
Abstract
The new era of technology allows us to gather more data than ever before, complex data emerge and a lot of noise can be found among high dimensional datasets. In order to discard useless features and help build more generalized models, feature selection seeks a reduced subset of features that improve the performance of the learning algorithm. The evaluation of features and their interactions are an expensive process, hence the need for heuristics. In this work, we present Heat Map Based Feature Ranker, an algorithm to estimate feature importance purely based on its interaction with other variables. A compression mechanism reduces evaluation space up to 66% without compromising efficacy. Our experiments show that our proposal is very competitive against popular algorithms, producing stable results across different types of data. We also show how noise reduction through feature selection aids data visualization using emergent self-organizing maps.
Introduction
In the past decade, thanks to numerous improvements in technology it is possible to capture more data than ever before, hence, increasing the dimensionality for several machine learning applications [8]. Notable areas with a very high increase in data dimensionality are Bio-informatics and microarray analysis [35], where several thousand of features per sample are common nowadays. However, these high-dimensional datasets usually are plagued with irrelevant and noisy features, therefore generalization performance can be improved by using only good features [28] while also getting additional benefits in the form of reduced computational cost.
The increase in dimension (features) leads to a phenomenon called the curse of dimensionality where data becomes sparse in a high dimensional space which causes issues with algorithms not designed to handle such complex spaces [16]. To mitigate this problem it is imperative to do some dimensionality reduction. Since 1960 this has been under research community investigation [18], it had an important boom in 1997 with special issues on its relevance [4, 21], however back then only a very minimal set of domains had more than 40 features [15].
In order to achieve the goal of dimensionality reduction, there are two main approaches, feature extraction and feature selection. The feature extraction approach seeks to transform the high dimensional features into a whole new space of lower dimensionality, usually, by a linear or nonlinear combination of the original set of features, an example of these techniques are Principal Component Analysis (PCA) [37] and Singular Value Decomposition (SVD) [12].
In this paper, we will focus on the other approach which is feature selection, as this is usually a more useful method in a real life scenario where it is important to understand which features of the original space are the most representative. Nonetheless, both approaches aim to have a reduced number of features [7] as experimentation has shown that a subset of features may help reduce overfitting [19].
Since 1980 we can see the development of several algorithms for feature selection that have been successful in different areas such as: Text categorization [11], pattern recognition [26], image processing [32] and bioinformatics [33]. However, more than three decades of research have not yet found an all-around best algorithm and many conclusions lead to believe that the solution is data-dependent. Therefore it is very important to continue the development of new approaches to handle different scenarios in the data, however, even with considerable options in algorithms, the key idea remains the same; try to keep the most relevant features and remove the rest.
There are several proposals to define what a relevant feature is, however in this paper we take the definition of John et al. [20] where they establish two different kinds of relevance:
Strong relevance: are features that, if removed, would cause a drop in classifier performance. Weak relevance: these features can be removed from the full set without considerably affecting the classifier performance.
Any feature that is not relevant is therefore irrelevant and could be divided into two main groups:
Redundant features: those that do not provide any new information about the class and therefore can be substituted by another feature. Noisy features: includes the features that are not redundant but, do not provide useful information about the class either.
In the seek for these relevant features, there are at least 4 key parameters that affect the search performance [4]:
Search direction:
Forward: we start with an empty set of features and new ones are being added once they are evaluated as useful. Backward: the full set of features are setup at first and then irrelevant features are being dropped. Search strategy: These are based on corresponding heuristics for each algorithm, one example could be Greedy search. Evaluation criterion: how the features are selected, the criteria or threshold that needs to be overcome in order to tag a feature as useful. Stopping criterion: this determines if the algorithm will just stop after a given number of iterations or will hold until a given threshold could be reached, this has a direct impact on the feature set size, where the optimal size may be defined by the number of instances [27].
When designing a feature selection algorithm there are at least three challenges to address [2]:
Small sample size: as the number of features increases, the number of instances required to produce a stable selection increase as well, however, there are many areas where samples are expensive to gather and the result is a dataset with thousands of features with only hundreds of samples which makes the process prone to overfitting. Data noise: if the algorithm is not robust enough, noisy features would guide the selection erroneously as the algorithm will try to learn the noise as if it were a real pattern. Selected features: algorithms that only rank features have to deal with the issue of how many features to choose for the final subset. Some other approaches use thresholds to automatically select the number of features.
Supervised feature selection algorithms use the statistical relation between the data and the labels [15] to select the features. These algorithms can be divided into three major groups: Filter, Wrapper, and Hybrid [2]. For low-dimensional data, it is possible to use different techniques, even the wrapper approach could be used, but once the dimension grows at a considerable scale of thousand of features, the computation complexity becomes a problem, and the filter approach, being the more efficient becomes a very popular option. Our algorithm is a filter approach.
Filter model: these algorithms are completely independent of any classifier, hence the final selection depends only on the characteristics of the data itself and its relation to the target [13, 38]. Filter models are overall very efficient, scalable and their results are usually portable as they do not depend on external components such a guiding classifier, these advantages make them very suitable for high dimensional data. Wrapper model: these algorithms use a classifier to evaluate their performance [20, 21], the initial feature selection is usually achieved by a greedy search strategy, the classifier performance is evaluated with the selected features and if the result is satisfactory the search stops, otherwise the whole process is repeated again but this time with a different subset. This is a very expensive process usually applied for low-dimensional data only. Hybrid model: As we have seen the filter models are more efficient, while the wrapper models are usually more accurate, in order to achieve a balance, the hybrid model is proposed to fill the gap between those approaches [6]. In the search step they employ a filter selection to reduce the number of candidates, later a classifier is used to select the subset that provided the best accuracy.
For low-dimensional data, it is possible to use different techniques, even the wrapper approach could be used, but once the dimension grows at a considerable scale as thousand of features, the computation complexity becomes a problem and the filter approach being the more efficient becomes most of the time the only feasible option.
In a previous work [17] we compared our algorithm Heat Map Based Feature Selection (HmbFS) with three well-known feature selection techniques, this work presents a ranking variation of the original HmbFS algorithm, a more in depth comparison, new datasets and algorithms to provide a better understanding of its capabilities.
The remaining of this paper is structured as follows: In Section 2, related work is being presented. In Section 3 we present HmbFS formal definition and discuss how it works. In Section 4 we describe our experiments and results. In Section 5 we present the final conclusions and discuss future work.
There are multiple techniques used for feature selection, according to the work of Li et al. [22], we can identify some groups of algorithms based on their fundamental idea, in this work we consider: information theoretical (MRMR, CIFE, CMIM, DISR), similarity based (ReliefF, Fisher) and statistical based (Gini). Although the main idea behind every algorithm remains the same, each of them presents their unique formulation for feature importances, in the following paragraphs we give a brief introduction for each algorithm.
Fisher score
This algorithm performs selection based on the difference of feature values, under the rationale that samples within same class have small differences and features values from other classes are larger [9]. The usefulness of each feature is calculated as follows:
As it can be seen from Eq. (1), the feature score is calculated from the difference between the mean for each feature
The Relief algorithm was originally designed to solve binary problems only, however, the ReliefF variant provides an extension to tackle multi class data [31]. The feature score is calculated as follows:
Where
The minimum redundancy and maximum relevance (MRMR) [29] algorithm is based on mutual information feature selection (MIFS) [3] and it is calculated as follows:
First part of Eq. (4) gives us the feature importance given its information gain and the second term is used to penalize feature redundancy with the already selected features
The Conditional Infomax Feature Extraction (CIFE) algorithm [23] presents the idea of conditional redundancy as other studies [1] have shown that the redundancy evaluation performed by MRMR or MIFS could be improved. The resultant equation now includes a third term as shown below:
As shown by Brown et al. [5], information theoretic based algorithms can be reduced to a linear combination of Shannon information terms, one example is Conditional Mutual Information Maximization (CMIM) [10], where the main idea is to add features that maximize the mutual information with the target but those features need to look different to already selected ones, even if they have strong predictive power. The equation is as follows:
Another technique is Double Input Symmetrical Relevance (DISR) [25] which uses normalization techniques, hence it normalizes mutual information as follows:
As with other techniques, DISR can also be reduced to a conditional likelihood maximization framework.
The idea behind Gini index is to identify which features are able to separate instances from different classes given if features values are lower or greater than a reference point. The equation is as follows:
Unlike other algorithms, in the case of Gini index, the idea is to minimize the score. In Eq. (8),
Every algorithm has its pro and cons due to their specific designs, given their mathematical formulations, it is hard to estimate their performance in real life situations. Hence, in this work, we perform a practical evaluation using real-world datasets with complex features-to-samples ratios.
A core part of our algorithm is working with heat maps, which is commonly used in high dimensional spaces such as genomic data to unravel hidden patterns, in recent studies we can see how heatmaps are being used to understand data structure [14] so for this work we use an internal heatmap generation to aid in the search of regions of interest.
The idea behind Heat Map Based Feature Ranker (HmbFR) is to estimate the predictive power of a feature given its association with others, an exhaustive feature combination is avoided under the rationale that high dimensional data usually keeps an intrinsic structure. Even if this order does not apply to all datasets, we consider the evaluation of features in groups of continuous features as a useful approach for high dimensional data.
The algorithm is composed of two main stages: compression and ranking. The core idea is to build groups of features and later evaluate their predictive power as a group to estimate individual feature power.
In compression stage, we build the heat map, which is a color representation of the data, in order to build it, a color model is required, since our design uses groups of 3 features, the RGB model is a perfect fit as it requires three channels, therefore 3 features
The first step for compression is the normalization isolated features, each of them is treated independently, to formalize this, let
Where
https://www.w3.org/TR/html4/types.html#h-6.5.
To formalize the information quantization, let
Once all the distances between true color and reference color have been calculated, we select the reference color
Dataset reduction is possible due to the fact that the reference color is represented by a single value (e.g. red, which is composed of RGB values of 255,0,0) instead of three different features, this compression makes possible to reduce the original dimension of any dataset to a third with very minimal loss of information, however although there is indeed a loss, this can be negligible as the data transformation is only used for the feature selection process, and the original information suffers no changes.
After compression is completed, ranking relevant features is based on the rationale that different classes should look different, hence their associated quantized colors should look different as well. The ranking occurs in the new compressed dataset, the process sees regular features
[b]
Dataset with full number of features Subset of best predictive features Normalize Data 0–255;
there are more features \\Compression
Save quantized 4-bit version of
HmbFR, Heat map based Feature Ranker
Since we are using a 16 color scheme to build the heatmap, each feature can have as much as 16 possible values (in the compressed space), to estimate its predictive power, we iterate over the color spectrum searching for different ratios in the conditional probability to find a color given a reference class. The score for each feature is then calculated as follows:
Where
After all features have been ranked, we need to restore the ranking to the original space as all the process was performed on the compressed data, however, the mapping process is very efficient as the groups were formed from continuous features, e.g., in the compressed space
To evaluate the usefulness of HmbFS we have prepared a series of tests through different datasets and compare multiple techniques for feature selection. In the next section, we discuss more in depth the results.
In order to estimate algorithms performance in high dimensional data, it is very important to find their order of complexity as some algorithms might not scale well, this results in useless approaches once the feature space grows out of a manageable threshold. Some algorithms exhibit orders of
Test scenarios for algorithm order behavior
Test scenarios for algorithm order behavior
We first analyzed how an increase in the number of classes affects the scalability of each algorithm, fixing the other parameters (instances and features) we increased only the classes, starting in 2 up to 10 to see the behaviour. The Fig. 1 shows the results.
