
Abstract
Pavement crack assessment is an important indicator for evaluating road health. However, due to the dark color of the asphalt pavement and the texture characteristics of the pavement, current asphalt pavement crack detection technology cannot meet the requirements of accuracy and efficiency. In this paper, we propose an end-to-end multi-scale full convolutional neural network to achieve the semantic segmentation of cracks in road images by learning the crack characteristics in the complex fine grain background of asphalt pavement. The method uses DenseNet and deconvolution network framework to achieve pixel-level detection and fuses features learned from different scales of convolutional kernels through a full convolutional network to obtain richer information on multi-scale features, allowing more detailed representation of crack features in high-resolution images. And the back end joins the SVM classifier to achieve crack classification after crack segmentation. Then we create a road test standard data set containing 12 cracks and evaluate it on the data. The experimental results show that the method achieves good segmentation effect for 12 types of cracks, and the crack segmentation for asphalt pavement is better than the most advanced methods.
Keywords
Abbreviation
Convolutional Neural Networks
Stochastic Gradient Descent
Signal Noise Ratio
Graphics Processing Unit
Deep Neural Networks
Support Vector Machine
Introduction
According to statistics, the length of the world road network has reached 6,4285,000 km [1], and since the 1950 s, with the development of road and bridge technology, the road network around the world has entered a rapid construction phase. However, the design of roads and bridges is generally 50 years. Many roads and bridges have problems such as fatigue stress, overload operation, disrepair, and aging of pavement structure. These problems lead to microscopic cracks on the surface of roads and bridges. Pavement cracks are further expanded under the influence of bad weather and human factors, which ultimately affects the physical structure of roads and bridges, causing serious engineering accidents and traffic hazards. And with the development of the traffic network, the daily maintenance and regular test of the road costs more and more manpower and material resources, which has become a common problem in the world.
Accurate and timely identification of pavement diseases has become a key component of regional road maintenance during routine maintenance of roads. This is because early detection of pavement diseases helps to develop effective repair schemes and prevent further changes in pavement structure. Among them, cracks are widely considered as an important indicator of pavement degradation. Based on the morphology and location characteristics of cracks, internal damage, degradation and potential causes of cracks can be inferred, providing reasonable guidance for structural evaluation [2]. Therefore, accurate, timely and energy-saving identification of cracks is of great significance to road maintenance and conservation costs. Traditional manual visual inspection methods have been eliminated by most countries due to labor intensive, subjective, and low efficiency. Currently, the mainstream crack detection methods are camera images [3], infrared images [4], ultrasound images [5], and laser images [6], in which camera images are widely used due to low equipment cost and strong environmental applicability. In the camera image, the crack is a linear and curved structure, which can be regarded as a pixel-level edge feature, so crack detection is essentially an edge detection problem, which is a hot issue of computer vision [7].
However, camera pavement detection in the actual image acquisition process due to the complexity of pavement grain, weather light differences, roadside construction blocking, different pavement cleanliness, weak signal at the edge of the cracks, resulting in uneven image acquisition information and complex and variable pavement background, causing great difficulties to accurate crack detection. Therefore, in the past decade, various methods have been proposed to overcome these challenges. Depending on the computer vision approach, it can be divided into a morphology-based approach and a machine learning-based approach. The morphology-based approach essentially uses structural features to detect cracks. Lee and Kim [8] proposed a simple feature extraction method for crack classification, which defines the concept of crack type index. Later, A. Ayenu-Prah et al. [9] used the edge detection method of Canny and Sobel algorithm to detect the crack. Yiyang et al. [10] proposed a crack detection algorithm based on digital image processing technology, which first smooths the image and then performs threshold segmentation of the crack afterwards. Adhikari, R. S. et al. [11] used Fast Fourier Transform (FFT) to improve the robustness of light and shadow changes. Wang et al. [12] attempted to use the wavelet transform method to identify the existence of cracks and observed promising results. Although these methods make the global features of the image more obvious, there is still potential for improvement in different crack detection. Huang et al. [13] avoided the interference of global processing on features by dividing the image into grid cells. Later, Yeum et al. [14] proposed a detection method using IPTs combined with sliding window technology, which can effectively remove unnecessary interference features. Morphology-based crack detection studies are rich, but the robustness of the detection is not as good as expected when brightness, shading, and resolution are different from the expected settings. Therefore, the method based on machine learning [15] has also attracted many scholars to conduct research.
In the early days, a typical machine learning approach was to use an ML-Artificial Neural Network (ANN) to classify images to determine if a small image was part of a crack [16]. Moreover, Kaseko et al. [17] performed a comparative evaluation of neural network classifiers with Bayesian classifiers and k-nearest neighbor (k-NN) traditional classifiers to summarize the potential of neural networks in the classification of pavement cracks. Gavilan et al. [18] established an adaptive road crack detection system using support vector machine (SVM) integration. Mokhtari et al. [19] used artificial neural networks (ANN), decision trees and k-nearest neighbors to classify crack and crack-free labels on pavement images; neural networks proved to be superior to decision trees and k-nearest neighbors. Fujita et al. [20] proposed a classification model based on linear support vector machine, which uses a set of manual features extracted from digital images. However, due to the limitations of early computer computing power, neural networks generally have a simple structure and cannot classify complex cracks. Researchers are trying to achieve better performance through other machine learning methods. Cha et al. [21] proposed a hybrid method of crack detection combined with linear support vector machine and Hough transform; Zou Lihong et al. [22] constructed a three-step crack tree and generated a probability map for crack location identification. Nhat-Duc Hoang [23] concluded that the machine learning approach to crack detection has been comprehensively ahead of the morphological approach by summarizing and comparing the machine learning approach. However, due to the lack of representation of nonlinear features by traditional machine learning methods and the inability to perform deep excavation of features, the accuracy of the method for complex crack classification cannot be further increased.
