
Abstract
Facial emotion recognition (FER) has been extensively researched over the past two decades due to its direct impact in the computer vision and affective robotics fields. However, the available datasets to train these models include often miss-labelled data due to the labellers bias that drives the model to learn incorrect features. In this paper, a facial emotion recognition system is proposed, addressing automatic face detection and facial expression recognition separately, the latter is performed by a set of only four deep convolutional neural network respect to an ensembling approach, while a label smoothing technique is applied to deal with the miss-labelled training data. The proposed system takes only 13.48 ms using a dedicated graphics processing unit (GPU) and 141.97 ms using a CPU to recognize facial emotions and reaches the current state-of-the-art performances regarding the challenging databases, FER2013, SFEW 2.0, and ExpW, giving recognition accuracies of 72.72%, 51.97%, and 71.82% respectively.
Introduction
The evolution of robotics and artificial intelligence has taken a qualitative leap in domains such as dynamic stability [1], autonomous navigation [2], or speech recognition [3] among others, in the last decade. This has allowed social robots, which must be designed based on human-oriented perception, to behave and adapt to complex scenarios in more advanced manners [4], involving emotional feedback during human-robot interaction (HRI) [5]. Emotion estimation is a key for such applications and by improving its performance accuracy, enhances the living conditions of several social groups such as elders with mental diseases [6], autistic [7], and hospitalized children and their families [8], even open up to other categories.
Emotion estimation is a complex task [9], and despite the variability of emotional responses and their dependence on culture [10], there is a need to narrow down the reference system for experimental research by creating an emotional model. Based on psychological studies, emotions are generally divided into six prototypical categories [11]: anger, disgust, fear, happiness, sadness, and surprise; which the neutral emotion is defined as a baseline. Emotion recognition systems are developed based on several modalities such as: facial expressions [12, 13, 14], body gesture [15], speech [16], and physiological signals [17, 18].
Facial emotion recognition (FER) systems can be designed using two different strategies: Image-based and video-based. Although, video-based systems carry a high amount of emotional information due to their dynamic properties, they require a more complex analysis which is still complicated to implement in real-time systems. For this reason, this methodology was tested first using a simplified approach on static images; however, it is worth mentioning that FER in these conditions, stills a challenging task due to multiple environment variations such as brightness, occlusions, or body posture, which can affect the information available in the processed image.
Globally, FER image-based systems consist of three major stages: face detection and pre-processing, feature extraction, and classification. The first stage aims to detect the region of interest (face) in goal of removing unnecessary information to recognize the facial expression such as the background; it becomes challenging when acquisition conditions are poor mainly the lighting. The feature extraction leads to represent the pre-processed image with a characteristic vector including the relevant features. In FER, feature extraction techniques could be divided into two main categories: appearance-based and geometric-based methods. The first methods aim to detect textural information from face images using well-known feature extractors such as Gabor filters [19] and local binary patterns (LBP) [20]. Strategies based on geometric properties use overall the detected facial landmarks to encode the geometric information like angles and distances. The extracted features are then used for classification to recognize facial emotions.
In the last few years, the use of deep learning in several applications [21, 22] has become possible, since powerful graphics processing units (GPUs) are now available. Compared to traditional methods based on the aforementioned feature extraction techniques, convolutional neural networks (CNN) based techniques have achieved the FER state of the art recognition rates [14]. However, due to the training process’s stochastic properties, different sets of weights are found on each trained neural network; therefore, an intuition could lead to train several models to combine their predictions as an ensemble, and subsequently, may lead to a reduction of the generalization error in most cases since each single CNN extracts discriminative features for a specific task, as shown in our published paper [23].
However, it is worth mentioning that training FER models face two major challenges. First, environment variations such as brightness, occlusions, or body posture, can affect the information available to recognize a facial expression, and secondly, most of databases designed for training are prelabeled by humans, which contain inherent bias due to emotion perception complexity, as shown in Fig. 1. Thus, train a model with a wrong target class may lead to learn incorrect features and subsequently decrease the accuracy performance and generalization capabilities.
