level, sentence level, and aspect level. The first two levels identify the sentiment polarity of the whole document or sentence, which is not always useful, as different sentiments can be expressed towards multiple aspects in the same text. Unlike these two levels, the aspect level, also referred to as aspect-based sentiment analysis (ABSA), enables the extraction of the discussed aspects and the identification of the sentiment polarities expressed towards each aspect.
ABSA can be divided into three main tasks: aspect term extraction, aspect sentiment classification, and aspect category detection (ACD). The first task aims at extracting the discussed aspect word that literally appears in the text, whereas the second task identifies the corresponding sentiment polarity to each aspect. For the ACD task, the purpose is to detect the discussed aspect category given a pre-defined list of categories. The aspect category is a coarse-grained aspect that does not necessarily appear as a term in the sentence. In this paper, only the ACD task is performed.
Arabic is one of the most spoken languages in the world, with more than 440 million speakers [5]. It is ranked as the 4th most used language on the internet, with an internet users’ growth of 9348.0% in the last twenty years 1 . Thus, Arabic sentiment analysis has attracted increasing attention from the research community in recent years. However, most existing Arabic sentiment analysis papers have tackled the document or sentence levels, with little attention to the aspect level [6].
In addition, the majority of the existing Arabic ABSA models were implemented using rule-based or machine-learning-based methods, whereas deep learning techniques are under-discovered in this area [7]. Besides, most of the proposed deep learning methods are initialized using context-free word embedding models, which fail to capture polysemy. Therefore, this study aims at overcoming these limitations by providing a deep learning model based on BERT contextualized embeddings. Additionally, BERT is combined with a temporal convolutional network (TCN) and a bidirectional gated recurrent unit network (BiGRU) to enhance the extracted semantic and contextual features further. Besides, a set of methods are examined to handle the class imbalance problem in the evaluated dataset. The main contributions of this paper are: Implementing a deep learning-based model to handle the ACD task without the need for external linguistic resources or tedious feature-engineering tasks. Combining BERT with a TCN-BiGRU model to handle the ACD task. To our knowledge, this is the first time to use this combination to accomplish this task. Investigating a set of methods to overcome the problem of the imbalanced dataset. To our knowledge, this is the first time to handle this issue in this task in Arabic.
The rest of this paper is structured as follows: Related work to Arabic ACD is overviewed in Section 2. Section 3 introduces the research methodology. Section 4 describes the dataset and comparison models. Section 5 provides the experimental results. The class imbalance issue is discussed in Section 6. Finally, Section 7 concludes the paper and provides future work directions.
Literature review
Arabic ABSA is attracting much less attention from researchers compared to English. Moreover, work on Arabic ACD is limited compared to other tasks, namely aspect term extraction and aspect sentiment polarity classification [8]. This section overviews Arabic ACD methods implemented based on deep learning models.
To the best of our knowledge, the first deep learning-based models that performed the ACD task in Arabic were that of Ruder and Ghaffari [9] and Tamchyna and Veselovská [10]. Both models were submitted to the SemEval 2016 task 5 workshop [11]. The former is a multi-label model implemented using a convolutional neural network (CNN), where vector representations were randomly initialized for the Arabic language. A threshold was fixed to predict the category labels of each sentence. The proposed model was ranked first in this task for Arabic by achieving an F-1 score of 52.1%. The latter is implemented as a binary classifier for each aspect category. A long short-term memory (LSTM) was used as an encoded layer to capture long-term dependencies in the data, followed by a logistic regression classifier for label prediction. The model obtained an F1-score score of 47.3%.
An attempt to enhance the previous results was introduced in Al-Dabet and Tedmori [12]. The authors proposed a combination of CNN with a variant of LSTM, called independent long short-term memory network (IndyLSTM), to handle the ACD task. They used a binary relevance (BR) classification approach, in which the proposed model was decomposed into a set of independent binary classifiers to train each category independently. The experimental results achieved an F1-score of 58.1%.
A recent study in Bensoltane and Zaki [8] has achieved enhanced results compared to previous models. The authors proposed a deep learning model based on BiGRU to handle the Arabic ACD task. Besides, different word embedding models were examined to initialize vector representations, namely word-level, character level, domain-specific, and contextualized embeddings. The best results were achieved using BERT contextual embeddings with an overall enhancement of more than 7% compared to the previous model of Al-Dabet and Tedmori [12].
Another enhanced model based on BERT was introduced in Bensoltane and Zaki [13]. The authors investigated two methods of implementing a BERT model for the ACD task: fine-tuning and feature extraction. The first method fine-tuned the BERT model using a linear layer for multi-class classification. The second method extracted word embeddings from BERT while freezing its parameters, then a CNN-based model was trained for the classification task. The proposed models were evaluated on an Arabic news dataset. The Evaluation results proved the effectiveness of fine-tuning compared to feature extraction (F1-score=82.8% vs. 77.5%), especially in low resource settings.
In this study, an improved model of the previous method is presented. The proposed model enhances BERT contextual and semantic features by integrating a TCN-BiGRU model with the BERT fine-tuned model. Besides, different methods are investigated to overcome the problem of class imbalance in the used dataset.
Methodology
Task description
Given a sentence
Model overview
The proposed model combines BERT with TCN-BiGRU along with global pooling mechanism to perform the ACD task. First, a BERT layer is used to provide contextualized word embeddings. Then, a TCN layer is applied to extract temporal features, followed by a BiGRU layer to further capture long-term sequence dependencies form both left and right sides. Next, global maximum and global average pooling layers are applied simultaneously on the output of BiGRU layer to reduce the dimensions of previous layers while capturing meaningful features. Finally, the output of the concatenate layer is fed into a fully connected layer for category label prediction. Figure 1 illustrates the overall architecture of the proposed model. A detailed description of each layer is provided in the following subsections.
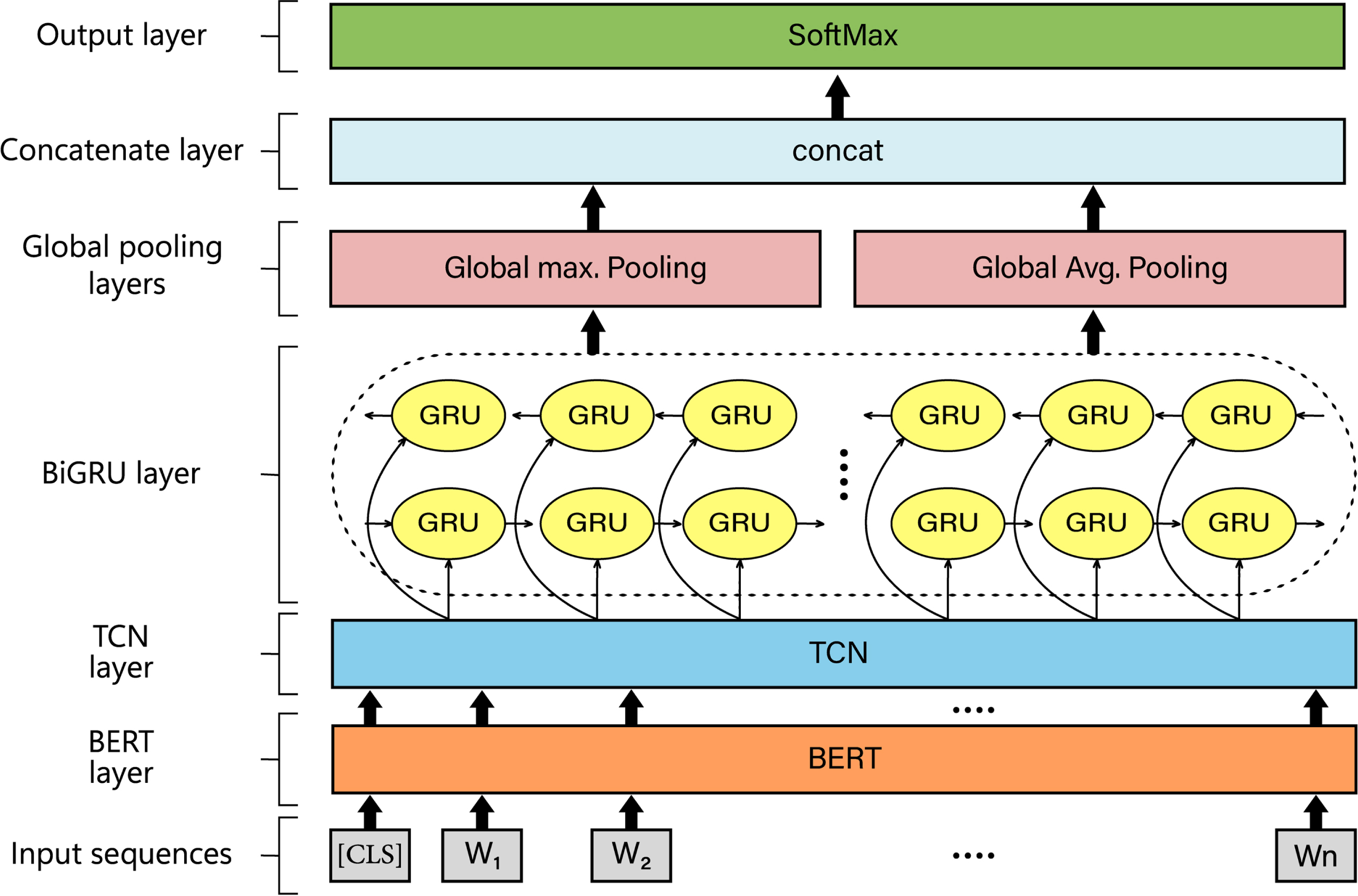
Overall architecture of the proposed model.
