
Abstract
Pattern matching can be used to calculate the support of patterns, and is a key issue in sequential pattern mining (or sequence pattern mining). Nonoverlapping pattern matching means that two occurrences cannot use the same character in the sequence at the same position. Approximate pattern matching allows for some data noise, and is more general than exact pattern matching. At present, nonoverlapping approximate pattern matching is based on Hamming distance, which cannot be used to measure the local approximation between the subsequence and pattern, resulting in large deviations in matching results. To tackle this issue, we present a Nonoverlapping Delta and gamma approximate Pattern matching (NDP) scheme that employs the
Keywords
Introduction
Pattern matching (or string matching [1, 2, 3, 4]) is a key issue in computer science [5, 6, 7, 8] and plays an important part in many applications, such as pattern mining [9, 10, 11], knowledge discovery [12], bioinformatics analysis [13], fault detection [14], and time series forecasting [15]. In recent years, pattern matching with multiple gap constraints, as an important branch of pattern matching [16, 17], has attracted a great deal of attention in many fields, such as time series analysis [18, 19], sequential pattern mining [21, 22], and text key phrase extraction [23]. A pattern with gap constraints can be written as
In a pattern matching problem with gap constraints, the number of occurrences is exponential if there are no constraints [25], and some researchers have therefore focused on pattern matching under the one-off condition [26]. However, the one-off condition is too stringent, and means that some useful information is lost. Ding et al. [27] then proposed the concept of nonoverlapping. The nonoverlapping pattern matching was proved to be solved in polynomial time complexity [28]. To make the gap constraint more suitable for practical applications, non-overlapping pattern matching with general gaps was studied [29]. Nonoverlapping sequential pattern mining is able to find valuable frequent patterns effectively [30]. To reduce the number of redundant patterns, nonoverlapping closed sequential pattern matching was explored and improved the mining performance [9].
However, the above mentioned researches are exact pattern matching [28, 31]. It means that noise is not allowed in the above researches, which is difficult to obtain valuable information. Approximate pattern matching [32, 33] allows for noise, and it can therefore handle practical problems more effectively. The Hamming distance [34, 35] is commonly applied in approximate pattern matching. But the Hamming distance only reflects the number of different characters, and ignores the distances between characters. Therefore, nonoverlapping approximate pattern matching scheme based on the Hamming distance may cause large deviations when applied to time series [36, 37]. Inspired by
Figure 1 shows the matching results of symbolized time series of pattern
Pattern 
The contributions of this paper are as follows.
To avoid large deviations of Hamming distance, we present a Nonoverlapping Delta and gamma approximate Pattern matching (NDP) shceme and propose an efficient algorithm called NetNDP (a local approximate Nettree for NDP). NetNDP employs the concept of a local approximate Nettree and MRD (Minimal Root Distance) to improve the efficiency. We carry out numerous experiments to verify the efficiency of NetNDP, and show that the
The rest of this paper is organized as follows: Section 2 presents some relevant definitions. Section 3 introduces related work. Section 4 explores the local approximate Nettree structure, and proposes the NetNDP algorithm. Section 5 presents results that validate the performance of NetNDP. We conclude this paper in Section 6.
.
A sequence
.
A pattern with gap constraints can be expressed as
.
Given any two characters
.
Suppose we have two sequences
.
Suppose
.
Suppose we have a sequence
(local constraint) (global constraint)
.
.
The NDP problem is to find the maximum
.
We have a sequence
Pattern matching can be divided into exact [28, 31] and approximate pattern matching [32]. Exact pattern matching requires that the pattern and subsequence are the same, which limits the flexibility of matching, while approximate pattern matching allows differences between the pattern and subsequence, and can discover more useful information. For instance, Hu et al. [32] implemented a string similarity search through a gram filter. Chen et al. [33] discovered all subsequences with
.
Suppose we have a sequence
All 
The subsequence
From the perspective of description an occurrence, there are loose pattern matching and strict pattern matching. Loose pattern matching uses the last position in the sequence to express an occurrence [40], while strict pattern matching uses a set of positions to express. Under loose pattern matching [40], there are only two
There are three kinds of conditions in strict pattern matching, no special condition [35], the one-off condition [26], and the nonoverlapping condition [34]. Example 3 can be seen as no special condition, since the condition has no restrictions on characters, which result in the number of occurrences grows exponentially. The occurrence under the one-off condition may be any of the four occurrences, since any character of the sequence can only be used once. For instance, if we select
Although nonoverlapping pattern matching has been investigated in [28], it is an exact pattern matching approach which does not allow noise. To the best of our knowledge, the researches in [40, 34, 37] are the most closest studies. The drawbacks are as follows.
