
Abstract
Event extraction (EE) is an important natural language processing task. With the passage of time, many powerful and effective models for event extraction tasks have been developed. However, there has been limited research on complex overlapping event extraction. Therefore, we propose a new cascade decoding model: A Joint Learning Framework for Cascade Decoding with Multi-Feature Fusion and Conditional Enhancement for Overlapping Event Extraction. 1) In this model, we introduce a cascade decoding mechanism with multi-feature fusion to better capture the interaction between decoding layers. 2) Additionally, we introduce an enhanced conditional layer normalization (ECLN) mechanism to enhance the interaction between subtasks. Simultaneously, the use of a cascade decoding model effectively addresses the problem of overlapping events. The model successively performs three subtasks, type detection, trigger word extraction and argument extraction. All three subtasks learned together in a framework, and a new conditional normalization mechanism is used to capture dependencies among these subtasks. The experiments are conducted using the overlapping event benchmark, FewFC dataset. The experimental evaluation demonstrates that our model achieves a higher F1 score on the overlapping event extraction task compared to the original overlapping event extraction model.
Introduction
Event extraction (EE) involves identifying the type of sentence, trigger words, and arguments within a given sentence. As shown in Fig. 1(a), this is a Judgment event with the trigger words “sentenced”, and its arguments are “court”, “Qinshang Group”, and “3 million yuan”. “Court” serves as the subject role of the argument, while “Qinshang Group” plays the object role of the argument.
There are two examples of events, flat event (a) and overlapping event (b). Trigger words are marked with gray boxes and argument words with underscores for easy distinction. At the same time, to make the overlapping events (b) clearer, we use two colors to distinguish the two types.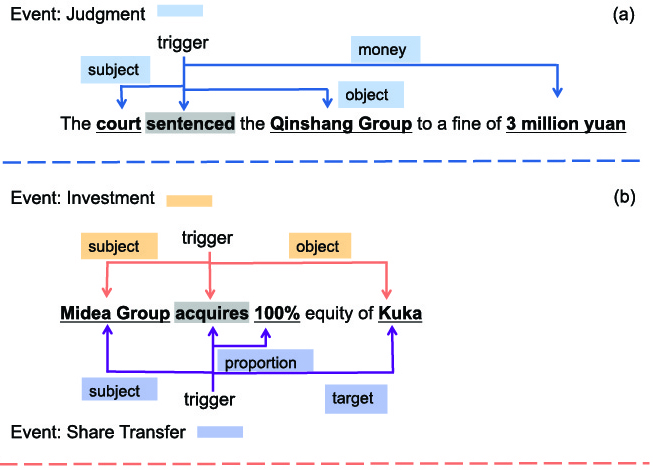
Nowadays, there are primarily two methods for extracting useful information from massive data. One is manual analysis and extraction, while the other is automatic analysis and extraction. With the advancement of science, the latter method typically yields far better results than the former. Currently, event extraction tasks are widely used in the construction of knowledge graphs, news summarization, and financial consulting, among other fields.
In the past, traditional event extraction tasks [13, 12] treated event extraction as a sequence labeling problem. These models are classic, but they have overlooked a significant issue: the presence of complex and irregular event extraction samples in the dataset. Consequently, they have not explored solutions for handling the problem of overlapping events in event extraction tasks.
Traditional event extraction methods often assume that there are no overlapping events in the dataset. In this study, we will discuss the extraction task of overlapping events. What are overlapping events? For example, Fig. 1(b) shows that “acquired” triggers both an Investment event and a Share Transfer simultaneously. In a single sentence, one word is used as the trigger for two different event types due to different arguments.
Sheng et al. [14] categorized overlapping events into three types: 1) a word can serve as a trigger for different event types across multiple events; 2) a word can act as an argument with different roles across multiple events; and 3) a word can play different roles as an argument within a single event.
