
Abstract
Automated railway security systems prevent train collisions with trackside obstructions that cause accidents in high-speed railways. Rail safety is being improved and accident rates reduced through continuous research. A rapid advancement in deep learning has promoted new possibilities for research in this field. In this work, a novel deep learning-based FOD-YOLO net is proposed for detecting the fasteners faults and objects in the railway tracks. There are two basic components in the deep learning-based YOLOv8: the backbone and the head. YOLOv8 utilizes an improved version of the CSPDarknet53 network for detecting objects on the railway track. The head of YOLOv8 consists of EfficientNet with various convolutional layers with squeeze and excitation blocks for detecting any defect in the track fasteners. These layers are liable for detecting the objectness scores, bounding boxes and class probabilities structured with fully connected layers for the objects and faults in tracks. Based on the results from the Yolo network, the alert message is sent to the loco pilot to avoid accidents using fuzzy logic. The experimental fallouts of proposed FOD-YOLO net achieve higher accuracy and yields better evaluation results with 98.14% accuracy, 98.84% precision and 95.94% recall. From the experimental results, the FOD-YOLO net improves the overall accuracy range by 5.44%, 4.72%, 0.73%, and 13.18% better than Fast RCNN, YOLOv5s-VF, YOLO-GD, and 2D-SSA + Deep network respectively.
Introduction
A railroad track is the most important part of a rail system, and the rails should be fastened to the crossties for a safe journey. Railways have always placed a great deal of importance on automatic track inspection as they expanded their networks [1, 2]. The nation will be greatly impacted by major advances in this field. In order to prevent accidents on the rails, it is imperative that the rails are properly monitored and maintained because of their enormous size. Many lives are affected by the absence of carelessness [3]. An accident prevention method has been introduced to prevent this from happening on railways. Specifically, this approach is focused on regions where animals are frequently seen on railroad tracks. It is simple to detect organisms using cameras, preventing accidents [4, 5].
Manual examinations and the use of specialized equipment take time and require knowledgeable personnel [6]. The use of vision-based technologies has grown in popularity as a result of the expansion of railroad networks, since they are effective at identifying components as they are based on railroad track images [7, 8]. Deep learning has rapidly advanced, creating new prospects for study in the subject. Track employees initially do track patrol and maintenance on foot before progressively transitioning to using track patrol automobiles, but they remain solely dependent on human visual inspection [9, 10]. However, manual detection of an object and defect in the railway track is time consuming. Study on railway scrutiny systems has engrossed on infrastructure systems, surface defect identification, fastener detection, etc [11–13]. To avoid train derailments and other kind of harsh accidents caused by defective or failed railway track elements, it is essential to inspect rails, bolts, and clips, which fastener rail ends composed at a joint, and rail flexible clips that attach rails to rail sleepers. The fastener consists of clip and bolt together. Advances in image processing can efficiently prevent accidents on railway track [14, 15]. Deep neural networks and machine learning have produced promising fallouts in all real-time applications. The use of deep learning for collision identification between any organism on track can help prevent such accidents. The primary contributions of our research are listed as follows: The key objective of this research is to present a novel FOD-YOLO model to identify the objects and faults in the railway tracks to avoid the terrible accidents. In FOD-YOLO model, the self-attention integrated CSPDarkNet53 (SE-CSPDN53) is used as a backbone structure for feature map extraction from the initial stage to the final stage of the network to efficiently detect the objects on the track. In FOD-YOLO, the head consists of EfficientNet with squeeze and excitation modules (SE- EfficientNet) as well as Gelu activation functions with convolution layers for detecting track fastener defects in the track. Finally, the Fuzzy based decision making is performed using the both scenarios from the detection results of the FOD-YOLO model are compared to alert the loco-pilot and also to nearby control room. The effectiveness of the proposed FOD-YOLO net shows high performance in terms of accuracy, specificity, precision, recall, mAP, FPS, and F1 score with respective values.
The rest of this work is structured as follows: section 2 designates the related works on object detection in railway tracks, section 3 explains the inclusive work of the proposed FOD-YOLO net, section 4 describes the experimental results and discussion and the section 5 enfolds with the conclusion and future work.
Literature Survey
In this section, researchers have proposed several object detection strategies for detecting the organism on the railway track in recent years. This section provides a brief overview of several recent machine and deep learning and machine learning studies on the detection of objects and faults in the railway tracks to avoid accidents.
In 2022 Wang, M., et al., [16] suggested a YOLOv5s-VF, a revolutionary rail surface fault detecting network. V-CBAM with two essential parts: SSA and FCAM. The collection of rail image is based on human labelling of flaws to train an object identification network, it is available on open source due to the scarcity of publicly available datasets. The result demonstrates the overall speed of 114.9 fps and accuracy of 93.5% that YOLOv5s-VF exceeds current rail surface object identification approaches.
