
Abstract
While conventional crime prediction methods rely on historical crime records and geographical information of the location of interest, we pursue the question of whether a social media context can provide socio-behavior “signals” for a crime prediction problem. The hypothesis is that crowd publicly available data in Twitter may include predictive variables which can indicate changes in crime rates without being only limited to the availability of historical crime records of specific locations. We developed a prediction model for crime trend prediction, where the objective is to employ Twitter content to predict crime rate directions in a prospective time-frame. The model employs content, sentiment, and topics, as the predictive indicators to infer the changes of crime indexes. Since our problem has a sequential order, we propose a temporal topic detection model to infer predictive topics over time. The main challenge of topic detection over time is information evolution, in which data are more related when they are close in time rather than further apart. Our proposed topic detection model builds a dynamic vocabulary to detect emerging topics rather than considering a vocabulary in bulk. We applied our model on data collected from Chicago for crime trend prediction using historical tweets. The results have revealed the correlation between features extracted from the content as content-based features and the crime trends. Moreover, the results indicate the feasibility of our proposed temporal topic detection model in identifying the most predictive features over time compared to a static model without time consideration. We also studied the contribution of socio-economic indexes and temporal features as auxiliary features. The experiment shows the content-based features improve the prediction performance significantly compared to the auxiliary features. Overall, the study provides a deep insight into the correlation between language and crime trends and the impact of social data as an extra resource in providing predictive indicators.
Keywords
Introduction
Crime, which can be defined as any unlawful act punishable by law, not only affects individuals who are involved but the society as a whole. In criminology, crime in all its facets occurs due to a set of situations known as the “social context” [1]. Crime and the risk of being victimized are variants that depend on the social context. Social context in general is viewed by two different dimensions; physical and social. The physical view refers to the specific geographical locations where crime is more common, such as locations with a higher population and a lower economic status or limited accessibility to education facilities [2]. However, social dimensions are concerned with socio-psychological factors such as individuals personality, communities, level of education, students behavior at school, or environment.
Crime analytics in general and crime prediction in specifics have drawn the attention of researchers to very diverse fields including law-enforcement and policing, social science, and data mining. The main objective in crime analytics is to help law enforcement agencies to more effectively allocate their scarce resources by predicting criminal movements which requires mining vast amounts of crime data, demographic and socio-economic information, and recently, social data.
Conventional crime prediction methods rely on historical socio-economic indexes and demographic information which are collected from the areas of concentrated crime, known as hot-spot maps, and applied to predict distributions of crime from different natures. However, there is some debate about that whether these maps indicate the concentration of all crime types [3]. As an example, taxicab robberies take place in different locations which are not always representative of high crime regions [3]. Another major issue is the lack of data for the prediction model. In conventional methods, historical criminal records must be available for prediction models. Overall, the main drawback of these methods is that they reduce the social context to historical crime records while ignoring socio-behavioral data of the community including both victims and criminals. In fact, the contextual data can be leveraged as a signal to predict upcoming incidents.
Nevertheless, observing the socio-behavioral data of a large society is a challenging task, whereas social media allows users to share their concerns, ideas, and daily activities. The content shared by the individuals when combined together provides a rich resource of naturally occurring data. Twitter, as one of the most popular social services, provides natural social data; users are more willing to express their opinions, interests, and activities without being worried about other opinions [4]. Therefore, Twitter provides content which is representative of its users’ social behavior. Numerous studies have explored extracting behavioral patterns from Twitter, including personality detection [5], language differences [6], and crowd behavior to monitor lifestyles [7].
In this study, we hypothesize that information captured from Twitter may provide socio-behavioral signals to predict crime rate directions as a “crime trend”. A future trend is predicted based on the information observed from the content of tweets posted earlier. We propose a prediction model which converts the trend prediction to a classification problem. In order to handle the lack of data in supervised learning, the model addresses automatic data annotation. In this model, the learning examples are aggregated tweets with different smoothing windows. The examples are labeled with the knowledge inferred from the problem (in our case, crime trend) in a prospective time-frame. In fact, the concept of data annotation is similar to other labeling approaches such as the classic lexicon-based approach. In this approach, polarities or strengths are inferred, based on a set of dictionaries. Thus inspired, in our prediction model we infer labels based on the objective trend. The content of collective individual users is labeled positive or negative if the trend goes up or down, respectively, in the prospective time-frame.
In contrast to the keyword based methods [8], our model does not exploit any topics or content that explicitly refer to criminal activities. In fact, filtering messages, based on the keywords, limits the study to the specific groups of users. Furthermore, searching targeted topics, keywords, or content, may be more descriptive than predictive, which means those targeted signals narrate stories that already happened rather than predict future events. For example, if we rely on searching terms such as “shooting” in tweets as a predictive signal, more likely we will collect tweets that report a recent shooting in the neighborhood. We believe relevant content posted in Twitter includes hidden signals that reflect users’ concerns, sentiments, and social events which are not necessarily presented with explicit terms. Moreover, our model captures collective patterns from the user crowd rather than a selected group of users [9]. We consider all observed users as a crowd, as opposed to user centric approaches, to take advantage of more content and to follow the theory that every user’s opinions and activities tend to have social impact on the community [10]. We explore the correlation, between content, sentiment, and topics as features, with the crime trend. However, there are some challenges in exploiting such aforementioned variables. Despite having problems with processing the content of tweets – abbreviation and the limited numbers of characters – time plays a crucial role in a topic detection model. In another meaning, information changes over time and new text documents are very likely to carry a new vocabulary. Therefore, the detected topics are shown to have birth and death over time [11, 12]. We develop a temporal model, which addresses temporary characteristics of observed terms. The idea is to extract emerging topics as the predictive features over time. In this regard, the proposed topic model builds a dynamic vocabulary, which is updated over time to infer emerging topics and fade away the vocabularies that are no longer popular.
