
Abstract
Directed networks find many applications in computer science, social science and biomedicine, among others. In this paper we propose a new graph mining algorithm that is capable of locating all frequent induced subgraphs in a given set of directed networks. We present an incremental coding scheme for representing the canonical form of a graph, study its properties, and develop new techniques for pattern generation suitable for directed networks. We prove that our algorithm is complete, meaning that no qualified pattern is missed by the algorithm. Furthermore, our algorithm is correct in the sense that all patterns found by the algorithm are frequent induced subgraphs in the given networks. Experimental results based on synthetic data and gene regulatory networks show the good performance of our algorithm, and its application in network inference.
Introduction
Directed networks are graphs in which each node or vertex has a label, and each edge is directed from one vertex to another. Such graphs are used to model complex information or structures in a variety of applications. For example, in Internet engineering, the world wide web is modeled as a directed graph, in which each node represents a web page, and each edge is a hyperlink connecting two web pages [5]. In molecular biology, gene regulatory networks are represented by directed graphs, in which each node is a gene or transcription factor, and each edge represents a regulatory relationship between two genes [19]. In social network analysis, communications in a message board are modeled by a directed graph. In this graph, nodes represent individuals and edges represent the flow of influence, where the influence is calculated by considering the propagating terms in messages among individuals [21]. Figure 1 shows a directed network
Example of a directed network.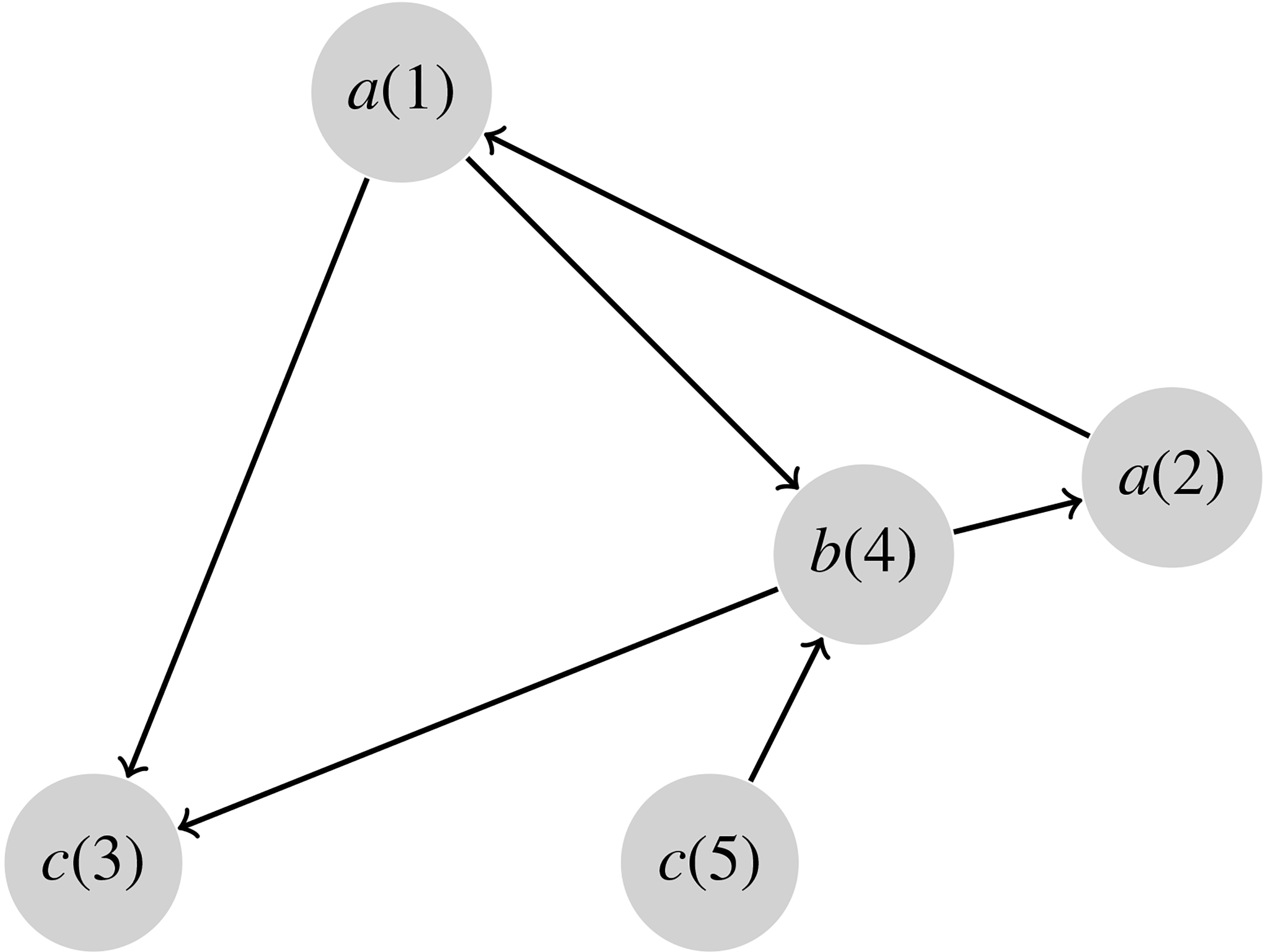
Graph mining aims to find frequent patterns in multiple graphs or networks.1
We use the terms “graph” and “network” interchangeably in the paper, and the term “network” refers to “directed network” when the context is clear.
