
Abstract
Heterogeneous information network (HIN) are becoming popular across multiple applications in forms of complex large-scaled networked data such as social networks, bibliographic networks, biological networks, etc. Recently, information network embedding (INE) has aroused tremendously interests from researchers due to its effectiveness in information network analysis and mining tasks. From recent views of INE, community is considered as the mesoscopic preserving network’s structure which can be combined with traditional approach of network’s node proximities (microscopic structure preserving) to leverage the quality of network’s representation. Most of contemporary INE models, like as: HIN2Vec, Metapath2Vec, HINE, etc. mainly concentrate on microscopic network structure preserving and ignore the mesoscopic (intra-community) structure of HIN. In this paper, we introduce a novel approach of topic-driven meta-path-based embedding, namely W-Com2Vec (Weighted intra-community to vector). Our proposed W-Com2Vec model enables to capture richer semantic of node representation by applying the meta-path-based community-aware, node proximity preserving and topic similarity evaluation at the same time during the process of network embedding. We demonstrate comprehensive empirical studies on our proposed W-Com2Vec model with several real-world HINs. Experimental results show W-Com2Vec outperforms recent state-of-the-art INE models in solving primitive network analysis and mining tasks.
Introduction
Illustrations of different networks’ node representations in PCA-3D plot through Metapath2Vec and W-Com2Vec approaches.
Recently, INE [1, 2, 3] has become the most popular researching area from in information network analysis and mining field. Multiple INE models have been proposed and achieved considerable attentions from many researchers and organizations due to its effectiveness in preserving the complex structure of real-world HINs as well as high performance in a wide range of applications. Up to present, recent INE models have been shifted to the development of effective and scalable representation learning mechanism which are applied for highly complex and large-scaled network like as social networks (Facebook, Twitter, etc.). Most of previous proposed INE models [1, 4, 5, 6, 7, 8] aim to embed the network’s nodes into a latent low-dimensional vector space by preserving the nodes’ attributes and their order proximity. Contemporary network embedding models like as DeepWalk [9], LINE [10] and Node2Vec [11] learn the node representation by preserving the node first-order and second-order proximities to ensure the similar embedded representations between nodes which are linked or shared same sets of contextual nodes. The sets of contextual nodes for each target node are generated via different approaches like as random walk [9], neighborhood (first/second) order node evaluation [10, 11], etc. From the past, most of the previous INE models are mainly designed to work on Homogeneous Information Networks (HoINs). These HoIN-based models treat all nodes and relations as the same type. Extending the idea of using node order proximity of HoIN-based model in preserving network structure, recently there are some emerged models have been proposed to challenge the diversity of nodes and links in HINs. Some HIN-based INE models (HIN2Vec, Metapath2Vec, etc.) use meta-path-based random walk mechanism to obtain the network’s structure. In general, all of these HoIN-based and HIN-based methods only focus on the “microscopic” structure (pairwise nodes and links) of the network. Therefore, these models fail to capture higher-level of network’s structure such as communities, clusters, network’s centroids, etc. These network’s structural aspects are called as “mesoscopic” level structure. In fact, community structures are considered important factors for network analysis and representation learning. In specific area of INE, community structure is one of the most important structural descriptions of the networks. Such as in social network analysis, communities naturally reveal the organizational structures as well as principal components of social networks (Facebook, Twitter, Weibo, etc.), like as user’s groups, friends, social clubs, etc. The use of preserving community structure in INE can help to improve the quality of node representation. Recently, there are some mesoscopic structural network embedding techniques have been proposed to tackle the problem of capturing global properties of the networks like as ComE [12], M-NMF [13], etc. However, these models can only be applied for homogeneous networks and fail to learn the rich semantics of network’s heterogeneity. These models only capture the community proximity of single-typed nodes which are linked by one type of links. Therefore, they are unable to combine different semantic paths in forms of meta-paths between two same-typed nodes in HINs. Moreover, most of recent meta-path-based INE models are mainly concentrated on the node order proximity between pairwise nodes. They largely ignore the topic similarity between text-based nodes within meta-paths in content-based HINs. It is needless to say that most of real-world HINs are composed with large quantity of text-based nodes like as comments, posts in social networks (Facebook, Twitter, etc.), papers in bibliographic networks (DBLP, DBIS, etc.), etc. By evaluating the topic similarity between text-based nodes within meta-paths, we can improve the quality of node order proximity evaluation in INE. To fill gaps between approaches of microscopic and mesoscopic structure preserving in HIN-based INE and topic similarity evaluation in content-based HINs, we clearly define these challenges as well as contributions of our works in the introduction of W-Com2Vec model. The W-Com2Vec model is designed to enable for capturing both microscopic topic-driven node proximity as well as mesoscopic structure (intra-community) of given HINs by using meta-path.
Figure 1 illustrates the community-aware representations of author’s nodes (in DBLP network) (Fig. 1A) and karate-club’s members (in Zachary’s karate club network) (Fig. 1B) which are obtained by using Metapath2Vec and our proposed W-Com2Vec models. As shown from Fig. 1, our proposed W-Com2Vec model achieves better quality than well-known Metapath2Vec [7] model in preserving the mesoscopic network structure (intra-community). Such as in DBLP network, we applied the W-Com2Vec model to embed author node along with their associated community, so relevant authors who belong to same community will be represented as similar vectors in vector space (as shown in Fig. 1B).
