
Abstract
To assess non-verbal reactions to commodities, services, or products, sentiment analysis is the technique of identifying exhibited human emotions utilizing artificial intelligence-based technology. The facial muscles flex and contract differently in response to each facial expression that a person makes, which facilitates the deep learning AI algorithms’ ability to identify an emotion. Facial emotion analysis has numerous applications across various industries and domains, leveraging the understanding of human emotions conveyed through facial expressions, so it is very much required in healthcare, security and survelliance, Forensics, Autism and cultural studies etc,.. In this study, facially expressed sentiments in real-time photographs as well as in an existing dataset are classified using object detection techniques based on deep learning. Fast Region-based Convolution Neural Network (R-CNN) is an object detection system that uses suggested areas to categorize facial expressions of emotion in real-time. Using a high-quality video collection made up of 24 actors who were photographed facially expressing eight distinct emotions (Happy, Sad, Disgust, Anger, Surprise, Fear, Contempt and Neutral). The Fast R-CNN and Mouth region-based feature extraction and Maximally Stable Extremal Regions (MSER) method used for classification and feature extraction respectively. In order to assess the deep network’s performance, the proposed work builds a confusion matrix. The network generalizes to new images rather well, as seen by the average recognition rate of 97.6% for eight emotions. The suggested deep network approach may deliver superior recognition performance when compared to CNN and SVM methods, and it can be applied to a variety of applications including online classrooms, video game testing, healthcare sectors, and automated industry.
Introduction and literature survey
Facial emotion analysis holds great potential to enhance a wide range of applications, from improving user experiences to advancing research in psychology and neuroscience. However, it’s important to navigate ethical considerations related to privacy, consent, and potential biases when implementing emotion analysis technologies. Charles Darwin published the first scientific investigation on emotional expression on the face in 1872 [1]. His research demonstrated the consistency of various facial expressions with certain emotions and clarified why certain expressions go along with particular emotions, even if other emotions can be displayed while masking the underlying mood. It was argued that despite efforts to hide them, genuine emotions can still be shown. Dr. Paul Ekman writes in [2] that he used the Facial Action Coding System, where less than 25% of his participants were unable to consciously regulate an involuntarily generated muscle contraction, to demonstrate that Darwin’s hypothesis was right. This method, which is seen in Fig. 1, is used to identify and categorize human facial motions as well as determine which set of muscle movements are responsible for each emotion portrayed on the face.. Any movement made by any muscle has a name for each unique direction. Swedish anatomist Carl-Herman Hjortsjo is credited with creating this method [3]. He related 24 different emotional states to groups of face muscle movements. The following are a few instances of the emotional states: dejected, tortured, bewildered, pained, contemptuous, and disgusted.

Facial Action Coding System (Image taken from- https://www.eiagroup.com/the-facial-action-coding-system/).
Happiness –Raised eyebrows and corners of the mouth
Surprise –Raised eyebrows but not drawn together, raised upper eyelids, jaw dropped down
Anger –Eyebrows pulled down, eyes open wide, lips pursed tightly together
Fear –Jaw dropped open, lips pressed backwards horizontally, upper eyelids raised
Sadness –frowned smile with lip corners pulled down, inner corners of the eyebrows pulled together, eyelids drooped.
Disgust –Upper lip raised in a ‘u’ like shape, eyebrows lowered, wrinkling of the nose
Contempt –Raised lip corner on one side of the face, this is the only signifier but it can also be accompanied by a smile or angry expression.
The Wheel of Emotions, devised by Robert Plutchik in 1980 to assist illustrate the Psycho evolutionary Theory of Emotion [4], is a graphic representation of eight fundamental emotions depicts in Fig. 2. According to the hypothesis, emotion is not just a state of feeling, but also a complicated series of events that, when recreated, would cause sensations that would lead to behaviors. A person would smile when they were feeling happy. The four pairs that make up the eight fundamental emotions are: joy - sadness; trust - disgust; fear - anger; and anticipation - surprise. Any two fundamental emotions placed adjacent to one another can create an emotion. On the other side of the 2D emotion wheel is the opposing feeling to the one that was formed. The challenge in facial emotion analysis lies in accurately and robustly detecting and interpreting human emotional states from facial expressions captured in varying environmental conditions. This problem is characterized by the need to develop computational models capable of discerning nuanced and contextually diverse emotional cues across individuals, cultures, and demographics. Factors contributing to the complexity of the problem include variations in lighting, pose, occlusions, facial morphologies, and the dynamic nature of emotional expressions. Moreover, addressing ethical concerns such as privacy, bias mitigation, and data security further underscores the multifaceted nature of this problem. The objective is to devise methodologies that balance sensitivity, specificity, and execution efficiency while accounting for the intricacies inherent in human emotional expression, leading to more accurate, reliable, and ethically sound facial emotion analysis solutions.
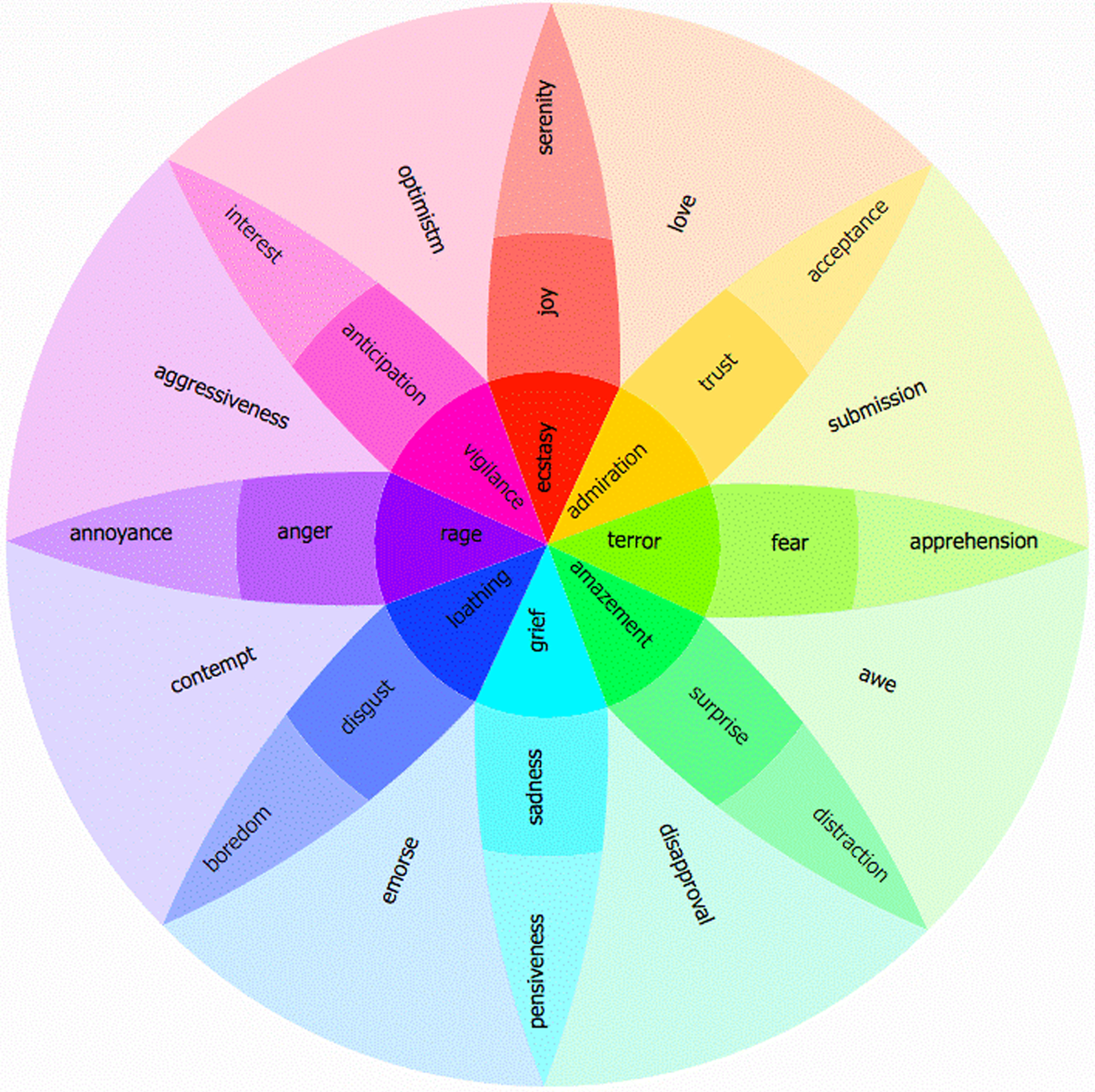
Wheel of emotions.
