
Abstract
The issue of privacy preservation is receiving more and more attention when publishing trajectory data. In this paper, we study the challenges of published trajectory data anonymization. Most existing anonymization methods directly delete the trajectories or locations violating specific constraints, it is likely to cause a large loss of information. To address the problem, this paper proposes a trajectory privacy preservation method based on 3D-Grid partition in order to reduce information loss in the process of trajectory anonymization. This method first divides the trajectory region into several spatio-temporal units (denoted as 3D-cells), and then conducts location exchange or suppression in each spatio-temporal unit. Based on the trajectory data partition, within each 3D-cell, the proposed method exchanges locations among trajectories or removes very few locations of some sub-trajectories which do not meet the conditions rather than the whole trajectory. Our method considers three scenarios of trajectory distribution and measures trajectory similarity based on time, orientation, spatial locations and other features of trajectory. After the reconstruction of the related anonymous sub-trajectories, an anonymized trajectory dataset is obtained. Theoretical analysis and experimental results show that, compared to other methods, the proposed algorithm effectively preserves trajectory data privacy and improves the anonymous results of trajectory data in terms of accuracy and availability.
Keywords
Introduction
With the rapid development of mobile smart terminals, positioning and storage technology, it is possible to collect and store location and trajectory data of a large number of moving objects. These trajectories contain abundant temporal and spatial information. Collecting, analyzing and mining trajectories can support various applications related to moving objects [1, 2, 3, 4]. Examples include location-based services, traffic monitoring, urban and road planning, user behavior analysis and travel recommendations [5, 6, 7].
Trajectory data represents the moving routes of moving objects. The release of a large number of trajectory data is bound to pose a threat to the privacy and security of users [8]. For example, by analyzing trajectory data, combined with other relevant background information, an attacker can easily obtain some users’ name, gender, work unit, home address, hobbies, behavior patterns, social habits and other privacy information, the vital interests of users have thereby been harmed [9]. Some research results have been achieved for the privacy preservation of a certain location at a certain time [9, 10]. However, the trajectory privacy preservation method for continuous location information remains to be further studied. With the increasing concern about the preservation of personal privacy information, the privacy-preserving issue in the release of trajectory data has gradually become one of the research hotspots in data mining field [11, 12, 13]. When publishing trajectory data, the data publishers should ensure that the anonymous trajectory data does not reveal personal privacy information while maintaining high availability for accurate analysis. Therefore, how to effectively preserve trajectory privacy of moving objects without destroying the data usability has become an urgent problem to be solved in trajectory data publication.
As the generalization method can achieve a good balance between individual privacy preservation and trajectory data availability, generalization-based trajectory
To sum up, this paper makes the following contributions:
Effective 3D-Grid partition of trajectory data. A novel and effective trajectory partition method that holds the potential features of trajectory data is presented, in order to benefit trajectory similarity evaluation and trajectory anonymization. The method is based on the spatio-temporal features of trajectory. And a new concept 3D-cell is proposed.
Trajectory similarity measurement based on different scenarios. Three scenarios of trajectory distribution are analyzed and a comprehensive trajectory distance calculation method is proposed, which is used to measure the similarity between any two trajectories.
Location exchange and trajectory reconstruction. A privacy preservation method of trajectory data publication, denoted as TPPG, is proposed. It is based on the 3D-Grid partition of trajectory data and similarity measurement between sub-trajectories within each 3D-cell.
Experimental study. The proposed algorithm is tested on both synthetic and real-life trajectory datasets. Theoretical analysis and experimental results show that our algorithm effectively preserves trajectory data privacy and improves the accuracy and availability of anonymized trajectory dataset.
The rest of this paper is organized as follows. In Section 2, we introduce the related work. Section 3 introduces preliminary concept of an enhanced trajectory model. In Section 4, we introduce the trajectory privacy preservation model and the measurement. Section 5 presents a trajectory privacy preservation algorithm. Experimental results and analysis are presented in Section 6. Section 7 concludes the paper and provides future research directions.
In recent years, the scientific issue of trajectory privacy preservation has received more and more attention in academia [14, 15, 16, 17, 18]. Many achievements have been made on privacy preservation of traditional relational data [19, 20, 21], but that can not be directly applied to trajectory data privacy preservation because trajectory data containing rich spatio-temporal information is significantly different with the relational data. In the case of trajectory privacy preservation, any location or time can be used as a quasi-identifier.
