
Abstract
This paper use multinomial nave Bayes to improve multi-label classification methods in a number of ways. First, we use the value weighting method, a new fine-grained weighting method, to calculate the weights of the feature values. Second, we employ a co-training method to incorporate the dependencies among the class values. The results of our experiments show that the proposed approach outperforms other state-of-the-art methods.
Introduction
Correctly identifying documents according to particular categories remains a challenging task due to the vast amount of features in a given dataset. In particular, multi-label text classification problems have received a considerable amount of attention because this allows for each document to be associated with multiple class labels. In this paper, we explore the multi-label text classification problem, and there are two issues of relevance.
The first issue is to improve the performance of the multi-label text classification tasks. A multinomial nave Bayes (MNB) algorithm is the most common for multi-label text classification problems. A MNB classifier is an efficient, reliable text classifier, and many researchers usually regard it as a standard nave Bayes text classifier. However, their performance is not as good as some other learning methods, such as support vector machines and boosting. In this paper, we first investigate the reasons behind the poor performance of the MNB. Then, to improve the performance of the MNB method, we propose the value weighing method for MNB learning by implementing a new paradigm.
The second issue in multi-label classification is to effectively make use of the dependencies between class labels, and one common approach to process these class dependencies is to use the binary relevance method (BR) to treat each class as a separate binary classification problem [17]. When building the classifiers, BR does not directly model correlations that exist between labels in the training data, resulting in too many or too few predicted labels [17]. Apparently, this model ignores the dependencies between the labels. However, in many real-world tasks, labels are highly interdependent, and therefore the key to successful multi-label learning becomes is to effectively exploit the dependencies between different labels.
To capture the dependencies between labels, this paper presents a new method that uses the co-training method to learn two separate classifiers over the features and/or label sets. The co-training algorithm is used to capture the dependencies between the class labels, and doing so improves the classification performance. Furthermore, we also compare the performance of the proposed model, which combines the value of the weighting method and co-training with that of other state-of-the-art multi-label classifiers.
Related work
Text classifiers based on nave Bayes have been extensively studied in the literature. In particular, there has been much research on the use of the MNB model for text classification.
McCallum and Nigam [15] compared the classification performance between the multi-variate Bernoulli model and the multinomial model, and they showed that the multi-variate Bernoulli model performs well with small vocabulary sizes, but the multinomial model usually performs even better at larger vocabulary sizes.
Rennie et al. [18] introduced the complement nave Bayes (CNB) for skewed training data. CNB estimates the parameters using data from all classes except the currently estimated class. Furthermore they demonstrated that MNB can achieve better accuracy by adopting a TF-IDF representation, which is traditionally used in Information Retrieval.
Schneider [22] addressed the problems of a nave Bayesian text classifier and showed that they can be solved by some simple corrections, and he effectively removed duplicate words in a document to account for the burstiness phenomena in text.
Zhang and Zhou [27] defined the ML-kNN based on the kNN algorithm. They first identified the k nearest neighbors of the test instance where the label sets of its neighboring instances were obtained and then predicted the set of labels of the test instance by maximizing a posterior principle. In recent years, there has been a significant amount of study in multi-label classification problems, as motivated from emerging applications. As mentioned above, the key to successful multi-label learning is how to effectively exploit dependencies between the different labels.
Ghamrawi and McCallum [8] proposed two undirected graphical models that directly parameterize label dependencies in multi-label classification. The first is Collective Multi-Label classifier (CML), which jointly learns parameters for each pair of labels. The second is Collective Multi-Label with Features classifier (CMLF), which learns parameters for feature-label-label triples.
McCallum [16] defined a probabilistic generative model according to which, each label generates different words. Based on this model, a multi-label document is produced by a mixture of the word distributions of its labels.
Read et al. [17] introduced a classifier chain. The classifier chain is a binary relevance-based method that consists of binary classifiers linked in a chain, which overcomes predicted labels from BR that contain too many or too few labels or labels that never co-occur in practice.
M. Zhang and K. Zhang [28] tried Bayesian network structure to encode the conditional dependencies of the labels as well as the feature set. With the help of this network, multi-label learning is decomposed into a series of single-label classification problems.
Dembczynski et al. [6] distinguished two types of label dependences, namely conditional and marginal dependence. Subsequently, three scenarios in which one of these types of dependence may boost the predictive performance of a classifier were presented. In this regard, a close connection with loss of minimization was also established, showing that the benefit of exploiting label dependence also does not depend on the type of loss to be minimized.
