
Abstract
Association rule mining is one of the most important tasks to describe raw data. Although many efficient algorithms have been developed to this aim, existing algorithms do not work well on huge volumes of data. The aim of this paper is to propose a new genetic programming algorithm for mining association rules in Big Data. The genetic operators of our proposal have been specifically designed to avoid a growing in the complexity of the solutions without an improvement in their fitness function values. Furthermore, it introduces a repairing operator to improve the convergence. Additionally, to facilitate its application on real world problems a grammar has been included, allowing it to introduce subjective knowledge into the mining process and to reduce the search space. Due to the growing interest in data gathering, a unique implementation of the proposed algorithm is not useful so different implementations (considering different architectures such as RMI, Hadoop and Spark) are required depending on the data size. All these adaptations obtain exactly the same solutions as those of the original algorithm since they only differ on the software architectures. The experimental study considers more than 75 datasets and 14 algorithms and the results reveal that the proposed algorithm obtains excellent results for more than 12 quality measures. The scalability of the proposal is also analyzed by considering the three parallel implementations on high dimensional datasets (3,000 millions of instances) and file sizes up to 800 GB.
Introduction
As technology advances, high volumes of valuable data are generated in modern organizations. Nowadays, the extraction of knowledge from such raw massive data is a priority to support decision making. It has driven and motivated the research in improving techniques for data analysis in such massive datasets, giving rise to the new buzzword Big Data [30]. This term encompasses a set of techniques to face up the problems derived from the management and analysis of these huge quantities of data [10].
The extraction of patterns of interest that represent intrinsic and important properties of data plays an important role in data analysis. Nevertheless, the knowledge extracted by a single pattern might be meaningless, and a more descriptive analysis can be required. In this sense, the concept of association rules was proposed by Agrawal et al. [2] as a way of describing correlations within patterns of potential interest. Association rule mining was firstly described in the context of market basket analysis [40], where it was used to determine which products were bought together. Nowadays, though, the applications are not limited to the market basket analysis and more and more domains [16, 18, 26] are interested in using this kind of relationships.
First approaches in the association rule mining [1] field were based on the Apriori algorithm. It is an exhaustive search algorithm that extracts associations of interest by dividing the problem into two sub-tasks: (1) finding patterns whose frequency of occurrence is greater than a minimum threshold; and (2) extracting association rules from the previously obtained patterns. Despite the fact that this first algorithm [2] worked well in many different fields, the number of applications has grown exponentially and this rapid increment in size and number of datasets has given rise to some limitations. For instance, obtaining all the rules could be unfeasible if the dataset has a high number of
In order to overcome existing drawbacks in the mining of association rules, many research studies [36] have been focused on extracting these relationships by means of Evolutionary Algorithms (EAs). The use of EAs enables to extract association rules in a single step, not requiring a previous subtask for mining frequent patterns. Multi-objective optimization [31, 32] has been also considered by different researchers to extract association rules by means of EAs [12, 20, 21]. Additionally, some researchers [22] have applied EAs for optimizing patterns in continuous domains, not requiring any previous discretization step. But even more important than all of this is the reduction in both the computational time and the memory requirements by considering the pattern mining problem as a combinatorial optimization issue. Even when really efficient algorithms have been proposed for mining association rules, truly Big Datasets hamper the process of mining association rules. In the 1990s, 20 attributes were called a large-scale problem [27]. Nowadays, the number of attributes in many areas, e.g. gene analysis, can easily reach thousands or even millions [33]. Under these circumstances, new forms of processing data are needed to enhance the process of decision making and knowledge discovery when massive data are considered [14, 17]. Additionally, parallel computing is being applied in this field, by considering both multi-core processors and multiple computers through a Remoted Method Invocation (RMI). In this sense, Cano et al. [5] proposed the use of Graphics Processor Units (GPUs) to speed up the process of mining association rules. GPU computing allows thousands of cores to be used at the same time, however, it could not be enough when truly Big Data are considered. In this regard, MapReduce [6] has emerged as a paradigm to tackle Big Data. It uses multiple machines in a distributed way, enabling a higher level of parallelism. Nevertheless, not only are new huge quantities of data available but also a massive number of decision variables, different mathematical properties of the data or even various type of constraints. Thus, this problem cannot be solved by only increasing the computational power or by using paradigms such as MapReduce. Hence, novel methods and algorithms based new advances in distributed computing [27] have become a necessity [25].
The goal of this paper is therefore to propose a new efficient EA to extract association rules in Big Data. The baseline of this work is a new Grammar-Guided Genetic Programming algorithm to optimize Leverage, Support and Confidence, known as G3P-LSC. The proposed model makes use of a context-free grammar to encode the solutions and it allows to restrict the search space by adding some syntax constraints, i.e. it enables expert’s knowledge to be introduced into the mining process. Furthermore, our proposal is eminently designed to be as parallel as possible so Big Data can be tackled, and its operators have been specifically designed to avoid the loss in large search spaces as well as to maintain diversity in the solutions. In this regard, its genetic operators provide a reduced set of rules with high values for many different quality measures and few attributes, making it easier to understand from a user’s perspective. Taking the proposed sequential algorithm G3P-LSC as a starting point, different approaches have been finally implemented considering both RMI and MapReduce (Hadoop and Spark). In order to analyze the scalability of the proposal and its parallel versions, the experimental study includes different data sizes, considering datasets with more than 3,000 millions of instances. G3P-LSC has been compared with other 14 algorithms and using more than 75 datasets. Results state that the proposed G3P-LSC algorithm mines rules by optimizing the desired qualities, providing the user with rules of high interest. Finally, the proposed approach presents a good computational cost and a promising scalability when the size of the problem increases.
The rest of the paper is organized as follows. Section 2 presents the most relevant definitions and related work; Section 3 describes the proposed algorithm; Section 4 presents the datasets used in the experiments and the results; finally, some concluding remarks are outlined in Section 5.
Preliminaries
In this section, the association rule mining task is formally defined, and the MapReduce paradigm is analyzed.
Association rule mining
Association rule mining (ARM) [40] is considered as one of the most relevant tasks in unsupervised learning. It aims to discover accurate associations between item-sets of interest for the application domain. These associations have a descriptive nature, describing useful behaviors for the end user.
In a formal way, it is possible to define an association rule as follows [36]. Let
ARM obtains relationships from data were no information is known, so the extracted knowledge might be hardly quantifiable sometimes. In general, association rules represent data behavior and their interest is quantified by means of metrics that determine how representative a specific rule is within a dataset. Tons of quality measures have been defined for this aim [35], being support and confidence the two most widespread metrics in literature [13]. The support of the item-set
In the same way, the support of an association rule
As for the confidence quality measure [1, 13, 40], it determines the strength of implication of the rule, so the higher its value, the more accurate the rule is. In a formal way, the confidence measure (see Eq. (2.1)) is defined as the proportion of transactions that satisfies both the antecedent
Even though these quality measures are extensively used in the field, they have some downsides [13, 36]. First, the confidence measure does not detect statistical independence or negative dependence between items. Second, item-sets with very high support are a source of misleading rules. To overcome these drawbacks, many researchers have proposed several measures for the selection of interesting rules, and leverage is one of the most alluring since it satisfies the three properties proposed by Piatetsky-Shapiro [28]. Leverage (see Eq. (2.1)) calculates how different is the co-occurrence of the antecedent
MapReduce [6] is a recent paradigm of distributed computing in which programs are composed of two main phases defined by the programmer: map and reduce. MapReduce considers that the input and output are based on (key, value) pairs, which are also denoted as tuples
Diagram of a generic MapReduce framework.