Meta-path-based intra-community network structure preserving
Despite high performance in accuracy and great potential applications of recent intra-community based embedding models, there are remaining challenges which are related to the capability of capturing rich semantics of heterogeneous types of nodes and links. Recent intra-community based embedding models such as ComE [12], M-NMF [13] only focus on evaluating node and intra-community proximity of single-typed nodes in HoINs, such as friendship networks (only contains user’s node and friendship relation) or authorship network (only contains author’s node and coauthor relation). Contemporary community detection techniques are only applicable for single-typed nodes and links of HoINs. They are definitely invalid for evaluating complex topological features of multi-typed nodes and links of real-world HINs. It is undeniable that using HoIN-based community detection techniques can’t fully reflect the real situation of linked nodes. For example, the authorship relation is actually a sequence of relations between two author and a paper node in forms of meta-path: A[author]-P[paper]-A. Or there are several types of friendship relation in complex social networks such as Facebook: mutual friends (U[user]
Topic-driven community detection and intra-community network embedding
Beside the challenges of different types of nodes and links, the content and topic similarity preserving of rich-text network’s nodes is also a considerable problem which deeply affect the quantity of node’s representations. Most of real-world networks contain large number of text-based nodes, such as posts, comments, etc. in social networks (Facebook, Twitter, Weibo, etc.), movie’s descriptions, user’s comments in movie’s networks (IMDB, TMDB, etc.), papers in bibliographic networks (DBIS, DBLP, etc.), etc. called content-based HINs. From the past, the task of community detection and embedding only involve in discovering groups of nodes which are connected densely via evaluating their inter-connected relations. They concentrated on using graph analysis techniques to extract topological structures of how network’s nodes are linked rather than node’s attributes. Content and topic attributes of text-based nodes play an important role in attribute-level node proximity measurement. For example, two authors are likely to be cooperating more (A-P-A) if they are working on the same fields/subjects, or two users likely to be familiar if they frequently comment similarly on common posts. In content-based HINs, topic attribute of text-based nodes can help to leverage the network structure preserving and node representation by rendering more information for nodes as well as their relations. Community detection problem in HINs is considered as an approach of using different meta-paths between target same-typed nodes to identify densely connected nodes. Traditional approaches of community detection in HINs do not consider the weights of relations between nodes within the communities. All paths between same-typed nodes are considered as the binary weighting relations, 1 for existed relation and otherwise 0. Therefore, it is necessary to propose a new approach which can help to analyze the topic similarities between two nodes and are used as the weights of relations between them.
Our contributions
In this paper, we propose a novel approach of topic-driven meta-path-based intra-community network embedding, namely W-Com2Vec. Our proposed model supports to preserve both node order and community structure proximity for INE. In particular, we continue to improve and apply our previous works on topic-driven community detection to detect communities in HINs. To learn the node representation via node order proximity, we apply our previous proposed model on topic-driven meta-path-based network embedding (W-Metapath2Vec) [14, 15] to learn the node’s presentation. Then, the detected communities are combined with node’s representations in previous stage to form the final network representations which enable to exploit the consensus relationships of node order proximity as well as community structure in INE. We conduct extensive experiments on various real-world HINs, including: DBLP and MoviesLen1M to evaluate the performance of our proposed model in principal mining tasks (clustering and multi-classed classification) with recent state-of-the-art INE baselines. To sum up, our contributions in this paper can be summarized as following points:
First of all, we present the approach of topic similarity measurement between text-based nodes in content-based HINs via applying LDA (Latent Dirichlet Allocation) topic model. These topic similarity values are then used as the weights for meta-paths between target nodes in topic-driven community detection and network’s node representation. Next, we demonstrate the approach of combining between order proximity based node representation with detected community to produce the final network’s representations of W-Com2Vec model. The W-Com2Vec can ensure both microscopic (node order proximity via meta-path-based random walks) and mesoscopic (intra-community) structure are preserved. Finally, we perform comprehensive experiments on benchmark datasets to show significant improvements of our proposed W-Com2Vec models with up-to-date INE models in multiple network mining tasks.
The rest of our paper is organized into 4 sections. In Section 2, we give brief reviews and discussions about previous works and our motivations. In Section 3, we demonstrate the background concepts and methodology of our W-Com2Vec model. All algorithms, model’s architecture and optimization strategies also introduced in this section. For Section 4, we present extensive experiments of W-Com2Vec model on different benchmark datasets as well as discussions about the experimental outputs. Finally, we conclude our works and provide our future continual improvements in Section 5.
Preliminaries and backgrounds
An information network is defined as an directed/undirected graph, denoted as:
Traditionally, INE models focuses on capturing the network’s featured properties by preserving node order proximity, including first-order, second-order and k-order proximity (Definition 2) to enforce same sharing neighboring nodes (also called contextual nodes) to have similar embedded vectors. There are two main ways for extracting the set of contextual nodes. The first one is node’s neighborhood evaluation and the second one is using random walk on graph. LINE is the most well-known model which use first-order (LINE_1) and second-order (LINE_2) node’s neighborhood evaluation techniques. Similar to the approach of LINE, DeepWalk and Node2Vec use random walk mechanisms to capture contextual nodes for each target node in a given network. These most well-known HoIN-based INE models like as DeepWalk, LINE, PTE and Node2Vec treat all nodes and links as the same type (
Illustration of community structure preserving (MeNSP) in network representation learning.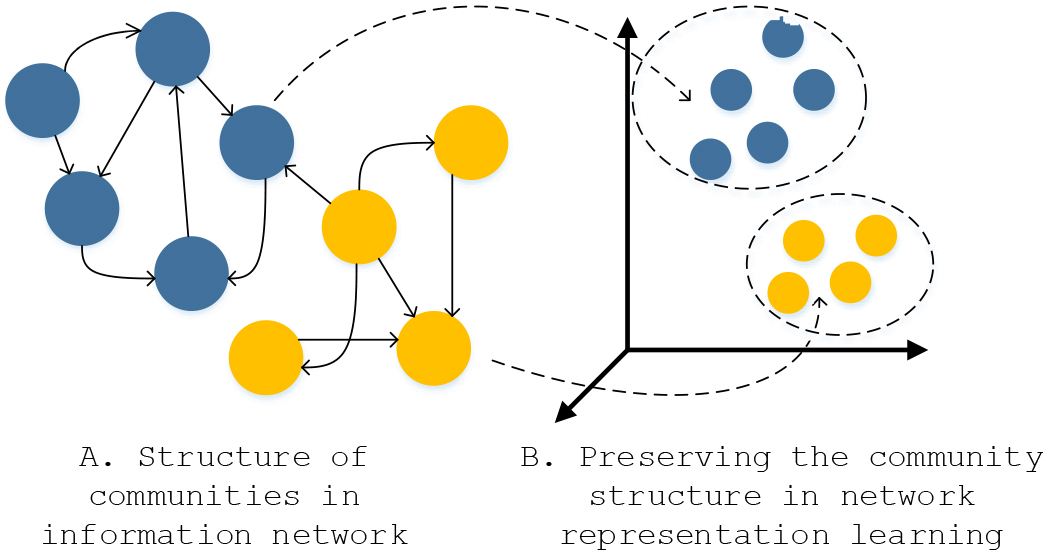
However, the views of INE have been recently changed. Most of node order proximity models are considered as the microscopic network structure preserving (Definition 3) approach and they fail to capture higher level of network’s structure like as communities (illustrated in Fig. 2), clusters and other network’s global properties, called mesoscopic network structure preserving (Definition 4). In fact, community structures are very important in network representations which enable to generate insights for subnetworks analysis, in-community node ranking and similarity measurement. Many researches have demonstrated the effectiveness of combination between nodes order proximity and intra-community evaluations in network representation learning. Two well-known ComE [12] and M-NMF [1] models are designed to be used for capturing both microscopic and mesoscopic network structures. ComE is a model for network and graph analysis which formulate community embedding as tuples of mean vectors. Similar to that, M-NMF combine between node first-order and second-order proximity with community detection to leverage the network’s structure preserving. M-NMF uses matrix factorization to learn the node presentation from both node order proximity and global intra-community properties. However, these models are only applied for homogeneous network only which are unable to capture rich semantics of network’s heterogeneity.
