
Abstract
With the prevalence of online review websites, large-scale data promote the necessity of focused analysis. This task aims to capture the information that is highly relevant to a specific aspect. However, the broad scope of the aspects of the various products makes this task overarching but challenging. A commonly used solution is to modify the topic models with additional information to capture the features for a specific aspect (referred to as a targeted aspect). However, the existing topic models, either perform the full analysis to capture features as many as possible or estimate the similarity to capture features as coherent as possible, overlook the fine-grained semantic relations between the features, resulting in the captured features coarse and confusing. In this paper, we propose a novel Hierarchical Features-based Topic Model (HFTM) to extract targeted aspects from online reviews, then to capture the aspect-specific features. Specifically, our model can not only capture the direct features posing target-to-feature semantics but also capture the latent features posing feature-to-feature semantics. The experiments conducted on real-world datasets demonstrate that HFTMl outperforms the state-of-the-art baselines in terms of both aspect extraction and document classification.
Introduction
On the popular online review websites, like Twitter and Amazon, people can discuss the interested or purchased products [24, 11]. These online reviews in turn help other users make purchase decisions and consist of broad aspects. Each of these aspects contains several highly related features that can describe the characteristics of the aspect, namely, these features are aspect-specific. For example, Imaging is an aspect of camera, and it contains several related features, such as the focusing function and the full-frame of a camera. In reality, when browsing the online reviews of a product, people always tend to find the features about some specific aspects, i.e., targeted aspects, rather than the coarse features from broad aspects. Therefore, focused analysis emerged for this situation [30].
Topic modeling is an effective technique to learn the unknown features structure in large-scale data, so as to support various applications, such as recommendation systems [37, 26, 3], document classification [25, 6, 20], and sentiment analysis [36, 27, 2]. However, to capture the features for a targeted aspect, the broad aspects of large-scale online reviews pose two research questions to the existing topic models: (
The models in the first category capture the aspect-specific features as many as possible by employing additional information, such as sentiment [10, 1, 28], word linking [9, 22, 29], and ratings of a product [15, 23, 18]. The introduced information poses a constraint over the words and helps reflect each word into a corresponding aspect by performing the full analysis, so as to identify the targeted aspects. However, the simple constraint at the whole corpus level aggravates the sparsity problem in word space. Moreover, as the introduced information is not highly related to the target aspects, it may capture unrelated features. Therefore, the captured features are too general to describe a specific aspect, which means these models cannot answer RQ1 very well.
The models in the second category capture the aspect-specific features as coherent as possible by improving the semantic similarity at the document level or the sentence level [24, 16, 21, 8]. The content with a higher semantic similarity has a higher probability to share the same targeted aspect. Hence, the overall coherence can be enhanced by improving the semantic similarity between the captured features. For instance, TTM [30] is a representative topic model, which captures the aspect-specific features with the highest similarity to a set of keywords. These models can estimate semantics between features and an aspect, so as to identify the targeted aspects, which answers RQ1 very well. However, they overlook the latent semantics between features. Therefore, these models cannot answer RQ2 well.
The limitations of the existing approaches lie in the overlook of the intrinsic semantics between features. Actually, all the aspect-specific features exist in two layers in a hierarchy rooted by a targeted aspect. The upper layer consists of direct features posing target-to-feature semantics, and the lower layer consists of latent features posing feature-to-feature semantics. Below we introduce an example to show the two types of features and the motivation of our work.