BERT [14] is a deeply bidirectional and pre-trained language representation model implemented based on transformers. It has achieved enhanced results in many NLP tasks, such as text classification [15], sentiment analysis [16], and named entity recognition [17]. BERT was pre-trained on two unsupervised tasks: masked language modeling (MLM) and next sentence prediction (NSP). For the MLM task, 15% of tokens are randomly masked, and the model is then trained to predict the hidden tokens. The second task helps the model understand the relationship between two sentences.
Unlike traditional word embedding models like GloVe [18] and Word2Vec [19], BERT provides different vector representations for the same word depending on the context in which it appears. Table 1 shows an example of a sentence with different meanings of the word “\epsfbox G:/Tex/IOSPRESS/IFS/0-221214/IF-01.eps”. It can be noticed that BERT provides different vector values for this word based on the context in which it occurs. It is noteworthy that, in this study, BERT is fine-tuned on the downstream task in order to release its true power [20].
An example of a sentence with different meanings of the word “ ”
”
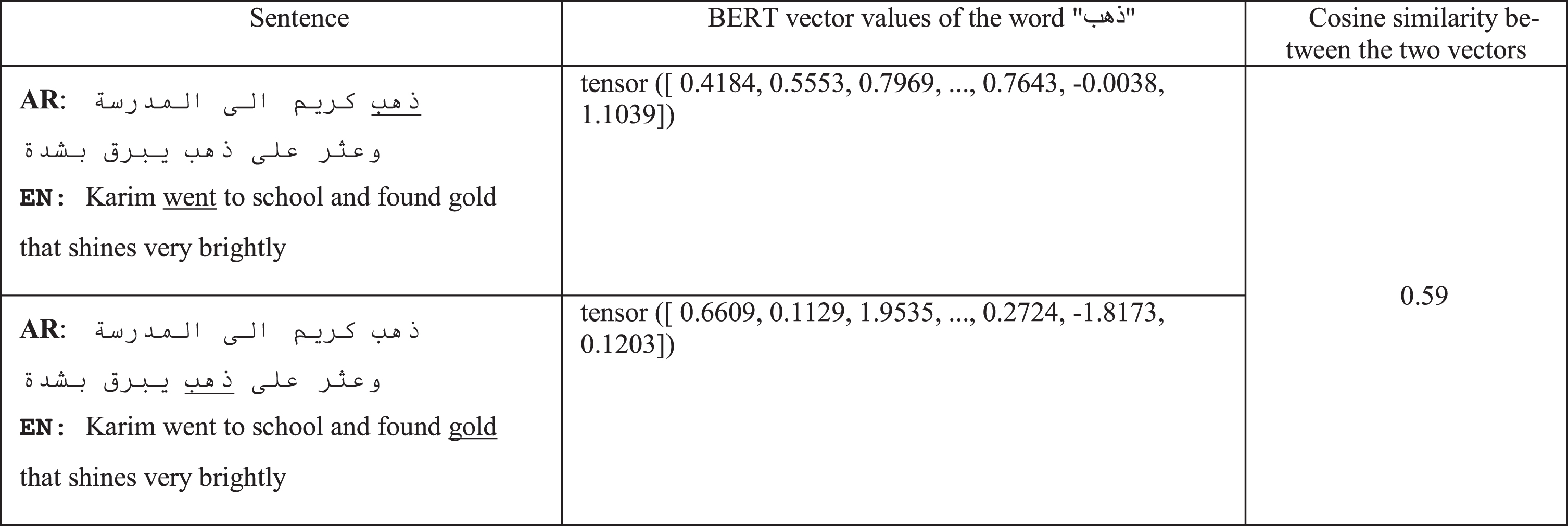
An example of a sentence with different meanings of the word “”
Before feeding the input sequence into the BERT model, special tokens, namely [CLS] and [SEP] are added to the beginning and end of each input text. Each input token is fed into token embedding, segment embedding, and position embedding layers. The token embedding layer converts each word into a vector representation of a fixed dimension. The segment embedding layer distinguishes between two sentences in an input sentence pair. In this study, we use only one input sentence. Thus, 0 is assigned to all the tokens of the sentence. The position embedding layer numbers each position in the sequence. These three embeddings are linearly summed to generate a single representation that is fed into the BERT’s encoder layer.
BERT uses a transformer encoder, which adopts a self-attention mechanism to capture the relationship between words in the context by computing the attention between each token in the sequence. The attention is computed using three input word vector matrices: Query Vector Q, Value Vector V, and Key Vector (K), as illustrated in the following formula:
Where d k denotes the input vector dimension, and SoftMax is used to obtain the weights on the values through converting a vector of numbers into a vector of probabilities. The final output is provided by summing the weights of all input vectors.
Additionally, the transformer uses multi-head attention with h attention heads in parallel to capture information from different representation subspaces. More details can be found in Vaswani and Shazeer [21].
TCN is a variation of CNN that combines causal convolution and dilated convolution. It has a backpropagation path that is different from the temporal direction of the sequence, which enables it to avoid the gradient explosion or gradient disappearance of RNN. TCN also allows the parallel computing and enables controlling the sequence memory length by changing the size of the receptive field. Readers can refer to the original paper of TCN [22] for more details. The main components of TCN are:
where k is the kernel size, and d is the dilation factor. A TCN receptive field can be increased by choosing a larger kernel size or increasing the dilation factor.
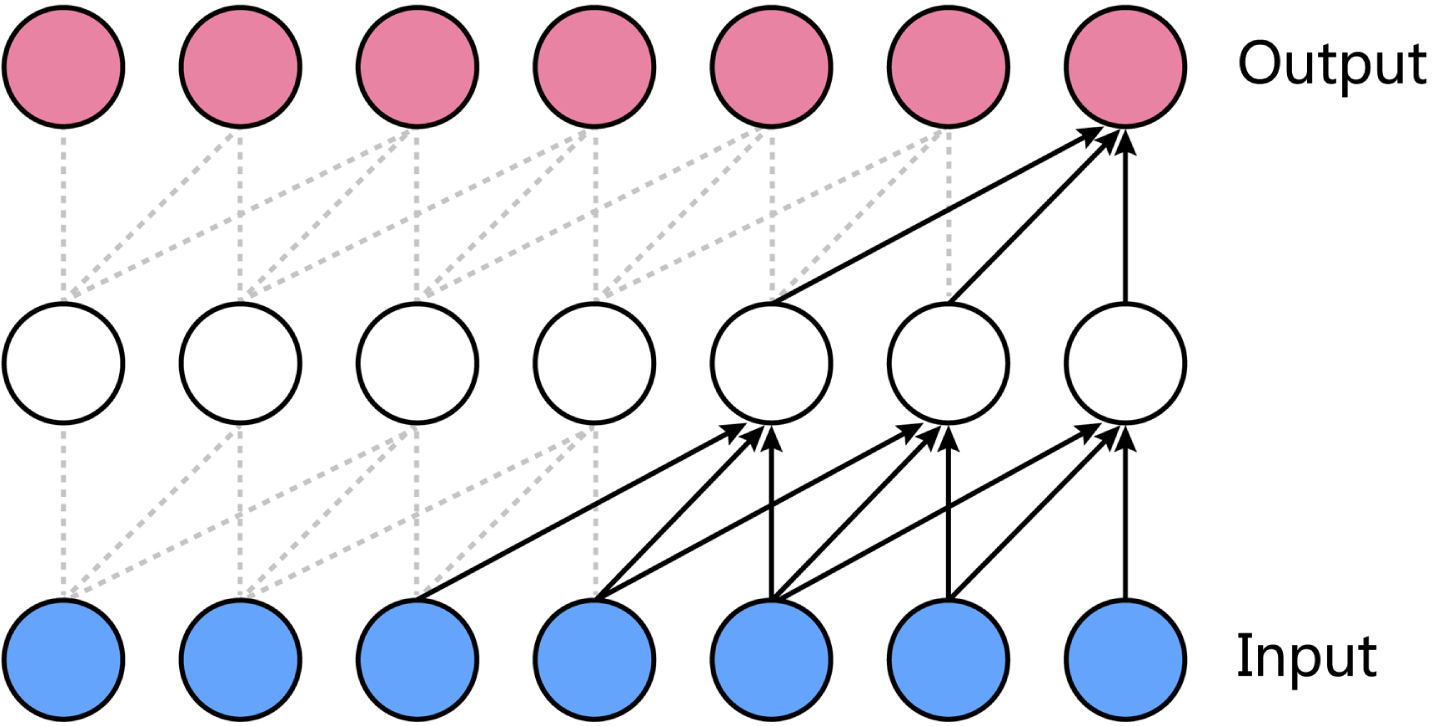
A causal convolution with two layers and kernel size=3.
For one-dimensional input sequence X and a filter f:
Where s–d.i denotes the direction of the past, which represents the d.i element index before s.