The study aims to achieve the following objectives:
Ascertain the contribution of the content, voluntarily shared on Twitter, in a crime prediction model. Our findings could potentially contribute to the real decision support systems and facilitate research on understanding the crime causes. In addition, the proposed model can help decision makers in law enforcement agencies and police to efficiently manage their limited resources. Identify an efficient temporal prediction model which captures the most relevant features, such as temporal topics for prediction. Understanding how topics evolve over time is potentially important research in text analysis. It has applications for online topic detection models and time-dependent topic models. As an example, temporal topic detection of news documents where new and old documents are different in terms of word usage is very important to provide insight on how information is evolved and spread in the future. Explore the temporal effects of the content on crime directions to determine the lag between the predictive features and the crime trends. It helps socio-behaviour analysis investigators to understand the effects of social behaviour on different crime types with the delay related to each type. It is important to understand how the users’ social activities, interests, and opinions over time are related to illegal activities from different types.
The remainder of the paper is structured as follows: the next section provides a review of historical crime index prediction methods as well the recent studies in applying social context in crime prediction. Section 3 describes the dataset and how they were obtained. Section 4 discusses the prediction model along with features involved in the prediction. Section 5 introduces our temporal topic detection model for the trend prediction. Section 6 presents our experimental results. Finally, conclusions of the study with open problems are summarized in Section 7.
Crime analytics has significantly improved the ability of law enforcement to make decisions quickly and perform intelligent actions on different incidents. In fact, the advancement in knowledge discovery and the development in IT technologies, help law enforcement in analyzing past data and predicting future incidents. In crime analytics, technologies and applications use data from three different categories: historical activities of criminals, spatio-temporal information and, more recently, social media. The first set of applications are focused on criminals and their networks as they call “heat list” (Chicago predictive models in 2013). However, these applications to be prone to specific profiles such as a race which raises many issues. The next group applies spatio-temporal features such as location and the time of the day to predict future incidents. On the contrary, the third group does not target specific persons but focuses on the publicly available social media. For instance, FBI tools look for emerging threats in social media. However, the main issue is the validity of tracking significant words for the prediction of future incidents which requires deep analysis of the keywords that were included in the content.
However, conventional techniques, used by law enforcement agencies, are mostly based on generating hot-spot maps [3, 13], which are unique to a specific location and thus cannot be generalized. To overcome this problem, other techniques are proposed to incorporate background knowledge about spatial features, such as the distance to intersections and highways, schools and businesses, and other information about the neighborhood [14, 15]. Mohler et al. [16] proposed a framework that models future crimes as the consecutive to ones currently committed. Another line of research considers social fabric of the neighborhood as a key factor, which has an influence on criminal activities [17, 18]. The most recent works studied the predictive power of mobile network activities for the similar problem [19, 20]. Overall, the historical data which is needed for the mentioned models, is grouped into three main categories: the location of criminals (i.e. the locations they live and appear such as escape route and tourist regions), time and weather, and criminal networks.
As discussed earlier, the main characteristic of the crime prediction methods is to leverage historical data of high crime areas for the prediction model. Despite the fact that crimes mostly happen in high crime neighborhoods, the information in a hot-spot map of a small geographical size does not necessarily represent crime rates in bigger communities. Studies have shown that at the community level activities in hot-spot maps are not always representative of future crime rates [21]. The other challenge in using the hot-spot map approach is that it is location-specific.
As a result, crime prediction of a specific location cannot be easily generalized to the other locations. The location-specific characteristic of hot-spot map models implies that we need to collect enough data from the location of our interest. An alternative approach is to build a generalizable model from a type of data which is freely and publicly available and not restricted to a geographic neighborhood. The social media data has these characteristics in addition to its contextual features that can implicitly represent the socio-behavioral state of the public.
There have been enormous efforts in utilizing micro-blog data to predict real-time notifications, social conflicts, and public health risks [22, 23, 8]. Leveraging user-generated data reveals underlying patterns in different domains. Chen et al. [24] applied textual content of Twitter in the form of user language to detect name-calling harassment. Bollen et al. [25] also successfully implemented trend prediction in Twitter. In their work, individual behaviors is extracted from the content of daily tweets and utilized to predict socio-economic indexes. In another study, Hale et al. [26] studied validity of the language gap between different locations. In this research, the latent factors, extracted from user-generated content, are utilized to detect the communities.
Considering other social topics, far too little attention has been paid to the effect of on-line user generated data and its associations with crime prediction. Some studies have leveraged density of the data captured from social media in crime prediction. Bogomolov et al. [19] have explored the predictability of the data coming from mobile phones as defined as “human behavioral data” for crime prediction. Similarly, in another study [27], the frequency of violent mobile messages was compared to the residential population for capturing crime hot-spots. However, in both studies demographic information is exploited while contextual social data are not contributed in the prediction model.