A motivating example with camera reviews from Amazon.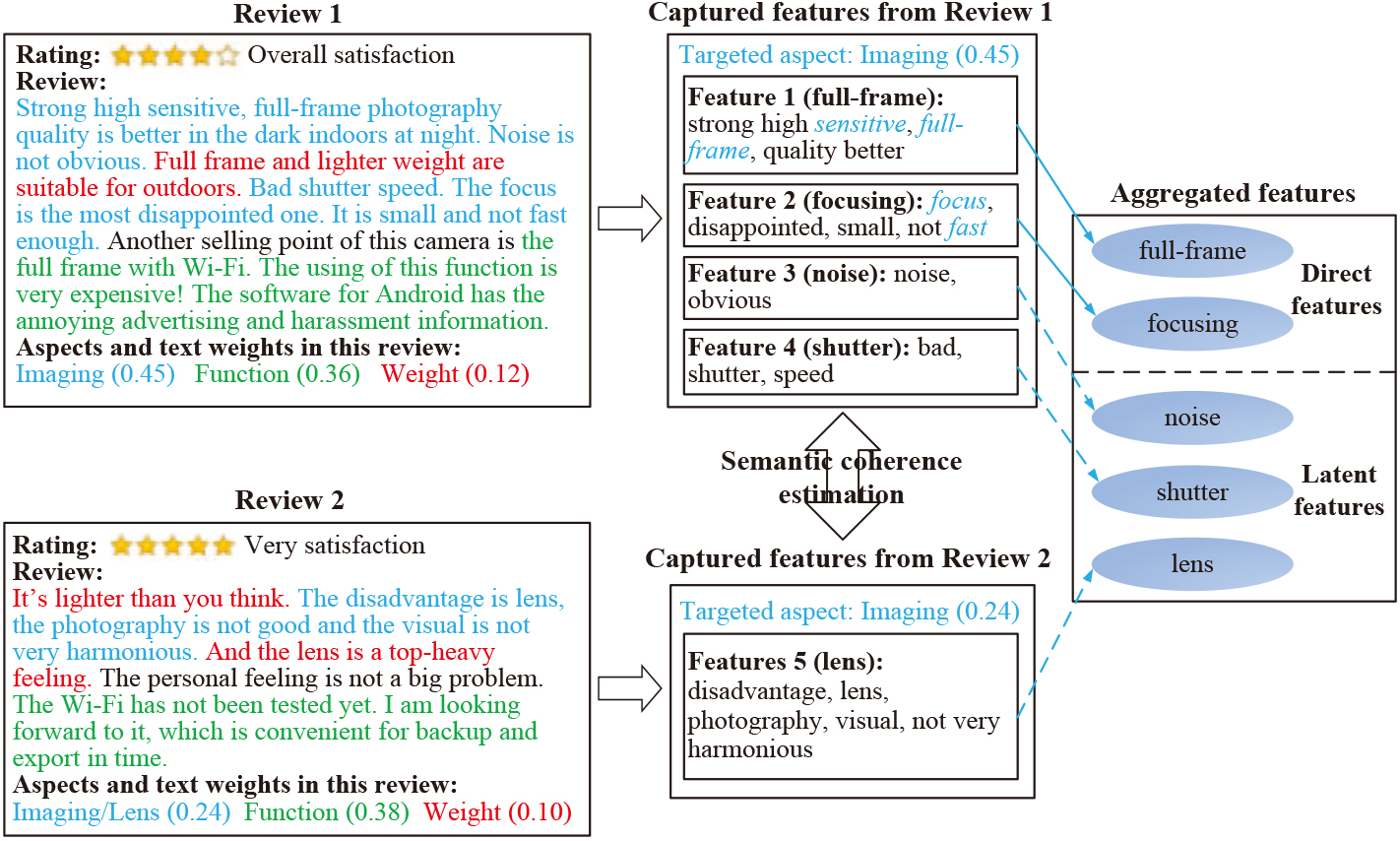
An example of the hierarchy formed by a targeted aspect and its two types of features.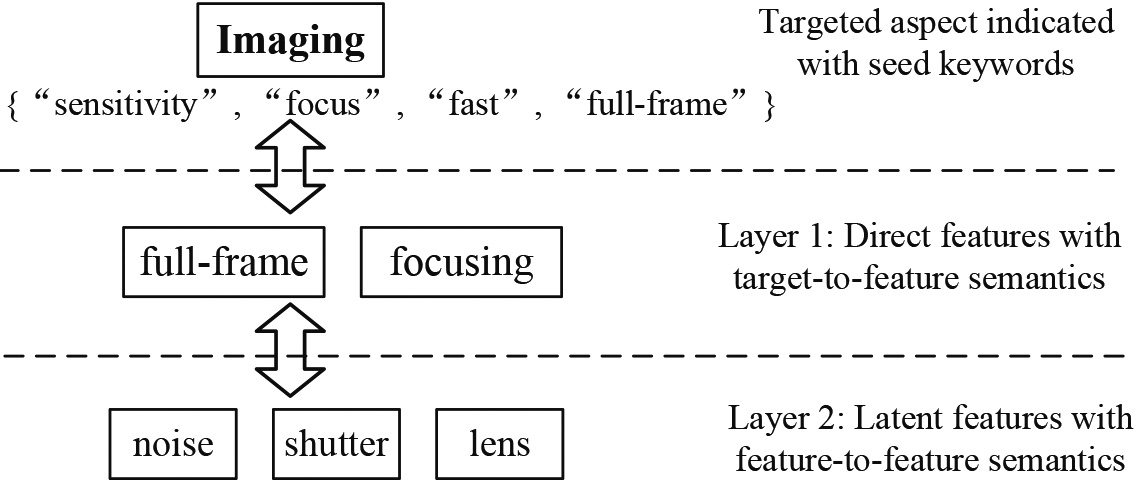
To capture the features for the targeted aspect Imaging, a user specifies the targeted aspect with seed keywords, such as {“sensitivity”, “focus”, “fast”, “full-frame”} denoted in blue italics in Fig. 1. There are two types of features, i.e., direct features and latent features. The direct features explicitly describe the targeted aspect with the keywords. For example, the feature full-frame in Review 1 covers the keyword “sensitivity”. By contrast, latent features do not contain the keywords but have semantics linking to the direct features, i.e., they describe the targeted aspects with feature-to-feature semantics. For example, the feature lens in Review 2 is semantically coherent to a direct feature focusing, since a good focusing function of the lens can assist in imaging. Therefore, a targeted aspect, its direct features, and corresponding latent features form a two-layer hierarchy (see Fig. 2), while direct features and latent features describe the target-to-feature semantics and feature-to-feature semantics, respectively.
