
Abstract
Storyline generation aims to produce a concise summary of related events unfolding over time from a collection of news articles. It can be cast into an evolutionary clustering problem by separating news articles into different epochs. Existing unsupervised approaches to storyline generation are typically based on probabilistic graphical models. They assume that the storyline distribution at the current epoch depends on the weighted combination of storyline distributions in the latest previous
Introduction
Storyline generation aims to produce a concise summary of related events unfolding over time from a collection of news articles. It enables people to gain a quick glimpse of the development of current events without the need of reading through a large number of news articles. It has been intensively studied in recent years [13, 8, 24, 23, 22].
Storyline generation can be cast into an evolutionary clustering problem by separating news articles into different epochs [7]. Most existing approaches to storyline generation can be categorized into two types, pipeline methods and joint methods. The pipeline methods usually first cluster the events in every epoch, and then link those related events across epochs to form storylines. For example, in [13, 8], events were extracted separately from different time periods and were subsequently combined as storylines in a post-processing step. An obvious drawback of the pipeline methods is error propagation. The joint models perform event extraction and storyline generation simultaneously, and are typically based on probabilistic graphical models. For instance, Zhou et al. [23] proposed a Dynamic Storyline Extraction Model (DSEM) which considers the dependencies among events across different epochs but belonging to the same storyline by using a pre-defined exponential decay function to quantify the degree of dependency. However, the actual degrees of dependencies over the past epochs are an unknown priori. Liang et al. [14] proposed a Dynamic Clustering Topic Model (DCT) which is able to track the time-varying distributions of topics over documents and words over topics. Nevertheless, the DCT model is suitable for short documents and it also can not extract structured representations of storylines.
To extract structured storylines and capture the dependencies between events in same storyline, in this paper, we propose a nonparametric generative model for the generation of storylines which can capture the amount of historical contextual information automatically. To make it easier to understand, we clarify several basic definitions in our approach:
Event: an event
In our approach, each news article is assumed to describe one storyline
The main contributions of this paper are summarized below:
A non-parametric generative model is proposed to extract storylines, which can capture the dynamic temporal dependencies of related events in different epochs over news stream. Collapsed Gibbs sampling [16] and a fixed point iterative estimation method are used for parameter inference. The proposed model has been evaluated on three news corpora and shown a significant improvement for storyline extraction compared to a number of state-of-the-art approaches.
The remainder of the paper is organized as follows: Section 2 discusses related work; Section 3 describes the proposed model; Section 4 discusses our experiments and we conclude this paper in Section 5.
There are two lines of research related to our work, storyline extraction and topic tracking over time. In this section, we will give a brief review about the two lines and discuss the most related models about them.
Storyline extraction
There have been many studies on storyline detection and extraction from text. For example, to generate storylines from massive texts on the Internet, Yan et al. [19] calculated correlations of individual summaries on each date generated using a text summarization algorithm. Lin et al. [15] extracted storylines by first obtaining relevant tweets and then generating storylines via graph optimization. Binh et al. [3] chose relevant time points and contents to be included in a storyline summary using a linear regression model. Radinsky and Horvitz [18] constructed storylines based on text clustering and entity entropy. Specifically, articles after clustering are either generated within a threshold time horizon or the date of an article is mentioned in a text of a more recent article in the chain. The performance of these pipeline approaches rely on the accuracy of calculating context similarity and time closeness, which suffer from the problem of error propagation. For joint model, Huang et al. [10] developed a mixture event aspect model to distinguish local and global aspects of events described in sentences and utilized an optimization method to generate storylines. Huang et al. [11] first extracted topics from a short text corpus based on word co-occurrence patterns, and then developed an event evolution mining algorithm to discover hot events and their evolutions. To make use of the complex relationship between articles, Yu et al. [20] proposed a context-dependent news article storyline detection model based on dense subgraph learning, which adaptively learns a set of cross-article link patterns. However, an event is represented by a set of raw articles, lacking of effective representation. Zhou et al. [23] proposed a non-parametric generative model called Dynamic Storyline Extraction Model (DSEM) to extract structured storylines in which the Chinese Restaurant Process (CRP) [4] was used to determine the number of storylines automatically. However, it models the storyline dependencies with a fixed decay function, which is a strong assumption and might not be suitable for the real world data.