Song and Lee [23] improved the performance of the multinomial nave Bayes classification of documents by using a new fine-grained weight method, called the value weighting method. Unlike traditional feature weighting methods that assign the same weight to word features, the fine-grained weight method assigns a different weight to each world frequency. They have thus shown that the new weighting method could significantly improve the performance of multinomial nave Bayes learning.
This paper is an extension of Song and Lee’s work [23]. In a multi-label classification problem, class labels are known not to be independent of each other. For example, if a certain document is classified into Sports, it is also likely to be classified into Entertainment. As such, these label dependencies are utilized in this paper by using the co-training method. While previous work in [23] improves multi-label classification of documents using a fine-grained weight method, this paper improves its performance even further by utilizing the interrelationships among class labels.
Two mutually disjoint feature sets, label value set and word feature set, are defined and label dependencies are represented as the features in the label value set. By combining fine-grained weighting and co-training, we could improve the performance of multi-label classification in documents.
Improving the performance of multinomial naïve Bayes in document classification tasks
In this paper, we assume that documents are generated according to a multinomial event model. Thus each document can be represented as a vector
where
MNB provides reasonable prediction performance and is easy to implement. However, it has some unrealistic assumptions that affect the overall performance of the classification. The first is that all features are equally important in MNB learning. Since this assumption is rarely true in real-world applications, the predictions provided by MNB are sometimes poor. The second is that the probabilities for word occurrence are independent of document length, and due to these assumptions, the parameters are clearly dominated by the word count coming from long documents. The performance of the MNB can thus be improved by mitigating these assumptions. The following section describes these issues in further detail.
Since the assumption that all features are equally important hardly holds true in real world applications, there have been some attempts to relax this assumption in machine learning methods. The feature weighting in nave Bayesian approaches is one method to ease the assumption of the independence, and it assigns a continuous value weight to each feature. The feature weighted nave Bayesian method involves a much larger search space than the feature selection, and it is generally known to improve the performance of nave Bayesian learning [12].
The MNB classification is a special form of feature weighted naïve Bayesian learning. The MNB classification with feature weighting is represented as follows.
The basic idea of feature weighting is that the more important a feature is, the higher its weight is. In feature weighting naïve Bayes, each word
In traditional MNB Eq. (1), the frequency (
Kim et al. [11] proposed a feature weighting scheme using information gain. The information gain for a word given a class, which becomes the weight of the word, is calculated as follows
where
In this paper, we think of a new method in which weights are assigned in a more fine-grained way, and we treat each occurrence of a word differently in terms of its importance. When a certain word appears for the first time in a document, it becomes very important with respect to the classification of the document. However, when the same word already appeared many times, say 100, the next occurrence has virtually no importance. The probability of the second occurrence is much higher than that of the first occurrence. Since MNB treats the significance of each occurrence of a word equally, the MNB model does not take this phenomenon into account. In this paper we will investigate whether assigning different weights to each word count can improve the performance of the classification.
In order to implement the fine-grained weighting, we first discretize the term frequencies of each word. The discretization task converts a continuous term frequency
We refer to this method as the value weighting method. As we can see, unlike the current feature weighting methods, the value weighting method calculates a weight for each word frequency bin. The value weighting method in MNB can be defined as follows
where
This section describes the method used to calculate the weights of the frequency bins. We use an information-theoretic method to assign the weights to each word frequency bin. The basic assumption of the value weighting method is that when a certain word frequency bin is observed, it gives a certain amount of information to the target word feature. The more information a word frequency bin provides to the target class, the more important the bin becomes. The critical part now is how to define or select a proper measure that can correctly measure the amount of information.
In this paper, the amount of information that a certain word frequency bin contains is defined as the difference between a priori probability distribution and a posteriori distribution of class label under the word frequency bin. We employ Kullback-Leibler measure (Kullback and Leibler, 1951) to calculate the difference between these distributions. The Kullback-Leibler measure (denoted as KL) for a word frequency bin
The formula
where
Binary relevance method (BR)
Many of the proposed methods tackle multi-label problems by first transforming a multi-label problem into a set of independent binary classification problems and then employing ranking or thresholding schemes for the overall multi-label classification.
One of them is the binary relevance method (BR), which treats each class as a separate binary classification problem. The BR method has several advantages. It is theoretically simple, intuitive and generally has low computational complexity, but it results in too many or too few predicted labels [17]. Apparently this model is ignoring the dependencies between the labels.