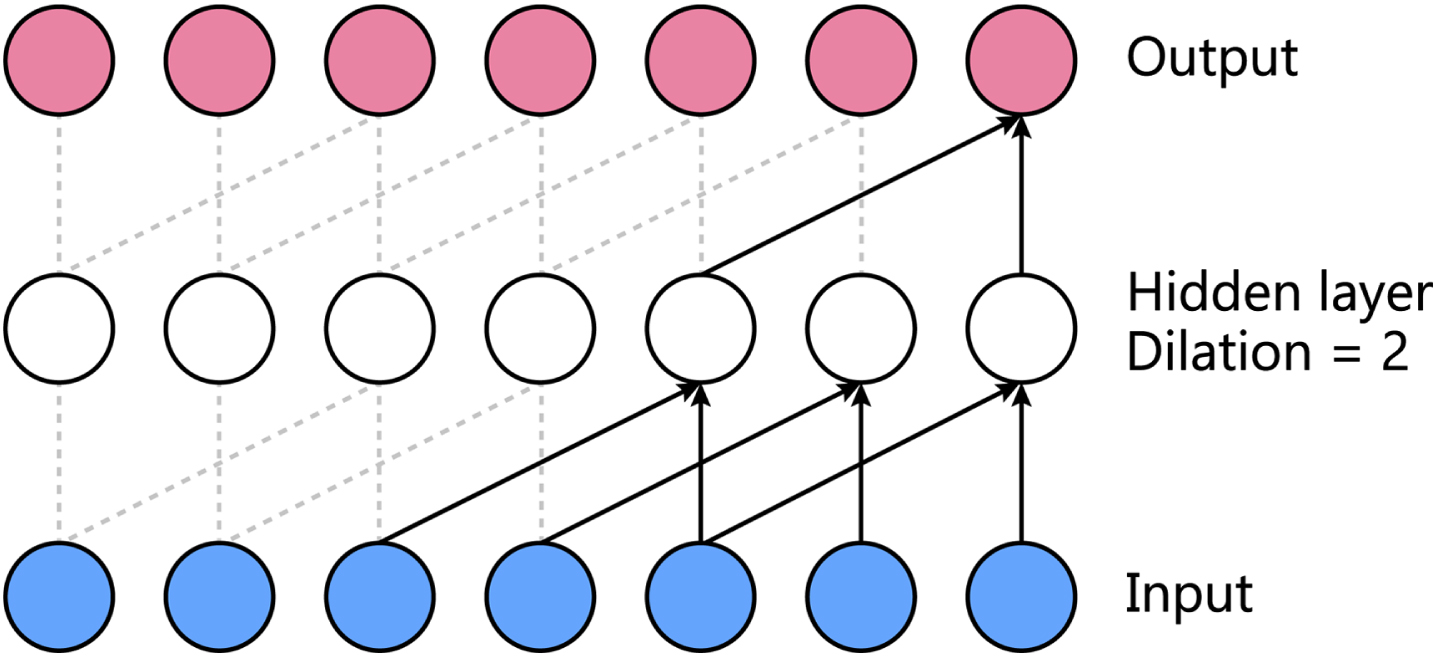
A dilated causal convolution with two layers, kernel size=2, and dilation=2.
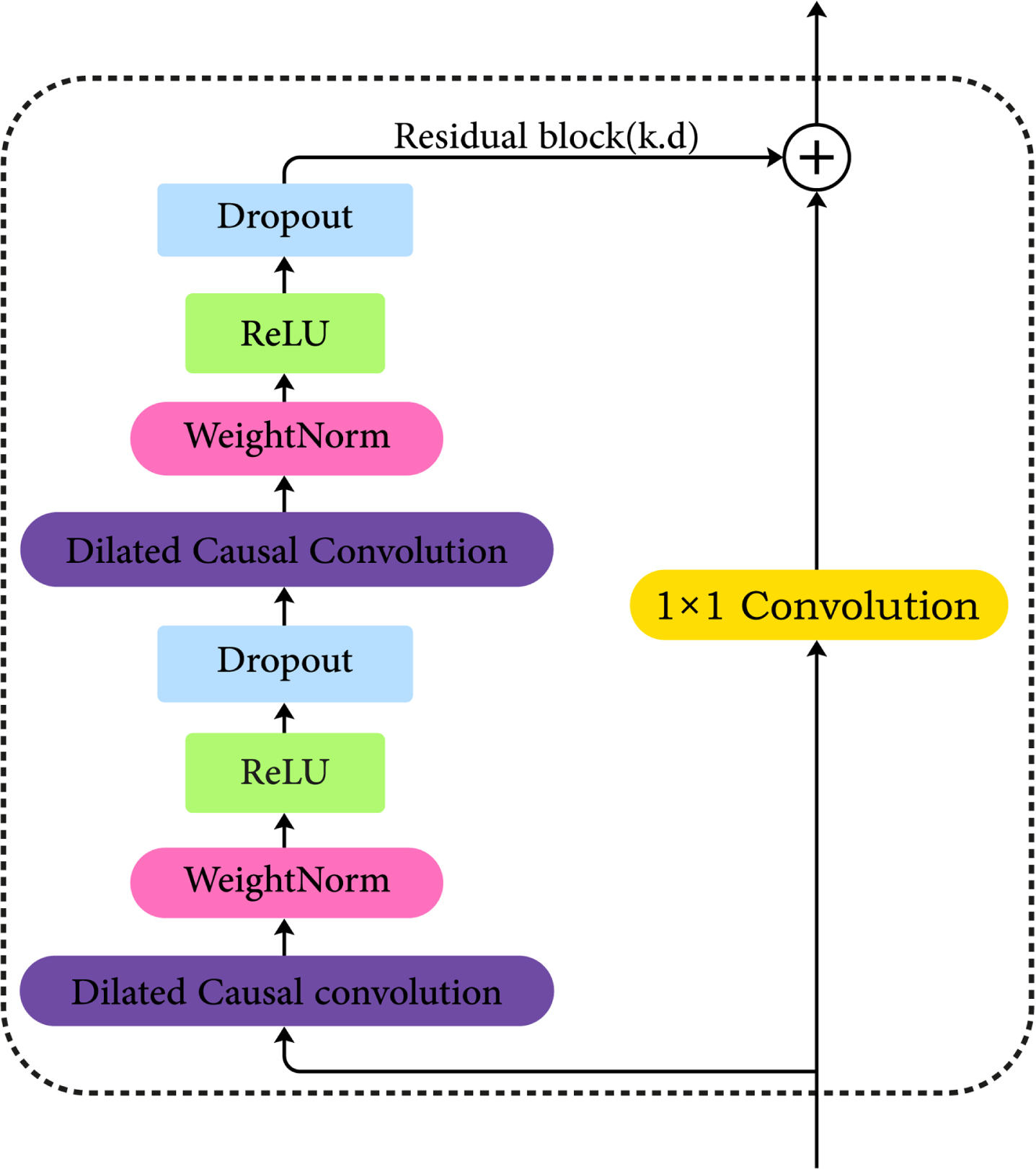
TCN residual block.
The output of the residual block is computed as follows:
Where X is the input,
1×1 convolution is added to ensure that the input and output have the same dimensions and can be added together.
Gated recurrent unit (GRU) [24] is a type of recurrent neural network (RNN), which is an artificial neural network adapted to handle data that involves sequences. Since RNNs suffer from the gradient vanishing problem, LSTM and GRU were introduced to overcome this shortcoming. GRU has a less complex structure compared with LSTM, which combines the input and forget gate of LSTM into a single update gate and combines the hidden and cell states into a single hidden state. The architecture of GRU is illustrated in Fig. 5. The update gate z
t
decides the amount of the past information that needs to be passed along to the next state. The reset gate r
t
dermines how much of the past information to neglect. The detailed calculation formula is as follows:
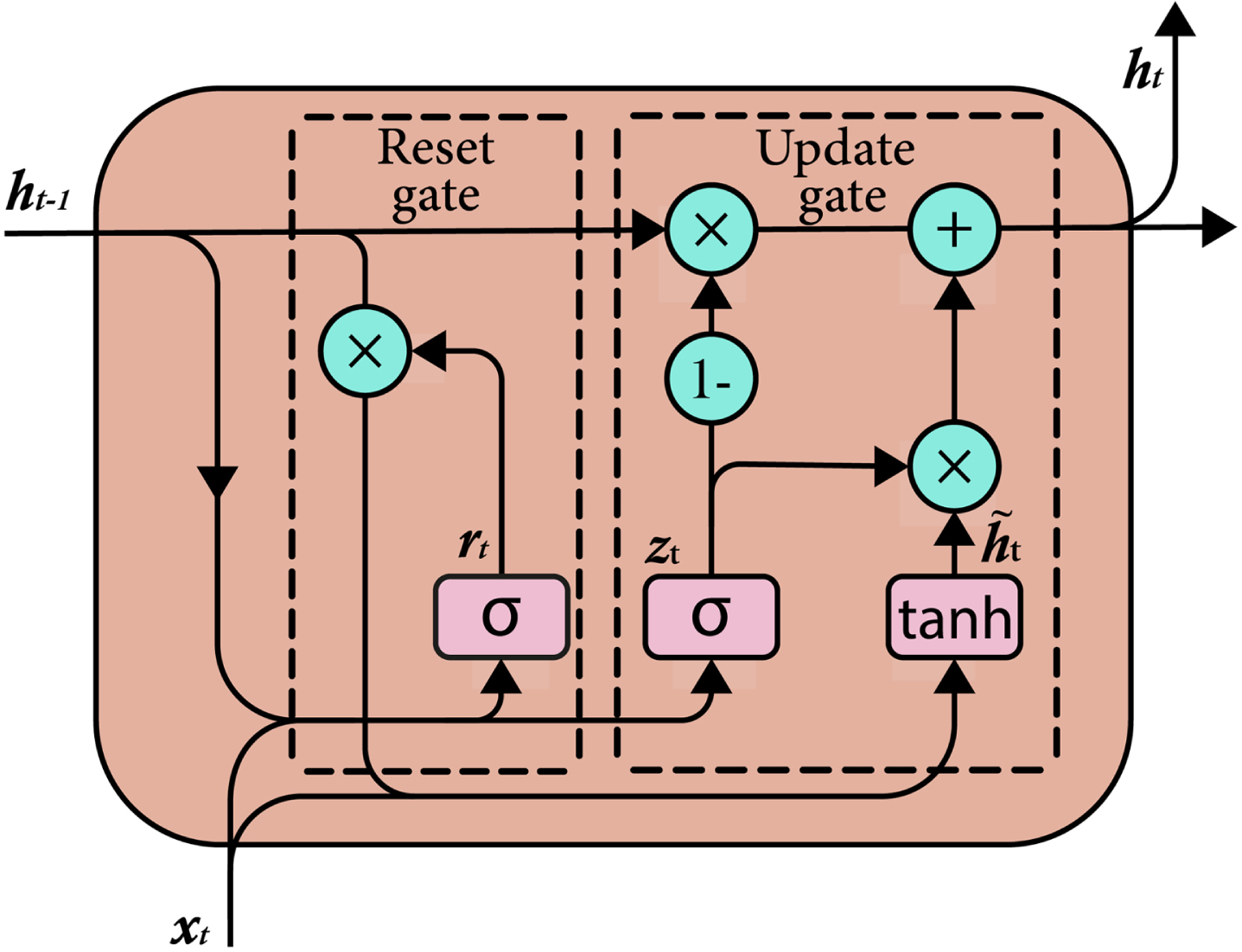
Architecture of GRU.