Hadoop [15] is the de facto standard for MapReduce applications. Hadoop implements the MapReduce paradigm and provides a distributed filesystem known as Hadoop Distributed File System (HDFS), which replicates file data in multiple storage nodes that can concurrently access to the data. The main drawback of Hadoop is that it imposes an acyclic data flow graph, and there are applications that cannot be modeled efficiently using this kind of graph such as iterative or interactive analysis [38]. Moreover, the communication among mappers and reducers are performed using disk. This operation could cause problems of I/O, when the number of (key, value) pairs are extremely large. The disk being the main bottleneck due to the slow speed of read/write. All of this has hampered the modeling of efficient iterative algorithms in this platform. To solve these downsides, a novel solution has been proposed known as Spark [38]. This new proposal is eminently designed to be used in iterative and interactive algorithms. To speed up the process of tackling huge amounts of data, it introduces an abstraction called Resilient Distributed Datasets (RDDs). RDD represents a read-only collection of objects partitioned across a set of machines stored in main memory. It allows us to load a dataset in memory one time, and read multiple times without having to load it from disk in each iteration as Hadoop does. Furthermore, the communication among mappers and reducers are performed in memory, being much faster than the approach followed by Hadoop. One of the main strengths of Spark is its rich application program interface, which provides a set of in-memory primitives facilitating the modeling of algorithms.
The main motivation of this work is to propose an EA based on grammars for mining association rules. This work has been eminently designed to tackle massive amounts of data, where its genetic operators enable to scale on huge search spaces without losing accuracy and maintaining diversity among solutions. Its repairing operator allows to improve the convergence in complex spaces. Additionally, the fitness function has been explicitly designed to find frequent and reliable rules whose antecedent and consequent are not independent. To accomplish this, two different populations and three genetic operators as well as a grammar have been used. Also, due to the growing interest in data gathering, a unique and universal implementation of the proposed algorithm is not useful, so different adaptations are carried out depending on the data size. Hence, different adaptations have been performed in function of the used architecture, and all of them are fully described in further sections. Finally, it is worth noting that all of these adaptations obtain exactly the same solutions, the unique difference among them is the used software architecture.
Baseline
The baseline of this work is a new EA, known as G3P-LSC, that makes use of a context-free grammar to constrain the search space. Many authors have explored the use of grammars in pattern mining, achieving excellent results in both introducing subjective external knowledge into the mining process and restricting search space by introducing some syntax constraints [19]. A major strength of using grammars is the adaptability to represent solutions with different forms and features in such a way that a simple change in the grammar is able to produce completely different solutions. However, the user should be cautious when using grammars in pattern mining since the fact of reducing the search space may produce the loss of high interesting solutions, e.g. those that do not satisfy the constraints provided by the grammar. Besides, another major limitation of using grammars is the possibility of bloating by which the trees expand without control and the complexity increases. All these downsides are overcome in the proposed G3P-LSC as it is described below.
Context-free grammar defined by G3P-LSC.
G3P-LSC represents each solution as a derivation syntax tree encoded by means of a set of production rules from the context-free grammar shown in Fig. 2. It is defined as a four-tuple (
Terminal symbols are literals of the grammar and cannot be changed using the rules of the grammar. For example, the value of an attribute does not change even when the rules of the grammar are modified. Additionally, terminal symbols do not appear in the left-hand side of any production rule. On the contrary, non-terminal symbols are lexical elements used to form a grammar, and they can be replaced to produce different solutions Non-terminal symbols may appear in both left and right-hand side of the production rules. In order to encode a solution, a number of production rules from the set
To generate each solution, the derivation syntax tree is obtained by applying a series of derivation steps from the start symbol of the grammar. From this symbol, the algorithm searches solutions belonging to the set P, until a valid derivation chain is reached. Additionally, in order to avoid bloating that is one of the main problems of using grammars, a maximum number of derivations is previously determined as an input parameter. In this regard, there is a maximum length that no rule can excess. Genetic operators are aware of this maximum length so they are specifically designed to avoid an uncontrolled growth of the solutions.
Evaluation procedure
In any evolutionary approach, the evaluation process is cornerstone since it is responsible for assigning a fitness value to determine how promising each rule is for a specific aim. The proposed fitness function
The fitness function has been precisely designed to avoid frequent (support) and reliable (confidence) rules where the antecedent and consequent are not independent. Using the product of these metrics it is obtained that when leverage is zero, then the overall fitness value is also zero.
Finally, it is important to highlight that the evaluation procedure is carried out in a sequential way, where the whole dataset has to be read from one processor, evaluating each rule of the main population in each instance.
Algorithm
The G3P-LSC algorithm proposed as baseline for mining association rules in Big Data environments is depicted in Listing 1. It starts by encoding rules (line 1, Listing 1) by using the context-free grammar defined in Fig. 2 and the extracted metadata. Additionally, the maximum feasible length of this grammar is set to the number of attributes in data, so it is possible to obtain rules comprising the whole set of features.
After selecting a set of individuals to work as parents (line 7, Listing 1), the next step is to apply the crossover operator with a certain probability. If the crossover operator is applied, two offspring will be generated, which could be independently mutated with a certain probability. On the contrary, if the crossover operator is not applied, then the two parents could be separately mutated with a certain probability (see lines 7 to 16, Listing 1). A major feature of G3P-LSC is the elitism, in which best solutions are guaranteed a place
in the next generation. It is especially important in mining association rules since both crossover and mutation are too disruptive operators and may cause the loss of really promising solutions. This evolutionary process is repeated a number of generations specified by the user.
Genetic operators
The crossover genetic operator works by interchanging a random sub-tree between two parents, whereas the mutation operator applies changes to attributes from the antecedent and the consequent. These are high disruptive operators, giving rise to solutions whose fitness values highly vary from the original solution (parents). This issue is caused by the ARM problem itself since the simple fact of changing a single attribute in a rule may produce wrong solutions or even completely different leverage, support and confidence values. In this regard, G3P-LSC also proposes a repairing operator used to improve the algorithm’s performance by modifying invalid rules. The main idea is really simple since this operator checks whether the antecedent and consequent of the rule include similar items, and it is checked on each of the resulting solutions. It is important to highlight that, according to the formal definition of association rules provided in Section 2.1, both the antecedent and consequent cannot include the same items, i.e.
Scaling G3P-LSC using parallel and distributed computing
Focusing on the same idea of G3P-LSC, different parallel and distributed computing architectures have been used to speed up the mining of association rules in Big Data environments. In these implementations, the evaluation procedure has been the unique parallel phase since it has been proved to be the most time consuming [5]. Each version is developed following a different kind of implementation, although all the versions share the same idea and the same results are therefore obtained.
RMI version
The first parallel version of the G3P-LSC algorithm is based on a master/slave architecture that uses RMI to communicate the master process with each slave. This version, known as G3P-LSC RMI, uses multiple threads and different processes that are distributed among a cluster of machines (See Listing 2).
