
Abstract
Storyline extraction aims to generate concise summaries of related events unfolding over time from a collection of temporally-ordered news articles. Some existing approaches to storyline extraction are typically built on probabilistic graphical models that jointly model the extraction of events and the storylines from news published in different periods. However, their parameter inference procedures are often complex and require a long time to converge, which hinders their use in practical applications. More recently, a neural network-based approach has been proposed to tackle such limitations. However, event representations of documents, which are important for the quality of the generated storylines, are not learned. In this paper, we propose a novel unsupervised neural network-based approach to extract latent events and link patterns of storylines jointly from documents over time. Specifically, event representations are learned by a stacked autoencoder and clustered for event extraction, then a fusion component is incorporated to link the related events across consecutive periods for storyline extraction. The proposed model has been evaluated on three news corpora and the experimental results show that it outperforms state-of-the-art approaches with significant improvements.
Introduction
With the rapid development of social media, massive data is generated on online news media each day. Facing tremendous news articles, how to digest such large volumes of data effectively is crucial for the public. Storyline extraction aims to extract a series of concise summaries of related events unfolding over time from a collection of news articles. It can help readers to have a quick glimpse of the development of current events without the need of reading through a large number of articles specifically. Therefore, automatically extracting storylines from text has been intensively studied in recent years [33, 13, 17, 7, 38, 37].
Generally, a storyline can be considered as a cluster of documents where documents describing the same event are clustered based on their content and temporal dependency across neighboring periods. Therefore, storyline extraction can be formalized as an evolutionary clustering problem. Most existing approaches to storyline extraction can be categorized into two classes, pipeline methods and end-to-end methods. The pipeline methods first extract events in each time epoch separately, and subsequently link those related events across epochs to form storylines by using a post-processing procedure. For instance, Huang et al. [14] first extracted topics of short text-based on word co-occurrence patterns, and then proposed an event evolutionary algorithm to extract storylines. And Yu et al. [34] developed a context-dependent storyline detection model by using subgraph learning. Different ways of measuring the event similarity between documents are employed [17, 21]. However, pipeline methods suffer the error propagation problem. Compared with the pipeline methods, the traditional end-to-end methods typically use probabilistic graphical models to describe the extraction process of storylines [13, 7, 38]. For example, Diao et al. [7] developed a probabilistic model to extract events and topics simultaneously by using the Recurrent Chinese Restaurant Process (RCRP) to capture the essence of events from tweets. And Du et al. [8] proposed to combine the Dirichlet process and Hawkes process to capture the characteristics of asynchronous streaming data. However, their parameter inference procedures are often too complex which leads to a long convergence time. It makes them impractical to be deployed in real-world applications. Instead of employing probabilistic graphical models, Zhou et al. [37] developed an unsupervised neural network-based approach for storyline extraction using a pairwise ranking loss. However, it is unable to learn latent event representation which is crucial for storyline extraction.
To overcome the limitations mentioned above, in this paper, we propose a novel unsupervised deep neural network-based approach for jointly learning latent event representations and extracting storylines without any annotated data. To extract the inherent structure of storylines and capture the contextual information of the same storyline automatically from news stream data, a non-linear autoencoder is employed to learn a global mapping from raw documents to underlying semantic features. Then storyline distribution is learned by calculating the distance between the mapped documents and their corresponding meta-events. The model parameters are refined iteratively to minimize the KL divergence between the storyline distribution and the normalized distribution. Moreover, a fusion component is incorporated into the deep clustering framework as a constraint in latent event space to link related events in neighboring time epochs for constructing storylines.
The main contributions of this paper are summarized below:
A novel unsupervised neural network-based model for jointly learning latent events and extracting storylines from temporally ordered news articles is proposed. A fusion component is employed to connect the related events in neighboring epochs. To the best of our knowledge, this is the first attempt to perform storyline extraction by incorporating the deep embedded clustering framework. We evaluate the proposed approach on three corpora and observe significant improvements on three metrics when compared with the state-of-the-art approaches to storyline extraction.
The remainder of the paper is organized as follows: Section 2 discusses related literature on storyline extraction and describes the deep embedded clustering framework briefly; In Section 3, we provide the details of the proposed model; Section 4 will discuss our experiments and we conclude this paper in Section 5 with suggestions for future work.