Where σ is the sigmoid function, ⊙ denotes the element-wise product of the matrix, W and U are the weight matrices that need to be learned.
Since TCN cannot see the future data, a BiGRU layer is used to enable handing data in both directions and provide complete contextual information. Indeed, BiGRU structure is composed of forward GRU and backward GRU, which can capture the past and future information. The calculation formulas are:
The hidden layer output h
t
of BiGRU at time t is the concatenation of the forward and backward states:
Finally, the output of BiGRU is:
The output of BiGRU layer is simultaneously fed into a global maximum and global average pooling layers. The former layer retrieves a maximum value of each feature in the BiGRU layer, whereas the latter one retrieves each feature’s average value. Finally, the concatenation of both layers is passed to the final output layer. The calculation formulas are as follows:
Where gavg and gmax are the global average and global max pooling operations, respectively. concat is a concatenation operation.
The output layer consists of a fully connected layer with a SoftMax activation function for predicting the category label as follows:
Where
The objective of the training process is to minimize the cross-entropy of the predicted and true results. The categorical cross-entropy is used as a loss function since the ACD task in this study is a multi-class classification problem. The calculation formula is:
Where
Dataset
The dataset used in this study was provided by Al-Ayyoub and Al-Sarhan [25]. News posts and comments about the Gaza Attacks in 2014 were collected from Facebook to examine the effect of the news on readers. The dataset was manually annotated following the SemEval 2014 task 4 [26] annotation guidelines. The discussed aspect terms, aspect categories, and the corresponding sentiment polarities were annotated for each post. The dataset is composed of 2265 posts written in modern standard Arabic (MSA). Four pre-defined categories are considered: Results, Plans, Parties, and Peace. The distribution of posts per aspect category is illustrated in Table 2. Besides, an example of the Arabic news dataset schema is illustrated in Fig. 6.
Distribution of posts per category
Distribution of posts per category

Example of the Arabic news dataset schema.
The language development is Python 3.6, and the models were implemented using Keras and TensorFlow libraries. The base version of AraBERT model [27] is used in this study, which consists of 12 layers of transformers with a number of self-attention heads as 12 and a hidden size of 768. The adopted hyper-parameters in our experiments are shown in Table 3.
Experimental hyper-parameters
Experimental hyper-parameters
To compare our results to the baseline and prior models, precision, recall, and F1-score are computed as follows:
Where TP denotes the correct categories retrieved from the test set, FP is the irrelevant categories identified in the same dataset, and FN denotes the relevant aspect categories that have not been detected.
To evaluate the performance of our model, we compare it with the following models:
Results and discussion
Experimental analysis
The experimental results are illustrated in Table 4. They show that the proposed model outperforms the baseline model by more than 19% overall improvement. Additionally, our model has achieved better results than S-BERT (84.58% vs. 82.8%). This shows that combining the fine-tuned BERT model with more powerful layers yields enhanced results, confirming the findings of previous studies [13 and 29]. On the other hand, the AraVec-TCN-BiGRU model achieves lower results than the proposed model by more than 8%, proving the effectiveness of semantic features extracted by the BERT model. Additionally, BERT splits unknown words into known sub-words, which solves the out of vocabulary (OOV) challenging issue for NLP tasks, particularly in morphologically rich languages, such as Arabic. Moreover, our model has achieved enhanced results than the BERT-CNN-BiGRU model, indicating that TCN is better at modeling text sequences compared to a traditional CNN model. Besides, replacing BiGRU with a BiLSTM layer has dropped the overall performance. This proves that GRU is better at handling small-scale datasets than LSTM, which is the case of the existing Arabic ABSA corpora. This result affirms the findings of previous studies [30].
Main experimental results. The results with “†” are retrieved from original papers, and the best results are marked in bold
Main experimental results. The results with “†” are retrieved from original papers, and the best results are marked in bold
An ablation study is conducted in order to verify the effectiveness of each component of our model. The results of this study are illustrated in Table 5. We first remove the global pooling layers from the proposed model, which has led to a performance drop. This indicates the efficiency of the used pooling layers in capturing prominent tokens from the BiGRU layer. Besides, removing the TCN layer has dropped the overall performance by more than 1% in terms of F1-score, indicating the effectiveness of the temporal features extracted by TCN. On the other hand, removing the BiGRU layer has affected the performance of the model more than removing TCN or pooling layers, which shows the importance of capturing long-term dependencies from both left and right sides for the ACD task.
Results of ablation study
Results of ablation study
A comparative experiment on training time for these models: BERT-BiGRU, BERT-TCN-BiLSTM, BERT-TCN-BiGRU and BERT-CNN-BiGRU is conducted. All the models were trained on a NVIDIA Tesla K80. The experimental results are illustrated in Table 6. It can be seen that BERT-TCN-BiGRU is faster than the BERT-BiGRU model, proving that TCN has accelerated the training process of the proposed model. Besides, our model takes less time for training than BERT-TCN-BiLSTM, which can be justified thanks to the simplified structure of GRU compared to LSTM. On the other hand, BERT-TCN-BiGRU trains faster than BERT-CNN-BiGRU, indicating that TCN reduces the training costs better than a traditional CNN model.
Average training time per epoch
Average training time per epoch
The imbalanced data problem refers to the fact that the number of samples from one or more categories outnumbers the samples from the rest of the categories. Models trained on an imbalanced dataset will generally tend to misclassify instances belonging to smaller classes more than those belonging to larger categories. Based on the distribution size illustrated in Fig. 7, it can be noticed that the dataset used in this study is imbalanced. The following categories: Parties and Peace have much fewer samples compared to the rest of the classes. Given the confusion matrix in Fig. 8, our proposed model cannot learn enough information to distinguish the Parties category. Therefore, this section aims to investigate different techniques to overcome the shortcoming of the imbalanced dataset. Results achieved using different methods are illustrated in Table 7. Besides, precision, recall, and F1-score for each category are shown in Table 8. We notice that these techniques are applied to the training dataset only.
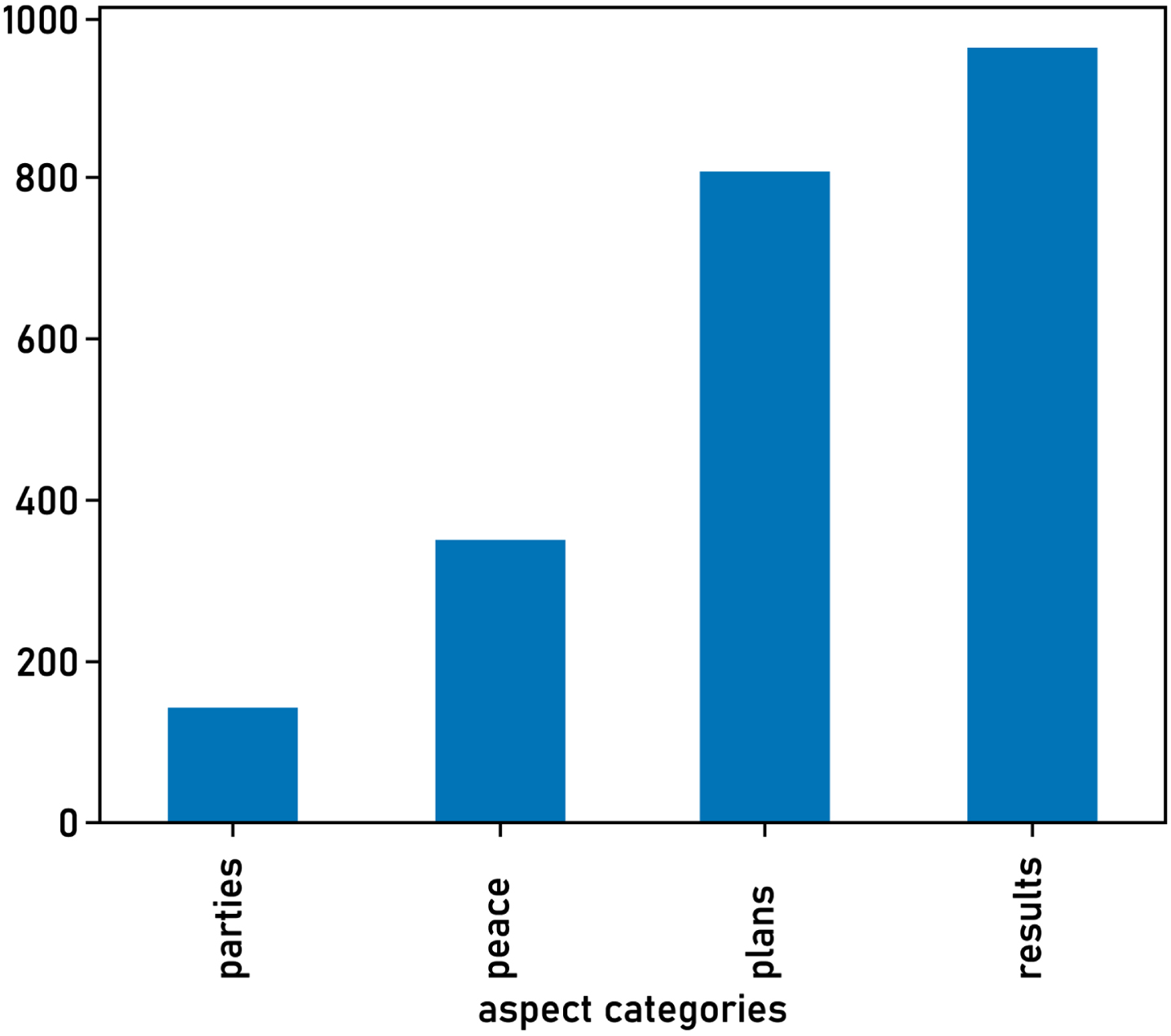
Distribution size of the evaluated dataset.
