
Abstract
Traditional community detection models either ignore the feature space information and require a large amount of domain knowledge to define the meta-paths manually, or fail to distinguish the importance of different meta-paths. To overcome these limitations, we propose a novel heterogeneous graph community detection method (called KGNN_HCD, heterogeneous graph Community Detection method based on
Introduction
Background
Community detection is a fundamental and important research area in network science, which aims to divide the tightly connected nodes in the network into communities, making the nodes within a community tight and the connections between communities relatively sparse [1, 2, 3]. In social networks, platform sponsors promote products and place topic recommendations [4, 5], and in this scenario, community detection reveals the complexity of metabolism and proteins with similar biological functions. Community detection in citation networks [6, 7] determines the importance and interconnectedness of research topics, evolution and identification of research trends.
Many excellent works have emerged for community detection tasks, and these research models can be divided into three main categories. Traditional community detection methods [8, 9, 10, 11] highly depend on the topological information of the network to detect communities, relevant examples of traditional methods are graph partitioning, and hierarchical clustering approaches. Graph embedding based approaches [12, 13, 14, 15] learn node representations which are subsequently exploited to carry out the community detection task. In recent years, graph neural networks have been widely used for various tasks on graphs, and important efforts have been made on community detection research topics [16, 17, 18], these approaches propagate node features from a node to its neighbors and aggregate these messages through. The node representations learned by graph neural networks have been shown to achieve state-of-the-art performance for community detection on most datasets.
However, most of the existing community detection tasks (e.g., [16]) focus on homogeneous graphs with the same node type and edge type. Since real-world networks tend to have multiple node and edge types, such solutions are obviously less effective on these networks. This kind of graph with multiple nodes and edges commonly exists in the real world is called heterogeneous graph. Heterogeneous graphs contain more comprehensive information and rich semantics, so it has been widely used in many data mining tasks, such as social networks, knowledge graphs, and citation networks. For example, in a citation co-authorship network with three node types including author, paper and conference, while edge types have both published (being published) and authored (being authored) relations. Existing community detection approaches on heterogeneous graphs are mainly divided into two types, one is to detect clusters which have multiple types of node objects inside as much as possible, and the other is to generate nodes to form clusters according to specific target types. In this paper, we focus on the second approach, which learns node embedding by graph neural network and cluster nodes to achieve a high degree of similarity and strong correlation among nodes in the same community.
Motivation
It is more challenging to detect communities on heterogeneous graphs, and the traditional graph neural network models cannot be directly applied to heterogeneous graphs due to their high heterogeneity. There exists a kind of composite relationship which has rich semantic information in heterogeneous graph which is called meta-path. In fact, because of the rich multi-hop semantic information in meta-paths, some nodes without direct edge connections are highly likely to form a community, so when performing community detection on heterogeneous graphs, it is important to fully consider the similarity in the feature space of nodes and their higher-order relationships, which cannot be limited to the existing topological edge connections only. To effectively capture higher-order information between nodes, many innovative studies have been proposed for community detection. However most of them rely on manually defined meta-paths [19], and they need to change meta-paths manually according to different datasets. These efforts are highly dependent on the quality of the meta-paths, and different meta-paths chosen by experts can cause quite markedly different results for the model. Moreover, the semantic information embedded in each meta-path is different, which means that for each meta-path it is desirable to distinguish their level of importance to better fit the research task and learn a more efficient and high-quality node representation.
To address these limitations, this paper proposes a
Main contributions
The main contributions of this paper are:
We construct the K-nearest neighbor graph topology by taking account of the feature information of the node space. We carry out information fusion to fully enhance the similarity of nodes and improve the probability of nodes that are divided into the same community based on the unconnected nodes in the meta-path. We propose a heterogeneous graph neural network community detection method called KGNN_HCD, which can learn meta-paths end-to-end, capture higher-order relationships, distinguish the importance between different meta-paths and can learn high-quality node representations. This paper also provides interpretability analysis of the Mp-Trans Layer. Numerous comparison experiments are conducted on three real heterogeneous datasets, ACM, DBLP and IMDB, and against many community detection models, such as CP-GNN and GTN. The experimental results show that the proposed KGNN_HCD method has significant improvement over existing state-of-the-art heterogeneous community detection methods, such as CP-GNN and GTN in terms of F1, NMI, ARI and Purity metrics.