Although the scheme in [40] focused on approximate pattern matching with the Although nonoverlapping approximate pattern matching has been investigated in [34], it adopts the Hamming distance to measure the distance between pattern and occurrence. But the Hamming distance only reflects the number of different characters, and cannot evaluate the distances between characters. However, our method employs Although
Our method can be used in repetitive sequential pattern mining [41, 42] and sequence classification [43, 44]. For example, the repetitive sequential pattern mining task is to discover frequent patterns in sequences whose supports are no less than the given threshold [45, 46]. To calculate the support of a candidate pattern is a pattern matching task. Thus, many gap constraints sequential pattern mining methods employed pattern matching strategies to discover the interesting patterns [47, 48]. Moreover, contrast pattern mining was investigated to extract the features for classification task [43, 44]. Hence, our method can also be applied in approximate repetitive sequential pattern mining and time series classification.
Section 4.1 introduces the local approximate Nettree. Section 4.2 explains how to transform the NDP problem into a local approximate Nettree and proposes the NetNDP algorithm.
Local approximate Nettree
.
A Nettree [35] is an extended tree structure with multiple roots and multiple parents. In a Nettree, nodes with the same ID can be found at different levels. To describe a node clearly, a node with ID
A standard Nettree is shown in Fig. 3. In Fig. 3,
A standard Nettree.
.
In a Nettree, a leaf at the
.
In a Nettree, a path from
.
An occurrence of pattern
Proof..
We know that an occurrence can be transformed into a full path in a Nettree [35], i.e. a full path
.
In a Nettree,
To effectively solve the problem of nonoverlapping approximate pattern matching with the
.
Local approximate Nettree has two features different from a Nettree.
Each node Each node
.
If
where
Proof..
According to Definition 12,
To illustrate the above concepts, an example is shown as follows.
.
Suppose we have a sequence
A local approximate Nettree.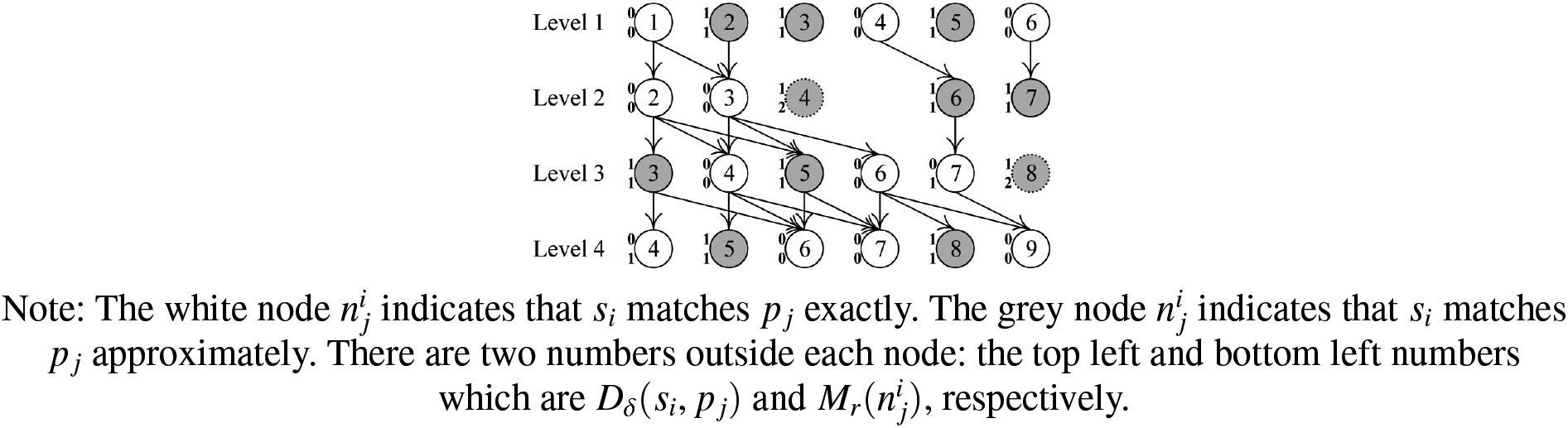
In Fig. 4, nodes with the same ID occur at different levels, such as
Creating the Nettree
There are two key issues in creating a local approximate Nettree: creating nodes and parent-child relationships. We propose Theorem 2 to reduce the invalid nodes, and explore Theorem 3 to reduce parent-child relationships.
.
If
Proof..
We know that
.
If
Proof..
Suppose
.
To illustrate the principles of Theorems 1, 2, and 3, we apply the same conditions as in Example 4.
We first deal with
We then turn to
We now deal with
We create the rest of the nodes in a similar way. Since
From Example 5, we see that MRD has the following three advantages.
