
Abstract
In recent years, Deep neural networks (DNNs) have achieved great success in sequence modeling. Several deep models have been used for enhancing Handwriting Text Recognition (HTR). Among these models, Convolutional Neural Networks (CNNs) and Recurrent Neural network especially Long-Short-Term-Memory (LSTM) networks achieve state-of-the-art recognition accuracy. The recognition methods for Arabic text lines have been widely applied in many specific tasks. However, there are still some potential challenges as the lack of available and large Arabic text recognition dataset and the characteristics of Arabic script. In order to address these challenges, we propose an end-to-end recognition method based on convolutional recurrent neural networks (CRNNs), which adds feature reuse network component on the basis of a CRNN. The model is trained and tested on two Arabic text recognition datasets named KHATT and AHTID/MW. The experimental results demonstrate that the proposed method achieves better performance than other methods in the literature.
Introduction
An important distinction in the offline handwriting recognition systems is between recognizing isolated digit, characters or words and recognizing whole lines of text. The better recognition results have been obtained for isolated digit and character but for text line is substantially harder [1, 2]. For text recognition tasks, the naive approach is to recognize individual characters and map them onto complete text. This could be done by pre-segmenting words into characters and classifying each segment. However, segmentation is difficult for cursive or unconstrained text unless the words have already been recognized [3].
Arabic characters shapes in different positions
Arabic characters shapes in different positions
In the last few decades, Arabic text recognition has attracted great interest and has become one of the challenging areas of research in the field of document image processing and computer vision [4, 5]. But, the most Arabic handwriting recognition systems are limited to model isolated characters, digits or word with a limited vocabulary. Very few researches are interested in recognition of unconstrained Arabic text in open or large vocabulary [6, 7]. Most of the recent approaches for Arabic handwritten text/word recognition have used HMM-based techniques or shallow Artificial Neural Networks (ANN) [4, 8]. Nowadays, the accelerating progress and availability of low-cost computer hardware and the growing difficulty of the tackled problems encouraged the use of computationally expensive techniques. Therefore, recent researches are focused on open vocabulary recognition to deal with continuous sequence in order to recognize words and text lines extracted from handwritten documents [1, 2, 6, 8].
Deep neural networks were ignored, for a long period, due to the lack of efficient training methods. The only deep architectures found in the literature were convolutional neural networks, which contain a limited number of free parameters thanks to the locality and weight sharing aspects of their architecture [9]. With better resources, more data and better hardware, it recently became possible to build deep, quite simply and efficiently neural network [9]. Deep neural networks brought significant improvements and reductions of error rates in many areas, including speech recognition and computer vision. During the past decade Deep Neural Networks (DNNs)have shown impressive results with several architecture in extracting patterns from different data types. For instance, Convolutional Neural Networks (CNNs) constitute the state-of-the art in extracting patterns from images [6, 10], while Recurrent Neural Networks (RNN) with Long Short-Term Memory (LSTM) units constitute the state-of-the art in extracting patterns from text data [11].
In this paper, we propose a recognition system for Arabic handwriting text line. We will demonstrate the interest of using deep Convolutional Neural Networks (CNN) to solve the problem of features extraction. Then, our motivation is to study the potential benefits of adding a densely layer to the VGGNet architecture [12]. We will present results for Arabic handwriting sequences in open vocabulary context. The rest of this paper is organized as follows. Section 2 gives a general overview of the Arabic script proprieties and its affect in the recognition process. Section 3 present some recent works based on deep learning techniques. In Section 4, we will present an overview of the proposed recognition model and will describe and discuss the improvements in feature extraction step and the recognition step respectively. Several combinations were tested and the results will be reported in Section 5. In Section 6, we will discuss the recorded results and we will finish in Section 7 by the conclusion.
The writing style in Arabic script is greatly different from other languages as English and Chinese. This script is purely cursive in both printed and handwritten forms written from right to left and have 28 letters. These makes Arabic text recognition a sophisticated process and present some unique challenges as shown in Fig. 1. The particular of the Arabic text is that the shape of characters may considerably change within a word according to its position in the word and its adjacent characters [13]. Each character has from two to four different forms which increase the number of classes to be recognized from 28 to 84 as shown in Table 1. Arabic letter shape can be isolated, connected from the right, from the left or from both sides which define the four connected forms respectively isolated, beginning, ending and middle [10, 13]. Therefore, one word may consist of one or many ligatures. The ligature contributes significantly in word formulation. There can result a vertical overlapping of characters in a word. Figure 1 shows examples of some problems in the Arabic handwriting text. This feature of connectivity will cause difficulty in the segmentation so in the recognition process. Dots are crucial component of the Arabic characters, indeed sixteen of them have from one to three dots. They can be above the character’s primary part like in the letter Thaal (Ø°>), below like in the letter Baa (ب>) or in the middle as in the letter Jeem (Ø>). Similar characters share the same primary shape and are differentiated by number and position of the dots such as Ø´> which consists of Ø> letter body and three dots above it. In addition, characters in Arabic word can have diacritics read as vowels and written as strokes. They are placed either on top of or below the characters. Some of the dots and strokes might be missed in the handwriting written as presented in Fig. 1 which affect the recognition system accuracy.
