
Abstract
This paper proposes a novel algorithm for addressing multi-objective optimisation problems, by employing a progressive preference articulation approach to decision making. This enables the interactive incorporation of problem knowledge and decision maker preferences during the optimisation process. A novel progressive preference articulation mechanism, derived from a statistical technique, is herein proposed and implemented within a multi-objective framework based on evolution strategy search and hypervolume indicator selection. The proposed algorithm is named the Weighted Z-score Covariance Matrix Adaptation Pareto Archived Evolution Strategy with Hypervolume-sorted Adaptive Grid Algorithm (WZ-HAGA).
WZ-HAGA is based on a framework that makes use of evolution strategy logic with covariance matrix adaptation to perturb the solutions, and a hypervolume indicator driven algorithm to select successful solutions for the subsequent generation. In order to guide the search towards interesting regions, a preference articulation procedure composed of four phases and based on the weighted z-score approach is employed. The latter procedure cascades into the hypervolume driven algorithm to perform the selection of the solutions at each generation.
Numerical results against five modern algorithms representing the state-of-the-art in multi-objective optimisation demonstrate that the proposed WZ-HAGA outperforms its competitors in terms of both the hypervolume indicator and pertinence to the regions of interest.
Keywords
Introduction
Multi-objective optimisation is the search for solutions that display the best performance in the presence of multiple conflicting objectives, see e.g. [1, 2, 3].
With the exception of a few trivial problems, these types of problem often do not have a single optimal solution. Instead, a (finite or infinite) set of solutions will offer the same level of optimality whereby an increase in the performance of one objective will result in the decrease of another [4, 5, 6]. Two solutions of this description are said to not dominate each other and the set of solutions which do not dominate each other is referred to as a non-dominated front. Conversely, when a solution outperforms another solution in respect to all the considered objectives, the solution can be described as dominating the other. The theoretical set containing all the solutions which cannot be dominated is referred to as the Pareto set, Pareto front, or simply the Pareto.
The algorithms that address multi-objective optimisation problems attempt to find a set that approximates the Pareto front, namely the approximation set, see [7, 8, 9]. According to the demands of the real-world problems, this set can be used to select one or a few candidate solutions to solve the problem. For example, in engineering design, although the problem is likely to be naturally multi-objective, often only one solution must be ultimately chosen to perform the implementation of the design suggested by the algorithm, see e.g. [10, 11, 12].
For these reasons, multi-objective problems can be considered to require a two stage approach: during the first stage an approximation of the Pareto is identified, see [13, 14], and during the second stage the decision regarding which solution must be selected from the approximation set, is made. The second stage is focussed on Decision Making and the criteria which articulate the biases of the decision making process are referred to as Decision Maker (DM) preferences.