Scalability behavior for class growth.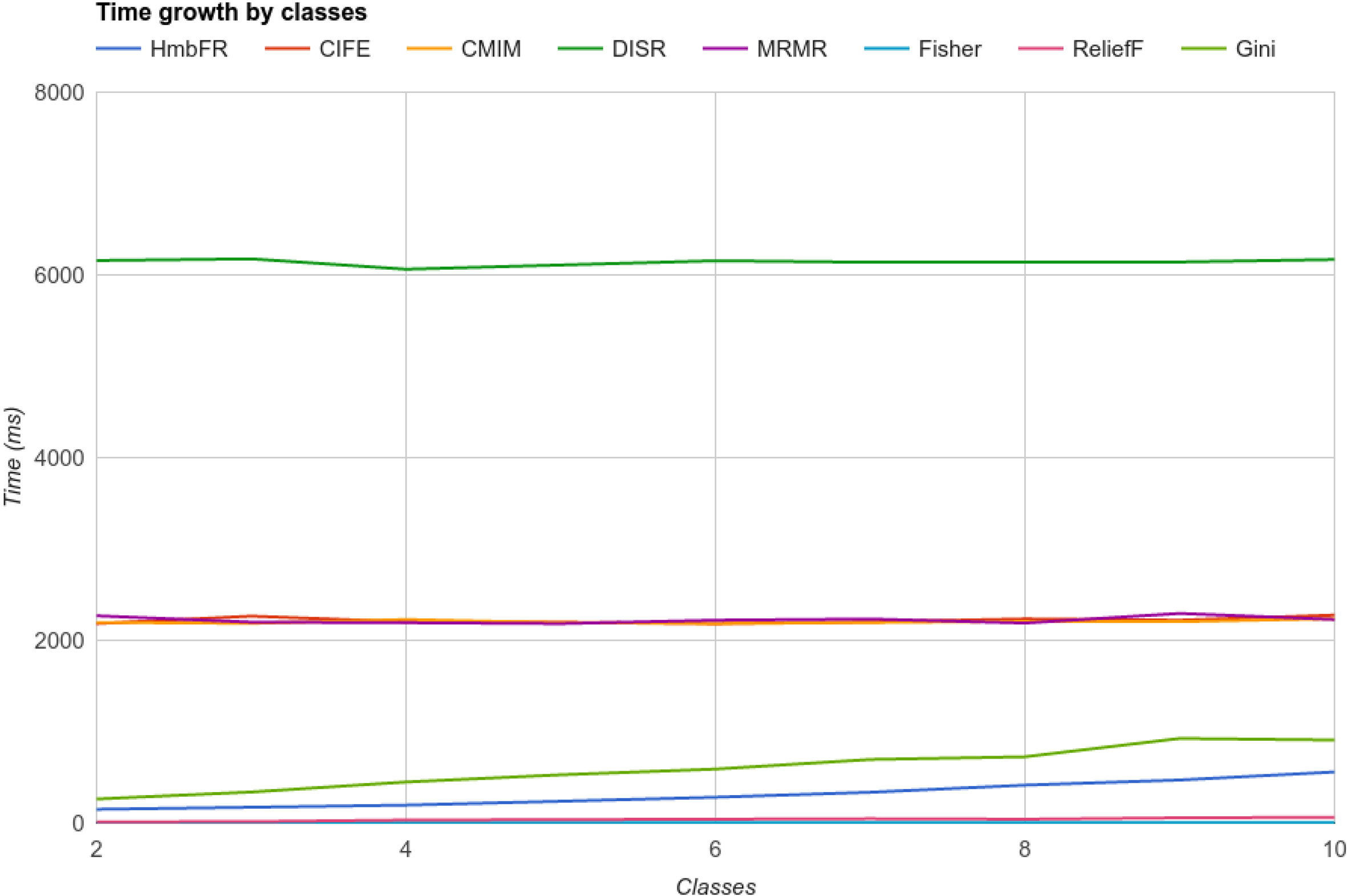
As we can see in Fig. 1, in terms of scalability due to increased number of classes, all reviewed algorithms handle the task very efficiently, at least complexity-order wise, we can identify 4 groups, DISR, which is not affected by class increase, but it’s quite slow, at least three times slower than other approaches such as CIFE, CMIM and MRMR all of which are not affected by class increase neither. A third group can be identified, Gini and HmbFR, both being slightly affected by class growth but not enough to fall even to a linear order scenario, finally a fourth group composed by ReliefF and Fisher, both performing very fast with no compromise in class size.
Next we continue with the analysis of sample growth.
Scalability behavior for samples growth.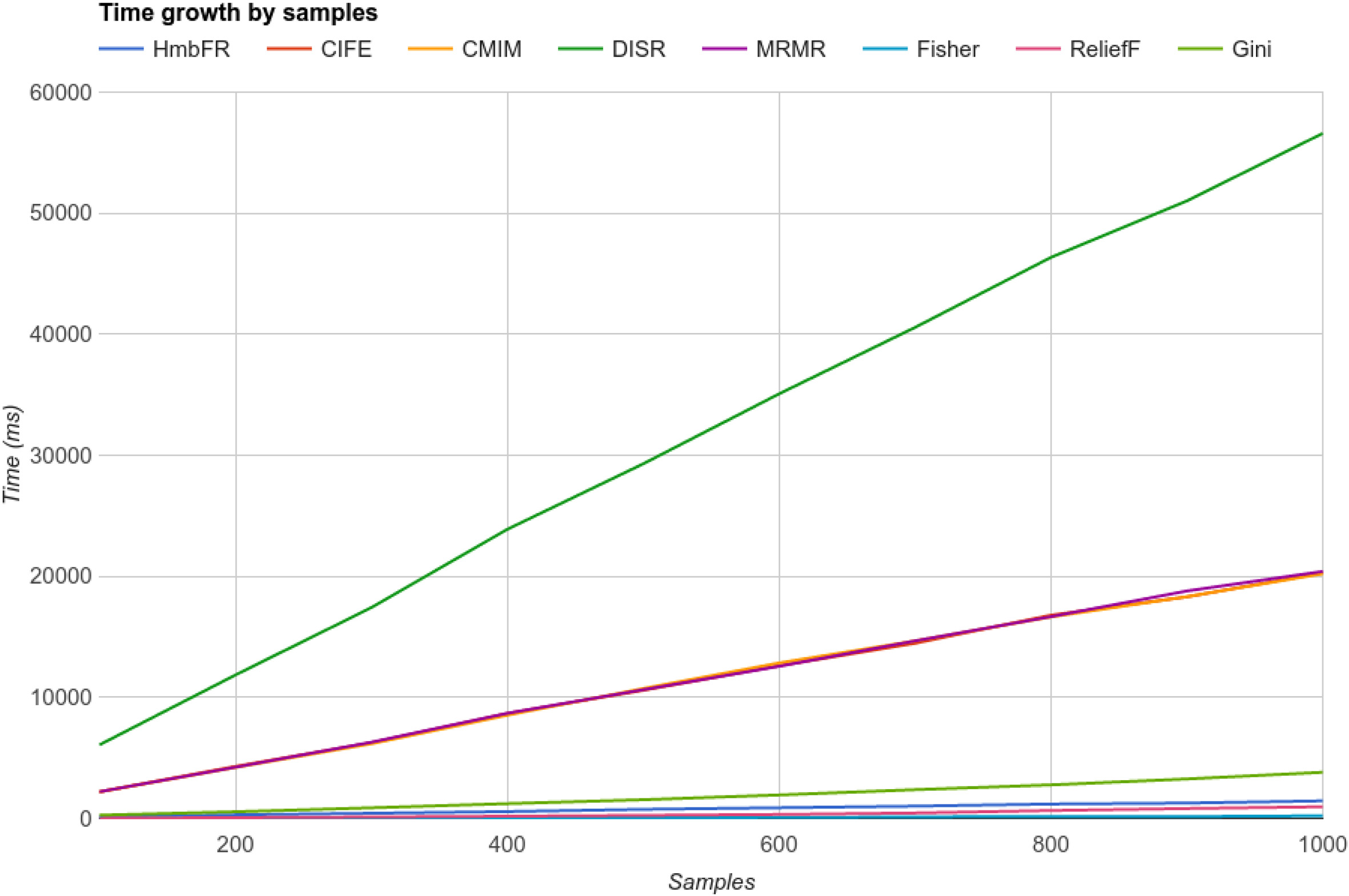
As far as samples increase, we can see in Fig. 2 most algorithms behave in a linear fashion, although some special cases need attention, once again DISR tops the time chart performing almost 300 hundred times slower than the fastest of the group, even scaling in a linear fashion. In terms of scalability issues, the worst scenario was for ReliefF which scaled at
Next, we review the case of features increase.
In Fig. 3 we can see the real issue with most algorithms, they scale at
Summary of scale behavior
Scalability behavior for features growth.
We can see that half of the algorithms (CIFE, CMIM, DISR and MRMR) do not scale well as the number of features increases, with an
Benchmark datasets details
In our experiments, most dataset easily exceed a thousand features, notable exception is the USPS dataset with only 256, but enough samples to cause troubles for algorithms such as ReliefF that scales quadratically with the number of samples. The need for more efficient algorithms is noticed more clearly when we consider high dimensional datasets such as GLI-85, with 22,283 features, trying to perform feature selection with algorithms such as DISR would be an infeasible task. We also include the feature to samples ratio to give an idea how disparity those values are, generally we would want more features if and only if those features are useful, otherwise, the less noise the better. To estimate how noisy the dataset is, we include the anomaly score as reported by IsolationForest [24] algorithm.
The benchmarking process consists of performing feature ranking for each dataset followed by a Stratified 10-fold cross validation that ensures class imbalance is considered in every fold. The whole process is repeated 10 times, every time using 10% fewer features (removing the less powerful ranked), this is done for 3 different classifiers as some datasets might favor a given learner. In total 300 setups are evaluated for every dataset using an F1 weighted (i.e, for each class) score to consider precision and recall in a single metric as Eq. (12) shows:
The Scikit-learn classifiers, as well as running parameters are being shown in Table 4.
Classifiers setup
The only parameter we carefully tuned was the number of estimators (or trees) for RandomForest using the formula in Eq. (13):
The rationale behind variable number of trees is that bigger and complex data sets usually need a higher number of trees, however, a higher number can be counterproductive for smaller scenarios and could lead to overfit.
In the following section, we present our analysis for each of the benchmarked dataset, as well as statistical significance analysis, this is done by comparing to a progressive linear reduction (PLR) algorithm, which only reduce features with no analysis involved, just linearly select a given amount. A t-test is performed against the PLR algorithm and the p-value is reported.
After feature reduction is completed, we take advantage of the smaller dimensionality dataset to enhance data representation. Given our reduced noise, we now use a 3 PCA vector representation that is being feed to an emergent self organized map (ESOM) [36] which will find a nonlinear representation in an unsupervised way that should provide an extra insight of dataset structure after noise has been reduced using only Top 10% of features as reported by HmbFR.
