
Abstract
It is easy to lead to poor generalization in machine learning tasks using real-world data directly, since such data is usually high-dimensional dimensionality and limited. Through learning the low dimensional representations of high-dimensional data, feature selection can retain useful features for machine learning tasks. Using these useful features effectively trains machine learning models. Hence, it is a challenge for feature selection from high-dimensional data. To address this issue, in this paper, a hybrid approach consisted of an autoencoder and Bayesian methods is proposed for a novel feature selection. Firstly, Bayesian methods are embedded in the proposed autoencoder as a special hidden layer. This of doing is to increase the precision during selecting non-redundant features. Then, the other hidden layers of the autoencoder are used for non-redundant feature selection. Finally, compared with the mainstream approaches for feature selection, the proposed method outperforms them. We find that the way consisted of autoencoders and probabilistic correction methods is more meaningful than that of stacking architectures or adding constraints to autoencoders as regards feature selection. We also demonstrate that stacked autoencoders are more suitable for large-scale feature selection, however, sparse autoencoders are beneficial for a smaller number of feature selection. We indicate that the value of the proposed method provides a theoretical reference to analyze the optimality of feature selection.
Introduction
Feature selection is called feature subset selection, i.e., N features are selected from the existing M features to optimize the specific index of system. Certainly, feature selection is also considered to be the process of selection some of the most effective features from the original features to reduce the dimension of data set [1, 2]. As is known to all, feature selection removes redundant and irrelevant features in data, thus suffering the less negative impact from the curse of dimensionality [3]. Particularly, in classification tasks, feature selection increases the precision of classification, so that the information for key features can be better understood [4]. Meanwhile, these useful features retained by feature selection are also used for subsequent learning tasks [5, 6]. As a result, feature selection has great importance effects on machine learning.
In many applications, data sets are usually rich features. Feature selection, aiming to select the most discriminative or informative features from data sets, is a hot topic in recent years [7–10]. There is two major challenges of feature selection. One is that the representation of data distribution in high-dimensional space requires a sufficient number of information [11], while data in high-dimensional spaces distributes too sparse to afford rich information. The other is that there exists an exponential searching space due to high dimensionality, i.e., the cruse of dimensionality), causing a negative influence to feature selection tasks [12–14]. Especially, the situation becomes worse while irrelevant features,.e.g., noise, produce interference [15]. Overall, it is a challenge for feature selection in high-dimensional data.
For machine learning tasks, feature selection has effects on the ability of model’s generalization, so the methods of feature selection are very important. Usually, the existing methods of feature selection are filter, such as in [16], wrapper, e.g., in [17], and embedding methods, e.g., in [18], in [19] and in [20]. Filter methods have to select data features before training learners. Through using evaluation functions, the correlation between features is declined while increasing the correlation between categories and features [21]. In practice, this is difficult to select or construct an objective evaluation function. While for wrapper methods, the selected features heavily reply on the capability of models, e.g., decision tree algorithm [22], support vector machine [23], etc. Although wrapper methods can select more useful features than filter methods, their evaluation mechanism is quite time-consuming since all possible feature subsets need to be evaluated, especially data is in very high-dimensionality. For embedding methods, all features as a whole are considered, certainly, also considering learning performance. Moreover, embedded methods integrate the process of feature selection and the training process into one process. These above involved conventional methods assign a common discriminative feature set to the whole sample space without considering the local behavior of data in different regions of the feature space [24, 25].
Recently, deep approaches have been successfully used for feature selection. For instance, in [26], neural networks controlled redundancy are proposed, similarly, in [27], in [28], and in [29]. While for deep neural networks, Scardapane [30] proposed a very general sparse regularization strategy, in order to deal with how to select the input variables and hidden nodes simultaneously.
Autoencoders is neural networks, which learn an encoding function of mapping background space to representation space as well as a decoding function of reconstructing original inputting from representation space [31], respectively. Autoencoders not only reduce data dimensionality, but also provide an effective approach as regard the unknown meaningful insights for classification discovery [15]. Moreover, autoencoders are substantially better capability in extracting semantic rich features and non-linear feature relations, since the representations learned by them are qualitatively easier to be interpreted [32]. Compared to these mainstream methods, e.g., in [16–23], feature selection approaches using autoencoders offer more powerful dimensionality reduction [33]. For instance, Hinton et al. [34] design a deep regularized autoencoder, whose the error is lower than that of principal components analysis method in dimensionality reduction. Lucas et al. [35] compress image using compressive autoencoders. In addition to this, several types of regularized autoencoders have been also used for feature selection [36]. For example, in [37], the interpretable and discriminative features are learned by using a simple sparse auto encoder, similarly, in [38–41].
