
Abstract
Video feeds from traffic cameras can be useful for many purposes, the most critical of which are related to monitoring road safety. Vehicle trajectory is a key element in dangerous behavior and traffic accidents. In this respect, it is crucial to detect those anomalous vehicle trajectories, that is, trajectories that depart from usual paths. In this work, a model is proposed to automatically address that by using video sequences from traffic cameras. The proposal detects vehicles frame by frame, tracks their trajectories across frames, estimates velocity vectors, and compares them to velocity vectors from other spatially adjacent trajectories. From the comparison of velocity vectors, trajectories that are very different (anomalous) from neighboring trajectories can be detected. In practical terms, this strategy can detect vehicles in wrong-way trajectories. Some components of the model are off-the-shelf, such as the detection provided by recent deep learning approaches; however, several different options are considered and analyzed for vehicle tracking. The performance of the system has been tested with a wide range of real and synthetic traffic videos.
Introduction
There has been a historic increase in video surveillance cameras in public and private places. This trend has resulted in a wide variety of research studies about automated systems for object detection to monitor different activities by recognizing the events that occur in the observed scene [1]. These systems play an important role in modern computer vision tasks such as autonomous driving [2], pedestrian identification [3, 4] image captioning [5, 6], object tracking [7, 8] ship detection [9, 10], face recognition [11, 12], traffic control [13, 14] action recognition [15, 16] environment surveillance [17, 18], video checking in sports [19, 20], building information [21, 22, 23], robotic disinfection [24], safety surveillance [25, 26] and many others. Deep Learning has been the main approach when dealing with images for the last decade. Beyond surveillance it is an approach also applied to other fields such as material analysis [27], earthquake detection [28], medical applications [29, 30] and recommendation systems [31].
This work focuses on vehicle detection, an important part of surveillance systems and intelligent transport systems. The widespread use of vehicles means that numerous incidents regarding traffic violations occur. These incidents can be seen as anomalies with respect to the usual traffic behavior and are typically a source of problems and dangers. Therefore the detection of anomalies in traffic surveillance such as traffic congestion, parking violations, and rash driving on the roads can be considered one of the most researched topics in vehicle detection [32].
However, the automated detection of vehicles that follow an unusual, wrong-way trajectory has not received much attention in the literature. Here a methodology to detect wrong-way vehicle trajectories is proposed. Its aim is to automatically spot potentially dangerous behavior. This information could be later passed on to a human operator so that the danger is further evaluated and cautionary measures can be taken. This model is capable of monitoring, frame by frame, the movement of the vehicles to identify vehicles that drive in an unusual way by using three basic steps: vehicle detection, vehicle tracking, and trajectory processing. Our proposal departs from the previous literature in several ways. Firstly, vehicle tracking is optimized by several enhancements in the assignment procedure of vehicle detections to trajectories. Also, tracking errors for pairs of nearby vehicles and large trucks are minimized by appropriate techniques. Finally, a robust anomaly measure is designed in order to effectively evaluate trajectories, and an anomaly criterion is proposed to ascertain whether a trajectory is actually anomalous.
For moving vehicle detection, a Convolutional Neural Network is used because it can perform end-to-end detection of objects without specific characteristics [33]. Then the set of detections computed by the network is filtered to execute the second step, vehicle tracking. In this stage, vehicles are tracked as they move around in a video using two popular object tracking algorithms, Simple Online Real Time tracking (SORT) and BYTE. These algorithms can make some tracking errors in specific situations so a custom tracking algorithm is proposed and compared with the previous ones. Once trajectories are detected they are processed, which is the third step. In this phase, the velocity vectors are estimated by comparing the difference in the position of the vehicle between consecutive image frames, and anomalies are detected by comparing the vehicle’s trajectories with the trajectories of its nearest neighbors using mean and median moduli of the differences among vector velocities.
As this method has many tunable parameters, a comprehensive survey was conducted, including the impact of adding techniques such as border correction and bounding box similarity. This fine-tuning process concludes in a suitable procedure for detecting anomalous trajectories.
To describe the above mentioned methodology in detail, the paper is arranged as follows. First, Section 2 summarizes the related work. Then, the methodology to solve the stated problem is described in detail in Section 3. After that, in Section 4, experimental results are provided to verify the performance of the proposed model. And finally, Section 5 outlines the conclusions.