When solving real-world multi-objective problems, the ideal optimisation algorithm is one which converges to an approximation set consisting of non-dominated solutions which are within the DM’s Region of Interest (ROI). The ideal algorithm would ignore solutions which are not of interest to the DM, even if they are non-dominated, and instead focus on areas of the objective space which are of interest to the DM. The integration of DM preferences into the algorithm can be interpreted as a simplification of the complexity of the problem since, effectively, it corresponds to a reduction of the search space, similar to what happens in various fields of engineering. This logic is commonly applied in finite element methods, see [15].
Other examples in computational mechanics and engineering are reported in [16] for structural damage detection, in [17] for selecting the most suitable type of foundation, and in [18] for non-linear system parameter identification and a reduction of the mathematical model. An application to seismic retrofit design with algorithmic distribution over multiple cores and computers has been proposed in [24].
The formalisation of the concept of interest is connected to the concept of the pertinence of an approximation set illustrated in Figs 1 and 2. An approximation set offers good pertinence if most of its solutions belong to the ROI, see Fig. 1, and is composed of a small set of solutions. Subsequently, the DM is not overwhelmed with a large set of global trade-off solutions (illustrated in Fig. 2) when using expert knowledge to select their desired solution [25].
Furthermore, when a ROI is specified through the definition of preferences (i.e. the importance or goal of each objective with respect to the others is defined), this piece of information can be integrated within the optimisation algorithm to guide the search and pursue only pertinent solutions. An algorithm modified in this way is able to exploit the information about preferences during the search to discard trade-off solutions which do not fall within the desired region, and to pressure the search towards the region by influencing the algorithm’s selection operator, see [26]. This additional preference information ultimately reduces the area of feasible solutions within the objective space, thus reducing the computational effort needed to produce a diverse set of pertinent solutions.
An approximation set containing five solutions with ideal pertinence, i.e., all Pareto Efficient solutions are within the rectangle defined by the DM’s preference vector.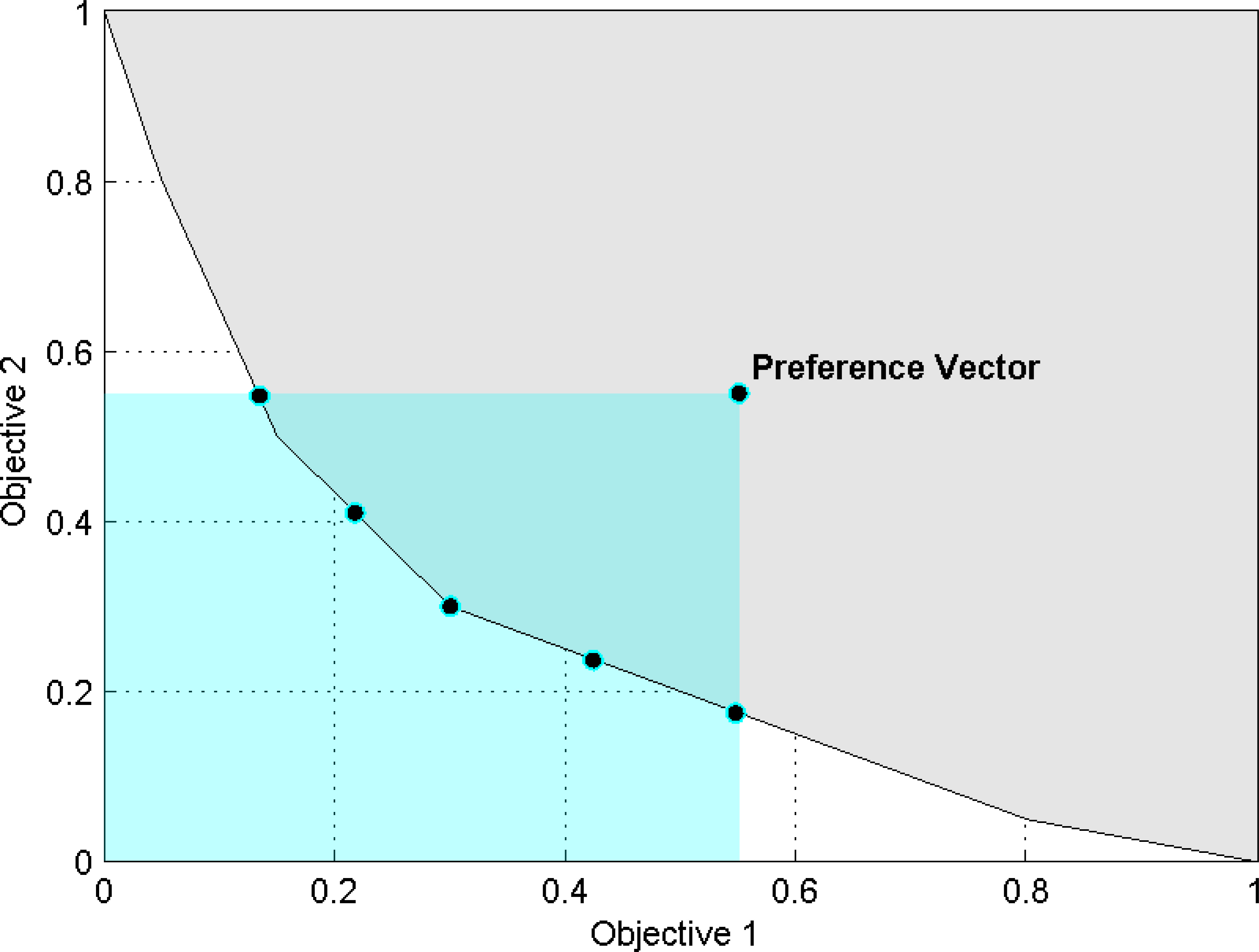
An approximation set containing seven solutions where four of them exhibit undesirable pertinence, i.e., there are four Pareto Efficient solutions that are not within the hyper-rectangle defined by the DM’s preference vector.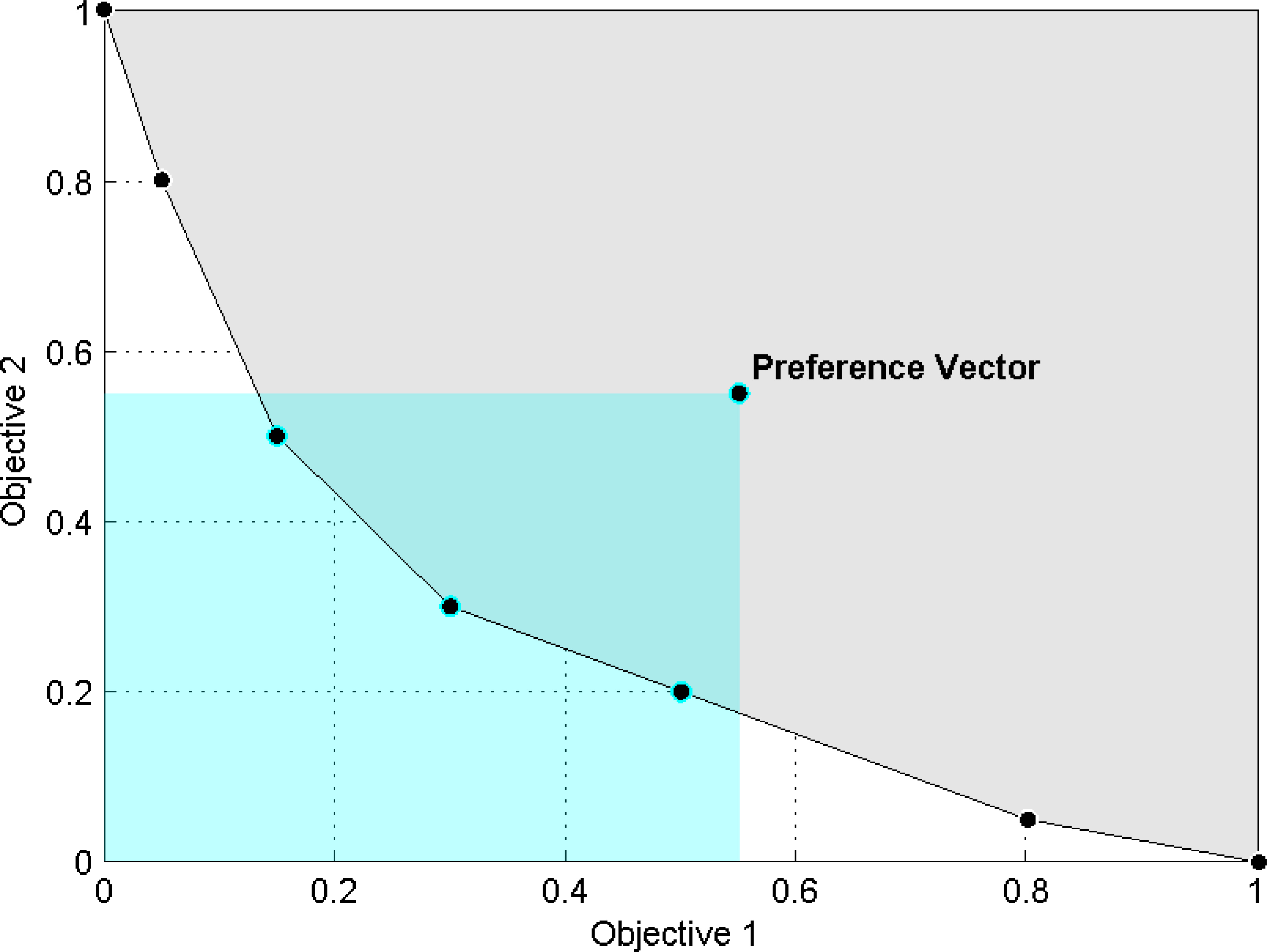
The action of the DM can occur in three moments of the optimisation, coinciding with the following approaches.
The main disadvantage of the a priori approach is that the DM may not be certain of their preferences prior to the optimisation process. As a result, some uninteresting areas of the search space could be unnecessarily explored and some areas of the search space which potentially deserve attention could be missed [20].
Whilst the a posteriori approach avoids this disadvantage by only considering preference information after the optimisation process, it does not offer any advantages throughout the optimisation process and causes an extremely high computational cost in comparison.
The progressive approach, which is the focus of this article, potentially enables the DM to alter their preferences during the optimisation process and incorporate knowledge that only becomes available during the search [28], such as the exact nature of trade-offs between objectives.