In recent years, deep learning has been considered as one of the most promising methods in the field due to its good feature generalization and feature mining. Young-Jin Cha et al. [23] proposed a crack detection based on convolutional neural network. The method divides the image and detects it by judging whether each subgraph contains cracks. Zheng Tong et al. [24] pre-processed the image by clustering method and then used DCNN network to identify the crack. Byunghyun Kim et al. [25] used a deeper deep learning network, AlexNet, to detect cracks, further improving the accuracy of crack detection. However, these methods only detect cracks and cannot segment and extract cracks. After that, Xincong Yang et al. [26] realized the pixel-level segmentation of the cement pavement through the FCN network, and obtained the length and width characteristics of the crack, which made the crack detection more accurate. However, the experiment of this method is carried out on a cement pavement with superior conditions, and it is impossible to explain the detection of the method on a bad road surface. To solve this problem, Arun Mohan et al. [27] input multi-mode data into the network and solved the feature generalization under severe conditions by increasing the dimension of features. Yuming Zhang et al. [28] Allen Zhang et al. [29] produced 3D data sets for network learning through 3D laser scanning surface pavement to improve the performance of crack features in the data. However, these methods are too demanding on data, and the workload is huge when collecting data. Later, people combined the traditional method with the deep learning method to improve the detection accuracy of the model. For example, Nhat-Duc Hoang et al. [30] combined the edge optimization algorithm with the convolutional neural network to improve the detection accuracy of the asphalt pavement model to 92.08%. And with the introduction of a new model of deep learning, more new models were used for pavement crack detection. For example, Qin Zou et al. [31] used the SegNet network to implement end-to-end semantic segmentation of crack images. Kaige Zhang [32] improved the accuracy of model detection by integrating T-DCNN network and multi-method detection into a unified loop detection process. And Sattar Dorafshan et al. [33] expressed the importance and development potential of deep learning methods in crack detection by comparing and analyzing various deep learning models and edge detector algorithms. However, at this stage, the detection of pavement cracks based on deep learning mostly focuses on the identification of low-pixel cracks on cement pavement. For asphalt pavements with dark road surface, low signal-to-noise ratio and no obvious cracks, in the case where the acquisition conditions are controlled, the current method cannot be well segmented and identified. Therefore, it is important to carefully craft a data set of various road defects and perform pixel-level segmentation of data with higher precision.
In this study, we use a DenseNet [34] and deconvolution network framework combined with multi-scale convolution to build a network model to identify cracks from asphalt pavements. The method is not affected by the light intensity, shadow projection, road surface blur, road surface foreign matter, and can accurately segment the road surface crack from the 1024*1024 asphalt road picture. And the network can achieve end-to-end training and detection, reduce the training difficulty of the model, and improve the convergence speed of the model. We have experimentally verified the impact of different network initial values and convolution kernels on segmentation results, and compared with the current mature deep learning model by this method, it is proved that we have better semantic segmentation effect for cracks in asphalt pavement with high signal-to-noise ratio. At the same time, we have built a well-structured and rich data set, including 12 kinds of cracks on cement pavement and asphalt pavement, and carried out sufficient experiments by the method in this paper. The content of this study is as follows: The first part introduces the research background and development status of pavement crack detection. The second part gives the road crack data set we created. The third part describes the overall situation of the method. The fourth part of the method is experimentally verified. The fifth part summarizes our work.
In general, this article has made three major contributions: A multi-type crack data set containing asphalt pavement cracks was fabricated. This paper designs a deep learning network model that can simultaneously perform segmentation tasks and classification tasks by combining DenseNet and deconvolution network frameworks and multi-scale convolution. This paper verifies the completeness of the data and the validity of the network model through sufficient experiments.
Production data sets
In order to ensure the spatial relationship of the image is unchanged during the data acquisition process, we make the vertical distance between the camera and the road surface unchanged. As shown in Fig. 1, the camera is fixed on the bracket, and the operator only controls the start and stop of the camera. In order to ensure the integrity of the data set, the continuous acquisition mode is adopted in the acquisition process, and we obtain crack images of different illumination, different weather and different road surfaces. The crack gap width of the asphalt pavement is larger than 3 cm, and the phenomenon of cracking and crack branching at the edge of the crack visible to the naked eye is called a crack.
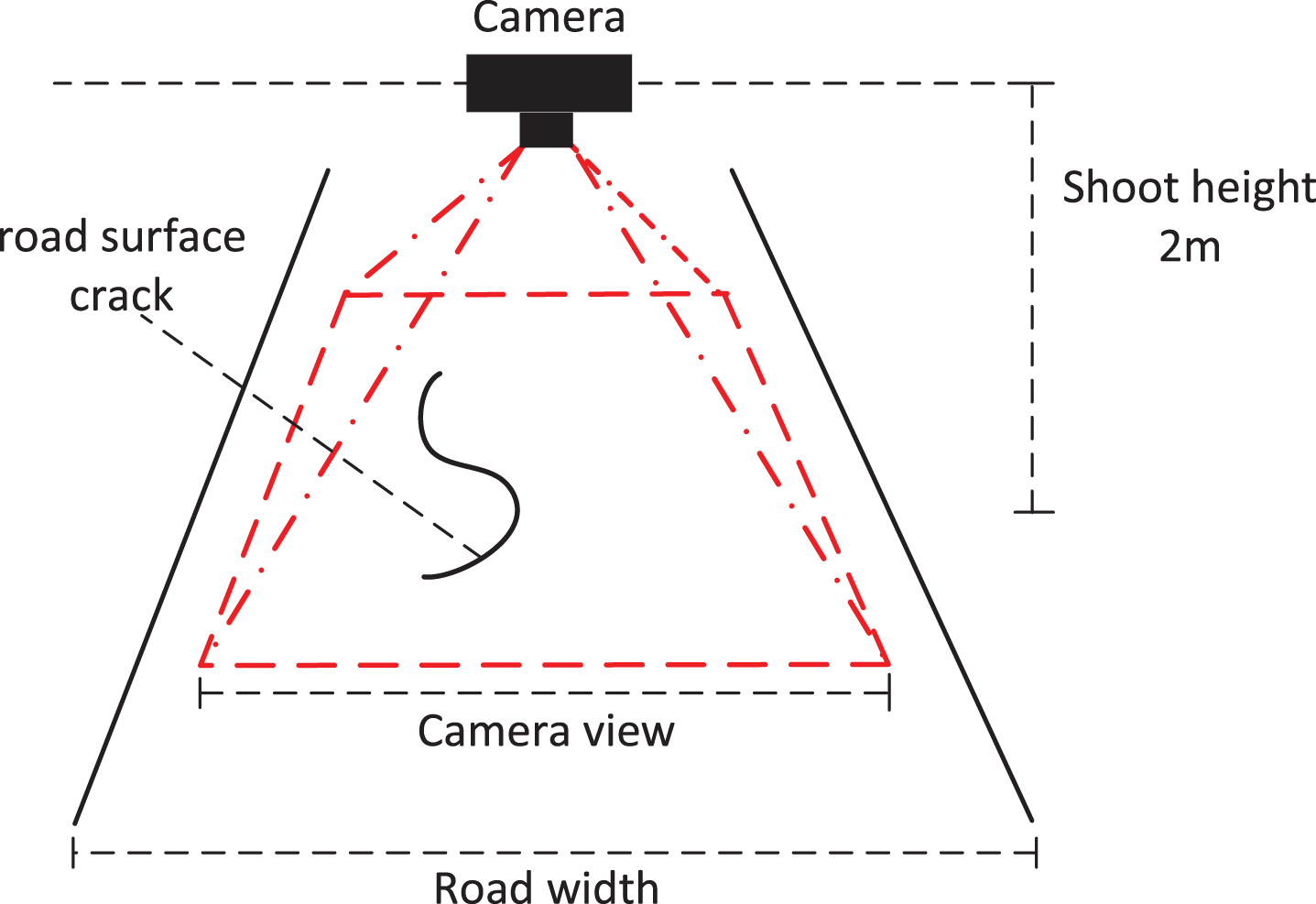
Actual collection scenario.