Generally for the BR model, suppose
where the classifier
An obvious drawback of such methods is that it ignores the interdependencies among multiple labels. In many applications, strong co-occurrences and interdependencies exist among multiple class labels. Capturing the dependencies among class labels during classification is thus expected to lead to an improvement in classification performance.
Many methods with this motivation have been proposed in the literature to exploit label correlations. Some approaches resort to external knowledge such as existing label hierarchies [3, 20, 4, 14] or label correlation matrices [10]. Some approaches exploit graphical models to capture the label dependencies and conduct structured classification, including those using Bayesian networks [26, 19]. These methods obviously have more expressive power to capture label dependencies than the BR method does. However, even though they require more complicated learning than binary classification models, they still can not fully exploit label dependencies due to the representational limitations of graphical models. Besides, it is almost impossible to find optimal instances of parameters in these graphical structures.
In this paper, we propose a new method to effectively utilize the dependencies of the labels. We employ a co-training method as a tool to capture the label dependencies. The co-training method is a semi-supervised learning technique that requires two views of the data. It assumes that each instance is described using two different feature sets providing different, complementary information of the instance.
The advantage of using co-training in multi-label classification is that the label dependencies can be effectively exploited by classifiers, and people have used a number of explicit tools to effectively represent dependencies between the different labels. However, in our co-training model, the class dependencies are implicitly represented as classification boundaries in a feature space as a result of learning. The dependencies are not explicitly explainable, but are treated implicitly in a form of black box. Since the proposed co-training method takes advantage of the expressive power of learning algorithms, the dependencies are represented in a more effective and fine-grained manner than the explicit expression tools.
Multi-label documents provide a natural environment for co-training classification learning. In this paper, we divide the features of multi-label documents into two different views. The first view consists of the traditional features generated from words in the documents while the second view we use is the class labels transformed into binary features. These feature sets are called Label Value Set (LVS) and Word Feature Set (WFS) respectively. Assuming
Notice that the way LVS is represented is different from that of traditional feature set. Each feature in LSV is actually a value (label) of the feature (class). In other words, each of these label values becomes a separate binary feature. For example, suppose there are eight possible labels, and a document is multi-classified as
The second feature set of the co-training method is called the Word Feature Set (WFS), which is defined as follows.
WFS consists of two parts: (1) the word frequency bins derived from words in the document, and (2) Label Value Set. As described in the previous section, the frequency term of each word is converted into word frequency bin, and we then apply the value weighting method to multinomial nave Bayes learning. These word frequency bins are the first component of WFS.
There are subtle differences between traditional co-training and the co-training proposed in this paper. The main difference is that in our co-training method, the word feature set (WFS) contains the second feature set (LVS). In a traditional co-training setting, the features are divided into two disjoint feature sets. However, in our co-training model, the two feature sets are not completely disjoint with each other because the Label Value Set
LVS is included in WFS for the following reasons. In traditional co-training, unlabeled data plays the role of the messenger passing predicted label information from one classifier to another, and different classifiers teach each other by using unlabeled data. The main topic of this paper is not about semi-supervised learning, and thus we assume there no unlabeled data are available. Therefore, we need a kind of messenger that transfers the learning results from one classifier to another. LVS plays the role of intermediate unlabeled data as a messenger. When one classifier classifies a document with multiple labels, the results are stored in LVS and are fed to the other classifier as features.
Building base classifiers
There are two classifiers in our co-training model: Dependency Classifier (DC) and Feature Classifier (FC).
Dependency Classifier, denoted
where
The value weighted MNB described in Eq. (3) is used again as the basic algorithm for a Dependency Classifier. Since Eq. (3) is based on the value weighting method, we need to develop a new formula to calculate the weight of the class value. A class takes on a binary value, and each binary class value might have different importance with respect to the target class due to the class dependencies. The approach that we used to calculate the weights of the feature values is used again to calculate the class labels. The importance of class value
We can apply the same value weighting method used in the weights of word frequency bins to calculate the weight of the class value by using the KL measure as follows
where
The second classifier in the modified co-training method is the Feature Classifier (FC). The Feature Classifier is also built based on the value weighted MNB. For each of class label
where
Notice that the first two elements of FC are identical to the formula of DC itself, and thus the prediction results of DC are automatically forwarded to FC.