The technique of progressively incorporating preferences into the multi-objective optimisation process is referred to as progressive preference articulation, see [28, 29]. A comparative analysis of the various approaches of preference articulation is reported in [30] and in the talk [31].
One of the first schemes for progressive preference articulation in population-based meta-heuristics for multi-objective optimisation was introduced by [32], and extended the Pareto-based ranking scheme used in the Multiple Objective Genetic Algorithm (MOGA) [27] to allow preferences to be expressed throughout the execution of a population-based algorithm. Subsequently, in [33] preferences are integrated in the algorithm simplistically by means of linear maximum and minimum trade-off functions. In [34] two methods based on a biased crowding technique are presented and compared.
The R-Non-dominated Sorted Genetic Algorithm II (R-NSGA-II) presented in [35], combines a preference based strategy with an evolutionary multi-objective algorithm, in order to demonstrate how a preferred set of solutions near a number of reference-points can be found simultaneously. In [36] the
To overcome the shortcomings of not having preference information in the selection process of the Indicator-Based Evolutionary Algorithm (IBEA) [38], the Preference-Based Evolutionary Algorithm (PBEA) was introduced in [39]. In [40] an approach that integrates the DM’s preferences into an estimation of the dominated portion of the objective space (hypervolume) is presented. In [41] two ranking schemes integrating the preference articulation have been proposed. However, the calculation of the hypervolume indicator presents the drawback that it depends exponentially on the number of objectives and therefore becomes infeasible for multi-objective problems with many objectives, see [42].
To effectively incorporate the DM’s preferences in well-known multi-objective evolutionary algorithms, new variants of Pareto dominance relations have been recently proposed. Popular examples are the
More recently, the Non-dominated Sorted Genetic Algorithm III (NSGA-III) [46], a many-objective optimisation algorithm, also aims to allow the incorporation of preference information. The incorporation of preferences is implemented by simply providing different weightings or “reference-points” when initialising the algorithm. However, there is no way for a decision maker to provide a preference vector or “goal”, they must instead design a structure of weights which are distributed to reflect the preferences. Although the NSGA-III implementation appears to have several ambiguities, see [47], the algorithm is an important contribution to the field.
Another fundamental and modern algorithm which makes use of structured weights, and enhances its convergence performance by decomposing the domain, is the
Preference articulation is applied to several engineering many-objective problems in [49]. Reference-points, similar to those employed in NSGA-III, are also used in [50]. The functioning of the latter is based on the use of an achievement scalarising function and the classification of solutions into several fronts.
In [51] an interactive algorithm based on R-NSGA-II is proposed, and in [52] R-NSGA-II is modified by integrating a stochastic local search in a memetic fashion, see [53, 54, 55, 56].
Since the objectives of the problem are established a priori but their importance is adjusted on-line by human experts, progressive preference articulation can be interpreted as an interactive design method and can be linked to a large and interesting portion of the literature. In [57], a system that interactively collects data and predicts the posture of workers for medical purposes has been proposed. An interactive fuzzy multi-objective algorithm for engineering problems has been proposed in [58]. Interactive design with reference to steel structure design is achieved by integrating fuzzy logic into the constraint handling in [59, 60]. In order to handle large steel structures the algorithm proposed in [61] expands the previous the two studies above in a parallel fashion.
This paper proposes a novel progressive preference articulation mechanism for multi-objective optimisation problems. Furthermore, this mechanism is incorporated into an optimisation framework recently proposed in the literature, namely the Covariance Matrix Adaptation Pareto Archived Evolution Strategy with Hypervolume-sorted Adaptive Grid Algorithm (CMA-PAES-HAGA), see [62]. The resulting algorithm has been thoroughly tested and compared against modern algorithms which implicitly and explicitly incorporate preference articulation.
The remainder of the article is arranged in the following order: Section 2 describes all the components of the proposed algorithm. Section 3 describes the experimental setup, and presents the results of the multiple comparison between the proposed algorithm and five other many-objective optimisation algorithms, all of which represent the state-of-the-art in the field. Section 4 concludes the study and offers research directions for future work.
Weighted Z-score Covariance Matrix Adaptation Pareto Archived Evolution Strategy with Hypervolume-sorted Adaptive Grid Algorithm
This section describes the proposed algorithm, named the Weighted Z-score Covariance Matrix Adaptation Pareto Archived Evolution Strategy with Hyper- volume-sorted Adaptive Grid Algorithm. The proposed algorithm will be referred to as WZ-HAGA hereafter for brevity.
The proposed approach consists of two significant parts, these are:
The incorporation of DM preferences within the search logic to drive the search towards the ROI: the Weighted Z-score (WZ) preference articulation, The external framework for multi-objective optimisation that hosts the progressive incorporation of the WZ preference articulation: CMA-PAES-HAGA.
After a brief presentation of the required basic definitions and notation in Section 2.1, this section proceeds with the two main parts of the proposed approach as listed above, i.e. the WZ preference articulation (Section 2.3) and the external multi-objective optimisation framework (Section 2.2). The resulting algorithm is then outlined in Section 2.4. Finally, with the purpose of highlighting the differences between a priori and progressive incorporation of DM preferences, Section 2.5 contrasts both the implementations.
Background – notation
This section briefly presents some essential notation and background information that is required to clearly define the proposed progressive preference articulation approach.
Without loss of generality, let us define a general multi-objective optimisation problem (MOP) with
where
Given a population-based search algorithm, let us also define a population
In this paper we work within an evolution strategy framework. In accordance with the notation used in the field, the parent population size is indicated with
The external framework embedding the WZ preference articulation operator is the CMA-PAES-HAGA framework proposed in [62]. This algorithmic framework uses the search exploration of the Pareto Adaptive Evolution Strategy (PAES) using a random perturbation aided by a Gaussian distribution, see [21], combined with Covariance Matrix Adaptation logic, see [63]. The selection mechanism is based on the hypervolume indicator by means of a fast algorithm, see [62, 64] and is referred to as the HAGA selection scheme. The latter is a selection algorithm that maps a grid within the objective space and uses the grid location of the solutions to estimate the hypervolume indicator, i.e. the portion of objective space dominated by the approximation set. The estimation technique in [64] is almost as reliable as the hypervolume indicator, but is much faster in terms of calculation time.
Although all the implementation details about this framework are reported in [62], a simplified pseudo-code listing describing the working principles of CMA-PAES-HAGA is displayed in Algorithm 1 for the sake of clarity.
