
Abstract
Nowadays, many NoSQL systems are developed to deal with data elasticity in distributed environments. This is very useful for Data mining such as association rules technique which generates a huge number of rules. To avoid any manual post-processing for selecting the interesting rules, many researchers suggest integrating expert users’ knowledge by using ontology and rule patterns. Nevertheless, with NoSQL Big Data that contain very large data, the number of generated rules is so huge that any post-processing becomes complicated especially in industrial areas. Also, any solution and results have to be tested and checked with a real Big Data context. In order to deal with this issue, we use an adjusted approach with ontology and rule patterns to reduce database NoSQL context before generating any rule. After that, we conduct a real experiment on distributed industrial MongoDB database to calculate execution time and generated rules. This work proves the gain in performance for using association rules with ontology in the NoSQL systems.
Introduction
Nowadays, many industrial companies introduce different distributed NoSQL systems to manage their great precious information systems. These companies are also interested in Data Mining [28]. Their goal is to take advantage from their information systems and extract new knowledge, and thus provide early feedback means. These knowledge are generally hidden and can be extracted from historical data to guess new data, and predict anticipate actions in facts [9]. For instance, providers can use this knowledge to have ideas about general tendencies of their customers, and then improve their future clients’ satisfaction. A lot of methods and techniques (predictive and descriptive) have continually been developed in Data Mining. Among these methods, the technique of association rules (AR) is very useful and practical because it is simple to understand and to implement [3]. Many algorithms are developed to implement AR (see Section 2.1). However, their main common problem is the huge number of generated rules. To choose the interesting rules, a manual post-processing is required, and must be done by expert users in business domain. The selected rules are considered as effective knowledge. To help users and avoid them any manual hard investigation, many proposals are developed to find pertinent rules after generating all rules (see Section 2.2). Most of these proposals meet requirements in several cases.
Nevertheless, the volume of business data is now increasing very quickly, especially in industrial domains. Lots of manufactories and industrial companies are equipped with digital acquisition systems that generate very large amounts of data. So, new Big Data systems become currently very popular like NoSQL [27] and newSQL [11]. Also, many distributed environments have been developed to support storage and processing of Big Data as Cloud Computing, Hadoop and Spark [25]. In NoSQL systems, looking for the frequent itemsets and generation of all association rules become exceedingly difficult for both the storage and the processing sides.
In this article, we use our approach to deal with this problem in NoSQL systems. Firstly, we propose to integrate users’ knowledge as ontology in early step of the process. Then, we give concrete experiment applied to a Big Data NoSQL context in order to evaluate and prove the gain in performance.
The paper is organized in five sections. The first section gives an introduction. In the second section, we go over the constraints of AR and related work. Then, we focus on the impact of these constrains and solutions for NoSQL systems. In the third section, we present our approach based on the preselected rules patters. An experiment is given at the fourth section; historical NoSQL data of an industrial company [41] are used in this process, so a study will be conducted to get automatically the interesting target rules. In the fifth section, test cases are carried out to validate performance gain. A conclusion and perspective close this paper in the last section.
Problem with association rules and related work
Data mining is a set of theories and techniques that can extract, represent and integrate knowledge. Its role is to look for hidden correlations in databases, and transform them to knowledge. Data Mining is used and applied in many domains: client’s relation management (CRM), Business Intelligence (BI), statistics, scientific research, biology, etc. [17].
Many methods and tools are developed to serve data mining needs. These methods can be classified by principle (supervised, unsupervised) [17], by objective (descriptive, predictive) [42], etc.
There are many Data mining techniques [16], like association rules, clustering, decision trees, neurons network, genetic algorithm, nearest neighbor, etc. Choosing an appropriate technique depends closely on requirements and data nature. In this paper, we are interested in association rules technique.
Technique of association rules and its problem
The technique of association rules is an interesting topic in Data mining. It can detect association or links between data (itemsets) in form of rules (
An association rule
Each rule is evaluated by two measures: support and confidence.
a rule
a rule
For example, for the rule: “90% of customers who buy the product A, buy also the product B, and 40% of all customers have bought these two products”, we can say that this rule is verified with certitude more than 90% (confidence), and it is supported by at least 40% of customers (support).
Note that the support is a statistic measure, and the confidence is a measure for strength of the rule. A rule to be selected, must has its support and confidence greater or equal than user-defined thresholds called
After selecting and preparing data, the process of rule extraction can be done in two steps [2]:
Looking for the frequent itemsets (patterns). This first step dominates the processing time.
Generating all association rules. This step is rather straightforward.
Many efficient algorithms are proposed to implement the association rules. Among these, the well-known is Apriori algorithm [10] which has been very influential. Later, many other scholars have improved and optimized Apriori algorithm, many new variants algorithms have been presented like FP-Growth [15], Close [33], Closet [34], etc. Nevertheless, their entire major inconvenient resides in the important huge number of generated rules.
In Aprioi algorithm, all potential itemsets (set of items or attributs of a transaction) in a context are checked. After building the trellis (graph of all possible combinations of itemset subsets) in a context, if we have m itemsets in this trellis, then we will have
Consequently, a post-processing is necessary, and it must be done by expert users in order to target manually the interesting rules which can be considered as effective knowledge. The post-processing must to be efficient and adapted to both the user preferences and the data structure. However, in Big data context, this post-processing becomes very hard and it would be interesting to automatize it.