In 2022, Yue, X., et al., [17] introduced a YOLO-GD model to recognize dishes in images, including cups, chop sticks, bowls, and more. The catch point calculation was created on the basis of image processing for retrieving the catch point of the various kinds of dishes. According to the trial findings, YOLO-GD mAP achieves 97.38% that was 3.41% better than YOLOv4. The inference time for an image was reduced by the YOLO-GD model of mAP is 97.42%.
In 2022 Kapoor., et al., [18] devised a deep classifier network that is effective at identifying objects on the railroad track in front of the train. The 2D-SSA and deep network combination improves the performance of obstacle recognition. This technique also offers another way to locate railroad tracks. Additionally, utilizing the OSU thermal pedestrian benchmark database, the performance of this technique was examined under various lighting scenarios. It performs better with an accuracy rate of 85.2%.
In 2022 Rahman., et al., [19] a transfer learning model built on a convolutional neural network was applied to a unique dataset. A dataset that can be useful in identifying obstructions for rail crossings or tracks was created by gathering manual shot photos from a real-world train track. This suggested MobileNetV2 was demonstrated its effectiveness in utilizing resources and its capacity to find obstructions on the railway track. Even though the other networks like YOLOv5, Resnet50, VGG19, and VGG16 also utilized on the dataset, MobileNetV2 outperformed the other chosen models with the accuracy of 97.0%.
In 2020 Li, B., et al., [20] suggested a two-stage detection approach for locating equipment that identified the signal condition of a track circuit. It improves the network architecture to detect the equipment appearance. The ACU and recall rate of the suggested method is higher than those of a single target detection algorithm. This suggested two-phase detection method for improving the efficiency of YOLOv3 for detecting objects.
In 2020 Ranyal, and Jain [21] suggested employing one-stage RetinaNet deep convolution network architecture to locate rail fasteners on train lines. DJI Phantom was flown at a height of 100 meters were used to capture aerial images with a size of 5472×3078 to undertake a quantitative assessment. Results demonstrate that the obtained deep features were used to detect rail abnormalities that may need immediate repair and hold the promise of a robust technique when trained on a bigger dataset.
In 2020 Liu, W., et al., [22] presented a unified CNN architecture for identifying all CSC modules at different scales. Initially by enhancing and optimizing Faster R-CNN, a detection network for CSCs with huge sizes was introduced. The detection network for CSCs with large scales is then combined with a cascade network that was suggested for the identification of CSCs with small scales to develop a single network design. It was found that 92.8% of detections were accurate using the unified CNN architecture.
In 2020 Ye, T., et al., [23] design a DFF-Net for detecting railway traffic objects to stop railway accidents. The object detection engine takes the aforementioned anchor boxes as input and uses feature fusion submodules to enhance semantic information and achieve accurate object detection. In tests using a dataset of railway traffic, the suggested DFF-Net outperformed the most recent state-of-the-art detectors with mAP of 90.12%.
In 2021, Wisultschew, C., et al. [24] designed and implemented an edge IoT hardware platform for locating and tracking things on railway tracks. An extremely detailed point-of-cloud map is produced with the help of a low-resolution 16-channel 3D camera and LIDAR sensor. Models are quantitatively validated by implementing them on automobile roads and simulating railway level crossings.
In 2023, Meng, C., et al., [25] introduced the SDRC-YOLO to an efficient railway object intrusion detection system by employing a lightweight up sampling operator and convolution kernel. Simulated results show that SDRC-YOLO increases mean average accuracy (mAP) on datasets RS and Pascal VOC 2012 by 2.8% and 1.8% respectively. Small targets are more accurately identified than with the baseline YOLOv5s method.
From these literature review, the efficacy of the current approach is hampered by its reliance on the time-consuming process of detecting the objects. The majority of the studies mentioned above rely on single detection as input, which lowers performance rates. The development of automatic signal decomposition and categorization is necessary to address the aforementioned challenges. In this work, deep learning based FOD-YOLO net for improving the detection accuracy for detecting objects and faults in railway track for prevent accidents.
Proposed Methodology
In this section, a novel FOD-YOLO net is presented to detect the objects and faults in the railway tracks to avoid collisions and accidents. The investigations are performed with a set of pre-enrolled images that are openly available. Figure 1 illustrates the overall workflow of the proposed model.