Our work is the first work to perform storyline extraction by incorporating deep embedded clustering into the storyline extraction framework. To facilitate the description of our model, we will review existing storyline extraction algorithms and introduce deep embedded clustering briefly.
Storyline extraction
Storyline extraction from text has been extensively studied in recent years. Yan et al. [33] calculated the similarity of summaries on each date with a summarization method to detect the events. Kawamae et al. [15] proposed a trend analysis method to detect the topic evolution over time. Lin et al. [20] proposed to generate storylines via graph optimization with relevant tweets. Radinsky et al. [26] extracted storylines by text clustering and entity entropy. Huang et al. [13] developed a mixture event model to capture the local and global aspects of events and then generate storylines by utilizing an optimized method. Storyline extraction can be cast into the classical topic detection and tracking (TDT) problem if the storyline is considered as a hidden topic. Naturally, topic model-based methods are adopted intuitively to deal with the TDT problem because of their interpretability, however classical topic models such as Latent Dirichlet Allocation (LDA) [5] can not capture the dependency between topics across consecutive periods. Consequently, Blei et al. [4] developed a dynamic topic model that captures the evolution of topics in a sequentially organized corpus of documents. Zhang et al. [36] proposed an evolutionary hierarchical Dirichlet process by incorporating time-dependency to discover the topic evolution pattern from documents. Zhou et al. [39] proposed an unsupervised Bayesian model by modeling one storyline as a joint distribution over entities and topics. Zhou et al. [38] proposed a generative model to extract the event representations and generate storylines simultaneously, which uses per-token Metropolis-Hastings sampler to reduce sampling complexity. Li et al. [19] proposed to generate storylines with a time-dependent hierarchical Dirichlet process, which can detect different levels of topic information from the corpus. Li et al. [18] proposed to capture the topic evolution pattern in the storyline via an evolutionary hierarchical Dirichlet process. Instead of the method based on the Dirichlet process, Ahmed et al. [2] presented a time-dependent topic-cluster model, a hierarchical approach for combining LDA and clustering via RCRP [7]. Huang et al. [14] proposed a dynamic Chinese Restaurant Process (CRP) model, which considers the birth, survival, and death of a storyline which is more in line with the real situation of how the storyline develops over time. Tang et al. [28] developed a hybrid distance-dependent CRP based hierarchical topic model that is used for the news articles clustering. Nevertheless, probabilistic graphical models usually have complex structures and require a long time to converge, which hinders their application to the real world.
In recent years, deep learning has demonstrated its power in many research areas including natural language processing with high performance. There have been increasing interests in exploring neural network-based approaches for topic detection from text. For example, Cao et al. [6] explained topic models from the perspective of neural networks and proposed a neural topic model where the representation of words and documents are combined into a unified framework. Tian et al. [29] proposed a sentence-level recurrent topic model which is assuming the generation of each word within a sentence is dependent on both the topic of the sentence and the historical context of its preceding words in the sentence. Xie et al. [32] proposed a Deep Embedded Clustering (DEC) model that simultaneously learns feature representations and cluster assignments using deep neural networks by optimizing a clustering objective. Wang et al. [31] proposed an adversarial topic model by using Dirichlet’s prior and generative adversarial network to capture the semantic patterns among latent topics. Miao et al. [23] developed a neural variant document model for topic modeling by using the multivariate Gaussian as the prior distribution of the latent space based on variational autoencoder. Srivastava et al. [27] replaced the mixture assumption at word-level and proposed the ProdLDA to improve the performance of the topic extraction. However, the neural network-based model above can only extract events from documents independently and can not capture the event’s evolution pattern over time. Zhou et al. [37] firstly proposed a neural network-based approach for storyline extraction without any annotated data, however, the model can only perform rough event clustering across epochs and is not able to learn latent event representations which are crucial for storyline extraction.
Deep embedded clustering
Deep Embedded Clustering model is a neural network-based clustering approach [32], which has received widespread attention since been proposed. For example, Dizaji et al. [9] and Guo et al. [10] both borrowed the clustering objective of DEC to improve clustering performance by replacing the structure of autoencoder. Guo et al. [11] proposed a two-stage deep clustering algorithm by incorporating data augmentation and self-paced learning into the DEC framework. Li et al. [16] proposed deep boosted clustering by utilizing a convolutional autoencoder to improve the clustering of image datasets. Dizaji et al. [9] developed DEPICT by adding a balanced assignment loss to the DEC framework to alleviate trivial solutions. Moreover, Asadi et al. [3] proposed to deal with the spatio-temporal clustering problem by using DEC. Hadifar et al. [12] proposed to learn discriminative features by combining the SIF embedding and DEC framework. While DEC has been studied extensively in different areas, relatively few works have focused on various tasks of NLP.