Research on trajectory privacy preservation mainly addresses privacy-related issues in two applications. One is privacy preservation of trajectory data publication. The other is trajectory privacy preservation in LBS (Location Based Service) [22]. This paper studies the former, i.e., privacy-preserving trajectory data publication. In trajectory data publication, privacy of moving objects may be compromised because of two aspects: the disclosure of sensitive or frequently accessed locations in trajectories, and the disclosure caused by the linkage between trajectories and external knowledge.
Privacy-preserving trajectory publication methods can be classified into three categories.
Perturbation-based method
This method is to add false trajectories to the original dataset or to replace real trajectory with false data while ensuring that the disturbed data is not seriously distorted. The method is simple, but will generate large amount of data and result in lower data availability.
Hoh et al. [23] proposed a novel time-to-confusion metric and a disclosure control algorithm to deal with trajectory privacy preservation problems. Mano et al. [24] proposed a method that replaces user name with a pseudonym to achieve privacy-preserving trajectory data publication.
Suppression-based method
This method is to release trajectory data selectively. Sensitive data and frequent locations are suppressed or conversed before publication. It is a simple method with large information loss and low data availability.
Terrovitis and Mamoulis [25] proposed a trajectory privacy preservation method based on data suppression. The trajectory privacy is preserved by not releasing sensitive locations or frequently accessed location information. Chen et al. [11] performed trajectory privacy preservation based on the
Generalization-based method
This method extracts locations from trajectories, groups them into spatial clusters and uses the centroids of the clusters as generating points for anonymous region.
Trajectory
Abul et al. [27] proposed NWA (never walk alone) method that divides a trajectory dataset into disjoint subsets based on (
The ability of trajectory privacy preservation and the availability of trajectory data are mutually restricted. The above methods have achieved good results in preserving users’ privacy. However, on the one hand, these methods may suppress data according to the frequency of access, disturb data according to time, or exchange user identifiers with pseudonyms, without considering the information contained in trajectory itself, so the information loss is large after the anonymizing process. On the other hand, most of the methods are based on the processing of the whole trajectory, ignoring the possibility of high similarity between sub-trajectories. As a result, the published anonymized trajectory dataset with high data loss will decrease the quality of trajectory data mining.
In this paper, we partition each trajectory into several units and propose the TPPG algorithm. The method considers the similarity between different sub-trajectories and conducts anonymization within each unit, which improves the usability of trajectory data while protecting trajectory privacy.
Preliminary concept and problem definition
To address the privacy-preserving issue of trajectory data publication, it is necessary to determine the representation of trajectory, distance calculation between trajectories and trajectory privacy requirements. This section will introduce an enhanced trajectory model, a serial of calculation formulas of trajectory distance, and related concept of trajectory privacy preservation. For facilitating further description, the specific problem definitions and terms used in our study are listed below.
where
where
If
If
where
Hereinafter,
where “
where
where
If
Otherwise,
In this paper, trajectory distance is calculated based on trajectory orientation distance and trajectory location distance in order to improve the accuracy of trajectory similarity measurement and to reduce the loss of the trajectory inherent information. The larger the trajectory distance is, the smaller the similarity between trajectories is, and vice versa.
In this paper, we propose a method that allows anonymizing trajectories in order to prevent attackers from using their background knowledge to infer locations unknown to them.
Requirements of trajectory privacy preservation model
In generalization-based privacy preservation, there are two main models:
Trajectory data contains a large amount of spatio-temporal information. However, the essence of location privacy preservation method is spatial anonymity [34], which mainly uses transformed location coordinates to protect user location privacy [9]. It can not be directly used for trajectory privacy protection because it ignores the spatiotemporal correlation characteristics of trajectory data. Therefore, it is necessary to design a specific algorithm to reduce the possibility of trajectory privacy disclosure.
Note that trajectory privacy preservation technology must take both personal privacy security and data availability into account. That is to say, a privacy-preserving trajectory data publication method which can preserve users’ personal privacy while maintaining as high data availability as possible when trajectory data is published is required. Generally speaking, the higher the degree of privacy preservation, the worse the data availability. Therefore, the evaluation of a trajectory privacy preservation method must be conducted in terms of the ability to preserve trajectory privacy and the quality of published trajectory data.
