
Abstract
Meteorological hazards have great influence all over the world. An emergency plan is an important means of coping with meteorological hazards. The preparation of emergency plans needs to refer to historical emergency plans, but these are too numerous and are of uneven quality. We can alleviate these problems by means of recommender systems, which are very useful tools in many domains; however, they suffer from information overload. In this paper, we propose a Semantic-Aware Collaborative Filtering method, which is called SACF, for emergency plans recommendation to address the aforementioned challenges. It is designed to effectively present a highly targeted emergency plan recommendation list and recommend the most appropriate emergency plans for a targeted meteorological hazards event. Specifically, we use semantic knowledge to represent scenario-based meteorological hazards, including target and previous events. The search for similar events (i.e., neighbors) for a collaborative filtering recommendation algorithm is adopted. By helping to avoid both the generation of fake neighbors and also the omission of true neighbors the recommendation process is improved. Finally, extensive experiments are conducted on a real-world dataset, and the results demonstrate that SACF improves the accuracy of emergency plan recommendations.
Introduction
Meteorological hazards (MHs) cause numerous losses in life and infrastructure [1], but we can mitigate the impacts of these unfortunate events through emergency management [2]. Emergency planning for MHs can play a role in rapid responses [3]. Plan preparation teams need to consult and reference a large number of emergency plans that have been released for help and guidance. However, in recent years, the number of emergency plans in the world has been explosively increasing [4], and these emergency plans are of uneven quality. Finding emergency plans corresponding to the scenario of a target MH event quickly and accurately is a challenge [5] for emergency management. The solution to such a challenge is an emergency plan recommendation system. Selecting and offering event emergency plans that meet the target MHs can considerably increase the plan’s efficiency and quality.
One of the most popular recommendation strategies for emergency plan recommendations is collaborative filtering [6, 7], which is based on providing the target event with the recommendation plans of other previous events with similar characteristics (including hazards, the natural environment, and social economic scenarios [8]) and basic regional information (neighbors). The key factor when making a recommendation based on collaborative filtering is the formation of the neighbor because that determines the match of the recommendation to the target event [9]. The great diversity of the MHs that are available to program staff and the current abundance of null values in the data make the finding of similar events subject to the generation of fake neighbors [10] and the omission of real neighbors. The problem arises when events share similar values (including null values) for numerous properties (for which they are considered neighbors) but they differ with respect to their properties that are strongly relevant to the type of the target event. Meanwhile, some true neighbors, which differ with respect to numerous properties but share similar values for the most relevant properties, are excluded from the population of neighbors. For example, a flood event arises in Place A, and another flood event arises in Place B. The two events that are in places that have similar proportions of ethnic minorities, acreages and population densities but different terrain are fake neighbors because terrain is critical to flood responses while the other three properties are less important. In addition, utilizing semantic knowledge can improve the accuracy of the similarity computation [11] and in turn the recommendation process; therefore, we consider taking advantage of semantic knowledge in our recommendation algorithm.
The problems mentioned above can be summarized as two types: a. the data sparsity of the event-plan effect matrix, and b. the insufficient description of emergency plans and rough similarity calculating methods make it easy to generate fake neighbors and omit true neighbors.
Motivated by these observations, in this paper, we address these challenges through the following contributions.
A Semantic-Aware Collaborative Filtering method for emergency plan recommendations (SACF) is proposed in this paper. It uses the event-plan effect matrix and introduces semantic knowledge to capture more profound features for MH events. Specially, a semantic model of the event emergency scenario is established. It is composed of a disaster hazard factor, a natural environment scenario and a social economic scenario, which considers the basic geographic information. In SACF, to avoid the generation of fake neighbors and the omission of true neighbors to improve the recommendation process, many measures have been adopted such as the generalization of the properties, the reasonable treatment of the short text properties and our Flexible Mixed Weight-Calculation method.
The remainder of the paper is organized as follows. Section 2 presents related works and Section 3 gives some basic definitions in this paper. The Semantic-Aware Collaborative Filtering method for emergency plans (SACF) is described in Section 4. Section 5 describes the experiments that are designed and analyzed to evaluate the accuracy of SACF. Section 6 concludes the paper and provides an outlook on the possible continuation of our work.
To respond to MHs in a fast and effective manner, it is of critical importance to have efficient plans that lead to minimum losses [12]. Researchers have paid an increasing amount of attention to gaining knowledge and experience from past plans and utilizing computer and database technology to manage and assist the development of emergency plans and the recommendation of emergency plans, which have become a new concern in the field of emergency plan research [13, 14].
The collaborative filtering algorithm is a popular recommendation technique for information filtering in all fields. The most important aspect of collaborative filtering algorithms is how they differ in their computing similarity, i.e., how they select neighbors [15]. Traditional object recommendations (such as those for products and literature) usually utilize a user-item rating matrix to select neighbors. For example, [16] compares the active user’s rating and the neighbor’s rating to recommend products for purchase to the active user. The emergency plan recommendation is different because the buying behavior of a user can occur many times while a disaster event occurs only once, and it adopts or refers to the corresponding emergency plan once. In this way, the event-plan effect matrix will be inevitably sparse, and it is infeasible to select neighbors using only the effect matrix. With respect to the data sparsity problem in recommendations, auxiliary information is introduced to calculate the similarity and obtain the neighbors. The model in [17] not only considers the local contextual information of user ratings but also considers the global preferences of users to improve the recommendation performance. In this paper, we utilize the semantic knowledge of event emergency scenarios and basic regional information to select neighbors and combine the event-plan effect matrix to generate recommendations.