DEC considers the problem of clustering a set of
In the clustering step, it clusters the samples by iteratively minimizing the distance between mapped point
where
where
The clustering objective is defined as a KL divergence loss between
Considering that documents describing the same event should share a similar storyline distribution and the clustering advantage of DEC that mapping the input data to latent distribution space, we incorporate DEC into our framework to extract storylines. Thus our model can perform event representation learning and storyline extracting jointly.
To model the generative process of a storyline in consecutive periods from a stream of documents, we propose Deep Embedded Storyline Extraction Model (DESEM) for storyline extraction. In our model, storyline extraction is still considered as an evolutionary clustering problem. And deep embedded clustering is incorporated to cluster events in each time epoch. Moreover, we use a fusion component to link related events across epochs to cluster events and construct a storyline jointly in an end-to-end manner. For understanding easily, we explain several basic definitions in our model:
Event: an abstract concept describing things that happened in some places at some time. We model each event
Meta-event: the specific embodiment of the event
Epoch: the raw corpus is divided into several slices from the corpus
Storyline: an event sequence
Storyline Extraction: a process which aims to extract the storyline set
Overall architecture of the DESEM. Top: the stacked autoencoder maps the quadruple of each document 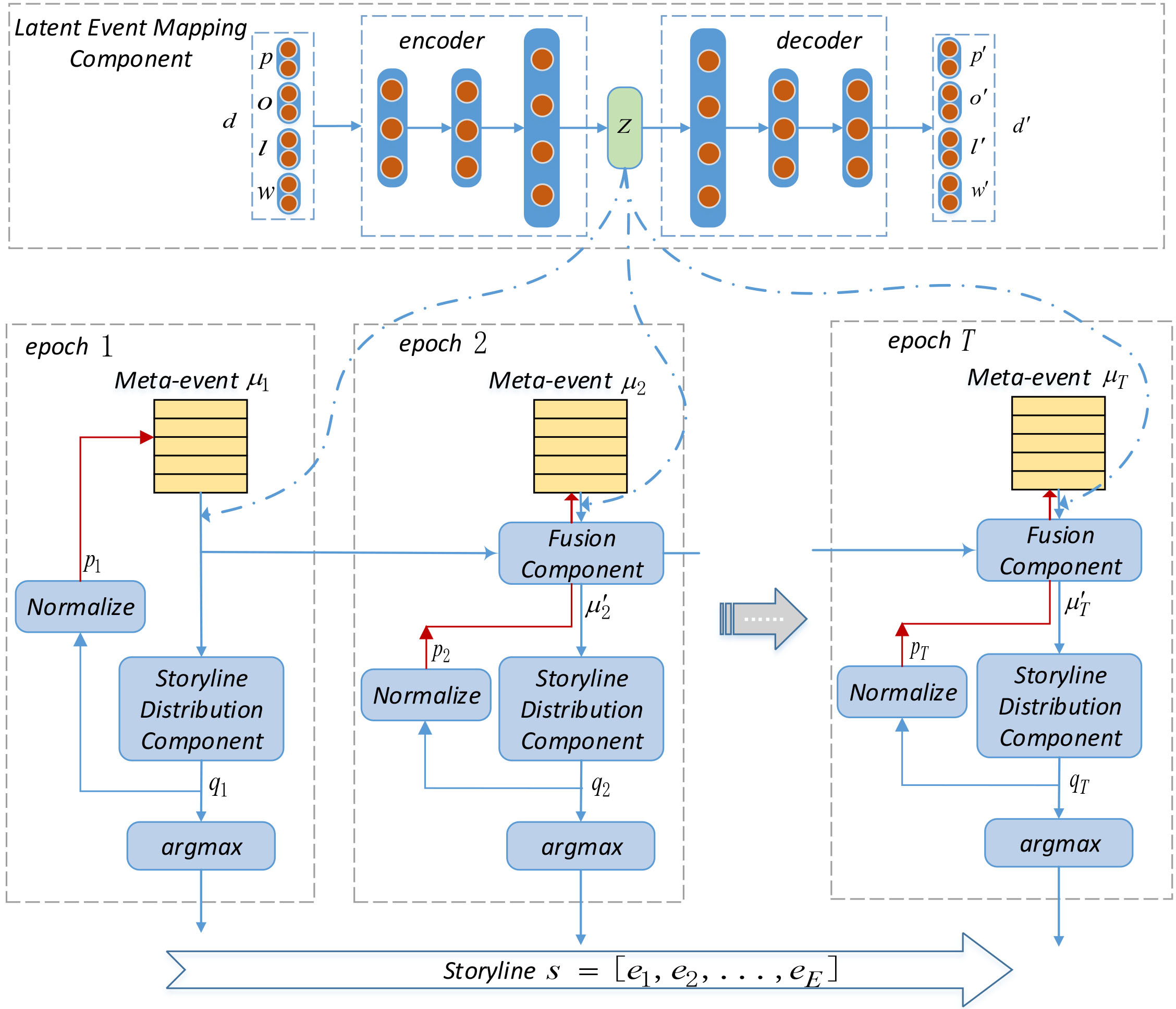
The DESEM structure is shown in Fig. 1. The proposed model contains three main components: (1) the latent event mapping component which is shown in the top part of Fig. 1, defines the representation mapping function which maps the original document features
Clustering original document features into events in raw space usually faces the problem of the “curse of dimensionality” because of the high dimension of input documents. Furthermore, documents that describe the same event may not share many words in common and could use different expressions. Thus, it is more sensible to learn low-dimensional representations to capture the most salient event features in documents. We assume that each news document is an instance of the corresponding event (i.e., meta-event) and the documents describing the same event would scatter around the same meta-event in a latent space.
In the Latent Event Mapping step, we use a deep non-linear Stacked Autoencoder (SAE) to learn the mapping from the original feature space of documents to the latent event space as is shown in the top of the Fig. 1. The stacked autoencoder consists of two non-linear mapping units, an encoder function