Miss-labelled data samples from the FER 2013 training set, neutral emotions were labeled as happy, afraid, angry and sad respectively.
This paper extends the CNN ensembling method for facial emotion recognition proposed in our previous work [23], by including the label smoothing technique to deal with the miss-labelled data. Additional computation is provided through three different hardware setup, with two possible face detection systems depending on the image acquisition complexity respect to environment variation. The methodology was tested on three challenging databases, collected in real-world conditions and in unconstrained manner, FER 2013 [24], SFEW 2.0 [25], and ExpW [26].
The rest of the paper is organized as follows: Section 2 presents the related works, the proposed method’s stages are described in details in Section 3, followed by the experimental results as well as discussions in the fourth section. Conclusions and perspectives are drawn in Section 5.
In the facial emotion recognition field, several research works have been carried out to improve the emotion estimation accuracy. The use of deep learning has outperformed the conventional approaches that use the traditional feature extraction techniques; their training methodology can generally be divided into two main categories: single network learning and ensemble network learning.
The single network learning category uses only one architecture for the feature extraction and the recognition task. For example, Mollahosseini et al. [27] designed a CNN architecture of two convolutional layers and four inception layers for FER. In [28], they used a deep neural network with relativity learning (DNNRL) of three convolutional layers followed by three inception layers and trained by the triple loss. A multi-task convolutional network for simultaneous facial landmarks detection and facial expression recognition, is proposed in [29]. Tang et al. [30] proposed the DLSVM by replacing the softmax layer with a linear support vector machine (SVM) for FER application. Lian et al. [31] studied the contribution of each face region in the facial expression recognition using the class activation mapping technique (CAM) and a visualization model based on the Densenet-BC architecture.
The ensemble network learning methods adopt the ‘divide and conquer’ approach; the input image is fed through a set of deep architectures and the final decision is obtained by the combination of each network score output. Overall, the ensemble network learning methods achieve a better performance compared to the single learning category, since each network extracts different relevant features and may lead to minimizing the generalization error; however, this methodology requires additional computing time, given that for the same task, multiple networks are used compared to the first approach.
Levi et al. [32] proposed a novel method based on a deep ensemble network. First, by applying different radius parameters, LBP codes are extracted and mapped to a 3D space using multidimensional scaling (MDS); afterwards, the original RGB images and the mapped codes are used to train a set of 20 CNN models, and the predicted emotion is then obtained by the weighted average of each model’s output. Kim et al. [33] proposed to fuse information about non-aligned and aligned faces for FER. They introduced an alignment mapping network (AMN) to estimates aligned states of non-alignable faces, then with a set of 9 deep convolutional neural networks (DCNs), the average or the majority voting rules are used to compute the emotion prediction. Similarly, Pramerdorfer et al. [34] trained an ensemble of 8 CNNs achieving the best state-of-the-art performance on the FER 2013 database [24].
Most of the previous studies do not take into account the computation time of the FER system and its integration capability in real devices; furthermore, the miss-labelled training data that drives the model to learn incorrect features are not studied. Similar to [32, 33, 34], we proposed in [23] a deep network ensemble including only three CNN, with a comparable accuracy performance.
In this paper, we propose two possible implementations, with/without dedicated GPU by providing additional computations to evaluate our proposed model under the real-time constraints and its integration capability for global use, according to three hardware configurations. In regards to the miss-labelled data, we propose to use the label smoothing technique [35] by reducing the confidence given to image labels during the training process.