It allows us to know whether or not a node has root paths that satisfy the global constraint. If Some invalid nodes can be pruned, such as We can prune invalid parent-child relationships. For instance, a parent-child relationship cannot be established between
Algorithm 1, called CreLANtree, is used to create the local approximate Nettree for a sequence
[t] : CreLANtree
Section 4.2.1 explains the principle used to create a local approximate Nettree, where the corresponding occurrences of all full paths satisfy the local constraint. In this section, we will introduce the principle of searching for the nonoverlapping occurrences that satisfy the global constraint.
.
Let
Proof..
Suppose we have
In a local approximate tree, when we search for occurrences from an absolute leaf to its roots, we first assess whether or not the rightmost parent satisfies the condition. If not, we will assess the second rightmost parent, until a qualified parent is found. This is known as the rightmost parent strategy.
For nonoverlapping exact pattern matching, NETLAP-Best [28] adopts the rightmost parent strategy, and iteratively searches for the rightmost occurrence of the max absolute leaf, and deletes both the occurrence and the related invalid nodes. However, this method cannot be employed to solve our problem, since this method is too blind, which will lead to the loss of solution. An illustrative example is shown as follows.
.
We use the same conditions as in Example 4.
In Fig. 4, suppose the global threshold
To avoid the drawbacks of NETLAP-Best algorithm, NetNDP applies two steps to obtain the rightmost occurrence. In the first step, we recalculate the MRD of each node in the subNettree of the max root, and judge whether the root can reach the absolute leaves under the condition of the global constraint. If so, we obtain the rightmost absolute leaf of the max root. In the second step we get the rightmost occurrence using the rightmost parent strategy with the rightmost absolute leaf. We iterate the above process until no new occurrences are found.
The ReachLeaf algorithm, which obtains the rightmost absolute leaf from the max root, is shown in Algorithm 2.
[t] : ReachLeaf
After obtaining the rightmost absolute leaf, we prove that we can obtain the rightmost occurrence without the need for a backtracking strategy.
.
In the subNettree of a root, if the root can reach
Proof..
If the root can reach
Based on Theorem 4, we develop the RightOcc algorithm to obtain the rightmost occurrence, as shown in Algorithm 3.
[h] : RightOcc
Example 7 illustrates the principle of NetNDP.
.
We use the same conditions as in Example 4.
In Fig. 5,
MRD for each node in the subNettree of 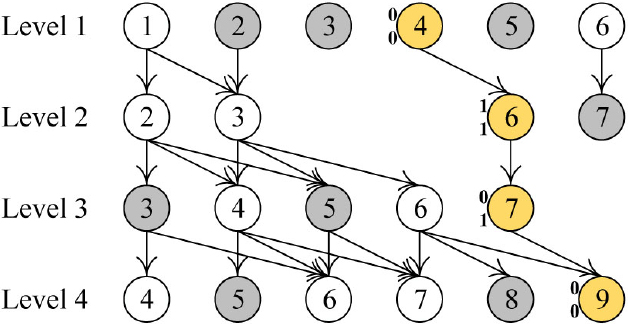
MRD for each node in the subNettree of 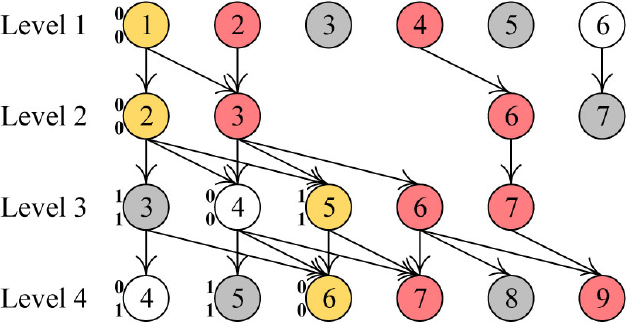
We delete
We now delete
The main steps of NetNDP are as follows.
Step 1: NetNDP uses Algorithm 1 to create a local approximate Nettree at first.
Step 2: NetNDP adopts Algorithm 2 to determine the max root which can reach the absolute leaves under the condition of the global constraint.
Step 3: If we can obtain the rightmost absolute leaf of the max root, then we employs Algorithm 3 to get the rightmost occurrence using the rightmost parent strategy with the rightmost absolute leaf.
Step 4: We iterate Steps 2 and 3 until no new occurrences are found.
The NetNDP algorithm is shown in Algorithm 4.
[h] : NetNDP
Experimental environment and datasets
In this paper, we focus on the problem of NDP, and propose the NetNDP algorithm. To validate the performance of NetNDP, we select the following competitive algorithms.
