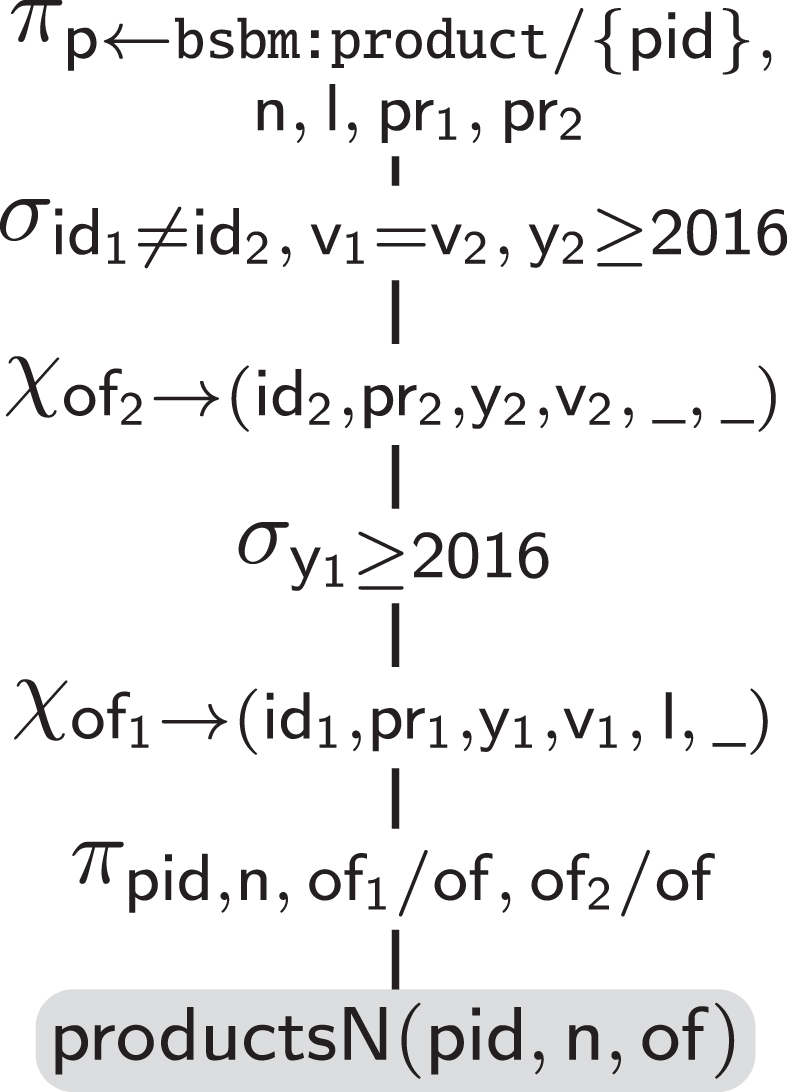The database (DB) landscape has been significantly diversified during the last decade, resulting in the emergence of a variety of non-relational (also called NoSQL) DBs, e.g., xml and json-document DBs, key-value stores, and graph DBs. To enable access to such data, we generalize the well-known ontology-based data access (OBDA) framework so as to allow for querying arbitrary data sources using sparql. We propose an architecture for a generalized OBDA system implementing the virtual approach. Then, to investigate feasibility of OBDA over non-relational DBs, we compare an implementation of an OBDA system over MongoDB, a popular json-document DB, with a triple store.
This article is an extended and revised version of an article that appeared in the proceedings of the 17th International Conference of the Italian Association for Artificial Intelligence (AI*IA) [4].
To cope with the requirements of a variety of modern applications and their differing needs with respect to data management, in the last decade we have witnessed a strong diversification in the landscape of database (DB) management systems (DBMSs). Traditional relational DBMSs now coexist with so-called NoSQL (“not only” sql) DBs, which redefine the format of the stored data, and how it is queried. These non-relational DBs usually adopt one of four main data models: (i) Column-oriented DBMSs maintain data tables similarly to traditional relational DBMSs, but store such tables by column, rather than by row. This allows for executing queries, which are expressed in traditional query languages like sql, more efficiently for certain workloads. (ii) graph databases organize data in the form of elements (i.e., the nodes) connected by various relations (i.e., the edges), and are equipped with query languages based on graph navigation, such as sparql. (iii) Key-value stores represent data as a collection of key-value pairs, where keys are unique in a collection and are used to access the data. (iv) Document stores organize the data in documents, which have a hierarchical structure, are accessed via a key, and are encoded in some standard format, such as XML or json. Typically, they offer ad-hoc, in some cases quite expressive querying mechanisms (e.g., the aggregation framework of MongoDB), or even require writing JavaScript functions (e.g., CouchDB
1
). This wider choice of DBMSs offers the possibility to match application needs more closely, allowing for instance for more flexible data schemas, or more efficient (though simple) queries.
As a result, accessing data using native query languages is getting more and more involved for users. In this article, we rely on the ontology-based data access (OBDA) framework as a uniform solution to this problem. The OBDA paradigm [20, 26] has emerged as a proposal to simplify access to relational data for end-users, by letting them formulate high-level queries over a conceptual representation of the domain of interest, provided in terms of an ontology. In the classical virtual OBDA approach, data is not materialized at the conceptual level (which justifies the term “virtual”), and instead queries are translated automatically from the conceptual level into lower-level ones that DB engines can directly evaluate. The translation exploits a declarative specification of therelationship between the ontology and the data atthe sources, provided in terms of mapping assertions. This separation of concerns between query formulation at the conceptual level and query execution at the DB level has proven successful in practice, notably when data sources have a complex structure, and end-users have domain knowledge, but not necessarily data management expertise [1, 12]. Traditionally, in OBDA, the DB is assumed to be relational, the ontology is expressed in the owl 2 ql profile of the Web Ontology Language owl 2 [17], the mapping is specified in r2rml [9], and queries are formulated in sparql, the Semantic Web query language [13].
Extending the classical OBDA setting to arbitrary DBs requires to generalize some of its components. The first contribution of this work is to present such a generalized approach that enjoys all benefits already offered by OBDA. In particular, it allows for hiding from the user low-level concerns such as data storage and direct access to data (using the native query language of each data source), and it provides users with a high-level querying interface, closer to application needs. One could argue that OBDA is even more valuable in the NoSQL case compared to the relational one, as the gap between these low and high-level concerns tends to be wider. However, this extension also carries its own challenges, such as handling different data formats, the need for more advanced query optimization techniques due to lower-level query languages, or a possibly increased need for post-processing.
A second contribution is to investigate the applicability of the generalized OBDA framework in the practically significant case where the data source is a document store that offers rich querying capabilities, so that it is in principle feasible to fully delegate query answering to the source DB engine. In our investigation, we focus on MongoDB, a document-based DBMS, and one of the most popular NoSQL DBMSs as of today. MongoDB can be queried via a very expressive language, the so-called MongoDB aggregation framework, which has a more procedural flavor than sql or sparql, and therefore can be complex to manipulate. Such a setting appears particularly well-suited for exploiting the added value offered by the OBDA paradigm.
Document-based DBMSs can also leverage the denormalized structure of their data: a document-based DB instance (i.e., a collection of documents) can often be seen as a denormalized version of a relational DB instance (where some joins are pre-computed). Therefore a natural question is whether OBDA over MongoDB can take advantage of such structure in order to answer queries efficiently, while at the same time offering a more user-friendly query language. As a third contribution of this work, we provide support for a positive answer. We do so by instantiating the generalized OBDA framework over MongoDB as an extension of the OBDA system Ontop [6], and comparing its performance with a triple store, which does not benefit from such denormalization. We adopt the triple store Virtuoso [11], using as dataset an instance of the well-known Berlin sparql Benchmark (BSBM) [3].
The rest of the article is structured as follows. In Section 2, we recall the standard OBDA framework over relational data sources. In Section 3, we introduce our proposal for generalizing OBDA to access arbitrary DBs, and present the architecture of a generalized OBDA system. In Section 4, we introduce MongoDB, describe our extension of Ontop over MongoDB, and illustrate the generalized OBDA architecture with a running example. In Section 5, we evaluate the performance of this system and compare it to the triple store Virtuoso using BSBM as dataset. In Section 6, we discuss related work, and we conclude the article with Section 7.
Ontology-based data access
We recall the traditional OBDA paradigm for accessing relational DBs through an ontology [26]. An OBDA specification is a triple , where is an ontology modeling the domain of interest in terms of classes and properties, is a relational DB schema, and is a mapping consisting of a finite set of mapping assertions. We note that here we use the term “ontology” to denote a set of axioms involving only classes and properties, but not mentioning individuals. In other words, consists only of the intensional part (typically called TBox) of an ontology in the sense of owl 2. This choice is motivated by the fact that in OBDA, the extensional component (typically called ABox) is provided by the DB instance via the mappings, as illustrated below.
To define mapping assertions, we make use of (rdf) term constructors, each of which is a function f (x1, …, xn) mapping a tuple of DB values to an IRI or to an rdf literal. Given a DB schema and an ontology , a mapping assertion between and is an expression of one of the forms
where A is a class name in , P is a (data or object) property name in , φ (
x) and φ (
x,
x′) are arbitrary (sql) queries expressed over , and f and f′ are term constructors [15, 20]. Mapping assertions allow one to define how classes and properties in should be populated with values in a DB instance of and with objects constructed from such values via the term constructors.
