
Abstract
Authorship Attribution is a process to determine and/or identify the author of a given text document. The relevance of this research area comes to the fore when two or more writers claim to be the prospective authors of an unidentified or anonymous text document or are unwilling to accept any authorship. This research work aims to utilize various Machine Learning techniques in order to solve the problem of author identification. In the proposed approach, a number of textual features such as Token n-grams, Stylometric features, bag-of-words and TF-IDF have been extracted. Experimentation has been performed on three datasets viz. Spooky Author Identification dataset, Reuter_50_50 dataset and Manual dataset with 3 different train-test split ratios viz. 80-20, 70-30 and 66.67-33.33. Models have been built and tested with supervised learning algorithms such as Naive Bayes, Support Vector Machine, K-Nearest Neighbor, Decision Tree and Random Forest. The proposed system yields promising results. For the Spooky dataset, the best accuracy score obtained is 84.14% with bag-of-words using Naïve Bayes classifier. The best accuracy score of 86.2% is computed for the Reuter_50_50 dataset with 2100 most frequent words when the classifier used is Support Vector Machine. For the Manual dataset, the best score of 96.67% is obtained using the Naïve Bayes Classification Model with both 5-fold and 10-fold cross validation when both syntactic features and 600 most frequent unigrams are used in combination.
Keywords
Introduction
Over the last two decades, Internet has evolved from being a network of interconnected computers for sharing data to being the part and parcel of our lives. But the overuse of Internet has its bad share as well. The rapid and voluminous generation of online texts poses serious threat to users of the cyber world. Issues such as spamming, phishing, spread of offensive language, distribution of illicit and pirated materials, cyber bullying etc have mushroomed immensely. These activities are popularly clubbed under the notion of Cybercrime [1] as illegal activities done online through global electronic networks [2].
The generation of textual content, especially anonymous data is increasing exponentially. Researchers are exploring varied methodologies and/or approaches for dealing with the task of Authorship Attribution i.e., for predicting the true author of a given unknown text [3]. The true essence lies in revealing the identity of the writer through an automated system so that issues like preventing theft of articles, giving proper citation and due credit to the real author etc can be mitigated in a better and efficient way [4].
The primary objective of Authorship Attribution is to define an appropriate characterization of documents that captures the writing style of authors [5] and identify authors or writers from emails, books, tweets, blogs, posts, comments, research papers and other textual documents. Traditional stylometric features and document fingerprinting features [38], unsupervised learning approach [39] or combination of textual distance, supervised and unsupervised techniques [40] have all shown promising results. Sometimes, AA is often misinterpreted to be synonymous with Author Profiling (AP) or Author Characterization. Unlike AA that predicts the name of true author(s) based on proper training as well as comparison results to reveal writing style similarities and differences within a certain category [6], AP is concerned with determining features of an author such as age, gender, geographical location, personality traits etc. Thus, AP does not usually attempt to identify the name of a specific author [7].
This work focuses on identifying the real author of a text using token n-grams and other time tested features. Three datasets, with 3 different train-test split ratios viz. 80-20, 70-30 and 66.67-33.33, have been used in this research. Along with the various feature types such as lexical, syntactic and content-specific features, the experimentation has been performed on the ensemble feature types as well. Most frequent words on token n-gram features have been taken according to the dataset, where n
The rest of the paper is organized as follows – Section 2 discusses the related works on Authorship Attribution by different researchers. In Section 3, the proposed methodology has been described thoroughly using system architecture and a flowchart. Section 4 describes the implementation strategy through discussion of the feature sets, datasets and classification techniques used in this study. Section 5 presents the results obtained and an analysis is done to bring to the fore the effectiveness of each proposed approach. Section 6 concludes the paper and the finally the next line of actions are discussed in Section 7.
Related work
A lot of research has been carried out in the domain of Authorship Attribution since last few decades. With the ever-increasing amount of texts being generated online, especially the documents that are characterized by anonymity, the AA task becomes critical and worth exploring.
Many researchers have focused on showcasing the different properties of texts, namely the content of the text and the writing style of the author. In 2003, Kopple et al. [8] have used lexical features, part-of-speech (POS) tags and idiosyncratic features for their experiment and have implemented the AA model using linear Support Vector Machine (SVM) and Decision Tree classifiers. The best accuracy score of 72% is achieved with Decision Tree algorithm.
Hu and Liu in the year 2004 have achieved an accuracy value of 84% through the use of WordNet [9]. In 2006, Zheng et al. [2] have applied supervised learning techniques viz. Decision Tree, SVM and Back Propagation Neural Network (BPNN) on both English and Chinese language datasets, subsequently yielding accuracy values of 97.69% with English dataset and 88.33% with Chinese dataset.
