
Abstract
Breast cancer is a significant global health concern, highlighting the critical importance of early detection for effective treatment of women’s health. While convolutional networks (CNNs) have been the best for analysing medical images, recent interest has emerged in leveraging vision transformers (ViTs) for medical data analysis. This study aimed to conduct a comprehensive comparison of three systems a self-attention transformer (VIT), a compact convolution transformer (CCT), and a tokenlearner (TVIT) for binary classification of mammography images into benign and cancerous tissue. Thorough experiments were performed using the DDSM dataset, which consists of 5970 benign and 7158 malignant images. The performance accuracy of the proposed models was evaluated, yielding results of 99.81% for VIT, 99.92% for CCT, and 99.05% for TVIT. Additionally, the study compared these results with the current state-of-the-art performance metrics. The findings demonstrate how convolution-attention mechanisms can effectively contribute to the development of robust computer-aided systems for diagnosing breast cancer. Notably, the proposed approach achieves high-performance results while also minimizing the computational resources required and reducing decision time.
Keywords
Introduction
Breast cancer is recognized as one of the most significant health challenges impacting women worldwide. According to data from The International Agency for Research on Cancer (IARC), breast cancer affected approximately 7.8 million women in the five years prior to 2020. It is estimated that 2.3 million women worldwide were diagnosed with breast cancer, resulting in 685000 fatalities, as illustrated in Fig. 1. This highlights breast cancer as a significant global health concern. Early diagnosis remains crucial in addressing this disease and devising timely treatment plans [1]. In clinical practice, various techniques, such as histopathology [2], CT scan images [3] and ultrasonography imaging, are employed to detect breast cancer [4]. Mammography images [5], can provide greater sensitivity in distinguishing between cancerous masses. These images are typically categorized into benign and malignant lesions, providing more precise and detailed diagnostic information. [6]. Pathologists are essential in the identification and classification of tissue samples used in the diagnosis of breast cancer, and microscopic examination is one of the important methods for diagnosing BC [7]. However, manual diagnosis is labor intensive and susceptible to mistakes, especially when performed by inexperienced pathologists [8]. Computer-aided diagnosis based on convolutional networks has become the dominant system in medical vision tasks [9]. In practical applications, CNNs have achieved significant success. A typical CNN architecture is composed of various layers, with the most common layers being convolution, pooling, fully connected, dropout, and rectified linear activation function (ReLU) [10]. The investigated tasks include extracting and segmenting breast cancer tumour lesions, as well as classifying breast tissue to determine whether it is benign or malignant [11].
The global incidence of breast cancer in different countries worldwide in 2020.
Recently, there has been an increase of interest in using self-attention approaches in computer-aided diagnosis (CAD) due to the success of vision transformers (VITs) [12]. The attention mechanism based on self-attention layers used in transformers splits the image into multiple patches, linearly embeds them, and then applies the attention directly to this collection of patches [13]. First, it excels in capturing long-range relationships between image pixeles. Second, its capacity for adaptive modelling through the dynamic computation of self-attention weights enables the network to effectively highlight relevant images regions while suppressing noise, contributing to improved object recognition and feature extraction. Finally, the inherent ability the attention mechanism to provide saliency maps offers valuable insights into the specific areas of interest within an image, making it an indispensable tool for enhancing the interpretability and performance of computer vision models [14]. However, there are some drawbacks to vision transformers ViT, which can be quite demanding in terms of computer resources in regard to training and testing data. They also have many parameters, which makes the model more complicated [15]. Recently, there has been a growing interest in combining CNN models with ViT to overcome these challenges [16]. In medical applications, both ViTs and CNNs face difficulties in achieving the best performance, especially when little data are available. The complex structure of ViTs and long training times of CNNs can be particularly challenging. On the other hand, the fusion of VIT-CNN models is more effective at reducing the decision time and resources required for training [9].
Our objective is to evaluate and compare the performance of vision transformers utilizing convolution layers for feature extraction using the different optimizers Adam, AdamaX, and SGD to increase the classification accuracy. The primary goal of this method is to significantly reduce training time and minimize parameters for medical data analysis. Our study presents three notable contributions, as outlined below:
We explore whether the self-attention transformer model can be used for mammogram imaging tasks, and discuss how it can be adjusted and improved medical images analysis. We show that combining CNNs with ViTs can greatly enhance medical images are analysed. We introduce the tokenlearner transformer model, which stands out from current methods. This model has accurate performance, and low decision time, especially when dealing with limited data.