Background and related work
In order to automatize and optimize the post-processing, many approaches were developed to find pertinent rules. Some approaches, like that of Silberschatz and Tuzhilin [38] proposed to decrease the number of generated rules by using interest measures which can be objective or subjective [38]:
Objective measures are relied just to data structure (algorithm). Many works, like guided by Piatetsky-Shapiro et al. [35], Bayardo and Agrawal [6], Hilderman and Hamilton [18], Tan et al. [43], Guillet and Hamilton [14], etc., have summarized these measures and compared their definitions and properties. However, these objective measures offered just a partial response to post-processing, because they are limited to just data evaluation.
Subjective measures integrate explicitly expert’s or manager’s knowledge [36]. Approaches which integrate these measures are mainly distinctive with representation models of knowledge.
Some authors proposed using templates to describe interested and uninterested rules [20]. Others used two representation models for user’s conviction [23]: General Impressions (GI) and Reasonably Precise Knowledge (RPK). A version of RPK in fuzzy logic has been developed by Liu and Hsu [22] to select the classification rules based on syntactic comparison. Other more exact representation of user’s knowledge by using rules has been developed by Padmanabhan and Tuzhuilin [32], and the rule interest was defined by logical contradiction.
In 1995, Srikant and Agrawal [10] proposed to represent user’s knowledge by General Association Rules (GAR), and integrate knowledge by hierarchal taxonomy of attributes. The introduction of knowledge in attributes structure allowed decreasing number of rules.
Later in 1999, Liu et al. [24] developed this taxonomy to become rule patterns which can represent vast user’s knowledge in a particular domain on database. These rule patterns allowed defining a characteristic form of interested rules which will be selected among all calculated rules.
In their French article named “Vers la fouille de règles d’association guidée par des ontologies et des schémas de règles” [26], LINA–COD team (Claudia M. et al.) proposed as a new approach to introduce user’s knowledge in the extraction of association rules by using ontology associated with rule patterns. This approach is detailed in the next section. So since that, ontology has been introduced in association rules process, and then let ontology’s benefits to be enjoyed. Ontology is a conceptual database which allows users to modelize knowledge and provide a common shared vocabulary. It allows users to understand, define, structure and standardize the semantic of the terms and concepts in a domain [12]. For a company, ontology represents its memory and a reference vocabulary for its interesting domains [31]. Many classifications are defined for ontology [4,13,19].
As result, most of these proposals listed above allow integrating gradually and efficiently the users’ knowledge and they contribute to automate the post-processing. However, they continue steadily to deal with the huge number of rules, because all possible association rules are generated. So, as soon as the number of rules increases, the post-processing will become hard and consumer in time and space.
In other side, data are continually increasing nowadays, and many Big Data concepts are soon emerged. For industrial companies, all their historical data must be accumulated and safeguarded. A lot of these companies have recently opted for Big Data systems as NoSQL [27] and NewSQL [11] which are eventually deployed in distributed environments.
At present time, many scholars are interested in association rules with NoSQL systems. Most of them propose many variant parallel algorithms with Map/Reduce technique [5,8,21,37,45,46]. However, the Data mining process turn out to be more and more outsized, and the process of generating association rules becomes very hard and complicated in Big Data context such as NoSQL. The huge number of generated rules cannot be supported and covered by the above proposals. To cope with this problem, we give our approach and we perform a real experiment with NoSQL to validate their performance in the next section.
Our proposal
We propose to use our approach to solve the issue of association rules in NoSQL systems.
Firstly, we are interested in using the LINA–COD’s approach [26]. This approach is very efficient since it integrates users’ knowledge by using ontology coupled with rule patterns in its process. Later, we will adapt this approach to the Big Data context.
As shown Fig. 1, LINA–COD team’s approach is based on three main elements:
a database from which all association rules are extracted;
an ontology which represent knowledge related to the database;
a set of rules schemes that can link ontology concepts to interesting rules.
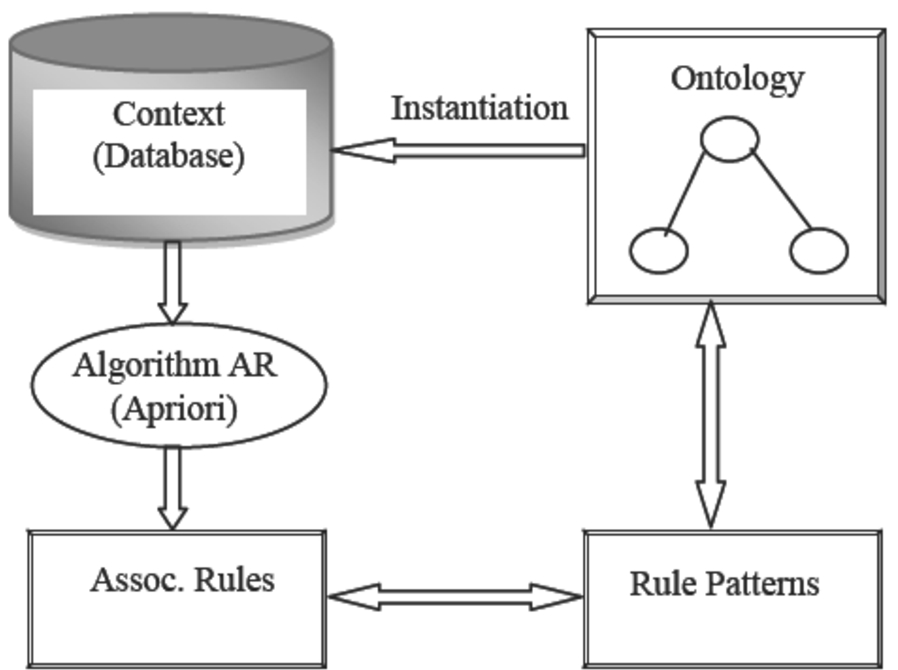
Representation of LINA–COD team’s approach [26].