Related work
There are many techniques proposed in the literature to detect on-road traffic. Object detection can be performed using either classical image processing techniques or deep learning networks. Today, deep learning object detection is a modern approach widely accepted by researchers, involving two main types of detectors: two-stage target detection algorithms and single-stage target detection algorithms. As a general algorithm for target detection, all the deep learning models can be applied to vehicle detection tasks. Two-stage detection algorithms divide the vehicle detection task into two stages: generating vehicle region proposals and finding vehicle targets from the region proposal. One-stage detection algorithms eliminate the operation of generating vehicle region proposals and unifies vehicle identification and detection into one network for processing.
An example of a traditional proposal can be found in [34], where it uses a foreground object detection method and a feature extractor to obtain the most significant features of the detected vehicles into several categories such as car, motorcycle, truck, or van. The same task is addressed by two-stage algorithms in [35, 36] and [37] where a Convolutional Neural Network (CNN) is used in the first two cases and a Faster Regional Convolutional Neural Network (Faster R-CNN) in the third one. The most representative one-stage detector is YOLO [38] (You Only Look Once) and [39] combines it with other traditional classifiers to create a real-time vehicle detector. In [40] a comprehensive review of existing Faster Region-based Convolutional Neural Network (Faster R-CNN) and YOLO-based vehicle detection and tracking methods are included so the interrelations between both methods can be highlighted.
After carrying out an assessment of the advances in the field of traffic video surveillance, it is interesting to notice that there are other relevant problems whose solution is related to the analysis and detection of vehicles along the road. This is the case of the detection of pollution levels of transport vehicles problem which has been addressed in [41, 42]. In these works, the object detection and classification process are based on a pre-trained Faster-RCNN model [43]. With that recognition and vehicle tracking, the system predicts the pollution of the selected area in real time. Another example can be found in [44], where a video measurement system for road traffic surveillance has been developed and applied to acoustic surveillance. This system includes a trained deep learning YOLOv2 object detection model and uses it to show the usefulness of Intelligent Transportation Systems (ITS) in the fight against citizens’ exposure to noise.
In terms of trajectory analysis, the problem has also been approached with classical algorithms before deep learning such as [45], which analyses vehicle trajectories using clustering algorithms; or [46] using single-class SVM clustering to allow trajectory classification with no a priori information on the distribution outliers. Modern approaches often rely on neural networks as [47], which trains a neural network model to detect pedestrian trajectory anomalies by comparing predicted and actual trajectories; in [13], authors propose a methodology to detect anomalous vehicle trajectories by applying YOLOv5 as a vehicle detection network; [48] uses multi-scale tracking and multiple similarity metrics to refine anomaly via backtracking after detecting vehicles using YOLO; [49] also uses YOLO, Non-Maximum-Suppression algorithm and DeepSort [50] to obtain trajectories prior to filter them; [51] implements a noisy network using deep deterministic policy gradients to deal with the tracking task and predict the trajectory result; [52] uses spatio-temporal autoencoder and sequence-to-sequence long short-term memory autoencoders in order to model spatial and temporal features in video to detect road accidents; [53] proposal is to use YOLO and KCF object tracking algorithm to get initial trajectories to later apply polynomial approximation and Ramer-Douglas-Peucker thinning to train agglomerative hierarchical clustering in order to classify into normal or anomaly trajectories; [54] implements NLP-inspired embedding to create vector representations for each vehicle trajectory in order to compute their similarities so a hierarchical clustering algorithm can be used to identified falsified trajectories; [55] extracts CNN features to perform two separate traffic analysis, the first one is based on the speed estimation using camera calibration and the second one based on detecting abnormal events using optical flow. However, there are also works nowadays using more classical approaches: [56] proposes a model to detect anomalies in vehicle trajectories by using federated learning based on support vector machines and isolation forests; [57] uses main flow direction vectors to cluster coarsely vehicle trajectories prior to apply K-means clustering algorithm to obtain fine classifications to distinguish outliers and then apply a hidden Markov model to obtain path pattern within each cluster.