An induced subgraph of the network in Fig. 1.
Discovering frequent induced subgraphs (FISHs) from directed networks is useful in a variety of applications. For example, many software tools have been developed to infer gene regulatory networks (GRNs) from gene expression data [19]. However, the accuracies of these tools are low. By finding common FISH patterns from the GRNs constructed by the existing software tools, one may be able to identify the true regulatory relationships between transcription factors and target genes. As another example, an influence diagram is a compact, directed graphical representation of a decision situation. In general, multiple influence diagrams can be obtained from multiple products. Finding common FISH patterns in multiple influence diagrams, which could be from the same or different manufacturers, may help identify common building blocks in making the products and also help identify common decision flows among the different manufacturers [24]. Below we review several methods that are closely related to our pattern finding algorithm.
AGM (Apriori-based Graph Mining) [13] is the first frequent subgraph mining algorithm that uses a pairwise-join based pattern growth strategy to generate frequent patterns. The algorithm employs the Apriori principle [1] and generates candidate subgraphs of size
The gSpan [30] program is arguably the most widely used tool for graph mining. The gSpan algorithm grows undirected connected subgraphs in a depth first search (DFS) manner by adding an edge to each possible position on the rightmost path of a known frequent subgraph. Specifically, the algorithm uses DFS lexicographic ordering to construct a tree-like lattice over all possible patterns, resulting in a hierarchical search space called a DFS code tree. Each node of this search tree represents a DFS code. This search tree is traversed in a DFS manner and all subgraphs with non-minimal DFS codes are pruned so that redundant candidate generations are avoided. With the assistance of the DFS code tree, gSpan can discover connected patterns from undirected graphs efficiently.
FFSM [10] focuses on graphs that are dense with a small number of labels. FFSM adopts the same canonical adjacency matrix (CAM) representation used by AGM. A tree-like structure, namely a suboptimal CAM tree, is constructed to include all possible patterns. Each node in this suboptimal CAM tree is created by either a join or an extension operation. FFSM maintains embedding lists for the discovered patterns to avoid explicit subgraph isomorphism testing in the support counting phase [15].
Gaston [23] is a unified graph, sequence and tree extraction algorithm. Given a database of graphs, Gaston finds all frequent subgraphs by using a level-wise approach in which simple paths are first considered, then more complex trees and finally the most complex graphs are considered. Consequently the subgraph mining procedure is invoked only when needed. To determine the frequency of a graph, Gaston employs an occurrence list based approach in which all occurrences of a small set of graphs are stored in main memory. Gaston also maintains embedding lists when growing patterns, to avoid unnecessary subgraph isomorphism testing.
The limitations of these existing methods are that they are mainly designed and implemented for finding frequent general, not induced, subgraphs in undirected networks. By contrast, our work focuses on finding frequent induced subgraphs in directed networks. In addition, our algorithm tackles both connected and disconnected subgraphs, which are common in social and biological networks as those networks are often sparse graphs. Because of these three properties (induced subgraphs, directed networks and disconnected subgraphs), our pattern growth procedure is different from those employed by the existing methods. Moreover, we incorporate a novel de-canonicalization component, which was not used in the existing methods, into our pattern mining process to ensure that no candidate pattern is missed, and all candidate patterns can be generated by our algorithm.