The Carcinom dataset has the most number of classes of our tests with 11, and with the only exception of the class 0, all others are nonlinearly separable in our 2D PCA representation as it can be seen in Fig. 4.
For this particular dataset Logistic Regression performed the best, achieving better performance across all number of selected features, these results can be seen in Table 5. Starting with a baseline score of
Logistic Regression for Carcinom
Logistic Regression for Carcinom
Carcinom visualization.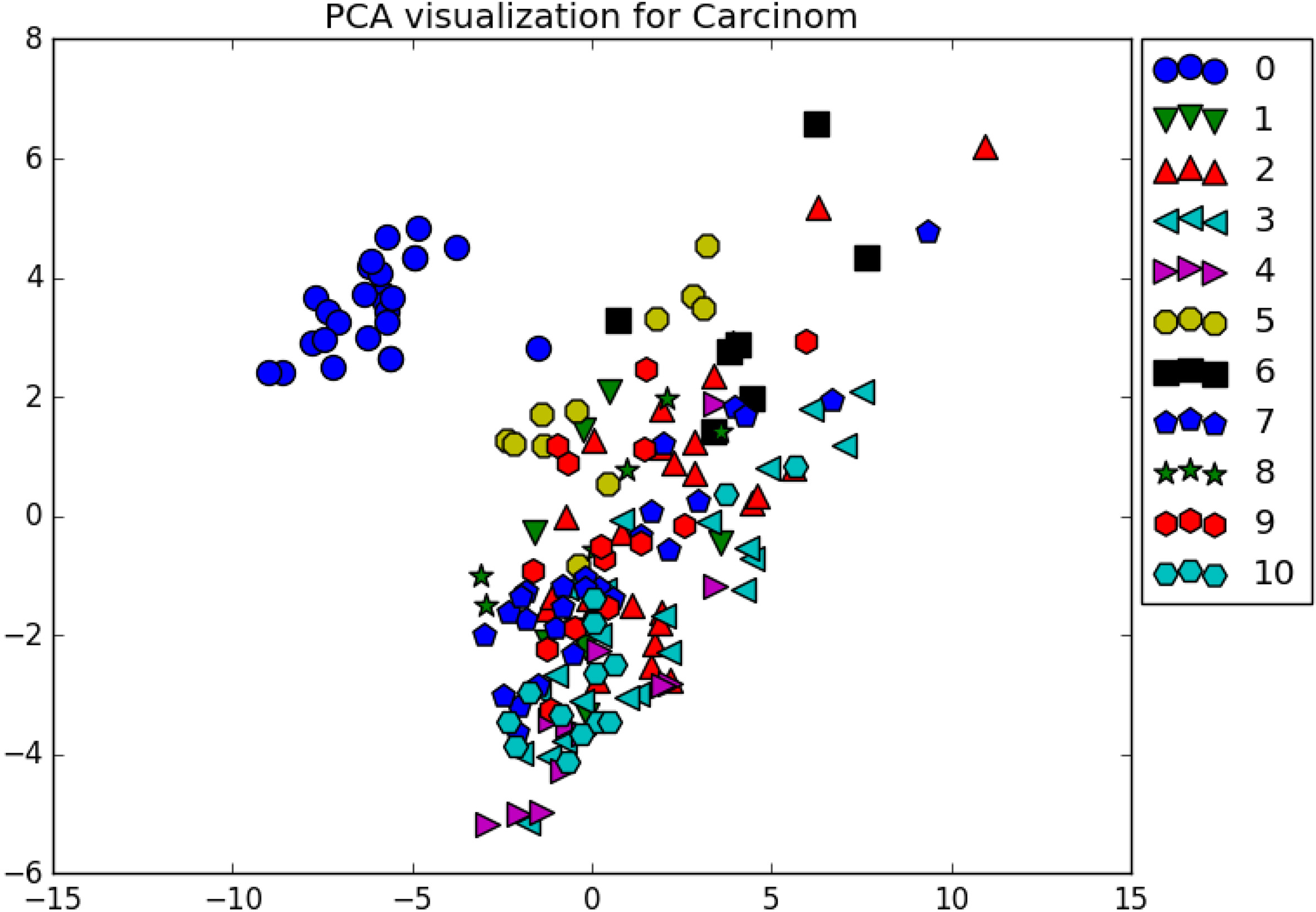
Carcinom reduced features SOM plane.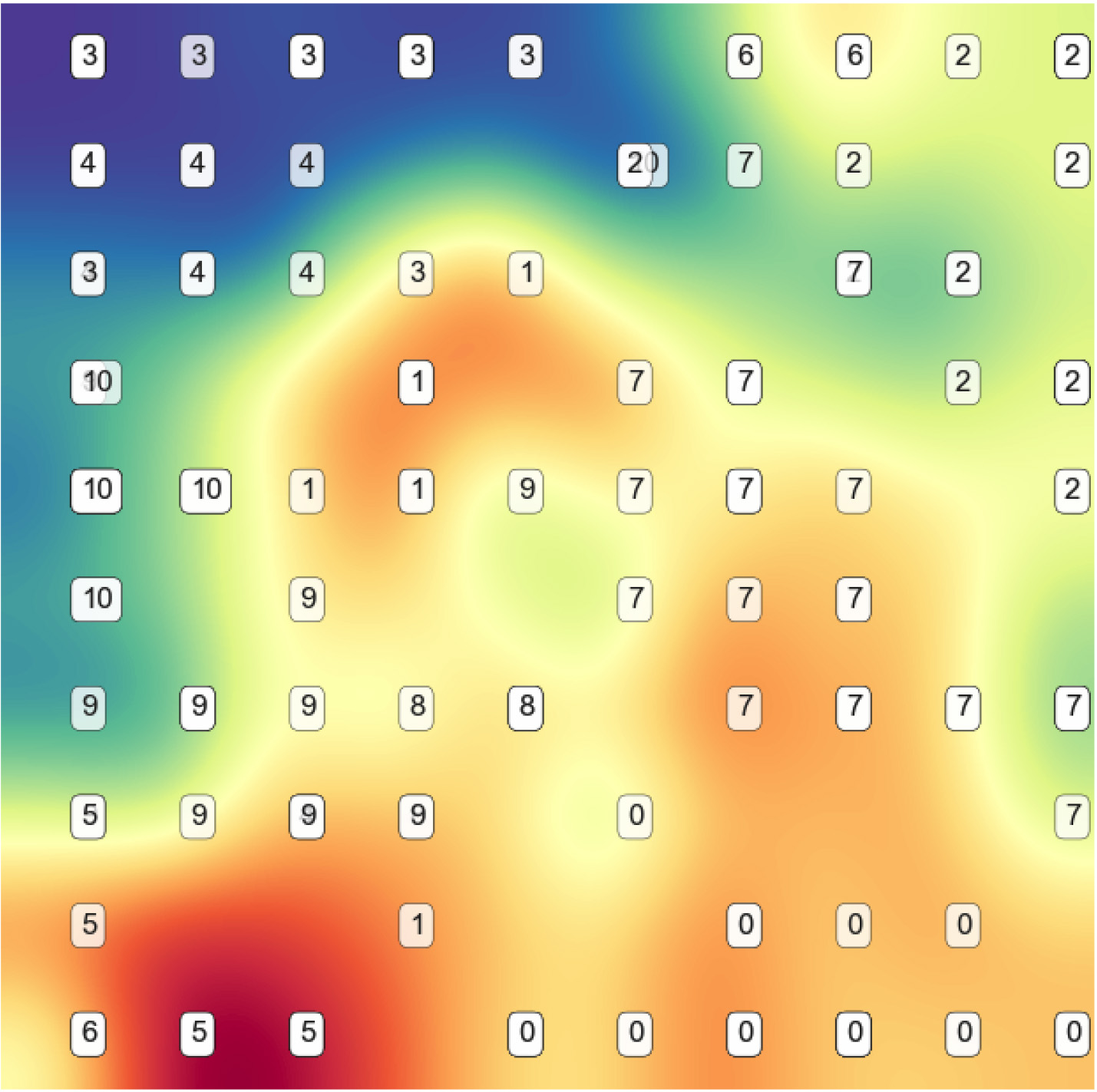
Colon visualization.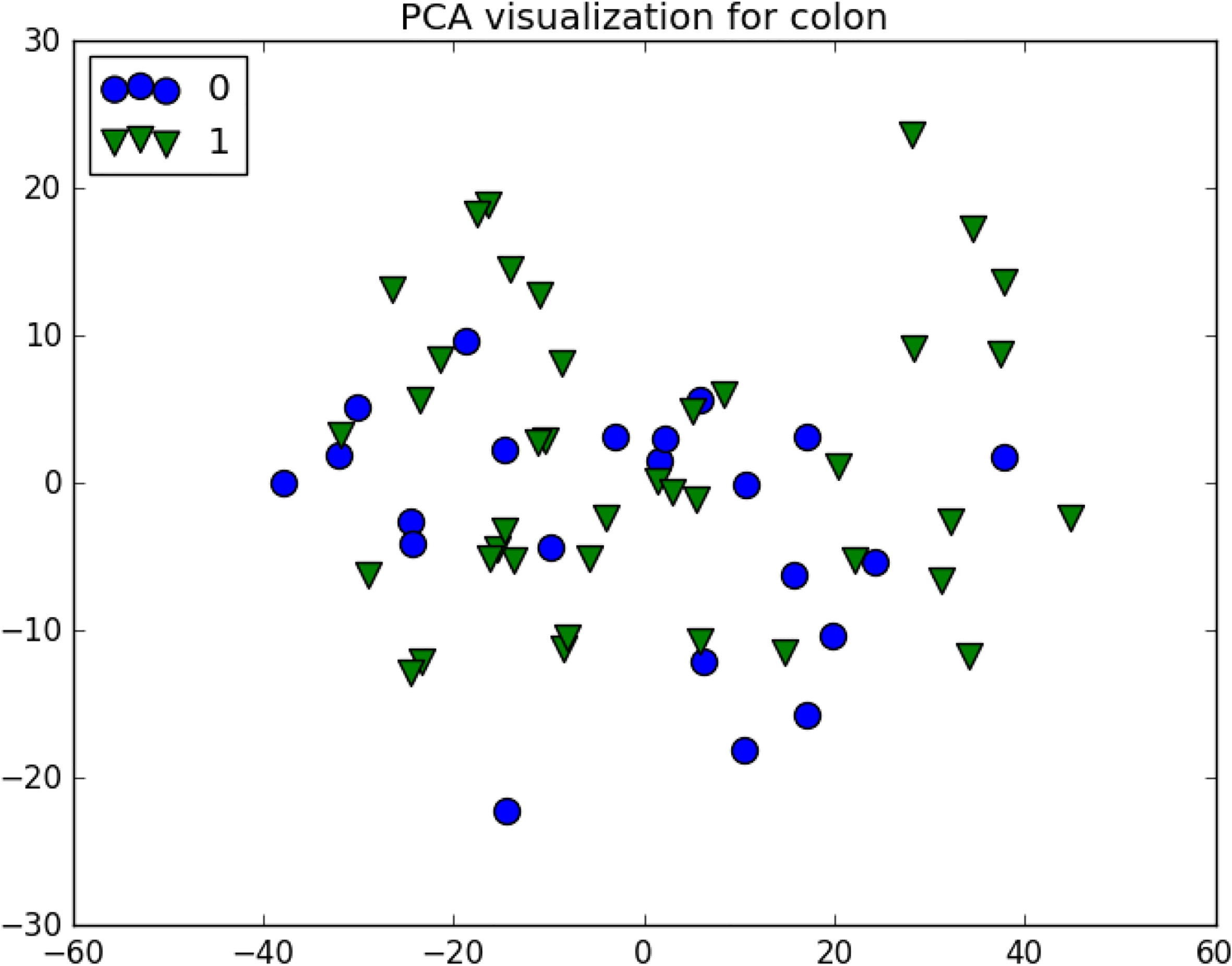
Using only 10% of the original features, it was possible to improve in 2% the baseline model, although at minimal improvement, we can see in Fig. 5 that the ESOM plane makes much better job at separating the instances while still maintaining a similar structure, for instance, classes No. 5 and 0 are very similar spaced as they were in the original PCA plot but now have better margins vs other classes.