During the collection process, we collected concrete pavement and asphalt pavement, and after intercepting and scaling to a uniform size (1024*1024), a total of 95,000 high-quality data were screened. Through manual screening, the pictures are divided into two categories according to the type of road surface materials, and 10 kinds of cracks according to the different types of road surface cracks. The specific data set size is shown in Table 1.
Data set structure
It can be seen in the process of analyzing the gray value of the crack image. Because of the obvious difference between crack gray scale and background gray scale in cement pavement, it is feasible to distinguish gray scale by traditional methods. However, there is no obvious difference between crack gray scale and background gray scale for asphalt pavement, so it can only be distinguished by other methods. And we can see in Fig. 2 that the cement pavement histogram has obvious peaks, but the asphalt pavement is more balanced. Therefore, it is very challenging to perform pixel-level segmentation of cracks under asphalt pavement.
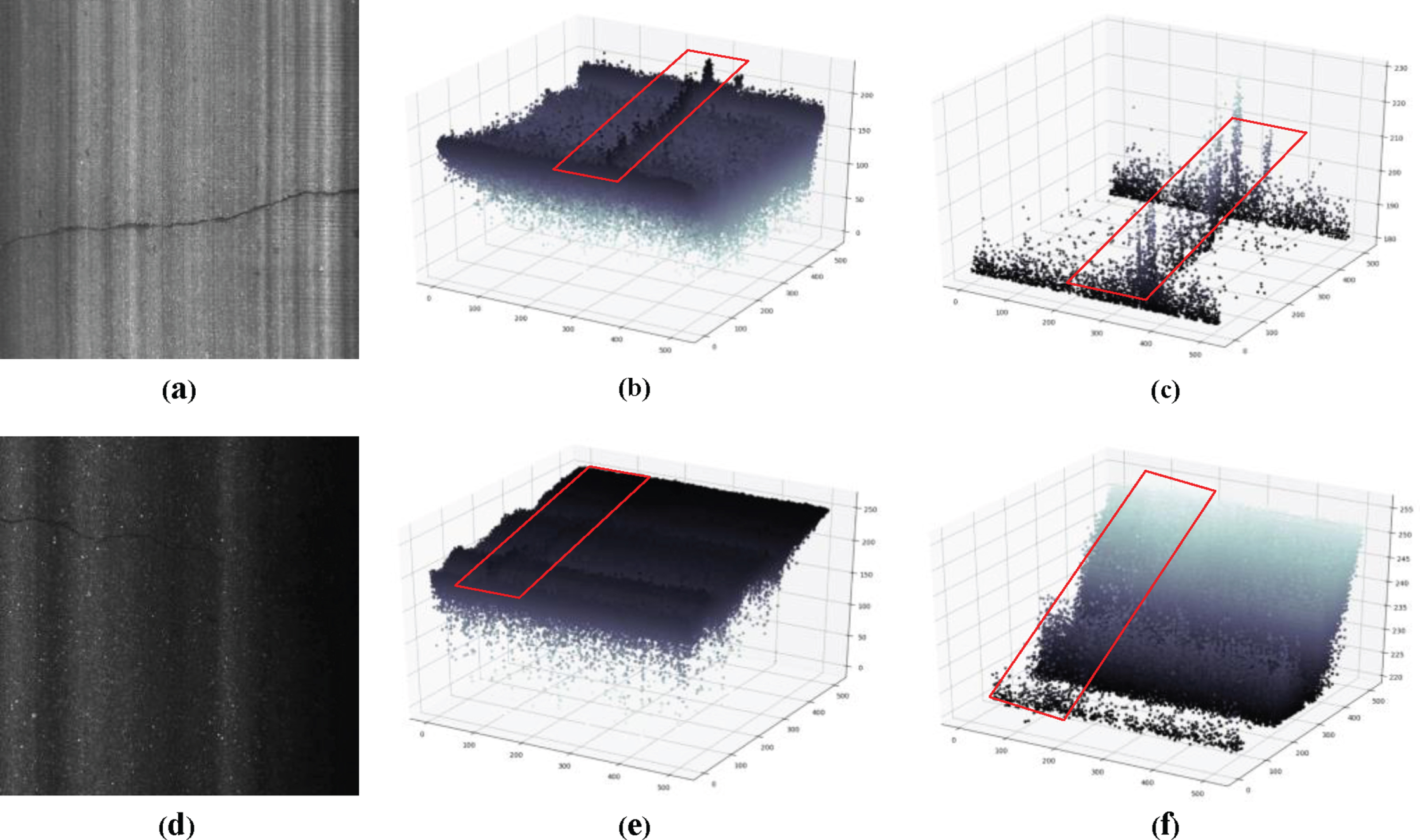
Concrete pavement and asphalt pavement are based on the difference of gray value. (a) is the original concrete pavement, (b) is the original asphalt pavement, (c) is the spatial distribution of the gray value of the concrete crack, (d) is the spatial distribution of the gray value of the asphalt pavement, and (e) the histogram distribution of the concrete crack, (f) is the distribution of the asphalt pavement histogram.