In information network analysis and mining, node and community embedding have been extensively studied recently. In term of network’s node order proximity preserving, almost network embedding techniques such as DeepWalk [9], LINE [10], PTE [16] and Node2Vec [11] obtain the distributions of nodes by capture first and second orders of nodes. Most of recent INE models fall into this approach. DeepWalk is a most well-known model which is inspired from the Skip-grams of Word2Vec model to learn the latent representation of network’s nodes from their contextual nodes. Similar to the idea of Word2Vec, nodes that share similar contextual nodes in random walk sequence will be represented similarly in the corresponding embedding spaces. Beside that LINE model is proposed to enable for learning the representations of node by preserving the first-order (LINE_1) and second-order (LINE_2) proximities instead of using random walks to exploit the network’s structure. Following the DeepWalk’s network learning architecture, Node2Vec proposes a novel flexible contextual node sampling strategies, including BFS (breadth-first-sampling) and DFS (depth-first-sampling). The Node2Vec’s sampling strategies are considered be better in capturing first-order, second-order and high-order node proximities. Naturally, most of real-world networks are composed by communities which their inside nodes are densely linked to each other and sparsely linked to nodes in other communities. Community structure is considered as very important in information network analysis and mining which help to identify groups of nodes which share common attributes. For example, users who share common interests in social networks like as Facebook, Twitter, etc. often form a community. Or in bibliographic networks, like as DBLP, DBIS, etc. authors/researchers who work on similar research topics tend to frequently cooperate to each other. In terms of the target network’s structure to embed, most INE methods focus on nodes and links which try to preserve nodes’ proximities which are reflected by their inter-connected local structure. Recently, there are intra-community representation learning models which are proposed to learn richer informative node representations. The ComE [12] model combines network’s nodes and community embedding by using community detection techniques. In ComE model, the community embedding is defined as a multivariate Gaussian distribution, which help to characterize how network’s nodes are distributed inside each community. However, ComE does not support to represent detected communities as vectors which is considered as indirect approach for optimizing the relationships between network’s nodes and their communities. Node and community embedding must be incorporated to each other to generate more accurate high-order node as well as community-aware proximity representations. To challenge problems related to the relationship between node and intra-community proximity, M-NMF [13] model is proposed to leverage broader network’s structure representation learning. The M-NMF model relies on matrix factorization to learn both microscopic structure (the first-order and second-order proximity) and mesoscopic structure (the intra-community proximity) of given networks. In contrast to recent intra-community network representation learning model, the target to embed multi-typed nodes and links in HIN is not given. Hence, the remained challenge is how to properly generate multi-typed nodes and their communities of HINs into common embedding spaces simultaneously.
Methodology
In this section, we demonstrate the heterogeneous network structural microscopic (node embedding) and mesoscopic (intra-community) embedding approaches of the proposed W-Com2Vec model. For the microscopic approach, we apply the meta-path-based random walk mechanism to obtain the node embedding, denoted as:
Meta-path-based microscopic network (node proximity) embedding
Meta-path-based node proximity embedding by random walk
Consider a given HIN, denoted as:
Where,
Most of real-world HINs contain a large number of text-based nodes like as papers in bibliographic networks (DBLP, DBIS, etc.) or comments, posts, etc. in social network (Facebook, Twitter, etc.) or movies’ descriptions in movie networks (IMDB, TMDB, etc.). These text-based nodes are ubiquitous and rich in semantic which can help to leverage the outputs of network analysis and mining tasks. For example, we can effectively group relevant authors in DBLP network depending on the topic similarities in their published papers such as “Jiawei Han”, “Christos Faloutsos”, “Philip S. Yu”, “Rakesh Agrawal”, etc. in “data mining” topic or “Christopher D. Manning”, “Tomas Mikolov”, “Yoshua Bengio”, “Quoc V. Le”, etc. in “machine learning/natural language processing” areas, etc. Another example to illustrate the importance of text-based nodes in social networks such as Facebook, by evaluating the similarity in the contents of users’ posts or comments, we can identify groups of similar users who are interesting on same subjects/areas and these data are very useful for constructing recommendation system. Therefore, in this part, we present an approach of using the topic distributions of text-based nodes for calculating the topic similarity weights of meta-paths in content-based HINs.