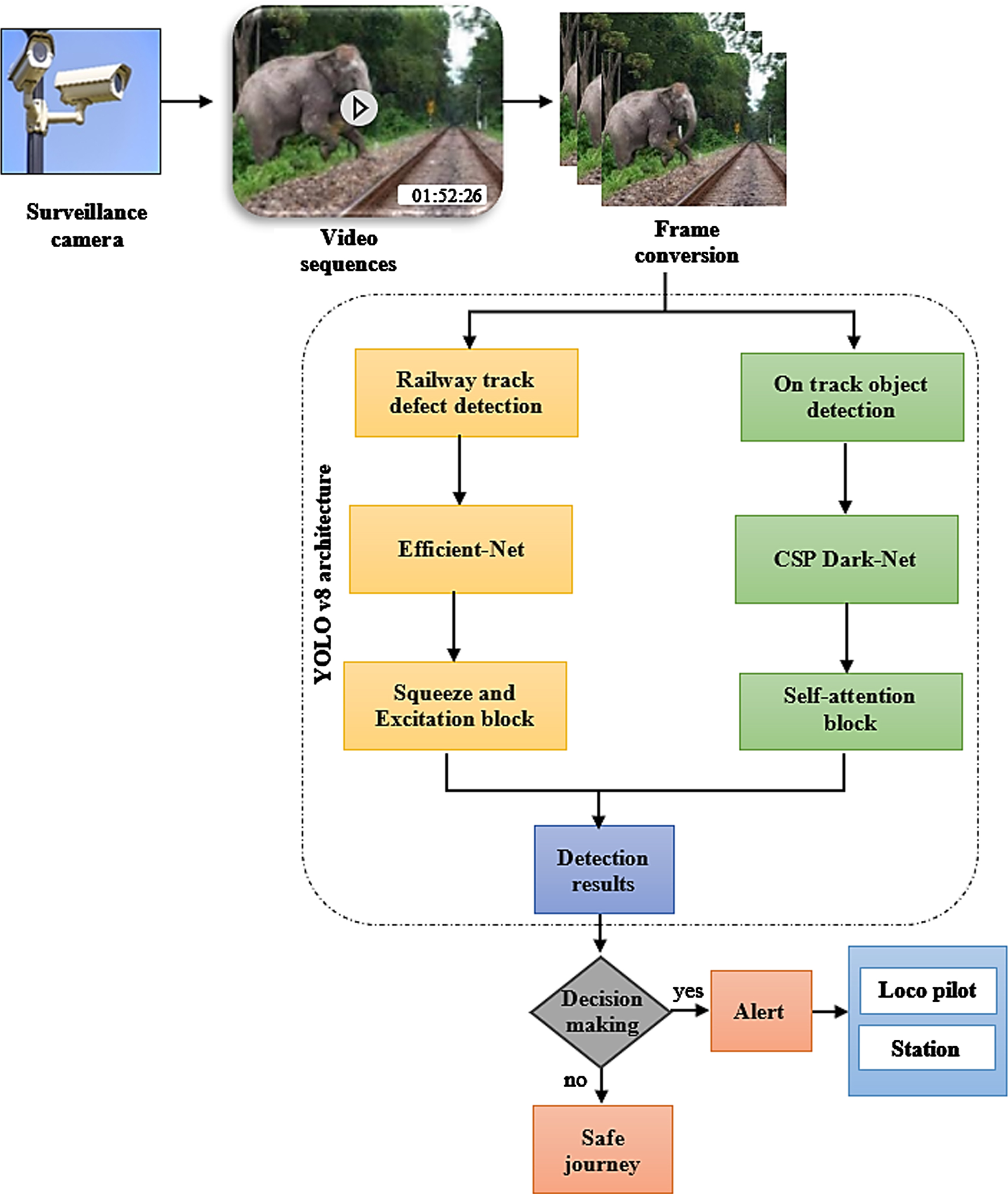
Schematic representation of the proposed methodology.