Topic tracking over time
There have been many studies on tracking the dynamic variation of topics over time. Blei et al. [5] proposed a Dynamic Topic Model (DTM) which captures the evolution of topics in a temporally organized corpus of documents. It models the topic dependencies by chaining the natural parameters of topic distribution in a state space model that evolves with Gaussian noise. To model higher order dependencies, Ahmed and Xing [2] proposed a temporal Dirichlet process mixture model (TDPM). In every epoch, it calculates the contributions from previous epochs, which decay exponentially over time. To adaptively track topic, Iwata et al. [12] proposed a Topic Tracking Model (TTM) which can adaptively track the variations in interests and trends based on current purchase logs and previously estimated interests and trends of users. In specific, the current Dirichlet prior is obtained from the mean of posterior Dirichlet parameters in previous epochs and a precision variable is used to represent the topic persistency over time. In a similar vein, Liang et al. [14] proposed a dynamic clustering topic model (DCT) which is able to track the time-varying distributions of topics over documents and words over topics on short documents. DCT models temporal dynamics by factorizing the Dirichlet parameter into the mean of the distribution at the previous timestep and a set of precision values like that in TTM. However, such approaches are not suitable for storyline tracking, a more complex task comparing to topic tracking.
Our proposed approach is partly inspired by DSEM. However, DSEM only models the storyline dependencies of temporally-ordered documents using a fixed exponential decay function without considering the variation of dependencies in data. Our proposed Dynamic Dependency Storyline Extraction Model (D
Methodology
In this section, we propose the Dynamic Dependency Storyline Extraction Model (D
Notations used in the article
Notations used in the article
To model the generation of storylines and characterize the variation of distributions across epochs, we assume that the storyline
The graphical representation of D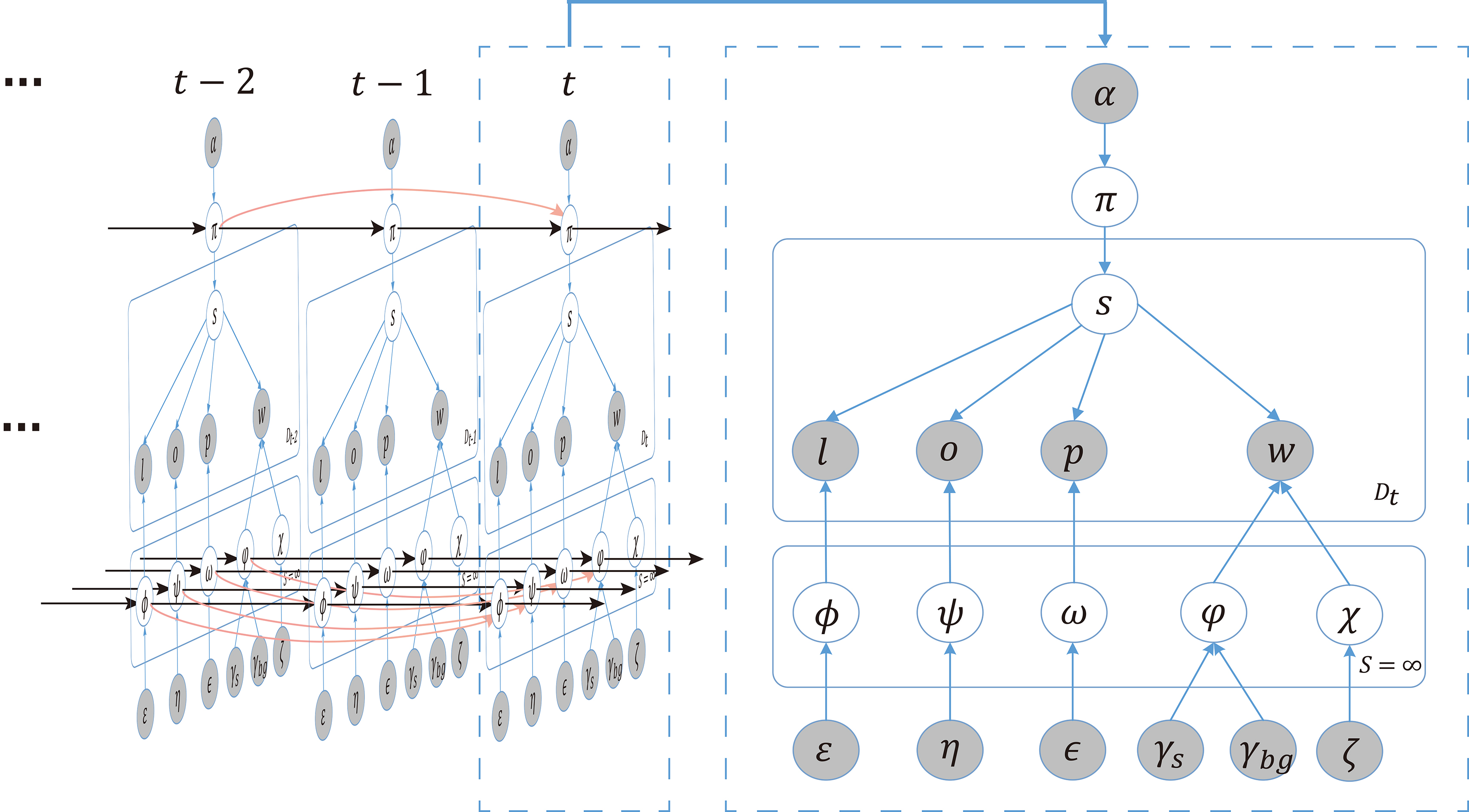
In static topic models such as Latent Dirichlet Allocation (LDA) [6], there is an underlying assumption that the topic distribution and word distribution are independent of the past distributions, and they have Dirichlet priors with a static set of parameters. However, the independence assumption is not realistic when it comes to dealing with data streams. For storyline extraction, the distributions at epoch