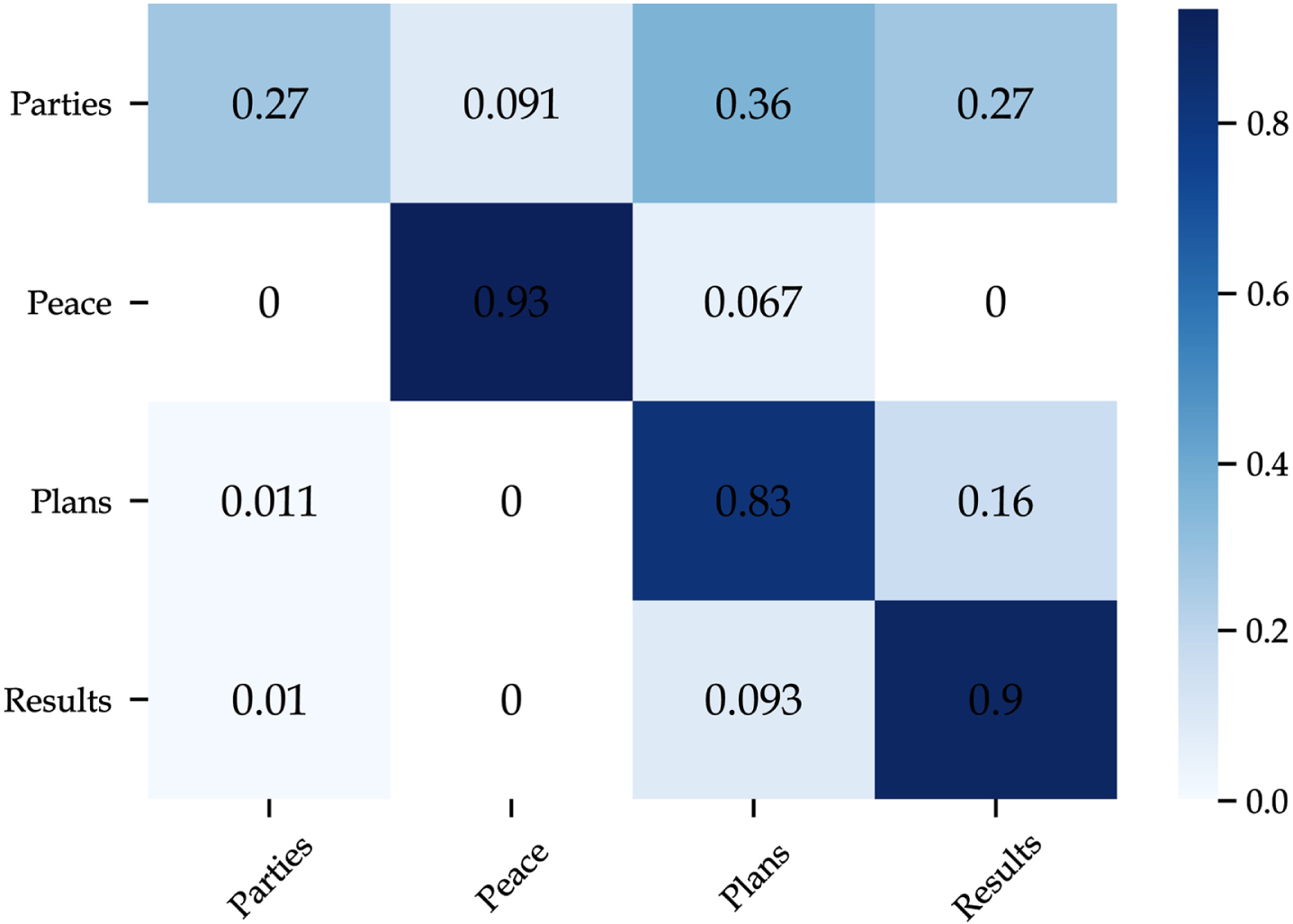
Confusion matrix of the proposed model on the original dataset.
Results using different approaches to handle the class imbalance problem
Precision, recall, and F1-score for each category
The sampling method is a widely used data analysis technique that aims to adjust the class distribution of a dataset. We can distinguish two main techniques of sampling: oversampling and undersampling methods.
Oversampling
The oversampling technique re-balances the categories in the dataset by randomly duplicating samples from minority classes [31 and 32]. After applying this technique, the new distribution size of the training dataset is illustrated in Fig. 9, which shows a balanced distribution between the examples of each category. However, our model achieves lower results on this new data, as shown in Table 7 and Fig. 10. This can be justified because duplicating original data has led to over-fitting on the minority class training instances.
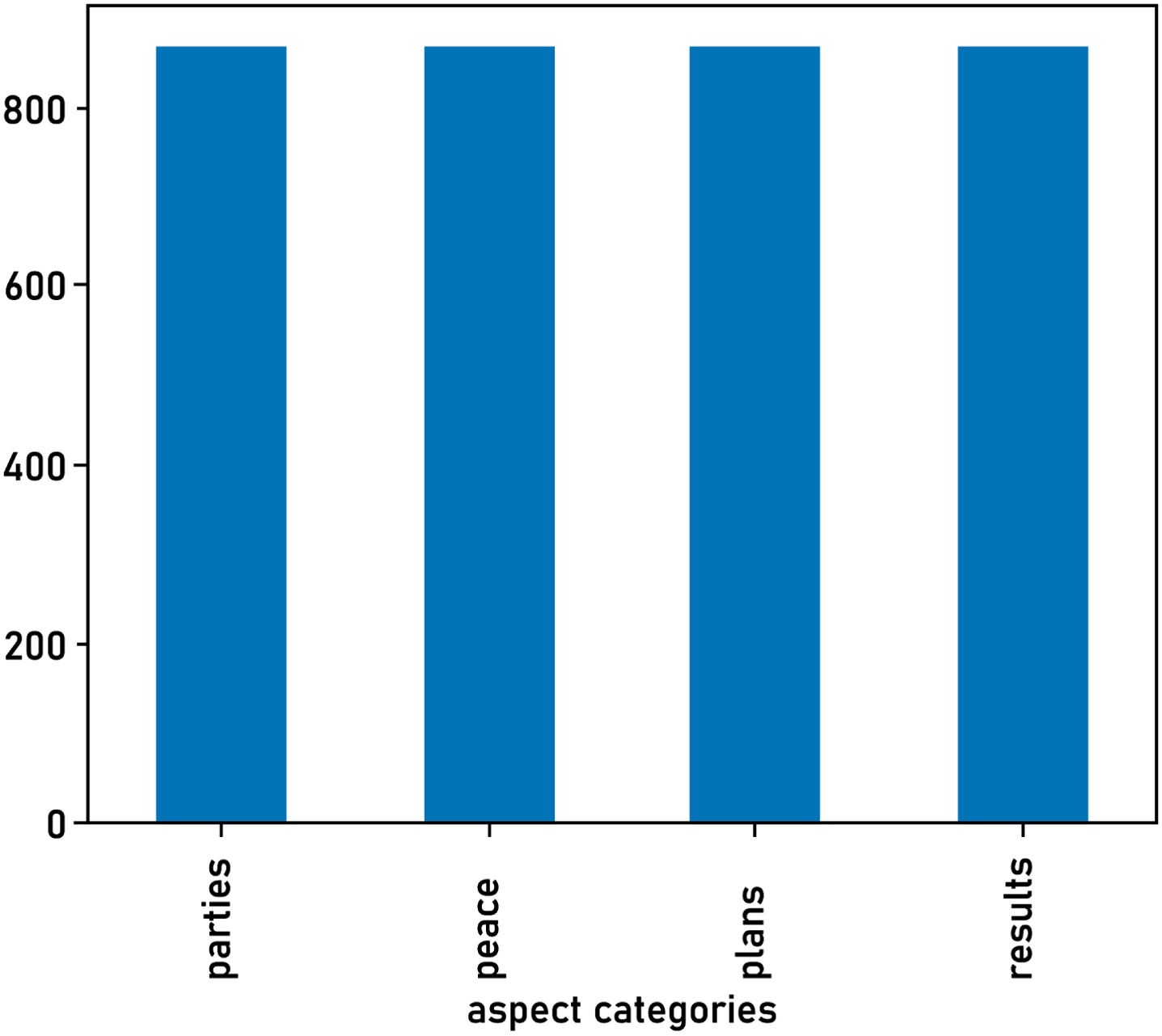
Distribution size of training dataset based on oversampling.