The colon dataset looks simple to separate (see Fig. 6), a single decision tree might do a very good job on its own, and with only two classes its not surprise that Random Forest performed the best in this scenario.
An interesting result (Table 6) arise from the colon dataset, all algorithms achieved a very high p-value, meaning that for this dataset with so few features (2000), feature reduction might be trivial, ReliefF and HmbFR achieved the best peak result with 0.865 and 0.851 although HmbFR seems a bit more stable with a better average score. Fisher and Gini performed poorly in this task with a score even lower than PLR.
Random forest for colon
Random forest for colon
Colon reduced features SOM plane.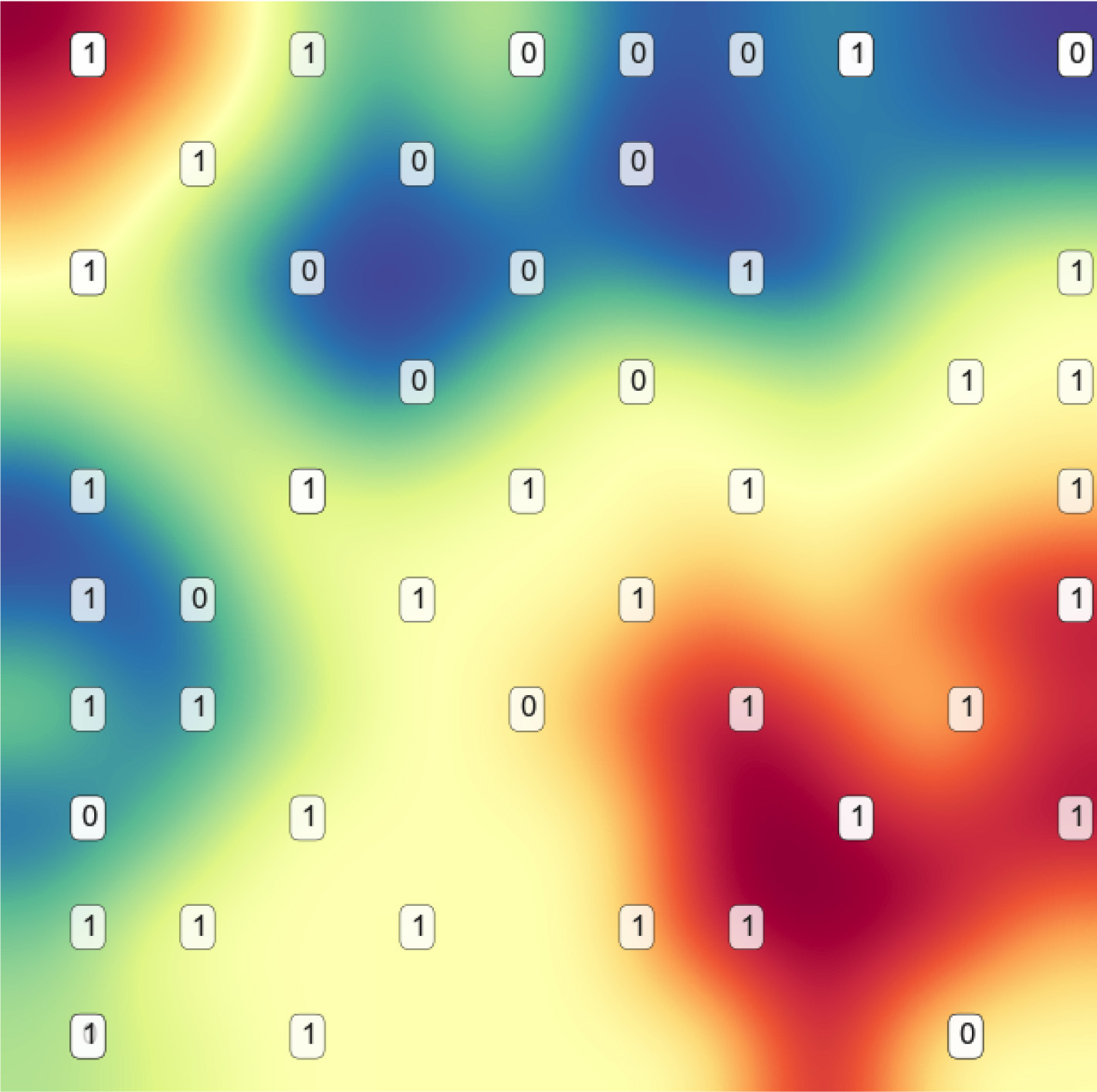
With a 3% improvement in model performance, and after removing 90% of the original features, the visualization of the Colon dataset is dramatically improved by the ESOM plane, while the PCA plot hardly separates the classes, the new representation shows a clear separation as seen in Fig. 7.
The GLI-85 dataset has the most potential for feature reduction, given the over 22,000 features and the dataset characteristics, it seems some parts of the data are linearly separable as we can see in its PCA visualization in Fig. 8.
As expected from the PCA analysis, all algorithms seems to be improving classification performance when Logistic Regression is used (Table 7), the reductions are very good, using only 10% of the original features (
Logistic regression for GLI-85
Logistic regression for GLI-85
GLI-85 visualization.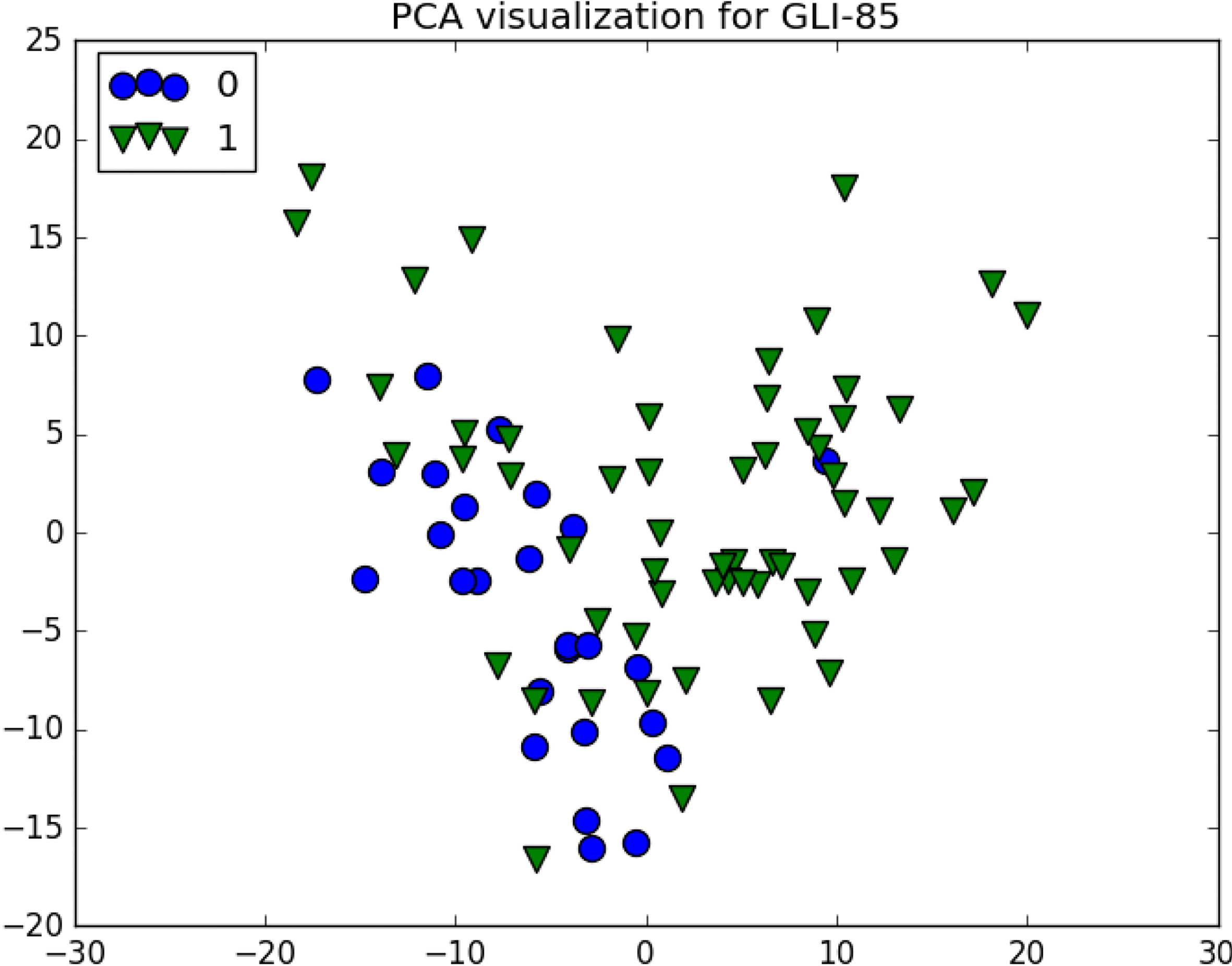
Using only 10% of the original features helped to boost the model performance 4%, the dataset is a bit unbalanced in favor of positive class and so can be noticed for both the PCA and the ESOM plots. However, after reduction, we can see a much clearer representation, although some outliers are still present as seen in Fig. 9.
GLI-85 reduced features SOM plane.
The Glioma dataset represents a huge challenge for feature selection, as there are way too many classes (4) for a very small number of samples (50) as it can be seen in Fig. 10, to make the scenario worse, the classes are all merged with no apparent linear separability.
According to p-values in Table 8, Fisher is the more likely to be different than the simple PLR, however it felt short as peak performance regards, running behind Gini and HmbFR with 0.821 and 0.815 however, each algorithm reached that score with a very different set of features, while Gini required 90% of the original space, HmbFR used only 60%. The average score is improved for all algorithms vs PLR.
Random forest for Glioma
Random forest for Glioma
Glioma visualization.
For the Glioma dataset, best reduction threshold seems to be around 70% of original features, however, to help reduce potential noise, we still keep only 10% of the data for build the ESOM planes, in this case, using 443 features which still provides an improvement vs the base model. From the original PCA plot, we can see classes 0 and 1 are overlapped as well as 2 and 3. However, in the ESOM plane, we can a see a more clear separation as shown in Fig. 11.