Schematic overview of the proposed FER system, Stage 1 includes the face detection procedure and Stage 2 performs the facial emotion recognition.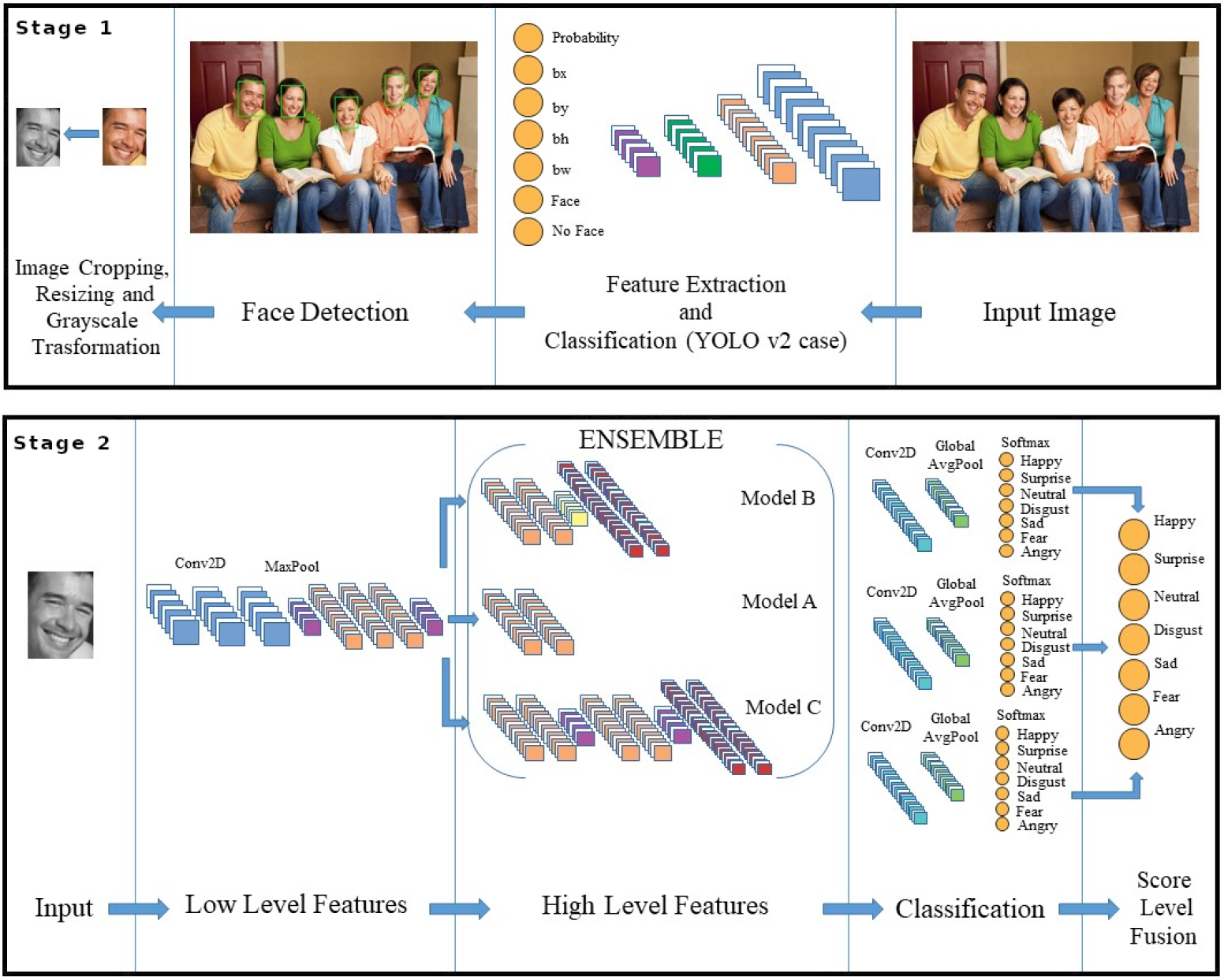
The proposed framework is based on the following stages: Face detection and pre-processing, feature extraction and classification using deep neural networks, and label smoothing optimization followed by ensemble learning approach. Figure 2 shows a schematic overview of our proposed FER system.
Face detection and pre-processing
The face detection stage aims to reduce the amount of information given to the CNN networks designed to recognize facial emotions. Face detection is a highly investigated area, while the most known algorithm is the Viola-Jones method [36] based on the Haar feature-based cascade classifiers.