In the field of natural disaster emergency plan recommendations, the existing method for finding neighbors determines the similarities of the properties of the events [13]. However, different properties have different importance in finding neighbors, and [17] explains how they can improve the recommendation system by removing some minor properties. In addition [13], considers only a disaster hazard factor’s simple quantitative representation with respect to the target event when computing events’ similarity, such as the wind-force and wind speed of a typhoon, in the search for a suitable plan. Considering only the hazard factors leads to very low similarities for some disaster events with different types and high reference values for the target event, which omit the true neighbors. Considering only a simple quantitative representation as the disaster hazard factor results in a rough similarity computation and the generation of fake neighbors [10]. In summation, an insufficient description of emergency plans and a rough weight distribution when calculating the similarity causes inferior neighborhood quality, which leads to poor recommendations for target events.
Generally, compared to existing methods, SACF considers event emergency scenario information, establishes a semantic model of an event emergency scenario, and utilizes semantic knowledge during the recommendation to avoid the generation of fake neighbors and the omission of true neighbors, which makes the recommendations more accurate.
Basic definitions
This section introduces several fundamental definitions and some descriptions related to this research. The proposed SACF will be described later based on these basic backgrounds.
The internal structure of the event base
The internal structure of the event base
A collaborative filtering recommendation algorithm is adopted to generate appropriate recommendations. SACF calculates the rate of some previous emergency plans in a logical way for a target MH event, then presents an emergency plan recommendation list and recommends the most appropriate emergency plans.
Moreover, one of our important contributions here is our neighborhood formation approach in which we use semantics to avoid the generation of fake neighbors and the omission of true neighbors, as discussed in Section 1. Specifically, we undertake the following.
We generalize the properties (that are embodied in the model). For a target event such as a typhoon, the model considers the concrete effects of the disaster events, such as the number of houses that collapsed instead of the wind-force, to avoid the omission of true neighbors that are not typhoons. Short text properties are processed into composite simple properties and the semantic knowledge is incorporated into the similarity computation. A Flexible Mixed Weight-Calculation method (FMWC) is proposed.
Basic symbols and notations
Table 2 summarizes the basic symbols and notations that are used in this paper.
After the introduction of the basic definitions in Section 3, this section describes the proposed SACF in detail. We first present the whole process of SACF. Then, Section 4.1 explains the semantic model of the event emergency scenario for MHs, Section 4.2 introduces the neighborhood formation that avoids the generation of fake neighbors and the omission of true neighbors, and Section 4.3 gives the details of calculating ratings and generating recommendations.
Our strategy can be divided into two parts. First we compute the event similarity to form a neighbor. Second, we obtain the prediction score of the emergency plan for the target event and form the emergency plan recommendation list. Figure 1 shows whole process of SACF.
SACF algorithm flow chart.
The same event is handled differently when there are different geographical features. For example, the regional proportion of ethnic minorities is related to the treatment of the people in a disaster area. Therefore, we think that basic geographic information (BG) is regionally indigenous special information that must be considered when selecting neighbors, and it is independent of the event. To formalize the MH event domain (all types), we build an emergency scenario semantic model – the event emergency scenario ontology – a brief excerpt of which is shown in Fig. 2. In Fig. 2, white ellipses, white squares, gray squares and gray ellipses denote the MH event classes, the MH event, the property value and the property value classes, respectively. In addition, we utilize the geographic ontology as presented in [19] as shown in Fig. 3. From these two ontologies’ metadata specifications, the atomic semantic features of events are extracted. The two ontologies are linked together by the place (where the event occurs) name property. The event emergency scenario ontology and geographic ontology are combined to form the event ontology.