Bayesian methods can estimate some unknown states with subjective probability under incomplete information, so they play a prominent role in solving the variable selection problem. For instance, in [42] and in [43], a Bayesian classifier is used for feature selection to text. Abbas et al. [44] achieve feature selection tasks by consisting of the Particle Swarm Optimization algorithm and the Bayesian methods. Bayesian methods not only show excellent ability of feature selection for text, but also have outstanding talent as regards feature selection for high-dimensional data. Zhao et al. [45] propose a novel Bayesian regression framework, successful selecting features from ultra-high dimensional data. Bayes methods exhibit these excellent capabilities in feature selection due to supporting accurate perception of informative data [46]. This perception ability is mathematically interpreted in detail in [47–50]. Moreover, Bayesian method is also less sensitive to missing data.
Given these complementary advantages between autoencoders and Bayesian methods, this is very attractive to study a hybrid approach of them for feature selection. In this work, our primary goal is to select non-redundant features from high-dimensional data. However, our final goal is to explore the ability of deep architectures for feature selection. Here, we proposed a hybrid model consisted of an autoencoder and the Bayesian method (AEBd) to achieve our studied targets in the following steps: 1) an autoencoder owned three-hidden layers is designed. The first and second hidden layer are used to for non-redundant feature selection. 2) The third hidden layer, namely ‘Bayesian layer’, is a special layer. Because Bayesian methods consider the occurrence probability of various events and the loss caused by misjudgments, the Bayesian layer is suitable to control feature misjudgments during selecting. Finally, the proposed method is tested and validated comprehensively on a handwritten digits recognition task.
We summarize the main contributions of this work as follows: The hybrid model consisting of an autoencoder and Bayesian methods is proposed for feature selection to high-dimensional data. The proposed model improves the precision of feature selection while reducing the probability of feature misjudgments during selecting. As regards feature selection, autoencoders combined by probabilistic correction methods are more valuable than stacked architectures or adding constraints to autoencoders. Stacked autoencoders have more advantages for a larger amount of feature selection, while sparse autoencoders are beneficial for a smaller number of feature selection.
Preliminary
In section 2.1, we review Bayesian methods, which is helpful for optimizing our model. In section 2.2, autoencoders are described. These knowledge provides theoretical support for our model.
Bayesian method
Let us assume that sample x contains C categories w1,...,w m . Then Bayesian method judges the sample category, having that
We hope that the classification error rate can be minimized while classifying, having that
In Equation (2), for all x, P(e|x)>0 and p(x)>0 hold. So the min P(e) means that this minimize all x. According to Bayesian method, the decision of minimization error rate is the decision of maximization posterior probability. The posterior probability of each class can be regarded as a discriminant function of class. The decision process is to compare all kinds of discriminant functions and finally choose the largest one. For a problem with class C classification, the average error rate should be weighted by the C(C-1) terms. Due to the large amount of calculation of error rate, it can be converted to calculate the average correct rate P(C) to calculate error rate, having that
In decision, we are not only concerned with the correctness of decision, but also are concerned with the loss caused by an inappropriate decision, having
Equation (4) is a loss function, which represents the loss for the misjudgment of class j as class i. The loss matrix C×C is constituted by λ. The decision function of the minimal risk Bayesian is as following
For multiple classification problems, Bayesian methods are highly efficient, and do not increase too calculation complexity. In the case where the assumption of distribution independence is true, Bayesian methods perform exceptionally well, and is better than logistic regression.
Autoencoders, which are unsupervised neural networks, learn the implicit features of input data. Obviously, autoencoders are used for feature dimensionality reduction, similarly, principal component analysis (PCA). But their performance is better than that of PCA, because autoencoders can extract more effective new features. Besides of feature dimensionality reduction, autoencoders also act as feature extractors. The new features learned by them can be fed into the supervised learning models. Certainly, as unsupervised learning, autoencoders are also allowed to generate new data of different from training sample. So that autoencoders are usually considered to be generative models.