An OBDA instance is a pair , where is an OBDA specification and D is a DB instance satisfying . The semantics of is given with respect to the rdf graph induced by and D, defined by
where ans (φ, D) denotes the result of the evaluation of φ over D. Then, we define a model of to be simply a model of , i.e., a first-order interpretation that satisfies all axioms in and all facts in . We observe that provides a set of extensional facts, but such facts are typically kept virtual, i.e., they are not actually materialized.
Queries are usually formulated in sparql, the Semantic Web query language that allows for formulating expressive high-level queries over an rdf graph [13, 19]. Such queries are answered over an OBDA instance according to the semantics of the chosen sparql entailment regime, considering as the ontology, and as the RDF graph. Typically, in OBDA, the ontology is expressed in owl 2 ql, and the corresponding entailment regime is that of owl 2 ql [14]. We denote with the answers to a sparql query q over an OBDA instance according to the owl 2 ql entailment regime.
Generalized OBDA framework
In this section, we introduce a generalization of the OBDA framework to arbitrary DBs, and then propose an architecture for a generalized OBDA system.
OBDA over arbitrary databases
We assume to deal with a class D of DBs, e.g., relational DBs, xml DBs, or json stores, such as MongoDB. Moreover, we assume that D comes equipped with:
Suitable forms of constraints, which might express both information about the structure of the stored data, e.g., the relational schema information in relational DBs, and “constraints” in the usual sense of relational DBs, e.g., primary and foreign keys. We call a collection of such constraints a D-schema (or simply, schema).
A way to provide a (flat) relational view to D-schemas and D-instances satisfying such schemas: for a D-schema , is the corresponding relational schema, and for a D-instance D satisfying , 〚D〛 is a relational DB over . The function 〚·〛 is called relational wrapper.
A native query language 𝒬, such that, for a query φ ∈ 𝒬 and for a D-instance D, the answer ans(ϕ,D) to φ over D is defined (and is itself a D-instance).
Now, given an ontology and a D-schema , a mapping is a set of classical mapping assertions φ ⇝ h between and , i.e., φ is a sql query over . Then, an OBDA specification is a triple . This is analogous to the relational case, except that now is a D-schema (equipped with a relational wrapper) as opposed to a relational schema. An OBDA instance consists of an OBDA specification and a D-instance D satisfying . The semantics of such an instance is derived naturally from the relational instance 〚D〛 corresponding to D via the relational wrapper 〚·〛.
Note that our assumption that a relational wrapper is available for the class D of DBs is not restrictive in any way, since any form of data can be represented using relations, independently of how it is structured. Observe also that the source query in a mapping assertion in our generalized setting is not a native 𝒬 query, but a sql query. Our framework has the advantage of having a uniform and expressive mapping language that is independent of D and 𝒬. It does not mean, however, that the concrete user mapping language must strictly follow this specification. When it does not, the system should only be able to transform user mapping assertions into classical ones.
When referring to OBDA, we typically assume that it follows the virtual approach, in which materializing the rdf graph is avoided, and instead (part of) query answering is delegated to the DB. In this approach, the query answering process can be depicted as in Fig. 1, and consists of 4 main steps: (a) An input sparql query q is first rewritten with respect to the ontology into qr (according to the semantics of the entailment regime, this step only rewrites the basic graph patterns (BGPs) in q [14]). b The rewritten sparql query qr is translated into one or several native queries ψ ∈ Q. When the DB engine does not support (efficiently) some sparql operators, multiple native queries might be required, and the evaluation of the unsupported operators may be postponed to the final post-processing step. c The native queries ψ are evaluated by the DB engine to produce D-results rψ. d The results rψ of all queries ψ are combined and converted into the sparql result rq in the post-processing step. In the generalized OBDA framework the post-processing step may be more involved than in the classical relational case, mostly due to the fact that the DB system may offer limited querying capabilities. In particular, some NoSQL DBs do not support joins. Another reason for not delegating certain query constructs to the DB is efficiency. For instance, in the case of nested data (e.g., json documents containing arrays), the unnesting (i.e., flattening) of nested objects into tuples may produce output objects that are much larger than the input, and so it may be preferable to perform unnesting as a post-processing step, so as to reduce network load between DB and client.
Query answering in OBDA.
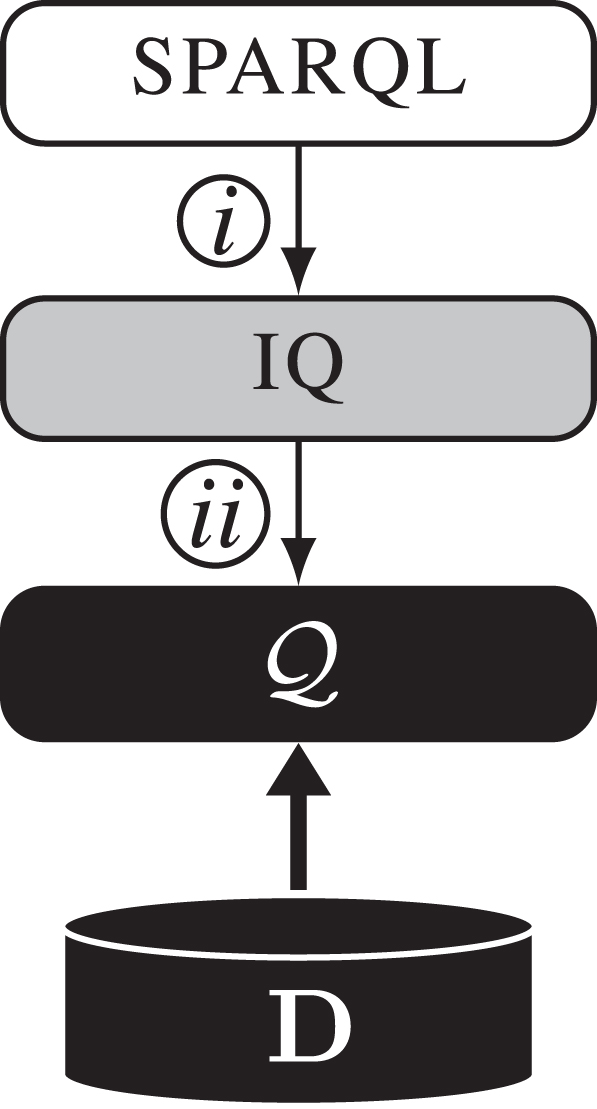
For the generalized OBDA framework, we propose to translate sparql queries to native queries in two steps (cf. Fig. 2): first translate the input sparql query to an intermediate query, subject to transformations, and then translate the (transformed) intermediate query to a native query. The intermediate query language, denoted iq, is expected to be a more high-level language than 𝒬, and can vary depending on 𝒬, but also on the considered fragment of sparql. On the one hand, it should at least capture such fragment (e.g., for BGPs, joins are sufficient, while for a fragment with property paths, iq should include some form of recursion). On the other hand, iq may include other operators that are present/expressible in 𝒬 (e.g., an unnest operator for dealing with nested data). Note that Relational Algebra (RA) as iq is sufficient for the first-order fragment of sparql and for relational DBs. Our framework, relying on the use of iq, provides several advantages: (i) it offers a better support for query optimization, since iq, unlike sparql, can take into account the structure of the data, without necessarily being as low-level as 𝒬; (ii) the optimization techniques devised for iq are independent of 𝒬; (iii) the translation from sparql to iq is standard and depends only on the mapping (since iq subsumes RA, such a translation has to extend the well-known translation from sparql to RA).
sparql to native query translation.
Architecture of an OBDA system over heterogeneous data sources
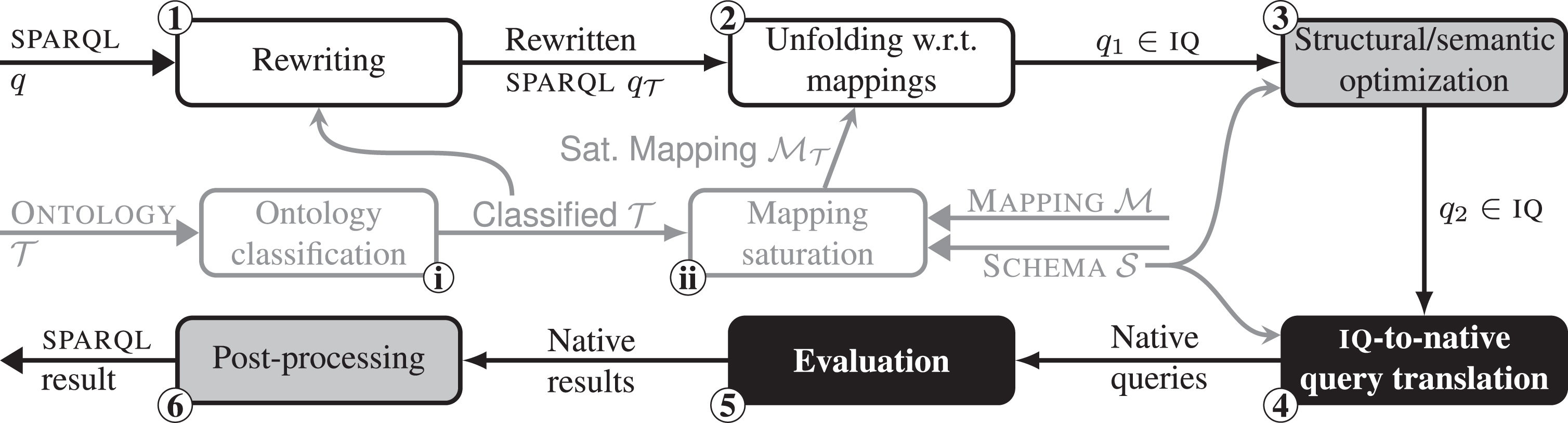
We propose an architecture for an OBDA system able to answer sparql queries over heterogeneous data sources. This architecture, depicted in Fig. 3, is composed of an offline stage, independent from the input sparql queries, and an online stage, dedicated to query answering.
