
Abstract
With the rapid development of artificial intelligence and the continuous improvement of machine learning technology, speech recognition technology is also developing rapidly and the recognition accuracy is improving to meet the higher requirements of people for smart home devices, and combining smart home with voice recognition technology is an inevitable trend for future development. This study aims to propose a speech fuzzy enhancement algorithm based on neural network for smart home interactive speech recognition technology, so the study proposes a combination of fuzzy neural network algorithm (FNN) and stacked self-encoder (SAE) to form SAE-FNN algorithm, which has better non-linear characteristics and can better achieve feature learning, thus improving the performance of the whole system. The results show that with the SAE-FNN algorithm, the maximum relative error absolute value, average relative error and root mean square error are 0.355, 0.063 and 0.978, which are significantly higher than the other two individual algorithms, and the noise of the sound signal has little effect on the SAE-FNN algorithm. Therefore, it can be seen that the proposed SAE-FNN algorithm has excellent noise immunity performance. In summary, it can be seen that this neural network-based speech fuzzy enhancement algorithm for smart home interaction is extremely feasible.
Keywords
Introduction
Smart home is a home as a carrier to centralize the management of home facilities [1], which is both convenient and comfortable, as well as safe and environmentally friendly, and can bring intelligent and stylish living to families and improve the quality of living [2]. In recent years, with the development of technologies such as machine learning and artificial intelligence, as well as the rapid development of Internet media and the widespread use of mobile phone applications [3], it has led to a great expansion of the speech recognition library and provided a large number of training examples for acoustic and language modelling for speech recognition, as well as its strong learning capability [4], allowing optimization and tuning of model parameters to improve the recognition rate of the model. The introduction of intelligent speech recognition technology in the smart home has freed people from the shackles of manual operation, thus creating a new smart home [5]. Based on this, the research aims to propose a neural network-based speech fuzzy enhancement algorithm for smart home interaction. The research mainly consists of four parts, the second part is a review of the application of neural network-based smart home interactive speech fuzzy enhancement algorithm for domestic and international research status, the third part is the sound signal pre-processing and model construction of neural network-based smart home interactive speech fuzzy enhancement algorithm, and the fourth part is the performance of neural network-based smart home interactive speech fuzzy enhancement algorithm model Evaluation.
Related work
The reason why smart homes have developed so far and so well is by no means a one-off, and in recent years there have been a number of scholars in China who have explored it in depth to promote the development of this field.
The multiple-MKL algorithm proposed by Chang and Zhao not only maintained good performance in the original classes, but also improved the recognition of new classes with only few training samples [6]. To generate the optimal scheduling problem for smart home energy management systems, Zhao and Keerthisinghe [7] proposed an under-uncertainty fast real-time control strategy using Bellman optimality conditions and long short-term memory recurrent neural networks (LSTM-RNN) with errors in the range of 0.8%, saving at least 20% of the computation time. Pustokhina et al. [8] proposed an approach using fuzzy logic controllers based on high response time and network load being the limiting factors for IoT deployment and thus improve the reliability of IoT gateways. Kulkarni and Kulkarni [9] proposed a fuzzy neural network (FNN) for pattern classification, which, unlike other clustering algorithms used to build the hidden layer of RBFNN, is fast to train and retrieve, guaranteeing 100% accuracy for any training set. Zheng et al. [10] proposed a fuzzy system-fuzzy neural network-backpropagation control system in order to solve the control problem of complex robotic systems with uncertainties and disturbances, which can guarantee accurate, stable and efficient control, and experimental results proved the stability of their algorithm.
Kagan et al. [11] bridged the widely accepted model of biological systems based on Tsetlin automata acting in a stochastic environment, which implements multi-valued non-heterogeneous operators applied to aggregated inputs and internal states, and then uses these neurons to build networks, and studies have shown the stability of the algorithm due to similar algorithms. Ai et al. [12] solved the problem of observation repetition and lack of full graph in the observation repetition and lack of full graph problem of integrated learning using attentional model integrated convolutional recurrent neural networks (ACRNN) for unbalanced speech emotion recognition, and finally extensive experiments on IEMOCAP and Emo-DB samples demonstrated the superiority of our proposed method. Song et al. [13] proposed a speech-based method for automatically detecting frustration during game interactions, improving system performance from 58.8% unweighted average (UAR) to 93.1% due to continuous improvements in the use of convolutional neural networks (CNN) to implement speech recognition tasks. Alam et al. [14] survey reviewed state-of-the-art deep neural network architectures, algorithms, algorithms for speech and vision applications and systems, the study provides the most comprehensive survey of recent developments in intelligent speech and vision applications from the perspective of software and hardware systems, proving that it will revolutionize future research and development of speech and vision systems. Saadi and Belhadef [15] present a deep neural network-based system for extracting specific entities from natural language text with an accuracy of 96.81%, better than the state-of-the-art results.