In 2007, Dominique Labbe [10] has utilized intertextual distance as a feature, thereby reaching a fair accuracy of 62% with the sliding window concept. In the same year, Company and Wanner [11] have achieved a better accuracy score of 82.72% by employing stylometric features along with the bag-of-words and TF-IDF for the experiment. Bozkurt et al. [12] also performed a similar experiment using stylometric features, vocabulary diversity, bag-of-words and frequency of functions and reached 95% accuracy. Many techniques are applied such as Histogram method, K-Nearest Neighborhood method, Parzen Windows, Bayes Classifier, K-means clustering, SVM and combination of various classifiers.
Ramnial et al. [7] have extracted stylometric features in their work have achieved a better accuracy value of 98% with K-Nearest Neighbor and SVM techniques. Another popular research by Efstathios Stamatatos is performed by using function words and character n-grams and more than 80% accuracy is achieved through SVM [13].
Prasad et al. [14] have used Decision Tree, Neural Network, KNN and Naïve Bayes for the purpose of experimentation and have yielded the accuracy score of 87.5%. Leo Wanner [15] has performed many similar experiments in the same year and with SVM classification model, a higher accuracy of 91.41% is achieved. In [16], Wanner has used various datasets and has achieved more than 80% accuracy on all datasets.
In the year 2020, Rocha et al. [17] have achieved 92% accuracy on AVASUS database by utilizing a handful of stylometric features and have applied classification techniques viz. SVM, Logistic Regression, Naïve Bayes, KNN, Gaussian Process classification and
Comparative study of related works on authorship attribution
Comparative study of related works on authorship attribution
Bernoulli Naïve Bayes for the experiment. Tamboli and Prasad [18] have used SVM and have achieved 94.83% accuracy value by using character n-grams, word n-grams and part-of-speech n-grams.
Noura Khalid Alhuqail in the year 2021 [4] has used SVM, Random Forest, Bidirectional Encoder Representations from Transformers (BERT) and Logistic Regression classifiers for model generation. Latent Sentiment Analysis and bag-of-words are used in the experiment and the highest accuracy achieved is 94.9%.
Table 1 presents a detailed comparative study of the related works on AA as discussed in this section, especially focusing on parameters such as contribution, limitations, corpus used, features extracted, techniques followed and results reported in terms of accuracy scores.
The proposed work focuses on solving the task of Authorship Attribution. Three datasets, with 3 different train-test split ratios viz. 80-20, 70-30 and 66.67-33.33, have been used in this research. The datasets are as follows:
Initially, the collected data is in raw form. While extracting the select stylometric features [2, 7, 11], data cleaning operations are not performed. This is done as stylometric features are style markers that furnish details about any author’s writing style. Features such as Lexical, Syntactic and Content-specific are mainly used in this work [2, 7]. Along with such earmarked features, permutation and combination of these features is done and the ensemble feature sets are tested on individual datasets. Next, for extracting features such as n-grams, BOW and TF-IDF, data cleaning is done. During the Data Pre-processing stage, operations such as tokenization, removal of punctuations & stopwords and lemmatization are done. After cleaning the data, token n-grams, namely Uni-grams, Bi-grams, Tri-grams and Tetra-grams are extracted from the corpus [16, 18, 35]. In the process, as many as 100, 300, 600, 900, … most frequent words from individual datasets are extracted [16] and the iteration stops when accuracy score starts to decrease. Next, bag-of-words (BOW) [4, 12, 16] and TF-IDF values are calculated on the datasets individually. Some popular text classification models have been built and tested. These include Naive Bayes, Support Vector Machine, K-Nearest Neighbor, Decision Tree and Random Forest. The WEKA data mining tool has been used for implementing the different classifiers. The architecture of the proposed system is presented in Fig. 1 and its working principle is explained with the help of a flowchart in Fig. 2 next.
Architecture of the proposed system.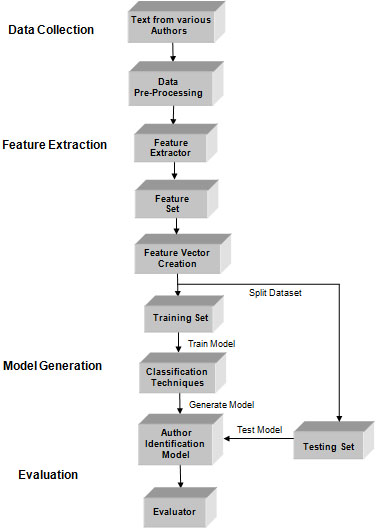
Text in raw form is fed into the feature extractor module which transforms input text or tokens into multidimensional vectors, one per instance, with each feature value as a dimension. These vectors and the ground truth label of each instance are given as input to a Machine Learning algorithm, which extracts patterns from the training material and makes predictions on unseen instances. For prediction, the algorithms work on the feature vectors of the test set that has been obtained after splitting dataset into training and test datasets in three different split ratios.