In the stacked autoencoder, each pair of the layers (the forward
where
After latent event mapping, we keep the encoder
Generally, a news article usually contains only one major event, thus we assumed that there is at most one event in each news article. And the document
Storyline construction
With the assumption that meta-event extracted in previous time epoch
Supposing that
where
For the initial epoch, we use the meta-event
With the fusion component, we can construct storylines by our proposed end-to-end DESEM approach directly. Furthermore, our approach can deal with flexible types of storylines, such as intermittent storylines (storyline ends at a certain epoch and then resumes some epochs later), without any post-processing. This is because that the meta-event
In the training step, we first pretrain the stacked autoencoder and initialize each layer of it with a denoising autoencoder. After initialization, we finetune the stacked autoencoder using the training set. Then, we iteratively refine the meta-event
Then, we compute the reference distribution
From the Eq. (2), it can been seen that the auxiliary reference distribution
We optimize
We use standard backpropagation to update the model parameters. Based on the model structure and the loss function described above, the training procedure for DESEM is given in Algorithm 3.5.
[H] Training procedure for the DESEM[1] Max training iterations MaxIter, Total epochs
In this section, we first describe the details of datasets, baselines approach and the hyper-parameters setting in our experiments, and then we present the evaluation results of our model compared with baseline approaches. Moreover, we implement ablation experiments to evaluate the effectiveness of various components in our model. In addition, we visualize the latent meta-event and structured representations of storylines to validate the effectiveness of storyline extraction.
Datasets
To evaluate the proposed DESEM, we use the three datasets from [38] which were crawled from the GDELT Event Database.1
Dataset I contains more than 500K news articles published in the month of May in 2014. Dataset II, a subset of Dataset I, contains news articles published in the first week of May 2014. It consists of more than 100K documents, and altogether 77 storylines were manually annotated for evaluation. Dataset III includes 30 different types of storylines manually constructed from Dataset I, and four types of storyline are contained in this dataset: (1) long-term storylines which last for more than two weeks; (2) short-term storylines which last for less than one week; (3) intermittent storylines which last for more than two weeks in total, but stop for a period of time and then appear again; (4) new storylines that emerge in the middle of the whole period, not starting at the beginning.