It can be seen from the research of domestic and international scholars based on fuzzy neural network algorithm (FNN) and stacked self-encoder (SAE) that there are more studies on fuzzy neural network algorithm (FNN) and stacked self-encoder (SAE), but there are relatively few studies on the fusion and optimisation of SAE and FNN to achieve interactive speech recognition for smart homes. Therefore, this research mainly conducts research on smart home interactive speech recognition by integrating SAE and FNN algorithms. Compared with a single algorithm, the proposed algorithm can improve its recognition rate to a greater extent, and its feasibility and optimization are well verified.
Construction of a neural network-based fuzzy enhancement algorithm model for smart home interaction speech
Preprocessing method of sound signal
The usual pre-processing processes for smart home interactive speech are: pre-emphasis and windowing framing [16]. The study addresses this issue by using digital filtering techniques to pre-process the voice signal and improve its high frequency performance. The pre-emphasis digital filter is usually a first order digital filter with the expression shown in Eq. (1).
In Eq. (1),
Framing diagram.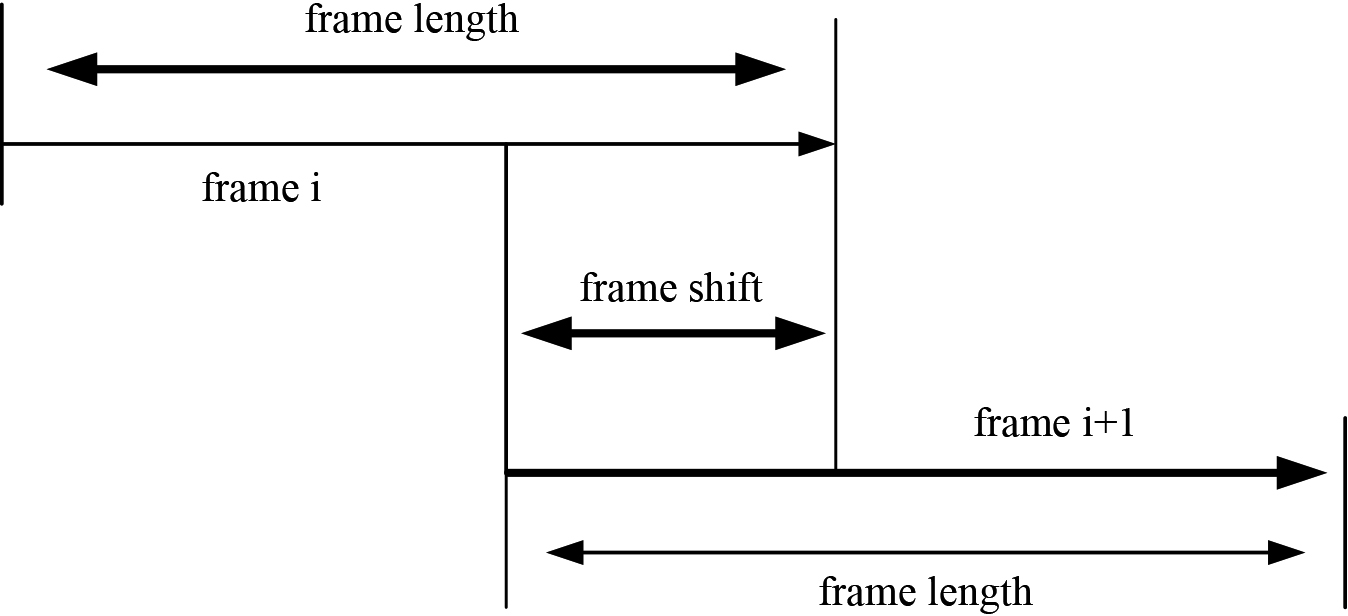
The long segmented speech signal after framing is a very short, finite signal and therefore often causes truncation when it is extracted for features, which means that spectral leakage occurs when the Fourier transform is applied to the finite signal, resulting in anomalous boundary values. To reduce the effect of the speech signal after framing, the method of adding windows must be used. Rectangular windows and Hamming windows are the two most common forms [18], and their functional forms are shown in Eqs (2) and (3) in that order.