Of course, in previous research, some researchers have also recognized the issue of overlapping events and provided proposed solutions. Yang et al. [20] introduced a framework based on pre-trained language models (PLMEE), which achieved remarkable results in event extraction tasks using pre-trained language models. They also observed the phenomenon of argument overlap but did not provide a corresponding solution for trigger word overlap, which can easily lead to error propagation. Sheng et al. [14] proposed a joint learning framework for event extraction based on cascade decoding (CasEE), the first paper to simultaneously handle all three types of overlap. However, we believe that CasEE is not fully utilizing the conditions, and the model rarely incorporates interactions between words, indicating that there is still significant room for improvement in the task of extracting overlapping events.
To address the above-mentioned issues, we propose the CMCEE model (A Joint Learning Framework for Cascade Decoding with Multi-Feature Fusion and Conditional Enhancement for Overlapping Event Extraction). As shown in Fig. 2. Specifically, CMCEE consists of three sub-tasks: event type detection, trigger word extraction and argument extraction, these sub-tasks correspond to three decoders: the event type detection decoder, trigger extraction decoder, and argument extraction decoder. By adopting a cascading decoding method, we have designed a residual structure and incorporated it into the argument decoder module. This enhancement enables the model to capture more text features. Additionally, we have introduced a new conditional layer normalization mechanism and the Enhanced Conditional Layer Normalization (ECLN) function. These innovations help integrate multiple conditions into text encoding simultaneously and model the interaction between subtasks more effectively.
There are four contributions to this article:
We propose CMCEE, a multi-feature fusion and conditionally enhanced cascade decoding joint learning framework for overlapping event extraction. It can simultaneously address three types of overlapping events more effectively. We have designed an enhanced conditional fusion function, which can integrate multiple conditions simultaneously and obtain more effective interaction information between subtasks. We have designed a cascade decoding mechanism with multi-feature fusion, providing a new approach for the application of cascade decoding models in text processing tasks. We conducted experiments on the FewFC dataset and compared our model with similar original models. Our model demonstrated superior performance.
Event extraction technology involves extracting events of interest from unstructured information and present them to users in a structured way. It is one of the key tasks of natural language processing [1, 6]. The traditional event extraction methods primarily include pipeline-based event extraction [1, 17], which divides event extraction into sub-tasks with a sequential order, and these sub-tasks are independent of each other. First, trigger word extraction tasks are performed, and event types are detected based on triggers. Then, the argument extraction task is carried out, simultaneously relying on the predicted results of event types and trigger words. However, the pipeline method suffers from the problem of error propagation, which can degrade the model’s performance. The other approach is the joint extraction model [21, 8, 15], which allows trigger word extraction and argument extraction tasks to be completed simultaneously. This not only overcomes the error information propagation caused by event detection but also shares hidden layer features. For instance, Nguyen et al. [13] proposed JRNN, a joint event extraction model based on recurrent neural networks, utilizing two bidirectional RNNs to obtain richer representations and effectively avoiding error propagation issues in pipeline models. In the methods and models mentioned above, there has been limited attention given to overlapping event extraction, as they assume that the dataset is regular. However, this assumption does not imply the absence of overlapping events in the dataset.
In existing methods, Yang et al. [20] noted the phenomenon of argument overlap, but did not provide a corresponding solution to the issue of trigger word overlap. Furthermore, since PLMEE is a pipeline model that performs event extraction tasks in a pipeline manner, it is prone to the impact of error propagation. Wei et al. [19] introduced CasRel, a novel cascading labeling strategy for extracting overlapping relational triplets without being affected by the problem of overlapping triplets. For complex event extraction tasks, Sheng et al. [14] proposed CasEE, which represented the first attempt to handle overlapping event extraction within a cascading decoding joint framework. Sheng et al. [14] divided overlapping event extraction into three sub-tasks that were executed sequentially: event type detection, event trigger extraction, and argument extraction. Simultaneously, they leveraged the interaction between these sub-tasks to extract overlapping targets separately.