Some of handwriting Arabic script characteristics.
The literature of Arabic handwriting recognition contains a wide range of approaches. In this section, we present a survey of recent existent systems.
Some recent works used traditional classifier such as HMM and SVM with handcrafted features. Siddhu et al. [14] proposed a recognition method based on the combination of statistical and structural approaches for feature extraction. The main body of a character is modeled by the statistical method using modified direction features and Support Vector Machines. The structural method uses the dot descriptors to recognize the character. Hassan et al. in [15] proposed method for recognition handwritten Arabic word without segmentation to sub letters based on feature extraction scale invariant feature transform (SIFT) and support vector machines (SVMs). Salam et al. in [16] proposed system for offline isolated Arabic handwriting character. Although half of the dataset used for training the Support Vector Machine (SVM) and the second half used for testing, the system achieved high performance with less training data. Jayech et al. in [17] proposed system based on a synchronous multi-stream HMM (MSHMM) which has the advantage of efficiently modelling the interaction between multiple features. These features are composed by a combination of statistical and structural ones, which are extracted over the columns and rows using a sliding window approach. In fact, two-word models are implemented based on the holistic and analytical approaches without any explicit segmentation. Mezghani et al presented in [18] a system for offline recognition of cursive Arabic handwritten text based on Hidden Markov Models (HMMs). The authors studied the shape modelling of different handwritten Arabic characters using HMMs to make training and recognition of characters more efficient. The number of HMMs is reduced substantially while still capturing the variations between the character shape models. This led to a robust and efficient recognition with only 61 models.
Other Arabic handwriting recognition models are focused in combining deep neural network with traditional classifier. Elleuch et al. [19] investigate the combination of Convolutional Neural Network (CNN) and Support Vector Machine (SVM). In addition, in this work, authors study applicability of dropout in the proposed model. The evaluation of the model is conducted on HACDB and IFN/ENIT databases. Amrouch et al. [20] considered and compare two strategies of feature extraction combined with HMM as recognizer. The first one use CNN named CNN-features-HMM and the second use handcrafted features named Handcrafted-features-HMM. The first strategy allows operating directly on the images and extracting relevant characteristics. It doesn’t need much emphasis on feature extraction and pre-processing stages as the second strategy.
Summary of handwriting recognition models using deep learning
Summary of handwriting recognition models using deep learning
Then, deep neural networks were used in both feature extraction and classification for alphanumeric recognition. El-Sawy et al. [22] provided a Convolutional Neural Network (CNN) technique which is implemented using LeNet-5 architecture and were evaluated on a large Arabic digit’s database (MADBase). Ashiquzzaman et al. [23] proposed a novel model based on Convolutional Neural Network (CNN) and it used the Rectified Linear Unit (ReLU) activation function with the dropout technique as a regularization layer. Alaasam et al. [24] designed a CNN to recognize historical Arabic handwritten text and Younis [25] used a CNN for handwritten Arabic character recognition. Khémiri et al. [26] proposed a comparison study that demonstrate that the capacity of Bayesian and convolutional neural networks (CNNs) are very efficient compared to other methods.
Recently, the proposed recognition models investigate the combination of several deep neural networks. Elleuch et al. [27] applies a Convolutional Deep Belief Networks (CDBN) method. For text line recognition, Ahmad et al. [28] proposed an MDLSTM based Arabic character recognition system. Connectionist Temporal Classification (CTC) is used as a final layer to align the predicted labels according to the most probable path. KHATT datasets was used for experiments. Jemni et al. [29] proposed an Arabic handwriting recognition system based on multiple BLSTM-CTC combination. Authors presented a comparative study of different combination levels of BLSTM-CTC recognition systems trained on different feature sets. The experiments were conducted on the Arabic KHATT dataset. Noubigh et al. [30] proposed a hybrid CNN-BLSTM model for Arabic handwriting text line recognition using KHATT database. The CNN is used for feature extraction. Then, the bidirectional long short-term memory (BLSTM) followed by a connectionist temporal classification layer (CTC) is used for sequence labelling. Noubigh et al. [31] combine very deep CNN model with BLSTM for open vocabulary Arabic text recognition. The CTC beam search decoder was used with BLSTM for sequence modeling. Jemni et al. [32] proposed model based on MDLSTM and CNN. The main contribution of this work is a novel OOV (Out of Vocabulary) detection and recovery method that considerably improve the system performance. Experiments were performed using KHATT and AHTID/MW databases. Table 2 display a summary of the literature reviewed on Arabic handwriting recognition.
Overview of the recognition system.
