
Abstract
In the modern era, digital data processing with a huge volume of data from the repository is challenging due to various data formats and the extraction techniques available. The accuracy levels and speed of the data processing on larger networks using modern tools have limitations for getting quick results. The major problem of data extraction on the repository is finding the data location and the dynamic changes in the existing data. Even though many researchers created different tools with algorithms for processing those data from the warehouse, it has not given accurate results and gives low latency. This output is due to a larger network of batch processing. The performance of the database scalability has to be tuned with the powerful distributed framework and programming languages for the latest real-time applications to process the huge datasets over the network. Data processing has been done in big data analytics using the modern tools HADOOP and SPARK effectively. Moreover, a recent programming language such as Python will provide solutions with the concepts of map reduction and erasure coding. But it has some challenges and limitations on a huge dataset at network clusters. This review paper deals with Hadoop and Spark features also their challenges and limitations over different criteria such as file size, file formats, and scheduling techniques. In this paper, a detailed survey of the challenges and limitations that occurred during the processing phase in big data analytics was discussed and provided solutions to that by selecting the languages and techniques using modern tools. This paper gives solutions to the research people who are working in big data analytics, for improving the speed of data processing with a proper algorithm over digital data in huge repositories.
Introduction
In this digital world, all people are generating a huge volume of information as data for their real-world applications and needs. Every day plenty of data were created in various domains like healthcare, retail, banking, industries, and companies [1]. The data warehouse has been generated to store and the time taken for getting it on time is miserable. Multiple methods and algorithms are used in a data warehouse as a mining process but are not apt for plenty of situations. Later, data analytics disseminate to the market for managing large amounts of data from various repositories [2]. Accessing those data is using modern tools like Hadoop and Spark [3], and after that applying data mining algorithms for analytics. Modified data stored in various places according to user requirements. The major problem will occur during the extraction phase due to data location and volume of the repository over the network [4]. Figure 1 explains the main V’s used in big data and how it is processed.

Main V’s used in Big Data.
To provide the solution for the high volume data storage, the classic scale-in database storage was developed but not sufficient. Later, scale-out concepts were introduced as commodity hardware by Hadoop [5]. So Hadoop will provide better solutions to handle data storage in mega repositories in the form of clusters. There are single and multimode clusters in Hadoop with Hadoop Distributed File System (HDFS) [6] for huge dataset storage over a network. Though the data was stored in HDFS clusters, it will be accessed via many algorithms and classifications for extracting them into real-world applications. The problem faced by most companies while extracting the data is waiting time and accessing time from the repository [7]. Hadoop handles this problem with Map Reduce concepts for giving solutions to inadequate time. Map Reduce is a new paradigm introduced by Google, its purpose is to handle the high volume of data by using a map and reducing functions [8]. The entire input file is split into small pieces then map the related data as keys and send it to reduce. Reducers collect those keys and combined them into the appropriate output. This entire process is done by data mining algorithms and various techniques but the time taken to do this task is not the user’s concern. Because the input of Hadoop is a batch processing method, it is not suitable for real-time applications [9].
For parallel processing of data over networks, Hadoop Framework is used. The data processing between the nodes is based on their location and migration of their place. So aligning and arranging all individual nodes for performing distributed data processing at a time is complicated [10] using normal client-server or peer-to-peer networks. The distributed framework was used to disseminate the data from the repositories but the accuracy level and latency are the factors affected in large networks while accessing huge data sets. To overcome this problem Hadoop framework came and manage all those critical situations easily as commodity hardware. It is a vertical storage data processing system that is fast to recover the data elements even from a large dataset or huge repository.
History of HADOOP
In earlier days, distributed network node files are sending through a client-server architecture system with limited size. If huge files are sent across the network, latency, throughput, and speed of the transfer are very low [11], and maybe a loss or corruption of files also happened. When data storage is more it is not suitable for data processing within a stipulated period is not possible. So instead of the scale-in concept working in RAID methodology [12], storage has been extended to a different level. But also a lot of difficulties occurred in the distributed database process. The same concept is used online also. Searching for an element from a huge database and given to the user is not succeeded on time. In 2002, nutches were created by yahoo as a web crawler to identify the highest count of elements searched in browsers using the internet [13]. The time taken is quite fast when searching the recent data whereas old data has to be extracted from the database that was not archived quickly. So Google has introduced the concept of Google File System (GFS) [14] with a file access index table for the reference of the files in a network. Based on that index searching method instead of web crawlers, the entire distributed network finishes the searching element task within optimal time. After that Google introduced Map Reduce programming concept to optimize the searched elements from a huge database by map () and reduce () functions. Distributed File System (DFS) was introduced to store a large volume of data from the commodity hardware nodes using Hadoop. So it is called a Hadoop Distributed File System (HDFS). Yahoo was supported by 1000 individual nodes as a cluster to distribute database parallel. But when Hadoop came into this scenario, all nodes are connected with different commodity clusters by the scale-out process where data distribution happened without any clumsiness. Finally, Hadoop was introduced as an open-source framework by Apache and developed by java programming as a core language. Hadoop has introduced its commercial product in the name of Apache Hadoop with basic versions. Though Hadoop has supported parallel distributed databases with Shared Nothing Architecture (SNA) [15] principle, it will support some modern tools for doing data processing. It is called Hadoop Eco System which supports all data processing and analytics work. Figure 2 gives a detailed history of Hadoop and its limitations.
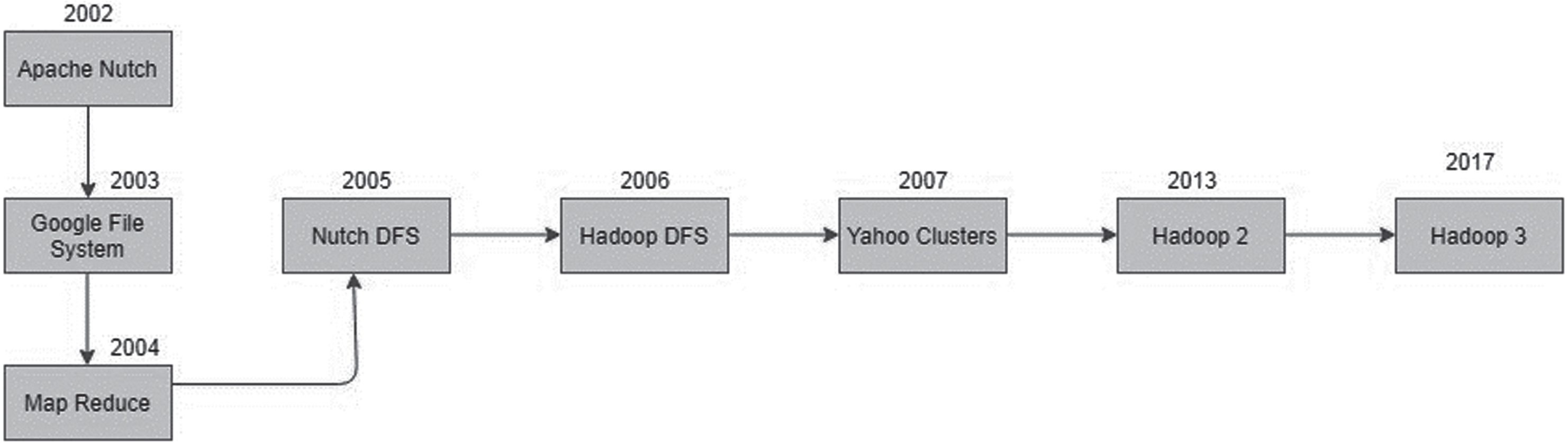
History of Hadoop.