The modified co-training method first predicts the labels by using a BR classifier
Figure 1 illustrates the co-training process with an example.
Experimental evaluation
In order to evaluate the performance of each proposed method, we divide the experiment into two subsections. First, the performance of the value weighting method is compared to that of the MNB. Second, we compare co-training with other multi-label algorithms.
Effect of value weighting method
In this section, we describe how we conducted the experiments to measure the effects of the value weighting method. We then present the empirical results obtained using these methods. We used four text datasets to conduct our empirical text classification study. All these datasets have been widely used in text classification and are publicly available. Table 1 provides a brief description of each dataset.
The “New3” [25] dataset contains a collection of news stories and “Ohsumed” [25] is a dataset of medical articles. The “Amazon” [7] dataset is derived from the customer reviews in the Amazon Commerce Website for authorship identification. “CNAE-9” [7] is a dataset of free text business descriptions of Brazilian companies. The continuous features in datasets were discretized using equal distance method with 5 bins.
Test datasets for the value weighting method
Test datasets for the value weighting method
Example of the co-training process.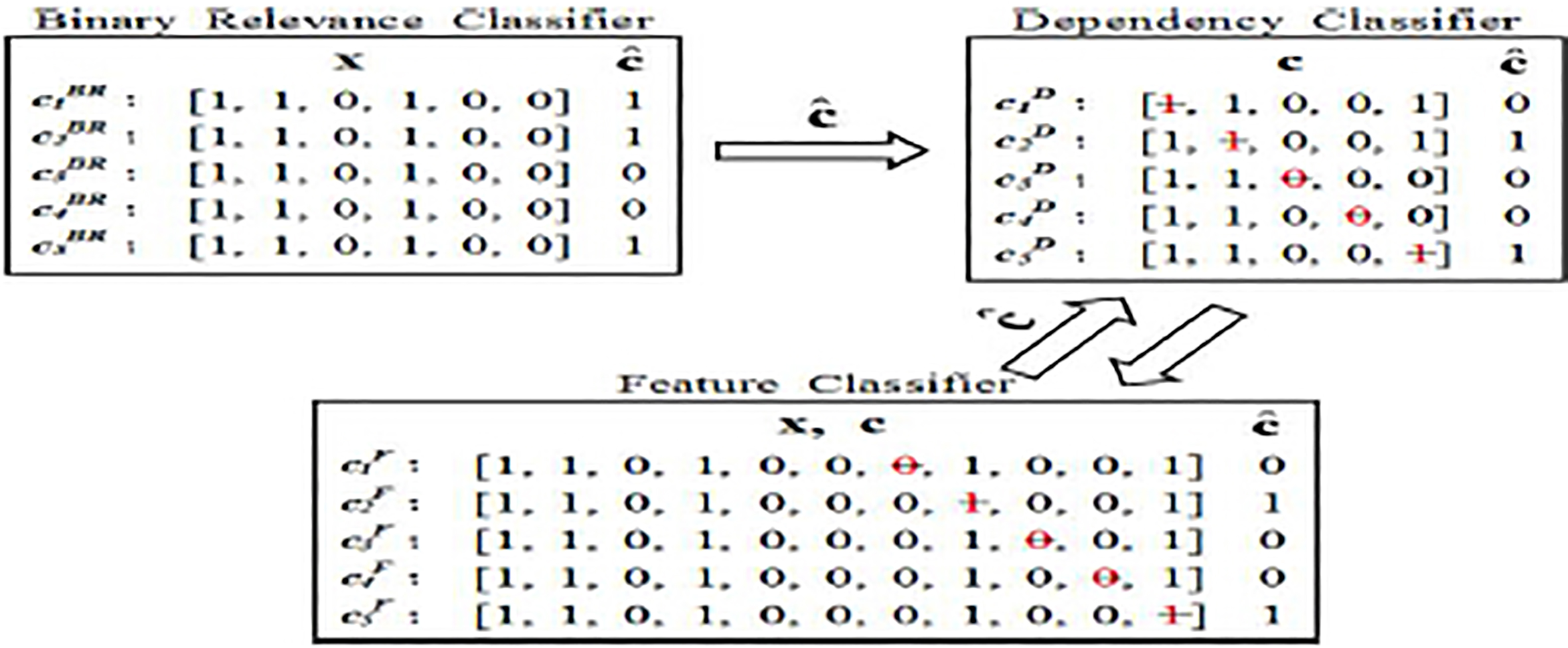
Single-label classification was conducted in this experiment. So the value weighting method (MNB-VW) was used without employing the co-training model. The proposed MNB-VW is compared with regular naïve Bayes (NB) and multinomial naïve Bayes (MNB).