Initially, the gathered video frames are converted into images and these images are denoising for lessening the noise distortions. The collected images are denoised through AGS filter to deduce the noise distortions. The image pre-processing method that manipulates the intensity range inside sub-blocks by locally adjusting the intensity by using Adaptive Gaussian star (AGS) filter. A Gaussian filter is a low pass filter used to blur portions of the images and reduce distortion (high frequency elements). In an amplitude spectrum, the pattern of a typical periodic noise is sometimes viewed as a star. In order to form the shape of a star, two 2D elliptical filters were positioned perpendicular to each other. AGS filters are represented in the frequency domain by the following equation (1),
The following are the parameters of AGSF:
The noise-free images are given as an input to the proposed FOD-YOLO net to accurate detection of objects on tracks and faults in fasteners. The FOD-YOLO net is an advanced version of YOLOv8, in which two YOLO networks are used for object detection on tracks and fault detection in railway track. In the FOD-YOLO net, there are two different modified structures are used for efficient detection of objects and faults in the railway tracks. The structure of the proposed FOD-YOLO net is displayed in Fig. 2. In the Object detection phase, the self-attention-based Cross-Stage-Partial DarkNet53 (SA-CSPDN-53) is used a modified backbone structure to detection the objects on the railway track. Controlling deeper networks with gradient paths was enable the SA-CSPDN-53 structure to learn and converge successfully. Several kinds of convolutions are used to create the CSPDN-53 structure. Simultaneously, in the fault detection phase, squeeze and excitation based EfficientNet (SE- EfficientNet) is introduced with the Gelu activation function for efficient fault detection in railway tracks. During the convolution layer, with SE module is utilized. An adaptive SE module selects the size of the 1D convolutional filter, and the dimension is preserved during local cross-channel interactions by lessening network complexity. The proposed FOD-YOLO ideally balances speed and precision to detect the object and faults in railway track.
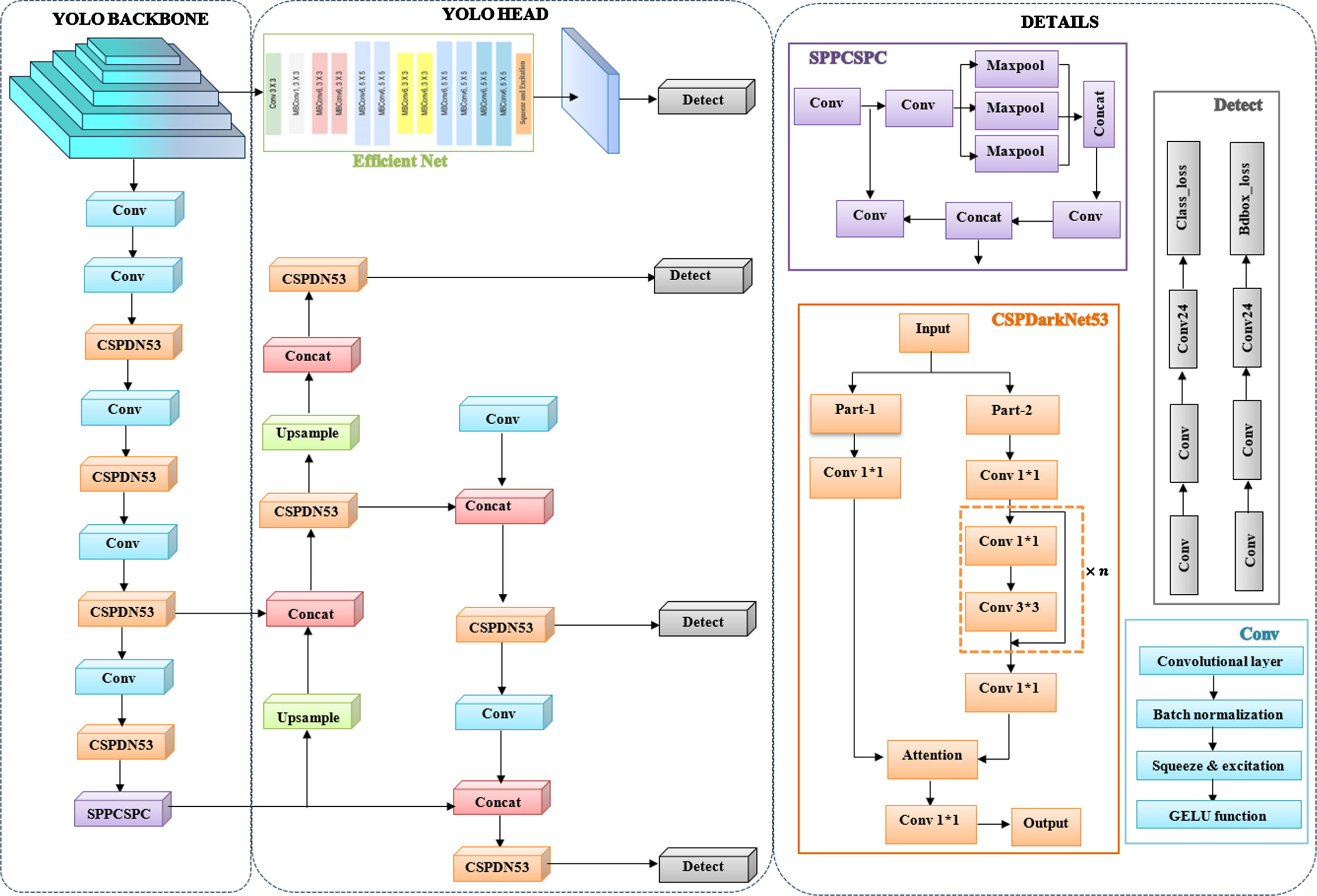
Architecture of the proposed FOD-YOLO net.