Respect to the deep learning era, several object detection techniques have been proposed in the literature, which could be categorized into two main approaches: region proposal based network and one-shot based network. The region proposal based methodology including RCNN [37] and its improved versions, Fast RCNN [38] and Faster RCNN [39], consists of two stages, first, the possible regions containing objects in the input image are selected, and then fed into a CNN for feature extraction and classification to identify the object and the coordinates of its bounding box. The one-shot based methodology, including SSD [40] and YOLO [41], needs only a single stage for detection and classification, contrary to the first approach.
Overall, the one-shot based methods are faster compared to the region proposal based methods which are computationally expensive, since they use two stages for object detection [42]. You Only Look Once (YOLO v2) [43] is fast and accurate, since it achieved a performance of 76.8 mAP outperforming the Faster-RCNN and SSD on the standard database VOC 2007 at 67 FPS, which it is suitable for real-time applications. It divides the input image into a
We have chosen to deploy for our FER system, two face detection methodologies, the Viola-Jones technique as non-deep learning-based method and extend the YOLO v2 model, as a deep learning-based method, to deal with the face detection by training the network on the fully annotated face database, WIDER DB [44]. This choice is based on the final user’s hardware configuration since deep learning requires a GPU to deal with a high amount of computations.
Detected faces are cropped, converted from RGB to grayscale space, and resized to a resolution of 48
Deep feature extraction and classification
Deep convolutional neural networks have achieved the best state-of-the-art performances in most computer vision and AI applications, thanks to their learning capability of high abstract representations, in comparison to classical feature extraction methods. However, they require large amounts of data to achieve a proper generalization, and a substantial computing capacity due to their significant trainable parameters.
Overall, the first convolution layers extract low-level features such as shapes and edges, while the deeper layers, learn more complex features. Therefore, our starting point consists of defining architecture as a baseline, intended to have as less number of parameters as possible to deal with the computation issue, then from this, we derive a set of deeper architectures to explore the complexity of facial emotions.
Description of our baseline structure (Model A),
width,
height,
filters,
stride,
depth
Description of our baseline structure (Model A),
Description of the Model B last layers by extending the baseline model from the Conv A-7 layer,
Description of the Model C last layers by extending the baseline model from the Conv A-7 layer,
First, a series of well known deep learning architectures were tested and finally Conv-Pool-CNN-C was taken from [45], called hereafter model A and defined as our baseline. This choice was based on the tiny network architecture, composed of a set of 9 convolutional layers with a 3
Derived model architectures
By adding maxpooling, dropout, and a set of convolutional layers, after the baseline’s Conv A-7 layer (see Table 1), three architectures have been derived, hereafter called: Model B, Model C, and Model D, respectively.
In Model B, we modified the Conv A-8 layer’s kernel size to 3
Description of the Model D last layers by extending the baseline model from the Conv A-7 layer,
width,
height,
filters,
stride,
depth
Description of the Model D last layers by extending the baseline model from the Conv A-7 layer,
One of the main problems when facing the facial emotion recognition (FER) is that it contains miss-labelled images (see Fig. 1); thus, the model is prone to learn incorrect features from the source data. With this in mind, a strategy can be carried out based on label smoothing [35].
In the learning process, each label is assumed to be correct and categorical. The model is expected to learn from the input data and predicts the expected label. The latter is closely related to the loss function and driving gradients, which lead to reduced expected errors.
An intuitive example is given based on the cross-entropy loss function for classification according to
Labelling data with high confidence of
The fact under the assumption of having databases with incorrectly labelled data, due to human-error produced bias since the labelling is carried out by multiple participants, which may have different criteria. The solution, therefore, involves the confidence given to image labels. This produces a decrease in the loss function for the case of using miss-labelled data, circumventing the model for driving the gradients far away from the objective function. For that, label smoothing has been applied with a smoothing factor
A set of different factors can be involved in that strategy. First, the way the training data is used to feed the models: One strategy uses k-fold cross-validation, were
or:
Where
Emotion class distribution regarding the facial expression databases, FER 2013, SFEW 2.0 and ExpW
To verify the validity of our method, we have carried out several experiments according to three phases. First, we trained our single models (A, B, C and D) on the FER 2013 database without label smoothing technique; afterwards, all possible ensembles have been built to investigate the ensembling generalization capability against single models. In the second phase, we have trained the single models using label smoothing with
To keep our recognition performances regarding FER 2013 and SFEW 2.0 databases, comparable with those reported in the literature, we have trained the four single models with/without label smoothing using the same training subset according to each original holdout dataset split. Similarly, for the ExpW database since any particular split is initially provided, the FER 2013 ratio has been considered, 80% for training, 10% for validation, and 10% for test.