Focusing on the master process, only a single master procedure is used since it is the coordination point. The master process is almost the same as the baseline approach shown in Listing 1, being the difference the function evaluate_rules. In this case, this function splits the main population in as many subpopulations as number of slaves exist (see Listing 2). The aim of each slave is to evaluate the subpopulation of rules in the whole dataset. Furthermore, each slave is located in a different computer node, enabling parallel and distributed computing, and achieving a better performance.
Although RMI provides a high-level programming interface, the load balancing, fault tolerance and the coordination among slaves are very troublesome to manage. In this approach, the dataset has to be replicated in each slave, provoking both high network and I/O activity. Even when this implementation works well for large datasets, the use of truly Big Data hampers the process of replicating data. Some researchers have proposed distributed file systems to solve this issue. However, it is not enough when truly Big Data is considered since each slave process has to read the whole dataset and this operation becomes impossible if the file size is big enough.
MapReduce versions
These versions have been implemented in two different MapReduce architectures (Apache Hadoop and Apache Spark). Both implementations share the same approaches, even though slight adaptations have been required to adapt to the used architecture. They require three different processes: (1) the driver performs the main code of G3P-LSC baseline, however, the evaluate_rules function has been implemented to use MapReduce. Thus, in each generation of the evolutionary process a MapReduce phase is required to evaluate the main population; (2) Mappers in which the main population of rules is evaluated; (3) Reducers which collect the data produced by mappers, and return the evaluated main population for the whole dataset.
In the mapper phase (see evaluatorMapper procedure, Listing 3) each mapper receives as input a sub-set of the dataset and the main population. A group of pairs (key, value) are generated by each mapper, where the key is the individual (rule or solution within the population set), and the value is a tuple consisting of values for the support of the antecedent, consequent and rule. Hence, each evaluatorMapper procedure produces the same number of (key, value) pairs as number of individuals exist in the main population. Hence, the number of (key, value) pairs in each generation is calculated as the number of mappers multiplied by the number of individuals in the main population. The reducer phase, on the contrary, receives these (key, value) pairs, calculating the total sums of support antecedent, consequent and rule for each individual. Hence, the reducer produces the same quantity of (key, value) pairs as individuals exist in the main population (see reducer procedure, Listing 3). At the end of this phase, the output is the evaluated main population. Finally, the driver continues the evolutionary procedure similar to the baseline of G3P-LSC. The procedure followed by MapReduce versions can be summarized as illustrated in Fig. 3, where the input of the MapReduce phase is the dataset and the main population (shaded rectangle). The output is the evaluated main population which is returned to the driver.
Flowchart for each generation in G3P-LSC versions based on MapReduce. It receives the main population and the dataset as inputs, and it produces as output the evaluated main population. The main population is returned to the driver.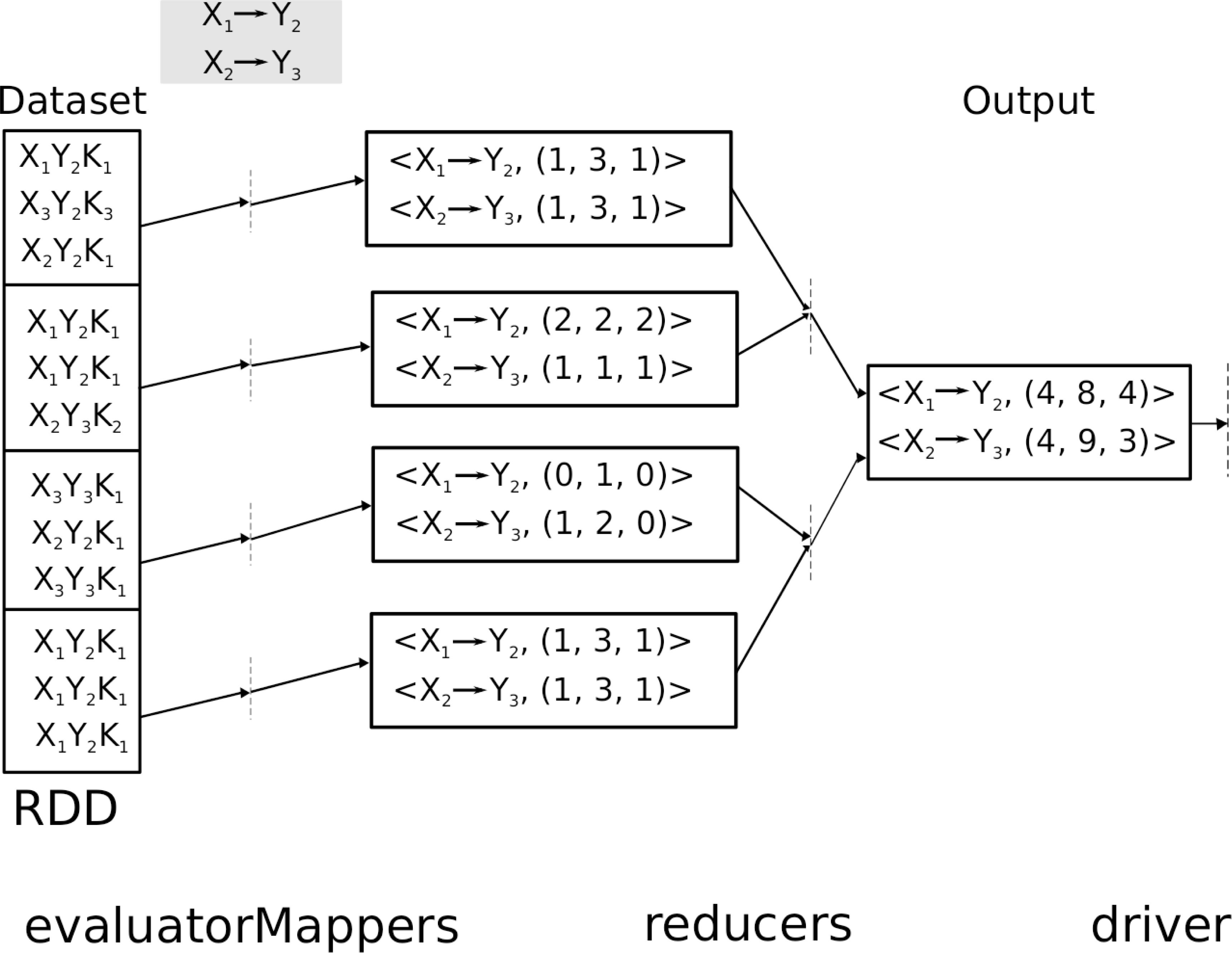
Although the two implementations (Hadoop and Spark) share the same approaches some slight differences exist. These differences are produced by the structure of each platform. Hadoop version uses disk as the way of communicating. Thus, communication among driver-mappers, mappers-reducers and reducers-driver are performed using disk. Furthermore, Apache Hadoop does not provide any way of saving the dataset in main memory so each generation has to read the dataset from disk. It should be noted that the process of this algorithm in each generation is exactly the same, so the dataset is loaded in each generation and the outputs are written on disk. In cases where the dataset is big enough, the reading process could be very time consuming so reading once, saving in main memory and using multiple times could be more efficient. On the other hand, Apache Spark allows to communicate among processes using main memory and enabling a faster communication. The main difference between Hadoop and Spark versions is that in the first generation of Spark, the whole dataset will be loaded in main memory using a RDD. It is split into the cluster, and each mapper could access to one different partition (sub-dataset). Unlike the previous Hadoop version, the dataset is loaded in memory only once, so it does not require a loading for each generation and the global performance can be substantially improved. Moreover, the communication among mappers and reducers are not performed using disk but memory, being this much faster. Both versions return exactly the same set of rules as the previous versions. In order to clarify these points, all the source code is available at
The aim of this section is to study the performance of the G3P-LSC algorithm and its versions on different parallel architectures when different data dimensionalities are considered. The goal of this study is three-fold:
To prove the quality of the obtained solutions. In this sense, a comparative study has been carried out by using exhaustive search algorithms to prove that our proposal is able to discover global optimum solutions in a reduced quantum of time. Additionally, a set of EAs for mining association rules has also been considered in this experimental study, and a comparative analysis of different quality measures has been carried out. A set of statistical tests [8, 9, 10, 11] has been applied to compare the differences. To analyze the scalability of the proposed algorithm when different parallel implementations are considered truly Big Datasets are used in this section to prove scalability considering both synthetic and real-world datasets. To show the interesting of using grammars is to restrict the search space and to include external subjective knowledge that helps in the process of mining association rules.