Some works have also explicitly studied the problem of wrong-way vehicle detection. Early works used traditional image processing techniques such as background subtraction, and optical flow estimation [58, 59, 60], but these require very stable scene conditions and a relatively long training stage for each video sequence. More recent works make use of deep learning models to detect vehicles but usually require some degree of manual setup or assume a specific scene orientation to determine the natural direction of traffic flow in the scene [61, 62, 63]. In contrast, our approach is automatic, fully unsupervised, and does not require long training times for each specific scene. It is also dynamic: it does not look at whole trajectories post facto, but works frame by frame, using only past and present information at each frame to flag vehicles as following anomalous trajectories.
Methodology
To detect anomalous trajectories in sequences from traffic cameras, a model is proposed to monitor the movement of vehicles across the camera’s field of view frame by frame, with an architecture structured in three stages: vehicle detection, vehicle tracking and trajectory processing. a schematic view of the model is shown in Fig. 1.
Schematic depiction of the proposed model.
Figure 1 shows a schematic of the proposed model: a video sequence from a traffic camera (a) is fed, frame by frame, to an object detector that outputs the vehicles’ bounding boxes (b). A tracking algorithm incrementally recovers vehicle trajectories (c, d) from the bounding boxes, possibly enhanced by various heuristics (not shown). At each frame
Our proposed model starts with the application of a deep convolutional network for object detection to obtain tentative detections of vehicles. Let us note as
where
A minimum confidence level
where
The next step consists in passing the filtered set
The second stage is object tracking: after objects have been detected and their bounding boxes defined at isolated image frames, the next challenge is to track the objects, associating bounding boxes across sequences of image frames conforming to the trajectories of each tracked object. Sophisticated tracking strategies are required when many objects move across the camera’s field of view.
For objects detected with bounding boxes, object tracking is frequently posed as a linear sum assignment problem (LSAP) [64] between the detections at frames
The performance of the pipeline is evaluated with two well-known, generic, LSAP-based object trackers, SORT [65] and BYTE [66], as well as a custom tracking algorithm. SORT and BYTE specify the assignment cost
When a vehicle detected in frame
The performance of LSAP-based algorithms is adequate as long as objects movements between one frame and the next one are comparatively small, and the detection of the objects during the frame subsequence where they are visible is consistent. Videos acquired by traffic surveillance cameras used in this work usually fulfill the first condition. However, the second condition is not met even for object detectors with a very good mAP score for vehicles that appear small in the video. To address this limitation and enhance the performance of our custom tracking algorithm, we avoid making the assignments (i.e. matching bounding boxes for frames
Given the two axis-aligned bounding boxes, the ratios of their sizes differs more than a given threshold in any of the two dimensions (horizontal or vertical). This aims to avoid false tracking events among vehicles of very different apparent sizes. Moreover, the system becomes more robust whenever the object detector fails and the bounding box estimations fluctuate from one frame to the next. The distance between the centers of the bounding boxes in both frames is larger than a predefined threshold. The threshold is computed for each pair of bounding boxes relative to the smallest dimension of the bounding box at frame
Many tracking errors happen as a result of object detection errors and induce false, large one-frame displacements in trajectories, potentially confounding the anomaly detection procedure into generating false positives (see next subsection). In the case of small vehicles, such tracking errors can happen when two vehicles are close, only one is detected at frame
This is a similar problem to vehicle re-identifica- tion [68], and can be solved with similar techniques. Concretely, to compute a similarity measure between the contents of the bounding boxes, the contents of each bounding box are resized (respecting the aspect ratio with letterboxing) to the input size of a standard deep classification network such as ResNet or VGG. This network is applied to the contents of the bounding box, and the feature vectors from one of its final layers are extracted. These feature vectors convey semantic information about the input image, and their distance can be used as a similarity measure for images. With this information, two bounding boxes are determined to be part of the same trajectory only if the similarity measure is below a given threshold.
To measure the distance between feature vectors, cosine similarity is used:
This has practical advantages over Euclidean distance: the range of cosine similarity is clamped to the interval
As a result of the vehicle tracking stage, vehicle trajectories are recovered across the camera’s field of view. The detection of anomalous maneuvers carried out by the vehicles can be done by comparing the trajectory of the offending vehicles to those of the vehicles in their vicinity. We propose a straightforward but effective procedure to accomplish this task which is based on measuring the difference between the velocity of the vehicle with respect to the velocities of its nearest neighbors. Here the velocity is taken as the difference in the position of the vehicle between consecutive image frames.