where
In the dynamic setting, the dependencies of storyline distributions in the past latest
where
Accordingly, the storyline distribution
where
In a similar way, the dynamic variation of the multinomial distribution
Given the historical storyline distributions
For each time epoch
Draw a distribution Draw a distribution over word switch variable For background words, draw a background word distribution For each existing storyline
Draw a distribution over location Draw a distribution over organization Draw a distribution over person Draw a distribution over keyword For each document
Draw a storyline indicator
If If For each location For each organization For each person For each word position
Draw a switch variable If If
where
We use Collapsed Gibbs sampling to infer the parameters of our model given observed news stream documents. Gibbs sampling is a Markov chain Monte Carlo method which allows us to repeatedly sample from a Markov chain whose stationary distribution is the posterior of interest,
Storyline sampling
Letting the subscript
where
Letting the subscript
where
The posterior probability of the word token
where
During sampling, at each iteration, the weight parameters
where
Based on the recurrent structure of the D
[!h] Inference for the D
In this section, we first describe the datasets, baselines and parameters setting used in our experiments. Then we evaluate the performance of our D
Setup
To evaluate the proposed approach, we use the three datasets as in [23]. The statistics of the three datasets are presented in Table 2.
Statistics of the three datasets
Statistics of the three datasets
From the Table 2, it can be seen that the Dataset I is a large dataset and without any manually anotated storyline. The Dataset II is a one-week data extracted from Dataset I with 77 storylines are identified. In [23], storyline is categorized into four types: (1) long-term storylines which last more than 2 weeks; (2) short-term storylines which last less than 1 week; (3) intermittent storylines which last more than 2 weeks and interrupt in the middle period; (4) new storylines which start in the middle of the period, not the beginning. Since not all these types of storylines exist in Dataset II, the Dataset III is manually constructed containing four types of storylines, altogether 30 storylines are identified.
In our experiments, we used the Stanford Named Entity recognizer1
We chose the following four models as the baselines.