This paper mainly focuses on a variant of trajectory
Trajectory attack model
At present, most of trajectory privacy preservation technologies are designed based on the specific environment. When trajectory data is released, the disclosure risk of individual privacy is related to the background knowledge mastered by the attacker.
In privacy-preserving trajectory data publication, different privacy levels can be provided based on different assumptions about original trajectory dataset, anonymous trajectory dataset and adversary capabilities. An important feature of trajectory data is that any location may be sensitive, so for any location, knowing that a particular user has visited it may be useful to an attacker. Most background information is related to semantic locations. Because in real life, locations and sub-trajectories can be easily exposed. Therefore, referring to the attack model proposed by Literature [5], we assume that the attacker has the following background knowledge:
BK1: The attacker can access any location in the anonymous trajectory dataset
Note that the attacker’s knowledge makes an important difference from the previous adversarial models, our method used for transforming
According to the above background knowledge, we define the attack model as follows:
AC1: The attacker can determine that
If one of the above attack cases AC1–AC3 is met, we conclude that the user’s privacy is revealed.
Trajectory privacy preservation measurement
Trajectory privacy preservation degree is generally reflected by the disclosure risk of trajectory privacy. The smaller the risk of disclosure, the higher the degree of privacy preservation. The disclosure risk refers to the probability of trajectory privacy disclosure in certain circumstances. The disclosure risk of privacy is associated with the background knowledge mastered by the attacker. The more background knowledge the attacker has, the higher the disclosure risk of privacy is. The privacy preservation performance considered in trajectory anonymization is as follows [5].
Entropy metric
In information entropy theory,
In our trajectory privacy preservation measurement, the idea of information entropy is referenced.
where
Consider the original trajectory
Trajectory availability measurement
In privacy-preserving methods with data loss, errors can be formed before and after anonymizing of dataset. But it is required that less impact on the results of corresponding mining and query will be generated. Data quality is primarily measured by accuracy, completeness, and consistency [35]. Estimating the availability of anonymized trajectory dataset is challenging, since it highly depends on its intended use [26]. Unlike traditional data, trajectory data includes availability features such as the number of locations, the number of trajectories and spatio-temporal information. In order to accurately measure the availability of anonymous trajectories, the following metrics are used in our experiments [5, 14]. These metrics can reflect trajectory changes and measure the effect of related queries after trajectory anonymization.
Average location loss
The objective of any privacy preservation algorithm is that no fake or inaccurate locations replace original locations. That is, locations in the anonymized trajectories should be locations contained in the original trajectories, without any generalization or accuracy loss. Therefore, location loss is adopted as a metric to evaluate the trajectory privacy preservation method. Location loss refers to the ratio of the number of different locations at the same time between
where
The average location loss of the trajectory dataset
where
It is a metric measures the change in the number of appearances of locations in the original and the anonymized datasets. For each location
where
Trajectory loss refers to the ratio of the number of deleted trajectories to that of original trajectories, denoted as
where
Spatio-temporal information loss refers to some errors caused by the comparison of the anonymous trajectory with the original trajectory. By comparing the original trajectory dataset
After a series of anonymizing operations, the original trajectory dataset is transformed to an anonymous one. In the anonymizing process, some information is missing or incorrect. The spatio-temporal information loss at single timestamp can be calculated as:
where
Therefore, the spatio-temporal information loss of the total trajectory dataset is calculated as:
Accuracy ratio of AOI (Area Of Interest) query metric, denoted as ARAOI, estimates the ratio of the number of AOIs that are correctly retrieved in the anonymized dataset based on the same retrieve mechanism, where AOI refers to the area wherein the point density is higher than the specified threshold. AOI is a statistic result useful for many applications, including the personalized recommendation and path planning. Higher ARAOI score indicates that the number of AOIs is identified more accurately based on the anonymized data. To measure ARAOI, we compare the retrieved results on anonymized trajectory dataset with that on original dataset. The calculation method is as follows:
where
Algorithm idea
Privacy preservation algorithms must balance data security and data availability, trajectory privacy preservation algorithm is no exception.