Next, a more detailed description of this procedure is given with the help of some mathematical notation. Let
Please note that in the above equation the camera frame rate is subsumed as a scale factor. In the case that a vehicle
After that, the subset
Once the set of nearest neighbors
It must be highlighted some issues with
such that
Vehicle position estimation example.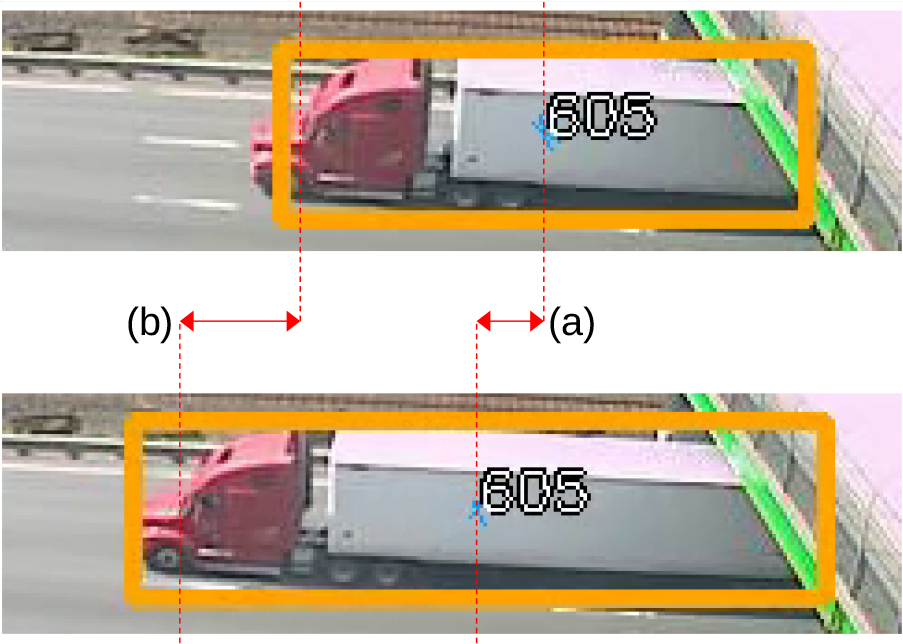
A second issue is that
Also, there is an issue when vehicles take several frames to gradually go from being partially occluded to fully visible: the larger the vehicle, the lower the apparent velocity. This happens because the object detector defines the vehicle’s boundary relative to its visible portion, and the center of the bounding box is taken as a proxy for the position. As larger and larger portions of the vehicle become visible in the image, the bounding box will gradually grow, and the velocity of the center of the vehicle will be slower than if the vehicle were fully visible (see Fig. 2). This issue can happen with any road occlusion such as bridges or large trees, but the effect is especially acute at the borders of the camera’s field of view, since in general there will be one or more borders where traffic will appear or disappear.
This might not be a problem unto itself, because it just means that velocities will be generally slower near borders and road occlusions. However, the severity of the effect varies greatly according to apparent vehicle size, so large trucks will have significantly slower velocities than cars and motorcycles, and for longer stretches of road. When comparing these velocities of large trucks to cars, there will be a greater probability of marking the former as anomalous. To mitigate this effect, border correction is performed, i.e. filtering out as not potentially anomalous any
Parameters of the model
The final step is to classify a potentially anomalous
Its value relative to the A long record of potentially anomalous values has been accumulated for the vehicle during a number of consecutive frames. This criterion depends on the characteristic time and size scales of the vehicles in the traffic scene.
Figure 2 shows a vehicle position estimation example: the vehicle position is estimated as the center of the bounding box. Velocity is estimated as difference between such positions (a). For comparison, in this figure the real velocity (b) is estimated by measuring the distance between frames for a specific keypoint (the windshield). As a result, large vehicles appearing into the scene may be erroneously considered to be slower than they really are, thus potentially flagging them as anomalous. This problem is most common along the borders of the image, and a pragmatic and effective solution is to ignore vehicles near the border.