We extract quadruple
In our experiments, we follow the pre-processing step as describe in [38]. We used the Stanford Named Entity Recognizer2
We set the dimension of the encoder network which is a fully connected multilayer perception (MLP) to
For the DESEM, NSEM, and SDM, we run the official codes with the default parameters setting except the parameters we mentioned below with the same dataset slices, the number of storylines is set to 200 on Dataset I and 100 on Dataset II and Dataset III.3
Although the number of storylines is fixed as prior knowledge for all the models, some of the storyline indicators are not assigned with any documents (i.e., empty clusters). As such, the number of extracted storylines actually varies by different models.
We use evaluation metrics in [38] to evaluate our model. We evaluate the performance of storyline extraction in precision, recall, and F-measure which are commonly used in evaluating information extraction models. The precision is calculated based on the following criteria: 1) The entities and the keywords extracted refer to the same storyline; 2) The duration of the storyline is correct.
For Dataset I, it is difficult to obtain the gold standard, thus we check the extraction results manually by searching for the relevant news articles (e.g. entities and keywords) in the same period, Moreover, three annotators carry out the evaluation task and manually compare the retrieved results with the extracted results relying on the criteria listed above and then determine the correctness of the extraction results. After reaching consensus, the result is considered as the ground truth. Meanwhile, We ignore the duplicate storylines extracted in the experimental phase.
Experimental results
The experimental results of the proposed approach in comparison with the baselines on Dataset I, II and III are presented in Table 1. For Dataset I which contains more than 500K news articles, since no ground-truth is available, we only report the precision values of our model and baselines approaches by manually examining the extracted storylines. Meanwhile, it is difficult for a topic model-based method such as RCRP to extract storylines efficiently with such massive documents. Thus, the RCRP is not implemented on Dataset I, but we compare the performance with our model on Dataset II and Dataset III.
Performance comparison of the storyline extraction results on Dataset I, II and III
Performance comparison of the storyline extraction results on Dataset I, II and III
It can be observed from Table 1 that DESEM evidently achieves the best performance in all three datasets. Specifically, for Dataset I, DESEM extracts 173 storylines among which 142 are correct and gives high precision values with a large margin compared to the other three baselines. For Dataset II which contains 77 storylines, our DESEM gives similar recall value compared to NSEM, but with a higher precision value, which leads to an improved F-measure overall, outperforming the best baseline NSEM by 2.86%. For Dataset III, DESEM outperforms all the baselines by a large margin, achieving superior performance in F-measure, with the improvements ranging between 4.6% and 30%. The remarkable improvement on Dataset III which has 30 complex storylines empirically verifies that the DESEM is more suitable for dealing with a flexible storyline than those baselines approaches.
We can also observe that RCRP gets better results than SDM on Dataset III while gets worse on Dataset II with all metrics, a reasonable interpretation is that Dataset III contains more flexible storylines such as storylines happened in the middle of the period or storylines started at the beginning but with no relevant articles in the middle of the time period and appeared again later. SDM aims to capture the long-distance dependency by taking statistics in the past
To evaluate the effectiveness of various components in our proposed DESEM framework, we conduct experiments with some of the key components of DESEM removed or replaced. We try two variants, DESEM-AE and AE+
Comparison of storyline extraction performance with variants of DESEM
Comparison of storyline extraction performance with variants of DESEM
It can be observed from Table 2 that DESEM-AE gives the worst result. DESEM with the autoencoder leads to remarkable improvements in precision and recall, indicating the importance of using the autoencoder for extracting latent event features from the simple weighted aggregation of word embeddings of key event elements in the original news articles. This is shown that although word embeddings capture the syntactic and semantic regularities to some extent, more high-level feature extraction is required in order to achieve better storyline extraction results. Compared with AE+
We present the structured representations of storylines “Saudi MERS” and “American MERS” as is shown in Fig. 2 where the structured event (entity, person, organization, keywords) about storylines and the duration time of the storylines can be observed easily. From Fig. 2, it can be seen how the two storylines develop according to the keywords. At the initial epoch, the Saudi and the American found the MERS virus simultaneously, and then the MERS virus starts to spread. In the end, the American patient with MERS is improving. However, there is panic in Saudi Arabia at the end. Thus, two storylines have a similar trend at an early stage and different endings which is accord with Fig. 3.