Related work
Traditional community detection methods
Traditional community detection methods highly relied on the network structure to explore communities, which has attracted a great deal of research attention [20, 21, 22]. The Infomap [21] algorithm simultaneously encoded the communities in the network and the nodes in the communities to generate unique encoded representations of the nodes. After that, a random walk is performed on the network to obtain a set of total encoding lengths, and when the encoding length reached the shortest, the tightly connected nodes are divided into the same community so that the optimal solution is obtained. LPA [22] used the label information of marked nodes to predict the label information of unmarked nodes and then identify the communities. However, the methods mentioned above work on homogenous graphs. Other works [23, 24, 25] are designed for heterogeneous graphs. Het-SE and Het-RSE [23] applied
Network embedding based community detection methods
Community detection based on network embedding is a network representation learning method that represents a high-dimensional, sparse vector space associated with nodes with a low-dimensional, dense vector space and enhances the representation of node embeddings based on community characteristics. Many researchers are committed to solving the problem of community detection with the help of network embedding. Deepwalk method [12] obtains the co-occurrence relationship between nodes in the graph by simulating uniform random walks in the network, and then learns the vector representation of nodes. The sampling strategy in Deepwalk can be regarded as a special case of node2vec with
Graph neural network-based community detection methods
Graph neural network-based community detection methods are deep learning methods on graph domain, they can capture the independence of graphs, solve the disorder of input graphs, and learn the state embedding of each node’s neighbors, so scholars have researched many novel graph neural network-based methods. As one of the widely used deep learning techniques, graph neural networks rely on their own advantages to learn graph structured data, extract and explore features and patterns in graph structured data and have shown great ability to occupy a place in the field of community detection. LGNN [16] exploits the adjacency information of edges in the graph with powerful feature representation capabilities for homogeneous community detection. HAN [16] was one of the earliest works on heterogeneous graphs, which required predefined meta-paths applicable to the datasets. The hierarchical attention mechanism is used to capture node-level importance and semantic-level importance, and GAT is applied to assign attention scores to neighbors based on different meta-paths to get the final representation. MAGNN [18] improved HAN, which only considers the nodes at both ends based on the meta paths by using several Meta-path Encoders to encode all the information along the meta-paths. CP-GNN [6] proposed the context path based on the meta-path, which indicates that two primary nodes have a semantic relationship if they are connected by the context path. CP-GNN maximized the co-occurrence probability of context neighbors to learn the node embeddings, capturing higher-order relationships, and do not need to define the meta-path in advance. Gsim [44] proposed a new correlation measurement method based on GNN for heterogeneous graphs, which extends CP-GNN to measure correlation in heterogeneous graphs. It theoretically proves that GNN can effectively measure correlation and capture the semantics of correlation measurement. GTN [30] is a method for heterogeneous graphs that does not require manual definition of meta-paths. GTN can be regarded as a graphical simulation of spatial transformation networks that explicitly learns the spatial transformation of the input network or features to obtain an effective node representation, reducing high heterogeneity and enhancing community detection results.