In reviewing works in Table 2, we can conclude that the SVM and HMM classifier was not advantageous for handwriting Arabic text recognition since the recognition rate was very low. The extraction of relevant feature for Arabic handwriting presents an interesting problem. Researchers try to apply several techniques for breaking through the complex problems of handwritten Arabic script. Some works try to combine CNN with SVM and HMM instead of handcrafted features. Other works are focused in improve CNN architectures. Results are improved but still insufficient. Despite these efforts, most of the recorded results are not significant and suboptimal, since it was trained and tested on little data or private datasets. The proposed models have obtained effective results with small or limited datasets, but the problem is still present as a challenge for very large databases. Indeed, despite the fact that the IFN/ENIT database is limited in terms of writing variations and vocabulary, it is still used on the large number of recent systems. The research in handwritten Arabic character recognition is still in an early stage when compared to Latin and other languages. Arabic handwriting in the field of handwriting recognition needs more focus. Until now, the most Arabic handwriting recognition systems are limited to recognize numerical character or words in limited vocabulary. Therefore, this area of research is still open for further enhancement and extensive research need to be conducted. Moreover, many of recent applications are interested to solve the problem of text line recognition in an open or vary large vocabulary.
In this section, we present an overview of the proposed recognition model. It is a hybrid approach based on combining CNN architectures with BLSTM flowed by CTC decoder layer. It consists of three main steps as presented in Fig. 2. The first step is the preprocessing of the input image in order to reduce the generated noise and eliminate any variability resource that occurred during the images scanning phase. Second step is the feature extraction in order to get relevant descriptors of the images based in two CNN architectures. Finally, the recognition step consists on the sequence modeling using the BLSTM network and training by CTC decoder. Therefore, we are focused on describe these two steps for the proposed recognition model.
CNN layers configuration
CNN layers configuration
Feed-forward neural network with batch normalization.
As CNNs have provide high performance in many fields especially in image classification and object detection, various architectures are proposed to deal with different requirements. In this section, we will present the most important models which was the winner of the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) competition [33]. The ImageNet is an image dataset with about 15 million images with over 22000 different categories. The principal premise and architecture of CNN are LeNet, AlexNet, VGGNet, GoogLeNet, ResNet and DenseNet [33]. In this section, we describe the feature extraction step of the proposed recognition model. It is based mainly on two CNN architectures. The first one is inspired by the VGGNet architecture. The second is based on a densely layer inserted on the VGGNet architecture to instigate the advantage of reuse features.
VGGNet-based feature extraction
We introduce the proposed architecture used for feature extraction. It follows the standard model of VGGNet with some differences. It contains 10 convolution layers with a filter size (3
Each two convolutional layers are followed by a max-pooling layer defined by the Eq. (2).
Max-pooling uses a 2