In Eqs (2) and (3),
In Eq. (4),
In Eq. (5),
It has been found that the human ear perceives different frequencies of sound in different frequency bands. At low frequencies of speech, the relationship between human auditory performance and auditory frequency is linear; while at higher frequency bands, the ability to perceive frequencies shows: a logarithmic relationship. To accommodate the auditory characteristics of the human ear at different frequencies, researchers Davis and Mehlstein proposed the Mel inverse spectral coefficient (MFCC). A logarithmic relationship exists between the Mel frequency of the MFCC and the conventional frequency, and its expression is shown in Eq. (7).
In Eq. (7),
In Eq. (8),
MFCC extraction schematic.
In the extraction of emotional features of speech signals, each feature is expressed in a different way and its range of values varies greatly. Therefore, in order to measure the various types of features effectively, the extracted features must first be analysed and the various types of features normalised in the following two main ways.
The first method is min-max normalisation, which maps its original data to the range [0, 1] and performs a transformation of the initial data as in Eq. (9).
In Eq. (9), represents the value of the dimension
In Eq. (10),
There are a large number of machine learning algorithms available for smart home interactive speech recognition technology, and neural networks are one of these algorithms. ANNs are essentially simple constructions and simulations that take advantage of the variance that a computer can handle. Firstly, it is adaptive and self-learning in that it can adjust and adapt the connections of each neuron in the network based on the desired outcome and feedback, resulting in a continuous improvement of the network’s network structure. The second feature is associative memory, where neurons are able to store messages and make full use of this property in their internal neuronal connections; in a feed-back neural network, neurons are able to make full use of their information with pre- and post-neurons, which in turn enables association. Thirdly, because ANN has excellent optimisation properties, it can optimise any non-linear function at