Introduction to the overall process
This section summarizes the entire process of the framework of this article. As shown in Fig. 3, the framework is divided into training sessions and testing sessions. In the training session, the network iterative training is carried out by means of supervised learning. We input the original road crack picture of 1024*1024 and the produced target data. In this paper, the crack is defined as the crack visible to the naked eye in the picture. For the background in the picture, we have selected many types of pictures containing lights, shadows, and road foreign objects. In the training, 31,000 pictures are used as training data, including 15,000 crack pictures, 4000 plate break pictures, 4000 corner peeling, 4000 broken pictures, and 4000 repair pictures. In the test session, we only input the original road crack image of 1024*1024 into the network, and we can get the pixel-level segmentation result and crack type.
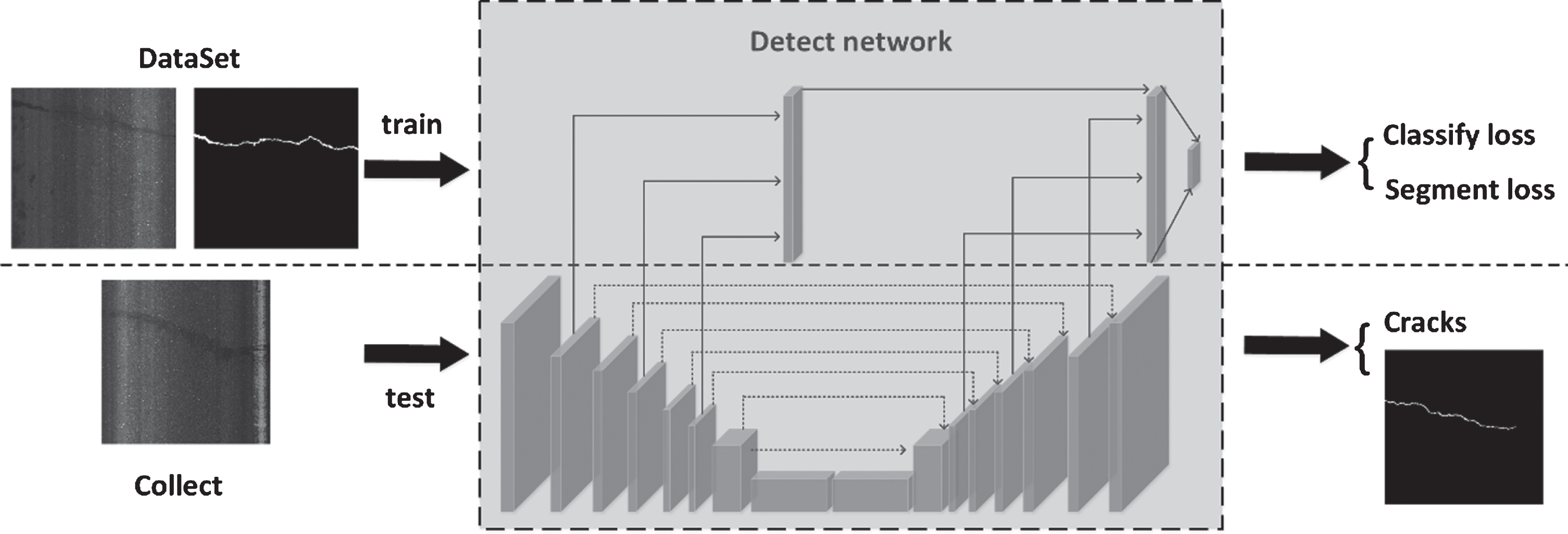
The training link is on the dotted line. The input is the training picture and label, and the output is the training loss rate. Below the dotted line is the test link, the input is the test picture, and the input is the segmentation result and the crack type.
The deep learning model of crack detection is the key part of this study. This section describes the overall framework of the network and the details of the use of each layer in the framework. The network is divided into two parts, the first part is the segmentation network, and the second part is the identification network. In the segmentation network, it is different from the general CNN network. In the segmentation process, the network framework uses only the convolutional layer and the deconvolution layer, and does not use the pooling layer and the fully connected layer. As shown in Fig. 4, the split network has 16 layers, including 8 layers of convolution and 8 layers of deconvolution. In each layer of convolution, we use different scale convolution kernels to make each layer get different view size features, and increase the feature transfer between layers through the DenseNet network, reducing the gradient disappearance during training. And the details of each layer are described in detail in Table 1. In the second part of the identification network, we use the fully connected network and sigmod classifier for type classification, the segmented results can be classified by crack types. The network structure is shown in Fig. 4. In Table 2, we detail the specific parameters of the network.
