
Abstract
Sentiment analysis of text data, such as reviews, can help users and merchants make more favorable decisions. It is difficult to use the popular supervised learning method to complete the sentiment classification task because marking data manually is time-consuming and laborious. Unsupervised sentiment classification methods are mostly based on sentiment lexicons. The existing sentiment lexicons are simply not capable of domain sentiment classification, it still requires to construct a domain sentiment lexicon. There are still many problems with the advanced domain sentiment lexicon construction methods, e.g., rely heavily on labeled data, poor accuracy. We propose a labeled data extension idea to reduce the dependence of supervised learning methods on labeled data. In order to solve the problems of domain sentiment lexicon construction, we proposed a novel framework based on multi-source information fusion (MSIF) for learning. We extracted four kinds of emotional information, which are lexicon emotional information, emotional word co-occurrence information, emotional word polarity information and polarity relationship information of emotional word pair. When extracting the co-occurrence information, a novel method based on the data extension idea is proposed to enhance its accuracy and coverage. In order to accelerate the solution of the fusion model, an optimization method based on the ADMM algorithm is applied. Experimental results on five Amazon product review datasets show that the sentiment dictionary constructed by the proposed method can significantly improve the performance of review sentiment classification compared with the current popular baseline and the state-of-the-art methods.
Introduction
With the development of Internet technology, more and more people tend to use popular e-commerce platforms to solve the various needs, such as the Amazon, Taobao and so on. A large number of internet users shop on the e-commerce platform every day and evaluate the products. Sentiment analysis of these large amounts of reviews can help both users and merchants. At present, this technology has been widely applied in many fields. For example, users can learn more real experience information about products through the reviews so that they can know more specific information about the product without any spending. It can improve the users’ shopping experience. Of course, e-commerce platform suppliers can also use the data to understand the inadequacies of the commodity so that they can optimize their products [20]. In addition, the researchers found that by analyzing the user-generated data, users’ preferences and personal features can be explored. It has a great effect on user personal recommendation, social advertisement recommendation, and user relationship management [5, 11]. Sentiment analysis of product reviews data is currently a research hotspot.
Machine learning method has always been a common method for text sentiment classification. The main idea of it is to predict the emotional polarity of the text through the learned machine learning model. Although this method has a good performance in text sentiment classification, it needs to manually label the text. In addition, commonly used methods of text sentiment classification are dictionary methods which classify text sentiment by combining sentiment lexicon with reliable rules. This method can use the general sentiment dictionary, or you can use your own emotional dictionary. General sentiment lexicon can only provide universal sentiment information and can’t catch the unique emotional characteristics of the field. In most cases, the classification result is mediocre, and it is necessary to construct a domain sentiment dictionary [24]. Although there are many methods for constructing emotional dictionaries at present, there is still no effective method for solving domain emotional dictionaries. Construction of domain emotional dictionary is still a challenge.
The comments generated daily by the user do not have a clear emotional orientation, but it still contains a large amount of emotional information available. If two identical emotional words appear frequently in all comments, they may exhibit similar emotional tendencies [26]. The researchers found that in the syntactic analysis results of the reviews, two emotional words connected by the coordinating conjunction often show the same emotional polarity, and by the adversative conjunctions often show the opposite emotional polarity [14]. The user’s evaluation words of the same object usually have the same emotional orientation in a comment [1]. These are valuable information that can be drawn from unlabeled review data. They can significantly reduce the dependence of text sentiment classification on labeled data. In addition, people shop on the e-commerce platform will not only generate review data but also generate rating data. For most users, the score tends to be consistent with the emotional preference of the corresponding comment, i.e., the emotional preference of user’s two comments corresponding to the same score is likely to be consistent. People tend to use emoticons to imply the emotional orientation in microblog data [10]. Comments have fewer emojis, but users have higher ratings. For most users, a project rating of 5 (or 1 point) indicates that the corresponding comment is positive (or negative) comment [21]. We can leverage the relationship between user ratings and reviews to extract valuable information to improve the performance of our text sentiment classifier.
Based on the above findings, in this article, we propose a fusion domain emotional dictionary construction model, which make full use of multi-source information extracted from the existing dictionary and user comments. The main contributions of this paper are summarized as follows:
We propose a labeled data extension method based on the relationship between user rating and review sentiment polarity, which can reduce the dependence of domain text sentiment classification tasks on labeled data to some extent. We propose a method of extracting emotional co-occurrence information from unlabeled data by using the idea of data expansion method and use it to construct domain sentiment lexicon. We propose a novel model (MSIF) which can combine multi-source data to construct a domain sentiment lexicons and uses an optimization method based on the ADMM algorithm to speed up the solution of the model. We evaluated the proposed approach using extensive experiments on five benchmark datasets, and the experimental results validate the effectiveness of our approach.
The rest of this article is as follows. In the subsequent section, we will briefly introduce the related work of the research direction. In the third section, we will discuss the idea of a labeled data extension method that we propose, and explain how to extract information from multiple sources. In Section 4, we will put forward a domain sentiment dictionary building model that combines the various sources of information, and elaborate on the optimization method based on the ADMM algorithm. In Section 5, we will show and discuss the results of our experiments. We will summarize our article in Section 6.
In this section, we briefly introduce several related works on sentiment lexicon construction and text sentiment classification.
Sentiment lexicon construction
Sentiment lexicon plays an important role in many text sentiment analysis tasks. At present, the existing and more popular sentiment lexicons include SentiWordNet [3], MPQA [27], etc. There are many related studies based on these lexicons, and our study is no exception. Khan et al. [18] uses SentiWordNet as a labeled training corpus to generate a new sentiment dictionary by calculating mutual information between words. The generated sentiment dictionary is used in the sentiment classification of movie review datasets and the classification result is obviously improved compared with the original dictionary classification results. Wu et al. [29] used a mixture of three sentiment lexicons such as SentiWordNet, MPQA and Bing Liu’s lexicon to combine them with multi-domain knowledge for the emotional classification of Amazon product review data and Twitter data. Compared with the commonly used machine learning methods, the classification results have been greatly improved. With the demands of sentiment lexicon application, the method of emotional dictionary construction has also been widely studied. The commonly used emotional dictionary construction methods are mainly divided into two categories, i.e., the method based on dictionary construction and corpus construction.
The main idea of dictionary-based construction is to use a small polar emotional word seed and a dictionary containing the relationship between synonyms and antonyms, such as the WordNet [22] dictionary, to expand the emotional words. Hu et al. [15] manually tagged 30 adjectives as seed words and used similar adjectives and opposite words of WordNet to predict the emotional orientation of the adjectives on the entire view. In the work of Bakliwal et al. [4], 45 adjectives and 75 adverbs were used as word seed, and a sentiment dictionary was also created using the relationship between word synonyms and antonyms in WordNet. The method based on dictionary construction is easy to implement, and it can easily complete part of the sentiment analysis task. Another method of constructing emotional lexicon is based on corpus construction. The idea of it is to build a sentiment dictionary through the co-occurrence of emotional words, syntactic analysis, label propagation, and emotional signs in a large number of text corpors [12]. Turney et al. [26] calculates the emotional orientation of candidate emotional words by calculating the co-occurrence relations between the candidate emotional words and two seed words (excellent and poor). Kiritchenko et al. [19] constructed two domain sentiment lexicons by using the SO-PMI relationship between emotional words and emoticons. Huang et al. [16] generates emotional word relationship diagrams through emotional word co-occurrence relationships, and uses graph propagation and label propagation algorithms to generate emotional words and their polarity values. Lu et al. [21] optimizes candidate emotional words to generate an optimal domain sentiment dictionary by using some rules, e.g., the candidate emotional words should approach to the general dictionary, maintaining the similar and opposite relationship of the words in the dictionary, maintaining the relationship among some words in the syntactic analysis and should be similar to the general emotional tendencies of the words extracted from the general ratings.