All the experiments have been run on an HPC cluster comprising 16 computing nodes, with two Intel E5-2620 microprocessors at 2 GHz and 64 GB DDR memory. Cluster operating system was Linux CentOS 6.3. As for the specific details of the used software, the experiments have been run on Hadoop 2.6.0 and Spark 1.6.0.
As previously described, the grammar considered in this approach is defined in Fig. 2. Considering this grammar
According to the grammar
Computational complexity
An analysis of the computational complexity is essential to determine the efficiency of the proposed approach. In this sense, we analyze each of its main procedures: encoding criterion, evaluator procedure and genetic operators. According to all these procedures, it is possible to determine the computational complexity of the whole algorithm.
As for the computational complexity of the encoding criterion, it depends on the number of derivations required to form the tree, which depends on the number of attributes in data as described in Section 4.1, i.e.
Analysis of the convergence of the three proposed genetic operators.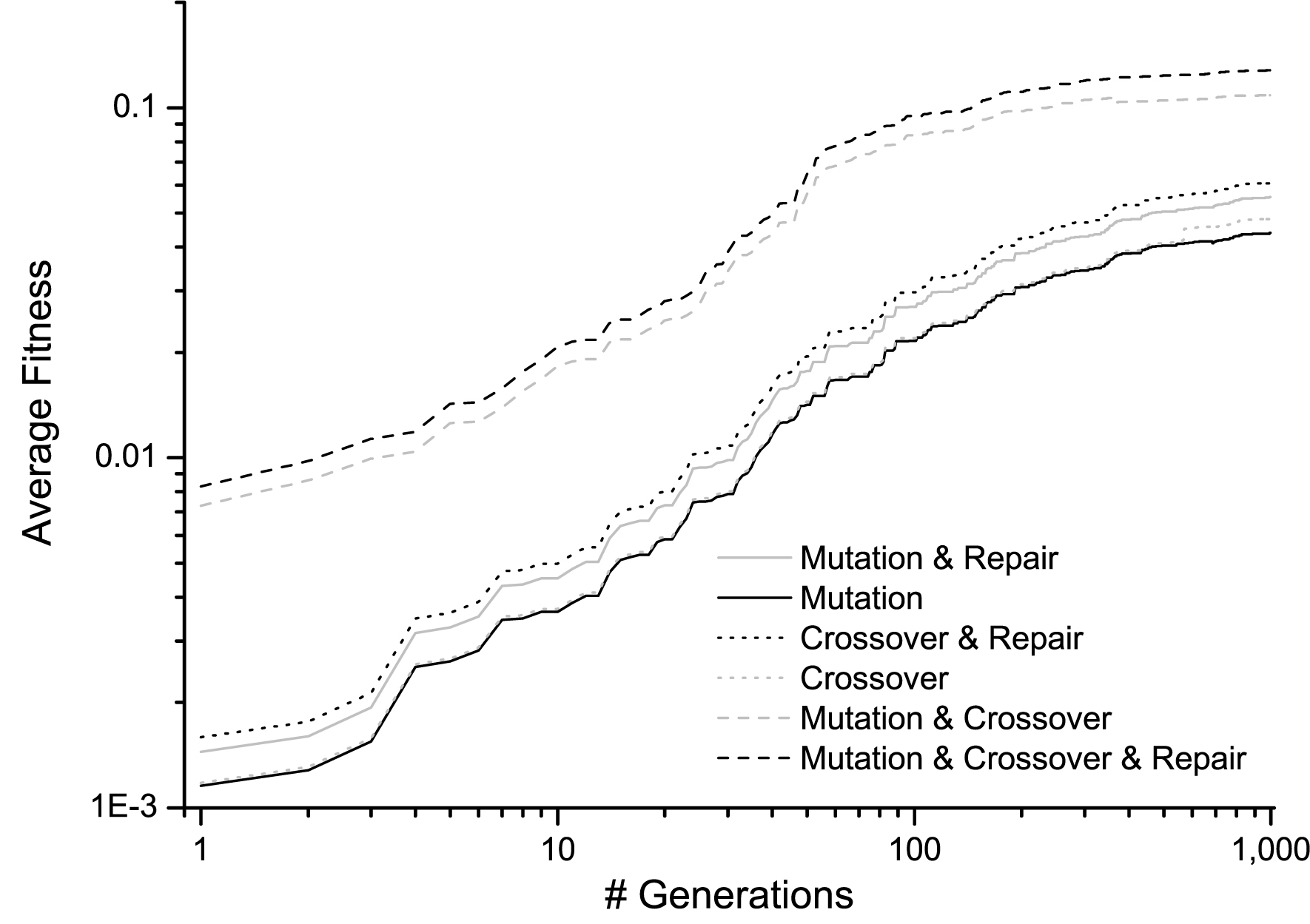
Analyzing the computing requirements for each procedure, it is stated that the number m of individuals is previously fixed, so it is considered as a constant with a complexity
In this section, an interesting analysis of the usefulness of the proposed genetic operators is carried out. The aim of this section is to demonstrate that the fitness function improves when the three proposed genetic operators are considered at time. To this aim, it is analyzed how the average fitness function improves along the generations when considering the same algorithm with, and without, the proposed genetic operators.
Datasets considered for the experimental study
Datasets considered for the experimental study
According to the results illustrated in Fig. 4, the worst results are obtained when the algorithm includes only a single genetic operator (either crossover or mutation). In fact, the behavior of the algorithm is almost the same for these two genetic operators, and only a slight difference is obtained close to the generation number 1,000 (the crossover operator converges faster than the mutation operator). However, when the repairing operator comes into play the results obtained by each of the previously analyzed genetic operators (mutation and crossover) are improved. Now, both genetic operators achieve a higher convergence. Finally, both mutation and crossover are considered at time including (or not) the repairing operator. As a result, it is obtained that the fact of considering the two main genetic operators (mutation and crossover) produces a huge improvement in the convergence of the algorithm. In fact, the resulting average fitness values are one order of magnitude better than those obtained when the genetic operators were considered in isolation. These results are even better when the three genetic operators (crossover, mutation and repairing) are considered at time.