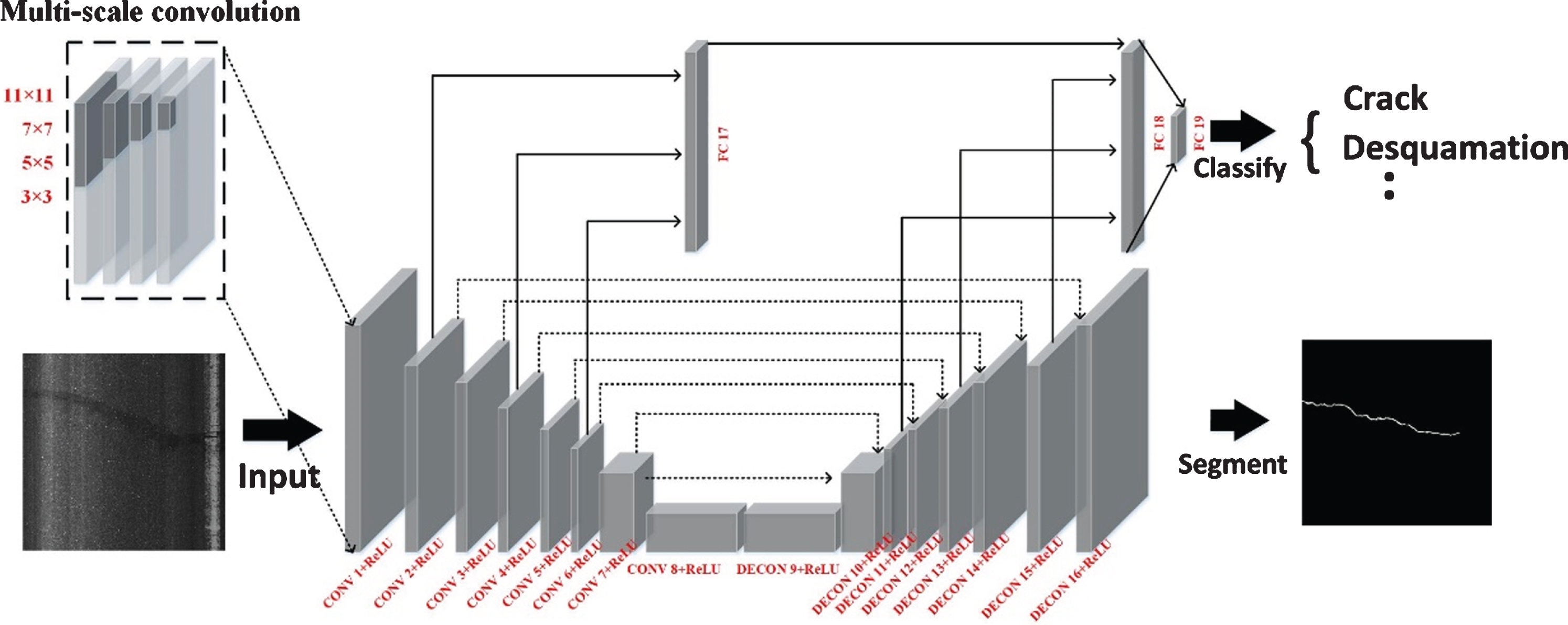
Network topic structure.
Network parameters
DenseNet network was proposed by Gao Huang et al. [34]. This network mainly solves the problem of gradient disappearance in the training process of deep network by adding connections between layers. The method proposed in this paper draws on the idea of DenseNet layer and layer connection. By adding the connection among convolution layer, deconvolution, and recognition network, the performance of the network is improved in three aspects:1. It increases the connection between the network layers and reduces the vanishing gradient.2. Increased the transmission between features.3. The number of parameters is reduced to some extent. And we verified our conclusion through experiments.
Multi-scale convolution introduction
The essence of convolution is to linearly transform and nonlinearly transform an image to form a new feature map during the transformation process. It should be noted that due to the limitation of the size of the convolution kernel, the convolution operation actually acquires the local information in the image. Although a large number of cracks can be detected using a fixed-size convolution kernel, due to the high signal-to-noise ratio of cracks in the asphalt image and the complex spatial structure of cracks in the asphalt image, a fixed-size convolution kernel does not perform global feature mapping well, not enough to achieve accurate detection of all cracks. Therefore, this study decided to use a multi-scale convolution for convolution operations.
In the mature AlexNet [35] network, a total of 11*11 and 5*5 and 3*3 convolution kernels are used to extract features. Different sizes of convolution kernels are used to adapt to different characteristics of images in different stages of network training. In the shallow stage of the network, the large convolution kernel of 11*11 expands the receptive field of the convolution, and the original texture details can be captured as early as possible. In the middle stage of the network, in order to prevent the loss of the association of features in a large local range, 5*5 and 3*3 convolution kernels are used to capture the change of details. However, the convolution kernel size of each layer in the AlexNet [35] network is a single constant, and each layer uses only one fixed-size convolution kernel itself to cause global feature loss.
In this framework, each layer of the network uses different sizes of convolution kernels for feature extraction, while taking into account the complete feature extraction under large field of view and the retention of detail features under small convolution kernels. The multi-scale convolution process can be expressed as:
X is the input element value, y is the output value, I and j are the length and width of the image. Q is a convolution kernel type. In this paper, Q is a convolution kernel of 4 different sizes. K is the convolution kernel element, and m and n are the length and width of the convolution kernel. W and b are weights and biases, and S is the step size in the convolution process. As shown in Fig. 5, the network uses a total of four convolution kernels of 11*11, 7*7, 5*5, and 3*3. The convolution of the feature map generated by each convolution kernel is then carried out in the next stage. And we verified the effectiveness of the method in subsequent experiments.
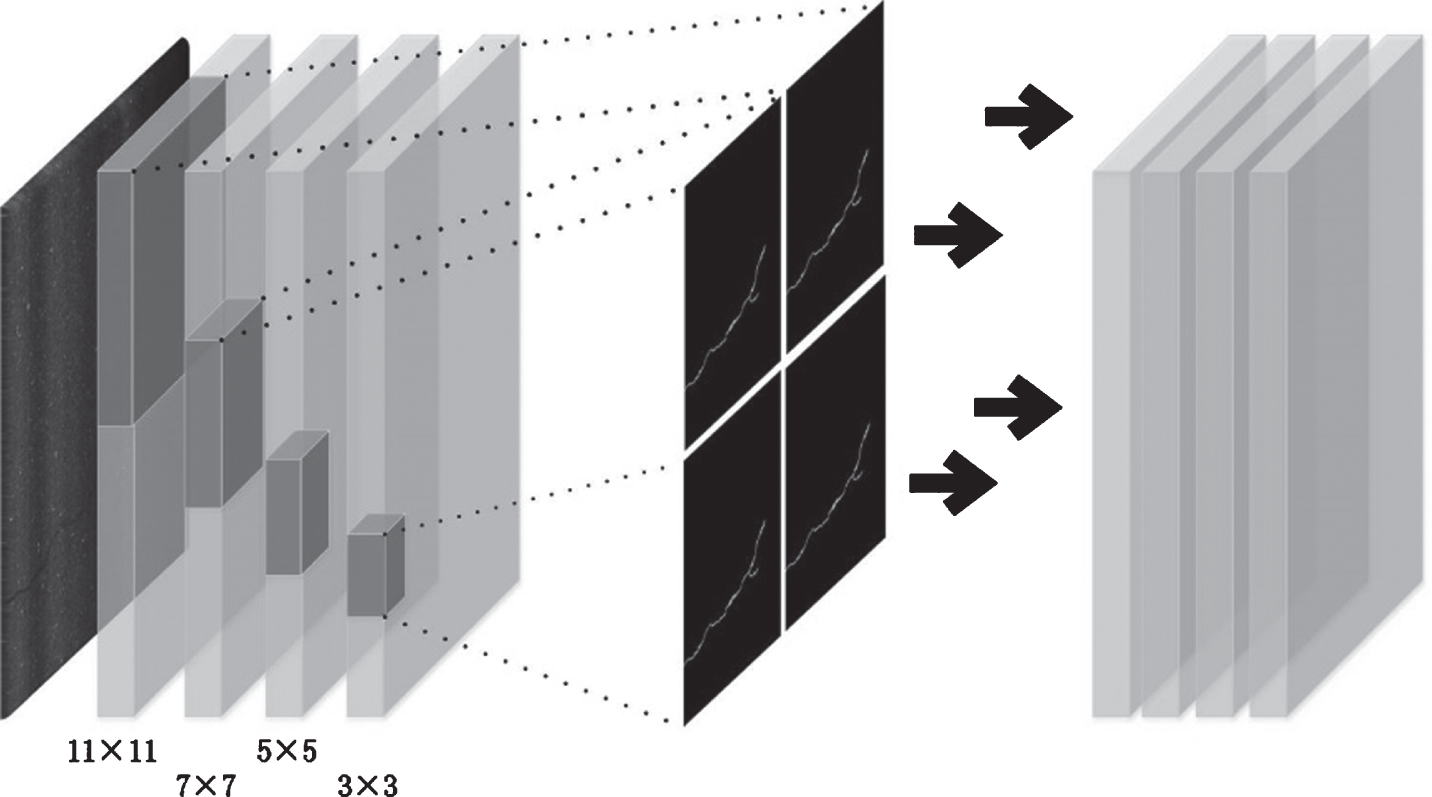
Schematic diagram of different convolution kernels.