Special attention has been paid to the FER processing time in order to verify the integration capability in real devices, facing the real-time constraints. Three different hardware configurations have been tested: Multi-core i7 CPU without dedicated GPU, multi-core i7 CPU with a GeForce GTX 1080 GPU, and the Jetson Nano with a Tegra X1 GPU for embedded systems. The time processing was computed on each hardware and for each frame, through the facial detection and facial expression recognition stages independently. For the face detection step, the Viola-Jones and YOLO-v2 methods were tested. The experimental protocol was performed using an attached webcam with a resolution of 640
All architectures have been implemented using keras framework, trained using the categorical cross entropy loss and Adam optimizer, with a batch size of 128 for 100 epoch each. We used the learning rate reducer and the early stopper callbacks to get the best model weights according to the validation set loss.
Databases
To validate and keep the highest challenge to implement FER in real-environment scenarios, experiments have been carried out on three benchmark databases collected in the Wild, FER 2013 [24], SFEW 2.0 [25], and ExpW [26] datasets.
FER 2013 database
FER 2013 is a large scale database, introduced in the ICML 2013 challenges in representation learning. It consists of 3 subsets of 48
SFEW 2.0 database
The Static Facial Expression in the Wild database (SFEW) is collected by selecting static frames from movies available in the Acted Facial Expression in the Wild database (AFEW) [47], including unconstrained facial expressions under challenging scenarios such as lighting and occlusions, for a total of 95 subjects. It consists of three subsets: 891 frames for training, 431 frames for validation, and 372 frames for test, labeled according to the six prototypical expressions: angry, disgust, afraid, happy, sad, and surprised, plus the neutral expression. The test set labelling is not publicly available.
ExpW database
The expression in-the-Wild database (ExpW) consists of 91793 unconstrained face images, collected using the Google image search API and manually labelled following the seven basic expressions: angry, disgust, afraid, happy, sad, surprised, and neutral. The database is fully face annotated and a confidence score from 0 to 100 is provided for each bounding-box as well non-face images were removed. Since the creators did not provide a particular validation split, we split the ExpW database similarly to the FER 2013 ratio, 80% for training, 10% for validation, and 10% for test; giving 73434, 9180 and 9179 images for each subset respectively.
The data distribution of each database are given in details in Table 5.
Obtained recognition performances for CNN single models with/without label smoothing on the FER 2013 validation and test sets
Obtained recognition performances for CNN single models with/without label smoothing on the FER 2013 validation and test sets
Obtained recognition performances using CNN ensemble models with/without label smoothing on the FER 2013 validation and test sets
Obtained recognition performances for CNN single models with/ without label smoothing oregarding SFEW 2.0 validation set
The obtained results can be analyzed according to three aspects, the ensemble performance, label smoothing optimization, and computation time. Tables 6, 8 and 10 show the single model performances with/without label smoothing technique regarding FER 2013, SFEW 2.0, and ExpW databases respectively. These models have been used to build the ensembles, which their performances are provided in Tables 7, 9 and 11. The best recognition accuracy for each benchmark database is then taken and compared with the reported performances in the literature and highlighted in Table 13.
Obtained recognition performances using CNN ensemble models with/without label smoothing on the SFEW 2.0 validation set
Obtained recognition performances using CNN ensemble models with/without label smoothing on the SFEW 2.0 validation set
Obtained recognition performances for CNN single models with/without label smoothing on the ExpW validation and test sets
Obtained recognition performances using CNN ensemble models with/without label smoothing on the ExpW validation and test sets
Comparative study of the proposed FER computation time, regarding three hardware configurations using the ensemble ABC
Comparative study of reported performances in the literature regarding FER 2013, SFEW 2.0 and ExpW databases
Obtained confusion matrices for the proposed single CNN models and for the two best ensembles regarding FER 2013 test set accuracy (Up: Average fusion strategy, Down: Maximum fusion strategy).