Our proposed CMCEE model can be broadly divided into a BERT encoder and three sub-tasks. These three sub-tasks correspond to three modules: type detection decoder, trigger word extraction decoder, and argument extraction decoder. Furthermore, we adopt the conditional layer normalization mechanism (CLN) and our newly proposed enhanced conditional layer normalization mechanism (ECLN).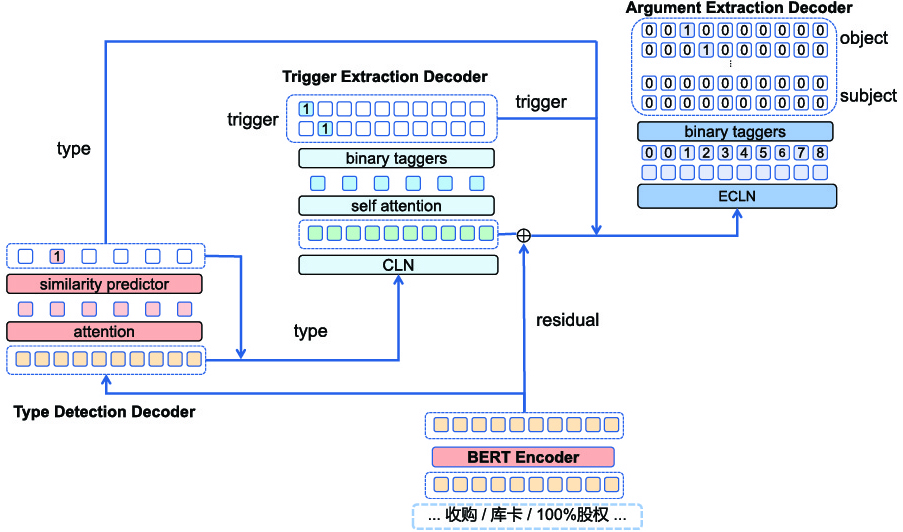
The structure of our model is shown in Fig. 2, featuring one encoder and three decoders: event type detection, event trigger word extraction, and event argument extraction. Meanwhile, to address the previously mentioned overlapping event problem, we adopt the cascaded decoding joint learning framework. Simultaneously, we incorporate the enhanced conditional layer normalization mechanism and the multi-feature fusion cascade decoding mechanism.
Specifically, we input the text sequence into the BERT encoder to obtain the characteristics of the word and sentence. Then, we identify the sentence trigger word, event type, argument as well as the corresponding role of argument. We have an event type set, denoted as C, and an argument role set R, based on the predefined event pattern. The overall goal is to predict all events in the golden set
where
Equation (3) exploits the interactions and dependencies among the type detection decoder, trigger word extraction decoder, and argument extraction decoder. The expression
Devlin et al. [12] introduced BERT, which is a pre-training model, utilizing the strategy of randomly masking words and predicting them subsequently. Through unsupervised training on a large corpus in its early stages, BERT acquires rich textual information and learns language, syntax, word meanings, and other information beneficial for downstream tasks. In downstream tasks, it employs a small number of target domain datasets for supervised training, thereby addressing the resource cost issue associated with extensive labeled datasets for supervised learning. Before the emergence of the BERT model, the primary approach involved identifying trigger words within the text and determining the event type based on these triggers. However, with the introduction of event extraction models based on the BERT model, new approaches have been proposed for event extraction methods grounded in deep learning.
We utilize BERT as our encoder. Specifically, given a token sequence
Event type detection encoder
In the previous step, we obtained the output of the BERT encoding layer. In this section, we will introduce the event type detection module’s contents. In the previous discussion, we emphasized our intention to fully leverage the interaction between the three decoder layers. Therefore, to enable subsequent event trigger and argument extraction, we must first detect the event type. Then, we can use type detection as conditional information to address the issue of overlapping trigger words.
Liu et al. [11] proposed an event type detection method that doesn’t rely on trigger words. Sheng et al. [14] also utilized trigger word-free event type detection in a cascaded decoding joint learning framework. Their experimental results highlighted the effectiveness of trigger word-free event type detection in event extraction tasks. Therefore, we also adopted a similar approach and designed an event type detection decoder to predict event types.