Recognition of facial expressions fits into the pattern recognition research paradigm. The three phases of a recognition system would be face detection, feature extraction, and expression categorization. These three crucial challenges of recognition of facial expressions have been the subject of extensive investigation. Different feature classification and extraction techniques have been used to create a range of face emotion recognition systems. ANN were used as the classifier in Tian et alstudy.’s on the combination of permanent characteristics and transient features [5]. In more recent study, Sánchez et al. used Support Vector Machine (SVM) as a classification approach and optical flow-based algorithms for feature extraction [6].
A real-time facial expression detection system with good recognition rates was created by Junnan Li et al. created a multi step feature extraction and picture preparation approach that enhances classification performance [7]. To specifically eliminate illumination variance, histogram rebinding to a normally distributed is utilized after photo metric normalization. To extract resonant characteristics from the pre-processed picture, Kernel Principle Component Analysis and Gabor wavelets were used. When compared to linear PCA, the nonlinear features retrieved by Kernel PCA offer higher recognition rates. The DNN is given the features for classification. A greedy layer-wise training technique is used by the deep network to enable learning from both labeled and unlabeled input. When there is a shortage of labeled data, using unlabeled data enables the system to learn better characteristics.
A deep cascade convolution network using Fast R-CNN for face identification was suggested by Wang, Dong, and Hu in [8, 9]. In [10], Li Shang, Qin, and Chen reported a method for applying Fast R-CNN object detector to detect and identify fish species underwater. When compared to a deform-able parts model (DPM), the Fast R-CNN increases mean average precision (mAP) by 12.2%, obtaining a mAP of 82.4% and outperforming the R-CNN object detector by 85 times. Facial expression recognition using a Faster R-CNN (Faster region-based Convolution Neural Network) approach was proposed by Li, Zhang, and their colleagues in [11]. In their suggestion, the facial expression picture was first normalized before the trainable convolution kernel was used to extract implicit features. In the field of facial emotion analysis, previous articles used LBP feature extraction, CNN and RNN deep learning features, Support Vector machines (SVM), Cross cultural analysis and LSTM based dynamic emotion analysis. Challenges before the proposed work is Capturing and interpreting subtle and context-dependent facial expressions, Defining universal emotional categories and addressing inter-annotator agreement issues and Obtaining balanced datasets for training models across different emotions and intensities.
Microsoft Azure, Face++, Face Reader offers various services and tools for facial emotion analysis using machine learning and computer vision techniques, but lacks with generalizing to diverse facial expressions, especially those not well-represented in the training data. While Azure offers pre-built emotion analysis models, customization might be limited in some cases. Fine-tuning models to specific use cases might require advanced expertise in machine learning.
The remainder of the study will first go proposed method in Section 2. Results and explanation of the proposed method in comparison to the current model are included in Section 3. Section 4 provides the proposed method’s conclusion.
Figure 3 shows the entire architecture diagram of the proposed method. The input image to be taken for facial emotion analysis is given for pre-processing and features are extracted and given to R-CNN deep learning approach to classify the emotion.