Formally, ontology is a set of concepts linked by relations of subsumption or conceptualization [26]. Each parent concept represents a generalization of its enclosed child concepts, and each child concept is a specialization of its parent, and a hierarchy of conceptual knowledge is obtained by these relations. So, ontology is an efficient tool to check or validate new knowledge in a related domain. This is very important, because ontology can take part in the data mining process by selecting, filtering and collecting knowledge (association rules, patterns, etc.).
Also, note that a rule pattern allows carrying out a supervised selection on association rules. It offers a method to express knowledge by using a model of investigated rules:
As a result, the rule patterns combined with ontology allow increasing capability to target just interesting rules in post-processing.
However, in this approach, we note that the whole context (database) is taken into account during exploration and searching association rules, and afterward the rule patterns are used to filter just the interesting rules. Also, we note that all possible itemsets in the context are considered during searching stage, regardless of what these itemsets would be considered or not by rule patterns later.
Using Apriori algorithm, many explorations must be done on the complete context to calculate support and confidence for each itemset. Even with other variants of Apriori algorithm, like FP-Growth [15], Close [33], etc., exploration is optimized by reducing the number of context access, but this number remains still very big, and the process of exploration continues to be high consumer in time and space.
In NoSQL systems, it is harder to take into account the entire context each time and consider all possible itemsets. So, to avoid these constraints, we propose to filter the context at the beginning by using only itemsets which are included and respect initially the rule patterns chosen by experts. These itemsets have to contain concepts (ontology) or attributs (context) that respect the NoSQL patterns (keys/values combination).
This can limit the field of investigation, so only a part of context, which contains itemsets appeared in the rule patterns, can be considered at exploration step. Later, in the generating rules step, only the rules that respected the chosen rule patterns can be generated.
As shown in Fig. 2, a proposed schema is given for our approach with NoSQL systems.
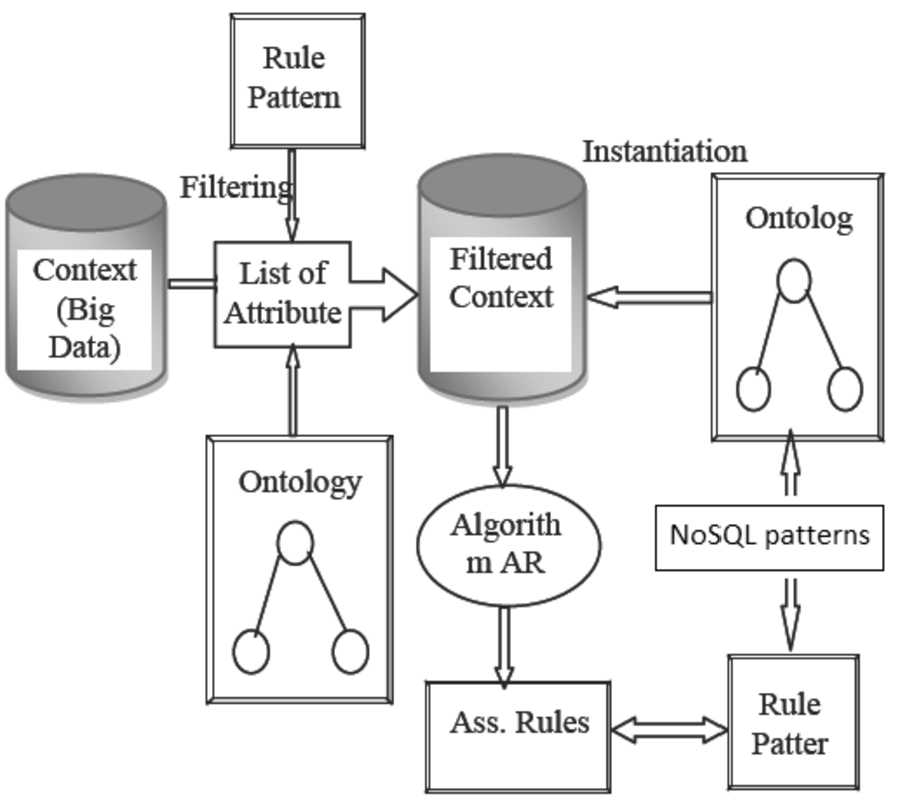
Representation of our proposed approach.
In the following, we give description of our proposal phases.
We use rule patterns to filer the NoSQL context in order to have just instances that contain the items included in these rule patterns. For example, let consider
(Using the filtered database context).
At this phase, we use the restricted context as the same method described in LINA–COD’s approach.