The rest of this paper is organized as follows. Section 2 presents basic concepts and terminologies. Section 3 describes in detail the FISHmine algorithm and shows the correctness and completeness of the algorithm. Section 4 presents experimental results as well as an application of FISHmine in gene network inference. Section 5 concludes the paper.
Preliminaries
We consider directed networks or graphs in which each node has a label and edges have a direction associated with them. Each graph has a finite number of nodes and edges. We allow different nodes to have the same label; cf. Fig. 1. The graphs have neither self loops (edges that connect nodes to themselves) nor multiple directed edges (two or more edges that connect the same two nodes in the same direction). Furthermore, the networks and subgraphs need not be connected.
We adopt the following commonly used definitions and terms to explain our algorithm design.
(Node-labeled directed graph).
A node-labeled directed graph
The number of vertices, i.e., the cardinality of
(Induced subgraph).
Given two graphs
Please note that the induced subgraph isomorphism problem is different from the general subgraph isomorphism problem. In dealing with induced subgraph isomorphism, the absence of an edge
(Support).
Given a set
(All frequent induced subgraph mining).
Given a set
(Node-adjacency matrix).
Suppose we arbitrarily and uniquely number the nodes of a graph
In general, the form of a node-adjacency matrix depends on the node numbering, where the node numbering is given by a permutation of indices
The above form would have been adequate for graphs without node labels. However, for a graph whose nodes have labels, its node-adjacency matrix needs to be augmented by its node label array in order to fully describe the graph. Given a particular permutation of node indices, we can always construct a node-adjacency matrix and its corresponding node label array. For example, the node-adjacency matrix of the network in Fig. 1 can be alternatively constructed based on a new permutation
Algorithm specific definitions and notation
(Node descriptor).
Given the node-adjacency matrix
where
Let
The node descriptor of
Table 1 shows the descriptor of each node in the matrix in Eq. (1) representing the network
Illustration of node descriptors
(Ordering of node descriptors).
For any two nodes
By concatenating all the node descriptors together, we can obtain a code for the whole node-adjacency matrix, as defined below.
(Matrix descriptor).
Given a node-adjacency matrix of graph
Again, this scheme for coding a node-adjacency matrix is incremental in that the sequence is obtained by concatenating the node descriptors with gradually increasing lengths. Refer to the node-adjacency matrix in Eq. (1). By concatenating the node descriptors in Table 1, we obtain the following descriptor for the matrix: (
(Canonical form of graph).
Let
By introducing the canonical form of a graph, we are able to check whether a graph
While various canonical forms including the above have been previously studied [13, 17, 30], it should be pointed out that the following properties and algorithm design are new, which have not been addressed or are different from the previous methods.
.
Proof..
(If) Since
(Core of node-adjacency matrix).
Let
The concatenation of the node descriptors of the first
(Core-canonicalized form).
Let
According to Theorem 1, it is easy to see that if a matrix
(Equivalence class).
Let
When
Let
Suppose we remove Suppose we remove any node
The proposed FISHmine algorithm employs the Apriori principle [1], which says that if a pattern is frequent (i.e., its support is greater than or equal to minsup), then all its sub-patterns must also be frequent. Specifically, we join smaller subgraphs that are already frequent to generate candidate subgraphs of larger sizes. Each candidate subgraph must go through an induced subgraph isomorphism test [26, 28], and the candidate subgraph becomes a qualified pattern if it passes the test. The following subsections describe the major phases of our algorithm.
Phase 1: Single-node subgraph discovery
Any single-node subgraph is automatically canonicalized. It is straightforward to find all frequent 1-subgraphs (i.e., frequent node labels) and their supporting lists. Specifically, we pre-process the graphs in the dataset
Phase 2: Two-node subgraph discovery
The second phase of our pattern growth algorithm is to find all frequent 2-subgraphs (i.e., subgraphs of size 2). Phase 1 produces all frequent 1-subgraphs (i.e., frequent node labels). In phase 2, we generate candidate 2-subgraphs by considering all possible pairs of the frequent node labels. Suppose
Four candidate 
For each candidate 2-subgraph, its supporting list is constructed by taking the intersection of the supporting lists of the two corresponding node labels. If the cardinality of the intersection list is greater than or equal to minsup, we calculate the support of the candidate 2-subgraph by invoking the candidate pattern verification procedure (i.e., induced subgraph isomorphism test [26, 28]). We keep only frequent 2-subgraphs. Clearly, each frequent 2-subgraph is a frequent induced subgraph.
