Data uncertainty is inherent in many real-world applications such as sensor data monitoring and mobile tracking. Mining sequential patterns from uncertain/inaccurate data, such as sensor readings and GPS trajectories, is important to discover hidden knowledge in such applications. This paper addresses the problem of pattern matching with periodical wildcards for uncertain sequences. We present a dynamic programming approach, called CoDP, to compute the exact probability that a pattern is a subsequence of an uncertain sequence , and this approach can be further applied to substring matching for uncertain sequences. The efficiency and effectiveness of our algorithm have been verified through extensive experiments on both real and synthetic data.
The problem of pattern matching with wildcards in certain sequences has attracted extensive attention in the research community due to its wide spectrum of real life applications, such as bioinformatics [1, 2] and text mining [3]. In bioinformatics, for example, TATA often occurs after the CAATCT with 30–50 wildcards in DNA sequences. In text mining [3], it is very natural to consider sequential patterns with wildcards where patterns are composed of words that can capture semantic relations between words.
Data uncertainty is inherent in many real-world applications such as sensor data monitoring [4], RFID localization [5] and location-based services [6]. It can be caused by various factors including data collection equipment errors, precision limitations, data sampling errors, and transmission errors.
As a result, attention has been drawn to uncertain data mining in recent research. A comprehensive survey of the techniques on uncertain data mining can be found in [7]. However, most of this work focused on uncertainty for itemset data, rather than the uncertainty for sequence data.
In this paper, we tackle the problem of pattern matching with wildcards for uncertain sequences. Our main contribution is the development of an efficient algorithm to compute the following pattern matching query: Given a certain sequence with wildcard gaps and an uncertain sequence , what is the probability that is a subsequence of ? Table 1 is an example of uncertain sequence . Each element of the set {A, C, G, T} has a probability of existence at every position of sequence , and the sum of the probability is one at each column of the matrix. If there is a sequence with wildcard gaps, for example, A[1,3]C[1,3]G, our goal is to calculate the probability that ACG is a subsequence of , and the minimum and maximum numbers that a wildcard can match between each element of should be one and three respectively.
An uncertain sequence of length 8
s[1]
s[2]
s[3]
s[4]
s[5]
s[6]
s[7]
s[8]
A
0.12
0.8
0.1
0.2
0.3
0.7
0.04
0.32
C
0.52
0.04
0.2
0.4
0.2
0.06
0.16
0.4
G
0.16
0.04
0.3
0.2
0.4
0.04
0.3
0.08
T
0.2
0.12
0.4
0.2
0.1
0.2
0.5
0.2
Matching a subsequence query pattern with periodical wildcard gaps in an uncertain sequence poses several challenges. (1) To compute the probability that is a subsequence of an uncertain sequence , a naive technique is to enumerate all the possible worlds. But the number of possible worlds will increase exponentially when the length of sequence increases. For example, the number of possible worlds of the sequence in Table 1 is 4 65536. (2) There are some algorithms about pattern matching in uncertain sequences, where unlimited gaps are allowed. And there are algorithms about substring matching in uncertain sequences, which requires that no gaps are allowed within the match. We think pattern matching with periodical wildcards in uncertain sequences are more complex than the above two cases, where gaps are limited. Specifically, we make the following contributions:
To our knowledge, this is the first work that attempts to solve the problem of pattern matching with periodical wildcards in uncertain sequences, the techniques of which are successfully used in a DNA application.
We present a dynamic programming approach, called CoDP, to compute the probability that is a subsequence of , and the time complexity decreases significantly compared with the naive approach.
Our algorithm can also calculate the substring matching probability in uncertain sequences with an arbitrary alphabet, which is verified by extensive experiments.
The rest of the paper is organized as follows: We first discuss related work in Section 2. Then we introduce the preliminaries of our work in Section 3. We give the formal definition of our model and describe our proposed approach CoDP in Section 4. Then we sketch an extension that leverages our solution for computing the subsequence matching probability in Section 5. In order to evaluate the effectiveness of our model, we conduct experiments in Section 6 and the experimental results show our model outperforms the state-of-the-art baselines. Finally, we conclude the paper and describe the future work in Section 7.
Related work
The problem of sequential pattern matching with wildcards has been well studied in the literature in the context of deterministic data, and many algorithms have been proposed to solve this problem. The work proposed in [8] focused on pattern matching with wildcards, gap-length constraints and the one-off condition. The authors proposed a graph structure WON-Net to obtain all candidate matching solutions, and designed the WOW algorithm with the weighted centralization measure based on nodes’ centrality-degrees. Xie et al. [9] proposed an efficient algorithm SPMW for sequential pattern mining with wildcards. And they proposed a new data structure level instance graph to represent all instances of a pattern with the gap constraint. Wu et al. [10] proposed two novel algorithms, MAPB (Mining sequentiAl Pattern using incomplete Nettree with Breadth first search) and MAPD (Mining sequentiAl Pattern using incomplete Nettree with Depth first search), to mine sequential patterns with periodic wildcard gaps. A more recent study [11] addressed a more general strict approximate pattern matching with Hamming distance, named SAP, and proposed an effective online algorithm named SETA, based on the subnettree structure (a Nettree is an extension of a tree with multi-parents and multi-roots).