In this phase, Cross-Stage-Partial DarkNet53 (CSPDN-53) is used to detection the objects on the railway track. CSPDN-53 divides the feature maps into two parts, processes them separately through two different branches of the network, and then merges them. This helps in improving information flow and enables better feature reuse across different stages of the network. Convolutional layers in CSPDN-53 involve the mathematical operation of convolution. CSPDN-53 is the default backbone of the YOLO v8. This backbone is a development of the backbone namely DarkNet53 which has added the Cross Stage Partial Connections (CSP) feature which integrates feature maps from the initial stage to the final stage of the network. CSP implementation reduces computation thereby outperforming other state-of-the-art backbone architectures. The structure of CSPDN-53 is shown in Fig. 2. The convolutional process is used to extract features from the input data using convolutional filters.
The MP module, Conv module, SPPCSPC module and three consecutive conv modules form the main network. Self-attention is highly flexible and allows the model to weigh the different parts of the input sequence. The primary purpose of self-attention mechanisms in CSPDN-53 is to enable the YOLO model to focus on different parts of the video sequence when making predictions for each frame in that sequence. The attention mechanism calculates a set of weights for each element in the sequence based on its relationship with other elements. The self-attention mechanism is also used with CSPDN-53 which helps in achieving high level of accuracy while the depth of the network increases. Applying convolution layers to extract the feature map from the input image, it utilizes the most pooling ‘n’ times the size of the input windows to create the feature set. First, three convolution operations are performed on an input feature map with various sizes. Different kernel sizes were used for max-pooling operations. The SPPCSPC engine can retrieve information about objects at multiple scales without scaling the feature map. The image is transmitted twice once to CSPDN-53 for feature extraction. The findings are produced last by the YOLO layer. The high accuracy and other good properties of the multibranch model are preserved in the final deployed model, as well as the high efficiency, which balances speed and accuracy and improves network performance. This model analyzes and identify objects of interest of varied sizes at various scales for object detection.
In this phase, a modified EfficientNet is introduced with the integration of squeeze and excitation (SE) module for efficient fault detection in railway track. Squeeze and excitation module [26] are used to enhance the efficiency of the yolo to model the dependencies between the channels of convolutional kernels. The architecture of SE-EfficientNet is made with the reversed bottleneck MB-Conv is displayed in Fig. 2. An MB-Conv block comprises with several layers that increase and decrease the channel. Connections are employed during bottlenecks with a smaller channel than extension layers to extract the relevant features as t
f
. In contrast to normal layers with around k2 factor, depth-separable convolution minimizes computation. The kernel size k
s
indicates the height and width of the 2D-convolution windows. In SE-EfficientNet, the GeLU is used as the activation function. As a result of compound scaling, the following criteria are obtained,
Squeeze and excitation module is introduced to increase the efficiency of the network for tuning the dependencies between channels of convolutional kernels. The squeeze process is applied to compress the feature maps U∑Rw×b×c2 with the spatial dimensions (w × b) that gives the channel-wise information F
sq
with global average pooling. The input of the squeeze block has a convolution layer. Then by the usage of average pooling each channel is lessen into a single value. The ReLU operation produces non-linearity which follows the dense layer. Here the sigmoid functions act as a gating function. Additionally, the squeeze block is computationally light, which improves the capability of the network and lessens computations.
The GeLU activation function is signified as δ. The learning parameters namely w1 and w2 regarding the non-linearity is aided by two fully connected layers. After rescaling, u
c
along with the activation s
c
.
The images of railway track compared and an alert message will be sent to the loco-pilot and also to nearby control rooms if an object or defect is detected using fuzzy logic. Mamdani fuzzy is made with a minimal number of rules for altering the loco pilot based on the detection results. The fuzzy logic controller was used to convert a linguistic control technique based on expert data into an independent control approach. A MFIS is consists of five building blocks: a database, a rule base, a decision-making unit, a fuzzification interface unit, and a defuzzification interface unit. The fuzzification unit changes the target value of the four detection fallouts (object, no-object, fault, no-fault) into fuzzy measures. The fuzzy rules are mathematically represented as,
If object detect on track and fault detect in track then alert the loco pilot If object did not detect on track and fault detect in track then alert the loco pilot If object detect on track and fault did not detect in track then alert the loco pilot If object did not detect on track and fault did not detect in track then did not alert the loco pilot.