Proposed architecture for an OBDA system.
The offline stage consisting of steps and , takes as input the ontology, mapping, and schema, and produces two elements, to be used during the online stage: the classified ontology, and the saturated mapping [21, 23]. The former makes also implied inclusion assertions between classes and between properties explicit, while the latter is constructed by “saturating” the input mapping with the classified ontology. The saturation is obtained by adding to the existing mapping assertions additional ones that are derived by combining information from the input mapping and from the ontology axioms. For instance, if contains an assertion and an axiom AsubClassOfB, then will contain also the assertion . Saturating the mapping essentially allows us to consider ontology axioms already in the offline stage, and avoid (or reduce) their use during query rewriting. In this way, we anticipate to the offline stage operations that otherwise would need to be performed in the online stage, and this reduces the overall time required for query rewriting, when multiple user queries need to be executed over the ontology. We also observe that the saturated mapping can be significantly simplified for the online stage, by using query containment-based optimization to remove redundant mapping assertions.
The online stage handles individual sparql queries, and can be split into 6 main steps: ➀ the input sparql query is rewritten according to the classified ontology; ➁ the rewritten query is unfolded w.r.t. the saturated-mapping, by substituting each triple with its mapping definitions;➂ the resulting iq is simplified by applying structural (e.g., replacing join of unions by union of joins) and semantic (e.g., redundant self-join elimination) optimization techniques; ➃ the optimized iq is translated into one or multiple native queries; ➄ these are evaluated by the DB engine over the underlying DB (which is not explicitly shown as input in Fig. 3); and finally, ➅ the native results are combined and transformed into sparql results.
Such an architecture allows for steps , , ➀, and ➁ to be independent of the actual class D of DBs (white boxes in Fig. 3). Steps ➂ and ➅ require an implementation specific to iq (gray boxes), while ➃ and ➄ are specific to D (black boxes).
We emphasize that the structural and semantic optimization step is crucial for OBDA to work in practice. In particular, unfolded sparql queries often contain significantly more joins than actually necessary, since sparql atoms are triples, while data is typically stored in the form of n-ary entities (e.g., n-ary relations in relational DBs). In the case of OBDA over a document-based DB, these techniques can be extended to take advantage of additional opportunities for optimization offered by the structure of the DB instance. Some of these optimization techniques are illustrated on the example presented in Section 4.4.
OBDA over MongoDB
We illustrate the generalized OBDA framework by focusing on a specific NoSQL DB, namely MongoDB,
2
a popular and representative instance of document DBs. First, we introduce the data format and the query language of MongoDB, and we briefly relate them to the nested relational model and nested relational algebra. Then, we describe our prototype implementation for answering sparql queries over MongoDB. Finally, we illustrate the generalized OBDA framework over MongoDB on an example inspired by the BSBM benchmark.
MongoDB
MongoDB stores and exposes data as collections of json-like documents.
3
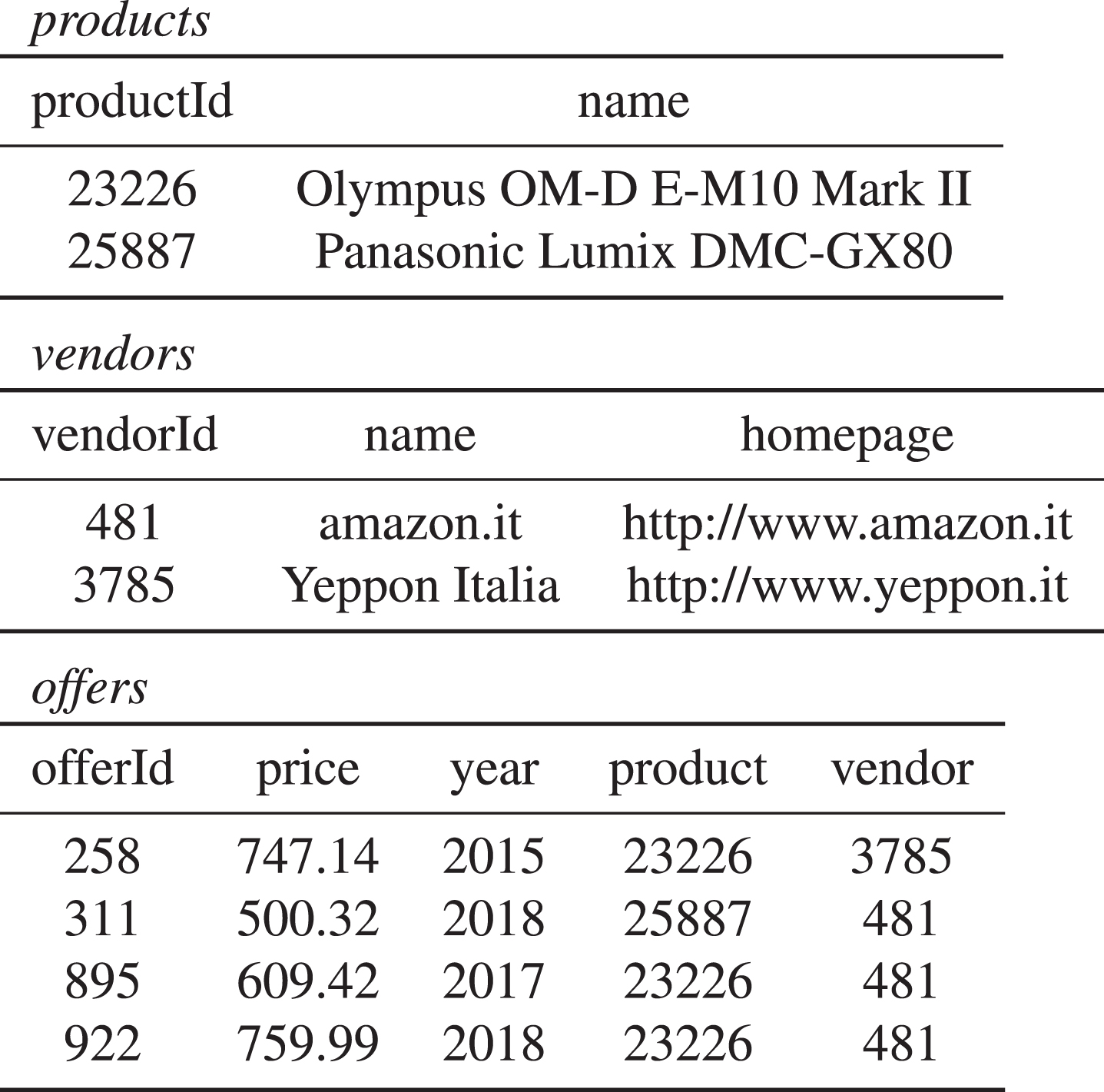
A sample collection of two MongoDB documents consisting of (nested) key-value pairs and arrays, is given in Fig. 4, where each document contains information about a product: its id, name, and a list of offers, in the form of a json array. Each offer has itself an id, price, year, and vendor (in turn with id, name, and homepage).
A collection Db of two MongoDB documents.
In accordance with the generalized OBDA framework defined in Section 3, we assume that an input collection D of MongoDB documents complies to a schema . In other words, documents in D are expected to represent objects of the same type, and thus to follow the same structure.
4
So if a field (e.g., offers or offers.vendor.homepage) has an array (resp., an object or a constant) as value in one document, we assume that in every document this field either has an array (resp., an object or a constant) as value, or is absent (in which case the value is considered to be null).
Note that in a normalized relational DB instance, this data would be spread across several tables. Indeed, our example is inspired by the e-commerce scenario of the BSBM benchmark [3], where the data is structured according to a relational schema consisting of multiple tables. Fig. 5 provides the relational view corresponding to this MongoDB collection, with distinct tables for products, vendors, and offers (the relational schema in the BSBM benchmark is actually morecomplex).
Relational view 〚Db〛 of the collection of Fig. 4, following the BSBM schema.
Note also that the json data in Fig. 4 is denormalized. In particular, it contains redundant information: the name and homepage of vendor 481 are present 3 times. Document-based DBMSs like MongoDB can take advantage of such redundancy. For instance, retrieving all vendors (with id, name, and homepage) of a given product over an instance of the relational schema of Fig. 5 requires two (potentially costly) join operations. But the same request over the denormalized data does not require any join: the relevant information is already grouped within adocument.
However, query execution can also be penalized by redundancy. For instance, a value for field offers.vendor.vendorId is always associated to the same value for field offers.vendor.name. But this type of constraint cannot be exploited by MongoDB (as of now) for query optimization. Therefore in order to retrieve the name(s) of vendor 481 for instance, MongoDB would fetch into memory all documents with an occurrence of 481 for field offers.vendor.vendorId, even though one document is sufficient in theory. Noticeably, this problem could be avoided by choosing a different document structure for the same data, with one document for each vendor rather than for each product, but with the drawback that the collection would then contain redundant information about products. In general, the choice of a particular document structure is a trade-off, favoring some queries, and penalizing others, and should be made according to the expected query workload (provided such information is available beforehand).
Like relational DBs, MongoDB allows for declaring indexes. By default, it creates a unique index over the (top-level) field _id, which serves as the primary key in a collection. Indexes can drastically speed up query execution. In particular, retrieving a (whole) document by a unique value of an indexed field (like the values of offers.offerId in Fig. 4) can be done very efficiently by looking up the value in the index, and then fetching from disk data that is likely to be contiguous. On the other hand, queries on values with non-unique occurrences (e.g., the values of offers.offer.vendorId) may be less efficient, because multiple (non-contiguous) documents may need to be fetched.