Specifically, we used an attention mechanism [18] to detect event types and capture as much relevant information about the relationship type as possible. The input to the event type decoder directly came from the output of the BERT encoding layer. We initialized a learnable type embedding matrix
where
Finally, according to Eq. (3.2), we calculate the value of
Among them,
Overlapping events can involve the issue of overlapping trigger words. To address the problem of overlapping event trigger words, we employ a trigger word decoder combined with conditional layer normalization (CLN). In essence, the input to the event trigger word decoding layer incorporates not only the output of the encoding layer but also takes into account the characteristics of the event type. Past research [19, 14] has proven the effectiveness of this approach.
In transformer models like BERT, the primary normalization method is Layer Normalization. Therefore, it is natural to consider transforming the corresponding
In previous research, [14], to obtain the characteristic conditions for other layers in the event argument extraction decoder design, researchers utilized the conditional layer normalization proposed by Su [16]. This normalization mechanism dynamically generates gain
where
Next, to further enhance the representation for trigger word extraction [14], we employ a multi-head attention mechanism in conjunction with the conditional layer normalization mechanism. The advantage of the attention mechanism lies in its ability to capture global connections. Additionally, it allows for parallelized calculations and, when compared with CNN and RNN, the model is simpler with fewer parameters. The specific design is as follows:
where
In the predictive trigger word module, we employ a binary taggers. Simultaneously, to address the issue of overlapping events, we extract all trigger words within a sentence. The specific operation is to predict whether each token
Where
In order to better solve the problem of overlapping arguments, we integrated dual text representations in the input of the argument extraction encoder within the event argument decoding layer. These representations include the output of the encoding layer and the output of the event trigger word decoding layer. This approach not only allows us to obtain rich semantic features from the encoder but also enables access to feature information from the trigger word extraction module.
In this section, we discuss how to extract arguments with specific event types
When it comes to Enhanced Conditional Layer Normalization (ECLN), this is a normalization technique used in neural networks that incorporates the concept of conditional layer normalization. The aim of this technique is to better handle input data with multiple conditions in a neural network, such as those associated with different categories, styles, or other characteristics.
Why do we call it a multi-feature fusion cascade decoder? It is because when we design the cascaded decoding model, our goal is to capture as many text features as possible in the input stage of the decoder, including the rich semantic features of the encoder and the text interaction provided by other decoders. Specifically, in the design of the event argument extraction decoder, we combine the outputs of the encoder and the event trigger word decoder as input and use this combination as input for the event argument extraction decoder.
In the enhanced conditional layer normalization of argument extraction module, the key is to combine the two sets of conditional information with the normalized parameters. This is usually done through the following steps:
First, for each sample, we calculate the mean and variance of its features. Then, the outputs of the event classification decoder and trigger word extraction decoder are provided as conditional information to the argument extraction decoder. This condition information will be used to calculate the normalized parameters for specific conditions. Second, we use the event classification decoder and trigger extraction decoder are used to extract the conditional information of the decoder to calculate the scaling and shift parameters under the given conditions. Finally, the calculated scaling and shifting parameters are used to normalize the features and maintain them within the appropriate range.
In conclusion, enhanced conditional layer normalization is a method that combines the concept of conditional layer normalization to make neural networks better adapt to a variety of input conditions. By incorporating multiple conditions into the normalization process, this technique can improve the flexibility and generalization performance of the model, and is suitable for a variety of tasks that involve dealing with different input conditions.