Additionally, we use Batch normalization layer before the ReLU layer to convergence and avoid over-fitting. Batch Normalization is a normalization technique done between the layers of a Neural Network instead of in the raw data. It is done along mini-batches instead of the full data set. It serves to speed up training and stabilize learning and make it easier. Also, it has been observed that BN reduces the effects of exploding and vanishing gradients because everything becomes roughly normally distributed.
We can define the normalization formula of Batch Normalization as:
where
VGGNet-based feature extraction architecture.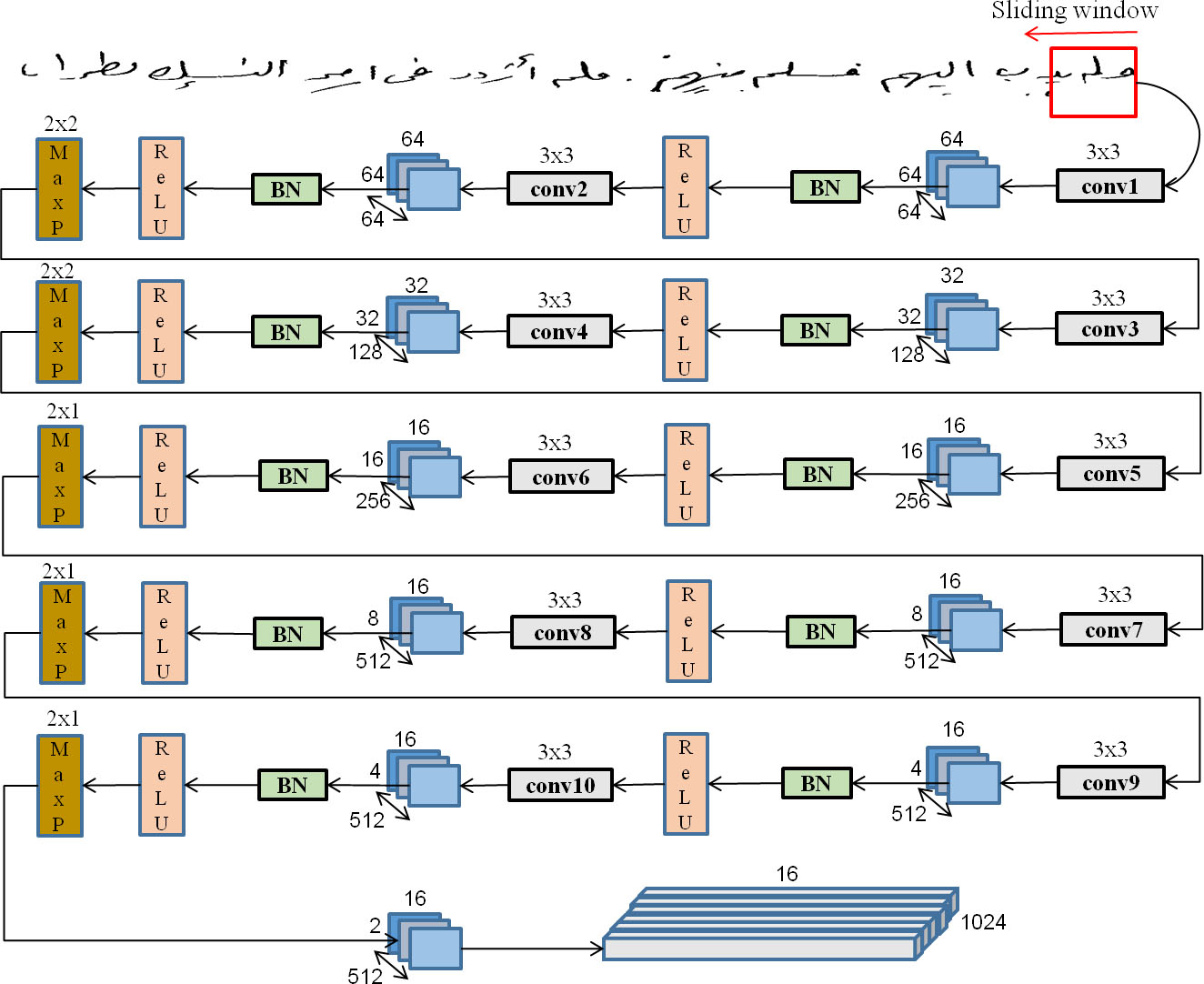
Batch Normalization (BN) is applied to the output of the neurons just before applying the activation function. Usually, a neuron without BN would be computed as follows in the Eqs (4) and (5):
where
where
An important issue in VGGNet-based feature extraction design is the selection of input text line image size. Our input images size is normalized to 64
Densely-VGGNet architecture for feature extraction.
The difficulties emerge with VGGNet when they go deeper. The augmentation of the path for information between the input layer and the output layer result its vanishing before reaching the other side. In this section, we describe the improvement affected to the VGGNet architecture describe previously. Inspired by the principle of other architecture as DenseNet and ResNet, we add a densely layer to the VGGNet by concatenate features maps. The objective is to decreases the vanishing-gradient problem by decreasing the depth of convolutional layers, improve feature propagation and encourage the feature reuse. As presented in Fig. 5, a layer that called Concat is added and some network parameters are adapted compared to the original network (Fig. 4).
In this model we have only 8 convolutional layer and all max pooling layer is applied with size of 2
The concatenation layer is followed by batch normalization layer for normalize and redistribute data. The low-level features and high-level semantic features are combined through the features maps concatenation. In consequence, this feature reuse network can greatly improve the performance of text line recognition because more detailed information of the original image can be retained. In addition, the model can be more robust to the shape and distortion of different characters in the image.
Sequence modeling step based on BLSTM-CTC
After extracting the features from image pixels rows, they are then independently used to train a BLSTM-CTC network. The network transforms a sequence of CNN-features of length T into a text line of length L. In this section, we will start by present the BLSTM network and then discuss the used CTC technique.
LSTM cell illustration.
The LSTM [34] cell is defined as in Fig. 6 and its mathematical form is as follows. We have the hidden state
The outputs
With
Bidirectional LSTM (BLSTM) [35] is a direct extension to LSTM, where the input sequence is scanned both in forward and backward direction and subsequently merged into a combined representation. In this architecture, there are two layers of hidden nodes. Both hidden layers are connected to input and output. The two hidden layers are differentiated in that the first has recurrent connections from the past time steps while in the second the direction of recurrent of connections is flipped, passing activation backwards along the sequence. It is in charge of processing a N dimensional input signal to produce an output signal that takes into account long term dependencies.
In order to do this the BLSTM is composed of two recurrent neural networks with Long Short-Term Memory neural. One network processes the data chronologically while the other processes the data in reverse chronological order. Therefore, at time t a decision can be taken by concatenate the outputs of the two networks, using past and future context as presented in Fig. 7.