The database consists of a set of N transactions described through P attributes. Let
Each transaction
Ontology is defined by a set of concepts
In this scenario, it is fundamental to be able to connect the database to ontology. Each concept of ontology is instantiated in database by a subset of records. A simple way to make this connection is to associate a concept directly to an attribute of the database. Other possibilities are also envisaged, like connecting a subset of attributes to a concept. Finally, a rule pattern can express knowledge about the form of the rules sought. The semantic extension of “general impression” allows joining in rule patterns not only constraints on attributes, but also constraints on concepts [26].
To recapitulate our proposal steps, an explaining diagram is given in Fig. 3.
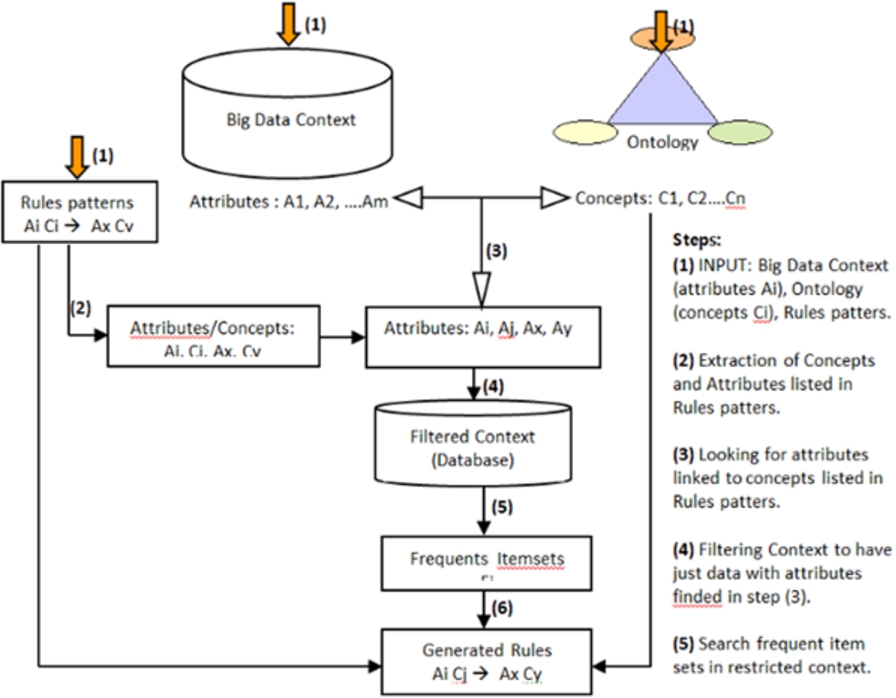
Representation of our proposed approach diagram.
To use our approach with NoSQL systems, we need to modulate
In conclusion, our proposition is useful, because it significantly reduces the cost related to execution time and space at the early steps. It provides an important all-purpose optimization of time processing and occupying space especially for Big Data.
In order to verify the effectiveness of this approach in NoSQL context, we conduct real experiment in the next section.
In this section, we perform a real experiment to bear out the efficacy of our approach on a distributed NoSQL system. Firstly, we present data used in experiments and their Big Data nature, and we give an extract of their related ontology. Next, we introduce our distributed platform. Later, we present an application that simplifies process to users, so they can build new interesting rule patterns or choose others from previous rule patterns recorded by experts.
Finally, we conduct our experiment by taking many interesting rule patterns chosen by users. These rule patterns can use concepts of ontology or attributes of database which are used as a guide for selecting association rules. We apply our approach to restrict the NoSQL context and select just the interesting itemsets, and then we can carry out the Apriori algorithm on this restricted context. The frequent itemsets are discovered with a minimum support and a minimum confidence previously chosen by users as parameters. Note that since the same data and ontology are used in experiment, the same number of pertinent association rules would be found at the end regardless of using or not our approach.
The results of these experiments are analyzed and interpreted in the next section.
Presentation of data and ontology
We use downstream activity data of an oil and gas company [41] which is composed of a head office and other productive plants. Its information system encompasses all business activities (production, maintenance, human resources, finances and support). Each plant has a large database for each domain. The head office has meanwhile large consolidated databases (Data Marts) which have been recently migrated from Oracle relational system to NoSQL MongoDB version 2.6 [30]. Note that data migration from Oracle to MongoDB has been done by using approach provided by D. Dahmani et al. [7].
Also, note that MogoDB has been chosen because it is a document store suitable for data nature. MongoDB is efficient, popular, and its current ranking [40] strengthen greatly this choice.
The industrial production is a strategic business domain regulated by international certifications and standards. This domain covers the following axes: production, stocks, prediction and programming of shipping, technique and laboratories management, security and installations, etc.
For our case study, we opt for industrial production data at the headquarters as shown in Fig. 4.
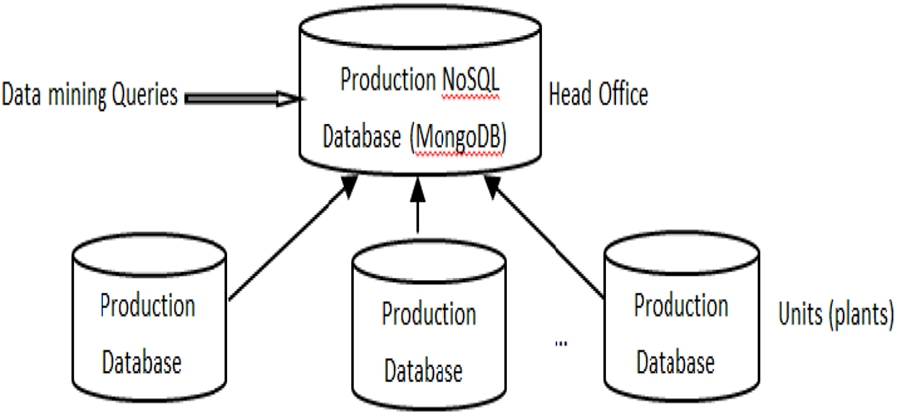
MongoDB databases (head office and units).