MongoDB provides an ad-hoc querying mechanism for formulating expressive queries by means of the aggregation framework.
5
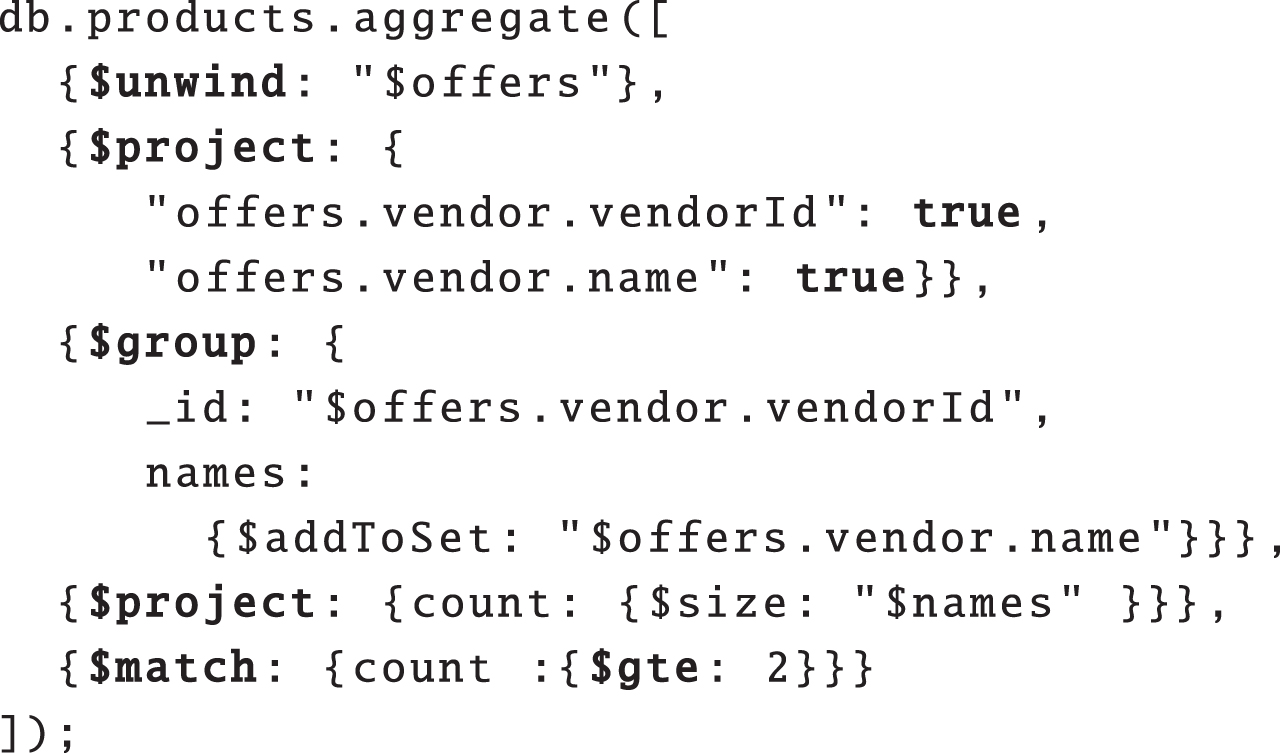
A MongoDB aggregate query (maq) is a sequence of stages, each of which takes one or two collections of documents as input, and produces another collection as output. This language is powerful, but also more low-level (less declarative) than some well known query languages such as sql or sparql. Because of this, maqs can be complex to read and manipulate. As an illustration, the maq of Fig. 6 retrieves all products offered twice by the same vendor since 2016. In comparison, the sparql query of Fig. 7 retrieves the same information, but can be more easily understood. The more procedural flavor of maq also means that the sequence of stages of an maq is closer to its actual execution, whereas relational DBs/triple stores hide from the user the complexity of query planning (e.g., the ordering of joins). Hence, from a user perspective, OBDA over MongoDB appears indeed as a promising alternative to manuallydevising maqs.
A MongoDB Aggregate Query (maq).
A sparql query corresponding to the maq of Fig. 6.
The nested relational model
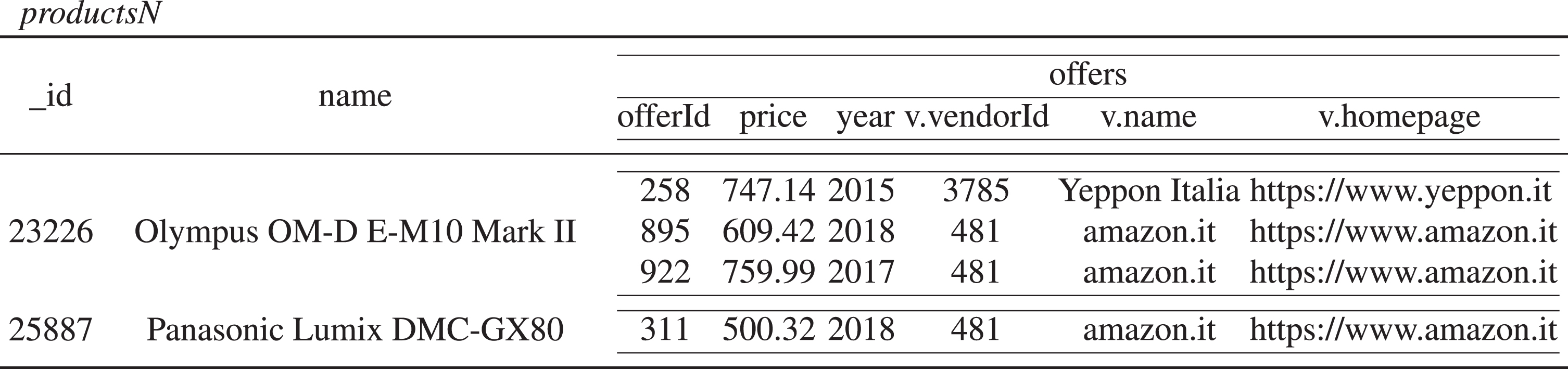
Alternatively, a collection of MongoDB documents can be viewed through the nested relational model, an extension of the relational model in which attributes can be also relation-valued, and not only atomic. Relation-valued attributes are called sub-relations. For instance, the MongoDB collection Db of Fig. 4 can be naturally represented in the nested relational model as the relation 〚Db〛 nested in Fig. 8, with a sub-relation for the field offers.
6
Nested relational view 〚Db〛 nested of the collection of Fig. 4 (where vendor is abbreviated as v).
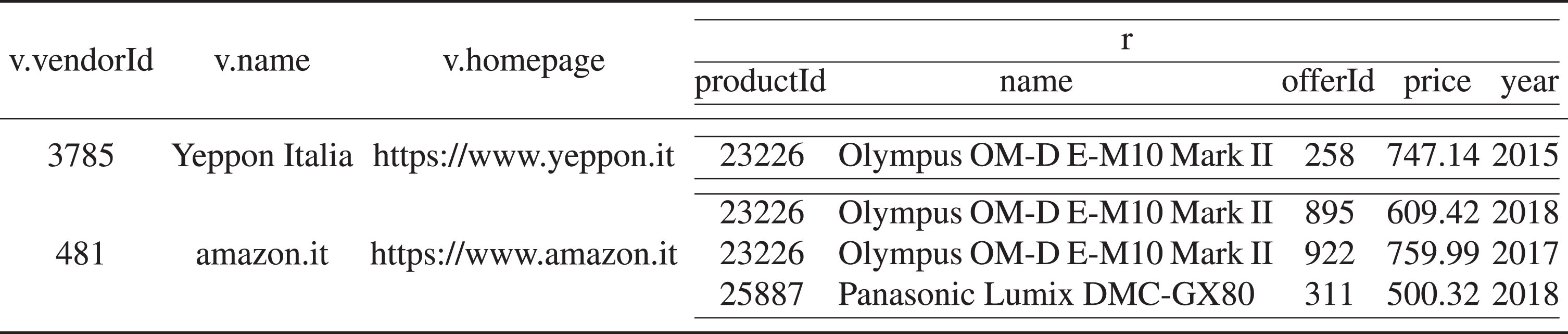
Nested relational algebra (nra) [25] extends ra to operate on nested data. It is of particular interest for modeling operations on MongoDB collections, since it is equivalent in expressive power to a fragment of maq, as has been shown in [5]. nra extends ra with two operators: nest and unnest. Intuitively, unnest flattens a sub-relation by concatenating each tuple in the sub-relation with the remaining attributes in the parent tuple. Instead, nest creates a sub-relation by partitioning the input relation, such that each element of the partition agrees on the values of the attributes that are not being nested. As an illustration, we first unnest the sub-relation offers, which yields the relation of Fig. 9. Then we nest all attributes except for offer.vendor.vendorId, offer.vendor.vendorName, and offer.vendor.homepage into a sub-relation r, which yields the relation of Fig. 10. As a result, tuples are grouped by vendor.
Unnesting the sub-relation offers in the relation of Fig. 8.
Nesting all attributes but v.vendorId, v.name, and v.homepage in the relation of Fig. 9.
Instantiation of OBDA for MongoDB
We built a proof-of-concept prototype for answering sparql queries over MongoDB, called Ontop/MongoDB, which extends the Ontop system [6] and implements the architecture described in Fig. 3. The current implementation supports the fragment of sparql including BGPs, Filter, Join, Optional, and Union over MongoDB 3.4. In this implementation of the virtual OBDA architecture, nra serves as iq, and maq as the native query language. The system is designed to fully delegate query execution to the MongoDB engine,
7
thus minimizing the amount of post-processing required in step ➅ of Fig. 3.