Our comparative study utilized an attention technique to divide breast images into patches, with a specific focus on patch size within tumor regions for creating mammography patches. Additionally, our study integrates attention techniques and convolution layers for classifying mammography images, offering a novel approach that could improve performance in medical data analysis for computer-aided diagnosis. The subsequent sections of this paper are organized as follows: A background on the mammogram images is presented in Section 2. A summary of relevant studies on this topic is given in Section 3. Our suggested self-attention method is explained in depth in Section 4. The results of our empirical evaluations, which were carried out with the use of the DDSM database, are presented and discussed in Section 5. A thorough description of the results is provided in Section 6. Possible directions for further study and development are described in Section 7.
Breast cancer incidence worldwide in 2022
In this section, we offer essential background information crucial for comprehending the subsequent content of the paper.
Mammography
Mammography is a method used for the early detection of breast cancer, employing a low-dose X-ray to capture images of the breast tissue interior. This technique enhances the visibility of potential signs. Malignancies such as masses, microcalcifications, ascites, and distortions can be visualized, serving as indicators of potential malignancy. Figure 2 illustrates a mammography system as an example. The process involves crossing the breast between the compression plate and the breast support. Subsequently, low -intensity X-ray beams are directed onto the breast from above using an X-ray tube. Mammography is widely adopted as the primary screening method for breast cancer due to its speed, cost-effectiveness, and minimal requirement for skilled operators [17].
An overview of the mammography setup, where a woman’s breast is placed on the breast support and an X-ray beam projection is generated in the X-ray tube (courtesy: Wikipedia).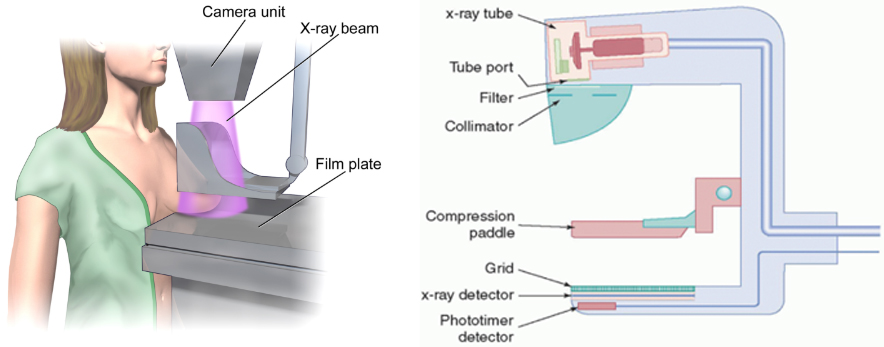
Each breast undergoes imaging from two distinct viewpoints, namely the Craniocaudal View (CC) and the Mediolateral Oblique (MLO) in mammography-based screening programs, as depicted in Fig. 3a. Sample mammograms from these viewpoints are shown in Figs 3b and 3c.
Mammography projection views used in breast cancer screening studies: (a) shows the direction of the two most commonly used view points to produce mammograms, (b) CC view, and (c) MLO view.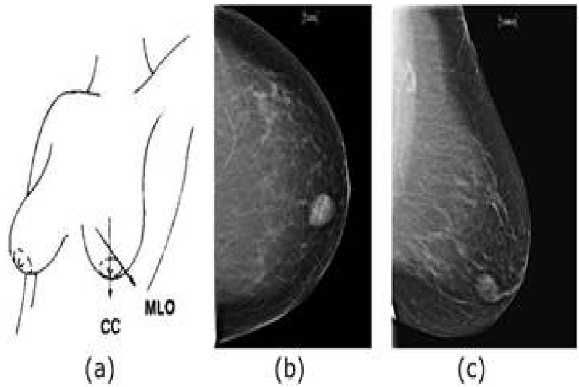
Upon identifying areas of concern, radiologists may conduct further image projections, such as enlarged views or mediolateral views. Traditionally, screen-film mammography (SFM) utilizes photographic films to capture breast scans. However, with advancements in imaging technology, high-quality full-field digital mammography (FFDM) is now employed, allowing for immediate viewing on computers. To address the limitations of standard 2D mammography, pseudo 3D digital breast tomosynthesis (DBT) has gained popularity as a novel imaging technique. In DBT, the X-ray tube traverses a narrow arc above the breast, capturing multiple low-dose X-ray images Fig. 4.
Schematic procedure of DBT, showing the movement of the x-ray tube to acquire images at different angles. Note that the geometry differs between manufacturers.
These exposures are post processed to generate pseudoo-3D breast volumes, with each slice representing a different depth of the breast tissue. Typically, slices are spaced at 1 mm intervals, facilitating improved visualization of interior breast tissue and reducing the overlapping effects observed in conventional mammography. Various DBT geometries and acquisition settings exist, each exhibiting different performances in detecting masses and microcalcifications. As illustrated in Fig. 5, different slices of breast DBT images are shown. Despite the increasing adoption of DBT, X-ray mammography remains the gold standard imaging modality for breast cancer screening due to its speed and cost-effectiveness [1].