INSGrow-appro, NETLAP- NetNDP-nonp: To verify the efficiency of our pruning strategy, we also develop an algorithm, called NetNDP-nonp, which does not prune invalid nodes and parent-child relationships. NetDAP [37]: To verify the NDP performance, we also select NetDAP [37] as a competitive algorithm which is
All of the algorithms are run on a computer with an Intel (R) Core (TM) i5-7200U, 2.50 GHz CPU, 8.00 GB RAM, and a Windows10 operating system. The compiling environment is VC
To verify the efficiency of NetNDP, we use eight real protein sequences (
Table 3 shows the patterns
Description of the datasets
Patterns
Trends in 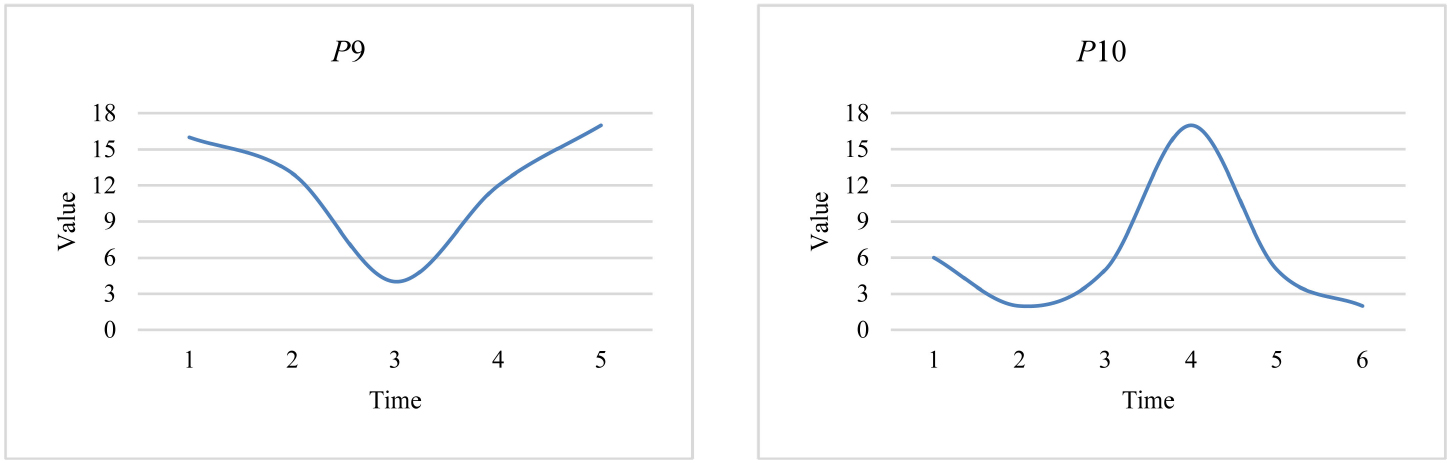
Since large deviations are not allowed in the matching results, the local threshold
Comparison of results for 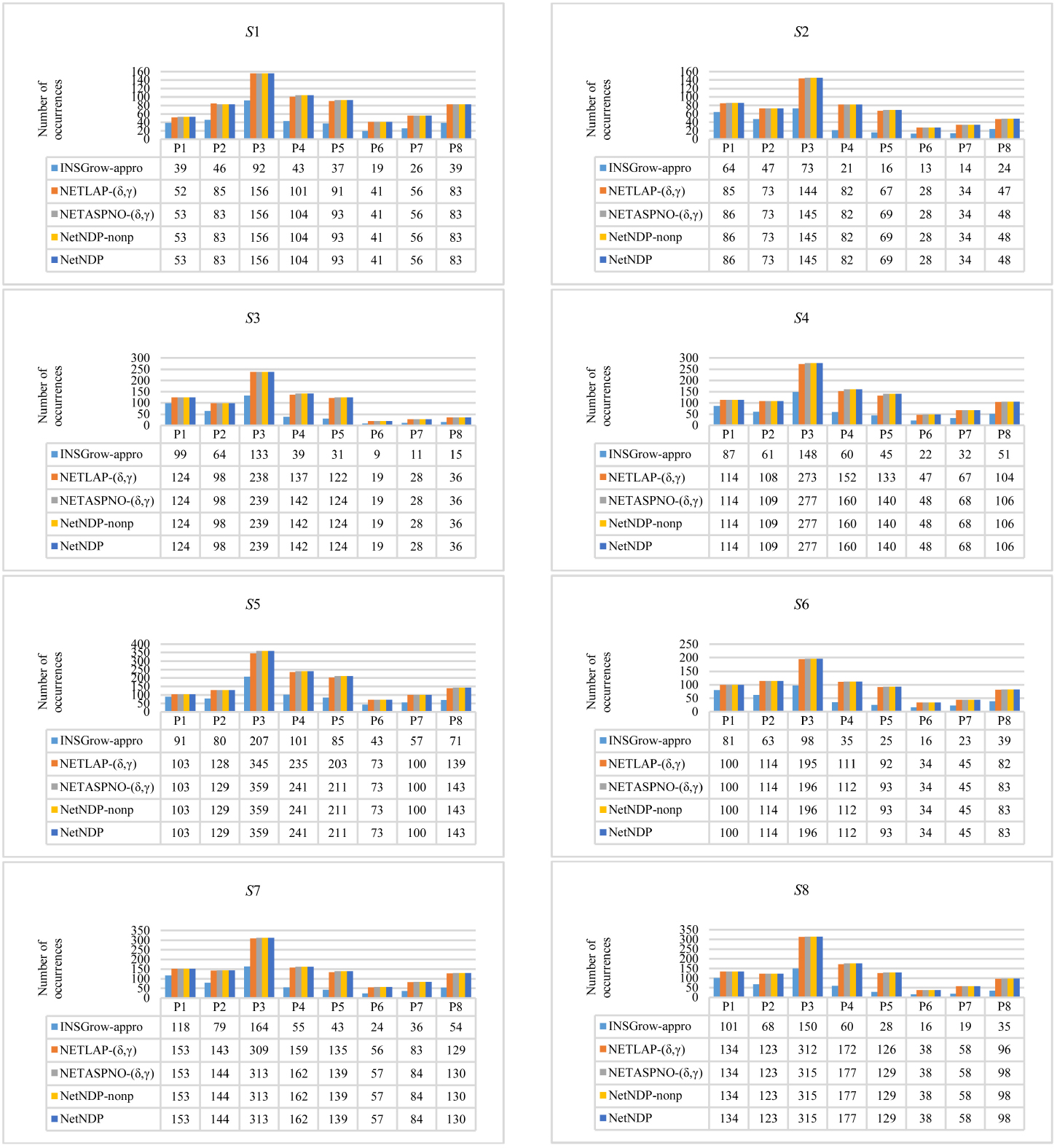
Comparison of running time for 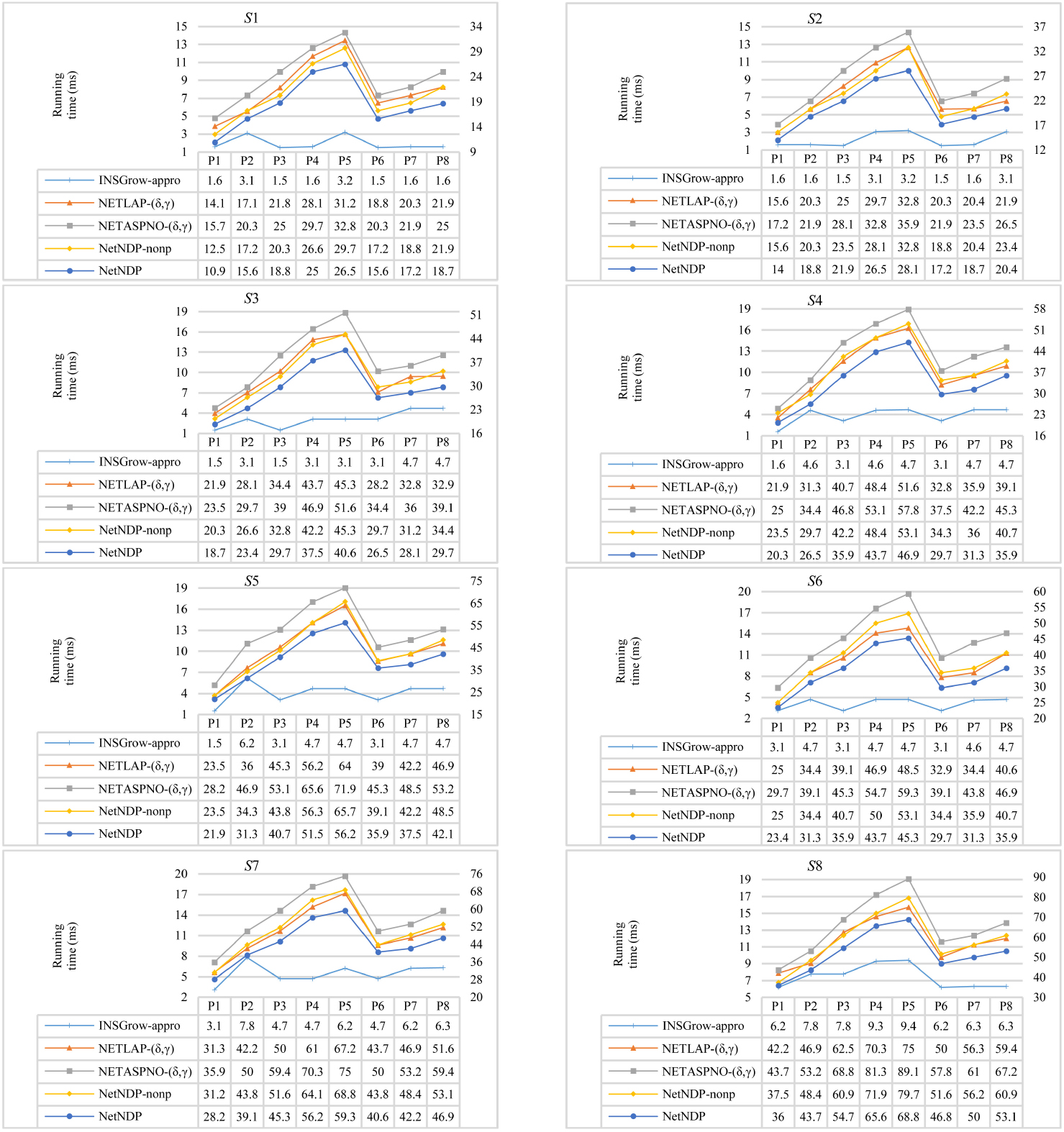
The results indicate the following observations.