In order to reduce information loss and to improve data availability in trajectory anonymization process, we propose a trajectory privacy preservation method based on 3D-Grid partition, it is denoted as TPPG. In this method, we take both temporal and spatial factors into consideration. The calculation of trajectory distance is based on the rate and time interval of contemporary trajectories and the spatial features.
TPPG is developed along three main phases to achieve trajectory privacy preservation. The block diagram of TPPG algorithm is shown in Fig. 1.
Trajectory pre-processing
(a) General processing of dataset. For one hand, the trajectory dataset
Trajectory similarity measurement
We need to enhance the data availability while preserving the privacy of published trajectory data. The distances between sub-trajectories within each 3D-cell are calculated to measure the similarity between them, which is a guidance for trajectory anonymization.
Trajectory anonymization
(a) Spatial locations conversion. To achieve the trajectory anonymization, some locations of sub-trajectories in the same 3D-cell are exchanged based on spatio-temporal attributes and trajectory similarity. (b) Trajectory reconstruction. It is necessary to reconstruct the sub-trajectories from different 3D-cells. After reconstruction of all the new sub-trajectories belonging to the same trajectory, an anonymous trajectory dataset based on real data is finally obtained.
The first part (a) in trajectory pre-processing phase is pre-experimental preparation, which is not difficult to achieve. Therefore, the above Steps 5.1.1) (b) – 5.1.3) of the algorithm will be focused on in the next section.
Algorithm description
Trajectory data partition
In order to improve the efficiency of trajectory anonymity algorithm, and to reduce the information loss generated by the anonymous trajectory, we firstly partition trajectory dataset into
The block diagram of TPPG algorithm.
Trajectory partition effect of synthetic dataset in 2D-plane.
As described in Definition 1, a trajectory is an ordered set of time-stamped locations. It is formalized as
The trajectory data partition of original dataset is implemented by Algorithm 1, denoted as SPTD. Given a dataset of
Notations used in the SPTD algorithm
The pseudo code of SPTD algorithm is given as follows:
Lines 1–16 are designed to get the collection of locations for each 3D-cell by comparing spatio-temporal features of each location with the upper and lower bounds of each 3D-cell. Here the spatio-temporal partition of trajectories is implemented based on the timestamps and (
After SPTD algorithm is executed, we distribute the locations into different 3D-cells. The 3D dataset Cells stores the information of such locations. In Line 17 of Algorithm 1, MergeTr is a function used to merge all locations belonging to the same trajectory into a sub-trajectory. The 3D dataset TS3d is used to store
Line 12 of Function 1 is repeated to obtain tdrow. For each iteration, a location (
Conducting locations exchange is a major method for achieving the purpose of privacy preservation. Random anonymity and exchange of trajectories or locations will degrade the data quality of anonymous trajectories. To ensure high data availability, we measure the similarity between any pair of trajectories, which serves as an basis for trajectory anonymization. Therefore, locations exchange is implemented based on the distance calculation between trajectories. The data availability is greatly improved by locations exchange between nearest neighbors.
Literature [5] concludes that not all similarity measurements between two trajectories are suitable for trajectory anonymization purposes. Many distance measures for trajectories or time series have been proposed in the past, such as the Euclidean distance, the Hausdorff distance, DTW, LCSS, EDR, etc. Most of them are ill-suited to compare trajectories for anonymization purposes, because the requirement for anonymization is not just similarity regarding trajectory shape, but also spatial and temporal closeness of trajectories. To address this issue, Domingo-Ferrer and Trujillo-rasua [5] proposed a trajectory similarity calculation method which considers the time and space dimensions. As described in Section 2, this method ignores other factors such as trajectory orientation, moving speed and continuity feature. Similarly, Wang et al. [14] took trajectory shape into account, but did not consider the continuity of the trajectory. Therefore, based on the execution results of SPTD algorithm, we propose a new distance calculation method to measure the similarity between two trajectories. Our method is designed for trajectory anonymization purpose and takes full account of the above factors when measuring the trajectory distance.
There are three main scenarios of the spatio-temporal relationship between two trajectories, which are shown in Fig. 3. The distance calculation depends on the specific scenario.
Three main scenarios of the relationship between two trajectories.