The above methods are relatively common domain sentiment lexicon construction methods. All of them can build a good domain sentiment lexicon, but there are still some shortcomings in these methods. The method of Hu et al. [15] and Bakliwal et al. [4] is based on a common dictionary, the generated sentiment lexicon can only grasp the general characteristics of the domain text. The work of Turney et al. [26] and Kiritchenko et al. [16] uses some relationships based on emotional words in domain text to build an emotional dictionary. Limited by extraction condition of emotional word information, the generated sentiment lexicon can only grasp a small number of domain characteristics. There are many co-occurrence relationships between emotional words in domain texts. Using the graph propagation and label propagation algorithms based on it is quite complicated, like the work of Huang et al. [16]. The work of Lu et al. [21] uses a lot of emotional information that can optimize the domain’s emotional dictionary, but still can’t handle some domain emotional words well. The method in this paper is similar to Lu et al. [21]. The difference is that we propose a novel model based on multiple emotional information so that we can better handle more domain emotional words. We also use the ADMM [7] algorithm to optimize the proposed model.
Text sentiment classification
The purpose of text sentiment classification is to automatically identify the emotional orientation of a text through a certain model, such as positive, negative, neutral [17], etc. There have been a lot of studies on text sentiment classification. Commonly used methods mainly include machine learning and dictionary-based text sentiment classification methods. The main difference between the two methods lies in the degree of reliance on labeled data. Machine learning methods are generally supervised learning and rely heavily on labeled data.
The most representative research is Pang et al. [23] using machine learning methods, such as Naive Bayes, maximum entropy model, support vector machine, etc., to train unigrams and bigrams emotional word features of IMDB movie review datasets. Using the generated model to complete the classification of some unlabeled positive and negative comments. In addition to machine learning methods that use emotional words as categorical features, many researchers have also discovered some other features that are used in the training machine learning model. Wu et al. [31] use many pieces of information extracted from labeled and unlabeled data to optimize the linear model for microblog sentiment classification. This method makes full use of the sentiment information in labeled and unlabeled data, which greatly improves the classification results compared to the basic machine learning methods. Another method is text sentiment classification based on sentiment dictionary, it is also very famous. Quan et al. [25] extracted positive and negative emotional words in the text through Stanford syntax analysis tools. Then use the HowNet dictionary to calculate the sentimental value of emotional words, negative words, and degree adverbs. Finally, the sentimental tendency of the text is obtained by summarizing the emotional tendency values of the emotional words, negative words, and degree adverbs. In the work of Cho et al. [9], a large number of existing sentiment lexicons were fused into a single emotional dictionary with a high coverage rate, and the polarity of each word in the original sentiment dictionary was standardized into a fused dictionary according to certain rules. Then, using the co-occurrence ratio of emotional words with the positive and negative text in the sentiment dictionary to delete some useless and neutral emotional words. Finally, the total emotional value of the unlabeled domain text will be calculated according to the collated dictionary and its emotional word polarity values, and the value is compared with a certain emotional threshold to complete the emotional classification.
The method of Wu et al. [31] has a good result in text sentiment classification, but it needs more labeled data. Tagging data Manually is extremely time-consuming and laborious. We use the dictionary-based method for text sentiment classification. The optimization model of emotional dictionary construction proposed in this paper is inspired by the idea of Wu et al. [31]. The model of Wu et al. [31] is very different from the model we proposed, but the optimization method is similar. Our main work is to construct a domain sentiment dictionary, so the sentiment classification method of this paper is similar to the methods of Quan et al. [25] and Cho et al. [9]. After completing the construction of the sentiment dictionary proposed in this paper, we will extract emotional words in each unlabeled text that needs to be classified. The text polarity is obtained according to the accumulation of the polarity values of each emotional word in the generated emotional dictionary.
Emotional information extraction
In this section, we introduce the labeled data extension idea we proposed at first. Then, we introduce how to extract various kinds of sentiment information from multiple sources. Four kinds of sentiment information are extracted and fused in our approach, i.e., lexicon emotional information, emotional word co-occurrence information, emotional word polarity information and polarity relationship information of emotional word pair. You can see the overview of the multi-source emotional information extracted in this article from the example given in Fig. 1. We will introduce them in detail.
Overview of the multi-source emotional information.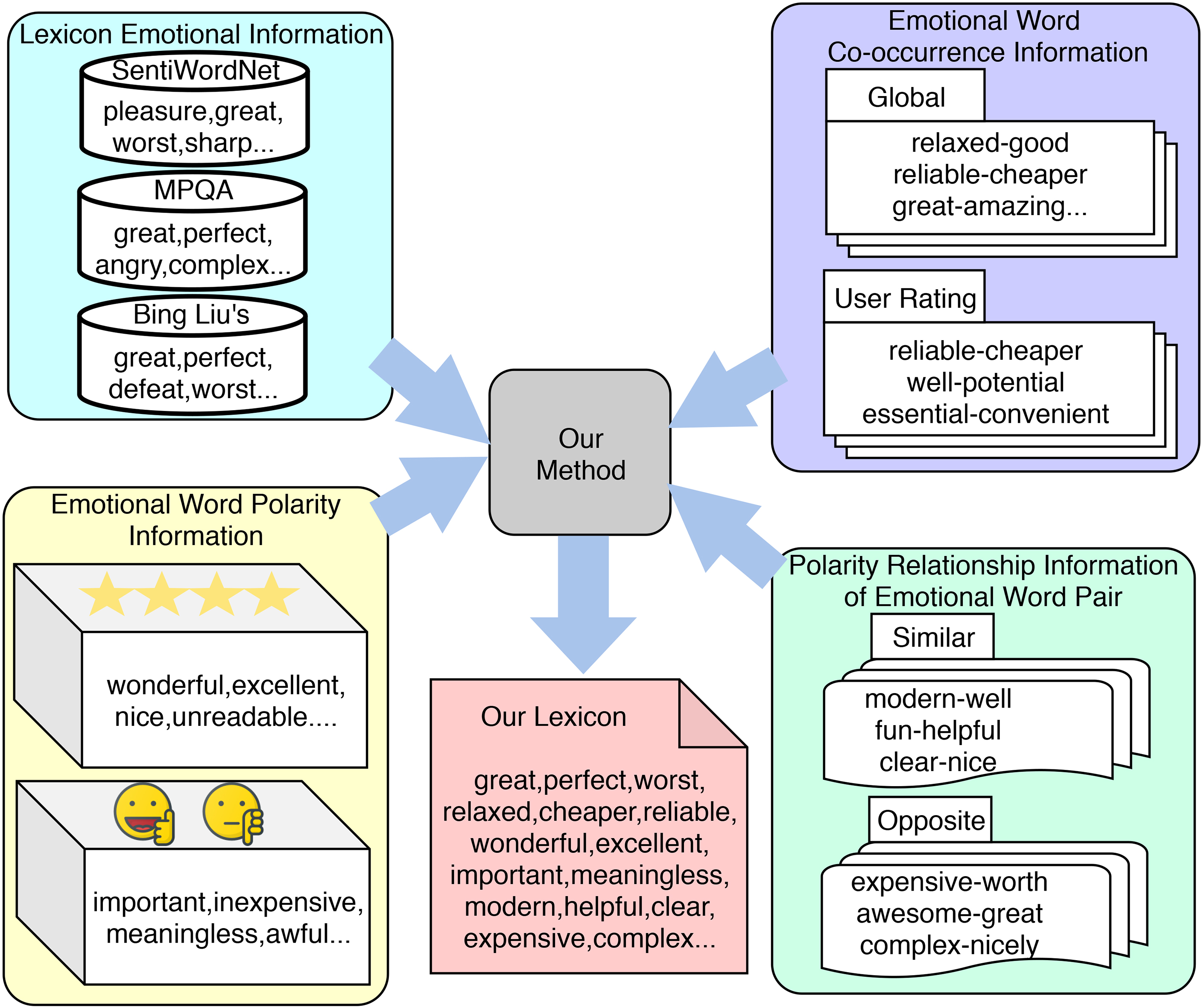
The data generated by the e-commerce platform generally include commodity reviews and ratings. Different users may have different rating standards, so we cannot accurately see how well the users evaluate the product only from the rating. For example, some users think that 3-point represent a neutral score. Scores greater than 3-point are a positive score, and less than the negative. There is also a user’s benchmark score equal to 2-point, i.e., greater than 2-point is positive, less than it is the others. We know that the supervised machine learning methods for product review data classification can help people automatically and quickly identify the sentiment orientation of product reviews, but it requires a large number of labeled reviews for training. Manually tagging reviews is extremely time-consuming and laborious. With the development of society, emerging commodities will continue to emerge, and there will be more and more product reviews in different fields. It is unrealistic to label huge amounts of data manually. In order to reduce the workload of acquiring labeled data, we propose using the relationship between user reviews and ratings as a bridge to evaluate the emotional similarity of user rating comments for labeled data expansion. It can be found that the user’s personal rating standard is basically unchanged, and the emotional tendency of comment is generally consistent with the corresponding rating. Therefore, the proposed idea is that the two reviews show the same emotional orientation if the user’s two reviews correspond to the same score.