BLSTM architecture.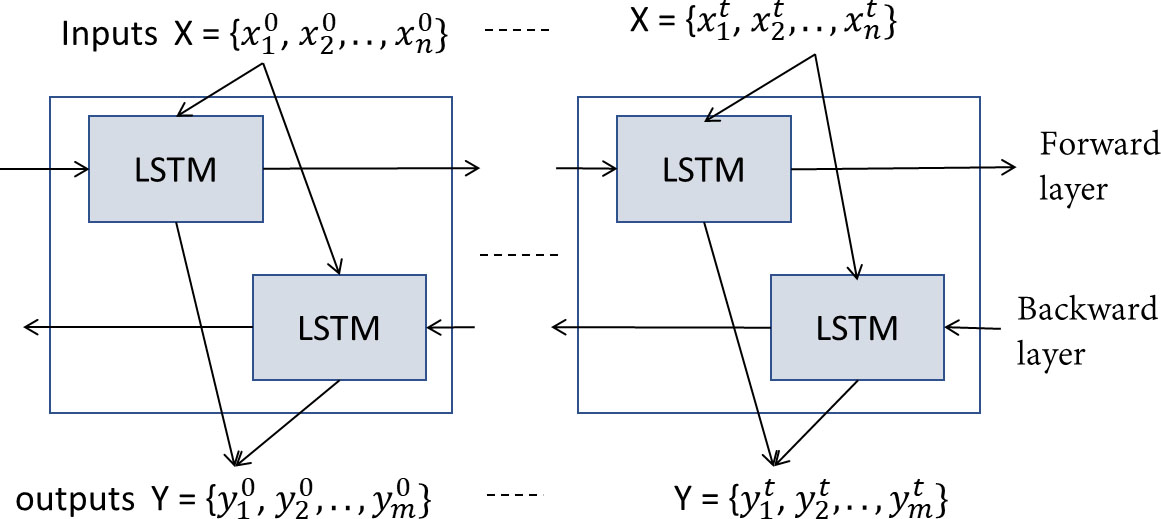
The proposed system present one Bidirectional LSTM layer with 512 neurons in each direction. The BLSTM output is a matrix of size
BLSTM modeling.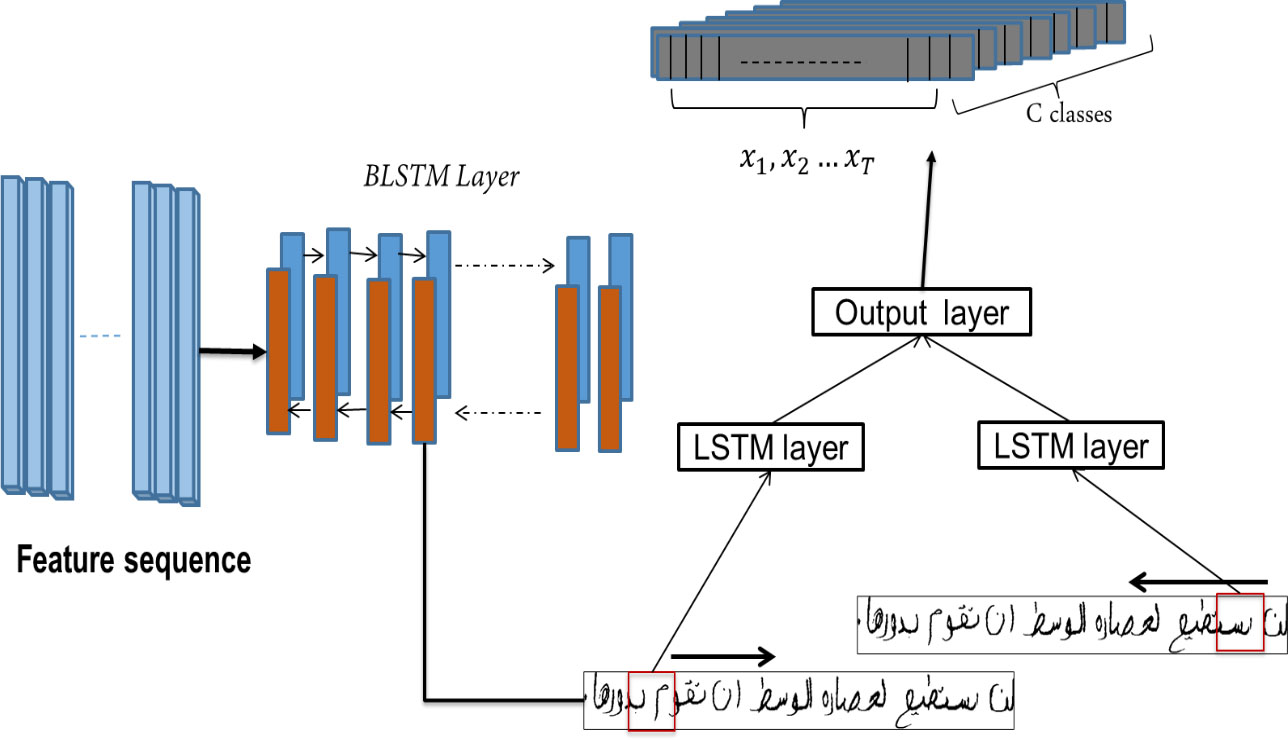
CTC model was introduced by Alex Graves in [36]. CTC can be applied to supervised sequence classification tasks, such as in our case the handwriting recognition. It is interesting for the fact that it doesn’t require any pre-segmentation of the input or any post-processing of the output labels to produce the final predicted label sequence. In handwriting recognition, the goal is to build a classifier which can convert an image to a sequence of labels. There are many challenges which get in the way of using simpler supervised learning algorithms. In particular input sequence and output sequence vary in length and we don’t have an accurate alignment of them. To address this issue, the Connectionist Temporal Classification (CTC) objective function was provided to infer this alignment automatically. For a given input it gives us a distribution over all possible outputs. A learning task using CTC, models are always ended with a softmax layer where the element represents the probability of emitting each label at a specific time step. After being trained with the CTC loss function (CTC-trained), the output of the network needs a CTC-decoder during inference.