Glioma reduced features SOM plane.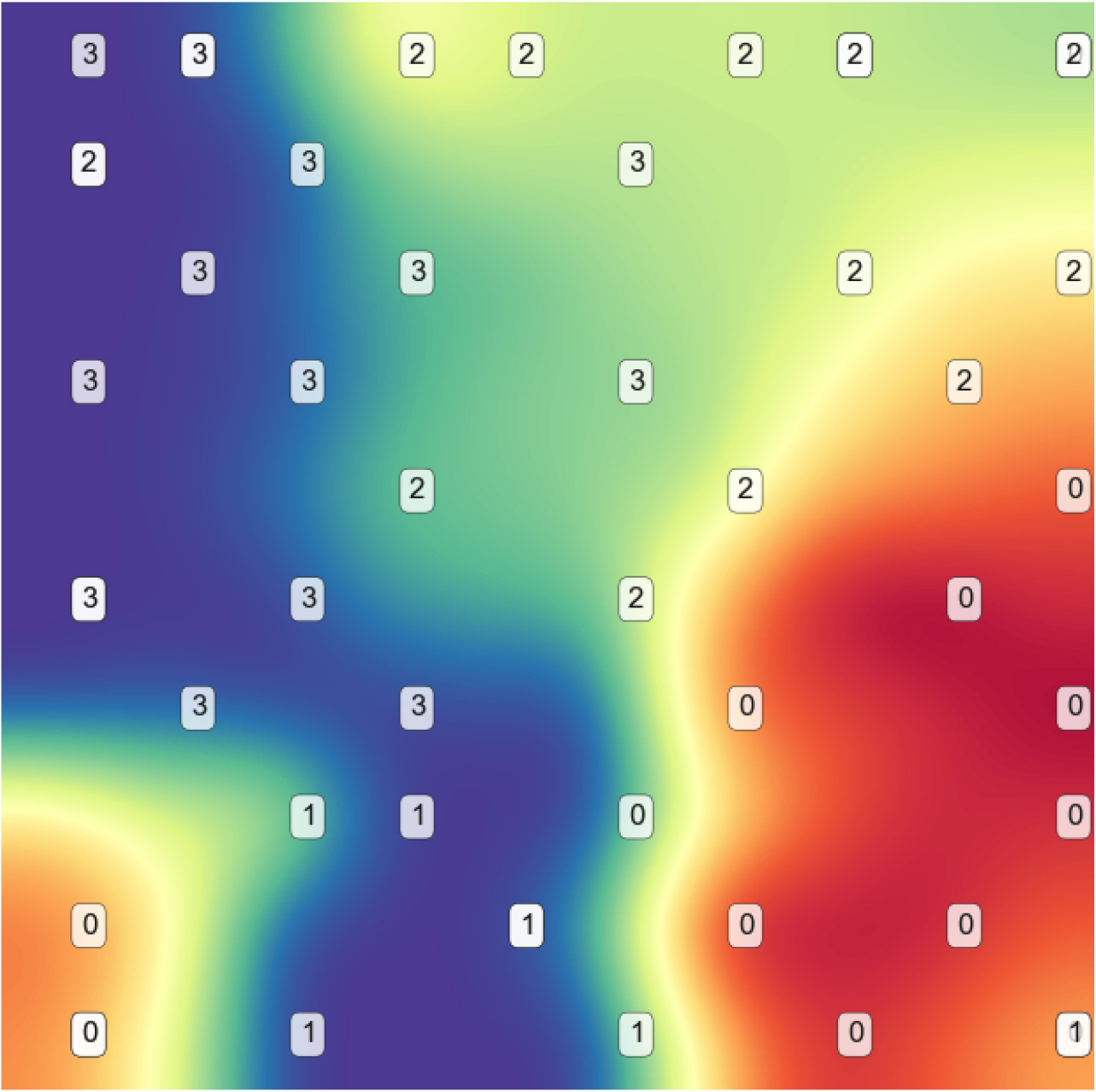
The Leukemia dataset looks complex for feature selection, with 72 instances and over 7,000 features, the chances of overfitting are huge, however as we can see from the PCA plot in Fig. 12, the data does not seem too hard to separate.
Leukemia visualization.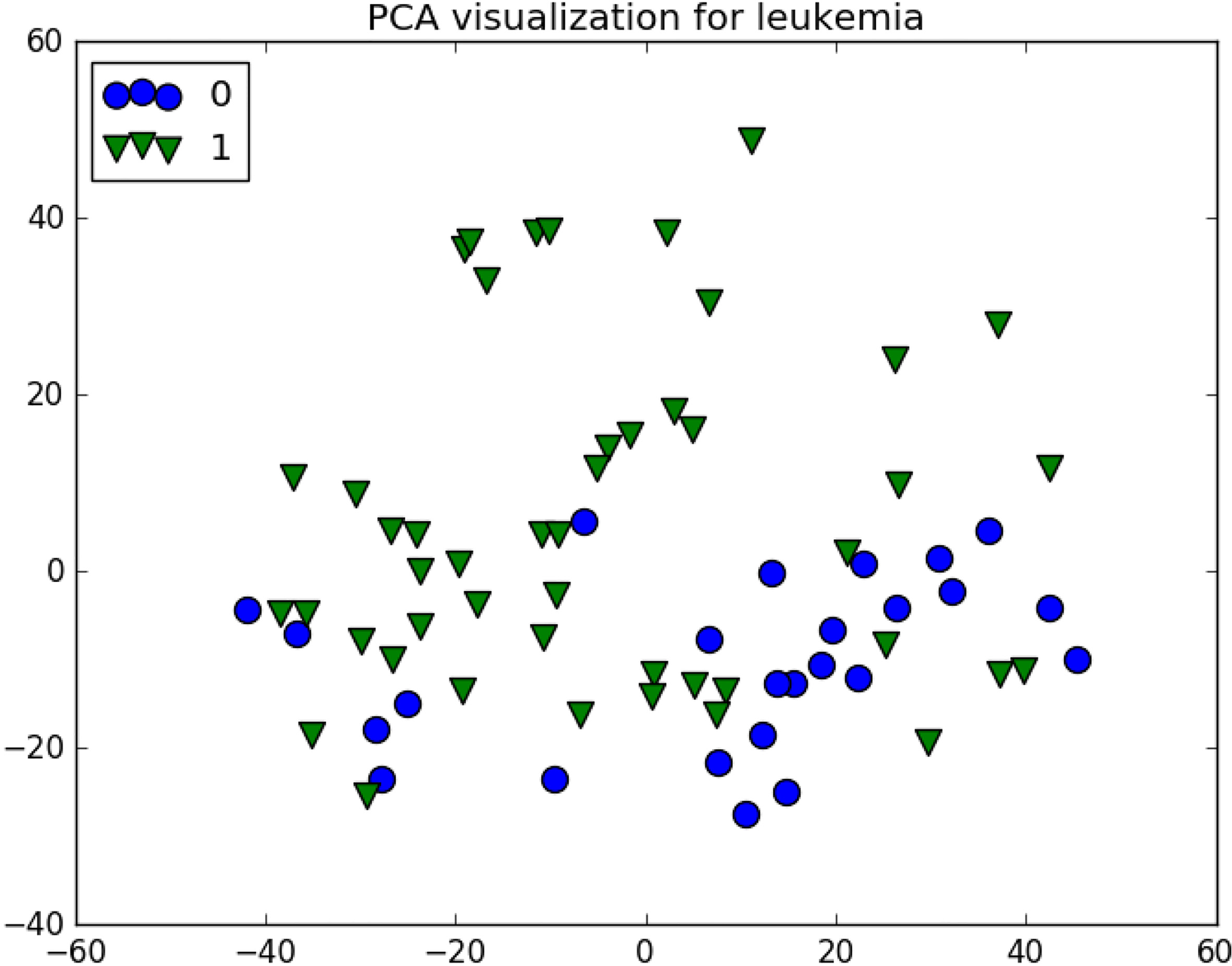
For this particular dataset Random Forest performed the best, with an impressive baseline performance of over 0.93 without any feature selection as shown in Table 9. It seems that the practical best possible score is 0.981 as all algorithms stuck in that mark, the PLR, in this case, performed way lower than the benchmark algorithms, all of them producing a much higher average score.
Random forest for Leukemia
In this dataset the classes are overlapped due to structure complexity, but also imbalance, a 3% increase in model performance is achieved after using only 10% of the original features, this reduction is also beneficial to visualization, as we can see in Fig. 13, although some overlap still exist, there is a better separation overall.
Leukemia reduced features SOM plane.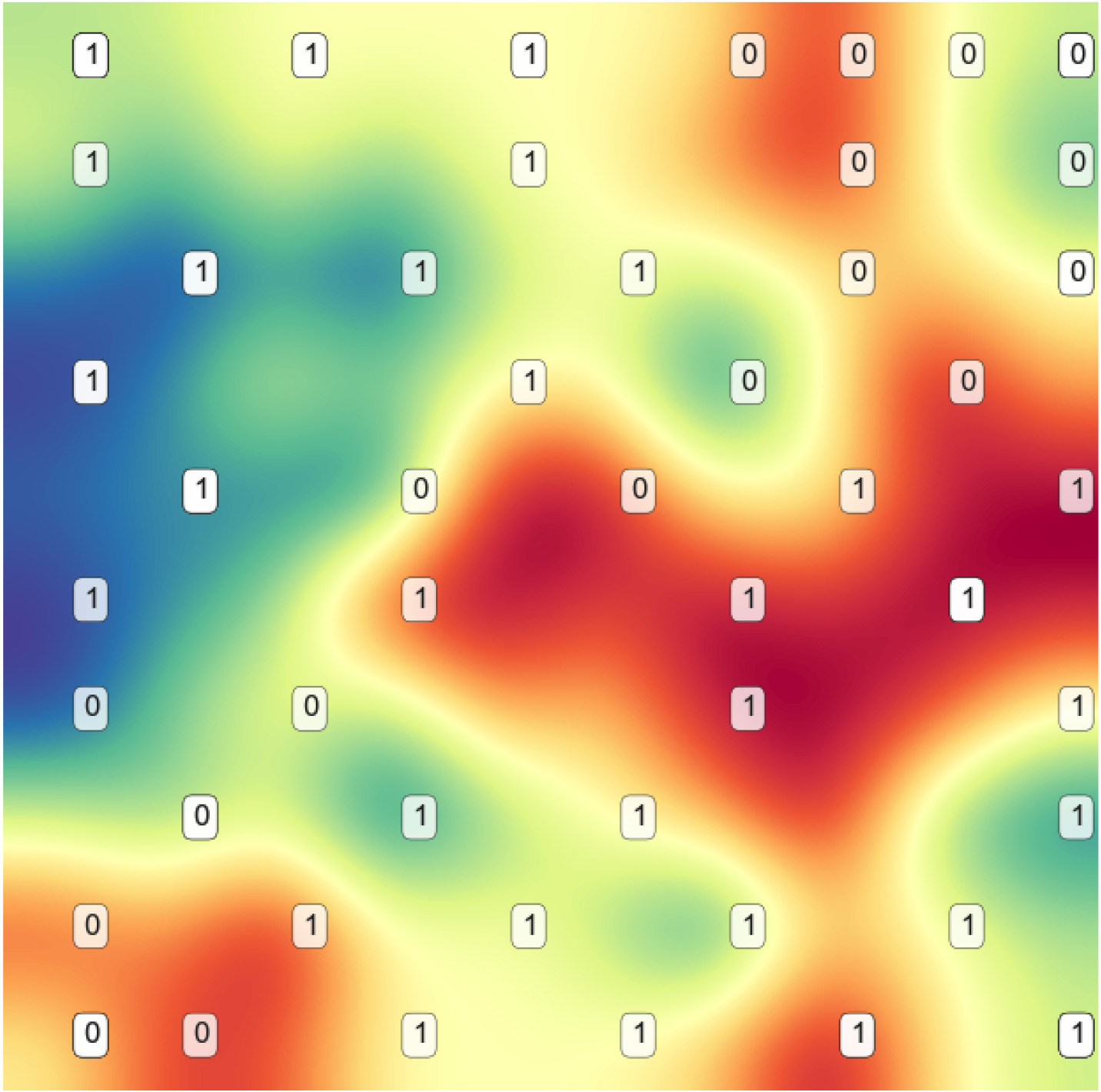
The Lung dataset is a challenge because it has many classes for a relative number of samples and features, in this particular case, more features would have benefited the data in order to improve separability especially for class 0 and 4 as can be seen in the PCA representation in Fig. 14.