Hadoop has supported many data mining algorithms and methods for accessing data from a huge data set with the help of modern tools as a supporting system. Data collection from different resources and stored in a warehouse has to be controlled and monitored for data flow access. This will help to find a minimal or optimal solution for time consumption issues in the Hadoop framework. Nevertheless, data generation and extraction have to be monitored using any of the tools in a Hadoop ecosystem that will give an immense result of required data to the user on time among the clusters. Researchers find difficulty over the network optimization time of the ETL (Extraction, Transaction, and Loading) process normally, because of the CAP (Consistency, Availability, Partition Tolerance) theorem concepts [16]. If any nodes got failure, then data alterations are quickly reflected in the cluster by Hadoop Eco-System Tools. So this system deals with the entire big data analytics concept via various tools. Table 1 the entire Hadoop Eco-System structure.
Hadoop Eco System
Hadoop Eco System
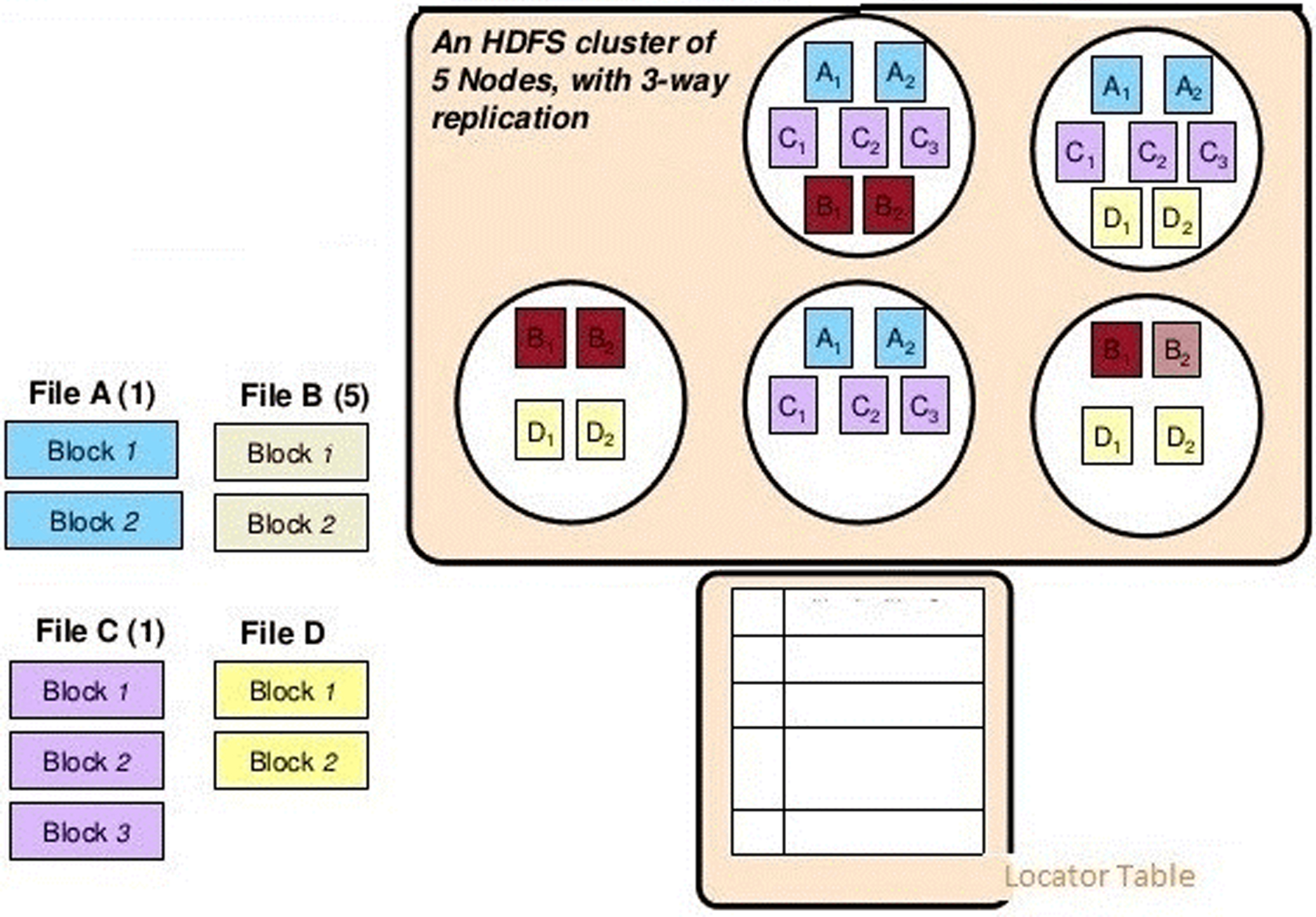
Hadoop Distributed File System (HDFS) consists of Name Node (NN) and Data Node (DD) in a single node or multi-node cluster setup. Classic Hadoop contains Job Tracker by name node and task tracker by data node to find the flow of the data access. But the limitations of Hadoop made this architecture with a new concept called replication. Each end every input the job has to complete and the output data will be stored in 3 data nodes as a replication [17]. The Metadata of the output data has been stored to avoid software or hardware fault during transmission time. If any node gets failure in a cluster the other nodes get activated and the data has to transfer without delay. In later versions of Hadoop, a Secondary Name Node (SNN) was introduced to avoid the failure of the name node and its data has to be copied as a FSI image. Figure 3 denotes the architecture of HDFS and its replication principles.
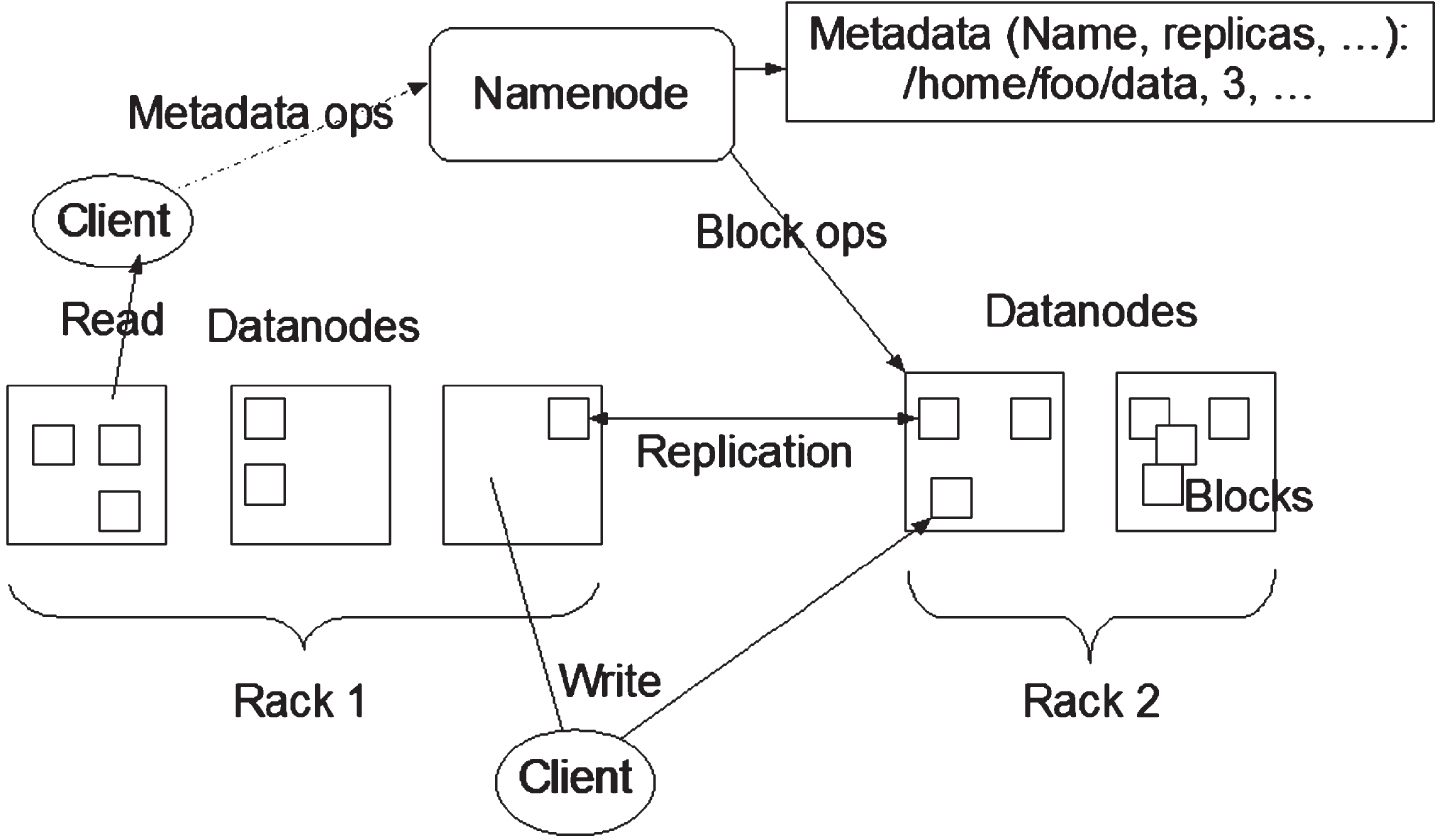
HDFS Architecture.