1) Only one location in each trajectory
The distance is calculated based on the Euclidean distance. For the two scenarios (a) and (b) in Fig. 3, the calculation equation is as follows:
where
2) Only one location in one trajectory, and at least two locations in another one
The distance is calculated based on the area of triangle. Without loss of generality, we assume
where
As is presented in Definition 2, the
3) At least two locations in each trajectory
This is the general scenario, as shown in (e)–(f) of Fig. 3, there are at least two locations in
The proposed method gets all the distances between each pair of sub-trajectories within each 3D-cell. This work is implemented by Algorithm 2, denoted as GD. The input of the algorithm includes a 3D dataset TS3d obtained from the execution results of Algorithm 1, a weight parameter
Notations used in the GD algorithm
The pseudo code of GD algorithm is given as follows.
In Line 6 of Algorithm 2, ComDist is a function used to calculate the distances between each pair of trajectories. Lines 7 and 8 achieve a combination of two weighted distances according to Eq. (13). The pseudo code of ComDist function is given as follows.
Lines 2–11 of Function 2 calculate the two 3D datasets time and
The proposed privacy-preserving trajectory data publication method is based on 3D-grid partition, so both the temporal and spatial attributes of trajectories need to be taken into consideration. When calculating the distance between two trajectories, most existing methods calculate spatial distance based on the center point and the length of each sub-trajectory [37, 38]. They ignore the continuity of trajectory. In our similarity measurement method, three main scenarios of spatio-temporal relationship between two trajectories are all considered, where the trajectory distance is calculated based on spatiotemporal attributes. Trajectory orientation distance and location distance are integrated in calculation of trajectory distance. In particular, the location distance based on area calculation is used to address the continuity problem of trajectory. Therefore, our distance measurement method considers the comprehensive impact of the internal and external characteristics of trajectory itself on the similarity between trajectories.
When the original dataset contains a large number of locations or trajectories, regional division and sub-regional anonymization can effectively reduce the amount of calculation in the process of trajectory similarity measurement and anonymization.
Based on 3D datasets TS3d and Dists, Algorithm 3 processes locations exchange to implement trajectory anonymization. Starting from the first trajectory in each 3D-cell of TS3d, the algorithm exchanges the corresponding time and locations between two nearest trajectory neighbors when the constraint of
Notations used in the TPPG algorithm
Notations used in the TPPG algorithm
The pseudo code of TPPG algorithm is given as follows:
In Line 1 of Algorithm 3, LocEx is a function used to swap the locations between two closest trajectories. Lines 2–12 are the reconstruction process of anonymous trajectory. Because each step before this algorithm is conducted on the sub-trajectories in 3D-cells, the final anonymous trajectory dataset must be obtained based on the reconstruction. Before Line 13 is executed, the dataset TSanony also conforms to the form same to the original dataset
Line 7 of Function 3 sets an exchange sign swaptrflag for each sub-trajectory, whose value is 0 before being exchanged and 1 after being exchanged. Line 8 of Function 3 sets an exchange sign swaplocflag for each location of each sub-trajectory, whose value is 0 before being exchanged and 1 after being exchanged. Lines 9–41 are the specific steps of trajectory anonymization, and Lines 33–39 are designed for processing the case that locations are sparsely distributed. Lines 10, 14 and 17 serve as the constraints on locations exchange.
Trajectory privacy preservation capability
Consider a sub-trajectory
TPPG algorithm performs 3-dimensional Grid partition on the original trajectory dataset, so each entire trajectory will be divided into different 3D-cells. Therefore,
In summary, even if the attacker grasps the background knowledge BK1 and BK2 defined in Section 4.2, the TPPG algorithm satisfies trajectory privacy preservation requirement according to the attack model defined in Section 4.2. In particular, there are three cases:
AC1: After being partitioned,
AC2: Because each trajectory has been partitioned into different 3D-cells, in which the locations of each sub-trajectory are exchanged with that of other trajectories. Anonymous trajectory is generated after the anonymized locations being reconstructed. As is described above, the probability of the locations in the reconstructed anonymity trajectory corresponding with
AC3: Because each location of
The time complexity of Algorithm 1 depends on the following two parts: (a) the time for computing the 3D dataset Cells, whose time complexity is
Algorithm 2 calls the function ComDist once for each 3D-cell of TS3d, that is,
Regarding Algorithm 3, we have precomputed its input TS3d and Dists using Algorithms 1–2. This is reasonable, because those datasets need to be computed only once, while the TPPG method need to be run several times (e.g. with different parameters
The time complexity of Algorithm 3 depends on the following two parts: (a) the time to execute the function LocEx, which is called once by Algorithm 3. From Lines 3–41 in Function 3, we know that each sub-trajectory in each 3D-cell of TS3d is scanned to process locations exchange. The time complexity of Lines 3–32 is
In summary, the total time complexity of the proposed method is:
Experimental results and analysis
In this section, we perform a set of experiments to evaluate the performance of the proposed algorithm in terms of data utility.