Sample DBT volume: Different slices of DBT volume traversing from left to right.
Given the intricate nature of breast anatomy and the challenges associated with cancer detection using mammography, there has been widespread recognition of the need for enhanced screening methods. Consequently, scientists and researchers have been diligently working to develop improved mammography techniques to facilitate early cancer detection. Regular mammograms remain one of the most effective diagnostic tools available to physicians, often detecting breast cancer up to three years before it becomes palpable.
The use of vision transformers with attention mechanisms in medical image processing has become increasingly popular, especially in computer-aided diagnosis. In 2021, Matsoukas Christos et al. questioned whether it is time to switch from CNNs to transformers for medical images [9]. They suggested that transformers can replace CNNs with minimal effort, especially for small medical datasets. In 2022, Henry Emerald U et al. explored whether the impact of transformers on computer vision extends to medical imaging [12]. Their paper compared the performance of transformers and CNNs across different medical imaging methods. In 2023, He Kelei et al. aimed to highlight the use of transformers in medical image analysis [18]. They emphasized that existing transformer methods can be easily applied to various medical imaging tasks with few modifications. In recent studies, Abimouloud M et al. [19] introduced Transformer (ViT) architectures utilizing various optimizers, such as Adam, Adamax, and SGD, on the DDSM dataset. They achieved accuracies of 99.89% with Adamax, 99.96% with Adam, and 99.81% with SGD. The corresponding training times were 633.73 seconds, for AdamaX, and 698.91 seconds for SGD for Adam 942.01 seconds. Boudouh, Saida Sarra et al. [20] proposed a method in which several filters were applied during the mammography preprocessing stage. Then, they utilized six transfer learning models for feature extraction and training: InceptionResNetV2, EfficientNetB7, DenseNet201, MobileNetV2, ResNet152V2, and VGG16. Their models achieved accuracies of 99.83%, 98.19%, 97.29%, 99.42%, 99.01%, and 99.83%, respectively. Ayana Gelan et al. [21] developed a method for classifying breast masses invia mammography using the DDSM dataset. Their approach involved training from scratch and transfer learning using ResNet, EfficientNet, Incep- tionNet, and vision transformers such as the Swin Transformer and Pyramid Vision Transformer. They proposed vision-transformer-based transfer-learning models, which All achieved an impressive area under the receiver operating curve (AUC) of 1