In Amazon’s product review data, we can find more examples of similar comments described by the proposed idea. For example, the user’s two comments are as follows. The first one is “Ultimately, I felt very comfortable going with the Bose brand”. The second one is “Well, the bose sound dock is a wonderful music dock. It is very simple”. The ratings of the two reviews are 4-point. We can easily find that two reviews have basically the same emotional orientation. Based on the above idea, we propose the following method of labeled data expansion. We can manually label the user’s partially rated comment data, and then mark more unlabeled data by using the proposed idea in same user reviews. Of course, some users may have many e-commerce platform data, and some users may have little. Given the characteristics of the above methods, we can correspondingly select those users with more comments for manual tagging, so that we can get relatively more labeled data. In order to verify the validity of the proposed idea, we also conducted a supervise learning experiment of text sentiment classification. The experimental part will be described in detail in Section 4.
Lexicon emotional information
The sentiment lexicon generally contains polarity information of some emotional words. At present, popular sentiment lexicons, such as SentiWordNet, MPQA, and Bing Liu’s sentiment lexicon [15], are built for general sentiment analysis. In other words, they only include generic emotional words. Therefore, we use these sentiment lexicons to find the common emotional information in texts. Inspired by the work of Wu et al. [29], we use the three emotional dictionaries of SentiWordNet, MPQA, and Bing Liu’s for hybrid extraction. In order to make full use of the universal sentiment dictionary, we use the following rules to obtain the sentiment information.
Considering that the three emotional dictionaries are constructed using different source texts, different methods, and other conditions, ambiguous vocabulary will inevitably appear in the emotional dictionary. For example, “defeat” is a positive emotional word in Bing Liu’s emotional dictionary, but it is a negative emotional word in MPQA’s emotional dictionary. So we first extract the words that are included in the three dictionaries and have the same emotional polarity as part of the emotional dictionary information. Meanwhile, in order to make full use of the three sentiment lexicons, we also found out the words that satisfied the following conditions were added to the sentiment dictionary information. Words only appear in two dictionaries and have the same polarity in both dictionaries. It can effectively ensure that the emotional polarity of words is correct, and the words are the common emotional word. We use the following formula to calculate general emotional dictionary information:
Among them,
Global emotional words co-occurrence information
If two emotional words appear frequently in the same review, they are more likely to exhibit similar emotional polarity. For example, we have found that “great” and “good” as well as “well” and “easy” appear in many user reviews at the same time. They may show similar emotional tendencies in new user reviews. We use the following rules to calculate the co-occurrence information of the emotional words.
Since the object of sentiment analysis is user comments, there is not many restrictions on the length of the text. Therefore, in order to better extract the emotional vocabulary co-occurrence information, we will divide each comment into sentences according to the English grammar rules to ensure that the emotions of one sentence in the comment are the same. The adversative conjunctions are likely to reverse the user’s attitude. If the adversative conjunction appears in the middle of a sentence, for example, “but”, “while”, etc. We use the adversative conjunction as a separation point, dividing this sentence into two sentences. If the adversative conjunction appears at the beginning or the end of the sentence, we extract the sub-paragraph containing the transitional word as a sentence, and the others as another sentence, so as to ensure that sentiment orientation of each sentence is consistent. Considering that negative words before the emotional words will change the polarity of the emotional words. Because of the relative complexity of processing, we do not consider the co-occurrence of these emotional words in the calculation of co-occurrence information.
If two emotional words appear in a sentence at the same time, we will increase their frequency by one. Finally, in order to facilitate the construction of the later model, we use the no logarithm PMI as a measure of similarity of two emotional words [13]. Its formula is as follows:
The above co-occurrence information of the emotional words is only suitable for the case where there are multiple emotional words in one sentence. There is no effect on a sentence that contains only a single emotional word, and this process lost some of the available data. In order to solve the above problems, we proposed the following idea. In Section 3.1, we propose the idea that user’s two identically rating reviews show the same emotional orientation. We combine this idea with the co-occurrence relationship of words, i.e., if two emotional words appear frequently in the user’s two reviews corresponding to the same score, we think that these two words have similar emotional tendencies. For example, we can find that “professional” and “special” often appear in two comments that correspond to the same score, they may appear in new user comments with similar emotional orientation. We use the following rules to mine the above findings. On the one hand, if there is adversative conjunction in a review that has the same rating for the user, we do not know that the user expresses the emotional preference first. We delete all of this comment. On the other hand, for emotional words modified by negative word, we remove all of this emotional word as Section 3.3.1. After the above processing, we can extract a large number of co-occurrence words from the comments corresponding to the same ratings of users. Same as the Section 3.3.1, we count these co-occurrence word pairs, set a threshold at the same time, and calculate the co-occurrence relationship of the emotional language in this section according to Eq. (2). It is not repeated here.
Emotional word co-occurrence information
Through the methods in Sections 3.3.1 and 3.3.2, we can extract co-occurrence information of emotional words in two co-occurrence situations. Summarize all the emotional words and denote the number of emotional words by
Where
Emotional word labels polarity information
The labeled review can give a very clear guide to the text sentiment analysis. In this article, we extract some representative polarity information of domain emotional words from a small amount of labeled review. The rules for information extraction are as follows.