We have chosen these data because of two reasons:
They are suitable to many Data mining queries that users are interested in.
Their characteristics are marked as NoSQL nature: volume (Tera bytes), velocity (data received every time by electronic capture systems), and variability (many data types) [27].
As experimentation, we use the shipping collection in MongoDB database. This collection contains all data about loading products into boats from different units and shipped to foreign clients. Users frequently focus their analysis on these data. An extract from this collection is shown in Table 1.
An extract from collection MongoDB
As shown in Fig. 5, ontology was created to represent knowledge and concepts related to this collection (units, products, clients, etc.). All relations between these concepts are defined. This ontology was implemented by using Protégé tool version 4.0.2 [39], and OWL language [44].

Ontology related to the shipping collection in production database.
Distributed environments are frequently used with NoSQL systems because their elasticity that improves greatly the performance of Data mining [7]. We use a distributed platform managed by MongoDB and composed of nodes (called Shards). This platform does not require many resources as other distributed platforms, i.e., Cloud IaaS, Hadoop, etc.
MongoDB has three following processes [1]: a Configuration server that stores metadata of each shard, a Mongos process that redirects client requests to the appropriate shards and groups the results before sending them back to the client, and a mongod process that hosts and manages data in the Shard. As shown in Fig. 6, we use a platform containing 7 nodes:
Mongo server that manages and distributes data within 5 Shards (mongod).
Configuration server used by Mongos to manage the configuration of shards and replications.
5 Shards servers, each one runs mongod service and hold a data partition distributed by Mongos.
All nodes are identical (HS21, Xeon quad core E5420, 3.5 Ghz/1333 Mhz, 16 MB RAM, 2×10 GB Disk). This configuration was chosen according to the good practices document of MongoDB [1].
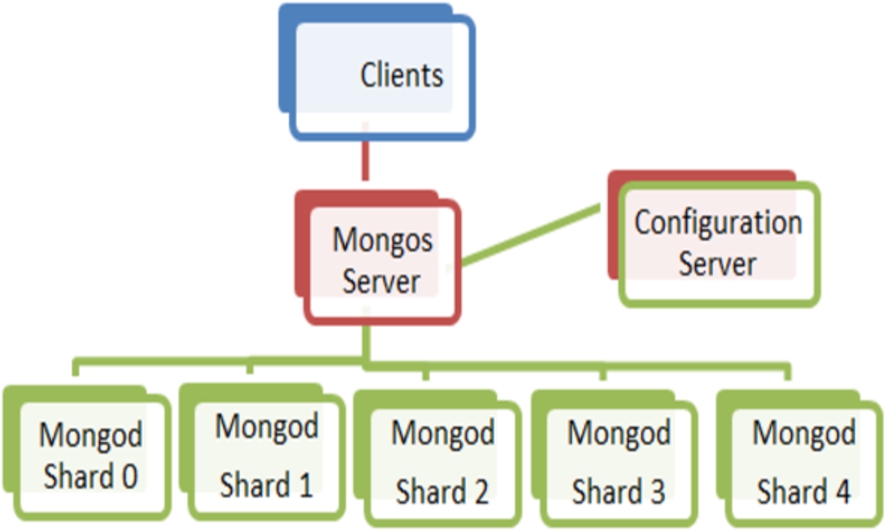
Distributed architecture MongoDB used in experiments.
Once the platform is prepared, we install a MongoDB distributed database according to the steps listed in the MongDB Sharding procedure [29]. Figure 7 displays information about our shards; we can see data distribution between different shards.
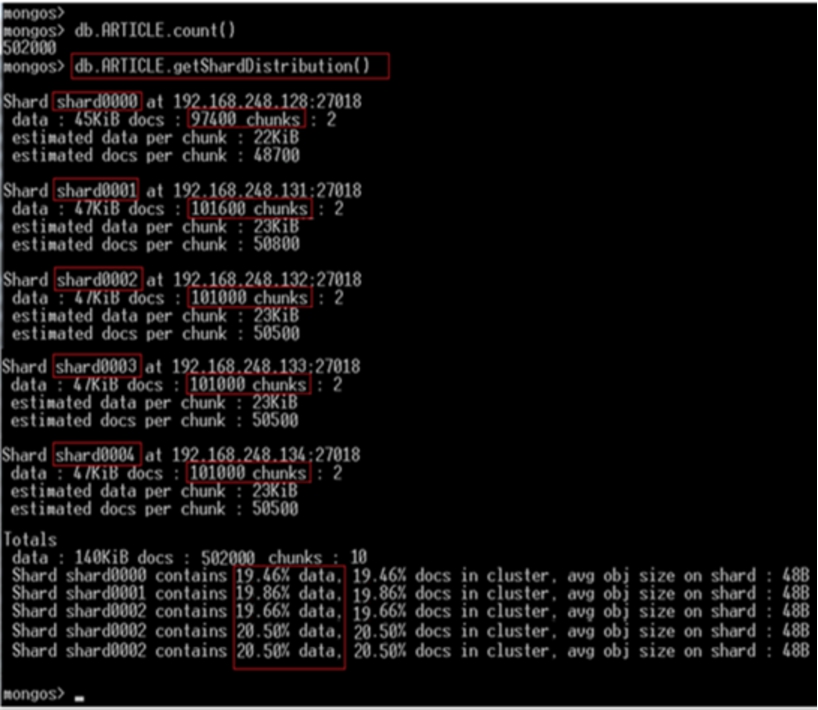
Distribution of data between shards.