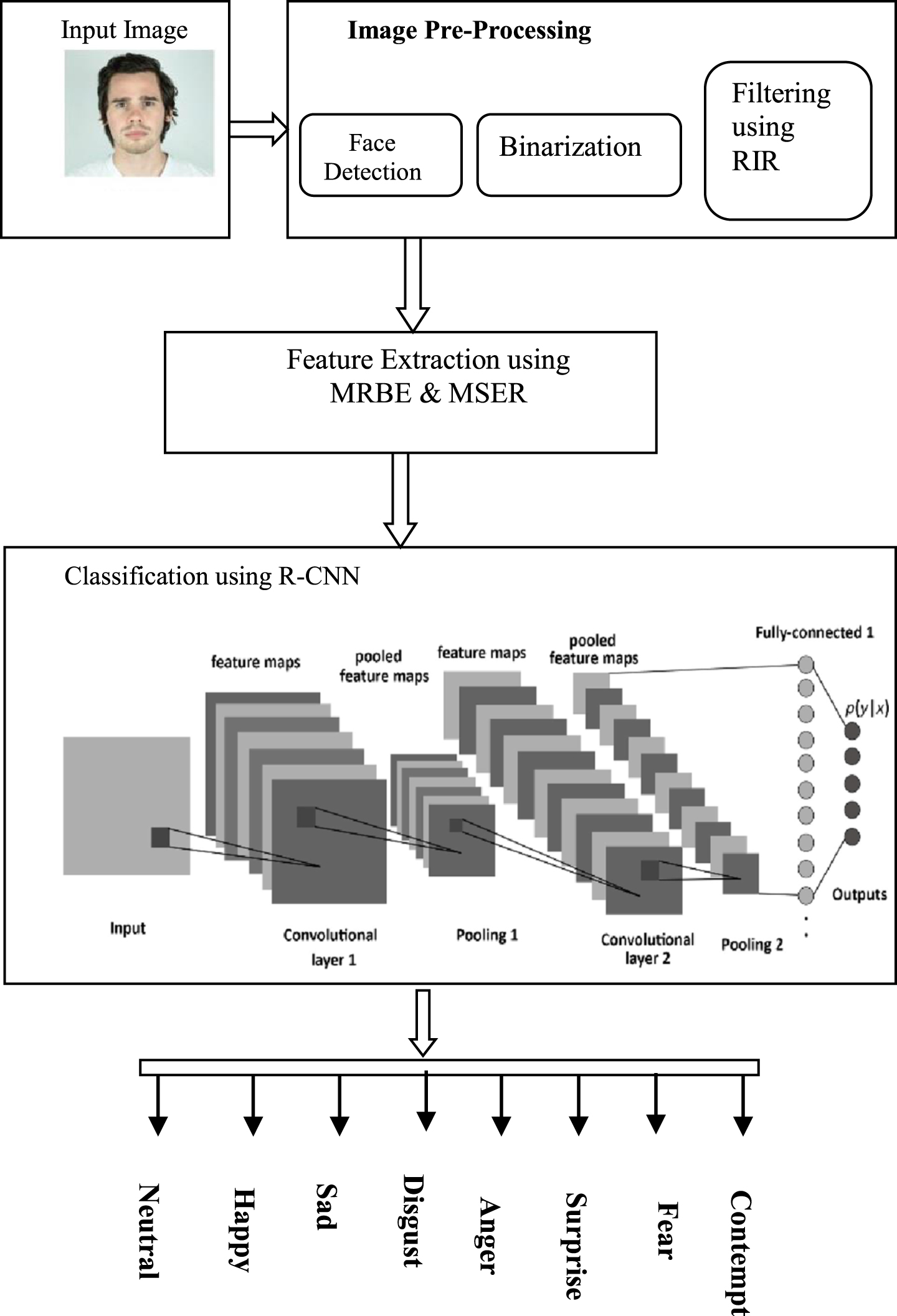
Architecture diagram.
The crucial component of a face emotion recognition system is image pre-processing. It significantly affects the system’s performance and robustness.
Pre-processing aims to improve the discriminating information present in pictures and lessen the impact of noise on feature extraction.
We require scale-normalized photos of frontal faces for our facial expression detection system. The ability to locate and extract the facial region from an image is crucial. Background must be excluded in order to classify expressions accurately. Numerous face identification algorithms have been developed, including approaches based on skin colour and shape information [6, 7].
The internal image is a quick-to-compute intermediate picture representation created by the Viola-Jones technique. Combining classifier in a cascade structure that can improve detection performance while lowering computing cost is how the face detection is accomplished. Skin-color-based approaches can only be used with coloured photos, whereas shape-information-based approaches are frequently too slow for real-time detection. The Viola-Jones face detection mechanism, a reliable algorithm that can analyse photos incredibly quickly for real-time applications [8], is what we employ in our system. It works best with frontal face photographs, which is precisely the kind of image used. According to tests, the Viola-Jones algorithm successfully detects all of the photos utilized in this study. Figure 4 shows the detected face.

Face detection.
Three channels with frequencies ranging from 0 to 255 make up a colour image. The conversion of grayscale photos into black-and-white is one of the main characteristics of binarization (0 and 1). Binarization makes the outlines of the numerous things shown in the image more distinct and obvious. Feature extraction enhances how AI models learn. By selecting a threshold value and classifying all pixels with values above it as white and all other pixels as black, the Otsu technique performs the picture binarization process. It eliminates the background noise and displays the foreground image’s contour.
Step 1: Input an image with G gray level values
Step 2: Set the threshold value Th, which will classify the object and background.
Where:
P(j) = Normalization of entire pixel values
G = Number of Gray levels
Object(Th) = Foreground Pixels
Background(Th) = Background Pixels
Figure 5 shows the output of the cropped and binarization process.

Cropped and binarization image.
The wiener filter [5] technique is a statistical approach to remove noise from every pixel in a picture. It carries out the best possible exchange between noise smoothing and inverse filtering. It is the ideal filter to use for reducing the total MSE during the noise smoothing process. By placing an MSE restriction between the predicted and the original picture, it attempts to construct an image. Wiener filters analyse data in the frequency domain, but they may fail to recover frequency components that have been damaged by noise and the minimized error is shown by Equation (3).
Figure 6 shows the output for the RIR filtering process.

Filtered image.
The mandatory step in facial emotion identification is applying the exact feature extraction technique to extract the features. Extracted features are given as the input to R-CNN Classifier to classify the emotions with better accuracy. The proposed work used two feature extraction techniques: Mouth region-based feature extraction and Maximally Stable Extreme Regions (MSER) method.
The region around the mouth can be extracted to identify emotions. The key procedures in calculating the mouth area include segmenting the mouth region, converting the grey mouth region to binary, and then performing morphological operations to produce the mouth region. First, input photographs are chosen from the database, and the Viola-Jones Mouth identification technique is used to segment the mouth region [12]. After the mouth region has been separated, pre-processing is done to turn the grey colored mouth regions into binary. The morphological opening function is used to both remove little objects from an image while maintaining the shape of larger objects. After opening an input image, the erosion function is used to reduce the foreground object’s size. By subtracting the opening picture from the erosion image, boundary extraction is obtained. Only the mouth region is removed in the following phase. Finally, any gaps around the mouth are filled using the fill function. The following formula is used to determine the mouth region’s area.
Region = Sum(b(:));
Area = Region * 0.2645;
The emotions are divided into happy, fear, sad, angry, disgust, and surprise categories based on the region values.
In Mouth based feature extraction method mouth area is calculated and based on that value the emotions are classified. In the MSER method, the features are extracted by using connecting components and then the extracted features are given to a simple ANN for classification. By Matas et al. [12], the theory of Maximally Stable Extreme Regions was first presented. Taking threshold values between 0 and 255 and obtaining the appropriate binary pictures is the first stage in MSER. The maximally stable extreme regions are those connected regions that, after getting all the binary images, remain unchanged with altering intensity values. As MSER key points, it is assumed that the locations of the stable regions and the associated threshold values. The mathematical formula is displayed below.
Where,
Ci - Threshold of Connected region
D - Grey value change
C(i) - Region changing rate
The following actions are taken to implement the MSER algorithm [13].
Figure 7 shows the output of the feature extraction process.

Output for the feature extraction process.