Experimental environment and dataset
Experimental environment
The experiments are conducted with Matlab 8.3 on a PC with Intel (R) Core (TM) 2 Duo CPU 3.7 GHz and 8 GB of RAM. The operating system is Microsoft Windows 7. Two datasets are used to compare TPPG with the prior work of GC_DM [14] and MDAV [5], where SwapLocations method is used in the anonymization process.
According to Algorithms 1–3, for each dataset, our experimental process is specifically arranged as follows:
Pre-processing the experimental dataset based on our proposed trajectory model. Calculating the 3D datasets Cells and TS3d by implementing Algorithm 1, and the 3D distance dataset Dists based on Algorithm 2. Completing the trajectory anonymization using Algorithm 3. Achieving the experimental results comparison based on various evaluation metrics.
As described in Section 6.1.1, in order to illustrate the superiority of our algorithm, we carry on a series of comparisons with two other algorithms GC_DM and MDAV, which were verified based on the following two datasets. Therefore, we also choose them to conduct the comparison experiments. Details as follows.
1) Synthetic dataset
The Brinkhoff generator [36, 39] is used in the experiments to generate 1005 synthetic trajectories, containing 45727 locations in the Oldenburg city of German. For ease of description, this synthetic dataset is denoted as SynDS. The parameters used are set as follows: the number of timestamps is 101, the number of moving objects classes is 6, the number of external objects classes is 1, the number of moving objects generated per timestamp is 10, the number of external objects generated per timestamp is 1, the speed of the moving objects is 250, the value of “report probability (0–1000)” is 1000, which means that a moving object is reported at every time stamp during its moving. There are at most 101 locations in each trajectory, and 45.5 locations per trajectory on average. The total area is 23.57 km
2) Real-life dataset
We also use the dataset of cab moving trajectories collected from San Francisco in the United States [40, 41] as the real-life dataset in our experiments, which is denoted as RealDS. It contains GPS coordinates of approximately 500 cabs collected in the San Francisco Bay Area during May 2008. The locations in this dataset are very fine-grained because the average time interval between two consecutive locations is less than 10 seconds [41]. The format of each mobility trajectory file is as follows: each line contains latitude, longitude, occupancy and time, where the occupancy is ignored in our experiments. Since the trajectory of a cab during an entire month can hardly be considered a single trajectory, we use the method in the literature [5] to pre-process this dataset. In particular, the trajectory data of the day between May 25 at 12:04 and May 26 at 12:04 is extracted because during this period there was the highest concentration of locations in the dataset [5]. After a trajectory filtering and location interpolation process, we obtain 480 trajectories and 244 locations per trajectory on average.
As mentioned above, when generating the dataset SynDS, the location at each timestamp is reported in each trajectory. We use these two datasets mainly for comparing our method with the GC_DM and MDAV algorithms. Therefore, a same pre-treatment method to the dataset RealDS is adopted to avoid missing values. Following the method of Literature [5], missing location at a certain timestamp is interpolated based on its two timewise-neighbouring locations. So there is no missing data for these two datasets. Noise is not considered in TPPG and the other two algorithms. The issue will be taken into account in our further research work.
Experimental results
In this section, a set of comparative experiments are conducted to evaluate the utility of the three algorithms. In our proposed method TPPG, the partition parameter
In order to illustrate the results of trajectory availability measurement clearly, we change the values of corresponding parameters in the algorithms. For one thing, we respectively change the values of parameters
Average location loss
Based on Eqs (16) and (17), the avgLL values of TPPG algorithm run on SynDS and RealDS are calculated and shown in Fig. 4. As is shown in Fig. 4a,
The avgLL values of TPPG algorithm run on SynDS and RealDS.
The avgLL values of GC_DM and MDAV algorithms run on SynDS and RealDS.