all three levels. This provides a powerful reference for solving certain complex problems. Fourth, because of the network’s good fault tolerance, damage to local neurons in a neural network does not have a significant impact on the overall operation of the entire network [20]. Figure 3 shows a simple three-layer structure consisting of an input layer, a hidden layer and an output layer.
Three-layer neural network structure.
A neuron is the most fundamental unit of operation in a neural network, usually a non-linear system with feedback inputs and threshold parameters. This is shown in Fig. 4.
Single neuron structure.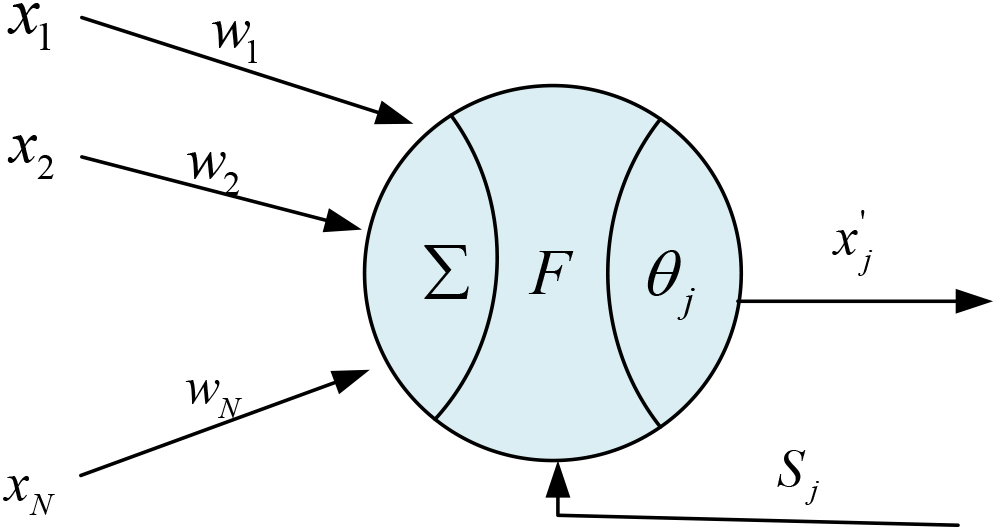
The relationship between the output
In Eq. (11),
Sigmoid function image.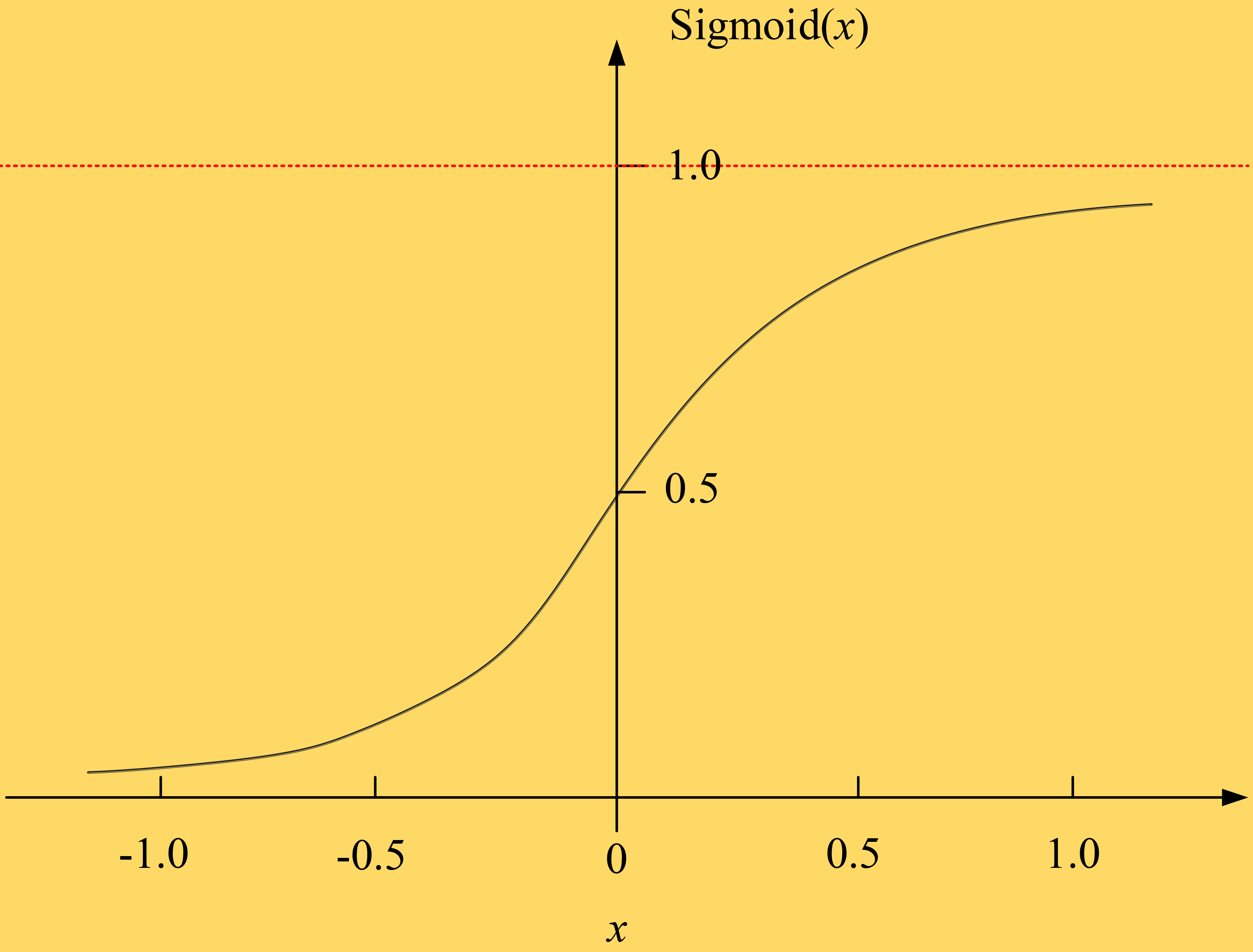
As shown in the graph of the Sigmoid function in Fig. 5, the closer the horizontal axis of the Sigmoid function is to the origin, the greater the change in the vertical coordinate, which is known as soft saturation, but it tends to lead to undertraining of the neural network; it is prone to problems such as gradient disappearance and gradient explosion. Deep learning methods can solve these problems well and play an important role in computer vision, speech processing, emotion recognition and so on. Through the study of a large amount of data, it is verified that feature extraction and recognition using deep learning networks can greatly improve the accuracy of classification. The following is a detailed analysis of the stacked self-encoder (SAE) used in this study. The autoencoder needs to acquire the key elements that can represent the characteristics of the input signal, while the autoencoder that extracts to its core retains only one implicit layer and utilizes unsupervised methods to search for the required information. The output information represents the input information. Assuming Sigmoid as its activation function, a neuron is activated when its output value exceeds that activation value, and the neuron returns to that activation state at the end of that activation cycle. Since most neurons are normally in an inhibited state, the concept of a “penalty factor” is proposed to reduce the activity of the neuron, as shown in Eq. (12).