After analysing results presented in Table 10, it seemed that the best practical score could be 0.976 as three algorithms stuck in such mark, however HmbFR managed to find a combination of features capable of 0.98, interesting enough, this combination is also with a smaller set of features of only 10% of the original data, the closest competition comes from Fisher, performing not only slightly less powerful but also requiring 60% of the original data. Averages and p-values are low enough across all methods.
Logistic regression for Lung
Logistic regression for Lung
Lung visualization.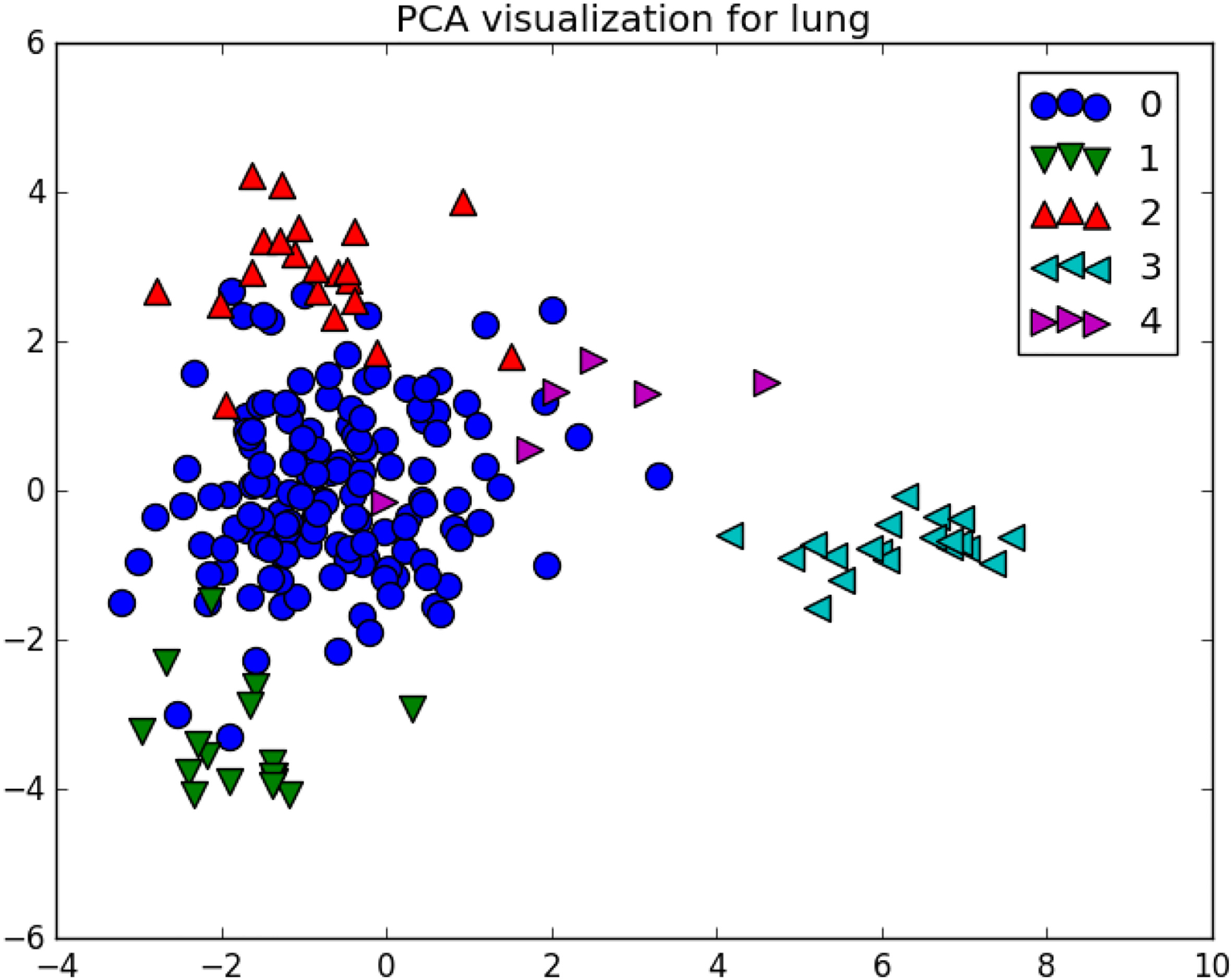
In this particular case HmbFS using only 10% of the features achieved the best overall performance, which can be a signal for very high improvements in visualization, starting with the original PCA, we can see class 0 dominating the plot and causing heavy overlap. In the ESOM plane (Fig. 15), the class separation is dramatically improved, for instance, class 1 and 0 that were previously overlapped now are fully separated.
Lung reduced features SOM plane.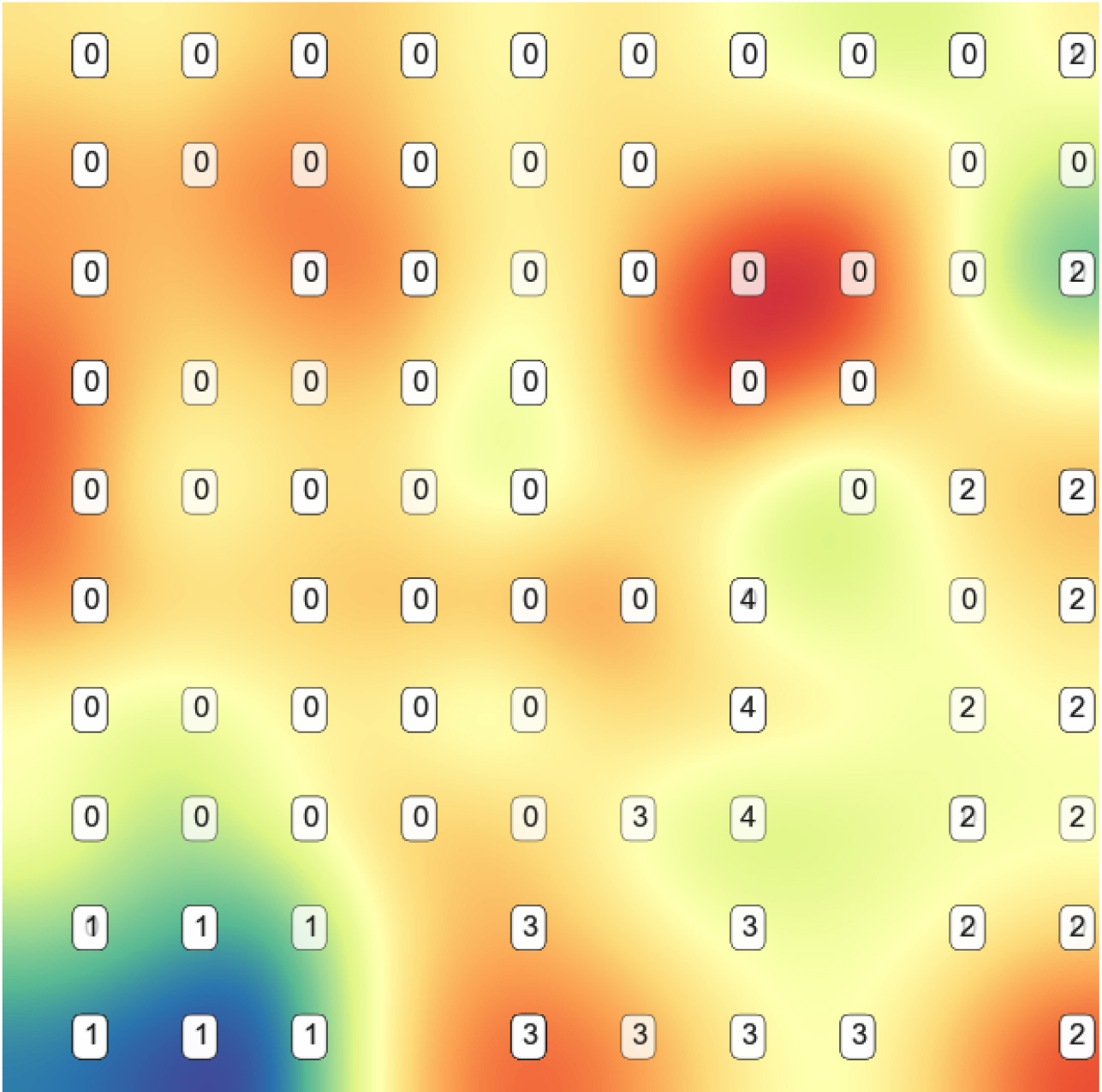
This dataset, being constructed by face images adds a new scenario for the benchmark, using pixels as features, the ORL face data has over 10,000 features to describe 10 classes (persons). The PCA analysis in Fig. 16 suggests that there is indeed some linear separability.