However, the existing approaches can only capture the direct features with target-to-feature semantics, overlooking the feature-to-feature semantics, no matter they either perform a full analysis to capture features as many as possible or improve the semantic similarity to capture features as coherent as possible. Therefore, they cannot answer both the research questions RQ1 & RQ2 well.
To overcome the above-mentioned limitations of the existing approaches, we propose a Hierarchical Features-based Topic Model (HFTM), which not only captures aspect-specific features, but also explains how they are hierarchically connected with the two types of semantics.
The characteristics and contributions of our method are summarized:
We first point out the importance of the hierarchy formed by a targeted aspect and its two types of features, including the direct features with target-to-feature semantics and the latent features with feature-to-feature semantics. We propose a Hierarchical Features-based Topic Model (HFTM), which captures both direct features and latent features for a targeted aspect and explains how these features are hierarchically connected. The experiments conducted on three real-world datasets demonstrate that our method outperforms the state-of-the-art baselines in terms of both aspect extraction and document classification.
The remainder of this paper is organized as follows. In Section 2, we briefly review related works. Section 3 presents the overall framework of our proposed method and technical details. In Section 4, we report experimental results and analysis. Finally, our work is concluded in Section 5.
In this section, we review the related work according to the two above-mentioned questions: (
Aspect extraction
To answer
The methods in the first category capture the aspect-specific features as many as possible by performing the full analysis at the corpus level. Thus, a natural strategy is to introduce additional information to help identify the target-to-feature semantics. For example, Ramage et al. [22] propose the LabeledLDA model with additional labels to classify each text to a corresponding aspect. Nimala et al. [19] propose RUSBTM with an additional sentiment layer at the whole corpus level. Besides the constraints over the word space, some approaches regard the pre-trained word embedding as additional information for aspect extraction [32, 35, 33]. Although the full analysis helps capture aspect-specific features to some extent, it aggravates the sparsity problem over word space as the additional information is too narrow, resulting in the latent semantic connection between words is filtered. Therefore, these approaches only focus on the target-to-feature semantics at the corpus level, such as posing the constraint over the word space to gather the related words for a targeted aspect [28], resulting in the captured features are too general to describe an aspect.
The methods in the second category capture the aspect-specific features as coherent as possible by improving the semantic similarity at the document or the sentence level. Thus, a common strategy is to accurately estimate the semantic similarity between a targeted aspect and a document. For instance, TTM [30] adopts a spike-and-slab prior while identifying similar features in each sentence. Chen et al. [8] propose the MaToAsp model to group similar features into the same aspect. Li et al. [16] capture the aspect-specific features by adopting the co-occurrence words in each sentence. Although these approaches can capture the coherent features for a targeted aspect, the similarity estimation at the document or sentence level can only capture the high-frequency features [30], resulting in the low-frequent and implicit semantics between features are overlooked.
Unlike the single-layer analysis adopted by the above-mentioned approaches, our work captures the aspect-specific features from the hierarchy formed by a targeted aspect, its direct features, and latent features. Therefore, the captured features contain both the target-to-feature semantics and feature-to-feature semantics, which help effectively describe a targeted aspect.
Feature semantics
To answer
The weighting-based methods assume that a stronger semantics has a higher frequency. For example, Bekoulis et al. [4] propose an alternative weighting scheme for feature assignment. Yang et al. [34] apply tensor factorization to infer the weights for features of an aspect. And LWE-TM [31] defines a group of probability-weighted coefficients to estimate the semantics between features. In contrast, WMD (word mover’s distance)-based methods assume that a more similar semantic has a closer distance. These methods estimate the similarity within a semantic distance. The commonly used strategies are word co-occurrence [9, 13], attention mechanism [24], and temporal distance [7]. It is worth mentioning that the feature semantics can be validated by the domain expert. For example, a set of pre-given keywords of an aspect [30] or some well-defined concepts can be used to represent the semantics of the real world [14].