The fuzzy inference process analyzes the values of an input and allocates values to the fallouts based on a set of rules. A fuzzy interference regulation is used to the results of the YOLO network. To prevent accidents, two membership functions are incorporated into the fuzzy system to produce a result for warning the loco pilot and control room.
In this section, the experimental setup of the proposed FOD-YOLO was implemented using MATLAB 2020b, and the ensuing experimental findings are represented. The proposed FOD-YOLO net was assessed with various measures viz., specificity, precision, F1 score, recall, and accuracy measures on the collected dataset.
Dataset acquisition
In this work, an annotated subset of 7500 training images from the public RailSem19 dataset as the training set, eliminating tramway images [27]. A total of 26,810 images were produced from these images by selecting different locations of interest and acquiring them at 224×224 resolution. Similarly, 12,81,167 images from the freely accessible ImageNet dataset [28] as additional non-railway image are also gathered for experiments. ImageNet dataset constitutes already labelled data for the better model for testing the query image type. Normally, the images are labelled by annotation and this ImageNet dataset consists of many categorizes. So, the re-labeling ImageNet training data is necessary. Original ImageNet annotation is a single label (“crack”), whereas the image contains multiple ImageNet categories (“crack”, “human”, and “animal”).
The official annotated test set from RailSem19 is used in the evaluation data collection Fishy-Rails. The resulting 7,142 images and segmentations are the result of embedding the images with objects from the public Pascal VOC object detection dataset [29] and fasteners fault detection dataset [30]. The sample images from the dataset are exposed in Fig. 3.
Sample images gathered from the different dataset.

Experimental results of the proposed FOD-YOLO net.
The proposed FOD-YOLO model was assessed by approximately metrics accuracy, precision, specificity, recall and mAP.
Precision and recall are used as significant indicators to measure the performance of object identification model. To evaluate the objective performance of the FOD-YOLO model, Mean Average Precisions (mAP) is calculated using equation (14).
The frames per second (FPS) of an object detection algorithm signifies the number of images frames the algorithm can process per second. The parameter FPS is calculated by taking the reciprocal of the processing time in seconds. According to the parameters given for the sample images, the proposed FOD-YOLO evaluation of performance is calculated as shown in
The findings attained by the proposed YOLO network for the collected datasets i.e., for object detection and for fault detection is illustrated in Table 1. The proposed FOD-YOLO net reaches the average accuracy of 98.14% and mAP of 96.85% for the gathered dataset. Figure 5 displays the performance of the FOD-YOLO based the network parameters. Additionally, the proposed FOD-YOLO net acquires the overall precision, recall, specificity and F1 score of 97.84%, 95.94%, 98.16% and 96.98% respectively.Table 1.
Performance scrutiny of the proposed FOD-YOLO network

Performance analysis of the proposed FOD-YOLO net for detecting (a) objects on track (b) faults in track.
Figure 5 (a) displays the efficiency analysis of the proposed FOD-YOLO net for detecting the objects on the railway track. Figure 5 (b) displays the efficacy analysis of the proposed FOD-YOLO net for the detection of fault on the railway track.
The accuracy graph of the proposed of the proposed FOD-YOLO net is presented in Fig. 6(a) as the accuracy value on the vertical-axis and the number of epochs on the horizontal axis. The epoch and loss range in Fig. 6(b) indicates that once the epochs are elevated, the loss of FOD-YOLO net declines. The proposed FOD-YOLO net achieves high levels of accuracy in terms of detecting the objects and faults in the tracks.