CMA-PAES-HAGA execution cycle
Initialise parent population
composed of
parent solutions and corresponding objective values
while termination criteria not met do
for all the
solutions of the offspring population do
Generate an offspring solution by variation operators, i.e. perturbation by means of Gaussian distribution and covariance matrix, as in [21, 63]
Check that the solution is within the bounds of the decision space. If it is outside the decision space, the solution is saturated to the closest bound.
Calculate the objective values of the solution
end
for
Perform the HAGA selection to compose the new parent population (select
solutions) by hypervolume estimation as in [62, 64]
Update the covariance matrix adaptive parameters as in [63]
end
while
CMA-PAES-HAGA execution cycle
Initialise parent population
Generate an offspring solution by variation operators, i.e. perturbation by means of Gaussian distribution and covariance matrix, as in [21, 63]
Check that the solution is within the bounds of the decision space. If it is outside the decision space, the solution is saturated to the closest bound.
Calculate the objective values of the solution
Perform the HAGA selection to compose the new parent population (select
Update the covariance matrix adaptive parameters as in [63]
Weighted Z-score (WZ) preference articulation is a recently proposed method for incorporating DM preferences, based around the use of z-scores (or standard scores) from Statistics [65, 66]. The purpose of the following procedure is to assign a score to each candidate solution which describes the position of the point (in the objective space) with respect to the ROI. These scores are then used during the selection.
Let us consider a population
Hence, we indicate with
With these values, a matrix, namely the
Each
With the
The entries of the
Thus, the generic individual
Furthermore,
Subsequently the scalar
The scalar
Let us indicate with
When the number of solutions within the ROI has satisfied the threshold (
Thus, each candidate solution
However, if
It can be observed that
With the entries of
At first, the normalised values (between 0 and 1)
where
The entries
The purpose of Eq. (10) is to ensure that those objectives that least satisfy the DM requirements must be corrected by the weighting factor
The final score
Thus, each candidate solution
This method attempts, when many solutions are outside the ROI, to move the search towards the production of solutions that are close in proximity to the ROI and within it, but does not attempt to minimise the solutions beyond the edges of the ROI.
For the sake of clarity, the working principles of the weighted Z-score preference articulation selection are highlighted in Algorithm 2.
Weighted Z-score preference articulation
Input the
Calculate the
Calculate the
Calculate
Calculate
Calculate
Calculate
Normalise
Calculate the element
Calculate
Let us consider a population
The selection of the WZ-HAGA, see Algorithm 1, operates in one of the following four phases to select the
Phase 1 is active when there are no solutions in the current approximation set which are within the ROI, i.e.
Phase 2 is active whilst the number of solutions in the ROI is below the threshold
Phase 3 is active when the number of solutions in the ROI equal or exceed
Phase 4 is active when among the
By using these four phases, the optimisation process is able to quickly get as close as possible to the DM’s expressed ROI, produce solutions within it, have a parent population with solutions only within that ROI, and then converge further into that ROI with a diverse approximation set. Finally, it is possible to regress from later phases to earlier ones depending on the optimisation context, i.e. if the DM alters their preferences during the optimisation process.
A priori and progressive preference articulation
Although this article proposes a progressive approach to preference articulation, WZ-HAGA can be implemented either with only a priori articulation of preferences, or Progressive Preference Articulation herein referred to as WZ-HAGA (PPA) in this section.
The pseudocode listing for the execution cycle of WZ-HAGA (PPA) has been illustrated in Algorithm 3. The pseudocode highlights the mechanism for handling solutions that are inside or outside the ROI by means of the phases described in Section 2.4. In its a priori version of the same algorithm, the input of the DM is established prior to the beginning of the algorithm execution and remains static throughout the entire optimisation process. In the PPA version described in Algorithm 3, the optimisation process can be configured to prompt the DM for a new preference point at configured intervals (e.g. every 100 generations). At these intervals, HAGA is used to reduce the approximation set for the DM, such that they are able to use new information about the objective space and the emerging trade-offs, to make an informed decision on a new set of preferences. The optimisation process then continues without discarding the existing solutions.
Progressive preference articulation and selection within WZ-HAGA
Input the initial preference vector
.
Initialise parent population in the search space and the corresponding vectors of objective values
while termination criteria not met do
(Optional) Input the updated preferences expressed by the DM and consequent modification of vector
and thus the ROI.
Progressive Preference Articulation
for all the offspring solutions
do
Apply CMA-PAES variation operators to the parent population in order to generate an offspring solution
Calculate and store the objective function values
Check the objective values and whether or not the solution is within the ROI
Merge parent and offspring population into
end
for
Calculate the number
of solutions within the ROI by Eq. (5) and perform the selection of the new parent population (
candidate solutions):
Selection mechanism
if
then
Phase 1: Use the
score values to select the best
solutions (W-phase)
else
if
then
Phase 2: Save the
solutions inside the ROI and use the
score values to select the best remaining
solutions (W-phase)
else
if
then
Phase 3: Save the
solutions inside the ROI and use the
score values to select the best remaining
solutions (Z-phase)
else
if
then
Phase 4: Discard the solutions outside the ROI and apply HAGA selection scheme [62, 64] to select
candidate solutions
end
if
end
while
Progressive preference articulation and selection within WZ-HAGA
Input the initial preference vector
Initialise parent population in the search space and the corresponding vectors of objective values
(Optional) Input the updated preferences expressed by the DM and consequent modification of vector
Apply CMA-PAES variation operators to the parent population in order to generate an offspring solution
Calculate and store the objective function values
Check the objective values and whether or not the solution is within the ROI
Merge parent and offspring population into
Calculate the number
Phase 1: Use the
Phase 2: Save the
Phase 3: Save the
Phase 4: Discard the solutions outside the ROI and apply HAGA selection scheme [62, 64] to select
This section presents the results of this study. The experimental setup is described, and then the results are presented and discussed. Finally, a real-world application of the proposed WZ-HAGA is demonstrated within the field of engineering control systems design.
Experimental setup
The performance of the proposed algorithm has been evaluated and compared against five state-of-the-art multi-objective optimisation algorithms. The algorithms included in this study are:
WZ-HAGA: with reference to Subsection 2.4 the parameter NSGA-III: with reference to [46] crossover probability 0.9, crossover distribution index 30, mutation distribution index 20;
g-NSGA-II: with reference to [44, 67] crossover probability 1, crossover distribution index 30, mutation probability r-NSGA-II: with reference to [43, 67] crossover probability WV-MOEAP: with reference to [67, 45] cros- sover factor
Preference vectors throughout the optimisation process
Preference vectors throughout the optimisation process
All the algorithms have been run with a population size of 100 individuals (in the WZ-HAGA case,
The competing algorithms belong to two groups: while NSGA-III and
The experiments have been designed to allow the fair comparison of the following performance characteristics:
The hypervolume indicator achieved by the final population of each considered algorithm on each considered test-case, see [68, 22]. This parameter measures the quality of the approximation set. The hypervolume indicator describes the portion of objective space that is dominated by the approximation set detected by the algorithm (thus the higher the hypervolume the better the performance). The number of solutions within the ROI achieved by the final population (the non-dominated final approximation set) of each considered algorithm on each considered test-case. This shows how the algorithm is able to focus the search towards the ROI and recover from the changes in the preference vector.