Materials and methods
In this section, we present an overview of the proposed systems, starting with a description of the DDSM dataset used for model development. Subsequently, we define the VIT, CCT and TVIT models, employing three different optimizers: Adam, Adamax, and SGD. The primary goal of these steps is to assess the effectiveness of the TVIT model compared to that of the VIT model in accurately classifying lesions in DDSM images as either malignant or nonmalignant. A block diagram of the proposed methods is shown in Fig. 6.
Details of vision transformer model variants
Details of vision transformer model variants
Block diagram of the proposed approach.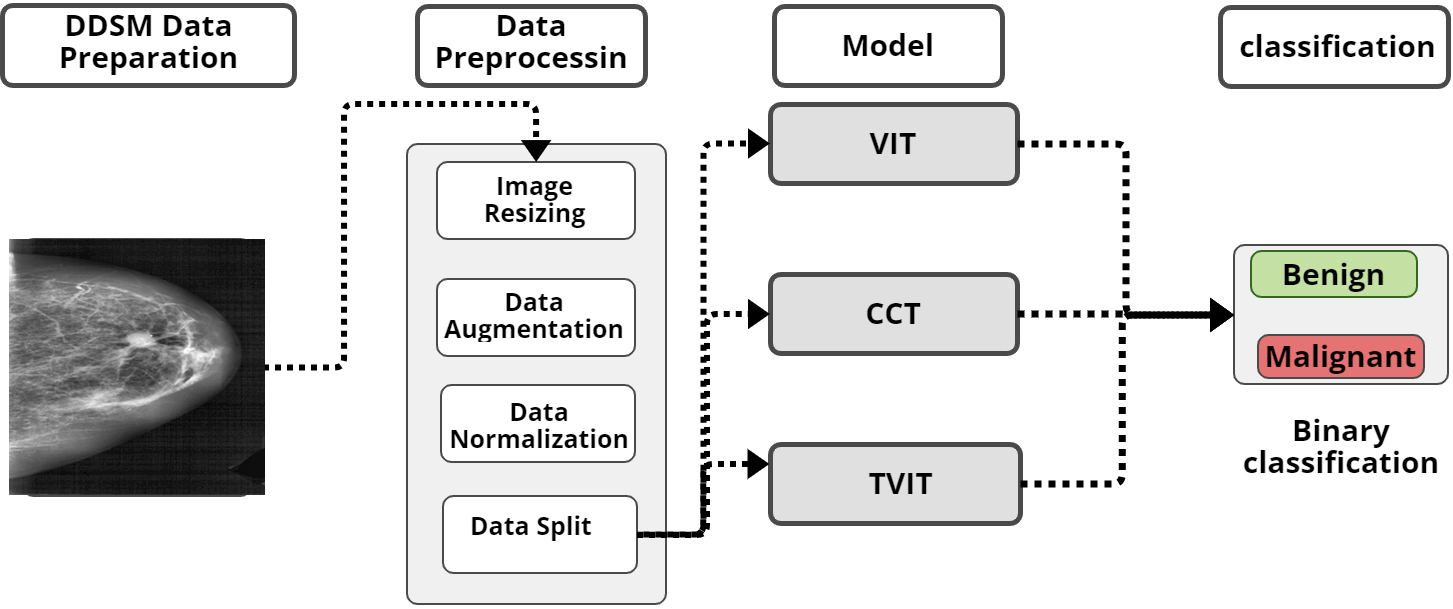
In this study, we utilized the Digital Database for Screening Mammography (DDSM) [25], which is publicly available and and accessible at:
Vision transformer
The Vision Transformer (ViT) architecture, as highlighted in our study, is instrumental in classifying breast cancer mammograms. This architecture is meticulously crafted to analyse and comprehend the intricate features present in images. The process, depicted in Fig. 8, begins by resizing the original images from 227
The steps of the vision transformer mechanism are as follows:
Each patch is flattened and projected into a higher-dimensional space The transformer encoder block integrates a forward connection that combines the original input with the outcome of multihead attention following the calculation of the attention function. This function involves computing the dot product between Q and the transpose of K, which is subsequently scaled down by a factor of The results from these steps are then forwarded to the MLP head layer. The MLP head leverages the outputs from the transformer encoder layers to generate a probability distribution of labels, facilitating the prediction of the image class. The architecture implemented in this work is described in the Table 3.
Details of CCT model variants
DDSM dataset images.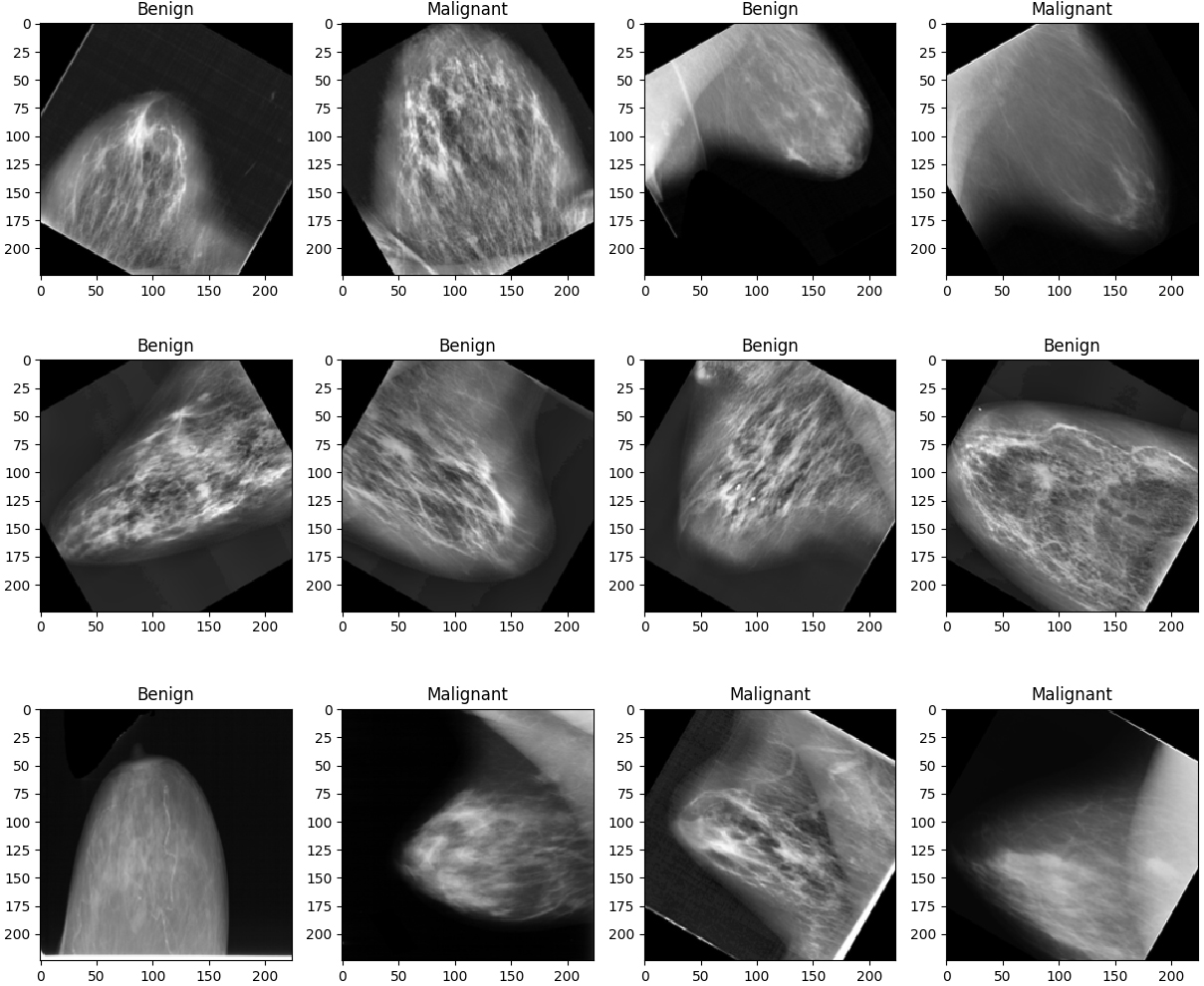