A micro-excerpt from our ontology of the MH event emergency scenario.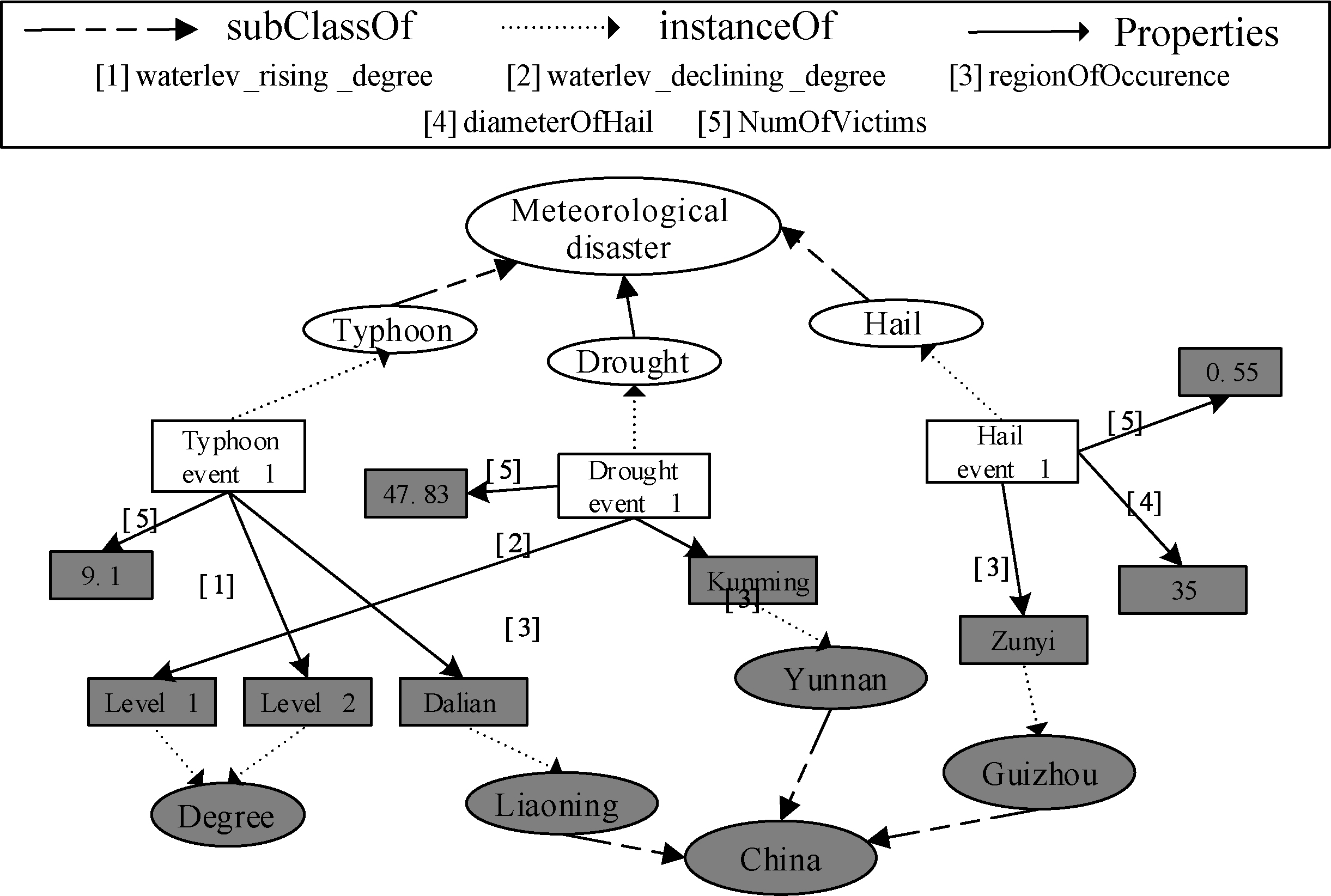
Geographic ontology introduced in the event ontology.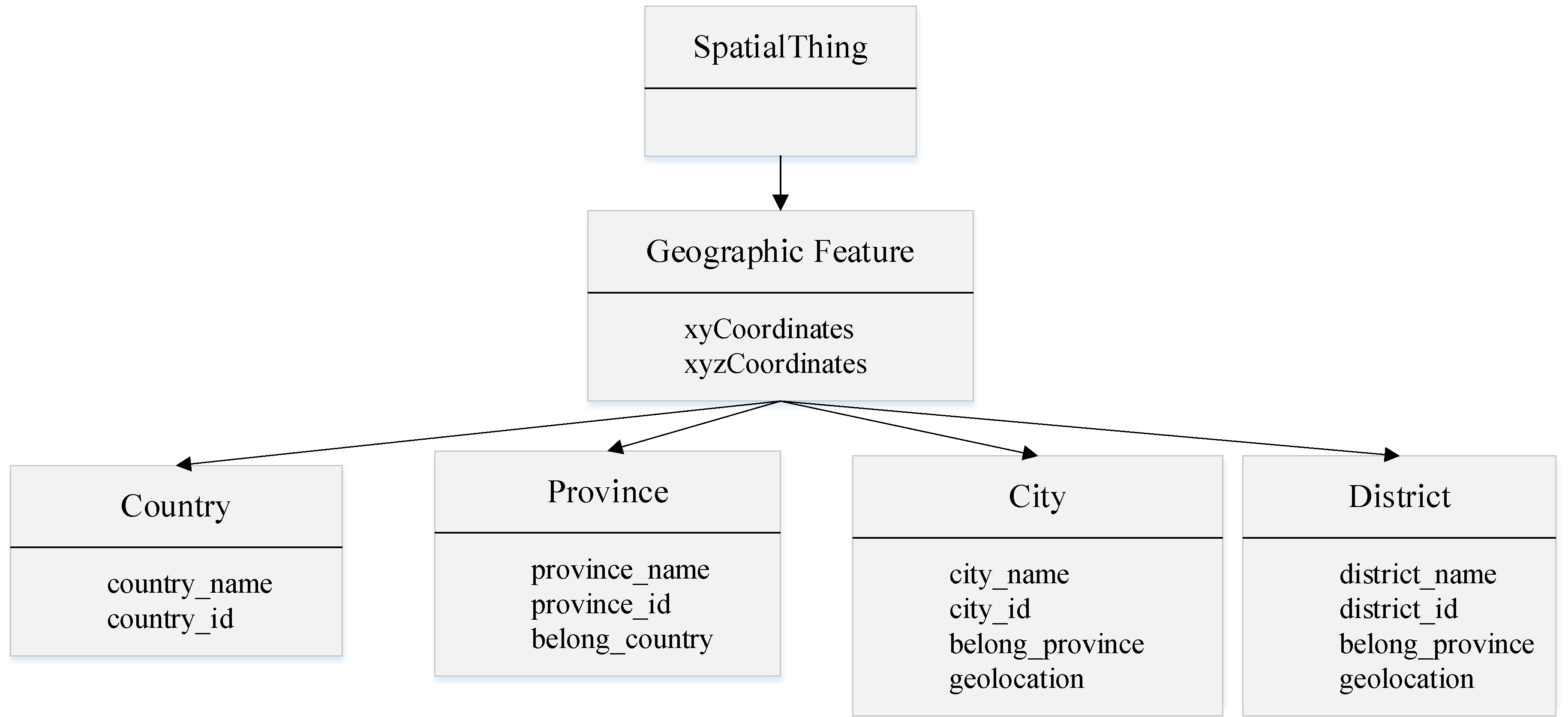
Due to the great diversity of MHs, our ontology contains multiple hierarchies of classes that represent the domain concepts (typhoon, flood, hail, etc.), as well as specific instances (flood event 1, typhoon event 1, etc.). In addition to the classes and instances of MHs, the ontology includes their properties. It is worth noting that some properties will be typical of a specific hierarchy of events and others will be general. For example, hail events will include the hail diameter while typhoon events do not, whereas the number of victims (data property) is important for all kinds of MHs. Each one of these properties is related to the corresponding MH event by conveniently labeled properties (water_lev_rising_degree, water_lev_declining_degree, regionOfOccurence, diameterOfHail, etc.). All properties (including the data property and object property) are added to the top class – MH – which means that all events share a set of properties.