The Hadoop framework is used to provide parallel distributed database access with a basic java programming paradigm [18]. It emphasizes the work done simplified by Map-reduce concepts working among the clusters. Hadoop was developed by Apache and the basic version was released with several features to do data processing within a short time. Initially, the Hadoop framework was designed only for performing data processing tasks on a distributed database parallel. The entire framework is running as a cluster-based network.
Hadoop 1. X version is a basic version that is explained two major components Map reduce and HDFS storage. Map-reduce is a programming model that reveals the input file is divided into the number of maps and converted into key-value pairs. Combiner parts get these maps as input and reduce them according to the keys produced by mappers. Finally, the reduced data will be stored in HDFS storage. Perhaps, this is a reliable storage system and redundant for a distributed database. It consists of a replication factor as 3 by default in master-slave architecture. Data nodes created 64 MB of blocks to store input data in HDFS.
Hadoop is Master-Slave architecture by nature and it is controlled by Name Node (NN) as a Master. The remaining nodes which are connected to this Name Node are called Data Nodes (DN) as a slave. If suppose NN got failure or is disconnected from the cluster the entire system will get collapsed. In this critical situation, the Name node has taken a photocopy of its data and stored it in a different node called Secondary Name Node (SNN) over the network to avail the CAP theorem concepts. This additional feature is available in Hadoop 2. X with the name of YARN (Yet Another Resource Negotiator). Here also replication factor is 3 but the block size is 128 MB for input data storage [17, 19]. Below Table 2 will give the technical differences between these versions.
Hadoop versions differences
Hadoop versions differences
Hadoop 3. X is the latest version of the Apache Hadoop developed by Apache to overcome the problems of previous versions. The problem in previous versions is mainly lying in the number of blocks allocated for input data. For example, if 6 blocks are needed for storing input data into blocks we need 6X3 = 18 blocks for replication. So the overhead storage value is calculated using extra blocks divided by original blocks and it will be multiplied by 100 which gives a 200 percent result. The extra memory space allocation causes more cost usage problems for business people. So in Hadoop 3. x erasure coding [20, 21] is used to reduce that extra memory space to 50 percent overhead. Figure 4 and Fig. 5 will explain it.

Replication.

Erasure Coding.
The above diagram describes erasure coding in the Hadoop 3. x feature. The replication of 3 nodes can be divided and combined with two nodes using the XOR function as parity block storage. The same 6 blocks were taken for input file storage, instead of 18 blocks only 9 blocks were allocated for storage which means 3 blocks for extra storage. So the overhead storage is 3 divided by 6 and multiplied by 100 gives 50% only. Here the storage has to be denoted as Data Lake [22]. Due to this erasure coding number of blocks assigned for incoming data is reduced. So memory has to be utilized in HDFS is very low. Moreover, Erasure coding help to get accurate data with low latency, because of using limited memory utilized in HDFS as a block.
One more feature added to this Hadoop 3. x is yarn architecture has slightly changed to adapt to the reduction of data blocks in HDFS. In this, the resource manager allocated the jobs to the node manager and it will be monitored by the application master. A container is a new feature that will give the request of each node to the Application Master [23] then the request is sent to the name node. If any failure between the nodes all status will be monitored by the application master and the container holds the status of the nodes, so latency and throughput will be high when using Hadoop 3. x. Figure 6 explains the YARN architecture.

Hadoop 3. X YARN Architecture.
There are lots of technical features changed in each version of Hadoop which improves the performance of the data processing speed in big data analytics. Table 3 will denote all the technical features of their versions.
Hadoop latest and previous version differences
In Hadoop, so many clients are sending their jobs for performing tasks. This can be handled by Job Tracker or resource Manager by Hadoop. There are two different versions are available in Hadoop named Hadoop 1. X and Hadoop 2.X.Here X denotes the version releases/updates. If Hadoop 1. X is used in the cluster, then the tasks can be controlled by the Job Tracker /Resource Manager. If it will be Hadoop 2. X, it may use the secondary node for the purpose of replica in the Name Node and will be used for copying Metadata [24] from the cluster. There are three main schedulers are available in Hadoop. FIFO Capacity FAIR
The following Table 4 [25] explains all the schedulers and their drawbacks.
Schedulers’ drawbacks
Schedulers’ drawbacks
The data processing speed is improved using the Hadoop framework because of its features [26]. It has a lot of advantages over the network. Table 5 explains the Hadoop features.
Hadoop Features
Hadoop Features
Though Hadoop has many features for huge data processing in clusters, it has some drawbacks while executing the tasks. Because the features may have some limitations while distributed data processing running inside the clusters [27]. Multiple factors will affect the Hadoop features and reduce the performance of Hadoop over distributed data processing scenarios. Some of the points are discussed below with their major parameters. While accessing the small files [28] due to the default block size their speed has less and the allocation of memory is huge. To avoid this Merging of small files, HAR extension files (Hadoop Archives), and H Base tools can be used. When big files have handled the speed of retrieval is slow and can be processed by SPARK Framework. Unstructured data processing initiates low latency due to different file formats and this could be handled by SPARK, FLINK, and RDD (Resilience Distributed Data set) is used for storage purposes. High-level data storage and network-level problems are raised when we talk about security concerns [29] in a larger network that can be solved using HDFS ACL for authentication purposes and YARN (Yet Another Resource Negotiation) as Application Manager. Batch-wise data input processing is working but not real-time data accessing. The tools like SPARK and FLINK is used to handle that. More lines of code (1, 20,000) [30] cannot be accessed but using SPARK and FLINK it is possible. It does not support repetitive computations and no delta iterations but the SPARK tool supported all with in-memory analytics technique. No Caching and Abstraction features are running in the Hadoop framework whereas SPARK.
Tuning Hadoop performance
Hadoop is used to perform parallel distributed data processing in different clusters. But it has a lot of problems with parallel processing among nodes. There are some bottlenecks which are affected the performance of Hadoop processing over the network. They are [31] All the key resources in the CPU can be utilized properly for Map and Reduce process. Master-Slave architecture is running in the data node as Main memory using RAM. Network and bandwidth traffic due to huge file size accessing. The throughput problem of input-output devices data storage over the network.
