
Abstract
Time series clustering has been attracted great interest in the last decade. Most time series clustering works focus on clustering algorithms and similarity measures. Recently a u-shapelet-based time series clustering method has been proposed which can not only hold a high performance of clustering but also offer an acceptable interpretation of clustering result. Time complexity is the major issue in the process of discovering u-shapelets, particularly for huge datasets. In this paper, we propose a Random Local Search algorithm that reduces the time to discover u-shapelets, meanwhile keeps or even improves the quality of clustering. Our algorithm first randomly samples subsequences from time series to reduce the time cost of the u-shapelet search problem. It then uses a local search strategy to make clustering result more excellent and stable. We test our approach extensively on 27 UCR time series datasets, and obtain improved clustering accuracies over existing approaches. The experiment shows that our method outperforms the primitive algorithm by up to 2 orders of magnitude on some datasets in runtime. Because the method allows a fast u-shapelet discovery, it is feasible to apply u-shapelets clustering on large datasets.
Introduction
Time series data mining techniques have been applied widely in many fields such as finance, business, bioinformatics, energy, medical science, etc. [26, 7, 8, 23]. In view of this, many researchers have made substantial efforts to propose efficient algorithms to obtain useful information from this type of data. As a fundamental research work, time series clustering has been studied most widely [9, 17]. The purpose of time series clustering is to group a set of unlabelled time series into multiple classes, where the similar time series are divided into the same class [27]. Many kinds of research focus on distance measures which estimate the level of similarity or dissimilarity between time series [1]. The experimental evidence suggests that Euclidean Distance (ED) is a common and simple measure. However, it is brittle to deal with noisy data and it requires the length of time series to be equal. The Dynamic Time Warping [5, 28] (DTW) can solve the above problems. However, as the number of series increases, the clustering accuracy of DTW converges with that of ED [10]. Furthermore, the DTW measure requires storing and searching the entire dataset which has high time and space complexity [24].
Various clustering algorithms have been used to distinguish different types of time series. A novel concept called shapelet was first introduced by Ye and Keogh [16] for time series classification. A shapelet is a subsequence extracted from one of time series within a dataset, which is the most representative of a class [19]. The shapelet can be spilt a dataset into two subsets, the left set and the right set. A time series belongs to the left set if its distance from the shapelet is less than a pre-calculated threshold value associated with the shapelet. The shapelet-based classification algorithms construct a decision tree classifier by recursively searching for discriminative shapelet on the right subset [2, 29].
Related work
Zakaria et al.[15] introduced the idea of shapelets into the time series clustering, using unsupervised shapelets (u-shapelets) for clustering time series, which has been proved more accurate and interpretable in clustering result than other clustering methods. The greatest difference between the idea and the previous clustering works is the u-shapelets methods use the local features of time series instead of the whole time series as the global features are more sensitive to noises in some cases. Figure 1 shows how u-shapelet is used to distinguish different classes.
Two time series from class 1 and class 2 of the Trace dataset [31], the whole shape of the two classes is quite similar, apart from the red marked segment. If we take the entire time series to compute Euclidean distance for pairwise similarities, it is hard to correctly separate these two classes of data as these data include noises. If we ignore some data, only consider the subsequence denoted red, the clustering result has improved drastically, and gives us a good explanation that why a particular series assigned to a particular class.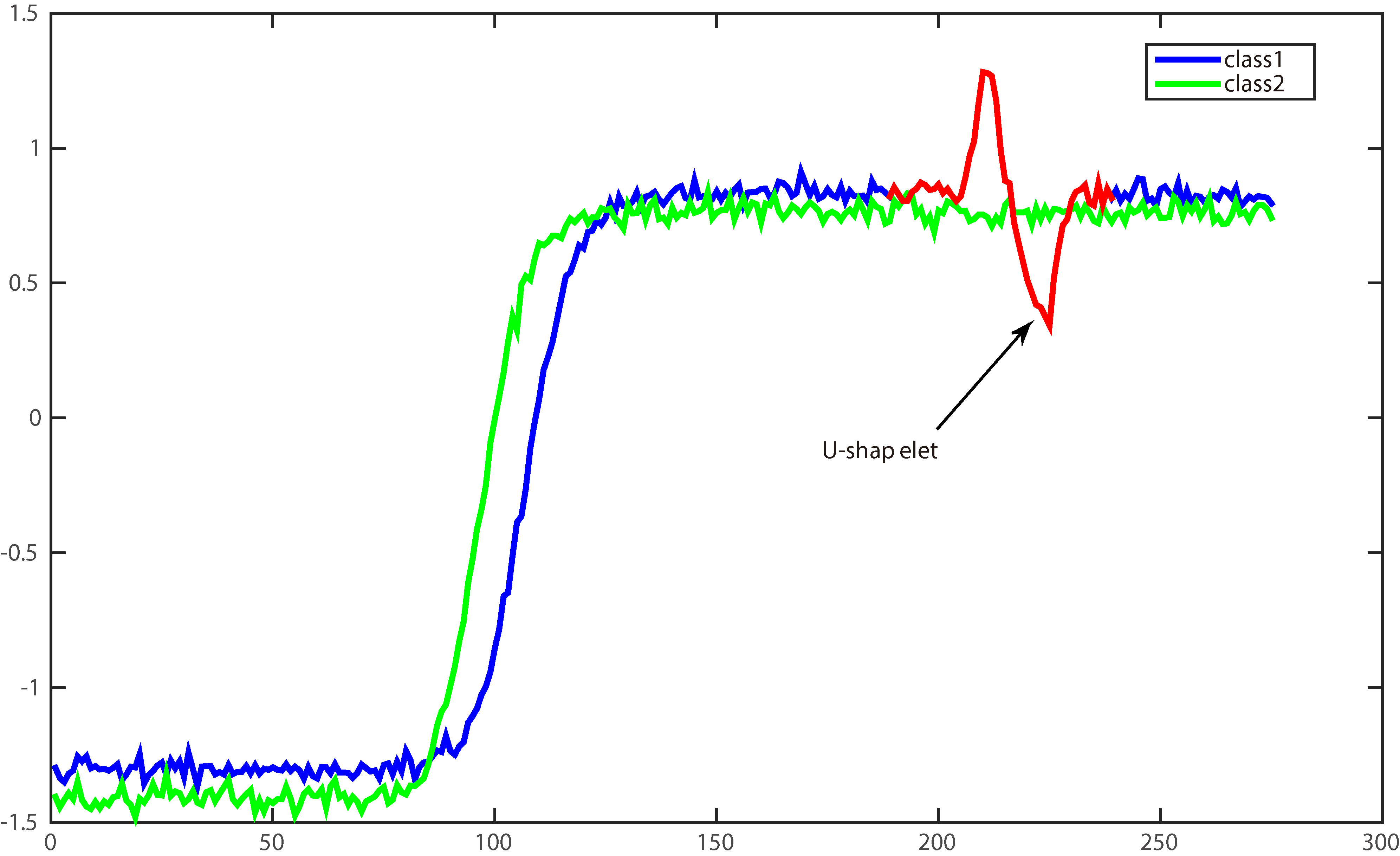
Moreover, the length of the time series can be unequal, which is not satisfied with most of the previous clustering works. These advantages have been confirmed by other researchers. However, the u-shapelet discovery process is very time-consuming. The straightforward way for finding u-shapelets is the exhaustive algorithm that generates all possible subsequences and examines these subsequences. The number of subsequences is liner in the number of time series in the dataset, and is quadratic in the length of the time series. These subsequences are u-shapelet candidates. In order to address the time-consuming problem, the Brute Force algorithm (the BF-algorithm for short) proposed by Zakaria et al. [15] only considers all possible subsequences of the first time series in the dataset, which makes the clustering result depend on the order of series in the dataset. If the first time series has few discriminative features, the result of time series clustering will be not good. Moreover, due to the fact that the u-shapelets extracted from a candidates subset, it is not guaranteed to achieve a comparable clustering result as the exhaustive search method.