The idea of applying social data for crime prediction can be observed in the works conducted by Wang et al. [9], Gerber [28], and Chen et al. [29]. The former is the first one to bring social media context into the problem of crime prediction. Wang et al. [9] extracted event-based topics from posted tweets to predict hit-and-run incidents in Charlottesville, Virginia. Although the approach is novel, the source of data is limited to a set of manually selected news agencies and neglects the vast amount of information contributed by the citizens. Also, the assumption that the content of these posts reflects the most recent local events is not always valid. Finally, it is unclear whether the same predictability will be observed when forecasting incidents, other than hit-and-runs. Gerber [28] recently utilized social media data to enhance Kernel Density Estimation (KDE) which is a technique widely adopted by the criminology community. Unlike previous authors, Gerber did not impose any restrictions on the source of tweets. He also assessed how much improvement can be achieved by adding topics extracted from Twitter for different crime categories. Similarly, Chen et al. [29] utilized the sentiment of Twitter data along with weather conditions in KDE for predicting the locations and time of theft. This study is limited to spatial information such as weather data for specific time and regions. In the mentioned studies, KDE as a location dependent technique cannot be easily generalized to other cities. There is also some type of crime which does not occur in the vicinity of previous incidents and the population of one area may change frequently [27].
While most of the research on crime prediction is limited to specific locations, crime types, communities and users, or focused on specific events, our proposed approach is one of the first crime prediction approaches that can be generalized. Furthermore, the proposed model learns the direction of changes in crime indexes rather than values. The importance of detecting crime trend direction is that policy makers and law enforcement agencies are mostly interested in determining if the crime in a neighborhood is declining or not. Another advantage of our approach compared to some of the previous research is that it works for a wide range of crime types. Our method does not target any specific communities, keywords, terms, hashtags, or events.
Dataset description
We collected Twitter data and crime rates from Chicago, Illinois between July 1, 2010 and November 30, 2013. Chicago has been targeted due to its importance as the third populous city in U.S as well as being among the top three cities which attracted the highest number of visitors during 2012.1
S. Department of Justice, FBI:
The criminal records were extracted from Chicago Data Portal.3
City of Chicago Data Portal:
Daily aggregated crime rates.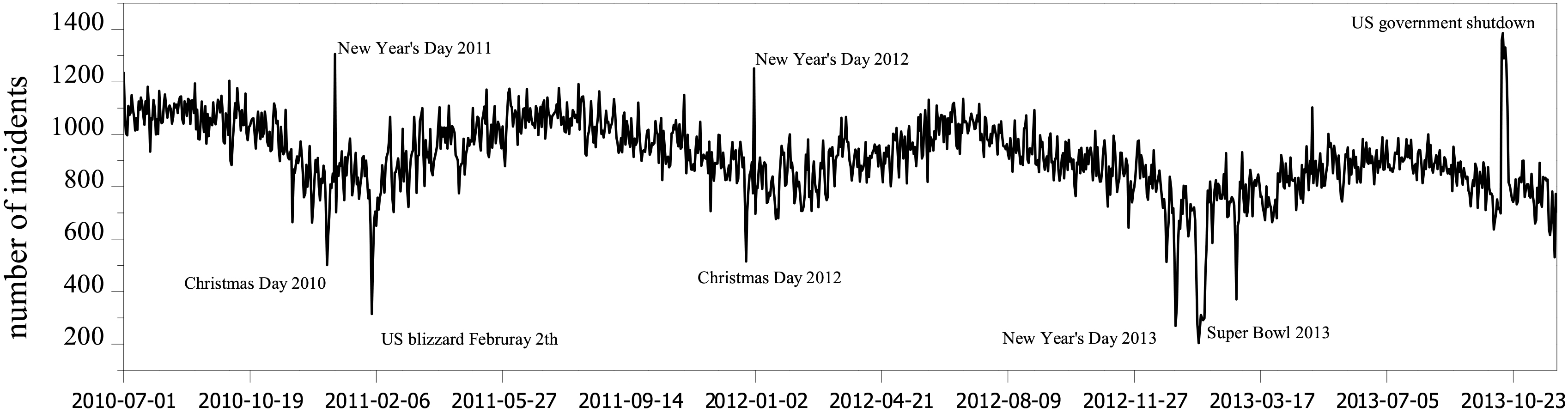
In order to retrieve the historical tweets, a set of Twitter users was collected using Coupling From The Past (CFTP) [31]. This approach guarantees a better convergence for perfect sampling of online social networks which is not biased toward active users. Historical timelines of the selected users were retrieved and restricted to the same timeframe – between July 1, 2010 and November 30, 2013. Daily statistics of the number of posts is presented in Fig. 2. The observed spikes in Twitter activity trend were corresponded with the important events in Chicago. The sharp spike in 2012 coincided with the presidential election in November. The high number of tweets in February 2013 is associated with Super Bowl Sunday period. The last spike is related to one day after Chicago Blackhawks won the Stanley Cup.
Daily number of tweets. 
Further, we also collected some other datasets such as unemployment rates4
Economic Research Federal:
The Weather Channel:
Crime index prediction, similar to any non-deterministic signal prediction such as stock price, is a difficult not impossible task. For example, predicting that 25 incidents of homeside will be occurred the next day seems impossible. On the other hand, the question “what direction does the crime trend may take tomorrow” may lead us to some extent to a possible answer. What we mean from “direction” is the sign of the change in signal at
In contrast to many classification problems, the proposed trend classification does not suffer from the lack of annotated data. Training data is generated by annotating available content as learning examples with knowledge inferred from the trend. This model infers the labels from environment, events, metadata or any background knowledge captured from the problem. The approach falls between semi-supervised learning and unsupervised learning. It is similar to semi-supervised learning in which they both employ unlabeled examples for training phase. However, available observations are fully unlabeled. In this work, the observations are represented with a set of features such as terms, sentiment, and temporal topics captured from Twitter posts.