Preliminaries
To facilitate the subsequent elaboration, some terms and network model definitions related to this research work are given here. The interpretation of the heterogeneous diagram is shown in Fig. 1, and in addition, Table 1 summarizes the notations commonly used for quick reference.
Notations
Notations
An illustration of heterogeneous graph (DBLP). (a) Three types of nodes (i.e., author, paper, conference). (b) Example of a heterogeneous graph on the DBLP dataset. (c) Three meta-paths used in DBLP (i.e. author-paper-author (APA), (author-paper-author-paper-author (APAPA), author-paper-conference-paper-author (APCPA)).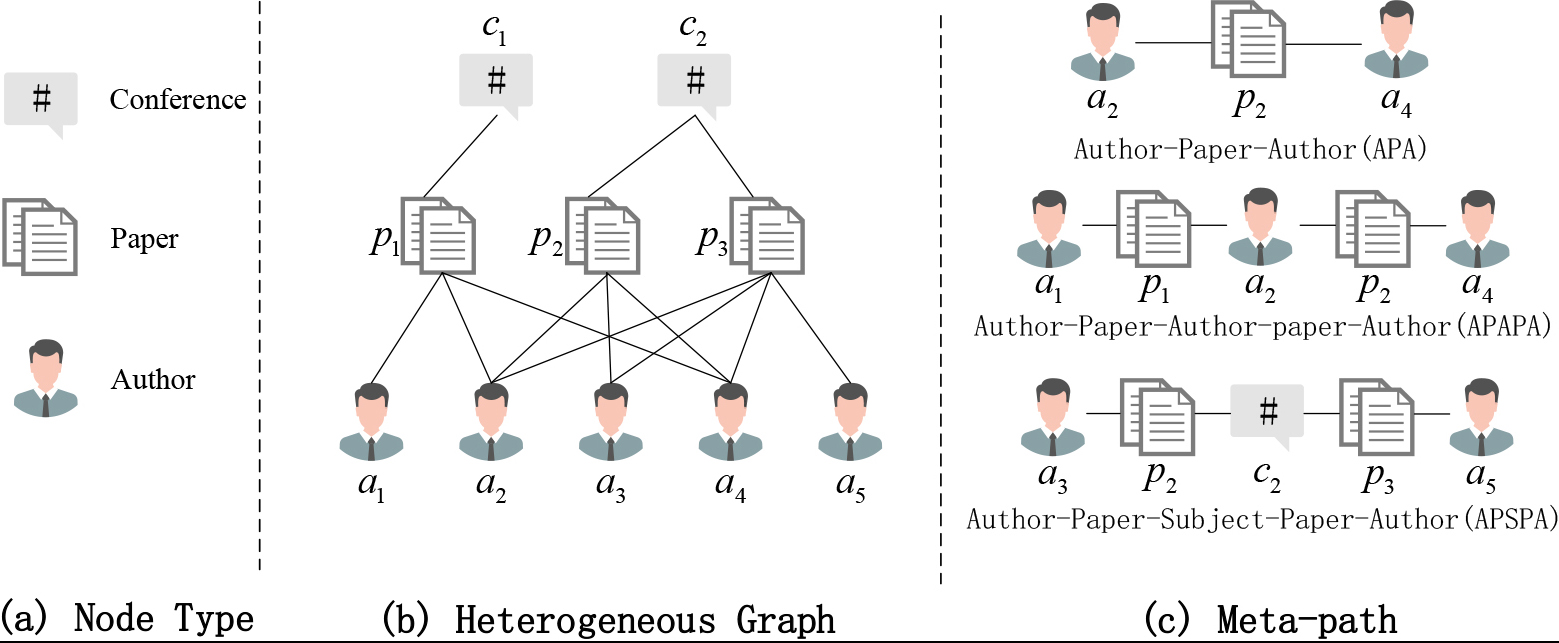
Without causing ambiguity if a composite relationship
where
The proposed method aims to mine the structural information in the feature space and generate high-quality node embeddings. The feature nodes are used to generate
The framework diagram of KGNN_HCD.
In Fig. 2, the input layer of KGNN_HCD consists of a heterogeneous adjacency matrix and a
Through the above steps, the KGNN-HCD model can extract structural information from the feature space and generate high-quality node embedding representations. This model utilizes a heterogeneous adjacency matrix to construct a meta path transformation matrix to capture the relationships between nodes, while performing graph convolution operations in GCN to learn more robust node representations. Finally, clustering algorithms are applied for node representation learning to detect community structures in heterogeneous graphs.
A good fusion capability of community detection should substantially extract and fuse the most correlated information; however, one biggest obstacle is that community detection methods that take a holistic approach find it difficult to take account of the specific connections and differences between individuals in the feature space, making it hard to discover the inherent connections between data objects. Therefore, in terms of technology, to obtain the structural information in the feature space, a
The construction process of K-nearest neighbor graph based on feature vectors.
In Fig. 3, the node similarity is calculated based on the feature vectors of the nodes, and the top-
Cosine Similarity: It measures the similarity by the cosine of the angle between two vectors, which takes values in the range
Heat Kernel: Its similarity is calculated as shown in Eq. (4), where
Dot Product: It is mainly applied to discrete data, such as bag-of-words, where the calculated similarity is only related to the number of identical words, as shown in Eq. (5).
The cosine similarity is uniformly chosen as the similarity measure to obtain the similarity matrix. After that, the top-
After the above operation, considering an individual approach, understanding the inherent relationships between data objects, maintaining the validity of associations during the clustering process, and further obtaining the underlying structural information in the feature space.
It also adds its most similar
The rich semantics of meta-paths is an important feature of heterogeneous information networks. Based on different meta-paths, objects have different connection relationships and different path definitions, which may affect many specific tasks. Previous meta-path-based works are highly dependent on pre-defined meta-paths, and relying on different meta-paths defined manually by domain experts directly affects the performance of the model. The difference is that KGNN_HCD can define meta-paths end-to-end and can generate meta-paths of arbitrary length depending on the characteristics of the dataset and the needs of the task.