In the context of uncertain databases, frequent itemset mining and sequential pattern mining are two of the most important pattern mining problems studied. For the problem of frequent itemset mining, earlier work often used expected support to measure pattern frequency [12, 13]. However, expected support based approaches do not consider probability distributions, that is, they are not able to give any probabilistic guarantees. In fact, an itemset whose expected support is greater than a threshold may have a low probability of having a support greater than this threshold. As a result, recent research focuses more on using probability measurements [14, 15, 16, 17]. Wang et al. [16] proposed the definition, probabilistic prevalent colocations, trying to find all the colocations that are likely to be prevalent in a randomly generated possible world. First, they proposed pruning strategies for candidates to reduce the amount of computation of the probabilistic participation index values. Next, they designed an improved dynamic programming algorithm for identifying candidates. Lee and Yun [17] proposed a List-based uncertain frequent pattern mining algorithm (LUNA), which is an efficient and exact method for mining uncertain frequent patterns based on novel data structures and mining techniques that can guarantee the correctness of the mining results without any false positives.
Unfortunately, there is limited work on the problem of sequential pattern mining on uncertain data. Zhao et al. [18] established two uncertain sequence data models abstracted from many real-life applications involving uncertain sequence data, and developed two algorithms, collectively called U-PrefixSpan, for probabilistically frequent sequential patterns mining. Work by Li et al. [19] focused on the core problem of computing substring matching probability in uncertain sequences and proposed a dynamic programming algorithm for this task. A study in [20] proposed a semantics called (k, )-matching queries and devised techniques for indexing and verification. All the work allowed either unlimited gaps or no gaps. To the best of our knowledge, currently there is no existing work about pattern matching with periodical wildcards in uncertain sequences.
Preliminaries
Let be a sequence that contains characters chosen from a finite alphabet . Let be a pattern with wildcards, where a wildcard can match any character of alphabet . The pattern contains m () characters chosen from the same alphabet . The gap represents the local length constraint of wildcards between and . For example, matches any characters with the length 9, 10, 11, or 12 between and .
Definition 1. The pattern is called a subsequence of , iff there exists an occurrence of in . An occurrence is a position sequence of in with the gap constraints. There exists at position in , , . It has to satisfy the Gap-Length Constraints (local length constraints) as follows:
The pattern may match in the sequence in several places. If is a subsequence of , it should match in in at least one place. In this paper, we tackle the problem of pattern matching in uncertain sequences. The significant difference between uncertain sequences and certain ones is that we do not definitely know whether a character appears in or not, that is to say, the occurrence of the character of is probabilistic.
Definition 2. An uncertain sequence is a sequence that contains n characters chosen from a finite alphabet . Each character () in is associated with a probability , which indicates the likelihood that character is present in . The sequence can be expressed by a probability matrix with the size of , where , .
To interpret sequence uncertainty, the Possible World Semantics (or PWS in short) is often used [21]. Conceptually, a sequence is viewed as a set of deterministic instances (called possible worlds), each of which contains a set of characters. For example, a possible world for Table 2a consists of the characters {AACA}, existing with a probability of 0.1 0.9 0.95 1 0.0855. Any query evaluation algorithm for a probabilistic sequence has to be correct under PWS. That is, the results produced by the algorithm should be the same as if the query is evaluated on every possible world [21].
Although PWS is intuitive and useful, evaluating queries under this notion is costly. This is because a probabilistic sequence has an exponential number of possible worlds. For example, length of the uncertain sequence in Table 2a is 4, and it has 4 64 possible worlds at most. Except for the possible world, whose possibility is zero, the number of possible worlds of the uncertain sequence in Table 2a is 4 2 2 16, and the possible worlds are enumerated in Table 2b. Performing query evaluation or data mining under PWS can thus be technically challenging.
Definition 3. The probability that a pattern with periodical wildcards is a subsequence of an uncertain sequence is called subsequence matching probability, and it is denoted as .
Our task is to calculate the subsequence matching probability, and we will describe our algorithm in Section 4.
An uncertain sequence and its possible worlds
(a): An uncertain sequence of length 4
S[1]
S[2]
S[3]
S[4]
A
0.1
0.9
0
1
C
0.3
0
0.95
0
G
0.1
0
0
0
T
0.5
0.1
0.05
0
(b): Possible worlds of the uncertain sequence
W
Characters in w
Prob.
W
Characters in w
Prob.
w1
AACA
0.0855
w9
GACA
0.0855
w2
AATA
0.0045
w10
GATA
0.0045
w3
ATCA
0.0095
w11
GTCA
0.0095
w4
ATTA
0.0005
w12
GTTA
0.0005
w5
CACA
0.2565
w13
TACA
0.4275
w6
CATA
0.0135
w14
TATA
0.0225
w7
CTCA
0.0285
w15
TTCA
0.0475
w8
CTTA
0.0015
w16
TTTA
0.0025
Calculating subsequence matching probabilities
Now, we will illustrate how to calculate subsequence matching probabilities under possible world semantics. Let be the instantiated sequence in possible world W, the subsequence matching probabilities can be computed by the following formula.
Example 1. Given the uncertain sequence in Table 2, and a pattern with wildcards C[0,2]A, the probabilities that is a subsequence of is:
Because the number of possible worlds will increase exponentially, it is costly to calculate sequence matching probabilities under possible world semantics. We will propose a dynamic programming algorithm for this task.
Our dynamic programming approach CoDP
Definition 4. For pattern with wildcards and uncertain sequence , and , where and .
Definition 5. is defined as the probability that is the subsequence of , where and .