Document generation
The problem of trend prediction is converted to a binary classification problem where the objective is to detect the direction of the target trend. Let
where
In our prediction model, the objective is to transform a prediction problem into a supervised classification task. In other words, we avoid to solve a multi-variable regression of a target variable (i.e. crime index in this research) and prefer a classification based on the categorical target variable (i.e. crime rate direction or change).
Let
where
The objective of the proposed method is to predict whether crime rate increased or decreased for the prospective time-frame. Therefore, a set of training data (
where in our target problem (crime trend prediction)
Terms as the features are referred to the unigram model without filtering any specific keywords. One might speculate that we must collect keywords to emphasize on the offensive language implying a rough context. Nevertheless, content is a rich data which contains valuable hidden variables including activities, topics of discussion, public interests, and sentiments, which might not be necessarily carried by the offensive language.
Sentiments are captured as another set of predictive features. Linguistic Inquiry and Word Count (LIWC) [32] was applied to extract polarity of five different sentiments consisting of “positive”, “negative”, “anxiety”, “anger” and “sad”. Sentiment features are estimated by the frequency of the words in each sentiment category. Let
Figure 3 demonstrates the daily scores of the different sentiments over the observation period. The figure indicates that the overall “negative” rates have increased during the past four years compared to the other sentiments.
Sentiment scores during the observation time.
Topic models are extensively applied to many text mining tasks either to indicate the similarities between two sets of documents [33] or to visualize high dimensional documents to a set of well-structured variables for exploration [34]. Nevertheless, with the increasing number of user-generated data in microblogs, there has been a great demand for topic models for learning meaningful patterns from data. Latent Dirichlet Allocation (LDA) [35] is the most popular topic model approach in identifying latent documents from the corpus where documents can be assigned to a set of semantic topics. LDA is well-studied in document clustering [36, 37], indicating the similarities between two sets of documents [33], finding trending topics [38], and event discover y [39]. In fact, in our study, LDA converts a high dimensional feature matrix to a low dimensional abstraction of documents which is important in text analytics. Although word order is not applied in LDA, due to the nature of our dataset (tweets), documents are short and more information can be inferred from the bag of words without considering the order. In addition, in contrast to deep analysis approaches such as word2vec [40], LDA leverages local context which captures many semantic relationships within a specific domain.
The list of notations employed in this section
The list of notations employed in this section
In LDA, inputs are a bag-of-words representation of documents and outputs consist of latent topics. A topic in LDA is a multinomial distribution of words in the vocabulary, while a document is a multinomial distribution of topics. In LDA, documents are given as a batch, which builds a static vocabulary for inferring topic distributions. However, in temporal analysis, where information changes over time and upcoming text documents most likely carry new terms, predefining a fixed vocabulary is not practical and raises many issues. However, in temporal analysis, where information changes over time and upcoming text documents most likely carry new terms, predefining a fixed vocabulary is not practical and raises many issues. First, topics have proven to have birth and death [11], when extracted from temporal text streams. Therefore, there is a significant need to have dynamic vocabularies over time to address emerging terms in topic inference and fade away vocabularies which are no longer popular. Second, in static LDA, insignificant topics may have a high chance to become involved. Because of having a broad range of documents (in our model, daily aggregation of conversations over a long period of time), topics consist of common words more likely generated if the documents are given as a single group for topic inference. Third, topics related to significant social events may not be captured. As an example in Fig. 2, a high number of tweets was observed during specific days which coincide with some events. If documents, collected during a long period of time, are given as a single batch, topics related to a specific event are less likely inferred due to the large number of words observed over time.
To tackle the aforementioned issues and to identify an efficient temporal topic model for trend prediction, the following characteristics have to be addressed:
A model where the size is not growing over time. Vocabulary is regenerated and terms previously seen but not in the future fade away. A model which can infer emerging topics over time. A model which is not converging in topics after a long period of time. Convergence can be prevented by training a new LDA model during each period of time rather than transferring learning parameters from the previously learned model. A model which can detect domain specific topics related to the significant events by regenerating vocabulary during different periods of time. A model which can handle sequential data and can be easily updated by introducing new documents.
A range of different approaches was proposed for time varying topic identification [41, 42]. In a temporal based topic model such as Online LDA [38], topics are extracted from the current time slice. Reassigning topics for new documents is performed by updating parameters based on the previous model, whereas we aim at detecting different sets of topics without the contribution of the previous model. Our proposed approach identifies different sets of topics in each time slice and the accumulation of detected temporal topics generates the main identified features for the prediction model. In this case, the temporal topic detection model constructs a dynamic vocabulary over time.
The generic procedure of the proposed temporal topic model is presented in Algorithm 1. In this model, an LDA model is trained separately for each time slice (partition) and a set of topics is inferred for each partition. A time slice or partition is a unit of time (a month, a year,
[t] Procedures of the temporal topic model[1]
Document partitioning.
Given all documents
In the temporal model, the LDA parameters are inferred as follows:
For each topic Draw For document Draw a distribution over topics, For each word in document Draw a topic T Draw a word
At the arrival of a new document for the next partition (
For each topic Draw For document Draw a distribution over topics, For each word in document Draw a topic T Draw a word
The process of topic inference will be continued by taking the next two partitions Eq. (5). In fact, by applying the new partitions, the dictionary is periodically updated over time and does not become too large.