An object detector called a fast region-based convolution neural network uses deep learning to categorize things in a picture. It employs an approach called Edge Boxes, which boosts an object detector’s computing effectiveness by producing effective region suggestions. An edge box is a straightforward measure of the objectiveness of a box that subtracts the edges that are a component of contours that cross the box’s border [17]. Algorithms for two-state detection make up the quick R-CNN. In the first step, areas in an image that could contain an item are narrowly defined (using edge boxes). The item is classified in each region in the second stage [18]. The entire image is processed by convolution layers in the first stage (feature extraction), which also processes edge boxes to produce region proposals and extract features from the image. Real-time emotion classification is achieved when face emotion detection is done using the Fast R-CNN object detector [19].
Using an image labeled is necessary for training object detectors like Fast R-CNN. An programme called an image labeled allows you to assign predetermined rectangular Region of interest (ROI) labels to a group of photographs.
Explored to a MATLAB workspace once each image in a collection has had its ROI created with a label. A command like “trainingData” would return the ground truth object as a table of training data once it has been exported as a ground truth to workspace.
The VGG-16 ConvNet [20] is also the foundation for the Fast R-CNN object detector developed for this study. The VGG-16 ConvNet is also subjected to the transfer learning approach. The region for each image in its corresponding emotion label column was set to [1,1,224,224] because every image in this image data store is a cropped image of a face expressing an emotion. The last three layers of the VGG-16 model, as well as the image input layer, were changed from [224, 224, 3] to [48, 48, 3]. Additionally, the grayscale picture data set was changed from [48, 48, 1] to [48, 48, 3]. In addition, a ROI pooling layer and a bounding box regression layer have been added, converting the pretrained network model into a Fast R-CNN identification network [21].
Extended Cohn-Kanade Data set (CK+):This is a database made up of 123 subjects, 593 images, and 327 emotion labeled sequences. The images are mostly gray with a resolution of 640*490 [14]. Japanese Female Facial Expressions (JAFFE): This is a database made up of 10 subjects, 213 gray images of 256*256 resolution [15]. MMI Facial Expression Database: Is a database made up of 75 subjects, 2900 videos of 720 * 576 resolution [16].
MMI Facial Expression Database
A growing online tool for basic emotion identification from face videos is the MMI Facial Expression Database. Over 2900 movies and high-resolution still photos of 75 subjects are included in the database. It is completely annotated (event coded) for the existence of AUs in movies and partially coded (frame-level) to indicate whether an AU is in the neutral, onset, apex, or offset phase at any given time. A tiny section was marked for audio-visual chuckles. Figure 8 shows the various sample emotions present in the MMI database. The scientific community can access the database for free [22, 23].

MMI facial expression database.
The MMI Facial Expression Database’s initial data consisted primarily of presentations of single Action Units(AU). There were a total of 1767 clips of the 20 contestants. All 31 AUs as well as a few more Action Descriptors were required for each participant to exhibit (ADs, also part of FACS) [8]. The subjects were requested to conduct two or three emotional states following the recording of all AUs (e.g. sleepy, happy, bored). For the purpose of increasing the dataset’s variety, the subjects were instructed to repeat each facial movement twice [29]. A mirror that faced the camera at a 45-degree angle was set up on a table adjacent to the participant while the recording was being done. 1767 images were taken for experiment from 1767 movie clips with various emotions contains 220 Happy images, 220 sad images, 220 disgust images, 220 angry images, 220 anger images, 220 surprise images, 220 fear images, 220 contempt images and 227 neutral images. Table 1 shows the properties of MMI Data set used in the proposed model.
Properties of dataset
The following table depicts the comparison of performance of existing facial emotion recognition algorithms like SVM, SBN-CNN, RETRaiN, CB-CNN and VGG-19 with proposed Fast R-CNN method [24, 25]. Table 2 shows the comparative analysis of recognition rate (Correctly identified Emotions). The proposed method is compared with the existing algorithms for same emotion recognition like SVM, SBN-CNN, RETRaiN, CB-CNN, and VGG19.
The proposed method achieves maximum of 98.6% as the recognition rate and average recognition rate is 97.6 which is high when compared to the existing existing algorithms (Existing achieved 96.3, 93.4, 88.9, 86.1, and 79.5 for SVM, SBN-CNN, RETRaiN, CB-CNN, and VGG19 respectively). This shows the proposed method outperforms with the highest recognition rate of 98.6%. Figure 9 shows the graphical representation of performance of the proposed method for recognition rate. Figure 10 shows the graphical representation of comparative analysis of average recognition rate of proposed with the existing methods.
Recognition rate of various emotions for different CNN
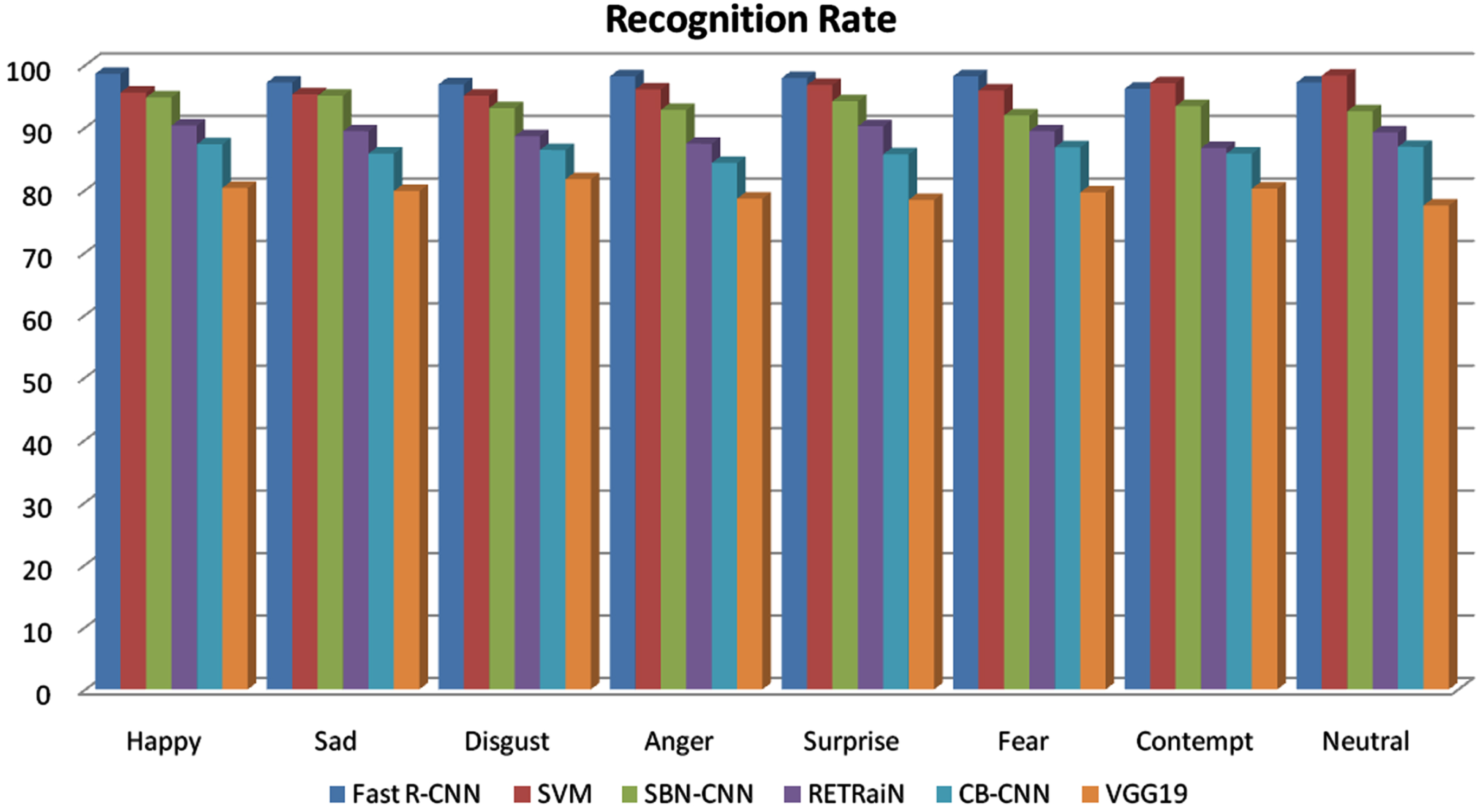
Recognition rate of various emotions for different CNN.