The treatment of periodical wildcards is a central feature of our approach. In our algorithm, the pattern has no repetitive characters, that is to say, . And the gap between two characters of the pattern is the same, i.e., . To develop a dynamic programming method that can handle the gap constraint, we introduce the notion of a tail gap [19].
Definition 6. Given a pattern and an uncertain sequence , where and , and given an occurrence . The tail gap, denoted as , is defined as .
Example 2. For and , .
Definition 7. Given a positive integer y, an uncertain sequence and an occurrence , where , we say fulfills the tail gap constraint iff satisfies .
Definition 8. is defined as the probability that is a subsequence of with tail gap constraint and Gap-Length Constraints.
The main idea of our approach CoDP is to split the problem of computing at the first j timestamps into subproblems of computing the frequentness probabilities at the first j-1 timestamps. Given a pattern with wildcards and an uncertain sequence , where and . If we assume that , then is equal to the probability . Otherwise, is equal to the probability . In our algorithm, the gap is allowed in a match. Thus, techniques for handling the gap constraint are required, which leads to Lemma 1.
Lemma 1. If , with Gap-Length Constraints is equal to the probability that satisfies the tail gap constraint . Otherwise, is equal to the probability that satisfies Gap-Length Constraints.
The occurrence of in should satisfy the gap-length constraints. In lemma 1, if , we will find at the first positions of to meet the minimum gap constraint. Because the gap-length constraints include both minimum and maximum gap, the position that matches also needs to satisfy the tail gap constraint.
By splitting the problem in this way, we can use the recursion in Eq. (3), which tells us what these probabilities are, to compute by means of the paradigm of dynamic programming.
where
However, Eq. (3) is not suitable for calculating the exact probability that the pattern is a subsequence of the uncertain sequence , because some special needs should be taken into account. In Table 2, for the pattern with wildcards , because , we will match at the second and third positions of according to Eq. (3). But also matches the first two positions of the instances in and , that is to say, we should match at the first three positions even though , otherwise, the probability we have calculated will be smaller than the exact probability. So, formula 3 should be modified as follows.
But there is still something incorrect in Eq. (4). In Table 2, for the pattern , the probability computed by Eq. (4) will be larger than the exact probability, because will be counted twice. In order to get the exact probability, we will subtract the probability that exists at the first positions with the tail gap constraint, and exists at the first positions of at the same time. Lemma 2 shows how to use the dynamic programming scheme to compute .
Lemma 2. Entry:
if
if
if
Lemma 2 is explained as follows. Equation (4.1) is the entry of our dynamic programming approach CoDP with , and . Then of Eq. (4.1) is calculated by Eq. (4.1) if or by Eq. (4.1) if . These equations are calculated recursively. The recursion termination conditions are shown in Eq. (8). In Eqs (4.1) and (4.1), the label common represents a function. The function common is used to calculate the probability that exists at the first positions with the tail gap constraint, and exists at the first positions of at the same time. To get the exact probability, bit sequences are adopted in the function. Details of the bit sequences will be discussed briefly.
Bit sequence representation of occurrences
In function common, for each occurrence, a bit sequence is constructed. If the character appears at the position of sequence , the bit is set to be .
For example, in Table 2, for the pattern , the probability that is a subsequence of the uncertain sequence can be calculated as follows according to Eq. (4.1).