An initial attempt at reducing the time consuming for discovering u-shapelets was published by Ulanova et al. [20]. The method (the SUSh-algorithm for short) is divided into two stages. Firstly, for all candidates of a given subsequence length, they use the Symbolic Aggregate approXimation (SAX) [13] technique to convert these continues real-valued candidates into a set of SAX words. Secondly, all SAX words are inserted into a table using a hash function, and a random projecting method [22] is used to filter out large numbers of candidates. The SUSh-algorithm has shown to be faster than the BF-algorithm. However, it has some disadvantages. Firstly, the method uses the hash table with random masking to identify similar subsequences which are really complicated. Secondly, the algorithm only extracts the u-shapelet candidates of a specific length. For a new dataset, we don’t have any prior knowledge about the appropriate length of u-shapelet.
In this paper, we inherit the merits and mitigate the limits of the above u-shapelets methods by introducing a Random Local Search algorithm (RLS-algorithm for short) that finds u-shapelets quickly with high-quality clustering result. The number of u-shapelet candidates examined with a random sampling way is only a small fraction of the exhaustive candidates. In the process of discovering u-shapelets, we introduce a local search strategy for refining the quality of u-shapelets. Our method exploits the fact that the discriminative subsequences are generally concentrated in local areas and are redundant.
Our contributions to this paper can be summarized as follows:
We propose an effective method of randomly extracting the u-shapelet candidates. It can discover u-shapelets quickly which allow u-shapelet-based clustering method to be applied to large datasets. Our work can fast search the entire subsequences space after examining a tiny subset of all subsequences, which obtains a more excellent clustering result than the previous u-shapelets-based methods. We use the local search strategy to obtain an improved the clustering result which is close to the result of the exhaustive search method. It also mitigates the instability problem of the random results. A comparison between our method and two previous u-shapelet-based clustering algorithms is conducted.
The rest of the paper is organized as follows. Section 2 introduces the necessary background materials and definitions. In Section 3 we introduce our algorithm. Section 4 we present the experimental results of our algorithm. Finally, in Section 5 we give conclusions and directions for feature work.
We firstly give the definition of time series:
.
A time series
A dataset
.
Subsequences
For a time series of length
Even tiny differences in scale and offset can result in a great error, it is necessary to z-normalize [4] the time series before computing the distance [6] between time series. The z-normalization of a time series
.
The normalized Euclidean distance between two time series
.
The distance between a time series
The minimum distance between a subsequence and a time series is the length-normalized Euclidean distance between the subsequence and the best matching subsequence of the time series. Figure 2 shows the idea.
The minimum distance between a time series and a subsequence.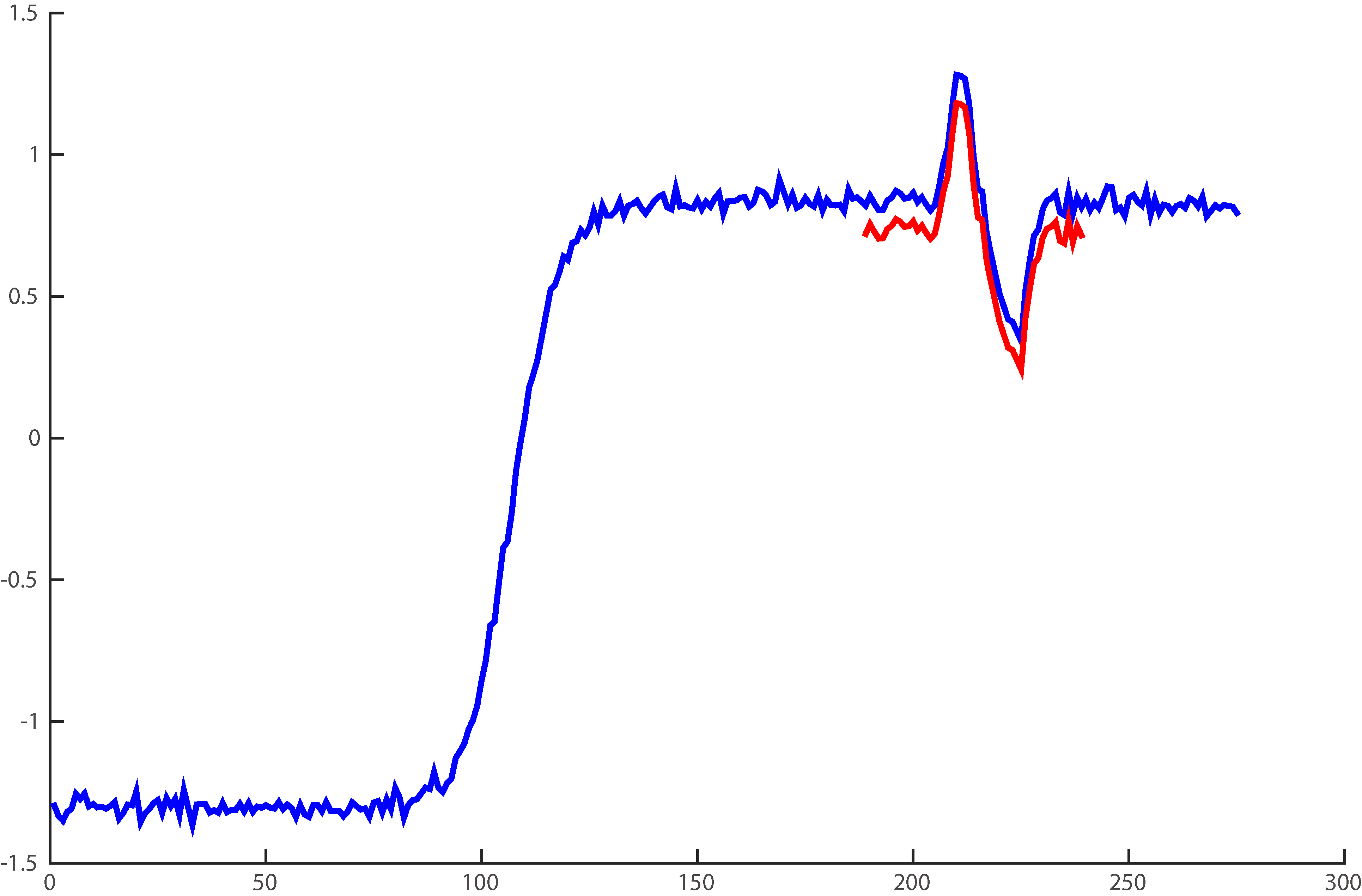
For each subsequence, we get a distance table which contains the sdist between the subsequence and all the time series in a dataset. The table is ordered increasingly by the sdist. Then the average distance between two adjacent distances is assigned as the split point. A greedy search algorithm is applied to separate the table into two subsets, i.e. the subset
.