A part of a MH event emergency scenario property layered system.
Through the establishment of an event emergency scenario semantic model, we summarized the MH event emergency scenario property layered system, as shown in Fig. 4. The first layer shows the semantic features, the last layer contains the properties (leaf properties) that are the atomic semantic features in the ontology, and a semantic feature includes multiple atomic semantic features. We have more than 200 leaf properties, including simple properties and complex properties. Short text property processing of a complex property is especially important.
We establish the relationships between the target event and the previous event ontology using the shared properties between their instances, that is, between the target event and previous events presenting common atomic semantic features. We start from a set of previous events for the target event. Our goal is to discover events that are similar to the target event. Namely, we identify the previous events whose emergency scenarios and basic geographic information of the area of the accident are similar to the target event needing emergency plan recommendations.
To this end, we propose a metric that quantifies the semantic similarities between a target event and previous events. Our semantic similarity metric is based on discovering the implicit relations between a target event and previous events to match. Then, the stronger the connections are between the two of them, the greater their similarity will be.
We discovered the relationships among a target event and previous events that share semantic characteristics (e.g., people, houses, economy, traffic, and infrastructure), including a series of leaf properties. Particularly, our metric distinguishes two types of connections: simple and complex. A simple connection includes 2 types: those that are established through a common property value (if the two events share some property value (the same instance in the ontology)), and those that are established through a sibling property value (if they have a property value belonging to the same class in the ontology). For example, between a flood disaster event whose number of disaster victims is 1.2 million and a typhoon event whose number of disaster victims is 1 million, there is a relation through a common property value duo within the numerical statistical error, whereas between the target event “Fishing vessel is damaged” and a previous event “Seafood production has a loss”, there is a relation through a sibling property value (seafood and fishing vessel belong to the same class in the ontology, which is fishery (loss)). Complex connections are established through short text properties whose value is represented by short text, which need to be split and processed into composite simple properties. Our metric considers the relations using a common property value that is stronger than that of a sibling property value.
Furthermore, the effects of a semantic feature on different target events are different. Consequently, the more important (for the target event) that the relations that we can infer between the target event and a previous event are (and the more important the relations from that set that are measured using a common property value), the greater their semantic similarity will be.
Next, we will analyze the strategy of selecting a neighbor from a specific and quantitative point of view. In our method, data preprocessing and our flexible mixed weight-calculation method are used to avoid the generation of fake neighbors and the omission of true neighbors.
Data preprocessing – Short text property processing
The data that are obtained from real-world problems are rarely complete [20] and cannot be directly used. The properties of the events that we obtained are mostly short text properties, and it is very important to split and process a short text property into composite simple properties.
We exploit the semantics when computing events’ short text property similarities, and with the help of a semantic property thesaurus, we split short text (property value) into a content phrase and degree phrase. For a content phrase, we use the phrase’s ancestor information instead of the short text property information itself. Thereby, even if there is no intersection between the two property value phrase sets, they may have high similarity. For example, in computing the similarity between “many oysters damaged” and “a large number of crabs died of anoxia”, there is no common word in these two short text property values, so the similarity is 0 according to a traditional statistical method; however, what they both declare is that seafood suffered heavy losses, and so their similarity is high.
A. Split short text property value
In our method, two data structures, “keyword-candidate list” and “property thesaurus”, are introduced to help split short text properties.
An example of a simple keyword-candidate list of the special barriers to the event processing property is described in Table 3. The keywords in the keyword-candidate list can be a word or multiple words that are related to a description of the corresponding short text properties.
Keyword-candidate list of special barriers to the event processing property
Keyword-candidate list of special barriers to the event processing property
In this paper, different short text properties extract different keyword-candidate lists from their respective property value sets. Some of the words in a short text property cannot exactly match the corresponding keywords in the keyword-candidate list since they have the same semantics but different expressions. Therefore, we assume that specific property thesauruses are built to support the keyword extraction, and different property thesauruses are built for different short text properties.