To satisfy the tail gap constraint, will exist at the third position of , and the bit sequence is constructed. The positions that exists in are the first and the second, and the bit sequence is . To compute the probability, we will use bitwise OR operations on the bit sequences and get a new one . The new bit sequence means there are possible worlds that and exist at the same time, and the probability is 0.3 0.9 0.95 0.2565. The bit sequences, which represent the positions that exists in , are . We can calculate the exact probability by using bit sequences. Figure 1 shows an example of how to use our dynamic programming approach CoDP to calculate .
An uncertain sequence
S[1]
S[2]
S[3]
S[4]
S[5]
S[6]
A
0
0
0.1
0
0.2
0
C
0.3
0.4
0.2
0.1
0.4
0
G
0.7
0.6
0.3
0.9
0.2
1
T
0
0
0.4
0
0.2
0
An example
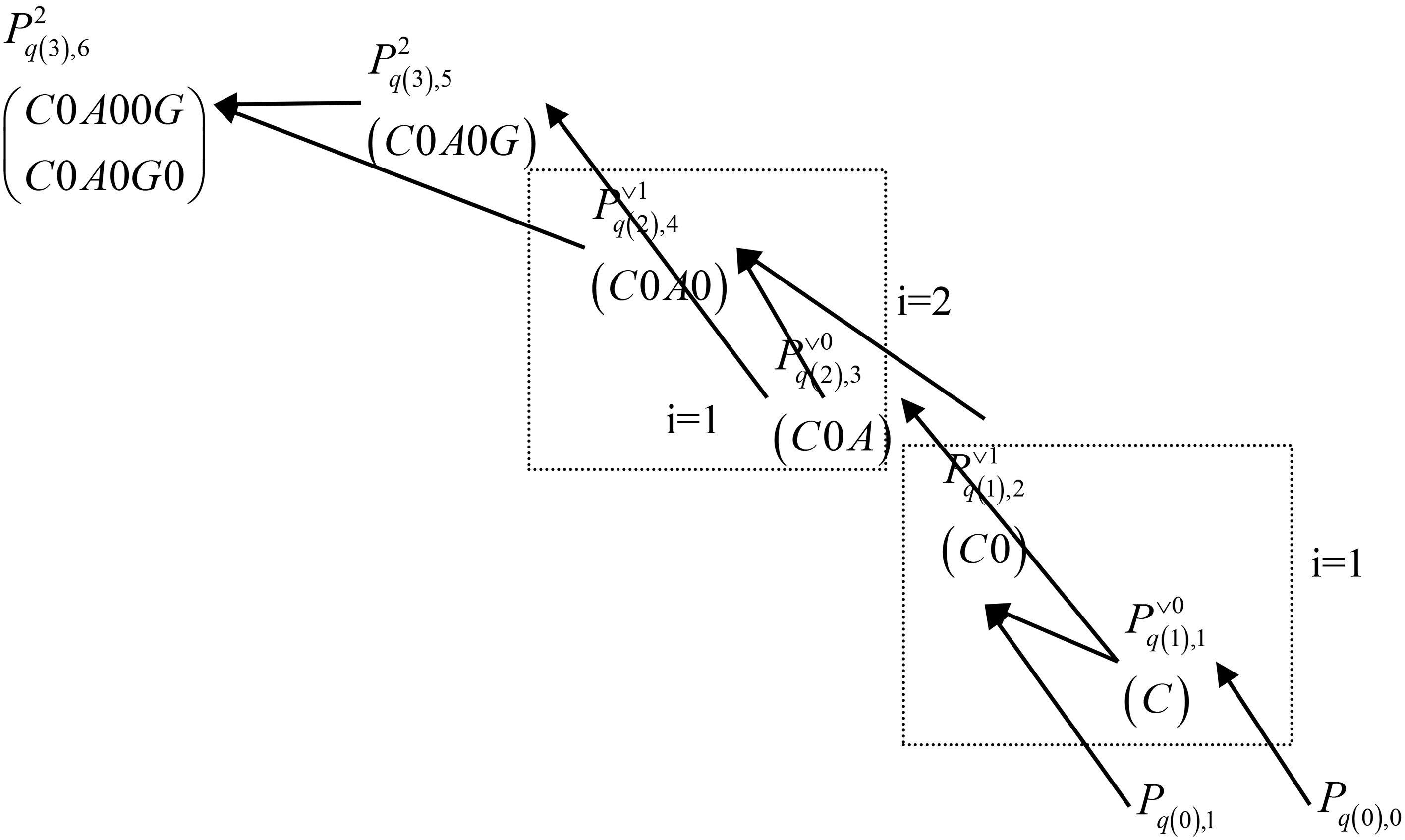
As shown in Fig. 1, and the sequence is shown in Table 3. There are layers in total. In each layer, . In the internal layer, such as 1 and 2, in each column, only those need to be calculated and stored. The rightmost node of each row gets for its column, where . Whilst the leftmost node of each row gets for its column, where , . Except for the bottom layer, bit sequences are stored with to get the exact probability.
Details of how to calculate .
Applications and extensions
In this section, we will sketch an extension that leverages our solution for computing the subsequence matching probability.
Since the difference between substrings matching and pattern matching with wildcards is that the former allows no gaps while the latter allows limited gaps, our approach can also be used to calculate substring matching probability after it is slightly modified.
Definition 9. The probability that is a substring of an uncertain sequence is called substring matching probability.
Lemma 3 shows how to use our modified dynamic programming scheme, called CoDPstr, to compute substring matching probability, denoted as .
Lemma 3. Entry:
if
if
Equation (5) is the entry of our modified dynamic programming approach CoDPstr with and . Then of Eq. (5) is calculated by Eq. (5) if . The recursion termination conditions are shown in Eq. (12). In Eq. (5), the label common stands for the probability that and exists at the first positions at the same time. Details of how to compute the value of common are shown in Algorithm 1.
Algorithm 1 Computing value of common
Input: string , matrix of uncertain sequence prob, array
Output: the value of common
1. for ; ; do
2. if [1] then
3. Common 0
4. else
5. if [1] 0 then
6. Common
7. else
8. if then
9. Common
10. else
11.
12. for 1; ; do
13. if [i] 0 then
14. break;
15. else
16.
17. if 0 then
18. for [i] 1; ; do
19. is the probability that
the element of pattern exists at the position of sequence
20.
21. Common
In Algorithm 1, four cases should be taken into account to compute the value of common. The first case is that is not big enough to let and exist at the same time, as shown in lines 2–3, and the value of common is 0. Lines 5–6 is the second case, is bigger and there is no overlap between the former and the latter part of , for example ATTGAC. Lines 8–9 is the third case, there is overlap between the former and the latter part of , for example ACTGAC, and is smaller than 2*m. The value of common is the product of the probability that exists at the first positions and the probability that exists at the first positions of sequence . The fourth case is shown in lines 11–21. In Algorithm 1, the array is used to record the positions, where there is overlap between the former and the latter part of . Details of how to get these positions are shown in Algorithm 2.
Algorithm 2 Finding overlapping positions
Input: string
Output: array
1. 0;
2. for 0; ; do
3. [i] 0
4. for 2; ; do
5. if ch[i] ch[1] then
6. break
7. if then
8. for 1; ; do
9. [j]
10. else
11. for ; ; do
12. if [i] [m] then
13. kk
14. for ; 1; do
15. if [j] [kk] then
16.
17. else
18. break
19. if 0 then
20. [l]
21.