Respect to the obtained confusion matrices for every single model illustrated in Fig. 3, trained on the FER 2013 database, we can figure out that single models outperform the generalization for particular emotions as is the case in Model A for ‘sad’ and ‘surprised’; Model B for ‘disgust’, ‘happy’ and ‘eutral’; Model C for ‘fraid’; and Model D for ‘angry’ and ‘neutral’. In comparison with ensemble models, ABC and ABCD ensembles take advantage of the generalization capabilities for each single model in contrast to using them independently, achieving our best result on FER 2013 with 72.47% using the ensemble ABC with the average score fusion strategy. It is validated on the SFEW 2.0 with the best accuracy of 51.04% using the ensemble CAD, and on the ExpW database with 70.69% using the ensemble BCD. The results thus obtained show that the ensembles outperform the single models in term of recognition accuracy.
It should be mentioned that the average score fusion strategy gives the best performance compared to the maximum score fusion strategy in most cases. This shows that the contribution of all single models to estimate the correct emotion outperforms the high confidence of only one model, since facial emotion recognition stills a challenging task even for humans due to similarities between emotional states. Furthermore, we can figure out that ensemble performance does not depend on the number of models that constitute it since the best accuracies on FER 2013, SFEW 2.0, and ExpW databases, have been obtained using only 3 CNNs instead of 4 CNNs.
Label smoothing analysis
Label smoothing technique improves the recognition accuracy compared to models trained without label smoothing, regarding our four single models and all experiments carried out on three databases, with the highest improvement of 0.84% for model C on FER 2013, 0.93% for model A and D on SFEW 2.0, and 1.33% for model A on ExpW, as shown in Tables 6, 8, and 10 respectively. This has contributed as well to improve the ensemble’s performances, built using the single models trained with label smoothing, achieving our best results with 72.72% using the ensemble ABC regarding FER 2013, 51.97% using the ensemble CAD regarding SFEW 2.0, and 71.82% using the ensemble ABCD regarding the ExpW database.