Ontop/MongoDB takes as input (in addition to the MongoDB database instance) an owl 2 ql ontology, a mapping, and a set of constraints. The constraints are user-defined unicity constraints (UCs) or functional dependencies (FDs) that hold over the json documents being queried. MongoDB may not be able to enforce such constraints, but they may nonetheless hold over the data. For instance, in the collection of Fig. 4, an FD holds from offers.vendor.vendorId to offers.vendor.name, meaning that the value of the former determines the value of the latter. These constraints can be used for query optimization (e.g., to eliminate redundant joins, as illustrated in Section 4.4). We also emphasize that it can be verified whether a manually declared constraint actually holds over the data, by evaluating an appropriate query over the MongoDB instance. For instance, the maq of Fig. 11 retrieves all sets of values (if any) that violate the FD from offers.vendor.vendorId to offers.vendor.name, in any MongoDB collection with the same schema as the collection of Fig. 4.
maq retrieving possible violations of the FD from offers.vendor.vendorId to offers.vendor.name, based on the schema of the collection of Fig. 4.
Note also that if the MongoDB instance is a denormalized version of an existing relational DB instance, then UCs and FDs can be directly inferred from keys declared in the relational DB schema. For instance, let us assume that the MongoDB collection of Fig. 4 is a denormalized version of the relational DB instance of Fig. 5, and that the attribute vendorId is declared as the primary key of table vendor. Then the FD from offers.vendor.vendorId to offers.vendor.name must hold over the MongoDB collection.
In step ➂, in addition to applying relational optimization techniques implemented by Ontop, Ontop/MongoDB also applies techniques specific to nested data, based on the equivalence with nra mentioned above. In particular, it can take advantage of the UCs and FDs just mentioned.
In step ➃, Ontop/MongoDB applies the nra-to-maq translation given in [5]. An important consideration in this translation process is that one has to take into account the internal limitations that MongoDB puts on the size of in-memory intermediate results during query evaluation (currently 16 MB for a single document, and 100 MB for a collection). For example, a naive iq-to-maq translation could produce an intermediate result in which the content of all input documents is merged into a single document, whose size might then exceed the memory limitations. Another key consideration is to take advantage of indexes available over the source json collection(s). Therefore Ontop/MongoDB does not apply the translation of [5] directly, but uses an optimized version, which makes the full delegation of query answering to MongoDBpractically feasible.
Generalized OBDA by example
We illustrate the generalized OBDA framework over MongoDB by elaborating on the running example inspired by the BSBM benchmark. The OBDA instance we consider is a pair , where , the database instance Db is the collection of documents given in Fig. 4, and is the schema defining the structure of such documents. In addition, contains two manually declared constraints, which hold over the data: (i) a UC for the field offers.offerId, meaning that each value of this field is unique in the whole collection;
8
(ii) an FD from the field offers.vendor.vendorId to the fields offers.vendor.name and offers.vendor.homepage.
We illustrate the evaluation over this OBDA instance of the SPARQL query q given in Fig. 7. The example focuses on the steps that are most relevant for the generalization of the OBDA framework. In particular, we do not illustrate ontology classification, mapping saturation, and sparql query rewriting (respectively, steps ➀, , and in Fig. 3), because these are identical to the case of OBDA over a relational database (for a detailed description, we refer to [14]). For this reason, we simplify the example by assuming that consists only of a vocabulary (i.e., it contains no axiom), so that ontology classification, mapping saturation, and sparql query rewriting do not produce any change on therespective inputs.
Mapping. The mapping is given in Fig. 12. The sql query φ in each mapping assertion is defined over the relational schema (corresponding to the DB instance 〚Db〛 of Fig. 5). For brevity, we use a set of RDF triples on the right-hand side of each mapping assertion. In such triples, {a} is a placeholder for the value of attribute a in each tuple in ans(ϕ,〚Db〛), and s1 {a} s2 stands for the concatenation of s1, {a}, and s2. In our case, since is empty, the saturated mapping coincides with .
Note that the concrete mapping language currently used by Ontop/MongoDB supports source queries over (rather than ), i.e., it defines json-to-rdf (rather than sql-to-rdf) mappings. Ontop/MongoDB converts internally such mapping assertions into sql-to-rdf ones. We only provide the latter here, to keep the exposition simple.
Unfolding into an iq. The unfolding phase (step ➁ in Fig. 3) starts with the sparql query , obtained by rewriting q w.r.t. the ontology (since is empty, coincides with q in our case). Each triple pattern in is substituted with the corresponding source sql query in the saturated mapping . This produces an ra query q1, with the guarantee that for any DB instance D over the schema , ans(q1, 〚D〛) = ans(q𝒯b, ℳb𝒯b(D)). This is in turn equivalent to ansql(q, 〈𝒫b, D〉), i.e., computing the answer to the original sparql query q over the OBDA instance according to the owl 2 ql entailment regime can be reduced to evaluating q1 over the relational view. The resulting query in our running example is given in Fig. 13. As is conventional, symbols ⋈, σ, and π respectively stand for inner join, selection, and (possibly complex) projection.
Unfolding over of the query of Fig. 7, w.r.t. the mapping of Fig. 12.
iq optimization. As mentioned in Section 4.3, in our instantiation of the generalized OBDA framework, nra serves as the iq language.
9
In the iq optimization phase (step➂ in Fig. 3), Ontop/MongoDB rewrites the unfolded ra query, expressed over the relational schema , into a semantically equivalent nra query over the nested relational schema (corresponding to the DB instance 〚Db〛 nested of Fig. 8). While doing so, it applies a series of query optimization techniques, some of which are langnra-specific.
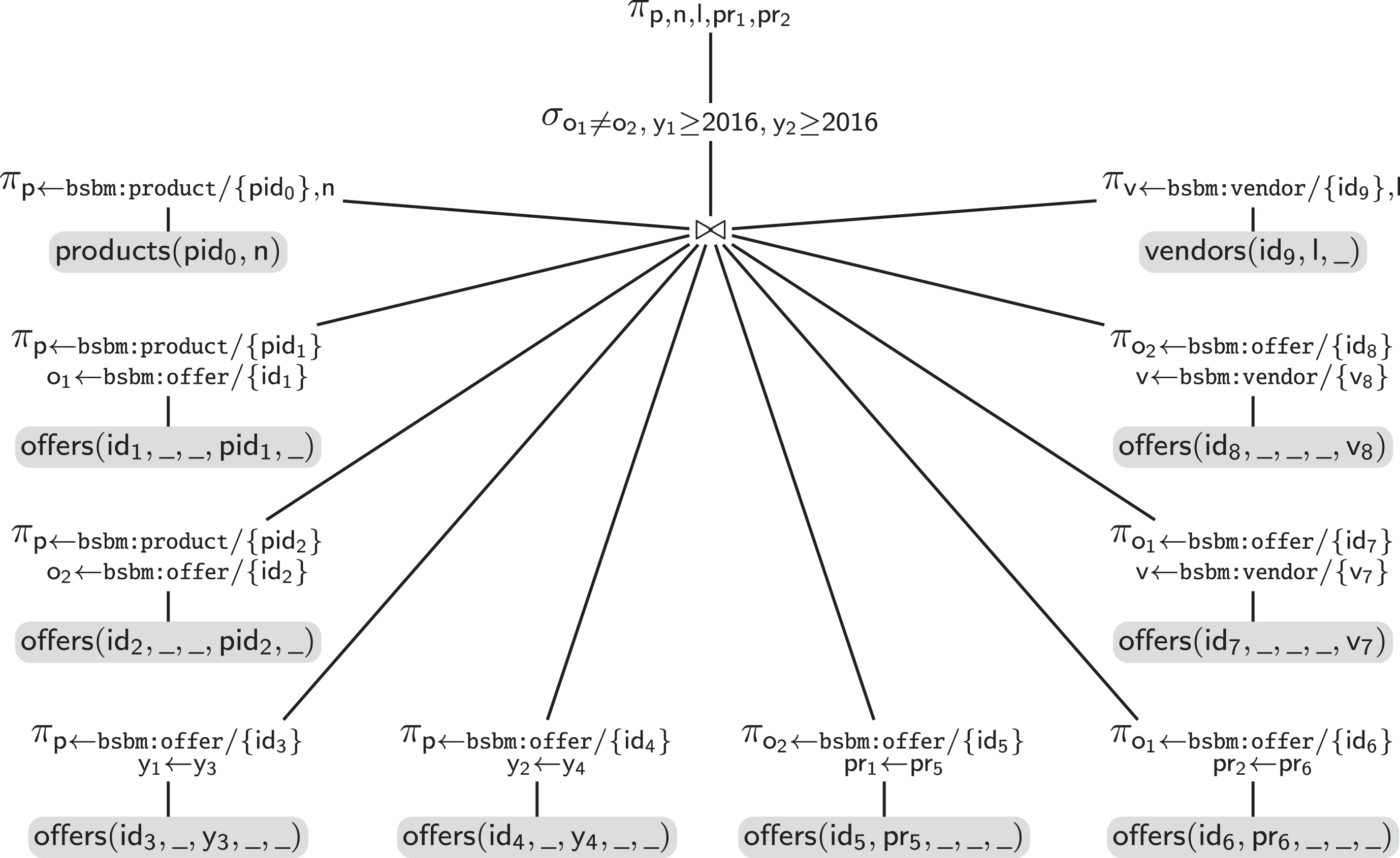
As an illustration, Fig. 14 provides a naive rewriting over of the query of Fig. 13, where all sub-relations are simply unnested (in order to “access” their attributes), and no optimization is applied. Symbol χ stands for unnest, and χofi→(_,_,_,_,_,_) for unnesting the sub-relation ofi (which counts 6 attributes). The resulting iq requires a total of 9 unnest operations and 9 binary joins, whose execution may be costly.