The 
Note that for clarity, only ordinals are represented on the horizontal axis in Fig. 4a. For example, the value on the location of
As is shown in Fig. 4a, with the change of
In GC_DM and MDAV algorithms, parameters
As is shown in Fig. 5a, with the change of
One can observe from Figs 4 and 5 that, compared with the average location loss caused by the GC-DM and MDAV algorithms, the loss caused by the TPPG algorithm is much smaller. It represents the anonymized data utility of our algorithm is much higher than that of the other two algorithms in terms of avgLL metric. This main reason is that TPPG uses the meshing method to divide the trajectories, the number of sub-trajectories contained in each 3D-cell is much smaller than the number of trajectories in the whole area. The GC-DM and MDAV algorithms implement anonymity for the entire whole trajectory dataset, the change of locations for each trajectory is more complicated and widely.
Based on Eq. (18), the
As is shown in Fig. 6a, with the change of
The
The 
As is shown in Fig. 7a, with the change of
One can observe from Figs 6 and 7 that, compared with GC-DM and MDAV algorithms, the average locations appearance ratio of TPPG algorithm is much higher. It represents the anonymized data utility of our algorithm is much higher than that of the other two algorithms in terms of
Based on Eq. (19), the
The 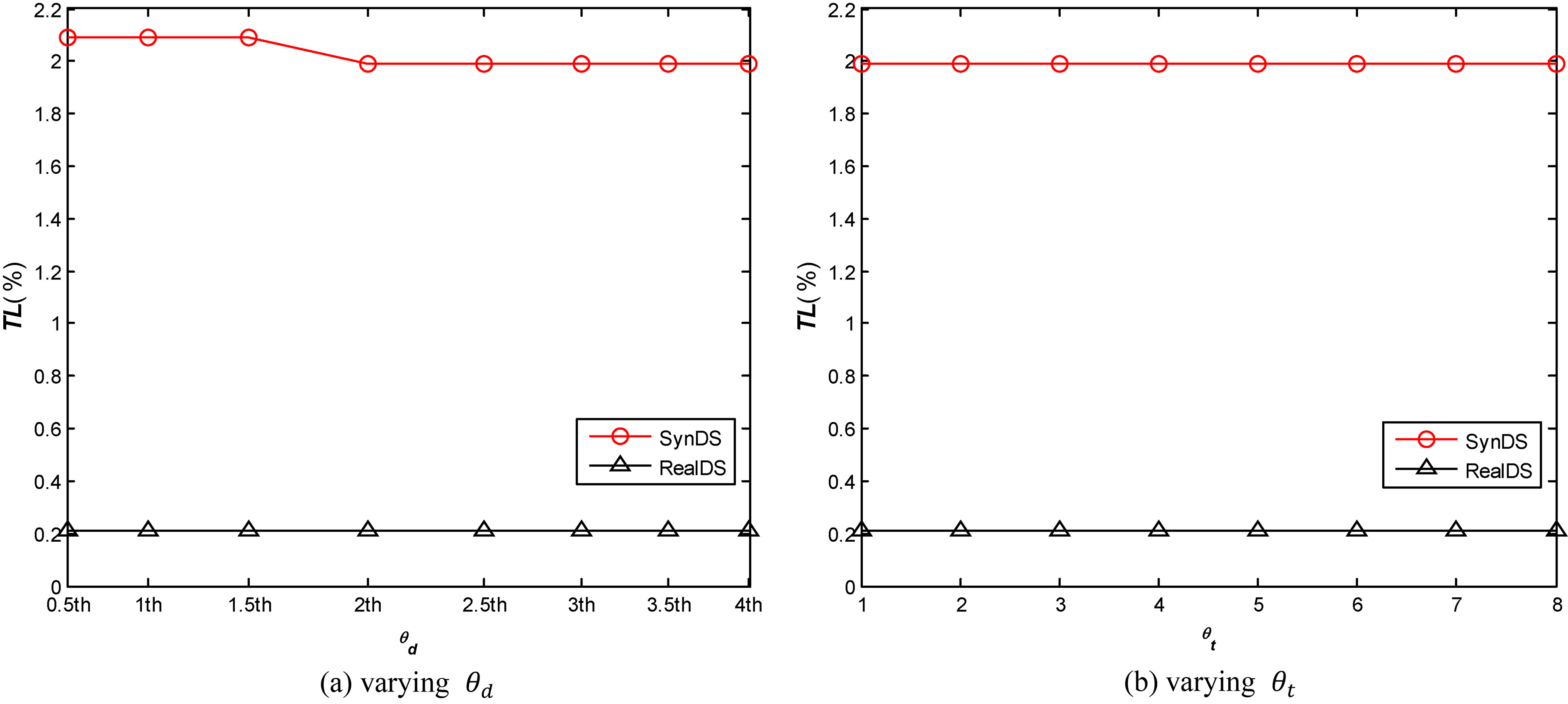
The 
As is shown in Fig. 8a, with the change of
The
As is shown in Fig. 9a, with the change of
One can observe from Figs 8 and 9 that, compared with GC-DM and MDAV algorithms, the trajectory loss of TPPG algorithm is much lower. It represents the anonymized data utility of our algorithm is much higher than that of the other two algorithms in terms of
Based on Eqs (20)–(22), the TIL values of TPPG algorithm run on SynDS and RealDS are calculated and shown in Fig. 10.