Flowchart depicting the Workflow of the proposed system.
This section discusses about feature sets, datasets and classification techniques used in this work. The predictions from any Machine Learning algorithm can only be as good as the dataset. Thus, an adequate number of documents are collected, so that each document contains a reasonable amount of words. This is a very crucial requirement for performing the AA task as the final results are very much dependent on the corpus.
Feature sets
In this work, four types of features viz. stylometric features, token n-grams, BOW and TF-IDF have been extracted.
Stylometric Features
In order to obtain best outcomes of the AA task and detect potential suspects of plagiarism, it is important to comprehend effectively the various stylometric features used so that the results do not suffer from any bias. Stylometric features are categorized as Lexical, Syntactic, Structural and Content-specific features.
Lexical features can be further divided into character-based and word-based features. In this research, 64 character-based lexical features and 34 word-based lexical features have been extracted.
Syntactic features include function words, punctuation, and parts of speech (POS) that can help in detecting an author’s writing style at the sentence level. The discriminating power of syntactic features is derived from a writer’s unique habit of organizing sentences. POS tags have not been used in this work. In total, 158 syntactic features have been used that incorporate a large set of 150 function words, which was selected based on the previous study [7].
Structural features such as paragraphs and greetings have not been extracted in this approach as the datasets have no paragraph type texts and almost each instance is in the form of a sentence(s).
Content-specific features are important discriminating features. These features are application dependent or semantic in nature as the selection of such features is dependent on the type of dataset used.
Token n-grams
n-gram is a contiguous sequence of n items from a given text. An n-gram of size 1 is referred to as a “unigram”; size 2 is a “bigram”; size 3 is a “trigram”; size 4 is a “tetragram”; size 5 is a “pentagram” and so on. A k-skip-n-gram is a length-n subsequence where the components occur at distance at most k from each other. Syntactic n-grams are n-grams defined by paths in syntactic dependency or constituent trees rather than the linear structure of the text. Syntactic n-grams are intended to reflect syntactic structure more faithfully than linear n-grams, and have many of the same applications, especially as features in a Vector Space Model. Syntactic n-grams for certain tasks give better results than the use of standard n-grams, e.g., in case of the Authorship Attribution task. In this work, 100, 300, 600, 900, … most frequent token n-grams (n
bag-of-words
The bag-of-words (BOW) model is the simplest form of text representation in numbers. BOW is used in Natural Language Processing (NLP) and Information Retrieval (IR). In this model, a text (such as a sentence or a document) is represented as the bag (multiset) of its words, disregarding grammar and even word order but keeping multiplicity. The bag-of-words model is commonly used in methods of document classification where the frequency of occurrence of each word is used as a feature for training a classifier [4, 12, 16]. There are some drawbacks of this model. It gives either 1 or 0. So, it gives same priority to 1 word and the same priority to 0 word.
Term Frequency-Inverse Document Frequency [32]
Term Frequency-Inverse Document Frequency (TF-IDF) is based on the bag-of-words (BOW) model, which contains insights about the less relevant and more relevant words in a document. The importance of a word in the text is of great significance in IR. Term Frequency (TF) is a measure of the frequency of a word (w) in a document (d). TF is defined as the ratio of a word’s occurrence in a document to the total number of words in a document. The denominator term in the formula (see Eq. (1)) is used to normalize since all the corpus documents are of different lengths.
Inverse Document Frequency (IDF) is the measure of the importance of a word. TF does not consider the importance of word. Some words can be most frequently present but are of little significance. IDF provides weightage to each word based on its frequency in the corpus D and is calculated based on the following formula (see Eq. (2)):
Three datasets, with 3 different train-test split ratios viz. 80-20, 70-30 and 66.67-33.33, have been used in this research. The datasets are as follows:
Spooky Author Identification Dataset [25]
This dataset, hereby referred to as Spooky dataset, contains text from works of fiction written by three horror authors of the public domain, namely Edgar Allan Poe (EAP), HP Lovecraft (HPL) and Mary Wollstonecraft Shelley (MWS). The data has been prepared by chunking larger texts into sentences using CoreNLP’s MaxEnt sentence tokenizer.