Let
Observe that the
Performing candidate subgraph generation by considering only canonical forms may miss some candidate patterns. For example, consider the node-adjacency matrix
After removing the last node, we get the following matrix
On the other hand, if we remove the second to the last node, we get the following matrix
To avoid duplicate patterns of size 4, all frequent 4-subgraphs must have been canonicalized. As a result,
To avoid missing candidate patterns, we propose a de-canonicalization process which aims to de-canonicalize
The FISHmine algorithm
The framework of FISHmine is given in Algorithm 1. At step 7, the algorithm finds all frequent
Discovering frequent induced subgraphs from directed networks
[1] FISHmine
Analysis of the algorithm
The proposed algorithm is correct in the sense that (1) it is complete, meaning that it finds all frequent induced subgraphs, (2) the found patterns are not redundant, and (3) any discovered pattern is indeed a frequent induced subgraph. We note that the completeness property in (1) does not mean that our algorithm finds all important patterns in real-world applications since how to define all important patterns requires the involvement of domain experts. The non-redundancy property in (2) is guaranteed because we use the canonicalization process to detect and remove duplicate patterns, and each frequent pattern is uniquely represented by its canonical form. The property of (3) is also guaranteed because we use the induced subgraph isomorphism test to calculate the support of a pattern, and only frequent patterns, i.e., patterns whose support values are greater than or equal to minsup, are output by the algorithm. We now show our algorithm is complete.
.
The FISHmine algorithm does not miss any qualified pattern in the sense that it can discover all frequent induced subgraphs.
Proof..
We prove the theorem by induction.
Basis: It is easy to see that all frequent single-node subgraphs (i.e., 1-subgraphs) and 2-subgraphs can be found correctly by the algorithm.
Inductive step: Let
Notice that when applying the de-canonicalization process to each frequent
Experiments and results
Performance evaluation of the algorithm
The proposed FISHmine algorithm is implemented in Java. We conducted a series of experiments to evaluate the performance of FISHmine using synthetic data. All the experiments were carried out on a Mac Pro, which has one Quad-Core Intel Xeon E5 processor, with 3.7 GHz speed. The processor has a total of 4 cores, with 10 MB L3 cache. The computer has 16 GB memory.
The synthetic data were created by a graph generator written by the authors. This generator has four parameters: (1) the lower bound of graph sizes (LB); (2) the upper bound of graph sizes (UB); (3) the number of graphs in the dataset (T); and (4) a flag F indicating whether node labels are unified (0), duplicate (1) or unique (2). By unified labels, we mean that all nodes in all graphs in the dataset have the same label. This is equivalent to say that all the nodes are unlabeled. By duplicate labels, we mean that a node label can repeatedly occur in a graph and also in other graphs in the dataset. For example, the graph in Fig. 1 has duplicate node labels (two nodes have the same label
The performance measures used in the experimental study included the running time of our algorithm and the number of qualified patterns found by the algorithm. These performance measures were calculated with respect to different minsup values and dataset sizes where graphs’ node labels were unified, duplicate, or unique. Using these performance measures allowed us to acquire an in-depth knowledge of the behavior of our algorithm, and the effectiveness of the de-canonicalization procedure employed by the algorithm.
Effect of minsup on the running time of our algorithm.
In the first experiment, we created three datasets, named D100_5_10_0, D100_5_10_1, and D100_5_10_2, respectively, by using the following parameter values of the graph generator: LB
Figure 5 shows the number of qualified patterns found by our algorithm as a function of minsup. As minsup increases, the number of qualified (i.e., frequent) patterns decreases. For graphs with unified node labels (i.e., unlabeled graphs), since matching a pattern with a graph only considers their structures without checking their node labels, many candidate patterns pass the verification step and become qualified patterns. By contrast, for graphs with unique node labels, the verification procedure considers both their structures and node labels, and hence the algorithm generates relatively fewer qualified patterns.
Effect of minsup on the number of frequent patterns found by our algorithm.