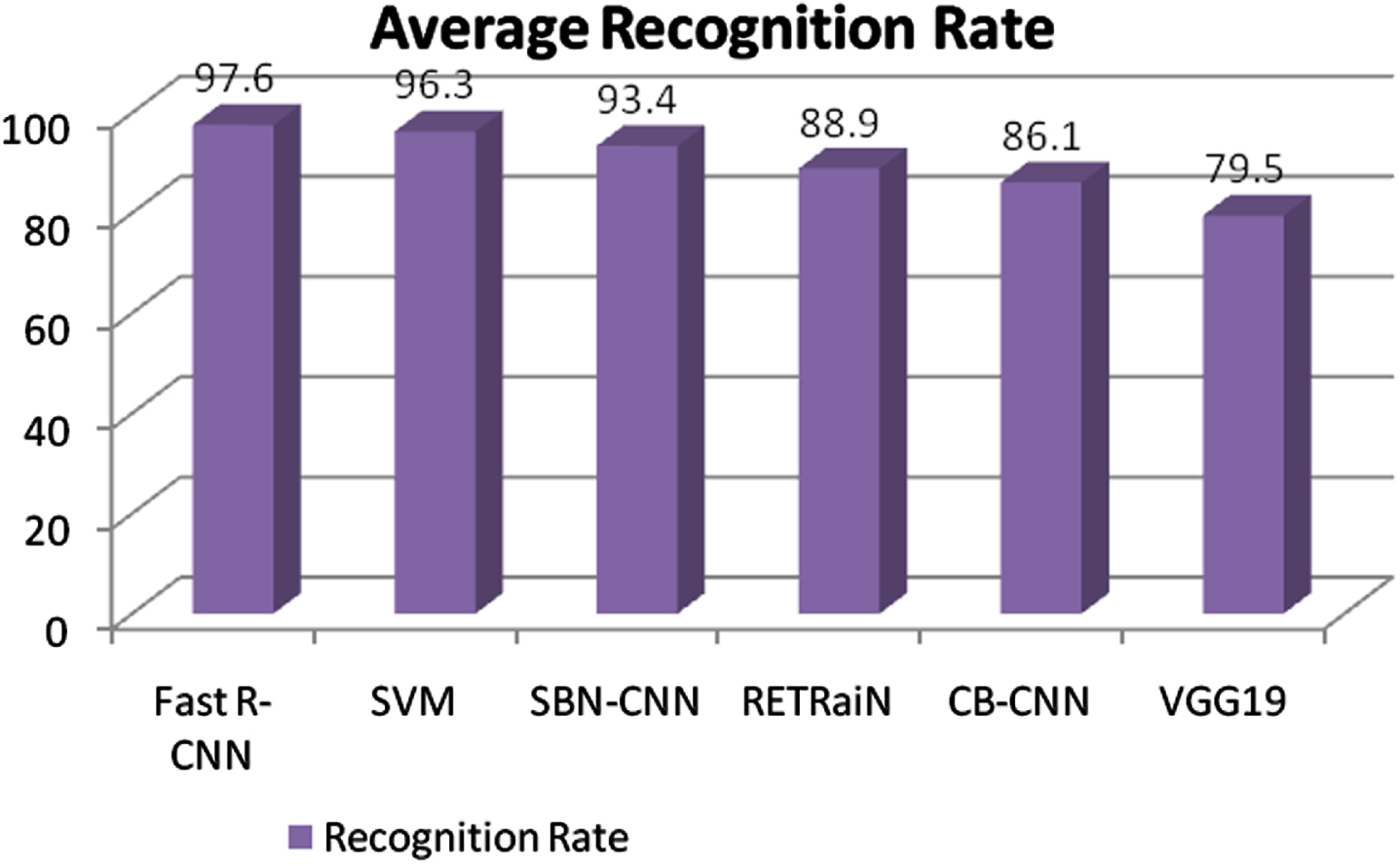
Average recognition rate of proposed with existing CNN network.
To check the performance of the proposed method, the following three parameters are taken in to account. Specificity, Precision and Recall, which are specified in equations 1 through 3, are among the metrics utilized for evaluation. Four separate parameters—true negative (TN), true positive (TP), false-negative (FN), and false positive—are used to measure these measurements (FP). Accuracy is defined as the proportion of documents from all the data that were correctly classified. Precision is the proportion of the performance that is relevant. On the other hand, recall is the percentage of correctly classified results that the algorithm produced for all functional outcomes [26, 27].
Table 3 shows the comparison of Precision, Recall and Specificity of the proposed algorithm for various emotions. Precision reached highest value of 0.898 and Recall reached 0.891 and Specificity reached 0.975. These figures shows that the proposed method achieves better values for Precision, Recall and Specificity.
Precision, specificity and recall of the proposed method fast R-CNN
Figure 11 shows the graphical representation of the same analysis. It shows that precision value for the Neutral facial expression is reached higher value and contempt shows the lower value. Recall value for neutral facial expression is high and fear is very low. Specificity value for surprise facial expression is more fear is very low. It shows that identifying some important facial expressions surprise, fear contempt and normal expression neutral can be easily identified when compared to the other facia expressions.