For a better check, we employed first a dimensionality reduction technique, principal component analysis (PCA), on the extracted features from the inner layers of models B and C, trained with/without label smoothing on the FER 2013 validation set, and then projected using t-SNE [53] to 2D space as shown in Fig. 4. We can figure out that several samples have been miss-labelled particularly happy emotion as neutral and afraid as a surprise. Thus, label smoothing technique contributes to clustering data distribution, which it will be easier for a multi-class classifier to separate the emotion classes, and this explains the improved performance compared to models trained without label smoothing
t-SNE visualization of extracted features from FER 2013 validation set using a trained network with and without label smoothing: (a) using trained Model B without label smoothing, (b) using trained Model C without label smoothing, (c) using trained Model B with label smoothing, (d) using trained Model C with label smoothing (miss-labelled samples are marked with red squares).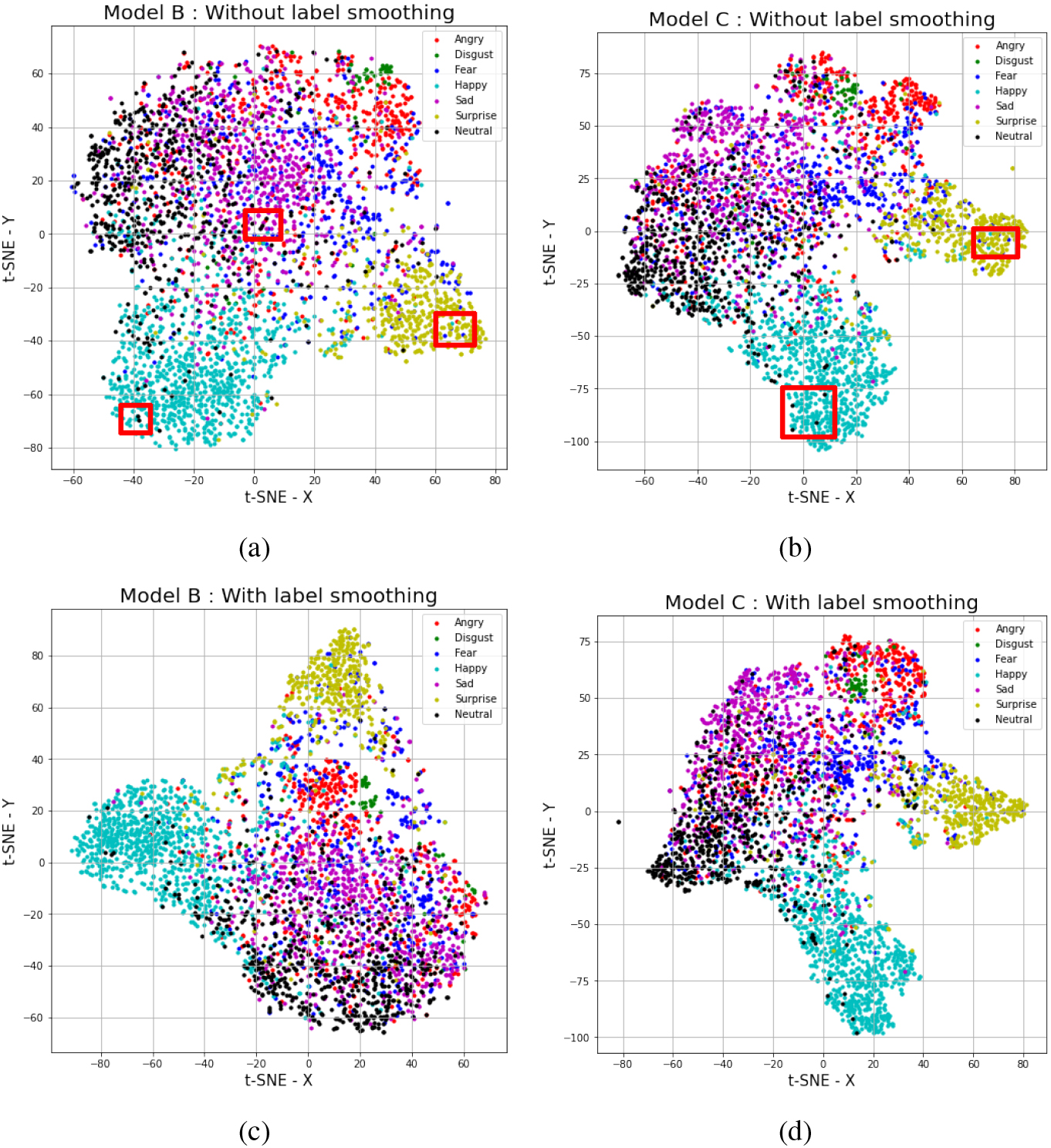
Face detection carried out with YOLO v2 model and Viola-Jones method on ExpW database samples: (Red) Detected bounding boxes using YOLO v2, (Blue) Detected bounding boxes using Viola-Jones method, (Green) Ground truth bounding boxes provided by ExpW database creators [26].
The system is capable of recognizing facial expressions in real-time constraints, as shown in Table 12. It takes only an average time of 13.48 ms when running on a hardware configuration of Intel i7 CPU and Nvidia GTX 1080 GPU, using YOLO v2 model for the face detection stage and an ensemble of 3 CNN (models A, B, and C) for the facial emotion recognition. This is a competitive solution that can be employed easily on videos with 60 FPS. In contrast, for hardware configuration with the only CPU, it takes an average time of 307.71 ms when YOLO v2 model is used for face detection and 141.97 ms when it is replaced by the Viola-Jones method since it uses low computations compared to the deep learning-based model, which it is fast enough for a video of 6 FPS. It depends on the environment scenario where facial emotion recognition is employed since YOLO v2 model is robust to detect unconstrained faces compared to the Viola-Jones. It should be mentioned that performance could be improved by reducing the video resolution from 640
On the other hand, artificial intelligence embedded in robotics is evolving to the use of GPU based hardware architectures [54, 55, 56] to take advantage of deep learning models, as for the Jetson Nano with Tegra X1 GPU, it takes 203.04 ms when using YOLO v2 model and 137.22 ms when using the Viola-Jones method for face detection. It can easily adapt to any robot as an embedded sub-system for task-oriented designs.