The
where
Next, an explanation of how KGNN_HCD learns meta-paths of arbitrary length is performed. Given a meta-path
where
Since these transition adjacency matrices contain the original node-edge relationship information, the characteristics of the original edge themselves are ignored when performing the fusion of meta-path information, so it is necessary to add the identity matrix
The main goal of this module is to perform community detection on the learned node representations. To enable the final node representation to contain rich meta-path semantic information, the variance of the data is high due to the scale-free nature of the heterogeneous graph. To address the above challenges, KGNN_HCD extends the information fusion at the meta-path level to multi-head channels and increases the number of output channels
After
where
After obtaining the node representations, the
Three real-world heterogeneous graph datasets are selected for the experiments, namely the heterogeneous citation networks ACM [16] and DBLP [37], and a movie dataset IMDB [18, 38], specifically, their detailed information including the number of nodes, number of edges, edge types, meta-paths, etc. are summarized in Table 2.
Datasets
Statistics of the datasets
Statistics of the datasets
ACM: The Association for Computing Machinery (ACM) dataset is a bibliographic information network that extracts papers published on KDD, SIGMOD, SIGCOMM, MobiCOMM and VLDB. The whole dataset includes 3 node types, which are 3025 Paper (P), 5835 Author (A) and 56 Subject (S), where the nodes with node type P have the three labels, i.e., Database, Wireless Communication and Data Mining, which means that nodes with node type P can be classified into three categories. The ACM dataset also contains four edge types, which are 9936 P-A and A-P, 3025 P-S and S-P respectively. Obviously, the dataset has four heterogeneous adjacency matrices corresponding to the node-edge relationships DBLP: The DataBase systems and Logic Programming (DBLP) dataset is a network that reflects the relationship between authors and papers. There are three types of nodes: 14328 Papers (P), 4057 Authors (A) and 20 Conferences (C). Authors are grouped into 4 fields: Database, Data Mining, Machine Learning, Information Retrieval. Each author is labelled with their research field according to the conference they submitted to. The DBLP dataset contains 4 edge types, which are 19645 P-A and A-P, 14,328 P-C and C-P. The corresponding heterogeneous adjacency matrices are IMDB: The Internet Movie DataBase (IMDB) is a website about movies and their related information, recording users’ preferences for different movies. This dataset contains 3 node types, which are 2939 Movie (M), 5841 Actor (A) and 2269 Director (D), where the nodes with node type Movie have three properties, i.e., Action, Comedy and Drama. There are four edge types, i.e., 4661 M-A and A-M and 13983 M-D and D-M, corresponding to heterogeneous adjacency matrices of
The proposed KGNN_HCD method is compared here with the state-of-the-art heterogeneous community detection methods such as CP-GNN and GTN. To fully verify the fairness as well as the validity of the experiments, traditional network embedding algorithms are first considered; these algorithms are originally designed to study homogeneous graphs. So, during the experiments, the heterogeneity of the nodes is totally ignored and the homogeneous operation is performed over the whole heterogeneous graph. Also, for a fair comparison, graph neural network-based approaches have been introduced, most of them designed for heterogeneous network embedding, and they all use meta-paths to capture features of heterogeneous information networks.
Traditional network embedding methods
Infomap [21, 39] is an algorithm based on information encoding theory that encodes paths generated by random walk and uses the encoding length as an objective function for optimal community partitioning. Here, this proposed method views the heterogeneous graph as a homogeneous graph, converting the community detection problem into an information compression problem. Node2vec [13] is a network embedding method that integrates DFS neighborhoods and BFS neighborhoods and can be seen as an extension of Deepwalk. Node2vec is a second-order random walk, which can not only travel far to depict the macroscopic characteristics of the network, but also random walk locally to retain the community information of nodes. Metapath2vec [28] (Mp2vec) is the most advanced heterogeneous information network embedding method. It uses random walks based on meta-path to construct heterogeneous neighborhoods of each node, and then uses Skip-Gram model to complete node embedding. Based on metapath2vec, the author also proposes metapath2vec HIN2vec [29] learns the richness of information in heterogeneous information networks by studying different types of relationships between nodes and network structure. It samples random walks based on meta-paths of a given size and feeds them into a neural network model to learn more meaningful node representations based on the fact that different meta-paths have different semantic information, encoding the rich information embedded in the meta-paths and in the overall network structure.