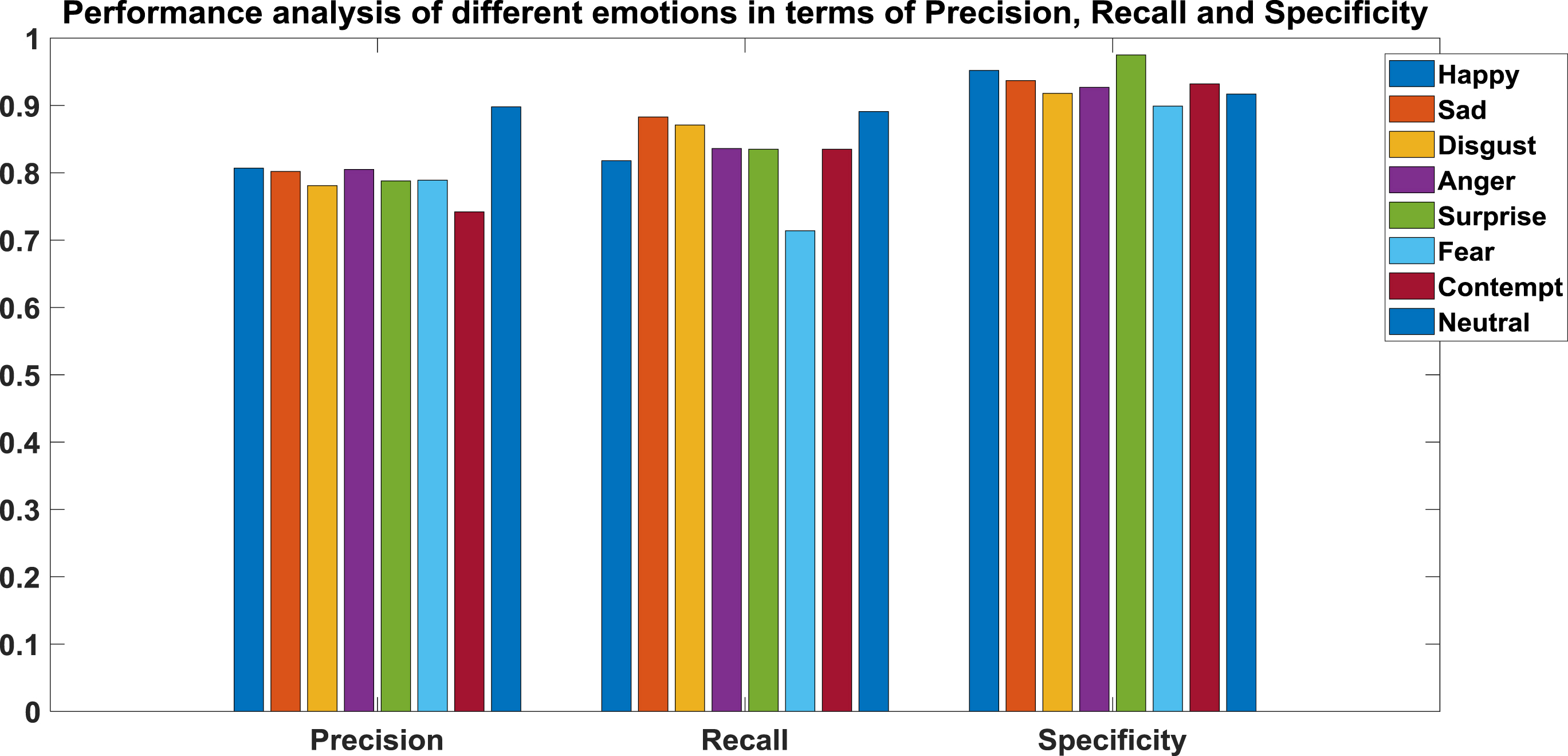
Performance analysis of different emotions (precision, recall and specificity).
In recent days, many number of FER-Face Expression Recognition Tools are available in market to recognize the facial emotions. The section uses the FER tools to compare with the proposed method. The standard tools are Microsoft’s Azure, Megvii’s Face++ and Noldus’s Face Reader. The following Tables 4 to 6 depicts the Accuracy, sensitivity and precision of proposed and existing FER Tools used in real world for emotion recognition purpose. Table 4 shows the comparative analysis for specificity of the proposed method and existing FER applications. For all the emotions, the proposed method achieved better specificity or equal specificity value when compared existing method and achieved maximum of 0.98 for surprise emotion and minimum of 0.89 for fear emotion. Figure 12 shows the graphical representation of specificity achieved in proposed work which shows that proposed work achieved better values for all the eight emotions taken for consideration, so proposed work outperforms with maximum specificity value of 0.98. The higher sensitivity value leads to reduced false positives, avoids mitigation and misinterpretation and Higher specificity prevents the system from overreacting to ambiguous or non-emotional facial expressions, leading to more natural and accurate responses.
Comparative analysis: Specificity
Comparative analysis: Precision
Comparative analysis: Recall
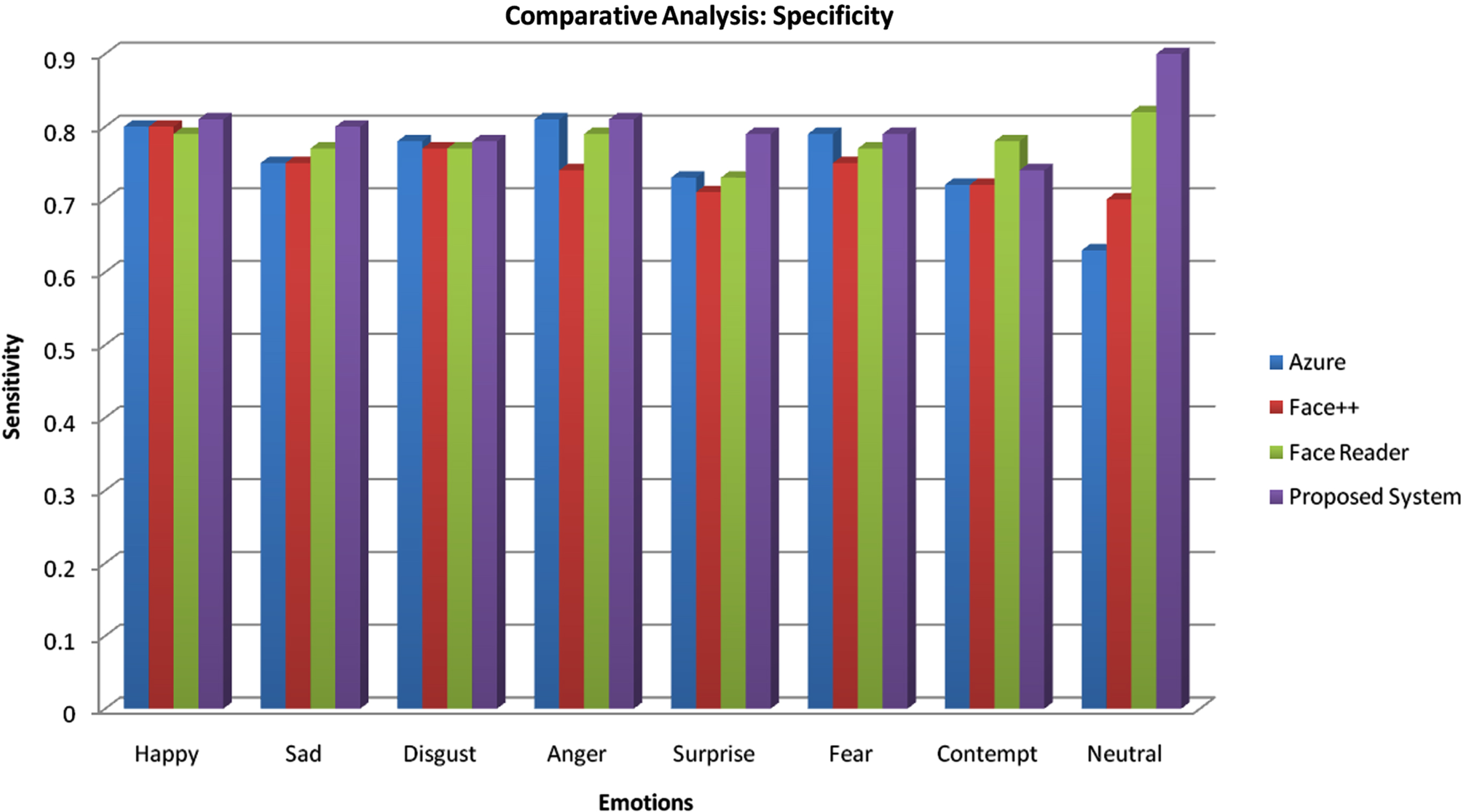
Comparative analysis of different emotion applications (Specificity).