ORL raws 10p visualization.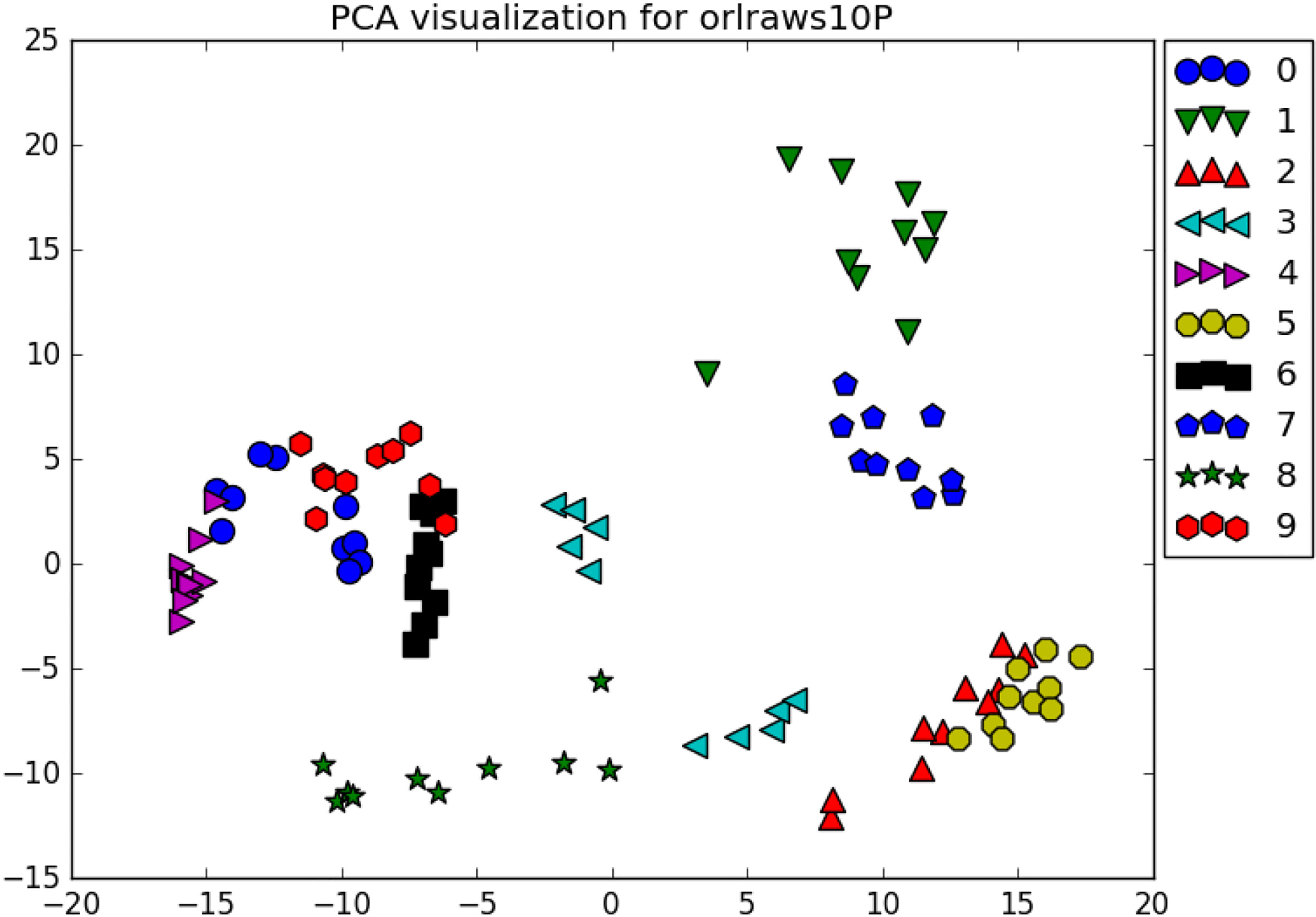
As expected from the data overview, it can be easily separated even without feature selection for a very powerful 0.967 baseline score as shown in Table 11. Notable, all algorithms managed to find a subset of features that improved such score, best two were HmbFR and Fisher, improving the recognition by 2% or in some cases a perfect F-Score by Fisher, the p-value, however, is much lower for HmbFR which seems to produce more stable results.
Logistic regression for ORL
Given the very little class overlap for the ORL dataset, improvement in model performance was limited to only 0.6% when using 10% of best features as ranked by HmbFR. The ESOM produced an overall good structure visualization as seen in Fig. 17, however, for this specific case, the PCA plot seems to provide a better overview, a signal that feature reduction might not always give an improvement.
ORL reduced features SOM plane.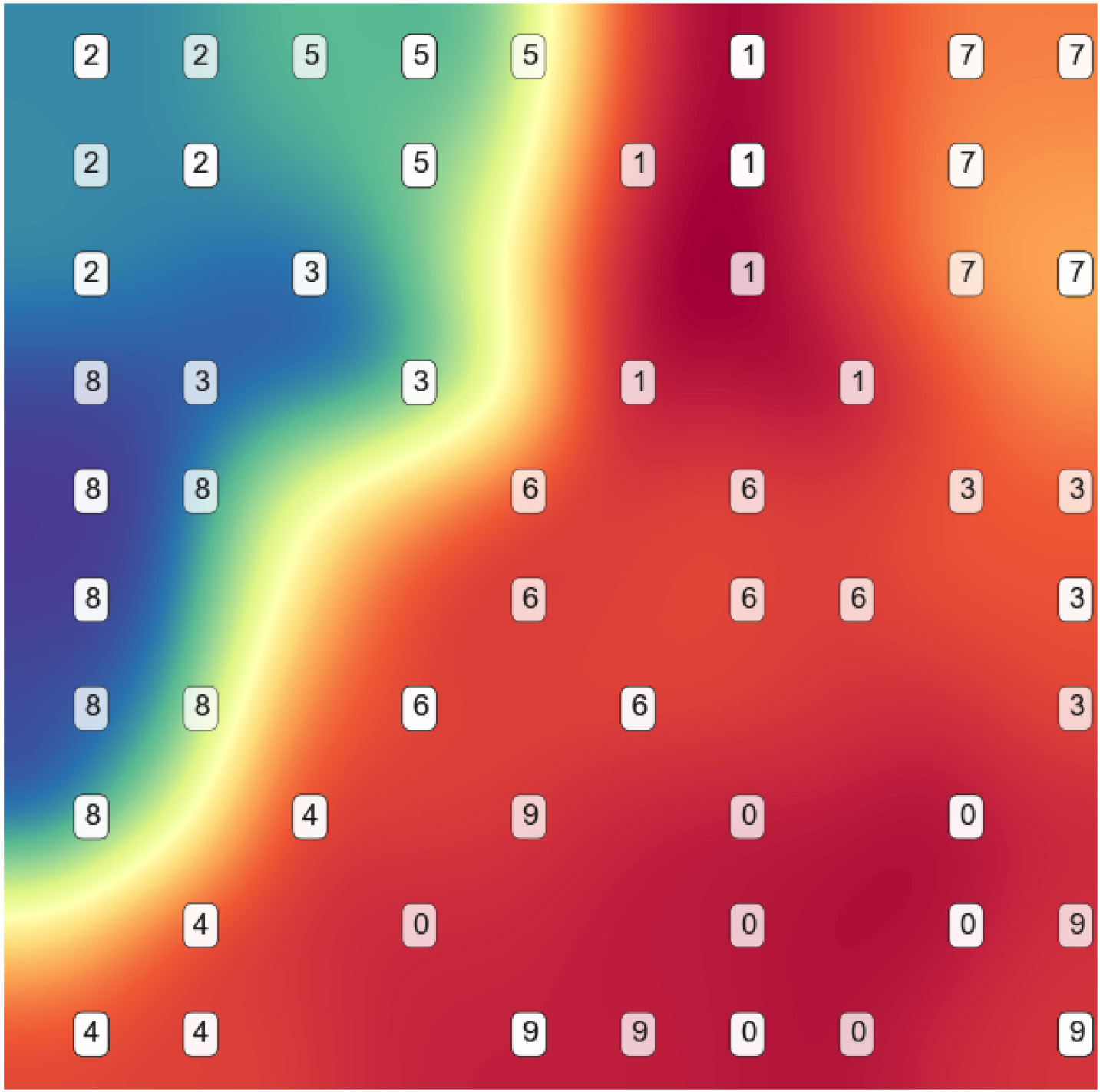
The prostate dataset has enough features to separate the binary classes with a very good performance as seen in Fig. 18, however, since some samples have heavy overlap, it is possible to reach a point where improvements become very hard.
For this datasets, all algorithms achieved a very low p-value as the baseline PLR performed very poorly doing progression reduction as shown in Table 12. It is worth noting how from 100% to 60% of features, most algorithms kept the original performance, except ReliefF which produced a good performance improvement. Best two approaches were HmbFR and ReliefF, with 0.939 and 0.95, both of them achieved such results with a very low number of features, 20% and 10% respectively.
Logistic regression for Prostate-Ge
Logistic regression for Prostate-Ge
Prostate GE visualization.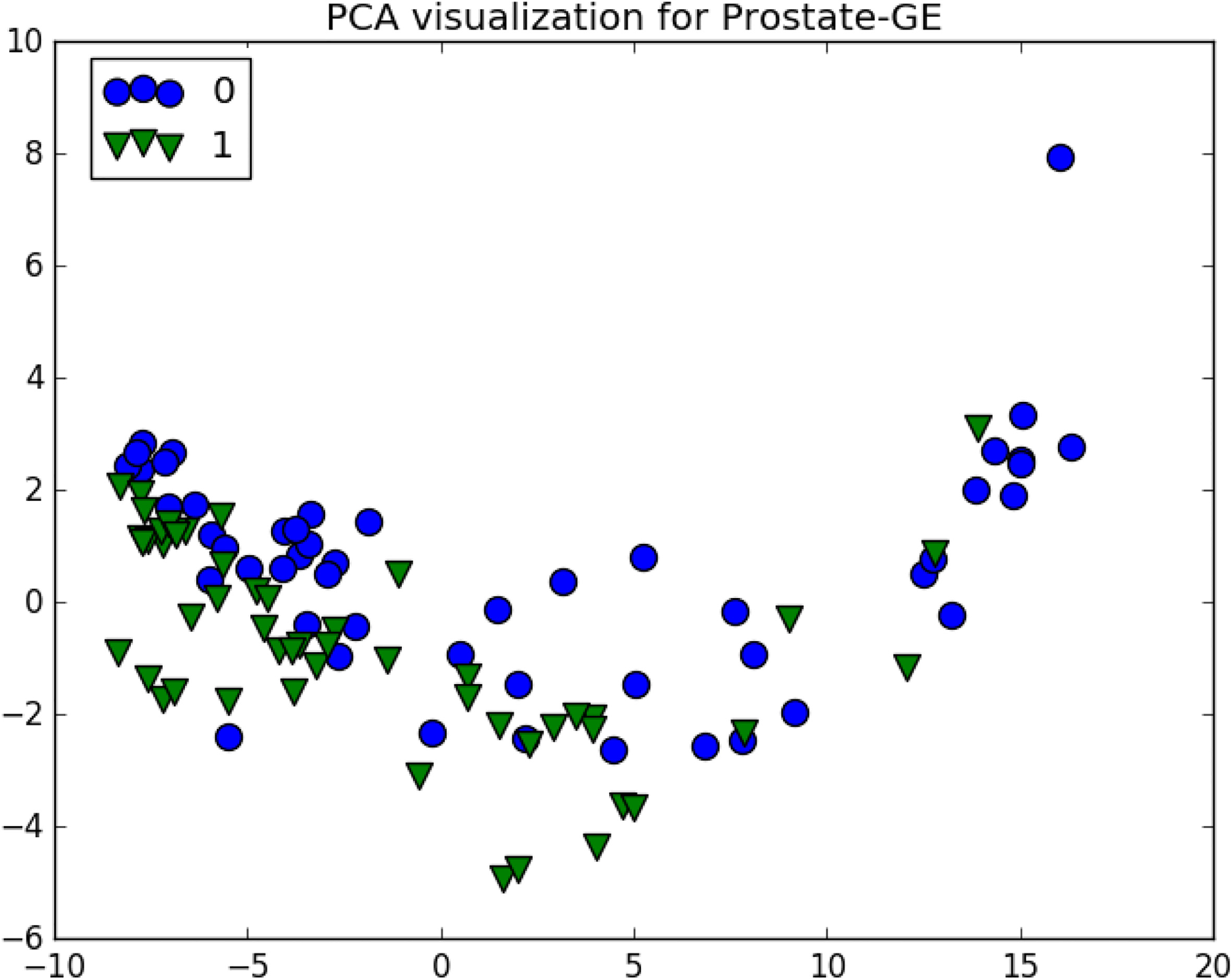
The prostate dataset gained around 2% when a 90% of features got removed, based on the original PCA representation, both classes are heavily merged, however in the ESOM plane as can be seen in Fig. 19, there is a very clear separation of classes with very minimal overlapping.