Graph neural network-based methods
GCN [36] is the state-of-the-art graph convolution method for homogeneous graphs. GCN is a semi-supervised graph convolutional network model that performs convolutional operations in the graph Fourier domain and captures global complex features by aggregating information from neighbors for learning node representations. The GCN is tested here on a homogeneous graph based on meta-paths and the best results from the meta-paths are reported. GCNKG [34] is a special GCN. In order to make a better comparison and to explore the advantages of GAT [40] is a semi-supervised homogeneous graph neural network model. The model performs convolutional operations in the graph space domain and introduces an attention mechanism. For each node, it aggregates neighbor representations by means of importance scores learned by node-level attention. Similarly, all meta-paths under the GAT model were tested and the best performance is reported. HAN [16] is one of the earliest attempts to address heterogeneous graphs by converting a heterogeneous information network into multiple homogeneous graphs with given symmetric meta-paths and using a hierarchical attention mechanism to capture node-level importance and semantic-level importance and gives the final representation by implementing node-level attention on its corresponding meta-path neighborhood graph via GAT. CP-GNN [6] utilizes the context path to capture higher-order relationships between nodes and builds a heterogeneous graph neural network model based on the context path. It recursively embeds higher-order relationships between nodes into node embeddings through an attention mechanism to distinguish the importance of different relationships. The embeddings of nodes are better learned by maximizing the expectation of co-occurrence of nodes connected by the context path. GTN [30] is a method suitable for heterogeneous graphs that automatically finds valuable meta-path, rather than relying on manual selection as HAN does. GTN considers all possible cases by calculating all possible meta-path-based graphs, on which performs graph convolutions.
Implementation details
For the proposed KGNN_HCD method, parameters are randomly initialized and Adam [41] is used to optimize the model firstly, after which the hyperparameters are chosen separately: the learning rate is set to 0.005 and the regularization parameter is set to 0.001, making each baseline yield its best performance. For the random walk-based models, the window size is set to 5, the step size is set to 100, the step size of each node is set to 40 and the negative sample number is set to 7. For semi-supervised graph neural networks including GCN, GAT and HAN, the same training set, validation set and test set are split to ensure fairness. For the KGNN_HCD method, the number of the Mp-Trans Layer of DBLP and IMDB datasets is set to 3, and the number of Mp-Trans Layer of ACM dataset is set to 2. In addition, for
Performance comparison
The proposed KGNN_HCD method first learns node embeddings and then uses the
Performance comparison of different community detection methods
Performance comparison of different community detection methods
From Table 3, it is clear that the F1 metric of the proposed KGNN_HCD method outperforms the GTN method by 2.68% on the ACM dataset, 1.35% on the DBLP dataset, and 1.89% on the IMDB dataset, and on both NMI and ARI, the proposed KGNN_HCD method improves by 2.54% and 2.56% on the ACM dataset, 2.59% and 1.47% on the DBLP dataset, and 1.22% and 1.67% on the IMDB dataset. The above results show that by fusing K-nearest neighbor graph information and transforming meta-path information, the structural information of the feature space can be captured and more meaningful meta-paths can be acquired adaptively so that the learned node representations are better adapted to community detection.
All network embedding-based methods outperform the traditional Infomap algorithm, showing their great potential for community detection tasks. For the network embedding-based methods, the overall performance of HIN2vec is better than Node2vec and Metapath2vec, but the superiority of HIN2vec is only outstanding on the ACM dataset, and the results are not satisfactory on the two datasets of DBLP and IMDB. This outcome depends on the fact that HIN2vec can automatically detect meta-paths which may not be suitable for community detection through random walks.
GCN, GCNKG and LGNN have the worst results in GNN-based baselines. The possible reason is that they were originally proposed for homogeneous graphs and did not consider the complex contextual information in heterogeneous graphs. GCNKG outperforms GCN in all results, which further demonstrates the need to introduce
The sensitivity comparative analysis experiments of parameters will be conducted on three different data sets such as ACM.
The dimensions of the final embedding
Four metrics of three datasets in different dimensions.
On all three datasets in Fig. 4, the performance increases first and then starts slowly decreasing as the embedding dimension grows. The reason may be that KGNN_HCD needs a suitable dimension to encode the meta-path information, and a smaller dimension may not lead to learn sufficient meaningful information, while a larger dimension may introduce additional redundancy. Therefore, according to several experiments, we found that 64 is the most appropriate embedding dimension.