In Algorithm 2, array is initialized as 0 at first. In lines 4–9, , if all the characters in string are the same. For example, if CCCC, , it indicates that the former three characters of are the same as the latter three ones, the former two letters are the same as the latter two, and the first is the same as the last. In lines 11–21, we scan the string in reverse. If [i] [m], we will check whether the former characters are the same as the latter ones. If yes, the position will be stored in array . For example, if CACACA, .
Use our modified dynamic programming scheme CoDPstr, as shown in Lemma 3, we can compute substring matching probability in linear time.
Experiments
In this section, we evaluate the performance of our proposed algorithms. All the experiments were carried out on the Windows 7 operating system, on a machine with a 3.7 GHz Intel(R) Core(TM) i3-4170 processor and 4GB memory. The programs were written in C++ and compiled on Microsoft Visual Studio 2013. All the results are the average of ten runs.
Evaluation of algorithm CoDP
We test the scalability of our proposed algorithm CoDP on a real-world uncertain DNA sequence database [22]. The database contains 593 uncertain sequences where {A,C,G,T}. Each uncertain sequence is relatively short (average size 10.79). Among all the sequences, the longest sequence’s size is 30 and the shortest one’s size is 5.
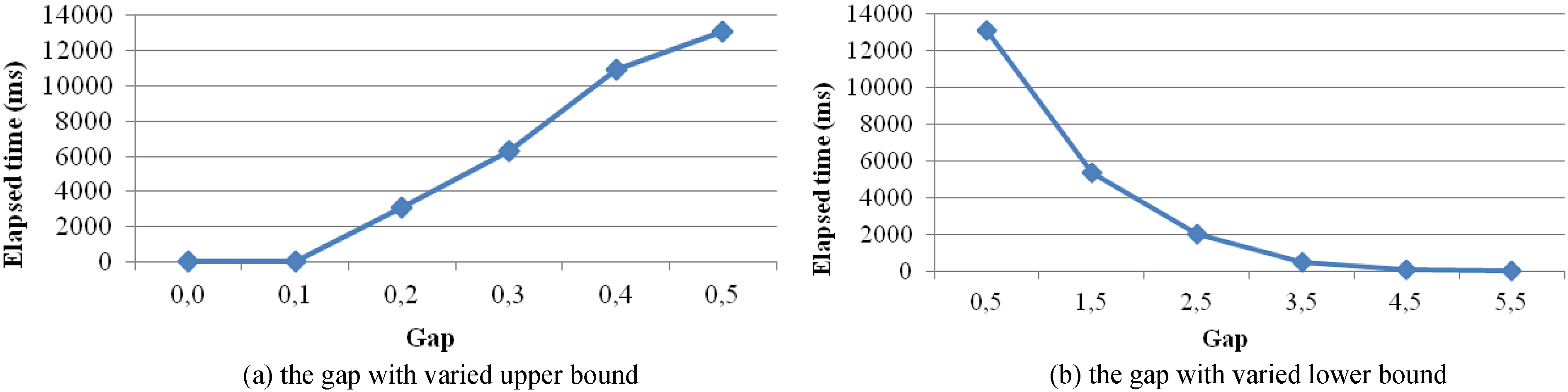
Figure 2 shows the average time needed to calculate the subsequence matching probability on the real-world dataset. the pattern is and the length of wildcards is different. In Fig. 2a the upper bound of the gap varies from 0 to 5, and the time increases with it. Because when the upper bound increases, the length of the gap also increases, and the time overhead is proportional to the length of the gap. In Fig. 2b the lower bound of the gap varies from 0 to 5, and the elapsed time decreases with it. Because when the lower bound increases, the length of the gap decreases.
The average time needed to compute the subsequence matching probability on the real-world dataset.
The average time needed to compute the substring matching probability on the first synthetic dataset.
Comparison between our method CoDPstr and DPstr
We compare our modified method CoDPstr with the approach for substring matching from [19], which we call it DPstr and it is proposed by Li et al., on three datasets. The first dataset has several synthetic uncertain sequences. For each uncertain sequence , the probability is randomly drawn from [0,1], where , , {A,C,G,T} and . The second dataset is the same with the one used in Sections 6.1. The third dataset is the synthetic dataset about weather. For each uncertain sequence , the probability is randomly drawn from [0,1], where , , {F, r, R, O, C, s, S, T} and . The letters ‘F’, ‘r’, ’R’, ’O’, ’ C’, ‘s’, ‘S’ and ‘T’ represent fine day, light rain, heavy rain, overcast, cloudy, light snow, heavy snow and sleet respectively.
The average time needed to compute the substring matching probability on the real-world dataset.
The average time needed to compute the substring matching probability on the weather synthetic dataset.
First, we give efficiency results obtained by utilizing different methods of computing the substring matching probability. Then, we discuss the performance and utility of these two substring matching algorithms.