The aforementioned methods notice the feature-to-feature semantics, which improves the completeness of the captured features to some extent. However, the weighting mechanism requires complex cross-validation and is not easy to repeat. Although WMD provides a better way to estimate feature semantics with a quantifiable distance, it cannot represent the target-to-feature semantics. Moreover, the lack of hierarchical analysis makes the captured features too special to represent as more angles as possible for a targeted aspect.
Our method
In this section, we propose our method in detail. We first present the definitions and notations. Then, the generative process and the inference are introduced. Finally, we introduce the capturing process with two types of sparsity. Table 1 lists the notations used in this paper.
A list of notations
A list of notations
Given a corpus consists of
Direct feature
A direct feature
Latent feature
A latent feature
Hierarchical features
For a targeted aspect
Co-occurrence word pairs
In this paper, we use co-occurrence word pairs (also called biterm [9]) to compose the latent features, rather than use a single word (also called unigram [9]). A word pair
It is worth mentioning that the extraction of co-occurrence word pairs in this paper is different from the method in [9]. We employ an adaptive size of sliding window based on a Poisson distribution of each sentence’s length, rather than use a fixed size. We assume that each sentence contains only one feature because the average number of words in a document is too short to cover multiple features.
To capture the aspect-specific features for a targeted aspect from online reviews, we propose a novel Hierarchical Features-based Topic Model (HFTM), which not only answers how the targeted aspects are highly related to the features, but also answers how these aspect-specific features are connected with each other.
There are two phases in our HFTM model. In Phase 1, a keyword indicator
Figure 3 presents the graphical representations of the two phases. Each node in the figure denotes a random variable, while a shaded one denotes an observed variable. And each rectangle denotes an iteration with the number of iterations is shown in the bottom right corner.
Graphic representations with two phases (a) sampling the relevance status, and (b) capturing both direct features and latent features for the targeted aspect of our proposed HFTM model.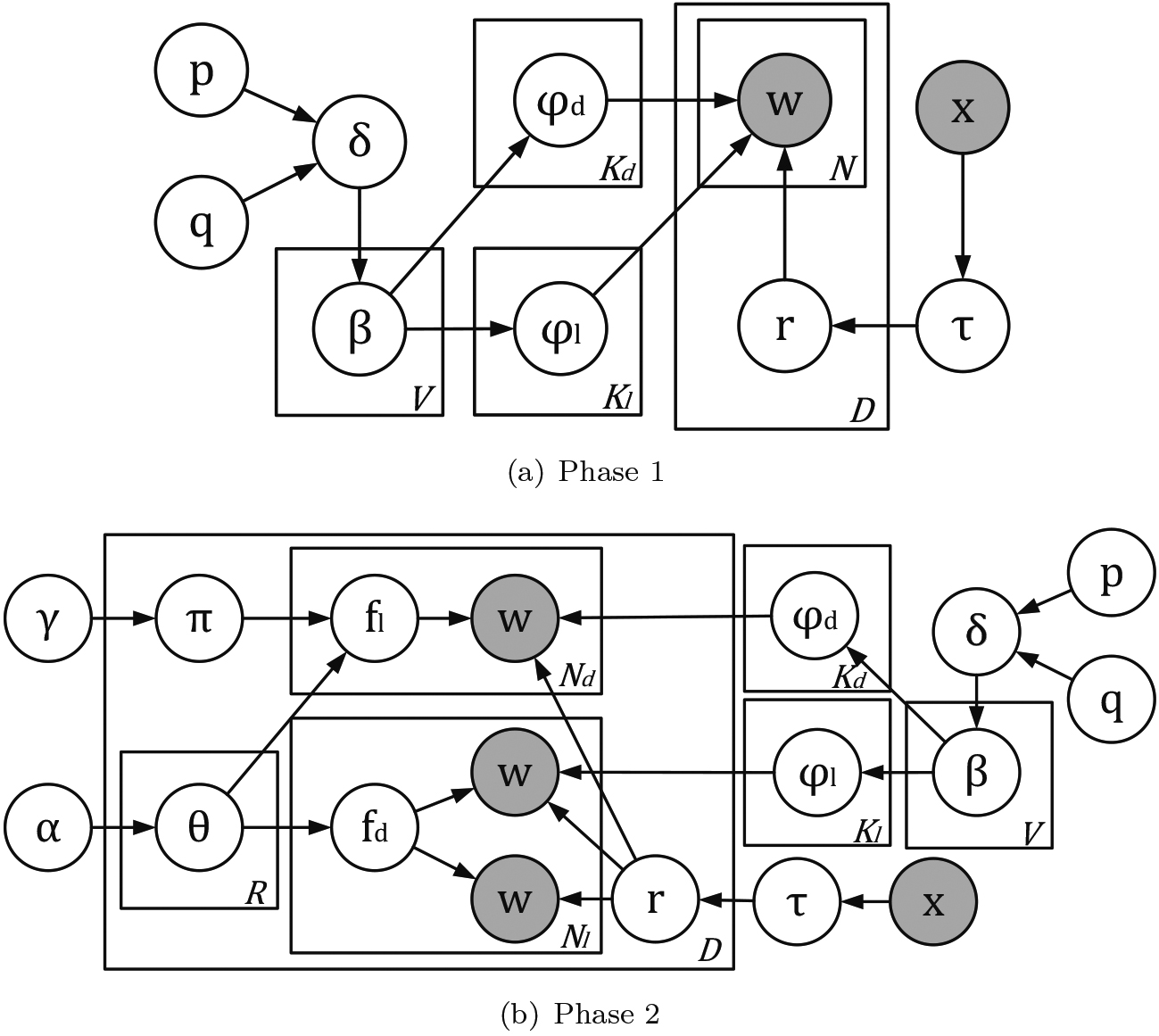
[b] Sampling the relevance status (Phase 1)[1]
Feature
Document
Here, we describe the model and introduce the overall generative process with the two phases. First, Phase 1 is to sample the relevance status for each document to a targeted aspect. The generative process is as described in Algorithm 3.
Given the corpus consists of
Second, Phase 2 is to capture the two types of features, including the direct features and the latent features. The generative process is as described in Algorithm 3.
[h] Capturing both direct features and latent features (Phase 2)[1]
Draw the feature distribution
Direct feature
Latent feature
Aggregate final features by ranking the similarity values.
Based on the relevance status