In the following, we use our approach and distributed platform to carry out a real interesting experiment for the company’s users.
In order to make work easy, we use our java application called Prontodam (see Fig. 8) that implements Apriori algorithm. This application allows users to connect to MongoDB database, choose minimum thresholds for support and confidence, select ontology, and build pattern rules from concepts or their related attributes with NoSQL key/value model. With this application, a user can easily build manually new interesting rule patterns or choose them from a previous list of rule patterns which can be already recorded by other experts (see Fig. 9). This let users not only build gradually an interesting catalog of rule patterns, but also check and validate the process of the association rules.
Additionally, this application can be executed with two alternatives: (1) with our approach (2) or without it. By the way, these two execution alternatives allow us to compare the results and then have an idea on how gain could be obtained with implementing our approach.
Some print screens of ProntoDam application.
Firstly, we give an example of a rule pattern chosen by users in the shipping collection. The users’ goal is to discover the client’s interest in each product delivered by different units. Note that the same product is different in units because its quality depends on some specific parameters delivered by this unit. For instance, the specific calorific power (SCP) is an important parameter for Liquefied Natural Gas (LNG) product. After each boatload, a quality certificate of product is delivered by the company and checked by clients. Users like to have an idea about product quality sought by each client. So, the following rule pattern is given: “The client is interested in such product produced by such unit”.
The rule pattern above means that users are interested in association rule with the following form:
“Client → Product, Unit”. This pattern rule is very useful for managers because it allows them to qualify the clients’ interests in order to satisfy their upcoming needs, and recommend product quality to units according to the clients’ needs. Note that Client, Product, Unit are concepts in ontology, and they can be translated into their equivalent attributes Code_Client, Code_Product, Code_Unit respectively.
Experts can just use Prontodam to choose or compose this rule pattern if it does not exist, and all remaining things can be done automatically. Figure 9 shows a Prontodam print screen of the composition of our rule pattern. After that, users can carry out the operation to generate association rules.
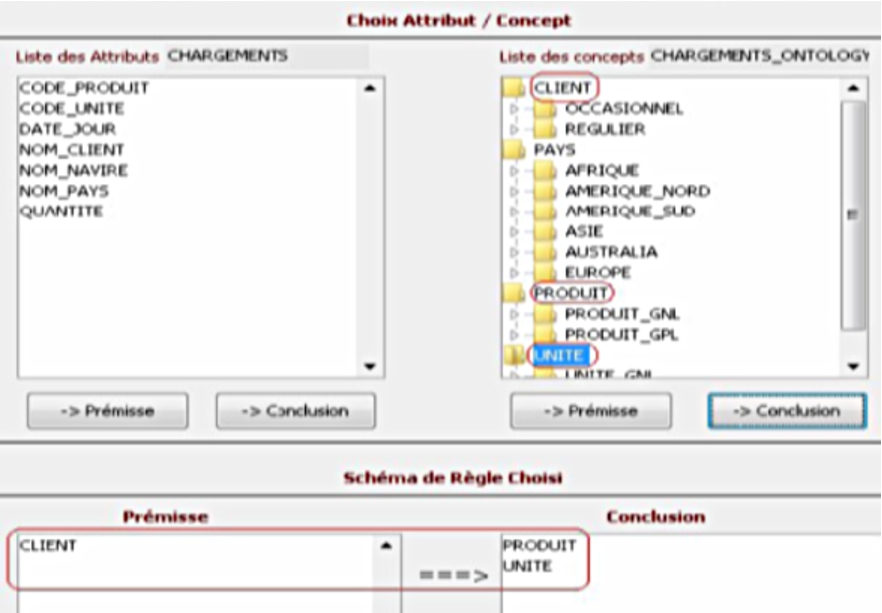
Compositing a rule pattern from concepts and attributes in Prontodam application.
In Fig. 10, we can see the results of our rule pattern execution related to minima values 10.25% and 75% for support and confidence respectively.
Reminding that since the same data and ontology are used, the same number of rules would be found at the end regardless of using or not our approach.
In addition, we repeat many times the trial execution on the rule pattern “Client → Product, Unit” by:
Varying minimum values for support and confidence. (Note that these values are fixed by our experts based on previous statistical studies.)
Using alternatively our approach or not (to compare and calculate gain).
The results and the gain in performance are discussed in the next section.

Extract from the results of Prontodam for the rule pattern “Client → Product, Unit”.
Results of the rule pattern “Client → Product, Unit”
Results of the average of 15 different rule patterns “Xi → Yi”
As the previous example, users can use Prontodam to build many rule patterns “Xi → Yi” (
Then, many executions can be performed on these 15 rule pattern by (1) varying minimum values for support and confidence, and (2) using or not alternatively our approach.