The proposed WZ-HAGA has been tested on ten selected benchmark problems from the WFG [69] and DTLZ [70] test-suites. The test problems have been selected to prepare a benchmark exhibiting a variety of features (such as separability, multimodality, convex/concave/degenerated geometries, etc.). The list of studied problems includes: WFG1, WFG3, WFG5, WFG9, DTLZ1, DTLZ2, DTLZ3, DTLZ4, DTLZ5, and DTLZ6. Detailed descriptions of the characteristics of the benchmark problems can be found in [69, 70, 71, 72].
All WFG test problems have been configured with the following parameter values: number of objectives
All DTLZ test problems have been configured with the following: number of objectives
In order to test the performance of each considered algorithm in the presence of progressive preference articulation, the initial preference vector has been modified twice during the optimisation process. Thus, there are three preference vectors for each test problem: the first (initial) preference vector is in effect from the first generation, the second preference vector is in effect after 33% of the generations are completed, and the third preference vector is in effect after 66% of the generations are completed.
The preference vectors, for each benchmark problem, are displayed in Table 1, where
At each stage of the optimisation, the preference vector
The numerical results for the ten seven-objective optimisation test-cases have been listed in Table 1, these have been divided according to the two performance characteristics mentioned above.
The performance of the algorithms in terms of the hypervolume indicator values is displayed in Tables 2 and 3, for WFG and DTLZ problems respectively,
WFG test-case hypervolume results
WFG test-case hypervolume results
DTLZ test-case hypervolume results
WFG test-case ROI results
DTLZ Test-case ROI Results
(a–c) Mean hypervolume quality of the considered algorithms at each generation of the test-cases: WFG9 (0–33%), WFG9 (33–66%), and WFG9 (66–100%); (d–f) Mean number of solutions within the ROI for each of the considered algorithms at each generation of the test-cases WFG9 (00–33%), WFG9 (33–66%), and WFG9 (66–100%).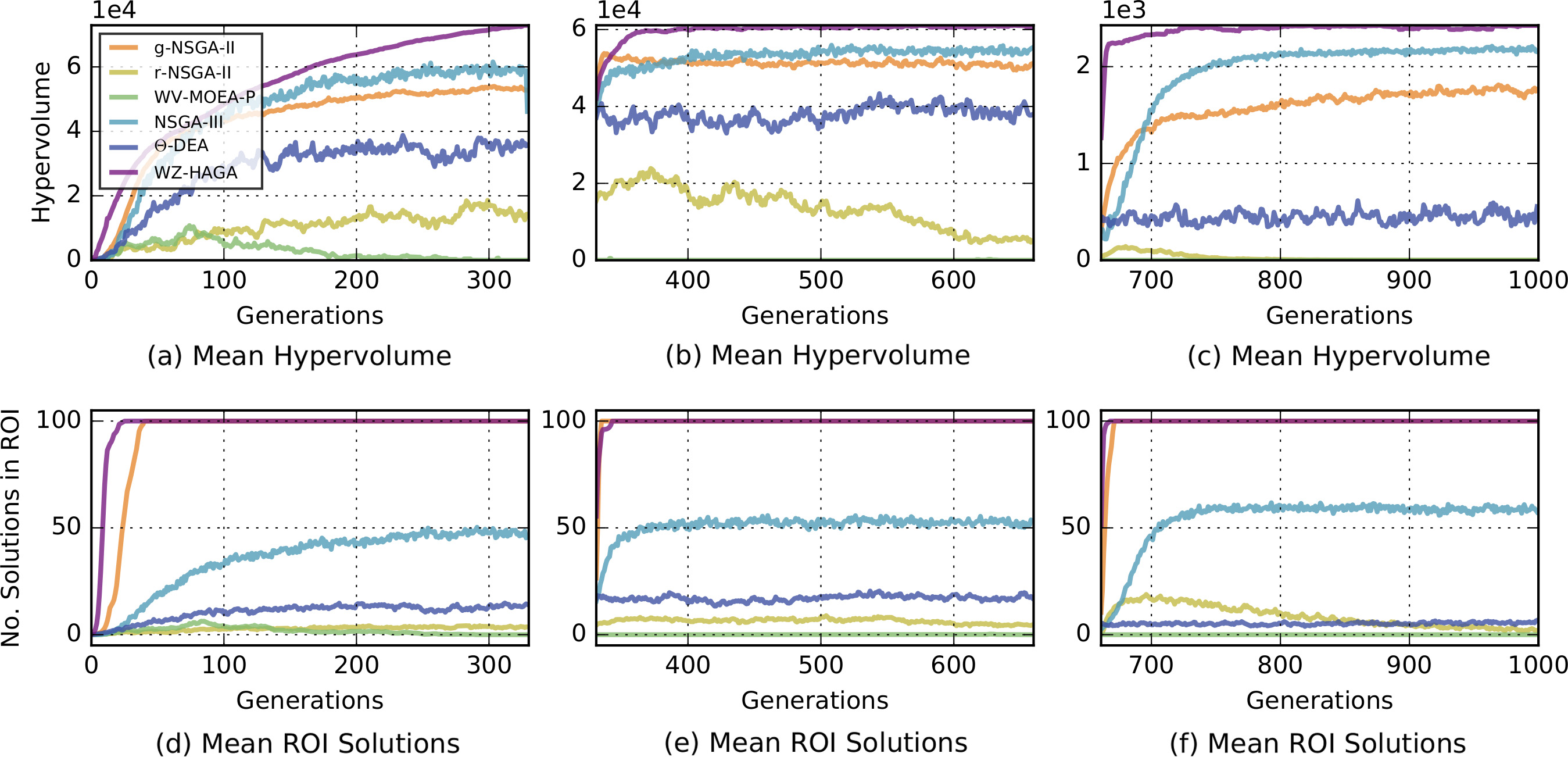
whilst the performance in terms of the number of solutions within the ROI is reported in Tables 4 and 5 respectively. In each table, mean (Mean), median (Median) and standard deviation (St.D.) values are displayed. The best results are emphasised in bold.