CTC-trained: To deal with the issue that output length is shorter than input sequence, CTC adds a blank symbol as an additional blank label to the label set and allows repetition of labels. We define the CTC loss function as introduced on [25].
Assume that
Finally, a mapping function noted
We can evaluate the probability of a given labelling
However, it is virtually impossible to sum the probabilities of all the paths in
CTC-decoder: Decoding a CTC network means finding the most probable output sequence for a given input. The first and simplest approximation of decoding the RNN output is the best path decoding presented in [36]. It is based on the selection of the most probable character per time-step, the most probable sequence will correspond to the most probable labelling. This approach is not sufficient to satisfy the needs of many sequence tasks although it can already provide useful transcriptions. Other decoding algorithm called beam search is described in the paper of Hwang and Sung [37]. Multiple candidates for the final labeling are iteratively calculated and are called beams. At each time-step, each beam-labeling is extended by all possible characters. Additionally, the original beam is also copied to the next time-step. The Beam Width (W) is defined to give the number of beams to keep (the best beams). The beam width determines the complexity and the accuracy of the algorithm. If W is big enough, the probability will be one and the algorithm will be too complex. But if W is too small, the probability of using beam search to find the correct answer will be too small. So, there is a tradeoff between the size of W and the accuracy.
The CTC beam search decoding searches for the most probable sequence in all the sequences (length
The CTC beam search proved its effectivity for end-to-end sequence recognition and it accelerates the decoding process. According to our knowledge, there is no existing work for Arabic text recognition use CTC beam search decoding and it is used for the first time in this work. To understand the difference between the two algorithms, we reference to the work of H. Scheidl et al. [38] which explain their principles.
We take example testcase of the RNN output matrix contains 2 time-steps (t0 and t1) and 3 labels (a, b and – representing the CTC-blank) as shown in Fig. 9. Best path decoding takes the most probable label per time-step which gives the path “
Result paths of CTC best path (in the left) and CTC beam search (in the right).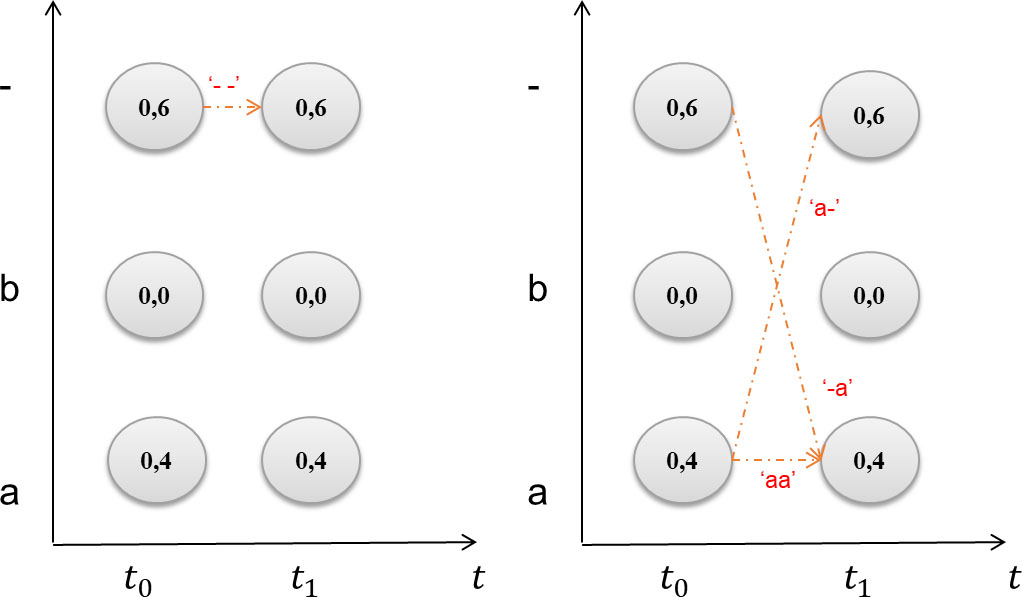
Statistics about the two used databases; KHATT and AHTID
Used databases
KHATT database
The offline Handwritten Arabic Text database KHATT presents a challenging unconstrained Arabic text database [39]. It contains 4000 grayscale subsubsection images and its ground-truth. This database is written by 1,000 distinct male and female writers representing diverse countries, age groups and education levels. It is grouped in two categories. The first present 2000 of these images contain similar text each covering all Arabic characters and shapes whereas the remaining. The second present 2000 images contain free texts written by the writers on any topic of their choice in an unrestricted style. In this work, all the line images, with similar text and free texts, is used in the experiments. This database is divided in training, validation and test subsets. Figure 10 shows examples of images extracted from KHATT database.
Examples of images extracted from KHATT database.
The Arabic Handwritten Text Images Database AHTID/MW has been built at the University of Sfax -Tunisia in join collaboration with the Institute for Communications Technology (IfN), Braunschweig Germany [40]. The AHTID/MW contains 3710 text lines and 22,896 words written by 53 native writers of Arabic. These images are divided into five equilibrated sets. The four first sets are available for scientific community. The database is freely available for worldwide researchers. Figure 11 shows examples of text line images extracted from the database.