Let x = [x1, x2,..., x
n
] be the input of autoencoders, the compressed representation y = [y1, y2,..., y
m
] in the hidden layer, and the output
In encoding, i.e., y = f (Wx + b), it can be seen that encoding is a linear combination followed by a nonlinear activation function. Without the non-linear wrapping, autoencoders are no different from a regular PCA method. Using the obtained y, the input x can be reconstructed, i.e., decoding stage x′ = f (W′x + b′).
Autoencoders learn latent, compressed representations of the input through minimizing the error between the input and the reconstructed output [51]. Since it is no meaningful to simply reconstruct the original input, in order to learning more meaningful representations, we expect that autoencoders can capture the more valuable original information. Usually, we give some restrictions on autoencoders, e.g., W′ = W T . In addition, also including appending constraints, for instance, denoising autoencoder and sparse autoencoder are belong to this kind of case.
Method
In section 3.1, Bayesian combination methods are described in detail. In section 3.2, the proposed model is given, and then the model’s rationality is interpreted. Finally, training and testing of the model are displayed in section 3.3.
Bayesian combination methods
Given a class label, let us assume that classifiers are mutually independent, i.e., conditional independence. The item p(c i ) denotes the probability that sample x is tagged by classifier L i in class c i ∈ Class list.
The results of conditional independence is given, having that
Since the denominator in Equation (7) is not based on w
k
(that is a property of Bayes formula), this part can be ignored. As a result, w
k
is calculated in the following equation.
Thereafter, we discuss how to calculate a C×C confusion matrix for classifier L i . C is the number of the classes. In the confusion matrix M, Let the M i (j,u) represents the number of dataset elements which have the class label of wj, and are assigned to class w u using the classifier L i . Dj determines the number of class w u .
According to the [52], the probability estimate p(c
i
|wj) and the prior probability for class cj are replaced by using the
Noting that if zero is used as the estimate of p(c i |w k ) in Equation (8), this automatically nullify Ξ k (x). Hence, Equation (9) indicates the probability that sample x labeled as class cj is Ξ k (x).
We developed the proposed AEBd, including three hidden layers, shown Fig. 1. The first and second hidden layer are used for non-redundant features selection. Bayesian methods are designed the third hidden layer, namely ‘Bayesian layer’, this purpose is to increase the precision during selecting non-redundant features. In input layer, the number of neurons is equal to input data dimensionality. In output layer, the final features selected are presented.
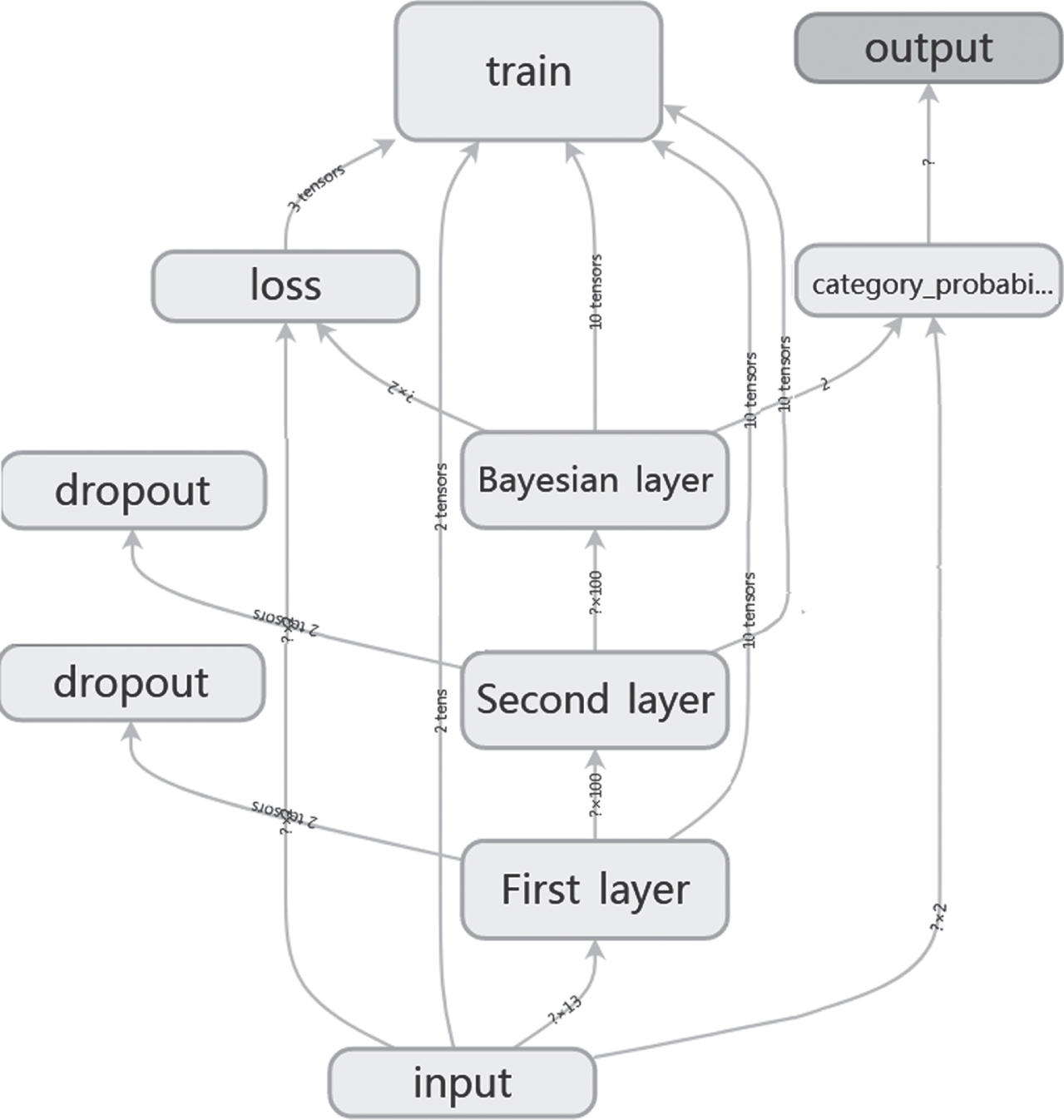
The architecture of AEBd.