We give in Table 2 the average results of this experiment by using the average of the 15 rule patterns. To reduce display, we do not give the number of frequent item sets founded because the final goal is the number of generated rules and execution time.
Results and discussion
In this section, we discuss the results of experiments. For instance, in Table 2 we have recapitulated the results of the rule pattern given as example (see Section 4.3.1), the data context size, and the numbers of both frequent itemsets and generated rules. Note that the context is filtered with our approach, so we give a good reduction. Note also that the final goal is the number of generated rules obtained.
However, by using our approach we notice that only 109 frequent itemsets are founded, and 19 pertinent association rules are directly generated, so the execution time is 5 minutes and 22 seconds. On the other hand, without our approach, there are 525 frequent itemsets founded, 1516 pertinent rules generated which are filtered to 19 rules later than. So the execution time is 59 minutes and 33 seconds.
In Table 3, we give the results for general experiment that represent the average of the 15 rule patterns. Notice also that the same numbers of pertinent association rules are always found using ontology. However with our approach, the context is initially filtered, and so the frequent patterns and the target rules are obtained with a very high-speed manner and we give a high well reduction in all results.
Finally, different graphs are presented in the following for the average of the 15 rule patterns.
The graph at Fig. 11 compares and shows the great difference for the number of frequent itemsets with or without our proposal corresponding to different support and confidence values.
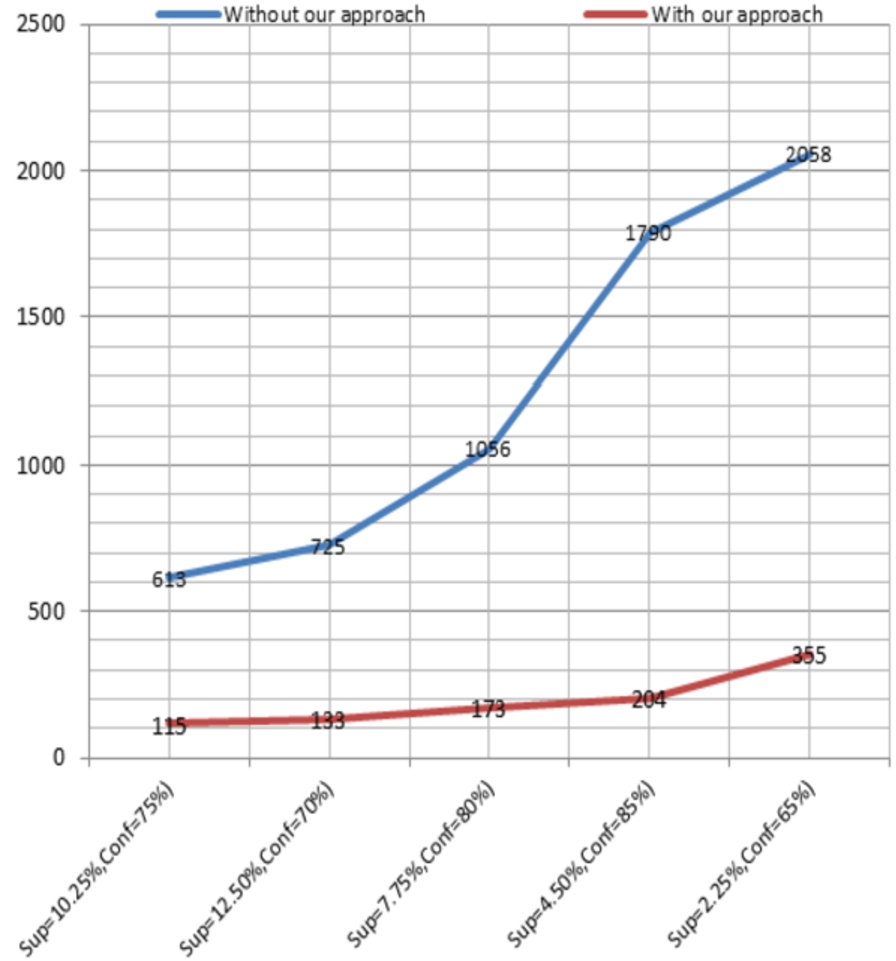
Comparing the number of frequent itemsets.
In the same way, the graphs Fig. 12 shows the great difference between the numbers of pertinent rules generated directly with and without our approach for the three experiments.