In temporal topic detection, every two partitions are considered as heterogeneous sources since they were generated in different timestamps. Accordingly, the topics as the predictive variables (in our prediction model) derived from each partition are variant due to emerging information over time. Figure 5 presents the frequency of the top 2000 words (stemmed words) over two consecutive years (2012 and 2013). From the Fig. 5, we can also observe that the frequency of the words is variant over time. As an example “gun”, “energi”, and “basketball” were popular in 2012, while “cancer” and “campaign” were more popular terms in 2013. However, some words such as “data” and “develop” are constantly repeated over the two years with similar word frequencies.
In the temporal topic model, we also address topic evolution by ignoring topics repeated over time and selecting emerging topics in new partitions. This topic selection process allows us to select the topics which are diverse enough to represent emerging context and provides more predictive features. Topic selection is implemented in two steps. First, topic similarities are calculated and then, based on a predetermined threshold value, topics with a similarity smaller than the threshold are selected.
Word frequency over two different years. The second graph is a zoomed version of the first graph.
Similarities between topics captured in partition
where the distances are summed if a one to one linkage has low similarity. Distance is the distance function calculated based on the Jaccard
The next step is to rank and select novel topics. Topic novelty is measured by one of the two characteristics as follows: (i) a novel topic should have a different word distribution compared to the previous partition; or (ii) a novel topic should introduce emerging words to the dictionary.
So far, for each two partitions the asymmetric one-to-one corresponding distance between topics were measured. To select the best emerging topics, a hybrid score as a linear combination of their similarity measures are calculated. The rank is given to all topics in
After topic inference and selection, each document (
Since the topics were extracted based on the different partitions, we approached a normalization to standardize topic distribution. Each topic distribution is normalized with respect to the partition where the topic was inferred. As an example, if the topic was extracted from the partition
where
Training and test data are split into different sizes. In each experiment, the F-measure is presented for the holdout and progressive CV.
In this section, the experimental results are presented based on the contribution of different features. In the content-based model, the predictability of different smoothing windows was examined. In addition, a set of experiments was conducted to study the predictability of the content compared with auxiliary features. We also present how a prediction is different with the availability of historical data. For the topic model, experiments indicate that there is a need for an appropriate temporal model for detecting latent topics. It is shown how the topics are variant when inferred from the temporal model in terms of document-topic and term-topic matrices. Moreover, we also examined the predictability of topics detected by the temporal model compared with the batch model. Similar to the content-based model, the predictability over different crime types as well as different lags is presented.
For the classifier, we applied linearSVC which is the implementation of liblinear [43]. LinearSVC is faster compared with LinearSVM [44], since kernel transforms are not used and it scales better for large datasets in a linear classification problem. For the topic identification, Online LDA proposed by Hoffman et al. [45] was applied. Their model uses variational Bayes for posterior inference, which has shown to be faster for large dataset analysis. While the model identifies novel topics in each iteration and adds them to the total number of final topics, the number of topics (
The evaluation is processed by calculating the Macro-average F-measure with two different scenarios, holdout and progressive Cross-Validation (CV) [46]. The dataset is divided into two sets: training and test data. In the holdout scenario, training data is from 1 to
In order to illustrate the performance of the two different evaluation scenarios, dataset is split into training and test sets with different sizes. The results have been displayed in Fig. 6. The figure illustrates that in most cases, the progressive CV outperformed the holdout. In fact, for long term prediction, updating the training model is crucial. However, as shown in Fig. 6, when 10% of the test data is left, the holdout is sufficient enough to yield a decent performance and avoid the cost of re-training the classifier many times.
Content-based prediction
In content-based prediction, documents are texts with n-grams where
Smoothing temporal data
As discussed in Section 4, each temporal document (
The prediction performance based on different aggregation windows (
)
The prediction performance based on different aggregation windows (
Another set of experiments was conducted to measure the impact of historical data on prediction performance. This was done to find out if the crime trend becomes more predictable as we observe more historical data or not. Contrary to the previous experiments, the size of test data remains unchanged (August 2013 to November 2013), and the size of training data is started from 31 days of the latest historical data (July 2013) to predict test data. In the next experiment, the size of training date is increased by sliding training window 31 more days into the past. In fact, in each experiment, the size of training data is increased by involving more documents retrospectively. The experiments are repeated until all the historical data were involved. Figure 7 depicts the results with the different historical training windows for all the incidents. The highest predictability is obtained when whole historical data contributes to the prediction model. However, the result by the seventh months is comparable to the overall performance, while adding more historical contributes little.
Test data consist of documents during August, 2013 and November, 2013. First experiment applied the training data during July 2013. For the next experiment, the training window is increased by one more month retrospectively (June 2013 and July 2013). The experiments repeated until the whole historical training data was involved. The figure indicates the F-measure for each experiment. For some of the results, the period of contributed training data presented.