Different from the general segmentation network, the network has completed two tasks of segmentation and recognition, so our loss function is composed of two parts. For the segmentation task, it can be regarded as a binary classification problem. We use the cross entropy loss to measure the error, and the loss function performs well in the DNNs network, For the identification task, it can be seen as a multi-classification problem, we use the mean square loss to classify. Therefore, this study defines the loss function as:
Where N is the total number of samples, k is the crack type, P is the probability value for calculating the category, y is the label value, and a is the generated data. The loss function in this paper is divided into two parts. During the training process, the two parts are completely independent and can be trained separately.
In this section, we first introduce the experimental setup and then study the performance of different types of cracks under different conditions. Finally, the results of deep crack detection and comparison methods are reported.
Experiment setup
Implementation details: Our network uses the well-known deep learning framework Tensorflow [36] in the community. In our network, whether it is convolution or deconvolution, batch regularization is performed after each layer of convolution, which can speed up the convergence in the training process. The MSRA method is used to initialize all the weights in the network to zero. During the training process, the initial global learning rate is set to 1e-5, divided by 10 after every 10 k iterations. Momentum attenuation and weight attenuation are set to 0.9 and 0.0005, respectively. The network parameters are updated using the stochastic gradient descent method (SGD), and the minimum batch size for each iteration is 2. We train the network for 10 K iterations. All experiments in this article are performed using four 1080TI GPUs.
Data set: In this study, we use 95,000 road crack images as data sets, two-thirds of which are used for training, and one-third are used for testing. The image size is 1024*1024. The actual cracks on the asphalt pavement are marked by our special marking tools. All asphalt pavement cracks are tested in the control experiment.
Evaluation criteria: For each test image, the detected crack is first compared with the manually marked crack, and the accuracy and recall rate can be calculated. The model is then evaluated using a combination of segmentation accuracy and recognition accuracy.
Control experiment: This part mainly tests the performance of the model by testing the network for different hyperparameters and displaying the data during the training process. The convergence of the method is demonstrated by showing the loss rate during the training process and the loss.
Method comparison: The performance of asphalt pavement crack detection is compared with the most advanced deep learning method: RCF [37]: This network combines multi-scale convolution features on the basis of the VGG16 network. segNet[38]: This network uses a convolutional deconvolution network for end-to-end image segmentation. U-net [39]: This network implements end-to-end image segmentation using cross-layer connections at the network layer. SE [40]: This method uses a random decision forest to extract a straight line structure for line feature recognition. DeepCrack [31]: This method uses a deconvolution network combined with a cross-layer network for end-to-end image segmentation. MU-net: This method is used in this paper.
The performance of the method is verified by analyzing the accuracy of the segmentation results. The performance of this method is proved by the network training time. The generalization of the method is demonstrated by the effect of segmentation of different cracks. Through the quantitative analysis of the segmentation results, the semantic segmentation effect of the network on different cracks is demonstrated. The comparison of the segmentation results under different scale convolution kernels demonstrates the effectiveness of the innovations in this paper. By using different network initial values and network components to analyze the difference between network convergence and recognition accuracy under different structures.
Experimental display
In the experimental part, we first verify the convergence of the mode for Fig. 6. Fig. 7 can be seen from (a) that the loss of each model during training is stable and convergent, but the convergence rates of different networks are different. As can be seen from (c), although different initial values of the model can affect the convergence rate, with the increase of iterations, the impact of initial values is smaller and smaller. It can be seen in (d) that as the complexity of the model increases, the recognition accuracy is further improved.