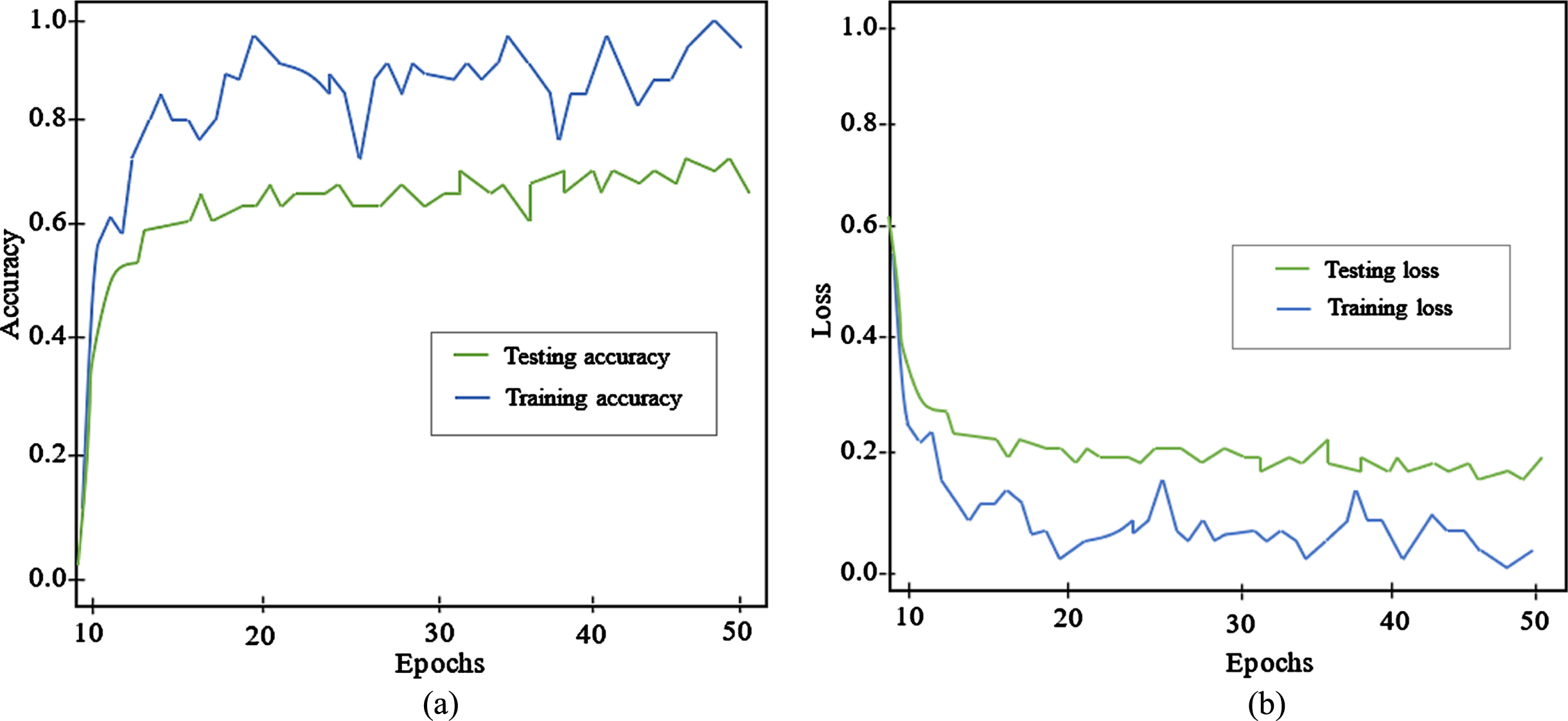
(a) Accuracy curve (b) Loss curve of the proposed of FOD-YOLO net.
The efficiency of traditional networks was measured for validating that the results of the proposed FOD-YOLO net attain high accuracy. This assessment was conducted in contrast with the proposed YOLO network and conventional networks SSD, Mask RCNN, and Faster RCNN.
The proposed FOD-YOLO model is contrasted with three current strategies in a comparative analysis. The effectiveness of DL models as a whole is contrasted with the proposed approach in Table 2. The FOD-YOLO network is contrasted with DL techniques such as YOLO v8, Mask RCNN, Faster RCNN, and SSD. Performance evaluation was based on various metrics like precision, specificity, recall, and accuracy of the DL technique. However, conventional networks have performed less well than the proposed networks. YOLO network progresses the detection accuracy by 8.57%, 4.82%, 5.44%, and 1.23% better than SSD, Faster R-CNN, Mask R-CNN and Yolo v8 respectively.
Comparison of conventional object detection networks
Comparison of conventional object detection networks
Figure 7 displays the detection results of the proposed FOD-YOLO performs faster and attains best results in object detection. Though, the conventional object detection models are not performed well when compared to the proposed FOD-YOLO. From the above comparison the proposed FOD-YOLO yields higher detection than the conventional approaches such as SSD, Faster RCNN, Mask RCNN and YOLOv8. The proposed FOD-YOLO increases system performance and reduces false positive rate by achieving precise accuracy of 0.99. So, the predicted fallouts of the proposed FOD-YOLO are highly reliable for detecting the objects and faults in the railway tracks.

Detection comparison results of conventional object detection network.