In order to verify the statistical significance of the results, the Wilcoxon signed-rank test [73] has been performed on the mean values where WZ-HAGA is taken as the reference. The statistical significance is indicated with a “
As shown in Table 2, the proposed WZ-HAGA achieves the best performance, regarding hypervolume values on WFG problems, this holds true in the majority of the test-cases (it is outperformed only twice out of twelve times). In all the other test-cases the proposed WZ-HAGA significantly outperforms all of its competitors. Specifically,
Results in Table 3 show that for the DTLZ problems the proposed WZ-HAGA is never outperformed as it performs either equally or significantly better than its competitors. It must be noted that in the DTLZ benchmark problems some of the selected preference vectors are purposely set beyond the theoretical points of Pareto front, see [70] and DTLZ3 appears to be unfeasible for all the algorithms in this study. This choice has been made to realistically simulate the interaction between the DM (which may be overwhelmingly optimistic/demanding) and the optimisation algorithm (which has to deal with the mathematical limitations of the problem).
The numerical results listed in Table 4, in terms of the number of solutions within the ROI, show that WZ-HAGA outperforms all its competitors in the majority of the WFG problems considered. In the majority of the cases, WZ-HAGA is able to maintain its population within the ROI. The proposed WZ-HAGA is outperformed only by g-NSGA-II for the WFG1 problem (first two stages: 0–33%, and 33–66%). The results in listed Table 5 show that WZ-HAGA is never outperformed on the DTLZ problems.
Figures 3 and 4 show two examples of the trend of average (over the 30 runs) hypervolume indicator values and numbers of solutions within the ROI, during the optimisation process. Figure 3 shows the evolution for WFG9, while Fig. 4 shows the performance parameters for DTLZ4. In each figure, the upper three subplots show the hypervolume variation in the three stages of the optimisation, while the lower three subplots show the variation of the number of solutions falling within the ROI.
(a–c) Mean hypervolume quality of the considered algorithms at each generation of the test-cases: DTLZ4 (0–33%), DTLZ4 (33–66%), and DTLZ4 (66–100%); (d–f) Mean number of solutions within the ROI for each of the considered algorithms at each generation of the test-cases DTLZ4 (0–33%), DTLZ4 (33–66%), and DTLZ4 (66–100%).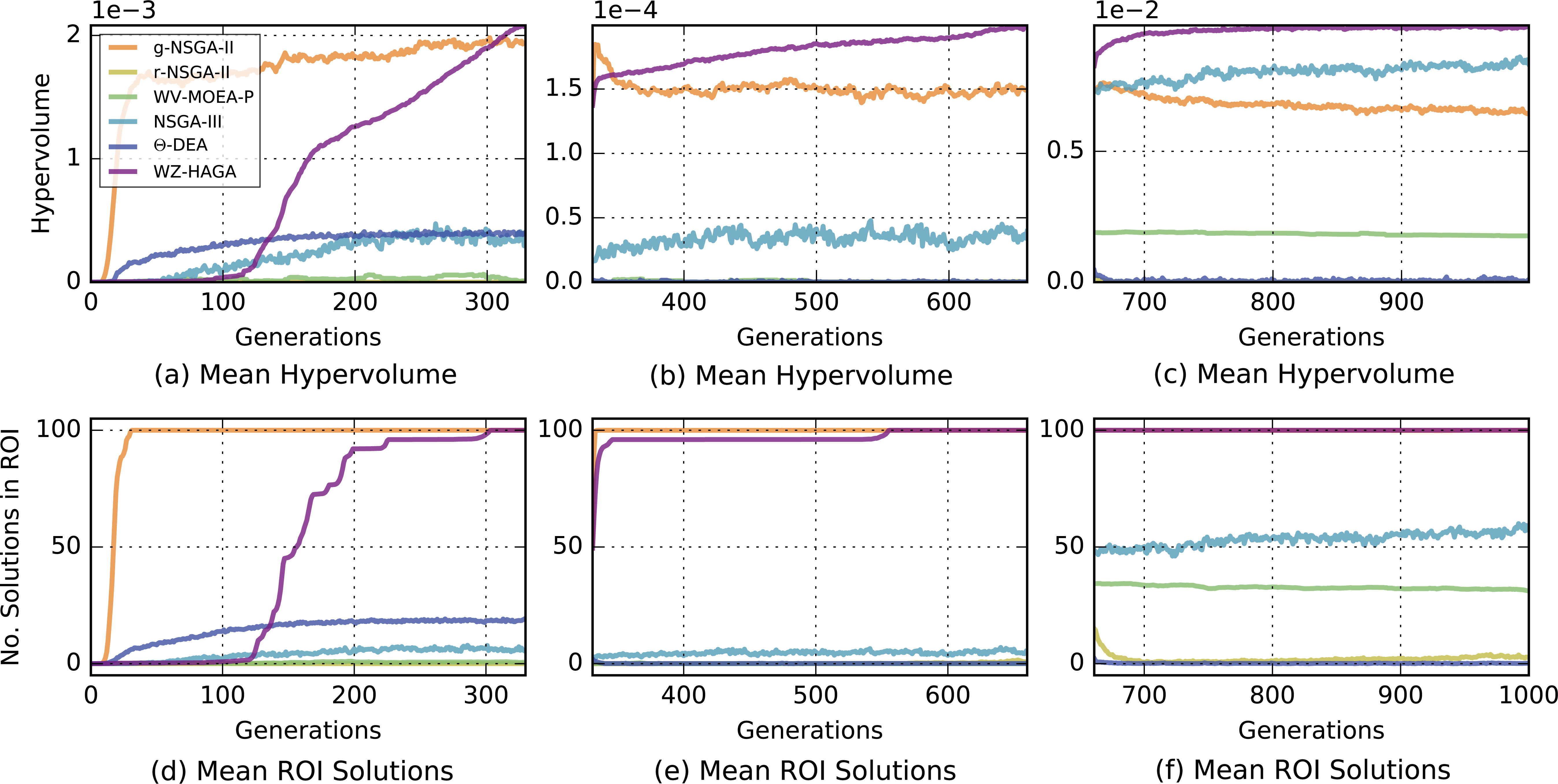
Figure 3 shows that WZ-HAGA displays the best hypervolume performance. The WZ-HAGA hypervolume rapidly achieves the highest values, and proceeds to maintain steady growth during the later generations. It is worth noting that when the preference vector changes the hypervolume value drops (for all the algorithms) as this preference vector is used to calculate the hypervolume. WZ-HAGA recovers quickly from this drop and achieves higher values, thus displaying resilient and robust behaviour. Some other algorithms, such as WV-MOEAP, appear to be unable to recover from the change in the preference vector after some initial improvements in the hypervolume values. NSGA-III and g-NSGA-II also display resilient behaviour, although they are outperformed by WZ-HAGA in this regard.