Building on previous research, we utilized embedding encoding relative to the trigger word positions to obtain token-level representations:
where
Specifically, Enhanced Conditional Layer Normalization (ECLN) incorporates two sets of conditional information 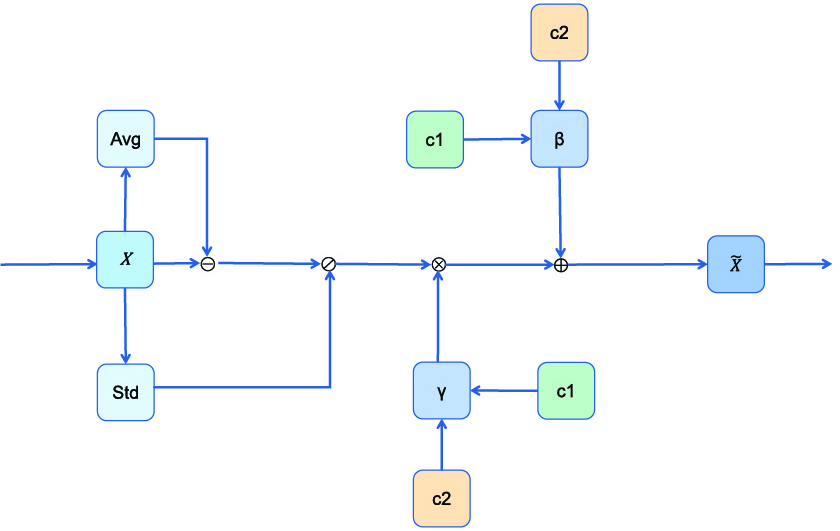
During the experiment [19, 14], we observed that Su’s [16] conditional fusion function could only fuse one condition. However, in our model, there are three decoders. Therefore, building upon prior work, we have further designed an enhanced conditional fusion function. As shown in Fig. 3, on the basis of the conditional layer normalization mechanism proposed by Su [16], we transform multiple input conditions into the same dimension as
where
After getting a text representation that combines multiple features, we can input this text representation into the enhanced conditional layer normalization mechanism. Here, we embed the average values represented by the token at the start and end of
Compared with previous work (CasEE) [14], we have reduced model redundancy by implementing “model pruning” to remove some “unimportant” parameters and modules from the model. Therefore, when designing the argument decoder structure, we did not utilize a multi-head attention mechanism.
Finally, in the prediction argument section, we utilize a set of role-specific binary label pairs [14] for the independent variables. Similar to the prediction of trigger words, for each token
Among them,
Considering that not all roles belong to a specific type
Among them,
In this module we design related questions about model training. First, we define the overall goal
Among them, Ł represents the total training objective, while the sub-objectives
Where
In the previous section, we introduced the concept and structure of the CMCEE model, which is used for the task of overlapping event extraction. Next, we compare the performance with other baseline models. In this module, we have designed experiments to verify the effectiveness of CMCEE.
Datasets and evaluation metrics
Our experiment uses the Chinese financial event extraction benchmark FewFC [22]. FewFC has a total of 12,890 events, encompassing 10 financial field event types and 8,982 sentences, of which 1,975 overlapping events. As shown in Table 1, we divided the 8,982 sentences in the data set into the training data set, validation dataset, and the testing dataset in an 8:1:1 ratio. Among them, there were 7,185 sentences in the training data set, 899 in the validation set, and 898 in the testing set.
In the FewFC dataset, there are 10 event types, such as Pledge, Sue and Investment. There are 18 argument role classes, such as “proportion”, “money”, and “number”. In the test and validation sets, the event types are evenly distributed, with ten event types. FewFC is a Chinese financial event extraction dataset, and the language is independent. The FewFc dataset is publicly available at
The various data of the FewFC [22] dataset are shown in Table 1. Each column represents the number of sentences with overlapping elements, sentences without overlapping elements, all sentences, and all events. Each row represents the number of training set, validation set, testing set and the whole dataset.
Statistics for the dataset
Statistics for the dataset
The event type distribution of the data is shown in Table 2. Column 1 represents 10 event types, while columns 2, 3, and 4 represent the number of samples of event types in the training set, validation set, and testing set, respectively.
Event type distribution of dataset
In the evaluation part, we follow past traditions [1, 5, 14] and divide into four evaluation metrics: 1) Trigger Identification (TI): When predicting a trigger, if the span of the predicted start position and end position matches the gold span, then it identifies the correct trigger; 2) Trigger Classification (TC): When classifying triggers, if the trigger is correctly recognized and the classification result is correct, then the trigger is correctly classified; 3) Argument Identification (AI): When predicting arguments, if the event type classification of the argument is correct, and the span of the predicted start and end positions matches the golden span, then it correctly recognizes the argument; 4) Argument Classification (AC): When classifying arguments, if the argument is correctly identified and the predicted character matches the golden character, then the argument is correctly classified.