The activation f of the ith node (i = 1,2,..) in the jth (j = 1,2) hidden layer is given by Equation (10). W ij 12 denotes the connection weight in the input layer to the jth hidden layer. b i 12 denotes the bias for the ith hidden node. The activation f of the lth node (l = 1,2,..) in the third hidden layer is given by Equation (11). The f is the logistic sigmoid function in Equation (12), which is widely used in machine learning and pattern recognition tasks [40]. In addition, the proposed model is trained by using the loss function of minimizing the negative logarithmic likelihood, i.e., L = - log P (x|x′)
Rationality. We adopt the hybrid architectures combining an autoencoder with Bayesian methods, because we take advantages of them, which are excellent ability to capture feature (the former) and correction capability of classification features (the latter). The high-quality nonlinear features can be obtained by deep architectures from the high-dimensional data [53–55]. Obviously, autoencoders can further tune the acquired features accuracy after combining Bayesian method, due to Bayesian methods consider the occurrence probability of various reference events and the loss caused by misjudgment. If the two can be integrated, the proposed AEBd can be expected to select higher quality features to high-dimensional data.
Training. To reduce the risk of over-fitting, in process of training, the dropout method worked by probabilistic turning off some neurons is used for the first and second hidden layers in AEBd. Until the parameters converge, then the training is completed.
Testing. Once AEBd is well trained, given a testing data set, AEBd presents the output results.
Experimental settings
In section 4.1, we describe the dataset. In section 4.2, the competitors and theirs parameters are presented. In addition, assessment metric is also given in section 4.3.
Datasets description
The MNIST digits dataset is a popular dataset of handwritten digits of being widely used for machine learning, including digits from 0 through 9. The MNIST, which has a training set of 60,000 images, and a test set of 10,000 images, has effectively become a benchmark. Each image in the MNIST dataset has not only been sized and normalized, but also has been centered in a fixed-size image. Hence, the MNIST is very suitable for verify our method
Comparison methods and parameters
In order to objectively assess the ability of our method, the hybrid approach, i.e., Bayesian AutoEncoder (BAE) in [45], is used as a compared object. In addition, we also opt for two kinds of autoencoders as competitors, i.e., the Stacked AE in [40], and the sparse autoencoder (SAE) in [41]. The sparse autoencoders are a type of regularized autoencoders by adding a penalty term into loss function to make representation layer sparse. The reason of selection the two autoencoders as compared objects is that we deeply explore the effects on the accuracy of feature selection via changing the autoencoder architectures, e.g., stacked patterns, or adding constraints to autoencoders, e.g., adding sparse items.