To sum up, both crossover and mutation genetic operators play an important role in the convergence of the algorithm and they should be considered at time. The fact of including the repairing operator in the proposed algorithm slightly improves the obtained results, and this improvement is higher when the number of generations increases.
This experimental section considers a large number of datasets (see Table 1) comprising both synthetic and real-world datasets. The goal of these studies is to analyze the performance of different algorithms for mining association rules on a high number of datasets and to prove the scalability of the proposed approach. Thus, the used datasets depend on the type of experiment as described below.
In the first analysis only real-world datasets have been considered since the quality of the solutions have been studied. In this sense, a total of 41 real-world datasets have been analyzed, their main characteristics are shown in Table 1. Here, the label Attributes (R/I/N) states for the number of Real, Integer, and Nominal features included in each dataset; File size denotes the size in terms of memory for each dataset; whereas the Instances variable indicates the number of transactions within each dataset. It should be pointed out that all these datasets are freely available and the source to be downloaded is specified for each one. Finally, the second study considers 35 synthetic datasets so the scalability of the proposal can be analyzed. Synthetic datasets have been required since the number of both instances and attributes can be changed to illustrate the performance of different implementations. In these datasets, the number of instances ranged from 1
Sequential algorithms and set up
In these experimental studies, 14 different non-parallel algorithms have been considered to be analyzed, comprising both exhaustive search and evolutionary approaches. All these algorithms have been selected according to their efficiency and significance within the association rule mining field. The aim of this first study is therefore to analyze the resulting set of solutions in terms of quality measures. Each of these non-parallel algorithms has been briefly described as follows:
Apriori [2]: first algorithm for mining association rules, which is based on an exhaustive search methodology. It exploits the search space by means of the downward closure property. Eclat [39]: it employs a depth-first strategy by extending prefixes of candidate itemsets. GENAR [23]: genetic algorithm for mining qua- ntitative association rules without a previous discretization step. Each solution is encoded by using the minimum and maximum intervals of each numerical attribute. GAR [24]: extension of the GENAR [23] algorithm. Each solution is encoded by using all the attributes within data. EARMGA [37]: genetic algorithm for mining association rules in continuous domains. It does not require a minimum predefined support threshold. Alatasetal [3]: genetic algorithm for mining quantitative association rules. This algorithm is able to extract both positive and negative relationships between item-sets. G3PARM [19]: grammar-guided genetic programming algorithm for mining different types of association rules by means of a predefined grammar. MOEA_Ghosh [12]: multi-objective genetic algorithm that extracts useful and interesting association rules. It is based on three measures: comprehensibility, interestingness and accuracy. MOPNAR [21]: multi-objective evolutionary algorithm that mines positive and negative qua- ntitative association rules. It looks for a good trade-off between comprehensibility, lift and performance (product of support and certainty factor). MODENAR [4]: multi-objective differential ev- olutionary algorithm based on the proposed algorithm in [3]. It weights four quality measures: support, confidence, comprehensibility and amplitude of the attributes. ARMMGA [29]: multi-objective evolutionary algorithm based on EARMGA [37]. It looks for a good trade-off between support and confidence. NSGA-G3P [20]: multi-objective version of the G3PARM [19] algorithm. It is based on the well-known NSGA-II multi-objective algorithm [7]. SPEA-G3P [20]: multi-objective version of the G3PARM [19] algorithm. It is based on the well- known SPEA multi-objective algorithm [36]. QAR-CIP-NSGA-II [22]: multi-objective evolutionary algorithm that extends the well-known NSGA-II algorithm [7]. It performs an evolutionary learning of the intervals of continuous attributes.
All the configurations are those provided by the original authors. A summarizing table could be found in the supplementary material.
Comparative of efficiency and effectiveness among Apriori, Eclat and G3P-LSC
The aim of this study is to analyze the quality of the solutions obtained by G3P-LSC. First, our proposal is compared to exhaustive search algorithms so only datasets comprising nominal attributes are considered. No minimum quality threshold has been considered so any solution present in the dataset is obtained. In this regard, the best solution found by Apriori or Eclat represents the best possible solution within the dataset since all the existing rules are discovered by these algorithms. Any solution is ranked by the aforementioned fitness function (
Table 2 shows the results, where the average fitness function represents the obtained average by the 20 top rules, whereas the maximum fitness function states for the best value
Comparative of the single values obtained within the fitness function Apriori, Eclat and G3P-LSC
Comparative of the single values obtained within the fitness function Apriori, Eclat and G3P-LSC
Obtained ranking after executing 10 times each algorithm in the whole set of real-world datasets. Different well-known quality measures have been calculated. Values in bold typeface represent the best ranking for each quality measure
Finally, the average values for each of the quality measures (support, confidence and leverage) that form the fitness function are also illustrated in Table 3. As it is shown, the results obtained by G3P-LSC are quite similar to those obtained by exhaustive search approaches.
To prove that there is no statistically significant difference in the average fitness function values, a Wilcoxon signed rank test has been used. A
Once it is demonstrated that G3P-LSC converges well to the global optimum, a comparative study among different EAs have been performed by considering continuous and discrete attributes. In this experimental study, all the described datasets in Table 1 have been used, and each EA has been run 10 times for each dataset. Note that EAs are non-deterministic algorithms so the results shown are the obtained average results for these executions. Table 4 shows the obtained average ranking for different quality measures after running all the algorithms on all the datasets. It should be noted that these algorithms were run on their original versions, so each one optimizes its own fitness function. Due to space limitation only the ranking table has been illustrated in this paper, although the whole set of results can be checked in the supplementary material. Different quality measures have been selected to quantify the quality of the rules. In Table 4, each column represents a different EA, whereas each row is used to represent a different quality measure.
As it is illustrated in Table 4, G3P-LSC obtains the best results in Leverage, NetConf, Pearson and Laplace quality measures. If we focus on the Confidence quality measure, the ranking values determine that G3P-LSC does not behave well for this specific quality measure. However, if we analyze the confidence values for each run it is obtained that all the values are above 0.9 and, in some specific datasets, the confidence values obtained are greater than 0.95. Thus, it is possible to assert that the results of G3P-LSC for this quality measure are alluring enough. In the same way, the ranking values for support seem to be worse than for other algorithms. It is worth noting that extremely high support values, as it is obtained by some algorithms, imply misleading rules according to some of the quality measures. In fact, maximum support values, i.e., 1.00, imply misleading rules since they do not provide unknown information about the dataset. As it is demonstrated by analyzing the rankings (see Table 4), the rules obtained by G3P-LSC present values for the interestingness measures that are better than or similar to the obtained by the analyzed algorithms.
Statistical differences among distinct measures and algorithms according to the Bonferroni-Dunn test. G3P-LSC achieves the highest number of significant differences and it does not almost loss. QAR-CIP-NSGA-II is the algorithm more similar to our proposal
In order to prove if the differences obtained by the ranking analysis are statically significant, a Friedman test [10, 11] for each quality measure is carried out. In this regard, we consider the null hypothesis
As a result, G3P-LSC behaves statistically better for more quality measures and in very few cases the quality measures obtained by other algorithms behave statistically better than G3P-LSC.