This subsection presents the inference details of HFTM to explain how our model captures both direct and latent features for a targeted aspect with the hierarchically formed semantics. This part also explains how to answer the two research questions proposed in Section 1. We use the collapsed Gibbs Sampling [12] to derive the variables in our model.
In Phase 1, HFTM samples the relevance status
[b] Hierarchical semantic estimation. [1] The relevance status distribution,
The sampling process in Phase 1 is as follows. First, we sample the prior Beta distribution
Second, we sample the relevance status
In Phase 2, HFTM captures topical words for both direct features generated from the documents with
Specifically, if
If
where
At last, we adopt a semantic estimation to aggregate all the discovered features as described in Lines 14–20 of Phase 2. We adopt cosine similarity to form the hierarchical semantics with both target-to-feature semantics (i.e., Layer 1 with direct features) and feature-to-feature semantics (i.e., Layer 2 with latent features) as described in Algorithm 3.3. In Algorithm 3,
In this part, we discuss two types of sparsity in capturing aspect-specific features, i.e., (1) the sparsity over word space caused by the global word constraint, and (2) the sparsity over co-occurrence word pairs caused by the length limitation on each document.
The first type of sparsity is caused by the word constraint over the word space when pre-giving the set of keywords of a target, i.e.,
The second type of sparsity is caused by the limitation of text length. For example, Amazon limits the length of a review to be no more than 200 characters, while Twitter limits the length of a tweet to be no more than 280 characters. Such limitations lead to the sparsity over the number of features that a document can contain. In addition, the statistic information, such as word frequency, cannot be fully utilized due to this sparsity, resulting in the overlook of the feature-to-feature semantics. Although this type of sparsity has less impact on the direct features, it negatively affects latent features. To address this problem, HFTM enriches the feature space with co-occurrence word pairs. The extraction for co-occurrence word pairs is in a global semantic distance (i.e., within a self-adaptive sliding window size), which is denoted as
where
Therefore, the utilization of co-occurrence word pairs can alleviate the second type of sparsity, which helps capture the latent features. And Eq. (3.3) presents the latent feature assignment for each co-occurrence word pair.
In this section, we present the experiments conducted on three real-world datasets. Specifically, our experiments wish to answer the following four key questions:
Experimental settings
For each dataset, we conduct the standard pre-processing as follows: (1) convert letters into lowercase, (2) remove meaningless words and the characters not in Latin as stop words, (3) remove the low-frequency words (whose frequency is less than 2), and (4) remove the documents whose length is smaller than 5 words. After the pre-processing, the statistics of the datasets are summarized in Table 2.