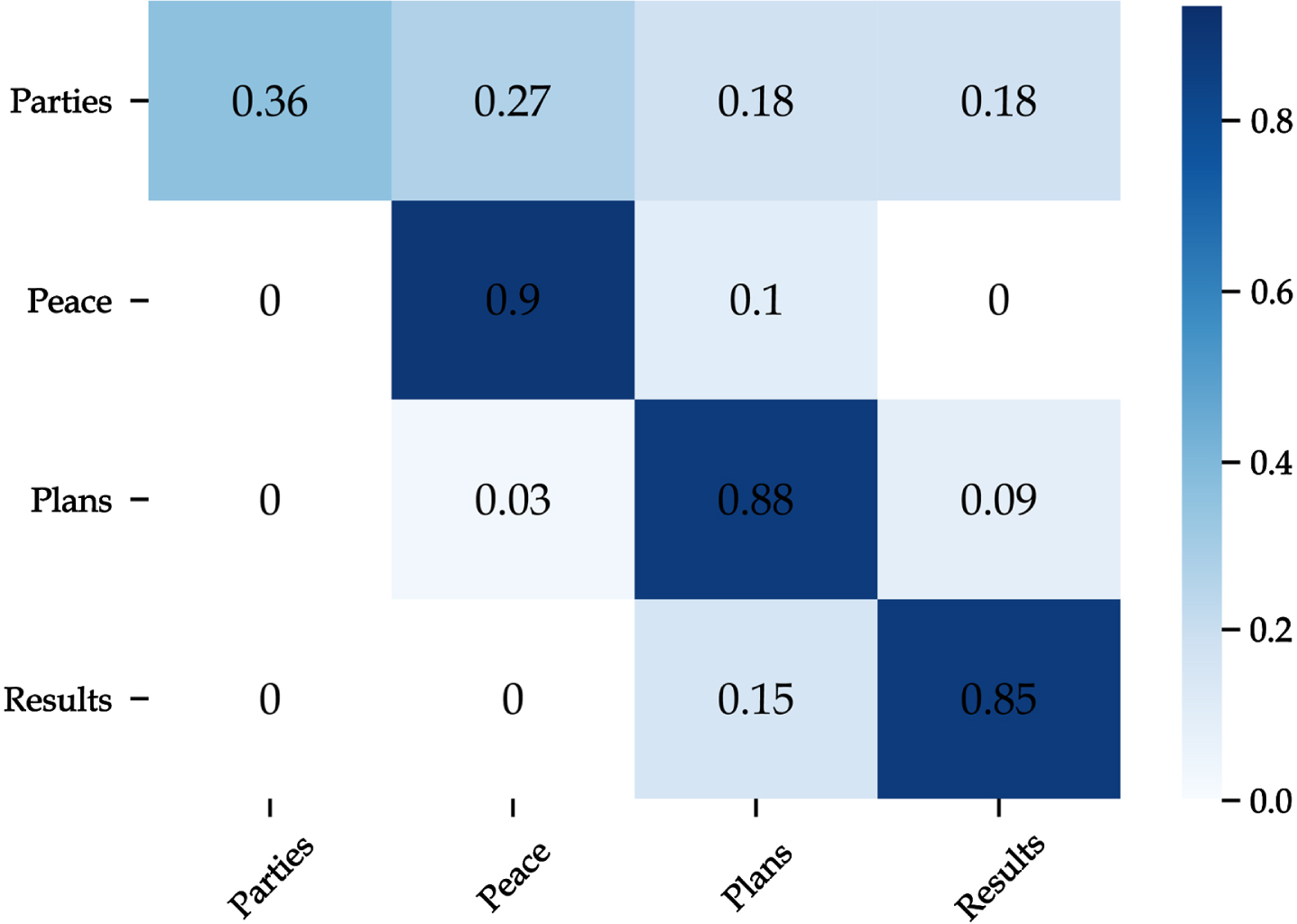
Confusion matrix of the proposed model based on oversampling.
This method tends to remove samples from the majority categories to adjust the class imbalance [33 and 34]. Figure 11 shows the distribution size of training data after undersampling. Nevertheless, as illustrated in Table 7 and Fig. 12, the performance of the proposed model has significantly dropped when using this dataset. This can be justified because removing samples has led to information loss, especially with data scarcity in this study.
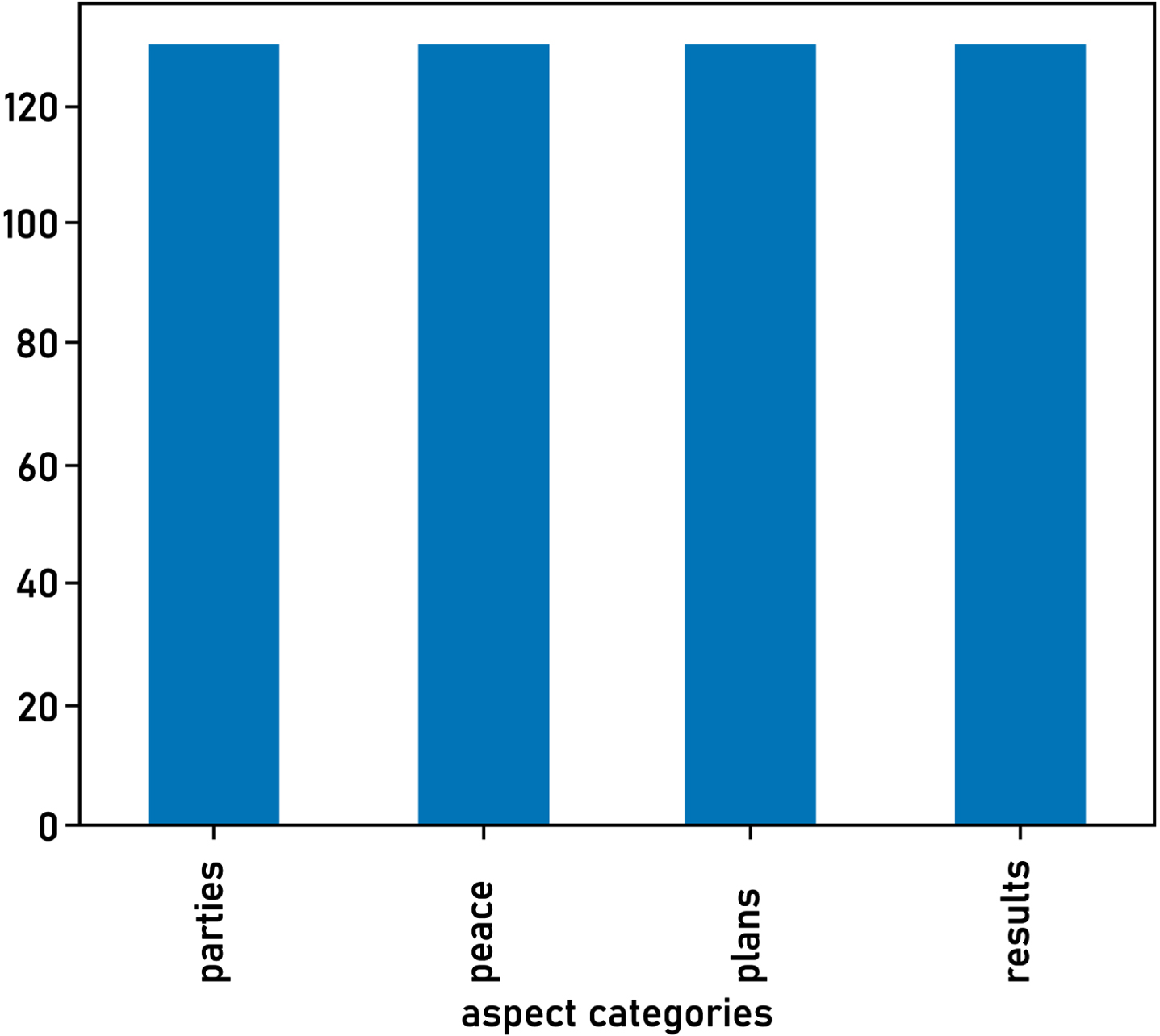
Distribution size of training dataset based on undersampling.
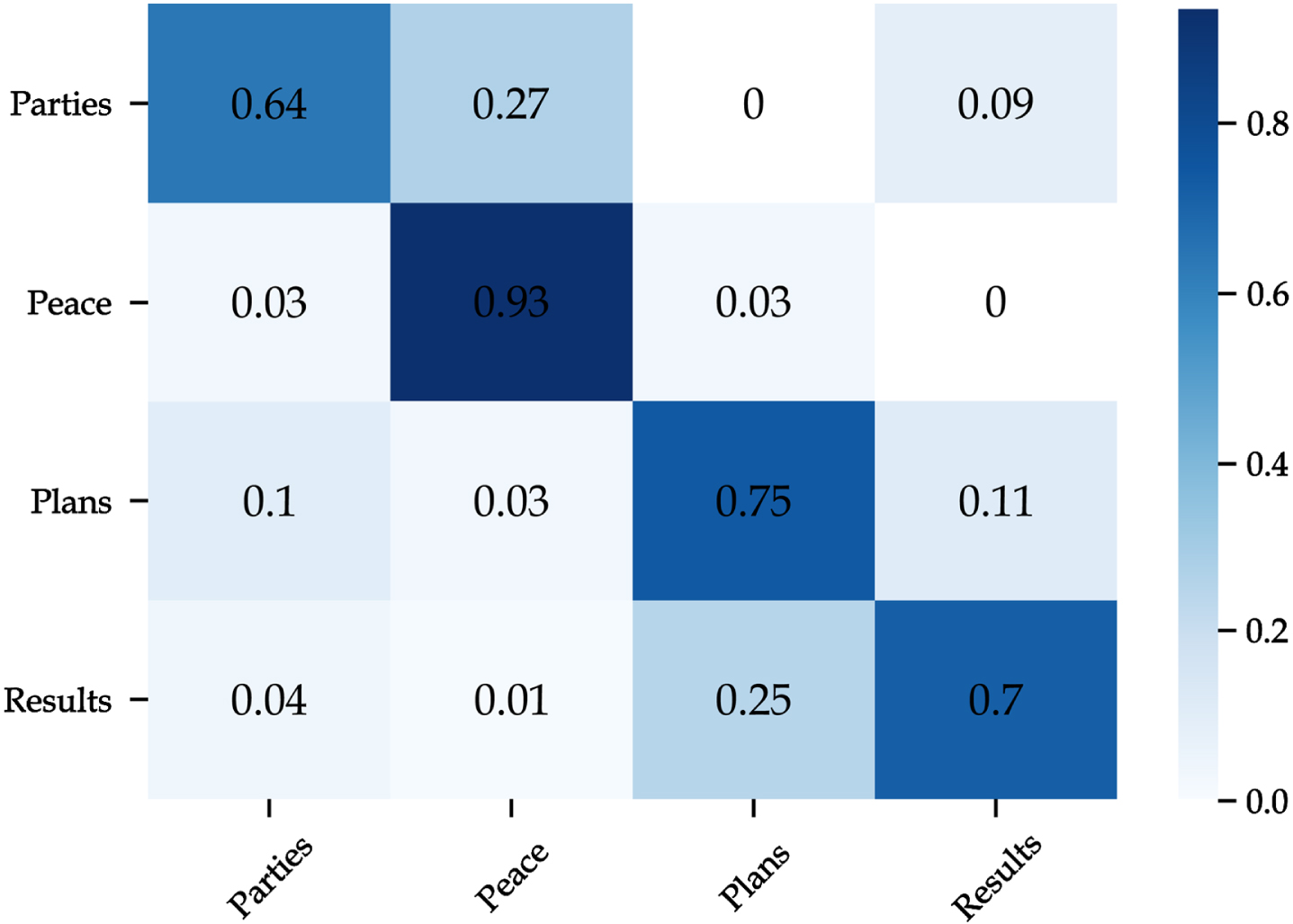
Confusion matrix of the proposed model based on undersampling.