Reuter_50_50 Dataset [26]
This dataset is the subset of RCV1. This corpus has already been used in Author Identification experiments. In it, top 50 authors, with respect to the total size of articles, are selected. 50 authors of texts labeled with at least one subtopic of the class CCAT (corporate/industrial) are taken. It is an attempt to minimize the topic factor for distinguishing among the texts in a better way. The corpus consists of 5000 texts, with 100 texts per author.
Manual Dataset
This dataset comprises short stories of three authors namely, Ernest Hemingway, Mark Twain and O’Henry. 10 literary documents of each author have been collected manually and a dataset of 30 documents has been assorted. More details about the various documents of this dataset is provided in the previous work [19].
Performance comparison of different classifiers for best performing stylometric features on Spooky dataset
Performance comparison of different classifiers for best performing stylometric features on Spooky dataset
In this work, a total of five supervised learning algorithms have been employed for solving the text classification problem. The classification techniques are as follows:
Naïve Bayes
This technique performs classification by making an assumption of conditional independence over the training dataset. In this work, multinomial Naïve Bayes classifier has been employed. Learning such classifiers can be greatly simplified by assuming that features are independent of each other given the class as seen from the following formula (see Eq. (3)):
where
Support Vector Machine
This algorithm is used to find a N-dimensional hyperplane which distinctly classifies any data points. Here N is the number of features. SVM does not only focus on creating a hyperplane. It also creates two hyperplanes which are passing through the nearest positive and negative points of that hyperplane. The difference between these two points is called margin. The aim is to maximize the marginal distance to increase the accuracy [28].
k-Nearest Neighbors
In k-NN classification, an object is classified by a plurality vote of its neighbors, with the object being assigned to the class most common among its
Decision Tree
It is a predictive model in machine learning. In decision analysis, a decision tree is used to represent decisions and decision-making trees visually and explicitly. Tree models where the target variable can take a discrete set of values are called classification trees, leaves represent class labels and branches represent conjunctions of features that lead to those class labels [30].
Random Forest
Random Forest is based on the concept of ensemble learning. This classifier contains a number of decision trees on various subsets of the given dataset and takes the average of all outputs to improve the predictive accuracy of that dataset. Instead of relying on one decision tree, the random forest takes the prediction from each tree and based on the majority votes of predictions, it predicts the final output [31].
In this section, different results have been tabulated for three datasets for an easy comparison amongst the performances of five classification techniques used. The confusion matrix is also plot for better understandability. All the experiments are conducted with help of WEKA data mining tool. Waikato Environment for Knowledge Analysis (WEKA) contains a collection of visualization tools and algorithms for data analysis and predictive modeling, together with graphical user interfaces for easy access to these functions. WEKA supports several standard data mining tasks, more specifically, data pre-processing, clustering, classification, regression, visualization and feature selection [20].
Performance comparison of different classifiers for best performing token n-grams on Spooky dataset
Performance comparison of different classifiers for best performing token n-grams on Spooky dataset
Performance comparison of different classifiers for BOW on Spooky dataset
Performance comparison of different classifiers for TF-IDF on Spooky dataset
Performance comparison of different classifiers for best performing stylometric features on Reuter_50_50 dataset
Performance comparison of different classifiers for best performing token n-grams on Reuter_50_50 dataset
Performance comparison of different classifiers for BOW on Reuter_50_50 dataset
Performance comparison of different classifiers for TF-IDF on Reuter_50_50 dataset
Performance comparison of different classifiers for best performing stylometric features on manual dataset
Performance comparison of different classifiers for best performing token n-grams on manual dataset
Performance comparison of different classifiers for BOW on manual dataset
Performance comparison of different classifiers for TF-IDF on manual dataset
Comparison of classifier performance using combination features on manual dataset
Comparison of best accuracy scores of the proposed work with few related works
Stylometric features include F1 that denotes character based lexical features, F2 that denotes word based lexical features, F3 that denotes syntactic features and F4 that denotes content specific features. Most frequent words on token n-gram features have been taken according to the dataset, where n
Next token n-grams (n
Tables 4 and 5 show the accuracy results when different classifiers are employed for bag-of-words (BOW) and TF-IDF features on the Spooky dataset.
In the similar way, the steps are repeated for the other two datasets viz. Reuter_50_50 dataset and Manual dataset for different feature types and the results for five different classifiers are represented in a tabular fashion. As seen from Table 6, the best result is calculated for the combined set of features (F1
Analysis
The best obtained result for stylometric features on Spooky dataset is 66.2581% in 70:30 train-test dataset splitting and the algorithm which is used on full feature set i.e., on a total 460 stylometric features is Support Vector Machine. The precision, recall and F-score values are calculated as 0.669, 0.663, 0.658 respectively. For the token n-gram features on Spooky dataset, the best accuracy obtained is 71.9612% in 80:20 dataset split and the algorithm which is used on Unigram feature set with 1200 most frequent words is SVM. The precision, recall and F-score values are 0.73, 0.72, 0.719 respectively. With BOW and TF-IDF features, the best accuracy scores of 84.14% (Naïve Bayes with 80:20 split) and 83.71% (SVM with 80:20 split) respectively have been obtained.