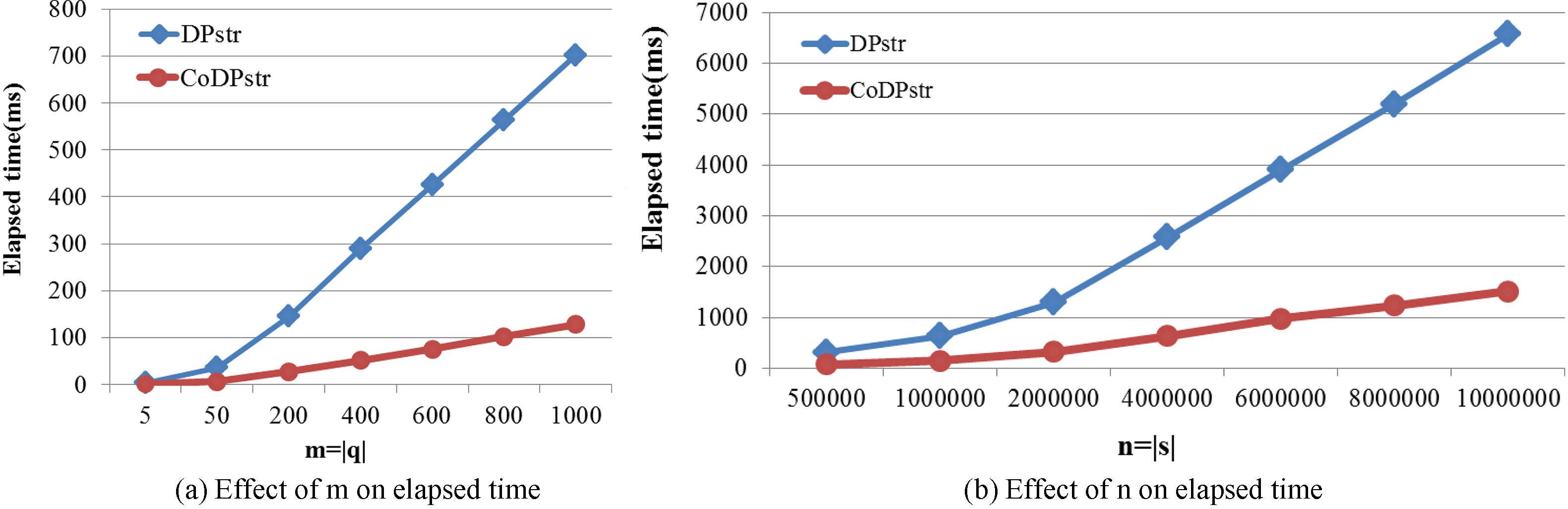
Figure 3 shows the average time needed to compute the substring matching probability on the first synthetic dataset, across different choices of and s. Figure 3a compares the elapsed time for computing of our approach against the method proposed by Li et al. The size of the query substring varies from 5 to 1000. In Fig. 3b, the size of the uncertain sequence varies from 5*10 to 10, and the size of the query substring is 10.
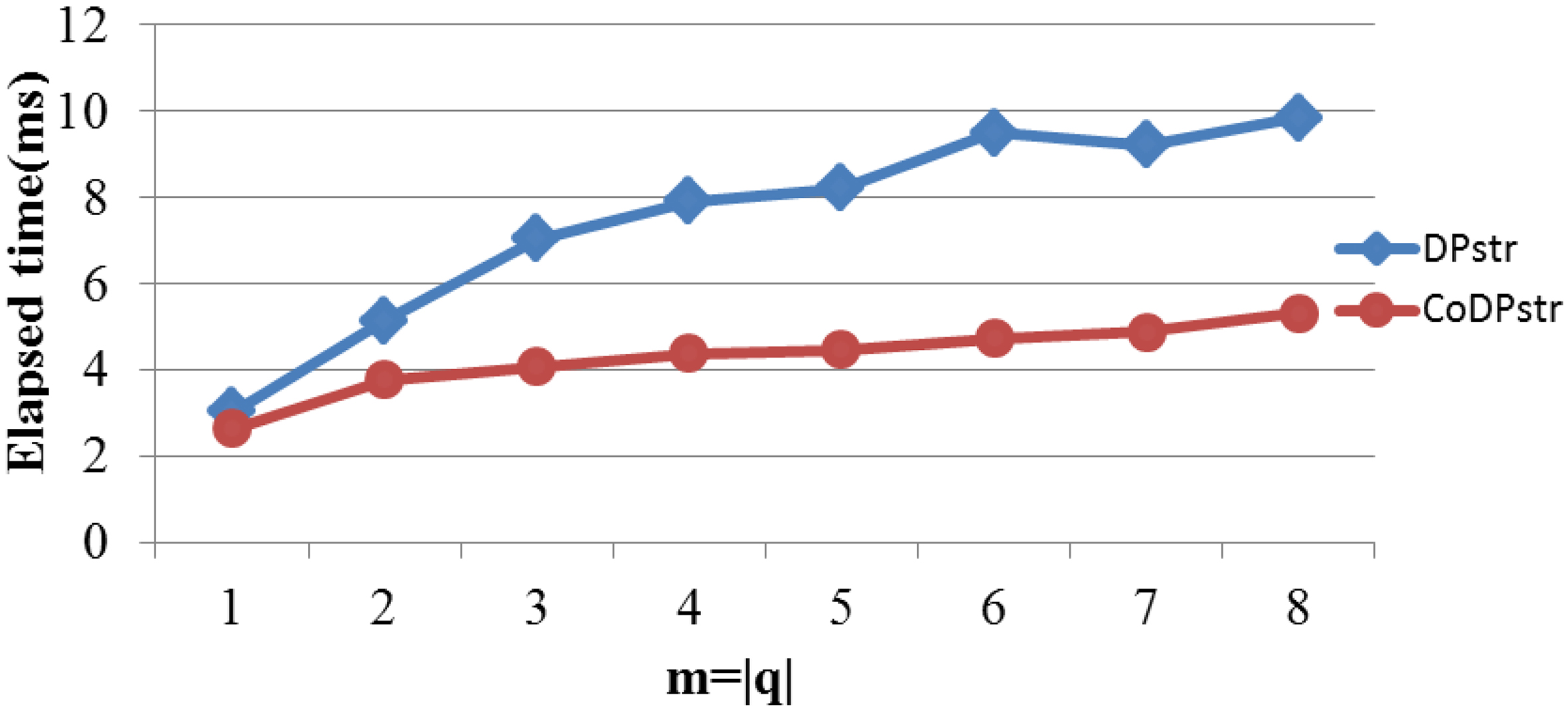
Figure 4 compares the average time overhead of these two methods on a real-world dataset, which is needed to compute the substring matching probability. The size of the query substring varies from 1 to 8, because the average size of the 593 uncertain sequences is 10.79.