The proposed model has been evaluated with a dataset several times, testing various configurations. The source code is available at
Methods
All proposals have been implemented using Python (
Yolov5, a well-known neural network model, is used as the object detection method. We only need to detect vehicles, so yolov5’s configuration has been altered to only return objects from the following classes: car, motorcycle, bus, and truck. Most Yolov5 configuration values are the standard (particularly
Concerning anomaly detection parameters, the number of nearest neighbors to check if a trajectory is anomalous (size of
Table 1 provides a concise view of the parameters of the model. Exhaustive search to determine parameters
For vehicles having very large For vehicles keeping anomalous
Different videos selected from several datasets have been considered in the experiments. With these sequences, the performance of the model can be analyzed under different anomaly conditions related to wrong-way driving, such as a vehicle in the opposite direction or backing onto roads. Videos from four datasets were used:
First subset: three videos from a project [69] dealing with anomalous trajectory detection in traffic videos. The selected sequences are a real video (Clip from 02:10 to 02:31 in this Youtube video: Second subset: Six videos from the Ko-PER Intersection dataset [71]: the sequences 1a-SK_1, 1a-SK_4, 2-SK_1, 2-SK_4, 3-SK_1, and 3-SK_4. Each pair of sequences with the same prefix and ending in _1 or _4 are recordings of the same scene from two different cameras, providing valuable validation of the model for scenes that should result in similar predictions in each case. Videos with prefixes 1a- and 3- do not actually show anomalous trajectories, while videos with prefix 2- show a vehicle that waits in the middle of the intersection to turn. To test the proposed methodology, that vehicle has been considered anomalous. Third subset: Three videos from the 2014 CDNET dataset [72]: the sequences highway, streetLight, and traffic. All of them were taken from a camera looking at traffic on a straight road from different orientations (respectively: from the front, side, and rear). None of them show anomalous vehicles. Fourth subset: Fifteen videos from the training set of the 2021 NVidia AI City Challenge [73], Track #4: videos 1, 2, 3, 5, 9, 13, 14, 17, 20, 22, 25, 33, 39, 41, and 50. These were selected with two criteria in mind: avoiding views of intersections and avoiding videos where the off-the-shelf object detector struggles to detect vehicles reliably (see Section 4.3.6 for details on these limitations). Each video is 15 minutes long. For practical reasons, each video was divided into 15 segments, approximately one minute each, resulting in 225 video clips. At 30 frames per second, these one-minute clips average 1800 frames each. It is worth noting that this dataset is designed as a challenge to detect traffic accidents where anomalous vehicles pull up to the roadside. However, our proposed method does not detect this type of anomaly, but wrong-way anomalies. Because of this, none of these one-minute video clips has any anomalous frame for our purposes.
Thus, we have four subsets of video sequences, 237 videos in total. The fourth one (the video clips from the NVidia AI City Challenge dataset) represents the vast majority of the videos (225), but they have no anomalous frames. The first three subsets represent a mix of videos of various lengths, some depicting vehicles in wrong-way trajectories. To effectively use computing resources, we will use videos from these first three subsets to evaluate the system’s performance under a wide variety of configurations. Once the best configuration is selected, we will also evaluate its performance with the fourth subset (the video clips from the AI City Challenge).
It should be noted that datasets containing many examples of videos with wrong-way, anomalous trajectories can be found for videos taken from dashcams. However, we do not know of such a dataset with videos taken from traffic cameras, and videos taken from dashcams are not suitable for the proposed model. While the model is designed for views of non-intersecting roads, videos from intersections depicting vehicles that might be considered anomalous have been included in the experiments, as described above. For comparison, videos of intersections without anomalous trajectories have also been included (it should be noted, however, that the proposed model does not work well for these).
Mean values for precision, recall, and Jaccard index, across videos from the first three subsets, for each combination of
For each video, ground truth is determined by manually labeling each frame of each video as being anomalous/not anomalous (in all instances, videos with anomalies had at most one anomalous car in each frame). At evaluation time, for each frame in a video:
If the frame was labeled as non-anomalous, it is a true negative (TN) if no trajectory was considered as actually anomalous by the model at that frame; false positive (FP) otherwise. If the frame was labeled as anomalous, it is a true positive (TP) if exactly one trajectory was considered as anomalous by the model at that frame; false negative (FN) otherwise.
With these considerations, standard measures such as precision
Please note that these formulae might become indeterminate for videos with no frames labeled as anomalous. In such cases, if there are no false positives, the algorithm performs perfectly. Because of this, when these formulae are indeterminate, the value is set to 1 if
Labeling anomalies at the bounding box level might be a more precise way to measure performance, but the proposed methodology works reasonably well for the use case exposed here.