We used Weka software to run NB and MNB. Even though MNB-VW is an iterative method, its computational complexity was not high and approached its optimal weight values quickly. In most cases, the algorithm converged within 10–20 iterations.
Accuracies of the methods
Table 2 shows the results of the accuracies of these methods. The numbers with bold letters mean they shows the best accuracy among NB, MNB, and MNBVW. The MNB-VW shows the best performance in all 3 cases, and it always shows better performance than the NB method. These results clearly indicate that assigning weights to each word frequency bin could improve the performance of the classification task of the nave Bayesian during document classification.
The average value weights used in above experiment are shown in Fig. 2. We calculated the average value for all features in each dataset, and the number of bins is 5, so all features have 5 discretized word frequency bins.
Average value weights of each dataset.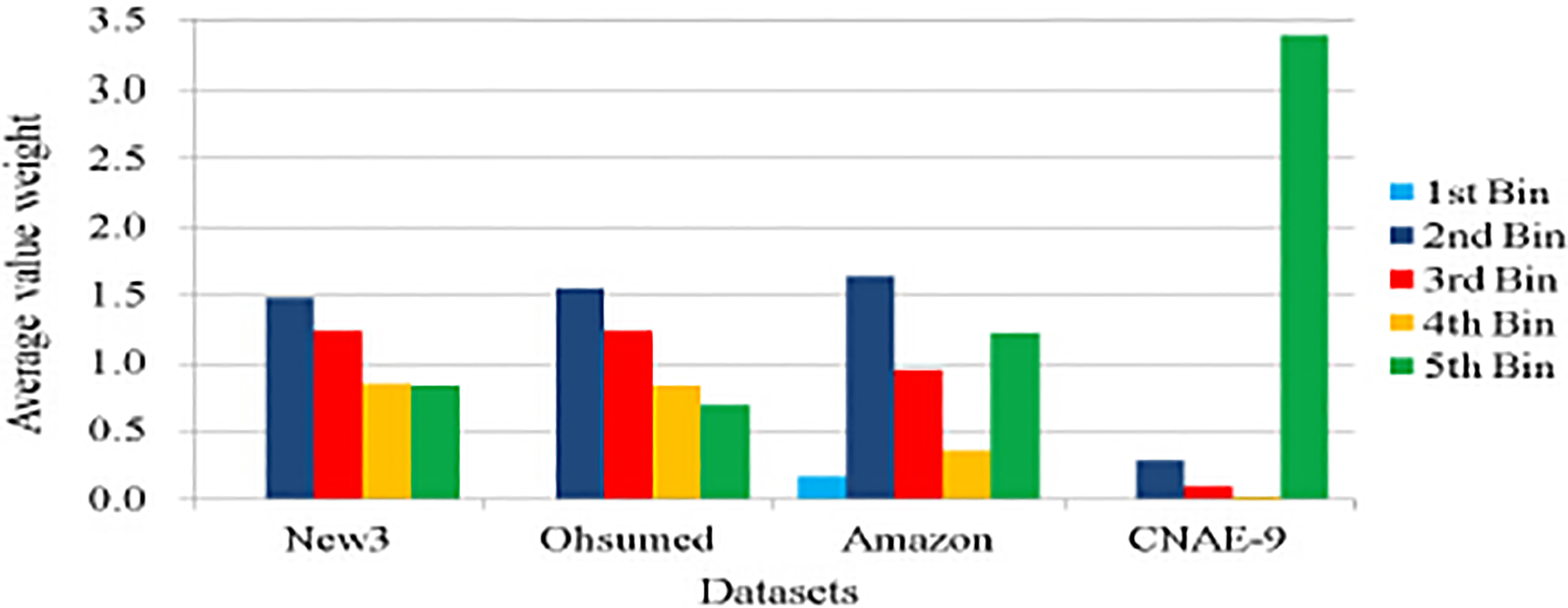
When the term frequency is zero, it is discretized into the first word frequency bin. The remaining term frequencies are discretized by equal distance, and the discretized values are assigned in order of frequency. The highest term frequencies are discretized to the fifth word frequency bin.
Figure 2 shows that the second word frequency bin has the highest average weight except for the CNAE-9 dataset and that the low word frequency bins generally have a higher weight than the high word frequency bins. The CNAE-9 dataset got an opposite result since it has abnormally high term frequencies.