Examples of symmetric text-based nodes in meta-paths of DBLP and IMDB networks.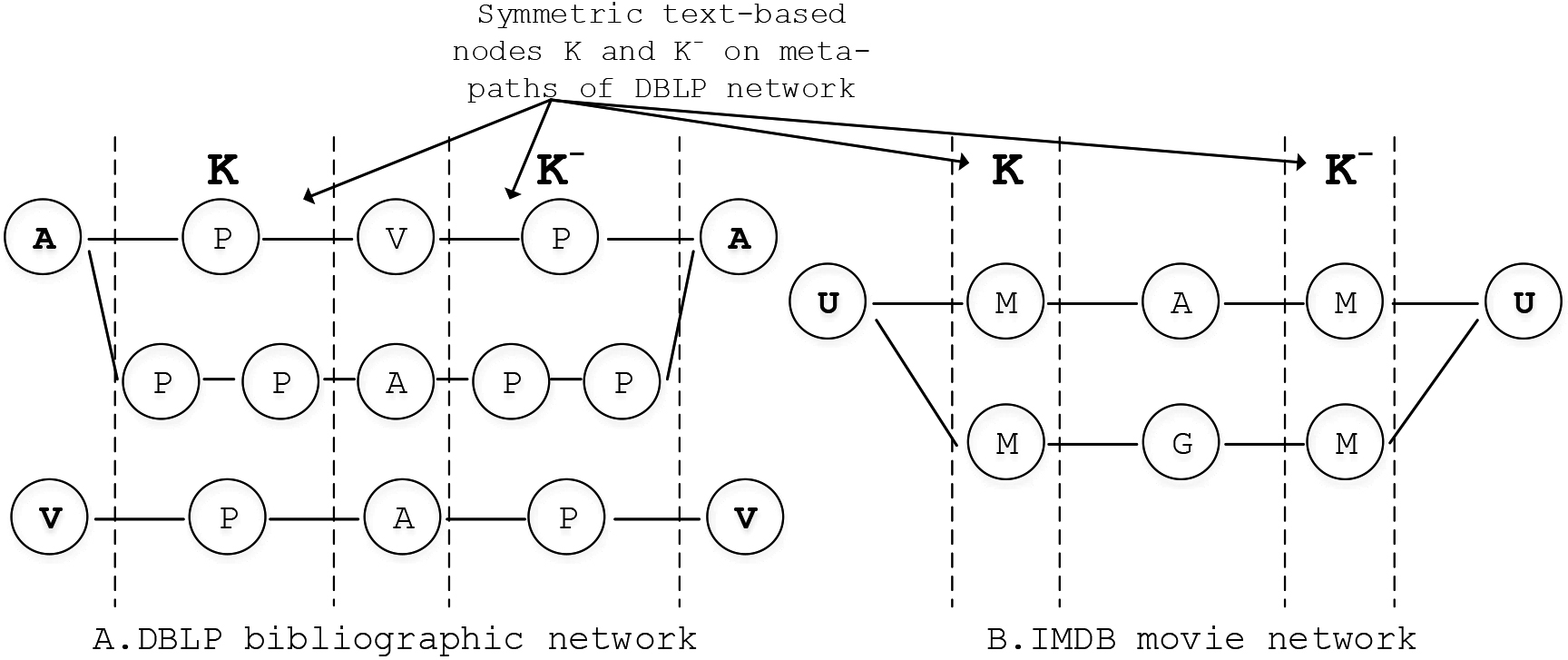
There are several methods for extracting distributions of topics from text-based nodes of HINs. One of the most common ways is applying the unsupervised probabilistic distribution evaluation technique to discover the latent topic distributions of given text corpora. Latent Dirichlet Allocation (LDA) topic modelling (Definition 5) is one of the most popular technique for doing this.
Consider each text-based node is a document denoted as (
Where,
In fact, calculating the topic similarity weight of path instances (see Fig. 4) between nodes can support the process of evaluating the node proximity while learning the microscopic network representations. By adding the topic similarity weight of meta-path to the transitional probabilistic calculation, we can provide a direct incorporation between content-based attributes (text, topics, subjects, etc.) with structure-based attributes (links) of network learning process. Traditional approaches of microscopic node proximity learning only focus on transforming network’s nodes into similar low-dimensional vector spaces if they have been linked via direct (first-order) or indirect (second-order, third-order, etc.) relationships. However, evaluating the similarity between nodes via their number of relations is not enough. For example, several authors working on multiple disciplines might share same sets of venues/conferences (A-P-V-P-A) because top authors usually submit/publish their works at same top venues/conferences. However, the differences in their interesting topics might make specific groups of authors who work on same topics be more similar than other groups, such as “Jiawei Han” and “Christos Faloutsos” must be similar to “Philip S. Yu” than “Yoshua Bengio” because they are all interesting on “data mining” topic. By combining the topic similarity weight of paths with transitional probabilities of path between same-typed nodes in content-based HINs, also called topic-driven meta-path-based random walk mechanism, our proposed W-Com2Vec model is promised to effectively perverse both content-based and structure-based attributes of given HINs.
Illustrations of topic weight similarity measurement 
In this part, we demonstrate the approach of using heterogeneous skip-gram model which are inspired from Metapath2Vec model [7] to learn the microscopic network representation. From topic-driven meta-path-based random mechanism (described in Sections 3.1.1 and 3.1.3), we obtain the set of contextual nodes, denoted as (
Where,
We further inspired the approach of heterogeneous negative sampling of Dong et al. in Metapath2Vec model which use the softmax function to normalize the node
with
Where,
In order to obtain the microscopic embedding of a heterogeneous network with given objective function (Eq. (4)), we apply the stochastic gradient descent (SGD). The SGD is used to approximate optimized model’s parameters by gradually adjusting the
In general, the embedding representation of
At first, we generate the sets of walks for each source node (
Louvain based community detection via meta-path
For modeling the intra-community-based structure of given HINs, we apply the maximum modularity technique to preserve the communities and network’s nodes relations. In this work, we use Louvain algorithm to detect existent communities via specific meta-paths of a given HIN. Louvain algorithm is considered as a network modularity based community detection technique which depending on calculating the changes of network’s modularity, also called “gain of modularity”, denoted as:
Consider a given HIN, denoted as:
Where,
Similar to the approach of Louvain, at the first phase, each node will be assign to each separated community, it means with
Where,
In general, the model loops through all communities of a given network and calculates all gain of modularity
The main idea of intra-community preserving is that these nodes which belong to a specific community will have similar embedding spaces. Inspiring from the approach of modularized non-negative matrix factorization (M-NMF) model, we use the matrix factorization approach to capture the node representations with two non-negative matrices, denoted as:
In this objective function,
For non-negative matrix
For estimating the representation of community embedding matrix
For the node-community membership indicator matrix
with
By using the Stochastic Gradient Descent (SGD) approach, the optimization process repeats the adjustments of
The overall process of intra-community network preverseing is described in Algorithm 2. At first, we apply the meta-path-based random walk embedding to obtain the microscopic network structure represenation,
To demonstrate the effectiveness of our proposed W-Com2Vec model, we conduct thorough experiments on real-world datasets compared to recent state-of-the-art INE models by solving the network’s node clustering and classification tasks.
Experimental settings and dataset usage
Experimental settings
To illustrate the correctness of our studies in this paper, we compare our proposed W-Com2Vec model against the following well-known embedding algorithms for both homogeneous (HoIN) and heterogenous (HIN) networks, which are (as shown in Table 1).
Comapred HoIN-based and HIN-based nework embedding algorithms
Comapred HoIN-based and HIN-based nework embedding algorithms
For all experiments, we use the same initialized model’s parameters for all network embedding algorithms, including embedding dimension (
Example of indexed topics for author “Yizhou Sun” in ACM digital library.