Table 5 shows the comparative analysis for precision of the proposed method and existing FER applications. For all the emotions, the proposed method achieved better precision or equal precision value when compared existing method and achieved maximum of 0.9 for neutral emotion and minimum of 0.74 for contempt emotion. Figure 13 shows the graphical representation of precision achieved in proposed work which shows that proposed work achieved better values for all the eight emotions taken for consideration, so proposed work outperforms with maximum precision value of 0.90. The higher precision value leads to accurate emotion detection and classification, reduced false positives and suble emotion changes. Table 6 shows the comparative analysis for recall of the proposed method and existing FER applications.
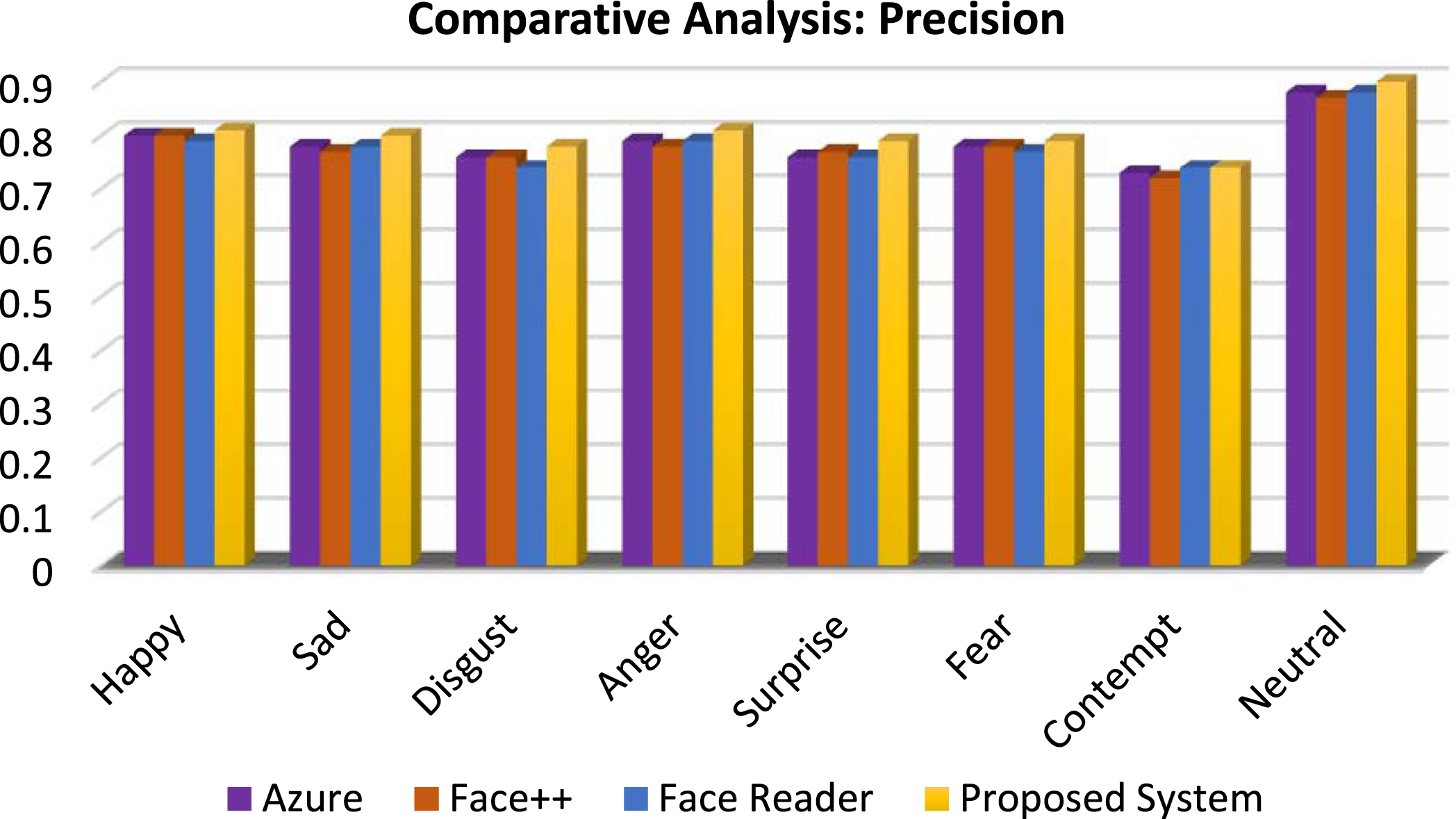
Comparative analysis of different emotion applications (Precision).
For all the emotions, the proposed method achieved better precision or equal precision value when compared existing method and achieved maximum of 0.89 for neutral emotion and minimum of 0.72 for fear emotion. For fear emotion Azur application achieved better recall value when compared to proposed precision value. Figure 14 shows the graphical representation of recall achieved in proposed work which shows that proposed work achieved better values for all the eight emotions taken for consideration, so proposed work outperforms with maximum Recall value of 0.89. The higher recall value leads to comprehensive emotion detection, reduced missed emotions and very effective in real world scenarios. In situations where missing an emotion could lead to incorrect decisions or judgments, higher recall is crucial to prevent unfair or biased outcomes.