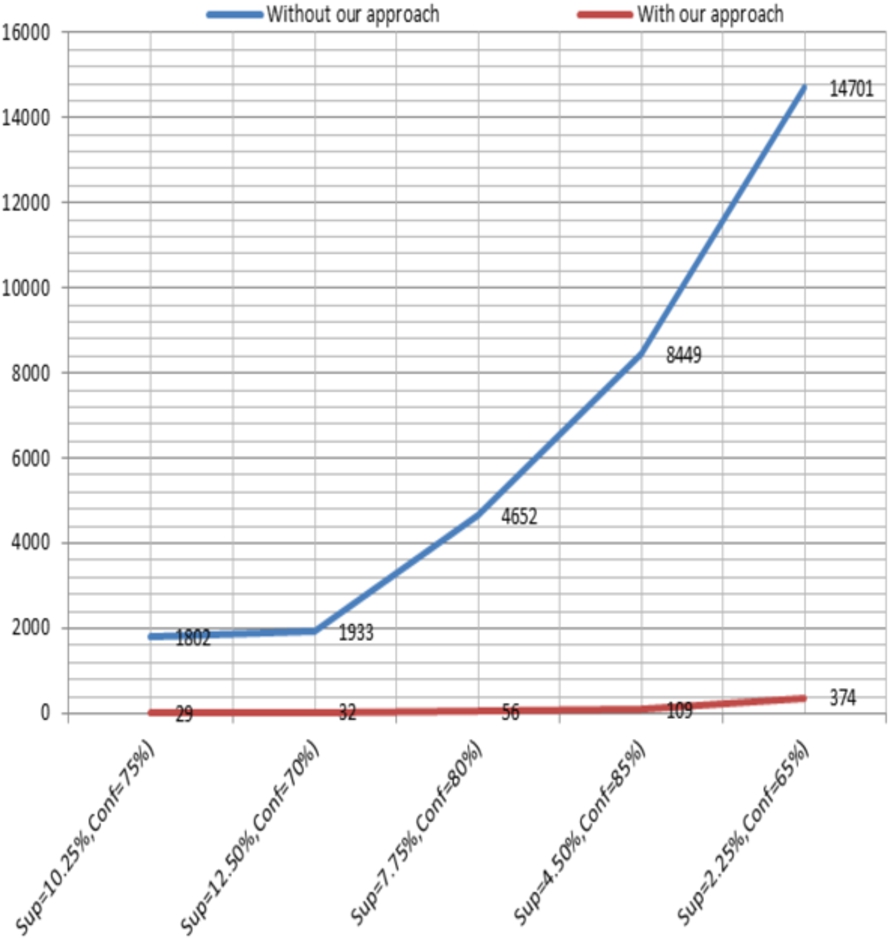
Comparing the number of generated rules.
The graph at Fig. 13 point up the profit given in execution time related to this experiment. We note the huge difference in execution time, and as the context increases gradually, the run time becomes more favorable for the suggested proposal.
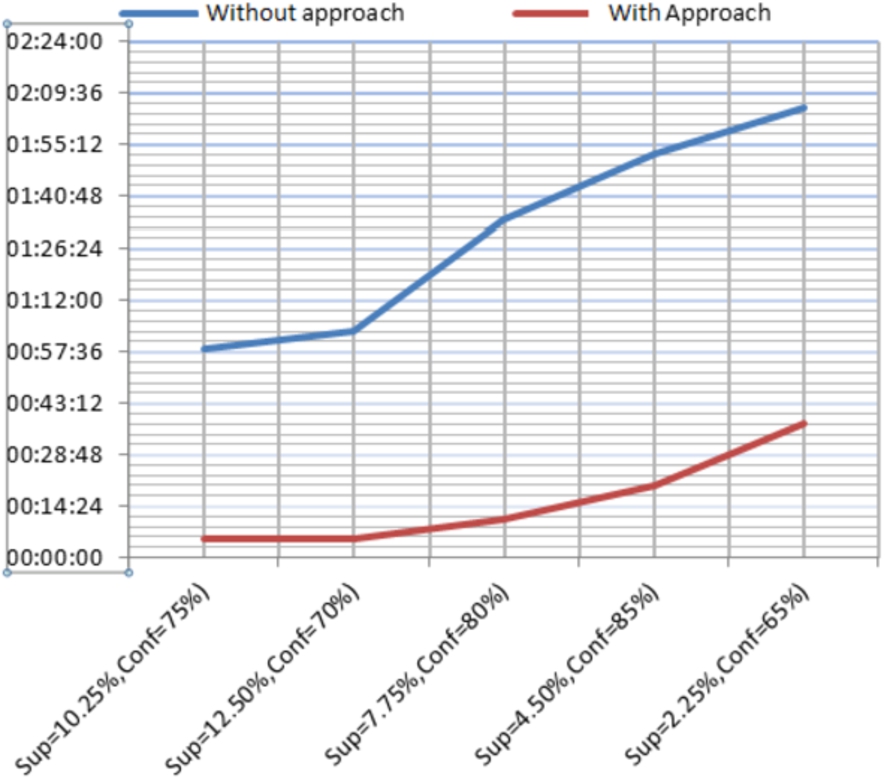
Comparing execution time for the experiment.
In this article, we have discussed the problem of association rules technique in Big data and especially with the NoSQL systems. We have gone over some proposals to solve the huge number of generated rules in general. We have chosen to integrate explicitly users’ knowledge by using ontology and rule patterns. The most interesting rules are automatically selected after generating all association rules. However, with the NoSQL systems this is not efficient and needs some adjustments.
To deal with this issue, we have presented an adjustment to improve the processing of generating pertinent association rules in such NoSQL systems. We use ontology with rule patterns to preselect data before any processing, and then filter at early step only the rule concerned by users’ choice. These data have to respect keys/values NoSQL model. Then, only the interesting rules are generated.
In order to prove the efficiency of our proposal, we have carried out a real experiment on industrial NoSQL data. After carefully scrutinizing the results of experiment, the adjustment given by our proposal allows to reduce significantly the execution time, the number of frequent itemsets, and only the interesting rules targeted by users are gererated. As result, this proposal proves its benefits increasingly and becomes very interesting in NoSQL systems.
As perspective, we plan to extend this work to a large-scale cloud environment, and use it for the NewSQL systems.