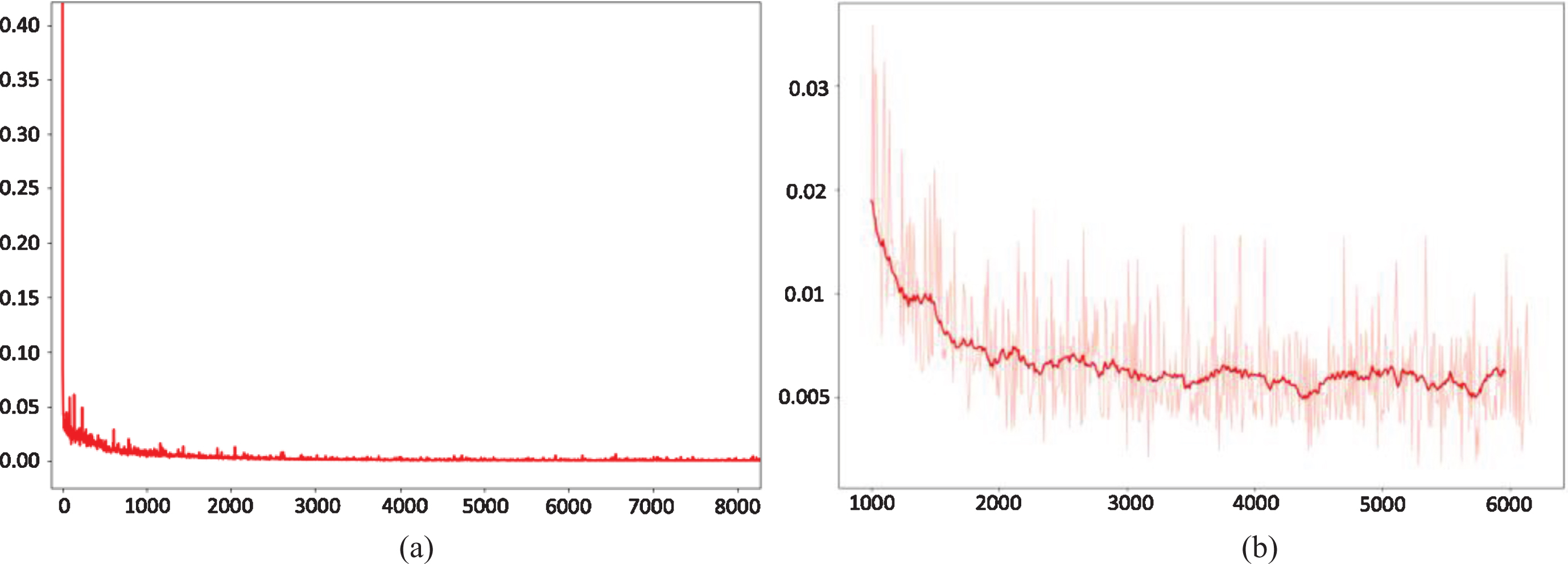
(a) Is the model training loss rate, (b) is the model test loss rate.
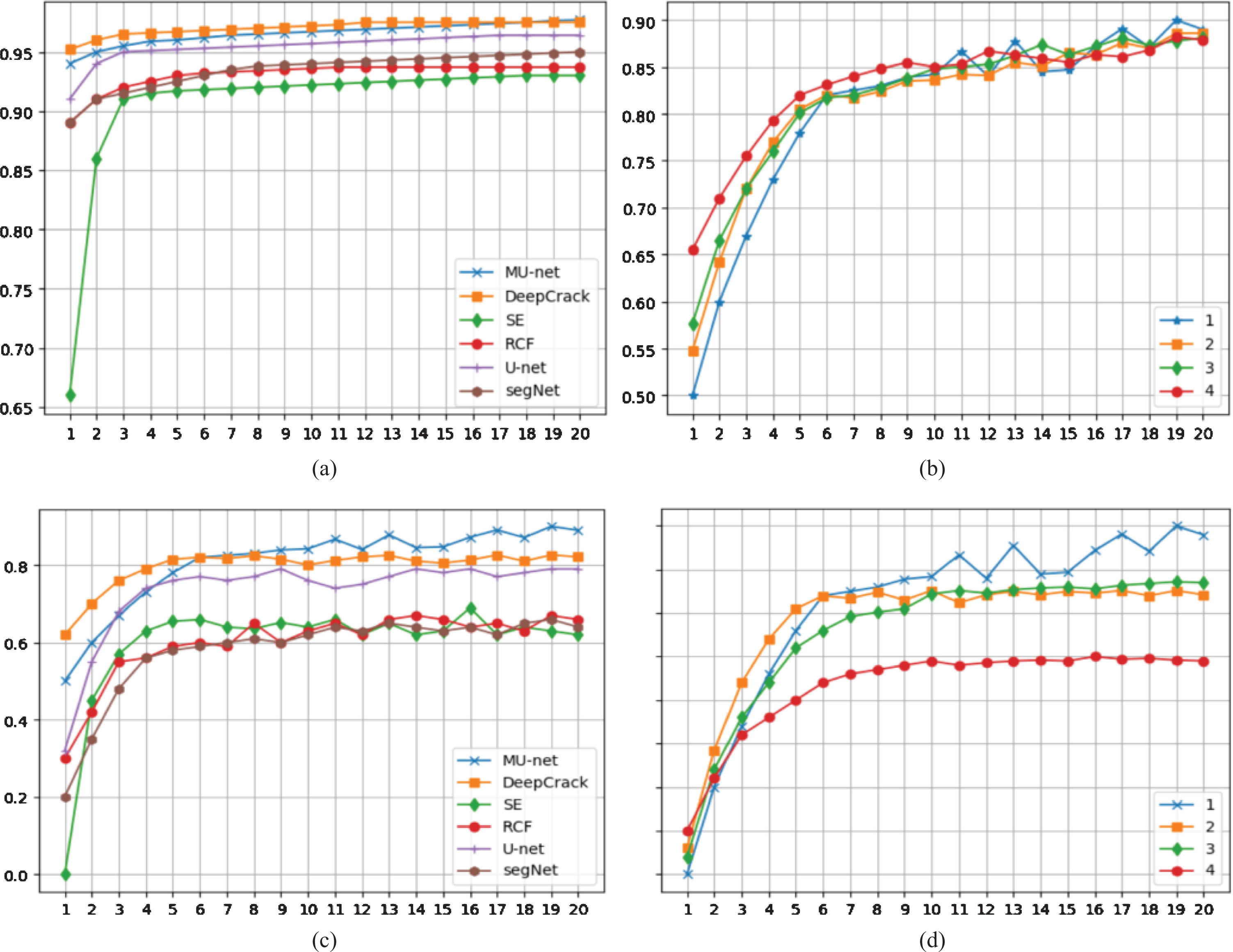
Model performance control experiment, (a) shows the accuracy of different models in the training stage. (b) shows the accuracy of different models in the test phase. (c) shows the accuracy of the same model under different network initial values: 1 for zero initialization, 2 for Gauss distribution initialization, 3 for imageNet data set initialization, and 4 for COCO data set initialization. (d) shows the accuracy of the model under different model components: 1 is mu-net network, 2 is DenseNet and deconvolution network, 3 is deconvolution network, 4 is ordinary CNN network.