B. Short text property similarity computation
There are two types of property thesauruses: content and degree. Figure 5 is an example of a content property thesaurus. Degree property thesauruses measure the degree of the content property according to a property description. For a combination of multiple content phrases and a mixed combination of content and degree phrases, we handle these as follows.
An example of a simple property thesaurus of special barriers to the event processing property.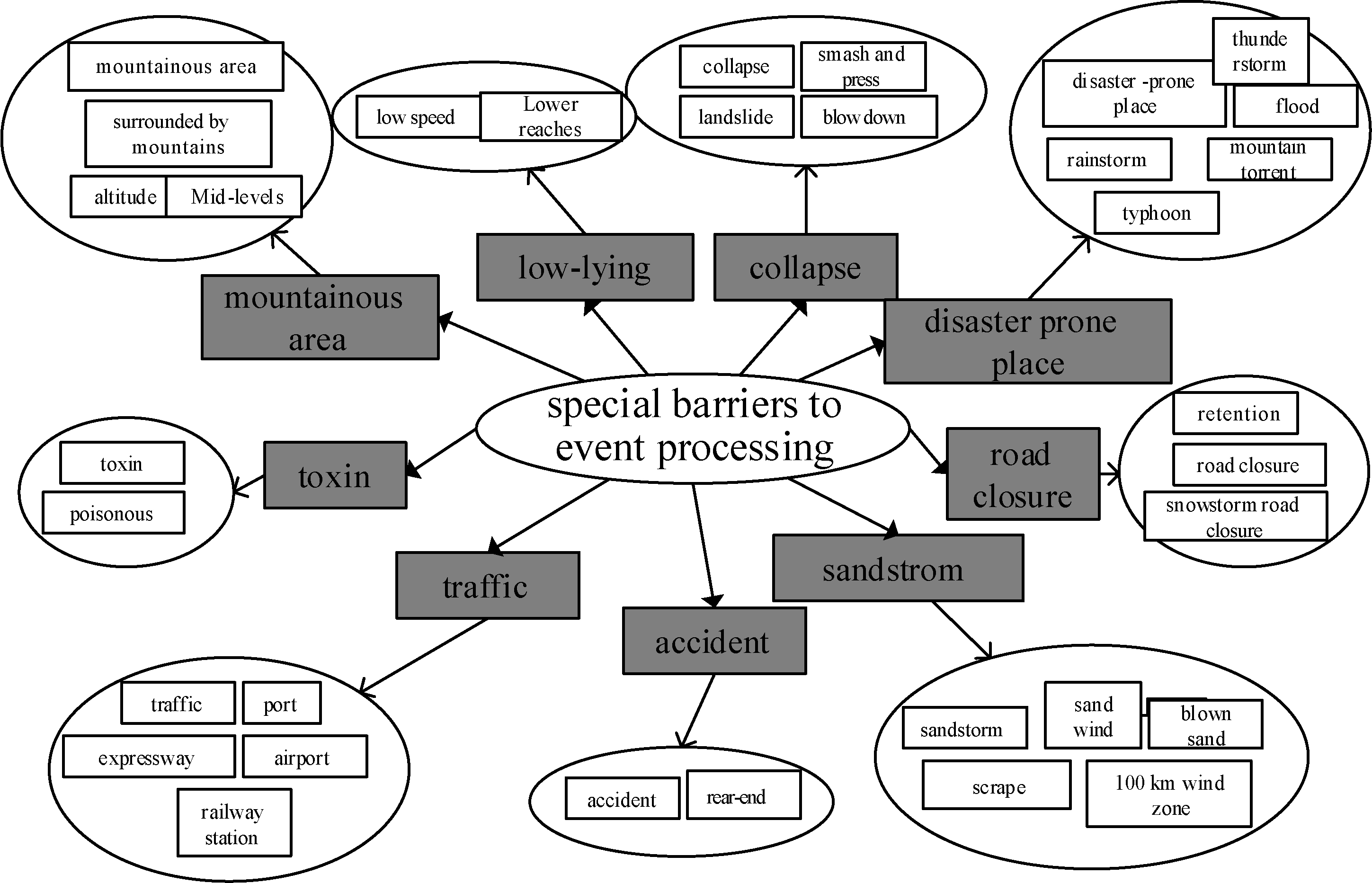
B.1. Pure content type – Multiple content keywords
According to the links among keywords, there are two types of structures for pure content phrases: coordination and tree. Coordination is the relation among content phrase sets where we change the original property into a composite property including multiple juxtaposed subproperties whose value is yes or no. For a tree, there is an overall partial relationship between the content phrase sets. For example, for the special circumstances of events, traffic locations include railway stations, highways, and subway stations. Because all these words can be organized from top to bottom into a tree-like structure, any word can be reached through another path in the tree. The relation between a word and another word can be reflected by their path length and their respective depth information. For such a property, we select only the phrase with the maximum depth from the property value phrase set to participate in the property similarity calculation.
Generally, when the length of the path from one word to another is much shorter, the relation of the two words is much closer, and their similarity is greater [22]. For example, the semantic similarity between the two phrases “harbor” and “railway station” is greater than that between “harbor” and “traffic location”. We evaluate the semantic similarity between two words or two concepts as follows:
where concept indicates a word, and LCS indicates the least common ancestor node of two content phrases.
Example of composite property – fishery loss property.
B.2. Composite type – Content and degree keywords
A property value may simultaneously refer to content and degree phrases, as shown in Fig. 6. For the property of fishery industry losses (under the semantic feature “economic loss”), the following provides some descriptive information on it.