Data statistics, where #Docs is the number of documents, V is the number of words, and AvgLen is the average number of words in a document
Latent Dirichlet Allocation (LDA) [5] is a conventional topic model, which captures features at the corpus level. It is worth mentioning that the full analysis may split the targeted aspects into multiple features without considering any hierarchically formed semantics. Biterm Topic Model (BTM) [9] is a co-occurrence word pairs-based method, which captures the features at the corpus level with the global semantics. The corpus-level features can be very effective on sparse data, like tweets. Simplified Hierarchical Features based Topic Model (S-HFTM) is a simplified version of our method, which captures aspect-specific features without the keyword indicator. This adjustment is to investigate how our model improves feature coherence by capturing hierarchical features rather than performing the full analysis at the corpus level.
Targeted Latent Dirichlet Allocation (T-LDA) is an updated model based on standard LDA. This adjustment is to enable LDA to capture aspect-specific features by employing the keyword indicator. We compare our model with T-LDA to investigate how the latent features enhance the overall coherence and validate the necessity of latent features. Targeted Biterm Topic Model (T-BTM) is an updated model based on standard BTM. This adjustment also enables BTM to capture aspect-specific features by employing the keyword indicator. We compare our model with T-BTM to investigate which of the two mechanisms (i.e., the co-occurrence word pairs and the latent features) contributes more to the improvement of feature coherence. Targeted Topic Model (TTM) [30] is a state-of-the-art method, which performs the focused analysis at the document level to capture aspect-specific features. We compare our model with TTM to investigate how the feature-to-feature semantics improves the overall coherence, i.e., to validate the effectiveness of latent features.
To answer the key questions Q1–Q4, we conduct the following four experiments and report the corresponding results, respectively.
Experiment 1: Quantitative evaluation of feature coherence (for Q1)
To answer
where
NPMI scores on the three datasets with the number of features
First, we can see from Table 3 that our HFTM model outperforms all the baselines on the three datasets. On the one hand, on average, HTFM significantly improves LDA, BTM, and S-HFTM by 93.48%, 70.38%, and 14.57%, respectively. This result demonstrates that our HFTM model can improve feature coherence by capturing the target-to-feature semantics with the direct features. On the other hand, the averaged improvements in NPMIs delivered by HTFM over T-LDA, T-BTM, and TTM are 65.86%, 42.22%, and 58.54%, respectively. This result demonstrates the latent features can complement the direct features, which prevent the captured features from being too specific.
Second, we can see that the targeted aspects oriented methods outperform the full analysis-based methods, especially when comparing our HFTM model with its simplified version S-HFTM. This result demonstrates that the extraction of targeted aspects at the document level or the sentence level is more effective to narrow the range of the aspects than performing a full analysis at the corpus level. Moreover, the improvement becomes more significant when introducing latent features.
Summary 1
Overall, our HFTM model significantly outperforms the existing methods for capturing aspect-specific features. Specifically, it enhances the single-layer semantics between a targeted aspect and features by introducing the latent features with feature-to-feature semantics, which improves the feature coherence.
To answer
Aspect-specific features of a targeted aspect Plot on Douban dataset with a fixed feature number
Aspect-specific features of a targeted aspect Plot on Douban dataset with a fixed feature number
As presented in the results of Experiment 1, the feature coherence of full analysis-based methods (i.e., LDA and BTM) is worse than that of the targeted aspects oriented methods (i.e., T-LDA, T-BTM, and TTM). Therefore, in Experiment 2, we only compare the performance of HFTM and the three targeted aspects oriented methods (i.e., T-LDA, T-BTM, and TTM). Moreover, we also compare our model with the simplified version S-HFTM to demonstrate the necessity of the latent features.
First, all the compared methods capture the direct feature script with some keywords, such as “script” and “scenario”. Specifically, our HFTM model captures better results with more discriminative words, such as “scriptwriter” and “ending” (two important factors of a film’s plot quality). In addition, our model can alleviate the influence of noise by capturing the fewest unrelated words than those of the baselines. For example, the direct feature script captured by TTM contains the unrelated words “look” and “brother”. T-BTM groups more adjectives together, such as “complete”, “motivational”, and “fantastic”. However, these words are not coherent to the plot of a film and make the result too general and confusing. Among these methods, T-LDA captures the worst result with many noisy words, such as “dad” and “horrible”.
Second, HFTM improves the interpretability of the features by complementing the direct features with the latent features. Specifically, the box-office (i.e., commercial sales of a film) and the actors are two factors that are highly related to a film’s plot. The two latent features captured by HFTM are more semantically coherent to Plot than the feature photography captured by both TTM and T-BTM. This is mainly because a good plot can directly improve the commercial sales of a film, but it cannot directly affect the audiences’ reflection of photography. In contrast, the representation of the plot requires good actors and the actors’ acting skills, in turn, improves the commercial sales of a film. In terms of S-HFTM, it can capture the direct features, but it cannot complement the direct features with feature-to-feature semantics, leading to the captured features that cannot describe the targeted aspect from multiple angles.