Although the main contribution of the paper is to study the correlation between content and crime trend, we also employ other auxiliary datasets which are widely applied in crime prediction. As discussed before, several studies have investigated the incorporation of socio-economic indexes and spatio-temporal features in crime prediction [47]. We also apply the other resources in our prediction model to understand the contribution of the content-based features in comparison to the other predictive variables. We selected a list of non-content features, which widely applied in crime prediction. The selected features are as follows:
We evaluated the performance of each feature as well as content-based features (n-gram) in predicting crime rate directions with lag up to 7. Figure 8 presents the performance of “day of week”, “number of tweets”, and “content” for predicting the increase and the decrease of crime rates. The results indicate that content-based features significantly improve the F-measure where the other features did not provide comparable results. The rest of the features such as “unemployment rate” and “events” could not achieve high performance compared to the other auxiliary features (in the best case, F-measure
Performance of different features for predicting crime rate directions.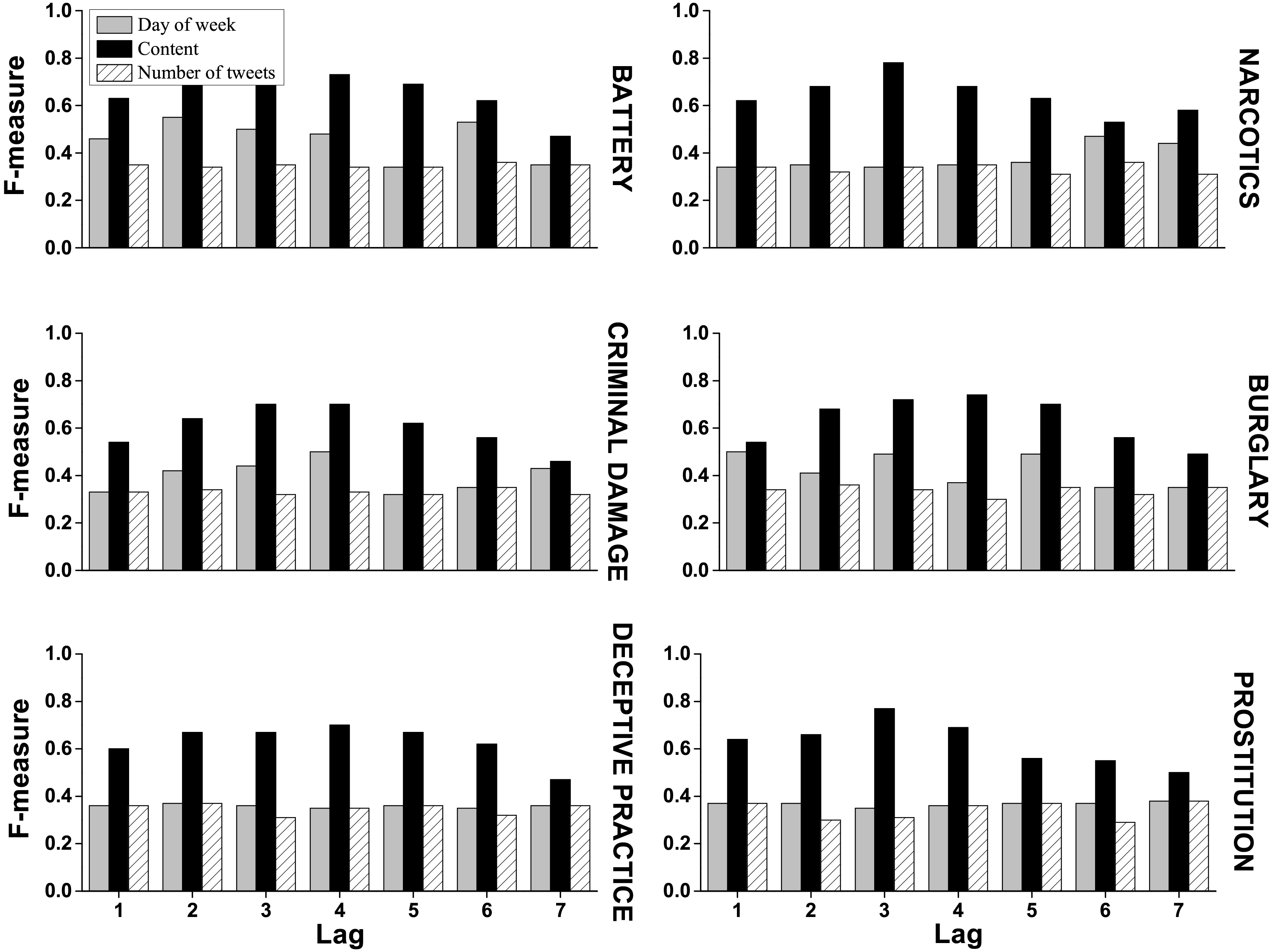
The most frequent terms distributions for the top 20 topics inferred by (a) baseline, and (b) temporal model.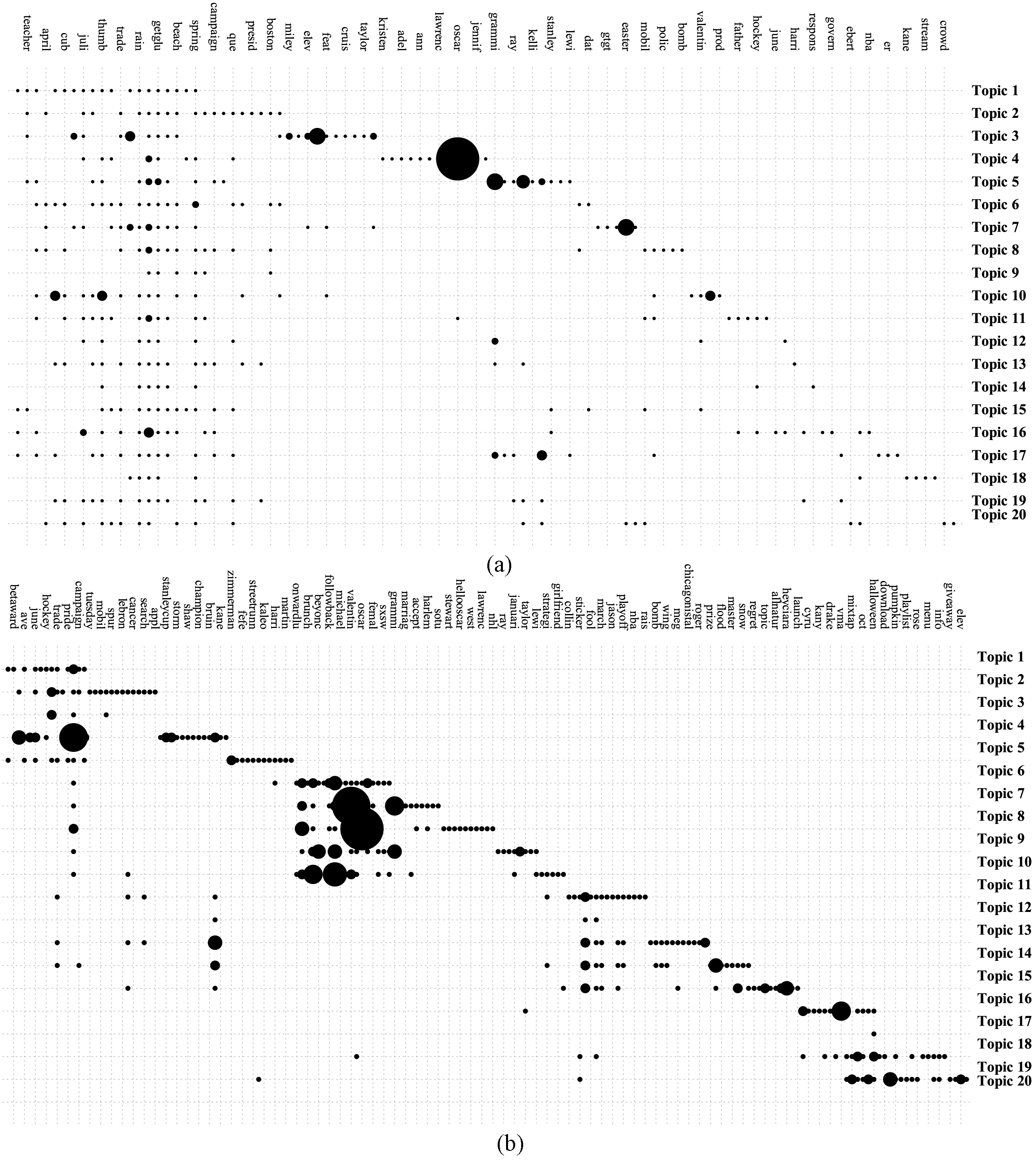
Topic distribution for each document based on different sizes of partition.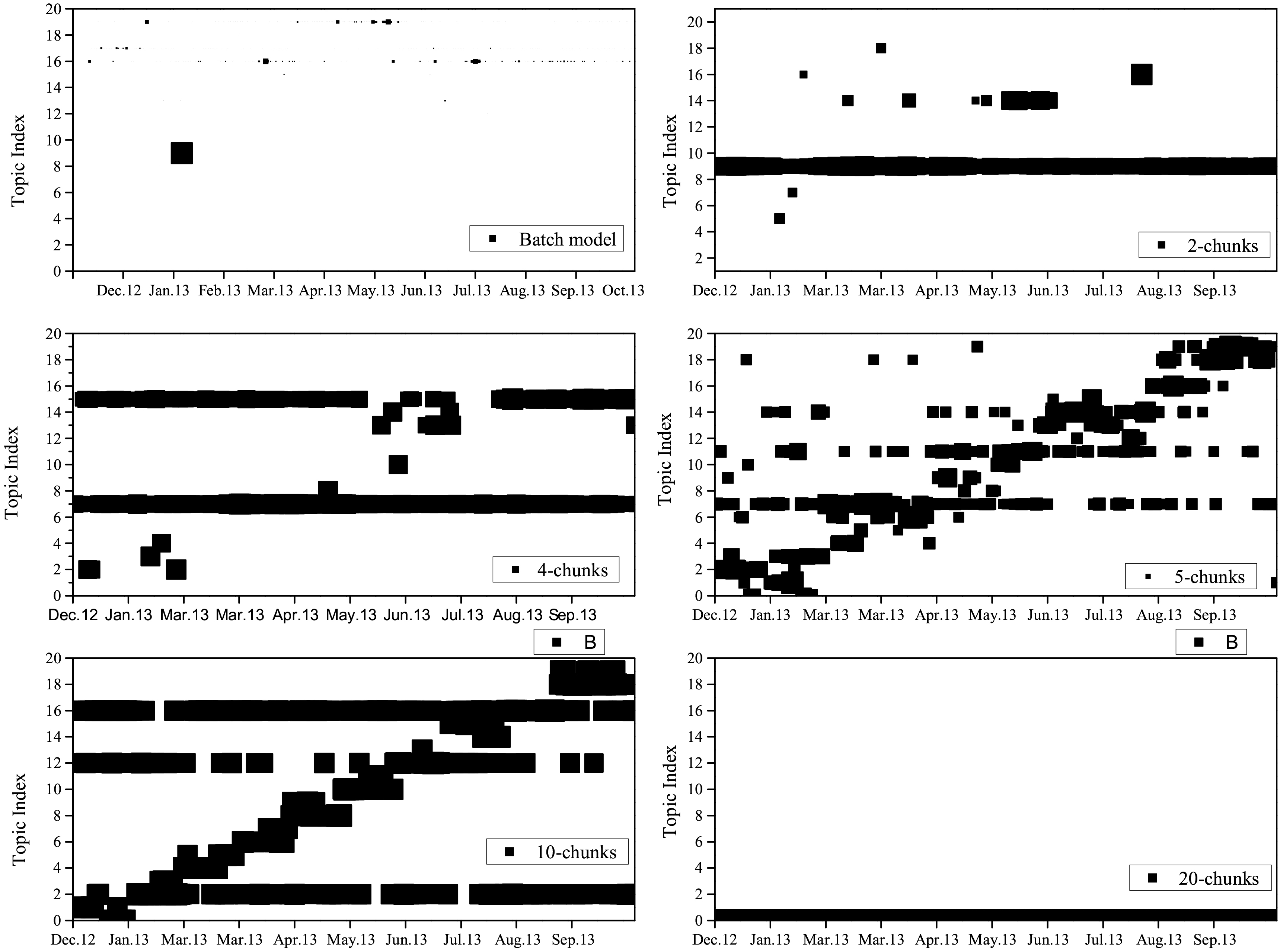
Unlike all the previous experiments which have been conducted using content-based features, this experiment is set up to test the predictability of sentiment features. The features are computed as explained before. A holdout evaluation has been applied to evaluate the predictions. The experiment is conducted on all the incidents for five individual sentiment variables and one incorporated sentiment. Then we repeated the experiment by adding sentiment variable to the content. The results indicated a low predictability for sentiments. In the best case, negative sentiment, the F-measure reached up to 0.55. In fact, the sentiment analysis was not able to perform better than the content-based features in any of the cases.