Figure 8 shows the segmentation effect of different types of cracks using different methods. It can be seen by using different methods that although the effect of various models on cement pavement crack segmentation is similar, the cracking effect on the asphalt pavement is not satisfactory, and the method of this paper achieves the best results.

Comparison of different methods for segmentation of cement pavement and asphalt pavement.
From Fig. 9, it can be seen that the method in this paper still has a good segmentation effect for asphalt pavement cracks under the condition of uneven light and foreign matter. At the same time, we also use this method to segment more types of pavement cracks, and achieve exciting results.

The segmentation effect of MU-net on asphalt pavement crack.
Figure 10 shows the effect of this method on the segmentation of other morphological cracks on the pavement. (a) is cracking of asphalt pavement, (b) is the repair of cement pavement, (c) is asphalt pavement, (d) is cracking of cement pavement, and (e) is crushing of cement pavement.

Shows the effect of this method on the segmentation of other morphological cracks on the pavement.
Figure 11 shows splitting effect of cracks under different illumination. Figures (a) to (e), the light intensity gradually weakens.
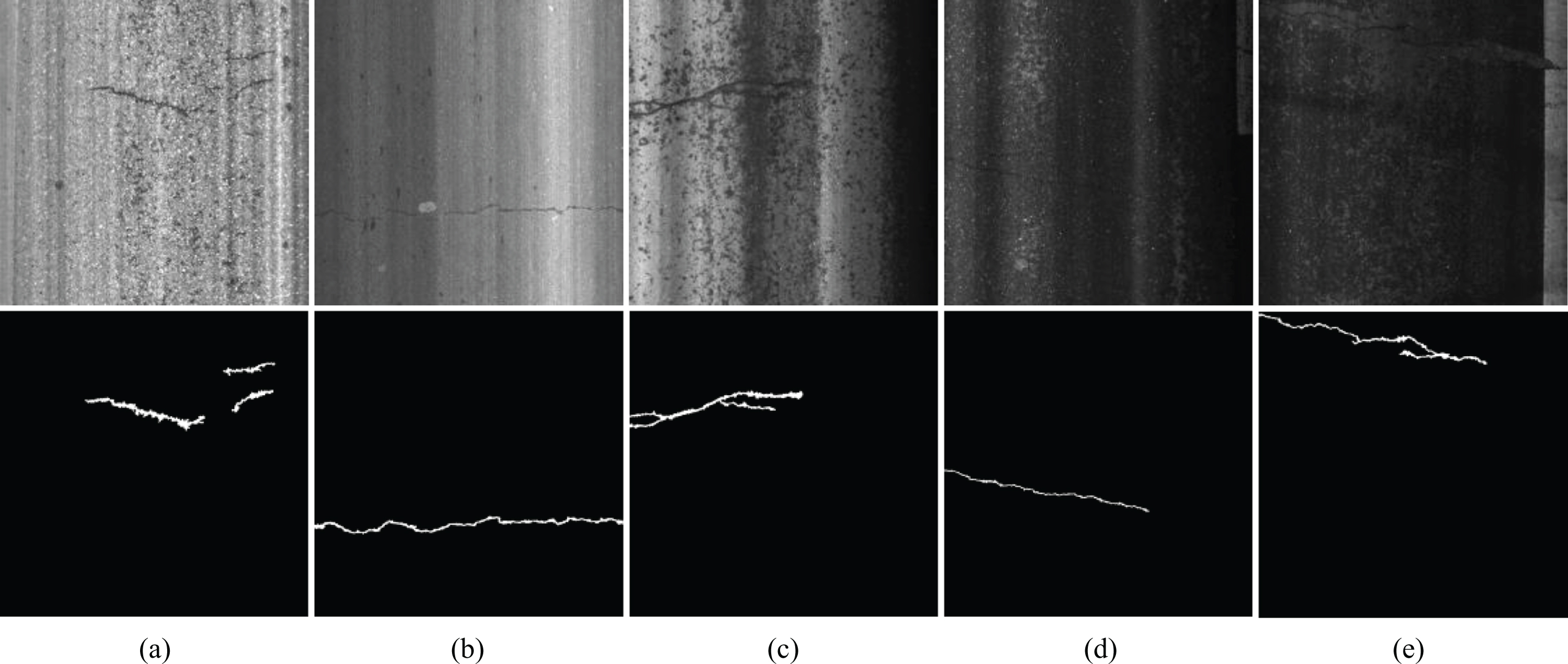
Shows splitting effect of cracks under different illumination.
This paper proposes a new end-to-end trainable convolution network for segmenting and identifying asphalt pavement cracks. For the fine cracks on asphalt pavement, multi-scale convolution is used to improve the sensitivity of the model to the features, and the DenseNet and deconvolution network framework is used to achieve pixel-level detection. Finally, the method can not only achieve the semantic segmentation of the crack at the pixel level, but also judge the crack type. For performance evaluation, we create a data set with 12 pavement crack characteristics. Experiments show that the accuracy of the test data set for the asphalt pavement crack detection model proposed in this paper reaches 98%. And through the comparison experiments, the multi-scale convolution and DenseNet and deconvolution network framework used in this paper are useful for crack detection under high SNR image of asphalt pavement.
And we will pay more attention to the improvement of the complex crack segmentation effect of this network in the future work. Mainly through the following methods: First, collect a more comprehensive data set. And generate more diverse data by Generative Adversarial Networks. Secondly, through the method of reinforcement learning, a new network convergence method with unsupervised or weak supervision is achieved. We will use the model in this article to test on more data sets.
Declarations
Funding
This work was partially supported by the National Science Foundation of China (Grants No. 61571404, No. 61871351 and No. 61801437), Science Foundation of Shanxi Province (Grant No. 2015021099), the Graduate Student’ Excellent Innovation Project of Shanxi (20172028), and the Science and Technology on Transient Impact Laboratory Foundation (No. 614260603030817).
Availability of data and materials
Not applicable.
Authors’ contributions
Yangxu Wu is the main writer of this paper. He proposed the main idea, completed the simulation, and analyzed the result. Wanting Yang completed the data annotation and code writing. Ping Chen and Jinxiao Pan completed the verification of the funding and final results of the project.
Competing interests
The authors declare that they have no competing interests.