An unsupervised-shapelet (u-shapelet) Ś is a subsequence that can divide a dataset
A good u-shapelet is expected to split the dataset into two subsets that are as clearly distinction as possible. In the original method [15], the separation power of subsequence is evaluated by the following equation:
Here,
In the BF-algorithm, the u-shapelets are generated iteratively. First, all possible subsequences are extracted from the first series of dataset
The process is repeated to generate the next u-shapelet in the rest of dataset. After generating a set of u-shapelets, the next step is to use them to cluster time series in
.
The distance map[15]
Then the distance map is used as the input to any off-the-shelve clustering algorithm such as k-means clustering [14], hierarchical clustering [18], etc. In BF-algorithm, a modified k-means algorithm is used for clustering through adding the distance vector to the distance map.
In this section, we introduce our RLS-algorithm in detail.
A motivating observation
As a concrete example, we analyze the much-studied Trace dataset [31] which contains 200 time series of length 275 from four different classes. We extract a u-shapelet with the length of 60 from one time series of class 1. The Fig. 3 shows the u-shapelet and 19 subsequences around it.
The neighbouring subsequences exhibits a similar pattern.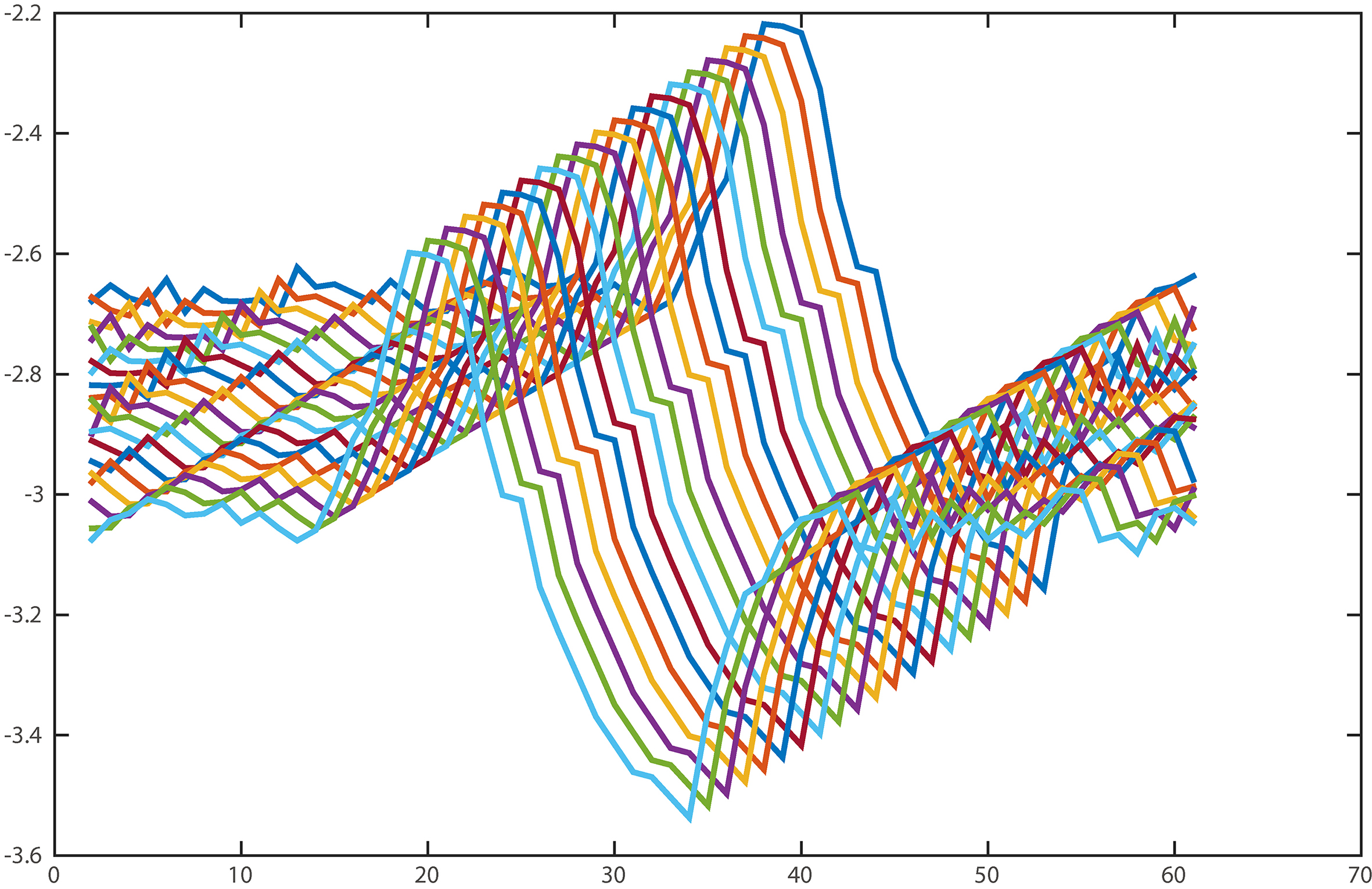
Clearly, the difference between two adjacent subsequences is extremely tiny. In many cases, the distances sdist between these subsequences and a new time series have no significant difference. Any subsequence from class 1 containing a similar pattern of the u-shapelet can be used to distinguish class 1 from other classes. Therefore, there is no need to exhaustively search the best u-shapelet for time series clustering, these subsequences that are similar to the pattern of the u-shapelet can be enough to obtain comparable results. We call these candidates as “good enough” u-shapelets. To understand how these “good enough” u-shapelets distribute in the candidates space, we do a simple test on the coffee dataset [31] which contains only 56 time series. Figure 4 shows the cumulative gap value of candidates of different lengths and different positions within the time series.