Discussion
The developed FER system proposes a robust solution for emotional state estimation based on facial expressions and for several end-user hardware configurations. Regards to applications that require an unconstrained face detection, it is recommended to use the YOLO v2 model than the Viola-Jones method, since it is robust in real-environment as illustrated in Fig. 5, where the Viola-Jones method often fails to detect occlusions and oriented faces, but in the price of a high amount of computations. Our system faces the real-time constraints when a powerful GPU is used such as the GTX 1080, since it runs smoothly and takes only 13.48 ms for face detection and emotion recognition. In contrast, To adapt to any robot, the Jetson Nano with Tegra X1 GPU could be an interesting solution as an embedded sub-system since our FER system will work easily on videos with 5 FPS.
The obtained recognition results are in good agreement with other studies [32, 33, 34] which have shown that ensembling learning often gives higher performance compared to single model’s performances. Furthermore, based on their reported results, our system reaches the current standards in facial emotion recognition with comparable performance regarding three challenging databases, FER 2013, SFEW 2.0, and ExpW, collected in the wild, without using any data augmentation or face alignment technique. It uses only 3 CNNs for a total of 5.25 million parameters regarding our best ensemble ABC on the FER 2013 database, against [32], which have used a set of 20 deep neural networks, or [33] with 9 DCNs, or [34] with 8 CNNs. Regarding the ExpW database, we achieved a slightly lower performance of 0.08% than [31]; nevertheless, in their experiments, they selected all images with a high box confidence score of 60 to 100 from this database, contrary to our work, which all images have been used even with the lower box confidence scores. Our system is quite straightforward and can be adapted easily for several computer vision and robotics applications.
In this paper, we extended our previous work [23] by adding the label smoothing technique to our models, reducing the confidence given to the training data labels, based on the assumption of having several miss-labelled data that can drive the model to learn wrong features. The label smoothing has demonstrated its efficiency on clustering data distributions as shown from the t-SNE visualization in Fig. 4, which miss-labelled data with a high amount of emotion similarity could join the correct cluster and further improving the recognition performance with an efficient classification stage. It should be mentioned that a few images could have clear wrong labelling from the source, like those marked with red squares from the t-SNE visualization in Fig. 4, and the label smoothing will fail to deal with these samples.
Conclusions
In this paper, we have proposed a framework for facial emotion recognition. It adopts the neural network ensemble learning with only three to four CNN architectures, for a better model generalization. Dividing and conquering has demonstrated to be a good strategy since the first stage deals only with the face detection and pre-processing in different conditions, and allow to focus the second stage only on inferring the emotional state; therefore, simplifying the whole process.
The label smoothing technique has clearly shown that reducing the confidence given to training labels improves the FER accuracy, and when combined with the ensembling learning, reaches the current state-of-the art performances according to three challenging databases, FER 2013, SFEW 2.0, and ExpW.
The proposed FER system provides an advanced solution to expand several computer vision applications and could improve human-robot interactions (HRI), mainly affective robotics, by rendering the robot accurately aware of the users’ emotional state. This could be used for therapeutic purposes such as autism’s and Alzheimer patients, and as a companion for elder people.
For future works, we plan to combine the findings on static images with the temporal information provided by videos to study in-depth the variations between the facial expression states, and further the emotional state provided by the speech intensity. This could lead to improve emotion recognition instead of using the images only.
Footnotes
Acknowledgments
We want to acknowledge to Programa de Ayudas a Grupos de Excelencia de la Región de Murcia, from Fundación Séneca, Agencia de Ciencia y Tecnología de la Región de Murcia.