Naive rewriting over of the unfolded query of Fig. 13.
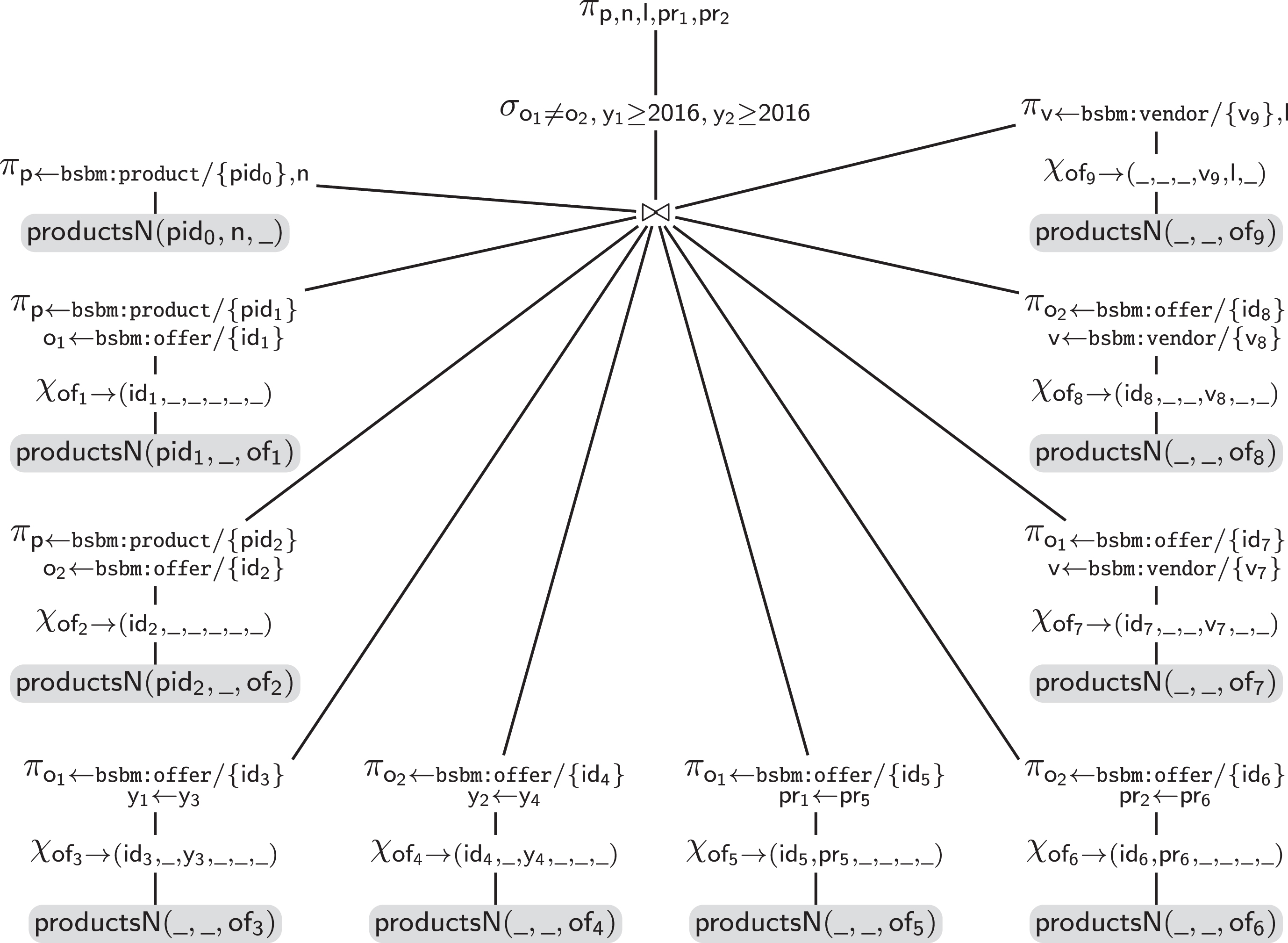
In comparison, Fig. 15 presents an optimized rewriting over , which contains no join, and only two unnest operations. A key technique to obtain this optimized rewriting is to identify redundant joins based on constraints holding over the schema . For instance, each value of _id can appear at most once in a MongoDB collection, therefore it determines the value of fields name and offers. This makes the join in Fig. 14 between the first three operands unnecessary (all operands are numbered from 0 to 9, counterclockwise). Similarly, the UC declared for offers.offerId guarantees that each value for this field determines the value of the other 5 fields in the sub-relation. More interestingly, the declared FD guarantees that a value for offers.vendor.vendorId is always associated to the same value of offers.vendor.name, which makes the join between operands 7 and 9 (or 8 and 9) unnecessary. This holds even though a same value for offers.vendor.vendorId may appear multiple times in the collection. So in this last case, in order to eliminate the redundant join, Ontop/MongoDB exploits an FD which does not follow from a UC. This is an example of nra-specific optimization, usually not needed for OBDA over relational DBs (assuming the database to be at least in third normal form).
Optimized rewriting over of the unfolded query of Fig. 13.
iq-to- translation.
In the iq-to-native query translation phase (step ➃ in Fig. 3), Ontop/MongoDB rewrites the optimized iqq2, expressed over , into an equivalent maqqm over (i.e., such that for every D satisfying , ans(q2, 〚D〛nested) = ans(qm, D)), based on the correspondence between nra and (a fragment of) maq established in [5].
Since the optimized iq in our running example (Fig. 15) does not contain binary operators, the conversion to maq is relatively straightforward: σ, π, and χ can be directly mapped to the maq operators $match, $project, and $unwind respectively, yielding the maq of Fig. 6.
Once again, query optimization techniques are applied by Ontop/MongoDB in order to produce a more efficient maq. These are maq-specific, i.e., they could not be implemented at the level of iq, and mostly pertain to the translation of binary nra operators (including a dedicated planner).
We nonetheless illustrate one optimization technique that applies to our running example. maq allows for prefiltering a collection of MongoDB documents, based on the value of a nested field nf, without the need to unnest the corresponding sub-relation first. If nf is indexed, this pre-filter can significantly reduce the number of required disk accesses during query execution, fetching only documents in which some occurrence of nf satisfies the filtercondition.
In our example, assuming that the field offers.year is indexed,
10
one can prepend a $match stage to the maq, in order to pre-filter products with at least one offer in the desired range of years (≥ 2016), before unnesting the sub-relation. The resulting maq is given in Fig. 16.
Native query evaluation and post-processing. The evaluation phase (step ➄ in Fig. 3) simply consists in evaluating the optimized maq over the MongoDB collection Db. Ontop/MongoDB offers the possibilty to fully delegate query execution to the source engine, meaning that the results returned by the source DBMS can be immediately converted to sparql solution mappings.
Full delegation of query execution may not be possible for all DBMSs though, or it may not be desirable, as explained in Section 3.1. This is the reason for the post-processing phase (step ➅ in Fig. 16). As a relatively basic illustration, Ontop/MongoDB offers as an option to postprocess the construction of IRIs. In this case, the last stage of the maq in Fig. 16 will not project the field "product".
11
Evaluation
We have carried out an evaluation that aims at determining whether OBDA over MongoDB is a realistic solution performance-wise, and in particular whether it is able to exploit the document structure of MongoDB collections. We focus on answering queries over datasets that do not fit into memory. In such a setting, a key concern for performance is to limit disk access, i.e., the number of non-contiguous pages that need to be fetched into memory.
To this end, we compare Ontop/MongoDB to the triple store Virtuoso [11], which represents a diametrically opposite approach to answering sparql queries, as far as the data and index structure are concerned. Indeed, Virtuoso stores data as quads (i.e., triples extended with the graph name), and for each element of the quads it maintains an extensive index structure, which is in particular highly optimized for retrieving (multiple) triples sharing a constant value.
12
In comparison, retrieving all documents for a given value of an indexed field may be inefficient in MongoDB if the value is not unique in the index, as it requires fetching multiple (non-contiguous) documents from disk. Instead, when the value is unique, MongoDB can fetch the whole document containing this value very efficiently, whereas for Virtuoso fetching the same data may require multiple diskaccesses.
We expect the evaluation to reflect these differences, i.e: (i) that Ontop/MongoDB outperforms Virtuoso for queries containing a unique constant in an indexed field, and fetching a single document; (ii) that Virtuoso outperforms Ontop/MongoDB for queries whose constants have multiple occurrences in the json collection.
An additional goal of the experiments is to determine whether the cost of query rewriting itself (i.e., generating the maq) introduces an excessive overhead.
Dataset and evaluation environment
As dataset we used an instance of the well-known BSBM benchmark [3], which emulates an e-commerce scenario, centered on offered products. The number of products in the instance is 4 million, giving 1.2 billion rdf triples, whose total size is 156 GB.
BSBM also provides a representation of this dataset as a relational DB instance, composed of 10 tables (product, offer, vendor, etc.). Based on the relational schema of this instance, we generated a 118 GB collection of json documents containing the same data. The structure of the documents in this collection extends the one of Fig. 4, grouping in each document all information pertaining to a single product.