Offer a new perspective in image analysis [26]. The core of CCT lies in its architecture, outlined in Fig. 9. Unlike traditional methods, CCT introduces a significant change in its model by replacing the patch and embedding block in VIT with a basic convolution block. This block comprises standard structural convolution, rectified linear unit (ReLU) activation, and a max pooling layer, which allows for enhanced flexibility in handling input images of various sizes.
For instance, given an image with dimensions represented as
Vision transformer self-attention architecture.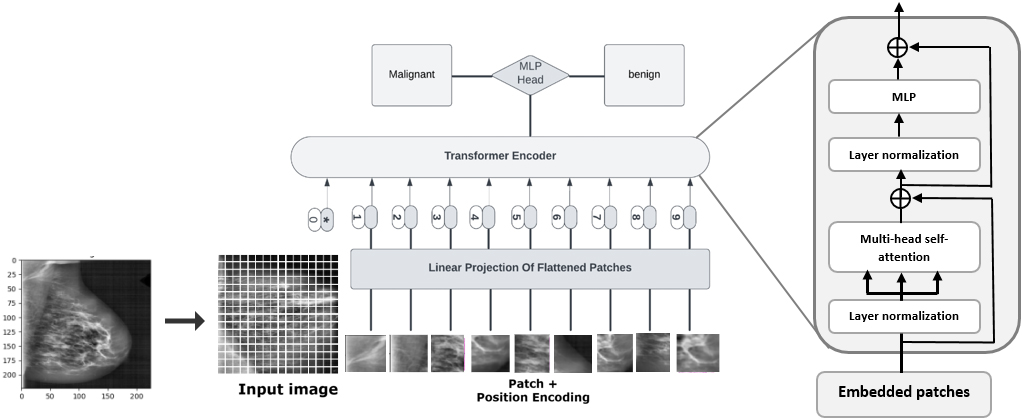
Architecture of the compact convolution transformer.
The TokenLearner model operates by first taking an image-shaped tensor as its initial input. This tensor then undergoes processing through multiple convolutional layers, generating distinct spatial attention maps to capture specific spatial features. Spatial attention mechanisms enable the model to focus on relevant regions within the input, which is essential for retaining important information. Subsequently, elementwise multiplication is employed to accentuate the importance of specific regions while de-emphasizing others. The resulting product is then aggregated using a pooling operation to condense the information into a pooled representation. The following is a breakdown of TokenLearner architecture:
Input Tensor: This tensor initially takes an image-shaped tensor Spatial Attention: Spatial attention allows the network to focus on relevant regions within the input, which is crucial for retaining important information. This ensures that the model emphasizes relevant areas, especially when working with a reduced number of patches. Elementwise Multiplication: The attention maps are applied to the original input through elementwise multiplication, accentuating the importance of specific regions while deemphasizing others. Pooling Operation: The resulting product from element-wise multiplication is aggregated using a pooling operation, condensing the information. Output: The output is a pooled representation treated as input to the transformer encoder block. This summary features a significantly reduced number of patches compared to the splitting image technique in the base self-attention model VIT. TokenLearner Module: This module combines convolutional layers, spatial attention, and pooling to efficiently process input images, providing a condensed yet informative representation with reduced training time and processing.