Prostate reduced features SOM plane.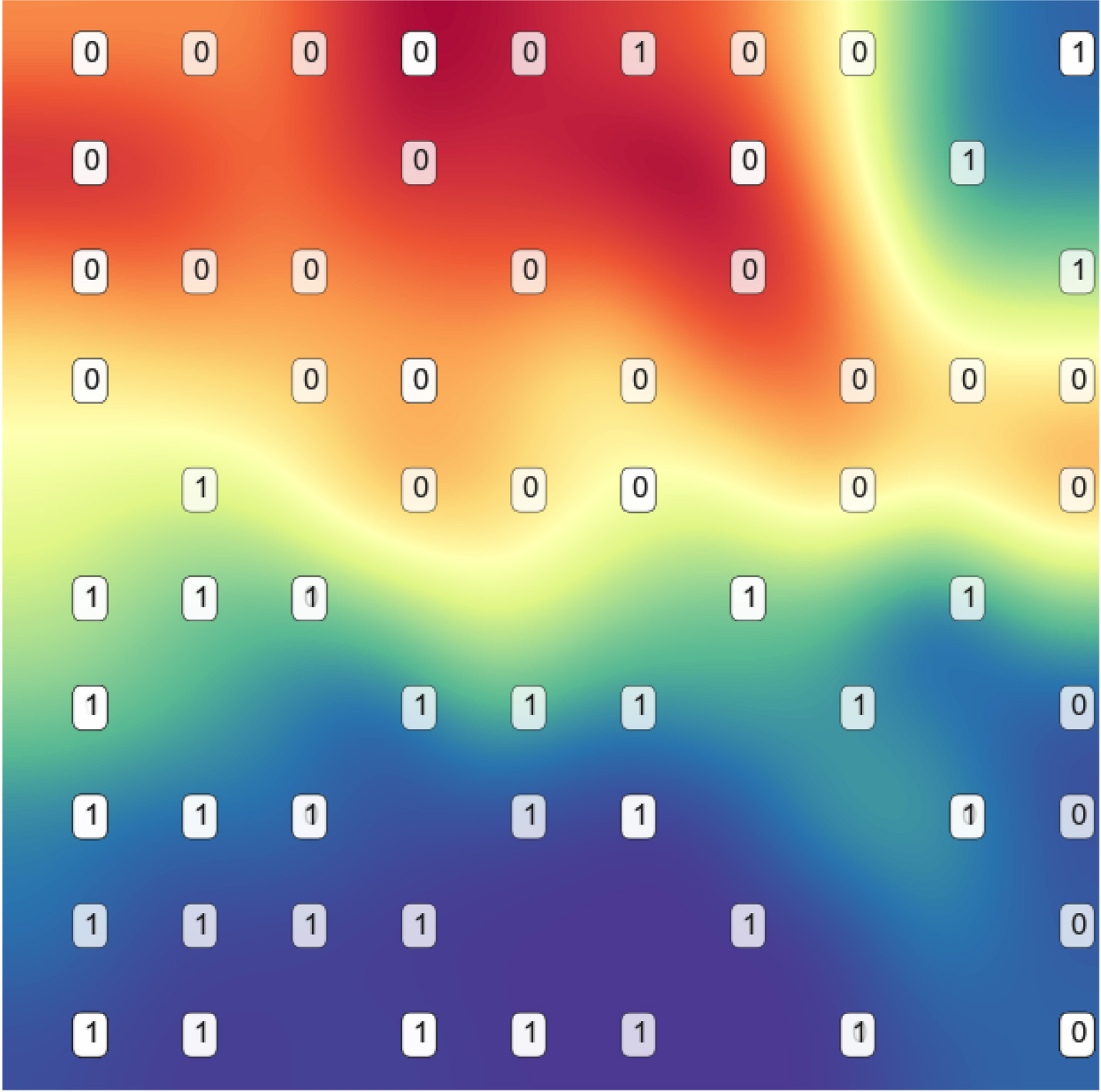
Just by looking at the PCA plot in Fig. 20, the USPS dataset is clearly a nice add-on to the benchmarks as it is very different, having almost 10,000 samples of hand written digits with a 16
USPS visualization.
For this particular dataset, it was possible to achieve 0.945 using Logistic Regression and 0.961 using Random Forest (RF), however, after using feature selection (FS) the results only got worse, although HmbFR achieved as high as 0.851 with RF using only 10% of features. For this analysis, we selected Naive Bayes (NB) as it indeed benefits from FS as we can see in Table 13. From the results table, it is clear how feature reduction is not trivial, PLR achieved scores as low as 0.327 where other techniques such as HmbFR using the same 10% of features achieved 0.685. Gini performed poorly in this case, while the two best were HmbFR and ReliefF, both of them with improvements over 8% and interesting enough, both of them achieved the peak performance with the same number of features at 50%.
Naive bayes for USPS
USPS reduced features SOM plane.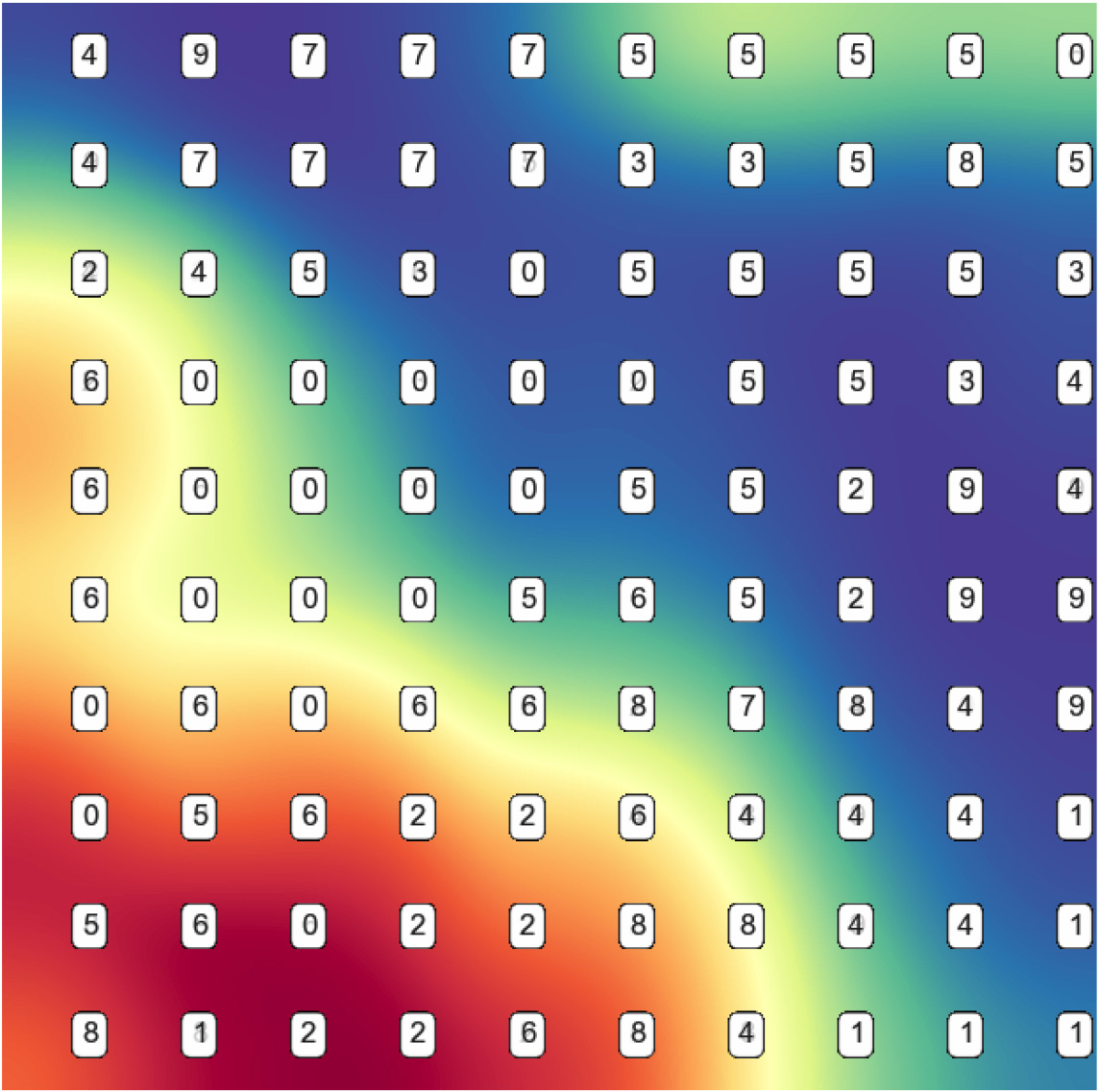
The USPS dataset is our biggest data in term of instances but the smallest in term of features, which means that most instances look very similar, and are all overlapped at least in a 2 dimensions space, after reduction to only 26 features and then building the ESOM plane (Fig. 21), the data seems a bit better represented but not enough to overcome the extra processing required.
Looking at the data it’s clear that linear separability is challenging, with so many classes and no apparent cluster regions as all classes are mixed together as we can see in Fig. 22, feature selection algorithms will be required to careful rank the features.
For this particular dataset, Logistic Regression performed a bit better, however, no useful conclusion could be made as feature selection (FS) did not provide any improvement, however, for Naive Bayes, the improvement is clear and low p-values support this improvement (see Table 14). Best algorithm was HmbFR with a 0.963 score, improving 3% over the baseline without FS using only 20% of the data, another notable result comes from Fisher, with a 0.955 score although using 30% of data.
Naive bayes for Warp pie 10p
Naive bayes for Warp pie 10p
Warp pie 10p visualization.
In this case, the original 2-dimensional representation is highly overlapped, as a similar scenario as USPS, however in this case, with much more features, noise reduction was actually beneficial, improving 2% with only 10% of the original space. The ESOM plane in Fig. 23 shows a huge improvement over the original data representation even when it shows some minor overlap.
Warp reduced features SOM plane.
Nowadays, we have powerful classifiers with built-in feature selection, however, for high dimensional spaces, there is still a lot of work to be done. As shown in our experiments, feature selection algorithms are pushing the performance of the classifiers in every case.
Based on our results, it is clear that the problem of feature selection is still dependent on the data structure, and there is no single best algorithm, however, for our particular setup, it seems that HmbFR and Fisher are more stable across different setups while Gini did not perform well with these datasets.
In general, our approach proved to be competitive with current algorithms while ranking in a compressed space and no evaluation of individual features required.
Data visualization is also an added benefit of feature selection, once space is reduced and only the best features are kept we are able to build more exhaustive dimensionality reduction techniques such as emergent self-organizing maps which proved to be a very effective approach.
Regarding our feature work, we can divide our efforts into two main paths, performance and enhancements. First, with the surge of powerful GPU, our heat map generation is a good fit for intensive parallelization which would allow stacking of heat maps to improve performance. Second, in sensitive applications, the raw performance improvement is negligible if it can not be properly explained, therefore given algorithm design, we plan to use our heat map as a visual aid to integrate Human-in-the-loop (HITL) in the selection process.
Footnotes
Acknowledgments
Conacyt – Maestria y Doctorado en Ciencia e Ingenieria.