The results in terms of solutions in the ROI show that WZ-HAGA and g-NSGA-II display a similar performance. For the specific problem, both these algorithms rapidly produce a population entirely within the ROI within the first 50 generations. This is because they both explicitly employ information regarding the preference vector within their search. The NSGA-III algorithm also displays good performance. According to our interpretations, this fact is due to the NSGA-III logic that encodes some DM information through its reference vector, and then makes an implicit use of it during the search.
Figure 4 shows that, for this problem, g-NSGA-II displays remarkably good performance, especially in the early generations (0–33%). It can be observed that g-NSGA-II is faster than WZ-HAGA in reaching a high hypervolume indicator value and at getting the entire population within the ROI. However, when the preference vector is changed, WZ-HAGA displays resilient behaviour in comparison to g-NSGA-II. This is clearly visible for the hypervolume results. While g-NSGA-II drops in hypervolume performance and does not appear to recover, WZ-HAGA quickly reaches higher hypervolume values.
The three main axes of an aircraft body.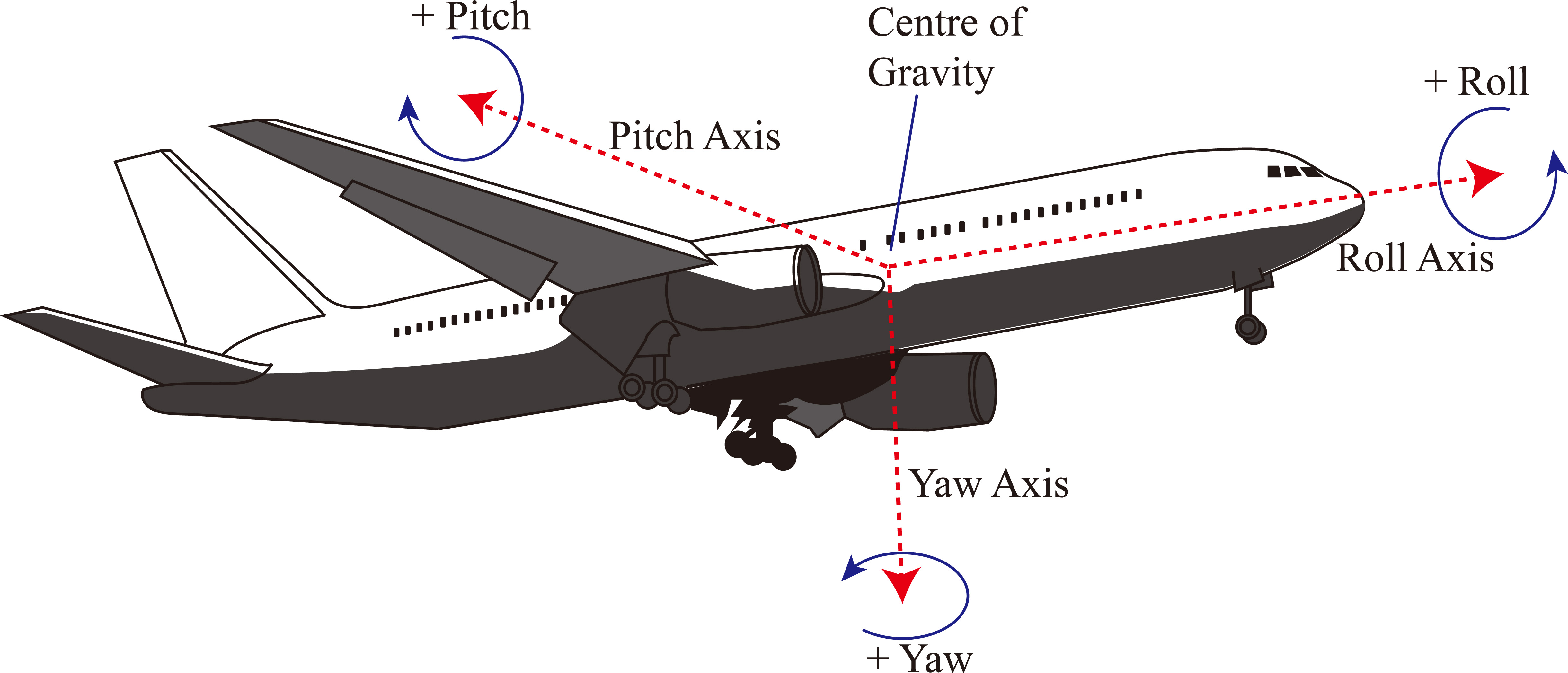
In order to demonstrate the practical usability of the proposed WZ-HAGA, it has been applied to the design of the flying control system of a fighter vehicle (aircraft). Figure 5 presents an illustration of an aircraft with the three main axes of motion labelled: the Roll (longitudinal) axis
From the perspective of this work, an aircraft is characterised by the following (time-dependent) state vector
where
The control vector is also expressed as:
The control problem under study consists of finding those gain coefficients
The spiral root The damping in roll root The dutch-roll damping ratio The dutch-roll frequency The bank angle at 1 second The bank angle at 2.8 seconds The control effort
The first four objectives in the list refer to undesired oscillations of the airplane, the fifth and and sixth objectives refer to the position of the airplane in crucial moments of the flight according to Military Specification [76, 77], the last objective refers to the fact that small gains in absolute values are preferred to guarantee the stability of the controller. Details about the controller can be found in [74].
In order to give a mathematically rigorous description of the multi-objective optimisation problem, let us consider the kinetic energy matrix
Let us now consider the following matrix equation:
LATCON preference vectors
LATCON hypervolume and ROI results
Comparison with results from the original article
The objective functions
The objective functions
Further details regarding the aircraft dynamic model and the problem variables are available in [77]. This optimisation problem will be referred to as Lateral Controller Synthesis (LATCON) herein.
By using the same notation above, the preferences of the LATCON problem are displayed in Table 6.