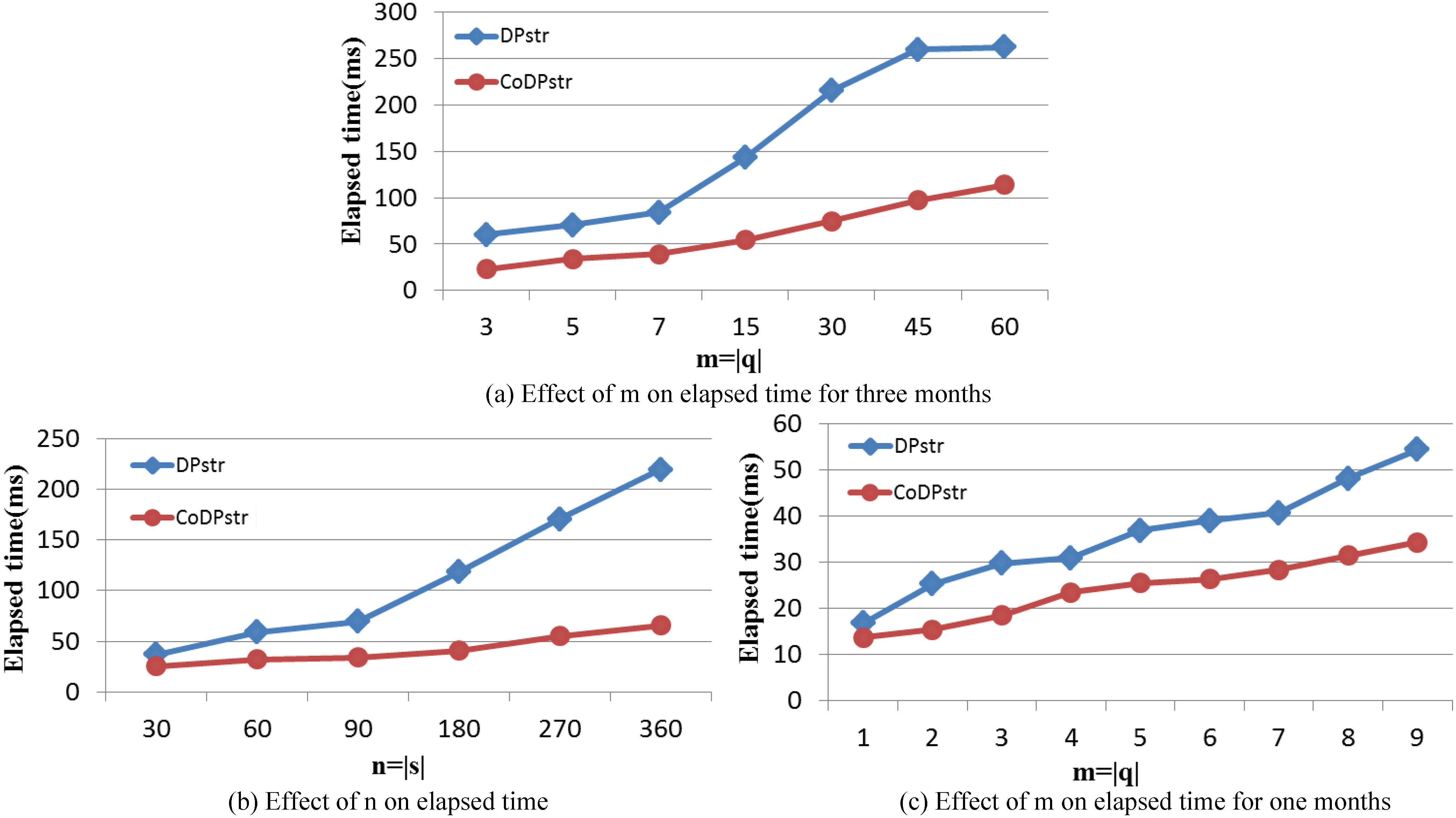
Figure 5 shows the average time needed to calculate the substring matching probability on another synthetic weather dataset, across different choices of and . Figure 5a compares the elapsed time for computing of our approach against the method DPstr. The size of the query substring varies from 3 to 60. In another words, we would like to inquire about how the weather has fluctuated for three days, five days and so on over the past three months. In Fig. 5b, the size of the uncertain sequence varies from 30 to 360, and the length of the query substring is 7. According to the results , we can learn about the weather changes for a week in the past month to year. In Fig. 5c, the size of the query substring varies from 1 to 9.
In Figs 3–5, the red dot line represents the time overhead needed to compute the substring matching probability using our approach CoDPstr. The blue diamond line is the elapsed time of the algorithm DPstr.