Analysis of
Analysis of 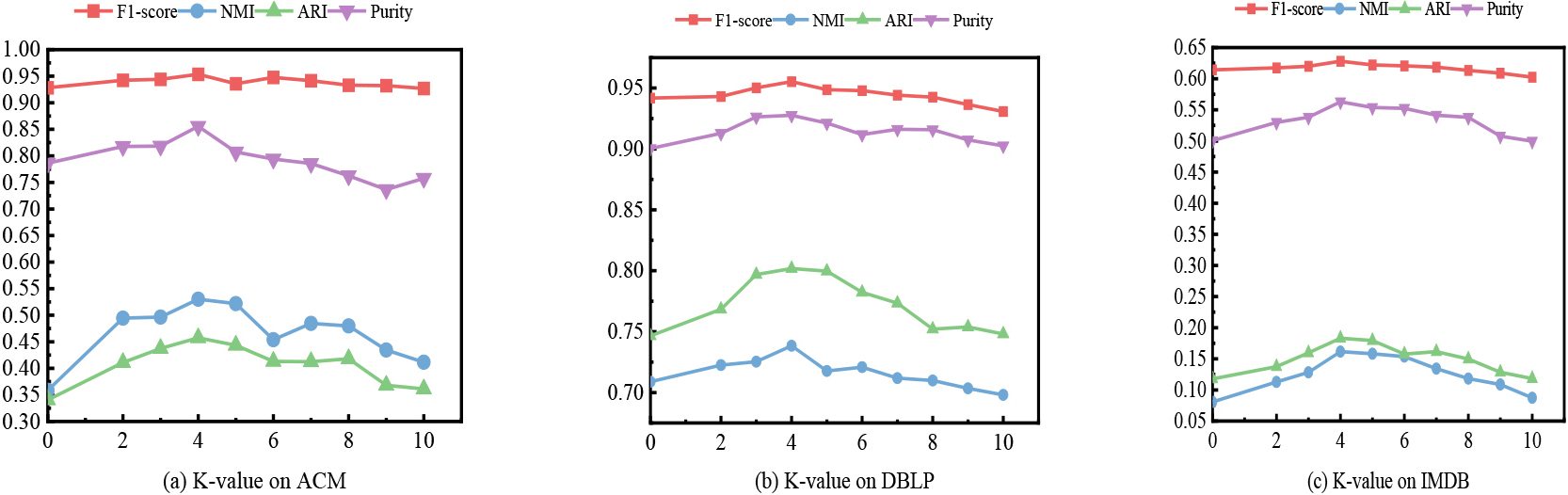
It can be intuitively found from Fig. 5 that for the three datasets of ACM, DBLP and IMDB, the accuracy of KGNN_HCD basically increases first and then decreases. This may be because the smaller the value of
The number of Mp-Trans Layers. To explore the effect of the Mp-Trans Layer on KGNN_HCD, the number of layers is set to 2, 3, 4, and 5 respectively, and the NMI and ARI metrics of the model are observed on the three data sets, as shown in Fig. 6.
Taking the DBLP dataset as an example, it is easy to see from Fig. 6 that the performance of KGNN_HCD continuously decreases when the number of layers increases. This is due to the fact that the role of the Mp-Trans Layer is to aggregate meta-paths, for the DBLP dataset, the longest effective length of the meta-path is 5, which is the APCPA. When the number of Mp-Trans Layers increases, meta-paths without semantic information will also be used by KGNN_HCD, causing additional redundancy and thus affecting performance. Therefore, according to several experiments, the overall performance of KGNN_HCD method is best when the number of Mp-Trans Layer is set to 2 for ACM dataset and 3 for DBLP and IMDB datasets.