From Figs 8 and 9, we can see that NetNDP outperforms INSGrow-appro. Figure 9 shows that INSGrow-appro is the fastest algorithm, since this algorithm is relatively simple. However, from Fig. 8, we know that INSGrow-appro has the lowest number of occurrences. For example, the running time for INSGrow-appro for NetNDP outperforms NETLAP- NetNDP outperforms both NETASPNO-
Total numbers of nodes and parent-child relationships for NetNDP-nonp and NetNDP with 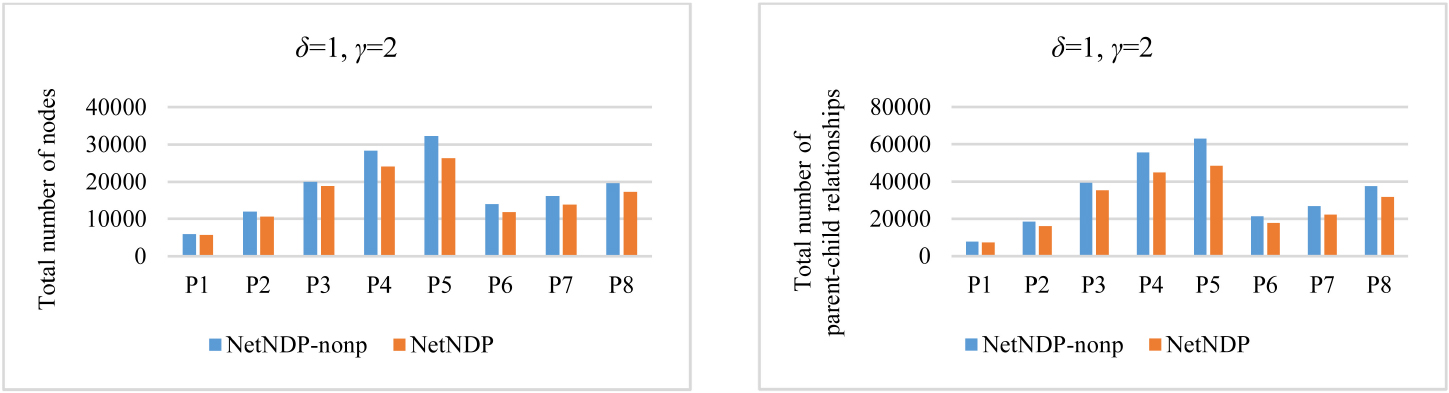
From Fig. 10, we can see that NetNDP-nonp has numerous invalid nodes and parent-child relationships, and therefore requires excessive numbers of invalid accesses, thus increasing the running time. Hence, NetNDP has better performance than NETASPNO-