Initalized model’s paramters
In order to evaluate the performance of listed network embedding algorithms (Table 1), we apply these baselines for solving two principal network analysis and mining tasks, which are:
Node clustering task experiment. Node clustering is considered as a primative task in network analysis and mining tasks. For the outputs of node’s reprensetations, we use k-means algorithm to group network’s nodes into defined Node classification task experiment. For node classification task, we use the defined dataset’s labels for determining the class of each network’s node. The outputs of network’s representation learning in each model are divided into two main parts, which are: training and testing. For each test case, we vary the training set from 10% to 90% and the remaining nodes are used for the testing set. Then the training set is used to train the Logistic Regression (LR) classifier to predict the classes of nodes in testing set. The class prediction outputs are then evaluated by Marco-F1 and Micro-F1 metrics. We repeat the node classification task 20 times for each network embedding model and report the average performance.
To evaluate the performance of embedding approaches, in this paper we use different model evaluation metrics, includes:
F-1 measure [18]: is calculated as: Purity [18]: is a traditional metric for evaluate the quality of clustering/classification model. It calculates the percentage of total corrected categorized data points within range [0, 1], denoted as: NMI (Normalized Mutual Information) [18]: is the most common metrics for evaluating the quality of classification/clustering models, denoted as: Cohen’s Kappa Index (
List of used datasets for experimental studies
In this section, we describe about the datasets which are used for conducting experiments with different network embedding baselines. For all tests of node clustering and classification, we use two real-world datasets, which are (as listed in Table 3).
Example of top venues/journals in “Artificial Intelligence” topic by GSM.
Example of a movie’s description which are collected from TMDb.
For DBLP dataset, we apply network embedding models to learn the representations of author and venue nodes. For author nodes representation learning, we use the meta-path: A-P-V-P-A, which indicates the relationships of two authors who frequently submit their works at common venues/journals, as the main meta-path for HIN-based models (HIN2Vec, Metapath2Vec and W-Com2Vec). For venue/journal nodes representation learning, we use the