The distribution of “good enough” candidates in candidates space.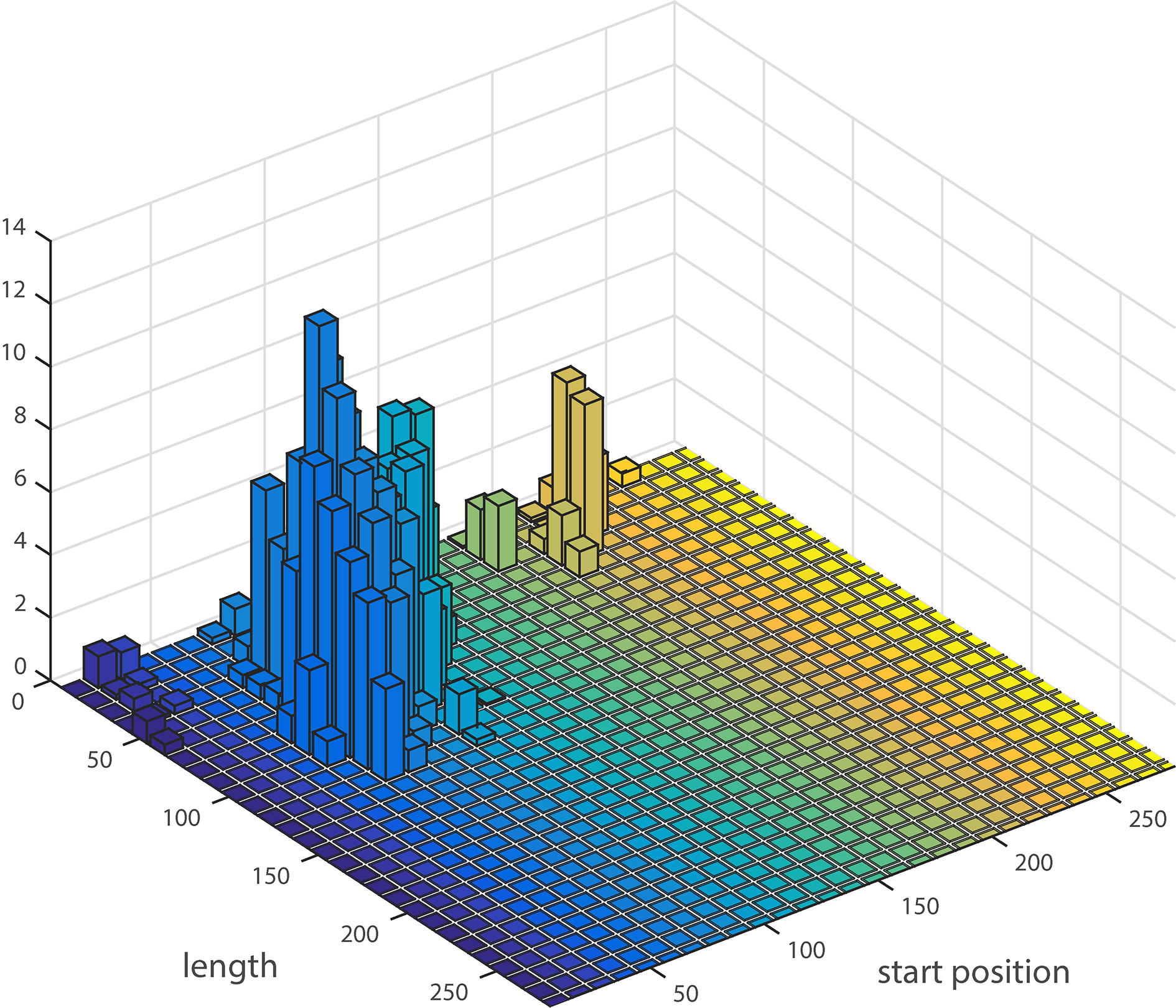
It is clear that these “good enough” u-shapelets from the same time series generally concentrate in local areas.
Sampling is the most effective approach to solve the scale of the input dataset, probably because it is easy to understand and implement [3]. UFS[21] employs random sampling to reduce the number of subsequences for time series classification. The experiment results show that a small fraction of sampling data is sufficient to achieve good classification results. Since we want to achieve “good enough” u-shapelets and we have no prior knowledge of where the informative candidates inside time series appear, we choose random sampling as our way of extracting candidates.
The random discovery process of u-shapelets
The u-shapelet discovery algorithm aims to obtain a set of u-shapelets which can be used to cluster time series, it’s the first step in our algorithm. The u-shapelet discovery process is carried out in an iterative way. At each iteration, the algorithm gets a u-shapelet with the maximal gap value from the u-shapelet candidates.
DiscoveryU-shapelet(
The Algorithm 3.3 provides the basic framework for discovering u-shapelets. The input has four parameters namely
The Algorithm 3.3 is a subroutine in line 4 of Algorithm 3.3 to find a u-shapelet. The parameters are the same as Algorithm 3.3.