To further demonstrate the impact of different threshold parameters on the experiment, we use values of
Total occurrences for 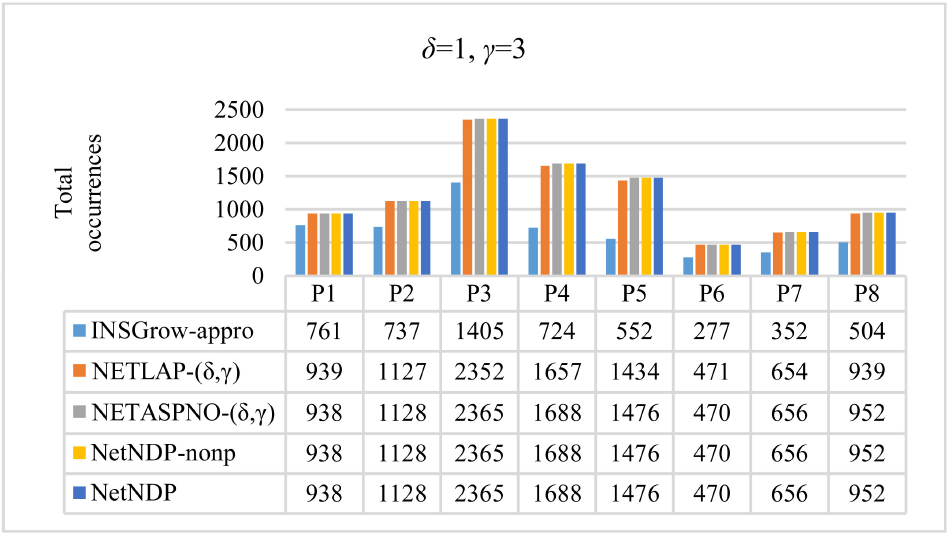
Total occurrences for 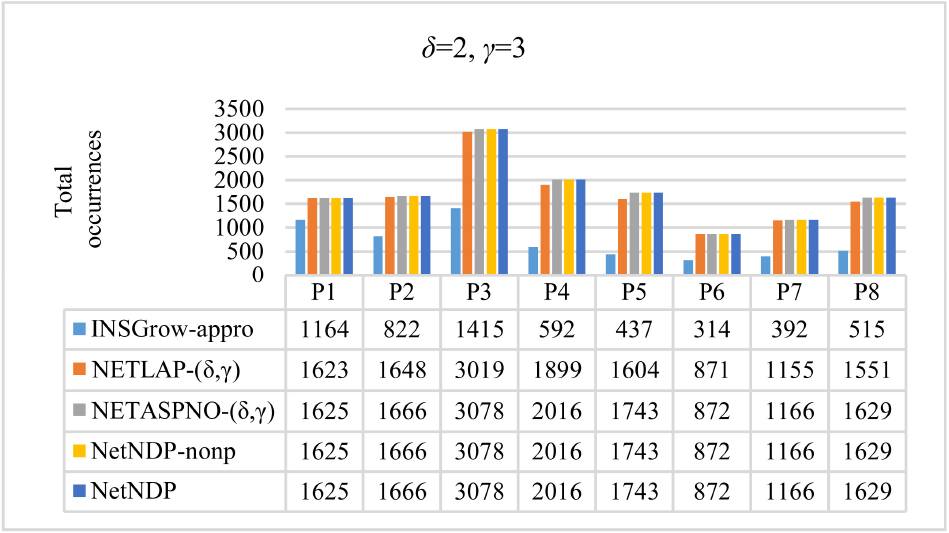
Total running time for 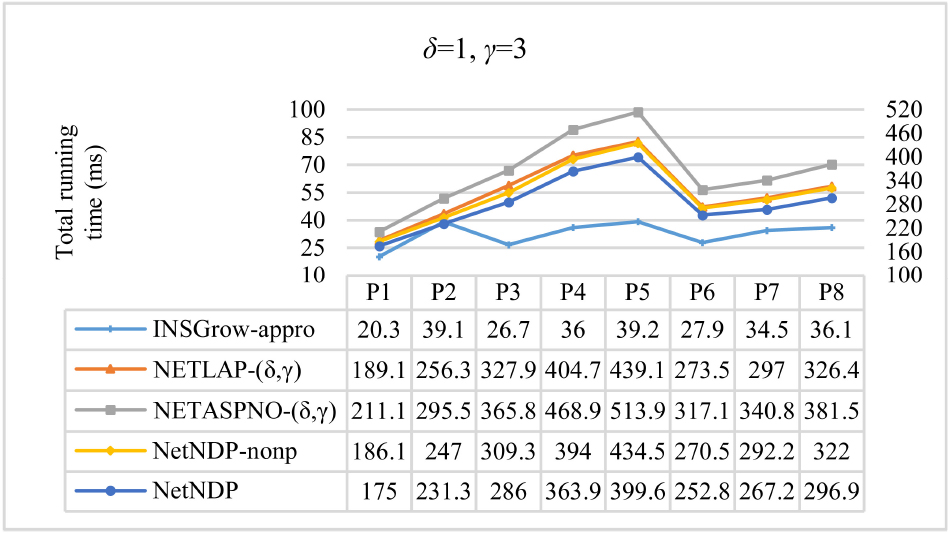
Total running time for 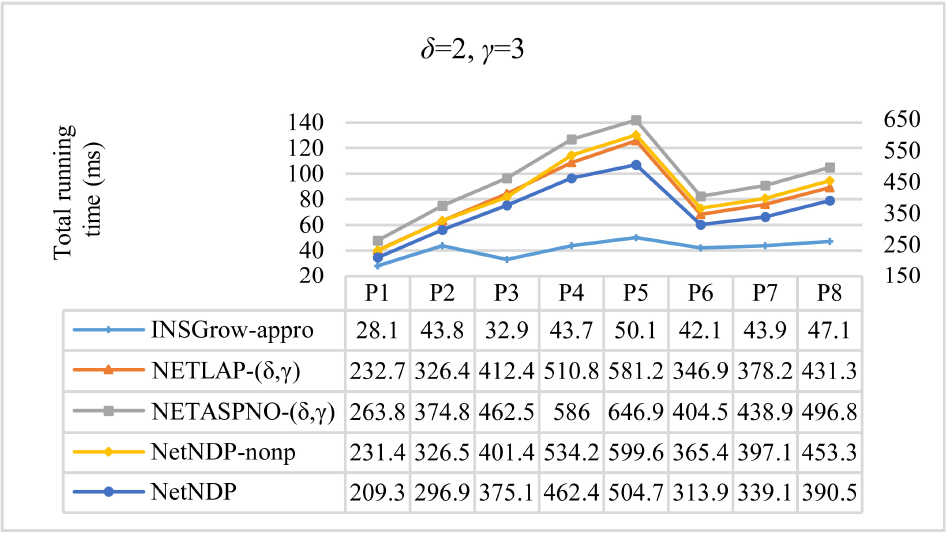
From Figs 11 and 12, we can see that NetNDP finds the same number of occurrences as NETASPNO- As can be seen from Figs 9, 13, and 14, the running time for NetNDP is positively correlated with
From Table 2, we can see that the length of
Table 3 shows that
From Table 3, we see that
In summary, the running time of NetNDP is consistent with a time complexity of