For each of these four metrics, we report precision (P), recall (R) and F-measure (F1) for each of the four metrics. Precision represents the proportion of the total number of correct extraction results to the total number of extraction results. Recall is the proportion of the total number of correctly extracted results to the total number of positive samples in the corpus. F1 is the most comprehensive metric.
In the comparison experiment, we will formulate several baselines according to the existing overlapping event substrate model schemes. Additionally, the comparison models we employ Additionally: a multi-stage approach with overlapping events and a joint sequence labeling approach.
The joint sequence labeling method transforms the event extraction task into a sequence labeling task. For the
The multi-stage method of overlapping events involves extracting event trigger words and arguments sequentially.
The first method involves using BERT initially to predict event types, and then utilizing MRC BERT to predict overlapping triggers and arguments based on event types, known as The second method focuses on extracting arguments based on type and trigger to address the issue of overlapping arguments. Firstly, MRC BERT is used to predict overlapping triggers with type, and then overlapping arguments are predicted based on type triggers, known as
We evaluated the performance of these models using the public dataset FewFC. Additionally, we applied the same data preprocessing steps to prepare these datasets, dividing them into training, validation, and test sets.
To emphasize the difference between CMCEE and the comparative model effectively, all models use the Chinese BERT-base model as the text encoder. They consist of 12 layers, 768 units in the hidden layer, 12 Attention heads, 110M parameter. As for the setting of hyper-parameters, the ranges thresholds
Hyper-parameter settings of CMCEE
Hyper-parameter settings of CMCEE
In this section we present the experimental results.
Compared with the baseline model
We trained and tested the aforementioned models, and recorded their performance metrics, including precision, recall and F1 score. We compared them with our proposed CMCEE model and the specific data are shown in Table 4. Through the evaluation of the data in Table 4, we can draw the following conclusions:
Our model outperforms the comparison models across all four evaluation metrics on the FewFC dataset, achieving the best results. In comparison with the joint sequence labeling method, CMCEE achieves 7.8% and 8.5% improvement over BERT-CRF and BERT-CRF-joint on the F1 score of TC, respectively. Moreover, it can be seen that CMCEE has the most significant effect on improving the recall rate. We believe that this is because the sequence labeling method has the problem of label conflict, and CMCEE can effectively solve this problem. In comparison with multi-stage methods with overlapping events, CMCEE surpasses them in F1 score. The results show that CMCEE improves F1 scores by 4.2% and 3.7% in TC and AC, respectively. Compared to the baseline MQAEE-2, CMCEE improved F1 scores in TC and AC by 1.5% and 5.2%, respectively. The reason is that CMCEE combines useful interactions and connections between subtasks when it jointly learns text representations of subtasks. When compared to CasEE, our model achieved improvements in TI, TC, AI, and AC, with improvements of 1.1%, 1.3%, and 1.1% in TC, AI, and AC, respectively. We analyze that it is because our proposed enhanced conditional fusion function and cascaded decoding mechanism of multi-feature fusion enhance the interaction between subtasks. While also enhancing the text features, so that CMCEE can achieve better results in the task of overlapping event extraction. The results of Trigger Classification (TC) in Table 4 show the performance of CMCEE event type detection. The experimental results show that the F1 score of the evaluation metrics TC is greatly improved compared with the past methods. Compared with CasEE, our method F1 score is 1.1% higher. Compared with PLMEE, our method improves the F1 score by 4.2%, which shows that CMCEE performs better than the traditional model in the event type detection task. We analyze the reason for this performance improvement is that our method adopts the enhanced conditional layer normalization mechanism, effectively addressing the challenge of overlapping events, a facet where our model outperforms traditional models.