meta-path: V-P-A-P-V. This meta-path indicates the relationships of venues/journals which share common sets of authors (who frequent published their works to these venues/journals). For MovieLens1M dataset, we use the meta-path: U-M-G-M-U which indicates two users who frequently rate for movies which belong to a same genre. For HoIN-based models, such as: DeepWalk, LINE, Node2Vec, ComE and M-NMF, we transform the two given heterogeneous datasets into homogeneous datasets (Hin2HoIN) by create new links between target-typed nodes (authors, venues in DBLP, users in MovieLens1M) following the used meta-path and removing all other node’s types. This make easier for HoIN-based approaches to directly learn target-typed nodes and their corresponding semantic relations which are represented via evaluated meta-paths (A-P-V-P-A and V-P-A-P-V in DBLP, U-M-G-M-U in MovieLens1M).
Node clustering
In this section, we demonstrate the experiments of using different network embedding model for solving node clustering task. The node representation outputs of embedding models are used as the input for k-mean clustering algorithm. The number of cluster (
Accuracy of author node clustering in DBLP dataset in terms of F1, Purity, NMI and Kappa Index (
) (
)
Accuracy of author node clustering in DBLP dataset in terms of F1, Purity, NMI and Kappa Index (
Accuracy of venue/journal node clustering in DBLP dataset in terms of F1, Purity, NMI and Kappa Index (
Accuracy of user node clustering in MovieLens1M dataset in terms of F1, Purity, NMI and Kappa Index (
Performance of author node clustering in terms of NMI evaluation metric (DBLP).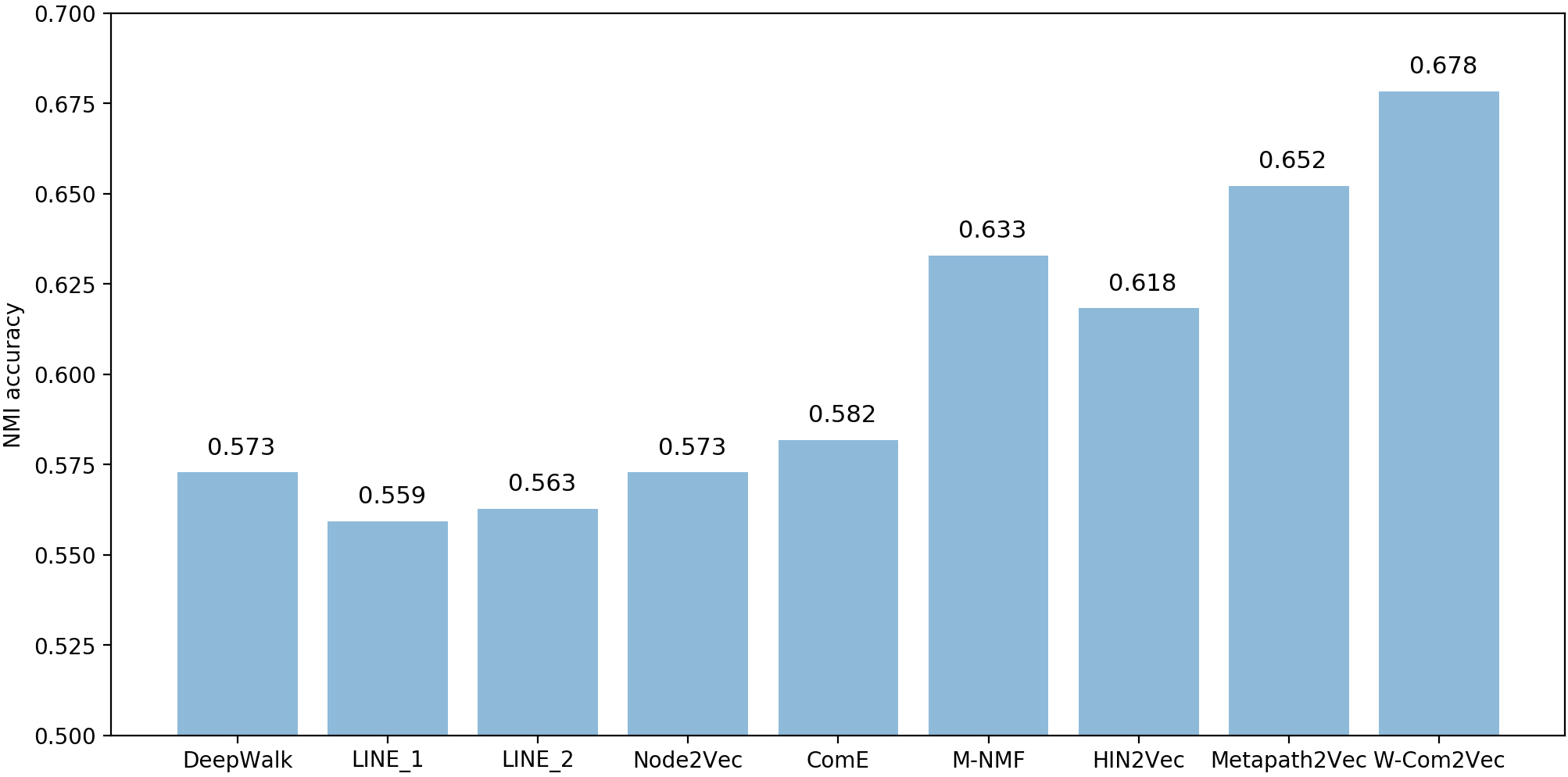
Performance of venue node clustering in terms of NMI evaluation metric (DBLP).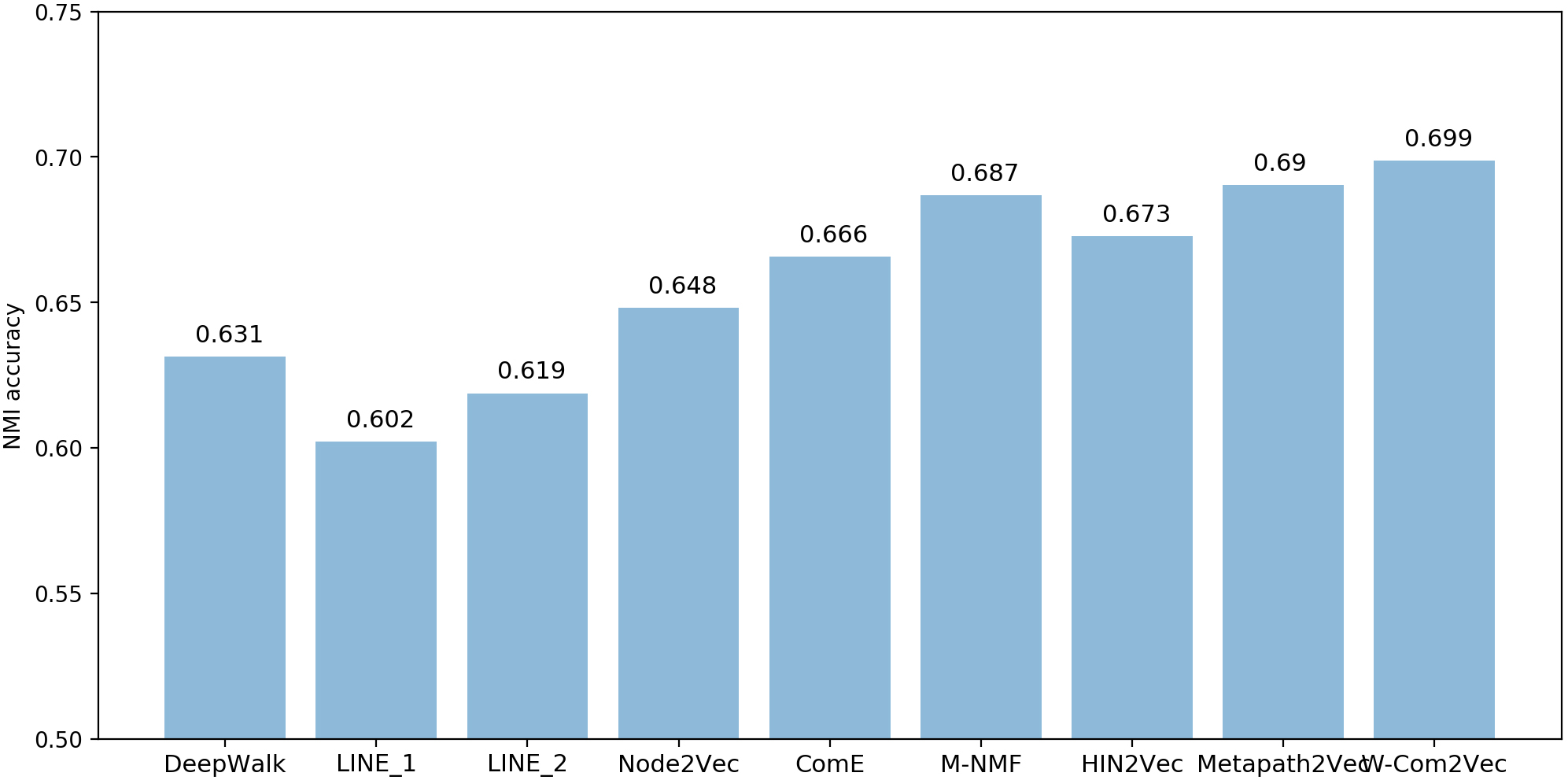
Performance of user node clustering in terms of NMI evaluation metric (MovieLens).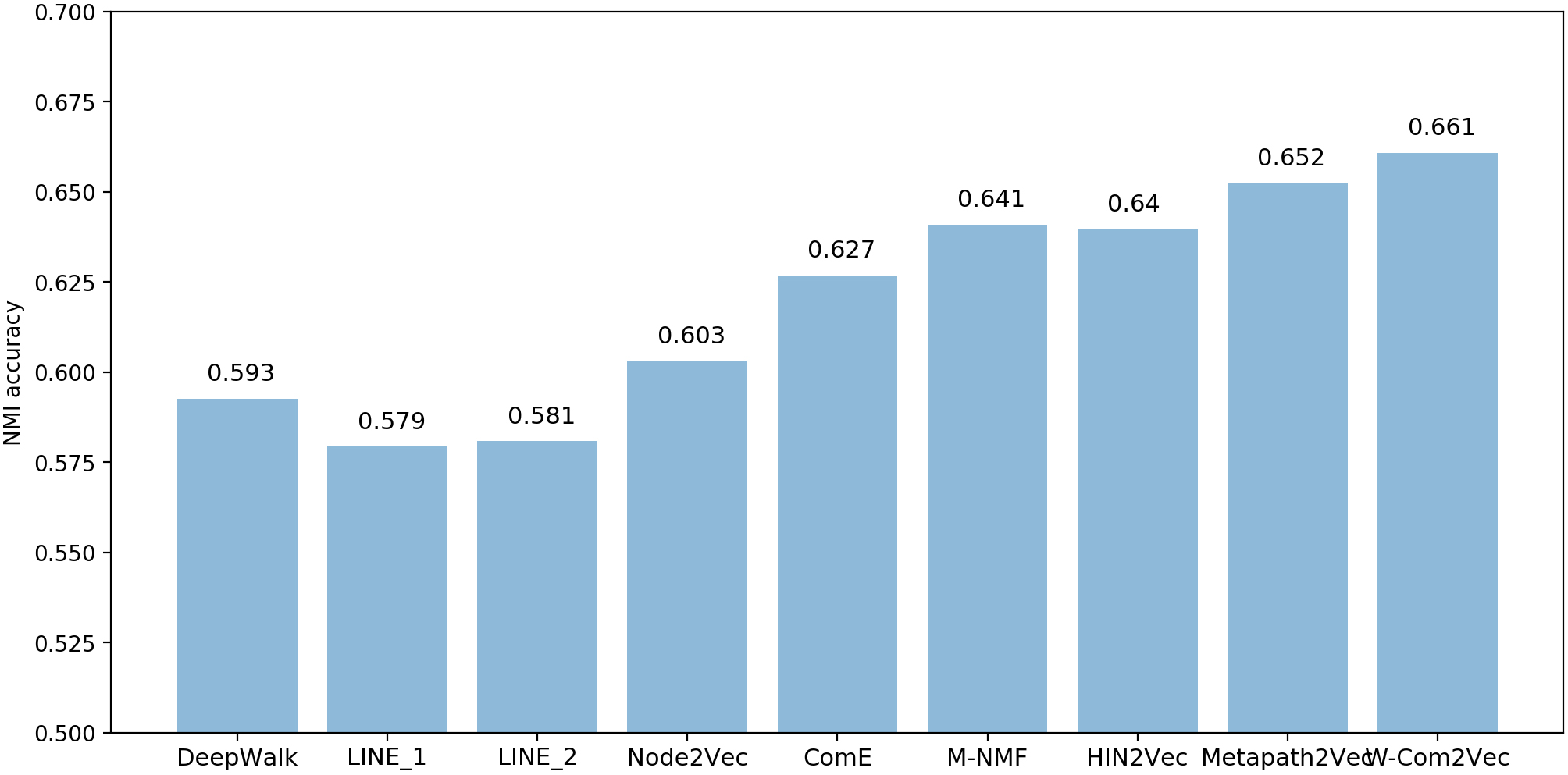
Cohen’s Kappa index vs. NMI metric for node clustering task of W-Com2Vec model in DBLP and Movielens datasets.
For DBLP bibliographic network, Tables 4 and 5 respectively report the experimental outputs in terms of F1, Purity and NMI for author and venue/journal nodes clustering tasks. In overall, our proposed W-Com2Vec model outperforms all state-off-the-art network embedding approaches. In comparing with HoIN-based approaches, W-Com2Vec model improve the performance of node clustering task about 14.35% (DeepWalk), 17.55% (average for LINE_1 & LINE_2), 12.76% (Node2Vec), 10.36% (ComE) and 4.34% (M-NMF) (Figs 8 and 9). For HIN-based approaches, such