Experiments were carried out to evaluate the performance of the model under various combinations of parameters. Because of the large number of parameters and unknowns, it was impractical to perform an exhaustive evaluation of performance for all possible combinations of parameters, with a large number of video sequences. Instead, a staggered approach was followed, conducting three studies of the performance of the system:
First, reasonable values were sought for the parameters With established values for A comparison of the performance yielded by other state-of-the-art LSAP-based trackers. In particular, our proposal is compared to two well-known methods: SORT and BYTE. Also, we study its performance in videos with added rain and snow.
The first two studies (Sections 4.3.1 and 4.3.2) require an extensive array of experiments. Because of this, the system’s performance with different configurations in these two studies is conducted with the videos from the first three subsets. Once the best configuration is determined, the third study (Sections 4.3.4 and 4.3.5) evaluates its performance on all videos from the four subsets. For more details on the four subsets of videos, see Section 4.2.
Results for the first stage are shown in Table 2. It shows mean values for precision, recall, and Jaccard index, across videos from the first three subsets, for each combination of
Mean precision, recall, and Jaccard index, across videos from the first three subsets, for configurations with
,
with border correction
Mean precision, recall, and Jaccard index, across videos from the first three subsets, for configurations with
Same as Table 3, but applying bounding box similarity only to vehicles of small apparent size
Same as Table 3, but for configurations without border correction
Best performance of the proposed method with different combinations of border correction and bounding box similarity
For the second stage, with the first parameters fixed to
Detailed performance values (TP, FP, TN, FN, precision, recall, Jaccard index) for the best configuration
Detailed performance values (TP, FP, TN, FN, precision, recall, Jaccard index) for the best configuration
The purpose of applying bounding box similarity is to limit errors in trajectory tracking. Given that the model already performed well for vehicles with large apparent sizes, we hypothesized that the relatively small performance improvement of bounding box similarity was the result of excessive disruption to the tracking of vehicles with large apparent sizes. In order to test this hypothesis, all experiments with bounding box similarity were run again, but restricting its application to vehicles of small apparent size (as described in Section 3.2, vehicles whose smaller side is below 2.5% of the largest side of the image). Results for this array of experiments are shown in Table 4. In this case, results improve significantly over using border correction alone for most configurations. However, no backbone and no threshold
The performance of the model was also investigated for configurations with bounding box similarity but not border correction. When applying bounding box similarity only for small vehicles with apparent size, results were consistently worse than also using border correction (data not shown). However, when applying it to vehicles of any size, some configurations outperformed border correction alone, as shown in Table 5, possibly because boxes of vehicles that are appearing/disappearing naturally tend to have lower similarity scores, thus having an effect similar to border correction. In this case, ResNet models outperformed VGG models, and deeper models produced better results.
According to these results, we determine the best configuration: use border correction and bounding box similarity just for vehicles of small apparent size, with threshold
Graphic depiction of the results for our best method with border correction and bounding box similarity (see Section 4.3.3 for details).
Predictions made for different videos in an specific instant. Left to right: Video1 (frame 247), Video4 (frame 873) and seq. 2 SK_4 (frame 672).
The configuration with the best precision and Jaccard index is the one with border correction and bounding box similarity applied only to vehicles with small apparent size, using the vgg11 backbone, and similarity threshold
The information in the table about the TP, FP, TN and FN frames is also shown in Fig. 3 in a more visual way: each video is represented by a horizontal bar whose length is its number of frames. These are the videos used to compute the statistics for Tables 2–6. For each video, its length is expressed in frames. Frames can be labeled as TP (bright red), FP (dark red), TN (bright green) and FN (dark green). Actually anomalous frames (ground truth) are the union of TP and FN frames, comprising one or two contiguous segments in several videos. For Video1, the anomalous segments are the periods when a car is backing onto a busy road. For Video2 and Video4, the anomalous segment includes cars engaging in counterflow driving. For seq. 2-SK_1 and SK_4, the anomalous segment depicts a car stopped in the middle of an intersection, flanked by fast traffic. All other videos lack anomalous segments. The bar is colored according to the status of each frame: TP frames are bright red, FP frames are dark red, TN frames are bright green, and FN frames are dark green. Given the above configuration, the frame-by-frame results for the tested video sequences are shown in Fig. 3. Video1, Video2, seq. 2, cam. SK_1 and seq. 2, cam. SK_4 contain real, well-detected anomalies (i.e. true positives). False positives typically represent very brief segments, and by analyzing the frames in which the false positives appear, two cases are deduced: the first time that, after the start of the sequence, any vehicle uses a lane of the road or an intersection, the system is likely to mark those vehicles as anomalous; the second case is when many overlapping trajectories accumulate in the same area (e.g. an intersection) due to the comparison between the trajectories of some vehicles with very different overlapping trajectories.