Hadoop tuning problems in data processing are discussed below with solutions. A large volume of source data can be tuned by Huge I/O input at the map stage [32] with LZ0.LZ4 codex Spilled records in the Partition and Sort phases are using a circular memory buffer using the formula Sort Size = (16 + R) * N / 1,048,576 R–number of Map N –dividing the Map output records by the number of map tasks are mapred.local.dir = 100MB Network Traffic at Map and reduce side can be tuned by Writing small snippets to enable or disable in the map-reduce program and default replication factor of 1,3,5,7 nodes in the single and multi-node cluster configuration. Insufficient Parallel Tasks [33] in idle resources are handled by adjusting Map, Reduce Tasks numbers and memory. There are 2 map, re- duce tasks, 1 CPU vcore and 1024MB memory allocated as a default configuration. For example, 8 CPU cores with 16 GB RAM on Node Managers, then 4 Map, 2 Reduce Tasks with memory 1024 MB allocated to each task and it leaves 2 CPU cores in a buffer for an- other works.
Hadoop Framework running with java programming language by map-reduce model for data processing from a huge dataset warehouse on real-time applications. For complicated analysis of the real world, problems can be easily solved by Hadoop with low-cost open-source. Though data warehouse engines work effectively, the speed of data retrieval is the major problem [34] in analytics. To improve the speed of the data processing in big data analytics the above-said tuning parameters of Hadoop can be implemented with any latest algorithms like Deep Learning, Machine learning, Artificial Intelligence, Genetic Algorithms, Data Mining, Data Warehouse algorithms, and block-chain [35, 36] concepts. Hence the huge dataset of big data is the cause for handling real-world scenarios in many companies. All their worry is to maintain that with low-cost server configuration and consistency should be controlled on time. The retrieval of data from the data warehouse has to be improved with the Hadoop framework by high throughput is succeeded.
Map reduces programming model
Map Reduce is an important programming model used in the Hadoop framework that accesses a high volume of data in parallel by disseminating the whole work into individual tasks. So that the input file can be accessed by map-reduce functions to minimize the size of the file coming in the output part with compression [37]. After this process, the user or client will get the exact files that they expected from the large volume of datasets.
Importance of map-reduce
Map-reduce is used to access a huge dataset that is stored in HDFS parallelly. Increasing the velocity and reliability of the cluster map-reduce plays a major role in processing. The latency and throughput of the entire system will be increased because of the time taken to complete the job.
Phases of map-reduce
Multiple phases are working in the map-reduce programming model because huge files are divided into independent tasks and each will work parallelly. Separate work has to be done in every stage of the map reduction.
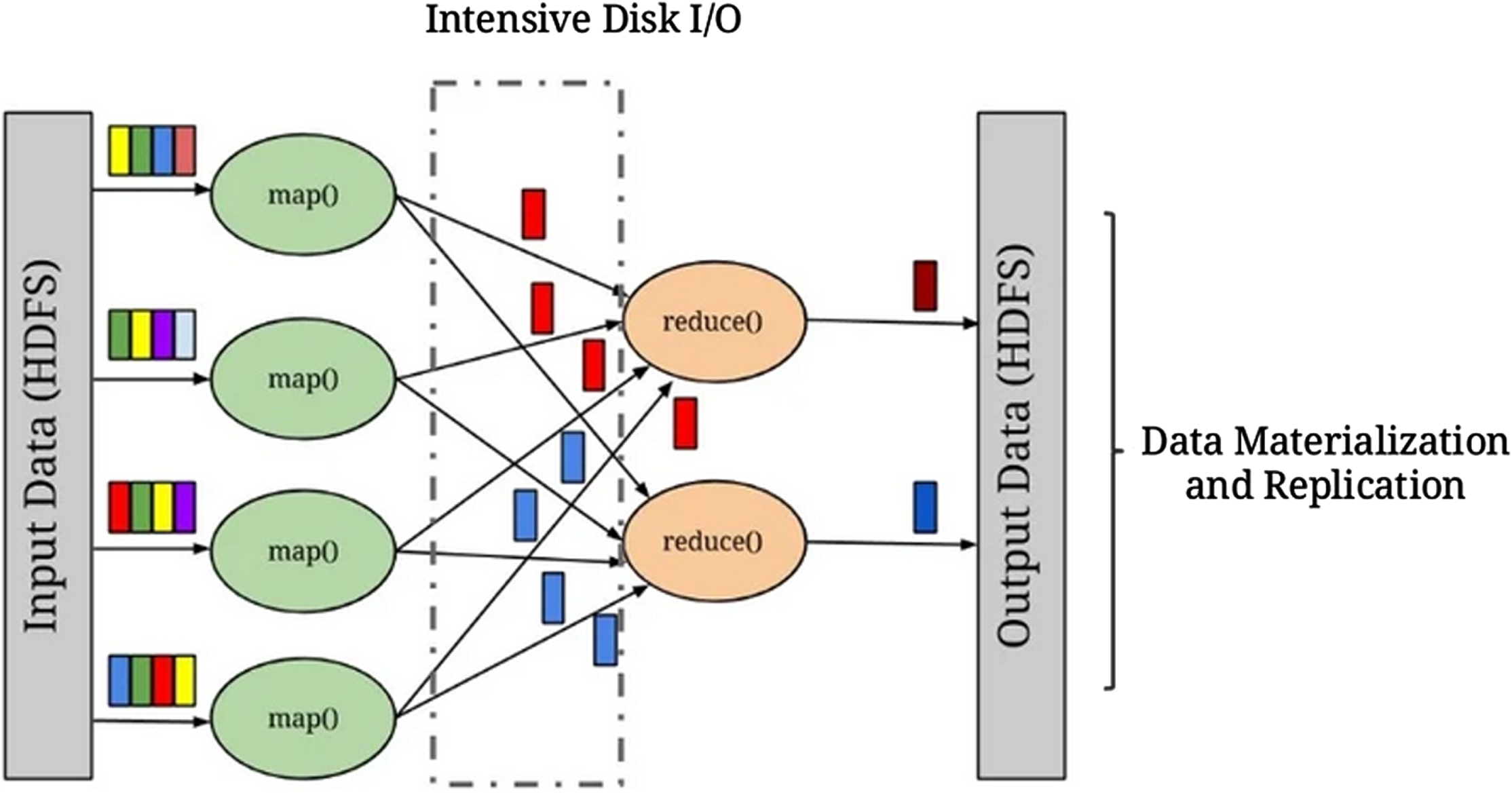
The Map-Reduce model is working only on the data which are stored in HDFS. Because all the operations working in Hadoop Cluster are only based on HDFS storage data. So the input from various sources has to be given to the map-reduce from HDFS is the first step of Map Reduce. According to the data size, the entire file is disseminated into individual tasks by a splitter. The input text format is changed into key-value pairs by the record reader function. Combiner is taking care of that key matches and it will make partitions over the HDFS disk based on the file size. The partitions are stored in the intermediate data of the mapper function to give the output to the next phase. But alignment is the major problem that leads to cause latency or throughput problems. So shuffling of keys and value pairs for each partition is running on the HDFS disk. The next important process that happened in Map Reduce is sorting [40, 41] based on keys from the HDFS. Using index searching techniques the sorted values are generated for the next phase. Reducer is important in map-reduce to optimize all the values into an appropriate format.