NMI and ARI with different numbers of MP-Trans Layers on three datasets.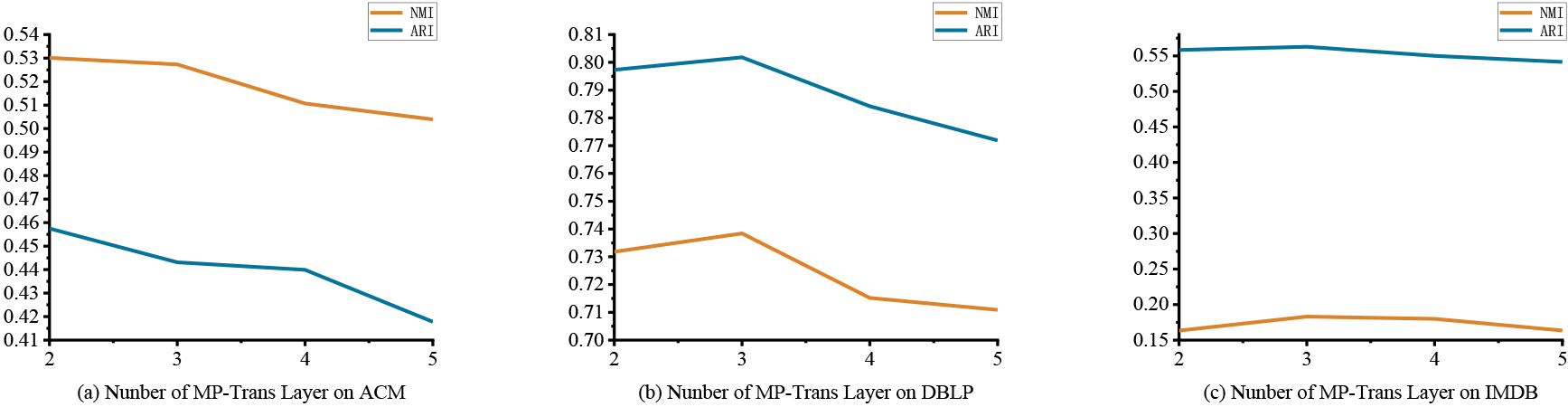
The function of Mp-Trans Layer is to fuse two meta-path information matrices to obtain a meta-path transition matrix with the degree of importance to further express the differences between different meta-paths. This section then explains in detail how Mp-Trans Layer distinguishes the importance of each meta-path from the generated meta-path transition matrix. For illustration convenience, the output channel is set to 1 here, and the convex combination of the adjacency matrix of the input heterogeneous graph is defined as
In Eq. (10),
This explains why KGNN_HCD is able to express the importance of different meta-paths. The weight
Figures 7a and b and 8a and b represent the attention scores of the adjacency matrices (edge types) from the first and second Mp-Trans Layers, where the ACM dataset and the IMDB dataset are chosen. In the ACM dataset, we have that the attention scores of the heterogeneous edge relations PA are the highest in the first meta-path transition layer; in the second layer, the attention scores of the heterogeneous edge relations AP are the highest. Obviously, the importance of meta-path PAP must be higher, which can be corroborated in Fig. 7c. In the IMDB dataset, the attention scores of heterogeneous edge relations MA and MD in the first layer have little different, but in the second layer, the attention score of DM is obviously higher than that of AM, so the importance of meta-path MDM is higher than that of meta-path MAM, which can be confirmed in the subsequent heat map. Meanwhile, in these four graphs, the attention weight of the identity matrix is relatively high, as discussed in Section 4.2, and KGNN_CD is able to try to adhere to a shorter meta-path even at a deeper level.
Numerical analysis in MP-Trans Layer on ACM dataset. (a) Attention scores corresponding to 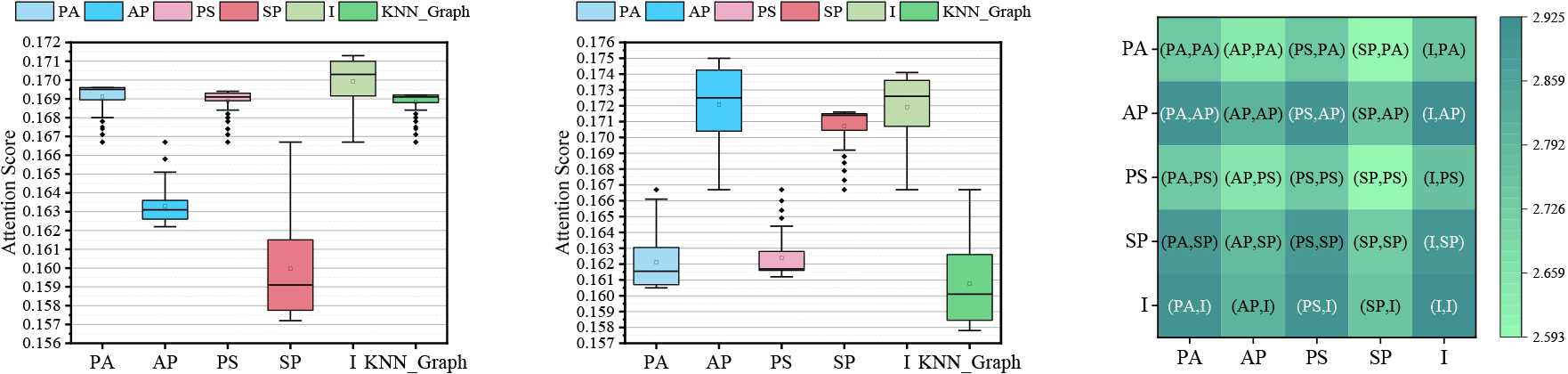
Numerical analysis in MP-Trans Layer on IMDB dataset. (a) Attention scores corresponding to 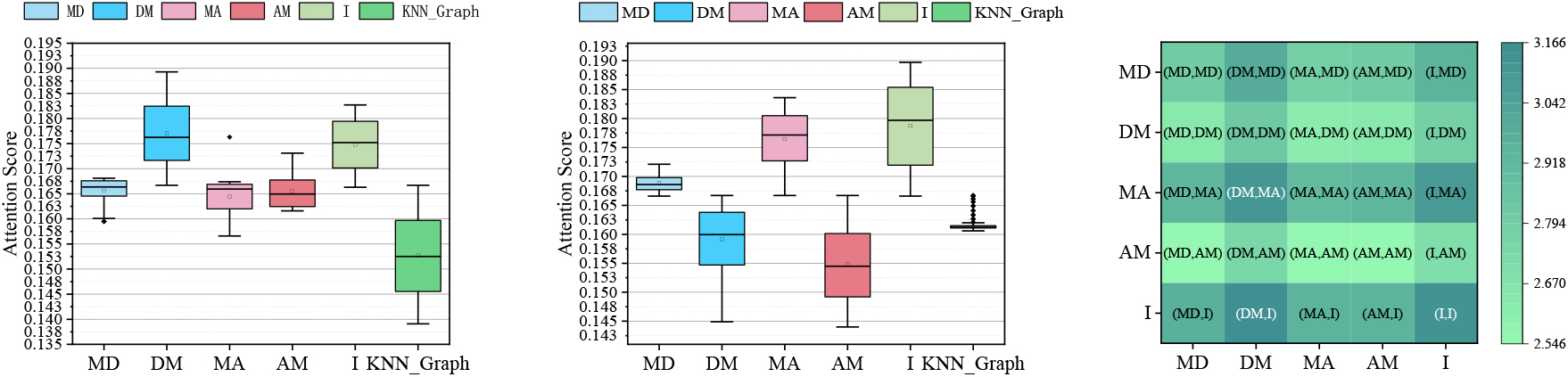