Event 1: More than 30 fishing boats had to lay off employees.
Event 2: Some oysters had been destroyed.
Event 3: Aquaculture facilities were severely damaged, and aquatic products died.
In this example, the keyword-candidate list of content information has two words: fishing boats and seafood. In addition, for the levels of damage regarding seafood and fishing boats are different.
We divided this property into two parts: content property and degree property.
First, the method to calculate the similarities between content phrases can refer to the way in which it is used to calculate the similarities between pure content properties. Finally, we can obtain the original property similarities by multiplying the two similarities of the subproperties.
A Flexible Mixed Weight-Calculation method is proposed for the event similarity computation.
In this paper, we use 3 steps to determine the importance weight of the semantic feature in the semantic feature set for the target event.
Step 1: We use the Analytic Hierarchy Process (AHP) [23] model to determine the theoretical weight vector
We construct the pair-wise comparison matrix in terms of the relative theoretical importance between each two semantic features. The pair-wise comparison matrix
After checking the consistency of the matrix, we then calculate the theoretical weight using the following function:
where
Step 2: We should consider a target event’s semantic feature’s value worth. Every semantic feature consists of multiple leaf properties, and we treat the percentage of leaf properties with nonempty property values as the semantic feature data worth of the target event. Then, we can obtain a target event’s data worth vector
Step 3: We obtain the semantic feature importance weight vector W of the target event as follows:
where
Then, the event emergency scenario similarity
where
The calculation process of a region’s intrinsic similarity
Finally, we can obtain the event similarity
where
Based on the similarities of the target event and previous events, further filtering will be conducted. Given a threshold
Once the set of the most similar events is found, the personalized ratings of each candidate emergency plan for the target event can be calculated. Finally, a high-target emergency plan recommendation list will be presented for the target event and the emergency plan(s) with the highest rating(s) will be recommended.
Here, we use a weighted average approach to calculate the rating preScore of an emergency plan for the target event.
where
where
Repeating these steps, we can calculate the predicted ratings of all candidate emergency plans for the target event. Then, we can rank the emergency plans using the ratings and present a high-target emergency plan recommendation list. Without the loss of generality, we assume that the plans with the higher ratings are more useful for the event. Thus, the plans with the highest rating(s) will be recommended for the target event. Alternatively, we can recommend the Top-p services for the event. Table 4 shows the basic algorithm of SACF.
The process of SACF
For each of these MHs in the MH case library, our algorithm produced a list of five ranked emergency plans. We then randomized the order within each group of five to obscure the algorithm’s ranking decisions. Three domain experts independently evaluated the relevance and quality of each emergency plan to its respective MH event. This process induced a human-generated ranking, which we then compared to the algorithm’s rank order. The rating scale that is used by the experts is from 1 to 5. A score of 5 is the best, meaning that the recommended emergency plan is quite useful to the event and the quality of the emergency plan is quite high.
The evaluation factors include two parts: the quality of the emergency plan (integrity, maneuverability, etc.) and the correlation degree between the emergency plan and the target event.
Metrics
We used two metrics to evaluate the relevancy and quality of our recommendations: the NDCG and k-precision.
The discounted cumulative gain (DCG) [24] is a measure of ranking quality. Highly relevant and high-quality emergency plans are more useful when they have a higher ranking, and the discounted cumulative gain is higher. The principle of the DCG is that if the high-quality results unexpectedly fall behind the low-quality results, then we should discount the score. The accumulated DCG containing
where
We use a graded relevance and quality scale of 1, 2, 3, 4, and 5, and computed the DCG for the ranked recommendations, which we did for each MH event. The ideal value of DCG (IDCG) is defined as the DCG that is based on the ideal ranking as judged by the experts. To obtain the IDCG, we sort the rankings that are given by the experts in decreasing order of relevance and quality scores and compute the DCG of the sorted ranking [25] This corresponds to the maximum theoretically possible DCG in any ranking of recommendations for that event. We normalize the DCG for our ranking using the IDCG to obtain the Normalized DCG (NDCG):
Here, we have 5 results, and we report NDCG(5) as NDCG, which is the overall rating for the ranking. The worst situation is that the 5 emergency plans, which are recommended for a target event, are graded by the experts as 5, 4, 3, 2, and 1 in that order; however, the results of our method are 1, 2, 3, 4, and 5 (indicating gain, where 5 is the best). Then, min(NDCG)
The formula of the precision of the top
We compare SACF with SACF that does not use the FMWC method (i.e., SACF_NW in the results figures). As shown in Fig. 7, at first, the SACF result’s precision is basically greater than 0.7 (except for sandstorms), and higher than that of SACF_NW under the same situation. Next, for sandstorm events whose precision is small because the emergency plans that are useful for sand storm events in the event database are rare, most of the useful emergency plans are successfully found in the front recommendation list while using SACF, thereby indicating the SACF recommended results are very good.
Comparison of the SACF and SACF_NW precision of the Top-p (
We classify the target events using different properties: the number of disaster victims, the number of collapsed houses, and the number of destroyed houses. Then, we calculate the top-10 precision of every group. We can see that the precision of our SACF is essentially relatively high, as shown in Fig. 8.