as: HIN2Vec and Metapath2Vec, W-Com2Vec also gain better performance approximately 6.67% and 2.57% in comparing with HIN2Vec and Metapath2Vec, respectively. The experimental outputs also demonstrate the author nodes clustering is more challenging than venue/journal nodes clustering task due to the larger number of nodes and clusters. With MovieLens1M dataset (see Table 6), the experimental results also indicate our proposed W-Com2Vec model produces better quality of node representations than recent network embedding baselines. The W-Com2Vec model achieves averagely 9.59% and 2.31% improvements in comparing with HoIN-based models (DeepWalk, LINE_1 & LINE_2, Node2Vec, ComE and M-NMF) and HIN-based models (HIN2Vec and Metapath2Vec), respectively (Fig. 10). To further observe the behaviors and performance of W-Com2Vec model in node clustering task, we calculated the Cohen’s Kappa index (
In this section, we demonstrate experimental studies on using multiple network embedding baselines for solving network’s node classification task. For DBLP network, we use the set of 300K author nodes which are assigned to 8 topics/classes by ACM digital library and the set of 280 venues which are assigned to 5 classes by GSM. For MovieLens1M network, we use the set of 6K users which are assigned to 15 movie’s genres/classes. At first, each embedding model is applied to learn representations of all network’s nodes. Next, we vary the size of the node embedding outputs from 10% to 90% which are used as the training set and the remaining part are used as the testing set. The training set is used to feed the Logistic Regression (LR) classifier and then is used to predict the class of nodes in testing set. For each embedding approach, we repeat the node classification experiments 20 times and report the average value as the final result. In this experiment, we use Macro-F1 and Micro-F1 metrics for evaluating the node classification outputs.
Author and venue/journal node classification tasks in DBLP with different sizes of training set (%) in terms of Macro-F1& Micro-F1 evaluation metrics.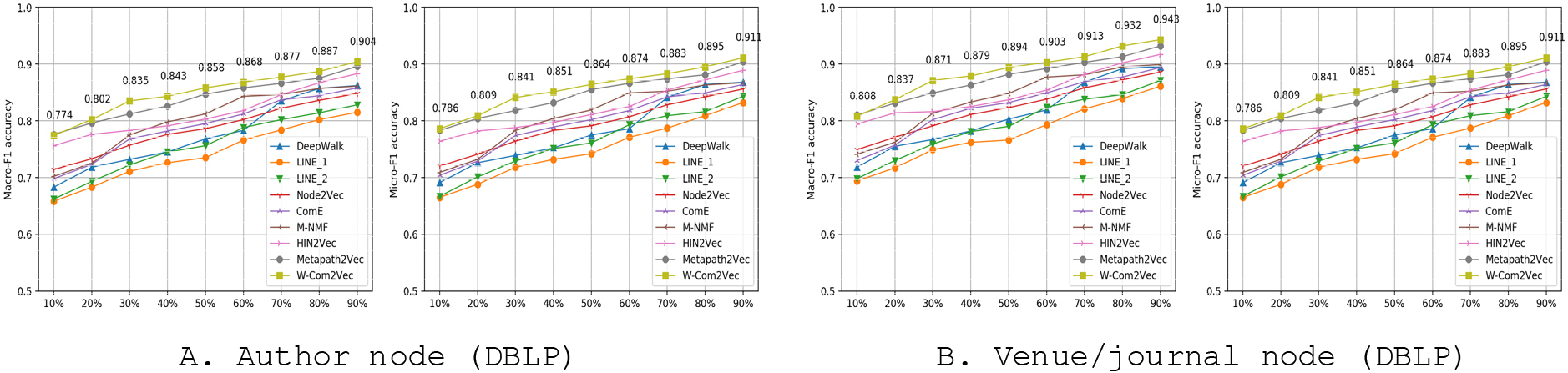
Accuracy for author nodes classification in DBLP dataset in terms of Macro-F1 and Micro-F1
Accuracy for venue/journal nodes classification in DBLP dataset in terms of Macro-F1 and Micro-F1
Accuracy for user nodes classification in MovieLen1M dataset in terms of Macro-F1 and Micro-F1
User node classification task in MovieLens1M with different sizes of training set (%) in terms of Macro-F1& Micro-F1 evaluation metrics.