As we can see, the elapsed time of our approach is much less than Li’s on both two synthetic datasets and one real-world dataset. The two approaches both use dynamic programming scheme, but subsequences matching process of them is different. In DPstr, four scenarios need to be considered at each step: forward matching, backward matching, tail matching and reset. The more scenarios need to be considered, the more time will elapse. Furthermore, each scenario is complicated and time consuming. In our approach CoDPstr, only one scenario should be taken into account at each step when . So our approach takes much less time than Li’s, and the time gap between these two methods becomes bigger when the size of query pattern increases. The time gap also increases with the size of uncertain sequences.
Conclusions
In this paper, efficient algorithms for computing subsequence matching probabilities with periodical wildcards in uncertain sequence databases are studied, which, to the best of our knowledge, has not been studied before. Then we extend our algorithm to handle substring matching problem. We experimentally showed that our proposed dynamic computation technique is able to effectively avoid the problem of “possible world explosion”. We plan to study the calculation of matching probabilities for other uncertain data models.
Footnotes
Acknowledgments
This work was supported by the National Key Research and Development Program of China under grant No. 2016YFB1000901, the National Natural Science Foundation of China (NSFC) under grants Nos. 61202227 and 61602004, and the US National Science Foundation (NSF) under grant IIS-1613950.
References
1.
PisantiN.CrochemoreM.GrossiR. and SagotM.-F., Bases of motifs for generating repeated patterns with wild cards, IEEE/ACM Trans Comput Biol Bioinform2 (2005), 40–50.
2.
OnB.-W. and LeeI., Meta similarity, Appl Intell35(3) (2011), 359–374.
3.
PasquierC.SanhesJ.FlouvatF. and Selmaoui-FolcherN., Frequent pattern mining in attributed trees: algorithms and applications, Knowledge and Information Systems46 (2016), 491–514.
4.
DeshpandeA.GuestrinC.MaddenS.R.HellersteinJ.M. and HongW., Model-Driven Data Acquisition in Sensor Networks, in: Proceedings of the 30th VLDB Conference, Toronto, Canada, 2004, pp. 588–599.
5.
ChenH.KuW.S.WangH. and SunM.T., Leveraging Spatio-Temporal Redundancy for RFID Data Cleansing, in: Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, Indiana, USA, 2010, pp. 51–62.
6.
LeiP.-R., A framework for anomaly detection in maritime trajectory behavior, Konwledge and Information Systems47 (2016), 189–214.
7.
AggarwalC.C. and YuP.S., A Survey of Uncertain Data Algorithms and Applications, IEEE Trans. Knowl. Data Eng.21(5) (2009), 609–623.
8.
GuoD.HuX.XieF. and WuX., Pattern matching with wildcards and gap-length constraints based on a centrality-degree graph, Appl Intell39 (2013), 57–74.
9.
XieF.WuX. and ZhuX., Document-Specific Keyphrase Extraction Using Sequential Patterns with Wildcards, in: 2014 IEEE International Conference on Data Mining (ICDM), Shenzhen, China, 2014, pp. 1055–1060.
10.
WuY.WangL.RenJ. et al., Mining sequential patterns with periodic wildcard gaps[J], Applied Intelligence41(1) (2014), 99–116.
11.
WuY.FuS.JiangH. and WuX., Strict approximate pattern matching with general gaps, Appl Intell42 (2015), 566–580.
12.
AggarwalC.C.LiY.WangJ. and WangJ., Frequent Pattern Mining with Uncertain Data, KDD’09, Paris, France, 2009, 29–38.
13.
LeungC.K.-S.MacKinnonR.K. and TanbeerS.K., Fast Algorithms for Frequent Itemset Mining from Uncertain Data, in: 2014 IEEE International Conference on Data Mining (ICDM), Shenzhen, China, 2014, pp. 893–898.
14.
GeJ.XiaY.WangJ.NadungodageC.H. and PrabhakarS., Sequential pattern mining in databases with temporal uncertainty, Knowledge and Information Systems51 (2017), 821–850.
15.
TongY.ChenL. and DingB., Discovering Threshold-based Frequent Closed Itemsets over Probabilistic Data, in: IEEE 28th International Conference on Data Engineering, 2012, pp. 270–281.
16.
WangL.WuP. and ChenH., Finding Probabilistic Prevalent Colocations in Spatially Uncertain Data Sets[J], IEEE Transactions on Knowledge & Data Engineering25(4) (2013), 790–804.
17.
LeeG. and YunU., A new efficient approach for mining uncertain frequent patterns using minimum data structure without false positives[J], Future Generation Computer Systems68 (2017), 89–110.
18.
ZhaoZ.YanD. and NgW., Mining Probabilistically Frequent Sequential Patterns in large Uncertain Databases, IEEE Transactions on Knowledge and Data Engineering26(5) (2014), 1171–1184.
19.
LiY.BaileyJ.KulikL. and PeiJ., Efficient Matching of Substrings in Uncertain Sequences, in: Proceedings of the 14th SIAM International Conference on Data Mining (SDM’14), pp. 767–775.
20.
GeT. and LiZ., Approximate Substring Matching over Uncertain Strings, Proceedings of the VLDB 2011 Endowment4(11) (2011), 772–782.
21.
DalviN. and SuciuD., Efficient query evaluation on probabilistic databases, The VLDB Journal16(4) (2007), 523–544.
22.
BryneJ.ValenE.TangM.MarstrandT.WintherO.Da PiedadeI.KroghA.LenhardB. and SandelinA., Jaspar, the open access database of transcription factor-binding profiles: new content and tools in the 2008 update, Nucleic acids research, 2008.