SACF precision of the Top-10 recommendation list for different groups.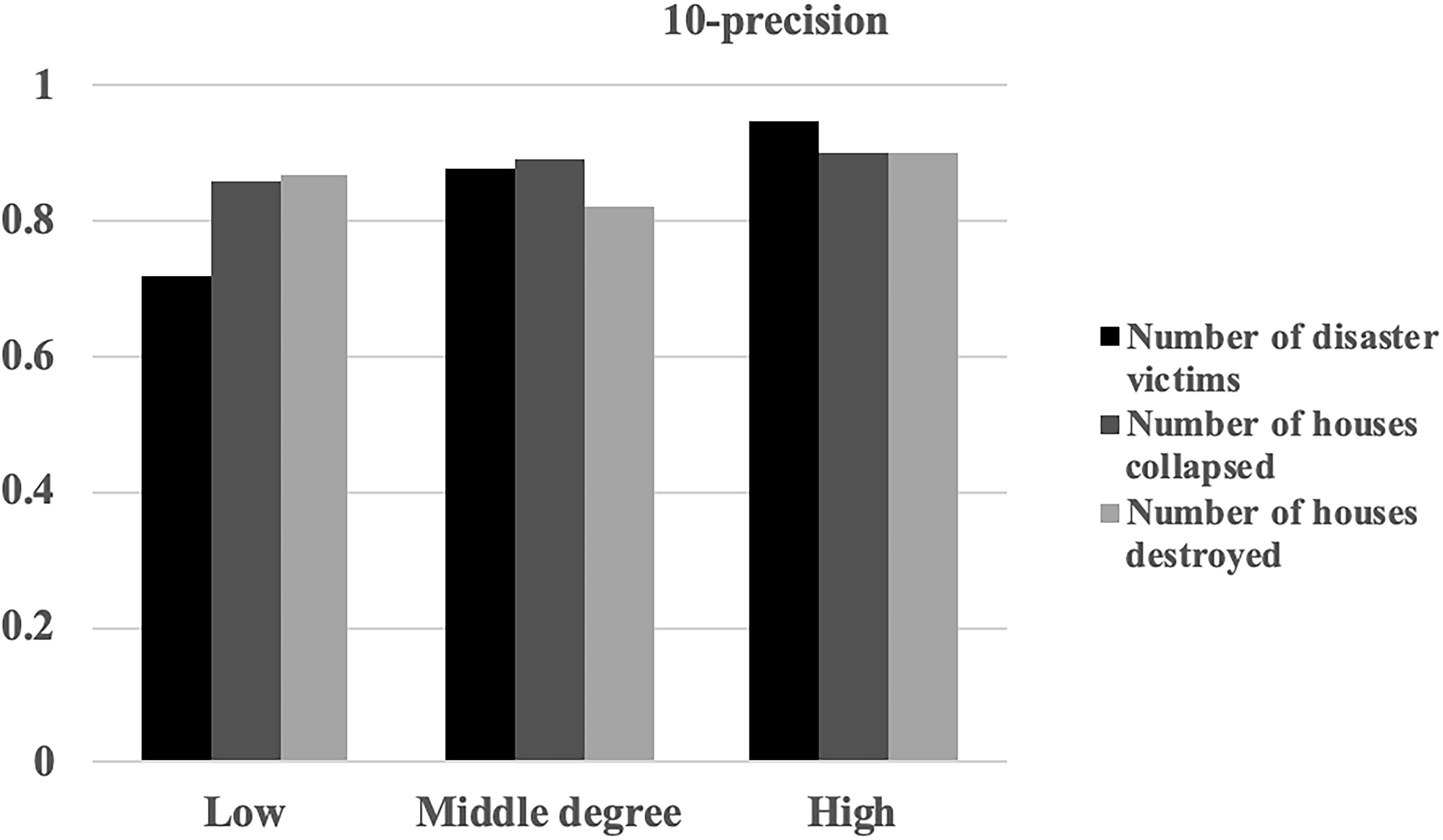
In Fig. 9, SACF’s NDCG of the Top-5 recommendation list under different disaster types is high, which reflects that the sequence of plans that is recommended by SACF is reasonable. Furthermore, compared to SACF using the FMWC method, our SACF’s NDCG is higher, which suggests that our FMWC method is useful for improving the recommended results.