If the emotional word appears in a positive user comment, the positive frequency of the emotional word is increased by one. Similarly, occurrence in the negative comment, the frequency of negative occurrences increases by one. We will ignore all labeled user comments that contain anti-joints. For an emotional word modified by a negative word, add its frequency to the opposite orientation frequency, that is, if the emotional word appears in the comment of the positive mark, and there is a negative word that modifies this word, the positive frequency of the word is increased by one. Through the above rules, we can get the frequency of emotional words appearing in positive and negative marker comments. An emotional word may appear in positive or negative reviews at the same time, which makes it impossible for us to identify the emotional orientation of emotional words. Inspired by the work of Wu et al. [31], we use the following formula to define the emotional word polarity score:
Where
A small amount of labeled comment data can only extract rare emotional word polarity information. In order to better use the rating information, we introduced the co-occurrence information between words and ratings to further expand the emotional word polarity information. The ratings of reviews generally range from 1-point to 5-point. Of course, we may not know the emotional orientation of reviews that correspond to 2-point and 4-point, and we even not know the polarity of comments that correspond to 1-point and 5-point. However, we know that in the eyes of most users, 1-point and 5-point respectively indicates the user’s positive and negative comments [3]. We can extract a large amount of emotional word polarity information by using the emotional orientation of most users and the statistical features of emotional words, i.e., if the probability that a word appears in all 5-point corresponding comments is much greater than the word appears in all 1-point corresponding comments, we can boldly guess that the polarity of this emotional word tends to be positive. Otherwise, the reverse. Based on the above ideas, we mark all 5-point reviews as positive reviews and all 1-point reviews as negative reviews. According to the processing method in Section 3.4.1, to extract more emotional word polarity information, it will not be repeated here.
Emotional word polarity information
Same to Section 3.3.3, obtained emotional word polarity information by fusing polarity information of two situations. Use
Among them,
We can find more polarity relationship information within emotional words through the syntactic analysis of the comments. There are two kinds of polarity relationship within emotional words, similar and opposite polarity emotional word pair. Emotional polarity similarity refers to the fact that two emotional words in a review are likely to exhibit similar emotional tendencies. Similarly, the opposite relationship of emotional polarity refers to the fact that two emotional words in a review are most likely to show opposite emotional tendencies.
For the emotional polarity similarity relationship, using the following two rules to extract emotional word pair polarity information. First, we know that the emotional orientations of two words connected by coordinating conjunctions are more likely to be similar [16, 28]. For example, in “these are very good for dvd or cd storage. fast and small”, “fast” and “small” are connected by “and”, and they are likely to show the same emotional tendency. If two emotional words are connected by coordinating conjunctions in a review, we extract such words as similar emotional word pair. Furthermore, the user’s emotional preference for the same evaluation object in one comment is more likely to remain unchanged [28]. For example, “beautiful” and “well” in “This beautiful ipod works well and I’m happy with it” is the evaluation of “ipod”. Both are positive evaluations. Since syntactic analysis is not a simple task, we only choose some simply relations that are easy to analyze. We extract all emotional words that embellish an object in one sentence of comment and compose these words into similar emotional word pairs. For the case where the emotional words are modified by negative words, which we will discuss later. The processing here is to retain the case of no negative word modification, and other words are directly deleted.
For the emotional polarity opposite relationship, using the following rule to extract. We know that adversative conjunctions are more likely to change the emotional orientation of the user’s expression [16, 14]. For example, in the review “The camera is expensive but ugly”, “expensive” and “ugly” are connected by “but”, and the polarity of the two is the opposite. We extract the emotional words connected by adversative conjunctions and combine them into opposite emotional word pairs. Similar to the extraction method of similar emotional word pair, we will discuss later on the emotional words that modified by negative word. Here we will directly delete this kind of emotional words.
In the case of negative word modification, the following rules can help us to handle it. For the first rule of similar emotional word pairs, if only one of the two emotional words is modified by a negative word, we will directly extract the two emotional words connected by the coordinating conjunction as the opposite emotional word pair. If two emotional words are modified at the same time by negative words, we will extract two emotional words as similar emotional word pairs. When the negative word appears in the process of extracting similar emotional words of the same object, we treat the emotional words without negative word modification as a pile and the other emotional words as another pile. All emotional words in the same pile, we compose similar emotional word pairs one by one. All emotional words not in the same pile, we compose opposite emotional word pairs one by one. If two emotional words are connected by adversative conjunction, and there is a negative word before the emotional word. Our treatment is similar to the processing of negative word appears in the emotional words connected by the coordinating conjunction. The difference is that the types of emotional word pair generated after processing are different, i.e., when a negative word modification occurs in the process of extracting similar emotional words, the extracted emotional word pair is the opposite emotional word pair, and here is treated as a similar emotional word pair. The others are similar and will not be repeated here.
Many emotional word pairs can be obtained through the above processing method. We use statistical methods to count similar and opposite emotional word pairs. Inspired by the work of Wu et al. [31], we use the following formula to measure the polarity relationship value of emotional word pair:
Among them,
Notations
First of all, we introduce some symbols that need to be used to facilitate understanding. We use
Sentiment lexicon construction model
After extracting emotional information from multiple sources, our goal is to build a more accurate domain sentiment dictionary from this emotional information. The model of our multi-source information fusion model (MSIF) is formulated into an optimization problem as follows:
Among them,
In this section, We will introduce the optimization method of the proposed fusion model. Our optimization method is inspired by the work of Wu et al. [29, 30]. First, the proposed model is transformed into the following equivalent forms:
To further equate it to the following form:
Among them,
We can easily prove that the proposed model is a convex function model. We use the algorithm of Alternating Direction Method of Multipliers (ADMM) [7] to calculate it. Before using this algorithm, we first convert our model into an optimization problem:
It will be further transformed into an Augmented Lagrangian problem:
Where
The update of
The update of
Where
The optimization algorithm for updating
In this section, we will introduce the results of the experiments. We introduce the datasets used in our experiments and the preprocessing steps. Then we evaluate the performance of data expansion method by comparing it with the traditional machine learning method. We also empirically analyze the influence of training data size on the performance of Data Expansion Method. After that we explore the performance of each source extracted information on emotional dictionary construction, and evaluate the performance of the fusion model by comparing it with several state-of-the-art methods. Finally, we explore the convergence and time complexity of our approach.
Datasets and experimental settings
Five datasets were used in our experiments. They are selected from the Amazon product datasets of 25 domains collected by Blitzer et al. [6]. It has been widely used as a benchmark dataset for sentiment analysis. Five datasets are basic information dataset for Amazon product purchases, i.e., DVD, video, electronics, toys&games, and kitchen&housewares. Each dataset contains 1000 negative and 1000 positive reviews, as well as a large number of unlabeled reviews. The basic statistics of five datasets are given in Table 1. In addition, each review also has a user ID and user product rating information.