Mean values for precision, recall, and Jaccard index across all videos, for configurations with
,
and using either SORT or BYTE instead of the custom tracking algorithm
Mean values for precision, recall, and Jaccard index across all videos, for configurations with
Pairwise Cochran’s Q tests between distributions of correctly classified frames for the best method with border correction and all other methods in Table 8
Specific vehicles with trajectories classified as anomalous by the model are shown in Fig. 4:
Left image: a vehicle is backing onto a busy road. Center image: a vehicle driving in opposite direction. Right image: a vehicle is stopped in the middle of a busy intersection.
Cyan-colored lines on the center of each vehicle bounding box represent the
Finally, the model was tested by substituting the custom tracker with two well-known generic LSAP-based trackers: SORT and BYTE. In this case, once the best configuration has already been established for our proposal, we test the performance of the models with all videos, including the fourth subset (see Section 4.2) with 225 one-minute video clips. As border correction is applied outside the tracking algorithm, both trackers were tested with and without border correction, finding that border correction can enhance the performance of both. Without border correction, SORT is superior to BYTE in all metrics. However, BYTE’s metrics are more significantly boosted than SORT’s, to the point that BYTE’s precision surpasses SORT’s with border correction, while its recall and Jaccard index get close but do not surpass SORT’s.
Table 8 shows average precision, recall and Jaccard index across all videos for six different possibilities: our best configuration (with vgg11 and similarity threshold
Lower-left corner of the frame 150 of Video1 with detections and trajectory identifier, same excerpt with synthetically added rain, and with snow. 
To validate the statistical significance of these results, we perform an array of statistical tests to validate that the distributions are different. However, in order to have a higher level of statistical significance, the statistical tests are performed not at the level of whole videos (237 videos in total) but over the population of all frames from all videos (418158 frames in total). At the frame level, a useful way to characterize each of these six methods is to consider the associated Boolean distribution that represents the set of frames correctly classified by that method (i.e., frames being either TP or TN). The Cochran’s Q test [74] assesses whether there is a statistically significant difference between binary distributions. To test whether these distributions are statistically different, we run pairwise Cochran’s Q tests between the distribution for the best method and all other methods. The resulting very low
As an anomaly detection system for outdoor cameras, it is also desirable to test its performance for traffic videos with rain and snow. The Aalborg dataset [75] provides real traffic videos in raining and snowing conditions. However, only select frames (i.e. not the full videos) are readily available, and all videos from this dataset depict intersections rather than highways. Instead, we tested the system’s performance by artificially adding rain and snow to all the videos (from all four subsets) using a publicly available library (
Comparison of mean values for precision, recall, and Jaccard index, across all videos, for the best method in different conditions
Comparison of mean values for precision, recall, and Jaccard index, across all videos, for the best method in different conditions
The previous sections explore the model’s performance of the model under good favourable conditions. However, it is also necessary to discuss the limitations of the proposed model. An important restriction is that all used videos have reasonably high framerates, translating into relatively small and smooth vehicle displacements from one frame to the next. When applying the method to videos with significantly lower framerates (from half to a third), we found the performance to be substantially poorer, as the various tested tracking subsystems failed to accurately track trajectories for very fast vehicles and vehicles of small apparent size. As a result, the statistical distribution of anomaly values significantly changed, dramatically increasing the number of false negatives.
Other limitations come from using a generic object detector (yolov5) as the detection stage: as the detector was trained on generic image datasets with very limited ranges of traffic conditions, the detecting performance is severely degraded in various scenarios:
For vehicles of very small apparent size (e.g. when using a wide camera aperture, or when cameras are placed relatively high). For overlapping vehicles of small apparent size (e.g. with very dense traffic, when the viewing angle does not minimize vehicle overlapping in the image). For unfocused vehicles (this is especially serious for vehicles of small apparent size). For scenes with bad illumination (e.g., videos recorded at night).