DTM [5], the dynamic topic model based on the Markovian assumption that the topic-word distribution at the current time period is only influenced by the topic-word distribution in the previous time period. RCRP [1], a non-parametric model for evolutionary clustering based on RCRP, which assumes that the popularity of the past story is a good prior for the popularity of the current story. SDM [24] assumes that the number of storylines is fixed and the storyline is modeled as a joint distribution over entities and keywords. The dependency of events at different time periods but belonging to the same storyline is captured by modifying Dirichlet priors. DSEM [23] is integrated with CRPs so that the number of storylines can be determined automatically without human intervention. Moreover, per-token Metropolis-Hastings sampler based on light LDA [21] is used to reduce sampling complexity. NSEM [22] is an unsupervised storyline extraction model based on neural network. In this model, title and main body of a news article are assumed to share the similar storyline distribution. Moreover, similar documents described in neighboring time periods are assumed to share similar storyline distributions. A pairwise ranking algorithm is used to optimize the network.
For DTM, SDM and NSEM, the number of storylines is set to 100 on both Dataset II and III.2
Although the number of storylines is set to 100 for all the models, some of the storyline indices are not assigned with any documents (i.e. empty clusters). As such, the number of actually extracted storylines varies by different models.
As there is no direct evaluation metric for evaluating storyline extraction, we evaluate the performance of storyline extraction in precision, recall and F-measure which are commonly used in evaluating information extraction systems. The precision is calculated based on the following criteria: 1) The entities and keywords extracted refer to the same storyline; 2) The duration of the storyline is correct. We assume that the start date (or end date) of a storyline is the publication date of the first (or last) related news article.
For Dataset I, there is no gold standard available, thus we check the extraction results manually by searching for the relevant news articles in the same period and compare the retrieved results with the model extraction results based on the criteria listed above. Especially, we modify the start and end time of search engine to make it consistent with the dataset. Then we retrieve the extracted event elements, i.e. entities and keywords. We keep the top 20 results and discard those which are not related to events. Based on the retrieved results, three annotators manually check the results and choose the most related event individually. After reaching consensus, the result is considered as the ground truth. As there might be duplicate storylines extracted, thus in the examing process, we ignore the the duplicate one.