Problems of map-reduce
Map Reduce is designed with java as a programming language platform working on a Hadoop cluster. The cluster may vary in their nodes named as a single node or multi-node cluster have master-slave architecture. The main problem of Map Reduce is extracting data from a huge dataset within a stipulated time but that is not achieved because of the input file size of data from HDFS. The challenge in map-reduce is to minimize or optimize the whole volume of data into compressed format low volume data. But the time to complete that process is very high. In other words, latency and throughput are very low. Normal data extraction from the data warehouse is a little bit slower because of the patterns and algorithms used for processing [42].
Read/write operations in map reduce
Map Reduce is running with batch processing on Hadoop cluster data input format which means once the input has to be taken another input is waiting for the completion of the previous task. This is the most important problem in Map Reduce and it will be accessed through iterations [43] in Map Reduce. Because once the reading operation has taken place from HDFS it will be processed by the Map-Reduce phases and write the output on HDFS [44]. The next iteration has taken the input from these previous writes on the HDFS disk. Likewise, if more number of iteration processes is compiled in Map-Reduce [45] then it will store HDFS permanently. If the user requires particular data from that they have to write queries using any Data Manipulation Languages (DML) for their results. In this scenario, more iterative operations are not possible by Map Reduce because in batch processing only once the input has to take. If more iterative operations (looping) [46–48] are running it will not apt for low latency data processing. Because every time the map-reduce model runs repetitive functions, it may not complete the task within time. Moreover, latency is also high while doing data processing. Figure 7 explains the read and writes operations of the data sharing function in Map reduce.

Data Sharing in Map Reduce.
The best example for Map Reduce is a java based Word Count Program in the Hadoop cluster. Initially, three sentences have to be taken for input and it will be split into different individual tasks as input split. The next mapping phase takes care of individual tasks and converts that input split into keys and values which means the number of presence of the word is calculated. Based on the alphabet criteria the keys are shuffled and sorted as an output of the mapper. Reducer collects those outputs and gives them as input to the combiner for alignment of key-value pairs. Finally, it collects the time of occurrences of each word from that three sentences and will be given to the output to the client or user. Here the final output will be in the compressed form of input data which leads to data processing with poor latency best throughput and. The size of the input file is low like KB means within a few seconds map-reduce has to be finished. If it will be in MB/GB, then the number of maps and reduces will be more for doing the Map-reduce function [49, 50]. Figure 8 gives the example of word count with three sentences. Finally, the output got by the user is a compressed number of occurrences as an output. Based on this word count all the files are handled by batch processing and perform Map Reduce operations. Figure 8 summarizes the word count example.

Word Count Example for Map Reduce.
Map Reduce function done in Hadoop cluster by job tracker and task tracker. Classic versions of Map Reducev1 function is working with trackers. But latest version MRV2 is running with YARN architecture. Because it gives the tracking feature of Map reduce job in every stage [51]. The schedulers and queues are used to give the job status of a given task. MRV1 only deals with output whereas MRV2 gives the status of the entire job. Figures 9, 10 illustrate the advantages and disadvantages of MR versions.

Map Reduce Version1.

Map Reduce Version2.
The Map Reduce performance can be accessed by several factors of the Hadoop framework and its features. Map Reduce performance can be affected in terms of speed, latency, throughput, and time taken to complete the task. There are several other factors that may exist during the transmission of data in the Hadoop cluster that will affect map-reduce [52]. They are Performance Programming model & Domain Configuration and automation Trends Memory
Performance
Initialization of Hadoop and Map Reduce will affect the performance due to the techniques used in the entire data processing system. Because Hadoop 1. x gives only the output but cannot give time to complete the task. But Hadoop 2. x overcomes this issue and tracks the status of the job throughout the task. At last, the latest Hadoop 3. x version describes the advanced MRV2 process for quick response over the network on the Hadoop cluster through its erasure coding techniques [52, 53]. So Hadoop framework and Map Reduce installation is the major issue in the performance of Map Reduce consideration. Figure 11 gives the issues of performance in Map Reduce.

Performance issue 1.
Scheduling of jobs in Map-reduce is an important concept in the Hadoop cluster. Continuously jobs are assigned in Hadoop Framework by the clients; the order of jobs taken for Map Reduce is a typical process. So the schedulers are used to perform this work with the help of queues. Three main schedulers are available in Hadoop namely FIFO, Capacity, and FAIR [54]. Coordination of jobs between the nodes is, coordination between the nodes on the Hadoop cluster disseminates the details of all nodes to consider as the main factor in tuning the Map-reduce function. While accessing a variety of jobs sequentially the resource manager. The status of the jobs will keep tracked and sent to YARN for monitoring. Finally, any jobs that want to kill or delete during the processing time should be controlled by YARN because of this coordination. Any data processing model contains a single input system for processing whereas here both inputs are merged together as a tagging method for easy access to the huge data sets. Figure 12 gives the issues of performance in Map Reduce.
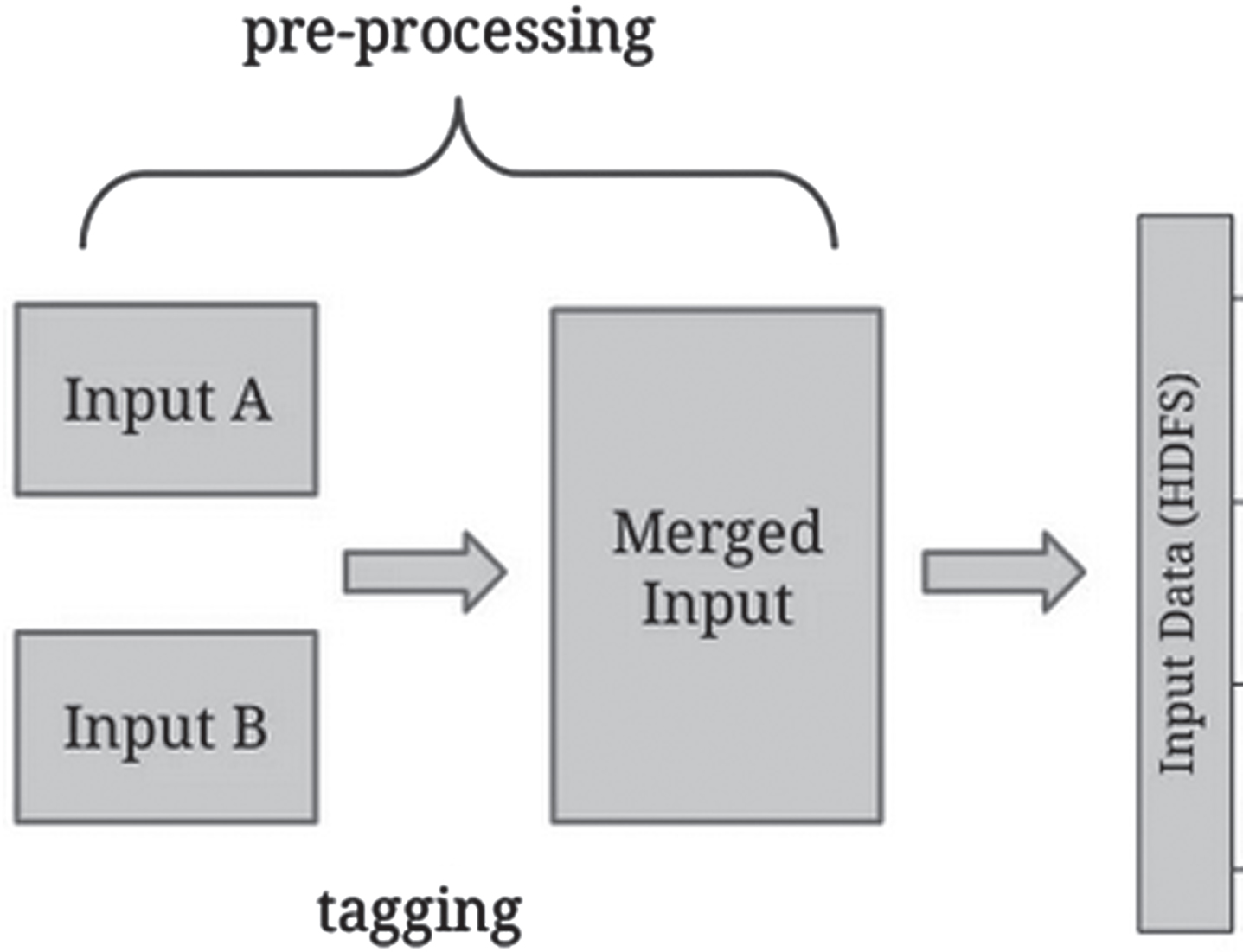
Performance issue.