To illustrate that the
Matching results for 
Matching results for 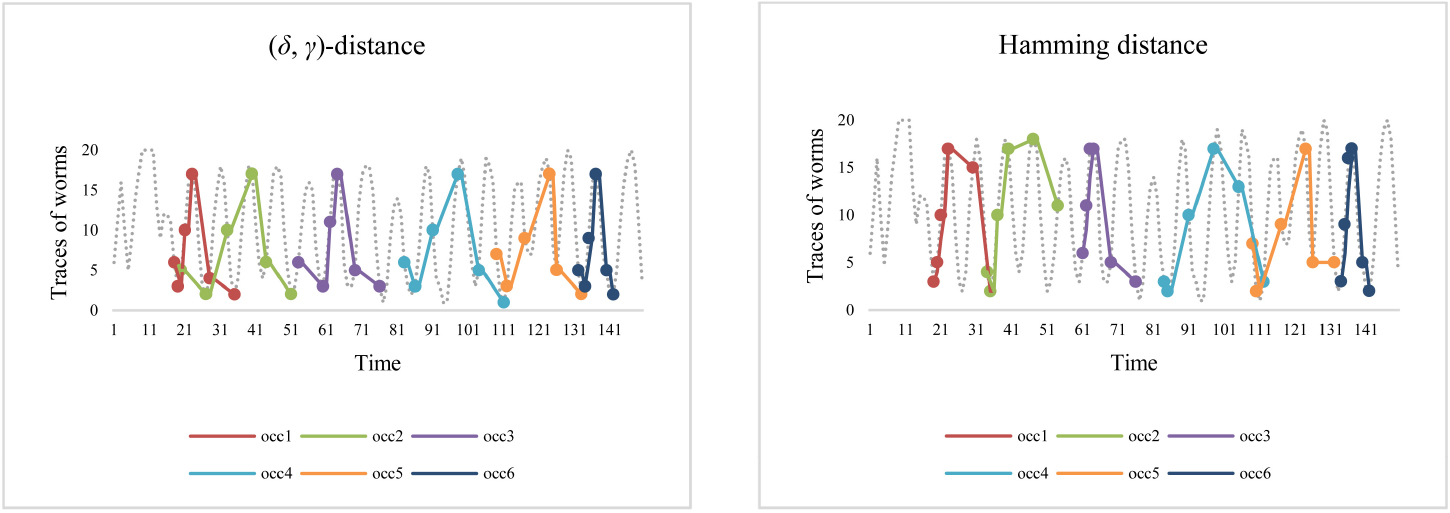
As can be seen from Fig. 15, the trends of all occurrences found with the
The Hamming distance cannot be used to measure the local approximation between the subsequence and pattern, resulting in large deviations in matching results. To overcome this weakness of the Hamming distance, we explore the use of nonpoverlapping approximate pattern matching with the
Footnotes
Acknowledgments
This work was party supported by National Natural Science Foundation of China (61976240, 91746209), National Key Research and Development Program of China (2016YFB1000901), Natural Science Foundation of Hebei Province, China (No. F2020202013).