Finally, the development of the system has been done with flexibility and ease of data collection in mind, resulting in a Python implementation that is significantly slower than it could be. The full-fledged system (using bounding box similarity and border correction) takes about 3.5 minutes to process a one-minute video clip in a machine with an Intel i7 processor and a 3080 GPU. Consequently, it cannot be used for real-time detection in its current state.
An approach to detect anomalous, wrong-way vehicle trajectories from traffic video sequences has been proposed in this work. This proposal computes the video frame by frame, and it is based on the velocity vectors of those detected trajectories. The proposed methodology is composed of several steps. First, the detection of the vehicles that appear in a frame is addressed by a component base on a deep learning model. Then, the trajectories of the detected vehicles are tracked. To enhance the performance of the tracker, the impact of adding techniques such as border correction and bounding box similarity has been analyzed. Once trajectories have been tracked, the velocity vector of each trajectory is computed and compared with velocity vectors from other spatially adjacent trajectories. This comparison aims to detect those unusual (that is, anomalous) trajectories.
Different experiments have been conducted to test the performance of the approach. A set of synthetic and real sequences and several methods from state-of-the-art have been considered in the comparison. Results demonstrate our proposal is suitable for detecting anomalous trajectories such as vehicles driving in opposite directions or backing onto a road.
Future works include the addition of a specific procedure to manage intersecting roads. In these situations, the velocity vectors of the normal trajectories exhibit two or more different modes associated with the allowed directions for the cars to traverse the crossroads. In other words, the velocity vector distribution is multimodal. This adaptation could be done by modeling each of the modes with a probabilistic mixture component, or any other unsupervised learning model that finds the clusters in a multimodal input distribution.
Another line of future work is the optimization of the implementation: if it were fast enough to be applied in real-time, it would allow for the online detection of anomalies, as at each time step, no information is used to determine if a trajectory is anomalous. This can be accomplished by reimplementing the deep learning parts of the pipeline in TensorRT, as well as carefully reimplementing the data structures used for trajectory tracking and anomaly detection, bounding their sizes and optimizing them for fast access times.
While the system as currently proposed works reasonably well in various weather conditions, another avenue for improvement is to optimize the off-the-shelf object detector. It can be fine-tuned to reliably detect individual vehicles in currently problematic scenarios such as nighttime, unfocused cameras, small apparent size and the high overlapping of vehicle silhouettes that can arise from a combination of the camera angle and dense traffic. In a related line of work, it should also be possible to tweak the trajectory subsystem to track trajectories at lower framerates reliably. This would enable application in real-time with less optimization work, and also application to video feeds that are naturally available at lower framerates.
To test other classification approaches we plan to test dynamic neural classifications [76], fast learning [77] and ensembles of classifiers [78], as well as to study the possibility of processing 3D data [79, 80].
Footnotes
Acknowledgments
This work is partially supported by the University of Málaga under grant B1-2022_14. This work is partially supported by the Ministry of Science, Innovation and Universities of Spain under grant RTI2018-094645-B-I00, project name Automated detection with low-cost hardware of unusual activities in video sequences. It is also partially supported by the Autonomous Government of Andalusia (Spain) under project UMA18-FEDERJA-084, project name Detection of anomalous behavior agents by deep learning in low-cost video surveillance intelligent systems. It is also partially supported by the Autonomous Government of Andalusia (Spain) under project UMA20-FEDERJA-108, project name Detection, characterization and prognosis value of the non-obstructive coronary disease with deep learning. All of them include funds from the European Regional Development Fund (ERDF). It is also partially supported by the University of Malaga (Spain) under grants B1-2019_01, project name Anomaly detection on roads by moving cameras; B1-2019_02, project name Self-Organizing Neural Systems for Non-Stationary Environments; and B1-2021_20, project name Detection of coronary stenosis using deep learning applied to coronary angiography. The authors thankfully acknowledge the computer resources, technical expertise and assistance provided by the SCBI (Supercomputing and Bioinformatics) center of the University of Málaga. They also gratefully acknowledge the support of NVIDIA Corporation with the donation of two Titan X GPUs. The authors also thankfully acknowledge the grant of the Universidad de Málaga and the Instituto de Investigación Biomédica de Málaga y Plataforma en Nanomedicina-IBIMA Plataforma BIONAND.