Summary 2
Overall, our HFTM model can capture the more interpretable features for a targeted aspect by considering the feature-to-feature semantics. Comparing HFTM with TTM, which is a representative model for targeted aspect extraction, the experimental results demonstrate that the hierarchically formed features are more effective in describing the targeted aspect.
To answer
In this experiment, we set the number of features
Robustness comparison between our model and the baselines with the changing of the number of features 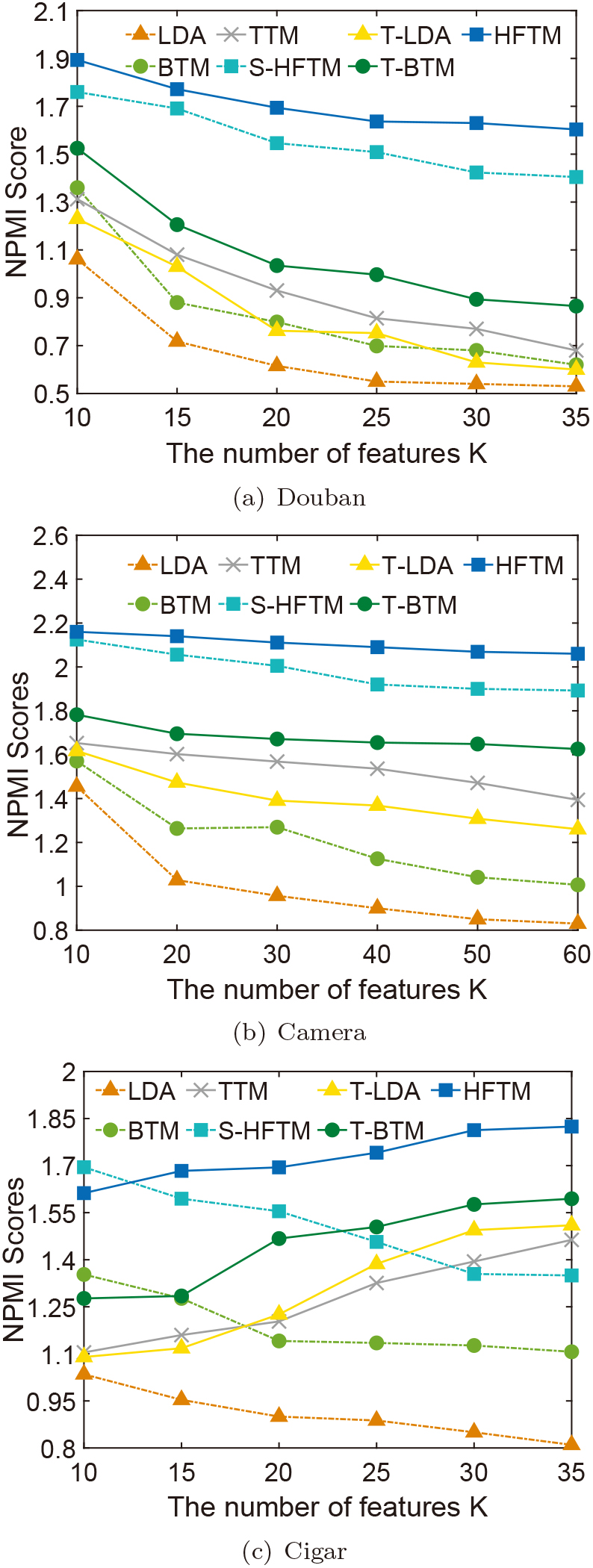
First, when
Second, we can see that, when the data sparsity increases (e.g., AvgLen is 54.99 on the Douban dataset drops to 5.49 on the Cigar dataset), the targeted aspects oriented models show an upward trend, while the full analysis-based models show a downward trend. Specifically, our HFTM model achieves the best robustness with the best NPMI, unless when
Summary 3
Overall, our HFTM model achieves the best robustness under the changes of two factors. In a few cases, the simplified model S-HFTM has slightly better performance. Nevertheless, the NPMIs of our model are more robust than the baselines, no matter with the less focus extent or with sparse data. The experimental results demonstrate the necessity of the latent features represented with co-occurrence word pairs.