For the three competition methods, we apply default parameters observed in the corresponding literature. Unless otherwise stated, all methods in this work all run on the same experimental settings.
Assessment metric
The receiver operating characteristic curve (ROC) and corresponding area under curve (AUC) are used to assess the accuracy of methods.
Results
All experimental results show that the proposed AEBd outperforms the three competitors BAE, Stacked AE and SAE in all considered cases as for the precision of feature selection. Section down below detailed the experimental results.
Accuracy of feature selection
To compare the performance of the four methods, we assess the accuracy with different number of features ranging from 20 to 120. Figure 2 displays the results of feature selection on the MNIST digits dataset. It can been seen that the performance of the four methods is decreased when more features are selected. Despite this, but the performance of the proposed AEBd is still better than the three competitors, as shown Fig. 2 (a). Further analyzing the accuracy of training in Fig. 2 (b) that AEBd provides greater improvement over than competitors. Especially, AEBd shows the obvious advantages as the number of feature selection augments.
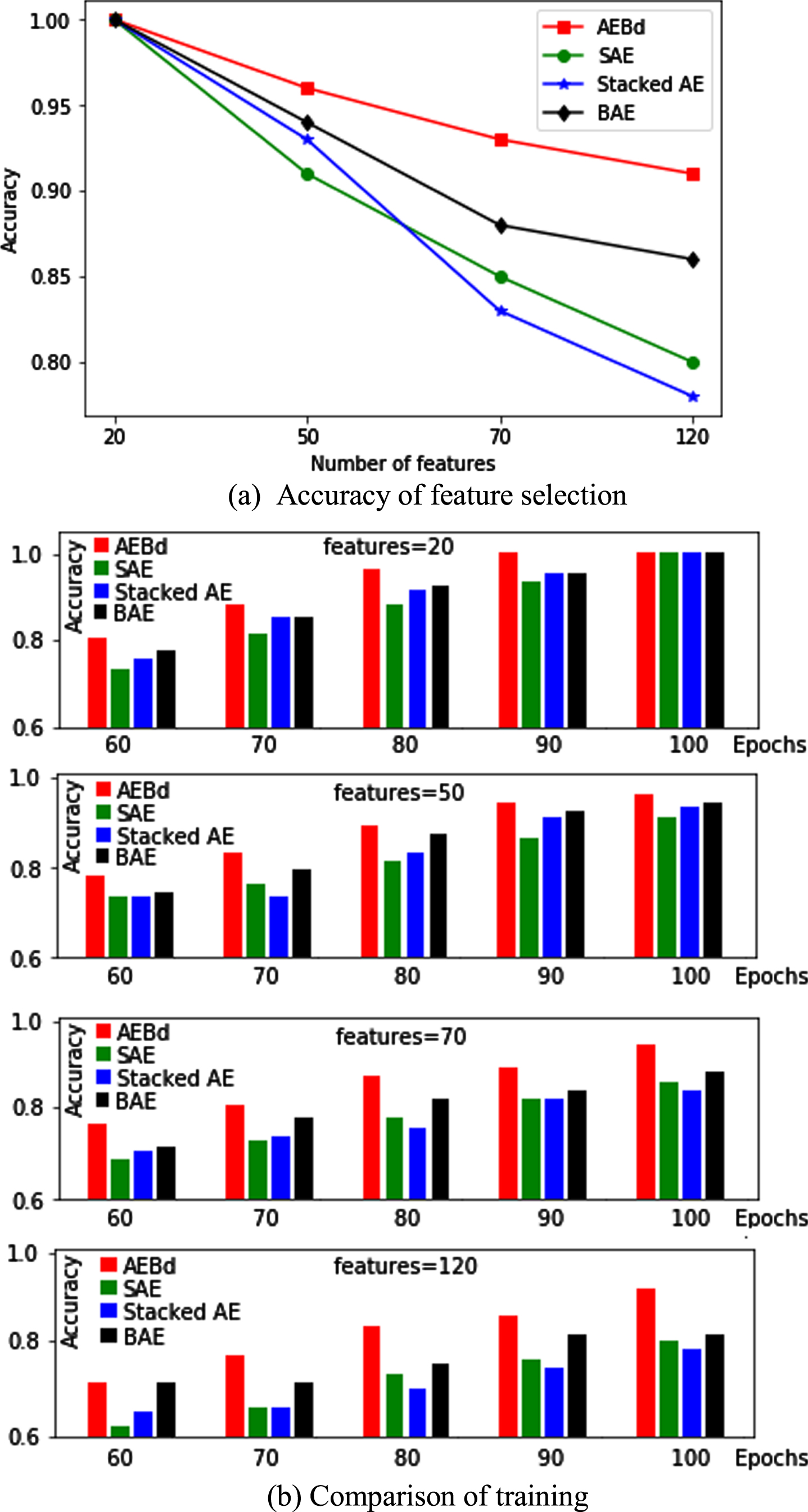
Results of feature selection.