Figure 8 summarizes the experimental setup with the test samples from the gathered to estimate the efficiency of prior frameworks based on different weather conditions such as normal, night, rain and snow. A performance measure was applied to compared the proposed with the prior models based on detection accuracy for different weather conditions. The FOD-YOLO net progresses the overall accuracy range by 8.57%, 6.17%, 5.19% and 1.24% better than SSD, Faster RCNN, Mask RCNN and YOLO respectively for normal conditions. Moreover, The FOD-YOLO net progresses the overall accuracy range by 14.7%, 13.0%, 9.65% and 7.51% better than SSD, Faster RCNN, Mask RCNN and YOLO respectively for rainy weather conditions. Though, the prior networks not achieved better fallouts in contrast to the proposed FOD-YOLO net in different weather conditions. However, the FOD-YOLO net does not achieve good results for rain, snow and night time.

Accuracy comparison of traditional object detection techniques.
Table 3 summarizes the experimental setup with the test samples from the gathered to estimate the efficiency of prior frameworks. A performance measure was applied to compared the proposed with the prior models based on detection accuracy. The FOD-YOLO net progresses the overall accuracy range by 4.72%, 0.73%, 13.18% and 5.44% better than YOLOv5s-VF [16], YOLO-GD [17], 2D-SSA + Deep network [18] and Faster RCNN [22] respectively. Though, the prior networks not achieved better fallouts in contrast to the proposed FOD-YOLO net. The FOD-YOLO net achieves a high accuracy value of 98.14% with minimal number of GFLOPS, demonstrating excellent object detection performance. However, the superior accuracy comes at the expense of computational efficiency. Its counterpart, the FOD-YOLO net, offers a faster demonstrating its proficiency in executing object detection tasks.
Accuracy comparison of prior techniques and Proposed FOD-YOLO net
The proposed FOD-YOLO increases mean average precision (mAP) by 3.41% and improves frames per second (FPS) by 12.5%, as seen in Fig. 9 when compared to the YOLO-GD [17]. The proposed FOD-YOLO achieves significant gains in detection speed and accuracy when compared with YOLOv5s-VF [16], 2D-SSA + deep network [18] and Faster R-CNN [22]. Figure 7 shows the comparison of the proposed approach outperforms the current techniques. By comparing FPS and mAP across several networks, the FOD-YOLO has successfully achieved a good balance between speed and accuracy. From this comparison, our FOD-YOLO net is superior than other methods. So, the detected results of the proposed FOD-YOLO net are highly reliable for the detection of objects and faults in railway tracks.

Performance comparison based on mAP and FPS.
An ablation study was made to measure the effectiveness of proposed FOD-YOLO based on the collected dataset. As a result of this experiment, the two modification was done in the backbone of the FOD-YOLO network for detecting the defects and objects in the railway tracks. The effectiveness of the proposed model was evaluated by removing one by one for the assessment. According to a comparison, the recognition accuracy by removing these modules was illustrated in Table 4.
Ablation study of the proposed FOD-YOLO model
Ablation study of the proposed FOD-YOLO model
The proposed FOD-YOLO network was examined in terms of the performance metrics by removing SA-CSPDNand SE-EfficientNet. In this comparison, the proposed model attains better accuracy (96.48%) with SE-EfficientNet which comparatively high than the with SA-CSPDN (95.21%). Similarly, all the metrics are varied as well as accuracy. The EfficientNet is more appropriate for assessing identifying featural changes. On the other hand, the combination of these two modules yields high level of recognition accuracy (98.14%). From this ablation analysis, the proposed FOD-YOLO network model with these modules attains high accuracy in the identification of faults and objects in the railway tracks.
This work presents novel FOD-YOLO net for accurate detection of objects on tracks and detect the faults in trach fasteners. The deep learning based YOLOv8 has a backbone with modified version of the CSPDN53 architecture for detecting the objects on the track. The head of YOLOv8 consists of EfficientNet with multiple convolutional layers for detecting any defect in the track fasteners. Objects in an image are identified using a set of fully connected layers that predict bounding boxes, objectness scores, and class probabilities. The detection findings demonstrate that the proposed FOD-YOLO net performs better by visual records from the gathered dataset. From the experimental analysis, the proposed FOD-YOLO net yields the overall accuracy of 98.14% for efficient detection of objects and faults. The proposed YOLO was contrasted with the tradition object detectors in which it increases the overall accuracy by 4.82%, 5.44%, and 1.23% better than SSD, Faster RCNN, and Mask RCNN respectively. The FOD-YOLO net improves the overall accuracy range by 5.44%, 4.72%, 0.73%, and 13.18% better than FOD-YOLO net, YOLOv5s-VF, YOLO-GD, and 2D-SSA + Deep network respectively. However, the FOD-YOLO net does not achieve good results for different weather conditions namely rain, snow and night time due to the limited number of datasets. In future, the proposed model will be trained and tested with different datasets. Moreover, the proposed model will be extended with the advanced deep learning algorithms with IoT devices for practical implementation to avoid the railway track accidents.