Context-free grammar modified to obtain negative items.
Context-free grammar modified to obtain rules having a single item in both the antecedent and consequent.
The aim of this section is to demonstrate how the grammar can be modified to achieve different results (see Table 7). All these alluring quantitative association rules have been obtained on the Stock dataset and the proposed G3P-LSC algorithm with different grammars each time. Taking the original grammar (see Fig. 2), the following rule is obtained:
Rules obtained by G3P-LSC when different grammars are considered on the stock dataset
Rules obtained by G3P-LSC when different grammars are considered on the stock dataset
As a matter of example, Table 7 shows some obtained rules for the stocks dataset when different restrictions are defined. For instance, it is possible to include not only positive but also negative associations, so a simple change in the grammar (see Fig. 5) allows to obtain rules as the one depicted in the second row. The consequent of this rule denotes that Company4 cannot include a value in the range [28.29, 57.96].
Finally, the third example is obtained from a grammar (see Fig. 6) that allows to obtain only rules having a single item in both the antecedent and consequent. Considering this grammar, an example of rule obtained from the stocks dataset is
The aim of this study is to analyze the performance of the different proposed implementations when the number of both attributes and instances increases. In the first part of this study, a set of synthetic datasets has been used that have been properly created to analyze how the number of both instances and attributes affect