The token vector generation form input patches (courtesy: [27]).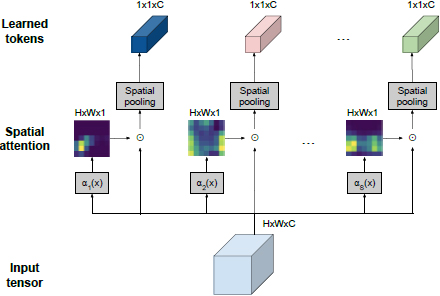
Dataset splitting
This paper aims to efficiently and accurately diagnose breast cancer (BC) using the DDSM dataset. The dataset was split into two segments for evaluating the effectiveness of the classification model. 80% of the dataset, which included 10,502 images, was designated for the training phase, while the remaining 20% (2,626 images) were set aside for testing. The training process was meticulously handled performed on an HP Z8 G4 computer workstation:
Memory (RAM): 96.00 GB Processor: Intel(R) Xeon(R) Silver 4108 CPU @ 1. 80 GHz 1. 80 GHz. Graphic Processing Unit: (GeForce RTX 2080 Ti, GeForce RTX 3090) System type: 64-bit operating system, x64 processor. We utilized Python 3.11.
Ensuring a balanced dataset is crucial for creating a reliable and fair classification model. When dealing with imbalanced datasets, such as those often encountered in medical contexts, there is a risk of poor generalization and greater chance of misclassification. To address this challenge with the DDSM dataset, we implemented data augmentation as a key strategy to overcome data scarcity. The specific details of our data augmentation approach can be found in Table 4. Additionally, the hyperparameters used in training our model are listed in Table 5.
Data Augmentation Parameters
Data Augmentation Parameters
Hyperparameter settings
To ensure the optimal training of the vision Transformer (VIT) model,various optimizers (Adam, Adamax and SGD) were tested. The performance of the model was assessed using a variety of evaluation metrics, such as the confusion matrix, ROC curve area, sensitivity, specificity, accuracy, precision, AUC, F1-score, total training time, and time per epoch. These metrics were meticulously used to thoroughly evaluate the model’s classification effectiveness and efficiency.
Performance comparison metrics of the optimizers
The best performance in binary classification for each model
Confusion matrices of the VIT Adam(1), Adam(2), SGD(3) optimizer respectively.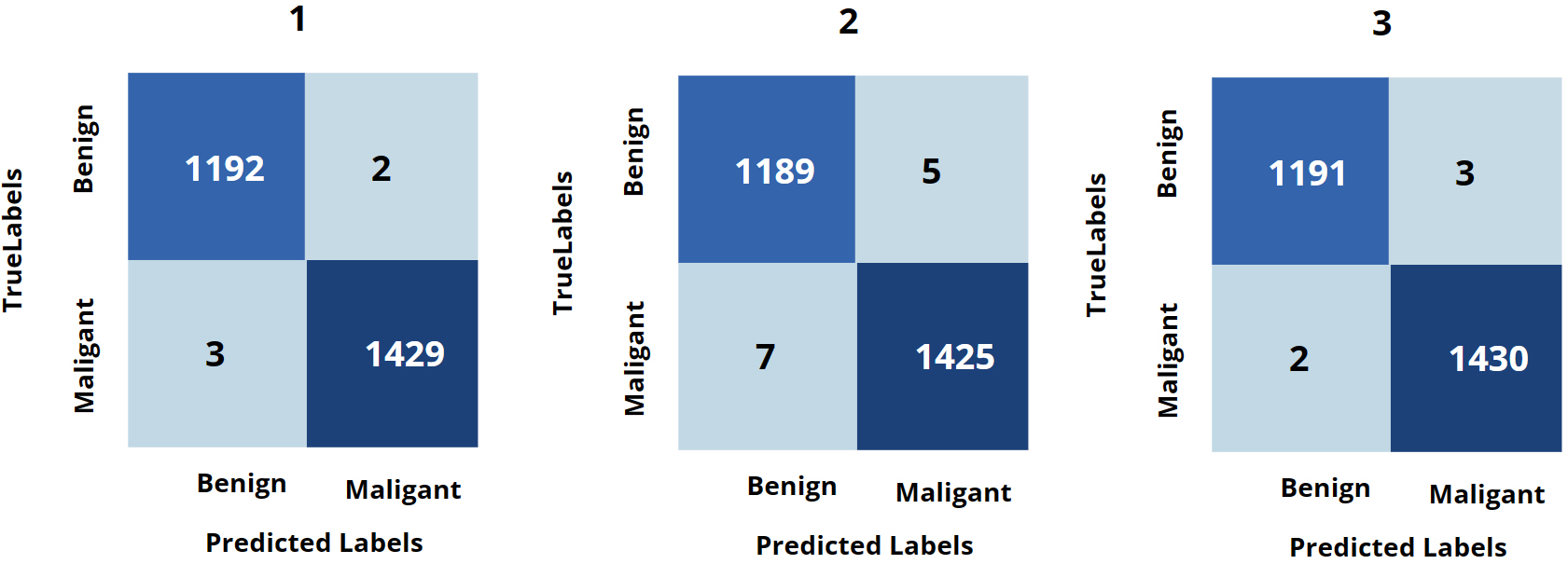
In this section, we conduct a comprehensive performance review of models, with three different optimizers: Adam, Adamax, and SGD. To provide a clear overview of our findings, the optimal performances of our proposed systems are meticulously detailed in Table 6.