Figure 6 details the number of qualified (i.e., frequent) patterns with respect to different pattern sizes where
Number of frequent patterns of different sizes.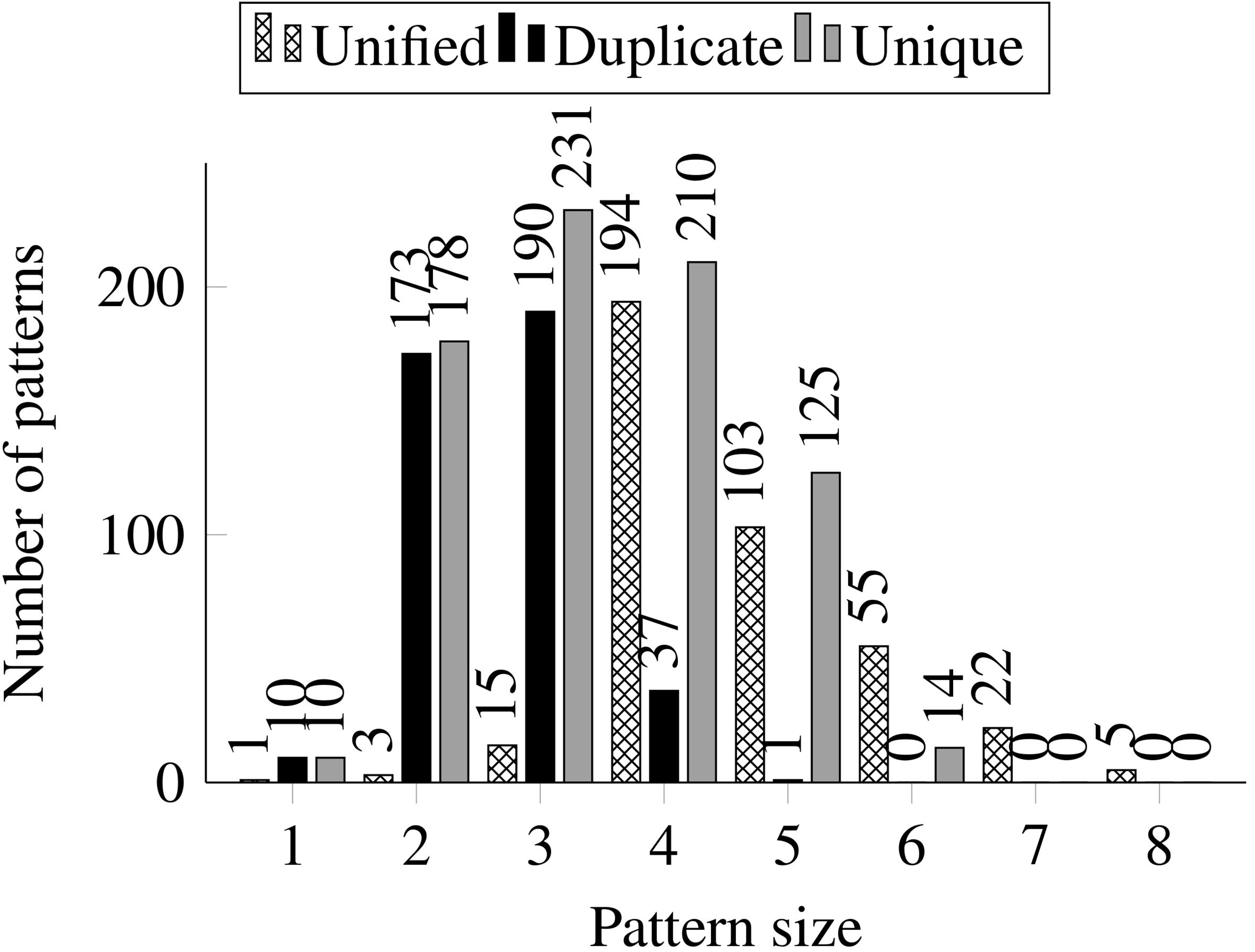
In the next experiment, we created 10 different datasets by varying the dataset sizes, from 100 to 1000. The minsup value was fixed at 4%; the other parameters had the same values as those in the previous experiment. Table 2 shows the running times (in minutes) of our algorithm on these 10 datasets with the three different types of graphs respectively. It can be seen from the table that, as the dataset size increases, the time required by our algorithm increases. This is understandable since with larger datasets, the algorithm needs to spend more time in performing the induced subgraph isomorphism test.