to the algorithms’ performance. Finally, note that all these algorithms obtain the same results being the followed approach to parallelize the unique difference among them. Analyzing Fig. 7, the results illustrate that the baseline implementation of G3P-LSC is the most efficient when a small number of instances is bore in mind. However, when the number of instances continues growing (up to 6
Runtime of different implementations when they are run on datasets comprising 48 attributes and a number of instances that varies from 1 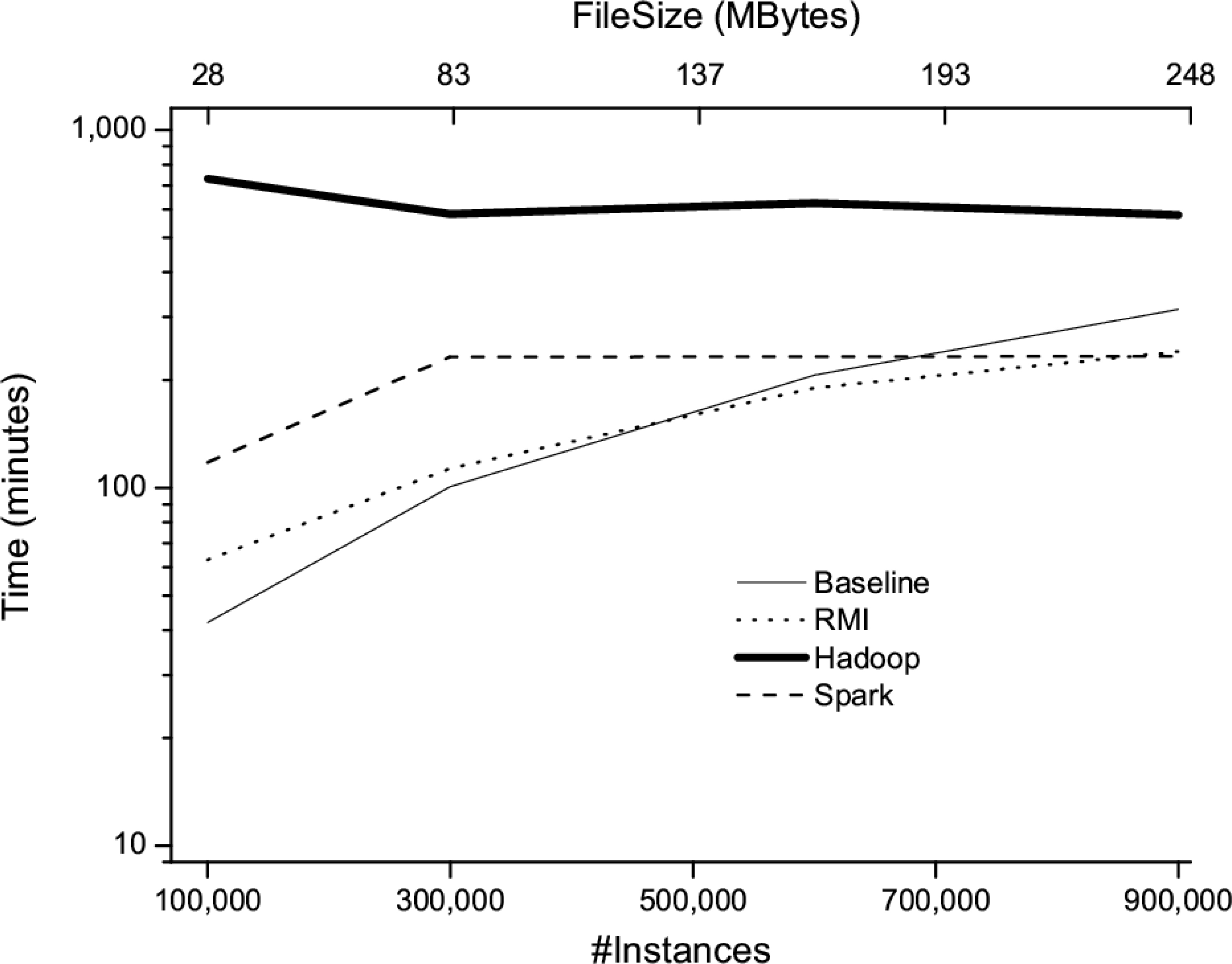
Although RMI obtains the same results using only a 15% of sequential runtime, it is not enough when huge datasets are considered. Spark’s implementation obtains the best results since the datasets could be stored in main memory. On the other hand, the implementation based on Hadoop obtains worse results than Spark. Again, the number of instances is increased from 1
Runtime of different implementations when they are run on datasets comprising 48 attributes and a number of instances that varies from 1 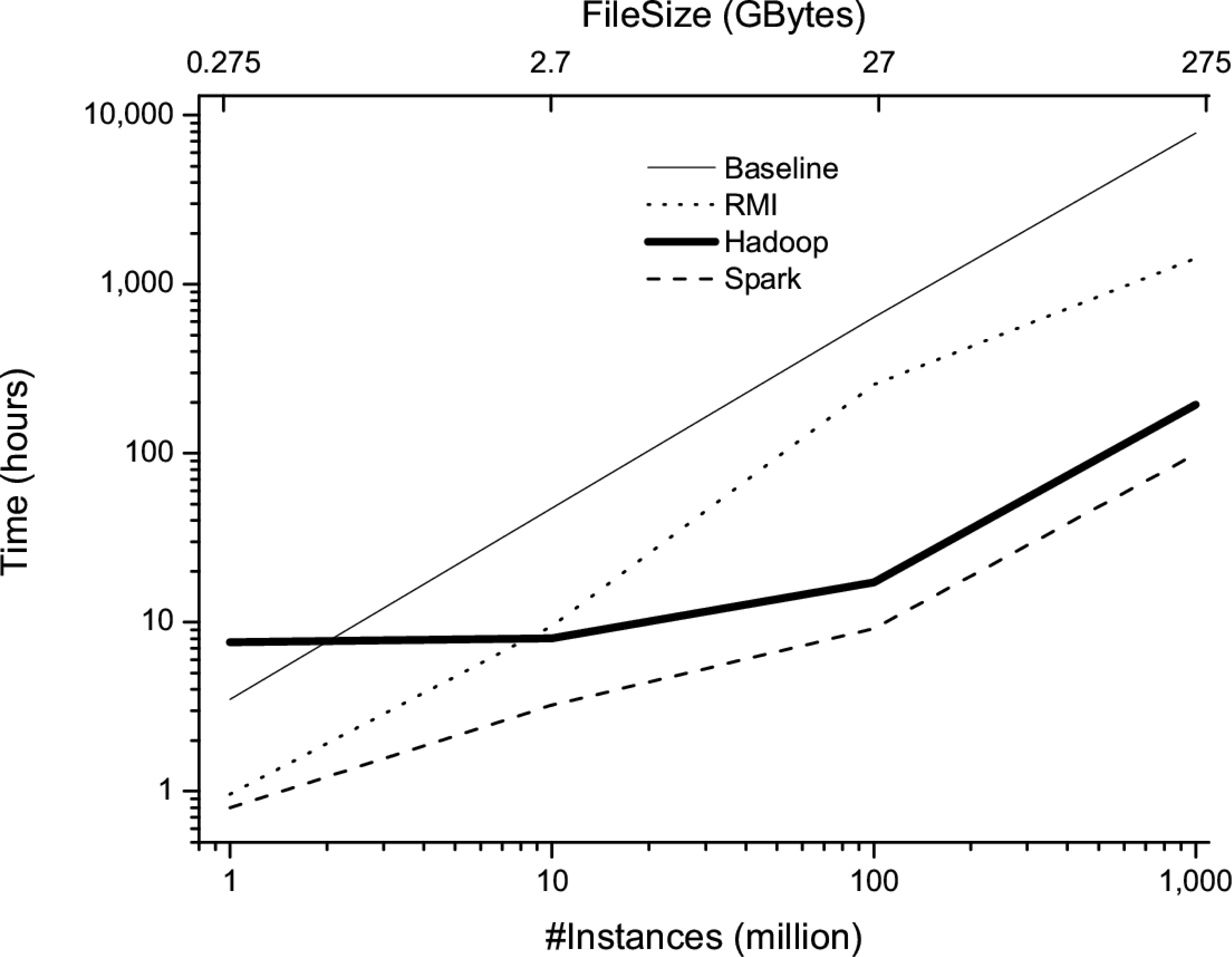
Runtime of different implementations when they are run on datasets comprising 1 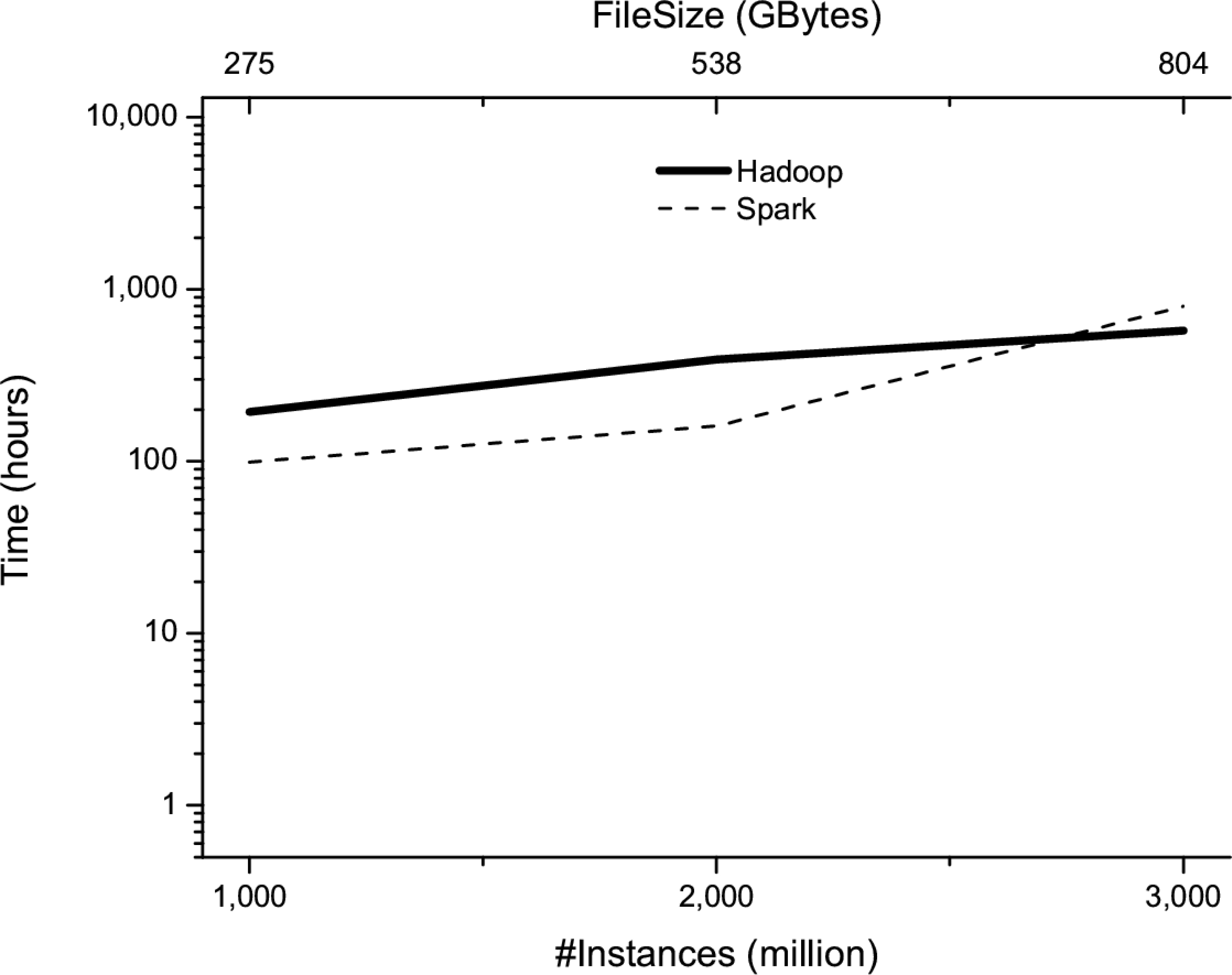
At this point, Spark begins to use both disk and memory as cache system (hard ware limitations), thus its behavior is almost the same as Hadoop having to read almost the whole dataset from disk in each generation. Thus, Spark is appropriate to handle an extremely large number of examples when data can be stored in main memory. On the other hand, Hadoop is quite appropriate to handle huge datasets that cannot be stored in main memory.