AUC/ROC for node classification tasks in different datasets.
For DBLP dataset, Tables 7 and 8 list the experimental outputs for author and venue/journal nodes classification in terms of Macro-F1 and Micro-F1. The experimental results demonstrate that our proposed W-Com2Vec model outperforms all recent embedding baselines. For author node classification task (Fig. 12A), W-Com2Vec significantly achieves better performance than HoIN-based approaches about 9.54% (DeepWalk), 13.36% (LINE_1 & LINE_2), 8.13% (Node2Vec), 7.52% (ComE) and 5.96% (M-NMF). With HIN-based approaches, W-Com2Vec model also slightly increases the performance of node classification task approximately 4.45% and 1.27% in comparing with HIN2Vec and Metapath2Vec models, respectively. In venue/journal node classification task (Fig. 12B), W-Com2Vec clearly outperforms averagely 10.05% in comparing with overall HoIN-based methods (DeepWalk, LINE_1 & LINE_2, Node2Vec, ComE and M-NMF) and 2.9% in comparing with two HIN-based methods (HIN2Vec and Metapath2Vec). For MovieLens1M dataset (as shown in Table 9), W-Com2Vec model also consistently shows better performance than both HoIN-based (9.69%) and HIN-based (3.1%) approaches (Fig. 13). In overall, the experiments on node clustering and classification show the superiority of our proposed W-Com2Vec model in heterogeneous network’s node representation learning. To evaluate the capability of distinguishing classes between nodes, we used the AUC/ROC metric to demonstrate the performance of node embedding quality by using our proposed W-Com2Vec model in node classification task with LR classifier (see Fig. 14). As shown in the second chart (Fig. 14), the venue (DBLP) node classification gain the highest AUC/ROC scores than author (DBLP) and user (MovieLens) nodes due to the small amount of nodes (about 280) and number of classes (only 5).
In this part, we conduct extensive experiments for studying the influences of W-Com2Vec model’s parameters on the quality of network representation output. We use the accuracy outputs of author and venue node clustering tasks which are evaluated by F1 metric, in DBLP network. The ultimate purpose of this experimental study is to show the effects of three parameters on overall model’s performance, include: embedding dimension (
Experiments on parameters sensitivity of W-Com2Vec model.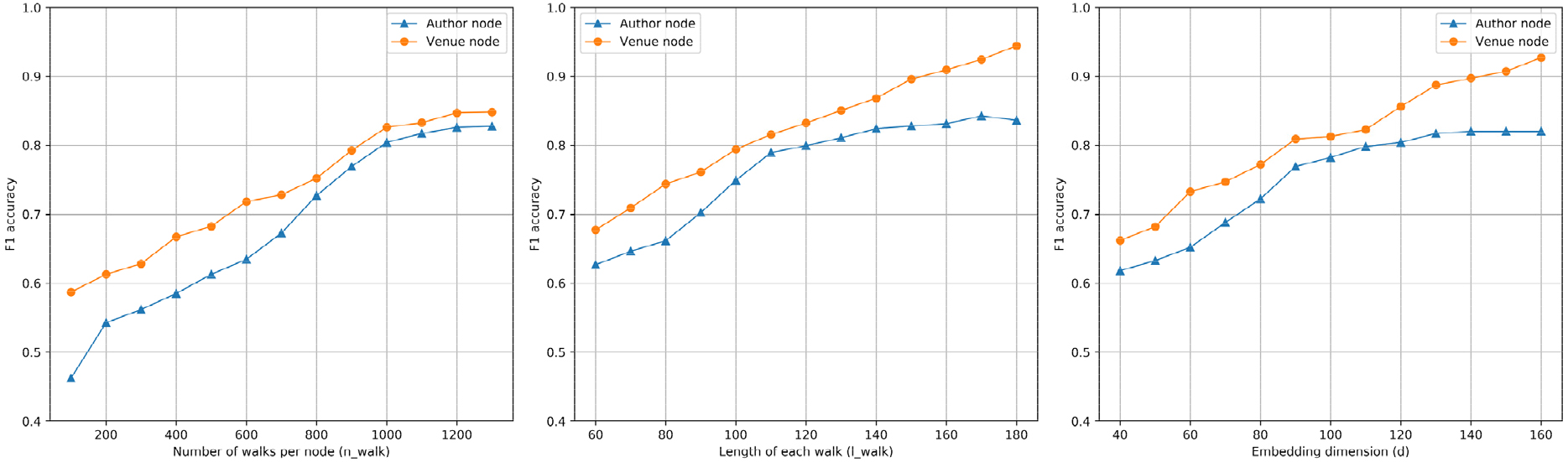
In this paper, we formally present a novel approach of network embedding, namely W-Com2Vec which enables to preserve both microscopic (node proximity via topic driven meta-path-based random walk) and mesoscopic (intra-community) structures of HINs. At first, we propose a topic-driven meta-path-based random walk for capturing sematic context of each given nodes via meta-path. The semantic contextual nodes are then used to learn the heterogeneous node representations. This representation is known as microscopic structure preserving. Next, we introduce a novel approach of meta-path-based Louvain community detection for discovering community in HINs which are used to combine with previous node (microscopic) representations to exploit the consensus relationship between network’s nodes and detected communities (mesoscopic). The matrix factorization technique is applied to jointly optimize both two representations in order to reproduce a final network’s node representations where each community has similar embedding vectors with their node members. Extensive experimental studies on two real-world networked datasets demonstrate the effectiveness of our proposed W-Com2Vec model in comparing with recent state-of-the-art INE baselines. For future improvements, we intend to implement our W-Com2Vec model under the distributed processing environment of Apache Spark in order to enable the capability of handling large-scaled networks for our proposed model.