Comparative analysis of different emotion applications (Recall).
The best recognition were detected in proposed method, where it was obtained almost 98% in the MMI database. We saw that facial images with extreme exhibited expressions recorded the best results. The outcome shows that the arrangement of the muscles around the eyes and the mouths are the most dependable decisive for auto facial expressions emotions. This accounts why recognition in the neutral face is poor. Thus the gain in these muscle arrangement increases the quality of auto recognition. The execution time for a pixel of size 100×100 is 2.3 Secs. Figure 15 and Table 7 shows the comparative performance of execution time with other famous organization’s face emotion recognition application. Having a lesser execution time in facial emotion analysis offers several advantages that can enhance the usability, responsiveness, and efficiency of the analysis process. It helps to achieve quick decision making, Efficient resource utilization, reduced latency, and In scenarios where emotion analysis needs to be performed on a large volume of data or in a crowd, reducing execution time allows for more efficient processing and quicker insights.
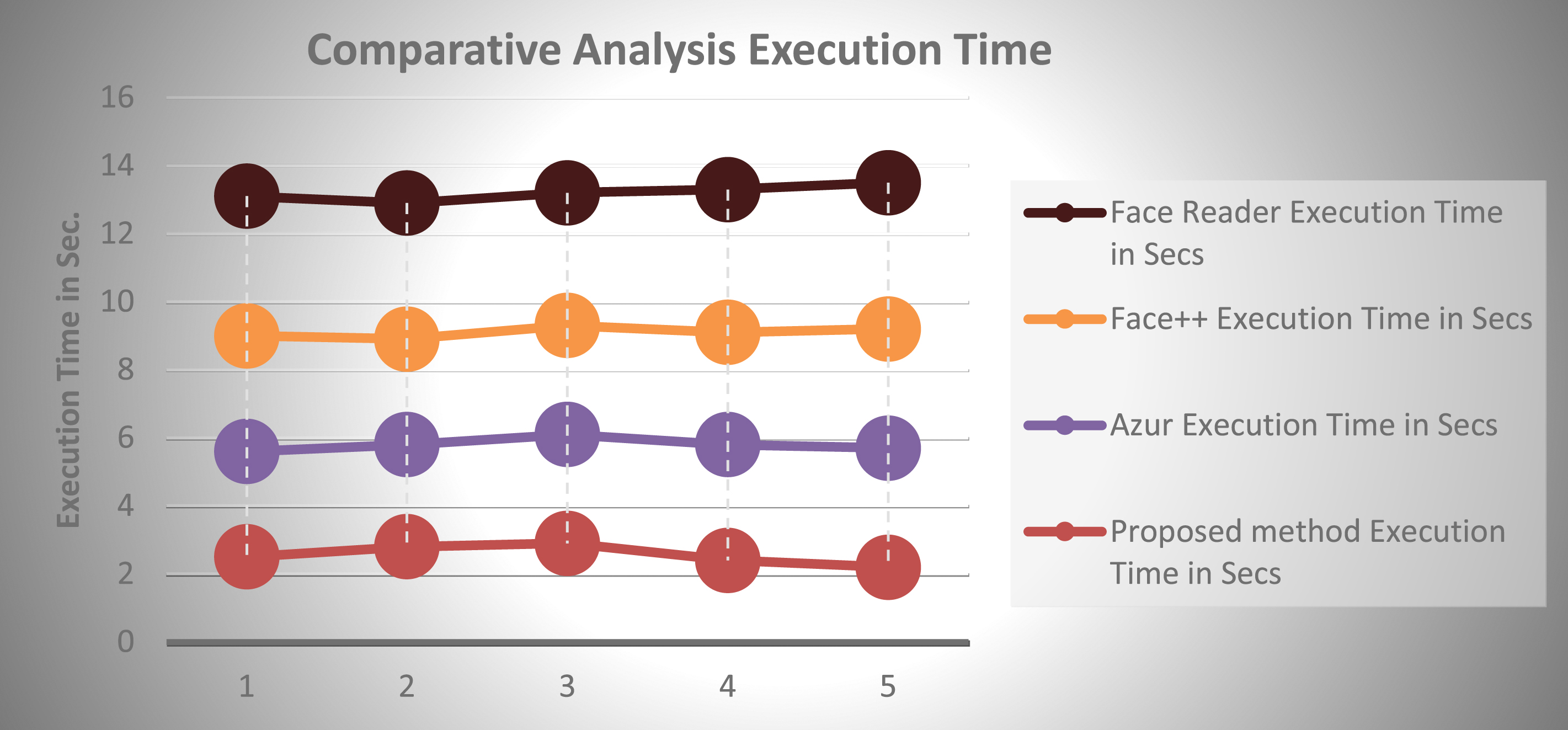
Comparative analysis: Execution time.
Comparative analysis: Execution time
We recorded an average recognition rate of 97.6% in MMI Database. The confusion matrix shows the performance of the proposed algorithms based on the recognition rate. Table 8 and Fig. 16 shows the confusion matrix and its pictorial representation. It represents that the proposed method done good classification of all emotions with higher accuracy, precision and sensitivity for the taken MMI database.
Confusion matrix

Performance analysis: Confusion matrix.
This study uses a variety of cutting-edge strategies to increase the recognition rate of the facial expression recognition system. The Cascaded Object Detection was used to carry out face detection. To lower the computational cost and prevent mis classification, features are extracted using MRBE and MSER Algorithms. A fast R-CNN classifier was fed the chosen features. Thus, sample datasets from MMI face expression databases are used to train the network. The average recognition rate in the MMI database is 97.6 %, and the execution time for a pixel with a size of 100×100 is 2.1 seconds. The performance of the suggested method is exceptional when compared to other ways. The study’s findings also demonstrate that automatic expression identification is approximately 100% accurate when detecting surprise, disgust, and happiness. The accuracy of mild emotions like sadness, fear, and contempt are lower. However, when anxiety is at its height, recognition accuracy can be quite precise due to the importance of facial deformations around the mouth and eyes. The number of neurons may be increased to accommodate expressions that recorded lower values in the future when recognition accuracy is improved. Emotions involve dynamic transitions, and relying solely on a single frame’s analysis might miss valuable information. Future work in facial emotion analysis is likely to focus on addressing existing challenges, improving accuracy, and expanding the application of emotion analysis technologies by multi-modal analysis, dynamic emotion analysis, cross cultural and age group analysis in real world applications with the help of Artificial Intelligence methods.