In the experiments of data expansion method, we used unigram and bigrams features to complete the supervised learning model training. The machine learning method used in this experiment includes logistic regression, naive Bayesian and SVM. They have been widely used to complete the task of text sentiment classification. In this experiment, we used 700 positive comments and 700 negative comments in the labeled data of five datasets as training sets. Other labeled data are used as testing sets. When extracting emotional information, We manually set
In order to achieve better model performance, our experiments performed some preprocessing of text data before the experiments, such as converting all the text to lowercase, removing the stop words, and converting the words into stems. Classification accuracy was selected as a performance evaluation metric in the experiments. Of course, for the accuracy of the experiments, Each experiment was repeated 5 times independently, and average results were selected as the final experimental result.
Performance of data expansion idea
In this section, we conducted experiments to evaluate the performance of data expansion idea by many machine learning methods. The results of the data expansion experiments were presented in Table 2. Among them, Source represents the source training set as the training set, Extend represents the labeled dataset expanded according to the source training dataset and the proposed method as the training set, and Source+Extend represents the labeled dataset composed of the above two datasets as the training set.
The statistics of different datasets
The statistics of different datasets
Commentary classification accuracy for data expansion experiments
Classification accuracy of data expansion experiments with different quantity training datasets using logistic regression model on video dataset.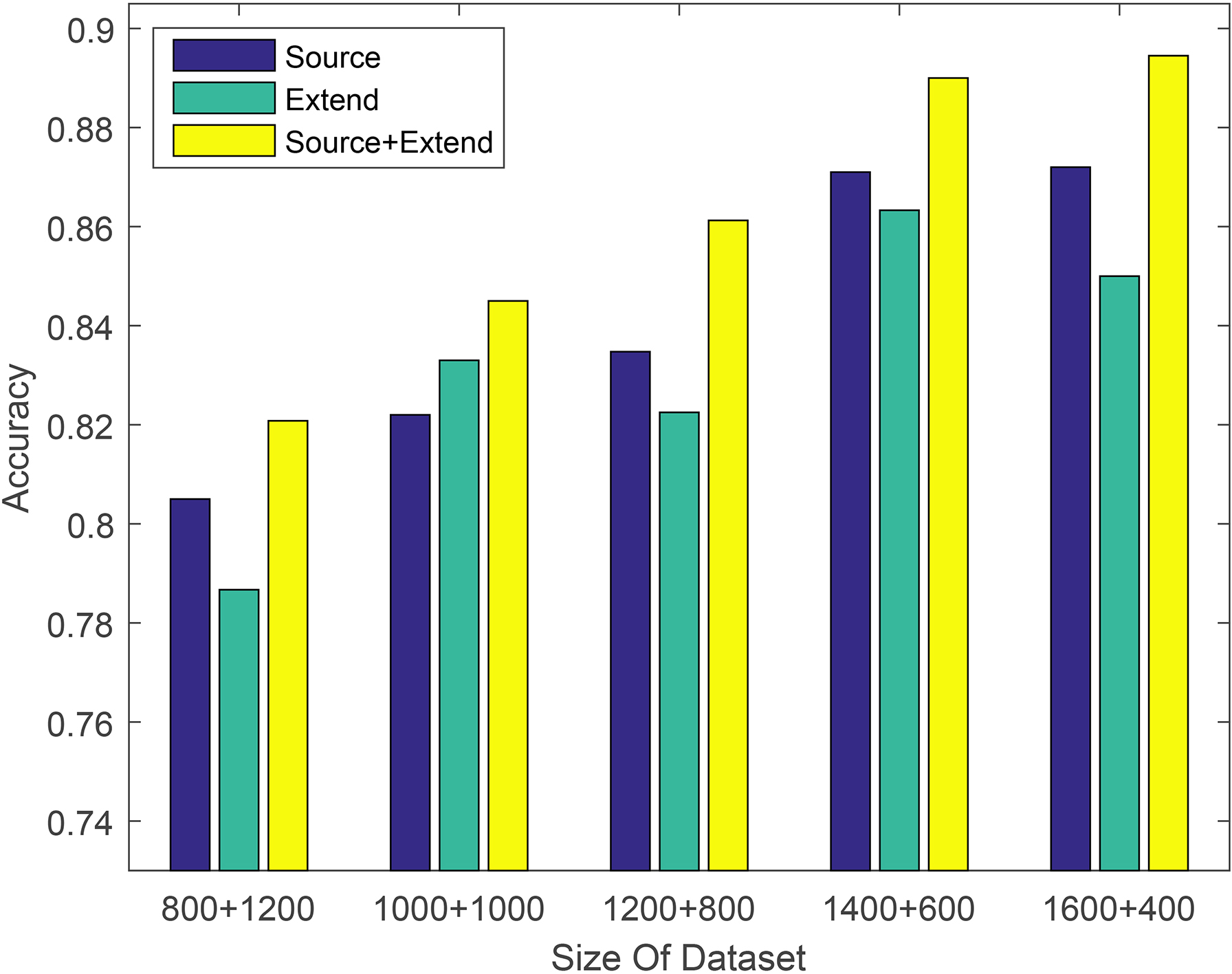