(a–c) Hypervolume quality of the considered algorithms at each generation of the different stages: 0–33%, 33–66%, and 66–100%; (d–f) Number of solutions within the ROI for each of the considered algorithms at each generation of the different stages 0–33%, 33–66%, and 66–100%.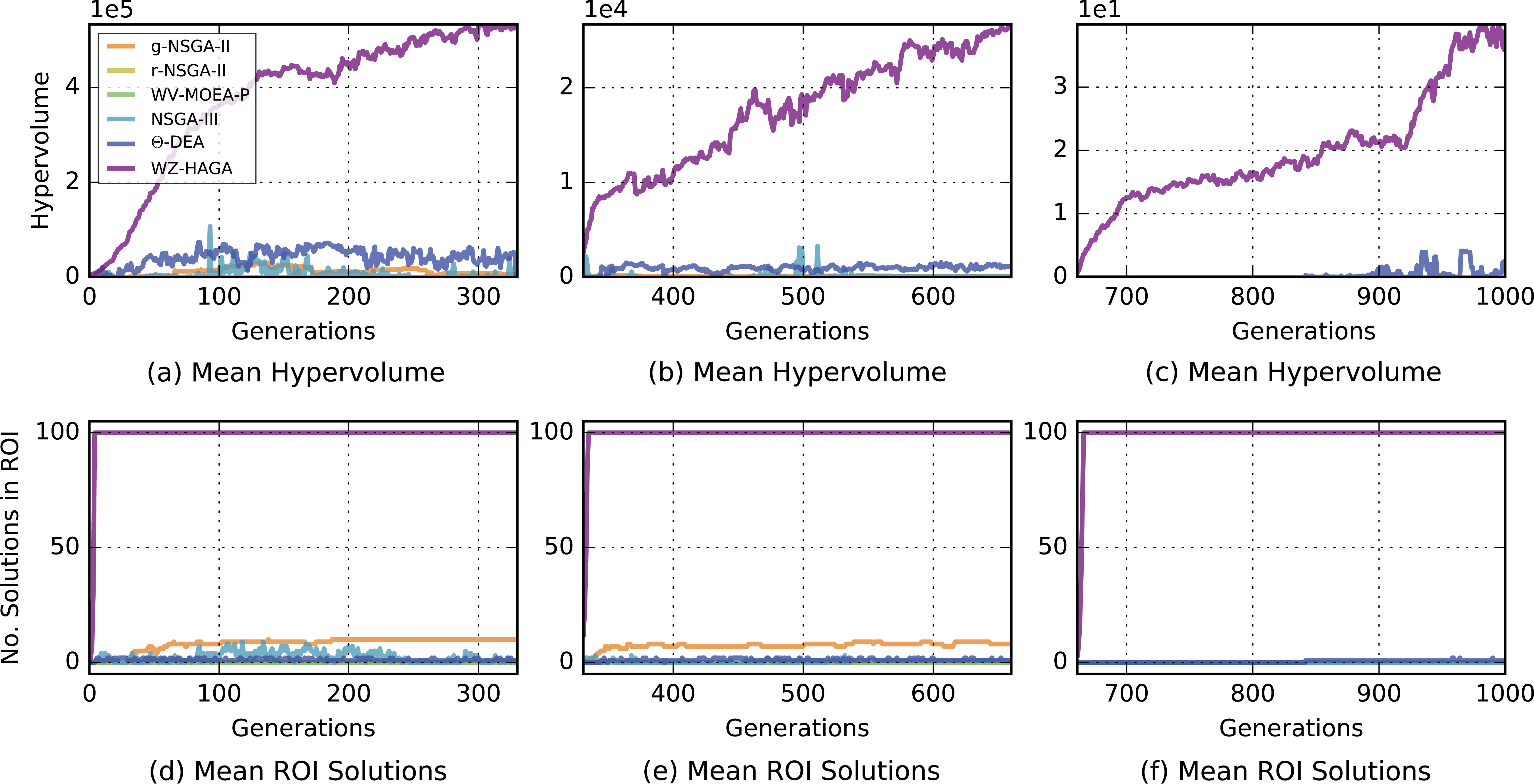
Although a detailed explanation of the physical problem does not fall within the scopes of this article, what follows is a brief explanation of the preference vectors in Table 6. Mathematically, the meaning of the preference vector is that each objective function
From an engineering perspective, negative eigenvalues (in their real part) lead to a stable control system but a higher performance is generally obtained when the eigenvalues are close to the imaginary axis. We are fixing a range that guarantees stability and a minimal performance of the control system (given by the
The same algorithms presented above with the same parameter setting above have been applied. The numerical results in terms of the hypervolume and solutions belonging within the ROI (mean values and Wilcoxon signed-rank test [73]) are displayed in Table 7. A graphical representation of the LATCON results is displayed in Fig. 6.
In order to better understand the meaning of the solutions detected by WZ-HAGA, a solution has been randomly selected from its final approximation set. The objective function values of this solution have been then compared against those obtained by one of the four solutions detected by the method originally proposed in [74]. These results are displayed in Table 8. It can be observed that the WZ-HAGA solution dominates the solution found in [74].
The results suggest that WZ-HAGA is able to quickly (within a few generations) find solutions within the ROI and continue to converge towards an approximation set which dominates more of the objective space. Following the beginning of each change in DM preferences, it can be observed that the entire population has converged to being within the ROI after at most ten subsequent generations. The reaction of the hypervolume indicator is slower but steadily grows within each stage and reaches the highest value, see Fig. 6.
The competitor algorithms, on this problem, display a significantly poorer performance than the proposed WZ-HAGA. The main limitation of these algorithms, including those that make use of progressive preference articulation, is that they appear to be unable to find enough solutions within the ROI.
This paper introduces a method for progressive preference articulation based on statistical theory used in a priori preference articulation, and integrates it within a previously proposed algorithmic framework for multi-objective optimisation. The proposed algorithmic component checks the number of solutions within the ROI indicated by the DM, and biases the search towards the ROI when not enough solutions are pertinent. An adaptive mechanism modifies the bias on the basis of the number of solutions within the region of interest, thus reacting every time the decision making circumstances change. A novel implementation of a complete algorithm for interactive multi-objective optimisation (WZ-HAGA) is then proposed.
The proposed WZ-HAGA has been thoroughly tested against five modern algorithms on a number of test problems and a real-world test-case. The numerical results show that the proposed method significantly outperforms its competitors in eight problems out of the ten considered. In these eight test-cases WZ-HAGA outperforms its competitors in terms of both the hypervolume indicator and the number of detected solutions within the ROI. The proposed WZ-HAGA also outperforms the other algorithms when compared within the real-world control engineering application.
It was found that WZ-HAGA, which uses an aggressive and targeted approach to selection pressure, is better suited to finding a ROI which has been defined by the DM’s preferences. In the presence of changing preferences throughout the optimisation process, i.e. progressive preference articulation, WZ-HAGA quickly finds the new preferred solutions and outperforms the considered algorithms in both the hypervolume indicator quality of the approximation set and the number of solutions found within the ROI.