Samples of text line image from the AHTID/MW database.
The experiments are carried out on two databases of handwritten text lines: KHATT and AHTID/MW described previously. We defined our classes by 101 Arabic characters, numbers and symbols extracted from the ground-truth of the two databases. Table 4 presents some useful statistics about the databases.
For all experiments, we used TensorFlow framework [41] to implement our network. In the training phase, we trained the RNN with CTC using the RMSprop (Root Mean Square Propagation) optimizer [42] method is used with the learning rate 10–4 and the training is stopped after 10 evaluations with no improvements of the character error rate. The CTC loss function is used for training. The CTC beam search are used for decoding. For the CTC beam search decoder, w was fixed experimentally to 30. Dropout layer are inserted between CNN and BLSTM with rate of 0.3. Commonly used performance measures for machine learning systems are the character error rate (CER) and word error rate (WER) for sequential data and more particularly handwriting recognition. We use those two measures to characterize the performance of our recognition systems.
The character error rate is calculated by the followed formula:
where
Similarly, the word error rate is obtained by the Eq. (19):
where
System evaluation with different LSTM layers
System evaluation with different hidden layer neurons
Results recorded with dense-VGGNet using KHATT and AHTID/ MW databases
Comparison study
A series of experiments are conducted to select appropriate parameters. The performance of the proposed method is heavily affected by three key parameters, namely the feature extractor architecture, the number of BLSTM layers and the number of its hidden neurons and the used decoder. In previous work [31], we proved the effectiveness the CTC beam search decoder combined with BLSTM. Therefore, the CTC beam search decoder will be used for all experiments in this work. We start by study the effects of the BLSTM parameters. Once all parameters are set, we compare the results of the two developed architectures VGGnet and densely-VGGNet. Lastly, we evaluate the performance of the final CRNN architecture and make comparisons with other state-of-the-art methods on KHATT and AHTID/MW.
BLSTM parameters
The number of LSTM layers are changed while other parameters are fixed. As Table 5 shows, the CER decreases obviously when the number of LSTM layers changes from 1 to 2. While changing from 4 to 6, the model performance decreases. It is proved that deeper LSTM may be negative to test results because of overfitting phenomenon. Therefore, we use two layers of LSTM in our model, considering the performance and speed.
In addition, the model performance is influenced by the number of hidden layer neurons in the LSTM network. In Table 6, we illustrate the CER values for each set of hidden layer neurons. When the number is set from 128 to 256, the CER decreases by almost 3 %. With increasing the number of hidden layer neurons to 512, the model performance doesn’t gain clear improvement but it still considerable. Therefore, we set the number of hidden layer neurons to 512.
Comparison between CER evolution using VGGNet and dense-VGGNet.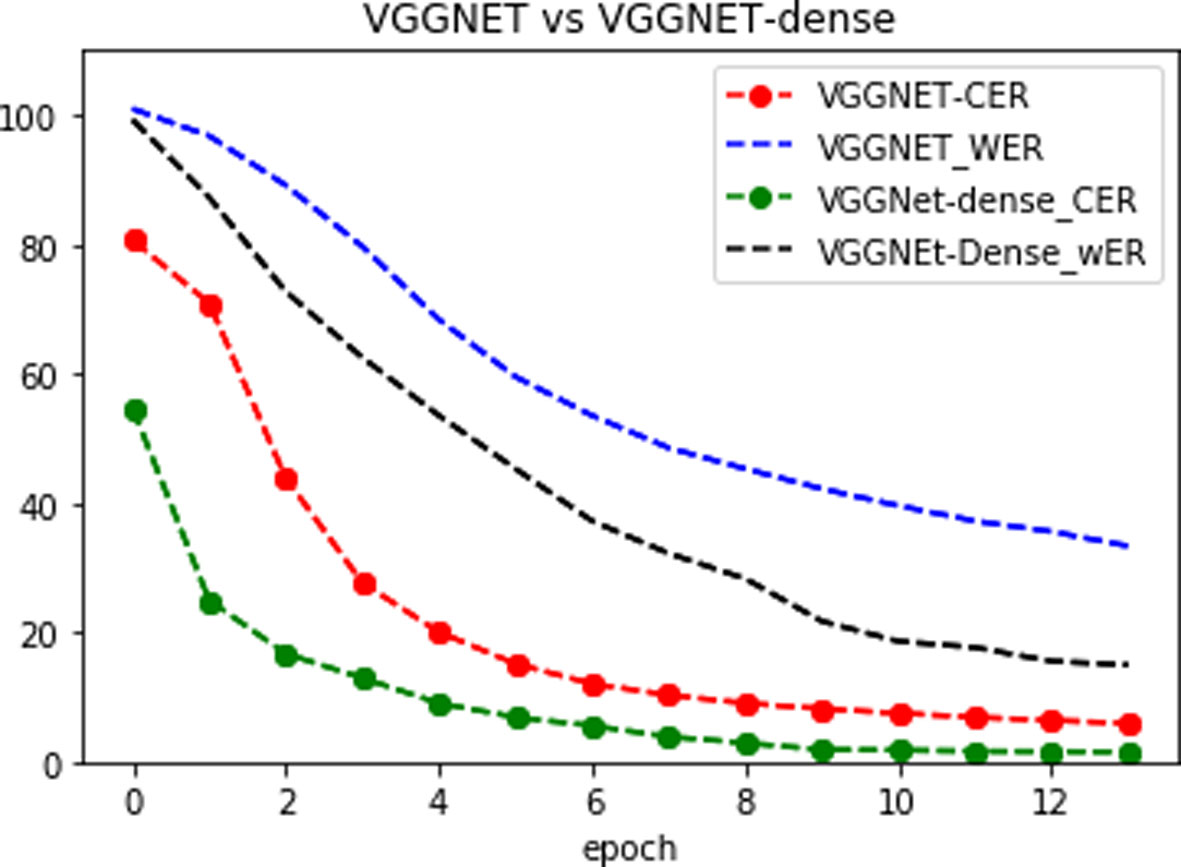
For the purpose of expose the advantages of the improved model dense-VGGNet, we compare the experimental results with those recorded by the original model [31]. Both KHATT and AHTID/MW handwriting Arabic text line databases are used for these experiments.