In Eq. (12),
In Eq. (13),
Denoising autoencoder network structure.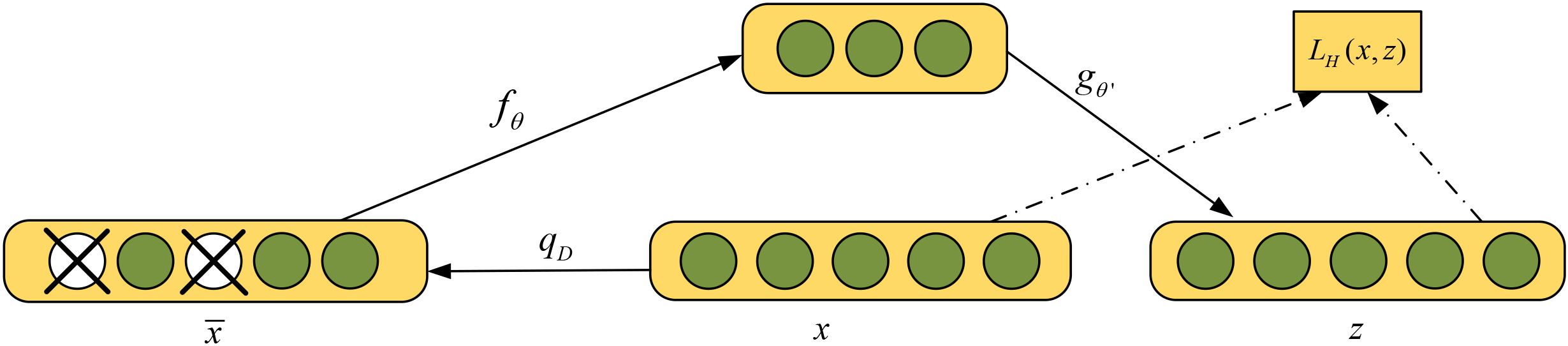
Due to the complexity of the sound signal and its indeterminacy, the study proposes a fuzzy neural network (FNN), which has the ability to describe and express fuzziness, and is capable of adapting itself in parameter learning. The first step is to introduce the logical inference of ANFIS, which gives the fuzzy rules for two inputs
In Eq. (14),
The third level is a type of fuzzy reasoning in which each neuron has a law of fuzziness.
The fourth level is the normalised layer, which normalises all inferred conclusions and all normalisations give a result of 1. The advantage of normalisation is that the series of data that follows can be inverted. When normalising the parameters, the corrected amplitude has a certain limiting value, thus effectively preventing the network from vibrating violently and thus allowing the convergence of the neural network to be improved. The fifth stage is the output stage, where the output after each normalisation is demodelled to obtain the corresponding classification of the input sample values. The above is the inference process performed on the SAE-FNN. The inverse transfer was used to adjust each parameter in the process of inverse transfer, based on which the weights of the output level, the weights of the Fuzzy level to the Fuzzy inference level and the affiliation parameters were returned.
The vocabulary used in this study ranged from 10 to 50. Due to the differences in vocabulary, there were differences in the recognition ability of each word.