The latest version of BSBM comes with 11 queries, numbered from 1 to 12 (there is no query 6 anymore). Among these, 3 were discarded, because they contain sparql features not (yet) supported by Ontop/MongoDB (Describe queries, bound operator, and variables over predicates). We instantiated 10 versions of each of the 8 remaining queries, replacing constant placeholders with values randomly sampled from the data. One version of each query was set aside for a cold run, and the 8 · 9 other instantiated queries were shuffled as a query mix. Execution times reported below are averaged over these 9 versions.
The systems being compared are Virtuoso v7.2.4 (over the rdf triples), and Ontop/MongoDB with MongoDB v3.4.2 (over the json collection). Queries were executed on a 24 cores Intel Xeon CPU at 3.47 GHz, with a 5.4 TB 15k RPM RAID-5 hard-drive cluster. 8 GB of RAM were dedicated to each system (MongoDB and Virtuoso) for caching and intermediate operations. The OS page cache was also flushed every 5 seconds, to ensure that each system could only exploit these 8 GB for caching. The query timeout was set to 500 s. For each constant appearing in a query, the corresponding field in the MongoDB collection was indexed.
An executable for Ontop/MongoDB is available online, together with the sparql queries, mapping, constraints, and both datasets (json and rdf), so that the experiment can be reproduced. The generated maqs are also provided.
13
Results and analysis
As a first element of answer, we observed that all maqs generated by Ontop/MongoDB are optimal with respect to the document structure, in the sense that no unnecessary join is performed that could be in theory avoided.
Table 1 reports the execution times for both systems. For Ontop/MongoDB, we distinguish query rewriting time (“rw”), i.e., the time spent generating the maq, from its actual evaluation (“eval”) by MongoDB. Rewriting time does not depend on the size of the data, but only on the query, mapping, ontology, and constraints, which are less likely to grow out of proportion. Still, for some of the cheaper maqs (< 100 ms), this overhead represents the major part of the execution time. This can be partly explained by the wide range of optimizations performed by Ontop/MongoDB. But it is also an aspect to improve, for OBDA over MongoDB to be considered a viable alternative to MongoDB itsef, at least in applications with high performance requirements.
Execution times (ms) for Ontop/MongoDB and Virtuoso, over the BSBM benchmark (4 million products). Values are averaged over 9 versions of each query
Query
1
2
4
5
7
8
10
12
rw
26
179
102
NA
417
838
22
35
Ontop/MongoDB
eval
2672
43
3713
NA
53
66
34
40
Virtuoso
eval
258
308
403
1179
3995
1897
3966
327
We now focus on query evaluation times. For each of the 9 versions of Query 5, the evaluation either timed out, or exceeded MongoDB’s memory limitations (see Section 4.3). This is explained by the fact that this query contains an anti-join, which requires a (close to) full collection scan from MongoDB. For the 7 remaining queries, we observe a sharp contrast in performance between the two systems, which matches the above expectations. Queries 1 and 4 present a very favorable setting for Virtuoso: the sparql BGPs are of limited size (≤ 5 triple patterns), and each of them contains 3 constants. On the other hand, because none of these constants is unique in the json collection, the evaluation by Ontop/MongoDB requires fetching multiple documents from disk. As expected, for these two queries, evaluating the sparql query with Virtuoso was one order of magnitude faster than evaluating the corresponding maq with Ontop/MongoDB. As for the 5 remaining queries, they all represent a setting where MongoDB can fully benefit from denormalization. First, all 5 queries require data contained in one document only. In addition, they all contain a constant in an indexed field, where the index is either declared as a unique (Queries 2, 7, 8, and 10), or contain only unique values (Query 12). For each of these queries, the evaluation was one to two orders of magnitude faster for MongoDB. This confirms that Ontop/MongoDB was able to generate maqs that take full advantage of the document (and index) structure.
Related work
The idea of using wrappers to access external data sources dates back to the 90s; see e.g., the Garlic data integration system [22]. In recent years, several extensions of the sql language have been proposed for accessing json data, e.g., sql++ [18]. These query languages are either directly supported by the source DB engines (e.g., Couchbase
14
and AsterixDB
15
) or by middleware. In the particular case of a MongoDB data source, such middleware includes Drill,
16
Dremio,
17
Studio 3T
18
, and the MongoDB Connector for Spark
19
. With such systems, users can query MongoDB collections as nested tables. sql queries are automatically translated to (basic) MongoDB queries, and post-processing is often required to compute advanced query constructs. These middleware systems differ fundamentally from OBDA systems in the type of virtual data representation they expose: a representation whose structure is derived directly from the one of the data source in the case of middleware systems, and an indirectly mapped RDF graph in the case of OBDA.
Several mapping language proposals already exist that extend r2rml for converting non-relational data sources to rdf, e.g., rml [10], xr2rml [16], kr2rml [24], and d2rml [8]. These languages extend the relational model used in r2rml to more general cases (e.g., csv, json, and Web Services). The corresponding systems are mostly used for data conversion; for instance, the implementation Morph-xr2rml also supports sparql query answering by partially materializing the relevant rdf graph.
Finally, the approach of [2] is comparable in spirit to ours, in that it also aims at delegating query execution to a NoSQL source engine, and relies on an object-oriented (OO) intermediate representation, similar to our “relational view”. A key difference though is that the mapping is from the ontology vocabulary to the OO layer, rather than from the source DB to the ontology vocabulary. The aim is to simplify the mapping specification, and make it independent of the underlying source DB. The expressivity of such a mapping is thus limited, essentially mapping OWL classes to (possibly nested) relations.
Conclusions
In this article, we have presented a generalized OBDA framework for arbitrary (not only relational) DBs. It provides a convenient uniform querying interface, by means of a high-level vocabulary coupled with a familiar query language (sparql), as an alternative to the variety of ad-hoc native query languages of NoSQL DBMSs. We also propose a practical architecture for a generalized virtual OBDA approach, that allows for answering sparql queries over arbitrary data sources.
We have instantiated this framework in the specific case of MongoDB, as an extension (called Ontop/MongoDB) of the OBDA system Ontop, and we have compared its performance to that of a triple store. The evaluation we have carried out shows that Ontop/MongoDB is able to generate queries in maq, the native query language of MongoDB, that take full advantage of the denormalized structure of the data.
As a continuation of this work, we plan to evaluate the impact of the different techniques implemented within Ontop/MongoDB to optimize the generated maqs, using a wider range of queries, but also different document structures for the same dataset.
Footnotes
json (or JavaScript Object Notation) is a format for organizing data in tree-shaped structures. So in spirit it is similar to XML, but it is significantly more lightweight.
This is not required by MongoDB itself, only by the OBDA framework.
Notice though that the elements of a MongoDB array are ordered, whereas this is not the case of tuples in a sub-relation.
An exception is the step that builds the returned rdf strings (IRIs and literals) from the constants retrieved from the DB.
Recall that MongoDB also enforces an implicit primary key constraint on the field _id.
Recall that nra subsumes ra, hence an ra query is also an iq.
We also assume that this index is optimized for ordering, e.g., is a B-tree.
Note that the _id field is systematically returned by MongoDB, therefore it does not need to be explicitly retained by the projection.
References
1.
AntonioliN., CastanòF., CiviliC., ColettaS., GrossiS., LemboD., LenzeriniM., PoggiA., SavoD.F. and VirardiE.. Ontology-based data access: The experience at the Italian Department of Treasury. In Proc. of the Industrial Track of the 25th Int. Conf. on Advanced Information Systems Engineering (CAiSE), volume 1017 of CEUR Workshop Proceedings, http://ceur-ws.org/, (2013), 9–16.
2.
AraujoT.H.D., AgenaB.T., BraghettoK.R. and WassermannR.. OntoMongo – Ontology-Based data access for NoSQL. In
AbelM.,
FioriniS.R., and PessanhaC., editors, Proc. of the 10th Seminar on Ontology Research in Brazil (Onto-Bras) and 1st Doctoral and Masters Consortium on Ontologies, volume 1908 of CEURWorkshop Proceedings, http://ceur-ws.org/,(2017), pp. 55–66.
3.
BizerC. and SchultzA.. The Berlin SPARQL benchmark. Int J on Semantic Web and Information Systems5(2) (2009), 1–24.
4.
BotoevaE., CalvaneseD., CogrelB., CormanJ. and XiaoG.. A generalized framework for ontology-based data access. In Proc. of the 17th Int. Conference of the Italian Assoc. for Artificial Intelligence (AI*IA), volume 11298 of Lecture Notes in Computer Science, (2018), pp. 166–180. Springer.
5.
BotoevaE., CalvaneseD., CogrelB. and XiaoG.. Expressivity and complexity of MongoDB queries. In Proc. of the 21st Int. Conf. on Database Theory (ICDT), volume 98 of Leibniz Int. Proc. in Informatics (LIPIcs), pp. 9:1–9:22, Dagstuhl, Germany, 2018. Schloss Dagstuhl– Leibniz-Zentrum für Informatik.
6.
CalvaneseD., CogrelB., Komla-EbriS., KontchakovR., LantiD., RezkM., Rodriguez-MuroM. and XiaoG.. Ontop: Answering SPARQL queries over relational databases. Semantic Web J8(3) (2017), 471–487.
7.
CalvaneseD., LiuzzoP., MoscaA., RemesalJ., RezkM. and RullG.. Ontology-based data integration in EPNet: Production and distribution of food during the Roman Empire. Engineering Applications of Artificial Intelligence51 (2016), 212–229.
8.