From the results summarized in Table 7, after adding reuse feature, the word recognition accuracy is improved by 1.1%. This is mainly due to the improvement of recognition accuracy for some difficult situations in the Arabic handwriting scripts such as characters with various sizes, fonts and shapes. As mentioned previously the feature reuse network combines semantic information with different degrees and fully considers of the relationship between context information. The graphic in Fig. 12. presents the evolution of the CER and WER. It illustrates the important improvement obtained with the dense-VGGNet model. The recognition accuracy tends to 89% (WER is about 11.5%) after 100 epochs.
Discussion and comparison
This work introduces a new recognition system using character modeling that improves previous proposed recognition model [31]. Our proposal defines a deep learning approach for Arabic handwriting text recognition combined very deep CNN architecture with BLSTM. The system relies on a cascade of CNN and BSTM and CTC layers. In order to validate the effectiveness of the suggested framework, we have presented experimental results using two Arabic text line handwritten databases namely KHATT and AHTID/MW. We introduce a study that explores the use of different deep CNN architectures in order to improve the Arabic handwriting recognition system.
It should be noted that increasing the depth of neural networks also increases the number of parameters in the models, and therefore their capacity. Thus, reusing the feature maps by adding a dense layer was proposed to ameliorate the system performance and it gives better results with reduced depth.
We can see that our densely-VGGNet architecture has achieved a very promising recognition rate of 89% and 85% when practiced to the KHATT and AHTID/MW databases, respectively.
Therefore, an even larger decrease in the word error rate of 9% was acquired utilizing densely layer compared to our basic deep CNN model [30]. Consequently, we have proven that reuse-features-based VGGNet is able to model perfectly the contextual information. For the BLSTM network, we have shown that increasing the number of units in the layer yielded better improvements than increasing the number of hidden layers proving that increase networks depth can result overfitting phenomenon. Additionally, we have demonstrated the capacity of BLSTM classifier combined with the CTC beam search decoder to treat the Arabic text specificities without the need to be segmented.
In another hand, the CTC beam search present in interesting part of the proposed model. it improves obviously recognition accuracy. With improving results over-fitting problem is also addressed by the use of data batch normalization and dropout.
Finally, we compared the performance of our model with models proposed for Arabic handwriting text lines recognition on KHATT and AHTID/MW databases. In Table 8, we present proprieties of each model and results. We introduce for each system the used database, the used model and the results.
We can conclude that the proposed system achieves higher accuracy as an open-vocabulary model compared with other methods based on limited vocabulary. We think it is mainly due to two advantages of proposed CRNN: one is that feature reuse network provides better feature representations compared with the way of simply stacked CNNs and the CTC beam search algorithm is more suitable for decoding inputted sequence.
The obtained results, are adequately considerable in comparison with the scientific research studies utilizing other classification methods. The contribution represents an interesting challenge in the computer vision and pattern recognition field since it will be a real motivation for the exploitation of deep learning strategies.
Conclusion
In this paper, we proposed an offline open vocabulary Arabic handwriting text recognition system. It is a quite hard problem since it is impossible to identify all the words of Arabic within a predefined lexicon. For that, we have done robust improvements on the different handwriting recognition system stages. Improvements were mainly based on preliminary efficient studies. We focus in on two main components: finding suitable features representation and implementing a robust recognizer engine. The proposed approach is based on two popular architectures: Convolutional Neural Network and Long Short-Term Memory Recurrent Neural Networks. We validated our approach on two public Arabic text line databases: KHATT and AHTID/MW.
We described details of the proposed recognition model. We provided several experiments and performed detailed analysis of the proposed module parameters. The results demonstrate a net advantage of the CRNN based on densely-VGGNet-dense and BLSTM.
The results of the proposed method in term of word recognition are still insufficient due to the lack of enough images for training and some weakness in the decoding process. Thus, to overtake this problem, we plan to improve in a future research the proposed system using transfer learning technique [21].