Classification accuracy of data expansion experiments with different quantity training datasets using naive bayesian model on video dataset.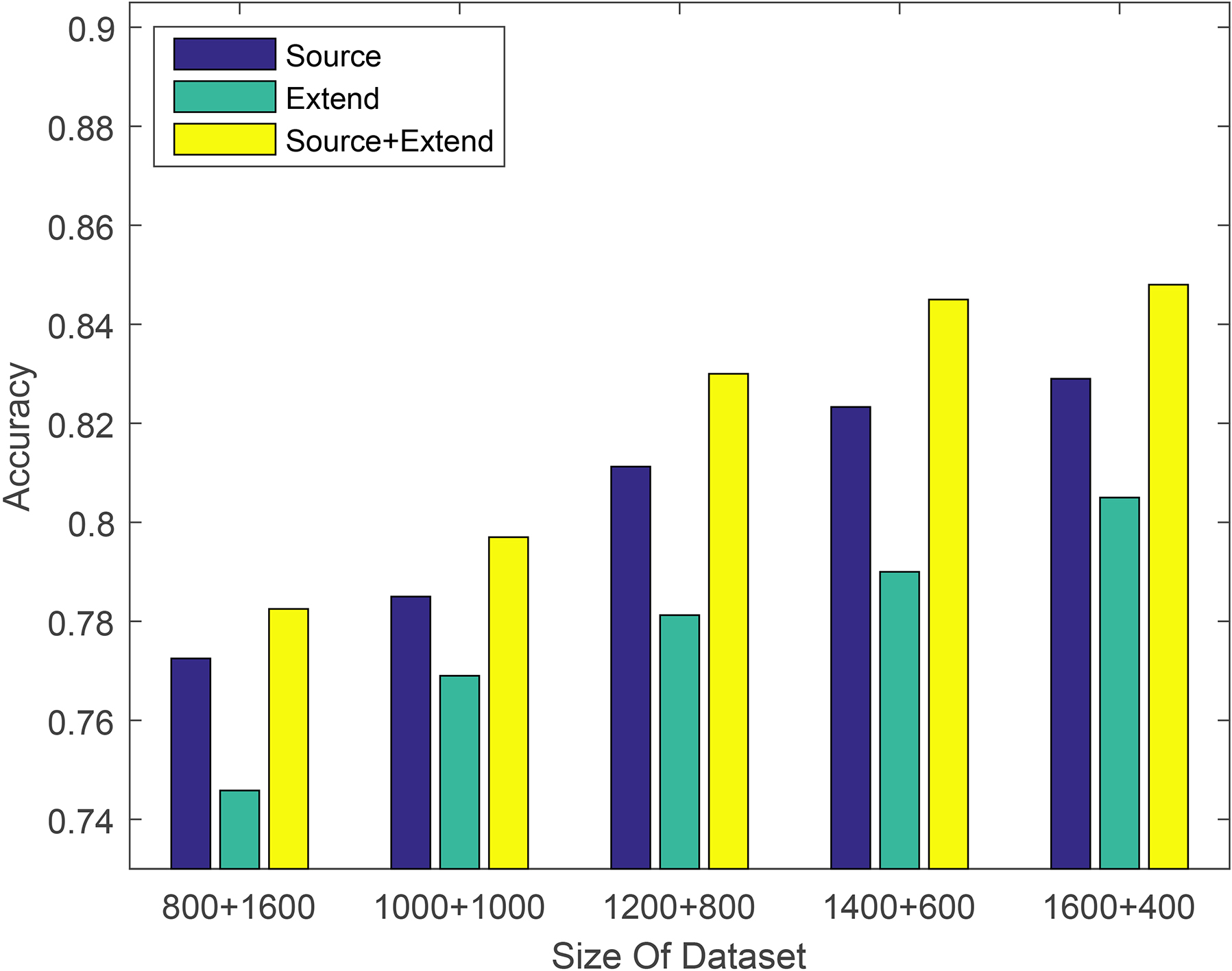
From Table 2, we can find that the prediction accuracy of the Extend labeled dataset as the training set is only one percentage point lower than the Source labeled dataset in most cases. It is sufficient to show that the expanded label dataset has higher label accuracy. The classification accuracy of the Source+Extend mixed dataset is improved compared to two separate datasets, but this improvement is not significant. For example, when using the logistic regression method on the electronics dataset to validate data expansion experiments, the performance was only improved by about 1%. And the improvement in many machine learning methods on other datasets is also less than 2%. We suspect that it is due to the different amount of training data, so we conducted some other experiments on Amazon datasets. Each experiment takes different proportions of training sets and testing sets to study the effect of dataset size on the proposed method. In order to conduct a more favorable analysis, we conducted two sets of experiments. Experiments were performed using different machine learning models on the same dataset. The experimental results are shown in Figs 2–4. Experiments were performed using different machine learning models on different datasets. The experimental results are shown in Figs 5–7. The x-axis is the division of the labeled dataset, the y-axis is the prediction accuracy, and the Source and Extend in the legend have the same meaning as before. The reason why the hybrid dataset has a smaller increase compared to two separate datasets, we will give the reason by analyzing the data expansion experiment results of different quantity training datasets.
Classification accuracy of data expansion experiments with different quantity training datasets using SVM model on video dataset.