ChortarasA. and StamouG.. D2RML: Integrating heterogeneous data and web services into custom RDF graphs, In Proc. of the Workshop on Linked Data on theWeb (LDOW), volume 2073 of CEUR Workshop Proceedings, http://ceur-ws.org/, 2018.
9.
DasS., SundaraS. and CyganiakR.. R2RML: RDB to RDF mapping language. W3C Recommendation, World Wide Web Consortium, September 2012. Available at http://www.w3.org/TR/r2rml/.
10.
DimouA. and Vander SandeM.,
ColpaertP.,
VerborghR.,
MannensE. and Van de WalleR.. RML: A generic language for integrated RDF mappings of heterogeneous data. In Proc. of the Workshop on Linked Data on the Web (LDOW), volume 1184 of CEUR Workshop Proceedings,http://ceur-ws.org/, 2014.
11.
ErlingO. and MikhailovI.. RDF support in the Virtuoso DBMS. In Networked Media, volume 221 of Studies in Computational Intelligence, (2009), pp. 7–24. Springer.
12.
GieseM., SoyluA., Vega-GorgojoG., WaalerA., HaaseP., Jiménez-RuizE., LantiD., RezkM., XiaoG., ÖzçepÖ.L. and
RosatiR.. Optique: Zooming in on Big Data. IEEE Computer48(3) (2015), 60–67.
13.
HarrisS. and SeaborneA.. SPARQL 1.1 query language. W3C Recommendation, World Wide Web Consortium, March 2013. Available at http://www.w3.org/TR/sparql11-query.
14.
KontchakovR., RezkM., Rodriguez-MuroM., XiaoG. and ZakharyaschevM.. Answering SPARQL queries over databases under OWL 2 QL entailment regime. In Proc. of the 13th Int. Semantic Web Conf. (ISWC), volume 8796 of Lecture Notes in Computer Science, (2014), pp. 552–567. Springer.
15.
LenzeriniM.. Data integration: A theoretical perspective. In Proc. of the 21st ACM Symp. on Principles of Database Systems (PODS), (2002), pp. 233–246.
16.
MichelF., DjimenouL., Faron-ZuckerC. and MontagnatJ.. Translation of relational and non-relational databases into RDF with xR2RML. In Proc. of the 11th Int. Conf. on Web Information Systems and Technologies (WEBIST) (2015), pp. 443–454.
17.
MotikB., FokoueA., HorrocksI., WuZ., LutzC. and Cuenca GrauB.. OWL Web Ontology Language profiles. W3C Recommendation,WorldWideWeb Consortium, October 2009. Available at http://www.w3.org/TR/owl-profiles/.
18.
Win OngK.,
PapakonstantinouY. and VernouxR.. The SQL++ query language: Configurable, unifying and semi-structured. CoRR Technical Report abs/arXiv.org e-Print archive, 2014. Available at http://arxiv.org/abs/1405.3631.
19.
PérezJ., ArenasM. and GutierrezC.. Semantics and complexity of SPARQL. ACM Trans. on Database Systems34(3) (2009), 16:1–16:45.
20.
PoggiA., LemboD., CalvaneseD. and De GiacomoG.,
LenzeriniM. and RosatiR.. Linking data to ontologies. J on Data Semantics10 (2008), 133–173.
21.
Rodriguez-MuroM., KontchakovR. and ZakharyaschevM.. Ontology-based data access: Ontop of databases. In Proc. of the 12th Int. SemanticWeb Conf. (ISWC), volume 8218 of Lecture Notes in Computer Science, (2013), pp. 558–573. Springer.
22.
Tork RothM. and
SchwarzP.M.. Don’t scrap it, wrap it! A wrapper architecture for legacy data sources. In Proc. Of the 23rd Int. Conf. on Very Large Data Bases (VLDB), (1997), pp. 266–275. Morgan Kaufmann.
23.
SequedaJ.F., ArenasM. and MirankerD.P.. OBDA: Query rewriting or materialization? In practice, both! In Proc. of the 13th Int. Semantic Web Conf. (ISWC), volume 8796 of Lecture Notes in Computer Science, (2014), pp. 535–551. Springer.
24.
SlepickaJ., YinC., SzekelyP.A. and KnoblockC.A.. KR2RML: An alternative interpretation of R2RML for heterogenous sources. In Proc. of the 6th Int. Workshop on Consuming Linked Data (COLD), co-located with ISWC, volume 1426 of CEUR Workshop Proceedings, http://ceur-ws.org/, 2015.
25.
Van den BusscheJ.. Simulation of the nested relational algebra by the flat relational algebra, with an application to the complexity of evaluating powerset algebra expressions. Theoretical Computer Science254(1) (2001), 363–377.
26.
XiaoG., CalvaneseD., KontchakovR., LemboD., PoggiA., RosatiR. and ZakharyaschevM.. Ontology-based data access: A survey. In Proc. of the 27th Int. Joint Conf. on Artificial Intelligence (IJCAI), (2018), pp. 5511–5519. IJCAI Org..

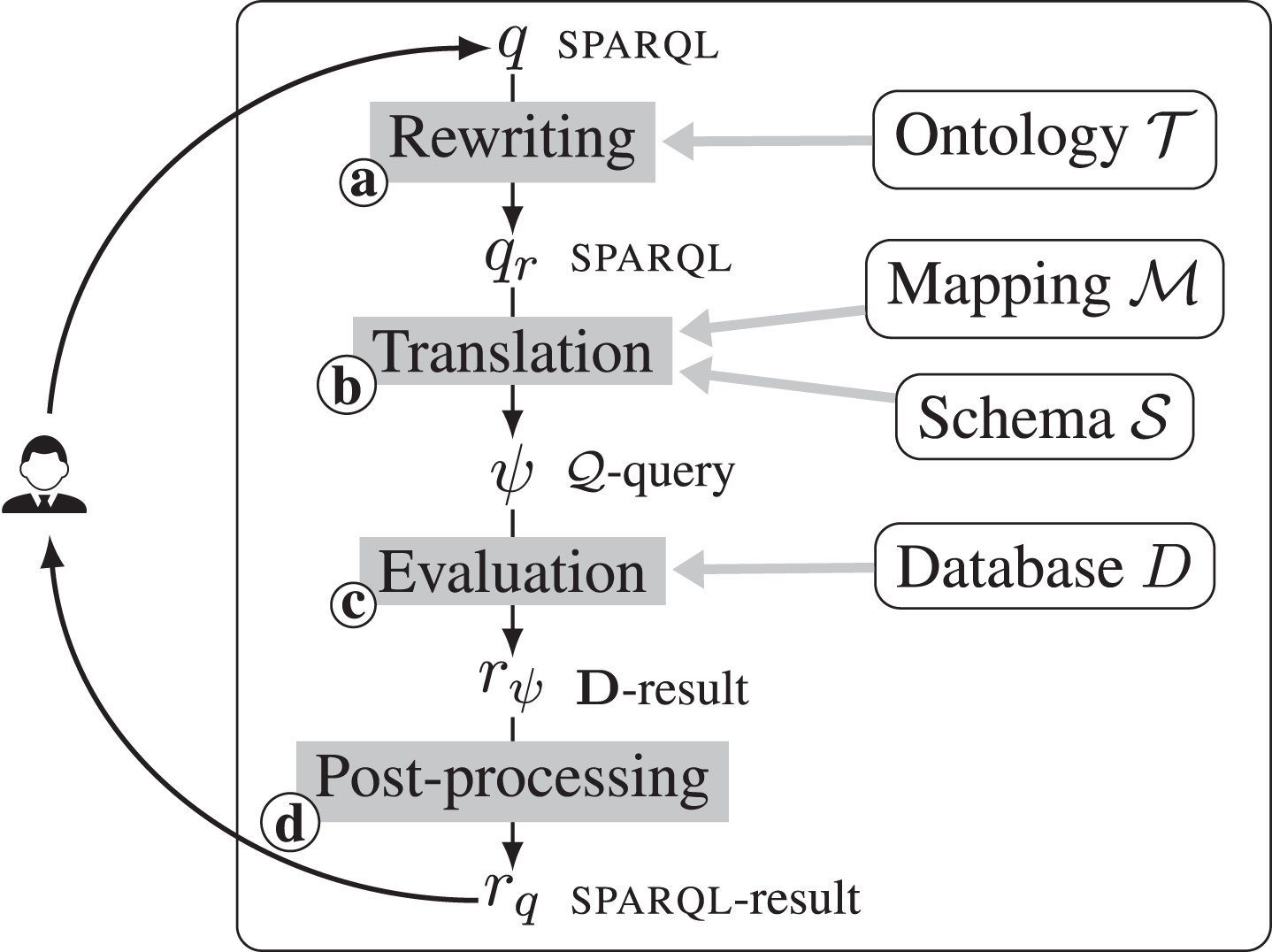
 and
and  , takes as input the ontology, mapping, and schema, and produces two elements, to be used during the online stage: the classified ontology, and the saturated mapping [21, 23]. The former makes also implied inclusion assertions between classes and between properties explicit, while the latter is constructed by “saturating” the input mapping with the classified ontology. The saturation is obtained by adding to the existing mapping assertions additional ones that are derived by combining information from the input mapping and from the ontology axioms. For instance, if
, takes as input the ontology, mapping, and schema, and produces two elements, to be used during the online stage: the classified ontology, and the saturated mapping [21, 23]. The former makes also implied inclusion assertions between classes and between properties explicit, while the latter is constructed by “saturating” the input mapping with the classified ontology. The saturation is obtained by adding to the existing mapping assertions additional ones that are derived by combining information from the input mapping and from the ontology axioms. For instance, if