Experimental results
Performance comparison of the storyline extraction results on Datasets I, II and III
Performance comparison of the storyline extraction results on Datasets I, II and III
The experimental results of the proposed approach in comparison to the baselines on Datasets I, II and III are presented in Table 3. For Dataset I, since no ground-truth is available, we only report the precision values by manually examining the extracted storylines. For the Dataset I containing more than 500 thousand documents, we only report the precision of SDM, DSEM, NSEM and our D
It can be observed from Table 3 that D
Compared with DSEM which models the dependency with fixed decay function, our D
Overall, D
The performance of D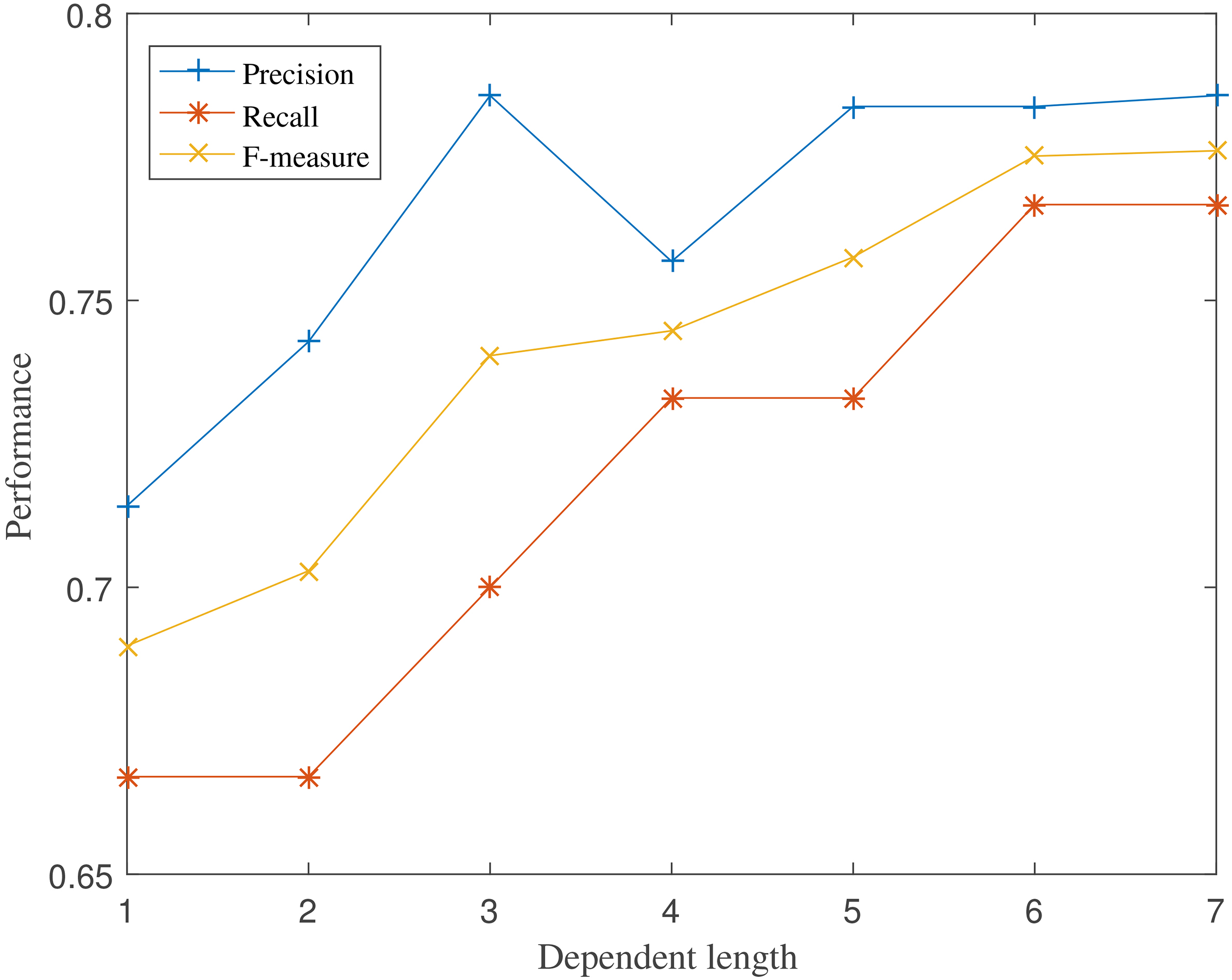
Intuitively, the performance of D
Figure 2 shows the precision, recall and F-measure results with different dependency length
The time complexity of D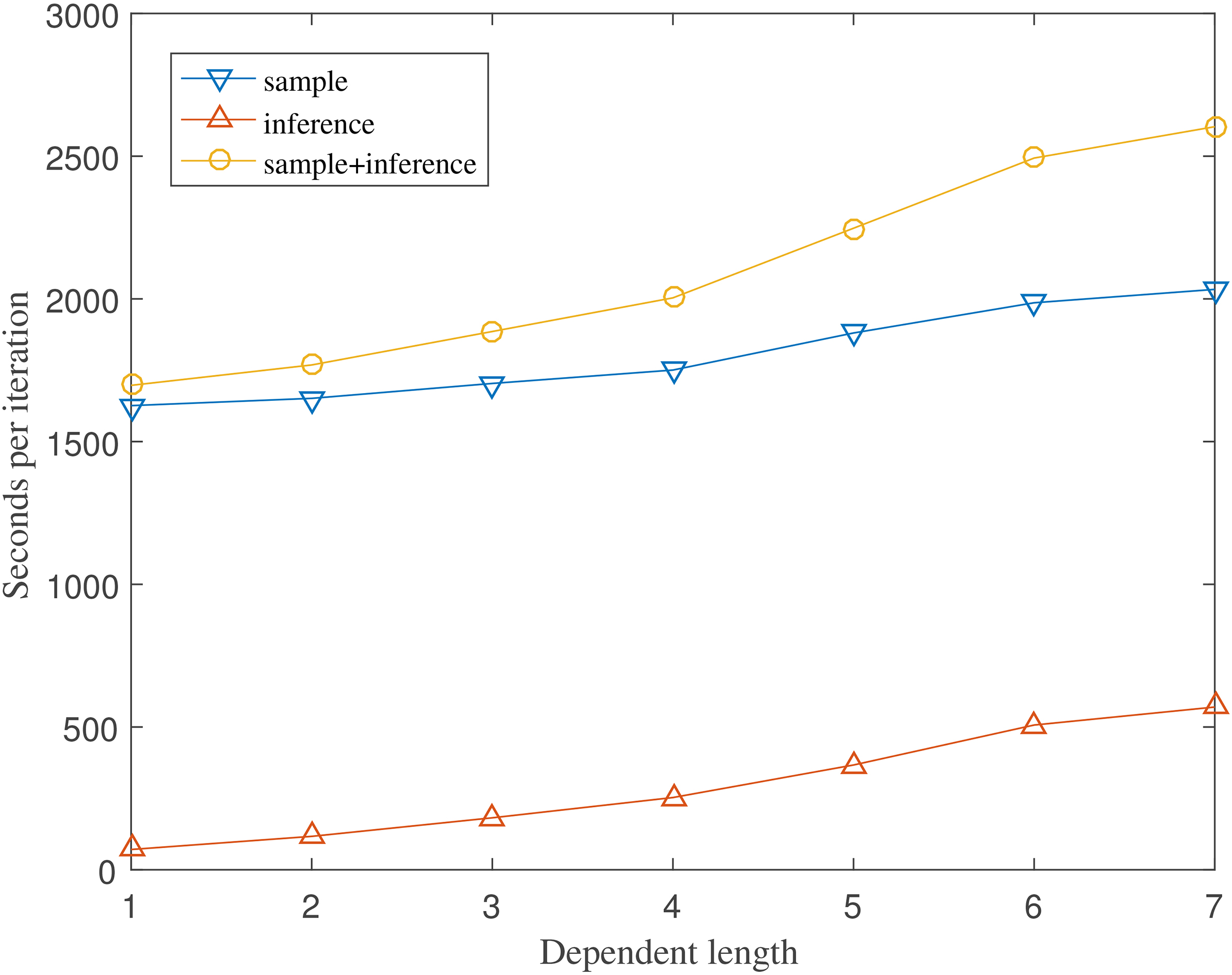
The time complexity of D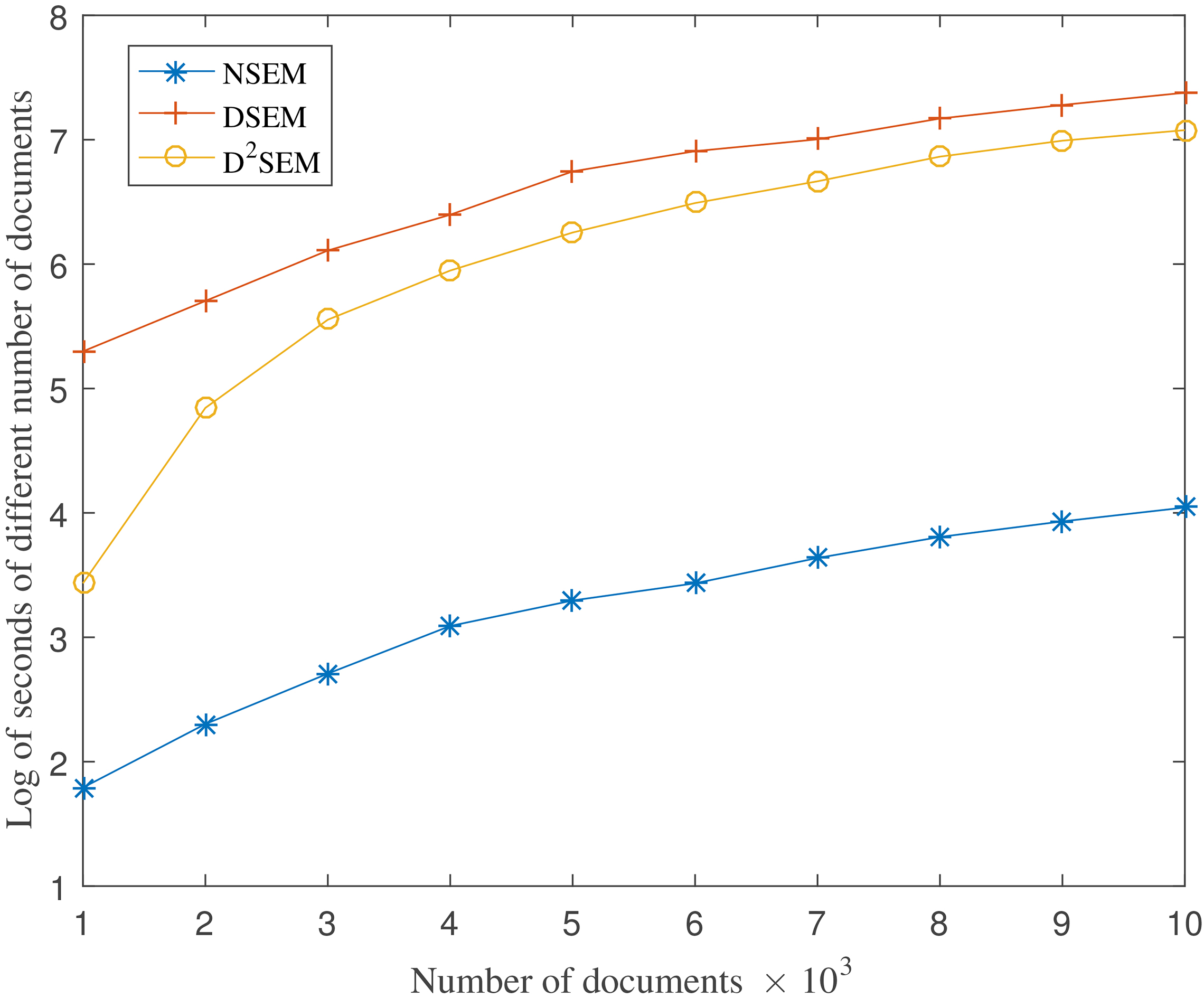
Since longer dependency lengths could result in higher computational complexity, we conduct an experiment on Dataset III by varying the length of dependency from 1 to 7 in epoch 7 in which has 4193 documents.
We train our model on an PC equipped with an Intel Core i7 3770 CPU which is a 3.40 Ghz processor and 16 GB DDR3 RAM. Figure 3 illustrates the time consumed in each training iteration with the ‘inference’ curve showing the time spent in the update procedure of precision coefficients, the ‘sample’ one representing the time consumed in Gibbs sampling and the third curve showing the total time consumed for the above two procedures. It can be observed that the run time of our model increases with the increasing dependency lengths and run time of ‘update’ grows faster than that of ‘sample’.
Since further increasing the dependency length incurs more higher computational cost but with little impact on the storyline extraction results, it is reasonable to limit
To explore the efficiency of the proposed D
To visualize the impact of dependency of historical context on the storyline extraction results, we conduct experiments on Dataset III with
Figure 5 shows the results with the subfigure (a) showing the storyline about ‘The MERS in Saudi Arabia’, the subfigure (b) showing the storyline of ‘Arrest of Gerry Adams over Jean McConville murde’ and the subfigure (c) showing the storyline of ‘The Kentucky Derby in Louisville’. In each subfigure, we also show three structured representations extracted by our model to illustrate what happened in the past.