The TIL values of TPPG algorithm run on SynDS and RealDS.
As is shown in Fig. 10a, with the change of
The TIL results of GC_DM and MDAV algorithms are shown in Fig. 11.
The TIL values of GC_DM and MDAV algorithms run on SynDS and RealDS.
As is shown in Fig. 11a, with the change of
One can observe from Figs 10 and 11 that, spatio-temporal information loss of trajectory of TPPG algorithm is less than that of GC-DM and MDAV algorithms. It represents the anonymized data utility of our algorithm is higher than that of the other two algorithms in terms of TIL metric. The main reason is that many locations are randomly exchanged in the anonymization process of GC-DM and MDAV algorithms.
We set
The ARAOI values of TPPG algorithm run on SynDS and RealDS.
As is shown in Fig. 12a, with the change of
The ARAOI results of GC_DM and MDAV algorithms are shown in Fig. 13.
The ARAOI values of GC_DM and MDAV algorithms run on SynDS and RealDS.
As is shown in Fig. 13a, with the change of
One can observe from Figs 12 and 13 that, compared with GC-DM and MDAV algorithms, the accuracy ratio of AOI query of TPPG algorithm is much higher. It represents the anonymized data utility of our algorithm is much higher than that of the other two algorithms in terms of ARAOI metric.
To sum up, compared with the other two algorithms, TPPG algorithm achieves higher data utility in the process of trajectory anonymization. It shows that TPPG algorithm effectively balances the availability of published trajectory data and the ability of preserving privacy.
In this paper, we propose a novel privacy-preserving trajectory data publication algorithm TPPG based on 3D-Grid partition. The trajectory region is first divided into several 3D-cells, and then locations exchange or suppression are conducted in each 3D-cell. Based on the trajectory data partition, within each 3D-cell, the proposed method exchanges locations among trajectories or removes very few locations of some sub-trajectories which do not meet the conditions rather than the whole trajectory. To achieve more accurate distance between two trajectories, our method considers three scenarios of trajectory distribution and measures trajectory similarity based on time, orientation, spatial locations and other features of trajectory. After the reconstruction of the related anonymized sub-trajectories, the anonymous trajectory dataset is obtained. Processing in sub-regions speeds up the trajectory anonymization process and improves data availability. Theoretical analysis and experimental results on real-life cab trajectory dataset and synthetic trajectory dataset show that the proposed approach is suitable for privacy-preserving trajectory data publication. In future research, we plan to integrate the features of stay points of each trajectory into our research in order to reflect the reality more accurately in trajectory privacy preservation.
Footnotes
Acknowledgments
The authors would like to thank the reviewers for their useful comments and suggestions for this paper. This work was supported by the National Natural Science Foundation of China (61702010, 61672039), the Natural Science Foundation of Anhui Province (1508085QF134), the University Natural Science Research Program of Anhui Province (KJ2017A327), and the Science and Technology Project of Wuhu City (2016cxy04).
Conflict of interest
The authors claim that no conflict of interest exists in the submission of this manuscript, and the manuscript is approved by all co-authors for publication. None of the material in the paper has been published or is under consideration for publication elsewhere.