Data augmentation refers to a set of techniques that artificially increase the amount of dataset by generating new data points from the existing dataset. This paper examines two data augmentation methods, namely random masking augmentation and back-translation, to increase the number of examples of minority classes.
Random masking augmentation
This method relies on a masked word prediction task. Words are randomly masked in each sentence, and the BERT model makes predictions for the masked words. Unlike context-independent word embedding models, BERT predicts possible values depending on the context of the sentence. It is worth mentioning that BERT supports only one masked word at a time. Thus, this technique is applied in series by tacking one different masked word at each time. Table 9 shows examples of generated sentences using this method. It can be seen that different variants of the same sentence can be obtained by randomly masking different words. The performance of the proposed model using the augmented dataset is illustrated in Table 7 and Fig. 13. We can notice that this technique has enabled the proposed model to predict more positive minority samples (50.0% vs 37.5% for F1-score of Parties category), hence improving the overall performance of the proposed model.
Examples of random masking generated sentences
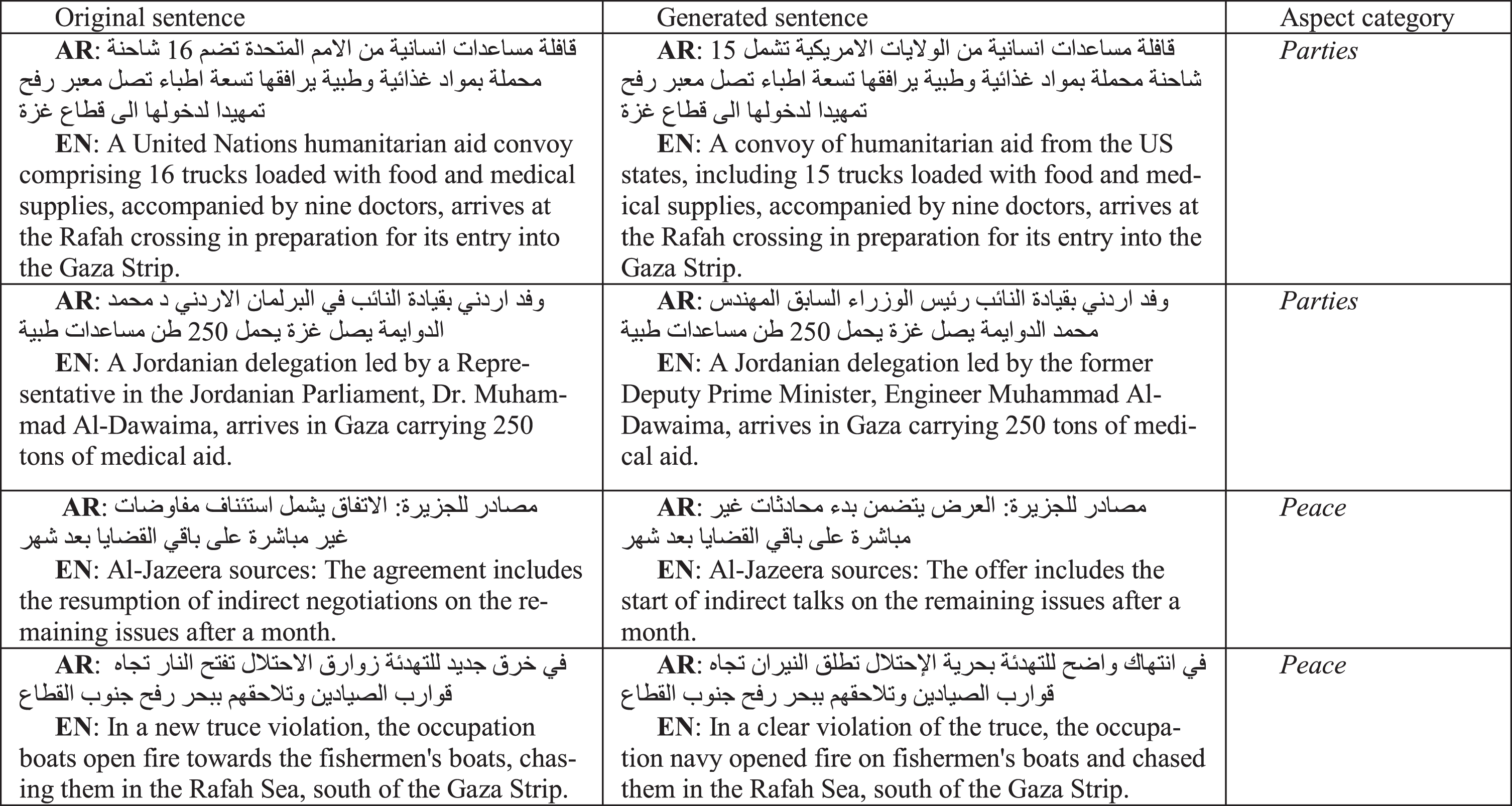
Examples of random masking generated sentences
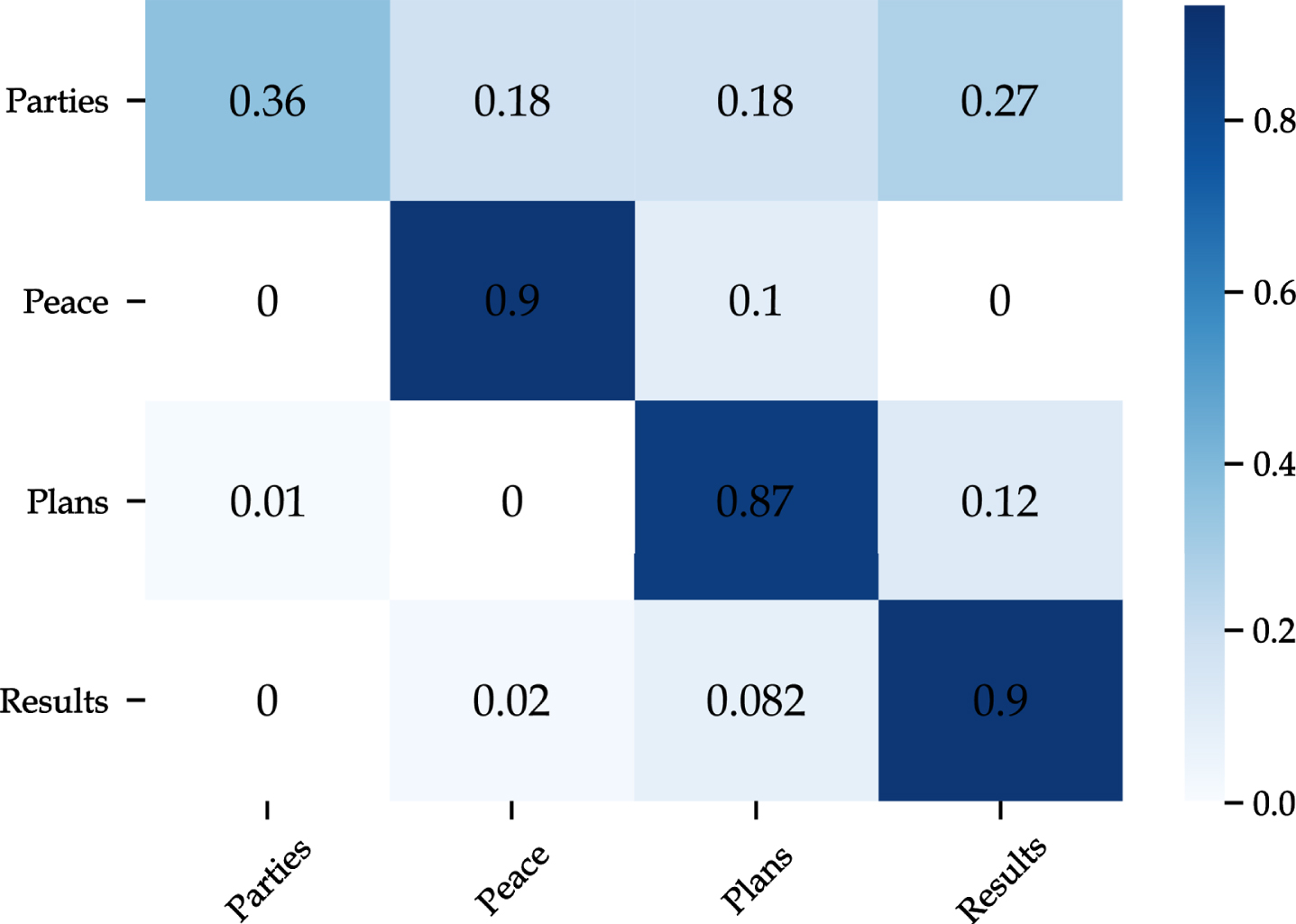
Confusion matrix of the proposed model based on random masking augmentation.