Dependencies visualization of three storylines.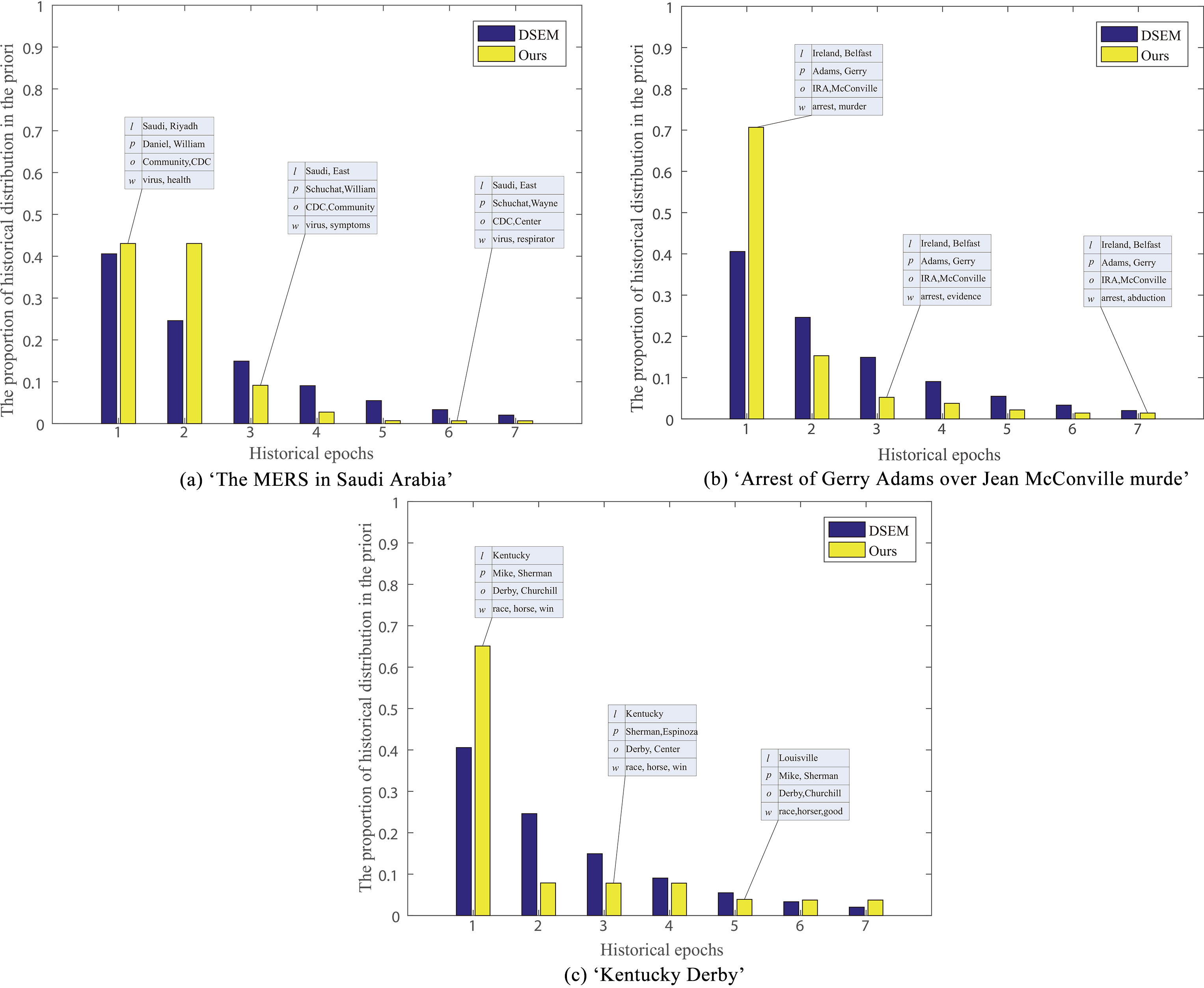
For comparison, we also conduct experiments using the exponential decay function
In this paper, we have proposed an unsupervised Bayesian model, called Dynamic Dependency Storyline Extraction Model (D
Footnotes
Acknowledgments
We would like to thank the reviewers for their valuable comments and helpful suggestions. This work was funded by the National Key Research and Development Program of China (2016YFC1306704), the National Natural Science Foundation of China (61772132) and the Natural Science Foundation of Jiangsu Province of China (BK20161430).