Comparison diagram before and after sound signal processing.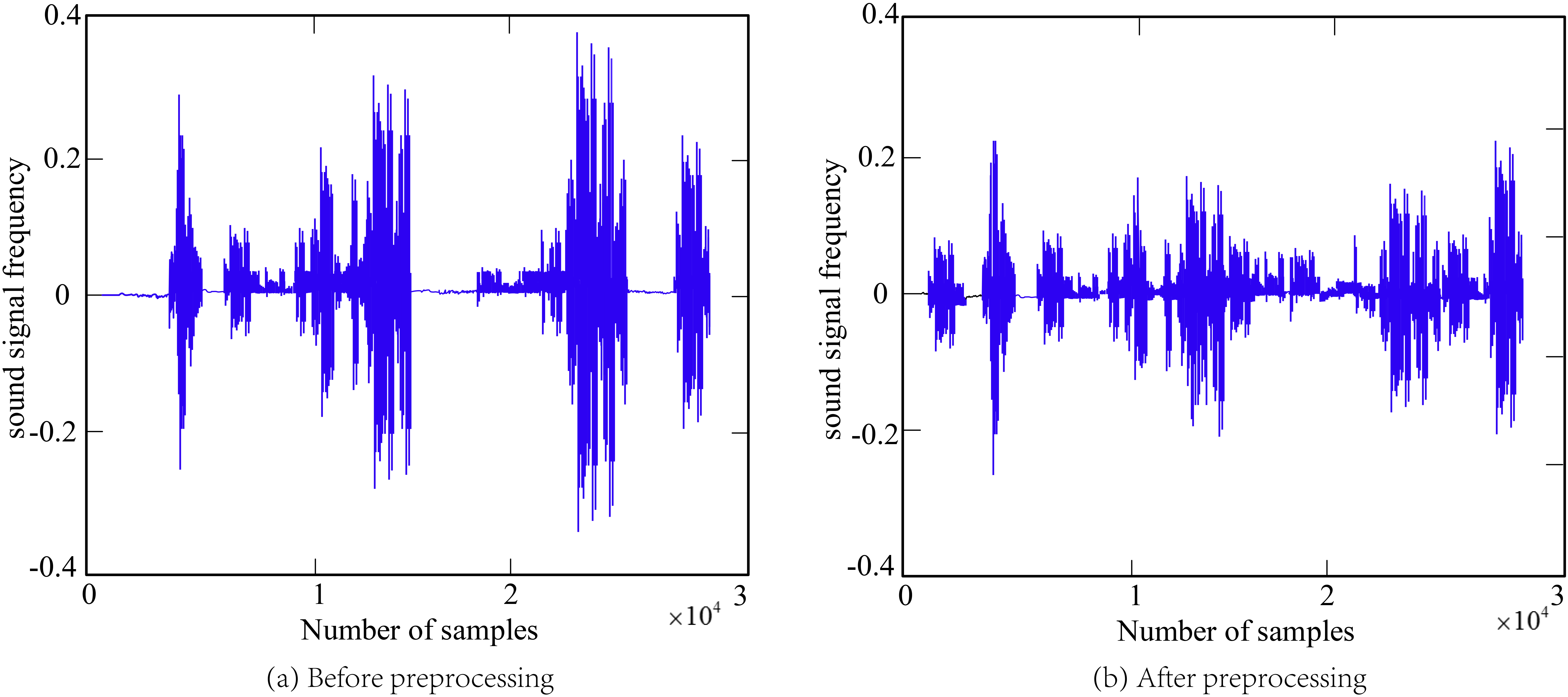
As shown in Fig. 7a, in the original voice signal, a longer segment of speech can be a kind of interruption, which has parts that do not include any message or have a lower message, e.g., a silenced part of speech; in order to reduce the overall computing power, the accuracy of speech is improved, and the overall voice is not continuous and the meaningful voice emotion is fragmented, so after pre-processing it, the voice signal After terminating the detection and removing the invalid segments, its audio image is stable and noise-free, and then the speech signal is imported into the set model. Considering the actual speech and speech recognition process, it is necessary to analyse the performance of the research method chosen for this study, in addition to training the fuzzy neural network algorithm (FNN), in this study the fuzzy neural network algorithm (FNN) and the stacked self-encoder (SAE) are combined to form the SAE-FNN algorithm. For comparison purposes, the basic BPNN algorithm, the FNN algorithm and the SAE-FNNN algorithm are used to train the network for comparison and to obtain training curves and recognition rate images.