We first randomly extract
The local search strategy
In Subsection 3.1, we have analyzed that the high-quality of u-shapelet candidates is usually concentrated in local areas. The gap value of adjacent subsequences roughly first increases then decreases, as shown in Fig. 5. Starting with the top-k candidates, that is to say, we first select
A neighborhood is the solution subspace of the current solution which defines the available moves for generating a new solution [11]. In this paper, we define a neighborhood by creating a circular plane that places the current candidate as its center. For a given candidate
Here
We treat the current candidate as a 2-dimensional point, where the first dimension represents the start position pos and the second dimension represents the length slen. Any subsequence from the same series satisfying the condition indicated in Eq. (6) becomes an element of the neighborhood
The gap value of the 20 adjacent subsequences from the same series roughly first increases then decreases, there is a maximum gap value.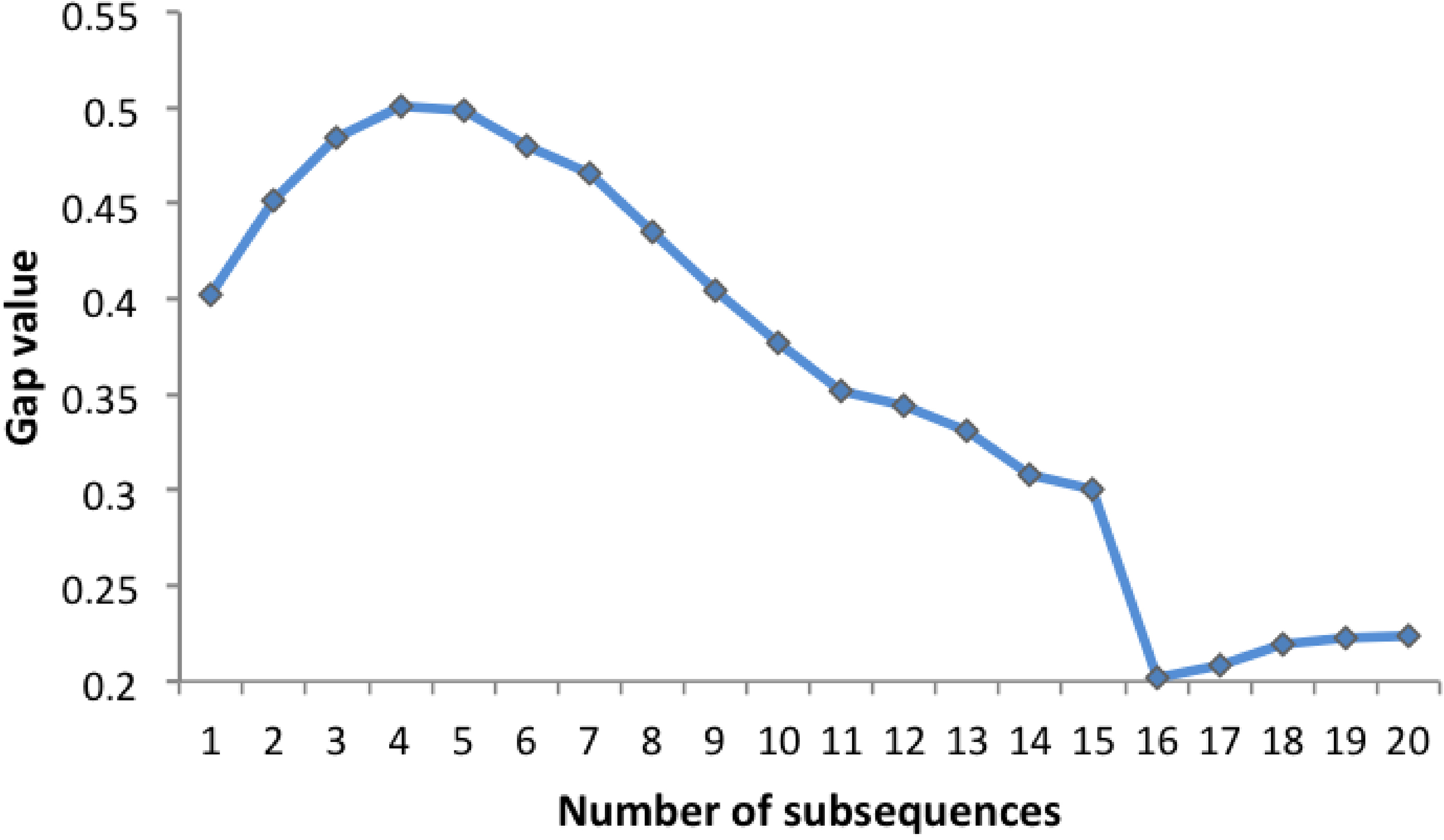
For each candidate, we first get the gap value of the current u-shapelet candidate in line 3. In line 4, a neighborhood
Information of datasets used in our experiment
In this section, we describe the results of our experimental evaluation. There are two criteria to evaluate the efficiency of our method. The first one is the quality of time series clustering result. The second one is the runtime of the whole process of u-shapelet discovery. A popular quality measure for evaluation of time series clustering is the Rand index (RI) [30] measures the correctness the sorting of elements into clusters. The RI is a number lies between 0 and 1, where it is close to 1 means a perfect clustering result. Additionally, the standard deviation of the clustering results is used to measure the stability of our method.
We conduct our experiments through two parts. In the first part, we determine the parameters of our algorithm, the two length parameters minlen and maxlen, and the best number of candidates to sample
Datasets
The experiment was carried out on 27 datasets from various domains such as speech recognition, activity recognition, medicine, image classification and several more. The datasets of Birds, ECG_PVC, ECG_APB, ECG_RT and PAMAP can be obtained form the paper [20]. The rest of the 22 datasets can be downloaded from the UCR Time Series archives [31] which is used commonly for time series classification and clustering. All of these datasets from the UCR Time Series archives have been split into 2 subsets: training and test sets. In our work, we use the mixed dataset, which consists of both training and test sets. Note that all the previous time series classification methods are experimented on small training set to discover shapelets.
Table 1 summaries the datasets we used which consist of both synthetic and real-world time series datasets. The dataset size ranges from 56 to 9236, the number of classes varies from 2 to 15 and the length of the time series varies from 24 to 1024. We use the largest dataset of the UCR datasets, StarLightingCurves, which contains 9236 time series of length 1024. In addition, many of the datasets contain noise or missing data such as CBF, Mallat, Syn_Control, etc. There are also 3 datasets contain time series with unequal length namely ECG_PVC, ECG_APB and ECG_RT. It proves the u-shapelets-based methods can be applied to the time series clustering with different length.