Map Reduce writing map and reduce functions using good programming is essential for the users. There are various programming languages supported by Hadoop for performing Map-Reduce operations. Every language is based on platform dependent or independent employing their characteristics. Some of the languages that support the Hadoop ecosystem are SQL, NoSQL, Java, Python, Scala, and JSON [55]. They have their own set of properties to perform operations like join and cross properties of the dataset. It supports the techniques of running iterations and incremental computations among the nodes in Hadoop for accessing distributed databases parallelly. Perhaps, many iteration operations will affect Map Reduce performance. Figures 13 and Fig. 14 denotes issues of programming models.
Programming Model issue 1.

Programming Model issue 2.
Self-tuning of the workload between the nodes can be balanced by a load balancer on Hadoop and the data flow sharing among the nodes is controlled adequately is a big challenge. If this work fails automatically Map Reduce will give poor output on the task. Input-Output disk minimization is the major drawback in Hadoop MR for accessing data regularly. Their performance is changed due to the size of input data and methods used for splitting are noted. If the number of reduces is less may increase MR performance. The code written in a specific language supports static code generation [56] and the index creation method on Map-reduce will increase the performance. Sometimes the specific language doesn’t adapt to the changes that are made by the client in the system. The entire system is aware of data optimization principles to provide better performance on Map-reduce.
Trends
Data warehouse data are accessed by the database engine on Map-reduce. But the data size is very large, and extraction of small data from that engine made it difficult. The time taken to complete the process is very high. But instead of disk processing, it should be done by memory processing directly will improve the MR performance by I/O disks. Indexing [57] is the traditional database technique that is used to search the elements in the database or files run in nodes. It gives the extracted data to the user very fast. It might not depend on the size of a file, in each file the same techniques have been used. Memory caching [58] between the nodes is very important to improve the performance in MR. It describes the status of every job condition and the previous computation level also. Caching helps to identify the location of the data on the node specifically by its memory allocated by the jobs. Even though the nodes or jobs are canceled due to any issues the next job or node will get active and start the process over the network without waiting for manual intervention. The materials required for the MR process can be verified initially before the start of the job allocation by the resource manager.
Memory
Map Reduce function fully depends on the number of maps and reducers used for every task in the Hadoop cluster. If it will get increase immediately the performance of the system goes very slow in terms of time taken to complete the task. Calculation of number of maps The number of maps assigned for every job by a client is too calculated by the size of the input file [59] and allocated blocks for accessing those data. The following formula denotes the number of maps required for performing Map Reduce operations.
By default, minimum of 10 –100 maps per node is assigned for the job. A maximum of 300 maps can be allocated to do Map Reduce job. For example, 10TB of input file size and 128MB block size are allocated by Hadoop 2. x means 10TB/12b MB = 82,000 maps are approximately assigned for completing that job.
Normally reducer is allocated for all maps reduce job is 1. If the number of reducers wants to be increased for huge processes, then the configuration file can be changed during installation or after using speculative tasks. The following formula denotes the number of reduces by default required for performing Map Reduce operations.
Skipping bad records To eliminate the bad records created during the Map-Reduce process can be changed using configuration files. By enabling the true or false function in the configuration file it can be removed. For example, in the word count Map Reduce program written by java only case the sensor output is required means making –DwordCount.case.sensitive = true/ false command during the run time will give better performance than the previous one [59]. Because the bad records can be eliminated using these commands. Task execution & environment The task tracker in data nodes keeps track of all information about the jobs and is sent to YARN Resource Manager consequently. But there is a limitation over these operations in terms of memory allocation in a map and reduction for task execution. The command
Map Reduce Implementations
Map Reduce Implementations
The Map-Reduce job allocated by the resource manager of Hadoop will improve the performance of the data processing speed and accurate results based on the configuration of the cluster and proper allocation of map-reduce tasks with their type of input data. Though LZO compression helps to compress input file size there will be a combiner between mapper and reducer is a must for improving map-reduce job performance optimization [61]. Most of the code data can be reused to avoid searching for data location time over the cluster.
There are some other important aspects used in the map-reduce programming model to provide solutions for map-reduce job performance improvement in the Hadoop framework. All factors have represented the flow of jobs from resource managers to data nodes and how data can deviate from the flow during run time. Because these factors are rectified means even a big job running on the Hadoop cluster will give output with low latency. Below Fig. 15 listed the factors for job optimizations.
Data colocation.
It is mainly used in Map reduce concept for aggregation of databases to utilize the filter data and perform operations like grouping, sorting, and converting [62, 63] output from one form to another form of operators. Pipelining is used to connect two jobs simultaneously to complete the job within time. But the issue is extended database lock or tie when reading/writing in response to the user request. So the iterate operations are used at that particular time to improve their performance during pipeline events.
The result of the map-reduce is approximate in terms of size, time, and accuracy. Even though the performance has to be increased during the running time it cannot be predictable by its output. Any files can be taken as an input format it will provide an output of map reduced function. The output cannot be accurate or reliable in such cases.
Since Map-Reduce works with key-value pairs, it is very complicated to align the order of the jobs by a resource manager. It allocates the task to the data node which may cause conflicts rapidly [57, 64]. So indexing techniques are used in this job execution by searching the elements based on the index key values stored in the index table. The table contains all key values of the independent task in the mapper task and will give exact data to the combiner to perform the merging option. But the issue is that merging also it is complicated by arranging values in any order. So sorting is a function used in between these and performs reducer value output effectively.
Map Reduce is specially designed for handling multiple jobs parallelly. If multiple jobs are running simultaneously, it is recommended to share those jobs by individual maps [65] in the function. That work was done by a splitter in the map-reduce function. The time taken to complete the job is decreased because of this sharing job process.
Data that is used for the Map Reduce function from the HDFS storage can be reused for next-level changes in the same input file. Reusability [66] in the form of inheritance and will reduce the number of lines of codes in a program.
Skew Mitigation is the main issue in Map reduce, solved by different techniques to avoid data transmission. Using skew-resilient operators, classical skew-mitigation problems were solved. By repartitioning the concept, skew mitigation can be handled in a big data environment using three major methods. Minimizing the number of times of repartition to any task can reduce repartitioning overhead. Then minimizing repartitioning side effects can be removed during the struggling time to remove mitigation ambiguity. At last, unnecessary recompilations are used to minimize the total transparency of skew mitigation [27, 67].
Same location files will be collocated on the similar locate of nodes is a new concept based on the locator of file attribute in the file characteristics. When the new file is creating its location, the list of data nodes and the number of files in the same case can be identified and stored all those input files in the same set of nodes automatically [17, 68]. It will improve the map-reduce performance by avoiding duplication and repetitions [69, 70] of files in a Hadoop cluster. Figure 15 describes the example of data colocation in the Hadoop cluster.
Map Reduce function can be written in java or any other higher languages, the performance should be changed according to the features of selected languages. Table 8 narrates the differences between java and python coding languages when map reduce can be written.