Based on the results presented in Table 7, it is evident that the CCT, particularly when coupled with the AdamaX optimizer, emerges as the top-performing model. It demonstrated remarkable accuracy, achieving 99.92%. Additionally, VIT, when paired with the Adam optimizer, achieves an accuracy of 99.81%, while TVIT, under the same optimizer, achieves an accuracy of 99.05%. Moreover, the configuration utilizing the AdamaX optimizer excels in terms of minimal training time, completing in 533.90 seconds. These results highlight the effectiveness and efficiency of the systems across various optimization techniques, offering valuable insights into their respective strengths and performance metrics. The confusion matrices of the models with Adam (1), AdamaX (2), and SGD (3) optimizers using the DDSM dataset are illustrated in Figs 11, 14, and 13.
Confusion matrices of the CCT Adam(1), Adam(2), SGD(3) optimizer respectively.
Confusion matrices of the Tokenlearner Adam(1), Adam(2), SGD(3) optimizer respectively.
Illustration of the ROC curves of VIT, CCT, and TVIT with best optimizer.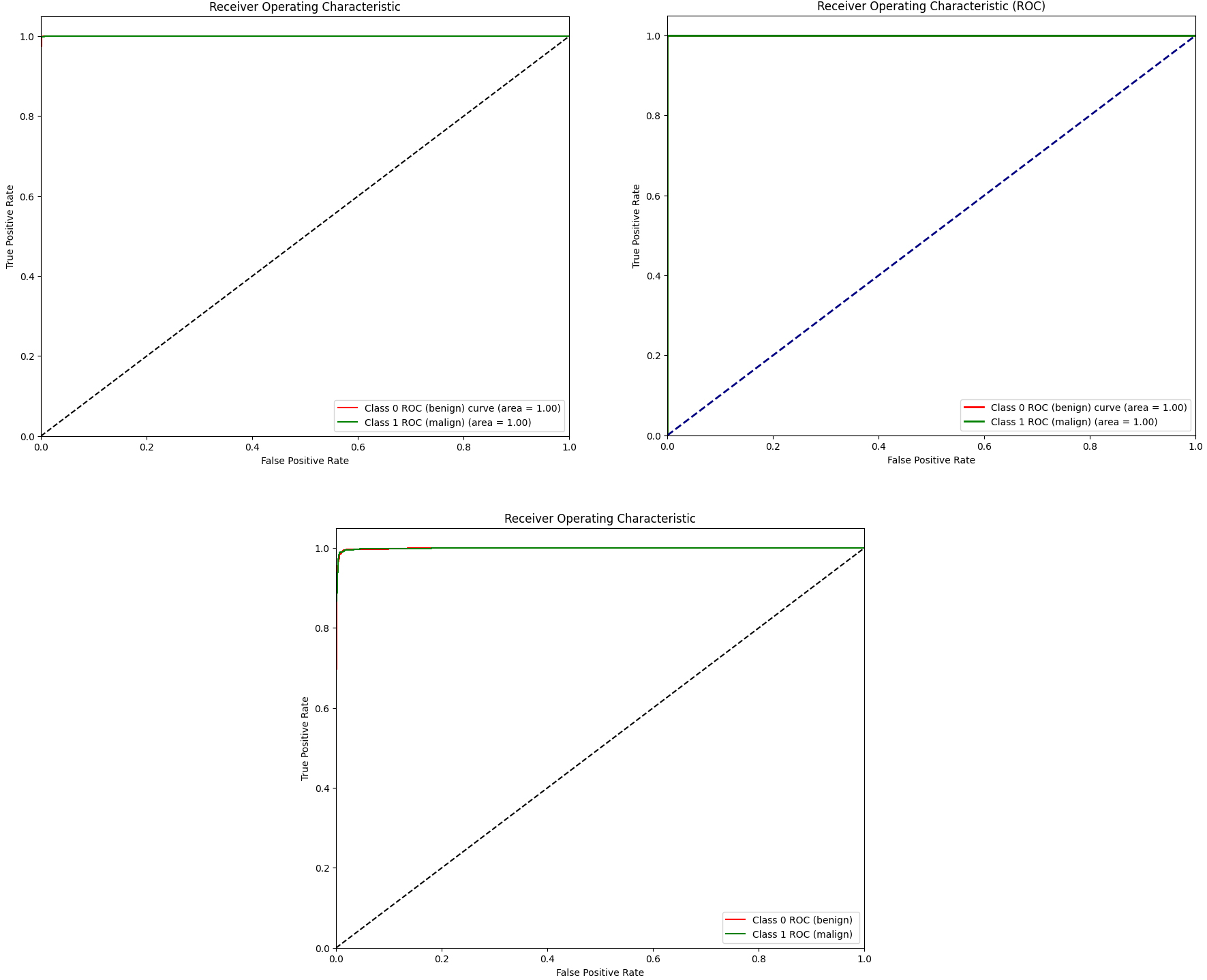
In this study, we introduced three systems self-attention vision transformer (VIT), compact convolution transformer (CCT), and Token learner (TVIT) utilizing different optimizers for the early diagnosis of breast cancer using the DDSM dataset. These systems demonstrated impressive performance in classifying breast cancer masses.