Determination of u-shapelet length
The process of u-shapelet discovery needs to set two parameters of length: minlen and maxlen. The two parameters determine the range of u-shapelet length, which control the scope of the discovery and help make the discovery process more efficient. However, it will prevent those informative subsequences from being selected if the parameters are setting inappropriate. If the length of u-shapelets is too short, the discriminant information contained is too small to represent the characteristics of the time series. If the length of the u-shapelet is too long, which is actually no difference compared with whole time-series. The advantages of accurate and interpretable of the u-shapelet technique are not reflected. We don’t have any prior knowledge about the appropriate u-shapelet length. So followed [12], we set the minimum length of u-shapelet to
Determination of r
The process also requires adjusting the parameter
Clustering result varying with 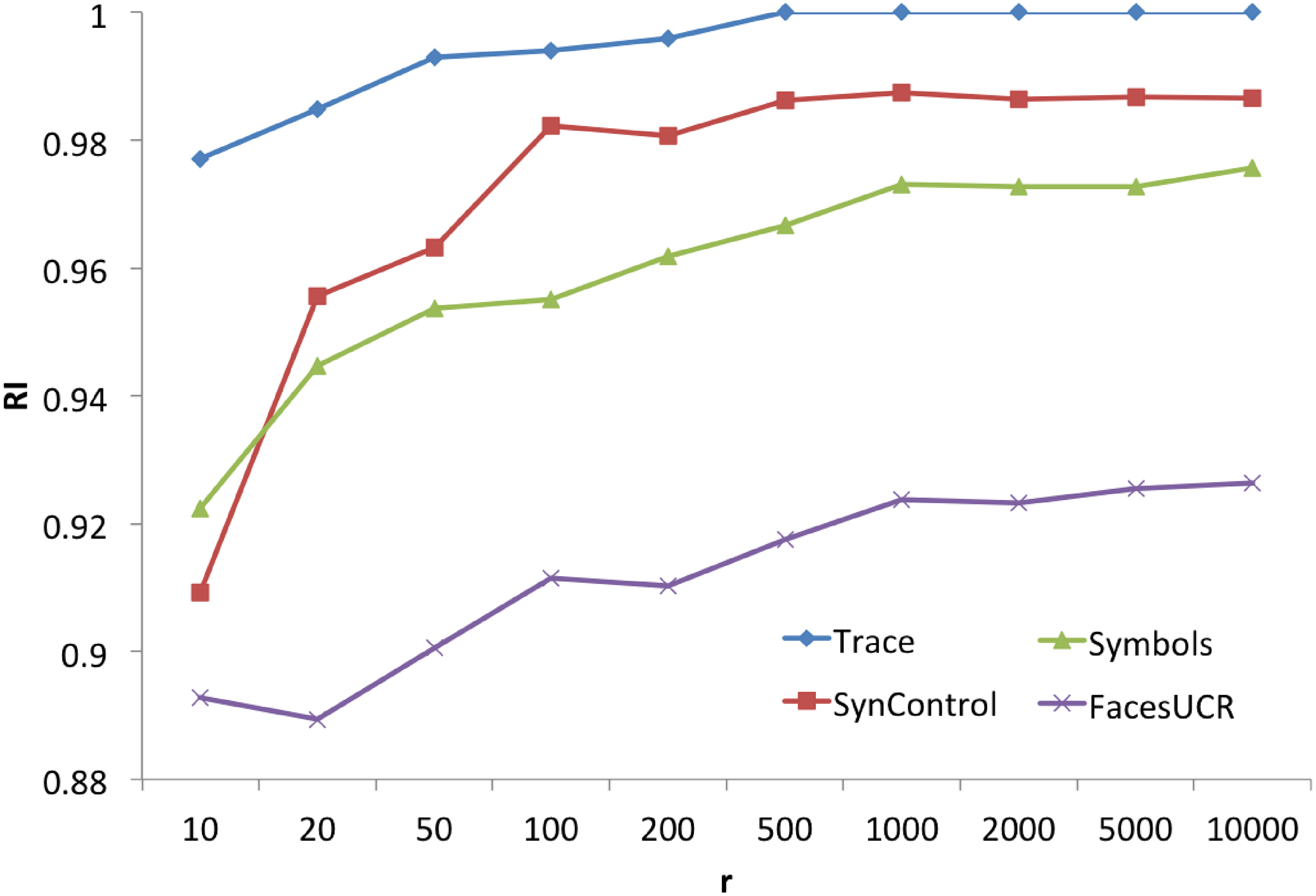
Runtime result varying with 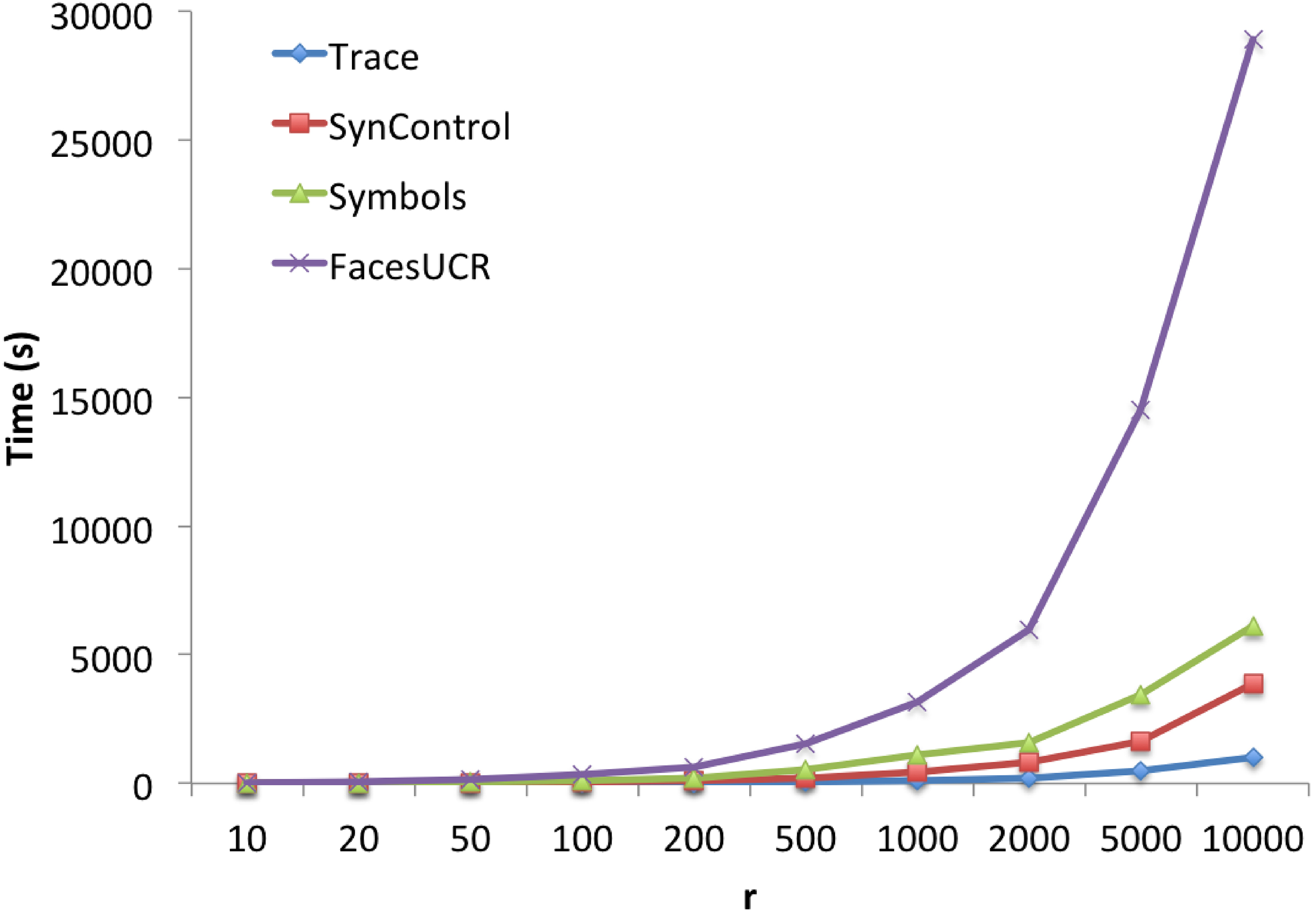
Figure 6 shows the accuracy of time series clustering. We can clearly see that the initial RI value of our RLS-algorithm remains close to the final result. This probably thanks to the randomization, a “good enough” u-shapelet is quickly obtained. With the increasing of
Compared with the BF-algorithm
To evaluate the effectiveness of u-shapelets generated by our algorithm, we compare the clustering result and execution time of our RLS-algorithm with the BF-algorithm which is the first article clustering time series with u-shapelets. The comparison is done on 17 small datasets from the UCR Time Series archives as the BF-algorithm on a large size dataset or on a dataset with a large time series length for u-shapelet discovery is extremely time-consuming. Table 2 represents the average results of each dataset. In particular, all experiments are done in the same environment and on the same input datasets, and the results of the BF-algorithm are reproduced with code available online. So we can be sure that the improvement is valid.