Map Reduce written in java and python differences
Map Reduce written in java and python differences
Apache Spark framework is an open-source used for distributed cloud computing clusters. It is working with the data processing engine concept meanwhile to be faster than the Hadoop Map Reduce for data analytics. Though Hadoop is used to provide big data analytics effectively, it has some drawbacks [70] with limited factors which were already discussed in section 4.
Figure 16 and Fig. 17 are explained the working principles of the Hadoop map-reduce and spark engine.

Working of Hadoop Map Reduce.
Working of Spark.
Many companies created terabytes of data through human and machine generation applications. Apache Spark is used to improve the company’s business insights [72]. Few examples of companies using SPARK in real-world applications.
Stand-alone Mesos and Cloud are the places where Spark can run on Hadoop. Machine Learning algorithms can be executed faster inside the memory using Spark’s MLlib in order to provide the solutions which are not given easily by Hadoop Map Reduce [73]. Cluster Administration and Data Management can be done by combining SPARK and Hadoop because SPARK does not have its own Distributed File System (DFS). Enhanced security can be provided by Hadoop, for making workloads. But Spark can be deployed on available resources at all places of a cluster. So there is no manual allocation and tracking of individual tasks. For the above-said features, SPARK is still used by big companies and industries those who are working on real-world applications.
Hadoop framework is working under the principle of master-slave architecture where used as name node and data node with replication principle. The output of each step in Hadoop has stored their data in the HDFS cluster continuously. So if the client needs to retrieve the data from the database it will be very easy to extract in Hadoop. Because the Hadoop framework takes replication of every job output data in the HDFS cluster disks.
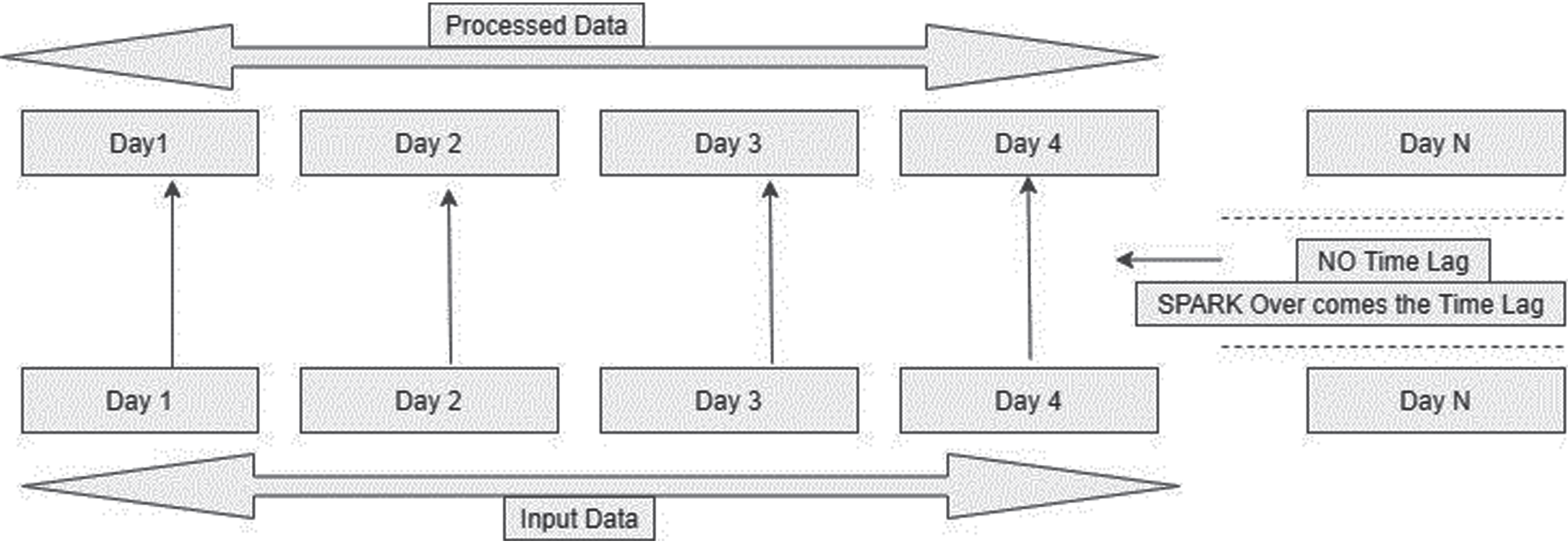
Spark is a distributed cluster framework for processing data on the memory of the nodes by its process engine. In-memory analytics data processing is used in SPARK, so the output of each step is stored in between the node memories for clients. For this, it consumes a lot of memory for storage. One big advantage of SPARK is to access real-time applications frequently. Although it is used for online generated data processing, streaming is mainly used. There is plenty of data generated online with every second. To maintain all those heavy storages and accessing engine or machine should be needed. So SPARK is used a lot of memory units in between the nodes on the network path. The time to complete the job is also very less by using SPARK [74]. Figure 18 differentiates the working of HDFS and SPARK clearly.
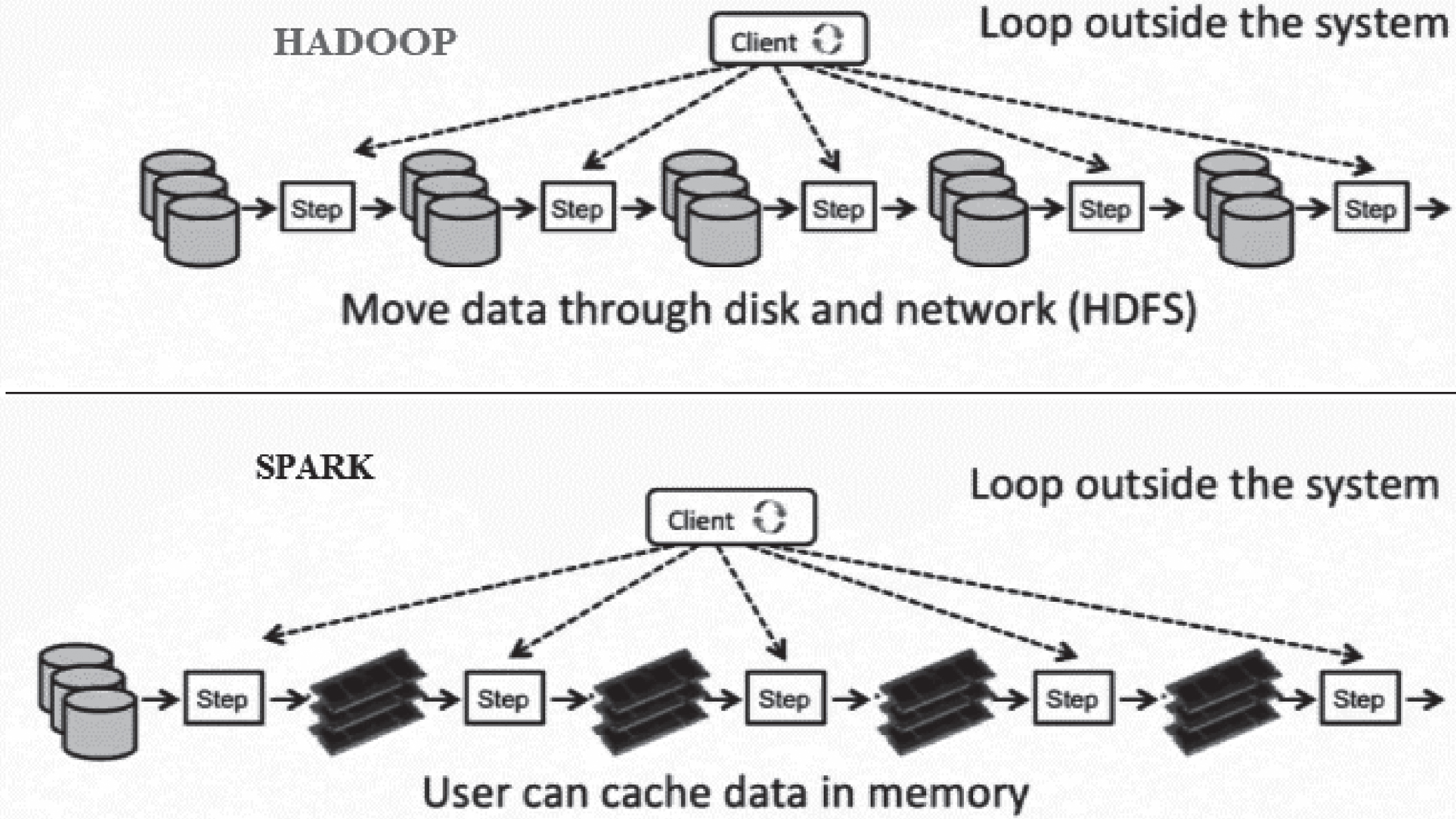
Working difference between SPARK and Hadoop.