To answer
Document classification performance of our model and the baselines with different number of features 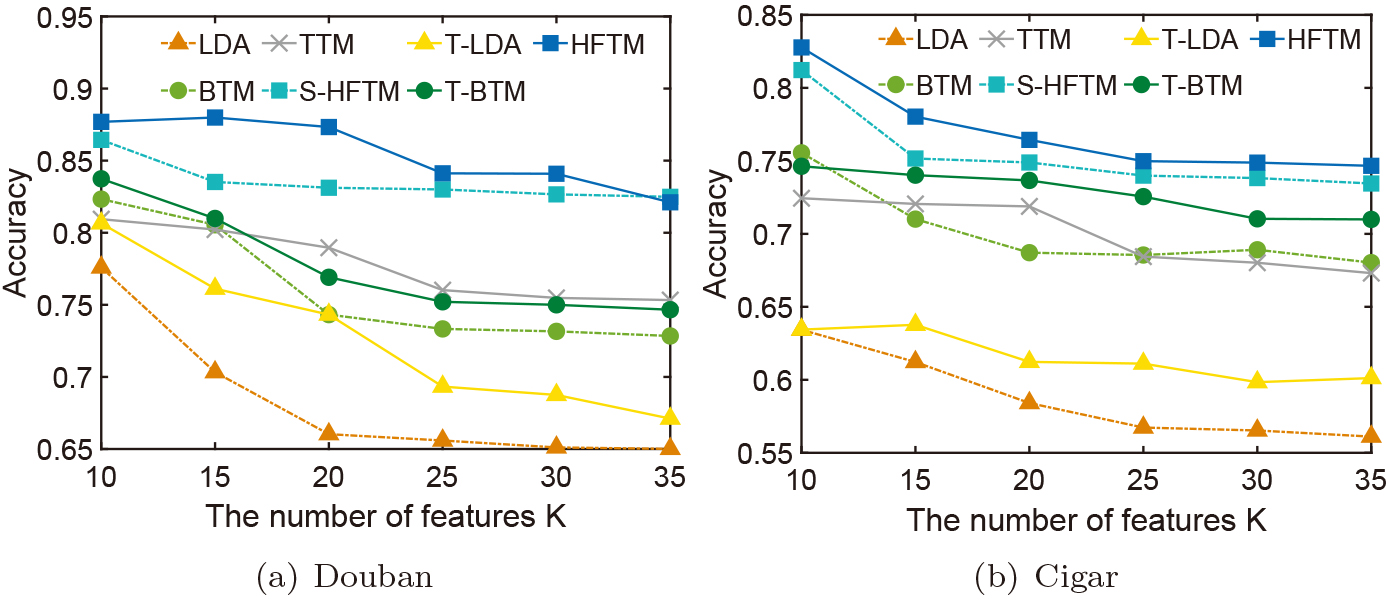
We have the following three observations: (1) On both datasets, our HFTM model achieves the best classification accuracy compared to the baselines. This result demonstrates the hierarchical features are more effective to describe the intrinsic semantics of a targeted aspect; (2) Compared with full analysis-based methods, the targeted aspects oriented methods have better performance. This is mainly because the category label of a document can be regarded as a target label of this document, which means that document-level modeling is more effective to capture this local feature; (3) Comparing the two datasets, Cigar consists of tweets while Doban consists of film reviews, which means that Cigar has a higher sparsity than Douban. It can be seen that both methods perform worse on the Cigar dataset than those on the Douban dataset. This result demonstrates that the updated method for each full analysis-based model can only improve the classification accuracy in a limited way. In other words, this result demonstrates the necessity of the latent features, which can complement the direct features to further improve classification accuracy.
Summary 4
Overall, our HFTM model is effective for the document classification task, which means the hierarchical features are useful for the real-world application. Especially when dealing with sparse data, the latent features represented with co-occurrence word pairs can enrich the local semantics to improve the classification accuracy.
In this paper, we have proposed a novel Hierarchical Features-based Topic Model (HFTM), which can capture aspect-specific features that exist in two layers in a hierarchy rooted by the targeted aspect. Specifically, the direct features in the upper layer pose target-to-feature semantics, while the latent features in the lower layer pose feature-to-feature semantics. The two types of features prevent the description of a targeted aspect from being too general or too special. Therefore, a person who browses the large-scale online reviews could effectively find the aspect-specific features coherent to his/her interest. The experiments conducted on three real-world datasets have demonstrated that our model is superior to the baselines for both aspect detection and document classification task.
In future work, we will consider improving our work with non-parametric sampling strategies to enable the method can suit more real-world scenarios. We are also interested in applying more personal information to generate an auxiliary user profile, like temporal behavior patterns.
Footnotes
Acknowledgments
This work has been supported by the National Key Research and Development Program of China under grant 2016YFB1000901, the National Natural Science Foundation of China under grant 91746209 and the Program for Changjiang Scholars and Innovative Research Team in University (PCSIRT) of the Ministry of Education of China under grant IRT17R32.