Effect of the dataset size on the running time of our algorithm
Figure 7 shows the number of frequent patterns found by our algorithm for varying dataset sizes. Since the minsup value is fixed at 4%, a qualified pattern needs to occur in more (fewer, respectively) input graphs in a larger (smaller, respectively) dataset. As a result, the number of qualified patterns is roughly the same for the different dataset sizes with respect to each type of graphs. For unlabeled graphs (i.e., graphs with unified node labels), when matching a pattern with a graph, our algorithm only considers their structures and hence produces more qualified patterns, as explained earlier. For graphs with duplicate and unique labels, the algorithm has to consider both their structures and node labels when matching a pattern with a graph. Consequently, relatively fewer qualified patterns are found. These results confirm that the more constrains a pattern must satisfy, the fewer qualified patterns one can find.
Effect of the dataset size on the number of frequent patterns found by our algorithm.
We also investigated the effectiveness of the de-canonicalization process. Table 3 shows the number of qualified patterns found by our FISHmine algorithm that comprises the de-canonicalization procedure. In addition, the table also shows the results from a baseline algorithm, which is the same as FISHmine except that the de-canonicalization step is not implemented in the baseline algorithm. Level
Impact of the de-canonicalization process
In the last experiment, we compared the proposed FISHmine algorithm with a closely related tool, gSpan [30]. Since gSpan is designed for undirected graphs whereas FISHmine is mainly for directed networks, we converted each input undirected graph
Experimental results showed that these two tools detected quite different patterns. Specifically, FISHmine can detect disconnected subgraphs whereas gSpan can not. For example, a pattern with two isolated nodes
As an application of the proposed work, we used FISHmine to identify common patterns in gene regulatory networks (GRNs) constructed by GRN inference tools [19, 25]. A GRN is represented by a directed graph in which each node represents a transcription factor or target gene, and each edge from node
We collected seven popular network inference tools including CLR [8], GENIE3 [11], MRNET [22], Inferelator [2], Jump3 [12], ScanBMA [31] and TimeDelay-ARACNE (TD-ARACNE) [36]. Among these seven tools, CLR, GENIE3 and MRNET are designed for steady state data while Inferelator, Jump3, ScanBMA and TimeDelay-ARACNE are for time-series data [19]. The datasets used here were taken from the dialogue for reverse engineering assessments and methods (DREAM) challenges [20]. The CLR, GENIE3 and MRNET tools were run on the DREAM4 [20] 10-gene knockdown dataset. The Inferelator, Jump3, ScanBMA and TimeDelay-ARACNE tools were run on the DREAM4 10-gene time-series dataset [4]. The 10-gene gold standard available from the DREAM4 challenges was used as the ground truth in the study.
Table 4 shows the ground truth and the seven networks inferred by the seven tools respectively for the ten genes G1, G2,
Results from the seven tools and ground truth used in the study
Results from the seven tools and ground truth used in the study
We have presented a new algorithm (FISHmine) capable of discovering all frequent induced subgraphs, both connected and disconnected, from directed networks. We have proved the correctness, particularly the completeness, of the proposed algorithm. Our FISHmine algorithm differs from existing graph mining algorithms [10, 13, 17, 23, 30] in several ways. First, FISHmine aims to discover frequent induced subgraphs, both connected and disconnected, from directed networks. By contrast, the existing algorithms mainly find connected general, not induced, subgraphs in undirected networks. Because of the differences in the networks and patterns found in the networks, the pattern growth procedure used by FISHmine differs from those employed by the existing algorithms. Moreover, we incorporate a novel de-canonicalization component into our pattern mining process to ensure that our algorithm is complete. A shortcoming is that this de-canonicalization procedure is time-consuming, where
We have implemented our algorithm in Java. This implementation has been applied and experimented on synthetic directed graphs with unified, duplicate or unique node labels, as well as gene regulatory networks with 10 genes. Our experimental results demonstrated the effectiveness of the proposed algorithm and its potential use in gene network inference. In practice, the patterns found by FISHmine become hypotheses, which can be validated in wet lab experiments [7]. In the future, we plan to extend FISHmine to handle more complicated networks whose edges are labeled or associated with weights, and whose nodes have attributes. We will also look into applications of FISHmine in various domains besides biology.
Footnotes
Acknowledgments
The authors would like to thank the anonymous reviewers for their constructive suggestions and useful comments. This research was supported in part by the National Key R&D Program of China (Nos. 2016YFB1000602 and 2017YFB0701501), MOE Research Center for the online education foundation (No. 2016ZD302), National Natural Science Foundation of China (Nos. 61440057, 61272087, 61363019 and 11690023), and SUNY Oneonta Faculty Research and Creative Activity Grant Program.