Classification accuracy of data expansion experiments with different quantity training datasets using logistic regression model on kitchen and housewares dataset.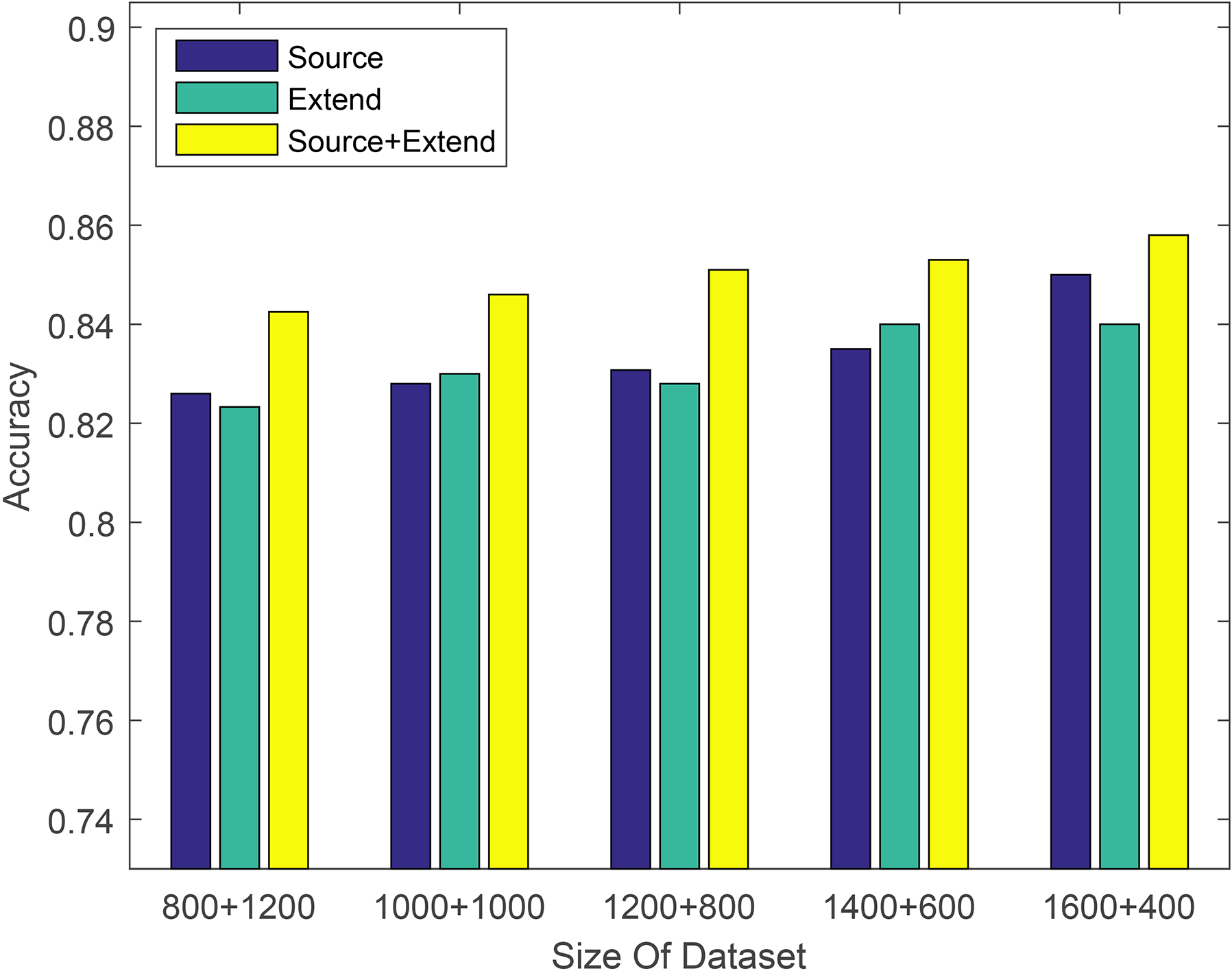
Classification accuracy of data expansion experiments with different quantity training datasets using naive bayesian model on electronics dataset.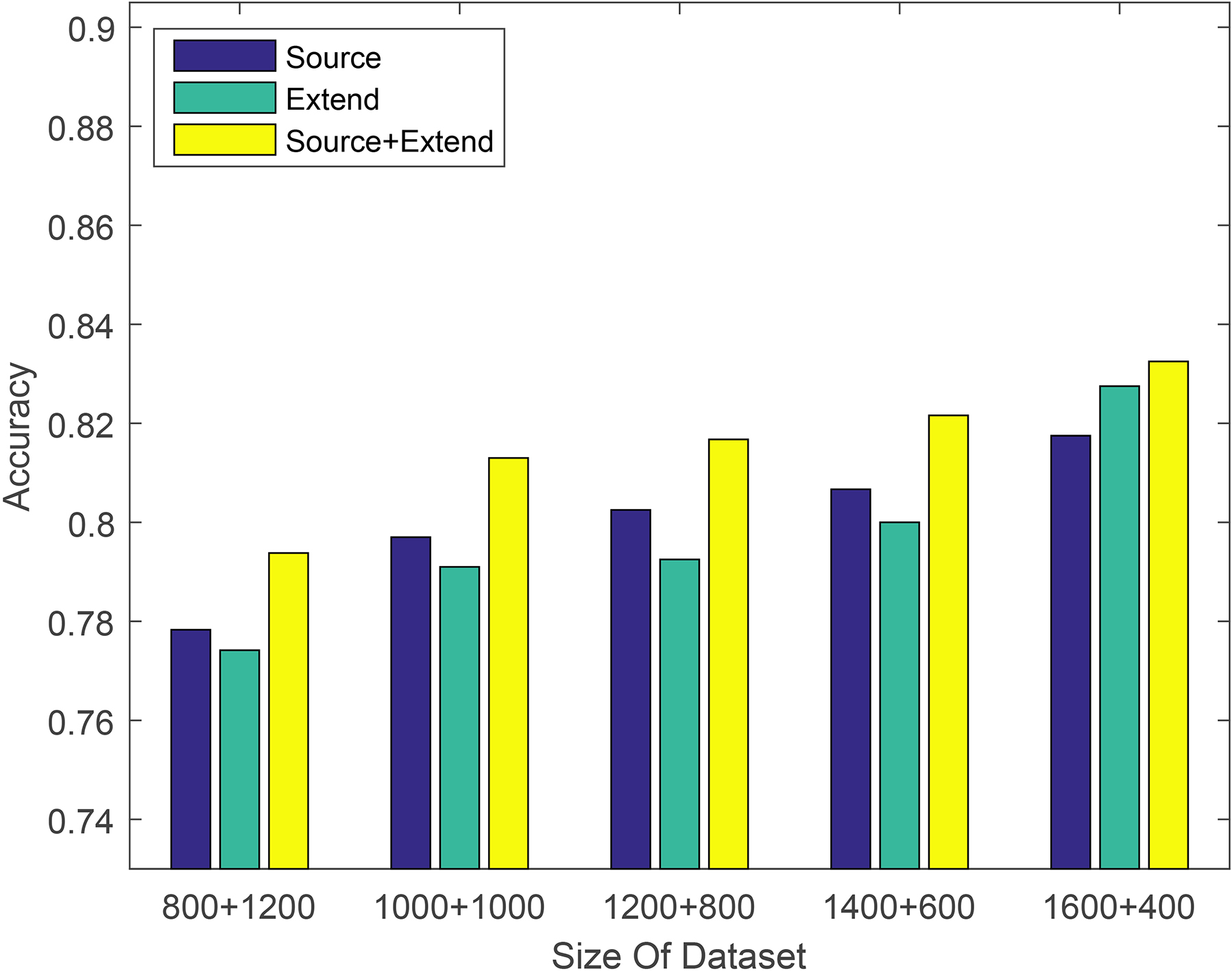
Classification accuracy of data expansion experiments with different quantity training datasets using SVM model on toys and games dataset.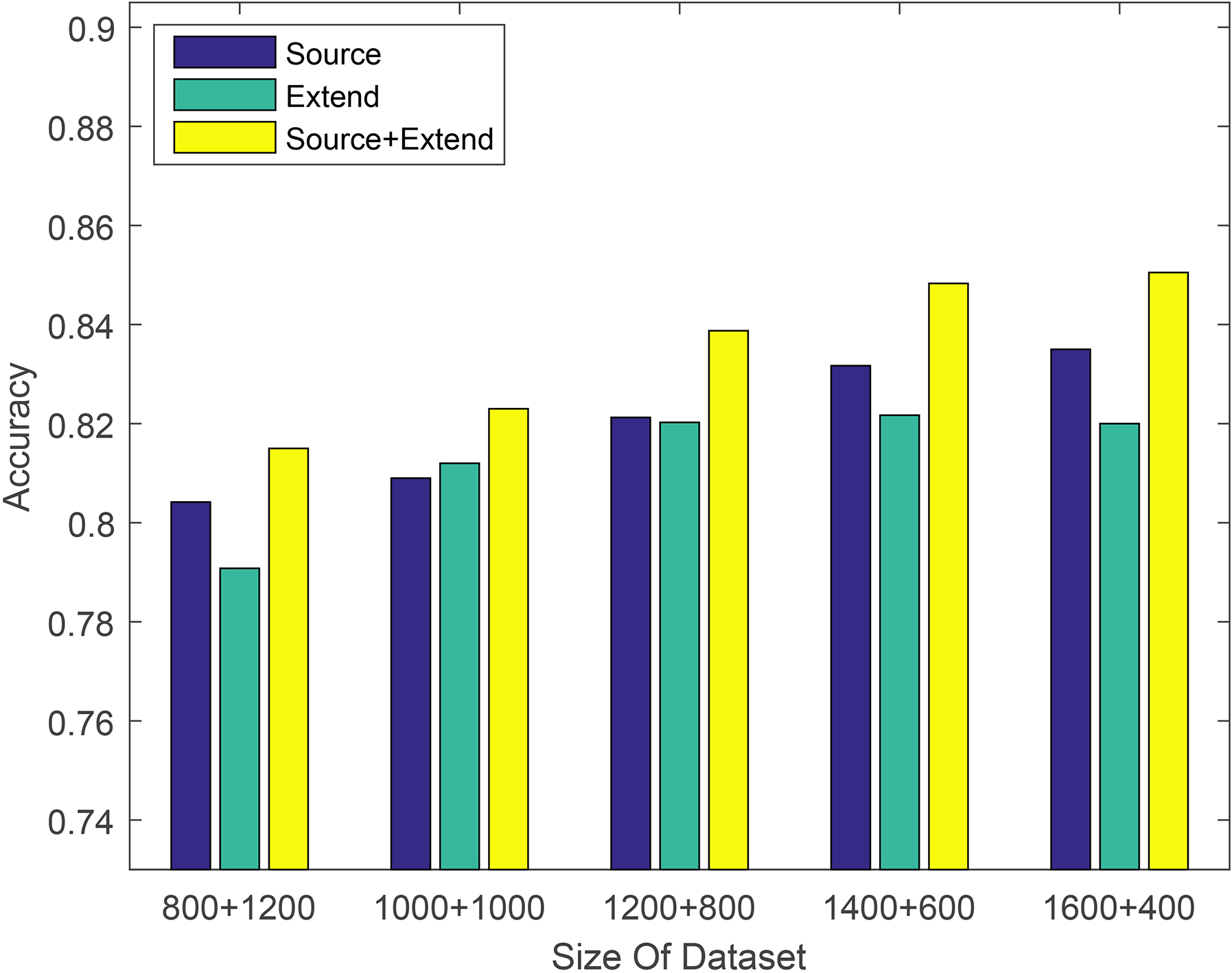
In the data expansion experiment results of different quantity training datasets, if you look carefully, you will find that compared to a single training dataset, the mixed training dataset has a tendency to increase first and then decrease in the improved degree of prediction accuracy. The analysis is as follows. When the training dataset is relatively small, it is not enough to represent the testing dataset. At this time, we can improve the number of training data to some extent by the data expansion method to improve the ability of the source training dataset to characterize the testing dataset. However, the labeled data is small, the amount of expanded labeled data is relatively small, so there is a certain limit in the improvement of the prediction accuracy. As the training data increases, the mixed training dataset is sufficient to characterize the testing dataset. At this time, the mixed dataset will exhibit a maximum value in the prediction accuracy improvement performance compared with the source training dataset. As the training data continues to increase, since the labeled data expansion method simply expands the labeled data, the source training dataset may actually only need a portion of the extended labeled data to be sufficient for characterizing the test dataset. That is, a part of the expanded labeled data is wasted, and the improvement of the prediction accuracy at this time is also reduced.