Figure 3 displays the results of feature selection on every digit. Results show that AEBd outperforms the three competitors for every digit. These results imply the clear benefit of feature selection using AEBd, that is, as the number of selected features increases, the accuracy of feature selection using AEBd is higher than that of using SAE, Stacked AE and BAE. As a result, AEBd demonstrates the utility of feature selection on digits. In addition, BAE shows better performance than both SAE and Stacked AE. This also demonstrates that autoencoders combined with probabilistic correction methods, e.g., AEBd and BAE, are more valuable than stacked architectures or adding constraints to autoencoders, e..g, Stacked AE and SAE. More importantly, all these trials used only a small fraction of the available data for training, thus validating the procedure for limited data situations.
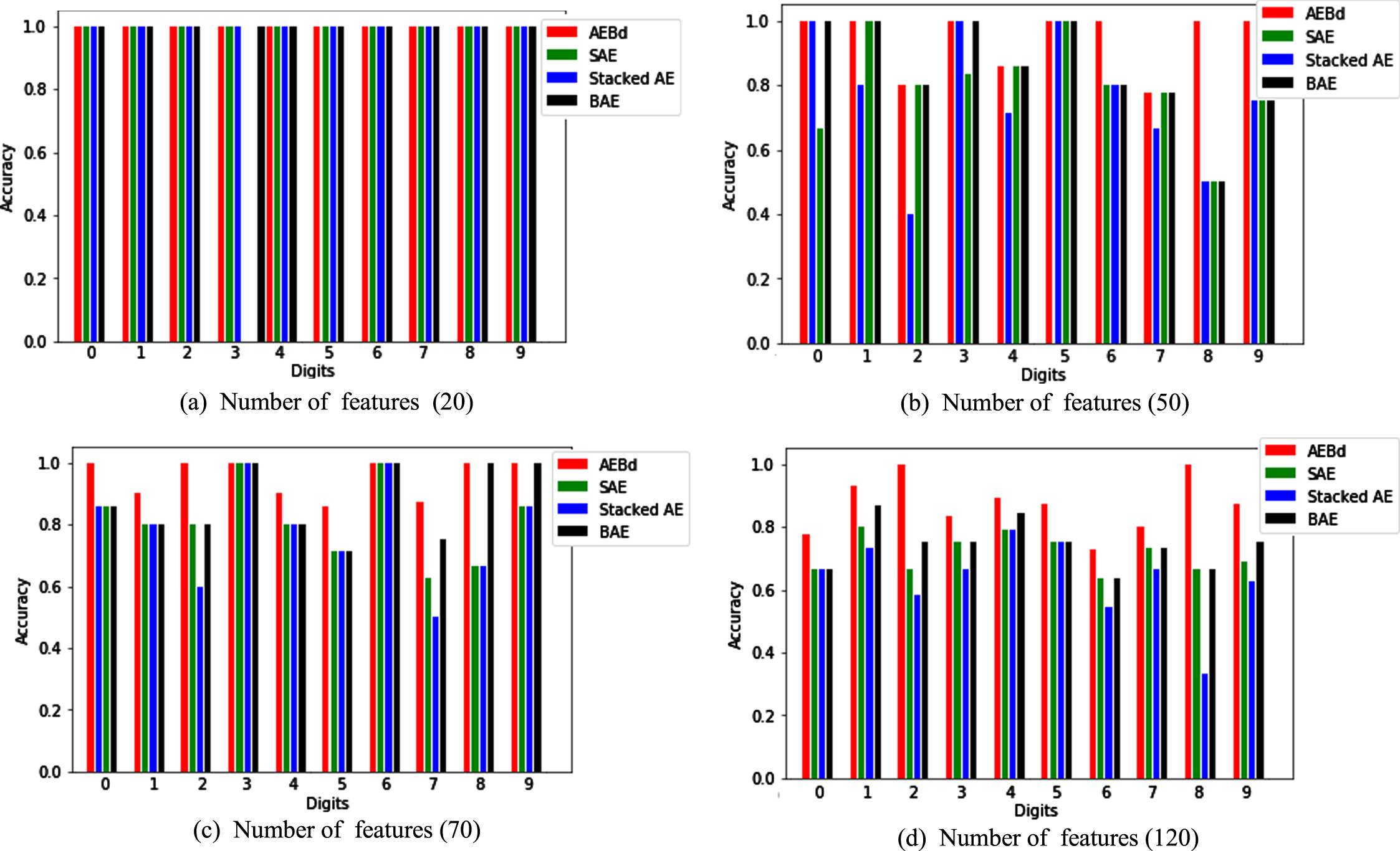
Effects on feature selection.