In general, the SPARK framework is used to access real-time data with its memory analytics processing over the big network without any delay or traffic. A normal SPARK architecture consists of a software driver program that has to be written in SCALA language [75] and it will control all the worker nodes.
The cluster manager has monitored all these works and it is located between the worker node and the driver program node. Spark context is a small program written only for doing the job of data processing on the nodes but the difference is mainly in the memory storage part. The worker node contains the task assigned by the cluster manager with the executor module. Once the program can be executed by a cluster manager, the executor module in the worker node access the input data from HDFS and immediately stores the output in memory. The client wants to know the intermediate data at every step of the execution they will retrieve from that. Figure 19 is clarifying the architecture of SPARK.

Architecture of SPARK.
In Hadoop Distributed File System, Map Reduce can use for data processing by mapper functions among nodes under the cluster. The input file is disseminated into the number of tasks by the splitter and each task is working individually for the Map Reduce operation. Every mapper output is collected as a key-value pair and it will be stored in a circular buffer [76–78] for alignment then whole files are stored in HDFS by partitions. Figure 20 will explain the working nature of Hadoop. The partitions R1, R2, and R3 have different outputs of the mapper from the circular buffer and are arranged them like an array based on the index value. So whenever multiple jobs are coming to HDFS stored the output continuously without any drawback. SPARK initial design is accessing the data from the input and performing the mapper function then suddenly storing the output to a separate partition like a queue. So when the client is required each step output from the HDFS storage, they can collect it directly from that. In that Fig. 20, R1, R2, and R3 are the partitions that collect the output of the mapper and stored it accordingly. During the shuffle section, c1 is a core that is used to denote mapper 1, and c2, c3, and c4 denote other mappers. So if shuffling will happen in SPARK, the mapper output of the particular mapper is stored in core 1. Likewise, an individual CPU node contains 4 cores [79] by default all the other mappers are stored on free cores which are represented by the mapper. Figure 20 will explain the shuffles used in Hadoop and SPARK respectively.

SPARK files system.
Features of big data eco system tools are listed below in Table 9 for all the tools. There are plenty of differences between Hadoop and SPARK. The experimental results of multi-node clusters are displayed in Table 10.
Specifications of all tools
Experimental results of multi-node cluster
There are plenty of technical differences between Hadoop and SPARK. Based on these results anyone can conclude that for computing their big data which framework is better to select for data processing? Moreover, these technical differences convey the message to the people who plan to initiate a start-up company using computers. They have planned to select the framework for their requirements in all aspects. Table 11 summarizes the features of both Hadoop and SPARK.
Hadoop Vs SPARK
Hadoop Vs SPARK
To summarize the contribution for this paper, the authors are explained the challenges and limitations faced in modern tools like Hadoop and SPARK for data processing as following points:
I. Authors were taken various techniques from many research papers on the topic of tuning the performance of the databases while scalability is increased, and all papers are discussed about the data extraction techniques from the huge repositories with low latency and high accuracy over large networks.
II. Authors were written this review paper about Hadoop versions and their features to extract the data from the repositories and also SPARK tool features with the latest techniques. A detailed review has been written in this paper while selecting the tool for extractions with their advantages and disadvantages.
III. Authors have suggested ways to improve the performance of the databases extraction from the repositories. Moreover, the difficulties faced in previous methods. Though modern tools are used for data extraction writing a map-reduce program in Hadoop with a recent algorithm is a challenging task. SPARK is an advanced tool but the cost spend for used that tool is unimaginable for small-scale companies. Here authors were given suggestions to improve the performance in both tools.
Conclusion and future scope
Big data analytics is an important technology in this era used to access huge datasets Parallelly in a distributed cluster environment. Based on the requirements of the client or user every software company is deciding to deploy its software and hardware frameworks. Many start-up companies are also confused about their infrastructure to build up. This paper provides a solution for all companies and research-oriented people to select their framework for data processing rapidly. Perhaps, the basic factors of the data processing projects like speed and cost are considered in all situations. The above said technologies and examples are given a transparent view of the big company’s infrastructure for dealing with real-world problems effectively. There is a million-dollar question raises in the software industry that the real world scenario problems have been solved only by big industries or those who are ready to invest more money is the only possibility. But there are other factors also considered in the same scene taken by different industries. The main problem is data-driven from the large datasets with fewer resources is a challenging one. This paper deals with all the points to improve the data processing velocity of big data analytics by the famous framework Hadoop vs. SPARK. Henceforth, the data generated day by day in the real-world can handle different latest algorithms for analytics, and processing from the huge volume is being possible with tuning the already existing methods or trends. There must be proper analysis and research problems finding capacity that should be needed to implement all the innovative solutions for real-world problems. Finally, the user wants to find a solution for their problem with big data analytics Hadoop and SPARK are the main frameworks to provide solutions but according to the user requirement, they have to choose the best one. For example, the client wants to start a company which has low investment but dealing big data problem for a complex solution means Hadoop is their best choice because of the cost and type of data. If the same company has the urge to handle real-world application data and ready to provide huge investment, obviously SPARK is the best tool for them. When we consider technical aspects like algorithm and methodology, both tools are using some common techniques but final decisions might be taken based on cost and type of data handling. The decision taken by all persons who are handling big data analytics, Hadoop Map Reduce is suitable for low-cost and batch processing whereas SPARK is apt for real-time processing and a high-cost tool for data processing.
There are plenty of tools available for handling big data in the IT world, but only limited ones are popular among companies and industries because of their user-friendly or cost-wise approach. Hadoop and SPARK are the tools used in very high-speed data processing by various factors. How long have these tools ruled the world with their updated versions and techniques? New tools of Apache like FLUME, FLINK, and Kafka [80] are also available for accessing both batch and real-time processing in big data analytics. Only the techniques are varied in all tools. The new FLUME tools are used to collect various logs and events from different resources and stored in HDFS with high throughput and low latency. Apache FLINK is used to access the huge datasets by the micro-batch method which runs the data in a single run time with closed-loop operations. So the time to complete tasks is very low and identifying the corrupted data part is also easy. Another tool Apache Kafka is a modern tool used to handle feed with high throughput and low latency in social media. Finally, plenty of tools are used in big data analytics for handling a huge volume of data sets with different mechanisms and approaches. User has to take a decision very carefully in accessing and protecting their data with big data analytics world. This paper has covered the challenges and limitations of big data analytic tools in all aspects and provides solutions to handle those problems in a systematic way of approach.