Runtime of different implementations when they are run on datasets comprising 1 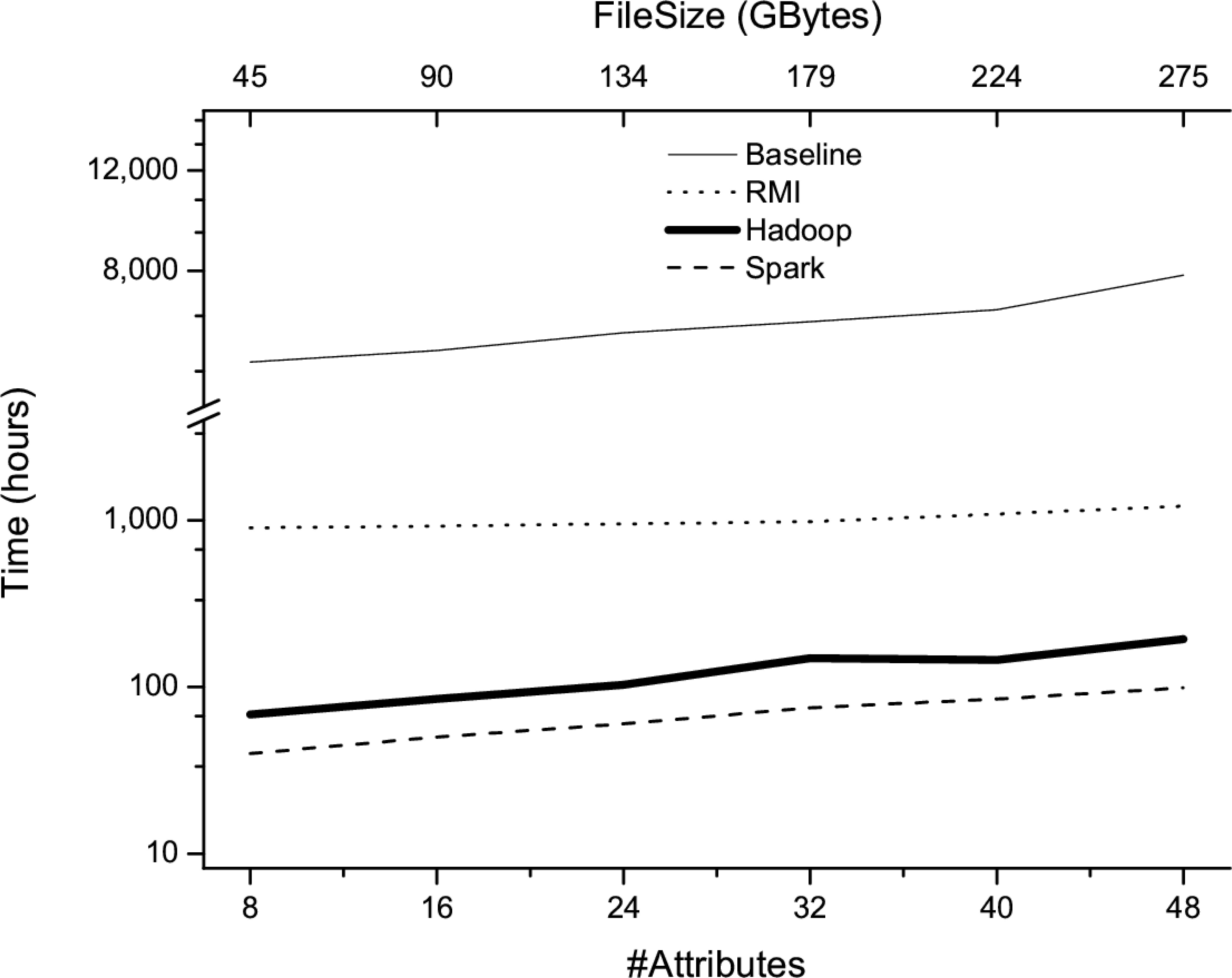
Runtime of parallel approaches when the number of nodes decreases. A dataset comprising 1 
Additionally, an analysis has been carried out to study how the number of attributes affects. In this regard, Fig. 10 illustrates how the number of attributes linearly affects to the global performance of the algorithms. Note that the higher the number of attributes, the higher the search space, so the convergence time increases linearly with the number of attributes.
In a third study, it has been considered interesting to note how relevant is the cluster capacity in the decision on which implementation should be used. Figure 11 illustrates how the performance is affected by the cluster capabilities. RMI is the implementation less improved when the number of nodes increases since each node has to evaluate the whole dataset. However, Apache Hadoop and Apache Spark benefit because a greater number of nodes means a greater level of parallelism, since each node evaluates a subset of the dataset.
Once it has been demonstrated that implementations based on Spark and Hadoop obtain alluring runtime on synthetic datasets, they have been run on real-world datasets. No comparison with sequential approaches have been considered since it was previously demonstrated that these algorithms cannot be run efficiently. Table 8 shows the obtained results for a set of Big Data real-world datasets. As it could be appreciated, the behavior is the same as was shown in previous studies. Spark achieves a better performance since the whole dataset could be stored in main memory. It achieves the same results as Hadoop but using only a half amount of the time, and in some cases Spark only needs a 13% of the time required by Hadoop. The issue of Hadoop is also shown, needing almost the same time to process several GB (Epsilon datasets) than several MB (Poker dataset). It is due to that much of the time is used to orchestrate the platform and no to our main computations, thus, Hadoop always needs a quantity of time to coordinate the platform independently of the size of the data. However, Spark does not require this large time in orchestration.
Runtime in hours required when large real-world datasets are used by running Spark & Hadoop implementation. As all these datasets could be stored in main memory
In this work, a genetic programming algorithm based on grammars for mining association rules in Big Data has been proposed, known as G3P-LSC. The novelty of this work is that it proposed a new evolutionary approach which is able to be run in a distributed way enabling the use of parallel paradigms such as MapReduce. Our proposal provides a reduced set of rules, easy to understand, and with a good level in many quality measures. The main aim of G3P-LSC is to optimize a set of well-known quality measures in the association rule mining field.
Currently, due to the increasing interest in data storage, a unique and universal implementation of a single algorithm is unfeasible and different adaptations should be done depending on the data size. In this sense, the proposed algorithm has been implemented on different architectures including a sequential approach, RMI and MapReduce. It should be noted that all the implementations return exactly the same results and the unique change is the architecture.
When comparing the obtained results with other 14 algorithms and using more than 75 datasets, it is obtained that the proposed G3P-LSC algorithm mines rules with better values for interesting measures and few attributes, providing the user with high quality rules. As a grammar is used, the user could even specify which set of attributes must appear in the proposed solutions, allowing to constrain the search space only for rules of his interest. Finally, the proposed approach presents a good computational cost in all datasets and good scalability when the size of the problem increases.
Future work
Finally, as a future work some parallel searches could be considered to be adapted to the extraction of association rules in Big Data. Its application is not trivial and these paradigms have not been studied yet in the association rule mining field and further research is encouraged. Next, each of the most well-known parallel models is analyzed [34]. Island models or even cellular EAs could be studied to mine association rules in a parallel way. Indeed, hybrid models could improve the convergence of the previous models, where some relaxations of the original methods could further improve the diversity.
Footnotes
Acknowledgments
This work was Supported by the Spanish Ministry of Economy and Competitiveness under the project TIN2014-55252-P, and FEDER funds. This work is also supported by the Juan de la Cierva Formacion post-doctoral grant, reference FJCI-2015-23560.