We give the ROC and the corresponding AUC in different dimensionality for the four methods, in Fig. 4. To intuitively observe different dimensionality, the results that dimensionality is equal to10 are visualized in Fig. 5. Several observations can be obtained down below in Fig. 4 and Fig. 5.
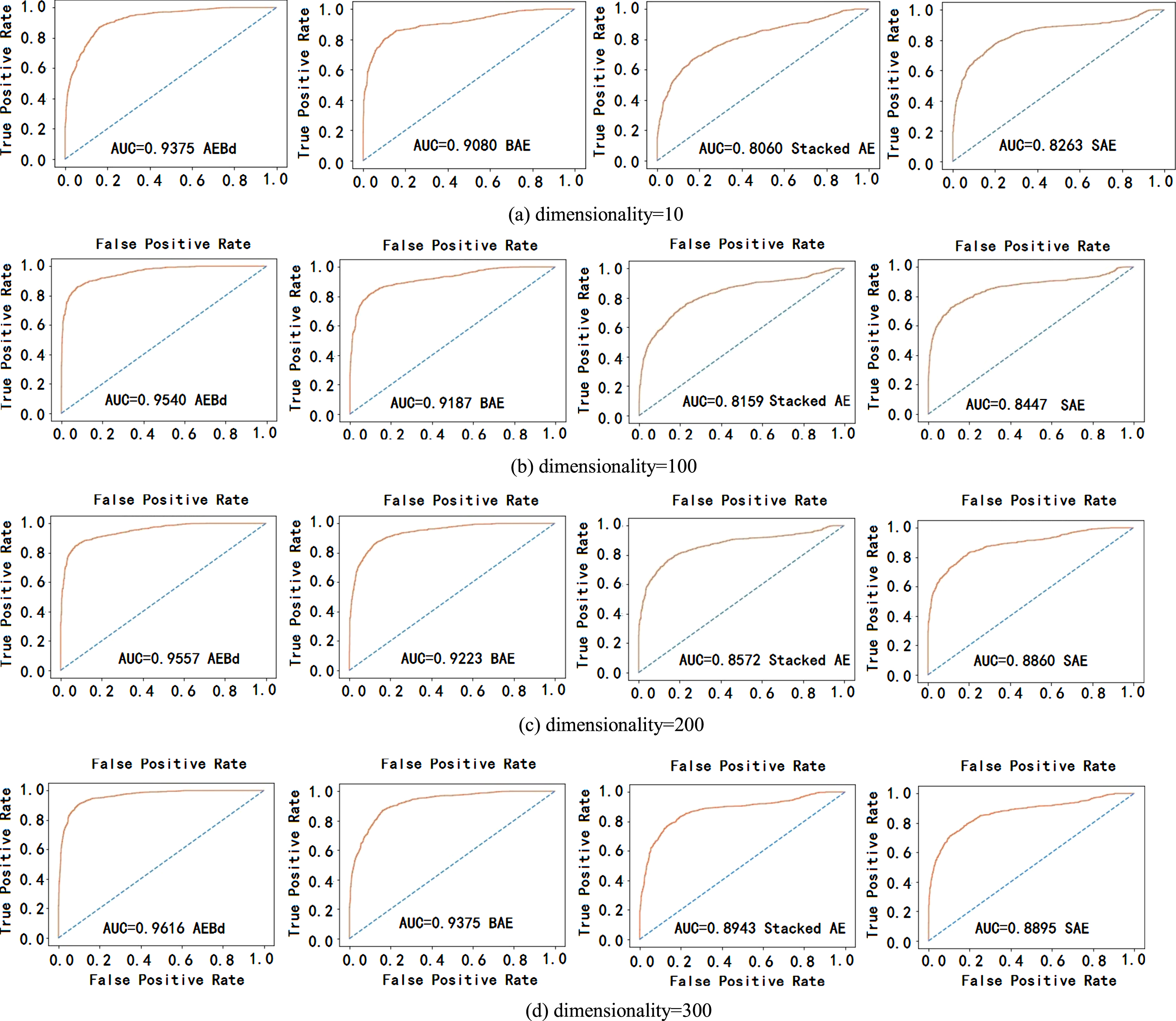
Accuracy of dimensionality reduction.