This technique first translates sentences to another language and then translates them back to the original language [35]. This helps in generating new sentences of distinct wording to the original ones while preserving the original context and meaning. We applied this method several times on examples of the minority classes in our dataset using different languages (i.e., English, French, Spanish, and Dutch). Table 10 shows some examples of the obtained sentences. It can be noticed that different variations can be obtained from the same sentence but using other languages. As illustrated in Table 7 and Fig. 14, the back-translation technique has enabled the proposed model to achieve the best results compared to the other evaluated techniques. Besides, the F1-score of Parties class has enhanced significantly in comparison to the first results (78.25% vs. 37.5%). This proves the efficiency of back-translation in improving the diversity and the quality of the data, thus enhancing the learning process and reducing over-fitting.
Examples of back-translated sentence
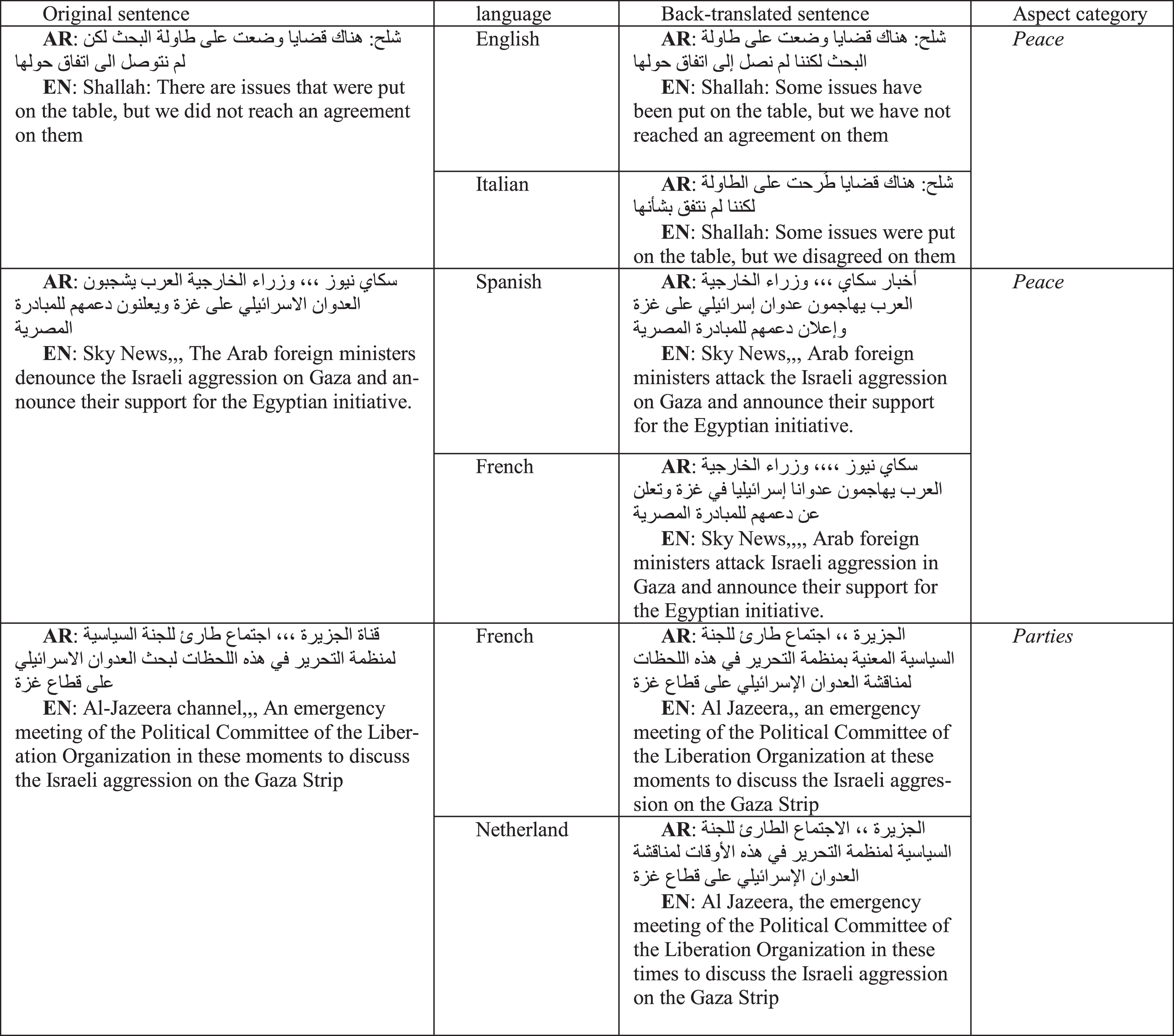
Examples of back-translated sentence
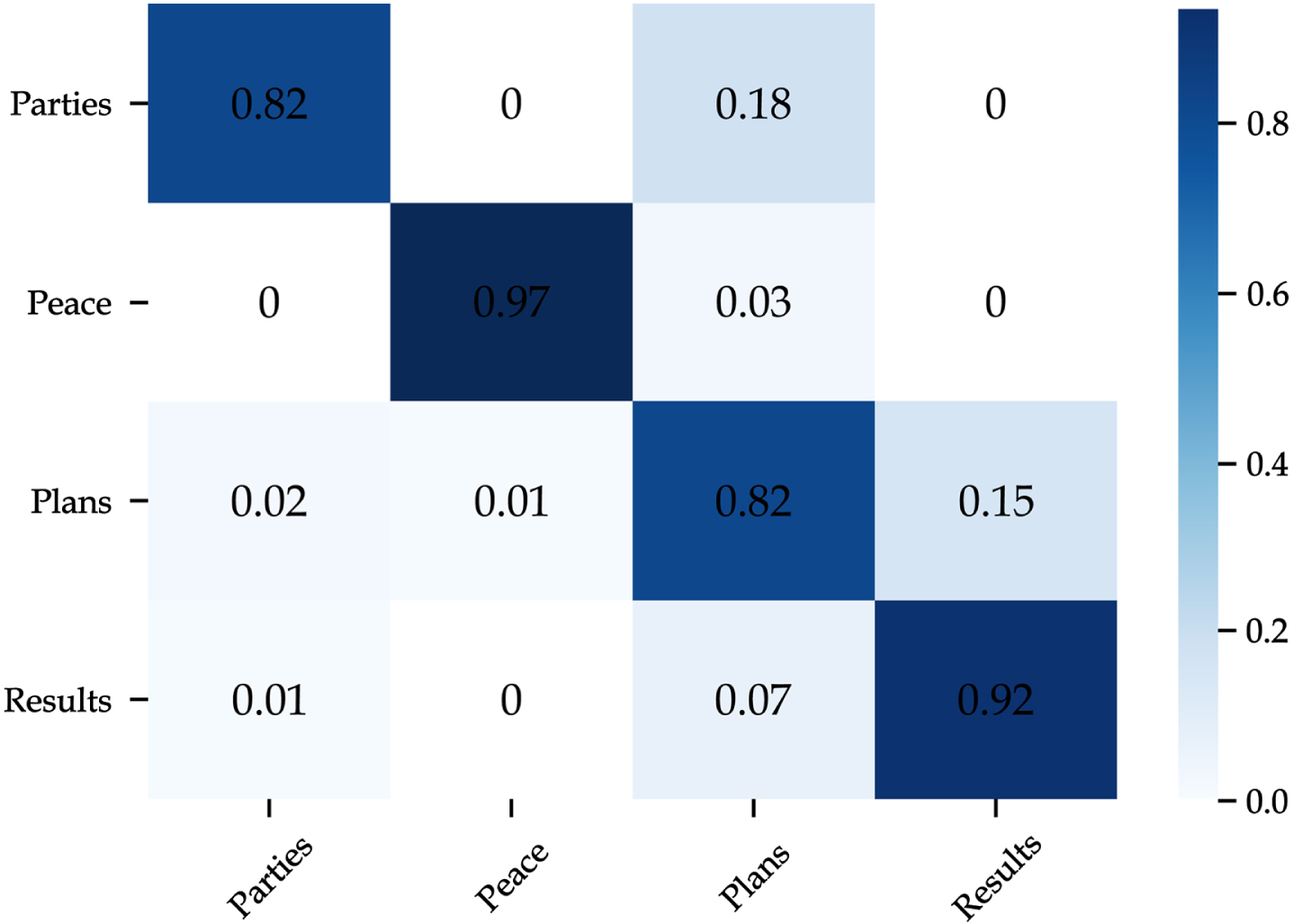
Confusion matrix of the proposed model based on back-translation.
This study proposes an enhanced deep learning model for handling the Arabic ACD task. The proposed model first extracts contextualized word embeddings using BERT, followed by a TCN-BiGRU model to enhance the extracted contextual and semantic features. Extensive experiments conducted on an Arabic reference dataset have shown the effectiveness of the proposed method compared to the baseline and related work models. The proposed model has achieved an overall improvement of more than 19% compared to the baseline model. Besides, an ablation study was conducted to prove the effectiveness of each component of our model. Furthermore, a set of methods were examined to handle the class imbalance problem in the used dataset. Indeed, data augmentation based on back-translation has shown effectiveness in generating diversity and high-quality datasets by enhancing the first results by more than 3% in terms of F1-score.
Future work includes adapting the proposed model to other ABSA tasks, namely aspect term extraction and aspect sentiment classification. Besides, we intend to evaluate our model on datasets in other languages than Arabic, particularly English. Furthermore, this paper has investigated some data-level methods to handle the class imbalance issue. Hence, other techniques are to be examined to solve this problem, such as paraphrasing and text generation using GPT2 [36] model. Moreover, we intend to handle this problem at the algorithm-level using different methods, such as cost-sensitive learning and one-class classification.