On Reuter_50_50 dataset, the best obtained result for stylometric features is 64.4706 % in 66.67:33.33 splitting and the algorithm which is used on full feature set (a total of 248 features) is SVM. The precision, recall and F-score scores are 0.656, 0.645, 0.645 respectively. For token n-gram features, 86.2% accuracy score is obtained in 80:20 splitting and the algorithm which is used on Unigram feature set with 2100 most frequent words is SVM. The precision, recall and F-score are calculated to be 0.875, 0.862, 0.863 respectively. While using the BOW and TF-IDF features, the best accuracy scores of 80.50% (SVM with 80:20 split) and 80.10% (SVM with 80:20) respectively are obtained.
The best obtained result for stylometric features on Manual dataset is 90% in both 5-cross validation and 10-cross validation testing and the algorithm which is used on only syntactic features (a total of 158 features) is Naïve Bayes. The precision, recall and F-score values are 0.923, 0.9, 0.898 respectively whereas for the token n-gram features, the best obtained result is 93.3333 % in 10-cross validation and the algorithm which is used on Unigram feature set with 600 most frequent words is Naïve Bayes. The precision, recall and F-score are 0.939, 0.933, 0.931 respectively. With BOW and TF-IDF features, the best accuracy scores of 86.67% (Naïve Bayes with both 5-cross and 10-cross validation testing) and 86.67% (Random Forest with 5-cross validation testing) respectively have been obtained.
It can be observed from Table 14 that when all the best performing features have been combined and the results are calculated for the Manual dataset, interestingly there is an enhancement in the performance of the AA model. When syntactic features and 600 most frequent unigrams are fed together in combination, the overall best accuracy value of 96.67% is obtained both in 5-cross validation and 10-cross validation when Naïve Bayes classifier is employed. Table 15 provides the summarized results of the proposed approach presented in this work and compares them with related works of other researchers.
It can be inferred from Table 15 that for the Spooky dataset, in comparison to the performances of Word2Vec model [21] and SVM model [22], the approach proposed in this paper using BOW features and Multinomial Naïve Bayes algorithm produces a better accuracy score of 84.14%. In case of Reuter_50_50 dataset, the use of 2100 unigrams achieves better accuracy score with SVM classifier compared to the previous works [33, 34]. For the Manual dataset, there is a perceptible improvement of 3.34% over previous research works published by a subset team [19]. Findings indicate that when syntactic features are used in unison with 600 unigrams then even Naïve Bayes algorithm yields better results compared to Neural Networks.
In this work on Authorship Attribution, different feature sets namely, stylometric features, token n-grams, bag-of-words (BOW) and TF-IDF features are used and experimentation has been performed using five different classifiers such as Naive Bayes, Support Vector Machine, k-Nearest Neighbors, Decision Tree and Random Forest. The models have been tested on three datasets viz. Spooky Author Identification dataset, Reuter_50_50 dataset and Manual dataset. The prime focus of this research work is to identify the author and determine true authorship of a given test document. Using supervised learning approaches, the proposed system tries to predict the name of author(s). For the Spooky dataset, the best accuracy score obtained is 84.14% with bag-of-words (BOW) features using Naïve Bayes classifier. The best accuracy score of 86.2% is computed for the Reuter_50_50 dataset with 2100 most frequent words when the classifier used is Support Vector Machine. The score of 96.67% with the combined feature set of syntactic features and 600 most frequent unigrams is the best amongst all using the Naïve Bayes Classification Model with both 5-fold and 10-fold cross validation testing for the Manual dataset.
Future work
Many possible extensions are in the pipeline for enhancing the outcome of the proposed AA system. More datasets with varied size and genre need to be employed. Apart from English, datasets in different languages like Thai [36], Spanish [37] etc need to be tested as well. In this work, the classification models have not been fine tuned by changing parameter values. So, model remains to be optimized and this task has been initiated. Only supervised algorithms have been used in this work. So, performance analysis of ML models after employing unsupervised algorithms is pending. On Reuter_50_50 and Manual datasets, F4 features (semantic or content-specific features) have not been extracted as the dictionary of literary and news words could not be arranged. Only token n-gram (for n