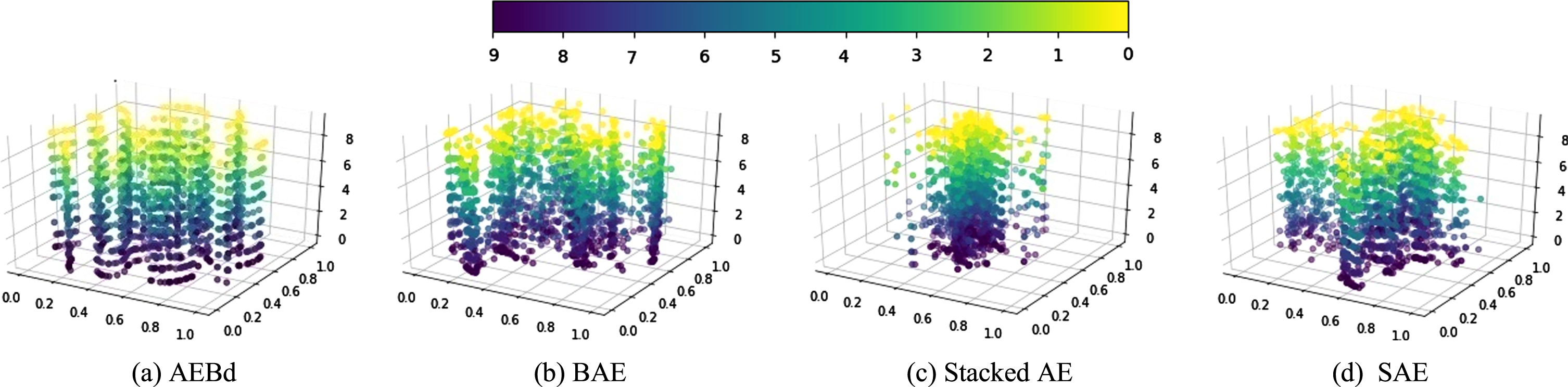
Visualization results. (Dimensionality = 10).
(i) In different dimensionality, the accuracy of AEBd outperforms that of the three comparison methods. In addition, BAE is better than SAE and Stacked AE in terms of accuracy. This demonstrates the advantages of autoencoders combined by probabilistic correction methods.
(ii) The more dimensionality is reduced, the more method accuracy drops. In spite of this, the downward in precision during dimensionality reduction using the proposed AEBd is slower than that of using comparison methods.
(iii) Autoencoders combined with probabilistic correction methods are more helpful to improve the results on feature selection than stacked architectures or adding constraints to autoencoders. For stacked autoencoders and sparse autoencoders, the former is more suitable for large-scale feature selection, while the latter is better for selecting a smaller number of features.
Using autoencoders to feature selection, we can not only modify autoencoders architectures, such as stacked autoencoders, certainly, but also add constraints, such as sparse autoencoders. Using these manners is difficult to avoid feature misjudgments during selecting. However, Bayesian methods are used in autoencoders, thus greatly increasing the precision of feature selection. This is also because our method outperforms the three competition methods.
In this work, we combined an autoencoder and Bayesian methods, aiming to select features that offer useful features for machine learning tasks while filtering irrelevant and unimportant features. Compared with the previously existing feature selection approaches, the proposed method outperforms them. Here, the values of our method provides a theoretical way to analyze the optimality of feature selection. In the future, we will continue to explore the approach as regards feature selection.
Footnotes
Acknowledgments
This work was supported by the Teaching Reform Research Program of Chongqing Municipal Education Commission of China under Grant 203604. And theAssociation Scientific Research Program of Chongqing Municipal Education Commission of China under Grant CQGJ19B139