Training result graph.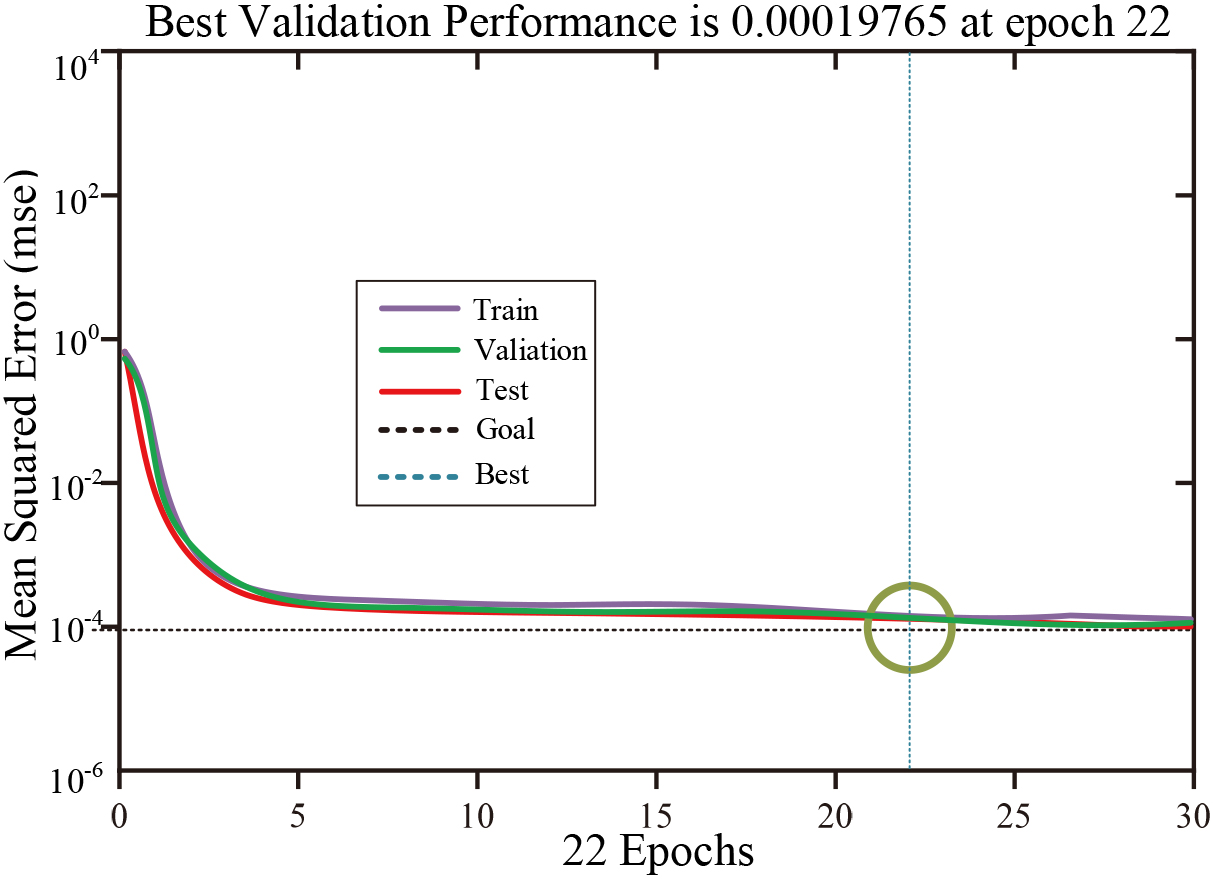
As can be seen in Fig. 8, this method achieves the pre-set target of 10
Training result graph.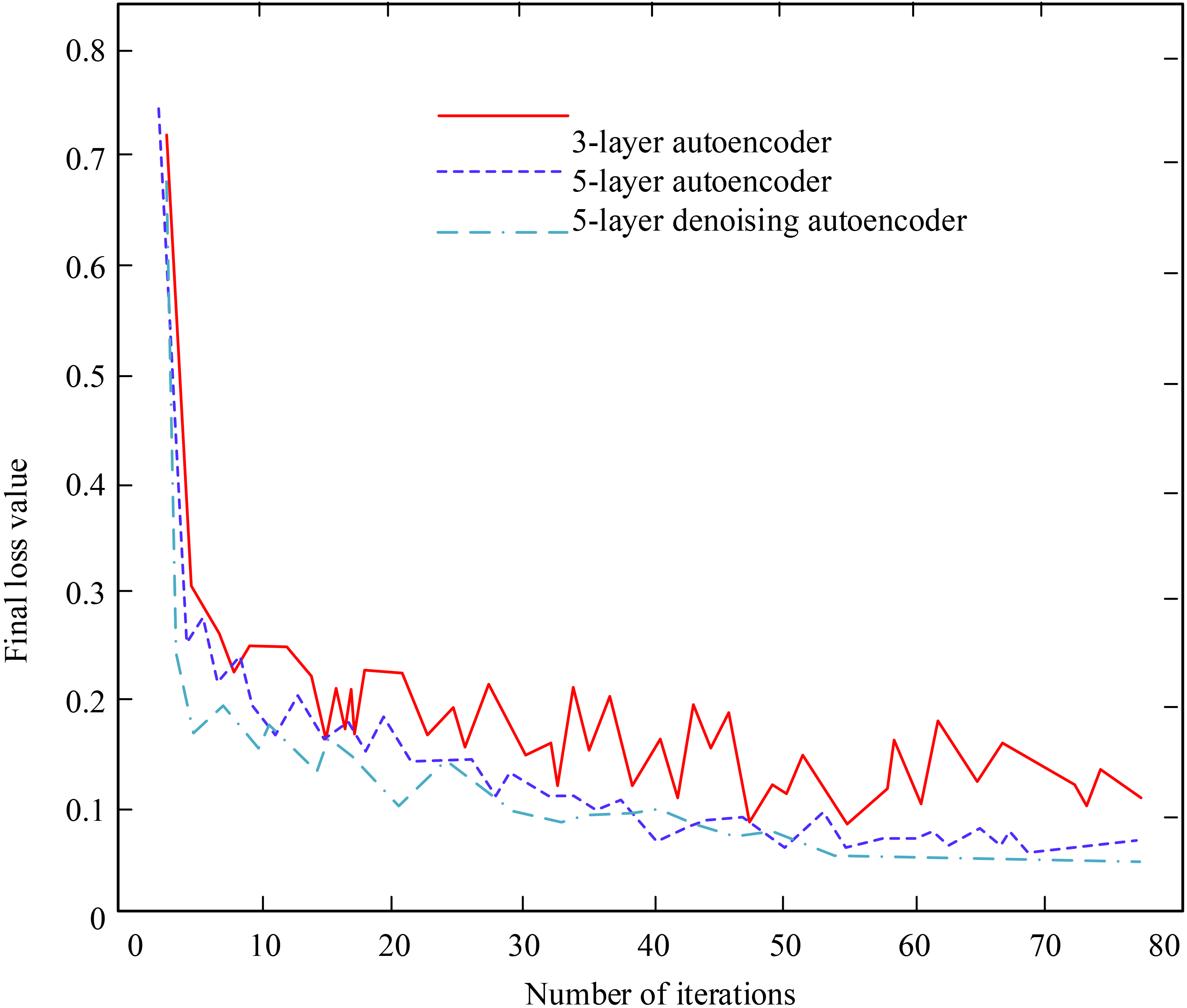
The previous speech signals were obtained in a laboratory, where such signals are relatively stable and not contaminated, and therefore the recognition rate is higher. However, in practice, the quality of the observed speech signal varies considerably and it is therefore essential to analyse the noise immunity of the speech recognition techniques and software under study. In this paper, a specific speech “3” is used as an example to compare the BPNN algorithm, the FNN algorithm and the SAE-FNN algorithm to obtain different recognition rates compared to the noise amplitude by using similar pre-processing, feature extraction and parameter setting methods as the previous methods and applying them to the learning of the network. This is shown in Fig. 10.
As can be seen from Fig. 10, the FNN algorithm and the BPNN algorithm significantly reduce the accuracy of discrimination against additive noise, especially in broadband Gaussian white noise, the effect is extremely significant, with a reduction of about 20%, while for the SAE-FNN algorithm, the noise of the sound signal has minimal effect, so it can be seen that the SAE-FNNN algorithm proposed in the study has extremely strong noise immunity. In order to evaluate the effectiveness of each model, the accuracy and stability of the three algorithms were evaluated using three performance indicators: the absolute maximum relative error
The calculation results of each model evaluation index
Influence of noise amplitude on recognition rate.
As can be seen from Table 1, using the BPNN model, although the modelling is simple and easy, it is greatly reduced in accuracy and the model has poor strain; using the FNN model, although the training time is shorter, the accuracy is lacking and the model is not stable enough. The combined SAE-FNN algorithm used in this research, however, can effectively compensate for the pain points of both algorithms and is highly feasible, and its evaluation indexes all maintain the lowest rank, so the performance of this smart home interactive speech fuzzy enhancement algorithm research model is reliable, thus providing the necessary conditions for smart home interactive speech recognition.
Smart home interaction speech emotion recognition helps the human-computer interaction method of intelligence and humanization, it has a good application prospect, the research proposed in this study combines fuzzy neural network algorithm (FNN) and stacked autoencoder (SAE) to form SAE-FNN algorithm, the study shows that the research algorithm can achieve the pre-set target of 10