Experimental results of overlapping event tasks on the FewFC dataset
We conducted separate experiments to analyze the enhanced conditional layer normalization (ECLN) mechanism to demonstrate the effectiveness of our enhanced conditional normalization layer. The specific experimental design is as follows:
We modified the CasEE model by replacing the conditional layer normalization layer (CLN) with our enhanced conditional layer normalization (ECLN) in the argument extraction decoder, and named the modified model
Subsequently, we trained and tested BERT-CRF, PLMEE, MQAEE-2, CasEE and CasEE-E on the FewFC dataset, and recorded their performance metrics, including precision, recall, and F1 score. Regarding the setting of hyper-parameters, the ranges of thresholds
Comparison results of CasEE-E and baseline model experimental data
Comparison results of CasEE-E and baseline model experimental data
Experimental results on the FewFC dataset
Table 5 presents the four evaluation metrics of BERT-CRF, PLMEE, MQAEE-2, CasEE and CMCEE. From this table, it is evident that data of CasEE-E outperform the four baseline models, confirming the effectiveness of our proposed Enhanced Conditional Layer Normalization (ECLN) in overlapping event extraction tasks. The reason why CasEE-E is better than CasEE in our analysis is that we use the Enhanced Conditional Layer Normalization (ECLN). Compared with CasEE, CasEE-E can effectively integrate the features of the event type detection encoder and trigger extraction decoder into the argument extraction decoder.
Table 6 demonstrates that our method outperforms CasEE and CasEE-E in all four evaluation metrics. Consequently, we can conclude that the multi-feature fusion cascading decoding mechanism we added to CasEE-E is effective. This mechanism allows us to obtain richer text features in the input of the argument extraction decoder, including the semantic features from the encoder and the text interaction provided by the trigger extraction decoder.
The result of the argument extraction decoder variant
The result of the argument extraction decoder variant
Table 7 further demonstrates the performance of our method. We conducted experiments on different argument extraction decoder variants, combined with type detection and trigger extraction. We set up specific experiments and there are three variants: 1) AED-1 only adds the attention layer to the argument extraction module of CMCEE; 2) AED-2 only removes the residual mechanism in the argument extraction module of CMCEE; 3) AED-3 removes the residual mechanism and adds a self-attention layer. Subsequently, we calculated the P, R and F1 scores of different argument extraction decoder variants in the argument classification (AC) metric. The experimental results demonstrate the optimality of our method.
The results indicate that the performance without residual structure decreases significantly on the F1 scores of the two AED-2 and AED-3 variants. This decrease occurs because the model fails to capture additional text features. In addition, the experimental results also show that the F1 score of AED-3 is higher than that of AED-2, which indicates that the self-attention mechanism can further refine the representation of argument extraction.
In this paper, we proposed the CMCEE model and explained the architecture of the model in detail. Then, we conducted experiments on the FewFC dataset. After comparing multiple baseline models, the CMCEE model we proposed was proved to be in the overlapping event extraction task. F1 scores have improved numerically. At the same time, based on the previous conditional layer normalization, this paper further proposes an enhanced conditional layer normalization (ECLN), which enhances the interaction between the event argument extraction decoder and other subtasks. At the same time, a separate experiment is designed, demonstrating that our proposed enhanced conditional layer normalization mechanism is proven to be effective on the overlapping event dataset FewFC.
Finally, we compare the metrics of CasEE-E and CMCEE on the overlapping event extraction task, demonstrating the effectiveness of our multi-feature conditional fusion cascaded decoding mechanism. To further demonstrate the performance of our method, we conducted experiments on different argument extraction decoder variants, combined with type detection and trigger extraction.
Nowadays, the Enhanced Conditional Layer Normalization (ECLN) is only proven to be effective on the event extraction task of the overlapping event dataset FewFC. Therefore, in future work, we will further study to make the enhanced conditional layer normalization mechanism common to other fields.
Footnotes
Acknowledgments
We would like to thank the anonymous reviewers for their insightful comments and suggestions. This research is supported by the National Natural Science Foundation of China [grant number U2003208], the Xinjiang Autonomous Region key research and development project [grant number 2021B01002] and The Xinjiang Autonomous Region major scientific and technological projects [grant number 2020A03004-4] and University research program projects, China [grant number XJEDU2022P018].
Conflict of interest
Competing interests statement: The authors declare that they have no competing financial interests.
Data availability statement
Data openly available in a public repository.
FewFC contains 10 financial field event types and 8982 sentences. The FewFC data supporting the results of this study is publicly available at