Prediction based on temporal topics
The characteristics of topics, extracted from temporal and batch models, are discussed. We also evaluate the predictability of topics as features in the proposed prediction model.
Characteristics of temporal topics
Identified topics from the temporal model have been compared with the baseline which is batch LDA without the time dimension. The comparison has been made in two different phases: first we compared how variant are the term distributions. Second we analyzed their differences in document-topic level.
Temporal topics as features
In order to present the predictability of the temporal topic models, the experiments were expanded to 22 different crime types. For the baseline model, a predefined number of topics was observed from training corpus. In this case, any topic shift is ignored. Whereas, the temporal topic model is concerned with topic shifts and time dimension as discussed before. Table 3 displays the best results for each individual crime type as well as the accumulated one. It shows that the temporal model, which detects novel topics, outperformed the baseline (in 17 cases) and content (n-gram). The performance was improved by the temporal topics to 21% higher than the baseline in the best predictable crime type (Burglary). Further analysis investigated the predictability of the proposed model for different lags.
F-measure of the best results for different crime types
F-measure of the best results for different crime types
Labeling approach for lag
The labeling approach based on (a) lag 
Holdout evaluation results for different crime types over 7 lags.
The predictability of the proposed model with temporal topics for different lags were examined. A set of test scenarios were implemented to examine the predictability of lags. Therefore, each document
Discussion and conclusions
In this paper, a prediction model for crime rate direction is presented based on mining posted tweets from a relevant geographic area. The conclusions and the findings of the paper are as follows: (i) the proposed method does not need any previously reported training data. In fact, the model annotates its own training data. In our prediction model, the labels are derived from a target signal (here, crime index) and then labels are assigned to the input data. (ii) Using the prediction model, the crime index prediction is reduced to a binary classification. The classifier predicts, given the input data, whether or not the crime index will be up (down) in future. (iii) In order to evaluate the predictability of user generated content in social media, no keywords and specific terms related to the crime were targeted. (iv) the lexicon-based sentiment analysis offered a poor or negligible prediction. (v) In addition to raw content and sentiment, the hidden topics of posted tweets were also extracted and employed as the features in the classifier model, which have shown to have the highest predictability compared to content and sentiment. Due to time varying nature of the content, a temporal topic model based on LDA was proposed and compared with the static LDA (batch). This model infers the hidden topics using a dynamic vocabulary. In fact, the vocabulary is regenerated in different time-frames to address information evolution for topic inference. The best topics, which are selected based on the diversity and novelty, are used as the predictive features in the prediction model.
We evaluated our method on crime trend prediction of Chicago, however, the model can be applied to other direction of various nature without relying on a specific location. Despite using fluctuated crime time series, the results offer a strong correlation between content and crime index direction. The content-based features significantly improve the results of prediction compared to other auxiliary variables. Particularly in case of using temporal topics, the results in most crime types suggests a strong correlation between the content of social media and direction of crime rates.
Although we do not track any specific keywords for our prediction model, sampling Twitter is important to avoid missing data. The sparsity of users’ activities plays a crucial role. The prediction model relies on the availability of content over time, which is affected by the absence of users’ tweets. In the future, we would like to propose a sampling approach in which we avoid missing of users’ activities as much as possible and collect Twitter data of users who are historically active. Overall, the study supported the importance of considering Twitter content as an extra data resource without suffering from the lack of training data. The predictability of some variables derived from Twitter content was successfully proven in this study, but further analysis on extracting other informative signals may be undertaken. We would like to analyze textual content semantically for better understanding the relationship between features. In this study, we were interested to present the effectiveness of the content-based model, but further analysis is needed to examine the incorporation of other socio-economic indexes, and geographical information that are correlated with criminal activities. In fact, the content can be applied as a valuable extra information along with other resources, which were shown to have correlation with different incidents.
Footnotes
Acknowledgments
This study was supported in part by the Natural Sciences and Engineering Research Council of Canada and Ontario Trillium Scholarship. The authors would like to thank Kenton White for providing Twitter dataset.