The structured representations of storylines “Saudi MERS” and “America MERS”.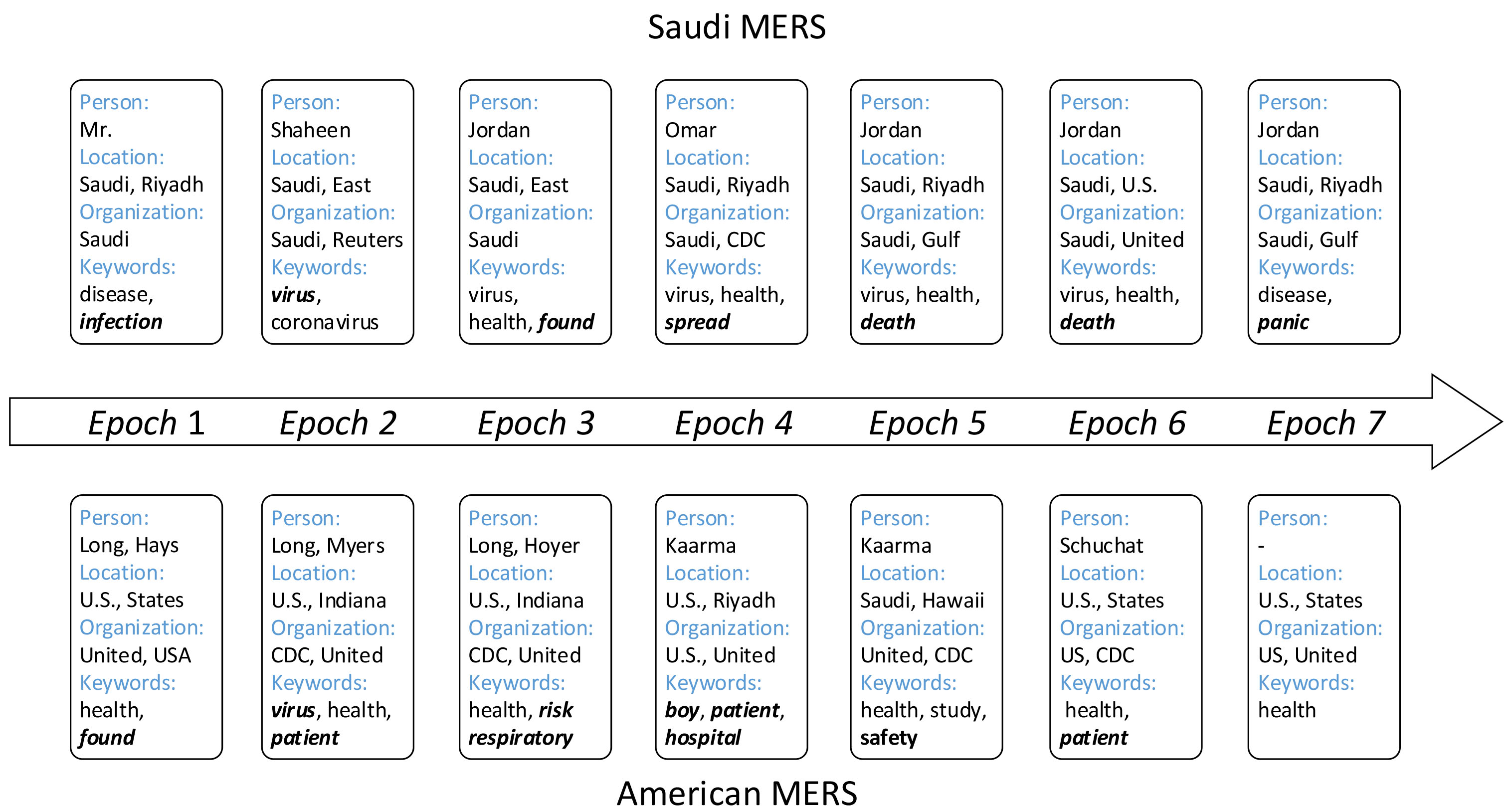
The representations of storylines evolved over time.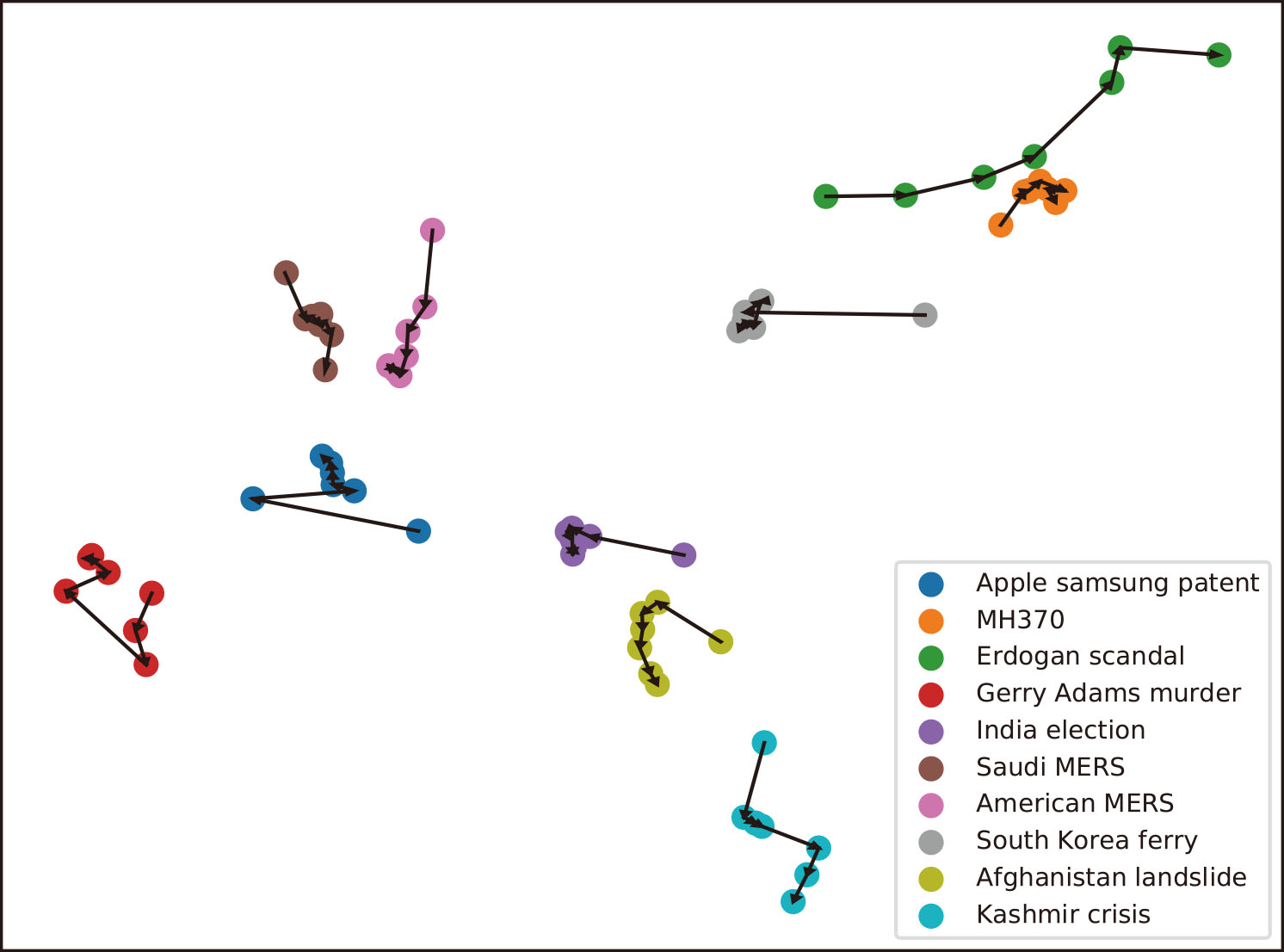
As the whole corpus has been mapped into the same latent space, we can observe how those storylines evolved over time. We randomly select some extracted storylines in Dataset II and visualize the meta-event
In this paper, we have proposed a novel unsupervised neural network-based storyline extraction model, termed as DESEM, to extract structured storylines from news articles over time. To jointly learning event representations and extracting storylines, a stacked autoencoder is employed to learn latent event representations from documents and a recurrent fusion component is used as a constraint to construct storylines by connecting related events across neighboring epochs. Experimental results show that our approach outperforms state-of-the-art approaches by a large margin. In future work, we will explore the extension of our proposed model to mine deep semantic relationships among events and establish the hierarchical relations of events in a more fine-grained scale.
Footnotes
Acknowledgments
We would like to thank the reviewers for their valuable comments and helpful suggestions. This work was funded by the National Key Research and Development Program of China (2016YFC1306704), the National Natural Science Foundation of China (61772132) and the Natural Science Foundation of Jiangsu Province of China (BK20161430).