SACF and SACF_NW’s NDCGs of the Top-5 recommendation list under different disaster types.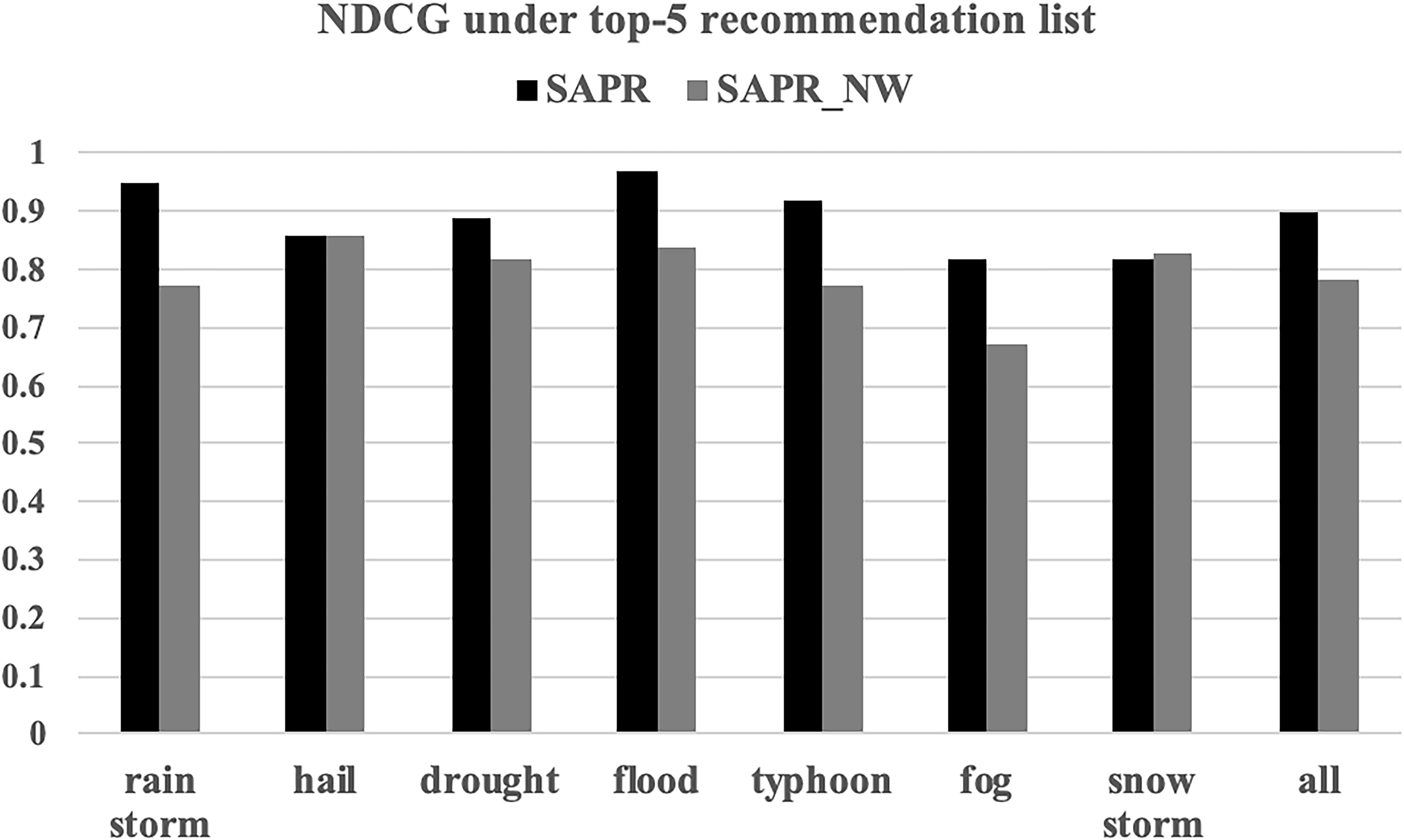
We cannot consider recall since we do not know the entire set of relevant emergency plans.
Considering only disaster hazard factors’ features while searching for neighbors can find only the neighbors whose type is the same of that of the target event. However, in a SACF recommendation, we can see that flood events’ neighbors may be typhoon events, whereas a flood event’s neighbor in a small village may not be a flood event in a large city because the difference between the two events’ basic regional information is too great. This shows that our SACF can accurately avoid the generation of fake neighbors and the omission of true neighbors.
In addition, removing some properties cannot allow one to find hidden referential neighbors. For example, agricultural loss is a relatively minor property, but after removing it, it is difficult to find a neighbor whose agricultural loss degree is similar to that of the target event. However, in a SACF recommendation, the “Emergency plan for agricultural natural disasters” that is adopted by a typhoon event (which is a neighbor of the target event with a similar agricultural loss degree) is recommended to a snow event (i.e., a target event) that occurred in Hengyang.
From the detailed recommendation results, we recommended Longyan’s preventative flood emergency plan to a typhoon event that occurred in Nantong. Although the two places are in different regions and the types are also different, the flood emergency plan obviously has some referential value for the typhoon event. A traditional keyword retrieval method and the case-based reasoning method of Zhang cannot obtain these results, which shows the superiority of our SACF.
In this paper, we have proposed a semantic-aware emergency plan collaborative filtering recommendation method named SACF. In SACF, a semantic model is used to represent an MH event emergency scenario, and a Collaborative Filtering algorithm is adopted to generate appropriate recommendations. More specifically, we avoid omitting true neighbors using property generalization, and keyword-candidate lists, a property thesaurus and semantic knowledge are provided to help compute short text property similarities. A weight calculation method called the FMWC is proposed to avoid the generation of fake neighbors and the omission of true neighbors and improve the accuracy and rationality of the recommendation algorithm. Our method aims to provide a highly targeted emergency plan recommendation list and recommend the most appropriate plan(s) to the events. Finally, the experimental results demonstrate that the KASR has satisfactory accuracy.
The work we presented here is a first step, and many opportunities for future work remain. First, the development of an event is dynamic, and the time period for collecting data has a great impact on the results. Nevertheless, we consider only a static emergency scenario at a certain point in time. A follow-up study can focus on the indication and similarity computation of a dynamic emergency scenario. Last, the content of the emergency plan is also related to the recommendation. In fact, lessons are drawn from only part of the emergency plans. Therefore, our follow-up research will be to split the MH emergency plan and recommend the appropriate portion of the emergency plan.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China under Grant No. 61672102, the National Social Science Foundation of China under Grant No. BCA150050, and the Program for New Century Excellent Talents in University of the Ministry of Education of China under Grant No. NCET-10-0239.