This means that higher weights are generally assigned to low term frequencies. Actually, the event for which a word occurs less frequently has more significance than the event for which a word occurs several more times.
The proposed co-training method was tested on 5 different benchmark multi-label text datasets [13]. All class variables of the datasets are binary. The features of the Eur-Lex and RCV1 datasets have numeric variables, and the features of the rest of the datasets are binary.
The numeric features in the datasets were discretized using the equal distance method, and the bin number of the Eur-Lex dataset is 6 while the bin number of the RCV1 dataset is 3. Since the term frequency intervals of each dataset are different, different bin numbers are used. All datasets are originally partitioned into training and testing datasets. The details of the datasets are summarized in Table 3.
Multi-label text datasets used in the experiments
Multi-label text datasets used in the experiments
We have considered four classifiers: binary relevance (BR), classifier chain (CC) [17], ensembled classifier chain (ECC) [17], and value weighting with co-training (MNB-VWCO).
The classifiers chain (CC) is multi-label classification method in a way to overcome the label independence assumption of BR. CC consists of L classifiers linked in a chain, such that each classifier incorporates the class predicted by the previous classifiers as additional features. The ensemble of the classifier chain (ECC) is a method that combines several classifier chains by changing the order of the labels. Using the previously predicted labels for additional features is very similar to our co-training model, so we are trying to compare the co-training algorithm with CC and ECC.
Since all algorithms are meta-learners, we used MNB-VW as a base learner for all of them. CC and ECC are implemented according to [17], with minor exceptions. The permutations of the labels in all chain-based algorithms have been generated at random, and the ensemble size in ECC was set to 10 [5]. The computational complexity of the algorithm was not high, and in most cases, the algorithm reached final sates within 10–15 iterations.
For comparison purposes, we used three different multi-label performance measures [17]:
Hamming Loss : Each label assignment is a separate binary evaluation
0/1 Loss: Any predicted set of labels hatc must match the true set of labels
Accuracy: Godbole and Sarawagi [9] introduced a multi-label accuracy measure
The tests were performed with original train and test dataset splits. For each data set, we provide a ranking of the algorithms and results are shown in Table 4.
Multi-label text datasets used in the experiments
As can be seen from this table, similar results are derived in each evaluation. BR is the only algorithm that does not incorporate the label dependencies, so it is not surprising that BR under-performed compared to the others. ECC is an extended version of CC that overcomes the order dependency problem. So it is also reasonable to expect that ECC has better performance than CC. The major outcome of the experiment is that the MNB-VWCO algorithm performs best, and the result clearly indicates that MNB-VWCO can more efficiently incorporate the label dependencies than CC or ECC.
In MNB-VWCO, The average rank of Hamming loss is better than the other evaluation measures. The Hamming loss is a label-based evaluation measure but not a label set-based one. Since MNB-VWCO deals with the multiple binary classification problem, our algorithm is well-suited for the Hamming loss. In reverse, 0/1 loss is a label set-based evaluation measure and has the lowest average rank.
In this paper, the multinomial nave Bayes algorithm is used to improve multilabel document classification in a number of ways. The value weighting method, a new weighting method that is further fine-grained, is proposed for multinomial nave Bayesian learning, and unlike traditional weighting methods, it assigns a different weight to each feature value. We also have employed a new co-training method to incorporate the dependencies among the class values.
The results of the experiment show that both value weighting and modified co-training methods are successful and show better performance in most cases than their counterpart algorithms. As a result, this work suggests that we could improve the performance of multinomial nave Bayes in multi-label text classification by using value weighting and co-training approaches.
For the future, it will also be interesting to use two different classifiers in the co-training method as the base classifier. In that case, each classifier in this paper can read the entire feature space and thus the performance of each classifier might increase accordingly. Another future work is that we employ a Bayesian Network as the base classifier of the Dependency Classifier. By using the Baysian Network as a Dependency Classifier (DC), DC has more expressive power and thus increases the performance of the Dependency Classifier.
Footnotes
Acknowledgments
This work was supported by the Korea Research Foundation (KRF) grant funded by the Korea government (MEST) (No. 2017R1A2A2A05069662) and by the Technology Innovation Program: Industrial Strategic Technology Development Program (No: 11073162) funded By the Ministry of Trade, Industry & Energy (MOTIE, Korea).