To mitigate overfitting, we employed data augmentation to generate additional images within the same dataset. Previous studies have focused mainly on classifying the DDSM breast cancer dataset using CNN models or traditional machine learning algorithms. However, our study emphasized feature extraction from tissue images within the DDSM dataset using attention techniques with convolution layers in the proposed systems. A significant contribution of this study was the use of various optimizers Adam, AdamaX and SGD, to minimize the error function (loss function) and improve production efficiency, based on the learnable parameters of the model. These parameters are crucial for adjusting the weights and learning rate of a neural network to minimize losses. This technique introduces a new approach of self-attention transformers and convolutional models, enabling accurate computer-aided breast cancer diagnosis with fewer computational resources and shorter training times, particularly for medical image datasets. Upon reviewing the table, it is evident that CCT achieves the highest accuracy of 99.92% in classification among all tested models, particularly when utilizing the AdamaX optimizer. The self-attention vision transformer achieves an accuracy of 99.81% with the AdamaX optimizer, while the Token Learner achieves 99.05% accuracy with the AdamaX optimizer. However, it is noteworthy that the Adamax optimizer consistently demonstrates superior performance compared to the Adam and SGD optimizer in terms of accuracy across the experiments. When considering the training time for each model, it’s evident that TokenLearner achieves the lowest training time, taking only 533.90 seconds. ViT followed with a training time of 819.77 seconds.
However, it’s important to note that CCT requires a longer time, with 8421.03 seconds. The CCT model incorporates convolution layers with an attention mechanism, which may contribute to its longer training time. On the other hand, the Token Learner model also utilizes same mechanisms in its architecture but requires less training time. This could be attributed to the tokenization technique employed in the Token Learner model, which dynamically highlights relevant regions in the input patches. This technique reduces the number of patches used in training, resulting in lower training time and complexity compared to the CCT model. The experiments show that there are still opportunities to enhance the performance of transformer-based models in breast cancer mammography, where accuracy is crucial. Our study suggested that transformer-based convolution models could benefit from better mechanisms for aggregating information. Models such as Token learner, which utilizes tokenization and attention maps to process image input efficiently at any resolution, should be considered.Finally, in contrast to recent research, this method demonstrated notably enhanced outcomes, of demonstrating the effectiveness of combining of VITs and CNNs for detecting breast tumors in mammography images. Moreover, through a comparative examination with models from prior studies, we noted that this approach consistently achieved superior performance, as illustrated in Table 8.
Assessment of the performance of previously published works on mammography for breast cancer detection using the DDSM dataset
Assessment of the performance of previously published works on mammography for breast cancer detection using the DDSM dataset
This approach introduces new hybrid transformer-convolution models, offering an advanced computer-aided analysis for diagnosing breast cancer through mammography images. This innovative approach significantly reduces the need for computational resources and training time, especially when dealing with large medical image datasets. The following is a summary of our experiments:
The hybrid attention convolution approach introduces an innovative method that combines the strengths of both techniques in medical visual diagnosis. Tokenization mechanisms provide a promising solution for medical scenarios with limited training data and restricted computational resources.
In future studies, we plan to explore a wider range of optimization techniques and fine-tune hyperparameters. Additionally, integrating multi modal data and validating our system with real patient data could further enhance diagnostic accuracy and clinical applicability. We also aim to investigate strategies for faster decision making with larger datasets, striving to continually improve our system’s efficiency and effectiveness in medical image analysis.
Funding
This study was not funded. The authors have no relevant financial or non-financial interests to disclose.
Availability of data and materials
The dataset analysed during the current study are available in:
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Footnotes
Conflict of interest
The authors declare that they have no conflicts of interest.