Figures 7c and 8c give the visualization of the correlation between each heterogeneous relationship in the first and second Mp-Trans Layers in the ACM dataset and IMDB dataset (For the clearer representation, the values are enlarged by 100 times here). It can be intuitively seen from the figure that meta-path PAP is more important than meta-path PSP. For example, according to the figure above, in the first Mp-Trans Layer, the attention score of PA is 0.1691, and that of PS is 0.1689; in the second MP-Trans Layer, the attention score of AP is 0.1721, and that of SP is 0.1707. According to equation
Comparison of similarity measures
4.1 provides a detailed introduction to several mainstream similarity measurement methods. To find the best measurement method, we conducted relevant experiments using the ACM dataset as an example and presented the results in Table 4.
Quantitative results of ablation experiments on ACM datasets for similarity measures
Quantitative results of ablation experiments on ACM datasets for similarity measures
In Table 4, KGNN_HCDw/Dot Product and KGNN_HCDw/Heat Kernel respectively represent the use of dot product and heat kernel methods for similarity calculation in constructing
To verify the validity of the components of KGNN_HCD, further experiments are conducted on different KGNN_HCD variants. The performance results for the three datasets are given in Table 5. KGNN_HCDw/oKG here indicates the removal of the
Quantitative results of ablation studies on ACM, DBLP, and IMDB datasets for community detection
Quantitative results of ablation studies on ACM, DBLP, and IMDB datasets for community detection
As can be seen from Table 5, KGNN_HCDw/oKG always has lower performance than KGNN_HCD in the three datasets, and there is a significant gap, which indicates the effectiveness and necessity of
In this paper, a heterogeneous graph community detection method based on
KGNN_ HCD only focuses on the excellent performance of symmetric meta paths in community detection. In the future, we will consider extending symmetric meta paths to asymmetric meta paths for community detection to capture richer relationships. In addition, heterogeneous temporal networks are considered to dynamically control community spatial changes, dynamic network pattern recognition and community detection robustness from both spatial and temporal dimensions, so as to achieve rapid capture and evolution of network communities.
Footnotes
Acknowledgments
This work was supported in part by Chongqing Federation of Social Sciences Key Project (2023NDZD09), Postgraduate Innovation Fund of Chongqing University of Technology (gzlcx20223202).