Comparison between RLS-algorithm and the BF-algorithm
Comparison between RLS-algorithm and the BF-algorithm
According to the results of Table 2, we observe that our RLS-algorithm clearly outperforms the BF-algorithm. In the third column of Table 2, the results by using the k-means algorithm on the whole time series are presented as a reference. In terms of the runtime, the time required to discover u-shapelets of our RLS-algorithm and that of the BF-algorithm are recorded in the 5–6 columns of Table 2. The last column lists the speedup factors of our method over the BF-algorithm, the greatest speedup we obtain on these 17 small datasets is 328 times, and we gain an average speedup exceeding 52 times. For the sake of clarity, we display the clustering results in Fig. 8. We also found that the speedup effect on some datasets is significant, while that of on some datasets is not satisfactory. The main reason is that the BF-algorithm only considers all possible subsequences of the first time series in a dataset, which makes the clustering result depend on the order of series in a dataset. If the length of the time series is short, the runtime of BF-algorithm is acceptable, but the clustering results may not be so ideal. In general, it is clearly that our method obtains more excellent results than the BF-algorithm.
The clustering result comparison with BF-algorithm.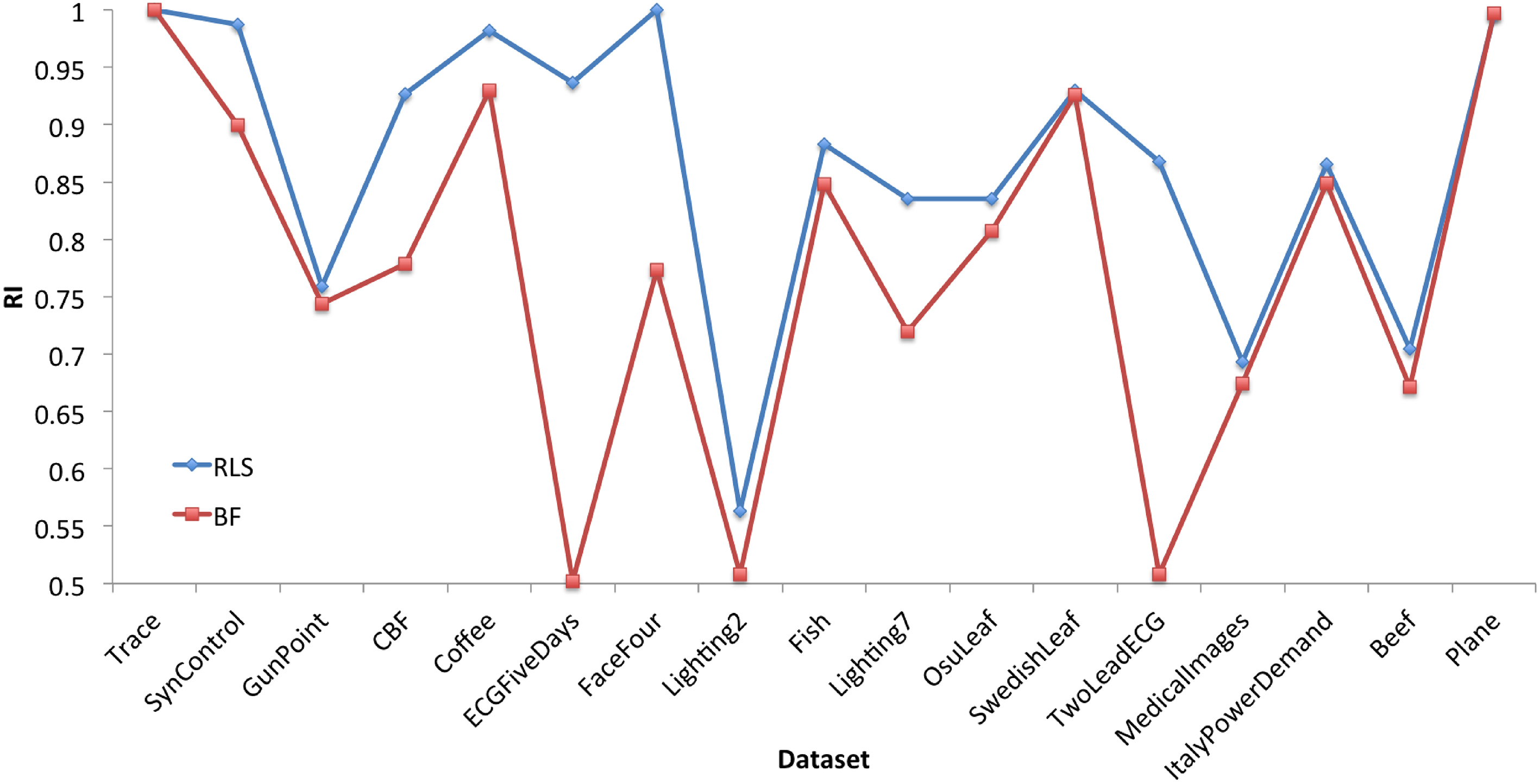
To further confirms that the effectiveness of the local search strategy, we present a comparison of our RLS-algorithm versus the simple random algorithm without local search process on the above 17 datasets. The means and standard deviations of the two methods are presented in Figs 9 and 10 respectively.