The amount of data used in this experiment is relatively small. The expansion of labeled data through our method has only 200 to 400 pieces of extended labeled data, and the amount of extended data is relatively small. If each user has a relatively large amount of comment data, the amount of expanded labeled data will be relatively large, and the greater its promotion of the training dataset will be.
In this section, we conducted several experiments to explore the performance of each source extracted information on emotional dictionary construction. Through this experiment, we want to verify why emotional information extracted from multiple sources can improve the proposed model. We only study the information extracted from one source at a time. When we study only one source information, we will simplify the proposed model into a model which only contains the information from a single source. For example, to study the influence of emotional word co-occurrence information, we will generate a model that only relates to the co-occurrence information, i.e.
Classification accuracy of sentiment lexicon constructed by various source information models on five datasets.
From Fig. 8, we can draw two conclusions. On the one hand, the emotional dictionary constructed from each source information has a significant improvement in the classification performance compared with general emotional dictionaries such as MPQA and SentiWordNet. This means that the information extracted from each source has a certain effect on model optimization. This also shows that whether it is a general emotional dictionary, or labeled and unlabeled review, or rating data, they can also contribute to the construction of the domain sentiment dictionary to some extent. On the other hand, the sentiment lexicon generated by merging information from each source has a significant improvement in the accuracy of sentiment classification compared to sentiment lexicon generated from each source information. This shows that the information extracted from multiple sources can be used together by the proposed model to improve the accuracy of constructing domain sentiment lexicon.
In this section, we will use the emotional dictionary generated by the proposed method and some baseline methods respectively for review sentiment classification and compare their performance to evaluate our proposed model. The comparison method is as follows:
SentiWordNet: An open source emotional dictionary derived from wordNet [3]. It provides three tag values for emotional words, such as positive, negative, and an objective tag value. We use certain rules to convert it into an emotional dictionary for sentiment classification. MPQA: A sentiment dictionary built by Janyce Wiebe et al. from Multi-perspective Question Answering (MPQA) Opinion Corpus [27]. The words of this emotional dictionary are only positive and negative. SWN-MI: An emotional dictionary construction method combining labeled data with SentiWordNet [2]. This method calculates the emotional word polarity value by the Mutual Information of word and labels and uses SentiWordNet to correct these polarity value. SO-SD: Construct a sentiment dictionary using the similarity calculation method of word vector [32]. This method uses the word2vec tool to generate word vectors of emotional words and calculates the polarity value of the emotional words by calculating the similarity difference between the emotional words and the two polar word seeds. SO-PMI: Construct an emotional dictionary using PMI-IR algorithm [26]. This method calculates the similarity difference between the emotional words and two reference emotional words, i.e., “excellent”, “poor”, and uses it as the polarity value of the emotional word. OPT: A domain sentiment dictionary generated by using an optimization model to integrate general sentiment dictionary signal, similar relationship signal of sentiment words in the dictionary, similar relationship signal of sentiment words in syntactic analysis, and relationship signal between text and scoring [21]. It is a state-of-the-art domain emotion dictionary construction method. MSIF: A domain sentiment lexicon construction method based on multi-source information fusion. This method is proposed in this paper.
The sentiment lexicon generated by the proposed model and the comparison method is used for sentiment classification of five review datasets, respectively. The sentiment classification accuracy obtained from the experiment is shown in Table 3.
Sentiment classification accuracy of emotional dictionary generated by various methods
The convergence curve of Algorithm 1 on the video dataset.
From Table 3, we can find that the sentiment dictionary constructed by the method proposed in this paper is superior to the baseline method in the performance of the text sentiment classification of the four datasets. The sentiment dictionary constructed by the MSIF method is compared with two existing general sentiment dictionaries. The accuracy of text sentiment classification on the four datasets is at least 17.9% and 11.2%, and the highest is 22.6% and 16.0%. Compared with the current popular baseline and the state-of-the-art domain emotion dictionary construction method, the domain sentiment dictionary generated by the proposed model has a minimum of 0.9% improvement in the accuracy of text sentiment classification, with a maximum increase of 2.4%. It shows that the proposed sentiment lexicon construction method can build a more accurate domain emotional dictionary. Using this domain emotional dictionary to replace the existing sentiment lexicon for sentiment classification of domain reviews can help to improve the classification performance. On the other hand, it also shows that the information extracted from existing sentiment lexicons, labeled review, unlabeled review, and rating data all contribute to the construction of domain sentiment lexicon. In this paper, the labeled data is relatively small, so the model is less dependent on the labeled data. If more labeled data can be provided, it is believed that the performance of the model will be better.
In this section, we conducted experiments to explore the time complexity of the optimization algorithm we proposed. The running time of the program has a great relationship with the experimental environment, so we use the convergence curve to evaluate the time complexity of the proposed optimization algorithm. We take the experimental results on Amazon video dataset as an example for analysis. We show the convergence curve of Algorithm 4.3 in Fig. 9. In Fig. 9, the proposed algorithm can converge to the global optima, which validates the effectiveness of the algorithm. In addition, the convergence speed of the proposed algorithm is quite fast. It can converge in less than 35 iterations, which is quite efficient.
Conclusion
This paper presents a domain emotional dictionary construction model based on multi-source information fusion. The model first extracts four types of information, i.e., emotional dictionary information, emotional word co-occurrence information, emotional word polarity information, and emotional word pair polarity relationship information, from multiple sources including existing sentiment lexicons, labeled and unlabeled reviews, user rating data. In the extraction of emotional word co-occurrence information, this paper uses a new user rating review emotional similarity idea. Before the co-occurrence information extraction, the labeled data expansion experiments prove the validity of the idea. The fusion of information extracted from multiple sources is used to construct a domain emotional dictionary. In order to speed up the solution of the proposed model, this paper also uses an optimization method based on the ADMM algorithm. Finally, this paper conducts review sentiment classification experiments on five Amazon datasets. The experimental results show that compared with the current popular baseline and the state-of-the-art methods, the model proposed in this paper can effectively improve the sentiment classification performance of the reviews.
There are still some deficiencies in the work of this article. For example, when extracting the emotional word polarity information, the rating is used as a comment emotional polarity indicator. It may have a certain amount of error, so the extracted polarity information will also have certain deviations, which will have a certain influence on the final result of the proposed method. In the future work, we will try to avoid the use of such noisy data to extract the emotional word polarity information and strive to find a better way to dig out the polarity information of emotional words.
Footnotes
Acknowledgments
This work was sponsored by National Natural Science Foundation of China (71790593), Postdoctoral Science Foundation of China (2018M642967) and Major Issues of Social Sciences Fund in Hunan of China (18ZWA15).