The average clustering results comparison between RLS-algorithm and the simple Random algorithm on 17 datasets.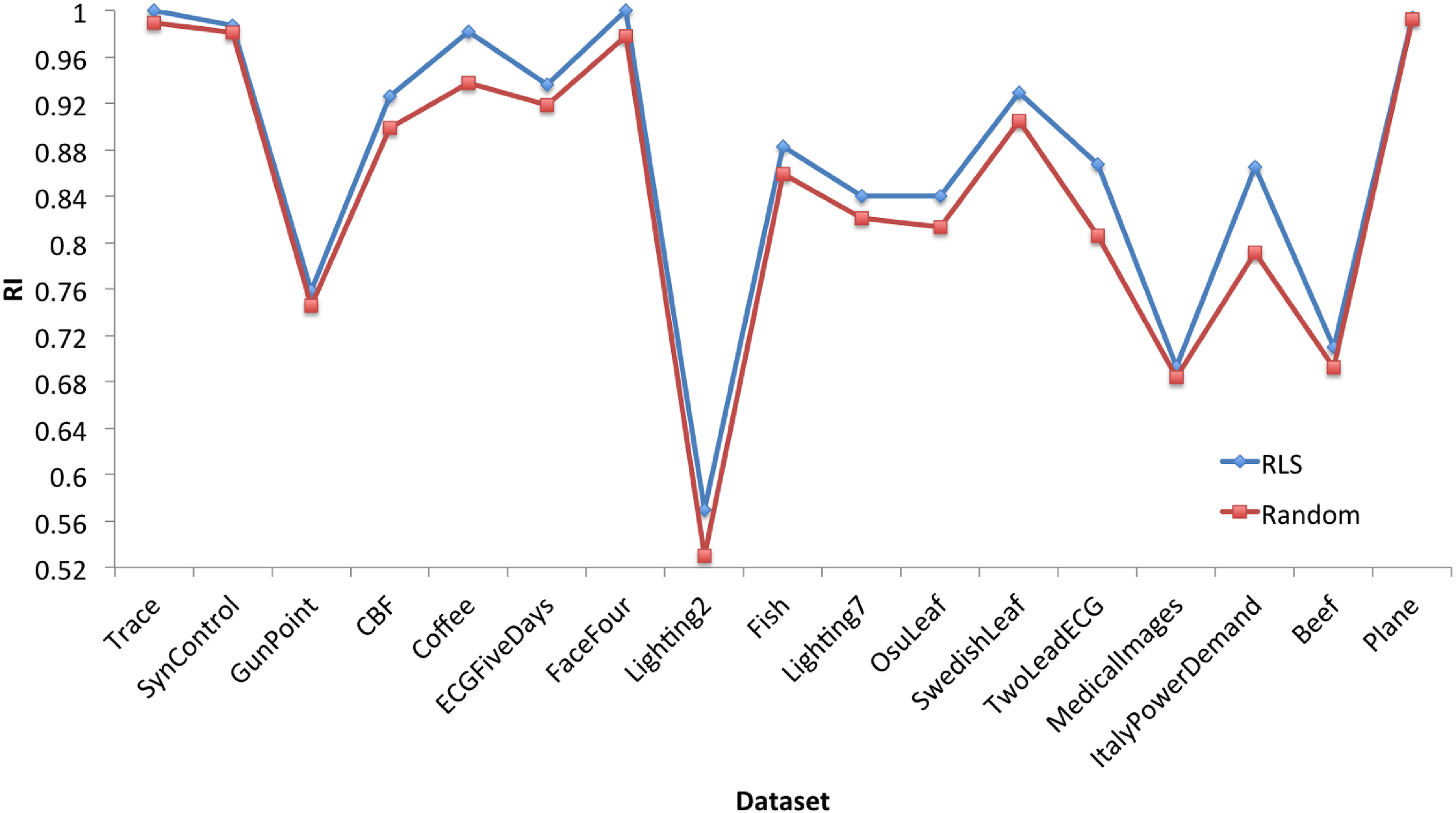
According to Figs 9 and 10, we conclude that our RLS-algorithm achieves more accurate clustering result than the random algorithm, while the standard deviations of our method are lower than that of the random method. It illustrates that the local search method gives an improvement in the clustering result, which makes the clustering results more better and stable.
In this subsection, we compare clustering accuracy and runtime of our RLS-algorithm with the SUSh-algorithm which is the current state of the art and is faster than the BF-algorithm. Since the SUSh-algorithm examines subsequences of a given length, and the SUSh-algorithm did not give the appropriate length for every dataset, the suitable length for u-shapelets is a difficult question to answer. To ensure a fair comparison, we re-implement the SUSh-algorithm with all possible lengths of u-shapelets, which requires a lot of work. Because the SUSh-algorithm uses a random projecting method to filter out large numbers of candidates, the result of each time is non-deterministic. The experiment results of the SUSh-algorithm in this paper are also performed 10 times. We compare the SUSh-algorithm with the proposed RLS-algorithm on all the datasets used in [20], except for the AMPds dataset that we did not get.
Table 3 records the Rand index of the two algorithms. It is clearly that our method achieves the same or even surpasses the quality of clustering as the SUSh-algorithm. The execution time of RLS-algorithm and that of the SUSh-algorithm are presented in Table 4. It illustrates that the runtime of RLS-algorithm is approximately same as that of the SUSh-algorithm. In summary, our method produces higher clustering quality than the SUSh-algorithm in the same time order of magnitude.
Rand Index of RLS-algorithm and the SUSh-algorithm
Rand Index of RLS-algorithm and the SUSh-algorithm
The standard deviations of RLS-algorithm and that of Random algorithm on 17 datasets.
Execution time of the RLS-algorithm and the SUSh-algorithm
This subsection will demonstrate that our method can be applied to large datasets. Thanks to the time reduction obtained with our RLS-algorithm, it is possible to allow large datasets to be analyzed in a reasonable time. We consider 5 datasets which size are larger than 1000 and the length of time series is quite long, the average clustering results are presented in Table 5.
Results of the RLS-algorithm on 5 large datasets
Results of the RLS-algorithm on 5 large datasets
As shown in Table 5, our u-shapelet discovery method is effective on the large dataset. Moreover, the time consumption of all datasets is reasonable, which has shown that RLS-algorihtm is especially helpful to solve the time-consuming problem of u-shapelet discovery on large datasets.
In this paper, we analyze the natural feature of time series subsequences and propose a Random Local Search algorithm to reduce the time complexity of the u-shapelet discovery. By using the random sampling technique, we reduce the size of the u-shapelet candidates set with a modification of the discovery process. By using the local search strategy, we improve the quality of the clustering result. Experiments indicate that our algorithm outperforms recently proposed approaches on both synthetic and real dataset in the time series clustering. Moreover, we also show the utility of our algorithm on large datasets.
Further work includes attempts to use methods of local search to further refine the quality of u-shapelets, as it may be more effective for improving the quality of u-shapelets. another future direction of work could consist in sampling subsequences from these feature points, instead of sampled randomly or uniformly.
Footnotes
Acknowledgments
The first author thanks Jesin Zakaria who provided the source code in .